IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 2.5, NO. 5 , MAY 1995 791
Document Retrieval Using Knowledge-Based
Fuzzy Information Retrieval Techniques
Shyi-Ming Chen, Member, IEEE, and Jeng-Yih Wang
Abstract-A knowledge-based approach for fuzzy informa- tion retrieval is proposed, where interval queries and weighted- interval queries are allowed for document retrieval. In this paper, knowledge is represented by a concept matrix, where the elements The implicit relevant values between concepts are inferred by the transitive closure of the concept matrix based on fuzzy logic. The proposed method is more flexible than the ones presented in [61 and [11] due to the fact that it has the capability to deal with interval queries and weighted-interval queries.
The rest of this paper is organized as follows. In Section 11, we briefly review the theory of fuzzy sets. In Section 111, the concepts of concept networks are introduced. closure of the concept matrices are presented for knowledge representation. In Section V, we present the query processing techniques for fuzzy information retrieval. The conclusions are discussed in Section
in a concept matrix represent relevant values between concepts. Section IV, the concepts Of concept matrices and the transitive
I. INTRODUCTION
HE PRIMARY purpose of establishing an information
T
retrieval system lies in assisting the users to efficiently acquire desired information. Current models of information re- trieval systems may be classified into the following categories [IS]:1) Boolean logic models. 2) Vector space models. 3) Probabilistic models. 4) Fuzzy set models.
Most commercial information retrieval systems currently still adopt the Boolean logic model. However, the information retrieval systems based on the Boolean logic model are rather restricted in applications since these systems are unable to rep- resent uncertain information. If there is uncertain information, the query processing of these systems is not handled properly. Several fuzzy information retrieval methods based on fuzzy set theory [21] have been proposed for improving the dis- advantage of the Boolean logic model which is incapable of handling uncertain information, such as [6], [ I 1]-[151, [191, 1201, and [22]. However, either efficiency or effectiveness of these methods are not satisfactory. In this paper,we propose a knowledge-based fuzzy information retrieval method to deal with documents retrieval, where the concept matrices are used for knowledge representation. The elements in a concept matrix represent relevant values between concepts. The implicit relevant values between concepts can be inferred by the transitive closure of the concept matrix based on fuzzy logic [21]. The proposed method allows the system's users to perform interval queries and weighted-interval queries. Efficient retrieving capability and flexible user's queries are consequently provided for.
Manuscript received August 27, 1993; revised July 3 . 1994. This work was
supported by the National Science Council, Republic of China, under Grant NSC 83-0408-E-009-04 1.
The authors are with the Department of Computer and Information Science,
National Chiao Tung University, Hsinchu, Taiwan, Republic of China. IEEE Log Number 940922 I .
11. FUZZY SET THEORY
The theory of fuzzy sets was proposed by Zadeh in 1965 [21]. Let U be the universe of discourse,
U
={ul. 112, . . . . ? i n } . and let A be a fuzzy set in
U.
then the fuzzy setA
can be represented as:where ,f.a. f.4 : U + [O. 11. is the membership function of the fuzzy set A: f A 4 ( u , ) indicates the degree of membership of ut in
A.
If the universe of discourse
U
is a finite set, then the fuzzy setA
can be expressed as follows:If the universe of discourse U is an infinite set, then the fuzzy set A can be expressed as:
Let f.4 and f~ be the membership functions of the fuzzy sets
A
and B , respectively. The basic operations of fuzzy setsA
and
B
are shown as follows: 1 ) Intersection:2) Union:
3) Complement:
794 IEEE TRANSACTIONS ON SYSTEMS, MAN. AND CYBERNETICS, VOL. 25, NO. 5 , MAY 1995
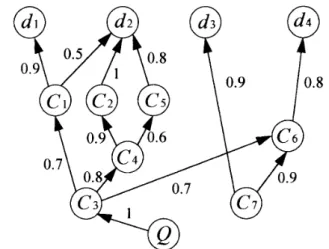
Fig. 1. A concept network
111. CONCEPT NETWORKS
In 1111, concept networks have been proposed for fuzzy information retrieval. A concept network includes nodes and directed links. Each node represents a concept or a document. Each directed link connects two concepts or directs from one concept Ci to one document d j and is labeled with a real value between zero and one. If C;
2
C j . then it indicates that the degree of relevance from concept Ci to concept Cj is p , where pLt [0,11.
If C, A d , , then it indicates that the degree of relevance of document d, with respect to concept Ci is p. where pG [0, 11. Fig. 1 shows a concept network which is adapted from [ I l l , where C1,C2. . . . ; and C7 are concepts; d l , dp. d g . and d4 are documents. From Fig. 1, we can see that document d2 can be expressed as a fuzzy subset of concepts, whered2 = {(Ci? 0.5); (Cz, I ) , ( C ~ ~ 0 . 8 ) ) . Let C be a set of concepts, C = {Cl,C2 :... C,,}. A concept network is assumed to consist of n nodes and some directed links. Let the value associated with the directed link form concept C; to concept C, be denoted by F ( C ; . (3,); where F is a mapping function,
F
: C x C + [O, 11, and F ( C ; , C,) E [0,1]. If the relevant value from concept C; to concept C, is F ( C z , C ] ) , and if the relevant value from concept C, to concept CI; is F(C,. C k ) . then based on the transitivity of link relationships, the relevant value from concept C; to concept CI; can be obtained by the following expression:F ( C z . C,) = Miri ( F ( C ; , C j ) . F(C,. C I ; ) ) . (7)
Similarly,ifF(Cl,Cp),F(C2,C,)
:... andF(C,-l.C,,) areknown, then based on the transitivity of relationships, we can get
F ( C I , C , , ) = M i r i ( F ( C l . C p ) . F ( C p . C , ) . . .
