國 立 交 通 大 學
資訊管理研究所
碩 士 論 文
應用社會性推薦於學術社群
Using Social Recommendation
in Academic Community
研 究 生:粘怡祥
指導教授:柯皓仁
應用社會性推薦於學術社群
Using Social Recommendation
in Academic Community
研 究 生:粘 怡 祥 Student:Yi-Hsiang Nien 指導教授:柯 皓 仁 Advisor: Dr. Hao-Ren Ke國 立 交 通 大 學
資 訊 管 理 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Information Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science
In
Information Management
June 2008
Hsinchu, Taiwan, the Republic of China
應用社會性推薦於學術社群
指導教授:柯 皓 仁 研究生:粘 怡 祥 國立交通大學資訊管理研究所摘要
網際網路提供一個開放的平台,利用網路取得資訊已經成為最方便的管道。 面對網路上充斥的大量資訊,使用者在找尋資訊時,相當的費時也不容易聚焦。 推薦系統成為改善資訊過載問題的方法之一。使用者除了本身的主觀喜好之外, 其行為容易受到人際關係的影響,於是虛擬社群與社會網路,成為許多使用者獲 得資訊情報的最佳來源。 本研究主要的目在於提出結合主題概念萃取與社會網路分析之資訊推薦系 統,以提供符合使用者需求之推薦資訊。本研究利用關鍵字分群演算法,萃取出 使用者感興趣的主題概念;並且分析使用者社會網路,進行使用者分群,以形成 主題社群;經由分析社群成員的主題偏好,預測使用者的潛在興趣,建構出更符 合使用者需求的資訊推薦系統,以提升資訊推薦的品質。 關鍵詞:分群演算法、社會網路分析、推薦系統、機構典藏、學術社群Using Social Recommendation
in Academic Community
Advisor: Dr. Hao-Ren Ke Student: Yi-Hsiang Nien
Institute of Information Management National Chiao Tung University
Abstract
Internet provides an open platform, which becomes a convenient channel to obtain information. Facing huge amount of information, users will spend a lot of time and become out of focus when they search information on Internet. Recommendation systems become one solution for information overloading. Besides the subjective preference of a user, interpersonal relationship will affect his/her behavior, and the concepts of virtual community and social network become one feasible information source for deriving interpersonal relationship.
This thesis proposes a recommendation system combining topic concept extraction and social network analysis to meet users’ needs. This thesis uses the keyword clustering algorithm to extract topic concepts that users are interested in, followed by the formation of topic communities by analyzing the users’ social network to cluster the users. By analyzing the preferences of community members, the system can predict the potential interests and improve the quality of recommendation.
Keyword:Clustering, Social Network Analysis, Recommendation System, Institutional Repository, Academic Community
誌
謝
隨著畢業口試的結束,兩年的研究所生涯也到達了尾聲,一路走來,心中除 了感謝還是感謝。 首先要感謝指導教授柯皓仁老師諸多指導與協助,引導我一步步地將論文完 成,心中的喜悅真是無法以筆墨形容。感謝口試委員謝建成老師與陳光華老師, 在口試時所給予的建議,使得本論文能更加嚴謹。 同時也要感謝研究室同伴建穎、有盈、姿婷及揚書,所辦的淑惠與欣欣,博 班學長姐曜輝與栩嘉,APC研究室以及網路研究室的各位,不論在研究上或生活 上,大家總是一起努力打拚,共同分享喜怒哀樂,你們都是陪伴我一起成長的好 夥伴,與大家相處的點點滴滴,都將是我人生中美好的回憶。 最後則是感謝家人與女友雅君的包容與愛護,讓我能無後顧之憂的朝目標前 進,有你們的支持才有現在的我! 粘怡祥 謹誌 2008年7月目
錄
中文摘要... i 英文摘要... ii 誌謝... iii 目錄... iv 表目錄... vi 圖目錄... vii 第一章 緒論... 1 1.1 研究背景與動機... 1 1.2 研究目的... 4 1.3 研究流程... 5 1.4 論文架構... 6 第二章 文獻探討... 7 2.1 分群演算法... 7 2.1.1 劃分式分群法... 8 2.1.2 階層式分群法... 9 2.1.3 主題關鍵字分群法... 11 2.2 社會網路分析... 15 2.2.1 社會網路分析單元... 16 2.2.2 社會網路量測指標... 17 2.3 推薦系統... 19 2.3.1 內容導向式推薦... 21 2.3.2 協同過濾式推薦... 22 第三章 研究方法... 25 3.1 前置處理... 25 3.1.1 斷詞切字與小寫化... 25 3.1.2 刪除停用字... 25 3.1.3 詞性標記... 26 3.1.4 片語化... 27 3.1.5 詞幹還原... 28 3.1.6 特徵選擇... 28 3.2 主題關鍵字分群... 30 3.2.1 使用者模型... 30 3.2.2 計算語意相關度... 31 3.2.3 建立語意網路圖... 31 3.2.4 關鍵字分群... 333.2.5 關鍵字分群標記... 37 3.3 建立主題社群... 39 3.3.1 使用者社會網路... 39 3.3.2 使用者分群... 40 3.4 推薦模式... 43 第四章 系統發展與實證分析... 44 4.1 系統發展... 44 4.1.1 系統架構... 44 4.1.2 系統介面... 45 4.2 評估方法... 48 4.2.1 以專家評估分群結果... 48 4.2.2 以專家評估推薦結果... 50 4.3 實驗結果... 51 4.2.1 分群結果評估... 51 4.2.2 推薦結果評估... 53 4.4 討論與分析... 54 4.4.1 社會網路分析... 54 第五章 結論與建議... 60 5.1 結論... 60 5.2 後續建議... 61 參考文獻... 63
表 目 錄
表 2-1 k-Means 演算法步驟 ... 8 表 3-1 部份停用字列表 ... 26 表 3-2 詞性標記處理結果 ... 27 表 3-3 片語化處理結果 ... 28 表 3-4 關鍵字分群標記範例 ... 38 表 3-5 使用者分群範例 ... 42 表 3-6 使用者多重主題範例 ... 43 表 4-1 主題分群之類別 ... 49 表 4-2 Kappa Statistics 範例 ... 50 表 4-3 Kappa Statistics ... 50 表 4-4 專家分類標示結果 ... 51 表 4-5 Precision 與 Recall ... 50 表 4-6 專家評估推薦結果 ... 53 表 4-7 收錄論文數大於 5 篇之作者 ... 55 表 4-8 中心性分析 ... 58 表 4-9 主題分群之中心性分析 ... 59圖 目 錄
圖 1-1 研究流程圖 ... 5 圖 2-1 分群演算法之分類 ... 7 圖 2-2 階層式演算法處理流程 ... 10 圖 2-3 Chameleon 演算法流程圖 ... 11 圖 2-4 關鍵字數量與分群準確率關聯圖 ... 12 圖 2-5 關鍵字網路圖 ... 13圖 2-6 Topic Keyword Cluster 主要步驟 ... 14
圖 2-7 協同過濾式推薦系統功能組成 ... 23
圖 3-1 原文範例 ... 26
圖 3-2 稀疏網路圖 ... 32
