以LSTM深度神經網路語言模型建構英文課程重點摘要
77
0
0
全文
(2)
(3) 誌謝 在研究生生涯中,每一位遇到的人都是我生命中的貴人,因為這些貴 人幫助我很多,讓我有榮幸得到碩士畢業這個學位。 首先我一定要感謝我的指導教授 蕭文峰老師,謝謝老師從我大學到研 究所這段時間中給我教導和幫助。在這學習的過程中遇到許多問題,老師 都會細心的教導我,並陪伴著我度過難關,除在論文指導上給予我許多的 建議,使論文內容更加完整外,也讓我在這段學習過程中學到技術與負責 任的態度。老師每月也會撥專案計畫的款給我們,陪伴著我們到中山大學 參與討論,讓我能夠順利完成本篇論文,真的是我人生中的一大貴人。 接下來要感謝每月陪我們一起參與討論的中山大學教授 張德民老師, 當學生遇到問題時會給予寶貴的建議,提供許多想法。感謝蔡孟琳老師蒞 臨指導並給予寶貴的意見和肯定,讓我在研究所的最後時段能受益良多。 研究所這段期間還有許多教導過我的老師,非常感謝屏東大學資管系 的所有老師,和資管系辦的助教。我還要感謝我的學長與學弟們,謝謝証 幃學長讓我在研究路途上並不孤單,以及志正、世勳兩位學弟在口試的幫 忙,讓我在論文口試能夠順利。 最後要感謝我的家人,一路上一直鼓勵著我,讓我有著最強大的精神 支柱,陪我走過許多不平凡的道路。 楊宗恩 謹誌 I.
(4) 于 國立屏東大學資訊管理學系研究所 中華民國一零六年八月. II.
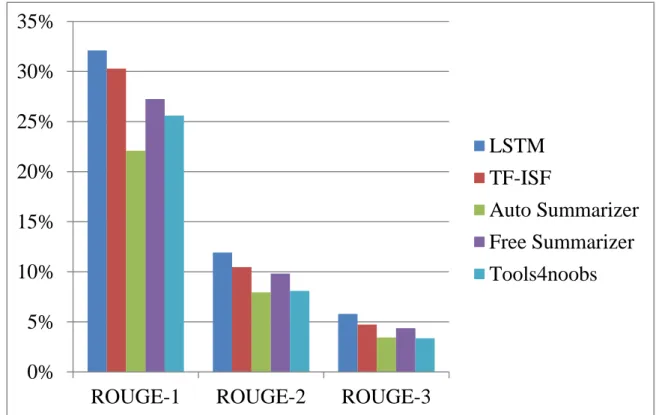
(5) 摘要 大規模開放式線上課程(Massive Open Online Courses, MOOCs)已逐漸 成為流行的學習方式,學習者可以在任何時間、地點、依自己的學習步調, 以任何手持設備上網學習自己所註冊的課程。但線上課程內容資料龐大, 學習者在學習時需花許多時間才能了解其內容。因此,提供一套協助學習 者快速掌握課程內容的輔助機制就益形重要。 本論文採用長短期記憶人工神經網路(Long-Short Term Memory, LSTM) 深度神經網路語言模型(Deep Neural Network Language Model)來對英文文 字稿內容進行分析,壓縮原始文件至一個精煉版本,並保留重要資訊的摘 要。最後本論文與黃喬(民 105 年)所提出的摘要擷取方法,以及 Free Summarizer、Auto Summarizer、Tools4noobs 之線上摘要器進行比較。實驗 結果顯示,在網路 2 層隱藏層的 LSTM 架構中,本論文的摘要法之 ROUGE-1 可達 32.12%、ROUGE-2 可達 11.93 %、ROUGE-3 可達 5.80%,結果一致顯 示本論文所提方法顯著(以 ANOVA 對三個 ROUGE 評估進行檢定其 p 值皆 小於 0.05)優於其他摘要器所提出的摘要擷取方法,此證明本論文所提方法 能夠有效擷取課程文字稿的摘要。. 關鍵字:深度學習、課程摘要、LSTM、課程文字稿. III.
(6) Abstract Massive Open Online Courses (MOOCs) have gradually become a prevailing learning method, learners can learn their signed-up courses with any handheld device at any time, place, and their own pace. But the content of any online course is huge, learners need to spend much time to grasp its key concepts. Therefore, providing a mechanism to assist learners to quickly master the key concepts of the course is more and more important. In this paper, we used Long-Short Term Memory (LSTM) deep neural network language model to analyze the content of the English course transcripts, compressed each original transcript to a refined version and obtained a summary of the transcript. Finally, we compare our proposed method with four different methods, including TF-ISF-LDA, Free Summarizer, Auto Summarizer, and Tools4noobs. Experiment results show that in the two layer hidden layer LSTM model, the proposed method can reach ROUGE-1 of 32.12%, ROUGE-2 11.93%, ROUGE-3 5.8%, and the results consistently showed that the our proposed method is significantly (with ANOVA tests, p’s are <0.05 for all ROUGE evaluations) superior to the other four methods, which provides the evidence that our proposed method can effectively extract key concepts of the course transcripts.. Keywords: Deep learning, Course Summary, LSTM, Course Transcript. IV.
(7) 目錄 誌謝 ........................................................................................................................ I 摘要 ..................................................................................................................... III Abstract................................................................................................................ IV 表目錄 .............................................................................................................. VIII 圖目錄 .................................................................................................................. X 第壹章 緒論 ......................................................................................................... 1 第一節. 研究目的 .......................................................................................... 3. 第貳章 文獻探討 ................................................................................................. 5 第一節. 大規模開放式線上課程(MOOCs) .................................................. 5. 第二節. 文件摘要 .......................................................................................... 5. 第三節. 深度學習 .......................................................................................... 7. 一、. 名詞解釋 .......................................................................................... 8. 二、. Word2vec 向量表示........................................................................ 9. 三、. 遞歸神經網路(Recurrent Neural Network, RNN) ........................ 11. 四、. 長短期記憶人工神經網路(LSTM) ............................................... 12. 五、. 深度學習之文件摘要 .................................................................... 14. V.
(8) 第四節. 一般性衡量指標 ............................................................................ 15. 第參章 研究方法 ............................................................................................... 17 第一節. 預處理 ............................................................................................ 18. 第二節. 標記句子類別 ................................................................................ 19. 第三節. 深度神經網路語言模型建立階段 ................................................ 23. 第四節. 擷取文字稿摘要 ............................................................................ 24. 第五節. 評估 ................................................................................................ 24. 第肆章 實驗結果 ............................................................................................... 27 第一節. 資料集說明 .................................................................................... 27. 第二節. 實驗一參數設定 ............................................................................ 28. 一、. 演算法參數設定 ............................................................................ 28. 二、. LSTM 參數設定............................................................................. 30. 第三節. 實驗二不同摘要器之結果比較 .................................................... 35. 一、. 質化分析 ........................................................................................ 35. 二、. 量化分析 ........................................................................................ 39. 第伍章 結論 ....................................................................................................... 48 第一節. 研究貢獻 ........................................................................................ 48 VI.
(9) 第二節. 未來研究方向 ................................................................................ 49. 第陸章 參考文獻 ............................................................................................... 50 第柒章 附錄 ....................................................................................................... 58 第一節. 研究計畫委員提問 ........................................................................ 58. 第二節. 論文口試委員之提問 .................................................................... 61. 第三節. 參考文獻 ........................................................................................ 64. VII.
(10) 表目錄 表 2-1 名詞定義解釋........................................................................................... 9 表 3-1 匹配準則例子......................................................................................... 22 表 3-2 ROUGE 結果例子 ................................................................................... 25 表 4-1 資料集內容............................................................................................. 28 表 4-2 Pcr 起始值之參數設定............................................................................. 29 表 4-3 是否只需移除標點符號之參數設定 .................................................... 30 表 4-4 取多個句子準則之參數設定 ................................................................ 30 表 4-5 不移除停用字資料集之文字稿內容例子 ............................................ 31 表 4-6 移除停用字資料集之文字稿內容例子 ................................................ 32 表 4-7 移除停用字資料集之 5 次交叉驗證平均結果(%、秒) ...................... 34 表 4-8 不移除停用字資料集之 5 次交叉驗證平均結果(%、秒) .................. 34 表 4-9 不同資料集產生一門新課程摘要的執行時間(秒).............................. 35 表 4-10 投影檔內容........................................................................................... 35 表 4-11 LSTM 之深度網路語言模型所產生的摘要內容................................ 37 表 4-12 TF-ISF 所產生的摘要內容 ................................................................... 37 表 4-13 Auto Summarizer 所產生的摘要內容 .................................................. 37 VIII.
(11) 表 4-14 Free Summarizer 所產生的摘要內容 ................................................... 38 表 4-15 Tools4noobs 所產生的摘要內容 .......................................................... 38 表 4-16 TF 摘要方法、TF-ISF 摘要方法和 TF-SF 摘要方法的平均 F1 值結果 ............................................................................................................................. 39 表 4-17 不同摘要器設定不同擷取摘要句子數上限之研究結果(%) ............ 41 表 4-18 LSTM 深度神經網路語言摘要模型之 ROUGE(%)結果 ................... 42 表 4-19 TF-ISF 摘要模型之 ROUGE(%)結果 .................................................. 43 表 4-20 Auto Summarizer 摘要模型之 ROUGE(%)結果 ................................. 44 表 4-21 Free Summarizer 摘要模型之 ROUGE(%)結果 .................................. 44 表 4-22 Tools4noobs 摘要模型之 ROUGE(%)結果 ......................................... 45 表 4-23 摘要器方法間的 ANOVA 分析 .......................................................... 47. IX.
(12) 圖目錄 圖 2-1 連續詞袋及 Skip-Gram .......................................................................... 11 圖 2-2 遞歸神經網路架構 資料來源(Liu et al. 2016) .................................... 12 圖 2-3 長短期記憶人工神經網路架構 資料來源(Greff et al.) ...................... 13 圖 3-1 系統主架構圖......................................................................................... 17 圖 3-2 匹配句子之演算法流程......................................................................... 22 圖 4-1 不同隱藏層的結果圖............................................................................. 31 圖 4-2 不同摘要器方法之平均 ROUGE 結果比較......................................... 47. X.
