明新科技大學 校內專題研究計畫成果報告
有限元素平行化三維
Poisson-Boltzmann Equation
程式之應用
Application of a 3-D Parallelized Poisson-Boltzmann Equation
Solver Using Finite Element Method
Abstract
Concurrent computation by taking the advantage of nearly 100% parallelism inherited with Poisson-Boltzmann eq. is the most feasible and efficient way to substantially reduce the computational cost. Parallel computation of Poisson-Boltzmann on PC clusters is an excellent alternative to that on expensive parallel machines due to its higher availability and much lower cost, especially in Taiwan. In this project, we will create a PC cluster, including server, computational nodes and high-speed switch/HUB, in order to program and test the parallel codes for the users.
Besides, it is proposed to apply a physical domain decomposition using message passing interface (MPI) and second-order shape function of Finite element method, to dynamically balance the workloads among the processors in the parallel implementation of Poisson-Boltzmann equation on heterogeneous PC clusters. Unstructured mesh is adopted for its flexibility in handling the boundary conditions and complicated object geometries.
目 錄
中文摘要... I Abstract ...II 目錄... III Chapter 1 簡介... 1 1-1 計畫動機 ... 1 1-2 論文回顧 ... 1 Chapter 2 叢集式電腦建置... 3 2-1 系統架構 ... 3 2-2 叢集式電腦程式設計的技巧 ... 4 2-2 Fortran程式撰寫技巧... 4 2-2-1 程式撰寫與編譯... 4 2-2-2 流程控制... 6 2-2-3 迴圈... 7 2-2-4 副程式及開檔案... 8 2-3 Cluster程式撰寫技巧... 9 2-3-1 PC Cluster介紹與指令 ... 9 2-3-2 MPI基本指令... 13 2-3-3 MPI集體通訊—廣播 (MPI_BCAST) ... 14 2-3-4 點對點通訊—傳送與接收 (MPI_SEND與MPI_RECV) ... 15 2-3-5 集體通訊—資料分派與集中 (MPI_SCATTER與MPI_GATHER) ... 18 2-4 FORTRAN常犯錯誤... 21Chapter 3 有限元素法與Poisson Boltzmann方程式驗證... 23
Chapter 1 簡介
1-1 計畫動機 叢集式電腦系統(Cluster)運算是結合數台個人式電腦或者工作站,來完成大型數 值的平行計算,最知名的例子就是電影鐵達尼號運用了五百多台叢集式電腦系統來進 行動畫模擬。叢集式電腦系統的發展,源自大型超級電腦建置不易,以及數值運算需 要大量 CPU 時間而出現,一般來說,利用幾台個人電腦或工作站,透過網路來傳遞 資料以及交換邊界條件,就可以取代超級電腦的工作,除了維護方便之外,擴充性也 是相當令人滿意,換句話說,剛開始可以選擇少 node 數來進行計算,當日後需要進 行大尺度的平行計算時,則可以增加 node 數量或更新硬體設備來解決。本研究期望 能夠建立 PC 叢集式電腦系統,提供使用者來練習撰寫平行化程式的能力,並進行初 步的程式測試。而本計劃最重要的目標是利用建立好的平行化系統,執行已開發完成 的3D Poisson-Boltzmann Equation 程式當做測試,並進一步開發出二階形狀函數元素 的有限元素法程式,期望能夠模擬更多的奈米生物相關數值問題。 一 組 叢 集 式 平 行 電 腦 至 少 需 要 一 台 伺 服 器 、 數 台 計 算 nodes 以 及 高 速 Switch/HUB。若想建立高效能且可提供大尺度計算的叢集式平行電腦,除了軟、硬體 設備需求較高之外,還需要管理人員來負責維護系統正常運作,對需要計算能力的使 用單位來說,無疑是沉重的負擔。通常使用者會選擇國家實驗研究院高速網路與計算 中 心 ( 簡 稱 為 國 網 中 心 , http://www.nchc.org.tw) 所 建 立 的 PC Cluster(http://pccluster.nchc.org.tw),但該中心所建立的系統資源是共享的,不太能夠 容許使用者在該平台上進行程式撰寫與測試。因此,本研究計畫的主要目的為建立一 套簡易的PC Cluster,提供使用者在利用國網中心的 PC Cluster 之前,來撰寫、測試 平 行 化 程 式 用 。 此 外 , 利 用 本 人 已 開 發 有 限 元 素 法 三 維 平 行 化 非 線 性 Poisson-Boltzmann 方程式程式(PPBS),可以利用該 PC Cluster 執行 cases,完成相關 模擬測試。1-2 論文回顧
平行化技術
在數值模擬領域中,大尺度的計算必須使用效能較好的電腦,而超級電腦並非人 人可以使用,但是因為有些方程式本身相當適合平行化(parallelization),例如:直接 模擬蒙地卡羅法(Direct Simulation Monte Carlo)、有限元素法(Finite Element Method)。
過去十年的研究均集中於此。但是計算平臺仍然是以超級平行電腦如IBM SMP,SP2
