國立臺灣大學電機資訊學院電子工程學研究所 碩士論文
Graduate Institute of Electronics Engineering College of Electrical Engineering & Computer Science
National Taiwan University Master Thesis
高速率湧泉碼解碼器之硬體架構設計與實現 High-throughput Hardware Architecture Design and
Realization of RaptorQ Code Decoder
藍 瑋 Wei Lan
指導教授:闕志達 博士 Advisor: Tzi-Dar Chiueh, Ph.D.
中華民國 103 年 10 月
October, 2014
誌謝
伴隨著這本論文的完成,在台大兩年多的碩士生涯也即將告一段落。回想過去 兩年多的研究所時光,發生了許多事、經歷了許多挫折,卻也成長了許多;而這本 論文的完成,要感謝一路走來曾經指導我、陪伴我以及鼓勵我的大家。
首先,最感謝的是我的指導教授,闕志達教授,謝謝老師在這段研究的過程中 對學生的指導以及包容,在學生研究遇到阻礙時給予適時且有效的建議,在學生徬 徨迷網時給予足夠的空間及體諒;除此之外,老師亦常常教導學生做事應有的態度 以及待人處事的道理,學生會謹記在心並在未來的生活中時常提醒自己,謝謝老師。
接著,感謝口試委員蘇柏青教授以及李佳翰博士的寶貴建議,使本論文的內容更臻 完善。
感謝微系統研究實驗室的大家,陪伴我走過這段刻骨銘心的研究所生活。感謝 以威學長、一斌學長、義堯學長、陳磊學長、政穎學長、哲銘學長、雅婷學姐與君 元學長的幫忙與照顧,給予我研究上的建議以及生活中的快樂。謝謝孟穎、文豪、
奕丰、怡豪以及柏崴在研究上的相互扶持與鼓勵,有你們的陪伴讓我在這段研究旅 程上並不孤單。謝謝學弟們,柏琛、裔民、家豪、鈺安和傑民,謝謝你們幫忙學長 們處理實驗室的事務,也祝你們未來研究順利。
謝謝交大的同學及學長們,肉粽、小英、龍青、玉堂、蛞蝓、霍華、具具、孟 搞、啟煌、任禎、bubble、喇叭、阿搞、昕翰、家瑋、老朱、灰灰、神恆、小籠包、
江愷、杜包、甲胖、火爺、棒賽、老羅、斥侯、乃珊、汝欣、柔君,謝謝大家上了 研究所仍保持聯繫,糾團吃飯、出遊,也謝謝大家的陪伴,讓我在這段時間有所成
長。
謝謝我的父母、姐姐、妹妹、大阿姨、舅舅、舅媽以及所有家人們;在這段研 究所生活中,當我沮喪時給予支持與鼓勵,當我遇到困難時給予經驗分享與幫助,
有你們的陪伴及分享是我不斷往前、繼續努力的動力。
感謝所有曾經幫助過我卻在上述遺漏名字的你,為我的疏失感到抱歉;最後由 衷地感謝所有幫助、支持、陪伴過我的貴人朋友們,謝謝大家,僅以此論文獻給大 家!
藍瑋 謹誌 於電機二館 329 實驗室 中華民國 103 年 11 月 25 日
摘要
隨著科技越來越發達,智慧型手機可以提供的功能也越來越多,其中多媒體串 流是普遍大眾經常使用到的ㄧ項服務;然而在此項服務中,傳遞延遲是影響視聽體 驗最重要的影響因素。不幸的是,無線通訊常常會受到通道效應的影響,因此若沒 有有效錯誤更正碼的協助,要提供ㄧ個可靠的無線通訊架構是幾乎不太可能的。傳 統的無線通訊主要是透過重新傳送直到接收端成功地收到為止,以提供可靠的無 線傳輸;然而湧泉碼的概念則是保留已成功收到的訊號,並繼續接收其他的編碼訊 號直到足以成功解碼為止,此一概念在近年來吸引了大量的注意,而且也已應用在 許多的環境設定中。
RaptorQ code 是目前最新ㄧ代的湧泉碼,相較於之前的湧泉碼,RaptorQ code 提供了更大的設計彈性以及更低的解碼失敗率,然而其解碼的架構亦相當複雜。傳 統的 RaptorQ code 解碼器需要求得ㄧ個相當大矩陣的反矩陣,為了避免此ㄧ部分 所需要的大量運算量,本論文改為事先求得ㄧ反矩陣,再根據遺失訊號所對應的列 向量去對已知的反矩陣作修正,使得大部分的運算量皆移至離線狀態。另ㄧ方面,
傳統演算法會先經由求得反矩陣的過程,同時得到中間訊號值,接著再利用中間訊 號進而還原出來源訊號;然而新式演算法在此ㄧ部分利用事先求得傳送矩陣反矩 陣的特性,將兩個步驟合併以進一步地化簡運算量。最後則是利用 RaptorQ code 的 有系統特性,避免再次求得成功收到的來源訊號。
本論文所提出的新式解碼演算法不僅用軟體完成模擬,亦將其實現成硬體電 路以及利用 FPGA 板驗證,以證明此一演算法的可行性。
關鍵詞:RaptorQ code decoder、Fountain code、湧泉碼、Matrix inverse lemma
ABSTRACT
With advances in technology, there are much more services that a smartphone can provide. The multimedia streaming is the most common one that people use. However, transmission latency is of utmost important to quality of viewing/listening experiences.
Unfortunately, wireless transmission often suffers channel fading that renders robust transmission almost impossible without effective error correction mechanism.
Conventional protocol generally retransmits the erased coded sequence until the receiver receives it correctly. Fountain codes, on the other hand, keep the partially decoded information and continue to receive and decode the coded symbol until the whole information sequence can be recovered. Such rateless code has drawn a great deal of attention and has been applied in many scenarios.
RaptorQ code is the latest generation of Raptor codes. Compared with the previous version, RaptorQ code provides higher flexibility and the lower decoding failure probability. However, the decoding procedure is also much more complicated.
Conventionally, the decoding of RaptorQ codes requires inverting a huge matrix. Instead of such costly matrix inversion, we proposed to calculate the inverse of another matrix whose rows are a little different from the one that needs to be decoded. Therefore, most computations are shifted offline. Next, previous decoding usually decodes the intermediate symbols while inverting the matrix, and recovers the information sequence from the intermediate symbols. With the pre-calculated inverse, the proposed algorithm combines the intermediate sequence decoding and the procedure of information sequence recovery to reduce the complexity. Last, due to the systematic code property of the
RaptorQ code, we proposed a new method that avoids many unnecessary computation when decoding the received information sequence. Finally, the proposed decoding algorithm is not only simulated on software, but also verified with FPGA board to prove its feasibility.