(13) 第壹章 緒論 傳統的教學方式,受到時間與空間上的限制,學生無法隨時的參與學 習。然而拜科技所賜,大規模開放式線上課程(Massive Open Online Courses, MOOCs)已逐漸成為現今教育方式之一,它是近年來迅速且廣泛發展的公開 教學管道,一種賦予大眾人群的線上課程,學習者可以在任何時間、地點、 自主的學習環境,以任何手持設備上網學習自己所註冊的課程。平台為了 協助學習,有些課程會提供線上課程文字稿及相對應的投影檔給予學習者 下載學習,但是線上課程內容資料龐大,學習者需花許多時間才能理解其 內容。因此,本研究試圖擷取文字稿重點摘要,提供給學習者使用;換句 話說,經由保持文字稿主要內容的完整性,減少文章內容到一個較短的版 本過程,來表達真實理想的意涵(Mani 2001)。學習者將能透過文字稿精鍊 摘要,搭配投影檔兩者並用,有助於學習者節省時間並掌握學習重點。 過去針對線上課程英文文字稿進行摘要擷取的研究多是透過建立文字 的模型以萃取文章的不同觀點,避免重複的內容被收錄至摘要中。例如曾 士昌(2010)採用 pLSA (probabilistic Latent Semantic Analysis)模型來抽取摘 要句、邱怡菁(2014)使用 LDA (Latent Dirichlet Allocation)建立主題模型以克 服 pLSA 為非生成模式的缺點、黃喬(2016)則進一步結合詞頻(TF, Term Frequency)、詞頻-逆向句子頻率(TF-ISF, Term Frequency-Inverse Sentence Frequency)至 LDA 以進一步提升摘要的召回率。這些方法對擷取英文文字 1.
(14) 稿的重點摘要有一定的幫助,但隨著文字稿的資料量提高,其所建立的模 式在擷取摘要的召回率上並無明顯改善。 深度學習(Deep Learning),是一種機器學習的演算法,它映射一個輸入 序列進入到另一個輸出序列,稱之為序列到序列(Sequence-to-sequence)的模 型(Nallapati et al. 2016)。以往的機器學習法有所謂的天花板效應(Ceiling Effect),亦即當資料量大到某一程度時,其正確率就無法再提昇。深度學習 可成功地克服天花板效應,因此已經在許多領域帶來了顯著的效果,著名 的應用包括機器翻譯(Machine Translation) (Bahdanau et al. 2016)、語音識別 (Speech Recognition) (Bahdanau et al. 2015)、圍棋程式 AlphaGo1。因此本論 文的目的之一即在於瞭解深度學習法用於摘要擷取的效益。 過去各種代表性的神經網路語言模型(Neural Network Language Model, NNLM)已被提出,像是遞歸神經網路(Recurrent Neural Network, RNN) (Elman 1990; Elman 1991)2,以及改善 RNN 所衍生的長短期記憶人工神經網 路(Long-Short Term Memory, LSTM) (Hochreiter & Schmidhuber 1997)。RNN 具有循環的理念,意味著神經元的輸出到下一個時間點能再到自身身上, 不過權重會隨著時間點的變化,可能會導致梯度消失(Vanishing Gradient)或 梯度爆炸(Exploding Gradient)問題(Hinton & Shallice 1991; Bengio et al. 1994)。於是 LSTM 方法就應蘊而生,LSTM 增加儲存細格(Memory Cell)的 1. 一種使用深度神經網路所開發的圍棋程式。. 2. 本論文使用時間遞歸神經網路,資料來源:https://zh.wikipedia.org/wiki/遞歸神經網路。 2.
(15) 概念,具有儲存所有資訊的用途,能緩解梯度消失與梯度爆炸的問題,改 善過度擬合(Overfitting)的情形發生(Bengio et al. 1994),詳細說明請至第貳 章第三節之三。 本論文採用 LSTM 深度神經網路語言模型(Deep Neural Network Language Model)來進行課程文字稿的摘要擷取,並探討其摘要擷取的品質 與現有課程摘要擷取方法的差異。目前用以評估摘要品質的方法,基本上 可分為兩類(Steinberger & Jezek 2012):外在技術(Extrinsic Techniques),基 於給定的任務來評判摘要的品質,像是分類或搜尋;內在評估(Intrinsic Evaluation),直接根據摘要的分析,透過原始資料的比較,來衡量兩者之間 的重疊度。本論文使用後者評估類型,應用召回率導向的摘要評估指標 (Recall-Oriented Understudy for Gisting Evaluation, ROUGE) (Lin & Hovy 2003; Lin 2004),計算字詞重疊比率,來評估結果摘要。. 第一節. 研究目的. 綜合上述,本論文的具體目的如下: (一)探討本論文所採用「LSTM 深度神經網路語言的摘要模型」、黃喬(民 2016)所提出「以詞頻、詞頻-逆向句子頻率和詞頻-句子頻率結合 LDA 之英 語課程文字稿摘要法」以及 Free Summarizer3、Auto Summarizer4、. 3. 資料來源:http://freesummarizer.com/。. 4. 資料來源:http://autosummarizer.com/。 3.
(16) Tools4noobs5的線上開放原始碼摘要法模型之間的優劣。本論文以量化評估 指標(使用者操作特徵曲線面積、ROUGE 指標的分類精確性、召回率以及 F1 值)進行評估。 (二)探討如何有效的自動化建立摘要句訓練資料集,並以此建立 LSTM 之深度神經網路語言模型。此過程需先將文字稿與投影片內容進行斷句, 接著比對投影片中的句子來決定文字稿中的每個句子是否屬於摘要句。這 其中牽涉句子與句子間的相似度計算方式,包含斷句方式(以句號來斷句顯 然並不足夠)、停用字是否移除、與是否做字根還原等處理,以及門檻值的 決定。. 5. 資料來源:http://www.tools4noobs.com/。 4.
(17) 第貳章 文獻探討 本節首先回顧大規模開放式線上課程及文件摘要,接著探討兩種不同 深度學習架構,最後說明目前用於文件摘要的一般性衡量指標。. 第一節. 大規模開放式線上課程(MOOCs). MOOCs 是近年來廣泛發展的公眾開放的教學管道,其課程活動主要是 發生在網路環境上的一種大規模、開放式教學的線上活動(Masters 2011), 學習者可以在任何時間、地點、自主的學習環境,以任何手持設備上網學 習自己所註冊的喜好課程。 此外,它的設計和課堂參與類似於學院和大學課堂。其中,它有兩個 顯著的特性:開放共享,參與者不必是在校付費學生,它給予參與者擁有 共享的機制,且絕大多數是免費的;可擴張性,因傳統面對面的課程是針 對一群學生對應一位老師,但 MOOCs 則針對於不確定的參與者而言來設計 課程。例如,Coursera6、Udacity7、edX8、Share Course9等。. 第二節. 文件摘要. 文件摘要試圖使用一個或多個文件內容,找尋最具有資訊的句子,來 建立一個表示概要或是整體文件的摘要,以此避免讀者花費過多的時間與 努力閱讀文件內容。約略來說,文件摘要的截取方式共可分成節錄式及抽. 6 7 8 9. https://zh-tw.coursera.org/。 https://www.udacity.com/。 https://www.edx.org/。 http://www.sharecourse.net/sharecourse/。 5.
(18) 象式摘要的兩種方法。 節錄式摘要(Jones 1999; Over & Yen 2003)透過原始文件中,串聯現有 的關鍵句子、片段等,且不需修改文件內容,並壓縮原始文件來產生簡短 且含有關鍵意涵的摘要;抽象式摘要是以建立內部語意表示,藉由自然語 言生成技術(Paice 1990; Witbrock & Mittal 1999)來建立摘要,此方式是較接 近於人類所產生的概念。雖然抽象式摘要比起節錄式摘要更能產生親近於 人類的文件摘要內容,但程式部分涉及深層的自然語言處理能力(Mitra et al. 1997),有難以建立的挑戰,因此本論文研究仍以節錄式摘要為主要的研究 方向。 此外,摘要技術能被分類為監督式及非監督式方法(Mani & Maybury 1999)。監督式方法為兩元分類(Binary Classification)問題,換句話說,判定 該句子是否屬於摘要。在訓練這類型的分類器前,需使用各種已知特徵描 述,藉由各種分類器的學習機制進行模型訓練。最後對尚未被摘要之測試 文件依學習特徵進行分析,依據既有特徵,來判定語句是否屬於摘要語句 (Lin & Chen 2009),截取關鍵摘要。典型特徵包含以下幾點: (一) 字詞出現的頻率:根據不同演算法,來計算所有文件中,個別 字詞出現的比率,例如 TF-IDF (Jones 1972)演算法。 (二) 句子的長度:相較於短的句子,長句子可能更為重要。 (三) 句子出現的相對位置:開頭的句子,或是出現於每個章節的首 6.
(19) 要句子。 (四) 各種布林(Boolean)語意特徵:像是所有大寫字詞、詞性等布林 特徵。 (五) 句子權重:能以簡單的演算法,來計算字詞頻率,並進一步衡 量每個句子重要性。 非監督式方法從不一樣的角度處理問題,不需要人力來輸入標籤,其 目的是去對原始資料進行分群,以便瞭解資料內部結構。像是詞彙鏈 (Barzilay & Elhadad 1999)、字詞共現(Word Co-occurrence) (Matsuo & Ishizuka 2004)的排名模型評分標準;以及 TextRank (Mihalcea & Tarau 2004)、 LexRank (Erkan & Radev 2004)以圖型為基礎的模型。. 第三節. 深度學習. 深度學習是一種用於監督式與非監督式特徵表示(Feature Representation)的方法10,可處理多重線性或非線性轉換(Linear or Non-Linear Transform)的問題,以多個所構成的處理層來建立對資料進行高 層抽象模式,達到監督式與非監督式的特徵學習及分層特徵提取,取代人 工取得特徵,因此它具有自動抽取特徵(Feature Extraction)的能力,也被視 為是一種特徵學習(Feature Learning)。它能在底層對非標籤的資料進行非監 督式學習的預訓練,如此一來能有助於後續監督式學習進行微調。. 10. 資料來源:https://en.wikipedia.org/wiki/Deep_learning。 7.