術研究單位才有機會使用。不過,在最近幾年個人電腦(PC)的風行(尤其在台灣), CPU 計算速度不斷爬升,價格不斷降低;加上網路溝通速度(networking speed)大幅提 升,使得利用叢集式個人電腦來做模擬計算變成相當吸引人。成本甚至是利用超級電 腦的1/100 以下。主要的原因是 PC 價格低廉、隨處可取、系統軟體免費(e.g., Linux) 等等。除此之外,利用此種叢集式個人電腦來做相關計算的經驗亦可以直接移轉給需 要的產業界。
平行化技術可以採用MPI (Message-Passing Interface, http://www-unix.mcs.anl.gov/ mpi/)架構,於 1992 年開始發展,是一套可用於平行電腦系統(包括 Distributed- Memory 和 Shared-Memory 架構)上的資料傳送模型,目標是建立一套和程式語言、 電腦種類無關的標準,用以撰寫收送訊息的程式碼,目前有Fortran 與 C 語言的版本。 Poisson-Boltzmann方程式應用 面對癌症細胞,傳統化療在殺死癌細胞的同時,也會將正常的細胞一倂殺死,因 此副作用大。而新一代的標靶藥物治療(Targeted Therapy) 不同於傳統化療「亂槍打鳥」 的治療方式,能夠更精準地將腫瘤當成標靶,集中火力攻擊。為了做好相關領域的基 礎研究,各國都投入了大量的資源,以 PC 叢集式(Cluster)平行電腦進行模擬,探討 particle-particle 與 particle-plane 之間的相互作用力,可以進一步了解標靶治療的物理、 化學特性。在電解液平衡的狀態下,可經由Poisson-Boltzmann equation electric double layer(EDL)理論得到帶電物體的勢能分佈。
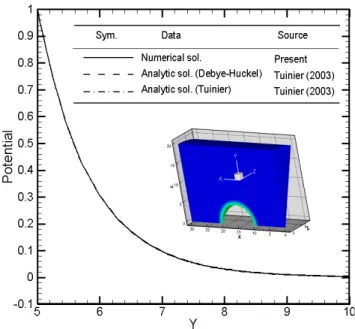
在本人先前的研究中,以非線性Poisson-Boltzmann 方程式採用非結構性四面體網
格之葛勒金有限元素法來完成程式開發,包括了典型的一階形狀函數元素。因為使用 了nodal quadrature 的技巧,使得原先的牛頓法 Jacobian 矩陣僅剩下對角線,以此擬牛 頓疊代法來處理非線性項矩陣的部份,有助於平行化程式的完成。接下來,則使用 SBS 的技巧搭配平行的共軛梯度法來處理線性矩陣方程組。完成的程式的範例是帶電 球體的勢能分佈,所得答案與解析解、近似解作一比較,結果相當正確。如下圖所示:
Chapter 2 叢集式電腦建置
2-1 系統架構 系統採用免費的作業系統 Linux,並使用免費的 mpich 與排程軟體來自行建置。下 圖為PC 叢集式電腦的簡易架構圖: Switch/HUB Servernode1 node2 node3 node4 node5 node6
Fig 2-2 PC Cluster @ MUST 2-2 叢集式電腦程式設計的技巧 1. 清楚的定義變數名稱:一個程式可能交由許多人來撰寫,如果變數定義不夠清 楚,在程式做組合的時候,就會造成困難。 2. 撰寫程式由上而下:先由宏觀的角度建構程式架構,然後再來細部分工到主程 式、副程式內。 3. 善用流程圖:利用流程圖來控制程式的流程走向,可以減少程式邏輯的錯誤。 4. 可讀性的提高:一個好的程式應該多多利用「縮排」、「空行」、「註解」來增加可 閱讀性,以避免日後維護時造成困擾。 5. 適當地使用副程式:一般在撰寫大型程式時,可以適當地使用副程式,除了可以 確保主程式的程序流暢以外,更可以將副程式的工作分配給其他人撰寫。 6. 考量使用者的感受:程式撰寫者往往只依照自己的感覺設計介面,沒有考慮到使 用者的輸入、輸出感覺,所以程式完成前需要做一些測試。 7. 完工後不要忘記撰寫手冊:清楚地寫下操作步驟、變數名稱…等等細節,有助於 幫助操作者或者自己日後的維護工作。 2-2 Fortran 程式撰寫技巧 2-2-1 程式撰寫與編譯
下「文字」: c...程式的開始 PROGRAM EX1 c...關閉所有預設的變數, 例如 I,J,K IMPLICIT NONE c...設定 AGE 為整數變數 INTEGER AGE
c...在螢幕顯示 How old are you? WRITE(*,*) 'How old are you?' c...讀取 AGE 變數
READ(*,*) AGE
c...在螢幕顯示 You are xx years old
WRITE(*,*) 'You are', AGE, ' years old' c...程式結束
STOP c...主程式碼結束 END
注意事項:
1. 如果在 Linux 系統下按 Backspace 鍵會出現亂碼,請使用 ctrl + Backspace 應該就可 以解決了
2. 有些編譯器會錯認 Tab 鍵,所以請儘量使用空白鍵來替代 Tab 鍵(也就是 Fortran 每
行程式碼前面須空6 個字元)
3. 在 Unix Like 執行單一程式的方法為 ./程式名稱 ( 如 ./test.exe )
這是因為避免發生駭客攻擊漏洞,前方的 . 代表目前資料夾
4. 連結上遠端伺服器可以使用 telnet 指令,善用 Windows 上快速鍵:複製 Ctrl + Insert 與 貼上 Shift + Insert
然後利用FTP 上傳到伺服器後,下指令
[maty@server1 maty]$ mpif77 -o ex1.exe ex1.f
其中mpif77 是編譯程式;ex1.exe 是預計產生的執行檔案;ex1.f 則是執行檔案
如果沒有發生任何的錯誤訊息,執行程式的方法為 [maty@server1 maty]$ ./ex1.exe
我們可以發現電腦會詢問問題,當我們輸入數字之後,並且按下Enter,可以得到
2-2-2 流程控制 請在文字編輯軟體輸入以下「文字」,並完成上傳以及編譯執行檔的動作: PROGRAM EX2 IMPLICIT NONE c c...weight 體重; age 年齡 INTEGER age,weight c c...輸入年齡與體重
WRITE(*,*) 'Please input your age?' READ(*,*) age
WRITE(*,*) 'Please input your weight?' READ(*,*) weight
c
c...過濾出年紀小於 30 歲,體重卻超過 100 公斤者 IF ((age .LT. 30) .AND. (weight .GT. 100)) THEN WRITE(*,*) 'You are overweighted!'
