行政院國家科學委員會專題研究計畫 成果報告
用於歌聲合成之歌唱共鳴產生之研究 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 100-2221-E-011-157-
執 行 期 間 : 100 年 08 月 01 日至 101 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學資訊工程系
計 畫 主 持 人 : 古鴻炎
計畫參與人員: 碩士班研究生-兼任助理人員:張家維 碩士班研究生-兼任助理人員:簡延庭 碩士班研究生-兼任助理人員:張世穎 碩士班研究生-兼任助理人員:林祐靖 碩士班研究生-兼任助理人員:陳彥華
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫可公開查詢
中 華 民 國 101 年 10 月 19 日
中 文 摘 要 : 我們藉由此計畫重新製做了一個基於 HMM 頻譜模型的華語歌 聲合成系統,而 HMM 模型之建造必需考慮不同文脈與音域組 合,如此才能合成出一致性的歌聲音色。此外,我們由實驗 發現,以歌唱方式發音的語料來訓練 HMM,即可讓合成出的 歌聲具有歌唱共鳴之特性。關於歌唱共鳴的產生模型,我們 基於高斯混合模型(GMM)之頻譜對映機制,研究了兩種轉換的 程序,而經由聽測實驗發現,第一種轉換程序(稱為基本轉換 法)的效能稍好一些,不僅可把 A 的音色轉換成近似 B 的,且 可以轉換出共鳴的特性,但是音質則仍需改進。
中文關鍵詞: 歌聲合成, 歌唱共鳴, 頻譜包絡, 高斯混合模型
英 文 摘 要 : In this project, an HMM (hidden Markov model) based Mandarin singing-voice synthesis system is
implemented. Notice that the context of a lyric vowel and the pitch height of the note sung must be taken into account when training the HMM models in order to have consistent timbre among the synthesized lyric syllables. To have the characteristic of singing resonance kept in the synthesized singing voice, it is enough that the corpus for training the HMM is collected by recording a real singer’s singing voice signals. As to the model for singing resonance
generation, the GMM based conversion mechanism for spectrum mapping is adopted here. We have developed two conversion procedures. The first conversion procedure (called the basic conversion method) is found to be slightly better in performance. It can not only convert the timbre of speaker A into a similar timbre of speaker B, but also keep the characteristic of singing resonance in the
synthesized singing voice. Nevertheless, the voice quality still needs to be improved.
英文關鍵詞: singing voice synthesis, singing resonance, spectral envelope, GMM
1
行政院國家科學委員會專題研究計畫成果報告
用於歌聲合成之歌唱共鳴產生之研究
Singing Resonance Generation for Singing Voice Synthesis 計畫編號:NSC 100-2221-E-011-157
執行期限:100 年 8 月 1 日至 101 年 7 月 31 日 主持人:古鴻炎 國立台灣科技大學資訊工程系
計畫參與人員:張家維、簡延庭、張世穎、林祐靖、陳彥華 e-mail: [email protected]
一、中文摘要
我 們 藉 由 此 計 畫 重 新 製 做 了 一 個 基 於 HMM 頻譜模型的華語歌聲合成系統,而 HMM 模型之建造必需考慮不同文脈與音域組合,如 此才能合成出一致性的歌聲音色。此外,我們 由實驗發現,以歌唱方式發音的語料來訓練 HMM,即可讓合成出的歌聲具有歌唱共鳴之 特性。關於歌唱共鳴的產生模型,我們基於高 斯混合模型(GMM)之頻譜對映機制,研究了兩 種轉換的程序,而經由聽測實驗發現,第一種 轉換程序(稱為基本轉換法)的效能稍好一些,
不僅可把 A 的音色轉換成近似 B 的,且可以 轉換出共鳴的特性,但是音質則仍需改進。
關鍵詞:歌聲合成、歌唱共鳴、頻譜包絡、高 斯混合模型
ABSTRACT
In this project, an HMM (hidden Markov model) based Mandarin singing-voice synthesis system is implemented. Notice that the context of a lyric vowel and the pitch height of the note sung must be taken into account when training the HMM models in order to have consistent timbre among the synthesized lyric syllables. To have the characteristic of singing resonance kept in the synthesized singing voice, it is enough that the corpus for training the HMM is collected by recording a real singer’s singing voice signals.
As to the model for singing resonance generation, the GMM based conversion mechanism for spectrum mapping is adopted here. We have developed two conversion procedures. The first conversion procedure (called the basic conversion method) is found to be slightly better in performance. It can not only convert the
timbre of speaker A into a similar timbre of speaker B, but also keep the characteristic of singing resonance in the synthesized singing voice. Nevertheless, the voice quality still needs to be improved.