(20) 一般而言,神經網路語言模型的輸入是以詞彙語意向量來表示(e.g. [-0.2, 0.9, …, 0.7]),此概念首先於 1986 年被提出(Hinton 1986; Bengio et al. 2003),俗稱詞向量(Word Vector)11,也稱之為分佈式語意(Distributional Semantics)。它在訓練資料中,依照已分類好的句子,利用不同架構所訓練 好的字詞向量作為模型的輸入,例如 Word2vec (Mikolov et al. 2013a; Mikolov et al. 2013b)、字詞表示的全域向量(Global Vectors For Word Representation, GloVe) (Pennington et al. 2014)等,根據字詞和鄰近周圍字詞 的關係,計算出向量中各個維度的值,再藉由所得值來表示字詞的語意, 抽取足以區別不同類別的特徵(Soutner& Müller 2014),進而識別句子的重要 性。本論文考量 Word2vec 發表於 2013 年,GloVe 發表於 2014 年,就以發 表日期而言 GloVe 是較新穎的技術,此外在文獻中 GloVe 的表現有時優於 Word2vec,加上 Glove 無論是用於小資料集或大資料集能有不錯的表現 (Pennington et al. 2014),因此後續研究我們採用 GloVe 作為模型的輸入字詞 向量。 過去用於建立神經語言模型之深度學習法包括,遞歸神經網路(RNN) (Lin et al. 2015)以及長短期記憶人工神經網路(LSTM) (Ghosh et al. 2016),而 本論文主要探討 LSTM 來建構深度神經網路語言模型。 一、. 11. 名詞解釋. 並非深度學習架構之一,但可用於語言模型的前處理。 8.
(21) 本論文提到多個專有名詞及 LSTM 名詞設定12,透過此小節詳細的解釋 各種名詞定義,如表 2-1 所示: 表 2-1 名詞定義解釋 名詞 學習分歧 (Learning Divergence) 過度擬合 (Overfitting) 層(Layer) 期(Epochs) 最佳化演算法 (OptimizationAlgo). 正規化 (Regularization). 權重初始值 (WeightInit) 學習率 (Learning Rate) 激活函數 (Activation Function) 二、. 12. 定義解釋 當矩陣中的權重非常大,會造成梯度太大而無法收 斂。 模型對樣本數據擬合非常好,但是對於樣本數據外 的應用數據,擬合效果非常差。 單層:適合於單一凸面區域的決策邊界。 兩層以上:能產生任意決策邊界。 完整的通過整個資料集的次數。 設定最佳化演算法。DL4J 提供多種不同的演算法, 包含隨機梯度下降法(Stochastic Gradient Descent, SGD)及 Conjugate Gradient 等。 可幫助避免過度擬合的發生,常見的正規化包含以 下幾種類型。 l1 與 l2 regularization:目的來懲罰太大的網路權 重,避免權重變得太大。實務上 l2 較為常用,普遍 設定 1E-3 至 1E-6。 Dropout:目的是防止過度擬合的狀況,隨機的使某 個節點設置為 0,表示丟棄的意思。通常預設為 0.5。 設定權重初始值,確保權重不會太大或太小,DL4J 支援許多不同種類的權重初始化參數,包含常用的 線性整流函數(Rectified Linear Unit, ReLU)、 UNIFORM、SIGMOID_UNIFORM 等。 影響神經網路收斂的速度。如設定太大,會造成模 型尚未學習足夠的特徵;如設定太小,則會造成過 度擬合的狀況。 用來加入非線性的神經網路模型因素,能逼近任意 函數,使神經網路更容易解決較為複雜的問題。. Word2vec 向量表示. 資料來源:https://deeplearning4j.org/troubleshootingneuralnets。 9.
(22) Word2vec 是一個可以高效率將文章字詞轉變為實數向量。它使用兩種 演算法來讀取字詞與字詞之間的概念,第一種是利用文章上下文的字詞當 作神經網路的輸入,來預測目標詞,稱為連續詞袋(Continuous Bag Of Words, CBOW) (Mikolov et al. 2013a);第二種與連續詞袋的想法相反,利用目標詞 當作神經網路的輸入,來預測文章上下文的詞,稱為 Skip-Gram(Mikolov et al. 2013a; Mikolov et al. 2013b),目的在於分群相似的詞向量於同一個分佈 下,其中詞向量的表示法可以做到字詞之間的對應,並能以數學方式進行 處理。例如 vector ("King") – vector ("Man") + vector ("Queen") ≈ vector ("Woman")或經由它們的主題來分群文件以及分類。因此輸出的詞向量可以 被用來做很多自然語言處理相關的工作,例如文章分類、找同義詞、詞性 分析、機器翻譯等;而分群的結果能形成搜尋的根據,情感分析,以及推 薦不同領域,像是科學研究、法律查詢等。 INPUT. PROJECTION OUTPUT. INPUT PROJECTION OUTPUT. w(t-2). w(t-1). w(t-2) w(t-1). SUM w(t) w(t). w(t+1). w(t+1). w(t+2). w(t+2) Skip-Gram. CBOW. 10.
(23) 圖 2-1 連續詞袋及 Skip-Gram13 三、. 遞歸神經網路(Recurrent Neural Network, RNN). 傳統遞歸神經網路(RNN) (Elman 1990; Elman 1991)是個兩種人工類神 經網路(Artificial Neural Network, ANN)的統稱,一種是時間遞歸神經網路 (Recurrent Neural Network),會隨著時間的推移而遞歸,透過時間因素來區 別序列元素之間的差異;另一種是結構遞歸神經網路(Recursive Neural Network),因沒有輸入序列的時間概念,必須透過解析樹的方式分層處理。 常見的遞歸神經網路屬於時間遞歸神經網路已被廣泛用於時間序列建模, 遞歸隱藏狀態可處理可變長度(Variable Length)序列,其每次的激活取決於 先前的時間(Chung et al. 2014),可用來學習一個序列的資訊,如圖 2-2 所示。 RNN 包含隱藏的狀態層(State Layer),用來儲存歷史資訊。此外,在倒傳遞 (Back-Propagation, BP)期間,梯度信號會經由連接到循環隱藏層神經元之間 的權重矩陣,來乘上大量次數(Hochreiter & Schmidhuber 1997)。意味著,權 重矩陣中的權重大小可以對學習過程造成強烈的影響。若矩陣中的權重非 常小(權重矩陣的特徵值小於 1.0),會造成梯度消失的問題,進而導致學習 變的非常慢,甚至停止運行;另一方面,若矩陣中的權重非常大(權重矩陣 的特徵值大於 1.0),會造成梯度爆炸的問題,進而導致學習分歧(LeCun et al 2002),換句話說,權重太大,會造成梯度太大而無法收斂。. 13. 資料來源:https://deeplearning4j.org/word2vec/。 11.
(24) h1. h2. h3. hT. X1. X2. X3. XT. softmax. y. 圖 2-2 遞歸神經網路架構 資料來源(Liu et al. 2016) 四、. 長短期記憶人工神經網路(LSTM). 為了避免 RNN 的問題發生,於是長短期記憶人工神經網路(LSTM)方 法就應蘊而生。它是一種特殊類型的 RNN,與傳統 RNN 最大差異在於加 入區塊(Blocks)組件,藉由核心元素來記住長時間的資訊,我們稱之為儲存 細格(Memory Cell)。儲存細格具有移除或添加資訊到狀態中,此結構稱之 為閘(Gate),是一種可選擇讓資訊通過的方式,其架構如圖 2-3 所示。 區塊主要是由以下四個主要元素所構成: (一) 輸入閘(Input Gate):決定當前的輸入有多少資訊將儲存在儲存 細格的狀態中。 (二) 自我循環連接(Self-Recurrent Connection):確保有 1.0 的權重, 並禁止外部干擾,儲存細格的狀態可以從某一時間步驟到另一步驟維 持不變。 (三) 遺忘閘(Forget Gate):決定上一時間點的資訊,將有多少應儲存 在儲存細格的狀態中。 (四) 輸出閘(Output Gate):控制儲存細格中,何種資訊將成為最後的 12.
(25) 輸出結果。. LSTM Block. Output gate Input Gate. Cell. t. ht. Self-recurrent connetion. Forget Gate. Xt :輸入向量 ht :輸出向量 Cell:單元狀態向量 :激活函數 :乘積. 圖 2-3 長短期記憶人工神經網路架構 資料來源(Greff et al.) 假設輸入、遺忘、輸出分別以 i、f、o 表示,其個別閘定義如下,(Hochreiter & Schmidhuber 1997): it = σg (Wxi xt +Whi ht-1 + bi ). (1). ft = σg (Wxf xt +Whf ht-1 + bf ). (2). ot = σg (Wxo xt +Who ht-1 + bo ). (3). 其中,t 表示時間序列,σ 為 sigmoid 函数,Wx.為各閘的權重,Wh.為 13.
(26) 各閘中隱藏層的權重,xt 為輸入,隱藏層為 ht-1,b.表示各閘的偏差項。儲 存細格由輸入閘與遺忘閘來控制其內容,定義如下: c̃t = tanh(Wxc ‧xt +Whc ‧ ht-1 + bc ). (4). ct = ft ‧ct-1 + it ‧c̃t. (5). 其中c̃t 表示上一時間序列與當前輸入計算而得。最後所得輸出如下: ht = ot ‧tanh(ct ) 五、. (6). 深度學習之文件摘要. 過去學者已經使用類神經網路為基礎的深度學習法來探討自動化文件 摘要的問題,其結果一致顯示優異的表現。不同類型的架構已在文獻中被 提出,如自動編碼器(Bengio 2009),King et al.(2011)提出一個最高頻率字詞 的特徵向量,來對句子進行編碼,應用於自動編碼器使能學習這些特徵的 精簡表示。此外,PadmaPriya & Duraiswamy(2014)提出另一個不同的特徵向 量應用於受限波茲曼機(Ackley et al. 1985; Pal & Saha 2014),針對句子抽取 一定特徵轉至句子的特徵向量進行模型訓練,透過找出使用者查詢與特定 句子之間的交叉點產生句子分數,並遞減排序,並依照使用者所輸入的壓 縮率來選擇句子以形成摘要。 另一曾使用於摘要的架構是遞歸類神經網路(Cao et al. 2015),他們開發 一個遞歸類神經網路的排名架構,對多文件的句子進行排名,且制定一個 句子排名任務為階層式的迴歸過程(Hierarchical Regression Process),並在剖 14.