圖 3-3 選出重要關鍵字 ... 33
圖 3-4 k-Nearest Neighbor Graph ... 34
圖 3-5 合併關鍵字子群 ... 35 圖 3-6 修正關鍵字子群 ... 37 圖 3-7 使用者與文件之關係矩陣 ... 39 圖 3-8 使用者共同作者矩陣 ... 40 圖 3-9 使用者社會網路 ... 40 圖 3-10 更新使用者向量模型 ... 41 圖 4-1 系統架構圖 ... 44 圖 4-2 依作者姓名排序瀏覽 ... 45 圖 4-3 依作者所屬主題社群瀏覽 ... 45 圖 4-4 個人資料介面 ... 46 圖 4-5 系統推薦介面 ... 47 圖 4-6 文件內容介面 ... 47 圖 4-7 Precision 與 Recall ... 52 圖 4-8 收錄論文統計 ... 54 圖 4-9 共同作者統計 ... 55 圖 4-10 共同作者社會網路 ... 56 圖 4-11 最大網路元件 ... 57 圖 4-12 最小網路元件 ... 57
第一章 緒論
1.1 研究背景與動機
隨著網際網路的普及與資訊技術的發達,網路提供了一個完全開放的資訊平 台,讓資訊得以快速地傳播、大量地複製與儲存,利用網路取得資訊已經成為最 方便的管道。但是面對網路上充斥的大量資訊,不但內容繁雜而且難以過濾,使 用者在找尋資訊時,相當的費時也不容易聚焦,以單純瀏覽的方式,在網路上尋 找資訊變得相當沒有效率,這使得人們在網路世界中寸步難行。搜尋引擎(Search Engine)與推薦系統(Recommender System)的出現,成為改善資訊過載(Information Overload)問題的兩大利器。 搜尋引擎是屬於一種資訊檢索(Information Retrieval)的方法,當使用者在資 訊需求較為明確的情況下,主動地以查詢的方式,來獲取其需要或是感興趣的資 訊,這是目前網路使用者最常使用的工具之一,例如Google、Yahoo 及百度等搜 尋引擎。而在使用者較不清楚本身的資訊需求時,可以透過推薦系統以被動的方 式取得資訊;推薦系統主要是利用資訊過濾(Information Filtering)的方法,在使 用者與網站的互動過程中,發掘使用者潛在的需求或興趣,用以比對推薦標的, 過濾出符合使用者需求的資訊,並進行推薦的動作,例如Amazon 與 eBay 等電 子商務網站,便是推薦系統應用上的佼佼者。 推薦系統已廣泛地運用在各種行銷策略上,更成為許多電子商務網站的核心 功能。推薦系統要得到較佳的推薦效果,首要的步驟是收集使用者資訊,不論是 外顯資訊的取得,例如使用者在網站上登錄的基本資料,以及對其購買產品或使 用過的服務做評比,或是隱性資訊的收集,例如將使用者的歷史交易紀錄,以及 瀏覽網站之行為加以分析;在取得使用者的相關資訊後,透過各種推薦方法的運 用,進而提供符合使用者需求的產品資訊,以作為使用者購買決策的參考指標。 利用有效的推薦資訊,不但可以節省使用者的搜尋時間,更能為企業帶來更多的要議題。 目前常應用在推薦系統的方法主要分為內容導向(Content-based)與協同過濾 (Collaborative Filtering)二種。內容導向方法主要是針對使用者喜好的項目進行內 容分析,經由分析項目的屬性特徵後,進而判斷並找出使用者可能有興趣的項 目,再將其結果推薦給使用者。協同過濾方法的主要目的在於發掘與其他使用者 間的關聯性,找出具有共同興趣的使用者以形成社群;經由分析社群成員共同的 興趣與喜好,以此作為推薦的參考依據,並用以推論或預測目標使用者的潛在偏 好。 除了上述所提到的兩種方法,Iskold [1]也以消費者的觀察角度,將推薦系統 分類如下: 1. 個人化推薦(Personalized Recommendation):依據消費者個人過去在網站 中的行為進行推薦。 2. 社會性推薦(Social Recommendation):依據過去和個人有相似行為的消費 者來進行推薦。 3. 產品為導向的推薦(Item Recommendation):依據產品本身的特性進行推 薦。 4. 綜合以上三種方法之推薦模式。 根據以上的脈絡,從消費者個人的資料入手,發現不足後,便運用所有消費 者資料,繼而整合之前所開發的技術,產生綜合策略;雖然各種分類角度有不同 的陳述,但結果卻是殊途同歸。 使用者除了本身的主觀喜好之外,其行為容易受到人際關係的影響。網際網 路提供使用者一個高度自主的環境,讓使用者可以輕易地進行資訊分享與訊息交 換,使得網路上的人際互動頻繁,無形中形成虛擬社群(Virtual Community)或社 會網路(Social Network)等非正式組織,例如部落格(Blog)、社交網路網站(Social Networking Site)與線上遊戲(Online Game)等;於是虛擬社群與社會網路,成為許 多使用者獲得資訊情報的最佳來源,Zhong[26]更是明確地指出,虛擬社群與社
會網路提供了從事推薦活動時的基礎資訊。 Staab[32]的研究指出,在市場行銷的戰役中,口耳相傳(Word of Mouth)對消 費者行為的改變有重要影響;社會網路的發掘與分析,有助於企業制定病毒行銷 (Viral Marketing)策略,在進行產品或服務的推薦活動時,使消費者間口耳相傳的 正面效果達到最大化,與忽略消費者互動及網路效應的傳統行銷模式相比,可以 使企業取得較高的獲利。 Hotta[10]認為將使用者的社會網路整合到推薦演算法中,可以獲得較佳的推 薦效果。在該研究中利用使用者基本資料與瀏覽網站的記錄檔(Log),建構使用 者設定檔(User Profile),其中包含使用者偏好表(Preference Table),並且以使用者 點擊網頁的內容與使用者社會網路連結來更新偏好表,最後以資訊過濾的方法, 產生符合使用者偏好的推薦資訊。
推薦系統有助於使用者獲得所需的資訊,並且能節省搜尋的時間成本;社會 網路對使用者決策行為的影響,也成為進行資訊推薦時不可忽視的重要因素。因 此本研究將深入探討如何運用社會網路提升資訊推薦的品質。
1.2 研究目的
本研究主要的目在於提出結合主題概念萃取與社會網路分析之資訊推薦系 統,並將其應用於學術社群。本研究利用關鍵字分群演算法,萃取出使用者感興 趣的主題概念;並且分析使用者社會網路,進行使用者分群,以形成主題社群; 經由分析社群成員的興趣偏好,預測使用者的潛在興趣,建構出更符合使用者需 求的資訊推薦系統,以提升資訊推薦的品質;整體研究目標如下: 1. 主題概念萃取 萃取出文件中的重要關鍵字,利用關鍵字分群,達到主題概念萃取的目 的,藉以瞭解使用者所關注的興趣與議題。 2. 形成主題社群將個別使用者轉換成以向量空間模型(Vector Space Model)來表示,並結 合使用者的社會網路,將相似度高且具有相同主題興趣的使用者群聚在一 起,以形成主題社群。 3. 資訊推薦 經由主題社群的產生,針對使用者個人的主題偏好,進行個人化推薦; 此外,更進一步分析社群成員共同的興趣與喜好,預測使用者的潛在偏好, 以建構出更符合使用者需求的推薦系統,提升資訊推薦的品質。
1.3 研究流程
本研究之研究流程如圖1-1所示,首先闡述本研究之動機與目的,並且收集 分群演算法、社會網路分析與推薦系統之相關文獻資料,探討其發展趨勢及有待 改善之處;而後針對先前三方面文獻的回顧,勾勒出一整合社會網路分析於推薦 系統之資訊推薦方法;並發展雛型系統進行資訊推薦,藉由分析實證結果得到本 研究之結論,並提供後續研究之建議方向。 研究動機與目的 文獻探討 分群演算法 社會網路分析 推薦系統 研究方法 主題關鍵字分群 建立主題社群 系統發展與實證分析 結論與建議 推薦模式 圖 1-1 研究流程圖1.4 論文架構
本研究共分為五章,說明如下: 第一章 緒論 說明本研究之研究背景與動機、研究目的及研究流程。 第二章 文獻探討 針對分群演算法、社會網路分析及推薦系統三方面與本研究相關之文獻進行 探討。 第三章 研究方法 描述本研究之資料前置處理流程、研究方法,並介紹系統之推薦模式。 第四章 系統發展與實證分析 經由雛型系統發展,進行資訊推薦,並就推薦結果進行分析與比較,以得知 推薦之效能與適用性。 第五章 結論 總結本研究並提出未來可供後續研究之方向。第二章 文獻探討
本章從相關文獻之蒐集、整理與分析,來探討分群演算法、社會網路以及推 薦方法之相關理論。分群演算法主要針對常用的劃分式(Partitional)與階層式 (Hierarchical)兩種方法進行討論[2],以k-means[14]及Chameleon[8]演算法舉例說 明,並且對本研究所採用之主題關鍵字分群法(Topic Keyword Cluster)[9]做進一 步討論。社會網路方面乃從其定義與建構社會網路之基本單元做說明,並且列舉 三項常用於分析社會網路的指標,以發掘個人在社會網路中所扮演的角色。至於 推薦方法的理論探討,則是針對廣泛使用的內容導向(Content-based)與協同過濾 (Collaborative Filtering)兩種方法進行闡述,並列舉相關之實際應用作為比較。
2.1 分群演算法
分群演算法在資料探勘(Data Mining)領域上是應用相當普遍的一種技術,主 要的目的在於將資料集裡的資料區分成數個群集(Cluster),使得每一個群集內資 料間的相似性高,而不同的群集之間的資料相似性低。分群演算法的選擇取決於 資料的類型、分群的目的與應用,根據Jain[2]的歸納,分群演算法主要區分為劃 分式(Partitional)分群法與階層式(Hierarchical)分群法兩大類,如圖2-1所示。 圖 2-1 分群演算法之分類[2]2.1.1 劃分式分群法