ELSE
WRITE(*,*) 'Your weight is under control' END IF c STOP END 請注意Fortran 數學運算: + 加法 ; - 減法 ; * 乘法 ; / 除法 ; ** 乘冪 計算優先順序:( )Æ **Æ */+- 在這個CASE,輸入以下的數值,會由不同的結果:
age weight WRITE(*,*) NOTE
30 100 Your weight is under control! age 與 weight 皆不符合 30 101 Your weight is under control! 僅 weight 符合
29 100 Your weight is under control! 僅 age 符合
29 101 You are overweighted! age 與 weight 皆符合
在這裡我們使用了一個IF…THEN…ELSE 函數,主要功能是用來進行流程控
制,所使用的邏輯判斷運算如下所列:
.EQ. 等於 .GE. 大於等於
.NE. 不等於 .LT. 小於
.GT. 大於 .LE. 小於等於
2-2-3 迴圈 請在文字編輯軟體輸入以下「文字」,並完成上傳以及編譯執行檔的動作: PROGRAM EX3 IMPLICIT NONE c c...定義雙精準度的陣列 A REAL*8 A(3,3) c...定義整數參數 INTEGER I,J,ROW,COL c...指定固定參數 PARAMETER (ROW=3,COL=3) c c...將陣列 A 放入變數 DO 10 I = 1, ROW DO 10 J = 1, COL A(I,J)= I*J*1.d0 10 CONTINUE c c...在螢幕顯示陣列 A DO 20 I = 1, ROW DO 20 J = 1, COL WRITE(*,*) A(I,J) 20 CONTINUE c STOP END 請注意Fortran 的浮點數 real 有兩種型態,分別是 REAL*4 單精確度:在個人電腦上佔了 32bits的長度,有效位數 6-8 位,可紀錄最 大值為3.4x1038,最小值則為1.18x10-38 REAL*8 雙精確度:長度為 64bits,有效位數 15-16 位,可紀錄最大值為 1.79x10308, 最小值則為2.23x10-308 在這個CASE,得到以下結果:
首先,當程式流程經過DO 10 I = 1, ROW 時,此時 I 等於 1,而 I 的變化值在 1 至 3 之間(因為 ROW 已經是固定參數 3)。接下來 J=1,COL 時,狀況跟 I 是相同的,變化值 也是1 至 3 之間(因為 COL 已經是固定參數 3)。 將I 與 J 帶入到 A(I,J)=I*J*1.d0 中 (其中 1.d0 的意思是 1x100),I=1、J=1,因此 A(1,1)就等於 1*1*1.d0。 程式繼續執行,遇到10 CONTINUE,意思就是回到最近的編號 10 的起點繼續執行, 最近的編號10 的起點就是 DO 10 J = 1, COL。此時 J 加 1 等於 2,但是 I 仍然等於 1。 帶入到A(I,J)=I*J*1.d0 中得到 A(1,2)=1*2*1.d0。如此類推,可得 A(1,3)=1*3*1.d0。
遞的變數與參數。 檔案的開啟練習在副程式2 當中,利用 OPEN 的指令開啟檔案,開啟時必須指定一 個讀取編號,由於一般內定的輸出編號,例如螢幕…等等,編號大多在 10 以內,所以 自行所選擇的讀取編號建議大於10 以上。 2-3 Cluster 程式撰寫技巧 2-3-1 PC Cluster 介紹與指令
PC Cluster 建置當中,最主要就是利用了 NFS(Network File Systems)與 NIS(Network Information System)的網路服務,將使用者帳號與磁碟空間結合起來,透過彼此機器的 相互信任(rsh),並且安裝平行計算 MPI(Message Passing Interface)的功能,就可以完成一 組PC Cluster 的建置,若是需要加上管理功能,則必須再安裝 DQS (Distributed Queueing System)。以下是幾個常用的指令,包括 Linux、mpif77、mpirun 與 DQS: Linux 指令 檢視檔案 指令:ls 例如:ls –l (檢視所有的檔案,包括隱藏檔案) ls -l | more (使用 |指向 至 more,超過一個畫面的長度就先暫停下來) 更換資料夾 指令:cd 例如:cd work (進入 work 資料夾) 建立資料夾 指令:mkdir 資料夾名稱
例如: mkdir hello (建立 hello 資料夾,注意:在 Unix Like 的 OS,大小寫的意義 不同) 刪除檔案 指令:rm –rf 檔案名稱或資料夾 例如: rm –rf for* (強制刪除所有以 for 開頭的檔案與資料夾) 複製檔案 指令:cp 檔案名稱 複製的新檔案名稱
移動檔案
指令:mv 檔案名稱 新的位置
例如:mv test.f ./work (將檔案 test.f 移動 至 目前資料夾下的 work 資料夾內)
查詢目前已經使用的硬碟空間 指令:du 資料夾路徑 例如:du –s (預設是目前所在的資料夾,顯示該資料夾下 檔案所佔的硬碟空間) 查詢目前硬碟所剩下的空間 指令:df 例如:df –k (以 k bytes 顯示,預設值) 更改檔案屬性權限 指令:chmod □□□ 檔案或資料夾名稱
例如:chmod 755 test.cmd (將 test.cmd 檔案屬性改成 755:擁有者可讀寫執行、 群組及全體使用者可讀、執行,不可寫入) 請注意: A B C 分別代表A擁有者;B群組;C全體使用者 的權限,每一個位置又有 三種不同的權限[rwx],開啟為 1 關閉為 0。以A擁有者為例,若只給執行(x)與讀取 (r)的權限,不給寫入(w)的權限,則為[1x22+0x21+1x20]=5 更改某個檔案或目錄的擁有者 指令:chown 擁有者 檔案或資料夾名稱
例如:chown –R maty test (將 test 資料夾的擁有者改成 maty,且在 test 資料 夾內 所有的檔案與資料夾的擁有者都一併都改成 maty)
更改某個檔案或目錄的擁有群組
指令:chgrp 擁有群組 檔案或資料夾名稱
例如:chown –R maty test (將 test 資料夾的擁有群組改成 maty,且在 test 資 料夾內 所有的檔案與資料夾的擁有群組都一併都改成 maty)
mpif77 與 mpirun 編譯
直接執行平行化程式(不經過 DQS 安排管理) 指令:mpirun –np cpu 執行個數 執行檔案名稱 例如:mpirun -np 4 ex1.exe 注意事項:CPU0 通常就是指下指令與資料讀取、回存的電腦,也就是 Server DQS 管理功能 檢查目前 DQS 狀態 指令為qstat332 (只顯示目前有工作的 CPU) 指令為qstat332 –f (顯示所有 CPU,無論是否有工作) 以下為DQS 狀態範例:
[maty@server1 maty]$ qstat332 -f
Queue Name Queue Type Quan Load State --- --- --- --- --- node001 batch 0/1 0.01 dr DISABLED node002 batch 0/1 0.00 er UP node003 batch 0/1 0.00 er UP node004 batch 0/1 0.00 er UP node005 batch 0/1 0.00 er UP node006 batch 0/1 0.00 er UP node007 batch 0/1 0.00 er UP
