以支持向量機應用於美國手語樣板數位影像辨識系統之成效研究
61
0
0
全文
(2) 2.
(3) 致. 謝. 首先要誠摯感謝我的指導教授 黃天佑博士,在我研讀碩士班期間,不時的對於論 文給予寶貴的建議與指導,在此再次由衷黃天佑博士兩年多以來的指導,並且感謝口試 委員陳俊麟教授與黃樹乾教授,感謝各位口試委員在百忙之中抽空來替學生口試,並對 於本論文當中考慮不周全的部份提出的建議。 感謝資科系的老師們,在我研讀碩士班期間,教導我豐富的知識,並給予我不同方 向的意見,以及資科系系助宜璋姐、俊宏哥,謝謝你們在這段期間幫助我們處理碩士班 的相關事物,再者感謝在資科系平時一起嘻鬧的同窗們,還有修讀師資培育課程,所認 識的可愛學弟妹,有你們的陪伴與鼓勵,讓我能同時兼顧研究所與師資培育的課程,快 樂且充實的渡過這段時光。 感謝施弼耀 教授提供中華扶輪教育基金會這筆獎學金訊息,並且鼓勵我參加甄 選,有了這筆獎學金的支持,讓我的求學之路更為順遂,在中華扶輪獎學金頒獎典禮上, 見識到了扶輪社許多的 Uncle、Auntie,他們都是社會上各領域成功、傑出的人士,在 頒獎典禮上,宣揚扶輪理念與分享生活經驗,讓我對於扶輪與扶輪精神,有了更深一層 的認識。 感謝 3460 地區台中中央社照顧社友 林嘉琪 女士,提供這筆冠名獎學金,讓我能 專心在學術的研究與學業的完成,期待台中中央社六月份例會的參與,能夠向台中中央 社的各社友與 林嘉琪 女士報告,目前學習的狀況與研究心得。期望著自己在不久的未 來,能學有所得、學以致用,把自己的能力貢獻給社會,做一個有用的人,才不會辜負 這筆冠名獎學金。. i.
(4) 摘. 要. 本研究旨在探討以支持向量機為基礎之手勢數位影像辨識,並以美國手語樣板,做 為支持向量機的訓練樣本與測試樣本的基準,設計一套手勢數位影像辨識系統,以此作 為人機介面的一種溝通方式。此系統應用 RGB 色彩模型轉換為 YCbCr 模型的方式,擷取 出符合人體膚色範圍的數位影像物件,使用形態學對手部物件做雜訊濾除與破碎填補, 之後剔除多餘手臂特徵的部份,以減少額外資訊量的影響,選取手部物件做物件中心點 角度調整,以此修正手部物件偏移的角度,之後做正規化,並將其正規化後的手部物件, 透過本研究所提出抽取支持向量機特徵向量的演算法,抽取手部物件的特徵向量,以此 做為辨識的基礎。本實驗收集美國手語樣本總數 170 個,經由實驗測試後,發現辨識正 確率可達到 98.18%,對於支持向量機應用於手勢數位影像辨識具有良好的分類效果。 關鍵字:支持向量機、美國手語、膚色偵測、手勢辨識。. ii.
(5) Abstract The purpose of this study is to design a gestures digital image recognition system based on Support Vector Machine, whose training and testing samples are American Sign Language Templates. This gesture Digital Image Recognition System is a kind of human computer interface which is used as a means of communication. The proposed system transfers RGB color space to YCbCr color space to get a digital image of the object in line with human skin color range, and uses morphology for hand objects to do noise filtering and crushing fill. Then the system removes excess arm features to reduce the amount of the excess information. Then the system selects the hand objects to do object center point angle adjustment, regularization, and normalizing hand object with our proposed algorithm in order to extract SVM feature vector. In order to extract the hand object feature vector, we use the feature vector as the basis for identification. We analyze 170 samples for American Sign Language. In this experimental test, we found the recognition accuracy can reach 98.18%. Experimental results reveal promising classification results for our proposed American Sign Language Templates Digital Image Recognition System based on Support Vector Machine. Keywords:Support vector machine、American sign language、Skin color detection、Gesture recognition.. iii.
(6) 目. 錄. 致. 謝 ................................................................ i. 摘. 要 ................................................................ ii. Abstract ............................................................... iii 目. 錄 ............................................................... iv. 圖目錄 .................................................................. vi 表目錄 .................................................................. ix 第一章 緒論 .............................................................. 1 第一節 研究背景 ...................................................... 1 第二節 研究動機 ...................................................... 1 第三節 研究目的 ...................................................... 1 第四節 論文架構 ...................................................... 2 第二章 文獻探討 .......................................................... 3 第一節 數位影像的種類介紹 ............................................ 3 第二節 色彩模型對於膚色偵測的應用 .................................... 6 第三節 數位影像處理技術 ............................................. 10 第四節 American Sign Language ....................................... 16 第五節 Support Vector Machine ....................................... 17 第六節 手部數位影像辨識相關文獻 ..................................... 20 第三章 以 SVM 為基礎之手部影像辨識 ....................................... 23 第一節 系統架構 ..................................................... 23 第二節 建立 ASL 樣板 ................................................. 24 第三節 影像前處理 ................................................... 25 第四節 轉換特徵向量 ................................................. 44 第五節 實驗結果 ..................................................... 45. iv.
(7) 第四章:結論與未來研究方向 .............................................. 48 第一節 結論 ......................................................... 48 第二節 未來研究方向 ................................................. 48 參考文獻 ................................................................ 49 . v.