劃分式分群法是分群演算法中最早發展的一種方法。劃分式分群法簡單地來 說,是由使用者指定將資料物件分割成k個群集,每一個劃分(Partition)代表一個 群集,也就是在分群前必須先定義目標分群的個數,此為劃分式分群法的特色。 k-means是劃分式分群法中最基本卻也是應用最為廣泛的方法,在1967年時 由MacQueen所提出[14],採用歐幾里得(Euclidean Distance)距離作為對資料分群 的基礎,距離公式如方程式(2-1)所示。分群過程中必須同時確保兩個條件: 1. 位於相同群集內的物件,彼此間相似度高,群集中心點為所有物件的向 量平均值,物件與群集中心點的距離愈小,則表示相似度愈高。 2. 位於不同群集內的物件,彼此間相似度低,即屬於不同群集的物件其距 離愈大愈好。 2 1 ( , ) in ( i i) d x y =∑
= x −y k-Means演算法的詳細步驟如表2-1所示: 表 2-1 k-Means演算法步驟 k-means 在結果群集是密集的、且群集與群集間有明顯區隔時,有相當不錯 的成效。若是分群資料中具有雜訊(Noise)或者是離群值(Outlier)時,其分群結果 輸入:n 個物件與分群的數目 k。 輸出:k 個群集。 (1) 任意選擇 k 個物件作為初始的群集中心。 (2) 重複以下步驟,直到群集的分佈不再改變。 (2.1) 利用距離最近者相似度最高的原則,依序計算每個物件與 k個群集中心點的距離,將每個物件歸屬到最相似的群集。 (2.2) 計算群組內所有物件間距離的平均值,作為各個群集的中 心點。 (2-1)將會受雜訊的影響而失真。總括而言,k-means 的優點為演算法簡單且計算快速、 效率高。缺點是使用群集的算術平均數做為群集的中心,使得群集的結果容易受 到雜訊或是離群值所影響而降低其正確性;而且k-means 只適用於數值型的資 料,涉及具有分類屬性的資料則不適用。
2.1.2 階層式分群法
階層式分群法是利用樹狀結構來表示資料分群的結果。每一個群集所代表的 節點可以往下再分裂成數個子群,或者同一階層的群集節點也可以往上再聚集成 一個更大的群集節點;因此階層式群集演算法的好處,就是可以藉由選擇不同的 階 層 來 檢 視 不 同 詳 細 程 度 的 分 群 結 果 。 階 層 式 分 群 法 一 般 區 分 為 聚 合 式 (Agglomerative)以及分裂式(Divisive)兩大類[2]。圖2-2分別描述聚合式與分裂式 兩種方法在一個包含五個物件的資料集合{a, b, c, d, e}上的處理過程。 1. 聚合式 聚合式方法採用的是由下而上(Bottom-up)的分群策略。聚合式方法開始 時將每一個資料物件當作單一群集,然後尋找相似度最高的群集,當相似度 大於既定的臨界值時,則往上一個階層聚合成一個更大的群集;經由反覆進 行群集聚合的步驟,直到所有的資料物件聚合成同一個群集,或是符合終止 條件為止。 2. 分裂式 分裂式方法所採用的策略與聚合式方法正好相反,分裂式分群法是一種 由上而下(Top-down)的方式。分裂式方法開始時將全部的資料物件當作同一 個群集,然後尋找相異度最高的群集,再往下一個階層分裂成較小的子群 集;經由反覆進行群集分裂的步驟,直到每個子群集都只有一個物件,或是 符合終止條件為止。圖 2-2 階層式演算法處理流程 在聚合與分裂的過程中,測量群集間距離的方式又可分為單一連結法(Single Link)以及完全連結法(Complete Link)兩種。單一連結法使用的是最短距離法,即 是以兩個群集間資料物件的距離最短者作為群組間的距離,而完全連結法則是使 用最長距離法,即是以兩個群集間資料物件的距離最長者為群集間的距離。 階層式分群法的概念雖然簡單,但是經常會遇到合併或分裂點選擇的困難。 資料物件一旦被合併或分裂,下一步驟的處理將依循先前的群集結果繼續進行, 並且群集之間不能交換物件。因此,若選擇了不適當的合併或分裂的條件,可能 會導致最終分群結果不佳。除此之外,此種分群方法的可擴展性不佳,因為合併 或分裂的決定需要檢查及估算大量的物件或群集。 Chameleon演算法[8]是在階層式分群法中採用動態模型的演算法。在分群的 過程中,當兩個群集間的互連性和相似度有高度相關時,則合併這兩個群集;基 於動態模型的合併過程,有利於同質性群集的發現。Chameleon演算法的步驟如 下,流程圖如圖2-3所示。 1. 將資料建立成一個稀疏圖形(Sparse Graph),每個點代表一個資料物
件,資料物件間的關係即代表一個具有權重的邊。 2. 以k-Nearest Neighbor 演算法[19]將圖形分割為多個子圖,即把相對較大 的群集,劃分成較小的子群集。 3. 透過聚合式演算法依照相似度反覆進行合併子群集,直到最後的結果群 集產生。以兩個子群集間的相對互連性(Relative Inter-connectivity)與相 對近似性(Relative Closeness)來決定相似度。 圖 2-3 Chameleon 演算法流程圖[8]
2.1.3 主題關鍵字分群法
主題關鍵字分群法(Topic Keyword Cluster)[9]是應用在文件分群上的一種方 法,採用與Chameleon演算法類似的想法。在分群的步驟上,首先取出文件中的 關鍵字(Keyword),將關鍵字分群之後,再計算文件與關鍵字群集之相似度,最 後將文件對應至最相似的關鍵字群集。詳細分群步驟如下:
關鍵字的選擇關係到分群結果的準確性,以及是否能夠適當地表達所代 表的主題。根據Koller[6]的研究,用來表示文件最適當的關鍵字個數為10~25 個,過多的關鍵字反而會降低重要關鍵字的顯著性,圖2-4為關鍵字的數量 對分群準確率的影響。因此透過停用字集(Stop Word)可移除詞頻較高的關鍵 詞及功能詞(Function Word),以達到篩選關鍵字的目的 圖 2-4 關鍵字數量與分群準確率關聯圖[9] 2. 計算關鍵字間的關聯性 當關鍵字間共同出現的頻率很高,則代表這些關鍵字間具有關聯性。主 題關鍵字分群法於是利用Mutual Information[27],計算關鍵字共現的頻率作 為關鍵字間的語意相關,計算方式如方程式(2-2)所示,分子為兩關鍵字共同 出現的頻率,分母則取兩關鍵字在語料庫中出現次數的最大值。 ( ) max{ ( ), ( )} i j ij i j f t t r f t f t = I 3. 建立關鍵字網路圖 根據圖形理論(Graph Theory)建立關鍵字網路圖,以關鍵字代表網路圖 中的一個點(Vertex),關鍵字間的語意相關度為一個邊(Edge),如圖2-5 (a)所 示。接著對網路圖內的連線進行刪減,只保留大於平均語意相關度的連線, (2-2)
將原本的網路圖修正為稀疏網路圖。如圖2-5(b)所示 圖 2-5 關鍵字網路圖[9] 4. 進行關鍵字分群 關鍵字分群的主要步驟如圖2-6所示。首先選取出侯選的關鍵字,侯選 關鍵字是由稀疏網路圖中選取權重大於平均的點。點權重CWi的計算如方程 式(2-3)所示,wi表示點vi的權重值,即關鍵字i在語料庫中TF-IDF值的加總; rij則表示所有與點vi有連線的點vj間之語意相關度,m為與點vi有連線的點個 數。 1 1
the weight of term in the document
ij ij i j N i j ij m ij j i i w tf idf i d w w r CW w m = = = × − = = +
∑
∑
接著將候選關鍵字利用k-Nearest Neighbor演算法[19]進行分群,以每個 候選關鍵字組為中心,向外還原先前與候選關鍵字組內的點有直接連線關係 的邊,形成候選關鍵字子群,並計算每個子群的權重。找出候選關鍵字子群 中互連性(Inter-connectivity)最強的兩個群將之合併,直到子群間的互連相關 度(Relative Inter-connectivity)都小於門檻值後停止,即得到關鍵字子群。 (2-3)圖 2-6 Topic Keyword Cluster主要步驟[9] 5. 修正關鍵字分群結果及文件分群 在合併候選關鍵字子群的過程中,會造成每一群包含的關鍵字個數產生 差距,進而影響文件分群的正確性,因此需要將每個子群內的關鍵字保持在 一定的差距內,當子群內的關鍵字數目大於平均關鍵字數目時,則依序移除 點權重最小的關鍵字。關鍵字子群修正完成後,將文件與每一個關鍵字群以 餘弦相似度(Cosine Similarity)計算相似度,並將文件對應至相似度最高的關 鍵字子群中,以達到文件分群的目的。相似度計算方式如方程式(2-4)所示 1 2 2 1 1 ( , y) n ij ij j n n ij ij j j x y sim x x y = = = × = ×
∑
∑
∑
(2-4)2.2 社會網路分析
