間諜軟體偵測系統之實作(第 3 年) 研究成果報告(完整版)
計 畫 類 別 : 整合型
計 畫 編 號 : NSC 95-2221-E-011-032-MY3
執 行 期 間 : 97 年 08 月 01 日至 98 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學資訊工程系
計 畫 主 持 人 : 洪西進
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 99 年 01 月 08 日
行政院國家科學委員會專題研究計畫 成果 報告
間諜軟體偵測系統之實作 研究成果報告(完整版)
計 畫 類 別:整合型
計 畫 編 號:NSC 95-2221-E-011-032-MY3 執 行 期 間:2006.08.01 至 2009.07.31 執 行 單 位:國立臺灣科技大學資訊工程系
計 畫 主 持 人:洪西進
報告類型: 完整報告
處理方式: 本計畫可公開查詢
中 華 民 國 98 年 10 月 16 日
至目前為止,大多數市售的防毒系統皆是使用更新病毒碼的方法防止惡意程 式的侵害,當新的惡意程式出現至病毒碼釋出期間惡意程式早已對電腦造成傷 害。有鑑於此,我們針對蠕蟲、病毒、木馬與後門提出了有別於一般防毒軟體的 偵測技術,讓惡意程式偵測系統不僅能有效偵測現有的惡意程式,更具有預測未 知惡意程式的能力。本文利用靜態分析的技術萃取出 PE Table 裡的特徵 ,再利 用資料探勘裡的資訊增益方法找出有用的資訊,而統計裡的主成份分析被用來減 少龐大的資料量與去除雜訊,主成份分析除了大幅度減少訓練時間外更增加系統 的偵測能力,最後使用支援向量機進行惡意程式的偵測。此系統對於已知惡意程 式有高達 99.8%的偵測率,面對新的惡意程式更有 93.6%的預測能力,在此系統 架構下更有自動蒐集惡意程式來重新訓練偵測模組的能力,即使惡意程式不斷推 陳出新,仍可保有最新的偵測能力。
關鍵字:惡意程式、主成份分析、資訊增益、支援向量機
Abstract
So far, most of AntiVirus software in the marketing is base on signature to defend the damage by Malware. The computer system had crashed from the new Malware was presented to release the antidote. In view of this, we propose a novel detecting technology which differs from technique of nowadays to be aimed at Worm, Virus, Trojan and Backdoor. The system (Malware Detecting System) can not only detect present Malware more effectively, but also predict unknown ones.
The thesis makes use of the technique with the static state analysis to extract the characteristic in the PE Table, and then finds out useful information by utilizing a method named Information Gain. The statistics PCA (the Principal Component Analysis) is used to reduce the huge quantity of data and clean noises;
in addition to the degree reducing train time substantially, it increases the ability of system to detect.
At last it proceeds detecting malice program by using SVM (Support Vector Machine). The system has detecting rate up to 99.8% on known malice programs, and predicting rate 93.6% towards new malice programs. Under this system structure, there are collecting malice program automatically to retain the ability of detective module. Even though the malice programs constantly weed through the old to bring forth the new, but this system still preserves the detective ability lately.
Key Word:Malware, PCA, Information Gain, SVM
第一章 簡介 ... 9
1.1 背景 ... 9
1.2 貢獻 ... 9
第二章 相關工作 ... 10
2.1 惡意程式(malware) ... 10
2.1.1 Virus ... 11
2.1.2 Worm ... 11
2.1.3 Trojan ... 12
2.1.4 Backdoor ... 13
2.2 傳統的偵測方法... 14
2.2.1 病毒碼掃描法 ... 15
2.2.2 啟發式分析法 ... 15
2.2.3 加總比對法 ... 15
2.2.4 先知掃描法 ... 16
2.3 機器學習理方法 ... 16
第三章 Support Vector Machine & Information Gain & Principal Component Analysis ... 16
3.1 資料探勘 ... 16
3.2 Information Gain ... 16
3.3 Principal Component Analysis ... 17
3.4 Support Vector Machine ... 21
第四章 Malicious Detection System ... 26
4.1 MDS的概念 ... 26
4.2 系統架構 ... 27
第五章 實驗與結果 ... 31
5.1 實驗資料集與實驗環境 ... 31
5.3 實驗結果 ... 32
第六章 結論與未來展望 ... 39
參考文獻 ... 40
Appendix ... 42
圖 2 - 2 變種病毒比例表 ... 12
圖 2 - 3 後門在惡意程式比率圖 ... 14
圖 2 - 4 後門成長比率圖 ... 14
圖 3 - 1 資料分佈 ... 18
圖 3 - 2 eigenvectors ... 19
圖 3 - 3 經PCA轉換後的資料分佈 ... 19
圖 3 - 4 經PCA轉換且減少為一維的資料分佈 ... 20
圖 3 - 6 不好的分界例子 ... 22
圖 3 - 7 最佳的超平面和邊緣 ... 22
圖 3 - 8 SVM在訓練錯誤的情況 ... 23
圖 3 - 9 映射函數Φ 投射到空間F ... 24
圖 4 - 1 實體系統架構圖 ... 26
圖 4 - 2 系統架構圖 ... 27
圖 4 - 3 程式版本資訊 ... 28
圖 4 - 4 PE Table 結構 ... 29
圖 4 - 5 Dependency Walker ... 29
圖 4 - 6 特徵產生器 ... 30
圖 5 - 1 不同Info Gain值Virus的偵測與預測率 ... 33
圖 5 - 2 不同Info Gain值Worm的偵測與預測率 ... 33
圖 5 - 3 不同Info Gain值Trojan的偵測與預測率 ... 34
圖 5 - 4 不同Info Gain值Backdoor的偵測與預測率 ... 34
圖 5 - 5 Virus Gain值經PCA轉換CV比較 ... 35
圖 5 - 6 Virus Gain值經PCA轉換OA比較 ... 35
圖 5 - 8 各類別PCA轉換前後OA比較 ... 37 圖 5 - 9 經PCA後的CV與OA ... 38 圖 5 - 10 經PCA後的TP與FP ... 38
表 一 惡性程式比較表[11] ... 10
表 二 PE Table 取出之特徵 ... 29
表 三 惡意程式數目表 ... 31
表 四 正常程式數目表 ... 31