node008 batch 0/1 0.00 eru UNKNOWN node009 batch 0/1 0.00 eru UNKNOWN node010 batch 0/1 0.00 eru UNKNOWN node011 batch 0/1 0.00 eru UNKNOWN node012 batch 0/1 0.00 eru UNKNOWN node013 batch 0/1 0.00 er UP
node014 batch 0/1 0.00 er UP node015 batch 0/1 0.00 er UP node016 batch 0/1 0.00 er UP
狀態說明:
dr DISABLED 代表CPU 目前被指定為不工作(Shutdown)
er UP 代表CPU 目前可以工作(RUNNING)
eru UNKNOWN 代表CPU 目前狀態不明(未開機或者 DQS 未啟動)
所 以 上 表 內 node001 為不工作(nolocal);node008, node009, node010, node011, node012 未開機;其餘電腦可以工作。換句話說,可以有 10 台 CPU 服務,如果使
用者的程式是需要5 台 CPU,那麼可以同時安排兩個使用者執行程式而彼此不受干
安排工作 指令為qsub332 dqs_job_shell 其中dqs_job_shell 為自行撰寫的 DQS 程序檔,參考範例 dqs.sh,如下: #!/bin/csh #$ -cwd #$ -l qty.eq.5 #$ -N project1 #$ -A maty
/usr/local/package/mpich/bin/mpirun -np $NUM_HOSTS -machinefile $HOSTS_FILE prog
其中 #!/bin/csh 表示為 C shell script
#$-cwd 表示在目前的目錄執行(預設是 home directory)
#$-l qty.eq.5 需要5 個 CPU,qty 是 quantity 縮寫,eq 則是 equation 的縮寫
#$-N project1 submit job 的工作名稱(Name)為 project1 #$-A maty 使用者帳號(Account),本範例為 maty
$NUM_HOSTS 代表目前需求的CPU 數量(來自 qty.eq.5 設定) $HOSTS_FILE DQS 安排這項工作的 node list
執行時直接在命令列下qsub332 dqs.sh 即可,如下所示:
[maty@server1 maty]$ qsub332 dqs.sh your job 40 has been submitted [maty@server1 maty]$
可以發現DQS 已經指派工作了,並且 process 編號是 40 (submit job process)
請牢記這個process 編號,如果想要把程式停下來,就會用到這個編號
如果使用qstat332 的指令來觀察 DQS 狀態,則會發現共有 5 個 CPU 在工作(node002, node004, node014, node015, node016)
[maty@server1 maty]$ qstat332
maty project1 node002 40 0:1 r RUNNING 04/07/102 09:59:11 maty project1 node004 40 0:1 r RUNNING 04/07/102 09:59:11 maty project1 node014 40 0:1 r RUNNING 04/07/102 09:59:11 maty project1 node015 40 0:1 r RUNNING 04/07/102 09:59:11 maty project1 node016 40 0:1 r RUNNING 04/07/102 09:59:11
也會增加三個檔案,分別紀錄程式執行過程中CPU0 在螢幕顯示的訊息、程式最後
[maty@server1 maty]$ ls -l
-rwxr--r-- 1 maty maty 0 4 月 7 09:59 project1.e40.7486* -rw-r--r-- 1 maty maty 90 4 月 7 09:59 project1.hosts40.7486 -rwxr--r-- 1 maty maty 286720 4 月 7 10:06 project1.o40.7486*
刪除工作
指令為qdel332 submit_job_process
其中sumbit_job_process 為當初安排工作(submit job)時的編號 [maty@server1 maty]$ qdel332 40
maty has deleted the job "40"
姊妹(MPI_COMM_SIZE),我是排行老三(MPI_COMM_RANK),這樣子兄 弟姊妹再工作時,才知道彼此之間先後的關係,以及最大的人數限制為
何。這兩個函數在主程式內只要使用一次即可,在Fortran 的敘述如下:
CALL MPI_COMM_SIZE (mpi_comm_world, nproc, mpierr) CALL MPI_COMM_RANK (mpi_comm_world, myid, mpierr)
其中所使用的引數mpi_comm_world 是內定的協同通訊參數,用來確定所
有參與計算的CPU 皆為同一個 communicator,不需要特別更改。
引數nproc 可取得參與計算的 CPU 數量,來自於 mpirun 所下的指令參數,
所以程式碼內可以寫一個預設的總CPU 參數,然後利用這個引數來比對指 令是否下的正確,免得做白功。而引數 myid 則是取得目前正在工作的電 腦編號,因為CPU 之間彼此要互相傳遞交換切割邊界的資料,所以必須知 道自己正在工作的電腦編號,以及在自己前後左右的CPU 是誰(編號)?這 樣才能傳遞成功。 2-3-3 MPI 集體通訊—廣播 (MPI_BCAST) 在平行化的處理上,常常需要將數個參數或者整個陣列由伺服器(CPU0)傳送給其他 CPU 做運算,就有點像村長伯利用廣播系統放送訊息給村民一樣,請在文字編輯軟體輸 入以下「文字」,並完成上傳以及編譯執行檔的動作: program bcast2d c...本範例練習 2D 陣列 c….如何使用 bcast 將資料廣播到各 CPU 去 c...預設共有四顆 CPU implicit none include 'mpif.h' integer mpierr,nproc,myid c integer lx,ly,lxly parameter(lx=4,ly=4) parameter(lxly=lx*ly) c integer i,j integer add integer node(lx,ly) integer iu c
c...Start MPI function
call mpi_init(mpierr)
call mpi_comm_size(mpi_comm_world,nproc,mpierr) call mpi_comm_rank(mpi_comm_world,myid,mpierr) c
c
if (myid .eq. 0) then add = 0 do 10 i = 1,lx do 10 j = 1,ly add = add + 38 10 node(i,j) = add end if c c...由 CPU0 向全體 CPU 廣播陣列 call mpi_bcast(node,lxly,mpi_integer, & 0,mpi_comm_world,mpierr) c...寫入檔案 iu = myid + 21 do 40 i = 1, lx do 40 j = 1, ly write(iu,*) i,j,node(i,j) call flush(iu) 40 continue c...End MPI function