社會網路(Social Network)是指在社會組織中,個人或是組織間相互連結的關 係集合[29]。社會網路分析(Social Network Analysis)是一種研究社會結構、組織 系統、人際關係、團體互動的概念與方法,是在社會計量學(Sociometry)基礎上 所發展出來的分析方法。社會學是最早注意到社會網路現象並且從事研究分析的 領域。心理學家Moreno[16]利用形式社會學派觀點和現象觀察的方式,將人際行 為、人際關係數量化,並且以圖形方式表達,呈現人與人之間互動的方向性、接 觸的距離等。 社會網路分析研究領域中,最著名的理論之一為「六度分隔」(Six Degrees of Separation)理論[40]。利用信件傳遞實驗,發現從寄件者到收件者之間,平均轉 寄了六次,根據這樣的實驗,得出了六度分隔的概念。六度分隔理論指的是互不 相干的兩個人,可經由六個人連結出某種關係,也就是最多透過六個人,就能夠 認識世界上任何一個陌生人。 經由社會網路分析,可以描繪出原本無法察覺的各種網路關係,無論是人際 關係、疾病傳播與文化時尚等,都可以運用社會網路來分析與解釋,並且利用各 項量測指標,得以評估社會網路的狀況,瞭解社會網路中的角色,來幫助解決所 面臨的問題,於是愈來愈多的研究致力於從不同角度發掘社會網路及其應用。 Tyler[17]利用電子郵件建構社會網路,將社會網路以圖形代表,接著使用中 介中心性(Betweenness Centrality)分析,區分出網路圖中的社群結構,用以表示 組織中的社群分佈,並且定義出具有領導地位的社群。 Mika[28]發展了一套名為Flink的系統,藉由分析網頁內容、電子郵件、論文 著作以及FOAF(Friend of a Friend)檔案,來發掘語意網(Semantic Web)研究領域學 者的社會網路,並以視覺化的方式表現社群中的社會網路關係,以及建構語意網 研究領域的主題本體論(Ontology)。
Conference on Digital Libraries)成員所發表的論文著作,從共同作者(Co-author) 的角度出發,分析在數位圖書館研究領域的社會網路關係,並且提出以此社會網 路為基礎的AuthorRank,來和分析網頁超連結關係所構成的PageRank[22]作一比 較。
POLYPHONET[35]是以JSAI(Japan Society of Artificial Intelligence)研討會的 參與成員為依據,利用搜尋引擎找回和參與成員相關的網路文件,並且從中萃取 出和個人相關的關鍵詞,來代表個人感興趣的研究主題,並計算成員間的情境相 似度(Context Similarity)以找出潛在的社會網路關係。
2.2.1 社會網路分析單元
社會網路分析的目的在於檢視人們在社會、經濟,文化等框架(Framework) 中所扮演的角色,並藉此分析個人與個人、個人與群體、群體與群體之間的互動 關係及影響。社會網路的分析單元共有行動者(Actor)、關係(Relation)及聯繫(Tie) 三種[42]。分別說明如下: 1. 行動者 網路中所定義的人、事、物,為網路的主體。社會網路分析著重在行動 者之間的關係。 2. 關係 兩個行動者間由於某種關係的存在而影響彼此之互動。關係的特徵可經 由內容、方向、強度及主動或被動關係來說明[31]。 (1) 內容:內容就是指兩行為者間之關係發生的原因與關係建構基礎。 (2) 方向:關係可分成有方向性(Directed)及無方向性(Undirected)。 (3) 強度:關係也有著程度不同的強度。其衡量方式可能因為不同的關 係型態而有所不同。 (4) 主動關係或被動關係:關係產生時,因為行為者本身意向之主被動 的不同,也是一種關係的特徵。3. 聯繫 聯繫是指兩行動者間的關係組合[23]。當行動者間建立某種形式的關係 時,必須透過某種途徑達成關係的建立,使行動者互相連結。聯繫所含的關 係可能由一種或是多種的關係組合而成,聯繫又可分成弱聯繫(Weak Ties) 及強聯繫(Strong Ties),另外亦可分為直接與間接兩種聯繫模式。 Granovetter[25]提出構成聯繫強度的四項屬性,分別為時間(Amount of Time)、情感強度(Emotional Intensity)、親密(Intimacy)以及相互服務 (Reciprocal Services)。他認為家人、朋友以及彼此接觸頻繁的人皆屬於強聯 繫;而弱聯繫是指透過本身關係以外的人事物所產生的關聯。研究中指出弱 聯繫所提供的資訊或資源較強聯繫更為有用。
2.2.2 社會網路量測指標
在社會網路分析的層面上,依照不同網路層級的特性,具有不同的量測指 標。個別行動者的分析主要透過程度中心性(Degree Centrality)、中介中心性 (Betweenness Centrality)及緊密中心性(Closeness Centrality)[21]。各項指標之說明 如下: 1. 程度中心性 計算特定網路成員與其他成員聯繫的數量,分數愈高表示其在網路中具 有重要的地位,其表示式如方程式(2-5)。 1 ( ): the edge for vertex to vertex
h ij j ij d i m m i j = = −
∑
2. 中介中心性 定義為網路關係中,任兩個成員的互動必須透過某個關鍵行動者連結的 程度,亦即衡量一個成員是否占據在其他成員相互聯絡的重要捷徑上,其表 示式如方程式(2-6)。 (2-5)1,
( )
: the number of geodesics between and that contain : the number of geodesics between and
n jik j k i jk jik jk g b i g g j k i g j k = ≠ = − −
∑
3. 緊密中心性 衡量成員和其他連結點之間的最短路徑加總,值愈小者表示和大多數成 員之間的關係較為緊密,其表示式如方程式(2-7)。 1 1 ( ): the shortest path of to
N j ij ij c i d d i j = = −
∑
Faust[20]認為網路中的行動者基於結構上的相似性,可分類為不同的網路角 色。以中心性作為分類的準則,區別主要的網路角色如下: 1. 網路中心(Hub) 即具有較高程度中心性之行動者。由於建立的連結多,在網路中較為活 躍,通常是決策的主導者、意見的領袖。 2. 橋樑(Bridge) 即具有較高中介中心性之行動者。橋樑行動者在不同社群間扮演聯繫的 角色,愈多社群倚賴特定行動者,而無其他替代溝通管道時,該行動者所具 有的橋樑特質愈為重要。 (2-6) (2-7)2.3 推薦系統
推薦系統的目的是從大量資訊中找出使用者最可能感興趣的部份,減少使用 者主動搜尋的機會成本。推薦系統已廣泛地運用在各種行銷策略上,成為許多電 子商務網站的核心功能,利用有效的推薦資訊,不但可以節省使用者的搜尋時 間,更能為企業帶來更多的顧客,提升顧客忠誠度,並且增加企業的收益,這使 得推薦機制成為重要議題。 Schafer[13]認為在運用推薦系統的機制下,對於電子商務上可獲取的效益為 以下三項:1. 將瀏覽者變成購買者(Browsers into Buyers)
使用者在網站上往往只是快速地瀏覽網頁內容,而不會主動購買商品, 利用推薦系統可以適時地推薦使用者感興趣的產品及服務,引發使用者的購 買慾望,使瀏覽者也成為購買者。 2. 交叉銷售(Cross-sell) 推薦系統透過對使用者提供已購買商品以外的產品建議,來產生交叉銷 售的效益,如果所推薦的產品符合顧客需求,則可以提高平均的交易量。舉 例來說,推薦系統可依據使用者購物車中的產品資訊推論使用者的興趣,並 依其興趣進行額外的產品推薦。 3. 提高忠誠度(Loyalty) 推薦系統透過學習的機制,瞭解使用者需要什麼,並且預測使用者的需 求以進行推薦。與其他的競爭者相比,若能利用推薦系統提供使用者需要的 資訊,則使用者將再度到訪能提供最符合其需求的網站,藉此可改善企業與 消費者的關係,同時提高顧客的忠誠度。 推薦系統在進行推薦之前,必須先取得使用者的相關資料,瞭解使用者對於 哪些資訊感興趣,才能使推薦符合個人需求,並且增加推薦的準確性。系統必 須獲得三種資料才能做出推薦,包含人口統計資料、物品的特徵屬性及使用者
的偏好[41],說明如下: 1. 人口統計資料 人口統計資料可做為辨別使用者類型的依據,例如推薦系統可分別採用 性別、年齡、教育、職業與薪水等統計資訊,區分出不同類型的使用者。經 由分析各種類型使用者的喜好特徵,可以依據不同的類型進行不同的推薦。 例如對於年輕女性,可能會推薦她們流行服飾或是保養品,高收入的中年男 性,則可能推薦高爾夫球。 2. 物品的特徵屬性 物品本身的屬性也可以做為推薦的依據,即具備類似或互補屬性的產品 將優先被推薦。屬性一般又可以分為外在屬性(Extrinsic Feature)及內在屬性 (Intrinsic Feature)。外在屬性是指無法用自動化方式取得的特徵,如品牌形 象、顏色、物品從屬關係等;相反地,內在屬性通常能藉由分析物品內容得 到,其內容或關鍵的屬性都可以被萃取出來。物品具備的屬性繁多,為了管 理上的方便,通常套用階層式架構,依不同的層次加以分類,將資訊有條理 地組織起來。在資訊量太大的情況下,以類別的推薦來代替物品的推薦會更 具有意義。 3. 使用者的偏好 使用者偏好(User Preference)是個人化推薦的重要依據,唯有瞭解使用者 本身的喜好才能達成個人化的推薦。即分析個人的興趣與喜好,建構使用者 設定檔,經由與產品項目間特徵屬性的比對,進行符合個人喜好的推薦。單 純用人口統計資料或物品特徵屬性來做推薦僅能作一般性的推薦,不會有個 別的差異。 一般常用的推薦機制有內容導性式推薦和協同過濾式推薦,分述如下:
2.3.1 內容導向式推薦