表 五 經PCA轉換前後特徵數目比較 ... 36
表 六 誤判率(FP)與程式數目 ... 39
第一章 簡介
1.1 背景
近年來惡意程式快速演變,除了程式推陳出新的速度越來越快,在網路上更流傳著一些病 毒產生器,使即使不會寫電腦惡意程式的人也可以輕易地的製造出對電腦或使用者有傷害程 式。在過去病毒(Virus)最主要為破壞電腦硬體或軟體,蠕蟲(Worm)則會發出大量封包癱瘓網 路與電腦。惡意程式目前的行徑已經與幾年前大不相同,以前這些電腦玩家撰寫惡意程式的主 要目的,不過是吸引社會大眾的注意,或是揭露電腦安全方面的漏洞。而現在這些惡意程式的 主要目的就是斂財。網路安全公司貓熊(Panda)軟體公司發表的最新調查結果顯示,目前在網 路中傳播的惡意程式中,百分之七十的惡意程式都與形形色色的電腦犯罪有關[1]。貓熊軟體 公司在二○○六年第一季進行的調查顯示,現今惡意程式的製造者以「財務利益為最高優先」, 這份報告揭露,今天的電腦駭客已經不再用電子郵件的蠕蟲病毒,他們改用更難發現的其他惡 意程式。貓熊軟體公司進行的調查發現,如今大約百分之四十的惡意程式都是間諜軟體 (Spyware),撰寫使用這些程式的主要目的就是蒐集網友的上網習慣,以便從中謀利。另外百 分之十七的惡意程式是木馬程式,包括「銀行家木馬程式」,這種惡意程式竊取金融業的機密 資料,或是把惡意程式下載到金融業者的電腦系統中,以便取得斂財的機會。百分之八的惡意 程式是「電話撥號者」,這種惡意程式可以在電腦使用者全然不知情的情形下,自動撥打價格 高昂的長途與國際電話。另外一種惡意程式稱為「寄生病毒」,電腦感染這種病毒後就會完全 成為他人利用的工具,百分之四的電腦感染這種病毒。從前以電子郵件傳送的蠕蟲病毒是網路 安全的主要威脅,現在蠕蟲病毒只占惡意程式的百分之四。利用電子郵件的蠕蟲病毒已經引起 社會大眾的注意,因此難以用來作為斂財工具。目前主要的惡意程式就是間諜軟體、木馬程式 以及寄生病毒。這些惡意程式可以在電腦使用者毫不知情的情形下安裝在電腦中,而且惡意程 式在執行任務時也根本無從查覺。因為惡意程式如此橫行,除了現今知名的防毒軟體公司(例:
Kaspersky[2],McAfee[3] ,Trend[4],Norton[5],Panda[6])提出了解決方法外,微軟 Microsoft[7]與Yahoo[8]都有意角逐這塊市場。
1.2 貢獻
這篇論文提出一個穩固與先進的架構能有效偵測window系統電腦中的惡意程式,除了偵測 現有已存在的惡意程式外,當有未知新病毒出現時,它也具有預測惡意程式的能利。我們利用 data mining方法從惡意程式的 Pe Table[9][10]中萃取出 DLL 與 API 做為訓練的特徵,再 把這些特徵利用Machine Learning 的方法做訓練與預測,系統更能根據client 偵測到的病毒 加以重新訓練,產生更新的偵測模組。
此篇論文裡探討的項目集中在 Virus、Worm、Trojan 與 Backdoor 這四類,完全集中在 Malware 這個範疇裡,像巨集程式其它類型的病毒不在我們的範圍裡。下一章裡將介紹各種惡 意程式的行為與特性,第三章會有這篇論文特徵採取方法的詳盡介紹,第四章則介紹整個系統 運作的實際流程,第五章為實驗結果,第六章結論。
第二章 相關工作
2.1 惡意程式(malware)
『電腦病毒』單純指的是『Virus』,而『惡性程式』(Malware)則泛指所有不懷好意的程 式碼,包括電腦病毒(Virus)、特洛伊木馬(Trojan)程式、電腦蠕蟲(Worm)。在早期電腦病毒、
特洛伊木馬程式、電腦蠕蟲都是各自獨立的程式而且彼此不相干,但近幾年來單一型態的惡性 程式愈來愈少了,大部份都以『電腦病毒』加『電腦蠕蟲』或『特洛伊木馬程式』加『電腦蠕 蟲』的型態存在以便造成更大的影響力,而且比率以前者居多。例如:『梅莉莎』(MELISSA) 便 是結合『電腦病毒』及『電腦蠕蟲』的兩項特性。該惡性程式不但會感染 Word 的 Normal.dot
(此為電腦病毒特性),而且會透過 Outlook E-mail 大量散播(此為電腦蠕蟲特性)。例外一 個耳熟能詳的案例是結合了『特洛伊木馬程式』及『電腦蠕蟲』兩項特性的『探險蟲』
(ExploreZip)。探險蟲並不會感染任何檔案,但是會覆蓋掉(Overwrite)在區域網路上遠端電 腦中的重要檔案(此為特洛伊木馬程式特性),並且會透過區域網路將自己安裝到遠端電腦上
(此為電腦蠕蟲特性)。 在本論文特別把後門程式從特洛依木馬程式裡分出來,因為這一類數 目特別多,所以我們特別分開進行討論。
電腦病毒 電腦蠕蟲 木馬程式 後門程式
感染其他檔案 O X X X
被動散播自己 O X O O
主動散播自己 X O X X
造成程式 增加數目
一般隨電腦使 用率提高,受 染感檔案數目
則增加
視網路連結狀況 而定,連結範圍 愈廣,散佈的數
目多
不增加 不增加
破壞能力 視寫作者而定 X 視寫作者而定 視寫作者而定 對企業的
影響性 中 高 低 低
表 一 惡性程式比較表[11]
2.1.1 Virus
電腦病毒[11]是一段程式,會將本身複製到其他乾淨的檔案或開機區的惡性程式[12],猶 如一般的生物病毒,當電腦使用者在不自覺的情形下執行到已受病毒感染的檔案或磁片開機 時,這個惡性程式將以相同的方式繼續散播出去,而它的目地是破壞電腦系統與檔案,它具有 傳播性、隱蔽性、感染性、潛伏性或破壞性。至於電腦病毒是不是都會在某特定日期發作且破 壞電腦資料這就和病毒的寫作者如何設計程式有關,並不屬於電腦病毒的特性。以台灣有名的 CIH為例,由於 CIH 獨特的感染模式,受到 CIH 感染的檔案大小可能和原始檔案相同。此病 毒會搜尋檔案內未使用的空間。接下來,它會把自己分解成較小的片段,將程式碼插入這些未 使用的空間。隨機資料覆寫硬碟,使用無限迴圈從磁碟的起點 (磁區 0) 開始。會一直不斷地 覆寫磁區,直到系統當機為止。因此,電腦將無法從硬碟或軟碟開機。同時,硬碟上被覆寫的 資料非常難以復原,其實根本就不可能復原。您必須利用備份還原資料。
2.1.2 Worm
電腦蠕蟲(Worm)[13]的行為有點像病毒一樣會進行複製,但病毒必需依附在某些檔案上,
而蠕蟲會複製許多自己的分身,在電腦網路中爬行,從一台電腦爬到另外一台電腦,它具有非 常強的傳播性而且速度極快,可能在數小時內癱瘓掉幾萬台電腦,它最常用的感染方法是透過 區域網路(LAN)、網際網路(Internet)或是 E-mail 來散佈自己,如圖 2-1,在發垃圾郵件 的事件裡,前十大幾乎都為Worm 所為,也是因為如此,中了蠕蟲病毒時最常見的特徵是網路 速度變的極慢,因為整個電腦網路的頻寬都被蠕蟲用來進行感染行為。以W32.Netsky.P@mm為 例,它是一種會寄發大量郵件的病蟲,它會掃描硬碟與網路磁碟並使用自身的 SMTP 引擎將自 己傳送給找到的電子郵件位址。還會藉由將自身複製到不同的共用資料夾,以試圖透過各種檔 案共享程式散播。該電子郵件的「寄件者」行會加以偽裝,而且其「主旨」行與訊息內文也會 因人而異。 附件名稱會隨 .exe、.pif、.scr 或 .zip 等副檔名而有所不同。
圖 2 - 1 發送垃圾郵件前十大的蠕蟲
由圖 2-2 很明顯地顯示出Virus 與 Worm 的變種病毒越來越多的趨勢[14],這是由於現
今網路上充斥著各種病毒產生器,只要使用一些簡單的軟體,勾選一些想要的功能,就能產生 一個變種病毒,防毒軟體就沒有能力偵測到新的變種病毒,這更顯現出新型防毒軟體的重要性。
圖 2 - 2 變種病毒比例表
2.1.3 Trojan
木馬這個字是源自於希臘木馬屠城神話[15],木馬程式通常偽裝或嵌入正常軟體裡面,這 些軟體提供一些有用的功能供使用者使用,但這些有用程式背後還藏著由駭客所寫而且使用者 並不知情的特別功能,它有著極高的隱密性不易被發覺。另一種讓使用者上當的方法是利用一 些特別字眼的檔名吸引使用者執行這些木馬軟體,最常使用的都是一些情色或是賺錢的廣告檔 名,即所謂的社交工程social engineering。特洛伊木馬程式就不像電腦病毒一樣會感染其他 檔案,特洛伊木馬程式通常都會以一些特殊管道進入使用者的電腦系統中,然後伺機執行其惡 意行為(如格式化磁碟、刪除檔案、竊取密碼等),Back Orifice特洛伊木馬程式便是一個案 例,透過該程式電腦駭客便有機會入侵主機竊取機密資料。一個完整的特洛伊木馬程序包含了 兩部分:服務端(伺服器部分)和客戶端(控制器部分)[16]。植入對方電腦的是服務端,而 駭客正是利用客戶端進入運行了服務端的電腦。運行了木馬程序的服務端以後,會產生一個容 易迷惑用戶的名稱的行程(process),暗中打開一個對外的埠,向指定地點發送數據(如網路 遊戲的密碼,QQ密碼和用戶上網密碼等),駭客甚至可以利用這些打開的埠進入電腦系統。下 表是木馬程式技術發展非常迅速。主要是有些年輕人出於好奇,或是急於顯示自己實力,不斷 改進木馬程式的編寫。以JS.Fortnight.C為例,它是一個特洛伊木馬程式,它會丟棄一個檔案 然後該檔案會被插入 Microsoft Outlook Express 的預設簽章中。於是每次當您使用 Outlook Express 來傳送電子郵件時,訊息內容就會包含一個程式編碼,會在每次收件者開啟訊息時嘗 試連上特定的網站。JS.Fortnight.C 會使用 IFRAME 標籤來探測 Microsoft VM 弱點,其中 SRC 欄位會被設為特洛伊木馬撰寫者的位址。在一連串的轉送之後,編碼過的 JavaScript 便 會載入包含該探測程式的 Applet。在未安裝修補程式的系統上,很多不同的登錄鍵與 Web 瀏