F(Cn-1: C n ) ) . (8)
Each document has a different relevant value with respect to each concept. The document descriptor for the document d, is defined as a fuzzy subset of the collection of concepts
Fig. 2. A concept network of Example 3.1
by the following expression:
d, = {(C7.fd,(Ci))lCz E C } ,
where f d J ( C ; ) , f d , : C 4 [0,1], represents the degree of
relevance of document d j with respect to concept Ci. Each user’s query can be represented by a query descriptor Q expressed as a fuzzy subset of the collection of concepts by the following expression:
62
= { ( C i ,f~(Ci))lCi
E C ) ,where ~ Q ( C ; ) . f~ : C + [0: 11, represents the relevant value of the query descriptor Q with respect to the concept Ci.
Example 3.1: Assume that the concept network shown in Fig. 2 consists of 4 documents d l , dz. d3: dq, and 7 concepts C1,C2;...C7.
If the query descriptor Q is:
Q
={(G.
1.0)},where 1 .O represents the relevant value of the query descriptor Q with respect to the concept C,, then the relevant value of document d2 with respect to concept C, can be calculated. From Fig. 2 , we can see that there are three different routes which can be applied for determining the relevant value of document d p with respect to the concept C3.
I ) The first route is: C, + C1 + dp.
respect to concept C, can be determined as follows: Miri (0.7.0.5) = 0.5.
Based on [ 111, the relevant value of document d2 with
2 ) The second route is: C g + C, --f C2 + d p .
Based on [ 111, the relevant value of document d2 with respect to concept C, can be evaluated as follows:
Min (0.8.0.9. 1) = 0.8 3) The third route is: C, + C, + Cj + dp.
respect to concept C, can be evaluated as follows: Based on [ 1 I], the relevant value of document d2 with
CHEN ANI> WANG. DOCUMENT RETRIEVAL USING KNOWLEDGE-BASED FUZZY INFORMATION RETRIEVAI. TECHNIQUES 795
Then, based on I l l ] , we can see that the relevant value of the document (12 with respect to the concept C, is:
Dejinition 4.2: Let M be a concept matrix,
Max (0.5. 0.8.0.6) = 0.8.
M = The reasoning procedure should be repeated n times if
there are n documents. If compound queries (i.e., queries with AND connectors or OR connectors) are used instead of simple queries, the reasoning process would slow down and become inefficient. As a result, once practically implemented, the concept network approach presented in I l l ] would have its limitations and would consequently be unable to satisfy the requirements of most users in terms of speed. Furthermore, in a concept network presented in [ 111, relevant values associated with directed links must be real values between zero and one. However, if we can allow them to be represented by real intervals between zero and one, then there is room for more flexibility. In this paper, we allow relevant values associated with directed links in a concept network to be represented by real intervals between zero and one.
IV. CONCEPT MATRICES
In this section, the definitions of concept matrices are presented to model the concept networks presented in [ 1 I ] . The definitions of concept matrices and the transitive closure of the concept matrices are described as follows.
Dejinition 4.1: Let C be a set of concepts, C =
{Cl. C2. . . . . C,,
}.
A concept matrixM
is a fuzzy matrix IS];M ( C , . C,) represents the relevant value from the concept C; to the concept C,. where M(Cj.C,) E [O. 11.
A concept matrix M has the following properties: 1) Reflexivity,
n / l ( C / . C / ) = 1. VCI E c 2) M may not be symmetric,
M ( C , . C,)
#
M(C,. C , ) . ..fll .f12 “ ’ f l f l f 2 1 f 2 2 ‘ . . . f 2 n . . . . . . . . ..
. . . . . - f n 1 f n 2 ‘ ‘ ’ f n nwhere rI is the number of concepts, f l , E [O. 11. 1
I
1I
n. and 1I
J5
n. and let (see (9) at the bottom of the page), where “V” represents the Max operation, and “A” represents the Min operation. Then, there exiqts an integer p5
rt - 1.such that 11.1” = MP+l = Mp+’ = . . t (please see [8, p.
1171). Let T = MP, 7’ is called the transitive closure of the concept matrix M .
Sometimes, the relevant value between concepts may hardly be represented by a crisp real value between 0 and 1. In this case, the relevant value between concepts can be represented by a real interval [f,“,
.
f3]
between 0 and 1 to describe the relevant value from concept C, to concept C,. where 0I
s,“,
I
fh
I
1.Dejnition 4.3: Let M be a concept matrix,
‘ 1
[ f ~ 2 l . f , / i 2 1 . . . [ f ! z n . f ; ; n ~
. . .
where [f:,.
f;:]
indicates the relevant value from concept C , to concept C,. 0I
j:]I
ft
I
1.15
/I
7 1 . 15
,I5
r i . andri is the number of concept, and let (see ( I O ) at the bottom of the next page), where “V” represents the Max operation and “A” represents the Min operation.Then, there exists an integer p
I
71 - 1, such that Mr’ = A P + l = = . . . .Let T = M p . T I S called the transitive closure of the concept
matrix M .