內容導向式推薦主要依據使用者個人過去所購買或曾接觸過的商品,得知使 用者的喜好,進而推薦使用者相近的商品。內容導向式推薦必須為每位使用者建 立使用者設定檔,對使用者的興趣詳加描述,推薦系統將物品的特徵屬性和使用 者的輪廓做比對,相似度高的物品將優先被推薦。主要的構想是從資訊檢索領域 延伸而來,以物件的屬性或特徵為每個商品建立向量,以向量間的餘弦相似度值 判斷兩個物件是否相關。當兩物件間向量的夾角越小時,代表相似度越高,反之 則越小。 內容導向式推薦常應用於可解析內容或描述之相關資訊推薦,例如網頁、文 件與新聞等,由於可將資訊之內容或關鍵屬性萃取並加以分析,因此成為內容推 薦之主要依據。內容導向式推薦也因為先天上的限制,具有以下幾項缺點: 1. 音樂、電影、照片等多媒體資料,無法以文字表逹,其內容維度因而較 難清楚定義,導致較難對此類型的商品進行推薦。 2. 內容導向式推薦系統因為是依照使用者過去的喜好做為推薦依據,因此 往往僅能推薦出使用者最喜好的商品,無法找到一些對顧客來說較特殊 或不一樣的產品,可能無法發現顧客的潛在需要。 內容導向式推薦的應用相當廣泛,一般使用資訊檢索的技術來分析文件內 容,並透過文件與使用者設定檔的比較來向使用者進行推薦。以下分別介紹內容 導向式推薦的實際運用。 InfoFinder[3]是經由訊息資料集(Set of Messages)或是其他的線上文件,來得 知使用者的資訊喜好類別。此系統的特點在於使用啟發式(Heuristic)的搜尋來取 得有意義的片語,優點在於不需要很多文件樣本就可以正確取得使用者的偏好。 ANATAGONOMY[12]則是從使用者瀏覽網頁的操作行為來學習使用者的個 人偏好。系統分為學習引擎(Learning Engine)以及評分引擎(Scoring Engine)兩個 部份。學習引擎從使用者操作行為中分析使用者偏好;而評分引擎則負責新聞文件的評分,並依據使用者設定檔建立個人化的電子報。研究中比較明顯性評分 (Explicit Rating)與隱含性評分(Implicit Rating)兩種模式的效果。在明顯性模式 中,使用者每閱讀完一篇文章,必須以分數來評估該文章與本身興趣的關連性; 在隱含性模式中,系統會記錄使用者閱讀文章時的動作,推導出對使用者對該文 章感興趣的程度。 SmartPad[33]為到賣場購物的使用者提供個人化的商品清單。此系統為所有 的商品建立一顆分類樹,經由分析使用者過去的消費記錄,計算出使用者對特定 商品類別的偏好程度。二商品間的相似度即以它們在分類樹中所在的相對位置表 達。SmartPad以使用者對商品類別的偏好程度,與商品間的相似度,為使用者提 供個人化的商品推薦清單。
2.3.2 協同過濾式推薦
協同過濾式推薦藉由發掘系統內使用者間的相關性,以此做為推薦的參考依 據,並用以推論或預測目標使用者的潛在偏好。使用者通常喜歡參考來自於與他 相同興趣之人的建議,透過統計分析的過程,找出與使用者本身最為相似的使用 者,依據相似使用者過去的交易記錄或其他屬性,預測使用者對於尚未見過事物 的喜好程度,進而推薦喜好程度最高的商品清單給特定使用者。 在Sarwar[4]的研究中,將協同過濾式推薦分成以下三部份,如圖 2-7 所示。1. 輸入資料的表示法(Representation of Input Data)
建立出系統中使用者購買產品的行為模式。將使用者的交易紀錄建立在 一個矩陣R中,以rij代表使用者i購買產品j的關聯。 2. 形成鄰近者(Neighborhood Formation) 經由分析使用者偏好與計算使用者間的相似度,找出具有相似偏好的使 用者社群,以社群成員之偏好及相似度做為進行推薦之依據。 3. 產生推薦(Recommendation Generation) 將使用者社群內所偏好的前n項產品資訊推薦給目標使用者,提供其做
為交易的參考依據。 圖 2-7 推薦系統的功能組成[4] 協同過濾依據其他顧客的意見來為目標顧客推薦產品,因此所推薦之產品可 能與使用者從前的喜好大不相同,但是卻能發掘出消費者的潛在需要。以下介紹 協同過濾式推薦的實際運用。 Tapestry[5]的主要目的在過濾電子郵件,之後延伸到所有的電子文件。系統 能夠讓使用者對電子郵件加上註解(Annotation),由使用者來判斷文件品質的優 劣,並且使用者可以透過查詢的方式,過濾瀏覽自己有興趣的電子郵件及註解紀 錄。但是此系統需要使用者被動地以查詢來過濾信件,而非系統主動地對使用者 進行推薦。 ReferralWeb[11]是一個結合社會網路與協同過濾的系統,主要利用使用者在 網路文件中的共現(Co-occurrence)情形,發掘社會網路關係,並以此進行資訊推 薦。該研究中提出的資料來源: (1)個人網頁的連結;(2) 論文著述間的共同作者 (Co-author)與共同引用(Co-citation)關係;(3) 使用者在網路論壇中的交流記錄; (4)組織架構圖。接著當使用者查詢某個關鍵字時,系統便會先從與使用者較相 關的人找起,以幫助使用者很快地找到該社會網路中的專家。
SiteSeer[18]是利用使用者的瀏覽器書籤(Browser Bookmark)判斷使用者的偏 好,比較使用者間書籤的相似度來找出具有相同偏好的使用者,並將相同偏好者 書籤裡的其他網站推薦給目標使用者。使用者會把網站加入書籤,表示使用者對 此網站具有相當程度的偏好,所以將書籤視為一個可信賴的隱含性評分。此外, 從使用者書籤的分類架構,也可以看出使用者的資訊分類方式,可作為呈現推薦 資訊時的依據。
第三章 研究方法
本研究以交通大學機構典藏系統 (National Chiao Tung University
Institutional Repository, NCTUIR) [38]所收集的期刊論文做為語料庫(Corpus),選 取標題(Title)、摘要(Abstract)、關鍵字(Keyword)及作者(Author)欄位做為資料來 源。後續研究中所提及之「使用者」即為NCTUIR中記錄之「作者」。 NCTUIR是將交通大學本身的研究產出,如期刊、會議論文、研究報告、投 影片與教材等,以數位的方式保存,並建立網路平台,提供檢索與使用的系統, 對內是研究人員的交流平台,能夠保存記錄研究傳承與發展;對外則能幫助展現 研究能量,提高學術成果的能見度與影響力,增加一個研究成果被使用的管道。 在本章中將闡述本研究提出的結合主題關鍵字分群演算法與社會網路分析 的資訊推薦方法。首先說明前置處理的步驟;再詳細描述進行主題關鍵字分群、 社會網路分析、形成主題社群以及資訊推薦的方法,本章會在每一節詳述每一個 流程的步驟。
3.1 前置處理
前置處理的目的在於提高資料的正確性,避免雜訊的干擾。此步驟包含斷詞 切字(Tokenization)、小寫化(Lowercasing)、刪除停用字(Stop Word Removing)、詞 性標記(Part-Of-Speech)、片語化(Chunking)以及詞幹還原(Stemming)。3.1.1 斷詞切字與小寫化
斷詞切字主要是用來找出文字的分界,在英文文件中是利用空格和標點符號 來判斷句子與單字,以達到斷詞切字的目的。字彙的大小寫會影響到計算字詞頻 率時的差異及詞性的判斷,為了避免判斷錯誤,本研究將全部的字小寫化,再進 行斷詞切字的處理。3.1.2 刪除停用字
停用字是指文章中沒有語意,一旦脫離文句語境來解釋,便沒有任何涵義存 在,但可用來平順語意的字詞。停用字一般包含介系詞、指代詞、連接詞與助詞 等。本研究以頻率來計算字詞的重要程度,這些停用字經常出現於文件中,反而 會被誤判為具有相當程度之重要性,因此在前置處理中將其過濾。表3-1 為部份 停用字列表。 表 3-1 部份停用字列表
Stop word list
about down get keep never re upon yourself after during give latterly often same very the became each hence less otherwise several via whom because everyone however many part take well anywhere can few if moreover perhaps thereby whatever an could former indeed neither rather until yet for
3.1.3 詞性標記
英文文件中的重要概念大多是由名詞或名詞片語所組成,故詞性標記也是篩 選字詞的重要步驟之一。本研究採用LingPipe NLP Toolkit[37]進行實作,LingPipe 是一套處理自然語言的JAVA API,提供的功能包含有詞性標記(Part-of-Speech Tagging)、中文斷詞(Chinese Word Segmentation)、情感分析(Sentiment Analysis)、 語言辨别(Language Identification)等等。其中詞性標記功能是以Brown Corpus作 為語料庫,Brown Corpus是由美國Brown大學於1960年代所建立,是一個根據系 統性原則採集樣本的標準語料庫,收集了約一百萬個字詞,並加上詞性標記。以 圖3-1的原文範例進行詞性標記,其結果如表3-2所示。圖 3-1 原文範例
Some combinatorial characteristics of matrix multiplication on regular two-dimensional arrays are studied. From the studies, the authors are able to design many efficient varieties of the cylindrical array and the two-layered mesh array for matrix multiplication.