覽器都會因此而遭到修改。至今木馬程式已經經歷了四代的改進:
z 第一代,是最原始的木馬程式。主要是簡單的密碼竊取,通過電子郵件發送信息等,
具備了木馬最基本的功能。
z 第二代,在技術上有很大的進步,冰河是中國木馬的典型代表之一。
z 第三代, 主要改進在數據傳遞技術方面,出現了ICMP(Internet Control Management Protocol)等類型的木馬,利用畸形報文傳遞數據,增加了掃毒軟體識別的難度。
z 第四代 在進程隱藏方面有了很大改動,採用核心插入式的嵌入方式,利用遠程插入執 行緒技術,嵌入DLL執行緒。或者掛接PSAPI,實現木馬程序的隱藏,甚至在Windows NT/2000 下,都達到了良好的隱藏效果。灰鴿子和蜜蜂大盜是比較出名的DLL木馬。
2.1.4 Backdoor
後門是木馬程式裡的一類,它跟木馬不同的地方在於它利用合法的途徑欺騙使用者,後門 程式通常跟一般的應用軟體很像,比如window 作業系統的登入畫面,使用者執行了後門程式 以後,當第二次開機時呈現需要使用者輸入帳號密碼的畫面同於平常所使用的登入畫面,其實 這就是之前已潛伏在電腦裡的後門程式,但使用者並不知情,取得進入電腦的帳號與密碼後,
駭客就可以在使用者電腦裡以合法的方式為所欲為,所以特洛依木馬與後門最大的不同為木馬 最主要偷取電腦裡的資料,而後門則假造類似使用者平常輸入密碼的畫面偷取密碼,從圖 2-3 可以明顯看出這樣的程式在惡意程式的比例有逐漸升高的趨勢[14],並且新種類的後門也出現 同樣的情況[14](圖 2-4),也因為這樣類型的惡意程式數目太多而且太過於危險,所以我們把 這一類從特洛依木馬程式裡分開討論。以Backdoor.Snowdoor為例,它會在受感染的電腦上打 開TCP埠 5,326 或 5,328。會允許未經授權的使用進入受感染的電腦。當Backdoor.Snowdoor 執行時,將會進行以下事項:
1. 將本身複製為:
z %System%\Swon6.exe z %Windir%\sk.exe
2. 將下列值:Snow %System%\swon6.exe 加入登錄鍵:
HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Run
3. 在 Windows 95/98/Me 電腦上修改 run= line of the Win.ini 為 run=%Windir%\sk.exe 4. 加 入 一 個 登 錄 鍵 建 立 C 磁 碟 機 共 享 : HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Network\LanMan\C$
5.在 5,326 或 5328 埠上等待進入連接允許駭客在您的電腦上進行活動。
圖 2 - 3 後門在惡意程式比率圖
圖 2 - 4 後門成長比率圖
2.2 傳統的偵測方法
從過去到現在有許多種病毒偵測技術被發表,大約可區分成下列幾種:病毒碼掃描法 (Scanning method)、啟發式分析法(Heuristics method)、加總比對法(Checksum method)、
先知掃描法(The Virus Instruction Code Emulation(VICE) method)、即時輸出入掃描法 (Real-time I/O scan method)。以下將介紹這一些傳統病毒偵測方式。[17]
2.2.1 病毒碼掃描法
這種方法是現今防毒軟體廠商最常用的技術,它從惡意程式中把一些特徵取出來,就像人 的 DNA 序列一樣,每一個人都是獨一無二的,只要比對 DNA 就可以知道某個人的身份,惡意程 式也是利用相同的道理,而就算是變種病毒互相之間也是會有差異,比如 S.a 這隻惡意程式會 在某個 registry 加入自動啓動的項目,而 S.b 則改由用插入 dll 的方式啓動,這樣的特徵就 不一樣,也就能清楚分辦是那隻惡意程式,所以各大企業都建有自己的資料庫,只要有新的惡 意程式出現,必需馬上從這些程式中找出對應特徵再把它們送給用戶端,但因為惡意程式出現 速度太快所以病毒碼機乎每天都在更新,甚至 Kaspersky 這家公司還提出每幾個小時就更新的 方法。
這種偵測惡意程式技術的優點是可以快速又準確的判別,又不會發生誤判,並且不必修改 程式,只要更新病毒碼即可,但缺點是如果有新的惡意程式出來但如果沒有即時更新病毒碼,
就無偵測病毒的能力。
2.2.2 啟發式分析法
這種方式是從大量的病毒資料庫中找出相似的程式語法,把這些語法建立成異常行為模式 資料庫 ,如果有程式語法與之前建立的異常行為太像,就很有可能是病毒,這種方法最大的 好處是不需要更新病毒碼,並且可以偵測變形或是新的病毒,但相對的這種方式如果做得不 好,誤判率(False Positive)會很高。
2.2.3 加總比對法
這個方法現在只能對病毒有些許的效用,它是利用病毒會依附在正常程式裡的特性來做偵 測,先把正常的程式相關特徵如:大小、公司名稱或版本放進一個特別的演算法裡得到一個數 值(類似檢查碼),把這些數值放到資料庫,這種演算法速度通常很快(例如:hashing
function),當使用者執行程式時就會把這個程式的相關特徵再經演算法得出一個值,再跟資 料庫裡的數值做比對,如果不一樣表示程式受病毒感染。這樣的方法實為不高明的方法,因為 當程式出現更新時,就必需要再替這個程式重新產生一個數值放到資料庫,而且並無法得知病 毒的種類。
2.2.4 先知掃描法
這個方法的觀念是在正常的作業系統下建立一個虛擬機器,這台虛擬機會模擬 CPU 的行 為對可疑的惡意程式先進行假執行,即為軟體模擬方法(software simulation),經過軟體模 擬行為後再經由一個事先被設計好的專家系統判斷是否為惡意程式。利用這種虛擬機器的方式 可以對抗多型(Polymorphic)與變種(mutation)的惡意程式,這些程式利用各種方法隱藏自己 的程式碼,常用的方法為壓縮或是加密的方法,只有在執行起來時才會知道,所以需要一台虛 擬機器來先做模擬。但這種方法極為浪費系統資源,所以很少有人利用這樣的方法開發防毒軟 體。
在這篇論文使用的方法較類似啓發式分析法,使用資料探勘的方法採集有用與重要的資 料,再利用機器學習的方法加以訓練與判定是否為惡意程式,在這篇論文裡資料探勘方法與機 器學習方法的組合有相當好的效果,並且誤判率比其它論文有更好的結果。
2.3 機器學習理方法
這裡的做法是利用資料探勘的方法加上機器學習理論的角度進行研究。首先從正常與惡意 程式裡取出特定的特徵,因為不是所有特徵都是有用的,必需有一套良好的特徵萃取方法把有 用與重要的特徵取出,在這裡它使用 Information Gain,取出有益的特徵後使用 Support Vector Machine。
第三章 Support Vector Machine & Information Gain &
Principal Component Analysis
3.1 資料探勘
資料探勘是從大量資料中找出其潛藏資訊的一種過程,資料探勘技術演算法主要被分成兩 類,一種是基於統計方法使用計算每一種資料的數目來辨別分佈情形,另一種是基於分群、分 類和相似度理論。現今資料探勘技術已被大量且廣泛的利用在商管、行銷、金融、資訊與生物 技術。在這篇論文裡我們使用了兩種資料探勘的技術:資訊增益(Information Gain)、主成份 分析(PCA: Principal Component Analysis)與一種機器學習(Machine Learning)方法:支援 向量機(SVM: Support Vector Machine),以下為各位簡介各種方法的概要:
3.2 Information Gain
J.R. Quilan提出了一個叫ID3 分類演算法[19],這是information gain最早的概念,"
The Information conveyed by a message depends on its probability and can be measured in bits".