Keywords: singing voice synthesis, singing resonance, spectral envelope, GMM
二、緣由與目的
電腦歌聲合成技術可用於製作歌唱教導 之軟體,以教導許多喜愛唱歌但是看不懂樂譜 的人士。作詞、作曲的專業人士,也可藉由歌 聲合成軟體快速地聆聽、評估自已的作品,以 作必要的修改。更進一步當歌聲合成技術日漸 成熟時,電腦虛擬歌手的想法,將變成實際可 行。近年來日本Yamaha 公司製作的歌聲合成 軟體Vocaloid [1],就塑造了一個虛擬歌手,稱 為”初音”。
過去,我們在歌聲合成領域研究了好幾 年,目前也已經發展出一個即時的華語歌聲合 成系統,可合成出自然度不錯的歌聲。不過,
當我們仔細聽前述系統合成出的歌聲時,會查 覺到歌聲的音質仍然存在一個不能忽視的缺 點,那就是歌聲信號太過於清晰,而缺少專業 歌手的歌聲中所呈現出的共鳴(resonance)特 性,一個重要原因是,過去我們都是使用以說 話方式發音的華語音節,去分析、求得信號合 成模型的參數。
因此,在本次計畫裡,我們把焦點放在 歌唱共鳴上,去分析歌唱共鳴在聲學上所呈現 出的特性,然後研究建立歌唱共鳴的產生模 型,以便讓我們的系統能夠合成出自然、且具 有共鳴特性的歌聲。與歌唱共鳴相關的幾個問 題是:(a)使用以歌唱方式發音的華語音節來分 析出信號模型的參數,是否就可以讓合成出的
2 歌聲具有歌唱共鳴? (b)當對一個錄音者的發 音建立歌唱共鳴的產生模型之後,這個模型是 否可被用來對另一個錄音者的說話方式發音 所分析出的信號模型參數作處理,以便合成出 具有共鳴特性的歌聲信號? 這些問題就是本 計畫要加以探討的。
三、文獻回顧
關於歌聲合成的研究,過去已有一些文獻 探討歌聲合成相關的議題[2, 3, 4],例如歌聲信 號合成的方法,咬字規則(articulatory rules)與 演奏規則(performance rules),抖音(vibrato)與 轉 音(portamento) 等 歌 唱 技 巧 的 基 週 軌 跡 訂 定,歌者共振峰(singer’s formant)的模擬,以及 歌聲表情的表達。其中歌者共振峰是探討不同 的發音方式(如歌唱、說話),對於同一個音素 的共振峰頻率與頻寬會造成什麼樣的影響。
關於歌聲信號的合成,過去已有一些方法 被提出,大致上可將它們畫分成時域上、及頻 域上的合成方法。一般來說時域上的合成方 法,事先需作基週頂點之標記,計算量較少,
例如PSOLA 合成法[5]、TIPW 合成法[6],其 實 這 兩 種 合 成 法 都 是 起 源 於 語 音 合 成 的 研 究。不過,適用於語音合成的方法,不見得就 適合用於作歌聲合成,因為歌聲需求的音高變 化(音域)及音長變化(tempo),是要比語音大很 多的。
屬 於 頻 域 上 的 合 成 方 法 包 括 了 phase vocoder 法[7],共振峰合成(formant synthesis) 法[7],基於線性預測之 source-filter 合成法[7, 8],弦波模型合成法[9],EpR(excitation plus Resonances)模型合成法[10],及最近我們加以 改進之HNM (harmonic plus noise model)合成 法[11, 12]。一般來說頻域上的合成方法較為複 雜且計算量較多,不過所合成出的歌聲信號的 音質較為清晰,並且當音高及音長改變時,音 質退化得較慢。因此在本計畫裡,我們決定使 用HNM 合成法。
關於歌唱共鳴的研究,所搜尋到的文獻並 不多,並且大多是在分析共鳴歌聲的一些頻譜 特性,例如受過訓練的歌手所唱出的歌聲信 號,在頻譜上3KHz 附近會出現不同於語音信 號的頻譜包絡突起,稱為歌者之共振峰,一個 例子如圖 1[13]所顯示的。不過,歌唱共鳴的 特性並不是對所有的歌者都是共通的,實際上 會因為音域的不同(如女高音或女低音)、男女 性別的不同、及族群的不同,而有不同的歌唱
方式及共鳴方式[14, 15, 16]。
雖然過去有少數歌聲合成的文獻[13],研 究以修改共振峰頻率、頻寬的方式,來產生出 具有歌者共振峰的頻譜包絡形狀,但是這種研 究方向仍然存在一些問題需要解決,例如共振 峰的頻率是否可以被所使用的程式很準確地 估計出來? 含多個母音之音節(如/iau/),其母 音之間的過渡區的頻譜要如何調整? 所以我 們覺得,一種基於自動學習的共鳴模型的塑模 方法,會比規則式的頻譜調整方法來得理想。
圖1 歌者共振峰之例圖[13]
四、研究方法
首先我們邀請一位男性歌手(A 語者)到隔 音錄音室錄音,分別以說話方式(A 語音)及歌 唱方式(A 歌聲)錄製相同內容的歌詞發音,以 建立 40 首歌的平行語料庫;此外,邀請另一 位男性(B 語者)以說話方式(B 語音),錄製相同 內容的歌詞發音。接著,我們製作基頻與頻譜 包絡參數的分析程式,以求取語音及歌聲信號 各 音 框 的 基 頻 值 、DCC (discrete cepstrum coefficient)係數值[17]。
關於歌唱共鳴的呈現,由於前人的研究多 認為與頻譜包絡的形狀有關,因此我們首先嘗 試拿歌聲錄音所分析出的 DCC 係數,帶入所 發展的HMM 訓練程式,去訓練出華語聲、韻 母的HMM (hidden Markov model)頻譜模型,
然後依照歌詞來選擇適合的HMM 頻譜模型,
去產生歌詞的一序列音框的 DCC 係數,接著 帶入HNM 信號模型去作信號合成。
此外,我們欲建立一個歌唱共鳴的產生模 型,以便讓其他以說話方式錄音的人,能夠使 用這一個模型來合成出具有共鳴的歌聲。因此 我們嘗試應用語音變換(voice conversion)領域 裡所發展出的技術,來研究建立歌唱共鳴的產 生模型,而這也是為什麼我們要錄製說話語音 和歌唱聲之平行語料的原因。
3
4.1 歌聲合成系統主流程—訓練階段 在本計畫中我們改採 HMM 頻譜模型來 重新製作一個華語歌聲合成系統,此系統在訓 練階段的主要處理流程如圖2 所示。我們先將 歌 聲 資 料 庫 的 歌 曲 一 句 一 句 切 成 樂 句 作 標 音、切音,之後使用STRAIGHT[18]程式對每 一個切割出的音節作分析以求得頻譜包絡資 料及音高資料;然後使用先前發展的離散倒頻 譜係數之估計程式,去求取歌聲音節各音框的 DCC 頻譜係數,由於使用 STRAIGHT 來分析 出頻譜包絡曲線,所以在 DCC 係數的計算過 程,我們調整了頻譜峰值之挑選方式;接著,