(27) 析樹中,同時衡量句子的顯著性,及成分結構(如段落)。. 第四節. 一般性衡量指標. 在機器學習裡,評價指標對於一個領域的研究水準有著直接的影響, 目前在文件摘要任務中最普遍的評判方法是 ROUGE,其基本思想是將待審 摘要和參考摘要之間的 n 位元組,以共現統計量的方式作為評價依據,其 公式如下(Lin 2004): ROUGE-N =. ∑s∈Ref∑gram ∈SCOUNTmatch (gramn ) n ∑s∈Ref∑gram ∈SCOUNT(gramn ). (7). n. 其中COUNTmatch (gramn )為系統摘要與參考摘要間共同出現的 N-gram 字詞,COUNT(gramn )為參考摘要中 N-gram 字詞的總字詞數。上述公式為 召回率版本,ROUGE-1.5.5(Ayana 2015; Al-Saleh & Menai 2017)14後續版本 也會同時計算精確度與 F1 的評估值,本論文使用 ROUGE-2.0 版本15。 本論文使用 ROUGE 之 F1 值來進行模型之間的評估依據。ROUGE-1(單 詞,Unigram)、ROUGE-2(雙詞,Bigram)、ROUGE-3(三詞,Trigram)的評 估想法,單詞可用來評估自動摘要結果的資訊性;雙詞用來審視自動摘要 結果的流暢性;而多詞則可用來衡量自動摘要結果的內容性與文法性16。 首先,精確度(Precision)表示猜測正確的次數比例,不過它有個致命缺. 14. 資料來源:https://github.com/andersjo/pyrouge/tree/master/tools/ROUGE-1.5.5。. 15. 資料來源:https://github.com/RxNLP/ROUGE-2.0。. 16. 資料來源:https://en.wikipedia.org/wiki/Automatic_summarization。 15.
(28) 點,如果數據集類別分佈不平衡,其中一個類別在資料集中權重占大多數, 有很大的可能性只會出現高精確度。以一個極端例子為例,假設有一組分 類動物的數據集,包含 999 筆狗的資料,只有 1 筆是貓的資料,因此共有 1000 筆資料。若猜測狗的次數為 1000 次,還是具有高達 99%的精確度。 第二,召回率(Recall),是另一個機器學習常見的衡量指標,用於猜測 正確的次數,在原始資料中所占的比例,與精確度也是有類似的缺陷,例 如:如數據集只有 1 筆數據為貓,若猜測非常多筆時,包含 1 筆數據為貓, 其他則不是,會產生召回率高達 100%,而精確度卻表現得非常差。 因此兩者單獨使用,並用於衡量模型的好壞是有疑慮的,故 F1 值(Larsen et al. 1999)被提出。它是精確度與召回率的調和均值,可判定分類表現的好 壞,如某一類別完全沒被分類時,F1 值結果就會顯示較低的值。因此本論 文會以 F1 值指標為主,以客觀的角度評估模型的優劣。. 16.
(29) 第參章 研究方法 為了評估 LSTM 深度神經網路之文字稿摘要句分類器的表現。本論文 使用 30 門線上課程文字稿為資料集,並抓取相對應的投影檔內容作為參考 摘要,透過 ROUGE 指標計算字詞重疊比率,進一步探討分類精確度、召 回率及 F1 值。 原始資料 ‧ 線上課程文字稿 ‧ 對應投影檔 預處理 ‧ 斷句 ‧ 字根還原 ‧ 標點符號移除 ‧ 切割資料集 標記句子類別 ‧ 制定演算法規則 ‧ 設定門檻值. 神經網路語言模型. 建立深度 神經網路語言模型 ‧ LSTM 擷取文字稿重點摘要 ‧ 限制擷取字詞數 評估結果 ‧ ROUGE指標. 圖 3-1 系統主架構圖. 17. 文字稿資料集 ‧ 不移除停用字資料集 ‧ 移除停用字資料集.
(30) 本研究 LSTM 深度神經網路語言模型系統主架構如圖 3-1 所示,主要 分成五步驟,包括預處理、標記句子類別,建立深度神經網路語言模型、 擷取文字稿重點摘要及評估結果。. 第一節. 預處理. 此階段的步驟,包含斷句、字根還原、標點符號移除以及切割資料集, 以便於自動摘要過程的準備。首先,本論文抓取線上課程文字稿及相對應 投影檔作為資料來源,由於文字稿與對應投影檔其內容是以雜亂的句子所 組成,本論文以句號、問號、分號及逗號為單位的斷句方式進行分割。逗 號斷句門檻須符合句子之字詞總數大於 10 個以上,才允許切割。透過有規 律的斷句方式,能有助於句子與句子之間的匹配。若原始文字稿內容如下: Welcome to the third lecture in the background and information module . In this lecture we'll talk about web 1.0 , 2.0 , and 3.0 architectures . I want to warn you again that , these are not standard definitions . 以句子為單位斷句之後,其內容如下: Welcome to the third lecture in the background and information module . In this lecture we'll talk about web 1.0 , 2.0 , and 3.0 architectures . 18.
(31) I want to warn you again that , these are not standard definitions . 另一步驟使文字稿與相對應投影檔句子轉換為小寫字元,並移除無意 義的標點符號,例如:&、~、#、?、!、*等字詞,不刪除數字原因是考量 到某些數字還是有一定的意義存在,例如 J48、M5P 等專有名詞。另一步驟 為字根還原,使用 Porter Stemming 演算法17,把字詞縮減至詞幹,能夠平 等對待不同字詞的變化,此方式能更正確計算字詞之間的重疊,不會因詞 性的差異而影響匹配。 最後,為了方便評估所提方法的好壞,我們挑選 3 門課程,觀察不同 參數設定能足以準確的匹配句子。並根據不同文字稿課程進行資料集切割, 80%為訓練資料集,其餘 20%為驗證資料集,以便找出 LSTM 深度神經網 路模型的較適參數(如隱藏層數量、模型輸入資料集、最佳化演算法、學習 率),再透過其餘 27 門課程視為測試資料集,並進一步與其他摘要法比較摘 要擷取效益。. 第二節. 標記句子類別. 此階段為本論文最重要的環節。為了比較句子間的相似性,一個最直 覺的答案是尋找完全符合的句子,不過當句子所有字詞都相同,但卻有大 寫字母、標點符號或空白間隔之間的差異,此做法可能會造成無法匹配情 境發生,因此我們採用近似句子匹配(Approximate Sentence Matching, ASM). 17. 資料來源:https://tartarus.org/martin/PorterStemmer/。 19.
(32) (Leveling et al. 2012)方法,是一個近似匹配的方法來比較句子之間的相似性, 找尋最高相似性的句子視為匹配句子,而非完全匹配的方式。 本論文使用多個篩選條件來判定句子是否屬於重要句子,進一步計算 句子間的近似匹配比率,並標記文字稿個別句子的類別標籤。為了方便解 說,個別定義以投影檔句子為基礎的匹配比率為Pcr : Pcr =. 投影檔與文字稿的重疊字詞總數 投影檔句子之字詞總數. (8). 以文字稿句子為基礎的匹配比率為Tcr : Tcr =. 投影檔與文字稿的重疊字詞總數 文字稿句子之字詞總數. (9). 句子間的近似匹配分數為Cp : Cp =. 投影檔與文字稿的重疊字詞總數 Max(文字稿句子之字詞長度,投影檔字詞長度). (10). 處理流程如圖 3-2 所示,參數設定詳細說明請至第肆章第二節之一: (一) 設定 Pcr 起始值,以持續遞減 0.025 的機制至 0.1 停止。設定 Pcr 起始值原因在於,投影檔句子之字詞有時非常少且是常出現字詞時, 如匹配比率越高,則文字稿句子較長者不會受到太多的處罰,並進 一步考量是否移除標點符號就能正確匹配句子,還是需移除停用字 才足以正確匹配句子。 (二) 若符合演算法一時,我們計算已匹配句子的 Cp 值,並進行降冪 排序,此規則能有效的懲罰長句子的問題,因句子長度越長,意味 20.
(33) 著字詞數越多,重疊的次數會因此提升,匹配比率也會提升。此外, 我們認為有部分文字稿句子會匹配到多個句子,因此加入可匹配到 多個句子規則: Pcr > 目前Pcr + 調節值. (11). 採用調節值原因在於,有時某門課程之文字稿內容名詞出現頻繁, 如不增加調節值會導致錯誤匹配的疑慮。當 Pcr 同時有多個比率超 過以上準則,才可選取多個句子,否則只能選擇最高 Cp 做為選取。 當取多個匹配句子且匹配到多個句子之 Cp 值相同時,會先選取第 一個匹配到的句子視為摘要句,此外會進一步累加 Tcr,並需滿足 累加 Tcr ≤ 1.0 的規則。此規則目的在於,當累加 Tcr = 1 時,表示文 字稿句子之字詞應全數匹配完成,若超過 1.0 則不符合配對原則。 圖 3-2 演算法規則以表 3-1 為例,其中取多個句子範例中,前 3 個句子 的 Pcr 值都符合演算法一與演算法二,且加總 Tcr 等於 1.0,並未超過 1.0, 但在第 4 個句子之 Pcr 小於 0.75 未符合演算法,且累加至 Tcr 等於 1.08,會 超過 1.0 之條件,並不符合取多個句子的條件,因此只有前 3 個句子是符合 多個句子之篩選條件;但在取單一句子時,因未達演算法一,因此以最高 Cp 值視為匹配句子。. 21.
(34) 演 算 法 一. 演 算 法 二. 1:for Pcr 起始值; Pcr >=0.1 ; Pcr -= 0.025 2: 移除標點符號匹配 or 移除停用字匹配 3:end for 1:計算已匹配句子Cp值 2:Cp值降冪排序 3:pool=null; 4:total_Tcr=0; 5:for each sentence i 6: if sentence i Pcr >= Pcr + 調節值 && total_Tcr <= 1.0 7: add sentence i to pool 8: total_Tcr+= Tcr of sentence 9: end if 10:next 11:if pool == null then 12: 取最高Cp值的匹配句子 13:end if. 圖 3-2 匹配句子之演算法流程 表 3-1 匹配準則例子 符合取多個匹配句子範例 備註:假設目前 Pcr 為 0.7,若需符合演算法二,則 Pcr 需大於 0.75 文字稿句子 投影檔句子 Pcr Tcr Cp understand evaluation explain popular machine learning 0.86 0.42 0.42 methods understand algorithms work various understand various representations 1.0 0.33 0.33 representations models models popular machine understand evaluation methods 1.0 0.25 0.25 learning algorithms understand doing 0.5 0.08 0.08 work 符合取單一匹配句子範例 備註:假設目前 Pcr 為 0.7,若需符合演算法二,則 Pcr 需大於 0.75 文字稿句子 投影檔句子 Pcr Tcr Cp context weka data mining workbench. data mining workbench. 1.0. data mining vs. machine 0.4 learning (未達演算法二) 22. 0.6. 0.6. 0.4. 0.4.