V. QUERY PROCESSING TECHNIQUES
3) Transitivity, Let
I‘
be a set of documents, I‘ = ((11. d 2 . . . ..
&}.
andC be a set of concepts, C =
{
C1. C2. . . ..
C,,}. A document in a document retrieval system is generally described by a set of concepts with each concept representing a topic. The M ( C ; . C,)2
+lax Aliri [ M ( C , .C,).
M(C,. C y k ) ] .796 IEEE TRANSACTIONS ON SYSTEMS. MAN, AND CYBERNETICS, VOL. 25, NO. 5 , MAY 1995
relations between documents and concepts can be represented by a document descriptor matrix D shown as follows:
c1 c2 . "
c,,
(11
t l l t 1 2 ' . . t l r i . . . . . . D = . . . $ I n t,l tm2 " 'where rn is the number of documents, n is the number of concepts,
t,,
represents the degree of relevance of document d, with respect to concept C,,t,,
E [O, 11.15
i5
7 u . and1
5
j5
71.In a document descriptor matrix D. the degree of relevance of each document with respect to a specific concept is deter- mined by experts. However, an expert may possibly neglect the degree of relevance of certain documents with respect to some specific concepts. Because concepts may be not independent from each other, the transitive closure T of the concept matrix M can be used to evaluate the implicit relevant values of each document with respect to specific concepts to improve this. Let
D"
= D @ T , where D is the document descriptor matrix and T is the transitive closure of the concept matrixM .
The document descriptor matrixD*
indicates the degrees of relevance of each document with respect to specific concepts, and is used as a basis for similarity measures between queries and documents as described later.Based on the vector representation method 111. the query descriptor Q can be represented by a query descriptor vector q . i.e.,
- .
where 2 , E [O. 11.1
5
i5
n. indicates the degree of strength that the desired documents contain concept C,. In a query descriptor vectorI.
if .rl = 0. then it indicates that documents desired by the user must not contain the concept C,. Furthermore, if the user considers that certain concepts may be neglected, then the user does not have to assign the degrees of strength with respect to such concepts in the query descriptor vector ij. The symbol "-" is used for labeling aneglected concept. Therefore, if z; = "-". then it indicates that concept C , is a neglected concept. In this case, the concept C; would not be considered in the document retrieval process.
Example 5.1: Assume there are five concepts in a fuzzy information retrieval system, and assume that a query descrip- tor I ) is specified to retrieve any document having a degree of strength of 0.6 with respect to concept C2. a degree of strength of 0.9 with respect to concept C,. and concept Cj excluded, i.e., Q = { ( C 2 . 0.6). (C4. 0.9), (Cs. 0 ) ) . Then, based on the vector representation method, the query descriptor Q can be represented by a query descriptor vector ij shown as follows:
-
(1 = (-. 0.6, -; 0.9.0).
In
IS],
a similarity measure was proposed for calculating thedegree of similarity between two real values. Let .c and y be two real values between zero and one. The degree of similarity between .cand y can be calculated by the function T . Le.,
( 1 1 ) T(z.:y) = 1 - 1.1;
-:()I,
where T ( x . y ) E [ O . 11. The larger the value of T(:I:. 71). the higher the degree of similarity between .c and y.
Let
&
be a document descriptor vector and (1 be a query descriptor vector, where-
d, = ( t j 1 . t i 2 . ' ' '
.
/L)q
= ( 2 ~ . : C 2 , " . . : I . , , ) .t i , E [O. 1].zj E [O. 11: 1
5
j5
/ I . I5
i
5
m. R is the-
number of concepts, and r n is the number of documents. Let q ( j ) denote the j t h component of the query descriptor vector
q.
Ifq(..i)
#
''2'. then it indicates that the concept Cj is a neglected concept with respect to the query. Then, the degree of similarity between the document descriptor vector;I;
and the query descriptor vector can be calculated as follows:where R S ( d , ) E [0,1]. and
k
is the number of not neglected concepts in the query descriptor vectorq.
The relevant values of neglected concepts can be eliminated from the computationCHEN AND WANG: DOCUMENT RETRIEVAL USING KNOWLEDGE-BASED FUZZ -1
1
1 0 0 0 0 - 0 1 0.4 0 0 0 0.8 0 0.4 1 0 0 0 0.5 0 0 0 0 1 0 0 . 9 0 0 0 0 0 1 0 . 7 -0 0.8 0.5 0 0.9 0.7 1 - -1 1 1 0 0 0 0 - 0 1 0.4 0 0 0 0.8 0 0.4 1 0 0 0 0.5 0 0 0 0 1 0 0.9 0 0 0 0 0 1 0.7 -0 0.8 0.5 0 0.9 0.7 1 - D = O 0 0 1 1 1 0 . M = 0 0 0 1 1 1 0 .:Y INFORMATION RETRIEVAL TECHNIQUES 197
-1 1 1 0 0.8 0.7 0.8- 0 1 0.5 0 0.8 0.7 0.8 0 0.5 1 0 0.5 0.5 0.5 T = 0 0.8 0.5 1 1 1 0.9 0 0.8 0.5 0 1 0.7 0.9 0 0.7 0.5 0 0.7 1 0.7 -0 0.8 0.5 0 0.9 0.7 1
-
of similarity since these neglected concepts are not necessary factors for the retrieval process.