我們依據所標記的音標資訊,將 DCC 係數分 類為聲母、韻母兩部分,並且進一步依據文脈 及音高資訊將聲、韻母作細分類;之後對各個 聲、韻母細類作HMM 訓練。
Start
標音、切音 STRAIGHT 分析
歌聲 資料庫
頻譜包絡資料 音高資料
DCC 係數估計 聲、韻母分類
聲、韻母細類 HMM 訓練 聲、韻母細分類
(依文脈、音高)
End
圖 2 訓練階段之主流程
4.2 歌聲合成系統主流程—合成階段 合成階段的主要處理流程如圖 3 所示。首 先對一個讀入的歌譜作文字剖析,以取得各個 歌詞的音高資料及音長資料。接著,將歌譜的 各個歌詞轉成聲、韻母之單位,再依據其文脈 及音高資料從HMM 模型集合中選取出最搭配 的HMM 模型。然後,根據音長資料及狀態駐 留參數,來決定一個聲、韻母HMM 模型內各 狀態應該指派的音框數量,並且使用HMM 各 狀態上的平均 DCC 向量去產生出各音框的
DCC 係數。求得 DCC 係數之後,再將各音框 的 DCC 係數帶入 GMM 音色轉換模組,以轉 換出具有另一人音色的 DCC 係數。接著,依 據音高資料去訂定各音框的音高數值;最後將 各音框的 DCC 係數、音高軌跡等資訊,帶入 HNM 模組去合成出歌聲信號。
選取聲、韻母 HMM 歌譜分析
音框DCC 係數產生
訂定音高軌跡 GMM 音色轉換
HNM 信號合成
音高 資料
音長資料 HMM
模型
歌聲信號 GMM 參數 歌譜
音框 DCC 係數
Start
End
圖 3 合成階段之主流程
4.3 DCC 係數估計
由於 STRAIGHT 分析出的頻譜包絡再據 以作合成而得到的語音信號,具有相當高的信 號自然度,這表示 STRAIGHT 分析出的頻譜 包絡非常準確。
因此,在本計畫裡,我們將切割好的歌聲 音節先拿去作 STRAIGHT 分析,以求得該音 節各音框的頻譜包絡曲線;然後對於一個有聲 音框的諧波部分,先將 STRAIGHT 分析所得 到的基頻值 F0 除於一個倍數 m,使得 x0 = F0/m 落在 40Hz 至 80Hz 之間,接著在頻率範 圍0 至 5500Hz 內,記錄 x0 的各個倍頻上的頻 率值及振幅值;對於雜音部分(即 5500Hz 之 後),則直接去偵頻各頻譜峰點的頻率值及其 對應的振幅值。依據前述記錄下來的頻率值及 振幅值的一些組合,接著就可執行離散倒頻譜 之計算模組,而求得一個音框的DCC 係數。
關於 DCC 係數的階數,我們量測了頻譜 包絡的逼近誤差,發現一直到階數高於80 時,
逼近誤差值的下降幅度才趨於緩和,因此我們 決定把階數值設為80。
4
4.4 基於 GMM 之音色轉換
音色轉換的程序是,首先依據目前歌詞音
節的韻母來選取該韻母所屬的 GMM 對映
(mapping)函數,然後讀入各音框的 DCC 係 數,分別將各音框的DCC 係數作 GMM 對映,
以獲得音色轉換後的音框 DCC 係數。至於 GMM 音色轉換的細節,我們研究了如下二種 的轉換方法:
(a) 基本轉換法:
首先使用A 語者的歌聲 HMM 模型來產生 出音框DCC 係數,接著,採用由 A 語者(來源 語者)和 B 語者(目標語者)的平行說話語料去 作GMM 訓練而得到的 GMM 參數,把各音框 的 DCC 係數拿去作 GMM 頻譜對映,而求得 轉換後的音框 DCC 係數。這個轉換法的處理 流程如圖4 所示。
韻母GMM 選取
HMM 產生之 DCC 係數
GMM 頻譜 對映
轉換後的 DCC 係數
Start
End
圖4 基本音色轉換法之流程
(b) 相對振幅轉換法
在圖5 裡輸入的音框 DCC 係數,是使用 A 語者的歌聲HMM 模型來產生出的,處裡的步 驟首先是作 GMM 對映,以把 A 語者的歌聲 DCC 係數轉換成 A 語者的語音 DCC 係數,在 此使用的GMM 模型參數是 A 語者所唱的歌聲 (來源語者)和 A 語者所唸的歌詞(目標語者)去 作GMM 訓練而得到。第二個步驟是,把前一 步驟轉換出的音框 DCC 係數,再作一次的 GMM 對映,以轉換出 B 語者的語音 DCC 係 數,在此使用的GMM 模型參數是 A 語者(來 源語者)和 B 語者(目標語者)的平行說話語料 去作GMM 訓練而得到。接著,把 DCC 係數 還原成頻譜包絡曲線Y(f)。
下一步,把第一次 GMM 對映後輸出的音 框 DCC 係數,還原成頻譜包絡曲線 X(f)。接 著,計算兩頻譜包絡曲線的振幅差值∆dB(f) = Y(f) - X(f)。然後,把輸入的音框 DCC 係數(未 作GMM 對映),轉成頻譜包絡曲線 Z(f),再將 Z(f)加上前二步驟算出的振幅差值∆dB(f),如
此就可求得音色轉換後的頻譜包絡。
音框DCC 係
數(A 歌聲) GMM 頻譜對映 (A 歌聲=>A 語音)
GMM 頻譜對映 (A 語音=>B 語音)
DCC 係數轉成 頻譜包絡Y(f)
轉換後之 頻譜包絡V(f) Start
DCC 係數 (A 語音)
DCC 係數轉成 頻譜包絡X(f)
計算頻譜振幅差值
∆dB(f)=Y(f) - X(f)
DCC 係數轉成 頻譜包絡Z(f)
頻譜包絡修正 V(f)=Z(f)+∆dB(f)
End
圖5 相對振幅轉換法之流程
在圖 4 和圖 5 裡的 GMM 頻譜對映方塊,
其執行的頻譜對映功能,若以數學公式來說 明,則如下式所示[19]:
( ; , ) y F x= μ Ψ =
( ) ( ) 1
1 1
( ; , )
( )
( ; , )
x xx
M m m m y yx xx x
m m m m
M x xx
m m m m
m
w N x
x w N x
μ μ μ
μ
−
=
=
⋅ Ψ
+ Ψ ⋅ Ψ ⋅ −
⋅ Ψ
(1)
其中x 表示來源語者的頻譜特微向量,y 表示 變換後得到的頻譜特微向量,M 是高斯混合 N(•, •, •)的總數,而 μ 及 Ψ 分別表示平均向量 與共變異矩陣的集合。
五、成果與討論
在本次計畫裡,我們重新製做了一個基於 HMM 頻譜模型的華語歌聲合成系統,而 HMM 頻譜模型的訓練則是使用新錄製的語料及自 行發展的程式(非現成軟體,如 HTK)。經由聽 覺聆聽所合成的歌聲,我們發現,如果只建造 21 聲母與 36 韻母的 HMM 模型,則合成的歌
5 聲在一些相鄰的音節之間會顯得不夠流暢,因 此我們把聲、韻母依照其文脈(前後文)作更細 的分類,以建造出較多的文脈相關之HMM 模 型,如此合成出的歌聲就能夠變得較流暢。除 了文脈因素之外,我們也發現歌唱者唱同一個 韻母時,如果所唱的音高(pitch)高低差許多,
則頻譜也會有明顯的差異(即造成音色的差 別),因此我們再加入了音高因素(分成高、中、