(8) 圖目錄 圖 1:彩色影像的手部影像 ................................................. 4 圖 2:彩色影像轉灰階影像的手部影像 ....................................... 5 圖 3:灰階影像轉二值影像的手部影像 ....................................... 6 圖 4:RGB 轉換 YCbCr 膚色偵測前 ............................................ 8 圖 5:RGB 轉換 YCbCr 膚色偵測後 ............................................ 8 圖 6:以 HSV 色彩模型偵測手部影像[(圖片來源[1]) ........................... 9 圖 7:Morphology 的 NOT、OR、AND、XOR 邏輯運算結果 ........................ 10 圖 8:侵蝕運算的結構元素排列順序 ........................................ 11 圖 9:二值化影像進行侵蝕運算前 .......................................... 11 圖 10:二值化影像進行侵蝕運算後 ......................................... 12 圖 11:膨脹運算的結構元素排列順序 ....................................... 12 圖 12:二值化影像進行膨脹運算前 ......................................... 13 圖 13:二值化影像進行膨脹運算後 ......................................... 13 圖 14:斷開運算的結構元素排列順序 ....................................... 14 圖 15:二值化影像進行斷開運算前 ......................................... 14 圖 16:二值化影像進行斷開運算後 ......................................... 14 圖 17:閉合運算的結構元素排列順序 ....................................... 15 圖 18:二值化影像進行閉合運算前 ......................................... 15 圖 19:二值化影像進行閉合運算後 ......................................... 16 圖 20:ASL 手語樣板(圖片來源[1]) ......................................... 17 圖 21:初始特徵空間(Initial feature space) .............................. 18 圖 22:初始特徵空間映射至高維空間(higher dimensional space) ............. 18 圖 23:一對一分類 ....................................................... 19 圖 24:Microsoft Kinect ................................................. 22. vi.
(9) 圖 25:系統架構 ......................................................... 23 圖 26:ASL 手語樣板,阿拉伯數字 0~9 ...................................... 24 圖 27:ASL 手語樣本,阿拉伯數字 0~9 ...................................... 25 圖 28:背景模型 ......................................................... 25 圖 29:手部影像 ......................................................... 26 圖 30:相減之後的影像差異圖 ............................................. 26 圖 31:YCbCr 色彩空間的 Cb 數值範圍 ....................................... 27 圖 32:YCbCr 色彩空間的 Cr 數值範圍 ....................................... 27 圖 33:以 Cb、Cr 第一高波峰(波寬範圍)作為參數的膚色切割 .................. 28 圖 34:Cb、Cr 第二高波峰(波寬範圍)作為參數的膚色切割 ..................... 28 圖 35:以 Cb、Cr 平均數作為參數的膚色切割 ................................ 29 圖 36:灰階化之前的手部物件。 ........................................... 30 圖 37:灰階化之後的手部物件。 ........................................... 30 圖 38:二值化之前的手部物件。 ........................................... 31 圖 39:二值化之後的手部物件。 ........................................... 32 圖 40:具有雜訊的手部物件 ............................................... 33 圖 41:斷開運算後的手部物件 ............................................. 33 圖 42:具有破碎的手部物件 ............................................... 34 圖 43:閉合運算後的手部物件 ............................................. 34 圖 44:ASL 手語樣板 ...................................................... 35 圖 45:輸入手部物件 ..................................................... 36 圖 46:選取出最長的連續線段(Lmax) ....................................... 36 圖 47:將 Lmin 之下的每條連續線段,剔除 .................................. 37 圖 48:輸出剔除多餘手臂特徵的手部物件 ................................... 37 圖 49:輸入手部物件(示意) ............................................... 39 圖 50:計算出畫面的中心(示意) ........................................... 39 vii.
(10) 圖 51:計算出手部物件的中心(示意) ....................................... 40 圖 52:進行手部物件偏移角度的調整(示意) ................................. 40 圖 53:輸入手部物件(實際) ............................................... 41 圖 54:進計算出畫面的中心(實際) ......................................... 41 圖 55:計算出手部物件的中心(實際) ....................................... 42 圖 56:進行手部物件偏移角度的調整(實際) ................................. 42 圖 57:正規化前 1024x768 的手部物件 ...................................... 43 圖 58:正規化後 32x32 的手部物件 ......................................... 44 圖 59:SVM 特徵向量表 .................................................... 45 圖 60:正規化維度參數與總體正確辨識率 ................................... 46 . . viii.
(11) 表目錄 表 1:FFT 三種辨識法手勢目標成功率測試影像非訓練資料與整體成功率 ......... 21 表 2:參數測試 ........................................................... 28 表 3:系統開發環境與硬體設備 ............................................. 45 表 4:正規化維度辨識率 ................................................... 46 表 5:3、5、7、9 類別各辨識率 ............................................ 46 表 6:FFT 三種辨識法手勢目標成功率測試影像訓練資料與整體成功率 ........... 47. ix.
(12) 第一章 緒論 第一節 研究背景 近年數位影像辨識處理的技術日漸成熟,而以數位影像辨識處理技術做為針對電腦 視覺化與人機介面溝通做研究的學術論文,更是不斷的推陳出新,數位影像辨識處理是 一種訊號處理的方式,藉由輸入數位影像經由系統辨識後,輸出訊號做為人機介面溝通 的應用。其中關於人體數位影像辨識的有人臉辨識、裸體辨識、手勢手語辨識、體感動 作辨識等等,有著許多不同類型的人體數位影像辨識與人機介面溝通方面的應用,而各 自使用的辨識方法與辨識成效也不盡相同。. 第二節 研究動機 電腦視覺化的人機介面溝通方式,大部分需要接觸式的控制裝置,如觸碰式面板、 按鍵式遙控器的使用來進行命令指令的輸入。所以,如果能夠將手勢辨識應用於人機介 面溝通,如此將能有助於提升人機介面溝通的便利性與直接性。手語是一種視覺性的語 言,如果能夠使用標準化的手語,例如 ASL 手語作為手勢辨識的基準。期望讓手勢辨識 應用於人機介面溝通能夠有一個標準的規格,使得不同系統的人機介面溝通,皆得能到 相同的命令指令,藉此增加其通用性。. 第三節 研究目的 本論文的主要目的在於探討以 SVM 做為手部數位影像辨識的可行性,期望,開發一 套以 SVM 應用於 ASL 手語樣板數位影像辨識系統,並以 ASL 手語樣板,做為 SVM 的訓練 樣本與測試樣本的基準,並且提出擷取局部手部特徵轉換為 SVM 特徵向量的演算法,藉 此提升以 SVM 應用於 ASL 手語數位影像辨識之成效。以 ASL 手語作為手勢辨識的基準, 能給人機介面溝通有個統一標準的規範,使不同系統的人機介面溝通,對此 ASL 手語都 能有著相同的解讀,不需要額外的學習。本論文應用 SVM 辨識與數位影像處理等相關技 術,開發出一套手部不需要額外穿戴上偵測器材的辨識系統,做為人機介面的一種溝通 方式。. 1.