z Information:
假如在一個集合 S 裡有 K 個類別, , 是第 i 個類別在 S 集合 裡的比例。很明顯的這裡的 Info(S)是同等於 S 的 Entropy(熵)。在我們的例子裡 Info(S) 應該是同等於下面的方式
∑
=−
= k
i
i
i p
p S
Info
1
2( ) log )
( pi
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛ +
− S
Benign S
Benign S
Malware S
Malware
2
2 log
log ⇒ S = Malware+ Benign
z Information Gain
計算某一特徵 A 的 entropy,Value A 可為 1 或 0 分別代表該特徵出現與否:
∈
∑
×
−
=
) (
) ( )
(
A Value i
i i
A Info S
S S S
Info , Si是 S 的子集,i為特徵 A 的值 )
( )
( )
,
(S A Info S Info S
Gain = − A , 根據 Information Gain 的定義我們應該選擇 gain 值 較大的。
以我們的情況來做個例子,只有兩種類別,正常或異常 正常程式:1555 惡意程式:3334 →總數 4889
某一特徵 A 在正常裡出現 200 次,惡意程式裡出現 250 次,所以它的 information 為
⎟⎠
⎜ ⎞
⎝
⎛ +
− 4889
log3334 4889 3334 4889
log1555 4889 1555
它的 information gain 為
⎟⎟⎠
⎜⎜ ⎞
⎝
⎛ ⎟
⎠
⎜ ⎞
⎝
⎛ +
⎟+
⎠
⎜ ⎞
⎝
⎛ +
− 4439
log3084 4439 3084 4439
log1355 4439 1355 4889 4439 450
log250 450 250 450 log200 450 200 4889
450
3.3 Principal Component Analysis
主成份分析(Principal Component Analysis)是統計學多變量分析裡的一個方法,在 1901 被提出來,1993 時由Hotelling加以發展,被廣泛應用在影像處理裡。目地是希望能用較少的 特徵數來表示原本資料中大部份的意思[20]。因為在一個資料集裡並不是每一項資料都是有用 的,但每一項資料都有它存在的必要性,所以透過PCA的方法能把整個資料集所有資料的權重 都投射到最前面幾個特徵向量,只要取前面幾個重要特徵向量就能代表大部份整個資料集,所 以PCA最主要用來減少特徵的數量,以加快運算的速度,進而減少時間的浪費。當然去除特徵 向量就會把原本資料集裡原有的資料給去除,而保留多少才是恰當的,會因每個分類器(在這 裡我們使用SVM)所需而不同。
在經 PCA 轉換後的資料每一個特徵向量都是互相獨立的線性組合。而經由線性組合所得
的成份之變異數為最大。
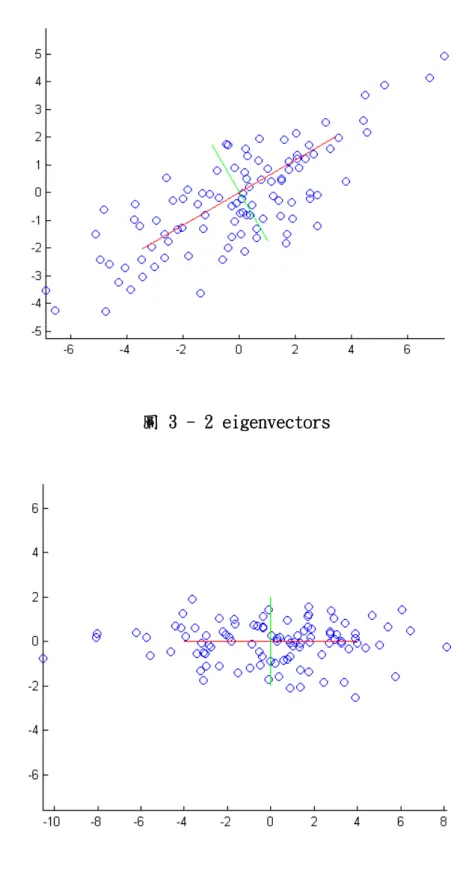
假如有一筆資料裡有兩個特徵向量,它的資料分佈如圖 3-1
圖 3 - 1 資料分佈 資料先經由 covariance 計算後得到
covariance = 0.8630 -0.5052 0.5052 0.8630
再算出它的 eigenvalues,最後得到 eigenvectors,因為這個範例只有兩維,所以算出的 來 eigenvectors 只會有兩個,如圖 3-2,紅色線(長線)是第一個 eigenvector,綠色線(短線) 是第二個 eigenvector,eigenvector 是互相正交的。如果我們完全都保留原來的資料不減少 特徵,等於只是把原來的資料映射到另一個空間而己(圖 3-3),這裡如果把維度減到一維,表 把所有資訊量都投射到第一個特徵上,如圖 3-4,在經轉換後仍然保有大量原使的資料分佈情 況。
圖 3 - 2 eigenvectors
圖 3 - 3 經 PCA 轉換後的資料分佈
圖 3 - 4 經 PCA 轉換且減少為一維的資料分佈
下面我們將實際舉一個例子[21]:
有一個二維資料集, ,其 mean 為
⎥⎥
⎥
⎦
⎤
⎢⎢
⎢
⎣
⎡
= 7 2
6 1
1 5
A [4 7]
經 Covariance 運算後為 ⎥
⎦
⎢ ⎤
⎣
⎡
−
− 5 . 18 5 . 1
5 . 1 7 對角化運算
[A−λI]X =0 → 0 (式 3-1) 5
. 18 5 . 1
5 . 1
7 ⎥ =
⎦
⎢ ⎤
⎣
⎡
−
−
−
− X
λ λ
求得兩個 IgenValue⇒λ1 =18.69,λ2 =6.8075代回式 3-1 各別求兩個解的 IgenVector
19 0 . 0 5 . 1
5 . 1 69 . 11
2 1
1 ⎥=
⎦
⎢ ⎤
⎣
⎥⎡
⎦
⎢ ⎤
⎣
⎡
−
−
−
→ −
x λ x
0 5 . 1 69 .
