1
國立臺東大學資訊管理學系 碩士論文
Department of Information Science and Management Systems
National Taitung University Master Thesis
地理標記語言之資料隱藏技術
A Study of Data Hiding Techniques for Geography Markup Language
研究生:林延錄 Yan-Lu Lin
指導教授:王聖銘 博士 Advisor: Sheng-Ming Wang, Ph.D.
中 華 民 國 九 十 九 年 七 月
July, 2010
2
3
4
5
致謝
研究所兩年的時光過得飛快,在整個求學期間與論文撰寫的過程中,最高興 的不單單只是論文的完成,更包含在台東求學兩年的過程。這期間所遇到的人事 物、以及學習到的知識與經驗,都將成為我美好的回憶與日後受用不盡的寶藏。
首先感謝恩師王聖銘教授與陳富美教授這兩年來在生活、課業與專案上悉心 指導與啟發,才能讓我在這兩年中不斷有所進步,更在王老師優越的專業能力、
洞悉問題核心的洞察力與豐富的實務經驗指導下,讓我如入寶山,滿手而歸,使 本論文得以順利完成,在此致上最高的謝意與敬意。
同時也要感謝資管系所有老師與行政助理平時的指導與照顧,不但讓我收穫 良多,更讓離鄉背井的我倍感溫暖。另外也要感謝口詴委員許志堅教授與邱景升 教授給予我寶貴的建議及指導,使得本論文內容更加豐富且完整。
另外也要感謝紹永學長幫忙校稿,使我的論文更加完整。還有感謝龍富、聖 熙、文翔、牧隴、冠廷、慧文、千秦與弘侑,除了學業上的相互扶持及討論外,
更彼此相互鼓勵與關心,使我能安心、專心於論文的研究。也感謝學弟名哲、昀 峰、瀚品、啟章、政鴻與俊德,幫忙處理實驗室的大小事務。
最後感謝家人的體諒與關懷,並在背後默默的支持我,讓我無後顧之憂。再 次鄭重向所有老師、親朋好友以及曾經幫助過我的人,致上本人最高的謝意與敬 意,謝謝。
林延錄 敬上 國立台東大學資訊管理學系碩士班 中華民國 99 年 7 月
I
摘要
本研究主要在研究如何將不同類型的資料隱藏(Data Hiding)技術導入地理標 記語言(Geography Markup Language, GML)的空間資料格式中,分析與探討 GML 空間資料格式在導入資料隱藏技術後的成效,並提出改善可擴展之可逆式向量地 圖資料隱藏演算法的方法。本研究中提出了無失真資訊隱藏法、PCA 排序法、
投影排序法與直接投影法等資訊隱藏處理方法,並藉此評估提升地理標記語言之 資料隱藏技術在地理資訊系統(Geographic Information System, GIS)的應用性。
本研究架構在既有的可擴展之可逆式向量地圖資料隱藏演算法與無失真資 料隱藏演算法上,並導入 GML 空間資料格式做應用評估。其目標除了求得可嵌 入的訊息量最大化之外,也希望能根據不同的應用目的、秘密訊息的容量大小與 GML 地圖的精度條件,規劃其所對應的資料隱藏演算法、前置處理流程與嵌入 資料的位置。是故,本研究針對可擴展之可逆式向量地圖資料隱藏技術提出三種 不同的前置處理流程:PCA 排序法、投影排序法與直接投影法,同時嵌入資料 的位置包含幾何圖形中的頂點、曲線與表面,並且將資料嵌入其所屬的圖徵當 中。其結果不但可以提升 GML 檔案中資料的隱密性、完整性與安全性,並且增 加地理標記語言之資料隱藏技術的可應用性,更可做為 GML 檔案的認證機制。
經由可嵌入訊息量、不可察覺性、可逆性、以及資料嵌入與擷取所需執行時 間等評估項目的比較,本研究的結果比直接應用可逆式向量地圖資料隱藏及無失 真資料隱藏法於傳統向量地圖資料格式的結果有更高的可嵌入資料量,同時所需 執行時間也較短。但本研究所提出的直接投影資料處理法在不可察覺性及可逆性 的評估項目中表現較差,是故,該方法只能適合於少量資料嵌入需求的應用。而 本研究也顯示,應用 GML 空間資料格式於向量地圖資訊隱藏的應用中,可降低 原先陳富美學者所提出之可逆式向量地圖資料隱藏演算法中資料前處理需先經 PCA 轉換的繁複程序,增加其應用的效率。本研究的結果可做為應用資料隱藏
II
技術於 GML 空間資料格式而達到空間資訊系統創新應用的基礎。針對未來研 究,建議可進一步探討 GML 空間資料格式中有關拓樸相關的特性,以及 GML 各種標籤元素的應用。
關鍵字:資料隱藏、地理標記語言、空間資訊系統、向量地圖、資料擷取
III
Abstract
This research is focused on analyzing and evaluating the results of applying different data hiding technologies to Geography Markup Language (GML) spatial data format and to propose the possible modification of existing extensive reversible data hiding algorithms. The data hiding processing methods, which include distortion free method, PCA sorting method, projection sorting method, and direct projection method, are proposed and evaluated in this research. The results of this research are also used for the evaluation of how data hiding technologies can be used for the enhancements of geographic information system (GIS) application based on GML spatial data format.
The existing extensive reversible data hiding algorithms to vector maps proposed by Chen and the distortion free data hiding algorithms proposed Bogomjakov are used in this research. The main purpose of this research is not only to maximize the capacity of embedding messages but also to construct the corresponding data hiding algorithms, data processing methods and data embedding position based on different application objectives, size of the secret message, and the precision of maps. Thus, in addition to the distortion free methods, there are three different processing methods for extensive reversible data hiding algorithms for vector maps: PCA sorting method, projection sorting method, and direct projection method; are applied to hide data in the points, curve (lines), and surface(polygons) data type in GML respectively. The results show that the mechanisms and methods proposed in this research not only can strengthen the privacy, integrity and security of the data hidden in GML but can also enhance the application of applying data hiding technology for the GML. Moreover, it can be used for GML authentication.
IV
Case studies are implemented for the comparison on data hiding capacity, invisibility effects, reversibility, and execution time for data embedding and extraction are made for evaluating the results in this research to the results that applying extensive reversible data hiding algorithm and distortion free data hiding algorithm to traditional vector data format. The results show that the mechanism proposed in this research is superior in data hiding capacity and executing time. However, the performance of the direct projection processing method proposed in this research is worse than the other methods. It indicate the method can only been used by the applications that need low data hiding capacity. As conclude by the case studies, the application of data hiding technologies in GML can reduce the complicated PCA pre-processing procedure in the algorithm proposed by Chen and promote the data hiding efficiency. The mechanism the apply data hiding technologies in GML proposed in this research can be used as the base the innovation applications of spatial information system. Moreover, the topological features and related Tag elements in GML can be used for the applications of data hiding in future studies.
Keywords: Data Hiding, Geography Markup Language, Geographic Information System, Vector Maps, Data Extraction.