Key Words: RaptorQ code decoder, fountain code, Matrix inverse lemma
目錄
國立臺灣大學電機資訊學院電子工程學研究所 ... I 誌謝 ... V 摘要 ... VII
ABSTRACT ... IX
圖目錄 ... XIII 表目錄 ... XV第一章 緒論 ... 1
1.1 研究動機... 1
1.2 湧泉碼介紹... 3
1.2.1 湧泉碼概念 ... 3
1.2.2 湧泉碼特性 ... 3
1.3 論文組織... 4
第二章 湧泉碼 ... 5
2.1 FOUNTAIN CODE ... 5
2.2 LT CODE ... 6
2.2.1 編碼方式... 6
2.2.2 Belief-propagation Decoding ... 7
2.3 RAPTOR CODE ... 11
2.3.1 編碼方式... 11
2.3.2 未活躍解碼... 12
2.3.3 解碼失敗率... 18
2.4 RAPTORQ CODE ... 18
2.4.1 Systematic code ... 19
2.4.2 Permanent Inactivation ... 19
2.4.3 Galois Field ... 21
2.4.4 解碼失敗率... 22
第三章 RAPTORQ 規格及其編解碼器架構 ... 23
3.1 RAPTORQ CODE規格介紹 ... 23
3.1.1 來源區塊組成... 23
3.1.2 八位組的算術運算... 24
3.2 編碼器架構 ... 25
3.2.1 加入填補訊號... 26
3.2.2 產生中間訊號... 26
3.2.3 產生編碼訊號... 28
3.3 解碼器架構 ... 29
3.3.1 Inactivation Decoding Gaussian Elimination[] ... 30
3.3.2 索引基礎解碼演算法[11] ... 34
3.3.3 遞迴解碼演算法[12] ... 36
第四章 新式解碼器演算法 ... 41
4.1SYSTEMATIC CODE ... 41
4.2MATRIX INVERSE LEMMA ... 42
4.3 結合 LT 編碼矩陣以及接收矩陣反矩陣 ... 44
4.4 通道狀況 ... 46
4.5 演算法效能比較 ... 49
第五章 新式解碼器硬體設計 ... 56
5.1 演算法硬體架構設計 ... 56
5.1.1 Read Only Memory... 57
5.1.2 Matrix Multiplication ... 59
5.1.3 Gaussian Elimination ... 60
5.1.4 RTL Simulation Result ... 65
5.2 電路架構彈性度 ... 66
5.3FPGA 板驗證 ... 69
5.4 電路效能比較 ... 73
第六章 結論與展望 ... 75 參考文獻 76
圖目錄
圖 1.1 多媒體串流趨勢圖[1] ... 1
圖 1.2 點對多點傳輸 ... 2
圖 2.1 Binary Erasure Channel ... 6
圖 2.2 Bipartite Graph ... 7
圖 2.3 BP decoding-1 ... 8
圖 2.4 BP decoding-2 ... 8
圖 2.5 BP decoding-3 ... 9
圖 2.6 BP decoding-4 ... 9
圖 2.7 BP decoding-5 ... 9
圖 2.8 BP decoding-6 ... 10
圖 2.9 多餘訊號 ... 12
圖 2.10 未活躍解碼範例 ... 14
圖 2.11 未活躍解碼-1 ... 14
圖 2.12 未活躍解碼-2 ... 15
圖 2.13 未活躍解碼-3 ... 15
圖 2.14 未活躍解碼-4 ... 16
圖 2.15 未活躍解碼-5 ... 16
圖 2.16 未活躍解碼化簡步驟 ... 16
圖 2.17 LT 訊號與 PI 訊號的編碼方式 ... 20
圖 2.18 不同 Galois Field 的解碼失敗率[3] ... 21
圖 3.1 RaptorQ 編碼架構圖 ... 25
圖 3.2 前置編碼矩陣 ... 27
圖 3.3 RaptorQ 解碼架構圖 ... 30
圖 3.4 階段(1)中
ˆA
的各個子矩陣 ... 31圖 3.5 階段(1)成功矩陣示意圖 ... 32
圖 3.6 階段(2)矩陣示意圖 ... 32
圖 3.7 IDGE 解碼完成矩陣示意圖 ... 33
圖 3.8 索引基礎最大四然估計解碼器之索引表 ... 34
圖 3.9 RaptorQ code 編解碼架構 ... 36
圖 3.10 傳送矩陣與接收矩陣關係圖[12] ... 39
圖 4.1 新式 RaptorQ code 解碼架構圖 ... 41
圖 4.2 新式解碼器的傳送矩陣與接收矩陣關係圖 ... 42
圖 4.3 新舊解碼演算法架構圖 ... 44
圖 4.4 加入新行向量示意圖 ... 48
圖 4.5 新式演算法解碼流程圖 ... 48
圖 4.6 運算量 ... 41
圖 4.7 運算時間 ... 42
圖 5.1 新式演算法硬體架構圖 ... 56
圖 5.2 輸入訊號波形圖 ... 56
圖 5.3 接收訊號的規格設計 ... 57
圖 5.4 修補訊號數與解碼失敗率曲線圖 ... 58
圖 5.5 處理單元架構圖 ... 60
圖 5.6 範例說明詳解 ... 62
圖 5.7 GE 電路架構圖 ... 63
圖 5.8 高斯消去法處理單元 ... 63
圖 5.9
R
矩陣示意圖 ... 64圖 5.10 RTL Simulation 輸入訊號圖 ... 65
圖 5.11 軟硬體模擬結果比較 ... 65
圖 5.12 硬體電路架構圖 ... 67
圖 5.13 RTL Simulation 輸入訊號圖 ... 67
圖 5.14 RTL Simulation 輸出結果圖 ... 68
圖 5.15 軟硬體模擬結果比較圖 ... 68
圖 5.16 Spartan 6 xc6slx150t ... 69
圖 5.17 Xilinx ISE 介面圖 ... 69
圖 5.18 測試訊號輸入 ... 71
圖 5.19 測試訊號產生之指令窗 ... 711
圖 5.20 VeriComm 輸出訊號結果 ... 722
圖 5.21 電路結果驗證指令窗 ... 722
表目錄
表 4.1 各演算法運算量估計 ... 50
表 5.1 RaptorQ code 實現規格 ... 57
表 5.2 RaptorQ code 實現規格 ... 66
表 5.3 Xilinx ISE 合成結果 ... 70
表 5.4 Timing Constraint ... 73
表 5.5 效能比較 ... 74
1. 第一章 緒論
1.1 研究動機
隨著網路科技的不斷發展與進步,無線通訊已成為一個相當普遍的資料傳遞 方式。多媒體串流是大眾體驗影音的方式之一,如移動裝置的線上直播視頻、影像 串流以及視訊會議等等;在圖 1.1 的分析趨勢圖中更可以看出,多媒體串流是未來 移動裝置傳遞的主要項目。而傳遞延遲是一個影響使用者體驗的重要因素,然而無 線通訊卻十分容易受到通道狀況的干擾,因此在沒有錯誤更正碼協助的情況下,要 提供可靠的無線傳輸是不太可能的。傳統的錯誤更正碼通常都是要求傳送端重新 傳遞遺失的訊號、甚至整組的編碼訊號,以防止解碼失敗;但這樣的重新傳遞可能 會導致過久的傳遞延遲,又若通道情況很差,可能會造成更嚴重的通道延遲。