(13) 第四節 論文架構 本論文共分為四章,其內容安排如下: 第一章:緒論 說明研究背景與動機、研究目的以及論文架構。 第二章:文獻探討 為使本論文的理論基礎與架構更完整,本論文搜集並整理與本研究題目所應用的數 位影像處理技術、膚色偵測、SVM、ASL 手語等相關文獻,歸納成下列數個單元來做 文獻的探討: 一、數位影像種類的介紹 二、色彩空間對於膚色偵測的應用 三、數位影像處理技術 四、American Sign Language 五、Support Vector Machine 六、手部數位影像辨識相關文獻 第三章:以 SVM 為基礎之手部影像辨識 第四章:結論與未來研究方向. 2.
(14) 第二章 文獻探討 現今隨著資訊科技的進步,電腦視覺化與數位影像處理的技術日漸成熟,在許多的 研究中,將兩者互相結合的應用也都有著不錯的辨識度。以手部影像辨識而言,正常人 體手部的指關節活動有著固定角度範圍與一定的特徵,因此將電腦視覺化與數位影像處 理技術,應用於手部影像的辨識上,是可行的,本論文與其他研究(Chang&Chang&Chu ng,2011)、(Flasin´&lin´,2010)、(J.W.Han&G.Awad&A.Sutherland,2009)都是屬於此 類研究的範圍,而以下幾節為本論文研究題目所應用的數位影像處理技術、膚色偵測、 SVM、ASL手語等相關的文獻探討。. 第一節 數位影像的種類介紹 本論文使用的數位影像是以二維平面空間表示,影像像素對應在此二維平面空間內 的每一個點,稱為像素點(Pixel),每一個像素點都為有限數值表示稱為"像素值",而 根據像素值的數值表示與表示數目的不同,可以劃分出不同的數位影像種類,本論文所 應用的數位影像種類為"彩色影像"、"灰階影像"、"二值影像"。以下將對於此三種數位 影像,做介紹。 一、彩色影像 RGB 色彩模型是三原色的模式,RGB 色彩模型的命名來自於三種原色的首字母 Red、 Green、Blue,是用三種原色紅色、綠色和藍色的色光以不同的比例相加,以產生多種 多樣的色光。而在彩色數位影像中,每ㄧ個像素點(Pixel),皆由 R、G、B,三種顏色組 成,個別可以 8 個位元來表示,顏色的變化,因此 28 × 28 × 28 這種組合,可以表現出 16777216 種不同顏色的像素值。. 3.
(15) 圖 1:彩色影像的手部影像. 二、灰階影像 灰階影像是指每一個像素點(Pixel)只用一個像素值表示,其數值範圍介於 0~255 之間,從暗點黑色(0)到亮點白色(255),一共有 256 種灰度深淺表示。因此灰階 影像又稱為灰度影像。YIQ 色彩模型是色彩空間的一種,其中 Y 為暗點(黑色)到亮點(白 色)之間的強度值,又稱為亮度(brightness)或流明度(luminance),I 與 Q 則為色彩的 資訊。而將 RGB 色彩模型轉為 YIQ 色彩模型的公式如下:. ⎡Y ⎤ ⎡0.299 0.587 ⎢ I ⎥ = ⎢- 0.596 - 0.274 ⎢ ⎥ ⎢ ⎢⎣Q ⎥⎦ ⎢⎣0.212 - 0.523. 0.114 ⎤ - 0.322 ⎥⎥ 0.311 ⎥⎦. ⎡R ⎤ ⎡ 0 ⎤ ⎢G ⎥ + ⎢128⎥ ⎢ ⎥ ⎢ ⎥ ⎢⎣B ⎥⎦ ⎢⎣128⎥⎦. (1). 而灰階影像只需要得到 Y 的強度值,因此將其公式(1)化簡為以下將 RGB 色彩模型的彩 色影像轉換為灰階影像的公式:. Gray Values = Y = 0.299 * R + 0.587 * G + 0.114 * B. 4. (2).
(16) 圖 2:彩色影像轉灰階影像的手部影像. 三、二值影像 二值影像是指每一個像素點(Pixel)只用一個像素值表示,其數值範圍介於 0~1 之 間為暗點黑色(0)到亮點白色(1)。只有兩種變化,因此,稱為二值影像。而將灰階影像 轉換為二值影像的公式,本論文採用的二值化演算法為 OTSU 演算法[17],經由 OTSU 演 算法計算後,便可以得到分割閥值(threshold value),分割閥值即為分割暗點黑色(0) 與亮點白色(1)的依據,該圖片的灰度值低於此分割閥值時,便將其設為暗點黑色(0)。 反之則設為亮點白色(1)。. OTSU 演算法概略原理如下: 假設,影像中有 L 個灰階度,且在第 i 個灰階度中有 Ni 個像素點,要找到一個二 值化臨界值 K,K 介於 1~L 之間。假設影像總點數為 N,每一個灰階度出現的比例 Pi, 則 L. N = ∑ Ni i =1. Pi = Ni/N 若以 K 為臨界值將影像灰階度分成兩群,分別為 1~K 及 K+1~L,則各群出現的機率 為 ω0 與 ω1. 5.
