Introduction to Reliable and Secure Distributed Programming
380
0
0
全文
(2)
(3) Christian Cachin Lu´ıs Rodrigues. •. Rachid Guerraoui. Introduction to. Reliable and Secure Distributed Programming Second Edition. 123.
(4) Dr. Christian Cachin IBM Research Z¨urich S¨aumerstrasse 4 8803 R¨uschlikon Switzerland [email protected]. Prof. Lu´ıs Rodrigues INESC-ID Instituto Superior T´ecnico Rua Alves Redol 9 1000-029 Lisboa Portugal [email protected]. Prof. Dr. Rachid Guerraoui Ecole Polytechnique F´ed´erale Lausanne (EPFL) Fac. Informatique et Communications Lab. Programmation Distribu´ee (LPD) Station 14 1015 Lausanne Bat. INR Switzerland [email protected]. ISBN 978-3-642-15259-7 e-ISBN 978-3-642-15260-3 DOI 10.1007/978-3-642-15260-3 Springer Heidelberg Dordrecht London New York Library of Congress Control Number: 2011921701 ACM Computing Classification (1998): C.2, F.2, G.2 c Springer-Verlag Berlin Heidelberg 2011, 2006 ⃝ This work is subject to copyright. All rights are reserved, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilm or in any other way, and storage in data banks. Duplication of this publication or parts thereof is permitted only under the provisions of the German Copyright Law of September 9, 1965, in its current version, and permission for use must always be obtained from Springer. Violations are liable to prosecution under the German Copyright Law. The use of general descriptive names, registered names, trademarks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use. Cover design: KuenkelLopka GmbH Printed on acid-free paper Springer is part of Springer Science+Business Media (www.springer.com).
(5) To Irene, Philippe and Andr´e. To Maria and Sarah. To Hugo and Sara..
(6)
(7) Preface. This book provides an introduction to distributed programming abstractions and presents the fundamental algorithms that implement them in several distributed environments. The reader is given insight into the important problems of distributed computing and the main algorithmic techniques used to solve these problems. Through examples the reader can learn how these methods can be applied to building distributed applications. The central theme of the book is the tolerance to uncertainty and adversarial influence in a distributed system, which may arise from network delays, faults, or even malicious attacks.. Content In modern computing, a program usually encompasses multiple processes. A process is simply an abstraction that may represent a physical computer or a virtual one, a processor within a computer, or a specific thread of execution in a concurrent system. The fundamental problem with devising such distributed programs is to have all processes cooperate on some common task. Of course, traditional centralized algorithmic issues still need to be dealt with for each process individually. Distributed environments, which may range from a single computer to a data center or even a global system available around the clock, pose additional challenges: how to achieve a robust form of cooperation despite process failures, disconnections of some of the processes, or even malicious attacks on some processes? Distributed algorithms should be dependable, offer reliability and security, and have predictable behavior even under negative influence from the environment. If no cooperation were required, a distributed program would simply consist of a set of independent centralized programs, each running on a specific process, and little benefit could be obtained from the availability of several processes in a distributed environment. It was the need for cooperation that revealed many of the fascinating problems addressed by this book, problems that need to be solved to make distributed computing a reality. The book not only introduces the reader to these problem statements, it also presents ways to solve them in different contexts. Not surprisingly, distributed programming can be significantly simplified if the difficulty of robust cooperation is encapsulated within specific abstractions. By encapsulating all the tricky algorithmic issues, such distributed programming abstractions bridge the gap between network communication layers, which are vii.
(8) viii. Preface. usually frugal in terms of dependability guarantees, and distributed application layers, which usually demand highly dependable primitives. The book presents various distributed programming abstractions and describes algorithms that implement them. In a sense, we give the distributed application programmer a library of abstract interface specifications, and give the distributed system builder a library of algorithms that implement the specifications. A significant amount of the preparation time for this book was devoted to formulating a collection of exercises and developing their solutions. We strongly encourage the reader to work out the exercises. We believe that no reasonable understanding can be achieved in a passive way. This is especially true in the field of distributed computing, where the human mind too often follows some attractive but misleading intuition. The book also includes the solutions for all exercises, to emphasize our intention to make them an integral part of the content. Many exercises are rather easy and can be discussed within an undergraduate teaching classroom. Other exercises are more difficult and need more time. These can typically be studied individually.. Presentation The book as such is self-contained. This has been made possible because the field of distributed algorithms has reached a certain level of maturity, where distracting details can be abstracted away for reasoning about distributed algorithms. Such details include the behavior of the communication network, its various kinds of failures, as well as implementations of cryptographic primitives; all of them are treated in-depth by other works. Elementary knowledge about algorithms, first-order logic, programming languages, networking, security, and operating systems might be helpful. But we believe that most of our abstractions and algorithms can be understood with minimal knowledge about these notions. The book follows an incremental approach and was primarily written as a textbook for teaching at the undergraduate or basic graduate level. It introduces the fundamental elements of distributed computing in an intuitive manner and builds sophisticated distributed programming abstractions from elementary ones in a modular way. Whenever we devise algorithms to implement a given abstraction, we consider a simple distributed-system model first, and then we revisit the algorithms in more challenging models. In other words, we first devise algorithms by making strong simplifying assumptions on the distributed environment, and then we discuss how to weaken those assumptions. We have tried to balance intuition and presentation simplicity on the one hand with rigor on the other hand. Sometimes rigor was affected, and this might not have been always on purpose. The focus here is rather on abstraction specifications and algorithms, not on computability and complexity. Indeed, there is no theorem in this book. Correctness arguments are given with the aim of better understanding the algorithms: they are not formal correctness proofs per se..
(9) Preface. ix. Organization The book has six chapters, grouped in two parts. The first part establishes the common ground: • In Chapter 1, we motivate the need for distributed programming abstractions by discussing various applications that typically make use of such abstractions. The chapter also introduces the modular notation and the pseudo code used to describe the algorithms in the book. • In Chapter 2, we present different kinds of assumptions about the underlying distributed environment. We introduce a family of distributed-system models for this purpose. Basically, a model describes the low-level abstractions on which more sophisticated ones are built. These include process and communication link abstractions. This chapter might be considered as a reference to other chapters. The remaining four chapters make up the second part of the book. Each chapter is devoted to one problem, containing a broad class of related abstractions and various algorithms implementing them. We will go from the simpler abstractions to the more sophisticated ones: • In Chapter 3, we introduce communication abstractions for distributed programming. They permit the broadcasting of a message to a group of processes and offer diverse reliability guarantees for delivering messages to the processes. For instance, we discuss how to make sure that a message delivered to one process is also delivered to all other processes, despite the crash of the original sender process. • In Chapter 4, we discuss shared memory abstractions, which encapsulate simple forms of distributed storage objects, accessed by read and write operations. These could be files in a distributed storage system or registers in the memory of a multi-processor computer. We cover methods for reading and writing data values by clients, such that a value stored by a set of processes can later be retrieved, even if some of the processes crash, have erased the value, or report wrong data. • In Chapter 5, we address the consensus abstraction through which a set of processes can decide on a common value, based on values that the processes initially propose. They must reach the same decision despite faulty processes, which may have crashed or may even actively try to prevent the others from reaching a common decision. • In Chapter 6, we consider variants of consensus, which are obtained by extending or modifying the consensus abstraction according to the needs of important applications. This includes total-order broadcast, terminating reliable broadcast, (non-blocking) atomic commitment, group membership, and view-synchronous communication. The distributed algorithms we study not only differ according to the actual abstraction they implement, but also according to the assumptions they make on the underlying distributed environment. We call the set of initial abstractions that an algorithm takes for granted a distributed-system model. Many aspects have a fundamental impact on how an algorithm is designed, such as the reliability of the links,.