V
目錄
摘要 ... I Abstract ... III 目錄 ...V 圖目錄 ... VI 表目錄 ... VIII
第一章 緒論... 1
1.1 研究動機 ... 1
1.3 研究流程 ... 5
第二章 文獻探討 ... 8
2.1 GML 介紹 ... 8
2.2 資料隱藏技術及應用 ... 11
2.2.1 向量地圖資料隱藏演算法 ... 15
2.2.2 可逆式向量地圖資訊隱藏系統 ... 19
2.2.3 可擴展之可逆式向量地圖資料隱藏演算法 ... 21
2.2.4 無失真資料隱藏演算法 ... 23
第三章 研究方法 ... 25
3.1 GML 空間資料格式 ... 26
3.1.1 GML 頂點格式 ... 28
3.1.2 GML 曲線格式 ... 29
3.1.3 GML 表面格式 ... 30
3.2 資料嵌入流程 ... 33
3.2.1 頂點之圖徵類型 ... 35
3.2.2 曲線之圖徵類型 ... 38
3.2.3 表面之圖徵類型 ... 40
3.3 資料擷取流程 ... 44
第四章 研究結果與分析 ... 46
4.1 實驗設計 ... 46
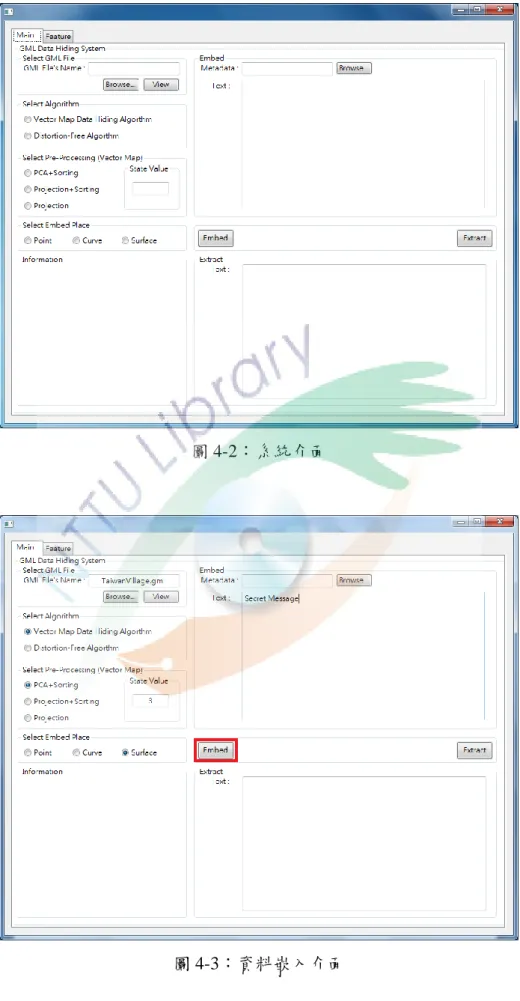
4.2 系統介紹 ... 48
4.2 可嵌入訊息量(Capacity)評估 ... 52
4.3 不可察覺性(Imperceptibility)評估 ... 54
4.4 可逆性(Reversibility)評估 ... 56
4.5 執行時間(Execute Time)評估 ... 58
第五章 結論與未來研究建議 ... 60
5.1 結論 ... 60
5.2 未來研究建議 ... 62
參考文獻 ... 63
VI
圖目錄
圖 1-1:研究流程... 6
圖 2-1:GML 文件組成 ... 10
圖 2-2:GML 文件說明 ... 10
圖 2-3:資料隱藏示意圖 ... 11
圖 2-4:資訊隱藏的分類 ... 12
圖 2-5:資訊隱藏應用目的 ... 13
圖 2-6:資訊隱藏與加密技術的比較 ... 14
圖 2-7:奇/偶數序列 ... 16
圖 2-8:定義區間... 17
圖 2-9:嵌入資訊「0」 ... 18
圖 2-10:嵌入資訊「1」 ... 18
圖 2-11:頂點位於狀態「0」之嵌入動作 ... 20
圖 2-12:頂點位於狀態「1」之嵌入動作 ... 20
圖 2-13:分割變數 s 與切割變數 c 與子區間個數 v 之關係 ... 21
圖 2-14:嵌入 2 位元資訊 ... 22
圖 2-15:置換端點排列順序嵌入訊息 ... 23
圖 2-16:無失真資料隱藏演算法... 24
圖 3-1:研究流程... 25
圖 3-2:圖徵之拓樸與幾何屬性 ... 27
圖 3-3:頂點語法示意圖 ... 28
圖 3-4:曲線語法示意圖 ... 29
圖 3-5:表面語法示意圖 ... 30
圖 3-6:資料嵌入流程 ... 33
圖 3-7:嵌入資料之圖徵類型分類 ... 34
圖 3-8:台灣五直轄市所在位置 ... 36
圖 3-9:讀取頂點標籤內容演算法 ... 37
圖 3-10:讀取曲線標籤內容演算法 ... 39
圖 3-11:空間資料儲存比較 ... 41
圖 3-12:讀取表面標籤內容演算法 ... 42
圖 3-13:資料擷取流程 ... 44
圖 4-1:台灣鄉鎮地圖 ... 47
圖 4-2:系統介面... 49
圖 4-3:資料嵌入介面 ... 49
圖 4-4:資料擷取介面 ... 50
圖 4-5:軟體架構... 50
VII
圖 4-6:系統特色... 51
圖 4-7:可嵌入訊息量 ... 53
圖 4-8:嵌入資料之 RMSE Ratio ... 55
圖 4-9:座標值與其鄰近座標值之距離 ... 55
圖 4-10:還原資料之 RMSE Ratio ... 57
圖 4-11:分割變數影響座標值差異 ... 57
圖 4-12:執行時間 ... 59
VIII
表目錄
表 2-1:子分割區間 ... 19
表 3-1:地理標記語言頂點屬性語法與說明 ... 28
表 3-2:地理標記語言曲線屬性語法與說明 ... 29
表 3-3:地理標記語言表面屬性語法與說明 ... 31
表 4-1:GML 檔案基本資料 ... 46
表 4-2:可嵌入訊息量 ... 52
表 4-3:嵌入資料之 RMSE Ratio ... 54
表 4-4:還原資料之 RMSE Ratio ... 56
表 4-5:執行時間... 58
表 5-1:研究結果比較 ... 60
1
第一章 緒論
1.1 研究動機
本研究主要在研究如何將不同類型的資料隱藏技術導入 地理標記語言 (Geography Markup Language, GML)的空間資料格式中,根據不同應用目的,選 擇對應的資料隱藏演算法,並提出不同的前置處理流程與可選擇嵌入資料的位 置,藉此提升 GML 檔案中資料的隱密性、完整性與安全性,同時比較不同資料 隱藏技術導入 GML 空間資料格式後與原研究結果的差異,分析與探討 GML 空 間資料格式在資料隱藏技術導入後的成效,提出改善資料隱藏技術應用的方法與 GML 地理資訊系統(Geographic Information System, GIS)上的創新應用。
因全球資訊化的腳步越來越快,人們可以輕易地從網路上竊取資料或重製散 播(Niu, Shao, & Wang, 2006),導致著作權(Copyright)以及資訊安全(Information Security)等相關問題產生,因此許多專家學者展開資訊隱藏(Information Hiding) 的相關研究(Chang & Tseng, 2009; Hong, Chen, & Shiu, 2008)。目前資料隱藏技術 在地理資訊上的相關研究非常少,主要針對向量地圖做研究(陳凱崴,2007;劉 秓良,2008;陳富美 2009),而向量地圖主要的優點在於以向量的方式來表現圖 徵,不用侷限於特定的螢幕解析度(Resolution),但缺點為詮釋與屬性資料頇分開 儲存,同時一個檔案僅可表示一種圖徵類型,因此需要多個檔案來描述真實現 象,且傳遞時需一併傳送其詮釋資料,容易造成外部資料與內部資料不一致的情 況。
Google 於 2008 年提出的地理資訊資料格式:鎖孔標記語言( Keyhole Markup Language, KML)是一種基於 XML 語法的檔案格式,可用於塑模與儲存例如點、
2
線、圖像、多角形與模型等地理特性,用以顯示在 Google Map、Google Earth 與 其他 GIS 上,使 GIS 不再只是單純的描繪地形或真實現象,透過結合不同的應 用程式,便可提供不同形式的服務,應用於不同領域(X. T. Wang, Shao, Xu, & Niu, 2007),例如實境導覽、教學或防災等應用(S.-M. Wang & Chen, 2008; 王聖銘 &
