An Intelligent News Recommender Agent for Filtering and
Categorizing Large Volumes of Text Corpus
Jung-Hsien Chiang* and Yan-Cheng Chen
Department of Computer Science and Information Engineering National Cheng Kung University
Tainan, Taiwan
Abstract
This paper presents an intelligent news recommender agent, called INRA, which can be used to filter news articles, as well as to recommend relevant news for individual user automatically. Three specific objectives underlie the presentation of the intelligent news recommender agent in this paper. The first is to describe the basic architecture of this approach, and the second is to show the design of the fuzzy hierarchical mixture of expert model for text categorization. The third and more elaborate goal is to demonstrate that the proposed system is able to perform news recommending process. We illustrate this approach with standard benchmark examples of the Reuters-21578 in order to verify the effectiveness of news recommending.
Key words: automatic text categorization, intelligent agent, news recommendation,
fuzzy networks, information retrieval
______________________________________________________________
1. Introduction
Exponential growth of the number of information sources accessible through the Internet makes searching for relevant information complicated. Almost everywhere in the world user can access tens of thousands of news articles of potential interest via the World Wide Web. One needs information filters to provide news articles according to priority so that user can spend more time reading articles of interest. Most of the filtering jobs were done by human experts. However, while humans are generally smart at deciding which information is good and why, they are much slower compared with the huge amount of information out there that requires filtering. Information overload is no longer just a popular jargon, but a daily reality for most of us. This leads to the demand for automated methods commonly referred to as intelligent agents that recommend news articles according to individual preferences.
Problem description
News recommending is a process of organizing user profiles and utilizing this information to better recommend desired stories for future reference. In general, users may use simple keywords to perform a news search in the recommending process from large volumes of documents. Another way to handle such data is to provide hierarchical categories to the users. This will enable users to search or read only those categories of interest to them. However, the set of documents of interest to a particular user seldom match exactly the existing categories. The inherent difficulty of news classification implies that each news document belongs to multiple categories and has different degrees of belongingness in respective categories. Figure 1 depicts a classic example. This document belongs to “jobs”, “GNP”, and “trade” categories in Reuters news data set.
Traditional application approaches build an individual classifier for each category. A news document is processed by each classifier to determine if the corresponding category is appropriate. It is ineffective to scan all the distributed categories in the data set. For example, Reuters data set has more than 100 categories. Instead, it is a better solution for a user to specify a filter that scans several potential categories in order to select interesting documents.
<TITLE>JAPAN UNEMPLOYMNENT RISES TO RECORD IN JANUARY</TITLE>
Japan's seasonally adjusted unemployment rate rose a record 3.0 pct in January, the worst since the Government started compiling unemployment statistics under its current system in 1953,up from the previous record 2.9 pct in December, the government's Management and Coordination Agency said.
Unemployment was up from 2.8 pct a year earlier. Unadjusted January unemployment totaled 1.82 mln people, up from 1.61 mln in December and 1.65 mln a year earlier.
Male unemployment in January remained at 2.9 pct, equal to the second-worst level set last December. Record male unemployment of 3.1 pct was set in July 1986.
Female unemployment in January remained at 3.0 pct, equal to the record level marked in April, August, September and December last year.
January's record 3.0 pct unemployment rate mainly stemmed from loss of jobs in manufacturing industries, particularly in export-related firms, due to the yen's continuing appreciation against the dollar, officials said.
Employment in manufacturing industries fell 380,000 from a year earlier to 14.30 mln including 1.83 mln employed in the textile industry, down 190,000 from a year earlier, and 1.06 mln in transport industries such as carmakers and shipbuilders, down 170,000.
Figure 1 Sample of a news story
The recommender system described in this paper uses an automatic text categorization-based method for recommending news articles to the users. Specifically, we provide a unique approach combining hierarchical text categorization and content-based filtering to recommend news documents that implements the tweak application, a double similarity finding procedure. Our approach fully realizes the strengths of content-based filters to overcome search drawbacks, such as similarity finding in simple keyword-based matching process. The automatic text categorization mechanism utilizes fuzzy network-based nonlinear decision framework to predict categories, and the learning procedure conducted for category assignment using the collection of positive and negative exemplars in training corpus. In contrast to natural language processing scheme developed from linguistic domain models, our approach is essentially documents driven. A set of appropriate categories with degrees of confidence is obtained for an unknown document in a single-pass run. We assume no theoretical model of what categories can be predicted given a document, but rather induce statistically a non-linear decision tree framework for category assignment from a collection of positive and negative examples.