call mpi_finalize(mpierr) c...END PROGRAM
程式的工作流程:先在 CPU0 將 node(i,j)陣列以 38 開始累加填滿,然後利用 MPI_BCAST 指令向所有的 CPU 廣播,最後在每一顆 CPU 寫入檔案。MPI_BCAST 函數在Fortran 的敘述如下:
MPI_BCAST (data, amount, data_type, root_cpu, mpi_comm_world, mpi_err)
其中 data: 送出的資料名稱,例如陣列或參數
amount: 送出的資料數量(例如陣列就是陣列大小)
data_type: 送出的資料型態,資料型態如下表所示
root_cpu: 由哪顆CPU 送出(通常是 CPU0)
MPI data types Fortran data types
MPI_CHARACTER CHARACTER MPI_LOGICAL LOGICAL MPI_INTEGER INTEGER
MPI_REAL, MPI_REAL*4 REAL, REAL*4
MPI_REAL*8, MPI_DOUBLE PRECISION REAL*8, DOUBLE PRECISION
MPI_COMPLEX, MPI_COMPLEX*8 COMPLEX, COMPLEX*8
program send_recv2d c...本範例練習 2D 陣列
c….send 資料到其他 CPU,然後其他 CPU 來 recv c...預設共有四顆 CPU implicit none include 'mpif.h' integer np,mpierr,nproc,myid,istatus parameter(np=4) c integer lx,ly parameter(lx=2,ly=4) c integer i,j,add,left_nbr,right_nbr integer node(lx,ly),id_node(lx,ly),itag(0:np-1) integer iu c
c...Start MPI function
call mpi_init(mpierr)
call mpi_comm_size(mpi_comm_world,nproc,mpierr) call mpi_comm_rank(mpi_comm_world,myid,mpierr) c
c...取得左右鄰居 CPU 的編號(每一個 CPU 都要做) if (myid .eq. 0) then
left_nbr = np - 1 else
left_nbr = myid - 1
end if
c
if (myid .eq. np-1) then right_nbr = 0 else
right_nbr = myid + 1
end if
c
c...取得自己 CPU 的目標(target 編號,每一個 CPU 都要做) do 10 i=0,np-1
itag(i)=i+101 10 continue c
c...初始值
if (myid .eq. 0) then add = 0 do 20 i = 1,lx do 20 j = 1,ly add = add + 1 20 node(i,j) = add end if c
if (myid .eq. 1) then add = 10 do 21 i = 1,lx do 21 j = 1,ly add = add + 1 21 node(i,j) = add end if c
if (myid .eq. 2) then add = 20 do 22 i = 1,lx do 22 j = 1,ly add = add + 1 22 node(i,j) = add end if c
if (myid .eq. 3) then add = 30 do 23 i = 1,lx do 23 j = 1,ly add = add + 1 23 node(i,j) = add end if c iu =myid + 21 c c...所有 CPU 做傳送(send)及接收(recv)動作 c...由自己 CPU node 陣列 c….傳給右邊 CPU 的 id_node 陣列 call mpi_send(node(1,1),lx*ly, & mpi_integer,right_nbr, & itag(myid), & mpi_comm_world,mpierr) c call mpi_recv(id_node(1,1),lx*ly, & mpi_integer,left_nbr, & itag(left_nbr), & mpi_comm_world,istatus,mpierr) c c...寫入檔案 do 40 i = 1, lx do 40 j = 1, ly write(iu,*) i,j,id_node(i,j) call flush(iu) 40 continue c
c...End MPI function
call mpi_finalize(mpierr) c...END PROGRAM
stop end
這個範例最主要的部份就是每一顆CPU 都會先取得自己的 CPU 編號(myid-自己壘
包編號)與自己左右的 CPU 編號(right_nbr 與 left_nbr-相鄰壘包編號)。除此之外,
也要賦予每一個 CPU 目標標號(itag(i)-球員球衣編號)。接下來的動作就是每一顆
CPU 產生自己的 node 陣列,這是假設每一顆 CPU 已經經過運算得到結果。接下來 就是每一顆CPU 往自己的右邊 CPU 傳送 node 陣列,右邊的 CPU 從左邊的 CPU 接
檔案內。可以得到答案如下:
CPU 編號 CPU0 CPU1 CPU2 CPU3
right_nbr 1 2 3 0
left_nbr 3 0 1 2
itag(i) itag(0)=101 itag(1)=102 itag(2)=102 itag(3)=103
檔案名稱 fort.21 fort.22 fort.23 fort.24
1 1 31 1 1 1 1 1 11 1 1 21 1 2 32 1 2 2 1 2 12 1 2 22 1 3 33 1 3 3 1 3 13 1 3 23 1 4 34 1 4 4 1 4 14 1 4 24 2 1 35 2 1 5 2 1 15 2 1 25 2 2 36 2 2 6 2 2 16 2 2 26 2 3 37 2 3 7 2 3 17 2 3 27 結果內容 2 4 38 2 4 8 2 4 18 2 4 28 以上的結果可以很清楚的看到,CPU0 所接收到的資料是來自 CPU3 所產生的;而 CPU1 所接收到的資料則是來自 CPU0…以此類推。這樣子的傳送資料方式,一定 要有一個傳送、一個接收,否則會造成通訊死鎖(communication dead-lock)。 MPI_SEND 函數在 Fortran 的敘述如下:
MPI_SEND (data_start, amount, data_type, idest, itag, mpi_comm_world, mpi_err) 其中 data_start: 送出的資料的起點,例如陣列第一個位置
amount: 送出的資料數量(例如陣列就是陣列大小)
data_type: 送出的資料型態
idest: 傳送到哪一顆 CPU 的 CPU 編號(傳球到哪一個壘包編號)
itag: 傳送與接收資料的目標編號(要傳給那個壘包上的球員球衣背號)
MPI_RECV 函數在 Fortran 的敘述如下:
2-3-5 集體通訊—資料分派與集中 (MPI_SCATTER 與 MPI_GATHER) 計算時,大多數的狀況都是將資料放在陣列中,當我們要進行平行運算時,最簡單 的做法就是將陣列中的資料「拆解」成N 個部份,平均地丟給 N 顆 CPU 去做計算,但 是平均地分割陣列並且進行分派的動作,如果光靠MPI_SEND 與 MPI_RECV 來處理, 恐怕會增加程式碼維護的困難度,於是利用MPI_SCATTER 則是相當不錯的選擇。請在 文字編輯軟體輸入以下「文字」,並完成上傳以及編譯執行檔的動作: program scatter2d c...本範例練習 2D 陣列 c….如何使用 scatter 將資料分散到其他 CPU 去 c...預設共有四顆 CPU implicit none include 'mpif.h' integer np,mpierr,nproc,myid parameter(np=4) c integer lx,ly,lxly,div_lxly parameter(lx=8,ly=4) parameter(lxly=lx*ly,div_lxly=lxly/np) c integer i,j integer add integer node(lx,ly),id_node(lx/np,ly) integer linear(lxly),id_linear(div_lxly) integer iu c
c...Start MPI function
call mpi_init(mpierr) call mpi_comm_size(mpi_comm_world,nproc,mpierr) call mpi_comm_rank(mpi_comm_world,myid,mpierr) c
if (myid .eq. 0) then open (25,file='node.dat') add = 10 do 10 i = 1,lx do 10 j = 1,ly add = add + 1 node(i,j) = add 10 write(25,*) i,j,node(i,j) close(25) c c...將 2D 的陣列轉成 1D 的陣列 add = 0 do 20 i = 1, lx do 20 j = 1, ly add = add + 1 20 linear(add) = node(i,j) end if c...將 linear 陣列分散到其他 CPU 去 call mpi_scatter(linear,div_lxly, & mpi_integer, & id_linear,div_lxly,mpi_integer, & 0,mpi_comm_world,mpierr) c...將 1D 的陣列轉成 2D 的陣列 add = 0 do 30 i = 1, lx/np do 30 j = 1, ly add = add + 1 30 id_node(i,j) = id_linear(add) c...寫出檔案 iu = myid + 21 do 40 i = 1, lx/np do 40 j = 1, ly write(iu,*) i,j,id_node(i,j) call flush(iu) 40 continue c...End MPI function
call mpi_finalize(mpierr) c...END PROGRAM
stop end
這個範例首先在CPU0 開啟一個 node.dat 的檔案,將 node(i,j)寫入到檔案內,證明 起始的陣列狀況。接下來將2D 的陣列 node(i,j)轉換成為 1D 陣列 leaner(add),並且 用MPI_SCATTER 分派到其他 CPU,然後再將 1D 的陣列 id_linear(add)轉換回 2D 的陣列id_node(i,j),最後在每一顆 CPU 寫下檔案內容。
MPI_SCATTER 的致命傷,恐怕就是資料在某些狀況下,必須將 2D 以上的陣列轉
結果,再來討論如果不將陣列轉換成為1D,會發生什麼事情: 11 (1,1) 12 (1,2) 13 (1,3) 14 (1,4) 15 (2,1) 16 (2,2) 17 (2,3) 18 (2,4) 19 (3,1) 20 (3,2) 21 (3,3) 22 (3,4) 23 (4,1) 24 (4,2) 25 (4,3) 26 (4,4) 27 (5,1) 28 (5,2) 29 (5,3) 30 (5,4) 31 (6,1) 32 (6,2) 33 (6,3) 34 (6,4) 35 (7,1) 36 (7,2) 37 (7,3) 38 (7,4) node.dat 內容 39 (8,1) 40 (8,2) 41 (8,3) 42 (8,4) Ð轉換 1D 2D 轉 1D 11 (1) 12 (2) ……… 41 (31) 42 (32) Ð 1DÆ2D
CPU 編號 CPU0 CPU1 CPU2 CPU3
檔案名稱 fort.21 fort.22 fort.23 fort.24
1 1 11 1 1 19 1 1 27 1 1 35 1 2 12 1 2 20 1 2 28 1 2 36 1 3 13 1 3 21 1 3 29 1 3 37 1 4 14 1 4 22 1 4 30 1 4 38 2 1 15 2 1 23 2 1 31 2 1 39 2 2 16 2 2 24 2 2 32 2 2 40 2 3 17 2 3 25 2 3 33 2 3 41 結果內容 2 4 18 2 4 26 2 4 34 2 4 42 如果沒有經過轉換1D 的過程,我們看一下發生了什麼事情:
CPU 編號 CPU0 CPU1 CPU2 CPU3
檔案名稱 fort.21 fort.22 fort.23 fort.24
一顆CPU,當迴圈達到最大值(38)時,又從最前方尚未分配的值(15)開始繼續分派。如 果您的程式剛好有這個需求,是再好也不過了,不過大多數的資料陣列都是有順序的,
為了避免發生不必要的「資料迷失」,建議您使用這個函數之前,還是先轉成1D 然後再
分派,或者利用這個特性來分派陣列。
MPI_SCATTER 函數在 Fortran 的敘述如下:
MPI_SCATTER (data, amount1, data_type1, idest_data, amount2, data_type2, root_cpu, & mpi_comm_world, mpi_err)
其中 data: 送出的資料名稱,例如陣列名稱
amount1: 分派給每顆CPU 的資料數量 data_type1: 送出的資料型態
idest_data: 接收的資料,例如陣列名稱
amount2: 由CPU0 接收的資料數量(通常與 amount1 相同) data_type2: 接收的資料型態
root_cpu: 由哪顆CPU 送出(通常是 CPU0)
既然可以將資料分派到每一顆CPU,當然也有指令將每一顆 CPU 的資料集中回到 CPU0 的函數-MPI_GATHER,為了節省時間,以下的範例僅用 1D 陣列來解說。請在 文字編輯軟體輸入以下「文字」,並完成上傳以及編譯執行檔的動作: program gather1d c...本範例練習 1D 陣列 c….如何使用 gather 將資料集中到 CPU0 去 c...預設共有四顆 CPU implicit none include 'mpif.h' integer np,i,mpierr,nproc,myid parameter(np=4) integer cpu_ans(1),cpu0_ans(0:np-1) c
c...Start MPI function
call mpi_init(mpierr) call mpi_comm_size(mpi_comm_world,nproc,mpierr) call mpi_comm_rank(mpi_comm_world,myid,mpierr) c cpu_ans(1) = myid+38 c c...將 cpu_ans 陣列集中到 c….CPU0 的 cpu0_ans 陣列去 call mpi_gather(cpu_ans,1,mpi_integer, & cpu0_ans,1,mpi_integer & ,0,mpi_comm_world,mpierr) c c...寫出檔案