(10) x. Preface. the degree of synchrony of the system, the severity of the failures, and whether a deterministic or a randomized solution is sought. In several places throughout the book, the same basic distributed programming primitive is implemented in multiple distributed-system models. The intention behind this is two-fold: first, to create insight into the specific problems encountered in a particular system model, and second, to illustrate how the choice of a model affects the implementation of a primitive. A detailed study of all chapters and the associated exercises constitutes a rich and thorough introduction to the field. Focusing on each chapter solely for the specifications of the abstractions and their underlying algorithms in their simplest form, i.e., for the simplest system model with crash failures only, would constitute a shorter, more elementary course. Such a course could provide a nice companion to a more practice-oriented course on distributed programming.. Changes Made for the Second Edition This edition is a thoroughly revised version of the first edition. Most parts of the book have been updated. But the biggest change was to expand the scope of the book to a new dimension, addressing the key concept of security against malicious actions. Abstractions and algorithms in a model of distributed computing that allows adversarial attacks have become known as Byzantine fault-tolerance. The first edition of the book was titled “Introduction to Reliable Distributed Programming.” By adding one word (“secure”) to the title – and adding one co-author – the evolution of the book reflects the developments in the field of distributed systems and in the real world. Since the first edition was published in 2006, it has become clear that most practical distributed systems are threatened by intrusions and that insiders cannot be ruled out as the source of malicious attacks. Building dependable distributed systems nowadays requires an interdisciplinary effort, with inputs from distributed algorithms, security, and other domains. On the technical level, the syntax for modules and the names of some events have changed, in order to add more structure for presenting the algorithms. A module may now exist in multiple instances at the same time within an algorithm, and every instance is named by a unique identifier for this purpose. We believe that this has simplified the presentation of several important algorithms. The first edition of this book contained a companion set of running examples implemented in the Java programming language, using the Appia protocol composition framework. The implementation addresses systems subject to crash failures and is available from the book’s online website.. Online Resources More information about the book, including the implementation of many protocols from the first edition, tutorial presentation material, classroom slides, and errata, is available online on the book’s website at: http://distributedprogramming.net.
(11) Preface. xi. References We have been exploring the world of distributed programming abstractions for almost two decades now. The material of this book has been influenced by many researchers in the field of distributed computing. A special mention is due to Leslie Lamport and Nancy Lynch for having posed fascinating problems in distributed computing, and to the Cornell school of reliable distributed computing, includ¨ ing Ozalp Babaoglu, Ken Birman, Keith Marzullo, Robbert van Rennesse, Rick Schlichting, Fred Schneider, and Sam Toueg. Many other researchers have directly or indirectly inspired the material of this book. We did our best to reference their work throughout the text. All chapters end with notes that give context information and historical references; our intention behind them is to provide hints for further reading, to trace the history of the presented concepts, as well as to give credit to the people who invented and worked out the concepts. At the end of the book, we reference books on other aspects of distributed computing for further reading.. Acknowledgments We would like to express our deepest gratitude to our undergraduate and graduate ´ students from the Ecole Polytechnique F´ed´erale de Lausanne (EPFL) and the University of Lisboa (UL), for serving as reviewers of preliminary drafts of this book. Indeed, they had no choice and needed to prepare for their exams anyway! But they were indulgent toward the bugs and typos that could be found in earlier versions of the book as well as associated slides, and they provided us with useful feedback. Partha Dutta, Corine Hari, Michal Kapalka, Petr Kouznetsov, Ron Levy, Maxime Monod, Bastian Pochon, and Jesper Spring, graduate students from the School of Computer and Communication Sciences of EPFL, Filipe Ara´ujo and Hugo Miranda, graduate students from the Distributed Algorithms and Network Protocol (DIALNP) group at the Departamento de Inform´atica da Faculdade de Ciˆencias da Universidade de Lisboa (UL), Leila Khalil and Robert Basmadjian, graduate students from the Lebanese University in Beirut, as well as Ali Ghodsi, graduate student from the Swedish Institute of Computer Science (SICS) in Stockholm, suggested many improvements to the algorithms presented in the book. Several implementations for the “hands-on” part of the book were developed by, or with the help of, Alexandre Pinto, a key member of the Appia team, complemented with inputs from several DIALNP team members and students, including Nuno Carvalho, Maria Jo˜ao Monteiro, and Lu´ıs Sardinha. Finally, we would like to thank all our colleagues who were kind enough to comment on earlier drafts of this book. These include Felix Gaertner, Benoit Garbinato, and Maarten van Steen..
(12) xii. Preface. Acknowledgments for the Second Edition Work on the second edition of this book started while Christian Cachin was on sabbatical leave from IBM Research at EPFL in 2009. We are grateful for the support of EPFL and IBM Research. We thank again the students at EPFL and the University of Lisboa, who worked with the book, for improving the first edition. We extend our gratitude to the students at the Instituto Superior T´ecnico (IST) of the Universidade T´ecnica de Lisboa, at ETH Z¨urich, and at EPFL, who were exposed to preliminary drafts of the additional material included in the second edition, for their helpful feedback. We are grateful to many attentive readers of the first edition and to those who commented on earlier drafts of the second edition, for pointing out problems and suggesting improvements. In particular, we thank Zinaida Benenson, Alysson Bessani, Diego Biurrun, Filipe Crist´ov˜ao, Dan Dobre, Felix Freiling, Ali Ghodsi, Seif Haridi, Mat´usˇ Harvan, R¨udiger Kapitza, Nikola Kneˇzevi´c, Andreas Knobel, Mihai Letia, Thomas Locher, Hein Meling, Hugo Miranda, Lu´ıs Pina, Martin Schaub, and Marko Vukoli´c. Christian Cachin Rachid Guerraoui Lu´ıs Rodrigues.