圖 1.1 多媒體串流趨勢圖[1]
湧泉碼(Fountain code),不同於傳統的錯誤更正碼,能保留成功收到的訊號,
並繼續接收來自傳送端的編碼訊號,直到有足夠的編碼訊號量以還原所有的資訊。
湧泉碼更是適用於點對多點的傳送(point-to-multipoint transmission),如圖 1.2;在 此一情況下,傳統的傳輸控制協定(Transmission Control Protocol, TCP)就比較不適 合,因為傳送端必須追蹤所有接收端的封包接收情形,針對不同接收端遺失的部分 做重新傳遞的動作;而用戶數據報協議(User Datagram Protocol, UDP)雖然沒有上述 的問題,卻缺少了 TCP 所能提供的可靠性。另ㄧ方面,湧泉碼則不需追蹤所有接 收端的情形,又能提供一定程度的傳輸可靠性,因此在多媒體串流需求量日益增加 的現代,湧泉碼是一個相當適合現今無線通訊的抹除碼(erase code)。
圖 1.2 點對多點傳輸
在湧泉碼中,猛禽碼(Raptor code)目前已廣泛地運用在許多無線多媒體傳輸標 準下,如 3GPP multimedia broadcast/multicast service(MBMS)以及手持式視訊廣播 (Digital Video Broadcasting-Handled, DVB-H),其中 RaptorQ code 為猛禽碼目前的 最新標準。
儘管如此,猛禽碼解碼器卻是相當的複雜,其中的運算需要求得接收矩陣的反
據現有的猛禽碼解碼器演算法,提出新的演算法架構,有效降低解碼時所需要的運 算量,此外也用硬體實現、並以 FPGA 板驗證。
1.2 湧泉碼介紹
在本節中將會簡單介紹湧泉碼的概念及其特性。
1.2.1 湧泉碼概念
如同在 1.1 小節中所討論的情況,我們希望無線傳輸架構中能夠完全沒有回授 或是幾乎沒有回授的情況,而湧泉碼能滿足上述的需求。湧泉碼的核心概念好比傳 送端是一個湧泉、傳送出的編碼訊號則是湧泉中的一粒粒水滴,而接收端則是一個 水杯;接收端在接收訊號如同用水杯盛裝湧泉的水,當水杯接收到一定量的水量後 即可還原出原本的訊號,水杯不用在意所收到的水滴是哪幾滴,而是當水滴達到一 定量後就能成功地完成解碼。
1.2.2 湧泉碼特性
湧泉碼的特性主要有以下三點:
(1) 傳送端能產生編碼率不固定(rateless)的編碼訊號,目標是讓接收端接收到足夠 的編碼訊號,因此編碼器必須要有能力產生夠多的訊號來滿足接收端的需求;
理想上,編碼器能產生出無限多個編碼訊號。
(2) 當接收端收到 N 個編碼訊號中任何一個大小為 K 的子集合時,湧泉碼解碼器即 能利用這 K 個編碼訊號還原出原本的來源訊號,而且無論此一子集和中的組成 為何,皆能成功地完成解碼。
(3) 編碼及解碼的運算時間需與編碼塊的大小成線性關係。
以上說明的特點也再次強調了湧泉的概念。
1.3 論文組織
本論文共分七章。第一章提出研究動機以及整篇論文的內容概要;第二章介紹 湧泉碼的概念以及湧泉碼的演進,包括 LT code、Raptor code 以及 RaptorQ code,
並簡述各個特性以及彼此之間的差異,此外也會大致地介紹其編解碼方式;第三章 則是更詳細地介紹本論文所設計的湧泉碼對象-RaptorQ code,會詳細地介紹其規 格、編碼步驟以及互聯網工程任務組(Internet Engineering Task Force, IETF)所提出 的標準解碼演算法;第四章則是介紹本實驗室所提出不同的 RaptorQ code 解碼演 算法及架構,包括索引基礎解碼演算法以及遞迴解碼演算法;第五章則是本論文所 提出的新式解碼演算法,會詳細介紹其所利用的觀點以及式子簡化的推導;第六章 是將本論文所提出的新式解碼演算法實現成硬體電路,並介紹電路中各個區塊的 設計;最後第七章總結本論文並且提出未來可能之研究方向。
2. 第二章 湧泉碼
本章將介紹湧湶碼的演進,包括 LT code、Raptor code 以及 RaptorQ code;
並描述演進過程的差異以及優劣處。
2.1 Fountain code
Fountain code(亦稱為 rateless erasure code)是一種抹除碼(erase code),其理 想特性是能利用給定的一組來源訊號產生無限多的編碼訊號;而接收端則能利 用這些編碼訊號的任一子集合,大小等於或略大於來源訊號數,以還原出原始 的來源訊號。Fountain 以及 rateless 皆表示此一編碼方式沒有固定編碼率的概 念。
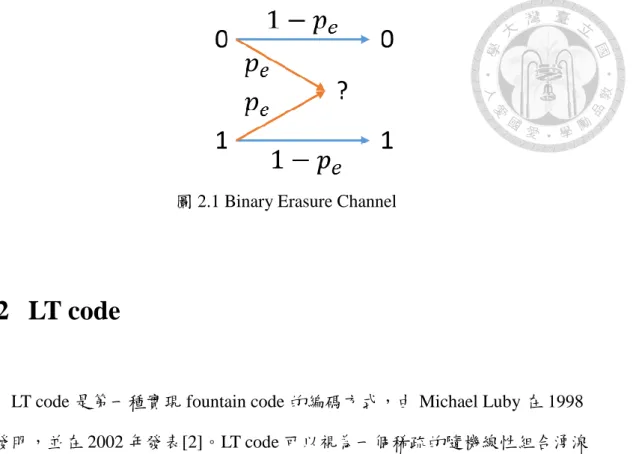
由於湧泉碼是抹除碼的ㄧ種,因此此種編碼所討論的通道皆為二位元抹除 通道(Binary Erasure Channel)。在此ㄧ模型下,當傳送端傳出ㄧ個位元(1 或 0) 後,接收端會收到此ㄧ位元或是ㄧ個訊息表示此ㄧ位元沒有接收到(被抹除),
如圖 2.1 所示;其中
p
e為通道遺失率,ㄧ個位元被成功接收到的機率為1 p
e, 而遺失的機率即為p
e。圖 2.1 Binary Erasure Channel
2.2 LT code
LT code 是第一種實現 fountain code 的編碼方式,由 Michael Luby 在 1998 年發明,並在 2002 年發表[2]。LT code 可以視為一個稀疏的隨機線性組合湧湶 碼,其編碼以及解瑪的運算皆是用簡單的邏輯異或(exclusive-or),降低了編碼 以及解碼的複雜度,且能達到不錯的效能。
2.2.1 編碼方式
假設現在有一組來源訊號,共𝑘個,分別為𝑥1, 𝑥2, 𝑥3, … , 𝑥𝑘,編碼步驟如下:
Step 1: 隨機地從一個 degree distribution 中挑選出一個𝑑值。
Step 2: 以均勻分布的機率從𝑥1~𝑥𝑘個訊號中挑選出 d 個相異的訊號,並做邏輯 異或的運算來產生編碼訊號。
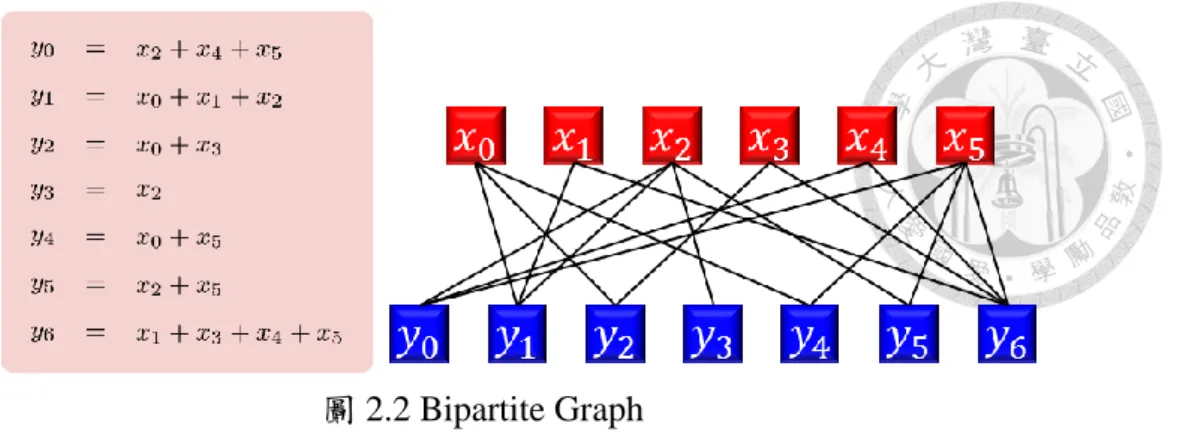
此一來源訊號與編碼訊號的編碼關係,在解碼時是需要被知道的,此一關 係可用二分圖(bipartite graph)表示,圖 2.2 為一個簡單的例子。
圖 2.2 Bipartite Graph
2.2.2 Belief-propagation Decoding
Belief-propagation decoding 的解碼方式為不斷地重複以下四個步驟,直到 步驟(1)失敗或是步驟(4)成功時停止。
步驟(1):
在編碼訊號中,找一個度數(degree)為 1 的訊號,令其索引為 i,而此ㄧ訊 號相對的來源訊號索引為 j;當找不到度數為 1 的編碼訊號時,則解碼失敗。
步驟(2):
解碼𝑥𝑗 = 𝑦𝑖。 步驟(3):
令𝑖1, … , 𝑖𝑙表示有連接到來源訊號𝑥𝑗的編碼訊號索引;又𝑦𝑖𝑠 = 𝑦𝑖𝑠+ 𝑥𝑗,其中 𝑠 = 1, … , 𝑙,來源訊號𝑥𝑗從𝑦𝑖𝑠中移除,同時也移除二分圖中的連線。
步驟(4):
若仍有未還原的來源訊號,則回到步驟(1),反之即完成解碼。
上述步驟若能成功 k 次而沒有被中止,則表示解碼成功,因為每成功一次 步驟(1)到步驟(4),就表示成功地還原了一個來源訊號。此外,BP decoding 的 運算量本質上與編碼的運算量相同,此一特性可以藉由觀察二分圖得知,每條 線就表示一個邏輯異或的運算;因此,BP decoding 的運算量與編碼時的 degree distribution 的平均呈線性關係。