(17) k. ω0 = ∑ Pi i =1. ω1 =. L. ∑P. i = k +1. i. = 1-ω0. 各群的灰階度平均值為 μ0 及 μ1,總灰階度平均值則為 μ = μ 0 × ω0 + μ1 × ω1. 各群的類間方差公式假設為 G,則為 G = ω0 × (μ 0 − μ) × (μ 0 − μ) + ω1 × (μ1 − μ) × (μ1 − μ). 將 μ 帶入 G 之後,則得 G = ω 0 × ω1 × (μ 0 − μ 1 ) 2. 若能夠找到一個臨界值 K 使類間方差最大,則這個臨界值 K 即為二值化所要的分割 閥值。. 圖 3:灰階影像轉二值影像的手部影像. 第二節 色彩模型對於膚色偵測的應用 影像偵測技術日漸發達成熟,目前更有許多關於人體的辨識或者移動物件偵測的相 關學術研究發表,本論文計畫,透過影像處理的方式,進而達到擷取手部動作,並對於 影像偵測技術在人機介面的發展上,做出有用的貢獻。而膚色偵測對於人體辨識應用方 6.
(18) 面,則具有相當的影響程度。以下將 YCbCr、HSV 對於此二種色彩模型對於膚色偵測的 應用,做介紹。 一、YCbCr 色彩模型 YCbCr 是色彩空間的一種,通常應用於影片中的影像連續處理,或是數位攝影系統 中。亮度(Y)是顏色的亮度(luma)成分,Cb 與 Cr 則是 RGB 色彩模型中,B(藍色)和 R(紅 色)像素值的濃度偏移量成份。 而將 RGB 轉換到 YCbCr 時,人的膚色,將會集中在某個 範圍值(Cb、Cr),近年許多膚色偵測的研究,[6][11][12][13]都以此做為研究的參考 基礎,本論文採用 RGB 轉換 YCbCr 作為膚色偵測的基礎。而將 RGB 色彩模型轉換為 YCbCr 色彩模型的公式如下:. ⎡Y ⎤ ⎡0.299 0.587 0.114 ⎢Cb ⎥ = ⎢- 0.169 - 0.311 0.5 ⎢ ⎥ ⎢ ⎢⎣Cr ⎥⎦ ⎢⎣0.5 - 0.419 - 0.081. ⎤ ⎥ ⎥ ⎥⎦. ⎡R ⎤ ⎡ 0 ⎤ ⎢G ⎥ + ⎢128⎥ ⎢ ⎥ ⎢ ⎥ ⎢⎣B ⎥⎦ ⎢⎣128⎥⎦. (3). 而考量亮度的影響與資訊量的運算,在 RGB 轉換 YCbCr 膚色偵測中,影響較重的參 數為 Cb、Cr,因此將其公式(3)化簡為以下將 RGB 色彩模型轉換為 YCbCr 色彩模型的公 式:. Cb = (-0.169 * R) + (-0.311 * G) + (0.5 * B) + 128 Cr = (0.5 * R) + (0.419 * G) + (0.081 * B) + 128. (4). Cb、Cr 的參數範圍,決定了膚色偵測的效果,而[9]則使用統計樣本 Cb、Cr 的平 均值,做為參數設定的依據。. 7.
(19) 圖 4: RGB 轉換 YCbCr 膚色偵測前. 圖 5: RGB 轉換 YCbCr 膚色偵測後. 二、HSV 色彩模型 HSV 色彩模型是依照色彩中的三個基本屬性:色相、飽和度和明度來確定顏色的一 種方法。色相(H)是色彩的基本屬性之ㄧ,指顏色名稱,如紅色、綠色、藍色等。飽 和度(S)是指色彩的純度,該飽和度越高,表示色彩顏色越純淨,越低則會逐漸變成. 8.
(20) 灰色。明度(V)是指示物體表面的發光或反射光線的強度。而將 RGB 色彩模型轉換為 HSV 色彩模型的公式如下: ⎧⎛ ⎫ G−B ⎞ ⎪⎜ 0 + Max − Min ⎟ × 60, if R = Max ⎪ ⎠ ⎪⎝ ⎪ ⎪⎛ ⎪ B−R ⎞ H = ⎨⎜ 2 + ⎟ × 60, if G = Max ⎬ Max − Min ⎠ ⎪⎝ ⎪ ⎪⎛ ⎪ R−G ⎞ ⎟ × 60, if B = Max ⎪ ⎪⎜ 4 + Max − Min ⎠ ⎩⎝ ⎭ if Max = 0⎫ ⎧0, ⎪ ⎪ S = ⎨ Max − Min Max ⎬ otherwise ⎪ = 1− ⎪⎩ Max Min ⎭ V = Max. (4). HSV 色彩模型可以作為偵測特定顏色的公式使用 Kyung-Min Cho&Jeong-Hun Jang&Ki-Sang Hong* (2011)、李健銘(2008)、Kyung-Min Cho& Jeong-Hun Jang&Ki-Sang Hong*(2001),因此只需在偵測目標,例如:手部戴上,特定顏色的手套,即可做為手 部影像偵測的依據。缺點是背景不可有與 HSV 偵測的特定顏色干擾。. 圖 6:以 HSV 色彩模型偵測手部影像 資料來源:(Flasin´& lin´,2010). 9.
(21) 第三節 數位影像處理技術 一、Morphology 形態學(Morphology),為數位影像處理經常應用的處理方式,目的在於進行分離背 景與所需擷取的物件,所造成的雜訊與破碎。針對雜訊進行斷開(Opening)運算,針對 破碎進行閉合(Closing)運算。而形態學(Morphology)演算法之應用基礎,大多建立於 侵蝕(Erosion)運算與膨脹(Dilation)運算之上。形態學(Morphology)針對二值化數位 影像的運算,為鄰接區域計算,而將此鄰接區域尺寸固定,則稱為結構元素(Structure Element),結構元素(Structure Element)對應到二值化數位影像的像素區域,進行相 關的邏輯運算,並將相關邏輯運算所得到的結果,輸出為二值化數位影像像素區域的對 應像素。而形態學(Morphology)運算的結果,通常決定於結構元素(Structure Element) 的尺寸與邏輯運算的性質,例如:NOT、ÁND、OR、XOR 等。. 圖 7: Morphology 的 NOT、OR、AND、XOR 邏輯運算結果 10.