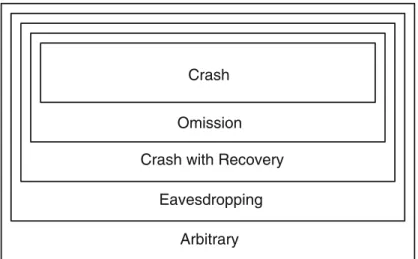
(13) Contents. 1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2 Distributed Programming Abstractions . . . . . . . . . . . . . . . . . . . . . . . . . 1.2.1 Inherent Distribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2.2 Distribution as an Artifact . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3 The End-to-End Argument . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4 Software Components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4.1 Composition Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4.2 Programming Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4.3 Modules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5 Classes of Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.6 Chapter Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1 1 3 4 6 7 8 8 11 13 16 17. 2. Basic Abstractions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1 Distributed Computation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.1 Processes and Messages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.2 Automata and Steps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.3 Safety and Liveness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2 Abstracting Processes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.1 Process Failures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.2 Crashes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.3 Omissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.4 Crashes with Recoveries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.5 Eavesdropping Faults . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.6 Arbitrary Faults . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3 Cryptographic Abstractions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.1 Hash Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.2 Message-Authentication Codes (MACs) . . . . . . . . . . . . . . . . . 2.3.3 Digital Signatures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4 Abstracting Communication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.1 Link Failures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.2 Fair-Loss Links . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.3 Stubborn Links . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.4 Perfect Links . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.5 Logged Perfect Links . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 19 20 20 20 22 24 24 24 26 26 28 29 30 30 30 31 32 33 34 35 37 38. xiii.
(14) xiv. Contents. 2.4.6 Authenticated Perfect Links . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.7 On the Link Abstractions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Timing Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.5.1 Asynchronous System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.5.2 Synchronous System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.5.3 Partial Synchrony . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Abstracting Time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.6.1 Failure Detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.6.2 Perfect Failure Detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.6.3 Leader Election . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.6.4 Eventually Perfect Failure Detection . . . . . . . . . . . . . . . . . . . . 2.6.5 Eventual Leader Election . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.6.6 Byzantine Leader Election . . . . . . . . . . . . . . . . . . . . . . . . . . . . Distributed-System Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.7.1 Combining Abstractions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.7.2 Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.7.3 Quorums . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.7.4 Measuring Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Chapter Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 40 43 44 44 45 47 48 48 49 51 53 56 60 63 63 64 65 65 67 68 71. Reliable Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.1 Client–Server Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.2 Multiparticipant Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2 Best-Effort Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.2 Fail-Silent Algorithm: Basic Broadcast . . . . . . . . . . . . . . . . . . 3.3 Regular Reliable Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.2 Fail-Stop Algorithm: Lazy Reliable Broadcast . . . . . . . . . . . . 3.3.3 Fail-Silent Algorithm: Eager Reliable Broadcast . . . . . . . . . . 3.4 Uniform Reliable Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.4.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.4.2 Fail-Stop Algorithm: All-Ack Uniform Reliable Broadcast . . . . . . . . . . . . . . . . . . . . 3.4.3 Fail-Silent Algorithm: Majority-Ack Uniform Reliable Broadcast . . . . . . . . . . . . . . . 3.5 Stubborn Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.5.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.5.2 Fail-Recovery Algorithm: Basic Stubborn Broadcast . . . . . . . 3.6 Logged Best-Effort Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.6.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.6.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.6.3 Fail-Recovery Algorithm: Logged Basic Broadcast . . . . . . . .. 73 73 73 74 75 75 76 77 77 78 79 81 81. 2.5. 2.6. 2.7. 2.8 2.9 2.10 3. 82 84 85 85 86 87 87 88 89.
(15) Contents. xv. 3.7 Logged Uniform Reliable Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . 90 3.7.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90 3.7.2 Fail-Recovery Algorithm: Logged Majority-Ack Uniform Reliable Broadcast . . . . . . . . 90 3.8 Probabilistic Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92 3.8.1 The Scalability of Reliable Broadcast . . . . . . . . . . . . . . . . . . . 92 3.8.2 Epidemic Dissemination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93 3.8.3 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94 3.8.4 Randomized Algorithm: Eager Probabilistic Broadcast . . . . . 94 3.8.5 Randomized Algorithm: Lazy Probabilistic Broadcast . . . . . 97 3.9 FIFO and Causal Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100 3.9.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101 3.9.2 FIFO-Order Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101 3.9.3 Fail-Silent Algorithm: Broadcast with Sequence Number . . . 101 3.9.4 Causal-Order Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103 3.9.5 Fail-Silent Algorithm: No-Waiting Causal Broadcast . . . . . . 104 3.9.6 Fail-Stop Algorithm: Garbage-Collection of Causal Past . . . 106 3.9.7 Fail-Silent Algorithm: Waiting Causal Broadcast . . . . . . . . . . 108 3.10 Byzantine Consistent Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110 3.10.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110 3.10.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111 3.10.3 Fail-Arbitrary Algorithm: Authenticated Echo Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . 112 3.10.4 Fail-Arbitrary Algorithm: Signed Echo Broadcast . . . . . . . . . 114 3.11 Byzantine Reliable Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116 3.11.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117 3.11.2 Fail-Arbitrary Algorithm: Authenticated Double-Echo Broadcast . . . . . . . . . . . . . . . . . . 117 3.12 Byzantine Broadcast Channels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120 3.12.1 Specifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120 3.12.2 Fail-Arbitrary Algorithm: Byzantine Consistent Channel . . . 122 3.12.3 Fail-Arbitrary Algorithm: Byzantine Reliable Channel . . . . . 123 3.13 Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124 3.14 Solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126 3.15 Chapter Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134 4. Shared Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137 4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138 4.1.1 Shared Storage in a Distributed System . . . . . . . . . . . . . . . . . . 138 4.1.2 Register Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138 4.1.3 Completeness and Precedence . . . . . . . . . . . . . . . . . . . . . . . . . 141 4.2 (1, N ) Regular Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142 4.2.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142 4.2.2 Fail-Stop Algorithm: Read-One Write-All Regular Register . . . . . . . . . . . . . . . . . . . 144.