A query expression can be subdivided into two types: 1 ) AND-connected queries: A query can be easily ex-
pressed by a query descriptor vector representing the “AND” connections of concepts. For example, consider the following query descriptor vector
q.
.
ij = (0.6.-. 0.5.0.7>-).
where the query descriptor vector ij means that the user wishes to retrieve any document containing the concepts C1, C,. and C4 having the degrees of strength of 0.6, 0.5, and 0.7, respectively.
2) OR-connected queries: A query expression is expressed by a number of query descriptors connected by OR connectors. For example, consider the following query expression:
(--,-.0.8.-.-) OR (--.0.7.-.-.-).
It indicates that the user wishes to retrieve any document possessing the concept C, having a degree of strength of 0.8 or possessing the concept C2 having a degree of strength of 0.7.
Consider the following OR-connected query:
the degree of similarity between the query descriptor vector
e
and the documents can be expressed by a 1 x r n matrixRS,.
where m is the number of documents, and 1
5
j5
2. The degree of similarity between the query and the documents can be calculated as follows:R S * ( d , ) = Max(RSl(d,).RS2(d7)). (13) where R S l ( I&) represents the degree of similarity between
the query descriptor vector
5
and the ith row of the docu- ment descriptor matrix D* . RS2 ( d i ) represents the degree of similarity between the query descriptor vector and the ith row of the document descriptor matrix D * . the retrieval status value RS*((1;)
represents the degree of similarity between the query and the document d ; , and 15
i5
r n . The information retrieval system would display every document having a retrieval status value greater than the threshold value A. where X E [O. 11. in a sequential order from the document with the highest retrieval Status value to that with the lowest one.Example 5.2: A concept matrix is assumed to be composed of seven concepts C1. C2. .
.
..
C7. and assume that there are seven documents in a fuzzy information retrieval system. Furthermore, assume that the document descriptor matrix D-0.5 0.7 1 0 0.7 0.7 0.7 1 1 1 0.4 1 0.7 0.9 0 1 0.5 0.5 0.9 0.7 1 0.6 0.7 0.9 0.4 0.7 1 0.7 1 1 1 1 1 1 0 . 9 0.8 0.8 0.8 0.7 0.9 0.7 0.9 . 0 0.9 0.8 0.9 0.9 0.9 0.9 Case 1: If the query descriptor vector ij is:
q =
(0.6,-,-.0.0.8,-,-), then we can getRS(d1) = 0.93 RS(d3) = 0.6 R S ( d 4 ) = 0.83 R S ( d 5 ) = 0.47 RS(d2) ~ 0 . 6 7 R S ( & ) ~ 0 . 6 7 RS(d7) = 0.47.
If the retrieval threshold value X = 0.5, then the list of documents responding to the user is listed in a sequential order from the document with the highest retrieval status value to the one with the lowest retrieval status value, Le., d l
>
d3>
d 2>
d6>
d3. In this case, the documents d j and d7 are not listed since their retrieval status values are less than the threshold value A. where X = 0.5.IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 25, NO. 5, MAY 1995
Case 2: If the query expression represented by query de- scriptor vectors shown as follows:
(0.6;---,-.-.-,-) OR (-,-,-.->-%->0.8)
then we can see that this OR-connected query expression is subdivided into two query descriptor vectors
E
andE .
i.e.,- q1 =(0.6.--.-.-.--.-.-)
E
=(-.-.-.-;-.-.
0.8). RSl(d1) = 0.9: RS2(dl) = 0.9 RSl(d2) = 0 .6 , RS2(d2) = 0.9 RSl(d3) =0.4, RSz(d3) = 0.8R & ( d J )
= 1.0; = 0.9 Then, we can getRSl(d5) = 0.6, RS1(&) = 0.8, RS2(d5) = 0.9 RS,(d6) = 0.9 RSl(d7)
=O.4,
I&(&) = 0.9.R S * ( d I )
=0.9 RS*(d3) = 0.8 R S * ( d 4 ) = 1 R S * ( d j ) = 0.9RS*(d(j)
=0.9 R S " ( d 7 ) = 0.9. Based on (13), we can getR S * ( & )
= 0.9If the retrieval threshold value is 0.5, then all the documents would be retrieved.
Consider the case of weighted queries for fuzzy information retrieval, where each query item in a weighted query can be expressed as an order pair:
( z,
.
PU]).
where :E, is the degree of strength of the user's desired
documents with respect to concept C j ; and 'iii; is the weighted value of the query with respect to concept C,. In this case, then the query descriptor vector ij can be expressed as follows:
q
= ((:El. w1). ( 2 2 : 1lJ2). ' '.