(22) (一) Erosion 侵蝕(Erosion)運算目的在於藉此清除雜訊。但是,亦會使物件邊緣被削減, 造成失真。本論文所使用的結構元素(Structure Element)尺寸固定為 3×3。Ae 為 要進行侵蝕(Erosion)運算的二值化像素點,Ae={(x,y)}。Be 為偵測相鄰像素(3by3) 的結構元素, Be={(x-1,y-1),(x+1,y),(x+1,y-1),(x-1,y),(x,y),(x+1,y),(x-1,y1+1),(x,y+1), (x+1,y+1)}={(b0),(b3),(b6),(b1),(b4),(b7),(b2),(b5),(b8)}。 侵蝕(Erosion)運算的公式如下:. Ae ΘBe = b 4 ∩ (b0 ∩ b1 ∩ b 2 ∩ b3 ∩ b5 ∩ b6 ∩ b7 ∩ b8). b0. b3. b6. b1. b4. b7. b2. b5. B8. 圖 8: 侵蝕運算的結構元素排列順序. 圖 9: 二值化影像進行侵蝕運算前. 11. (5).
(23) 圖 10: 二值化影像進行侵蝕運算後. (二) Dilation 膨脹(Dilation)運算目的在於藉此填補破碎。但是,亦會使物件邊緣被增脹,造成 失真。Ad 為要進行膨脹(Dilation)運算的二值化像素點,Ad={(x,y)}。Bd 為偵測相鄰像 素(3by3)的結構元素,Bd={(x-1,y-1),(x+1,y),(x+1,y-1),(x-1,y),(x,y),(x+1,y),(x-1,y1+1),(x,y +1),(x+1,y+1)}={(b0),(b3),(b6),(b1),(b4),(b7),(b2),(b5),(b8)}。 膨脹(Dilation)運算的公式如下:. Ad ⊕ Bd = b 4 ∪ (b0 ∪ b1 ∪ b 2 ∪ b3 ∪ b5 ∪ b6 ∪ b7 ∪ b8). b0. b3. b6. b1. b4. b7. b2. b5. B8. 圖 11: 膨脹運算的結構元素排列順序. 12. (6).
(24) 圖 12: 二值化影像進行膨脹運算前. 圖 13: 二值化影像進行膨脹運算後. (三) Opening 斷開(Opening)運算是先進行侵蝕(Erosion)後再進行膨脹(Dilation)運算,目的在 於使用侵蝕(Erosion)清除雜訊後,再利用膨脹(Dilation)使物件邊緣增脹,即可保持 物件形狀大小,不失真。AO 為 Erosion(Ae)運算後再進行 Dilation(Ad)運算的二值化像 素點。Bo= Be= Bd 為偵測相鄰像素(3by3)的結構元素。 斷開(Opening)運算的公式如下:. Ao o Bo = ( Ae ΘBe ) ⊗ Bd 13. (7).
(25) b0. b3. b6. b1. b4. b7. b2. b5. b8. 圖 14: 斷開運算的結構元素排列順序. 圖 15: 二值化影像進行斷開運算前. 圖 16: 二值化影像進行斷開運算後. 14.
(26) (四) Closing 閉合(Opening)運算是先進行膨脹(Dilation)後再進行侵蝕(Erosion)運算,目的在 於使用膨脹(Dilation)填補破碎後,再利用侵蝕(Erosion)使物件邊緣削減,即可保持 物件形狀大小,不失真。Ac 為 Dilation (Ad)運算後再進行 Erosion (Ae)運算的二值化 像素點。Bc= Bd= Be 為偵測相鄰像素(3by3)的結構元素。閉合(Opening)運算的公式如下:. Ac • Bc = ( Ad ⊗ Bd )ΘBe. b0. b3. b6. b1. b4. b7. b2. b5. b8. 圖 17: 閉合運算的結構元素排列順序. 圖 18: 二值化影像進行閉合運算前. 15. (8).
(27) 圖 19: 二值化影像進行閉合運算後. 第四節 American Sign Language ASL(American Sign Language)是美國、加拿大英語地區及墨西哥部分地區裡, 最常使用的標準手語之ㄧ,它包含了英文字母 A~Z 與阿拉伯數字 0~9,一共有 36 個不同 手部姿勢變化。天生具有聾啞障礙的人,自然可以用自己的手勢方式表達出意思與需 求,但是,這樣子的行為只適用於作為簡單的交流溝通。這些制定出標準的手語,才能 讓具有聾啞障礙的人與沒有學習過相關手語的人,彼此能夠順利溝通、協調。制定出標 準的手語也因此為聾啞基本教育訂下了學習的基礎。因此本論文使用此 ASL 標準手語作 為辨識模組樣板的基礎,期望讓手勢辨識應用於人機介面溝通能夠有一個標準的規格, 使得不同系統的人機介面溝通,皆得能到相同的命令指令,藉此增加其通用性,圖 20 即為 ASL 手語樣板英文字母 A~Z 與阿拉伯數字 0~9 總共 36 個手勢變化。. 16.
(28) 圖 20: ASL 手語樣板 資料來源:(李,2008). 第五節 Support Vector Machine 一、SVM 的由來與應用 支持向量機(Support Vector Machine)是根據統計學習理論為基礎,所提出的一種機 器學習方法, 最初 SVM 是做為解決二元分類問題的應用,而其實際的應用在分類技術 上,SVM 有著不錯的表現,因此,SVM 成為現在機械學習(machine learning)與資料開 採(data mining)標準工具之一。機器學習:結合了統計、數學與資訊科學等,研究如 何讓電腦具有學習的能力。 二、SVM 的分類概念 支持向量機(Support Vector Machine)是一種應用線性分類(Linear Classification) 的概念,目的在於尋找一個可以使得所有訓練用而且已經分類好的資料在初始特徵空間 (Initial Feature Space)中,透過映射(Mapping)可以將不同類別(class)清楚分開的 超平面(hyperplane),就像是對於及格與不及格的定義,我們可以用和及格與不及格關 聯性最高的分數列為基準,讓支持向量機將此分數列作為分類的重要參考依據。. 17.