(16) xvi. Contents. 4.2.3. 4.3. 4.4. 4.5. 4.6 4.7. 4.8. 4.9 4.10 4.11 5. Fail-Silent Algorithm: Majority Voting Regular Register . . . . . . . . . . . . . . . . . . . . . . . 146 (1, N ) Atomic Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149 4.3.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149 4.3.2 Transformation: From (1, N ) Regular to (1, N ) Atomic Registers . . . . . . . . . . 151 4.3.3 Fail-Stop Algorithm: Read-Impose Write-All (1, N ) Atomic Register . . . . . . . . . . 156 4.3.4 Fail-Silent Algorithm: Read-Impose Write-Majority (1, N ) Atomic Register . . . . . . 157 (N, N ) Atomic Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159 4.4.1 Multiple Writers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159 4.4.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160 4.4.3 Transformation: From (1, N ) Atomic to (N, N ) Atomic Registers . . . . . . . . . 161 4.4.4 Fail-Stop Algorithm: Read-Impose Write-Consult-All (N, N ) Atomic Reg. . . . . . . 165 4.4.5 Fail-Silent Algorithm: Read-Impose Write-Consult-Majority (N, N ) Atomic Reg. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167 (1, N ) Logged Regular Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170 4.5.1 Precedence in the Fail-Recovery Model . . . . . . . . . . . . . . . . . 170 4.5.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170 4.5.3 Fail-Recovery Algorithm: Logged Majority Voting . . . . . . . . 172 (1, N ) Byzantine Safe Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175 4.6.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176 4.6.2 Fail-Arbitrary Algorithm: Byzantine Masking Quorum . . . . . 177 (1, N ) Byzantine Regular Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179 4.7.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179 4.7.2 Fail-Arbitrary Algorithm: Authenticated-Data Byzantine Quorum . . . . . . . . . . . . . . . . . . 180 4.7.3 Fail-Arbitrary Algorithm: Double-Write Byzantine Quorum . . . . . . . . . . . . . . . . . . . . . . . 182 (1, N ) Byzantine Atomic Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188 4.8.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189 4.8.2 Fail-Arbitrary Algorithm: Byzantine Quorum with Listeners . . . . . . . . . . . . . . . . . . . . . . 189 Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194 Solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195 Chapter Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200. Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203 5.1 Regular Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204 5.1.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204 5.1.2 Fail-Stop Algorithm: Flooding Consensus . . . . . . . . . . . . . . . 205 5.1.3 Fail-Stop Algorithm: Hierarchical Consensus . . . . . . . . . . . . . 208.
(17) Contents. xvii. 5.2 Uniform Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211 5.2.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211 5.2.2 Fail-Stop Algorithm: Flooding Uniform Consensus . . . . . . . . 212 5.2.3 Fail-Stop Algorithm: Hierarchical Uniform Consensus . . . . . 213 5.3 Uniform Consensus in the Fail-Noisy Model . . . . . . . . . . . . . . . . . . . . 216 5.3.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216 5.3.2 Epoch-Change . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217 5.3.3 Epoch Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220 5.3.4 Fail-Noisy Algorithm: Leader-Driven Consensus . . . . . . . . . . 225 5.4 Logged Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228 5.4.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228 5.4.2 Logged Epoch-Change . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229 5.4.3 Logged Epoch Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230 5.4.4 Fail-Recovery Algorithm: Logged Leader-Driven Consensus . . . . . . . . . . . . . . . . . . . . . . 234 5.5 Randomized Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235 5.5.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236 5.5.2 Common Coin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237 5.5.3 Randomized Fail-Silent Algorithm: Randomized Binary Consensus . . . . . . . . . . . . . . . . . . . . . . . . 238 5.5.4 Randomized Fail-Silent Algorithm: Randomized Consensus with Large Domain . . . . . . . . . . . . . . 242 5.6 Byzantine Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244 5.6.1 Specifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244 5.6.2 Byzantine Epoch-Change . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246 5.6.3 Byzantine Epoch Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . 248 5.6.4 Fail-Noisy-Arbitrary Algorithm: Byzantine Leader-Driven Consensus . . . . . . . . . . . . . . . . . . . . 259 5.7 Byzantine Randomized Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261 5.7.1 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261 5.7.2 Randomized Fail-Arbitrary Algorithm: Byzantine Randomized Binary Consensus . . . . . . . . . . . . . . . 261 5.8 Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266 5.9 Solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 268 5.10 Chapter Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277 6. Consensus Variants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281 6.1 Total-Order Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281 6.1.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281 6.1.2 Specifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283 6.1.3 Fail-Silent Algorithm: Consensus-Based Total-Order Broadcast . . . . . . . . . . . . . . . . . 284 6.2 Byzantine Total-Order Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287 6.2.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287 6.2.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288.
(18) xviii. Contents. 6.2.3. 6.3. 6.4. 6.5. 6.6. 6.7. 6.8. 6.9 6.10 6.11 7. Fail-Noisy-Arbitrary Algorithm: Rotating Sender Byzantine Broadcast . . . . . . . . . . . . . . . . . . . 288 Terminating Reliable Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292 6.3.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292 6.3.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293 6.3.3 Fail-Stop Algorithm: Consensus-Based Uniform Terminating Reliable Broadcast . . . . . . . . . . . . . . . . 293 Fast Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 296 6.4.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 296 6.4.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297 6.4.3 Fail-Silent Algorithm: From Uniform Consensus to Uniform Fast Consensus . . . . . 297 Fast Byzantine Consensus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 300 6.5.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 300 6.5.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 300 6.5.3 Fail-Arbitrary Algorithm: From Byzantine Consensus to Fast Byzantine Consensus . . . 300 Nonblocking Atomic Commit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303 6.6.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303 6.6.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304 6.6.3 Fail-Stop Algorithm: Consensus-Based Nonblocking Atomic Commit . . . . . . . . . . 304 Group Membership . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307 6.7.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307 6.7.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 308 6.7.3 Fail-Stop Algorithm: Consensus-Based Group Membership . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309 View-Synchronous Communication . . . . . . . . . . . . . . . . . . . . . . . . . . . 311 6.8.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 311 6.8.2 Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312 6.8.3 Fail-Stop Algorithm: TRB-Based View-Synchronous Communication . . . . . . . . . . 314 6.8.4 Fail-Stop Algorithm: Consensus-Based Uniform View-Synchronous Communication . . . . . . . . . . . . . 319 Exercises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323 Solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324 Chapter Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337. Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341 7.1 Implementation in Appia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341 7.2 Further Implementations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342 7.3 Further Reading . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.
(19) Contents. xix. References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347 List of Modules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355 List of Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357 Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361.
(20) 1. Introduction. I am putting myself to the fullest possible use, which is all I think that any conscious entity can ever hope to do. (HAL 9000). This chapter first motivates the need for distributed programming abstractions. Special attention is given to abstractions that capture the problems that underlie robust forms of cooperation between multiple processes in a distributed system, usually called agreement abstractions. The chapter then advocates a modular strategy for the development of distributed programs by making use of those abstractions through specific Application Programming Interfaces (APIs). A simple, concrete example of an API is also given to illustrate the notation and event-based invocation scheme used throughout the book to describe the algorithms that implement our abstractions. The notation and invocation schemes are very close to those that are found in practical implementations of distributed algorithms.. 1.1 Motivation Distributed computing addresses algorithms for a set of processes that seek to achieve some form of cooperation. Besides executing concurrently, some of the processes of a distributed system might stop operating, for instance, by crashing or being disconnected, while others might stay alive and keep operating. This very notion of partial failures is a characteristic of a distributed system. In fact, this notion can be useful if one really feels the need to differentiate a distributed system from a concurrent system. It is in order to quote Leslie Lamport here: “A distributed system is one in which the failure of a computer you did not even know existed can render your own computer unusable.” When a subset of the processes have failed, or become disconnected, the challenge is usually for the processes that are still operating, or connected to the majority of. C. Cachin et al., Introduction to Reliable and Secure Distributed Programming, DOI: 10.1007/978-3-642-15260-3 1, c Springer-Verlag Berlin Heidelberg 2011 ⃝. 1.