低音域),而分別建造出不同文脈與音域組合 的HMM 模型,如此合成的歌聲其音色才會讓 人覺得是同一個人所唱的。
另外,我們也比較了兩種語料所訓練出 HMM 模型的差別,第一種語料是 A 歌聲(A 語 者以歌唱方式發音),而另一種語料是 A 語音 (A 以說話方式發音),把兩種 HMM 模型分別 拿去合成出A 語者的歌聲信號,我們聆聽後發 現,A 歌聲語料所訓練出的 HMM 模型,的確 可讓合成的歌聲具有歌唱共鳴的特性,然而A 語音語料所訓練出的HMM 模型,卻不能讓合 成的歌聲顯現歌唱共鳴特性,所以要讓合成歌 聲具有歌唱共鳴特性,只要使用歌唱方式發音 的語料來訓練HMM 模型就可以達成。
關於歌唱共鳴的產生模型,目的是讓以說 話方式錄音的人,能夠使用這一個模型來合成 出具有共鳴特性的歌聲。我們基於GMM 頻譜 對映去研究了兩種轉換方法,分別如圖4 和圖 5 所顯示的處理流程。在圖 4 的基本轉換法,
雖然只能夠使用平行說話語料去訓練GMM 頻 譜對映模型,但是使用該轉換法去合成出歌聲 後,我們聆聽合成的歌聲,發現基本轉換法確 實能夠讓合成出的歌聲具有共鳴的特性,並且 音色已經被轉換成很近似B 語者的音色。
在圖5 的相對振幅轉換法,當使用此轉換 法去合成出歌聲後,我們聆聽歌聲的感覺是,
圖5 的歌聲比圖 4 的清晰許多(即比較不悶),
但是音色方面就差了一些,音色比較不像B 語 者的音色。所以,圖4 和圖 5 的轉換法各有其 優缺點。
六、參考文獻
[1] Yamaha, VOCALOID: New Singing Synthesis Technology,
http://www.vocaloid.com/en/index.html .
[2] X. Rodet, “Synthesis and processing of the singing voice,” Proc. 1st IEEE Benelux Workshop on Model based Processing and Coding of Audio (MPCA-2002), Leuven, Belgium, pp. 99-108, 2002.
[3] P. R. Cook, “Singing Voice Synthesis: History, Current Work, and Future Directions”, Computer Music Journal, Vol. 20(3), pp. 38-46, 1996.
[4] J. Sundberg, The Science of the Singing Voice, North Illinois University Press, DeKalb, Illinois, 1987.
[5] N. Schnell, G. Peeters, S. Lemouton, P.
Manoury, and X. Rodet, “Synthesizing a Choir in Real-time Using Pitch Synchronous Overlap Add”, Int. Computer Music Conference, Berlin, Germany, pp. 102-108, 2000.
[6] H. Y. Gu and W. L. Shiu, “A Mandarin-syllable Signal Synthesis Method with Increased Flexibility in Duration, Tone and Timbre Control,” Proc. Natl. Sci. Counc. ROC(A), Vol.
22, pp. 385-395, 1998.
[7] C. Dodge and T. A. Jerse, Computer Music:
Synthesis, Composition, and Performance, Schirmer Books, New York, NY, 1997.
[8] Y. E. Kim, Singing Voice Analysis/Synthesis, Ph.D. thesis, Massachusetts Institute of Technology, 2003.
[9] M. W. Macon, L. Jensen-Link, J. Oliverio, M. A.
Clements, and E. B. George, “A Singing Voice Synthesis System Based on Sinusoidal Modeling”, Int. Conf. Acoustics, Speech, and Signal Processing, Munich, Germany, pp.
435-438, 1997.
[10] J. Bonada and X. Serra, “Synthesis of the Singing Voice by Performance Sampling and Spectral Models”, IEEE Signal Processing Magazine, Vol. 24, pp. 67-79, 2007.
[11] Y. Stylianou, Harmonic plus Noise Models for Speech, Combined with Statistical Methods, for Speech and Speaker Modification, Ph.D. thesis, Ecole Nationale Supèrieure des Télécom- munications, Paris, France, 1996.
[12] H. Y. Gu and H. L. Liao, “Mandarin Singing-voice Synthesis Using an HNM Based Scheme”, Journal of Information Science and Engineering, Vol. 27(1), pp. 303-317, 2011.
[13] M. E. Lee and M. J. T. Smith, “Spectral Modification for Digital Singing Voice Synthesis Using Asymmetric Generalized Gaussians”, Int. Conf. on Acoustics, Speech, and Signal Processing, pp. I260-263, 2003.