陳富美, 2009)。但目前 KML 的應用大多架構在 Google Map 與 Google Earth 上,
並未廣泛應用於不同的 GIS 中(何燦群,2010)。
因此本研究將探討一個地理資訊的標準資料格式:地理標記語言(Geography Markup Language, GML),是由 OGC(Open Geospatial Consortium)所認定的空間資 訊編碼規範,同時也是 ISO 國際標準,是一種基於 XML 技術發展的開放式標記 語言,透過標籤(Tag)來描述真實世界中的現象,以屬性的值來描述圖徵性質。
其中屬性的值可以是整數、浮點數、幾何或圖徵等型態,同時因具備自訂標籤的 特性,提供製圖者更彈性的方式來描繪地理特徵。與一般 VML(Vector Markup Language)和 SVG(Scalable Vector Graphics)地理資訊檔案格式不同,GML 將地理 資訊與其屬性封裝在一起,同時提供分散式的地理資料儲存。
而如何保護 GML 中的地理資訊與其詮釋資料(Mata-Data)在進行傳遞時不易 受到懷疑、甚至是竊取或竄改,確保資訊的隱密性和完整性,是一個相當重要且 值得探討的研究領域。有別於一般的金鑰加密技術,資料隱藏提供另外一種保護 秘密訊息的機制。目前在向量地圖相關的資料隱藏演算法中(S.-M. Wang, Chen, Chen, & Yang, 2009;陳凱威、王聖銘、張聖杰等,2007;陳凱威、王聖銘、鄭 友銘、王宗銘,2007),進行前置處理時,均利用主成分分析(Principal Component Analysis, PCA)將端點(Vertex)座標值轉換,其優點在於使用簡單,並且可提升安 全性與強韌性,但座標值一經轉換,其圖徵的精度就會降低,可應用的領域有限。
3
所以為了提升 GML 資料的安全性與 GML 資料隱藏技術之可應用性,同時 改善可擴展之可逆式向量地圖資料隱藏演算法造成精度降低的問題,因此本研究 主要研究如何將既有的可擴展之可逆式向量地圖與無失真資料隱藏技術導入 GML 空間資料格式中,透過標籤語法的特性,直接嵌入與擷取所需的資料,根 據不同應用目的選擇對應的資料隱藏演算法、前置處理流程與嵌入資料的位置,
藉此提升 GML 中資料的隱密性、完整性與安全性,同時增加 GML 資料隱藏技 術的可應用性。並比較資料隱藏技術導入 GML 空間資料格式後與可擴展之可逆 式向量地圖資料隱藏演算法之研究結果的差異,分析與探討 GML 空間資料格式 在資料隱藏技術導入後的成效,提出改善可擴展之可逆式向量地圖資料隱藏演算 法應用的方法與 GML 資料隱藏技術在 GIS 上的創新應用。
1.2 研究目的
本研究提出 GML 空間資料格式之資料隱藏技術應用,並評估不同資料隱藏 技術導入 GML 空間資料格式之成效。GML 空間資料格式之資料隱藏技術,透 過標籤語法的特性,分析圖徵的特性,根據不同應用目的選擇適用的資料隱藏演 算法、前置處理流程與嵌入資料的位置,藉此提升 GML 資料隱藏技術之可應用 性,同時增加 GML 資料的隱密性、完整性與安全性,並且提出改善資料隱藏技 術應用的方法。其中嵌入資料的位置包括不同的圖徵類型與不同的圖徵,而嵌入 的資料包含 GML 中圖徵的屬性資料與詮釋資料,將之直接嵌入 GML 空間資料 格式中,藉此避開竊取者的注意力,同時降低 GML 的檔案容量,不但達到保護 秘密訊息的目的,更提出創新的 GML 資料隱藏技術應用。因此以 GML 空間資 料格式做為掩護媒體,除了了解 GML 檔案的特性,並實際將可擴展之可逆式向 量地圖資料隱藏演算法(陳富美,2009)與無失真資料隱藏演算法(Bogomjakov, et al., 2008)導入 GML 空間資料格式之外,本研究的目標如下:
4
(1) 增加 GML 資料的安全性
將可擴展之可逆式向量地圖與無失真資料隱藏技術導入 GML 空間資料 格式中,藉此隱藏 GML 中圖徵的屬性資料與詮釋資料,並據根據不同 應用目的選擇資料隱藏演算法、前置處理流程與嵌入資料的位置,提升 GML 資料的在各方面的安全性。
(2) 提升 GML 資料隱藏技術的可應用性
利用標籤語法的特性,直接擷取所需的端點座標值,根據不同應用目的 選擇適用的資料隱藏演算法,並針對可擴展之可逆式向量地圖資料隱藏 技術提出不同的前置處理流程:PCA 排序法、投影排序法與直接投影 法,藉此提升可嵌入的訊息量與降低圖形的變形量,以應用於不同精度 條件與比例尺(Scale)需求的 GIS 中。
(3) 評估資料隱藏導入 GML 空間資料格式的結果
分別評估可擴展之可逆式向量地圖與無失真資料隱藏演算法導入 GML 空間資料格式後的結果,並比較不同前置處理流程與不同嵌入資料的位 置產生的影響,探討 GML 空間資料格式做為掩護媒體的成效。
(4) 透過 GML 特性改善原資料隱藏技術之結果
透過 GML 標籤語法的特性,根據不同的前置處理流程與嵌入資料的位 置,並利用分段處理的方式,藉此增加可嵌入的訊息量,同時不增加圖 形的變形量。
5
故本研究針對 GML 空間資料格式導入可擴展之可逆式向量地圖與無失真資 料隱藏演算法,並滿足上述的目標。在對 GML 空間資料格式嵌入高訊息容量的 同時,根據適當的前置處理流程與嵌入資料的位置,透過分段處理的方式,減少 失真並降低秘密訊息被竊取的機率。另外比較與評估可擴展之可逆式向量地圖與 無失真資料隱藏演算法導入 GML 空間資料格式之結果,探討可應用的領域,提 出改善資料隱藏技術應用的方法與創新的 GML 資料隱藏技術應用。
1.3 研究流程
本研究以 GML 空間資料格式為掩護媒體,實際導入可擴展之可逆式向量地 圖與無失真資料隱藏技術,提出改善資料隱藏技術應用的方法與 GML 在 GIS 上 的創新應用,流程如下圖 1-1 所示,依序在下列章節詳細說明。
6
文獻探討
前置處理流程 研究方法
結果與分析
結論
未來研究建議
資料隱藏技術 GML
標籤語法探討 無失真資料
隱藏技術 向量地圖資料
隱藏技術
選擇演算法 選擇資料
嵌入位置
圖 1-1:研究流程
首先第二章文獻探討說明本研究針對的檔案格式:GML,和其他資料隱藏 相關研究。由於目前沒有 GML 資料隱藏技術之相關研究,但 GML 的座標系統 與向量地圖相同,因此將向量地圖的資料隱藏技術導入 GML 空間資料格式,同 時為了比較不同資料隱藏演算法導入之成效,因此將無失真資料隱藏演算法導 入,比較其特性與成效。
7
第三章研究方法詳細說明本研究提出的導入資料隱藏技術的方法,透過詳細 了解 GML 空間資料格式,擷取出可用的屬性資料,根據不同應用目的與地圖精 度條件選擇對應的資料隱藏演算法、前置處理流程與嵌入資料的位置,其中針對 可擴展之可逆式向量地圖資料隱藏演算法提出三種前置處理流程:PCA 排序法、
投影排序法與直接投影法,並且詳細說明資料嵌入與擷取流程的各個步驟。