表 3-2 詞性標記處理結果 # Token (Prob:Tag)* 0 Some 1 combinatorial 2 characteristics 3 of 4 matrix 5 multiplication 6 on 7 regular 8 two-dimensional 9 arrays 10 are 11 studied 12 . 13 From 14 the 15 studies 16 , 17 the 18 authors 19 are 20 able 21 to 22 design 23 many 24 efficient 25 varieties 26 of 27 the 28 cylindrical 29 array 30 and 31 the 32 two-layered 33 mesh 34 array 35 for 36 matrix 37 multiplication 38 . 0.991:dti 0.973:jj 0.995:nns 1.000:in 1.000:nn 1.000:nn 0.997:in 1.000:jj 1.000:jj 0.992:nns 1.000:ber 0.999:vbn 0.797:. 1.000:in 1.000:at 1.000:nns 1.000:, 1.000:at 1.000:nns 1.000:ber 0.999:jj 0.954:to 0.953:vb 0.951:ap 0.985:jj 1.000:nns 1.000:in 1.000:at 1.000:jj 1.000:nn 1.000:cc 1.000:at 0.985:jj 0.898:nn 0.999:nn 0.994:in 1.000:nn 1.000:nn 0.988:. 0.007:rb 0.027:nn 0.005:nn 0.000:jj 0.000:nns$ 0.000:vb 0.003:rp 0.000:nn 0.000:nn 0.007:nn 0.000:nn 0.001:vbd 0.066:np 0.000:np$ 0.000:jj 0.000:nn 0.000:rb 0.000:jj 0.000:nn 0.000:vb 0.001:nn 0.046:in 0.047:nn 0.025:abn 0.015:nn 0.000:vbz 0.000:rb 0.000:jj 0.000:nn 0.000:np 0.000:vb 0.000:vb 0.015:vbn 0.101:jj 0.001:vbd 0.006:cs 0.000:nns$ 0.000:vb 0.007:np 0.001:ql 0.000:nns 0.000:jj 0.000:nn 0.000:jj 0.000:vbd 0.000:nn 0.000:rb 0.000:nns 0.000:np 0.000:vb 0.000:jj 0.059:rb 0.000:np 0.000:dts 0.000:nps 0.000:wpo 0.000:vb 0.000:nn$ 0.000:ql 0.000:vb 0.000:nn 0.000:jj 0.023:ql 0.000:rb 0.000:nn 0.000:rp 0.000:ql 0.000:nn$ 0.000:jj 0.000:nn 0.000:jj 0.000:nns$ 0.001:vb 0.000:vbn 0.000:nn 0.000:jj 0.000:jj 0.002:nn 0.000:np 0.000:nn$ 0.000:vbz 0.000:rb 0.000:vb 0.000:jj 0.000:ql 0.000:nns 0.000:vbg 0.000:vbz 0.000:rb 0.000:rb 0.039:nn 0.000:rb 0.000:nn 0.000:vbz 0.000:in 0.000:dts 0.000:nns$ 0.000:jj 0.000:nns 0.000:jj 0.000:vbz 0.000:jj 0.000:nns 0.000:nps 0.000:vb 0.000:dts 0.000:nns 0.000:vbn 0.000:rb 0.000:ql 0.000:nn 0.000:np 0.000:vb 0.000:jj 0.000:vb 0.000:vbd 0.001:rb 0.000:vb 0.000:nns$ 0.000:rb 0.000:vbg 0.000:np$ 0.000:vbn 0.000:cs 0.000:ql 0.000:rb 0.000:nps 0.000:ql 0.000:ql 0.026:nns 0.000:nr$ 0.000:np 0.000:nns$ 0.000:abl 0.000:nn 0.000:nps 0.000:rb 0.000:vbn 0.000:nn$ 0.000:vbg 0.000:rb 0.000:vb 0.000:np 0.000:vbd 0.000:pp$$ 0.000:np$ 0.000:vb 0.000:vbd 0.000:pps 0.000:vbg 0.000:nns$ 0.000:np 0.000:rb 0.000:np$ 0.000:vbn 0.001:nns
3.1.4 片語化
英文句子是由有意義的語意單位所組成,以單一字彙在語意判斷上是不足夠 的,後續在建立語意關聯時,必須統計字詞出現的頻率,若沒有經過片語化會把 字面相同但是意義不同的單字計算在一起,這樣就無法區分出語義的歧異(WordSense Ambiguity),故需將單一字彙組合成片語以表達正確的語意。片語化同樣 採用LingPipe NLP Toolkit進行實作。以圖3-1的原文範例進行片語化,其結果如 表3-3所示。 表 3-3 片語化處理結果 POS Phrase noun noun noun verb noun noun verb noun noun noun noun combinatorial characteristics matrix multiplication
regular two-dimensional arrays studied. studies author design efficient varieties cylindrical array two-layered mesh array matrix multiplication
3.1.5 詞幹還原
詞幹轉換即是去除型態學(Morphology)上的詞類型態變化,英文時常因為時 態或是句型文法變化將字詞的字尾形態改變,當進行資料擷取時,形態變化會導 致無法凖確地計算字詞出現的頻率,進而影響字詞相關度的計算結果。詞幹轉換 便是將經過變形的字尾以統一的結尾表示。本研究採用Porter演算法[39]進行詞 幹轉換。3.1.6 特徵選擇
本研究以向量空間模型(Vector Space Model)來代表個別使用者與關鍵字之 關聯,每一個單一的字詞都代表向量空間的一個維度(Dimension),沒有經過特徵 選擇的過程,將造成相當高維且稀疏的向量空間,在分群過程中耗費時間在處理 不具代表性或甚至是無意義的字詞上,同時也可能降低重要字詞的顯著性。故本 研究依據下列幾項規則對字詞進行過濾及篩選,以達到維度縮減(Dimension
Reduction)[7]的目的: 1. 僅保留名詞與名詞片語為侯選關鍵字。 論文中的主題概念通常以名詞或名詞片語表示,故本研究中僅保留名詞 與名詞片語為侯選關鍵字。 2. 移除在語料庫出現次數過多的字詞。 當一個字詞在語料庫內經常出現時,幾乎可以確定此字詞屬於過於常見 且不具有代表性之字詞。本研究將出現次數定義為出現該字詞的文章篇數, 且出現次數的上限為語料庫內文件篇數的10%。 3. 移除在語料庫出現次數過少的字詞。 若一個字詞出現的次數太少,則此字詞幾乎可以確定不適合用以表達文 件的概念。本研究訂定出現次數的下限為3次。
3.2 主題關鍵字分群
在主題關鍵字分群過程中,依據圖形理論(Graph Theory)將關鍵字及語意關 係建立語意網路圖,進行過濾及分群,以達到主題概念萃取的目的。主題概念萃 取的方法為將2.1.3節中所提之主題關鍵字分群(Topic Keyword Cluster)[9]演算法 加以修改,以符合本研究的需要。
3.2.1 使用者模型
在資訊檢索的領域中,最常使用TF-IDF(Term Frequency-Inverse Document Frequency)來評估詞彙在文件中的重要性。計算公式如方程式(3-1)所示。TF指的 是某一字詞在一篇文件或資訊內容中出現的頻率,當TF值愈高時,代表該文件 與此字詞的關聯性愈高;IDF為在全部文件中有多少文件包含此一字詞之倒數, IDF值愈高則此字詞愈能代表此文件。經由TF-IDF判斷文件與字詞的相關屬性, 可以進一步瞭解文件所代表的概念,藉由相似度的計算,可以達到文件分群的效 果。 2 log
frequency of term in the document of documents
: of documents that contain the term
ij i ij i ij i N tf idf freq n freq i j N n i − = × − : : # # 本研究的目的在於發掘使用者感興趣的主題,以及達到使用者分群的效果, 為此,採用TF-IAF(Term Frequency-Inverse Author Frequency)[30]來衡量使用者與 關鍵字間的關聯,並且利用相似度的計算,達到使用者分群的目的。其計算如方 程式(3-2)所示。TF指某一字詞在與使用者相關文件中出現的頻率,當TF值愈高 時,代表使用者與該字詞的關聯性愈高;IAF為全部使用者中,有多少使用者曾 經使用過此一字詞之倒數,IAF值愈高則此字詞愈能代表使用者。在計算完 TF-IAF之後,則每個使用者皆可以向量的形式來呈現,如方程式(3-3)所示。 (3-1)
2
1 2
frequency of term associated with author of authors
log
: of author that use the term