(&. 7&)).where 0
5 xJ 5
1 . 05
'w~j5
1, and 15
j5
n.Assume that ith row of the document descriptor matrix D* is ( t i l : t i 2 , . . . . t i n )
.
where t i j E [ 0 . 1 ] . 15
'i5
m , and 15
j5
71. Then, the retrieval status valueRS,(d,)
of thedocument di with respect to the query can be calculated as follows: T ( t ; ; . z , )
m#''-"
a n d = 1 1 . n x ' ~ j (14) kRS,(d;)
=where k is the number of not neglected concepts in the query descriptor vector
ij,4(j)
denotes the j t h component of the query descriptor vector ij> RS,(di) E [O. 11.15
i5
vi, and CY=] 'W,j = 1.In the following, we present the interval query processing techniques. By using the vector representation method, a document d j can be represented by a document descriptor vector
&
as follows:where
[ti,
t!] indicates the degree of strength that the document d; contains the concept Ci. 05
tl5
th5
1, and 15
1;5
ri.Similarly, a query can also be represented by a query descriptor vector ij as follows:
q
= ([xi;x::"]:
[x;,
x;]. ' . ' ;[xi,
%:I),
where
[x:,
zh] indicates the degree of strength that the user desired documents contain the concept Ci; 05 xf
5
xh5
1.1
5
i5
'ri. and ri is the number of concepts.The relations between documents and concepts can be represented by a document descriptor matrix D shown as follows:
Cn . . .
C1 C2
where 7r1 is the number of documents, 71. is the number
of concepts, [tl,,tfi,] represents the degree of relevance of document d, with respect to concept C,,O
5
tf,5
t:,
5
1.15 1 5
711, and 15
J5
n.Let D represent the document descriptor matrix and T represent the tran5itive closure of the concept matrix M . where
1
[fA,:.t~,
' . . [f:Ln>f;nl. . .
Then, let (see (IS) at the bottom of the next page).
The document descriptor matrix
D*
indicates the degrees of relevance of each document with respect to specific concepts. D* would be used as a basis for similarity measures between queries and documents.The user's query expression can be represented by a query descriptor vector ij. Le.,
ij = ([:xi.
47
; [ x i .$1.
. ' . , [Xf,. x;;]).where [xi,xh] indicates the desired degree of strength of the concept Ci with respect to the query, 0
5
xf5 xp
5
1: uvnd 1
5
i5
ri. The symbol "-" is used for labelinga neglected concept SO that such a concept would not be considered in a retrieval process.
In [23], a similarity measure was described to measure the distance between two real intervals. Let A and B be two real intervals contained in
[PI.
/j2]. where A = [ u l ; a21 and799 CHEN AND WANG: DOCUMENT RETRIEVAL USING KNOWLEDGE-BASED FUZZY INFORMATION RETRILVAL TECHNIQUES
B = [hl. b 2 ] . The distance between the intervals
A
and13
can be calculated as follows:Consider the following OR-connected
query:
It is obvious that if
A
and B are identical intervals, then A ( A , B ) = 0.Based on (16), the degree of similarity between the intervals A and
B
can be measured. If A and B are both real intervals in [0, 11, whereA
= [ul. a21 and B = [bl. b 2 ] . then1. i f b l
5
a15
a 25
h 2.
ot1ic:rwisc (17) where S ( A , B) E [O. 11. The larger the value of S ( A . B). the higher the similarity between the intervals A andB.
and a query descriptor vector (1 are assumed, Le.,
S ( A , B ) = 1 - (1.1 -
hl
+
b 2 - b2l){
2A document descriptor vector
-
dj = ([t;l.tl"l].
[ti2.
' . '.
[ L i F i .&])
(1 = ([x:. :I;:]. [:I$ . 4 ] . ' . '.
[:I;:,. .I;;]).where 1
5
j5
n. 15
i5
'rri. 1 1 is thenumber of concepts, rr), is the number of documents. Let y ( j ) denote the j t h component of the query descriptor vectorq.
If y(:j) = "-". then it indicates that the concept C3 is a neglected concept with respect to the query. Based on (17), the degree of similarity between the document descriptor vector and the query descriptor vector__
can be calculated as follows:
4(5)#''-"
and ,=1.. . . . I 1R S V ( d f ) = ' (18)
x:
where the retrieval status value RSV(d;) indicates the de- gree of the similarity between the query and the document d;. RS17(di) E [O. 11.1
5
i5
m. and k is the number of not neglected concepts in the query. The larger the value of R S V ( d i ) . the higher the similarity between the query and the document d i . The relevant values of neglected concepts can be eliminated from the computation of similarity since these neglected concepts are not necessary factors for the retrieval process.where ?ji and @j are query descriptor vectors. The degree of similarity between the query descriptor vector
c1,
and the documents can be expressed by a 1 x m matrix RSI',. where m is the number of documents, and 15
j5
2. In this case, the degree of similarity between the query and the documents can be calculated as follows:where RSV, ( d i ) represents the degree of similarity between the query descriptor vector and the %th row of the doc- ument descriptor matrix D* ~ RSV2 ( d ; ) represents the degree
of similarity between the query descriptor vector
E
and the %th row of the document descriptor matrixD*
.
the retrieval status value R S V * ( d ; ) represents the degree of similarity of the query with respect to document d;. and 15
i5
7 n . Theinformation retrieval system would display every document having a retrieval status value greater than the threshold value X in a sequential order from the document with the highest degree of retrieval status value to that with the lowest one, where X E [O, 11.
Example 5.3: Assume that the threshold value X is 0.5 and assume that there are seven concepts C1. C2.