Related Research
Research on intelligent information recommendation has attracted much attention recently [Goldberg, 1992; Resnick, 1997; Claypool, 1999]. For a news filter, some approaches support filtering according to content of documents [Malon, 1987; Pollock, 1988; Balabanovic, 1997; Mooney, 1998]. In content-based filtering, several systems were designed to support collaborative filtering [Billsus,1998; Joaquin, 1998; Konstan, 1998; Ahmad, 1999], and it simply means that the people collaborate to help
one another by recording their reactions to documents which they read that can be particularly interesting or not.
Text categorization can be constructed manually or by machine learning techniques. There has been extensive work on automatic text categorization using pre-labeled training text [Apte, 1994; Koller, 1997; Ng, 1997; D’Alessio, 1998; Joachims, 1998; McCallum, 1998; Lam, 1999]. Many different algorithms have been used for text categorization, including Bayesian classifiers [Yang, 1999], neural networks [Wiener, 1995; Manevitz, 2000], decision tree algorithms [Lewis, 1994; Cohen, 1996; Frasconi, 1999], and k-nearest-neighbor algorithms [Yang, 1999] from machine learning methodology.
The organization of this paper is as follows. We first give an outline of the news recommender agent architecture in Section 2, and then describe the INRA engine. In Section 3, we describe the proposed hierarchical text categorization model. We also provide a schematic structure of the fuzzy networks. Experiments are then discussed.
2. The INRA Architecture
The Intelligent News Recommender Agent (INRA) assists the users in the task of classifying documents automatically, and recommending them to the users according to the reading profiles. In our experiments, recommending tests were conducted using INRA for the Reuters news documents domain. In the following, we will describe the architecture of INRA in detail, which has been designed specifically for efficient processing of news articles.
2.1 Basic INRA Architecture
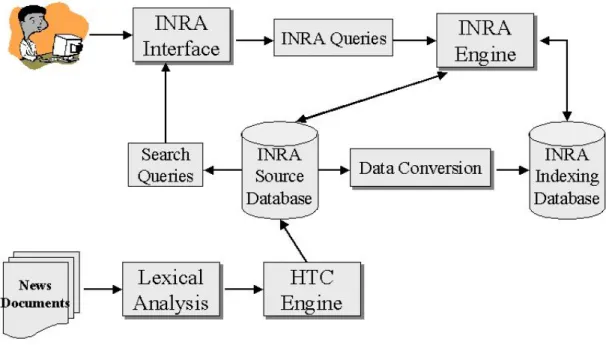
Figure 2 illustrates the overall architecture of the INRA. It consists of two parts –text categorization and recommender mechanism in the INRA system. Text categorization involves lexical analysis and hierarchical text categorization (HTC) engine. The remainders belong to the recommender mechanism. The task of text categorization is to assign categories for the incoming documents correctly, whereas the task of recommender mechanism is to recommend the most relevant documents with respect to users’ query. Integration of both methods is a good way to address the automated news routing application.
Figure 2 The overall INRA architecture
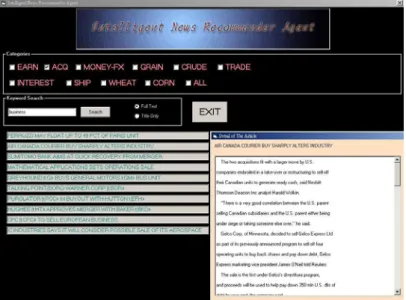
Figure 3 shows the user interface of the INRA system, which recommends personalized news stories to the user. Currently, the system provides access to news
stories both from 10 major news categories in Reuters-21578 data set and from the whole data set. When the user selects a particular news category, the system contacts that news category in the indexing database, and starts to receive requests and forward them to the INRA engine. The user can also ask the agent to compile a series of personalized recommending news. The goal of this process is to compute a sequence of news stories ranked according the user’s interests.