( , , ..., ) , if term is as ij i i i i ij ij i j j j mj ij i ij tf freq i j N N iaf n i n w tf iaf U w w w tf iaf i w = − : # ⎧ = − ⎨ # ⎩ = × = ×
− = sociated with author
, otherwise : #of keywords j m ⎧ ⎨ 0 ⎩ −
3.2.2 計算語意相關度
在計算語意相關度時,以「共現」(Co-occurrence)原則來判斷兩個關鍵字之 間是否具有語意關係,首先需要訂出一個範圍,在這個範圍內出現的關鍵字才具 有語意相關性。本研究以句子為範圍,即當兩個關鍵字在同一個句子內出現才表 示其具有語意相關性。 由於本研究採用論文為資料來源,根據論文的特性,標題與關鍵字通常是表 達文件的主題概念,出現於標題與關鍵字欄位中之字詞往往具有較重要的語意關 係,故在計算關鍵字間語意相關度時,透過增加此類關鍵字之權重來強化其代表 性,如方程式(3-4)所示。計算出語意相關度之後,並對其進行篩選,門檻值為所 有語意相關度的平均,只取大於門檻值的語意關係。1 , if term & term are both in title or keyword
( ) , otherwise max{ ( ), ( )} i j ij i j i j f t t r f t f t ⎧ ⎪ = ⎨ ⎪ ⎩ I
3.2.3 建立語意網路圖
根據圖形理論之原理,每個關鍵字都可表示為一個點,點權重為個別關鍵字 在使用者間TF-IAF值的加總,再加上該關鍵字所有語意相關度平均。如方程式 (3-5)所示,關鍵字間的關係表示成一個邊,邊權重即為關鍵字的語意相關度,如 (3-2) (3-3) (3-4)1 1
of authors
: the degree of vertex
N i j ij h ij j i i i w w r CW w h N h v = = = = + − : # −
∑
∑
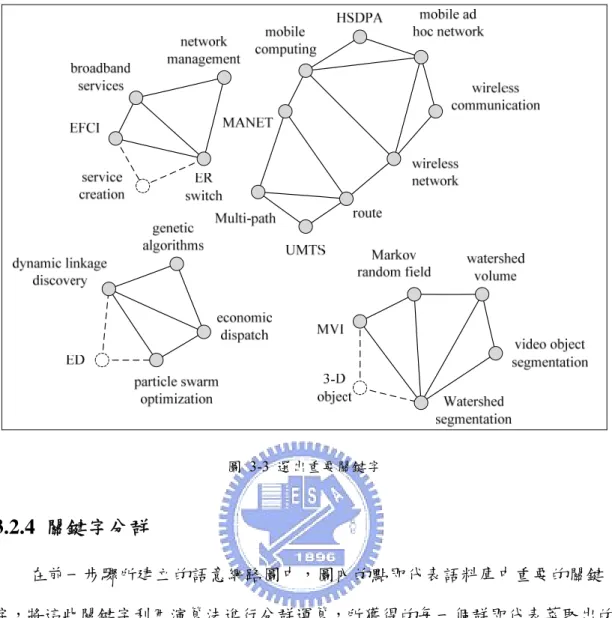
得到基本的語意網路圖後,依照下列的步驟對此網路圖進行處理: 1. 移除網路圖內不重要的邊 對網路圖內的邊進行刪減,取門檻值為網路圖內所有語意關係度的平 均,刪除小於門檻值的連線,將原本的網路圖修正為稀疏網路圖。如圖3-2 所示。 圖 3-2 稀疏網路圖 2. 移除稀疏網路圖內不重要的點 在移除不重要的邊之後,接著移除稀疏網路圖中不重要的點,將門檻值 訂為所有點權重的平均,移除小於平均值的點。如圖3-3所示。 (3-5)圖 3-3 選出重要關鍵字
3.2.4 關鍵字分群
在前一步驟所建立的語意網路圖中,圖內的點即代表語料庫中重要的關鍵 字,將這些關鍵字利用演算法進行分群運算,所獲得的每一個群即代表萃取出的 一種主題概念,此步驟在本研究中稱之為主題萃取,將重要的步驟詳述如下:
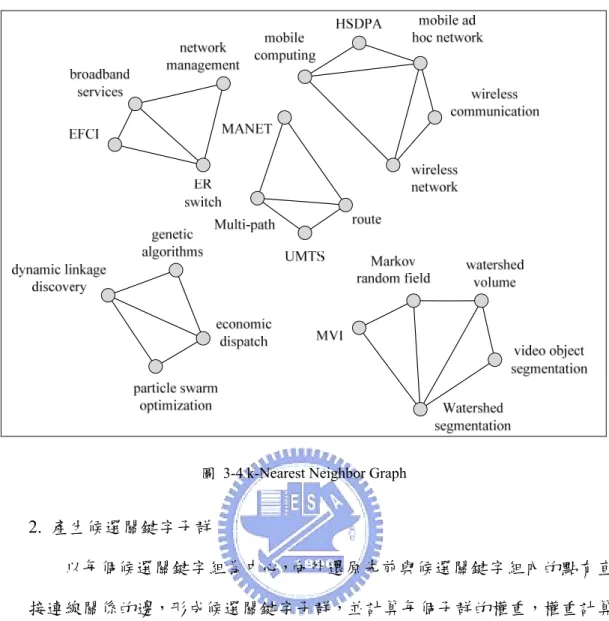
1. k-Nearest Neighbor Approach [19]
考慮圖中的每個點,取與該點最相近的k個點為一組,每組都為一個連 通圖(Connected Graph),本研究稱之為候選關鍵字組。如圖3-4所示。k值的 選擇會影響分群數目的多寡,當k值愈大,群數便會愈少,而每一群包含的 關鍵字也會較多,但當群內的關鍵字數量過多時,反而無法表達出清楚的主 題概念,降低重要關鍵字的代表性。
圖 3-4 k-Nearest Neighbor Graph 2. 產生候選關鍵字子群 以每個候選關鍵字組為中心,向外還原先前與候選關鍵字組內的點有直 接連線關係的邊,形成候選關鍵字子群,並計算每個子群的權重,權重計算 方式為該群內所有邊權重的總和,如方程式(3-6)所示,Gk表示某一候選關鍵 字組k,rij則是Gk內包含的語意關係。 k ij k G r G ij W =
∑
∈ r 3. 合併候選關鍵字子群 產生候選關鍵字子群之後,找出互連性(Inter-connectivity)最強的兩個子 群將之合併,直到子群間的互連相關度(Relative Inter-connectivity)都小於門 檻值後停止。互連性強度的判別是依據兩個候選關鍵字子群的互連相關度來 計算,計算方式為連接兩個子群的邊之權重總和再除上兩個子群的權重總 和,如方程式(3-7)所示,當兩個子群有交集的邊具有相當程度關係時,即將 (3-6)之合併。如圖3-5所示。 ( , ) | | ( , ) | | | | i j i j E G G i j G G W RI G G W W = + 圖 3-5 合併關鍵字子群 4. 修正並產生主題關鍵字分群 合併候選關鍵字子群之後,子群內關鍵字的個數會有不同,此現象將 會影響分群的正確性,因此本研究希望每個子群內的關鍵字個數保持在一定 的差距內。故當子群內的關鍵字個數大於平均個數時,則移除與該群最不相 關,即點權重最小的關鍵字。 若是子群內包含的關鍵字比平均個數少,但是子群權重卻大於平均權重 時,表示此群內包含重要的關鍵字關係,故將該群保留;若子群經修正後仍 小於平均權重,則表示該群內的沒有重要的關鍵字關係,故將該群直接刪 除。子群權重的計算方法如方程式(3-8) ~(3-10)所示,利用每個子群之邊權 (3-7)
子群內的邊個數除以該子群可能最大邊數,如方程式(3-8)所示。邊權重的計 算方式如方程式(3-9)。 | ( ) | ( ) (| ( ) | | ( ) 1|) / 2 ( ) | ( ) | ( ) ( ) ij ij r G E G CD G V G V G r AS G E G CW CD G AS G ∈ = × − = = ×
∑
以圖3-6為例,{ER switch, broadband services, EFCI, network management} 包含四個關鍵字,{HSDPA, mobile ad hoc network, mobile computing,
MANET, wireless network, wireless communication, route, Multi-path, UMTS} 一共包含九個關鍵字,{genetic algorithms, dynamic linkage discovery, particle swarm optimization, economic dispatch}包含四個關鍵字,{Markov random field, MVI, watershed volume, Watershed segmentation, video object
segmentation}則包含五個關鍵字,每群的平均個數為(4+9+4+5)/4=5.5,表示 每個子群最多只能包含五個關鍵字。因此需將包含關鍵字MANET的子群進 行修正,依序將不重要的關鍵字HSDPA、Multi-path、UMTS及wireless communication移除,以達到平衡子群內關鍵字個數的目的。若是子群內包 含的特徵少,但是子群權重卻大於平均權重時,表示此群內包含重要的關鍵 字關係,故將該群保留;反之,若子群經修正後仍小於平均權重,則表示該 群內的沒有重要的關鍵字關係,故將該群直接刪除。 (3-8) (3-9) (3-10)
圖 3-6 修正關鍵字子群
3.2.5 關鍵字分群標記
標記之目的是為了讓使用者能夠快速且容易瞭解每一個分群所代表的主題 概念,表3-4為主題分群標記之範列。由觀察得知名詞及名詞片語較能表達群的 主題概念,且名詞片語的重要性又大於名詞。故本研究依照下列兩項規則來挑選 主題概念: 1. 利用人力過濾出有意義的關鍵字; 2. 取權重最高的關鍵字做為最後的群標記。表 3-4 關鍵字分群標記範例
Topic label Keywords Associate weight
Mobile Computing
MANET
mobile ad hoc network route mobile computing wireless network 351.1895 152.5828 140.446 126.5852 95.5504 Genetic Algorithm genetic algorithm
dynamic linkage discovery particle swarm optimization GA economic dispatch 97.3025 66.415 53.332 41.3458 27.0827 Semantic Query Metadata Semantic query Digital library Structure clustering Structure expression 53.2695 40.1823 27.066 27.041 26.966 Neural Network neural network optimization problem constraint energy function 72.7728 49.7963 43.1446 38.9312 Watershed Segmentation watershed volume Watershed segmentation multiview images Markov random field 3-D model 82.466 78.002 66.1728 47.2012 33.5364 Parallel Algorithm Matrix Multiplication cylindrical array Parallel algorithms two-layered mesh array regular arrays 62.054 53.2935 49.8796 38.9645 38.6312
3.3 建立主題社群
在前一小節萃取出主題概念後,利用餘弦相似度計算使用者向量與各主題分 群的相似度,進而產生對特定主題感興趣的使用者社群,其目的在於發掘出具有 相同興趣的使用者,藉由分析或預測使用者的喜好,推薦使用者感興趣的論文清 單。 在建立使用者主題社群的同時,不僅僅專注於個別使用者的關鍵字分佈與主 題興趣,也把社會網路的互動關係對使用者的影響考慮進來,經由分析使用者的 社會網路,來衡量使用者間的相關係數,進而調整使用者與關鍵字的關聯。3.3.1 使用者社會網路