.
. . . Cy. and seven documents dl ~ d 2 . . . . . (17. Furthermore, assume that thedocument descriptor matrix D and the concept matrix M have the following forms (see bottom of next page). In this case, the transitive closure T of the concept matrix M can be calculated as follows (see bottom of next page).
The document descriptor matrix D* can be obtained based on the document descriptor matrix D and the transitive closure T of the concept matrix M as follows (see bottom of next page): if the user's OR-connected query is:
([0.S.O.8].-.-. [0.3.0.7]. [0.7. 11.-.-) OR
(-.
[0.6. 0.91. [0.4.0.6].-.-.--,-)IEEE TRANSACTIONS ON SYSTEMS, MAN. AND CYBERNETICS. VOL. 25, NO. 5, MAY 1995 d2 d j D = d4 d5 d~ then we can get
[ l . 11 [0.6,0.6] [O.O] [0.4.0.4] [l, 11 [O.O] [O.O] [O,0] [l. I ] [0.0] [O.5.0.5] [0.5,0.5] [0.4.0.4] [l. 11 [0.6,0.6] [O.5.0.5] [0.9.0.9] [0.4.0.4] [O,O] [1.1] [0.6.0.6]
[1.1] [O.O] [O.7.0.7] [1.1] [0.0] [0.5.0.5] [0.7.0.7]
[0.8.0.8] [0.4.0.4] [0.5.0.5] [0.7.0.7] [l. 11 [0.0] [ I , 11 Based on ( 1 9), we can get
-[1. I ] [1, 11 [l. 11 [O.O] [0.0] [O.O] [0.0]
M = [0.0] [0,0] [O.0] [l. 11 [l. 11 [l. 11 [O,O]
[O,O] [l, 11 [0.4.0.4] [O.O] [O.O] [O.O] [O.8.0.8]
[0,0] [0.4,0.4] [l. I ] [O.O] [0.0] [O.O] [0.5.0.5]
[0.0] [0,0] [0.0]
[o.o]
[l. 11 [ o . O ] [0.9.0.9][0.0] [O.O] [O.O] [O.O] [O,O] [l. 11 [0.7,0.7]
-[O.O] [0.8.0.8] [0.5.0.5] [O. 01 [0.9,0.9] [0.7,0.7] [l, 11
-
RSV*(d1) = 0.83 RSV*(d2) = 0.88RSV*
( d 3 ) = 0.88 R S V * ( d 4 ) = 1 RSV*(d6) = 1 RSV*(d7) = 0.85. R S V * ( d s ) =0.72 - [ l . 11 [l. 11 [ l . 11 [O,O] [0.8.0.8] [0.7,0.7] [0.8,0.8]- [O.O] [l. 11 [0.5.0 51 [O,O] [0.8.0.8] [0.7.0.7] [0.8,0.8] [O,O] [0.5.0.5] [l. 11 [O,O] [0.5.0.5] [0.5.0.5] [0.5.0.5] [0,0] [0.8.0.8] [0.5.0.5] [l, I ] [ l . 11 [l. I ] [O.9,0.9] [0.0] [0.8,0.8] [0.5.0.5] [O,O] [l, I ] [0.7.0.7] [0.9.0.9] [O.0] [0.7.0.7] [O.5.0.5] [O.O] [0.7.0.7] [ l . 11 [0.7.0.7] -[O.O] [0.8.0.8] [0.5.0.5] [O.0] [0.9.0.9] [0.7.0.7] [l. 11 -The larger the value of RSV*(d,), the more suitable the document d, to the user's interval query, where 1
5
Z5
7.-[0.5.0.5] [0.7.0.7] [ l . 11 [O.O] [0.7.0.7] [0.7.0.7] [0.7.0.7]- [l. 11 [l. 11 [l, 11 [0.4.0.4] [l. 11 [0.7.0.7] [0.9.0.9] [0.0] [l, 11 [0.5.0.5] [0.5.0.5] [0.9.0.9] [0.7.0.7] [1.1] = [0.6.0.6] [0.7,0.7] [0.9.0.9] [0.4.0.4] [0.7.0.7] [ l . 11 [0.7.0.7] [ l . 11 [l. 11 [ I . 11 [l. 11 11.11 [ l . 11 [0.9,0.9] [0.8.0.8] [0.8,0.8] [O.S.O.S] [0.7.0.7] [0.9.0.9] j0.7.0.71 [0.9,0.9] - [O. 01 [0.9.0.9] [0.8.0.8] [0.9.0.9] [0.9.0.9] [0.9.0.9] [0.9.0.9] - r , 1 =
C H b N AND WANG: DOCUMENT RETRIEVAL USING KNOWLEDGE-BASED FUZZY INFORMATION RETRIEVAL TECHNIQUES rate 100%
-
100% 0 : Precision rate 0 0 o ~ . . ~ . . 0 . Recall rate 0 0 . o o o o o 0 Prectsion/RecalI rate+
0 . Precision rate - 0 0 o ' Recall rate8 : 0 $ 0 0 *
0 Threshold value=O.50 . a
0 0 I I I l l 1 I I I I 0 Precision rate 0 o Recall rate 0 Threshold Values 1 0 801 PrecisioiwRewll rate+
0 : Precision rate o : Recall rate 0'
0 0 . 88
~ h o l d v d u e = O . 5 Fig. 3.values in a simple query.