11 1− 2 =
− x x (式 3-2) 0
19 . 0 5 .
1 1 − 2 =
− x x (式 3-3) 式 3-2 與 3-3 相加求得結果
0 69 . 1 19 .
13 1− 2 =
− x x
2
1 13.19
69 . 1 x
x ⎥
⎦
⎢ ⎤
⎣
⎡
= −
⇒ 得到第一個 IgenVector
69 0 . 11 5 . 1
5 . 1 19 . 0
2 1
2 ⎥=
⎦
⎢ ⎤
⎣
⎥⎡
⎦
⎢ ⎤
⎣
⎡
−
→ −
x λ x
2
1 1.31
19 . 10 x
x ⎥
⎦
⎢ ⎤
⎣
⎡
= −
⇒ 得到第二個 IgenVector
3.4 Support Vector Machine
Support Vector Machine(SVM) 是一個機器學習的方法,並且被應用在樣本分類上。SVM 能減少訓練(empirical risk)與測試(risk)錯誤的同時發生,因此 SVM 成為最受歡迎的演算法 之一。
SVM是由Vapnik[22],我們將在下面介紹這個分類器[23]。
對於這個典型的分類問題上,在討論之前我們先定義幾個注意事項:
x :一個向量(Vector)使用來描述一筆記錄的一個屬性(attribute), i yi∈RN,i=1,....l y :一個布林(Boolean)數字表示i xi是屬於那一類,表示yi∈
{ }
±1,i=1,....lS:是 xi 的資料集 L:是 yi 的資料集
f :決策函數(decision function) f(xi)=sign(w•xi +b), f:RN →
{ }
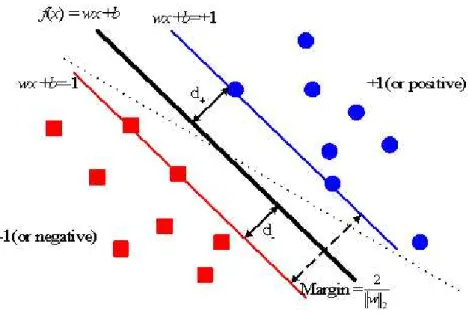
±1 使用 decision function 我們可以決定給定的 xi 是屬於那一類(+1 或 -1)在 SVM 的線性分類器裡主要的目地是使用訓練集裡的資料找出一個超平面(Hyperplane)來分 隔出它們所屬的類別(如圖 3-5)。因此我們必需找出( f :wx+ b=0
xj
0 )>
j xj
)這個 hyperplane 所對應的 向量 w 與系數 b 來區隔訓練資料集。當有新的資料 進來時我們能使用簡單的決策函數
來對它進行分類,如果 則 屬於類別 +1,否則如果 則 屬於類別 -1。
) (
)
(x sign w x b f i = • i +
0 ) (xj <
f xj
(x f
圖 3 - 6 不好的分界例子
對於超平面分類器如果我們能找到分隔兩個類別的最大邊緣(margin)(如圖 3-7)就能減 少在做測試時的錯誤(risks)。因為如此有可能不只只有一個超平面能區隔出最大的邊緣把兩 個類別分的最開,所以 Vapnik 與 Chervonenkis 指出最佳的超平面(OH: Optimal Hyperplane) 意思是能分開兩個類別並且它的邊緣是最大的。
根據 w 與 b 來調整它的值滿足函數 | (w x⋅ i)+ = b | 1 i=1,...,l,而正確分類的資料我們使用 這個函數 yi⋅((w x⋅ i)+ ≥b) 1,對於最佳超平面來說,邊緣的距離我們可以用 2 / w 來表示(如 圖 3-7), 此找到了最佳超平面就可以找出最大的邊緣因 ,我們使用yi⋅((w x⋅ i)+ ≥ ,b) 1 i=1,…,l 與最小函數 τ( )=1 2
w 2 w 。
+1
‐1 w
b
wx+b=0 圖 3 - 5 超平面分類器
圖 3 - 7 最佳的超平面和邊緣
找到最佳超平面是一個二次方程式的問題,我們可以使用 Largangian 定理與 Lagrangian 算子(Multipliers)來解決這個問題:
Lagrangian: 2
1
( , , ) 1 ( (( ) ) 1) 2
l
i i i
i
L w bα w α y w x b
=
= −
∑
⋅ ⋅ + −Lagrangian multipliers: αi ≥ 0
將LP
(
w,b,α)
分別對w跟b做偏微分,令其為 0,可求得下列兩個式子:1
1
0 0
l
i i
i l
i i i
i
y
w y x
α α
=
=
=
− =
∑
∑
, 我們得到1
, 0
l
i i i i
i
w α y x α
=
=
∑
≥把 w 放進 Lagrangian 裡我們能得到一個 dual optimization 問題,它是一個最大化問題,
maximize
( )
i j(
i j)
l
j i
j i l
i i
D y y x x
L =
∑
−∑
•=
=1 2 , 1
1 α α α
α
Subject to αi ≥0,i=1,K,l and
∑
=0i i iy
α
而決策函數是
1
( ) ( ) ( )
l
i i i
i
f x w x b α y x x
=
= ⋅ + =
∑
⋅ ⋅ +b對於每一個測試資料 x 則使用下面這個函數來預測它是屬於那一種類別:
1
( ( , )
l
i i i
i
sign α y k x x b
=
∑
+ )真實世界的很多問題往往不是資料可以分離的情形(Separable Case),所以原本的模型會 有問題(如圖 3-8),因為大多的問題是資料不分離的情形(Non-separable Case)。所以要把已 經求出的資料分離的情形(Separable Case)的公式擴大,在原本用到的式子中,加上一個正的 Slack Variable,ξi,i=1,K,l則會變成:
1 and
1 • + ≤− +
≥ +
•w b x w b
xi i
i
i w b
x • + ≥+1−ξ ∀y∈{+1},
i
i w b
x • + ≤−1+ξ ∀y∈{−1}, ξi ≥0 i∀ 組合上面的兩個不等式得到
錯誤! 物件無法用編輯功能變數代碼來建立。 ,錯誤! 物件無法用編輯功能變數代碼來建立。
錯誤! 物件無法用編輯功能變數代碼來建立。
對於資料不可以離問題的最佳化我們一樣再次使用 Lagrangian 來求得 minimize 2
2 2
2 2
1
C i
w + ξ
subject to yi
(
xi •w+b)
≥1−ξi i =1,K,l 這個 dual form 如下:maximize
( ) ∑ ∑ ( )
=
=
⎟⎠
⎜ ⎞
⎝
⎛ • +
−
= l
j i
ij j
i j i j i l
i
p i y y x x C
L 1 , 1
1 2
1 αα δ
α α
subject to
∑
,= l =
i i
yi 1
α 0 αi ≥0 i=1,K,l
圖 3 - 8 SVM 在訓練錯誤的情況
另一個解決不可以離問題的方法是使用一個非線性映射函數Φ (non-linear mapping
function)投射(project)到另一個空間 F:錯誤! 物件無法用編輯功能變數代碼來建立。 (如 圖 3-9),然後再使用線性分類。
在 optimal duel 問題上為了不要直接計算內積(Φ(x)Φ(y)),我們使用隱函核心函數 (connotative kernel function) k(x,y)=(Φ(x)Φ(y))來取代,使用核心函數計算在特徵空 間(feature space)資料的內積值,我們不必投射資料到那個特徵空間,通常有四個比較有名 的核心函數:
‧ Linear: K(xi, xj) = xi T xj .