[14] M. E. Bestebreurtje and H. K. Schutte,
“Resonance Strategies for the Belting Style:
Results of a Single Female Subject Study”, Journal of Voice, Vol. 14(2), pp. 194-204, 2000.
[15] E. Joliveau, J. Smith, and J. Wolfe , "Vocal Tract Resonances in Singing: The Soprano
6 Voice", Journal of Acoustical Society of America, pp. 2434-2439, 2004.
[16] N. Henrich, M. Kiek , J. Smith , and J.
Wolfe, “Resonance Strategies used in Bulgarian Women’s Singing Style: a Pilot Study”, Logopedics Phoniatrics Vocology, 2007.
[17] O. Cappé and E. Moulines, “Regularization Techniques for Discrete Cepstrum Estimation”, IEEE Signal Processing Letters, Vol. 3(4), pp.
100-102, 1996.
[18] H. Kawahara, I. Masuda-katsuse and A. De Cheveign, “Restructuring Speech Represen- tations Using a Pitch-adaptive Time-frequency Smoothing and an Instantaneous-frequency- based F0 Extraction: Possible Role of a Repetitive Structure in Sounds”, Speech Communication, Vol. 27, pp. 187-207, 1999.
[19] Y. Stylianou, O. Capp´e, and E.
Moulines, ”Continuous Probabilistic Transform for Voice Conversion,” IEEE trans. Speech and Audio Processing, Vol. 6, No. 2, pp.131-142, 1998.
1
出席國際學術會議心得報告
計畫編號 NSC 100-2221-E-011-157
計畫名稱 用於歌聲合成之歌唱共鳴產生之研究
出國人員姓名 服務機關及職稱
古鴻炎
國立台灣科技大學資訊工程系 副教授 會議時間地點 2011/10/15 ~ 2011/10/17, 中國上海
會議名稱 International Congress on Image and Signal Processing (CISP 2011)
發表論文題目 An Improved Voice Conversion Method Using Segmental GMMs and Automatic GMM Selection
一、參加會議經過
CISP 2011 國際研討會,由上海的東華大 學 所 主 辦 , 而 由 IEEE 生 醫 工 程 學 會 (Engineering in Medicine and Biology Society)協 辦,接受的論文將收錄於 IEEE Xplore 資料 庫。由研討會的名稱可知,接受投稿的領域包 含了影像處理、視訊處理、信號處理相關之子 領域及語音信號的處理。個人投稿的論文,屬 於語音處理,研究的成果是,提出以分段式 (segmental)高斯混合模型(GMM)的觀念,來改 進語音轉換的效能,並且發展了一個基於動態 規劃之自動 GMM 挑選的演算法,以實際應用 該觀念於線上(on-line)進行的語音轉換處理。
CISP 2011 接 受 的 論 文 , 分 成 28 個 sessions 分別進行口頭發表和壁報發表。由於 事先向主辦單位回應,希望以壁報方式來發 表,所以我的論文排於 10 月 16 日 13:30 ~ 15:30 的時段,以壁報方式進行發表。右邊上 圖就是在發表會場所拍攝的照片,而右邊下 圖,則是在晚宴會場所拍攝的照片。
2
在行程方面,於 10 月 14 日搭乘 14:15 由松山機場直飛上海虹橋機場的班機,然後從機場 搭乘地鐵,經換線後,到達會場的所在地點,即漕寶路 66 號光大會展中心,到達時已是 17:50。參加研討會後,則於 17 日晚間乘坐地鐵前往虹橋機場第一航站,然後搭乘 19:50 直航台 北松山機場的班機。
二、與會心得
CISP 2011 研討會接受投稿的領域包含了影像、視訊、與信號處裡之相關領域,所邀請的四 位 keynote speaker 都是 IEEE Fellow 級的專家。不過,演講的題目並沒有聲訊或語音處理方面 的,畢竟聲訊處理並不是此次研討會的焦點。
跟語音處理直接相關的論文,在此次研討會中共有 15 篇被接受。除了我的論文之外,其它 論文中有四篇是作語音辨識(speech recognition)的,有兩篇是作語者辨識(speaker recognition)的,
此外分別有一篇作語音合成(speech synthesis)和語音強化(speech enhancement)的,及一些作語音 分析的論文。雖然語音處理方面的論文篇數不是很多,但是也含蓋了幾個語音研究的子領域,
因此仍可相互了解不同子領域裡的研究情況。
3
An Improved Voice Conversion Method Using Segmental GMMs and Automatic GMM Selection
Hung-Yan Gu and Sung-Fung Tsai
Department of Computer Science and Information Engineering National Taiwan University of Science and Technology
Taipei, Taiwan
Abstract—In this paper, the idea of segmental GMMs is proposed for voice conversion. Also, to apply this idea to on-line voice conversion, we have developed an automatic GMM selection algorithm based on dynamic programming. In addition, to map a vector of DCC (discrete cepstrum coefficients) with only one Gaussian mixture, we have designed a mixture selection algorithm. For evaluating the performance of the idea, segmental GMMs, three voice conversion system are constructed and used to conduct listening tests. The results of the listening tests show that segmental GMMs proposed here can indeed help to improve the performances in both timbre similarity and voice quality.
Keywords-voice conversion; discrete cepstrum; Gaussian mixture model; timbre similarity; harmonic plus noise model
Introduction
The GMM based voice conversion method was introduced by Stylianou [1]. Afterward, many researches had tried to improve this method by considering one or several related issues [2-5]. Nevertheless, some serious problems still exist when applying the GMM based voice conversion method. The most noticeable one is that the converted spectrums are often over smoothed [2-4]. As a result, the converted voice is perceived with apparent distortion, i.e. the voice quality is significantly decreased. In addition, another noticeable problem is that two adjacent frames’ converted spectrums may become discontinuous when the over smoothing problem is tried to solve by using just the most probable Gaussian mixture to map the source spectral coefficients [4, 6].