(21) 2. 1 Introduction. the processes, to synchronize their activities in a consistent way. In other words, the cooperation must be made robust to tolerate partial failures and sometimes also adversarial attacks. This makes distributed computing a hard, yet extremely stimulating problem. Due to the asynchrony of the processes, the possibility of failures in the communication infrastructure, and perhaps even malicious actions by faulty processes, it may be impossible to accurately detect process failures; in particular, there is often no way to distinguish a process failure from a network failure, as we will discuss in detail later in the book. Even worse, a process that is under the control of a malicious adversary may misbehave deliberately, in order to disturb the communication among the remaining processes. This makes the problem of ensuring consistent cooperation even more difficult. The challenge in distributed computing is precisely to devise algorithms that provide the processes that remain operating with enough consistent information so that they can cooperate correctly and solve common tasks. In fact, many programs that we use today are distributed programs. Simple daily routines, such as reading e-mail or browsing the Web, involve some form of distributed computing. However, when using these applications, we are typically faced with the simplest form of distributed computing: client–server computing. In client– server computing, a centralized process, the server, provides a service to many remote clients. The clients and the server communicate by exchanging messages, usually following a request–reply form of interaction. For instance, in order to display a Web page to the user, a browser sends a request to the Web server and expects to obtain a response with the information to be displayed. The core difficulty of distributed computing, namely, achieving a consistent form of cooperation in the presence of partial failures, may pop up even by using this simple form of interaction. Going back to our browsing example, it is reasonable to expect that the user continues surfing the Web if the consulted Web server fails (but the user is automatically switched to another Web server), and even more reasonable that the server process keeps on providing information to the other client processes, even when some of them fail or get disconnected. The problems above are already nontrivial when distributed computing is limited to the interaction between two parties, such as in the client–server case. However, there is more to distributed computing than handling client–server interactions. Quite often, not only two, but several processes need to cooperate and synchronize their actions to achieve a common goal. The existence of multiple processes complicates distributed computing even more. Sometimes we talk about multiparty interactions in this general case. In fact, both patterns may coexist in a quite natural manner. Actually, many distributed applications have parts following a client–server interaction pattern and other parts following a multiparty interaction pattern. This may even be a matter of perspective. For instance, when a client contacts a server to obtain a service, it may not be aware that, in order to provide that service, the server itself may need to request the assistance of several other servers, with whom it needs to coordinate to satisfy the client’s request. Sometimes, the expression peer-to-peer computing is used to emphasize the absence of a central server..
(22) 1.2 Distributed Programming Abstractions. 3. 1.2 Distributed Programming Abstractions Just like the act of smiling, the act of abstracting is restricted to very few natural species. By capturing properties that are common to a large and significant range of systems, abstractions help distinguish the fundamental from the accessory, and prevent system designers and engineers from reinventing, over and over, the same solutions for slight variants of the very same problems. From the Basics . . . Reasoning about distributed systems should start by abstracting the underlying physical system: describing the relevant elements in an abstract way, identifying their intrinsic properties, and characterizing their interactions, lead us to define what is called a system model. In this book we will use mainly two abstractions to represent the underlying physical system: processes and links. The processes of a distributed program abstract the active entities that perform computations. A process may represent a computer, a processor within a computer, or simply a specific thread of execution within a processor. In the context of network security, a process may also represent a trust domain, a principal, or one administrative unit. To cooperate on some common task, the processes may typically need to exchange messages using some communication network. Links abstract the physical and logical network that supports communication among processes. It is possible to represent multiple realizations of a distributed system by capturing different properties of processes and links, for instance, by describing how these elements may operate or fail under different environmental conditions. Chapter 2 will provide a deeper discussion of the various distributed-system models that are used in this book. . . . to the Advanced. Given a system model, the next step is to understand how to build abstractions that capture recurring interaction patterns in distributed applications. In this book we are interested in abstractions that capture robust cooperation problems among groups of processes, as these are important and rather challenging. The cooperation among processes can sometimes be modeled as a distributed agreement problem. For instance, the processes may need to agree on whether a certain event did (or did not) take place, to agree on a common sequence of actions to be performed (from a number of initial alternatives), or to agree on the order by which a set of inputs need to be processed. It is desirable to establish more sophisticated forms of agreement from solutions to simpler agreement problems, in an incremental manner. Consider, for instance, the following situations: • In order for processes to be able to exchange information, they must initially agree on who they are (say, using IP addresses on the Internet) and on some common format for representing messages. They may also need to agree on some way of exchanging messages (say, to use a reliable data stream for communication, like TCP over the Internet). • After exchanging some messages, the processes may be faced with several alternative plans of action. They may need to reach a consensus on a common plan, out of several alternatives, and each participating process may have initially its own plan, different from the plans of the other processes..
(23) 4. 1 Introduction. • In some cases, it may be acceptable for the cooperating processes to take a given step only if all other processes also agree that such a step should take place. If this condition is not met, all processes must agree that the step should not take place. This form of agreement is crucial in the processing of distributed transactions, where this problem is known as the atomic commitment problem. • Processes may not only need to agree on which actions they should execute but also need to agree on the order in which these actions should be executed. This form of agreement is the basis of one of the most fundamental techniques to replicate computation in order to achieve fault tolerance, and it is called the totalorder broadcast problem. This book is about mastering the difficulty that underlies these problems, and devising abstractions that encapsulate such problems. The problems are hard because they require coordination among the processes; given that processes may fail or may even behave maliciously, such abstractions are powerful and sometimes not straightforward to build. In the following, we motivate the relevance of some of the abstractions covered in this book. We distinguish the case where the abstractions emerge from the natural distribution of the application on the one hand, and the case where these abstractions come out as artifacts of an engineering choice for distribution on the other hand. 1.2.1 Inherent Distribution Applications that require sharing or dissemination of information among several participant processes are a fertile ground for the emergence of problems that required distributed programming abstractions. Examples of such applications are information dissemination engines, multiuser cooperative systems, distributed shared spaces, process control systems, cooperative editors, distributed databases, and distributed storage systems. Information Dissemination. In distributed applications with information dissemination requirements, processes may play one of the following roles: information producers, also called publishers, or information consumers, also called subscribers. The resulting interaction paradigm is often called publish–subscribe. Publishers produce information in the form of notifications. Subscribers register their interest in receiving certain notifications. Different variants of the publish– subscribe paradigm exist to match the information being produced with the subscribers’ interests, including channel-based, subject-based, content-based, or type-based subscriptions. Independently of the subscription method, it is very likely that several subscribers are interested in the same notifications, which the system should broadcast to them. In this case, we are typically interested in having all subscribers of the same information receive the same set of messages. Otherwise the system will provide an unfair service, as some subscribers could have access to a lot more information than other subscribers. Unless this reliability property is given for free by the underlying infrastructure (and this is usually not the case), the sender and the subscribers must coordinate to.