‧ Polynomial: K(xi, xj) = (γxiT xj + r)d, γ> 0.
‧ Radial basis function (RBF): K(xi, xj) = exp(−γ||xi − xj||2), γ> 0.
‧ Sigmoid: K(xi, xj) = tanh(γxiT xj + r)
在本文中我們將使用SVM來判斷使用者所執行的程式是一個惡意或正常的程式,雖然SVM在過去 有一些安全性問題[24][25],但我們還是優先考量使用它,因為它的有許多其它分類器沒有的 優點。
圖 3 - 9 映射函數Φ 投射到空間 F
第四章 Malicious Detection System
在這個章節將介紹這個系統的架構與設計原理,我們盡量的把所有的細節談及,當您看完 這個章節後可以清楚知道整個系統如何運作與實做:
4.1 MDS的概念
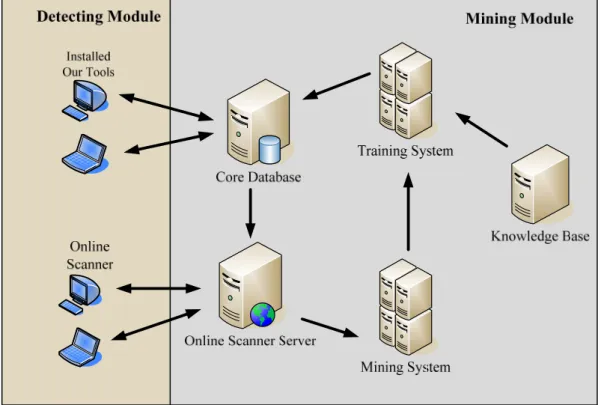
圖 4-1 是此系統的實體系統架構圖,整系架構分成兩個部份,分別為前端的偵測模組與後 端的資料探勘模組,偵測模負責偵測惡意程式,資料探勘模組負責特徵的採集、訓練與發佈。
首先由 Mining System 從程式資料庫中把每個正常程式與惡意程式裡的特徵萃取出來再轉送 給 Training System,Training System 的資料來源除了 Mining System 以外還有一部份是從 Knowledge Base 取出,Knowledge Base 這一部份是由人力介入挑選一些重要且有用的特徵出 來當作訓練資料,所以 Training System 收集完成資料後即開始進行訓練,把訓練出來的 SVM Detecting Module 再送到 Core Database 裡,而 Core Database 負責把 SVM Detecting Module 送到前端用戶端的電腦裡,用戶端可以定時的收到來自 Core Database 所訓練出的模組,以保 持有最佳的掃毒能力。在 Online Scanner Server 方面,這台 server 主要是被用來做為線上 掃毒服務,如果用戶端無安裝我們所開發的系統,可經由 IE Browser 進行網路上直接掃毒。
圖 4 - 1 實體系統架構圖
4.2 系統架構
圖 4-2 與圖 4-1 是互相對應的,所以它也分成兩部份:左半部的偵測模組(Detecting Module)與右半部的資料探勘模組(Mining Module),在這節我們將先從右半部的探勘模組談 起,再深入到左半部的偵測模組:
圖 4 - 2 系統架構圖
目前學界一般偵測惡意程式的研究方法主要有兩種做法:靜態分析和動態分析。靜態分析 指的是檢查程式還未執行起來的一些特徵,如檔案大小、建立日期。而動態分析則主要為監控 程式執行時的行為(例:是否有更改 Registry),本文所使用的技術全為靜態分析,因為它不 需要程式被執行起來就能判別是否為惡意程式,所以能避免某些惡意程式執行時的破壞行為,
使電腦系統更安全。
首先,我們從程式庫中(如圖 4-2 右下)取出每一隻正常程式與惡意程式裡的版本資訊與PE Table[9][10] 裡的內容做為我們的特徵,
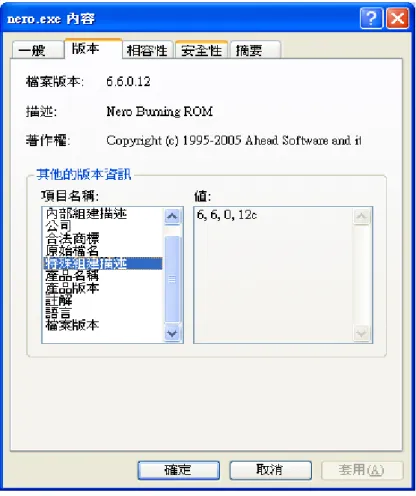
部份較有規模的公司所發行的軟體都會有版本資訊,如圖 4-3 這是 Ahead Software AG 這家 公司所發行的 nero.exe 燒錄軟體,它記載著詳盡的版本資訊,在附錄一裡記載著在版本資訊
裡取用的所有特徵。
圖 4 - 3 程式版本資訊
在Microsoft的window產品從win3.1 開始每一個執行檔都有所謂的PE Table,它記載了 這隻程式所有相關的資訊,包括程式本身的資料、使用的DLL(Dynamic Link Library)、API 等等資訊,如圖 4-4 為PE Table裡的內容,在這裡我們使用的特徵為程式使用的DLL與API,但 並不只是單單只取它的名字而已,我們使用一個小工具Dependency Walker[26](如圖 4-5)取 出一隻程式裡所使用的DLL與API,這隻工具較特別的一點是它能找到這個程式裡某一個DLL裡 還用到那些DLL,在這裡我們取的特徵有四種,第一為程式直接用到的第一層DLL,如圖 4-4 紅色 1 所示,第二為從第一層的DLL至最後一層使用到DLL的階層,取法為從第一個到最後一 個,如圖 4-4 紅色 2 所示,把每一個DLL串接起來即為另一種特徵,考慮使用這個特徵的原因 為惡意程式與正常程式使用DLL 的順序上會有所差異,第三種為第一層DLL裡被程式所使用到 的API名稱,如圖 4-4 紅色 3 所示,最後一種特徵為第一層DLL裡會被其它DLL用到的API名稱如 圖 4-4 紅色 4,所有特徵樣式如表二所示。
Sections
.Idata Section .Edata Section .Data Section .Text Section
Image Section Header
.Idata Section header .Edata Section header
Image NTHeader
.Data Section header .Text Section Header PE File Header Optional Header
PE File Header PE File Signature MS-DOS REAL-MODE Stub
MS-DOS MZ HEADER
圖 4 - 4 PE Table 結構
圖 4 - 5 Dependency Walker 表 二 PE Table 取出之特徵 第一種 SHFOLDER.DLL
第二種 VERSION.DLL\KERNEL32.DLL\NTDLL.DLL 第三種 VERSION.DLL_CR GetFileVersionInfoSizeA 第四種 VERSION.DLL_CR GetFileVersionInfoSizeW
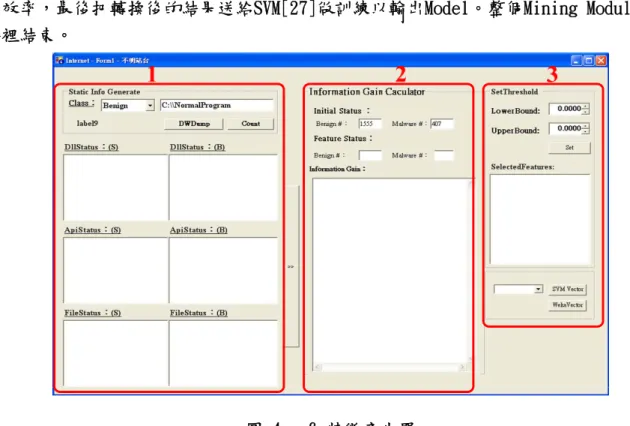
從程式資料庫中經過 Data Parser 後取出我們所需使用的特徵,如圖 4-5 的特徵產生器,
在圖中紅色 1 的地方各別分次指定惡意程式與正常程式的位置就能取出我們所需的所有特徵。
在下一個階段Feature Miner,使用的技術是在第三章提到的Information Gain,把所有 特徵使用Information Gain(圖 4-5 紅色 2)得到每個特徵的Gain值,再跟據不同的Gain值範圍 找出我們想要的特徵(如圖 4-5 紅色 3),經Information Gain 計算後再把特徵交由PCA做 Feature Reduction,因為PCA需要做大量的運算,所以這裡的程式我們使用C++實做,以增加 轉換效率,最後把轉換後的結果送給SVM[27]做訓練以輸出Model。整個Mining Module的程序 到這裡結束。
圖 4 - 6 特徵產生器
在左半部的 Detecting Module 必需使用到 Mining Module 所產生出來的三項資訊:經 Information Gain 計算後所選取的特徵、經 PCA 轉換後的維度與 SVM training 後的 Model。
這裡的程序與 Mining Module 有許多地方是雷同的,當使用者進行掃描時,一個執行檔進來我 們的系統會先把它的檔案特徵完全取出,再利用 Dependency Walker 取出 PE Table 裡的特徵,
而後比對 Mining Module 的 Information Gain 留下來的特徵,如果存在某個特徵則以 1 表示,