if (myid .eq. 0) then open(21,file='test.dat') do 10 i = 0, np-1 write(21,*) i,cpu0_ans(i) call flush(21) 10 continue end if
c...End MPI function
call mpi_finalize(mpierr) c...END PROGRAM
stop end
用MPI_GATHER 的函數集中回到 CPU0,並且寫入 test.dat 的檔案。MPI_GATHER 函數在Fortran 的敘述如下:
MPI_GATHER (data, amount1, data_type1, idest_data, amount2, data_type2, root_cpu, & mpi_comm_world, mpi_err)
其中 data: 預備由每顆 CPU 送出的資料名稱,例如陣列名稱 amount1: 準備送出CPU 的資料數量
data_type1: 送出的資料型態
idest_data: 準備接收的資料,例如陣列名稱
amount2: 準備接收每顆CPU 的資料數量(通常與 amount1 相同) data_type2: 接收的資料型態
root_cpu: 由哪顆CPU 集中(通常是 CPU0)
MPI 另外有提供兩個好用的函數—MPI_REDUCE 與 MPI_ALLREDUCE,可以立刻
M. 將整數當實數處理而產生的數值上的錯誤,比如說變數 a 和 b 宣告為整數,則 a 除以 b 時的商取整數部份,小數部份則略去而產生錯誤。
Chapter 3
有限元素法與 Poisson Boltzmann 方程式驗證
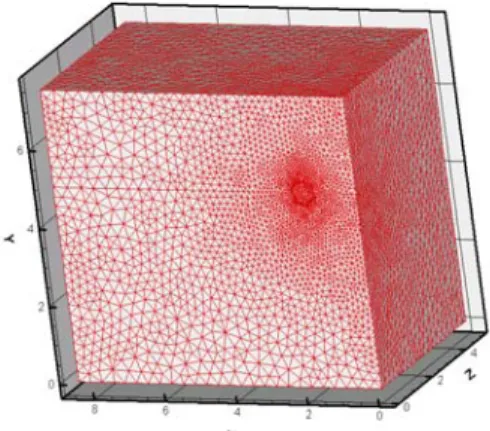
3-1 有限元素法簡介
有限元素法(Finite Element Method, FEM)是使用一不連續之函數來近似任一連續 量。換句話說,經由我們所建立的函數,可以描述一整體結構的行為。有限元素法的操 作方式是將一連續體分割成數個四面體(2D/三角形)、六面體(2D/矩形)或五面體,稱之 為元素(element),而元素之邊界點稱之為節點(node),例如四面體就有四個節點, 六面體則有八個節點,每個節點上皆可用數學方程式來描述,稱之為內插函數方程式 (interpolation equation),藉由這些內插函數方程式表達該連續體之分析行為,此群有 限個方程式之解稱為內插近似解(interposition approximation)。只要連續體之場變數(應 變、應力、溫度、電場、磁場、濃度…等)與相關正確,則近似解可視為精確解。 有限元素法的優點包括: 1. 元素的材料性質不需相同,例如非均質、非等向性,只要設定元素的條件,就 可以完成近似解求解。 2. 不規則形狀的邊界,能用直邊的小元素作近似估計,或用二階函數元素趨近。 3. 元素的大小、疏密,可經由實際所要計算的場來做調整。例如變化劇烈的區域 可以使用較密的元素來填佈。 4. 容易處理混合型的邊界條件。 因此,有限元素法被廣泛地應用在各種領域上,包括了固力、流力、熱力、製造以 及結構等。本研究所採用的是三維的元素網格,更可以實際模擬出立體的場變化。 3-2 電雙層理論與有限元素法的離散 當固、液、氣三相中之任二相彼此接觸時,於界面上因材料之電負度差異,會產生 分子間的電荷分佈不均,將使界面材料表面呈現帶電荷或極化情形。此材料界面上極性 會吸引帶異電性的電荷吸附與聚集,以形成所謂的電雙層(Electric double layer, EDL)。 根據其理論:電勢(electrical potential) ψ 與 每單位體積內的靜電荷密度ρe 的三維普 松方程式(Poisson’s equation)可以描述為 0 2 2 2 2 2 2 2 εε ρ ψ ψ ψ ψ e z y x ∂ =− ∂ + ∂ ∂ + ∂ ∂ = ∇ (3-1)
) exp( 0 T k e z n n b i i i ψ − = (3-2) 0 i
n 與 分別為bulk 離子濃度與 type-i 離子價;e為proton 的電荷, 是 Boltzmann 常數, i z kb T 是絕對溫度,exp( ) T k e z b i ψ 則是 Boltzmann 係數。因此,在流體中的單位淨電荷 為 ) sinh( 2 ) ( 0 T k ze zen n n ze b e ψ ρ = +− − =− (3-3) 將式(3-3)帶入式(3-1),則可以得到非線性的 Poisson-Boltzmann 方程式 ) sinh( 2 0 0 2 2 2 2 2 2 T k ze zen z y x b ψ εε ψ ψ ψ = ∂ ∂ + ∂ ∂ + ∂ ∂ (3-4) 接著,我們定義Debye-Huckel parameter T k n e z b 0 0 2 2 2 2 εε κ = ,並應用無因次化: x x=κ , y=κy, z=κz and T k ze b ψ ψ = (3-5) κ
1 (Debye length λd) EDL 最後 Poisson-Boltzmann
其中 是 的特徵長度。 , 可以被 改寫為 ) sinh( 2 2 2 2 2 2 ψ ψ ψ ψ = ∂ ∂ + ∂ ∂ + ∂ ∂ z y x (3-6) 接下來我們引入有限元素法,我們假設有一個函數ψ ,因此可得trial solution:
∑
= = + + + = 1 4 4 3 3 2 2 1 1 j j j 4 ) ( ) ( ) ( ) ( ) ( ) ( ( , , ) ~ e e e e e e a z y x N a N a N a N a N ψ (3-7) 應用Galerkin 法 ,帶入式(3-6),可得∫
∫
Ω ∂ Ω= Ω Ω ∂ + ∂ + ∂ N e ( ) 2 2 2 ) ( ψ ψ ψ ∂ ∂x y z d N d e i i sinh( ) ) ( 2 2 2 ψ (3-8)) ( 6 1 1 1 1 1 6 1 ) ( 4 ) ( * 4 ) ( 3 ) ( * 3 ) ( 2 ) ( * 2 ) ( 1 ) ( * 1 ) ( ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( ) ( * e e e e e e e e e e e e e e e e e e e e e e e b b b b V z z z z y y y y V b φ φ φ φ φ φ φ φ + + + = = (3-11) ) ( 6 1 1 1 1 1 6 1 ) ( 4 ) ( * 4 ) ( 3 ) ( * 3 ) ( 2 ) ( * 2 ) ( 1 ) ( * 1 ) ( ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( ) ( * e e e e e e e e e e e e e e e e e e e e e e e c c c c V z z z z x x x x V c φ φ φ φ φ φ φ φ + + + = = (3-12) ) ( 6 1 1 1 1 1 6 1 ) ( 4 ) ( * 4 ) ( 3 ) ( * 3 ) ( 2 ) ( * 2 ) ( 1 ) ( * 1 ) ( ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( ) ( * e e e e e e e e e e e e e e e e e e e e e e e d d d d V y y y y x x x x V d φ φ φ φ φ φ φ φ + + + = = (3-13) 且 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 4 ) ( 3 ) ( 2 ) ( 1 ) ( 1 1 1 1 6 1 e e e e e e e e e e e e e z z z z y y y y x x x x