Figure 3 The INRA user interface
There are two different databases in the INRA system. The source database contains all original news documents, while the indexing database converts source documents to plain texts by the data conversion component. This database stores the keywords, the classification tree obtained by the HTC engine module, and the location of each document indexed. The purpose of the indexing database is to reduce computation time with respect to similarity measurement between documents.
The purpose of the lexical analysis phase is the identification of the words in the text. In this work, the following four particular cases are considered with care: digits, hyphens, punctuation marks, and the case of the letters (lower and upper case).
2.2 The INRA Engine
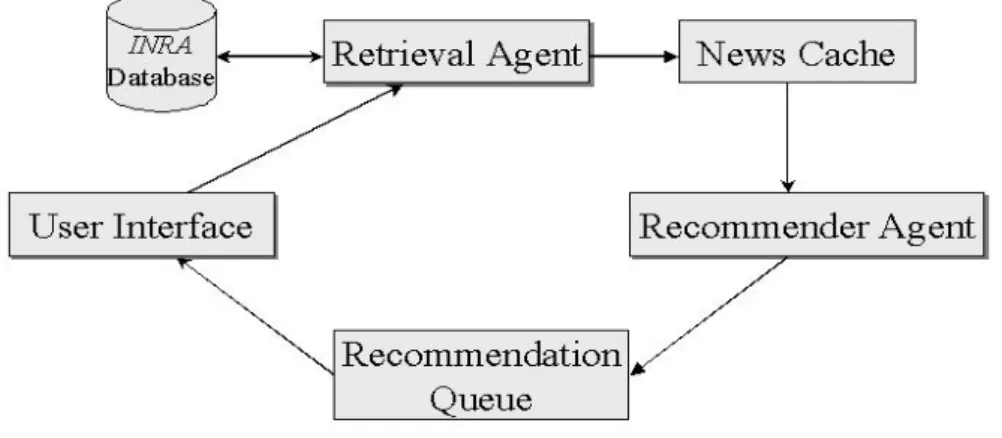
There are three main components – retrieval agent, sorting agent, and recommender agent in the INRA engine, as shown in Figure 4. Here is the working procedure for them. The retrieval agent contacts the INRA database, retrieves the related news articles, and then inserts them into the local news cache. The news cache
is used to accumulate all articles waiting to receive a relevance score. The recommender agent takes articles out of the news cache, and computes the relevance score. The top 10 high scores are kept in the sorted recommendation queue. When the user reads any one of those news articles, the user interface will take the top story out of the recommendation queue, and forward it to the user. The task of the sorting agent is to return a fixed-size rank list of target entities of length n (n = 10 in this work) ranked by its similarity to source entity.
Figure 4 The architecture of the INRA engine
The recommender agent involves similarity-finding and tweak-application. To perform similarity-finding, a large set of candidate articles is initially retrieved from the database. This candidate set is sorted according to the source query, and the top few candidates are returned to the user. Tweak-application is essentially the same as similarity-finding except that the candidate set is filtered prior to sorting, leaving only those candidates that satisfy the tweak. In this work, we use a simple term frequency and inverse document frequency (TFIDF) approach for similarity-finding. It filters out many candidates in tweak-application and returns the top few articles of interest to the user.
The main role of tweak-application in the recommendation agent is to retrieve the most related articles according to the articles that the user reads. It computes similarity values between the articles that user read before and the articles in the database. The similarity measure we used is Pearson correlation coefficient [Shardanand, 1995]. It provides a correlation measure between documents using term frequency. In the next section, we will describe the HTC engine in more detail.
3. Proposed Hierarchical Text Categorization (HTC) Model
The purpose of text categorization is to assign text documents to one or more predefined categories according to their contents. Many classification algorithms for text articles have been developed and extensive research results are available. However, very few of them are for automatic news recommender system or search engine even though news articles are available. In addition, there is no common agreement for news classes. Each method has its particular structure and classification scheme.