(29) 圖 21: 初始特徵空間(Initial feature space). 圖 22: 初始特徵空間映射至高維空間(higher dimensional space). 支持向量機(Support Vector Machine)利用在訓練資料集(Training data set)中的向 量點(vectors)來找到超平面(hyperplane),以用來將資料分類。構成超平面 (hyperplane),最大邊界的訓練資料點,稱為特徵向量(Super vectors),也就是在分 類上給予最多資訊的點。因為需要訓練資料,所以 SVM 也是一種監督式學習(supervised learning)的方法。 18.
(30) 三、SVM 的多元分類 前面提到最初 SVM 是做為解決二元分類問題的應用,而其實際的分類應用,經常面 對不止兩類的分類。對此本論文所使用多元分類策略為一對一(one against one),對 任意兩個類別進行 svm 分類,以二元樹的概念,進行分類辨識,如圖 23 所示。. 圖 23:一對一分類. 由樹的底層包含了所有的分類類別,由底層開始,進行分類辨識,第一次的分類結果為 2、3 類別,由 2、3 類別進行分類,最後得出分類結果為 2。. 四、Libsvm 本論文將透過數位影像處理所擷取出的手部物件,將其轉換為特徵向量,做為 SVM 運用於 ASL 手語樣板數位影像辨識系統之成效研究。這正是本論文選取 SVM 作為分類辨 識基準的決定因素之ㄧ。對此,本論文是使用臺灣大學林智仁博士等人(Chang& Lin, 2012)所開發的一套 Libsvm,作為分類辨識的基準。對於 Libsvm 分類,林智仁博士有以 下建議流程。 Libsvm 分類流程: Step01:將資料轉換為 Libsvm 所支持的格式 19.
(31) Step02:將訓練資料、測試資料做尺度調整 (Svm scale) Step03:選擇效能較佳的 RBF kernel Step04:利用交叉驗證 (Cross validation)選擇較佳參數 Step05:使用找到的參數做訓練模型 (Train model) Step06:將測試資料轉化預測資料(Predict data) libsvm 所支持的格式即為:<Label> <Index1>:<Value1> <Index2>:<Value2> … Label 對於訓練集而言是目標值,對於測試集而言是標記分類的整數,通常為實數。 Index 代表資料的索引,例如:第一筆訓練集的資料或第一筆測試集的資料。Value 代 表資料的特徵值。將資料集做尺度調整 (Svm scale)的原因在於避免特徵值的範圍過大 或者過小,因而造成 svm 的運算困難。對於交叉驗證 (Cross validation),Libsvm 提 供了 grid.py tool 以暴力法進行參數最佳化的測試選擇。RBF kernel 為 Radial basis function 對於映射函數做內積所得到的函數。預測資料 (Predict data)即為 Libsvm 經由訓練(Training) 所得到訓練模型(Train model),對於尚未有所分類的資料,Libsvm 使用先訓練模型(Train model)去建立這筆資料所屬的分類預測資料 (Predict data), 以進行辨識。. 第六節 手部數位影像辨識相關文獻 一、應用數位影像處理與辨識技術辨識 近幾年手勢辨識研究(Flasin´& lin´,2010)、(J.W.Han&G.Awad,A.Sutherland,2009)、 (Chang& Chang&Chung,2011)、(H.-D.Yang&S. Sclaroff&S.-W Lee,2009)等研究是應 用膚色保留的方式,先對於整張數位影像進行膚色偵測,將接近膚色的物件保留下來, 再加以判斷是否為手勢,而膚色偵測較常使用的色彩空間,有 YCbCr 與 HSV 等,應用色 彩空間的轉換計算做為膚色偵測的方式,而所應用的辨識技術也不盡相同,以下探討為 近幾年數位影像辨識研究,經常使用的演算法。. 20.
(32) 一、FFT 快速傅立葉轉換(Fast Fourier-Transform) FFT 快速傅立葉轉換(Fast Fourier-Transform)對於特徵向量的擷取方式,是 經由 FFT 演算法運算之後,將特徵向量轉換為頻率向量後,求出頻率向量中各分量 的強度,最後再取成自然對數,進而成為有著 256 個頻率強度值的特徵向量。在[2] 研究中將類別特徵向量與測試特徵向量中的 256 個特徵值相減之後,取得對於各類 手勢的誤差值,再轉換對各類手勢所代表的機率,並以此機率為辨識基準。. 表 1:FFT 三種辨識法手勢目標成功率測試影像非訓練資料與整體成功率 Hand-Pose No. Overall 1. 2. 3. 4. 5. 6. 7. Shift-Distance. 81%. 73%. 81%. 72. 90%. 72%. 73%. 77%. FFT Feature. 72%. 72%. 54%. 63%. 54%. 63%. 72%. 64%. Combined. 90%. 82%. 82%. 90%. 90%. 90%. 90%. 87%. 資料來源:(陳,2007). 二、應用數位影像處理與分類器辨識 2-1 單純貝氏分類器(Naïve Bayesclassifier) 單純貝式分類器(Naïve Bayes classifier)[3]是一種監督式的學習方法,透 過訓練樣本的訓練學習,用以辨識未分類的測試樣本。單純貝氏分類器主要是根據 貝氏定理(Bayesiantheorem)來辨識分類的結果,P(Ai)為邊緣機率即為 A 事件發生 的機率,P(Ai|B)為在 B 事件的條件之下,A 事件會發生的可能性,而單純貝氏分類 器會根據訓練樣本,針對測試樣本的性質,以具有最高機率值的類別為基準進行分 類辨識,貝氏定理的公式如下:. P ( Ai | B ) =. P ( Ai ∩ B ) = P (B ). ∑. P ( Ai ) × P ( B | Ai ) n. P ( Ai ) × P ( B | Ai ) i =1 21. (9).