第四章研究結果與分析說明本研究的結果,根據可嵌入訊息量、不可察覺 性、可逆性與執行時間這四項指標來評估不同資料隱藏技術導入 GML 空間資料 格式之結果,並比較與可擴展之可逆式向量地圖資料隱藏技術之研究結果的差 異,討論本研究提出的 GML 空間資料格式之資料隱藏技術在各方面的表現成果。
最後第五章結論與未來研究建議,針對第三章所提出的研究方法與第四章的 研究結果做綜合的比較與總結,陳述本研究之研究貢獻,並提出後續研究可改進 或加強的部分,討論未來可研究之方向。
8
第二章 文獻探討
在本章中,首先在 2.1 節說明本研究針對的掩護媒體:地理標記語言 (Geography Markup Language, GML)。其次在 2.2 節說明什麼是資料隱藏,並釐 清資訊隱藏、資料隱藏與浮水印之間的關係與相異之處,由於 GML 目前沒有資 料隱藏的相關文獻,故研究相同性質的向量地圖資料隱藏技術來探討在 GML 空 間資料格式上可應用的資料隱藏演算法,最後探討無失真的資料隱藏演算法,藉 此比較不同資料隱藏技術在 GML 空間資料格式上的差異。
2.1 GML 介紹
地形圖是一種重要的基本圖形資料,應用廣泛,如都市規劃、旅遊導覽等等,
然而不同的製圖單位所製作的地形圖,其資料格式不盡相同,使用地形圖的單位 也因其需求而使用不同的 GIS,導致地形圖必頇轉換檔案格式,造成檔案因轉換 而產生資訊的漏失,影響地形圖的正確性。因此追求地理空間資料的共通共享,
一直是 GIS 使用者共同的理想(陳勇仁,2007)。
地理標記語言(Geography Markup Language, GML)是 OGC(Open Geospatial Consortium)所認定的空間資訊編碼規範,同時也是 ISO 國際標準,是一個公開 且供應商中立(Vendor-Neutral)的標準,不被任何一家 GIS 軟體廠商所限制。GML 是一種基於可擴展標記語言(eXtensible Markup Language, XML)技術發展的開放 式標記語言,用以描述生活環境中之地理物件,以圖徵(Feature)為基礎,記錄地 理物件之空間位置或相關屬性內容,並且達成下列目的(鄧東波,2006):
(1) 透過網際網路分享和交換已編碼的地理資訊。
(2) 表達不同領域的地理語彙論述。
9
(3) 表達地理性網絡服務訊息元素。
現行版本 GML3.2.1 於 2007 發佈,已成為 ISO19136 標準,納入 TC/211 系 列標準之一(林信助,2008)。該版本加強了地理空間資料之表達所需的型態與方 式,支援多種物件(Objects)以描述地理資訊之相位關係、幾何性質、座標參考系 統、時間屬性值、多種比例尺、詮釋資料、網格(Grid)資料、和對地形及區域做 視覺化處理所需的預設樣式。
對於空間資訊而言,GML 是一個標準的詮釋語言(Meta-Language),可以完 整表達空間資訊的複雜性。以往以關連式資料庫為主的 GIS,雖然在分析及資料 處理上能力強大,但因為地理資料龐雜,導致需要更多的詮釋資料來說明地理資 料,而 GML 本身不但是詮釋語言,而且核心綱目提供大量地理語彙,因此可以 用來建構地理資料的語義(Semantic)和邏輯(Logic)模式,此外 GML 還有具有下列 特性,使得地理資料易於整合網路資源(鄧東波,2006):
(1) GML 資料可以直接被使用者讀取和了解。
(2) GML 可實現分散式空間資料集(Dataset)並且連結這些資料集,降低資料 成本。
(3) GML 資料可簡單混合非空間的資料,例如文字或影像等。
GML 文件是由三個部份所組成,分別為 OGC 所公佈的 GML 綱目(Schema)、
不同應用領域根據其需求所定義的 GML 應用綱目(Application schema)和來自資 料生產單位並根據 GML 應用綱目(Application schema)之架構產生之文件(GML Instance Data),該文件並提供給使用者,如下圖 2-1、圖 2-2 所示(鄧東波,2004)。
10
GML Application
Schema
GML
GML Schema
GML Instance
Data
圖 2-1:GML 文件組成 資料來源:(鄧東波,2004)
地表的現象
圖徵型態的模式
各式各樣 的圖徵
Application Schema
Data 對於真實世界,以
廣泛且明確的方式 來抽取地理圖徵。
以GML Schemas定義 Application Schemas 中的標準元素和型態 之使用。
資料因根據
Application Schema 而有邏輯結構。
以一組概念性的Schema Language來定義資料的 內容和結構,如UML 利用GML Application Schema定義真實世界中 的物件,使地理資料成 為GML文件
圖 2-2:GML 文件說明 資料來源:(鄧東波,2004)
其中 GML 綱目是平行的,且不針對任何一個應用領域,提供不同應用領域 的一般性構想和觀念。而 GML 應用綱目則如同堆積木,同樣規格的 GML 綱目
11
可以組合成不一樣的 GML 應用綱目。GML 除了提供已定義好的標籤來描述外,
更可讓使用者自訂標籤來描述現實的現象。
因此本研究希望藉由將資料隱藏技術導入 GML 空間資料格式中,透過不同 的圖徵特性、應用目的與地圖精度條件使用不同的資料隱藏演算法與其對應的前 置處理流程,以及選擇要嵌入資料的位置,同時嵌入的資料除了圖徵的屬性資料 與詮釋資料外,更可嵌入自訂標籤的屬性資料,除了達到資訊安全與資料一致性 的目的之外,更提出創新的 GML 資料隱藏在 GIS 上的應用方式。
2.2 資料隱藏技術及應用
資訊隱藏是一種秘密通訊的藝術與科技(Kahn, 1996),亦可稱為掩護寫入 (Covered Writing)或是在一般訊息內隱藏訊息的技術(Rabah, 2004),是一種將秘密 訊息隱藏到掩護媒體中的技術(Chao, Lin, Yu, & Lee, 2009),如下圖 2-3 所示。
傳遞者 接收者
竊取者 公眾頻道
(Internet)
秘密訊息
(010100) 掩護媒體
偽裝媒體 偽裝媒體
偽裝媒體 秘密訊息
(010100)
圖 2-3:資料隱藏示意圖 參考資料來源:(劉秓良,2008)
12
傳遞者將秘密訊息嵌入掩護媒體後產生偽裝媒體,利用偽裝媒體進行秘密通 訊的動作,當竊取者在公眾頻道中擷取偽裝媒體時,不知道媒體內藏有秘密訊 息,因此無法竊取到秘密訊息,當真正的接收者收到偽裝訊息時,即可將秘密訊 息擷取出來,達到秘密通訊的目的。因此資訊隱藏泛指將訊息、圖片或文字等資 訊藏匿在一媒體中。同時因目的不同,可以延伸出許多應用與分類(Pfitzmann, 1996),如圖 2-4 所示。
Information Hiding
Covert
Channels Steganography Anonymity Copyright
Marking
Linguistic Steganography
Technical Steganography