如無則以 0 表示,把整個比對後的字串乘上從 Mining Module 傳過來的 EigenVector 做 PCA 轉換減少維度,最後把降維後的特徵放入由 Mining Module 訓練出的 Module 做預測,如果不 是惡意程式則不與理會,但如果是則系統會把它回傳到病毒資料庫裡進行重新訓練,在這裡還 必需先由人工進行判斷是誤判或是真的為惡意程式才能放進資料庫,否則假設把誤判的程式放 入資料庫反而會影響訓練以後的結果。
第五章 實驗與結果
5.1 實驗資料集與實驗環境
實驗資料集我們從VX Heavens[28]這個網站上下載,這個站搜集了各種平台的惡意程式,
包括Win32、Unix、Dos等等。我們使用其中的Win32 病毒集,類別與數目如表三總數有 7862 隻惡意程式。其中Trojan的子類別更是多達 11 種,如此大大曾加了偵測的困難度。在正常程 式方面我們分別從國內知名的三個網站:史萊姆[30],軟體王[31] 與PCHomep[32]。軟體類別 與數如表四總數有 1555 隻。
表 三 惡意程式數目表 類型 Virus Worm Trojan
(AOL, ArcBomb, Clicker, DDos,
Downloader, Dropper, IM, Notifier, PSW, Proxy, SPY)
Backdoor Total
數目 913 808 2807 3334 7862
表 四 正常程式數目表
類型 商業軟體 網路軟體 多媒體 影像 工具 Total 數目 118 521 288 135 493 1555
5.2 符號與量測值
在我們的實驗裡有兩種評估系統好壞的方法,一個是對已知惡意程式的偵測率,另一個是 對未知惡意程式的預測率,這裡計算預測率的方法是使用 ten fold,把資料集分成十份,其 中九份拿來做訓練,一份做預測,重覆十次再取其平均值為我們的結果。
在這裡我們介紹幾個會使用到的符號:
首先必需先定義 P(Positive)是系統判斷為惡意程式,N(Negative)是系統判斷為正常程 式,T(True)是指系統判斷正確,F(False)指系統判斷錯誤。
True Positives(TP):TP 指的是系統正確的偵測到惡意程式,TP 偵測率可以用下面式子示
% 100 FN * TP
TP
+ 。
True Negatives(TN):TN 指的是系統正確判斷為正常程式,TN 偵測率可用下面式子表示
% 100 TN * FP
TN
+ 。
False Positives(FP):FP 指的是系統把某隻程式判斷為惡意程式,但其實它是正常程式,也 就是所謂的誤判,誤判率可用下面表示 *100%
TN FP
FP
+ 。
False Negatives(FN):FN 指的是系統把某程式判斷為正常程式,但其實它是惡意程式,FN 偵測率可用下面式子表示 *100%
FN TP
FN
+ 。
Overall Accuracy(OA):它的定義是 + + + ∗100% +
FN FP TN TP
TN TP
。評估這個 惡意程式偵測系統 的有效偵測率,它考慮的不只是較高的 TP 而且也考慮較低的 FP,所以 OA 是一個值得參考的 參數。
CV Rate:我們使用這個符號代表系統的預測率,表示偵測一個未知或新的惡意程式的能力,
它的計算公式同於 OA。
5.3 實驗結果
首先讓我們看四類惡意程式使用不同 Information Gain 值取出特徵再使用 SVM 訓練與預 測的結果,圖 5-1 為病毒的結果,圖 5-2 為 Worm 的結果,圖 5-3 為 Trojan 的結果,圖 5-4 為 Backdoor 的結果。橫軸為不同 Gain 值,縱軸為偵測率,Gain 值取法為從這個值至 1 為止(例 Gain 0.05 為 Gain 從 0.05 至 1 的範圍)我們可以很明顯的發現,每一類的偵測率(OA)與預測 率(CV)都隨著 Gain 值變小(特徵變多)而增加,到最後則有收斂的現象,不再增加,但很明顯 的可以發現,在 Trojan 與 Backdoor 這兩類整體的偵測率與預測率都小於 Virus 與 Backdoor,
原因是 Trojan 與 Backdoor 這兩類的程式與一般的程式非常類似,而且程式數目遠比前兩類高 出許多,所以效果較前兩類差。而 Trojan 這一類的 Gain 在 0.05 的預測率比其它 Gain 都要來 的高,這也許是因為 Trojan 這類惡意程式混雜了太多不同類型的程式在裡面所導致的原因。
95.91 95.91 95.18 95.06 94.41 92.95 91.49 90.76
86.39 85.90 83.72
98.87 98.78 98.66 99.31 97.65 98.78 96.88 96.35
93.11 91.37
86.55 86.02 83.72
95.95 96.07
80 82 84 86 88 90 92 94 96 98 100
1E-05 0.0001 0.0005 0.001 0.005 0.01 0.05 0.1 0.15 0.2 0.25 0.3 0.35
Info Gain
Detecting Rate(%)
CV OA
圖 5 - 1 不同 Info Gain 值 Virus 的偵測與預測率
95.64 95.39 95.18 95.30 94.37 92.59 91.49 90.77 88.66
81.38
98.43 98.31 98.14 98.65 98.18 95.39 94.03 92.64
88.91
81.38
95.68 98.43
80 82 84 86 88 90 92 94 96 98 100
0.00001 0.0001 0.0005 0.001 0.005 0.01 0.05 0.1
0.15 0.2
0.25
Info Gain
Detecting Rate(%)
CV OA
圖 5 - 2 不同 Info Gain 值 Worm 的偵測與預測率
92.73 92.62
92.56 92.11
91.84 91.59
95.40
89.41
97.89 97.78
97.75 97.43
97.32 96.70
96.22
93.35
85 87 89 91 93 95 97 99
0.00001 0.0001
0.0005 0.001
0.005 0.01
0.05 0.1
Info Gain
Detecting Rate(%)
CV OA
圖 5 - 3 不同 Info Gain 值 Trojan 的偵測與預測率
92.51 92.58
91.35 92.51
91.35 90.96
89.94
98.05 97.89
95.21 97.20
95.21 96.22
95.17
84 86 88 90 92 94 96 98 100
0.00001 0.0001
0.0005 0.001
0.005 0.01
0.1
Info Gain
Detecting Rate(%)
CV OA
圖 5 - 4 不同 Info Gain 值 Backdoor 的偵測與預測率
在這裡我們做一個小實驗,要把從 Information Gain 之後的特徵使用 PCA 減少維度,但
使用那一種 Gain 值經 PCA 轉換後的效果較好?使用原本 OA 較高的 Gain 為佳還是使用最多特 徵數的 Gain 值?我們以 Virus 為實驗對向,因為它在不同 Gain 下 OA 的差距最大,選擇 Virus OA 最高 99.31 Gain 值為 0.01,與特徵最多的 Gain 值 0.00001 其 OA 為 Virus 98.87,其結果 如下圖 5-5、5-6 所示,明顯的不管是 CV 或 OA 兩個不同 Gain 值做出結果有相當大的差距,在 特徵數較少但 OA 較高的 Gain 0.05 完全比特徵數較多但 OA 較小的 Gain 0.00001 效果還差,