(33) 三、應用影像感測器感測辨識 3-1Microsoft Kinect Microsoft 所研發的 XBOX360 的遊戲把手 Kinect,具有捕捉深度資訊與人體偵 測的功能,應用影像感測器感測辨識,可以減少許多手勢辨識所需要做的數位影像 處理技術,(Vinayak &Murugappana&Liu&Ramania,2013)從深度資訊辨識手部的形 狀,能簡單的就消除背景與減少雜訊,進而減少辨識手勢所需要花費數位影像前處 理的時間,應用影像感測器感測辨識的缺點為需要增加額外的硬體成本。. 圖 24: Microsoft Kinect. 22.
(34) 第三章 以 SVM 為基礎之手部影像辨識 第一節 系統架構 此系統的架構分成了三個模組,第一個模組是影像前處理模組、第二個模組為 SVM 特徵轉換模組、第三個模組則是 SVM 辨識模組。. 圖 25: 系統架構 23.
(35) 一、影像前處理模組 訓練背景模型,讓輸入的數位影像與背景模型相減,取得差異圖,使用 RGB 色彩模 型轉換為 YCbCr 模型與連通物件偵測,保留手部影像。再將保留手部影像的部份進行二 值化,並應用形態學(Morphology)對手部影像進行雜訊消除與破碎填補。 二、SVM 特徵轉換模組 因為 ASL 手語樣板,當中並無包含過多的手臂部份,所以,要剔除多餘手臂特徵, 以求減少多餘的資訊量,避免對於辨識正確率造成影響,之後校正手勢偏移角度,並且 將其正規化至 32×32 的大小、本論文所提出抽取 SVM 特徵向量的演算法,抽取手部物件 的特徵向量,將其轉換為 SVM 特徵向量,以此做為手語辨識的基礎。 三、SVM 辨識模組 輸入經過像前處理模組與 SVM 特徵轉換模組轉換的 SVM 訓練樣本與測試樣本, 建立訓練檔與測試檔,應用 SVM 進行辨識,最後再將手勢辨識正確率之結果輸出。. 第二節 建立 ASL 樣板 本論文採用 ASL 手語樣板中的阿拉伯數字 0~9,做為 SVM 的訓練樣本。SVM 在訓練 樣本時,需要正確的資訊,才能有效率的進行測試樣本辨識。因此,為要求其正確性, 建立樣板的時候,要求參與辨識的人員,皆需要擺出符合正確的 ASL 手語樣板的手勢。. 圖 26: ASL 手語樣板,阿拉伯數字 0~9. 24.
(36) 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 圖 27: ASL 手語樣本,阿拉伯數字 0~9. 第三節 影像前處理 ㄧ、背景相減 使用一張背景模型與目前手部影像,做互相減去之後,就可以求出其差異圖。差異 圖即為原本不存在背景之中的手部影像,又稱為前景物體。設定一門檻值(T),將背景 模型與目前影像相減之後的像素值。若大於門檻值(T)則將該點的像素值保留下來。背 景相減的優點在於相減過後,可以取得較為完整前景物體,缺點是在於相減過後,仍會 有許多雜訊保留下來。. 圖 28:背景模型. 25.
(37) 圖 29: 手部影像. 圖 30: 相減之後的影像差異圖. 二、Skin Detection 一般數位彩色影像中的像素是透過 R、G、B 三原色所組合而成的,也就是使用最 原始的 RGB 色彩空間來儲存。但由於 RGB 色彩空間對於光源的較為敏感,為了降低光源 所造成的影響,使用 YCbCr 色彩空間做膚色偵測之處理。RGB 色彩空間的圖像大小為 1024x768,一共有 786432 點像素點,將相減之後的影像差異圖,利用公式(3)化簡為公 式(4)做 RGB 轉 YCbCr 的矩陣轉換,計算後得到了 Cb、Cr 的數值範圍,Cb 與 Cr 則是 RGB 26.
(38) 色彩模型中,B(藍色)和 R(紅色)像素值的濃度偏移量成份。. 圖 31: YCbCr 色彩空間的 Cb 數值範圍. 圖 32: YCbCr 色彩空間的 Cr 數值範圍. 如圖 31、圖 32 所示,透過圖示可以發現 Cb 的最大值為 124,Cr 的最大值為 133,因此, 本論文以 Cb、Cr 的第一高波峰與第二高波峰的波寬,作為膚色切割的參數測試,Cb 與 Cr 則是 RGB 色彩模型中,B(藍色)和 R(紅色)像素值的濃度偏移量成份。而將 RGB 轉換 到 YCbCr 時,人的膚色,將會集中在某個範圍值(Cb、Cr),近年許多膚色偵測的研究, [6][11][12][13]都以此做為研究的參考基礎。 27.
(39) 表 2:參數測試 第一高波峰. 第一高波峰. 第二高波峰. 第二高波峰. (最大值). (波寬範圍). (最大值). (波寬範圍). Cb. 124. 118~131. 116. 112~117. Cr. 133. 124~139. 154. 143~160. 圖 33:以 Cb、Cr 第一高波峰(波寬範圍)作為參數的膚色切割. 圖 34:Cb、Cr 第二高波峰(波寬範圍)作為參數的膚色切割. 28.