Robust Copyright Marking
Fragile or Semi-Fragile Watermarking
Fingerprinting Watermarking
Imperceptible Watermarking
Visible Watermarking
圖 2-4:資訊隱藏的分類 資料來源:(Pfitzmann, 1996)
資訊隱藏依其應用的目的不同,可以分為兩大類:浮水印(Watermarking)與 資料隱藏(Data Hiding)(Popa, 1998),如下圖 2-5 所示。底下將分別對浮水印與資 料隱藏的目的與應用做簡單說明。
13 Steganography (covered writing, covert channels)
Protection against detection (data hiding)
Protection against removal (document marking)
Watermarking
(all object are marked in the same way)
Fingerprinting
(identify all objects, every object is marked specific)
圖 2-5:資訊隱藏應用目的 資料來源:(Popa, 1998)
浮水印是指將具代表性的文字或影像,稱之為浮水印(Watermark),嵌入需要 保護的數位媒體之中。當數位媒體遭受竊取者盜用或攻擊(Attack)時,原創者可 以藉由嵌入其中的浮水印證明該數位媒體的合法原始擁有者,其目的在於保護著 作 權 , 因 此 浮 水 印 的 技 術 必 頇 具 備 抵 抗 蓄 意 攻 擊 的 能 力 , 強 調 其 強 韌 性 (Robustness);反觀資料隱藏則是將欲傳送的秘密訊息嵌入一個不受他人注意的 掩護媒體上,藉此迷惑竊取者的注意力,透過傳遞此媒體來達到秘密通訊的目 的,故資料隱藏演算法著重於偽裝而非強韌性,強調嵌入訊息的容量。
資料隱藏是指將欲傳送的秘密訊息(Secret Message)嵌入(Embed)掩護媒體中 (Cover-Media),透過傳送已嵌入秘密訊息的偽裝媒體(Stego-Media)來間接傳遞秘 密訊息,達到秘密通訊的目的。與傳統對訊息加密(Encryption)再傳送的作法不 同,資料隱藏是利用偽裝的概念來提供維護資訊安全的另外一種機制,如下圖 2-6 所示。
14
Information Hiding
secret message Encryption
key
圖 2-6:資訊隱藏與加密技術的比較
資料隱藏依嵌入訊息的方式可區分為兩大領域(陳凱威,2007):空間域 (Spatial Domain)與轉換域(Transform Domain)。空間域的嵌入方式係透過改變媒 體本身具備的特徵來嵌入資訊,其處理速度較快但較不具備強韌性,例如掩護媒 體為一般圖片時,可改變其像素(Pixel)的數值;若為二維或三維模型時,可改變 模型上的座標(Coordinates)、法向量(Normal)或顏色(Color)等數值。轉換域的嵌 入方式則是先將媒體經過複雜的數學運算產生相對應的係數值,透過改變係數值 來嵌入資訊。其優點為強韌性高,可分散變形量,缺點為處理速度慢。
另外根據嵌入訊息時是否會改變掩護媒體的外觀,導致容易被竊取者發現,
可分為失真(Distortion)與無失真(Distortion-Free)。失真為嵌入訊息後,偽裝媒體 與原本的掩護媒體在幾何或拓樸上產生差異,導致竊取者容易察覺,但其優點為 可嵌入的資訊量較大。無失真為當嵌入訊息後,偽裝媒體與原本的掩護媒體在幾 何或拓樸上是相同的,但其缺點為可嵌入的資料量較小。
最後資料隱藏在擷取訊息時,可依其需要的資訊,分為告知擷取(Informed detection)與盲擷取(Blind detection)兩種方式。告知擷取需要原始掩護媒體輔 助才可以擷取資訊,而盲擷取則不需要原始掩護媒體,也不需要嵌入訊息的原始 資訊,即可擷取訊息。在秘密通訊的過程中,若要在傳送已嵌入訊息的偽裝媒體
15
之外,再另外傳送掩護媒體或其資料,很容易引起竊取者的懷疑。因此資料隱藏 技術發展至今,盲擷取是一重要項目,也可以方便接收方擷取秘密訊息。
目前在資料隱藏技術這方面,以圖片、音訊、視訊或是二維/三維模型為掩 護媒體所發展的資料隱藏技術已經有不少的研究,但在地理資訊的研究上,目前 僅針對向量地圖的部分。由於 GML 沒有資訊隱藏的相關研究,因此底下以與 GML 空間資料格式相同的向量地圖資料隱藏演算法,來探討導入 GML 空間資 料格式的資料隱藏技術。
2.2.1 向量地圖資料隱藏演算法
陳凱威學者於 2007 年提出向量地圖資料隱藏演算法(陳凱威,2007),針對 2D 向量地圖提供空間域的資料隱藏演算法。首先將掩護向量地圖中所有端點的 座標擷取出來,經過主成分分析(Principle Component Analysis, PCA)後,得到兩 個正交的向量,分別為第一主軸:PCA1,以及第二主軸:PCA2。然後以這兩個 主軸為基底,如式(2-1)和(2-2),形成一個以第一主軸為 X 軸和第二主軸為 Y 軸 的 PCA 座標空間,透過此基底將原向量地圖上所有端點的座標轉換到 PCA 座標 空間中,得到新的座標值 PPCA,i=(xPCA,i, yPCA,i),其轉換式如式(2-3)和(2-4),其中 n 為向量地圖端點的總數。經過空間轉換後,根據 PCA 座標空間中的 X 軸和 Y 軸分別對所有的頂點 PPCA,i由小到大作排序,得到兩個排序序列(Sorting List),分 別是 X 軸排序序列與 Y 軸排序序列。
1 2
1 2
1 PCA , 2 PCA
PCA PCA
x x
PCA PCA
y y
(2-1) PCA 座標空間的基底=[PCA1|PCA2] (2-2)16
, ,
,
, PCA i , 1, ,
i
i PCA i
PCA i
x x
P P i n
y yi
(2-3)1 2 ,
1 2 ,
PCA i
PCA PCA i
PCA PCA i PCA i
x x x x
y y y y
(2-4)嵌入資訊時,分別對 X 軸排序序列與 Y 軸排序序列嵌入資訊,假設 P’1,P’2,…,P’n為 X 軸排序序列中的頂點順序,X1,X2,…,Xn為這些頂點的 X 軸座 標值,n 為向量地圖端點的總數。利用分層的概念,首先將這些座標值分為兩大 類,分別是奇數序列(Odd list)與偶數序列(Even list)。奇數序列定義為將固定編號 為奇數的頂點不動,偶序列則相反,定義為將固定編號為偶數的頂點不動,如下 圖 2-7 所示。
P’PCA,1 P’PCA,2 P’PCA,3 P’PCA,4
X1 X2 X3 X4 X5
...
:固定不動的頂點 :可移動的頂點
P’PCA,5
PCA座標 空間X軸 X軸排序序列
奇數序列 偶數序列
...
...