接著,以圖 2.2 的例子來說明 BP decoding 的運作方式。首先我們可以找到 一個度數為 1 的編碼訊號𝑦3,並解碼出𝑥2 = 𝑦3;接著將與𝑥2相關的編碼訊號,
分別為𝑦0、𝑦1及𝑦5,從中移除𝑥2的成分,此外也將二分圖中的連線移除,如圖 2.3 所示。
圖 2.3 BP decoding-1
重新回到步驟(1),又可以找到一個度數為 1 的編碼訊號𝑦5,解碼出𝑥5,如 圖 2.4。
圖 2.4 BP decoding-2
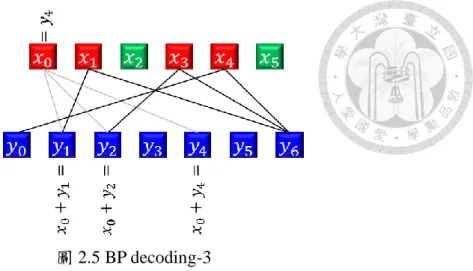
再一次,我們可以發現現在度數為 1 的訊號為𝑦4,如圖 2.5 所示。
圖 2.5 BP decoding-3
接著,共有三個度數為 1 的編碼訊號,分別為𝑦0、𝑦1及𝑦2,這裡我們選擇 𝑦0來還原𝑥4,如圖 2.6。
圖 2.6 BP decoding-4
最後分別利用𝑦2、𝑦6來還原𝑥3及𝑥1,如圖 2.7 及圖 2.8 所示。
圖 2.7 BP decoding-5
圖 2.8 BP decoding-6
然而此一解碼方式會遇到下列兩種問題:
在步驟(1)時,未必每次都能找到度數為 1 的編碼訊號,若步驟(1)無法 找到度數為 1 的編碼訊號,則 belief-propagation decoding 則無法繼續 進行。
又可能同時有太多度數為 1 的編碼訊號,會導致太多多餘的編碼訊 號,造成多餘的浪費。
因此,在編碼時的 degree distribution 設計十分重要,良好的 degree distribution 設計不僅讓解碼器能順利的完成解碼,同時也不浪費多餘編碼訊 號;因此也有許多研究會針對此ㄧ部分做較深入的探討,討論怎樣的編碼設計 可以利用最少的編碼訊號,並達到可以接收的解碼率,甚至針對不同重要性的 編碼訊號,提供不等錯誤保護(Unequal Error Protection)的編碼。各種不同的 degree distribution 探討可以參考文獻[3]。
2.3 Raptor code
Raptor code 的全名為 rapid tornado code[4],由 Amin Shokrollahi 於 2000/2001 年發明,並在 2004 年發表;Raptor code 是 LT code 的下一代湧泉碼,提供更快 的編碼及解碼演算法。
發明 Raptor code 的關鍵在前一小節的最後一段有稍微提到,主要原因是 LT code 設計的困難處在於每個編碼訊號的平均度數(average degree)是固定的,在此 一情況下,有很高的可能性會有一部分的來源訊號在編碼的過程中,並不會被挑 選中、加入編碼,因此這些未加入編碼的訊號是不可能被解碼器還原的,不管使 用哪種解碼演算法。
為了克服 LT code 在編碼時的困難,Raptor code 的編碼方式會先利用一種高 編碼率的編碼方式將來源訊號做編碼,所產生的訊號稱為中間訊號(intermediate symbol),接著再利用中間訊號透過 LT code 編碼產生最後的編碼訊號;此一產生 中間訊號的步驟稱之為前編碼(Pre-coding)。
2.3.1 編碼方式
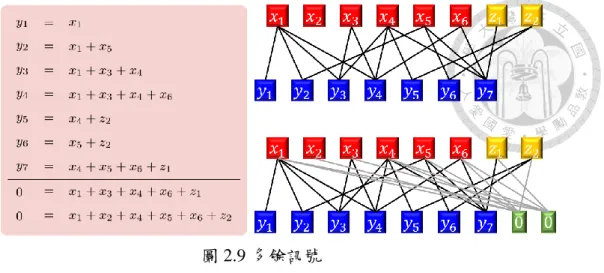
首 先 , 將𝑥1, 𝑥2, 𝑥3, … , 𝑥𝑘的 來 源 訊 號 經 由 一 個 適 當 的 二 位 元 編 碼 產 生 𝑧1, … , 𝑧𝑛−𝑘個多餘訊號(redundant symbol),其中𝑛 − 𝑘僅為𝑘的一小部分;將來源訊 號與多餘訊號串接起來,𝑥1, 𝑥2, 𝑥3, … , 𝑥𝑘, 𝑧1, … , 𝑧𝑛−𝑘,並稱之為中間訊號。而這𝑛 個中間訊號必須滿足𝑛 − 𝑘個限制,而這些限制可以視作”訊號”,稱之為限制訊 號。每個限制訊號皆為零,也就是說這些訊號限制了其相關的中間訊號總和為零。
圖 2.9 為一個例子,首先利用六個來源訊號經過前編碼產生兩個多餘訊號,
分別為𝑧1及𝑧2;而限制訊號的關係如圖 2.9 左下半部所示。
圖 2.9 多餘訊號
接收到的編碼訊號及限制訊號皆會用在中間訊號的解碼,其中因為解碼器已知道 限制訊號值為零,所以當有𝑁個編碼訊號成功收到,則表示有𝑁 + 𝑛 − 𝑘個訊號可 以用來解碼出 n 個中間訊號。更詳細的 Raptor code RFC 5053 規格可以參考文獻 [5]。
2.3.2 未活躍解碼
在前面 2.2.2 小節介紹過 belief-propagation decoding,但因為在 2.2.2 小節最 後 討 論的 困 難 因 素 , 因 此 belief-propagation decoding 需 要 較 多 的 額 外消 耗 (overhead)來達到一個較小的解碼失敗率。為了改善此一問題,進而發展出另一 種解碼演算法,稱為未活躍解碼(Inactivation Decoder);此一演算法結合了高斯演 算法的最佳性以及 BP decoding 的效能。
用矩陣表示來描述 inactivation decoding 最為清楚且方便;我們將成功收到 的編碼訊號以及限制訊號設定為列訊號(row symbol),而將中間訊號設定為行訊 號(column symbol),包括來源訊號以及多餘訊號。此一矩陣中,若在位置(i, j)有 1 表示行訊號 j 對列訊號 i 有貢獻,反之為零。整個解碼可以視為處理一個線性 關係的系統,利用列訊號來求得行訊號,因此列訊號的數目至少要和行訊號一樣
解碼步驟大致敘述如下。首先令所有行訊號的初始狀況皆為活躍 (active),
而所有的列訊號皆未配對(unpaired),每一列訊號的度數就是與其相關的行訊號 數目。接著,每次 belief-propagation 步驟都會找一個未配對且度數為 1 的列訊號,
並將其與對應的行訊號做配對(paired);完成配對後,再從所有含有此行訊號的列 訊號中扣除此一行訊號成分,同時也使得他們的度數減 1。
Belief-propagation decoding 就是不斷地重複上述步驟直到所有活躍的行訊號 都完成配對,或是直到沒有未配對且度數為 1 的列訊號。原本的 belief-propagation decoding 在沒有未配對且度數為 1 的列訊號的情況下,縱使其在數學上仍有可能 完成行訊號的解碼,仍宣告解碼失敗。修改過後的 belief-propagation decoding 則 可利用 inactivation decoding 的概念繼續解碼,直到最後所有未配對列訊號的度 數皆為零,即數學上不可能完成解碼,才會宣告解碼失敗。如若現在解碼進行到 沒有一個未配對且度數為 1 的列訊號,但有一個未配對且度數為 2 的列訊號,則 我們可以宣告其對應的其中一個行訊號為未活躍 (inactive),如此一來此一列訊 號的度數從 2 降至 1,使得 belief-propagation decoding 可以繼續進行,直到所有 的行訊號都與列訊號完成配對。