(35) 當同時符合以上篩選規則時,標記文字稿句子類別為 1,因部分文字稿 與投影檔句子間重疊字詞數過低,會因此未達以上的演算法規則,則標記 文字稿句子類別為 0。最後,藉由 GloVe 已訓練好的字詞向量18,來獲取句 子向量,形成我們往後所用的訓練與測試集。. 第三節. 深度神經網路語言模型建立階段. 在此階段,本論文採用 Deeplearning4J19中的 LSTM 來建立深度神經網 路語言模型。LSTM 可以被視為是一個兩層類神經網路模型,具有處理時 間性的架構,第一層是輸入層,使用原始資料中的各個句子,以一個低維 實數連續向量讀入;第二層為隱藏層,隱藏層中含有一個 Block,輸入層會 依時間步驟,將句子向量以不同函數(如雙曲函數(Hyperbolic Function))映射 至隱藏層中,藉由儲存細格的核心元素來評斷哪個句子向量是重要的,來 儲存到閘裡,並會在下一個時間點透過自我循環連接連到本身,因此使網 路具有動態記憶能力,且具有長時間記憶資訊的功用。 用 LSTM 建立深度神經網路語言模型時,因設定不同之參數會對模型 在訓練上有不同的效果存在,本論文透過實驗及參考 LSTM 所提供的參數 設定20,建構 4 層架構(2 層隱藏層)的 LSTM 深度神經網路語言模型來學習 句子特徵,以 300-175-50-2 來個別設定各層的神經元數目。並設定 epochs. 18. 資料來源:https://nlp.stanford.edu/projects/glove/。. 19. 資料來源:https://deeplearning4j.org/。. 20. 資料來源:https://deeplearning4j.org/troubleshootingneuralnets/。 23.
(36) 為預測值 1 次,最佳化學習演算法為 SGD,設定 l2 正規化為 1E-5,Dropout 為 0.5,權重初始化為 ReLU。 學習率是個極為重要的參數之一,通常無法直接決定為多少,經過本 論文測試,設為 1E-3。激活函數可以用兩個概念去思維:在 LSTM 的隱藏 層中,通常以雙曲函數(Tanh)做為考量,也可以其他的激活函數當作選擇, 不過容易造成過度擬合,因此本論文在隱藏層中採 Tanh 為激活函數;在輸 出層時,本論文採預設 SoftMax 函數為激活函數。. 第四節. 擷取文字稿摘要. 為了產生摘要,我們計算投影檔總字詞數,來限制摘要擷取的字詞數 上限,形成個別文字稿重點摘要。因部分投影檔字詞數過少,可能導致沒 有句子被截取為摘要,因此將投影檔字詞數過少的檔案移除。. 第五節. 評估. 為瞭解不同方法模型所獲取的文字稿摘要何者較佳,本論文透過 ROUGE-1、ROUGE-2、ROUGE-3,來比較 LSTM 深度神經網路語言的摘 要模型、黃喬(2016)LDA 主題模型,以及 Auto Summarizer、Free Summarizer、 Tools4noobs 之線上開放原始碼摘要法模型何者為佳。 精確度指標表示在待審摘要中出現的正確字詞數比例。如表 3-2 為例, 系統以 ROUGE-1、ROUGE-2、ROUGE-3 個別取 38、33、28 個字詞視為待 審摘要,且待審摘要與參考摘要個別重疊 11、6、2 個字詞,表示正確擊中 24.
(37) 11 = 0.2895、ROUGE-2 38. 的次數個別為 11、6、2 次,因此 ROUGE-1 的精確度為. 6 2 = 0.1818、ROUGE-1 的精確度為 = 0.0714。 33 28. 的精確度為. 召回率指標表示在待審摘要中,對於參考摘要字詞所占的比例。如表 3-2 為例,兩者摘要中 ROUGE-1、ROUGE-2、ROUGE-3 個別重疊 11、6、 2 個字詞,表示正確擊中的次數個別為 11、6、2 次,參考摘要個別為 12、 11 = 0.9167 、ROUGE-2 的召 12. 9、6 個字詞,可得出 ROUGE-1 的召回率為 6 9. 2 6. 回率為 = 0.6667 、ROUGE-3 的召回率為 = 0.3333。就如同 2.4 節所述, 單方面看精確度與召回率的衡量指標是不足的,必須再考慮兩者調和指標 F1 值。 表 3-2 ROUGE 結果例子 待審摘要 There are five classes altogether Each class consists of about six lessons Class 1 is Getting Started with Weka Then we're going to look at Evaluation in Class 2 and at the end there is a post-class assessment. ROUGE-1 ROUGE-2 ROUGE-3. 參考摘要 Class 1 Getting started with Weka Class 2 Evaluation Post-class assessment 2/3. 待審摘要之總字詞數 38 33 28. 參考摘要之總字詞數 12 9 6. 字詞重疊數 11 6 2. ROUGE 之 F1 值,是精確度與召回率的調和指標,因通常文字稿摘要 擷取字詞數越多時,精確度會越低,而召回率則會越高;相反的文字稿摘 要擷取字詞數越少時,精確度會高,而召回率反而會越低,因此我們需要 25.
(38) F1 衡量指標,以客觀角度進行評估模型之間的優劣,其公式如 12 所示。透 11 = 0.2895、ROUGE-2 的精確度為 38. 過上述個別得出 ROUGE-1 的精確度為. 6 2 = 0.1818、ROUGE-1 的精確度為 = 0.0714;ROUGE-1 的召回率為 33 28 11 6 = 0.9167、ROUGE-2 的召回率為 = 0.6667、ROUGE-3 的召回率為 12 9 2 = 0.3333,進一步依據公式計算出個別的 ROUGE-1 之 F1 值為 0.4400、 6. ROUGE-2 之 F1 值為 0.2857、ROUGE-3 之 F1 值為 0.1176。 F1 =. 2*Precision*Recall Precision+Recall. 26. (12).
(39) 第肆章 實驗結果 為了證明本研究 LSTM 之深度神經網路語言模型擁有更好的摘要擷取 效益,本論文共進行兩次實驗,並使用開放式線上課程文字稿作為資料集, 於第一個實驗中,我們選擇 3 門課程,觀察不同參數設定能足以準確的匹 配句子。並根據不同文字稿課程進行資料集切割,80%為訓練資料集,其餘 20%為驗證資料集,透過 5 次交叉驗證觀察不同輸入資料集方法(不移除停 用字資料集、移除停用字資料集)於不同參數設定之間的表現,以便找出 LSTM 深度神經網路模型的較適參數。 在實驗 2 中,使用本論文所整理的最新測試資料集(其餘 27 門課程), 探討本論文在較好的參數設定下、並與黃喬(2016)LDA 主題模型的摘要擷 取效益最好的方法,以及 Auto Summarizer、Free Summarizer、Tools4noobs 之線上摘要器,進一步透過客觀的評判指標 ROUGE-1、ROUGE-2、 ROUGE-3,來比較摘要擷取的效果。. 第一節. 資料集說明. 資料集是由開放式線上課程所取得的,線上課程來源是以 Coursera 平 台為主,此資料集內容共分為兩部分,分別為文字稿及相對應的投影檔內 容,共有 30 門課程。本論文以亂數的方式選擇 3 門課程,並以 80%訓練集 與 20%驗證集進行 5 等分交叉驗證來訓練模型,再進一步使用未訓練的 27 門完整課程作為測試集。資料集內容如表 4-1 所示。 27.
(40) 表 4-1 資料集內容 分割訓練集與驗證集之前 3 門課程 課程名稱 Data Mining with Weka Social Network Analysis Web Application Architectures 27 門課程測試集 課程名稱 Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Audio Signal Processing for Music Applications automata Beginning Game Programming with C Climate Change Computational Neuroscience Discrete Optimization Dynamical Modeling Methods for Systems Biology Edx Introduction to Computer Programming Part 1 Edx Introduction to Computer Science Experimental Methods in Systems Biology Foundations of Virtual Instruction Introduction to Chemistry Reactions and Ratios Introduction to Data Science Journalism Skills for Engaged Citizens LINCS Data Coordination and Integration Center Machine Learning Malicious Software and its Underground Economy Two Sides to Every Story Natural Language Processing 2013 Network Analysis in Systems Biology Probabilistic Graphical Models Surviving Disruptive Technologies Take the Lead on Healthcare Quality Improvement The Brain and Space Virology I How Viruses Work Writing in the Sciences. 第二節 一、. 實驗一參數設定 演算法參數設定 28. 章節數 28 12 34. 句子數 2653 1895 2891. 章節數 75 103 22 23 49 22 28 43 30 56 11 23 24 42 95 18 28 18. 句子數 14981 13115 2765 6831 6222 3383 5292 13883 7360 3105 25818 3923 1776 6653 5080 1834 2196 9789. 39. 4031. 116 33 20 42 18 51 59 36. 8317 3099 4846 3737 2265 3239 8795 3465.
(41) 為了證明本論文提出的演算法能正確匹配到相對應的句子,本論文會 事先移除標點符號,並計算演算法抽取的句子與匹配的投影檔句子之間的 重疊字詞,並累加所有重疊字詞除投影檔之總字詞數,得出最後正確重疊 字詞結果,公式如下: Match(演算法抽取的句子字詞,匹配對應的投影檔句子字詞) 投影檔總字詞數. (13). 由表 4-2 結果顯示,當 Pcr 起始值等於 0.8 時,正確字詞數比例達 56.29%, 較具有懲罰文字稿長句子的能力,具有最高的正確比例,因此後續研究固 定設定 Pcr 為 0.8。我們進一步實驗是否只需移除標點符號還是必須移除停 用字才能足以正確的匹配句子,由表 4-3 結果顯示,如只透過移除標點符號 匹配句子之正確率會持續下降,原因在於只使用移除標點符號就進行匹配, 則可能會發生匹配到停用字的誤差,導致標記錯誤類別,因此證明移除停 用字比起移除標點符號進行匹配句子更能準確的匹配到句子,後續研究只 考量移除停用字進行句子間的匹配。有時文字稿長句子能匹配到多個投影 檔句子,本論文設定取多個句子的演算法,如表 4-4 結果顯示,當 Pcr >目 前 Pcr + 0.15 之規則時,具有最高 57.54%的正確字詞數比例。綜合上述研究 結果,本論文設定 Pcr 起始值為 0.8,只考量移除停用字進行句子匹配及 Pcr > 目前 Pcr + 0.15 作為演算法的參數設定。 表 4-2 Pcr 起始值之參數設定 Pcr 起始值 Pcr<=?時,移除停用字 匹配多個句子演算法 正確率 29.