圖 2-7:奇/偶數序列 資料來源:(陳凱威,2007)
然後先對奇數序列、而後再對偶數序列進行嵌入資訊的動作,首先固定所有 編號為奇數的頂點之 X 軸座標值,並定義 Xm與 Xm+2為一區間,再將每一區間 平分為兩等分,區間的左半部份定義為狀態「0」,區間的右半部份定義為狀態
「1」,如下圖 2-8 所示。
17
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「0」 「1」
「區間」
圖 2-8:定義區間 資料來源:(陳凱威,2007)
定義了區間及「0」、「1」的狀態後,逐一對每個區間 XmXm+2中的頂點P’PCA,m+1
之 X 軸座標值 Xm+1嵌入一個位元的資訊。為了達到「可逆」需求,記錄了 Xm+1 到 HL或 HR所移動的距離,嵌入公式如式(2-5),其中 HL和 HR分別為左半部分 和右半部分區間的中點,R 為 Xm+1和 HL的差距,d 為欲嵌入的資訊。因此若嵌 入的資訊為 0 時,P’PCA,m+1的新 X 軸座標值定義為 X’m+1=HL+R, R=(Xm+1-HL)/4,
如下圖 2-9 所示。
1 1
1
, ( ) / 4, "0"
' , ( ) / 4, "1"
L m L
m
R m R
X R R X H d
X X R R X H d
(2-5)18
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「0」 「1」
「區間」
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
”
PCA,m+1X
’
m+1「0」 「1」
「區間」
HL
(a)原始情況
(b)嵌入資訊0
R
P
’
PCA,m+1Xm+1
圖 2-9:嵌入資訊「0」
資料來源:(陳凱威,2007)
同理,當嵌入的資訊為 1 時,P’PCA,m+1的新 X 軸座標值定義為 X’m+1=HR+R, R=(Xm+1-HR)/4,如下圖 2-10 所示。
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「0」 「1」
「區間」
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸
「0」 「1」
「區間」
(a)原始情況
(b)嵌入資訊1
R P
’
PCA,m+1Xm+1
HR
P
”
PCA,m+1X
’
m+1圖 2-10:嵌入資訊「1」
資料來源:(陳凱威,2007)
19
因此一 PCA 座標空間軸最大可嵌入(n-2)個位元,整個向量地圖最多可嵌入 2(n-2)個位元。
2.2.2 可逆式向量地圖資訊隱藏系統
劉秓良學者於 2008 年提出發展可逆式向量地圖資訊隱藏系統(劉秓良,
2008),與前一節提到的演算法不同,雖然可嵌入的資訊量仍為 2(n-2)個位元,卻 降低向量地圖的變形量。首先利用 PCA 座標空間中的 X 軸和 Y 軸分別對所有的 頂點 PPCA,i 由小到大作排序,得到 X 軸排序序列與 Y 軸排序序列。在嵌入資料 時,利用式(2-6)將區間分割成 4 個子分割,如下表 2-1 所示,r 為頂點原本所在 的區間,d 為欲嵌入的資訊。
2
s r d
(2-6)表 2-1:子分割區間 資料來源:(劉秓良,2008)
原本所在的區間 r 欲嵌入的資訊 d 新的子分割區間 s
0 0 0
0 1 1
1 0 2
1 1 3
然後利用式(2-7)和(2-8)進行嵌入資訊的動作,區間中頂點位於狀態「0」時 如下圖 2-11 所示;區間中頂點位於狀態「1」時如下圖 2-12 所示。
2
' 1
4 2
m m
m m
X X
X X s
(2-7)2
1 2
m m
m m
X X
X X r
(2-8)20
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「0」 「1」
「區間」
λ
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「區間」
λ/2
0 1 2 3
P
”
PCA,m+1 P”
PCA,m+1λ/2 (a)頂點位於區間「0」
(b)嵌入資訊d為0或1時
圖 2-11:頂點位於狀態「0」之嵌入動作 資料來源:(劉秓良,2008)
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「0」 「1」
「區間」
P’PCA,m P’PCA,m+2
Xm Xm+2
PCA座標 空間X軸 P
’
PCA,m+1Xm+1
「區間」
λ/2
0 1 2 3
P
”
PCA,m+1P
”
PCA,m+1λ/2 (a)頂點位於區間「1」
(b)嵌入資訊d為0或1時
λ
圖 2-12:頂點位於狀態「1」之嵌入動作 資料來源:(劉秓良,2008)
21
2.2.3 可擴展之可逆式向量地圖資料隱藏演算法
陳富美學者於 2009 年提出可逆式資訊隱藏技術應用於向量地圖後設資料嵌 入之研究(陳富美,2009),當中發表了可擴展之可逆式向量地圖資料隱藏演算 法,改善了前兩種資訊隱藏演算法可嵌入的資訊量固定的問題,提出嵌入量可變 動的資料隱藏演算法,其可嵌入的資訊量為 2(n-2)×s。首先利用 PCA 座標空間 中的 X 軸和 Y 軸分別對所有的頂點 PPCA,i由小到大作排序,得到 X 軸排序序列 與 Y 軸排序序列。透過分割變數 s 決定切割變數 c,切割變數 c 決定子區間的個 數 v,如下式(2-9)和(2-10),同時 γ 為子區間之狀態,如下圖 2-13 所示,來決定 子區間的個數和嵌入的資訊量。
(2s 1)
c
(2-9) ( 1)v c
(2-10)X
mX
m+2例子(一)
γ
1=0γ
2=1X
mX
m+2例子(二)
γ
1=00γ
2=01γ
3=10γ
4=11X
mX
m+2例子(三) 000 001 010 011 100 101 110 111
s=1, c=1, v=2
s=2, c=3, v=4
s=3, c=7, v=8
圖 2-13:分割變數 s 與切割變數 c 與子區間個數 v 之關係 資料來源:(陳富美,2009)
然後利用式(2-11)和(2-12)進行嵌入資訊的動作,其中 Hγ為子區間之中點。
( 1 ) 2
X
mH
R v
(2-11)1 ( )
X
m H
R
(2-12) 以嵌入 2 位元的訊息為例,如下圖 2-14 所示。22
Xm Xm+2
PCA座標 空間X軸 Xm+1
「區間」
「00」 「01」 「10」 「11」
原始狀態
Xm Xm+2
PCA座標 空間X軸 Xm+1
「區間」
「00」 「01」 「10」 「11」
嵌入「00」
X 00m+1
H00
R00
Xm Xm+2
PCA座標 空間X軸 Xm+1
「區間」
「00」 「01」 「10」 「11」
嵌入「01」
X 01m+1
H01
R01
Xm Xm+2
PCA座標 空間X軸 Xm+1
「區間」
「00」 「01」 「10」 「11」
嵌入「10」
X 10m+1
H10
Xm Xm+2
PCA座標 空間X軸 Xm+1
「區間」
「00」 「01」 「10」 「11」
嵌入「11」
X 11m+1
H11
圖 2-14:嵌入 2 位元資訊 資料來源:(陳富美,2009)
綜觀上述不同的向量資料隱藏演算法,皆是透過區間的方式嵌入資料,同時 所使用的座標值均經過 PCA 轉換,因此為了提升 GML 資料隱藏技術的可應用
23
性,本研究將針對不同的應用目的,提出不同的前置處理流程,分別是 PCA 排 序法、投影排序法與直接投影法。其中可擴展之可逆式向量地圖資料隱藏演算 法,除了可嵌入的訊息量最大之外,其圖形的變形量也控制在一定範圍內。故本 研究將以陳富美於 2009 年提出的向量地圖資料隱藏技術導入 GML 空間資料格 式中,透過 GML 檔案的特性,提出改善向量地圖資料隱藏技術的方法與 GML 在地理資訊系統(Geographic Information System, GIS)上的創新應用。
2.2.4 無失真資料隱藏演算法
Bogomjakov 等學者於 2008 年提出無失真資料隱藏用於多邊形網絡(Polygon Mesh)(Bogomjakov, et al., 2008),利用置換端點排列順序的方式來嵌入訊息,如 下圖 2-15 所示,應用於容許任意置換其成分的資料集合,改善了一般無失真資 料演算法的執行時間,同時利用參照排序(Reference Ordering)的方式,可抵抗所 有幾何類型上的攻擊,但也因此降低了可嵌入的資料量。
1
2 3
嵌入訊息 = 01 3
1 2
嵌入訊息 = 00
3
2 1
嵌入訊息 = 10
1
3 2
嵌入訊息 = 11
圖 2-15:置換端點排列順序嵌入訊息
首先計算出網絡端點的參照排序,並將該端點存入 ref[]陣列中,並根據下圖 2-16 進行資料嵌入的動作,並在底下簡單介紹。
24
for i = 0,...,n-1 k ←