不同於原本的 belief-propagation decoding,inactivation decoding 在完成 belief- propagation 的步驟時,每個行訊號值不一定等於其所配對的列訊號值,原因是有 些列訊號值可能仍與一些被宣告為未活躍的行訊號相關。已配對的列訊號則可以 用來移除未配對列訊號與活躍行訊號的關係,如此一來未配對訊號僅與未活躍的 行訊號相關,且兩者為一個線性相關系統,藉由解決此一系統可以求得未活躍行 訊號的值,通常此一部分會利用高斯消去法完成。最後,利用求得的未活躍行訊 號值以及先前得到的已配對列訊號值,可以得到所有的行訊號值完成解碼。
以下舉一個範例來說明 inactivation decoding 的解碼步驟,解碼對象的二分 圖如圖 2.10 所示:
圖 2.10 未活躍解碼範例
將例子整理成矩陣表示,如式(2.1)
1 1
2 2
3 3
4 4
5 5
6 6
7 7
0 0 1 0 0 1 0 1 1 1 1 0 1 0 0 0 1 0 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 0 0 0 1 0 1 0 1 1 0 0 1 0 0 0 0
x y
x y
x y
x y
x y
x y
x y
(2.1)
首先我們的目標是希望藉由行列運算,將矩陣化簡成一個近似的三角矩 陣。利用 2.2.2 小節所介紹過的 belief-propagation decoding,可以找到第一個度 數為 1 列訊號,如圖 2.11 (a)所示;圖中列向量旁的圓圈數字表示列的選擇順 序,而行下的圓圈數字則是還原的訊號𝑥𝑖。
(a) (b) 圖 2.11 未活躍解碼-1
接著可以再找到第二個度數為 1 的列向量,如圖 2.11 (b);此外我們將成功 還原的行向量標為粉色。在第二步驟之後,可以發現已經沒有度數為 1 的列訊號 可以選擇,此時就是利用 inactivation 概念的時候;我們將最後一個行訊號設為 未活躍並將其行向量標為藍色,如圖 2.12 (a)中𝑖1所示。也因此 belief-propagation 得以再次繼續進行,找到下一個度數為 1 的列向量,如圖 2.12 (b)所示。
(a) (b) 圖 2.12 未活躍解碼-2
此時我們又再一次地遇到沒有度數為 1 列訊號的情況,因此我們再令一個行 訊號為未活躍,如圖 2.13 中𝑖2所示。
圖 2.13 未活躍解碼-3
最後的兩個循環我們都能成功地找到度數為 1 的列訊號,如圖 2.14 (a)及圖 2.14 (b)所示。
(a) (b) 圖 2.14 未活躍解碼-4
接著,將矩陣依照 belief-propagation 時所標記的順序重新排列,如圖 2.15 所 示。
圖 2.15 未活躍解碼-5
再來依照下圖 2.16 所示的步驟將矩陣做化簡。
圖 2.16 未活躍解碼化簡步驟
最後的矩陣為一個相當簡單且稀疏的矩陣,在活躍的行向量中僅有一個 1,
且最後兩列的部分皆為零。需要注意的是,上述的行列互換以及行列運算一樣會 實現在式(2.1)的x向量以及
y
向量中,結果如式(2.2)所示。7 3
6 1
5 3
2 6
1 4
7
2 4
5
1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 1 0 1 1 0 0 0 0 1 0 1 0 0 0 0 0 1 1 0 0 0 0 0 1 0
x y x y x y
x y
x y
x y
x y
(2.2)
依照式(2.2)所示,我們可以藉由處理右下角的2 × 2矩陣來還原𝑥7以及𝑥4,如下所 示。
2 7
4 5
1 1 1 0
y x
x y
解得𝑥7 = 𝑦̂5,𝑥4 = 𝑦̂2+ 𝑦̂5;最後再將𝑥7及𝑥4帶回式(2.2)即可得到所有列訊號。
Inactivation decoding 的主要動機在於提供一個更有力的解碼演算法,也就是 當數學條件下仍有機會完成解碼,就會繼續嘗試解碼,同時也會應用效率較高的 belief-propagation 解碼。而此一線性系統設計的關鍵在於如何使線性關係矩陣有 很高機率能達到滿秩(full rank),即能成功地完成解碼,同時也讓解碼的運算量最 小化。
2.3.3 解碼失敗率
Raptor code 在運算量及解碼成功率的表現皆較 LT code 為好。其解碼能力也 相當不錯,根據[6]可以整理出 Raptor code 的解碼失敗率大致如式(2.3)所示:
(n, k) 1
0.85 0.567
f n k
if n k
p
if n k
(2.3)式(2.3)中,
p
f(n, k)表示解碼器在接收到 n 個編碼訊號,來源訊號共 k 個的情況 下,解碼器解碼失敗的機率。理想上的湧泉碼在𝑛 = 𝑘時,其解碼失敗率為零,而 Raptor code 卻仍有85%的失敗率;儘管如此,隨著接收到的訊號數上升,解 碼失敗率成指數性地遞減。
2.4 RaptorQ code
RaptorQ code 是最近一代的 Raptor codes,其開發目的亦是為了克服 Raptor codes 的缺點。不同於過去的 Raptor codes,RaptorQ code 在各方面都較之前版本 的猛禽碼提升許多,包括更大的設計彈性、支援更大的來源區塊數以及更好的編 碼效率。RaptorQ code 為一種有系統的湧泉碼(章節 2.4.1),其編碼方式大致都與 Raptor code 相同,主要不同的地方在於原本的 Raptor code 編碼都操作在二元的 Galois Field (GF(2)),RaptorQ code 除了操作在二元的 Galois Field 之外,也有部 分的編碼會用到八位組的 Galois Field (GF(256))。
操作在更大的有限域使得 RaptorQ code 克服了 Raptor code 的效率極限,因 為更大的有限域使得 RaptorQ code 可以用更小的額外消耗(overhead)來達到需要
的解碼成功率。除此之外,還有幾項較之前更為改進的特色,如 RaptorQ code 可 以在一個來源區塊內編碼 56403 個編碼訊號,而 Raptor code 僅能編碼 8192 個編 碼訊號,此外 RaptorQ code 可以產生至多到 16777216 個編碼訊號,是 Raptor code 的 256 倍。前面所提到的兩個變數增長使得 RaptorQ code 在檔案傳輸以及串流 服務中,都能有更大的使用彈性及效率。
RaptorQ code 的編解碼設計,我們會在第三章做更詳細的說明及介紹。
2.4.1 Systematic code
一種編碼若最後產生的編碼訊號中還有原本的來源訊號,則稱此種編碼為有 系統的(systematic)。前面章節所介紹過的 LT code 與 Raptor code 皆不是有系統的 編碼,而 RaptorQ code 為有系統的編碼方式。
有系統的編碼方式在許多應用中是十分重要的,如假設今天 Raptor code 完 成建立時,仍有部分接收機還沒有裝設解碼器;甚至在廣播(broadcast)的情況下,
一個沒有系統的(non-systematic)編碼傳送端必須依照不同的接收機傳遞不同的 訊號,即對於沒有解碼器的接收端只傳送來源訊號,對於有解碼器的接收端則傳 遞另一組編碼訊號,這樣的傳遞方式十分浪費資源。因此大部分的情況下,我們 會比較喜歡選用有系統的編碼方式更勝於沒系統的編碼方式。
2.4.2 Permanent Inactivation