(24) 1.2 Distributed Programming Abstractions. 5. agree on which messages should be delivered. For instance, with the dissemination of an audio stream, processes are typically interested in receiving most of the information but are able to tolerate a bounded amount of message loss, especially if this allows the system to achieve a better throughput. The corresponding abstraction is typically called a best-effort broadcast. The dissemination of some stock exchange information may require a more reliable form of broadcast, called reliable broadcast, as we would like all active processes to receive the same information. One might even require from a stock exchange infrastructure that information be disseminated in an ordered manner. In several publish–subscribe applications, producers and consumers interact indirectly, with the support of a group of intermediate cooperative brokers. In such cases, agreement abstractions may be useful for the cooperation among the brokers. Process Control. Process control applications are those where several software processes have to control the execution of a physical activity. Basically, the processes might be controlling the dynamic location of an aircraft or a train. They might also be controlling the temperature of a nuclear installation or the automation of a car production plant. Typically, every process is connected to some sensor. The processes might, for instance, need to exchange the values output by their assigned sensors and output some common value, say, print a single location of the aircraft on the pilot control screen, despite the fact that, due to the inaccuracy or failure of their local sensors, they may have observed slightly different input values. This cooperation should be achieved despite some sensors (or associated control processes) having crashed or not observed anything. This type of cooperation can be simplified if all processes agree on the same set of inputs for the control algorithm, a requirement captured by the consensus abstraction. Cooperative Work. Users located on different nodes of a network may cooperate in building a common software or document, or simply in setting up a distributed dialogue, say, for an online chat or a virtual conference. A shared working space abstraction is very useful here to enable effective cooperation. Such a distributed shared memory abstraction is typically accessed through read and write operations by the users to store and exchange information. In its simplest form, a shared working space can be viewed as one virtual unstructured storage object. In more complex incarnations, shared working spaces may add a structure to create separate locations for its users to write, and range all the way from Wikis to complex multiuser distributed file systems. To maintain a consistent view of the shared space, the processes need to agree on the relative order among write and read operations on the space. Distributed Databases. Databases constitute another class of applications where agreement abstractions can be helpful to ensure that all transaction managers obtain a consistent view of the running transactions and can make consistent decisions on how these transactions are serialized. Additionally, such abstractions can be used to coordinate the transaction managers when deciding about the outcome of the transactions. That is, the database.
(25) 6. 1 Introduction. servers, on which a given distributed transaction has executed, need to coordinate their activities and decide whether to commit or abort the transaction. They might decide to abort the transaction if any database server detected a violation of the database integrity, a concurrency control inconsistency, a disk error, or simply the crash of some other database server. As we pointed out, the distributed programming abstraction of atomic commit (or commitment) provides such distributed cooperation. Distributed Storage. A large-capacity storage system distributes data over many storage nodes, each one providing a small portion of the overall storage space. Accessing stored data usually involves contacting multiple nodes because even a single data item may be spread over multiple nodes. A data item may undergo complex transformations with error-detection codes or error-correction codes that access multiple nodes, to protect the storage system against the loss or corruption of some nodes. Such systems distribute data not only because of the limited capacity of each node but also for increasing the fault-tolerance of the overall system and for reducing the load on every individual node. Conceptually, the storage system provides a shared memory abstraction that is accessed through read and write operations, like the shared working space mentioned before. But since it uses distribution also for the purpose of enhancing the overall resilience, it combines aspects of inherently distributed systems with aspects of artificially distributed systems, which are discussed next. 1.2.2 Distribution as an Artifact Often applications that are not inherently distributed also use sophisticated abstractions from distributed programming. This need sometimes appears as an artifact of the engineering solution to satisfy some specific requirements such as fault tolerance, load balancing, or fast sharing. We illustrate this idea through state-machine replication, which is a powerful way to achieve fault tolerance in distributed systems. Briefly, replication consists in making a centralized service highly available by executing several copies of it on different machines that are assumed to fail independently. This ensures the continuity of the service despite the failure of a subset of the machines. No specific hardware is needed: fault tolerance through replication is software-based. In fact, replication may also be used within an information system to improve the read access performance to data by placing it close to the processes where it is likely to be queried. For a service that is exposed to attacks over the Internet, for example, the same approach also tolerates malicious intrusions that subvert a limited number of the replicated nodes providing the service. For replication to be effective, the different copies must be maintained in a consistent state. If the states of the replicas may diverge arbitrarily, it does not make sense to talk about replication. The illusion of one highly available service would fall apart and be replaced by that of several distributed services, each possibly failing independently. If replicas are deterministic, one of the simplest ways to guarantee full consistency is to ensure that all replicas receive the same set of requests in the.
(26) 1.3 The End-to-End Argument. 7. same order. Typically, such guarantees are enforced by an abstraction called totalorder broadcast: the processes need to agree here on the sequence of messages they deliver. Algorithms that implement such a primitive are nontrivial, and providing the programmer with an abstraction that encapsulates these algorithms makes the design of a replicated service easier. If the replicas are nondeterministic then ensuring their consistency requires different ordering abstractions, as we will see later in this book. The challenge in realizing these abstractions lies in tolerating the faults that may affect the replicas, which may range from a simple process crash to being under the control of a malicious adversary.. 1.3 The End-to-End Argument Distributed programming abstractions are useful but may sometimes be difficult or expensive to implement. In some cases, no simple algorithm is able to provide the desired abstraction and the algorithm that solves the problem can have a high complexity, e.g., in terms of the number of interprocess communication steps and messages. Therefore, depending on the system model, the network characteristics, and the required quality of service, the overhead of the abstraction can range from the negligible to the almost prohibitive. Faced with performance constraints, the application designer may be driven to mix the relevant logic of the abstraction with the application logic, in an attempt to obtain an optimized integrated solution. The rationale is usually that such a solution should perform better than a solution obtained by the modular approach, where the abstraction is implemented as an independent service that can be accessed through a well-defined interface. The approach can be further supported by a superficial interpretation of the end-to-end argument: most complexity should be implemented at the higher levels of the communication stack. This argument could be applied to any form of (distributed) programming. However, even if performance gains can be obtained by collapsing the application and the underlying layers in some cases, such a monolithic approach has many disadvantages. Most importantly, it is prone to errors. Some of the algorithms that will be presented in this book have a considerable amount of difficulty and exhibit subtle dependencies among their internal elements. An apparently obvious “optimization” may break the algorithm correctness. To quote Donald Knuth here: “Premature optimization is the root of all evil.” Even if the designer reaches the amount of expertise required to master the difficult task of embedding these algorithms in the application, there are several other reasons to keep both implementations independent. The most compelling one is that there is usually no single solution for a given distributed computing problem. This is particularly true because of the variety of distributed system models. Instead, different solutions can usually be proposed and none of these solutions may strictly be superior to the others: each may have its own advantages and disadvantages, performing better under different network or load conditions, making.