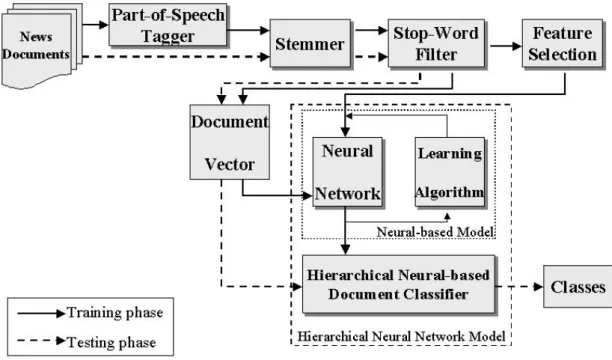
Hierarchical Text Categorization (HTC) engine is a kernel for text categorization inside the INRA. Figure 5 shows the proposed HTC model. A detailed description of the behavior of each component is described as follows.
Figure 5 The proposed hierarchical text categorization model
3.1 Feature Extraction and Selection
In machine learning, many have argued that maximum performance is often achieved not by using all available features, but by using only a “good” subset of those. This problem of finding a “good” subset of features is called feature selection. Applied to text categorization, this means that we want to find a subset of words, which helps to discriminate between classes. News documents are the collection of
text written in natural language. In order to extract important information from documents, we utilize a 3-stage feature extraction process. For the first step, we label occurrences of each word in the document as a part of speech in grammar. This is called the “Part-of-Speech (POS) Tagger” [Brill, 1994]. The POS tagger discriminates the part of speech in grammar of each word in a sentence and labels them. After all the words are labeled, we select those labeled as noun as our candidates. We then use the stemmer to reduce variants of the same root word to a common concept, filter the stop words, and finally remove the plurals.
Despite using stop list and stemming, which are techniques that reduce the number of words, the size of the document vector is usually too large to be useful for training a classification algorithm. In this paper, we use a TFIDF-based method to reduce the number of features as follows:
|| || log ) log 1 ( 2 , , d n N tf w t d t d t (1)
where the denominator || d|| is the 2-norm of document vector d; tft,d is the number of times the word t occurs in document d, n is the number of documents the t word t occurs, and N is the total number of documents. In this work, each category has an individual classifier. Therefore, to select a subset of features for each category, the top 200 words with the high weight values are chosen. After feature selection and training process, the trained classifier is ready to be used for categorizing a new document. The classifier is typically tested on a set of documents that are distinct from the training set.
3.2 Hierarchical Fuzzy Network Classifier
The serious problem of overlapping categories can not be easily solved by the classical classification approach. Since the implementation of the discriminant analysis requires determining statistical models in order to estimate decision boundaries, it becomes impractical for the case of each document having multi-category. In this paper, we proposed an improved implementation through the modified hierarchical mixture of expert (HME) model [Jordan, 1993; Ruiz, 1999]. We construct the hierarchical structure of fuzzy networks by using the HME model
derived from “the divide and conquer” principle. The main idea is to solve the problem by dividing it into smaller problems that are easier to solve, and then combine the solutions of small problems to obtain the overall solution. The HME model approaches the solution of a complex classification problem by dividing the input space into a nested sequence of regions and then train smaller classifiers that are specialized in classifing a reduced domain. The proposed model has two basic components: gating networks and expert networks. These components are organized as a tree structure where the internal nodes are the gates, and the leaf nodes are the experts. Figure 6 shows a schematic view of our model for a multiple level hierarchy. The categorization task starts at the root node. The gate decides whether any of its descendants need to check the input message. If this is true, then all the second-level nodes are activated and the process repeats until a leaf node is reached.
Figure 6 The proposed hierarchical classification scheme
It can be seen that we extend the HME’s architecture as hierarchical filters. Each node represents one filter. The filter decides whether the input document belongs to the corresponding category or not, and it bears analogy with a non-linear decision-maker. In other words, the overall architecture can be interpreted as a “non-linear” decision tree. In the proposed model, the gating networks govern the
evaluation of the unknown documents for successive sub-categories. Unknown news documents are represented by vectors. If the document contains the concept represented by that node, then the output confidence value of the network should be high; otherwise, low. In this work, the propagation flow is from left to right. The expert networks learn to recognize documents corresponding to specific categories whereas the gating networks learn to recognize documents corresponding to successive sub-categories in the training procedure using a set of selected documents.