(42) Pcr 起始值 Pcr<=?時,移除停用字 匹配多個句子演算法 正確率 1 1.0 0 56.07% 0.9 1.0 0 55.87% 0.8 1.0 0 56.29% 0.7 1.0 0 56.01% 0.6 1.0 0 54.25% 0.5 1.0 0 53.14% 0.4 1.0 0 46.60% 0.3 1.0 0 36.77% 備註:粗體字表示為最高值 表 4-3 是否只需移除標點符號之參數設定 Pcr 起始值 Pcr<=?時,移除停用字 匹配多個句子演算法 正確率 0.8 1.0 0 56.29% 0.8 0.9 0 56.29% 0.8 0.8 0 56.29% 0.8 0.7 0 51.57% 0.8 0.6 0 47.14% 0.8 0.5 0 44.15% 0.8 0.4 0 40.41% 0.8 0.3 0 37.58% 0.8 0.2 0 36.32% 備註:粗體字表示為最高值 表 4-4 取多個句子準則之參數設定 Pcr 起始值 Pcr<=?時,移除停用字 匹配多個句子演算法 正確率 0.7 0.8 0.2 57.54% 0.7 0.8 0.15 57.54% 0.7 0.8 0.1 57.12% 0.7 0.8 0.05 57.15% 0.7 0.8 0 56.30% 備註:粗體字表示為最高值 二、. LSTM 參數設定. 隱藏層的數量對深度神經網路而言是個重要的參數,因它對分類結果 具有深遠的影響。過去的方法大多用經驗法則(Boger & Guterman 1997),或 土法煉鋼的方式來實現,現存的方法仍未有確切的方式來決定(Mas & Flores 30.
(43) 2008)。本論文採用 5 次交叉驗證的方法來實驗,由圖 4-1 結果顯示,當模 型具有兩層隱藏層來訓練時,ROUGE-1、ROUGE-2、ROUGE-3 能達最高 的結果表現,表示兩層隱藏層就足以區分不同類別的特徵。 40% 35% 30% 25%. 0層隱藏層. 20%. 1層隱藏層 2層隱藏層. 15%. 3層隱藏層. 10% 5% 0% ROUGE-1. ROUGE-2. ROUGE-3. 圖 4-1 不同隱藏層的結果圖 在 LSTM 深度神經網路語言模型中,因不同序列向量輸入會有產生截 然不同輸出向量的結果表現,此實驗分別探討以下兩種資料集之間的差 異: 1. 不移除停用字資料集。內容如表 4-5 所示: 表 4-5 不移除停用字資料集之文字稿內容例子 文字稿內容 welcome everyone to this first lecture of the course on audio signal processing for music applications in this first lecture i want to introduce a few practical things related with the course 31.
(44) the first one is to introduce ourselves professor julius smith he's a professor at stanford university at the center for computer research in music and acoustics under whom i did my phd quite a few years ago and from whom i learned most of the things i know on audio signal processing and myself my name is xavier serra and i teach at the pompeu fabra in barcelona universityand i lead a research group in music technology and we have two teaching assistants in the course despite these pictures we are definitely not professional performers but we are definitely music lovers 2. 移除停用字資料集。內容如表 4-6 所示: 表 4-6 移除停用字資料集之文字稿內容例子 文字稿內容 welcome everyone first lecture course audio signal processing music applications first lecture want introduce few practical things related course first one introduce professor julius smith professor stanford university center computer research music acoustics under phd quite few years ago from learned most things know audio signal processing name xavier serra teach pompeu fabra university lead research group music technology two teaching assistants course pictures definitely professional performers definitely music lovers 表 4-7、4-8 的結果顯示,預處理的執行時間約花費 14 秒,是因此階段 仍為訓練階段,必須做標記句子類別的處理,所耗費的時間較久,但本論 文同時處理 3 門課程,而非單一章節,因此處理時間並非過久。從結果可 以得出移除停用字與不移除停用字資料集在預處理時間並非相差太多,至 於不移除停用字資料集摘要生成時間約花費 0.2 秒,比起移除停用字資料集 摘要生成時間約花費 0.14 秒來的快一些,因本論文所產生的摘要句子有依 照原始文字稿句子順序重新排序,在移除停用字資料集在比對原始句子時, 32.
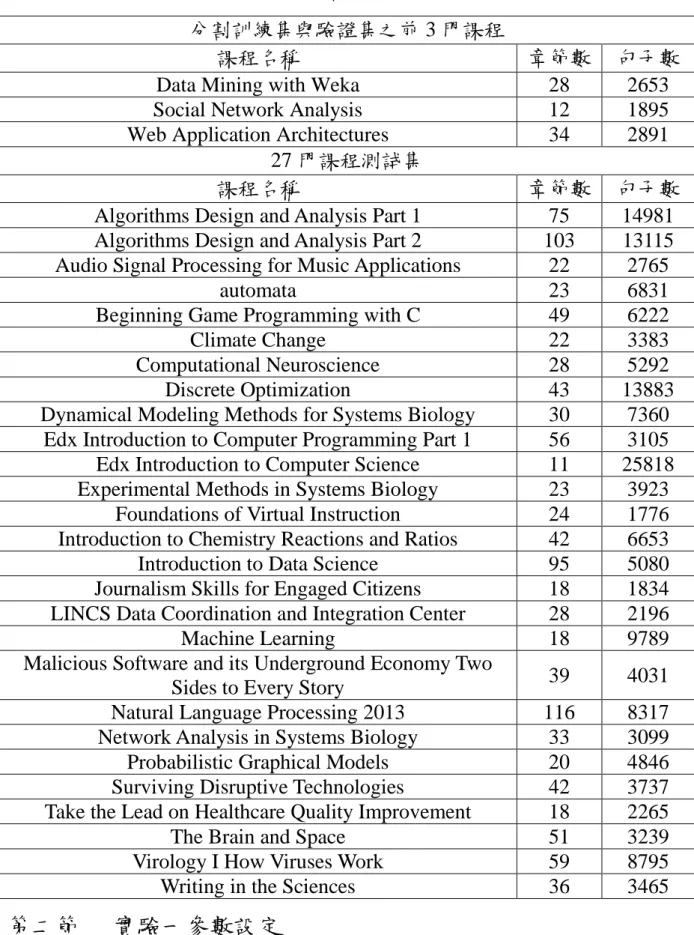
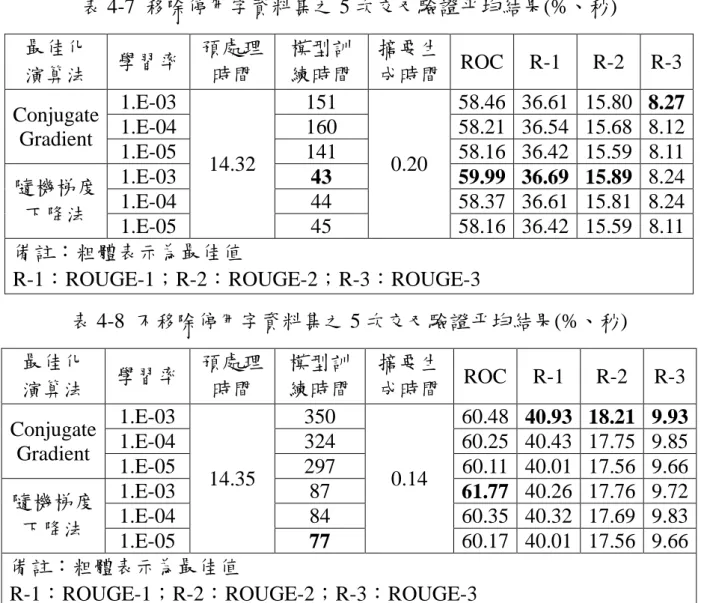
(45) 需將原始文字稿之句子做移除停用字,此階段花費的比起不移除停用字資 料集來的費時,因此最後生成摘要時間處理的較慢。 在設定相同參數時,因資料量大小的差異,不移除停用字資料集在模 型訓練會比移除停用字資料集來的久,雖然訓練時間相對較長,但是增加 些許時間就能進一步區別不同類別的特徵,能達到更高的 ROC 值與 ROUGE 值結果。因使用 LSTM 訓練出的模型是具有長時間範圍內的記憶功能,如 使用移除停用字資料集作為訓練,其模型較無法分辨每個序列向量之間的 區別,導致各類別特徵可能存在著模糊地帶的疑慮,進一步抽取各類別特 徵來識別於驗證集的句子上,是不足以區別不同的類別標籤。因此不移除 停用字資料集較適合作為深度神經網路語言模型的輸入資料集。 此外,若使用不移除停用字資料集中,隨機梯度下降(SGD)最佳化演算 法之 ROUGE 值結果顯示低於 Conjugate Gradient 最佳化演算法,但 ROC 值表現較好一點。因 ROC 值表現較好的參數,能夠判區分句子為正確的類 別標籤,因此得到較好的結果,且本論文進一步限制抽取摘要的字詞數上 限,因此透過句子被預測為摘要句的機率值進行降冪排序,在平均 ROUGE 值表現較好的參數中,分數較高的句子與投影檔的字詞數之重疊字詞比率 較高,造成計算出的平均 ROUGE 值較低。因 ROUGE 結果與 ROC 值並未 相差太多,且設定 SGD 來訓練模型所平均花費的時間約 80 秒,而 Conjugate Gradient 則需 325 秒,將近相差 4 倍,因此本論文設定最佳化演算法為 SGD。 33.