The precision rate and recall rate with respect tO different threshold Fig. 7. simple queries.
The precision rate and recall rate with respect to query numbers in
PreClSlOnlRecall PreclsloniReull Precision rate o Recall rate 0 0 0 o Thresholdvalue= 0 5 0 0 , 8 ~ ~ a o e o ~ 0 0 0 Precision rate O O 0 Recall rate
o o 8 8 a 8 °
0 0 Threshold Values 1 0 Fig. 8. weighted queries,The precision rate and recall rate with respect to query numbers in Fig. 4.
values in a n interval query.
The precision rate and recall rate with respect to different threshold
Precision/Recall rate 0 Precision rate
o
Recall rate8
Thresholdvalue=O 5 t o rate 100% I I I I I I I I I I ,I> I I I I'
I ThresholdValues1 0 Fig. 10. The precision rate and recall rate with respect to query numbers in Fig. 6 .
values in a weighted-interval query.
The precision rate and recall rate with respect to different threshold (Iueries'
Let the ith row of the document descriptor matrix
D*
be([tfl.
[&.
&].
. . ..
[ti,,.(:&I).
where 05
ti,
5
fJ
5
1. and 15
j5
11. Then, the degree of similarity between thequery and the document d, can be calculated as follows: From the above results, we can see that all of the retrieval
status values of the documents are larger than the threshold value
A.
where A = 0.5. We also can see that the documents&
and d o are most suitable to the user's interval query due to the fact that they have the largest retrieval status value.Weighted-interval queries can also be processed by our
4
)yo#''-"
a n d j=1;. . . nXSV,(d,) = X 1%
method. In weighted-interval queries, a query expression can be represented by a query descriptor vector ij shown as follows:
k
(20)
802 l E t E TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS. VOL 25. NO. 5. MAY 1995
degree of similarity between the query and the document d,.
RSV,,.(d;)
E [O. 11. 15
i5
711. and CJ”=l 1 ~ ’ ~ = 1.Example 5.4: Same assumptions as in Example 5.3. Let the user’s query expression be represented by the query descriptor vector (1 shown as follows:
(1=(([0.1.0.4].0.6)~-.-.([0.G.0.9].0.3). ([0.5.0.7], 0.1).
-.
-).
Then. the retrieval status values of the documents can be obtained shown as follows:
RSV,. ( d l ) = 0.625 RSV,,($*) = 0.41 XSV,(&) = 0.75 RSV,.(&) = o.ci9
nsv,,.
(dj) =0.44
RSV,,,(dG) = 0.64 R S V W ( & ) = 0.82.If the retrieval threshold value is 0.5, then the documents $2
and d g will not be retrieved due to the fact that the retrieval status values of the documents d 2 and d j are less than the threshold value. From the above results, we also can see that the document $7 is the most suitable to the user’s weighted interval query due to the fact that it has the largest retrieval status value.
VI. CONCLUSIONS
We have presented a knowledge-based fuzzy information retrieval method based on the transitive closure of concept ma- trices, where weighted queries and weighted-interval queries are allowed for document retrieval. The proposed method is more flexible than the ones presented in 161 and [ 1 I ] due to theft that it has the capability to deal with interval queries and weighted-interval queries. Efficient retrieving capability and flexible user’s queries are consequently provided for. We have implemented a fuzzy information retrieval system called MASTER based on the proposed method using Turbo C ver- sion 2.0 on a PC/AT, where one hundred books about computer science were acted as tested documents, and nineteen concepts were used to characterize these documents. According to [6], the performance of the implemented system can be examined through the measures of recall rate R and precision rate P defined as follows 1181:
riiirriher of itcrris retrieved arid rclcvant total relevant in collcction nitrriher of items rrtrieved and relevant
to t,al rc t,ricved
R = x 100% (21)
P = x
loo%#.
( 2 2 )Recall rate and precision rate are defined as the capability of accepting useful documents and rejecting useless documents, respectively. In this paper, four query types (i.e., simple queries, interval queries, weighted queries, and weighted- interval queries) are examined to measure the precision rate and recall rate of the implemented system MASTER. The curves of precision rate and recall rate with respect to different threshold values are shown from Figs. 3-6.
From these curves, some phenomenon were identified. The precision rate of the simple queries is similar to the interval queries, but interval queries are more flexible than the simple queries. The precision rate of weighted queries is higher than non-weighted queries. However, users can select the query types dependent on hidher requirements when retrieving documents.
The curves of precision rate and recall rate with respect to query numbers are shown from Figs. 7-10. We can see that the experiment results of the implemented system MASTER
successful.
REFERENCES
S. M. Chen. “A new approach to handling fuzzy decision making problems,” IEEETruns. Syst. Mun Cyber., vol. 18, no. 6, pp. 1012-1016,
1988.
-, “An improved algorithm for inexact reasoning based on ex- tended fuzzy production rules,” Cybernetic.\ and Systems: An Int. J . ,
vol. 23, no. 5, pp. 4 6 3 4 8 1 . 1992.