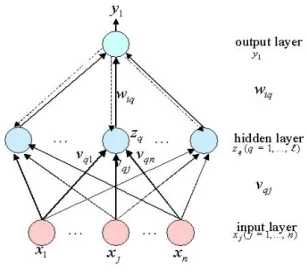
In both gating and expert networks, we consider not only whether a document is assigned to correct categories, but also whether the obtained degrees of possibilities of that document belonging to the corresponding categories are proper. The basic idea of the fuzzy network [Gader, 1995] is to compute a numeric score for a document to be classified according to its degree of membership in a certain category, and assign the document to that category if the numeric score is larger than the specified threshold value. We use the back-propagation learning algorithm for both gating and expert networks. The fuzzy networks that we use have three layers, as shown in Figure 7. The input layer consists of a set of features selected for each expert (or gate), the output layer is a single node, and the middle layer has a fixed number of hidden nodes.
Figure 7 Three-layer fuzzy network
In general, the output value of the neural network can be viewed as a label that classifies an object (document) to the specific category or not. We go beyond this in introducing the possibility distribution for the output categorical memberships, given a document as input. The membership value of the fuzzy network output in a category represents the typicality of the document in the category or the possibility of the document belonging to the category. Therefore, we specify the target confidence value
dj for network j as a corresponding membership function of fuzzy set
f +(x) = E (dj | x+) = n/ K (2)
f -(x) = E (dj | x-) = (K – n)/ K (3)
where E (.) is the statistical expectation and n is the number of positive documents x+
among K neighbors in the training set. It is indeed a fuzzy version of the K-Nearest Neighbors (K-NN) estimation since the true target function f(x) is interpreted as the degree of possibility of document x belonging to the category. It also satisfies the following conditions
x
0,1 f (4) 1 ) ( ) ( x f x f . (5)The K-nearest-neighbor scheme attempts to assign each document a confidence value with respect to the possibilistic distribution of positive training exemplars. Thus, the supervised learning problem for the fuzzy network is equivalent to estimating the corresponding fuzzy membership function in (2) and (3). It is reasonable to expect that imposing the corresponding constraints (4) and (5) on the resulting approximation f(x) should improve accuracy since outside information of the training data is being incorporated. We use the fuzzy K-NN scheme to train both expert and gating networks in this work. The expert networks train to recognize documents corresponding to specific categories, while the gating networks train to recognize documents corresponding to all successive sub-categories. Once gates and experts have been trained individually, we assemble them according to the proposed hierarchical structure. Since the output of the network has a confidence value between 0 and 1, we need to transform this fuzzy decision to a binary decision along the hierarchy for the purpose of classification. We will describe the detailed procedure in Section 4.
4. Experimental Design and Analysis
In this section, we present experiments to investigate the utility of the proposed INRA system, demonstrating that it can offer significant advantages in news recommending scenario. First, we present the automatic text categorization to illustrate our approach. We then demonstrate that the INRA system can be used to recommend appropriate news for users.
4.1 The Corpus
As a test bed for the experiments, we used the Reuters-21578 data set which comprises of 21578 news documents made publicly available for text categorization research [Lewis, 1996]. The size of the corpus is 28,329,363 bytes, yielding an average document size of 1,312 bytes per document. We consider only the categorization along the TOPICS axis. Almost half of the documents (e.g. 10,211 stories) have no topic and we do not include these documents in either training or testing sets. This leaves 11,367 documents with one or more topics. In our experiments, we divided the documents into a test set (of about 3000 documents) and a training set (the remainder) using a standard split suggested by the annotated Reuters collection. A few sample documents are shown in Figure 8. The average length of the stories is about 91 words, but some are as short as a sentence and others are as long as several pages.
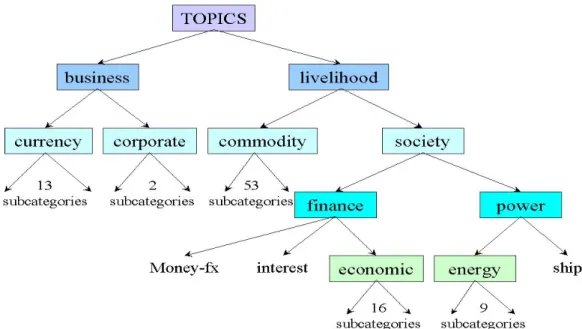
In this work, we constructed our own hierarchy of the 96 categories according to the relationships between the categories. The hierarchical structure of the categories illustrated in Figure 9 is derived from the correlation between categories in the way that they are assigned to documents. Categories are combined together if they co-occur frequently. We also exploit the category hierarchy in a top-down fashion to achieve performance improvements in the learning algorithms.