b ← peek(k + 1) //peek at next k + 1 bits if 2
k≤ b and b < n – i
advance(k + 1) //advance by k+1 bits else
b ← peek(k) //peek at next k bits advance(k) //advance by k bits end
perm[i] ← ref[b] //vertex b to permutation pef[b] ← ref[n - i -1] //replace with last vertex end
log2(n i
)
圖 2-16:無失真資料隱藏演算法 資料來源:(Bogomjakov, et al., 2008)
定義 n 為初始參照排序的端點總數,i 為已經重新排列的端點數,從 n – i 個 端點中挑選一個位置 b 的端點,並且將它輸出為下一個置換(Permutation)的端 點,b 為一個介於(0 , … , n - i - 1)的整數,可編碼輸入訊息 k =
log2(n i
)
個位 元。一開始先從輸入訊息中讀取 k + 1 個位元,若其 b 值小於 n – i 並且大於或等 於 2k,此時透過挑選位置 b 的端點可編碼 k +1 個位元,否則直接用 k 的 b 值當 作挑選端點的位置,此時可編碼 k 個位元。被挑選的端點輸出完畢後,便將該端點從參照排序中刪除,並且移動參照排 序中最末尾的端點到該位置,表示在參照排序中剩下的端點以連續的方式儲存於 陣列之中,因此時間複雜度為 O(n),同時可嵌入的訊息量為 log2(n!) – n + 1 個位 元。
25
第三章 研究方法
根據文獻回顧本研究發現,前述資料隱藏演算法都僅針對向量座標或特定概 念架構做研究,並未實際應用於地理資訊的檔案格式中,另外向量地圖資料隱藏 演算法所使用的座標值都經過 PCA 的轉換,導致座標值改變,使地圖的精度降 低,造成失真擴大的現象。因此本研究希望藉由將不同類型的資料隱藏演算法導 入 GML 空間資料格式,根據不同的應用目的提出不同的前置處理方法,進一步 探討可發展的 GML 資料隱藏技術應用,研究流程如下圖 3-1 所示。
GML空間資料格式資料隱藏技術
提出解決問題的方法
擬定評估準則
發展系統與執行測詴
驗證與評估
圖 3-1:研究流程26
本研究主要針對 GML 檔案提出資料隱藏技術之應用,除了實際將可擴展之 可 逆 式向 量地 圖資 料隱 藏演 算 法( 陳富美,2009) 與無失真資料隱藏演算法 (Bogomjakov, et al., 2008)導入 GML 空間資料格式中,以提升 GML 資料的安全 性外,並根據不同應用目的與地圖精度條件,針對可擴展之可逆式向量地圖資料 隱藏演算法提出三種不同的前置處理流程:PCA 排序法、投影排序法與直接投 影法,增加 GML 資料隱藏技術之可應用性,同時利用標籤語法的特性,將秘密 資料分別嵌入不同的圖徵類型與圖徵當中,藉此提升秘密資料的安全性,並且增 加可嵌入的資料量,達到 GML 空間資料格式之資料隱藏技術創新應用。同時利 用可嵌入訊息量、不可察覺性、可逆性與執行時間等評估指標,來衡量不同資料 隱藏演算法與不同前置處理方法導入之結果,評估 GML 空間資料格式資料隱藏 技術之成效。
因此底下第一節詳細分析 GML 空間資料格式,找出可應用的領域;第二節 將提出本研究的 GML 空間資料格式之資料隱藏技術,除了實際導入可擴展之可 逆 式 向 量 地 圖 資 料 隱 藏 演 算 法 ( 陳 富 美 , 2009) 與 無 失 真 資 料 隱 藏 演 算 法 (Bogomjakov, et al., 2008)外,並提出本研究之前置處理與資料嵌入流程。
3.1 GML 空間資料格式
GML 是以 XML 為發展基礎,提供多種地理資料的編碼方式,解決了異質 性資料整合的問題(林峰田,2006)。透過標籤來描述欲表達的現象,利用標籤的 屬性值來描述圖徵性質,而圖徵代表的是真實世界中的實際現象,其中屬性的值 可以是整數、浮點數或幾何等型態,甚至其他的圖徵也可以做為屬性的值。GML 空 間 資 料 格 式中 , 圖 徵 可以 分 為 兩種 屬 性, 分 別 是 拓 樸 (Topology) 與 幾 何 (Geometry),如下圖 3-2 所示(鄧東波,2004)。
27
Feature
Topology Geometry
Edge Node
Face
Point
Curve
Surface
Topology Property Grometry Property
Sub Type
Sub Type
圖 3-2:圖徵之拓樸與幾何屬性 資料來源:(鄧東波,2004)
簡單來說,拓樸是一種擺脫測量(Measurement)和距離(Distance)的一種幾何 數學上運用的方法,因為擺脫了計量法(Metrics)的約束,而能夠允許變形的發 生。在空間上,所有的扭曲、伸長或壓縮,從拓樸的角度來看,並不會對原本的 空間造成影響,因此在這個條件下,圓形和橢圓形是一樣的,球體也等於橢圓體。
且拓樸最大的特點在於:在一個已經發生變形的狀態下,仍然保有某些特定的性 質,而那些不變量(Invariants)便是拓樸所要研究的重點。有別於一般傳統的幾何 容易聯想到可測量的量,例如角度、距離、空間等等,拓樸則是著重其連續性 (Continuity)以及相對位置(Relative position)的關係。
由於本研究將導入的可擴展之可逆式向量地圖資料隱藏演算法(陳富美,
2009)與無失真資料隱藏演算法(Bogomjakov, et al., 2008),其方法架構於幾何上的 向量座標與多邊形網絡,與拓樸較無直接相關,因此本研究主要針對幾何屬性做 為導入資料隱藏技術的部分,其子類型分別為頂點(Point)、曲線(Curve)與表面 (Surface),詳述如下。
28
3.1.1 GML 頂點格式
首先頂點的部分,是以點的方式來描繪圖徵,其順序沒有意義,僅為名目上 之定義,例如標示城市位置、捷運站或疾病案例等資訊。其示意圖如下圖 3-3 所 示,語法如下表 3-1 所示。
10 60
10 60
20 30 40 50 20
30 40 50 y
x
圖 3-3:頂點語法示意圖
表 3-1:地理標記語言頂點屬性語法與說明
語法 說明
(1) (2) (3)
(4) (5)
<gml:pointArrayProperty>
<gml:Point>
<gml:coordinates>30,60 20,50 10,30 15,20 20,10 35, 0 45,10 50,30 50,45 45,55
</gml:coordinates>
</gml:Point>
</gml:pointArrayProperty>
(1) (2) (3)
以陣列的方式儲存頂點資料 定義元素為頂點
頂點的座標值,分別為 X 軸與 Y 軸座標值,中間以「,」區隔
29
3.1.2 GML 曲線格式
其次曲線的部分,是以線的方式來描繪圖徵,例如描繪公路線或下水道管線 等資訊。其示意圖如下圖 3-4 所示,語法如下表 3-2 所示。
10 60
10 60
20 30 40 50 20
30 40 50 y
x
圖 3-4:曲線語法示意圖
表 3-2:地理標記語言曲線屬性語法與說明
語法 說明
(1) (2) (3) (4) (5)
(6) (7) (8) (9)
<gml:curveProperty>
<gml:Curve>
<gml:segments>
<gml:LineStringSegment>
<gml:coordinates>30,60 20,50 10,30 15,20 20,10 35, 0 45,10 50,30 50,45 45,55
</gml:coordinates>
</gml:LineStringSegment>
</gml:segments>
</gml:Curve>
</gml:curveProperty>
(1) (2) (3) (4) (5)
定義曲線,其值域可以是幾何元 素或參照 XLink 的幾何元素 定義元素為曲線,由一或多個曲 線片段組成
為封裝曲線片段
一種曲線片段,由二維或多維座 標組成
頂點的座標值,分別為 X 軸與 Y 軸座標值,中間以「,」區隔
30
3.1.3 GML 表面格式
最後表面的部分,是以面的方式來描繪圖徵,例如描繪地形或行政區等資 訊。其示意圖如下圖 3-5 所示,語法如下表 3-3 所示。
10 60
10 60
20 30 40 50 20
30 40 50 y
x exterior
interior
圖 3-5:表面語法示意圖
31
表 3-3:地理標記語言表面屬性語法與說明
語法 說明
(1) (2) (3) (4) (5) (6) (7) (8) (9)
(10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) (32)
<gml:polygonProperty>
<gml:Polygon>
<gml:exterior>
<gml:Ring>