In this paper, we study to solve the over smoothing problem with a different approach. Note that the cause results to over smoothing is the summation across many Gaussian mixtures (usually 128 mixtures) in the GMM based mapping function,
( ; , ) y F x= μ Ψ =
( ) ( ) 1
1 1
( ; , )
( )
( ; , )
x xx
M m m m y yx xx x
m m m m
M x xx
m m m m
m
w N x
x w N x
μ μ μ
μ
−
=
=
⋅ Ψ
+ Ψ ⋅ Ψ ⋅ −
⋅ Ψ
(1)
where x denotes a feature vector of the source speaker, y denotes the converted feature vector for the target speaker, M is the number of Gaussian mixtures, and μ and Ψ represent the sets of mean vectors and covariance matrices,
respectively. To solve the problem of over smoothing, we think reducing the number of Gaussian mixtures, M, in the mapping function is necessary. Nevertheless, the probability density function (PDF) of the trained GMM would become coarse when the number of mixtures is directly decreased.
Therefore, we consider to segment each of the training sentences into a sequence of speech segments, and to group these speech segments into several classes. For example, a speech segment may be a phoneme or a syllable. After segmentation, the signal frames grouped to a class are taken to train a corresponding GMM with fewer mixtures (e.g. 16 mixtures). Then, this GMM is dedicated to convert the source frames recognized to belong to the corresponding class. In this way, the GMM based mapping function, i.e. (1), can be applied with fewer mixtures. That is, a complicated GMM is now replaced with multiple simpler GMMs, and each GMM is dedicated for converting the signal frames recognized to belong to its corresponding class.
In this paper, we study voice conversion for Mandarin, and Mandarin is a syllable prominent language. Therefore, we take each syllable of a labeled training sentence as a speech segment. Next, each segment is grouped to one of the 37 classes according to its syllable final. For each of the 37 syllable-final classes, a corresponding GMM is then trained.
After training, the 37 GMMs are used for on-line voice conversion. Nevertheless, there is a problem that must be solved beforehand. That is, how can the right class that an input frame belongs to be picked out? For this problem, we have developed an automatic selection algorithm based on dynamic programming. This algorithm will be described in Subsection III.A.
Besides using multiple segmental GMMs to reduce the number of mixtures, we advanced furthermore to use only one Gaussian mixture for mapping a source spectrum into its converted spectrum in order to solve the problem of over- smoothed converted spectrum. Nevertheless, two adjacent source frames’ converted spectrums may become discontinuous and result in artifact sounds. Therefore, we studied to design a dynamic programming based algorithm to consider both the likelihood (when using a particular Gaussian mixture) and spectral continuity simultaneously for a sequence of signal frames. This algorithm will be described in Subsection III.B. In addition, we have integrated the two solution methods mentioned to build an on-line voice
4 conversion system. Then, this system is used to conduct the
listening tests.
Training Procedure
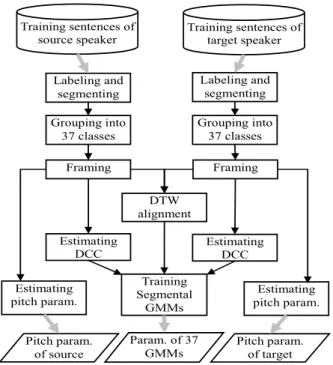
As an overview, the processing flow for the training stage of our voice conversion system is as that drawn in Fig. 1.
Three persons are invited to record 375 parallel sentences in a soundproof room. The sampling rate is 22,050Hz. Among the three persons, two are males, denoted as M1 and M2, and the other one is a female, denoted as F1. In this study, M1 is treated as the source speaker whereas M2 and F1 are treated as the target speakers, respectively. Therefore, the two voice conversion tasks here are converting the voice of M1 into the voice of M2 or F1.
Training Segmental
GMMs Labeling and
segmenting Training sentences of
source speaker Training sentences of target speaker
Labeling and segmenting Grouping into
37 classes Grouping into
37 classes
DTW alignment Estimating
DCC Estimating
DCC
Param. of 37 GMMs
Estimating pitch param.
Estimating pitch param.
Pitch param.
of target Pitch param.
of source
Framing Framing
Figure 1. Processing flow for the training stage.
Labeling and Grouping
First, the software package, HTK, was used to do forced alignment, i.e. automatic labeling. Here, the speech unit is syllable. Since many errors are found in the labeled syllable boundaries, manual checking and correcting of the syllable boundaries are thus required. Here, we used the software, WaveSurfer, to edit the labels and boundaries. Then, according to the information of syllable boundaries and phonetic symbol, each syllable’s signal was extracted and saved into a separate file which is named with sentence number, syllable number, and phonetic symbol. As a total, 2,926 syllables were extracted from the 375 recorded sentences of a speaker. Next, the syllables from the first 350 sentences are grouped into 37 classes according to the syllable-final symbol parsed from the filename of each saved signal file.
DCC Estimation
There are several methods proposed for estimating a signal frame’s magnitude-spectrum envelope (spectral envelope).
The method, STRAIGHT, is very accurate in its estimated spectral envelope but it requires a large amount of computations and cannot be used to implement a real-time system currently.
Therefore, in this study, we adopt the spectral envelope estimation method, discrete cepstrum [7, 8], and use the estimated discrete cepstrum coefficients (DCC) as the spectral parameters. For each signal frame, the DCC estimation scheme developed previously [8] is executed to obtain 40 DCC. Here, a frame’s width is 512 sample points, and adjacent frames are placed 110 points (about 5ms) apart.
Training of Segmental GMM
After the block, “grouping into 37 classes”, in Fig. 1 is executed, there would be 37 classes of syllable segments. For each class, a GMM of 16 mixtures is trained from those syllable signals grouped to the class. The GMM obtained is hence termed a segmental GMM.
Here, a parallel corpus is used. Each source syllable and its corresponding target syllable are time aligned first with DTW as indicated in the block, “DTW alignment”. Then, the DCC computed from a source frame is jointed with the DCC computed from the aligned target frame. With the jointed vectors of DCC, the training method based on maximum likelihood estimate is used to train a GMM for each class [9].