Figure 8 Sample news stories in the Reuters-21578 corpus.
4.2 Automatic Text Categorization Performance
In this section, we will describe the proposed hierarchical text categorization and some issues in the experiments. In the training phase of the text categorization, our experts and gates are trained individually, then we assemble them according to the hierarchical structure described before. The output confidence value of the gating networks is a real value between 0 and 1, and we need a threshold to transform it to a binary decision. To select the threshold value for each gating network, we decide the initial value according to the error rate of each category in the training phase, and then adjust the threshold value at each gate that maximizes the average F1 value for all the successive networks. When a new document arrives, it starts from the root node and the gate decides whether the document belongs to its sub-categories or not. If it is true, then all the second-level nodes are activated and the process repeats until a leaf node is reached. However, if an error is made at an upper level in the hierarchy, the document will stay possibly in the internal node.
To avoid this problem, we propose a method for selecting proper threshold values in multiple levels of the hierarchy. The key is that we set the lower the threshold values for the upper gates. The purpose of this idea is that the documents will reach the leaf nodes (expert networks) as far as possible, and filters the documents which do not belong to the gate to reduce the processing time. In this work, the threshold values within gating networks are set between 0.4 and 0.7 depending on the training results.
An important issue of text categorization is how to measure the performance of the classifiers. To evaluate the performance of the HTC system, we use measures of precision and recall. Moreover, we also evaluate precision and recall in conjunction, i.e. theFmeasure. Here we assign equal importance to precision and recall, resulting in the following definition forF1:
2 1 recall precision recall precison F
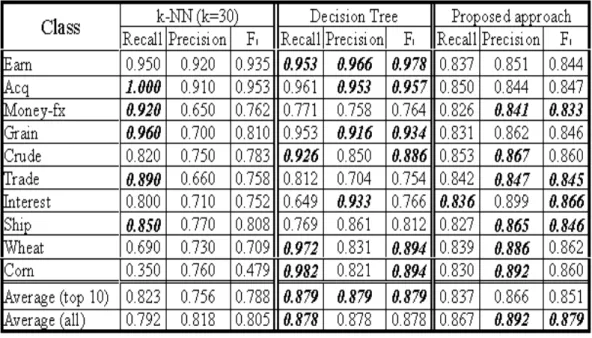
Table 1 shows the performance comparison between the proposed hierarchical model, the decision tree [Weiss, 1999], and the K-NN classifiers [Aas, 1999] for both the 10 most frequent categories and all categories. The result shows that the performance of the proposed HTC classifier is quite acceptable.
Table 1 Performance comparison between the proposed classifier, the K-NN method, and the decision tree
Furthermore, we made several important observations in this experiment. The advantage of the fuzzy network-based HTC is that it provides not only a set of categories, but also a set of graded membership values, and these membership values are essentially the confidence values of the document belonging to respective categories. Figure 10 depicts an example.
For a classifier to be useful in text categorization application, it demands high precision and high recall rates. But in both the K-NN and decision tree methods, they tend to have high recall but low precision, or have high precision but low recall. The differences between recall and precision are close to 40 percent in the K-NN approach and more than 25 percent in the decision tree approach. By contrast, it is less than 10 percent in the proposed system. Although our precision in some categories is lower than that of both the K-NN and decision tree, it can be seen that our system is more reliable than those two methods. In addition, our algorithm shows poor performance in several categories which have short news articles. Since these few articles can not provide sufficient information to the training set, it is reasonable to cause misclassification.
4.3 INRA System Performance
Apart from studying the effectiveness of automatic text categorization, the objective of this experiment is to investigate the utilization of the HTC process on the INRA system performance. Specifically, we study whether the HTC categorization will improve the performance compared with no HTC categorization. In order to evaluate the INRA system, we set up the experiment for the “Investment Management” course offered by the Department of Information Management, Chaoyang University of Technology, Taiwan. Students who took this course were asked to write a term paper of an investment case study using the Reuters news documents between the years of 1993-1996. In this experiment, more than 120 students were asked to interact freely with INRA during two weeks, and to record experimental results of average retrieval time for querying news documents using both the hierarchical text categorization (HTC) module and the plain keyword search module.