-, “A new approach to inexact reasoning for rule-based systems,”
Cyhernericx arid Systems: A n Int, J., vol. 23, no. 6, pp. 561-582, 1992. S. M. Chen. J. S. Ke, and J. F. Chang, “An inexact reasoning algorithm for dealing with inexact knowledge,” I n / . J. Software Engineering und Knotvledge Engineering, vol. I , no. 3, pp. 227-244, 1991.
-, “Techniques for handling multicriteria fuzzy decision-making problems,” in Proc. 4th lnrernationul Swnposium (in Computer and Inforinarion Sciences, Cesme, Turkey, vol. 2, pp. 919-925, Oct. 1989.
G. T. Her and J. S. Ke, “A f u n y information retrieval system model,” in Proc. I983 National Computer Symnp., Taiwan, R.O.C., 1983, pp.
147- 155.
M. Kamel, B. Hadfield, and M. Ismail, “Fuzzy query processing using clustering techniques,” Information Pn~cessing und Management, vol.
26, no. 2, pp. 279-293, 1990.
A. Kandel, Fuzzy Mathemutical Techniques with Applications. CA: Addison-Wesley, 1986.
D. H. Kraft and D. A. Buell, “ F u ~ z y sets and generalized Boolean retrieval systcms.” Int. J. Mmn-Machine Srudies, vol. 19, no. I , pp.
45-56, 1983.
C. C. Looney, “Fuzzy Petri nets for rule-based decision making,” /€E€
Trcrm. Sxst. Mun Cxher., vol. 18, no. 6, pp. 178-183, 1988.
D. Lucarella and R. Morara, “FIRST: Fuzzy information retrieval system.” J . I~forinufion Sci.. vol. 17, pp. 81-91, 1991.
T. Murai. M. Miyakoshi, and M. Shimbo, “A fuzzy docuinent retrieval method based on two-valued indexing,” Fuzzy Setv and Systems, vol.
30, pp. 103-120, 1989.
S. Miyamoto, “Information relrieval based on fuzzy associations,” F K L ~
Sets and Systems, vol. 38, pp. 19 1-205, 1990.
T. Radechi, “Mathematical model of time effective information retrieval sy$tem based on the theory of furry set,” Information Processing und
Muncigrrnent, vol. 13, pp. 109-1 16, 1977.
-.
”Furry set theoretical approach to document retrieval,” Infor-mation Processing and Munugement, vol. 15, pp. 247-259, 1979.
-, “Generalized Boolean methods of information retrieval,” I n t . J .
Mun-Muchine Studies, vol. 18, no. 5. pp. 409439, 1983.
R. Rourseau, “On relative indexing in fuzzy retrieval systems,” In-
f~irmation Procesving nnd Mrinagement, vol. 21, no. 5 , pp. 4 1 5 4 1 7 ,
1985.
G. Salton and M. J. Mcgill, Introduction to Modern Infi~rniution Re-
trie\d. New York: McCraw-Hill, 1983.
V. Tahani, “A fuz7y model of document retrieval system,” Iriformution Processing and Munagernent. vol. 12. pp. 177-187, 1976.
J . Y. Wang and S. M. Chen, “A knowledge-based method for fuzzy information retrieval,” in Pror. First Asian Fuzzy Systems - . Svmp., Sin- . . gapore, Nov. 1993.
L. A. Zadeh, “Fuzzy Sets.” Infonncrtion and Control, vol. 8, pp. 338-353, 1965.
M. Zeniankova, “FIIS: A fuzzy intelligent information system,” Datu Engineering. vol. 12. no. 2. 1989.
R. Zwick, E. Carlstein, and D. V. Budescu, “Measures of similarity among fuzzy concepts: A comparative analysis,” Int. J. Appro-ximate Rea.~nir~,?. vel. I . pp. 221-242. 1987.
CHEN AND WANG. DOCUMENT RETRIEVAL USING KNOWLEDGE-BASED FUZZY INFORMATION RETRIEVAL TECHNIQUES
Shyi-Ming Chen (M’88) was born on January 16, 1960, in Taipei, Taiwan, Republic of China. He received the B.S. degree in electronic engineering from the National Taiwan Institute of Technology, Taipei, Taiwan, in 1982, and the M.S. and Ph.D. degrees in electrical engineering from the National Taiwan University, Taipei, Taiwan, in June 1986 and June 1991, respectively.
From August 1987 to July 1989 and from August 1990 to July 1991, he was with the Department of Electronic Engineering, Fu-Jen University, Taipei, Taiwan. Since August 1991, he has been an Associate Professor in the Department of Computer and Information Science at National Chiao Tung University, Hsinchu, Taiwan. His current research interests include fuzzy systems, database systems, expert systems, and artificial intelligence. He has published more than 40 papers in intemational journals and conferences.
Dr. Chen is a member of the IEEE Computer Society, the IEEE Systems, Man, and Cybernetics Society, the International Fuzzy Systems Association (IFSA), and the Phi Tau Phi Scholastic Honor Society.
803
Jeng-Yih Wang was born in Taiwan, Republic of China, on September 29, 1963. He received the Ed.B. degree in industry education from the National Taiwan College of Education, Changhwa, Taiwan, in June 1987, and the M.S. degree in Computer and Information Science from the Na- tional Chiao Tung University, Hsinchu, Taiwan, in June 1993. His current research interests include fuzzy systems, database systems, and artificial in- telligence.