社會網路會由不同的觀察角度,產生不同的結果。採用研究論文為資料來源 時,通常經由共同作者或共同引用兩個角度來發掘社會網路。本研究是藉由分析 使用者間的共同作者關係建立使用者的社會網路。在衡量使用者社會網路時,採 用Shah[24]所提出之方法,利用Jaccard coefficient來計算使用者相關係數。首先 將使用者與文件之間的關係以矩陣W表示,如方程式(3-11)與圖3-7所示。1, if user is one of the authors in document 0 , otherwise ij i j W = ⎨⎧ ⎩ 0 1 0 1 0 1 1 1 1 0 1 0 W ⎡ ⎤ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ 圖 3-7 使用者與文件之關係矩陣 接著以S=W×WT表示使用者的共同作者關係,矩陣元素Sij代表使用者間 共同發表的論文篇數。如圖3-8 所示。 (3-11)
0 0 1 0 1 0 1 2 2 0 1 1 0 0 1 1 1 2 3 1 0 1 1 1 0 1 0 0 1 2 1 1 0 T S W W ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ = × =⎢ ⎥× =⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ 圖 3-8 使用者共同作者矩陣 隨後利用Jaccard coefficient 來計算使用者間的相關程度,即將矩陣 S 中的元 素Sij除以|Wi|+|Wj|-Sij(|Wi|表示使用者 i 所撰寫的文章篇數),如方程式(3-12)所 示;則使用者間的社會網路關係可以圖3-9 表示。 | | | | ij ij i j ij S J W W S = + − 2 2 0 2 3 1 0 1 2 ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ 2 1 0 3 2 1 1 3 4 1 0 1 4 ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ 圖 3-9 使用者社會網路 為了避免透過使用者社會網路對使用者本身的影響程度過大,對矩陣S 中的 Jaccard coefficient 作一調整,並且以矩陣 R 代表調整後的使用者相關係數,如方 程式(3-13)所示。調整係數 α 為一介於 0 與 1 之間的值,當 α 愈接近 0,則代表 使用者間互相影響的程度較小,反之則影響較大。 1 , if , otherwise : 0 1 ij ij i j R J α α α = ⎧ = ⎨ ⋅ ⎩ − < <
3.3.2 使用者分群
使用者分群的依據是使用者對主題分群間的相似度來衡量。也就是說當使用 者和特定主題分群關鍵字有較多的對應關係,代表使用者對此主題的偏好也會較 (3-12) (3-13)大,於是本研究透過相似度的計算,將使用者歸類到相似度較高的主題,以達到 使用者分群的目的。 將所有使用者向量模型以N×m的矩陣U表示,N代表使用者數目,m代表所 有關鍵字數目,矩陣U中每一行可表示個別使用者與關鍵字間的關聯。利用代表 使用者間相關係數的矩陣R,乘上以使用者向量模型構成的矩陣U,形成一新的 矩陣U’代表更新後的使用者向量模型,如圖3-10所示。 11 12 1 21 22 2 1 2 ... ... U= ... m m N N Nm w w w w w w w w w ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ M 11 12 1 11 12 1 11 12 1 21 22 2 21 22 2 21 22 2 1 2 1 2 ... ... ' ' ... ' ... ... ' ' ... ' U'= ... ... N m m N m m N N NN N N Nm R R R w w w w w w R R R w w w w w w R R R w w w ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢× ⎥= ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ M M 1 2 ' ' N N ... ' Nm w w w ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ M 圖 3-10 更新使用者向量模型 接著利用餘弦相似度,計算使用者向量模型與個別主題的相似度,如方程式 (3-14)所示。當使用者與主題間的相似度大於門檻值時,則認為使用者對此主題 具有相當程度的偏好,於是將其歸類到該主題。表3-5為使用者分群之範例。 1 2 3 1 2 ' ( ' , ' , ..., ' ) where 1, 2, ..., ' : the weight of keyword associated with user : # of users : # of keywords ( , , ..., ) where 1, 2, ..., , if ke j j j j ij k k k km km U w w w j N w i j N m C t t t k p t = = − − − = = 1 − =
(
)
(
)
(
)
{
1 2}
yword , otherwise : # of clusters , , , , ..., , 1, 2, ..., ; 1, 2, ..., k jk j j j k i C pSU sim U C sim U C sim U C
∈ ⎧ ⎨ 0 ⎩ − = = = (3-14)
表 3-5 使用者分群範例
Topic Name Weight
Mobile Computing Yuh-Shyan Chen Yen-Ku Liu Bing-Rong Lin Chi-He Chang Chi-Ming Hsieh 0.7314 0.7291 0.7291 0.7105 0.6993 Genetic Algorithm Ying-Ping Chen Ming-Chung Jian Wen-Chih Peng Ying-Hong Liao Ming-Da Wu 0.881 0.881 0.7508 0.5302 0.4556 Semantic Query Su-Hsien Huang Wei-Pang Yang Hao-Ren Ke Jen-Yuan Yeh I-Heng Meng 0.9532 0.7021 0.6059 0.4986 0.3326 Neural Network K. T. Sun J. J. Shann Jyh-Da Wei Y. S. Sun C. -C. Chuang 0.9476 0.5939 0.4999 0.4945 0.4945 Watershed Segmentation Yu-Pao Tsai Yi-Ping Hung Zen-Chung Shih Yao-Xun Chang Cheng-Hung Ko 0.8418 0.8418 0.8384 0.8367 0.8268 Parallel Algorithm Jong-Chuang Tsay Yeh-Chin Ho Pen-Yuang Chang Sy Yuan 0.901 0.9001 0.8521 0.7446
3.4 推薦模式
建立使用者社群之後,在個別社群中的成員,都具有相似的主題興趣,但是 由於多重主題(Multiple Topics)[9]的屬性存在,使得一個使用者可能對多種主題 都具有偏好。表3-6為使用者多重主題之範例。有鑑於此,本研究的推薦模式分 為個人化推薦與社群推薦等兩種,茲分述如下: 1. 個人化推薦 依據內容導向方法,對使用者進行論文推薦,即計算社群內成員所撰寫 的論文與個別成員的相似度,選取相似度最高的n篇論文給予推薦,同時排 除使用者本身所撰寫的論文。 2. 社群推薦 由於多重主題屬性的存在,可以透過分析社群成員對其他主題的興趣分 佈,統計出具有較高偏好比重的主題,推薦與該主題最相關的n篇論文給使 用者。 表 3-6 使用者多重主題範例Name Interest Topic Preference
Yi-Bing Lin Mobile Computing End-to-end Security 0.5774 0.1713 Ying-Dar Lin TCP PIM-SM Network Management Routing Protocol Bandwidth Requests 0.4739 0.46 0.3425 0.2674 0.2569 Hsin-Chia Fu SPDNN Neural Network Divide-and-conquer Learning 0.6769 0.4515 0.2448 Hao-Ren Ke Semantic Query Memory Cache Content Management 0.6059 0.4898 0.469 Wen-Chih Peng Genetic Algorithm
Mobile Computing 0.7508 0.1628 Yuan-Cheng Lai TCP Routing Protocol Network Management 0.6945 0.3787 0.3073

![圖 2-6 Topic Keyword Cluster主要步驟[9] 5. 修正關鍵字分群結果及文件分群 在合併候選關鍵字子群的過程中,會造成每一群包含的關鍵字個數產生 差距,進而影響文件分群的正確性,因此需要將每個子群內的關鍵字保持在 一定的差距內,當子群內的關鍵字數目大於平均關鍵字數目時,則依序移除 點權重最小的關鍵字。關鍵字子群修正完成後,將文件與每一個關鍵字群以 餘弦相似度(Cosine Similarity)計算相似度,並將文件對應至相似度最高的關 鍵字子群中,以達到文件分群的目的。相似度計](https://thumb-ap.123doks.com/thumbv2/9libinfo/8473922.183655/23.892.206.668.132.720/鍵字子群每一群包含每個子內當子移除鍵字子每一個關鍵鍵字子以達.webp)