Permanent Inactivation 是另一個 RaptorQ code 的重要特色。在 2.3.2 小節的 未活躍解碼中介紹過未活躍(inactivation)的概念,此一概念主要是為了讓 belief- propagation decoding 能過順利地繼續進行,當 belief-propagation decoding 找不到 度數為 1 的列訊號時,演算法會”動態”地選擇特定的行訊號為未活躍,此種未活
躍的選擇方式,我們稱之為動態未活躍(dynamic inactivation),與此小節所要介紹 的 permanent inactivation 做區分。
所謂的 permanent inactivation,意思是有些中間訊號在解碼執行前,就已經 被設定為未活躍;這些訊號稱為永久未活躍訊號(permanent inactivation symbol, PI symbol),而其他的中間訊號稱作 LT symbol;此外,編碼訊號的產生方式也與原 本的 LT 編碼有些許不同。首先,令共有
W
個 LT 訊號,分別為x x
1, 2,...,x ,
WP
個PI 訊號,分別為
y
1, y ,..., y2 p。接著,與之前一樣有一個度數分布 (x)
(degree distribution),此一度數分布應用在 LT 訊號的編碼,而另外還有一個應用在 PI 訊 號上的度數分布 (x)
。編碼步驟如下所述:步驟(1): 從
(x)
中取樣得到一個度數d
1步驟(2): 從
x x
1, 2,...,x 中選取一個大小為
Wd 的子集合
1S
步驟(3): 利用d 以及
1 (x)
來取樣出另一個度數d
2步驟(4): 從
y
1, y ,..., y2 p中選取一個大小為d 的子集合
2T
步驟(5): 利用下式求得編碼訊號值i j
i S j T
z x y
而z的度數
d d
1 d
2;下圖為此編碼方式的示意圖。圖 2.17 LT 訊號與 PI 訊號的編碼方式
由於 PI 訊號在一開始就被設為未活躍,也就是二分圖中的連線在編碼前就 減少了許多,因此大量地增加 LT 訊號能夠完成解碼的成功機率,也減少額外的 動態未活躍訊號。更詳細的推導可以參考文獻[3]。
2.4.3 Galois Field
在前面章節所討論的編碼運算皆為邏輯異或的運算,也就是操作在
GF (2)
的 運算。而在這樣的運算下,解碼成功率有一個極限存在,即便是設計最好的編碼 在收到K h
個編碼訊號的情況下,其解碼成功率大約為1 1
12
h
。而克服此一極限的方法就是讓運算操作在更大的 Galois Field,假設使用的 Galois Field
(256)
, 則在接收到K h
個編碼訊號的情況下,解碼成功率約為1 1
1256
h
。圖 2.18 為不 同 Galois Field(q)
的 overhead-failure curve。圖 2.18 不同 Galois Field 的解碼失敗率[3]
然而操作在較大 Galois Field 的缺點是所需要的運算量比單純的邏輯異或要 大上許多,因此 RaptorQ code 採用的方式是仍會用到較大的 Galois Field,但只 有一小部分,絕大部分的運算仍操作在
GF (2)
,如此便可兼顧較低的運算量以及 較佳的解碼成功率。2.4.4 解碼失敗率
討論到 Raptor code 的效果,解碼的成功與否是一個相當重要的因素。如同在 2.3.3 小節討論到 Raptor code 的解碼失敗率,根據[6]可以將 RaptorQ code 的解碼 失敗率整理如式(2.4)所示:
(n, k) 1
0.01 0.01
f n k
if n k
p
if n k
(2.4)(n, k)
p
f 表示解碼器在接收到 n 個編碼訊號,來源訊號共 k 個的情況下,解碼器 解碼失敗的機率。將式(2.4)與式(2.3)做比較,可明顯地看出 RaptorQ code 效果較 Raptor code 要好上許多。3. 第三章 RaptorQ 規格及 其編解碼器架構
本章節將詳細地介紹 RaptorQ code 的運作方式、編碼過程以及解碼器的架 構;其中解碼器的演算法為互聯網工程任務組(Internet Engineering Task Force, IETF)所釋出標準上提供的範例。
3.1 RaptorQ code 規格介紹
本小節將介紹 RaptorQ code 在編解碼中所使用到的標識以及架構等等。
3.1.1 來源區塊組成
為了利用 RaptorQ code 傳送物件,首先將此一物件會分成
Z 1
個來源區塊 (source block);而 RaptorQ code 編碼器會分別對各個來源區塊獨立地進行編碼,來源區塊之間會利用來源區塊號碼(source block number)進行區分,第一個來源區 塊從零開始編號,以此類推。每個來源區塊又會再細分成
K
個來源訊號,每個來 源訊號大小為T
octet;而來源訊號之間亦會利用編碼訊號標識符(encoded symbol identifier)作區分,第一個編碼訊號標識符為零,以此類推。進一步地,每一大小為
K
個來源訊號的來源區塊會在被細分為N
個子區塊 (sub-block),主要目的是為了使編碼訊號大小能夠讓接收端的解碼暫存器所接受。每個子區塊亦會再分成
K
個大小為T
octet 的子編碼訊號(sub-symbol)。值得注意的是上述中的每個來源區塊的來源訊號數
K
不必相同,且每個子區 塊中的子編碼訊號大小T
也不必相同。儘管如此,每個來源區塊的來源訊號大小T
以及同一個來源區塊中每個子區塊的子編碼訊號數K
必須相同。更詳細的來源 區塊與子區塊的切割方式可以參考文獻[8]。3.1.2 八位組的算術運算
RaptorQ code 規格中含有許多八位組(octet)的元素,這些元素會分別對應到 範圍從 0 到 255 的非負數整數,令一個元素為
B
, [7]B
、 [6]B
、 [5]B
、 [4]B
、[3]
B
、 [2]B
、 [1]B
、 [0]B
,其中 [7]B
為最高位元, [0]B
為最低位元,其元素會對應 到
i B
[ 7 ] * 1 2 8 B
[ 6 ] * 6 4 B
[ 5 ] * 3 2 B
[ 4 ] * 1 6B B
[ 3 ] * 8 B
[ 2 ] * 4 B
。 [ 1 ] * 2 [ 0 ] 兩個八位組u及v的加法定義為邏輯異或的運算,如下:^ u v u v
而減法則同樣定義為邏輯異或的運算,如下:^ u v u v
零元素(additive identity)即代表整數零的八位組。而u的加法逆元素(additive inverse)就是u本身,如下:
0 u u
八 位 組 的 乘 法 則 須 由
O C T
_L O G
以 及O C T
_E X P
兩 者 的 協 助 [8] 。 _OCT LOG 會將八位組對應到非負整數, OCT
_EXP 則會將非負整數對應乘八
位組。兩個八位組u及v的乘法定義如下:
* u v
0
, if either u or v are 0_ [ _ [ ] _ [ ]]
OCT EXP OCT LOG u OCT LOG v
, otherwise注意上式中的 "+" 號為平常的整數加法,因為加數與被加數皆為正常的整數。
兩個八位組u及v的除法定義如下,其中
v 0
:u v
0
, ifu 0
_ [ _ [ ] _ [ ] 255]
OCT EXP OCT LOG u OCT LOG v
, otherwise一元素(multiplicative identity)即代表整數一的八位組。另一個不為零的八位 組u,其乘法逆元素定義如下:
_ [255 _ [ ]]
OCT EXP OCT LOG u
3.2 編碼器架構
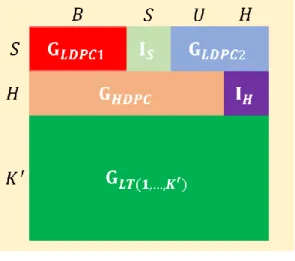
RaptorQ 編碼器的功能是利用一個含有𝐾個來源訊號的來源區塊,產生任意 數的修補訊號(repair symbol);圖 3.1 為 RaptorQ 編碼器的整體架構圖,整個編 碼的流程大致分為三個步驟。
圖 3.1 RaptorQ 編碼架構圖
3.2.1 加入填補訊號
第一個步驟是將𝐾個來源訊號補上零或多個填補訊號(padding symbol),使 得訊號總數𝐾′為介於 10 到 56403 共 477 個值中的一個[8],如(式 3.1);其中𝐾′
必須為規格中大於𝐾的最小值。
0
KK
x = x
(3.1)𝐾是決定一個來源區塊中含有多少來源訊號的值,因此傳送端及接收端都必須 知道𝐾的大小,如此傳送端及接收端都可以計算出𝐾′− 𝐾值並加上填補訊號,
而不需多餘的溝通。
填補訊號可以視為延伸後的來源訊號,但它們不會是編碼訊號,也就是不 會被當作編碼訊號一起傳出,接收端則是藉由計算𝐾′− 𝐾值來得知填補訊號 數,進而還原出原本的來源訊號。加上填補訊號的目的主要是讓編碼及解碼都 能更快速的進行,此外也能減少傳送端及接收端所需存放的資料量。
3.2.2 產生中間訊號
第二步驟則是利用𝐾′個來源訊號,經過前置編碼產生
M
個中間訊號。3.2.2.1 前置編碼矩陣
圖 3.2 為前置編碼矩陣。前置編碼矩陣
A
的大小為M M
,其中圖 3.2 前置編碼矩陣
前置編碼矩陣組成大致分述如下,
G
LDPC1及G
LDPC2為兩個低密度奇偶檢查 碼(low-density parity-check code, LDPC code)的子矩陣,定義在二元的 Galois Field (GF(2)),主要用來產生大部分的 LDPC 訊號。G
HDPC為高密度奇偶檢察碼 (high-density parity-check code, HDPC code)的子矩陣,定義在八位組的 Galois Field(GF (256)),主要用來產生少量的 HDPC 前置編碼多餘訊號;此一子矩陣也 是 RaptorQ code 不同於以往 Raptor code 的主要部分。最後一個子矩陣為(1,..., LT K)
G
,此一矩陣的組成與 Luby Transform 矩陣的前𝐾′個列向量視相同的,如此便可滿足 RaptorQ code 為一個有系統(systematic)的編碼。
中間訊號c的產生方式如(式 3.2)所示。其中,
M
個中間訊號必須滿足前置 編碼關係,見 3.2.2.2 所述。1 0M K '
c = A
x
(3.2)填補一個零行向量0M K '是為了滿足前置編碼矩陣的大小。
3.2.2.2 前置編碼關係
前置編碼關係為
M
個中間訊號必須滿足𝑆 + 𝐻個線性組合後的值為零。此 外共有𝑆個 LDPC 訊號以及𝐻個 HDPC 訊號,因此𝑀 = 𝐾′+ 𝑆 + 𝐻。另一種分類 方式是將M
個中間訊號分為兩類,一部分為𝑊個 LT 訊號,另一部分為𝑃個 PI 訊號,因此𝑀 = 𝑊 + 𝑃。𝑃個 PI 訊號是由𝐻個 HDPC 訊號以及其他𝑈 = 𝑃 − 𝐻個 中間訊號所組成,𝑊個 LT 訊號是由𝑆個 LDPC 訊號以及其他𝐵 = 𝑊 − 𝑆個中間 訊號所組成。承上段所述,
c [0] ~ c [ M 1]
為M
個中間訊號,其中:1.
c [0] ~ c [ B 1]
是 LT 訊號,但不是 LDPC 訊號的中間訊號。2.
c [ ] B ~ c [ B S 1]
是既為 LT 訊號,亦為 LDPC 訊號的中間訊號。3.
c [ B S ] ~ c [ W U 1]
是 PI 訊號,但不是 HPDC 訊號的中間訊號。4.
c [ M H ] ~ c [ M 1]
是既為 PI 訊號,亦為 HPDC 訊號的中間訊號。3.2.3 產生編碼訊號
最後一個步驟為產生編碼訊號,利用在第二步驟所得到的中間訊號與 LT
編碼矩陣
G
LT(1,...,N)相乘求得,如式(3.3)所示。G
LT(1,...,N)矩陣的大小為N M
,M
為中間訊號數,N
則是由編碼率以及預計通道遺失率所決定。(1,...,N)
e = G
LTc
(3.3)為了滿足有系統(systematic)的編碼特性,
G
LT(1,...,N)矩陣中的前K
個列向量 與前置編碼矩陣的G
LT(1,...,K')相同;其中,為了避免傳送編碼前所加入的填補訊號(padding symbol),
G
LT(1,...,N)的第K
到K
個列向量不會加入編碼。最後可以得 到N
個編碼訊號,其中包括K
個來源訊號以及N K
個修補訊號(repairsymbol)。
3.3 解碼器架構
解碼器架構與編碼器架構不同的地方在於前置編碼與 LT 編碼的順序互 換,整個流程如圖 3.3 所示。首先收到的訊號為
e
,依照編碼器與解碼器共同的 設定補上正確數量的填補訊號得到ˆe;接著將ˆe乘上A ˆ
1得到中間訊號,如式 (3.4);其中,ˆA
與原先的編碼矩陣不同的地方在於G
LT(1,...,N),傳遞的過程中遺 失的訊號無法加入解碼的過程,因此遺失訊號所對應的列向量就會從G
LT(1,...,N) 中移除。ˆ ˆ
1c = A e
(3.4)求得中間訊號後,利用來源訊號以及修補訊號皆為中間訊號的線性組合特 性還原來源訊號,如式(3.5)。
(1,..., )
LT K
x = G c
(3.5)圖 3.3 RaptorQ 解碼架構圖
由於
G
LT(1,...,K)為一個稀疏的二位元矩陣,因此整個解碼的運算量主要都集中在求得中間訊號,即式(3.4);因而,大部分的解碼演算法都是針對此一部分 化簡及優化。
3.3.1 Inactivation Decoding Gaussian Elimination[]
此小節要介紹的方法是由互聯網工程任務組(Internet Engineering Task Force) 提出的標準解碼演算法[8],稱為 Inactivation Decoding Gaussian Elimination。整 個演算法是藉由將
ˆA
化為一單位矩陣,同時求得中間訊號,如式(3.4)。接下來 所說明的步驟主要是針對ˆA
矩陣的行列運算,同時行列運算亦會對應到中間訊 號c以及接收到的訊號 ˆe 。整個 IDGE 演算法大致分為以下階段:
階段(1):
在第一階段的運算主要可以分成不同個子矩陣來觀察,如圖 3.4 所示。首 先,建立一個大小與
ˆA
相同的新矩陣X
,並將整ˆA
複製到X
;此外i
的初始值 為 0,u的初始值為 PI 訊號的數量P
,而一開始的V
矩陣即為ˆA
。圖 3.4 階段(1)中
ˆA
的各個子矩陣此一階段中,每一次都會從
ˆA
中挑選一個列向量,挑選的條件如下: 若
V
中所有項皆為零,即沒有列向量可以選擇時,表示解碼失敗 令r表示
ˆA
的列向量中在V
子矩陣中含有最少 1 的數目: 若
r 2
,則選擇在V
子矩陣含有r個1
且在ˆA
中含有最小度數的列 向量,但此一步驟不會先挑選 HDPC 列向量,除非所有的非 HDPC 列向量都已被選完。 若
r 2
,則選擇在V
子矩陣含有r個1
且含有最大組成成分元素 (maximum size component)的列向量。完成列向量的選擇後,將此一列向量與
V