<gml:curveMember>
<gml:Curve>
<gml:segments>
<gml:LineStringSegment>
<gml:coordinates>30,60 20,50 10,30 15,20 20,10 35, 0 45,10 50,30 50,45 45,55 30,60
</gml:coordinates>
</gml:LineStringSegment>
</gml:segments>
</gml:Curve>
</gml:curveMember>
</gml:Ring>
<gml:exterior>
<gml:interior>
<gml:Ring>
<gml:curveMember>
<gml:Curve>
<gml:segments>
<gml:LineStringSegment>
<gml:coordinates>30,50 20,30 30,10 40,20 40,40 30,50
</gml:coordinates>
</gml:LineStringSegment>
</gml:segments>
</gml:Curve>
</gml:curveMember>
</gml:Ring>
</gml:interior>
</gml:Polygon>
</gml:polygonProperty>
(1) (2) (3)
(4) (5) (6) (7) (8) (9) (17)
定義多邊形,其值域可以是幾何 元素或參照 XLink 的幾何元素 定義元素為多邊形
定義為多邊形之外框,若要定義 中空的多邊形之內框,則可用
<gml:interior>
連接不同的邊,形成環狀結構 成分為經由 XLink 屬性的曲線或 曲線成分
定義元素為曲線,由一或多個曲 線片段組成
為封裝曲線片段
一種曲線片段,由二維或多維座 標組成
頂點的座標值,分別為 X 軸與 Y 軸座標值,中間以「,」區隔 定義中空的多邊形之內框
32
其中幾何屬性中所有子類型均架構於座標系統上,透過不同的標籤來定義不 同的圖徵型式,同時因具備自訂標籤的特性,使用者可以自由描述現象。因此本 研究認為 GML 空間資料格式可用於可擴展之可逆式向量地圖、無失真以及與頂 點相關的資料隱藏演算法,並且可根據應用目的與地圖精度條件來進行不同的前 置處理方式與選擇嵌入訊息的圖徵類型與圖徵,同時可嵌入的資訊包含詮釋資料 或 GML 空間資料格式之屬性資料。第二節將詳細介紹本研究提出之 GML 空間 資料格式資料隱藏技術之嵌入資料流程,最後第三節介紹擷取資料之流程。
33
3.2 資料嵌入流程
本研究之資料嵌入流程如下圖 3-6 所示。
GML檔案
標籤讀取與分析
精度條件 容量分析
訊息嵌入
頂點 曲線 表面 秘密訊息
選擇演算法
選擇嵌入位置
參照排序
偽裝GML檔案 無失真資料
隱藏演算法
可擴展之可逆式 向量地圖資料隱
藏演算法 選擇前置處理流
程與嵌入位置
投影排序法
PCA排序法 直接投影法
投影座標與 兩軸排序 PCA轉換與
兩軸排序
投影座標無 重新排序
圖 3-6:資料嵌入流程
34
首先開啟 GML 檔案,除了擷取標籤進行分析外,並記錄該地圖資料的精度 條件,例如 1/5,000、1/10,000 或 1/25,000 等比例。然後擷取「頂點」、「曲線」與
「表面」三種類型的屬性資料後,根據秘密訊息的容量大小與 GML 檔案的精度 條件來選擇使用的資料隱藏演算法、前置處理的流程與嵌入資料的圖徵類型與圖 徵,最後進行秘密訊息嵌入的動作,得到偽裝 GML 檔案。
其中可擴展之可逆式向量地圖資料隱藏演算法的前置處理流程共分為三 種:「PCA 排序法」,將端點座標進行 PCA 轉換,得到兩軸資料,並分別進行排 序,得到兩軸序列;「投影排序法」,將端點的座標值投影到兩軸上,得到兩軸資 料,並分別進行排序,得到兩軸序列;「直接投影法」,將端點的座標值投影 (Projection)到兩軸上,得到兩軸資料,不進行排序的動作。而無失真資料隱藏演 算法的前置處理流程,僅需計算參照排序即可。另外嵌入資料的圖徵類型為幾何 屬性中之子類型,分別為:頂點、曲線與表面,分別進行資料隱藏的動作,分類 如下圖 3-7 所示,並分述如下。
GML檔案
頂點 曲線 表面
多個單一頂點 多個頂點
單一曲線 多條曲線
單一表面
多個表面
圖 3-7:嵌入資料之圖徵類型分類35
3.2.1 頂點之圖徵類型
頂點之圖徵類型可分為「多個單一頂點」與「多個頂點」兩種子類別,其中 多個單一頂點的部分,例如台灣地圖中五個直轄市的位置,如下圖 3-8 所示。每 個頂點代表不同的意義,可分開獨立使用,因此頂點的屬性值都跟隨著頂點,同 時只有一組頂點座標值。若針對累積多個單一頂點進行資料隱藏的動作,因頂點 數不足,若產生變形就更容易被察覺,而且需要移動大量的屬性資料,可能造成 資料損壞,因此本研究不對此類別進行資料隱藏的動作。例如針對標示台北市位 置的頂點進行資料隱藏的動作,因為只有一組頂點座標,故無法套用於可擴展之 可逆式向量地圖與無失真資料隱藏演算法;若將標示五都所在位置的頂點座標集 合起來進行資料嵌入的動作,可嵌入的訊息量非常少,同時需移動大量的屬性資 料,因此本研究不針對此類別嵌入資料。
36
新北市 台北市
台中市
台南市
高雄市
圖 3-8:台灣五直轄市所在位置
至於多個頂點類別,因頂點之間沒有直接相關,同時頂點的排列順序無特別 意義,故擷取各頂點之座標後,選擇適當的隱藏演算法,並依情況進行對應的前 置處理流程。
讀取標籤內容演算法如下圖 3-9 所示,其中「model」用來儲存 GML 空間資 料格式內的資料,「n」為記錄圖徵順序與編號。
37
FileInputStream File = new FileInputStream(gmlFile);
InputStreamReader ISReader = new InputStreamReader(File);
StreamTokenizer ST = new StreamTokenizer(ISReader);
Model2D model = new Model2D();
int n = 1;
scan:
while (true) {
switch (ST.nextToken()) { case StreamTokenizer.TT_EOL:
break;
case StreamTokenizer.TT_EOF:
break scan;
case StreamTokenizer.TT_WORD:
if (“gml:pointArrayProperty”.equals(ST.sval)) { ST.nextToken();
if (“gml:Point“.equals(ST.sval)) { ST.nextToken();
if ("gml:coordinates".equals(ST.sval)) { ST.nextToken();
while (ST.ttype != StreamTokenizer.TT_WORD) { if (ST.ttype == StreamTokenizer.TT_NUMBER) { x = ST.nval;
ST.nextToken();
y = ST.nval;
ST.nextToken();
Model.addVertex(x,y,n);
n++;
} else break;
}}}}}}
ISReader.close();
圖 3-9:讀取頂點標籤內容演算法
詳細步驟如下:
Step 1: 開啟 GML 檔案,讀取標籤內容。
Step 2: 搜尋<gml:pointArrayProperty>標籤。
Step 3: 判斷子標籤,找出<gml:Point>標籤。
Step 4: 判斷子標籤,找出<gml:coordinates>標籤。
Step 5: 擷取<gml:coordinates>與</gml:coordinates>標籤所包覆的座標值。
Step 6: 將 X 軸與 Y 軸座標分開儲存。
例如:<gml:coordinates>與</gml:coordinates>標籤所包覆的屬性值為
38
「30,60 20,50 10,30 15,20 20,10 35, 0 45,10 50,30 50,45 45,55」,因此 X 軸座標序列為「30, 20, 10, 15, 20, 35, 45, 50, 50, 45」, Y 軸座標序 列為「60, 50, 30, 20, 10, 0, 10, 30, 45, 55」。
Step 7: 重複執行上述步驟,直到所有的座標值都讀取完畢,才執行底下步 驟。
Step 8: 將得到的兩軸座標序列,根據所選擇的資料隱藏演算法與前置處理 流程,進行資料嵌入的動作。
3.2.2 曲線之圖徵類型
曲線之圖徵類型可分為「單一曲線」與「多條曲線」兩種子類別,首先單一 曲線的類別,因曲線當中的端點之間有關連性,同時不可任意更換端點的排列順 序,因此擷取各端點之座標值後,先記錄起始點與終點的座標值與原始排列順 序,接著選擇資料隱藏演算法,並依情況進行對應的前置處理流程,演算法如下 圖 3-10 所示。