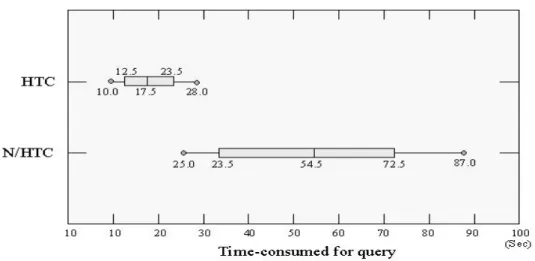
The INRA prototype system was packaged as a writing assistant for personal computers via the local area network sharing the Reuters news database, and most of the computers are Pentium-3 CPU 450MHz. Each student utilizes the writing tool to query desired news articles for specific investment target. The purpose of this experiment is to estimate the time spent on desired news query, and whether they use the HTC module or not. To illustrate the difference between using HTC and without using HTC, the box plots in Figure 11 show the distribution of time consumed for query using both approaches. The central line in the box indicates the median value,
while the horizontal lines extending from the left to the right of the box show the entire range of the time consumed for those 105 valid samples. We found that the time consumed for query without using HTC (N/HTC) is almost 3 times longer than that using HTC.
The two experiments described above demonstrate that it is not only feasible to utilize the HTC on content-based filtering, but also improves the recommendation effectiveness in the Reuters news database.
Figure 11 Box plots of the time consumed for the INRA system with and without HTC
5. Conclusions
Combining the hierarchical text categorization method with content-based filtering yields an intelligent news recommender agent, and it is particularly promising because the recommending performance is quick and reliable. Detailed analysis of the outputs of expert networks using the K-NN training strategy shows that good text categorization performance can be achieved by a fuzzy hierarchical mixture of expert model. It is surprising that the proposed approach was as good as or slightly better than the original K-NN classifier, given that the K-NN was one of the best approaches on Reuters news corpus. The INRA system assigned as a term report writing tool for a business investment course provides quick response to retrieval of desired news documents, suggesting a possible application in personalized document retrieval domain.
6. Acknowledgement
This research work was supported in part by the National Science Council Research Grant NSC90-2213-E-006-089.
References
Apte, C., Damerau, F. and Weiss, S., “ Automated Learning of Decision Rules for Text Categorization”, ACM Trans. on Information Systems, 12(3), 1994, pages 233-251,
Aas, K., and Eikvil, L., "Text categorization: A Survey", Report No. 941, Norwegian Computing Center, June, 1999, ISBN 82-539-0425-8.
Ahmad M. and Ahmad W., "Collecting User Access Patterns for Building User Profiles and Collaborative Filtering", In proceedings of the 1999 International Conference on Intelligent User Interfaces, 1999, pages 57-64.
Balabanovic, M., and Shoham, Y., "Fab: Content-based, collaborative recommendation", Communications of the ACM, 40(3) (1997) pages 66-72.
Billsus, D., and Pazzani, M. J., "Learning collaborative information filters", In Proceedings of the Fifteenth International Conference on Machine Learning, Madison, WI, 1998. Morgan Kaufman, pages 46-54.
Brill, E., Rule Based Part of Speech Tagger, Version 1.14, 1994, (http://www.cs.jhu.edu/~brill/RBT114.tar.Z ).
Claypool, M., Gokhale, A., Miranda, T., Murnikov, P., Netes, D., and Sartin, M., "Combining Content-Based and Collaborative Filters in an Online Newspaper ", In Proceedings of ACM SIGIR Workshop on Recommender Systems, August 19, 1999. Cohen, W. W. and Y. Singer, “ Context-Sensitive Learning Methods for Text Categorization”, Proc. of the 19th ACM SIGIR International Conference on Information Retrieval, 1996, pages 307-315.
D’Alessio, S. Kershenbaum, A. Murray, K. and Schiaffino, R., Hierarchical Text Categorization, Proceedings of the Sixth Workshop on Very large Corpora (COLING - ACL '98), 1998, pages 66-75.
Frasconi, P, Gori, M., and Soda, G., “ Data Categorization Using Decision Trellises”, IEEE. Trans. on Knowledge and Data Engineering, 11(5), 697-712, 1999.