矩陣的第一個列向量互換位置,並將其中ㄧ個
1
所對應的行向量移至V
矩陣的第一行,其餘的1
則移至最後r 1
行。接著利用高斯消去法,將第一行中除了第一個元素為1
外,其餘皆化簡為0
。上述的行列互換以及列除法不僅在矩陣ˆA
執行,同時也會在X
上作相同的 運算,但列向量的邏輯異或則不會在X
上執行。每完成一次上述步驟時,
i
值會增加1
,u則會增加r 1
;若i u M
,則 表示第一階段成功,也就是V
子矩陣在第一階段成功時,會化簡至消失如圖 3.5。但若因為V
子矩陣的元素全為零,而沒有列向量可以做選擇時,表示第一階段解碼失敗。
圖 3.5 階段(1)成功矩陣示意圖
階段(2):
此一階段是針對
ˆA
中的U
矩陣作處理,首先將U
矩陣拆為U
upper以及lower
U
,如圖 3.6 (a)所示;接著利用高斯消去法針對U
lower矩陣化簡,使其前u列 成為一個u u 的單位矩陣,最後在將剩餘的S H N M
個列向量移除,如圖 3.6 (b)。階段(2)的成功與否決定於U
lower的秩是否大於u,反之則解碼失敗。(a) (b) 圖 3.6 階段(2)矩陣示意圖
階段(3):
完成階段(2)後,整個矩陣
ˆA
中需要被化簡的部分僅剩下U
upper,此一矩陣的列數目
i
通常遠大於行數目u;除此之外,此時U
upper通常為一個密集的矩 陣,也就是其中的非零元素十分多,為了使其化簡為一個較為稀疏的矩陣,我 們將X
矩陣的前i
行及前i
列的交集,乘上ˆA
的前i
列,其結果矩陣在前i
行仍與 原本的ˆA
相同,但後半部的U
upper已化簡為一個稀疏的矩陣。階段(4):
利用先前得到的u u 單位矩陣,對
U
upper作化簡使得整個ˆA
化簡為一個單 位矩陣,如圖 3.7 所示。圖 3.7 IDGE 解碼完成矩陣示意圖
演算法到此一步驟已成功地將
ˆA
化簡為一個單位矩陣,同時求得中間訊號值。3.3.2 索引基礎解碼演算法[11]
Raptor code 與 RaptorQ code 的主要不同處在於編碼過程中,RaptorQ code 會 用到八位組的 Galois Field。此一演算法大致的解碼架構與章節 3.3 所介紹的演算 法相同,但有些部分做了較佳的規劃及修改。在步驟(1)的部分,含有八位組元素 的列向量不會成為主列向量(pivot row vector),而盡量使得此一部分維持二位元 的運算。
此一演算法主要特色在於建立一個索引表,將整個前置編碼矩陣以及第三階 段的 LT 編碼矩陣都建成一索引表;舉一例子,若一列向量為
1 0 0 1 0 ...
,則在索引表中則是記錄為
1 4 ...
,即此一索引表僅記錄一列向量中的非零項。由於來源訊號以及編碼訊號所對應的列向量皆十分稀疏,因此此一索引表能有效 地降低矩陣所需要存取的容量,如圖 3.8 (a)及(b)所示。
(a) (b)
圖 3.8 索引基礎最大四然估計解碼器之索引表[11]
除了大量地減少矩陣存取所需的空間外,演算法中二位元的行列互換以及列 運算也減化成索引表的更新,有效地減少運算量。
第m列與第n列向量互換:
將列向量在索引表中所對應的索引(index)互換即可。
第m行與第n行向量互換:
藉由索引表可以迅速地知道每個列向量的非零項位置,當一列向量中的 m位置與n位置有不同值時才須對索引表更新,反之則否。
第m列與第n列做列運算:
檢查第m列與第n列各含有的非零項,若兩者皆存有同一位置,則將其 存索引表中移除,又若某位置僅存在主列向量中,則目標列向量索引則 須增加其位置。
如: 主列向量索引為
2 4 7
,目標列向量索引為 2 4 6
,經過列運算後,目標列向量索引更新為
6 7
。由於矩陣的稀疏度,使得索引表所存取的空間遠小於
M ,而行列運算也從
2M
個元素降至些許的元素;因此整個運算量從原本
(M )3 降至
(M )2 。3.3.3 遞迴解碼演算法[12]
為了以下介紹表示的方便,我們將式(3.2)中的前置編碼矩陣以及式(3.3)中的 LT 編碼矩陣重新整理,稱其為傳送矩陣如式(3.6)所示。
2 LT
D = A
G
(3.6)其中
A
矩陣與原先的前置編碼矩陣相同,G
LT2則為G
LT(1,...,N)的第K 1 ~N列向量,修補訊號所對應的列向量,此外令一個
G
LT1表示G
LT(1,...,K'),即來源訊號所對 應的列向量。整個 RaptorQ code 編解碼架構重新整理如圖 3.9 所示。
圖 3.9 RaptorQ code 編解碼架構[12]
由於 RaptorQ code 為一個有系統的(systematic)編碼,因此來源訊號也會納入編碼
訊號(如圖 3.9 中的多工器),傳遞出的編碼訊號可表示為
x
y
。接著,編碼訊號在通道傳遞的過程中可能會遺失,在接收端所接收到的訊號我們表示為
x
y
,及其 所對應的接收矩陣如式(3.7)所示。2 LT
D = A
G
(3.7)如同前面所討論過的,整個 RaptorQ code 的解碼運算量大都集中在反矩陣 運算。藉由觀察可以發現傳送矩陣
D
與接收矩陣 D 只有部分的列向量不同,即遺 失訊號所對應的列向量;而此一演算法希望事前先求得傳送矩陣D
的反矩陣,接 收端則根據遺失訊號所對應的列向量,結合 Sherman-Morrison Formula[10]遞迴 地求得接收矩陣 D 的反矩陣。3.3.3.1 傳送矩陣的大小決定
由於湧泉碼的特性,傳送矩陣
D
的列向量數目應要為一任意數,使其能夠編 碼出足夠的訊號;然而為了要事前先計算出傳送矩陣D
的反矩陣,若D
的列向量 數太大的話,會導致解碼的時候要移除很多的列向量,相反地,若D
的列向量數 目太少,則可能會導致解碼時沒有足夠的列向量以求得接收矩陣的反矩陣D ,
† 屆時則需要加入新的列向量。因此,此一編碼矩陣的大小決定是為了讓解碼端能 夠有較好的初始值以有效地減少解碼運算量;無論此一編碼初始值為何,解碼器 都能得到一樣的解碼結果。RaptorQ code 通常都應用在網絡中較高層的部分,因此會有來自較低層的訊
號遺失率
p 。為了能成功地接收到
eK
個編碼訊號,此一演算法令預期接收到的編碼訊號數為
1
eK p
;因此選擇N作為傳送矩陣的列向量數,如式(3.8)。1 e
N K M K
p
(3.8)其中
M K
的原因是因為零行向量 0M K ,見式(3.2);換言之,傳送矩陣的大小為 NM。3.3.3.2 接收反矩陣的遞迴運算
令
m 為一索引,標記所有存在傳送矩陣
rD
、但不在接收矩陣 D 中的列向量,其中1
m
r N
,r
1,...,R N M
。被標記的列向量包括在傳遞過程中遺失訊 號所對應的列向量,以及當接收端收到足夠的編碼訊號而忽略的列向量;值得注 意的地方是當接收端收到足夠的編碼訊號時,就不會再繼續接收。接著定義另一個大小為NM的矩陣 D ,其第 j 列向量
d 定義如式(3.9):
j0 ,
1,..., ,
R j
j
j m m otherwise
d
d
(3.9)其中
d 為傳送矩陣
jD
的第 j 列向量,而 D 與D
的關係是如下式:1
r
R r m r


![圖 2.18 不同 Galois Field 的解碼失敗率[3]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9607889.633567/37.892.141.759.442.1065/圖218不同GaloisField的解碼失敗率3.webp)