Pitch Parameters
A pitch detection method based on both autocorrelation and AMDF is used to detect the pitch frequency of a signal frame [10]. Then, the pitch frequencies detected from a speaker’s utterances are collected to compute their average and standard deviation, which are the pitch parameters used in this study.
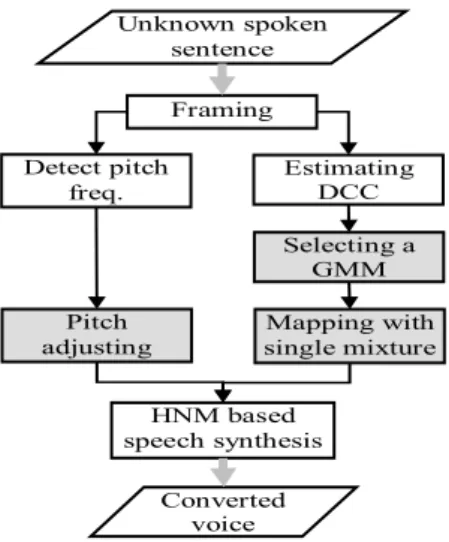
Conversion Procedure
The procedure proposed here for converting voice is as the processing flow drawn in Fig. 2. When a spoken sentence with unknown content is inputted, it will be sliced into a sequence of frames first with the frame width and shift as given in Subsection II.B. Then, the pitch frequency of each frame is detected in the left flow of Fig. 2 with the method mentioned in Subsection II.D. When a frame is detected to be unvoiced, the three gray colored blocks in Fig. 2 are bypassed directly.
That is, pitch adjusting is not needed and the spectral parameters, DCC, are not converted. On the other hand, when a frame is detected to be voiced, its pitch is simply converted as
( )
y y x
t x t
q μ σ p μ
= +σ − (2)
5 where pt is the detected pitch frequency, μx and σx are the
average and standard deviation of the source speaker’s pitch frequencies.
As for the right flow of Fig. 2, the input frames are processed one after another basically. Nevertheless, in the block, “Selecting a GMM”, we propose a selection algorithm that processes every 20 voiced frames in a batch. With this algorithm, the correct GMM (or its nearby GMM sometimes) can be picked out from the 37 GMMs for each frame. Then, in the block, “Mapping with single mixture”, only one mixture of the selected GMM is used to map the DCC in order to avoid spectral over smoothing. Nevertheless, the mixture selected for mapping is not always the most probable one. This is because spectral continuity between adjacent converted frames must also be considered to prevent artifact sounds from being generated. For the problem of mixture selection, we have developed a dynamic programming based algorithm that is different from the one studied by previous researchers [4].
Hence, in this block, a sequence of voiced frames bounded with left and right unvoiced frames are processed in a batch.
Finally, in the jointed block, “HNM based speech synthesis”, speech signals are re-synthesized using an HNM (harmonic plus noise model) based method [8, 11].
HNM based speech synthesis Pitch
adjusting
Selecting a GMM Mapping with single mixture Estimating
DCC
Converted voice Detect pitch
freq.
Unknown spoken sentence
Framing
Figure 2. Processing flow for the conversion stage.
GMM Selection
Since the content of the input speech is unknown, which one of the 37 GMMs should be selected for mapping each frame’s DCC becomes a problem that must be solved. In general, this is a problem of speech recognition. Nevertheless, it is not so serious because some frames are assigned with incorrect but similar GMMs are tolerable.
Here, we intend to use the 37 GMMs trained to take the role of HMM usually used for speech recognition. In addition, we observe that it is impossible for a person to utter more than 2 segments (i.e. syllables here) within a very short time interval, e.g. 100ms. Therefore, we decide to select GMMs for every 20 successive voiced frames (spanning 100ms of time) in a batch.
Then, only one or two of the 37 GMMs should be picked out.
Here, we have developed a dynamic programming based algorithm that selects one or two GMMs according to the criterion of maximum likelihood.
Let the probability that the t-th input frame’s DCC are generated by the s-th GMM be Gt(s). That is,
( )
1
( ) = ( ) ; ( ), ( ) .
M x xx
t m t m m
m
G s w s N x μ s s
=
⋅ Ψ
(3)
where wm(s) is the weight of the m-th mixture, and xt is the vector of DCC for the t-th frame. In addition, let R(t, s) be the logarithmic likelihood that the frames from time 1 to time t are all generated by the s-th GMM. In contrast, let D(t, s) be the logarithmic likelihood that the frames from time 1 to t are generated by two GMMs and the t-th frame is generated by the s-th GMM. In terms of these definitions, we can derive the two recursive formula,
( )
( , ) log t( ) ( 1, ) ,
R t s = G s +R t− s (4)
( ) 0 37, [ ]
( , ) log t( ) max max ( 1, ) , ( 1, ) ,
v v s
D t s G s R t v D t s
≤ < ≠
= + − −
(5) where the boundary values are D(1, s) = 0 and R(1, s) = log(G1(s)). Then, the maximum likelihood can be calculated as
[ ] [ ]
{
0 37 0 37}
( ) max max ( , ) , max ( , ) .
v v
A T R T v D T v
≤ < ≤ <
= (6)
where the final time T is set to 20 in this study. In terms of (4), (5), and (6), we can calculate the maximum likelihood, A(20), and then back track to find the sequence of GMM indices that are best for assigning to the batch of 20 voiced frames.
Mapping with Single Mixture
Mapping an input frame’s DCC with a single Gaussian mixture is meant that the summation and the weighting term of (1) are removed. That is, the converted DCC vector, y, is calculated as,
( ) ( ) 1
( ) y yx ( ) ,
k xx x
k k
k k
y F x= =μ + Ψ ⋅ Ψ − ⋅ −x μ (7) where x is the input frame’s DCC and Fk(x) denotes the mapping function using the k-th mixture.
The developed dynamic programming based algorithm for mixture selection is as the following. Let the index of the GMM selected by Subsection III.A for the t-th frame be I(t).