(27) 8. 1 Introduction. different trade-offs between network traffic and message latency, and so on. Relying on a modular approach allows the most suitable implementation to be selected when the application is deployed, or even allows choosing at runtime among different implementations in response to changes in the environment. Encapsulating tricky issues of distributed interactions by abstractions with welldefined interfaces significantly helps us reason about the correctness of the application, and port it from one system to the other. We strongly believe that in many distributed applications, especially those that require many-to-many interaction, building preliminary prototypes of the distributed application using several abstraction layers can be very helpful. Ultimately, one may indeed consider optimizing the performance of the final release of a distributed application and using some integrated prototype that implements several abstractions in one monolithic piece of code. However, full understanding of each of the enclosed abstractions in isolation is fundamental to ensure the correctness of the combined code.. 1.4 Software Components 1.4.1 Composition Model Notation. One of the biggest difficulties we had to face when thinking about describing distributed algorithms was to find an adequate way to represent these algorithms. When representing a centralized algorithm, one could decide to use a programming language, either by choosing an existing popular one or by inventing a new one with pedagogical purposes in mind. Although there have indeed been several attempts to come up with distributed programming languages, these attempts have resulted in rather complicated notations that would not have been viable to describe general-purpose distributed algorithms in a pedagogical way. Trying to invent a distributed programming language was not an option. Even if we had the time to invent one successfully, at least one book would have been required to present the language itself. Therefore, we have opted to use pseudo code to describe our algorithms. The pseudo code reflects a reactive computing model where components of the same process communicate by exchanging events: an algorithm is described as a set of event handlers. These react to incoming events and possibly trigger new events. In fact, the pseudo code is very close to the actual way we programmed the algorithms in our experimental framework. Basically, the algorithm description can be seen as actual code, from which we removed all implementation-related details that were more confusing than useful for understanding the algorithms. This approach hopefully simplifies the task of those who will be interested in building running prototypes from the descriptions found in this book. A Simple Example. Abstractions are typically represented through an API. We will informally discuss here a simple example API for a distributed programming abstraction..
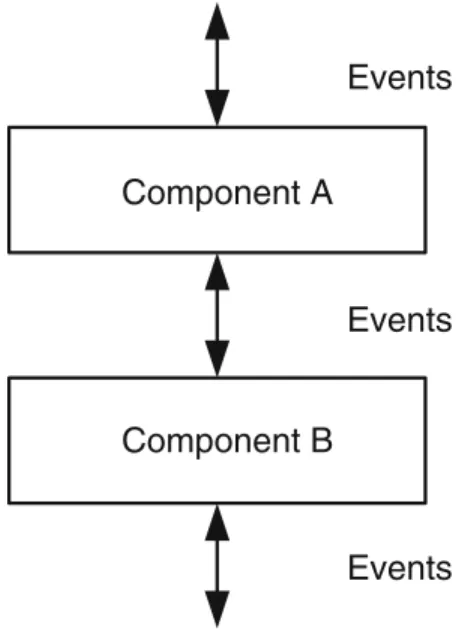
(28) 1.4 Software Components. 9. Events Component A. Events Component B. Events. Figure 1.1: Composition model. Throughout the book, we shall describe APIs and algorithms using an asynchronous event-based composition model. Every process hosts a set of software components, called modules in our context. Each component is identified by a name, and characterized by a set of properties. The component provides an interface in the form of the events that the component accepts and produces in return. Distributed programming abstractions are typically made of a collection of components, at least one for every process, that are intended to satisfy some common properties. Software Stacks. Components can be composed to build software stacks. At each process, a component represents a specific layer in the stack. The application layer is at the top of the stack, whereas the networking layer is usually at the bottom. The layers of the distributed programming abstractions we will consider are typically in the middle. Components within the same stack communicate through the exchange of events, as illustrated in Fig. 1.1. A given abstraction is typically materialized by a set of components, each running at a process. According to this model, each component is constructed as a state-machine whose transitions are triggered by the reception of events. Events may carry information such as a data message, or group membership information, in one or more attributes. Events are denoted by ⟨ EventType | Attributes, . . . ⟩. Often an event with the same name is used by more than one component. For events defined for component co, we, therefore, usually write: ⟨ co, EventType | Attributes, . . . ⟩.. Each event is processed through a dedicated handler by the process (i.e., by the corresponding component). A handler is formulated in terms of a sequence of instructions introduced by upon event, which describes the event, followed by pseudo.
(29) 10. 1 Introduction. code with instructions to be executed. The processing of an event may result in new events being created and triggering the same or different components. Every event triggered by a component of the same process is eventually processed, if the process is correct (unless the destination module explicitly filters the event; see the such that clause ahead). Events from the same component are processed in the order in which they were triggered. This first-in-first-out (FIFO) order is only enforced on events exchanged among local components in a given stack. The messages among different processes may also need to be ordered according to some criteria, using mechanisms orthogonal to this one. We shall address this interprocess communication issue later in this book. We assume that every process executes the code triggered by events in a mutually exclusive way. This means that the same process does not handle two events concurrently. Once the handling of an event is terminated, the process keeps on checking if any other event is triggered. This periodic checking is assumed to be fair, and is achieved in an implicit way: it is not visible in the pseudo code we describe. The pseudo code of a sample component co1 that consists of two event handlers looks like this: upon event ⟨ co1 , Event1 | att11 , att21 , . . . ⟩ do do something; trigger ⟨ co2 , Event2 | att12 , att22 , . . . ⟩; upon event ⟨ co1 , Event3 | att13 , att23 , . . . ⟩ do do something else; trigger ⟨ co2 , Event4 | att14 , att24 , . . . ⟩;. // send some event. // send some other event. Such a decoupled and asynchronous way of interacting among components matches very well the requirements of distributed applications: for instance, new processes may join or leave the distributed system at any moment and a process must be ready to handle both membership changes and reception of messages at any time. Hence, the order in which concurrent events will be observed cannot be defined a priori; this is precisely what we capture through our component model. For writing complex algorithms, we sometimes use handlers that are triggered when some condition in the implementation becomes true, but do not respond to an external event originating from another module. The condition for an internal event is usually defined on local variables maintained by the algorithm. Such a handler consists of an upon statement followed by a condition; in a sample component co, it might look like this: upon condition do do something;. // an internal event.