所以這裡證明了 Information Gain 都沒有用了?其實不盡然,因為在做出四類的 Information Gain 裡,如果平均 Gain 較高者,做出來的結果會特別好,所以如果事先知道 Information Gain 較好,即不用再浪費時間做訓練,以省下大量時間。
94.25
94.0894.0494.12
94.2994.33
94.2194.2594.21 94.33
94.57 94.45
94.57 94.81
95.02 95.18
94.84 94.67
95.34
95.06
94.65
95.1095.1095.06
94.7794.77 94.98
94.90 95.22
95.30 95.42
95.5495.50 95.34
95.26 95.50
95.30
95.5095.50 95.30
94 94.2 94.4 94.6 94.8 95 95.2 95.4 95.6
80% 82% 84% 86% 88% 90% 92% 94% 96% 98%
EigenValue Cumulation(%)
Detecting Rate(%) Gain 0.01 Gain 0.00001
圖 5 - 5 Virus Gain 值經 PCA 轉換 CV 比較
96.2796.4796.47
97.8198.01
96.68
95.58 97.37
97.12
96.23 98.01
97.6197.73
97.9798.17 98.54
98.0198.14 98.74
99.27
98.10
98.9198.95
98.6898.85
98.5898.7098.74
98.9598.99 99.27
98.74
99.07
98.70 99.51 99.07 98.87 98.58 98.38 99.03
95.5 96 96.5 97 97.5 98 98.5 99 99.5
80% 82% 84% 86% 88% 90% 92% 94% 96% 98%
EigenValue Cumulation(%)
Detecting Rate(%) Gain 0.01 Gain 0.00001
圖 5 - 6 Virus Gain 值經 PCA 轉換 OA 比較
經 PCA 轉換後的特徵數與原始數目是大不同的,PCA 可以從數千個特徵資料減少到數百 筆,比率大約 10:1,如表五為各類別經 PCA 轉換後被使用做為訓練特徵的比較表。
表 五 經 PCA 轉換前後特徵數目比較
類型 Virus Worm Trojan Backdoor 轉換前 1748 1802 2311 2561 經 PCA 後 307 240 284 207
由圖 5-7、5-8 與 5-9 所示,經過 PCA 特徵轉換後的 CV 與 OA 都有明顯的提升,證明了 PCA 不只可以減少維度並且有提高偵測率的功能,而且由圖 5-10 的 TP 可以看出,幾乎每一類別的 偵測率都逼近 100%,而誤報率平均在 3%以下,在 Virus 與 Worm 這兩類誤報率更是在 1%以下。
94.25
96.07 95.68 92.73
92.51
93.62
95.22 94.88 91.93
92.45
89 90 91 92 93 94 95 96 97
Average Virus Worm Trojan Backdoor Malware
Detecting Rate(%) After PCA CV Before PCA CV
圖 5 - 7 各類別 PCA 轉換前後 CV 比較
98.31
98.87 98.43
97.89 98.06
98.97
99.55 99.36 98.28
98.69
97.7 97.9 98.1 98.3 98.5 98.7 98.9 99.1 99.3 99.5 99.7
Average Virus Worm Trojan Backdoor Malware
Detecting Rate(%) Before PCA OA After PCA OA
圖 5 - 8 各類別 PCA 轉換前後 OA 比較
93.62 95.22 94.88 91.93
92.45 98.69
99.36
99.55
98.97 98.28
10 20 30 40 50 60 70 80 90 100
Average Virus Worm Trojan Backdoor Malware
Detecting Rate(%)
CV OA
圖 5 - 9 經 PCA 後的 CV 與 OA
99.8 99.9 99.6 99.7 99.9
2.37 0.6 0.78
4.3 3.8
0 10 20 30 40 50 60 70 80 90 100
Average Virus Worm Trojan Backdoor Malware
Detecting Rate(%)
TP FP
圖 5 - 10 經 PCA 後的 TP 與 FP
表六為經 PCA 後系統 FP 百分比與實際數目比較表,由表六可以看出整個系統的平均誤判 率並不高,在 1555 隻程式裡平均僅有 37 隻誤判,其中 Virus 與 Worm 各只有 9 與 12 隻,其它 兩類 Trojan 與 Backdoor 較高的原因為這兩類惡意程式跟正常程式行為非常相近,所以才會有 稍高的誤判。
表 六 誤判率(FP)與程式數目
Virus Worm Trojan Backdoor Average FP 0.6% 0.78% 4.3% 3.8% 2.37%
Number 10 12 67 59 37
第六章 結論與未來展望
在過去做病毒研究遇上的難題之一為病毒集的來源,沒有特定的病毒資料集,只能在網路 上零散的收集,直到近幾年才有 VX Heaven 這個網站提供一個完整的資料集,但仍只有少數 論文一次針對所有惡意程式進行研究,即使有使用程式數目仍不多,至目前為止只有本篇論文 使用高達約 10000 隻程式做實驗,並仍有很好的結果,而且有一般防毒軟體所沒有的偵測新型 惡意程式的能力。在資料探勘技術方面使用 Information Gain 與 Principal Component Analysis 兩個方法,從第五章的實驗結果可以明顯看出 PCA 的結果比 Information Gain 好,
並且可以使用更少的特徵,因為系統使用機器學習理論來實現所以會有誤判的行為,對於機器 學習誤判問題至今仍無一套適用於每一種系統的解決方法,所以將來可以針對這個系統提出解 決方案,如此才能離商業化越來越近。

![圖 3 - 4 經 PCA 轉換且減少為一維的資料分佈 下面我們將實際舉一個例子[21]: 有一個二維資料集, ,其 mean 為 ⎥⎥⎥ ⎦⎤⎢⎢⎢⎣⎡=726115A [ 4 7 ] 經 Covariance 運算後為 ⎥ ⎦⎢⎤⎣⎡−−5.185.15.17 對角化運算 [ A − λ I ] X = 0 → 0 (式 3-1) 5.185.1 5.17 ⎥ = ⎦⎢⎤⎣⎡−−−− Xλλ 求得兩個 IgenValue ⇒ λ 1 = 18](https://thumb-ap.123doks.com/thumbv2/9libinfo/9123397.407994/21.892.246.653.127.470/經轉換且減少為一維資料分佈下面我們將實際舉一個λ−−.webp)