Denote the mapping function using the k-th mixture as
( )( )
I tk t
F x . In addition, let C(t, k) represent the cumulated distance from time 1 to time t and the index of the mixture used at time t be k. Then, we design the recursive formula,
( ( ) ( 1) 1 )
0 ,
( ( 1))
( , ) min ( ), ( ) ( 1, ) ,
m
k m
I t t I t t w I tm M H
C t k dist F x F − x− C t m
≤ <
− >
= + −
(8)
6 to realize dynamic programming, where dist(•,•) is a
geometric distance measure for DCC, H is a threshold set to 0.3 empirically, and wm(s) is the weight of the m-th mixture.
At time 0, the values of C(0, k) are directly set as C(0, k) = 0, 0≤ k < M. Finally, at time T, the minimum cumulated distance B(T) is computed as
[ ]
0 , ( ( ))
( ) min ( , ) .
k M w I Tk H
B T C T k
≤ < >
= (9)
In terms of (8) and (9), the minimum cumulated distance can be obtained. Also, the sequence of mixture indices for the frames from time 1 to T can be obtained through backtracking.
HNM Based Speech Synthesis
In HNM, the spectrum of a voiced frame is divided into the lower-frequency harmonic part and the higher-frequency noise part. The frequency that the two parts are divided according to is termed the maximum voiced frequency (MVF). In the original work [11], a method is provided to dynamically detect each frame’s MVF. Here, to simplify the synthesis processing, we just use the static MVF value, 6,000Hz, across all voiced frames.
Suppose the i-th and (i+1)-th frames are both voiced and have L and i Li+1 harmonic partials, respectively. To synthesize a signal sample for the t-th sampling point between the i-th and (i+1)-th frames, we first derive the frequencies,
k( )t
f , and amplitudes, ak( )t , of the harmonic partials for this sampling point with linear interpolation. That is,
1
1
( ) , 1, 2,..., ,
( ) , 1, 2,...,
i i
i k k
k k
i i
i k k
k k
f f
f t f t k L
N
a a
a t a t k L
N
+ +
= + − =
= + − =
(10)
where N is the number of sampling points between two adjacent frames, L is the larger one of Li and Li+1, and fki and aikare the frequency and amplitude for the k-th harmonic partial of the i-th frame. The value of fki is simply computed as k × qi where qi is the converted pitch frequency for the i-th frame. As to aki, its value is derived from the converted vector of DCC. The detail of the derivation is referred to our previous work [8]. Here, we directly set i
ak= 0, k=L +1, …, i Li+1, if L is less than i Li+1. Then, the harmonic signal, h(t), for the t- th sampling point is computed as
1
( ) ( ) cos( ( )), 0 , ( ) ( 1) 2 ( ) / 22, 050
L
k k
k
k k k
h t a t t t N
t t f t
φ
φ = φ π
= ⋅ ≤ <
= − + ⋅
(11)
where φk( )t denotes the cumulated phase on time t for the k- th harmonic partial and 22,050 is the sampling frequency.
k( 1)
φ − is defined to be φk( -1)N of the last frame to keep
continuity of phase. If i = 0, i.e. there is no last frame, the value of φk( 1)− is then set randomly.
Experimental Evaluations
For evaluating the conversion method proposed here, we have constructed three kinds of voice conversion systems, named SOG, SSG, and SLG, respectively. In the system SOG (system using original GMM for mapping), a single GMM of 256 mixtures are trained with the 350 training sentences, and then the mapping function, (1), is used to convert the DCC of each input frame. In the system SSG (system using single Gaussian mixture for mapping), we still trained a single GMM of 256 mixtures. Nevertheless, in the conversion stage, the mixture selection method as described in Subsection III.B is applied, and then the DCC of a frame is converted with the single Gaussian mixture selected. As to the system SLG (system using selected GMM for mapping), we trained 37 segmental GMMs instead of a single GMM and the number of mixtures for each GMM is 16. Then, in the conversion stage, the GMM selection method as described in Subsection III.A is applied. Next, the mixture selection method as described in Subsection III.B is applied, too.
Using the three systems, we can obtain three different converted voice files for a source voice file. In terms of the converted voice files, we have conducted two types of listening tests. The first type is for timbre similarity whereas the second type is for voice quality. For each type of listening tests, 25 persons are invited to listen to the voice files and give relative scores. Among the 25 persons, 20 of them are not familiar with the research field of voice conversion.
Timbre Similarity Tests
In the tests of timbre similarity, 5 voice files are prepared first, which are named VS (uttered by the source speaker), VT (uttered by target speaker), VX1 (converted by SOG), VX2 (converted by SSG), and VX3 (converted by SLG). Among the 5 files, VS and VT are of same content whereas VX1, VX2, VX3 are of same content but different from VS and VT. These 5 files can be downloaded by accessing the web page:
http://guhy.csie.ntust.edu.tw/VoiceConv/. During listening tests, these files are played in the order ABX where A is fixed to VS, B is fixed to VT, and X is randomly selected from VX1, VX2, and VX3. Each time that three files, ABX, are played, the participant is requested to give a score. Here, the score range is from 1 to 9. The score 9 (1) means the timbre of X is sure to be that of B (A), the score 7 (3) means the timbre of X is more like that of B (A), and the score 5 means the timbre of X cannot be judged.
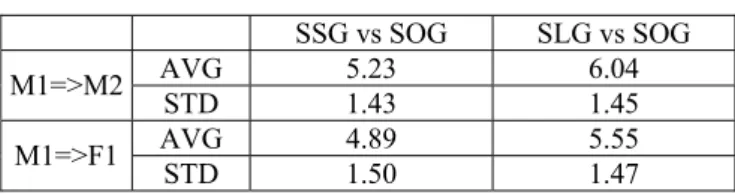
After listening tests, the scores given by the 25 persons are collected to compute average scores (AVG) and standard deviations (STD) for the three systems respectively. The results are those values listed in Table I. From this table, it can be seen that the average scores for voice conversion between different genders (i.e. from M1 to F1) are much higher than those for voice conversion between same genders (i.e. from