V = = volume of the element (3-14)
圖3-4 Poisson-Boltzmann 方程式驗證
下圖是測試case 的表面電荷分布:
圖3-5 表面電荷分布圖
下表是測試cases,包括了元素總 nodes 數量與四面體元素數量。
參考文獻
1. 精通 FORTRAN90 程式設計,碁峰出版社,彭國倫著,1997 年版
2. FORTRAN 語言 MPI 平行計算程式設計,國家高速電腦中心,鄭守成著,90 年版
3. http://www.nm.ncku.edu.tw/cname/computer/for/for5.html
4. J.-S. Wu, T.-C. Cheng, Y.-L. Shao and C.-H. Wu, " Development of a Micro-PIV System and Its Applications ", The 11th Symposium on Nano Device Technology (SNDT 2004).
5. 吳宗信, 邵雲龍, 黃柏誠, 鄭宗杰, "微混合器之製作與研究," 奈米通訊, Vol.12, I1, pp.21-27, 2005.
6. J.-S. Wu and Y.-L. Shao, "Comparison of the Micro-PIV Measurements with Lattice Boltzmann Method in Micro-Channel Flows," The 11th National CFD Conference, Tai-Tung, Taiwan, August, 2004. (One of the three Best Paper Awards out of 190 papers).
7. J.-S. Wu, Y.-L. Shao,C.-H. Wu and T.-C. Cheng, " Design, Manufacture and Performance Analysis for a MicroMixer ", The 11th Symposium on Nano Device Technology (SNDT 2004)
8. J.-S. Wu and Y.-L. Shao, "Simulation of Lid-Driven Cavity Flows by Rarallel Lattice Boltzmann Method Using Milti-Relaxation Time Scheme,"International Journal for Numerical Methods in Fluids, Vol.46, pp.921-937, 2004.
9. J.-S. Wu and Y.-L. Shao, "Simulation of Flow Past a Square Cylinder by Parallel Lattice Boltzmann Method Using Multi-Relaxation-Time Scheme," Journal of Mechanics, Vol.22, No.1, pp.35-42, 2006.
10. Y.-Y. Lian, K.-H. Hsu, Y.-L. Shao, Y.-M. Lee, Y.-W. Jeng and J.-S. Wu, ”Parallel Adaptive Mesh-Refining Scheme on Three-dimensional Unstructured Tetrahedral Mesh and Its Applications,” Computer Physics Communications, 2006 (Accepted). 11. Pavel Dyshlovenko, “Adaptive Mesh Enrichment for the Poisson-Boltzmann
Equation,” Journal of Computation Physics, 172, pp.198-208, 2001.
12. J.-S. Wu, and C.-K. Tseng, "Analysis of Micro-scale Gas Flows With Pressure Boundaries Using The Direct Simulation Monte Carlo Method," Computers & Fluids, Vol. 30, pp. 711-735, 2001.
13. Jeffrey D. McDonald, “A Computationally Efficient Particle Simulation Method Suited to Vector Computer Architectures.” PhD Thesis, Standford University, 1989. 14. D.M. Nicol and J.H. Saltz, "Dynamic Remapping of Parallel Computations with
Varying Resources Demands," IEEE Transactions on Computing, Vol. 37, 1998, pp. 1073-1087.
Layer Interaction between Colloidal Particles inside a Rough Cylindrical Capillary: Effect of Charging Behavior,” Colloids and Surface A, Vol.256, pp.91-103, 2005. 16. Dyshlovenko, Pavel, “Adaptive numerical method for Poisson-Boltzmann equation
and its application,” Computer Physics Communications, Vol.147, pp.335-338, 2002.
17. Gilson, M. K., Davis, M. E., Luty, B. A. and McCammon, J. A., "Computation of electrostatic forces on solvated molecules using the Poisson-Boltzmann equation," Journal of Physical Chemistry, Vol.97, pp.3591–3600, 1993.
18. Holst, M., Baker, N. and Wang ,F., “Adaptive multilevel finite element solution of the Poisson-Boltzmann equation I. Algorithms and examples, Journal of
附錄一 文字編輯器 pico
pico 雖然不是 Linux 所內定的文字編輯器,但是因為操作方式還蠻簡單的,非常適 合新手使用。進入文字編輯器的方式,為輸入pico 檔案名稱,例如 pico test.f
附錄二 二階四面體 Shape function 函數
The volume integrals can be easily evaluated from the relation V d c b a d c b a dv L L L L V d c b a 6 )! 3 ( ! ! ! ! 4 3 2 1 = + + + +
∫
We can use the equation to develop the volume integral, then