(30) 1.4 Software Components. 11. An upon event statement triggered by an event from another module can also be qualified with a condition on local variables. This handler executes its instructions only when the external event has been triggered and the condition holds. Such a conditional event handler of a component co has the following form: upon event ⟨ co, Event | att11 , att21 , . . . ⟩ such that condition do do something; An algorithm that uses conditional event handlers relies on the run-time system to buffer external events until the condition on internal variables becomes satisfied. We use this convention because it simplifies the presentation of many algorithms, but the approach should not be taken as a recipe for actually implementing a practical system: such a run-time system might need to maintain unbounded buffers. But, it is not difficult to avoid conditional event handlers in an implementation. Every conditional event handler can be transformed into a combination of a (pure) event handler and two handlers for internal events in three steps: (1) introduce a local variable for storing the external event when it occurs and install an event handler triggered by the external event without any condition; (2) introduce a local variable for storing that the condition on the internal variables has become true; and (3) add a local event handler that responds to the internal event denoting that the external event has occurred and the internal condition has been satisfied. 1.4.2 Programming Interface The APIs of our components include two types of events, requests and indications; their detailed semantics depend on the component at which they occur: • Request events are used by a component to invoke a service at another component or to signal a condition to another component. For instance, the application layer might trigger a request event at a component in charge of broadcasting a message with some reliability guarantee to the processes in a group, or propose a value to be decided on by the group. A request may also carry signaling information, for example, when the component has previously output some data to the application layer and the request confirms that the application layer has processed the data. From the perspective of the component handling the event, request events are inputs. • Indication events are used by a component to deliver information or to signal a condition to another component. Considering the broadcast example given earlier, at every process that is a destination of the message, the component in charge of implementing the actual broadcast primitive will typically perform some processing to ensure the corresponding reliability guarantee, and then use an indication event to deliver the message to the application layer. Similarly, the decision on a value will be indicated with such an event. An indication event may.
(31) 12. 1 Introduction. Layer n+1 Request. Indication (send). (deliver). Layer n (invoke). (receive). Request. Indication. Layer n-1 Figure 1.2: Layering. also take the role of a confirmation, for example, when the component responsible for broadcasting indicates to the application layer that the message was indeed broadcast. From the perspective of the component triggering the event, indication events are outputs. A typical execution at a given layer consists of the following sequence of actions, as illustrated in Fig. 1.2. We consider here a broadcast abstraction that ensures a certain reliability condition, that is, a primitive where the processes need to agree on whether or not to deliver a message broadcast by some process. 1. The procedure for sending a broadcast message is initiated by the reception of a request event from the layer above. 2. To ensure the properties of the broadcast abstraction, the layer will send one or more messages to its remote peers by invoking the services of the layer below (using request events of the lower layer). 3. Messages sent by the peer layers are also received using the services of the underlying layer (through indication events of the lower layer). 4. When a message is received, it may have to be stored temporarily until the adequate reliability property is satisfied, before being delivered to the layer above using an indication event. Requests and indications do not always carry payload data; they may also indicate conditions for synchronizing two layers with each other. For example, the broadcast abstraction may confirm that its service has been concluded reliably by triggering a specialized indication event for the layer above. In this way, a broadcast implementation can require that the application layer waits until a broadcast request is confirmed before triggering the next broadcast request. An analogous mechanism can be used to synchronize the delivery of broadcast messages to the application.
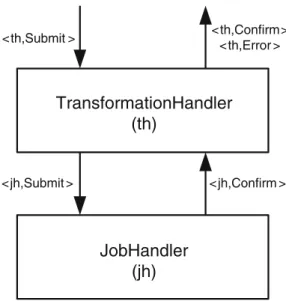
(32) 1.4 Software Components. 13. layer above. When the application layer takes a long time to process a message, for example, the application may trigger a specialized request event for the broadcast abstraction to signal that the processing has completed and the application is now ready for the next broadcast message to be delivered. 1.4.3 Modules Not surprisingly, most of the modules described in this book perform some interaction with the corresponding modules on peer processes; after all, this is a book about distributed computing. It is, however, also possible to have modules that perform only local actions. As there may exist multiple copies of a module in the runtime system of one process concurrently, every instance of a module is identified by a corresponding identifier. To illustrate the notion of modules, we describe a simple abstract job handler module. An application may submit a job to the handler abstraction and the job handler confirms that it has taken the responsibility for processing the job. Module 1.1 describes its interface. The job handler confirms every submitted job. However, the interface explicitly leaves open whether or not the job has been processed at the time when the confirmation arrives. Module 1.1: Interface and properties of a job handler Module:. Name: JobHandler, instance jh. Events:. Request: ⟨ jh, Submit | job ⟩: Requests a job to be processed. Indication:⟨ jh, Confirm | job ⟩: Confirms that the given job has been (or will be) processed. Properties:. JH1: Guaranteed response: Every submitted job is eventually confirmed.. Algorithm 1.1 is a straightforward job-handler implementation, which confirms every job only after it has been processed. This implementation is synchronous because the application that submits a job learns when the job has been processed. A second implementation of the job-handler abstraction is given in Algorithm 1.2. This implementation is asynchronous and confirms every submitted job immediately; it saves the job in an unbounded buffer and processes buffered jobs at its own speed in the background. Algorithm 1.2 illustrates two special elements of our notation for algorithms: initialization events and internal events. To make the initialization of a component explicit, we assume that a special ⟨ Init ⟩ event is generated automatically by the.
數據
+7
相關文件
1 Generalized Extreme Value Distribution Let Y be a random variable having a generalized extreme- value (GEV) distribution with shape parameter ξ, loca- tion parameter µ and
Recycling Techniques are Available to Address Specific Pavement Distress and/or Pavement Structural Requirement.. Introduction to Asphalt Introduction
The nanostructure with anisotropic transmission characteristics on ITO films induced by fs laser can be used for the alignment layer , polarizer and conducting layer in LCD cell.
一般我們如過是透過分享器或集線器來連接電腦 的話,只需要壓制平行線即可(平行線:兩端接 頭皆為EIA/TIA 568B),
一般我們如過是透過分享器或集線器來連接電腦 的話,只需要壓制平行線即可(平行線:兩端接 頭皆為 EIA/TIA 568B ), 如果是接機器對機器 的話,需要製作跳線( Crossover :一端為
3) 請先充分地搓 揉預計切除的部 分。這樣使外皮 會與裡面芯線產 生間隙。.. 4) 將網路線夾在剝 皮工具的最外側溝
3) 請先充分地搓 揉預計切除的部 分。這樣使外皮 會與裡面芯線產 生間隙。?. 4) 將網路線夾在剝 皮工具的最外側溝
• However, inv(A) may return a weird result even if A is ill-conditioned, indicates how much the output value of the function can change for a small change in the