(46) 表 4-7 移除停用字資料集之 5 次交叉驗證平均結果(%、秒) 最佳化 演算法. 學習率. 預處理 時間. 模型訓 練時間 151 160 141 43 44 45. 摘要生 ROC 成時間 58.46 58.21 58.16 0.20 59.99 58.37 58.16. 1.E-03 1.E-04 1.E-05 14.32 1.E-03 隨機梯度 1.E-04 下降法 1.E-05 備註:粗體表示為最佳值 R-1:ROUGE-1;R-2:ROUGE-2;R-3:ROUGE-3 Conjugate Gradient. R-1. R-2. R-3. 36.61 36.54 36.42 36.69 36.61 36.42. 15.80 15.68 15.59 15.89 15.81 15.59. 8.27 8.12 8.11 8.24 8.24 8.11. 表 4-8 不移除停用字資料集之 5 次交叉驗證平均結果(%、秒) 最佳化 演算法. 學習率. 預處理 時間. 模型訓 練時間 350 324 297 87 84 77. 摘要生 成時間. ROC. 1.E-03 60.48 1.E-04 60.25 1.E-05 60.11 14.35 0.14 61.77 隨機梯度 1.E-03 1.E-04 60.35 下降法 1.E-05 60.17 備註:粗體表示為最佳值 R-1:ROUGE-1;R-2:ROUGE-2;R-3:ROUGE-3 Conjugate Gradient. R-1. R-2. R-3. 40.93 40.43 40.01 40.26 40.32 40.01. 18.21 17.75 17.56 17.76 17.69 17.56. 9.93 9.85 9.66 9.72 9.83 9.66. 透過設定相同參數,進一步探討移除停用字與不移除停用字資料集所 訓練模型來產生新課程摘要的所需時間,詳細使用資料集說明請至表 4-1。 由表 4-9 結果顯示,其結果顯示是處理一門課程的平均時間,因資料量大小 的差異,不移除停用字的內容涵蓋較大,在評估階段處理時間較長,但生 成摘要時間處理較快,是因本論文所產生的摘要句子有依照原始文字稿句 子順序重新排序,在移除停用字資料集在比對原始句子時,需將原始文字 稿之句子做移除停用字,此階段花費的比起不移除停用字資料集來的費時, 因此最後生成摘要時間處理的較慢。 34.
(47) 表 4-9 不同資料集產生一門新課程摘要的執行時間(秒) 不移除停用字資料集 移除停用字資料集 備註:粗體表示為最佳值. 總處理時間 190 185. 評估時間 37 27. 生成摘要時間 0.818 1.171. 綜合上述研究結果,雖然不移除停用字資料集評估時間較久,但多增 加些許時間就能區別不同類別的特徵,得到較高的 ROUGE 值與 ROC 值, 因此本研究後續研究只探討不移除停用字資料集作為輸入模型的資料集, 隱藏層設為 2 層,最佳演算法參數設為 SGD,學習率參數則為 1E-4。. 第三節. 實驗二不同摘要器之結果比較. 以往的研究難以評估模型是否為好的模型,原因在於兩兩模型之間並 無存在一個評判的標準,無法直接做之間的比較。本論文探討質化分析(如: 句意是否完整、重點是否都有涵蓋)和量化分析(ROUGE)來評估不同摘要器 的優劣。 一、. 質化分析. 以 Beginning Game Programming with C 的 3.5 章節為例,其投影片內容 如表 4-10 所示: 表 4-10 投影檔內容 投影片內容 Lecture Selection : Switch Statements Last time , we talked about how we can use the various forms of the if statement to make decisions in our programs This time , we'll look at how we can use another statement - - the switch statement - - to make decisions 35.
(48) Another statement we'll use to perform selection in our C# code is the A : else statement B : switch statement C : witch statement D : warlock statement Start IDE and open Console App project Read in a your n from the user and print a message if they say y ( using a switch statement ) Add clause for a n message Add default clause Recap We discussed how to use the switch statement to select what our program does Next Time We'll discuss various applications of the selection construct in our games 本論文所採用的 LSTM 之深度神經網路語言模型、黃喬(2016)結合 TF-ISF 至 LDA 模型所產生的摘要,會根據原始文字稿的句子順序進行句子 還原的方式來產生,且英文大小寫也會同時還原。雖然 Auto Summarizer、 Free Summarizer 之線上摘要器也能依照原始句子順序來產生摘要,但它們 只以英文句點的結尾方式視為一個句子,跟本論文所使用的斷句規則不同, 因此最後產生的摘要有些許差異,而 Tools4noobs 之線上摘要器所產生的摘 要並不會還原成原始文字稿的位置,所產生的摘要相較之下較為不妥,但 線上摘要器 Auto Summarizer 能還原英文大小寫,Free Summarizer、 Tools4noobs 之線上摘要器並無此功能。 以 Beginning Game Programming with C 的 3.5 章節為例,LSTM 所產生 的摘要內容如表 4-11 所示;TF-ISF 所產生的摘要內容如表 4-12 所示;Auto Summarizer 所產生的摘要內容如表 4-13 所示;Free Summarizer 所產生的摘 要內容如表 4-14 所示;Tools4noobs 所產生的摘要內容如表 4-15 所示。 36.
(49) 表 4-11 LSTM 之深度網路語言模型所產生的摘要內容 擷取摘要內容如下 In this lecture , we're continuing our discussion of the selection control structure . This time , we're going to look at another C# statement we can use to implement the selection control structure in C# . And the way the switch statement works is we type the word switch , which is a keyword . Other programming languages let you do that . So it turns out , that we can list multiple cases , multiple values for the answer variable in this particular case that will do this stuff here . Still showing you that y works in both cases . Where it figures out which of these things matches , if you will , and does the appropriate stuff inside . An enumeration is basically a data type that has specific values . We'll look at enumerations and see how they all work so , 表 4-12 TF-ISF 所產生的摘要內容 擷取摘要內容如下 This time , we're going to look at another C# statement we can use to implement the selection control structure in C# . So it turns out , that we can list multiple cases , multiple values for the answer variable in this particular case that will do this stuff here . And so , if I just stack these values like this , then I can check both answer being lower case y and the answer being upper case y . I'll point out that I cannot down here decide , oh I want to do another thing with lower case y , because that has already been included . And , we're still going to have to add a break , because we add a break at the end of every clause we include in a switch statement . 表 4-13 Auto Summarizer 所產生的摘要內容 擷取摘要內容如下 That statement is called the switch statement . That error message says we can't fall through from this case to other cases . So it turns out , that we can list multiple cases , multiple values for the answer variable in this particular case that will do this stuff here . And so , if I just stack these values like this , then I can check both answer being lower case y and the answer being upper case y . Because we sure don't want to have to say , case a , case , upper case A , case b , all of the other possible characters that are not y or n . 37.
(50) 表 4-14 Free Summarizer 所產生的摘要內容 擷取摘要內容如下 So the new statement we're looking at is the switch statement . And the way the switch statement works is we type the word switch , which is a keyword . So we have case , lower case y . And that error message says we can't fall through from this case to other cases . So it turns out , that we can list multiple cases , multiple values for the answer variable in this particular case that will do this stuff here . And so , if I just stack these values like this , then I can check both answer being lower case y and the answer being upper case y . Because we sure don't want to have to say , case a , case , upper case A , case b , all of the other possible characters that are not y or n . I'm going to have you , if you do the optional lab , I'm going to have you do some practice with both if statements and switch statements , because they're both useful tools for selection . 表 4-15 Tools4noobs 所產生的摘要內容 擷取摘要內容如下 So , you might wonder why we care ? If we already have this if else , if else structure , why would we want a switch statement instead ? And it turns out that I covered it here because it's sort of the other statement we use for selection in C# . And , we're still going to have to add a break , because we add a break at the end of every clause we include in a switch statement . Because we sure don't want to have to say , case a , case , upper case A , case b , all of the other possible characters that are not y or n . So at the end of every case we do , we're going to type the word , break . 從上表 4-11 至 4-15 不同摘要器所產生的摘要結果,透過句意是否完整、 重點是否都有涵蓋的概念來看,LSTM 與 TF-ISF 摘要器句意相對其他摘要 器而言較為完整,較能理解投影檔所想表達的意涵,至於 Auto Summarizer 與 Free Summarizer 摘要器只有直接提到關鍵工具名稱,並未提到此章節想 表達的意義,較無法直接聯想到投影檔的涵義。而 Tools4noobs 因並未將生 成摘要依照原始文字稿句子順序重新排序,會造成前後文內容毫無頭緒的 38.
(51) 情形發生,是 5 種摘要器中較為不好的摘要器。但單單透過質化分析來證 明模型是否優劣是不夠堅固的,仍必須進一步透過量化分析(ROUGE 表現) 才能證明何者模型表現是最好的。 二、. 量化分析. 本實驗目的會與黃喬(2016)LDA 主題模型,以及 Auto Summarizer、Free Summarizer、Tools4noobs 之線上開放原始碼摘要法模型進行比較,透過客 觀指標 ROUGE 來觀察本論文所採用的 LSTM 建立深度神經網路語言模型 表現是否優於先前的研究。 黃喬(2016)研究結果如表 4-16 所示,此方法使用各種不同的演算法用 於 LDA 模型進行訓練,我們直接以平均 F1 值來看,使用 TF-ISF 方法的表 現是優於其他兩者方法,因此我們後續研究只考量用於 LDA 之 TF-ISF 方 法進行模型比較。 表 4-16 TF 摘要方法、TF-ISF 摘要方法和 TF-SF 摘要方法的平均 F1 值結果 測試資料集未加提示詞 章節數 Chapter 數 Perplexity TF 0.3289 0.3280 0.3256 TF-ISF 0.3271 0.3282 0.3258 TF-SF 0.3248 0.3257 0.3227 測試資料集使用 TF 正規化加權提示詞 章節數提示詞 TF 正 Perplexity 提示詞 TF 正 Chapter 數 TF 正 規化 規化 規化 TF 0.3205 0.3218 0.3167 TF-ISF 0.3231 0.3220 0.3206 TF-SF 0.3107 0.3100 0.3103 測試資料集使用提示詞出現次數乘上提示詞 TF 值加權提示詞 章節數提示詞次數 Perplexity 提示詞次數 Chapter 數提示詞 39.