Gader, P., M. Mohamed, and J.-H. Chiang, " Comparison of Crisp and Fuzzy Character Neural Networks in Handwritten Word Recognition", IEEE Trans. on Fuzzy System, 3(3), 357-363, 1995.
Goldberg, D., Nichols, D., Oki, B. M., and Terry, D., "Using collaborative filtering to weave an information tapestry", Communications of the ACM, 35(12), Dec 1992, pages 61-70.
Joachims, T., "Text categorization with Support Vector Machines: Learning with many relevant features", In Machine Learning: ECML-98, Tenth European Conference on Machine Learning, 1998, pages 137-142.
Joaquin D., Naohiro I., Tomoki U., Content-based Collaborative Information Filtering: Actively Learning to Classify and Recommend Documents, in Cooperative Information Agents (CIA1998), 1998, pages 206-215.
algorithm, Technical Reports A.I. Memo No. 1440, Massachusetts Institute of Technology, 1993.
Koller, D., and Sahami, M., "Hierarchically classifying documents using very few words", Proceeding of the 14th International Conference on Machine Learning ICML97, 1997, pages 170-178.
Konstan, S. B., Konstan J. A., Borchers, A., Herlocker, J., Miller, B., and Riedl, J., Using Filtering Agents to Improve Prediction Quality in the GroupLens Research Collaborative Filtering System, Proceedings of the 1998 Conference on Computer Supported Cooperative Work, Nov 1998, pages 345-354.
Lam, W., “Intelligent Content-based Document Delivery via Automatic Filtering Profile Generation”, Int’l Journal of Intelligent Systems, 14(10), 963-979, 1999.
Lewis D. D., and Ringuette, M., "A comparison of two learning algorithms for text categorization", In Third Annual Symposium on Document Analysis and Information Retrieval, 1994, pages 81-93.
Lewis, D. D., Reuter-21578 collection, 1996
http://www.research.att.com/~lewis/reuters21578.html.
Malone, T. W., Grant, K. R., Turbak, F. A., Brobst, S. A., and Cohen, M. D., "Intelligent information sharing systems", Commun. ACM 30, 5 (May 1987), pages 390-402.
Manevitz, L. M., and Yousef, M., Document classification on neural networks using only positive examples, ACM SIGIR, 2000, pages 304-306.
McCallum A., Rosenfeld R., Mitchell T., and Ng A.Y., "Improving text classification by shrinkage in a hierarchy of classes", in Machine Learning, Proceedings of the Fifteenth International Conference (ICML'98), 1998.
Mooney, R. J., Bennett P. N., and Roy, L., "Book Recommending Using Text Categorization with Extracted Information", AAAI-98/ICML-98 Workshop on Learning for Text Categorization and the AAAI-98 Workshop on Recommender Systems, Madison, WI, July 1998.
Ng, H. T., Gog, W. B., and Low, K. L., "Feature selection, perceptron learning, and a usability case study for text categorization", In Proceedings of the Twentieth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, July 1997, pages 67-73.
Pollock, S., "A rule-based message filtering system", ACM Trans. Inf. Syst. 6, 3, Jul. 1988, pages 232-254.
Resnick, P. and Varian, H. R., "Recommender systems", Communications of the ACM, 40(3), 1997, pages 56-58.
Ruiz, M. E., and Srinivasan, P., Hierarchical Neural Networks for Text Categorization, in Proceeding of the 22nd
ACM SIGIR International Conference on Information Retrieval, 1999, pages 281-282.
Shardanand, U., and Maes, P., "Social information filtering: Algorithms for automating "word of the mouth"", Proceedings of the Annual ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'95), 1995, pages 210-217. Weiner, E., Pedersen, J., and Weigend, A., "A Neural Network Approach to Topic
Spotting", In Proceedings of the Fourth Annual Symposium on Document Analysis and Information Retrieval (SDAIR'95), 1995, pages 317-332.
Weiss, S.M., Apte, C., Damerau, F.J., Johnson, D.E., Oles, F.J., Goetz, T., Hampp, T., "Maximizing text-mining performance", IEEE Intelligent Systems, Volume: 14 Issue: 4, July-Aug. 1999
Yang, Y., "An evaluation of statistical approaches to text categorization", Journal of Information Retrieval, 1, 1999, pages 67-88.