(52) TF TF-ISF TF-SF. *TF 0.3282 0.3267 0.3239. TF TF-ISF TF-SF 備註:粗體表示為最高值 資料來源:黃喬(2016). *TF 0.3273 0.3281 0.3252 平均 F1 值 0.3247 0.3252 0.3195. 次數*TF 0.3253 0.3256 0.3222. 由不同摘要器所產生的摘要結果,並與投影片進行比對計算 ROUGE-1、 ROUGE-2、ROUGE-3,以探討摘要擷取效能。我們設定擷取摘要的句子數 上限比較不同摘要器的優劣,因線上摘要器 Free Summarizer 無法設定句子 上限,及 Auto Summarizer 內部設定 5 個句子產生 1 個句子、10 個句子產生 2 個句子的方法,無法保證能依照不同上限句子的規則來產生摘要,如加入 探討可能會有疑慮,因此兩者並未做進一步的探討。 透過表 4-17 結果顯示,TF-ISF 所擷取的字詞數為最高,LSTM 則為最 低,原因在於不同摘要器的斷句方法不同,句子所涵蓋的字詞數而有所差 異,造成擷取摘要的字詞數有一定的差距。此外,TF-ISF 摘要器設定句子 上限較少時,比起 LSTM 的 ROUGE 結果較佳,是因當限制越少摘要句子 數中具有越高總字詞數時,因尚未達到參考摘要的總字詞數,因此最後得 出的 ROUGE 表現必然會越好;但當擷取摘要的總字詞數超過參考摘要的 總字詞數,ROUGE 表現則會漸漸遞減。 本論文透過最高 ROUGE 值及摘要字詞數來比較不同摘要器的表現,. 40.
(53) 三種摘要器限制摘要句子數上限為 25 時,同時具有最高的 ROUGE 表現。 LSTM 只需擷取 450 個平均字詞數能達到最高 31.57%的 ROUGE-1、11.85% 的 ROUGE-2 表現,Tools4noobs 則擷取 528 個平均字詞數才能達到最高的 5.78 的 ROUGE-3 表現,且並未明顯優於 LSTM 的 ROUGE-3 表現。但不同 摘要器所擷取的平均字詞數有所差異,並無法明確地看出何者摘要器能有 較好的表現,因此我們進一步固定限制摘要的總字詞數上限,來探討模型 之間的優劣。 表 4-17 不同摘要器設定不同擷取摘要句子數上限之研究結果(%). LSTM TF-ISF Tools4noobs. ROUGE-1 16.43 23.01 21.24. LSTM TF-ISF Tools4noobs. ROUGE-1 23.87 28.19 26.99. LSTM TF-ISF Tools4noobs. ROUGE-1 27.88 30.10 29.18. LSTM TF-ISF Tools4noobs. ROUGE-1 30.19 30.62 30.06. LSTM. ROUGE-1 31.57. 上限 5 句 ROUGE-2 ROUGE-3 5.95 2.92 7.62 3.27 8.06 3.73 上限 10 句 ROUGE-2 ROUGE-3 8.60 4.12 9.39 4.18 10.13 4.76 上限 15 句 ROUGE-2 ROUGE-3 10.14 4.81 10.67 4.75 10.89 5.16 上限 20 句 ROUGE-2 ROUGE-3 11.09 5.26 11.12 5.04 11.37 5.43 上限 25 句 ROUGE-2 ROUGE-3 5.68 11.85 41. 平均摘要字詞數 98 196 138 平均摘要字詞數 192 355 249 平均摘要字詞數 282 498 349 平均摘要字詞數 369 630 441 平均摘要字詞數 450.
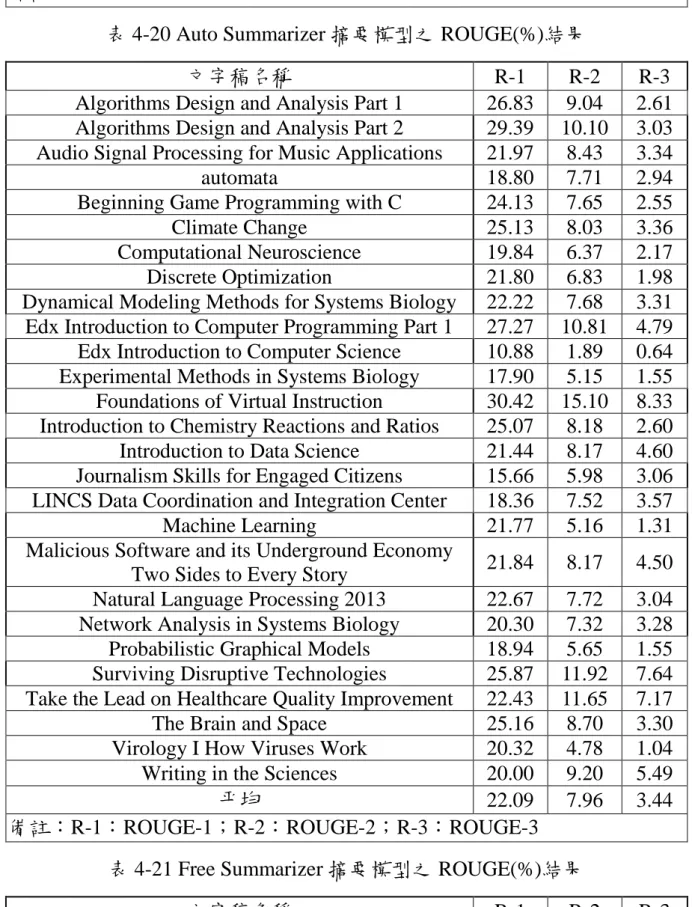
(54) TF-ISF 30.64 Tools4noobs 30.51 備註:粗體表示最佳值. 11.40 11.53. 5.24 5.78. 751 528. 本論文計算投影檔總字詞數,來限制摘要擷取的字詞數上限,因部分 投影檔字詞數過少,可能導致沒有句子被截取為摘要,因此我們設定摘要 擷取的句子數下限為一個句子,以便能直接的觀察不同摘要器的優劣。 本論文所採用的 LSTM 深度神經網路語言摘要模型的詳細結果如表 4-18 所示;TF-ISF 摘要模型的詳細結果如表 4-19 所示;線上摘要器 Auto Summarizer 的詳細結果如表 4-20 所示;線上摘要器 Free Summarizer 的詳細 結果如表 4-21 所示;線上摘要器 Tools4noobs 的詳細結果如表 4-22 所示。 表 4-18 LSTM 深度神經網路語言摘要模型之 ROUGE(%)結果 文字稿名稱 Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Audio Signal Processing for Music Applications automata Beginning Game Programming with C Climate Change Computational Neuroscience Discrete Optimization Dynamical Modeling Methods for Systems Biology Edx Introduction to Computer Programming Part 1 Edx Introduction to Computer Science Experimental Methods in Systems Biology Foundations of Virtual Instruction Introduction to Chemistry Reactions and Ratios Introduction to Data Science Journalism Skills for Engaged Citizens LINCS Data Coordination and Integration Center Machine Learning Malicious Software and its Underground Economy Two Sides to Every Story 42. R-1 29.26 34.13 20.14 51.14 27.45 29.02 34.34 34.06 37.91 42.06 20.12 31.88 28.77 28.85 26.58 34.10 30.28 32.12. R-2 9.36 10.98 5.98 17.08 8.29 7.37 12.83 11.03 16.46 18.89 3.45 9.42 14.07 10.09 9.68 15.31 10.81 10.88. R-3 2.82 3.57 2.05 5.23 2.91 2.55 5.67 3.55 9.91 10.33 0.97 3.94 8.42 3.99 5.51 9.23 5.49 3.53. 32.12. 14.14. 8.51.
(55) Natural Language Processing 2013 26.60 Network Analysis in Systems Biology 32.73 Probabilistic Graphical Models 31.71 Surviving Disruptive Technologies 39.19 Take the Lead on Healthcare Quality Improvement 42.53 The Brain and Space 29.95 Virology I How Viruses Work 26.52 Writing in the Sciences 33.56 平均 32.12 備註:R-1:ROUGE-1;R-2:ROUGE-2;R-3:ROUGE-3. 8.57 12.27 9.04 19.63 22.19 11.54 6.97 15.91 11.93. 3.24 5.86 2.77 13.55 14.75 5.45 2.42 10.50 5.80. R-1 27.88 33.92 21.30 48.36 25.61 29.26 31.50 29.21 34.16 38.82 16.79 31.71 29.51 28.54 25.20 31.12 32.83 27.99. R-2 9.26 11.16 7.59 15.75 7.51 8.69 10.13 8.02 13.03 16.19 2.16 9.71 12.78 9.50 9.25 12.16 12.58 7.22. R-3 2.80 3.44 3.42 4.84 3.02 3.12 3.84 2.01 6.64 8.24 0.71 4.03 8.13 2.81 5.37 6.69 6.49 1.60. 31.64. 11.79. 6.91. 25.77 31.13 28.48 36.56 39.43 28.84 25.66 26.59. 7.93 10.80 7.29 18.02 18.67 9.64 6.16 9.65. 2.69 4.43 1.96 12.31 11.37 4.11 1.57 5.21. 表 4-19 TF-ISF 摘要模型之 ROUGE(%)結果 文字稿名稱 Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Audio Signal Processing for Music Applications automata Beginning Game Programming with C Climate Change Computational Neuroscience Discrete Optimization Dynamical Modeling Methods for Systems Biology Edx Introduction to Computer Programming Part 1 Edx Introduction to Computer Science Experimental Methods in Systems Biology Foundations of Virtual Instruction Introduction to Chemistry Reactions and Ratios Introduction to Data Science Journalism Skills for Engaged Citizens LINCS Data Coordination and Integration Center Machine Learning Malicious Software and its Underground Economy Two Sides to Every Story Natural Language Processing 2013 Network Analysis in Systems Biology Probabilistic Graphical Models Surviving Disruptive Technologies Take the Lead on Healthcare Quality Improvement The Brain and Space Virology I How Viruses Work Writing in the Sciences 43.
數據


+3
相關文件
• Algorithmic design methods to solve problems efficiently (polynomial time).. • Divide
• makes a locally optimal choice in the hope that this choice will lead to a globally optimal solution.. • not always yield optimal solution; may end up at
Textbook Chapter 33.4 – Finding the closest pair of points.. Closest Pair of
✓ Combining an optimal solution to the subproblem via greedy can arrive an optimal solution to the original problem. Prove that there is always an optimal solution to the
✓ Combining an optimal solution to the subproblem via greedy can arrive an optimal solution to the original problem.. Prove that there is always an optimal solution to the
• Step 2: Run DFS on the transpose
Textbook Chapter 4.3 – The substitution method for solving recurrences Textbook Chapter 4.4 – The recursion-tree method for solving recurrences Textbook Chapter 4.5 – The master
Calculate the amortized cost of each operation based on the potential function 4. Calculate total amortized cost based on