(40) 如圖 33、圖 34 所示,透過圖示可以發現單以一個波寬作為膚色偵測的效果,無法 確實把手部皮膚範圍順利切割。. 圖 35:以 Cb、Cr 平均數作為參數的膚色切割 因此以 Cb、Cr 高於平均數的值,作為膚色切割的參數依據,從以圖 33、圖 34、圖 35 發現,Cb、Cr 參數若取的不好,對於膚色切割的影響,則佔有相當的比重。. 三、灰階化 使用公式(1)化簡為公式(2),將膚色偵測之後保留的手部物件做灰階化的轉換,而 進行灰階化主要目的能有效減少所需要處理的手部物件資訊量,以利之後的影像處理, 圖 36 為做為背景相減與 RGB 轉換到 YCbCr 膚色切割所保留下來的手部,圖 37 則是將 圖 38 進行灰階化轉換之後的手部物件,灰階影像是指每一個像素點(Pixel)只用一個像 素值表示,其數值範圍介於 0~255 之間,從暗點黑色(0)到亮點白色(255),一共有 256 種灰度深淺表示。. 29.
(41) 圖 39: 灰階化之前的手部物件。. 圖 40: 灰階化之後的手部物件。. 四、二值化 將做完灰階化轉換的手部物件,進行二值化。二值影像是指每一個像素點(Pixel) 只用一個像素值表示,其數值範圍介於 0~1 之間為暗點黑色(0)到亮點白色(1)。只有兩 種變化,因此,稱為二值影像。而將灰階影像轉換為二值影像的公式,本論文採用的二 值化演算法為 OTSU 演算法,經由 OTSU 演算法計算後,便可以得到分割閥值(threshold 30.
(42) value),該圖片的灰度值低於此分割閥值時,便將其設為暗點黑色(0)。反之則設為亮 點白色(1)。 進行二值化的主要目的就是讓灰階化後的手部物件,產生明顯的暗、亮效果,將具 有 0~255 個灰度等級的手部物件,使用分割閥值(threshold value)劃分後,取得仍然 可以反映整體手部物件與特徵如圖 39 二值化之後的手部物件,可以有效的減少所需要 處理的手部物件資訊量,以利之後 Morphology 的影像處理。. 圖 41:二值化之前的手部物件。. 31.
(43) 圖 42:二值化之後的手部物件。. 五、Morphology 形態學(Morphology),為數位影像處理經常應用的處理方式,目的在於進行分離背 景與所需擷取的物件,所造成的雜訊與破碎。針對雜訊進行斷開(Opening)運算,針對 破碎進行閉合(Closing)運算。而形態學(Morphology)演算法之應用基礎,大多建立於 侵蝕(Erosion)運算與膨脹(Dilation)運算之上。 由於每次拍攝手部手勢時,不太可能有機會每次的光線亮度、背景、膚色都完全一 樣,因此在背景相減、膚色偵測時,會造成背景雜訊的干擾與手部物件破碎情形發生, 所以本論文使用公式(5)針對背景雜訊干擾的進行消除,使用公式(6)針對手部物件破碎 情形進行填補,圖 43 為執行斷開運算之前,在紅色圓圈標示處標示具有雜訊干擾的部 分,圖 44 即為執行斷開運算過程之後消除雜訊干擾的結果,而圖 45 為執行閉合運算 之前,在紅色圓圈標示處標示,在手部(主體)物件上具有破碎的部分、圖 46 即為執行 閉合運算過程之後填補破碎部分的結果。. 32.
(44) 圖 47:具有雜訊的手部物件. 圖 48:斷開運算後的手部物件. 33.
(45) 圖 49:具有破碎的手部物件. 圖 50:閉合運算後的手部物件. 六、剔除超過 ASL 手語樣板的多餘手臂特徵 從圖 20 中發現,完整的 ASL 手語樣板,包含的手臂部份,並不多,所以必須將超 過 ASL 手語樣板的多餘手臂特徵,進行剔除。對此部份,本論文提出剔除多餘手臂特徵 的演算法,以求減少多餘的資訊量,如此才不會對於辨識的正確率造成過多的影響,圖. 34.
(46) 51 在紅色圓圈的標記處即為需要剃除的多餘手臂特徵。. 圖 52: ASL 手語樣板. 剔除多餘手臂特徵演算法如下: Stage1:Intput:輸入手部物件。 Step1:計算出每條存在手部物件上,且斜率為 0 的連續線段。 (1)選取 Lmax:即為在手部物件中最長的連續線段。 Step2:與 Lmax 之下的每條連續線段相減。 (1)選取 Lmin:與 Lmax 相減之後,差值最大的連續線段。 Step3:將 Lmin 之下的每條連續線段,剔除。 Stage2:Output:輸出剔除多餘手臂特徵的手部物件。. 35.
(47) 圖 53:輸入手部物件. 圖 54:選取出最長的連續線段(Lmax). 36.
(48) 圖 55:將 Lmin 之下的每條連續線段,剔除. 圖 56:輸出剔除多餘手臂特徵的手部物件. 圖 57 為依據雜訊干擾或手部(主體)破碎程度條件,進行斷開運算或閉合運算之後 的手部物件,圖 58 為找手部(主體)距離最長的水平線段 Lmax,圖 59 為剔除在 Lmin 之下的手部部分,以紅色標示其該剃除區域,依照人體正常範圍,手掌與手臂連接的手 腕關節附近,比手掌與手臂還要細,因此以此作為手掌與手臂的分割線即為演算法中的 Limn,而圖 60 為剔除手腕關節之下多餘的手臂延伸部分的輸出。 37.
(49) 七、校正手部物件偏移角度 每次拍攝影像的角度與手部擺放的位置,皆不太可能,可以達到完全相同。因此將 手部物件做偏移角度的校正,使得每張手部影像的中心,皆可以相符,以求修正不同拍 攝影像的角度與手部擺放的位置,偏移的物件,做中心調整,有助於正確辨識率的提升。 對此部份,本論文提出剔除多餘手臂特徵的演算法,調整物件重心做法為先計算出 畫面的中心與物件的中心,將兩中心相減,可得出△X、△Y 之偏移量,再利用此偏移量 與物件的每一點像素點座標做運算,進行物件中心的調整,如此才不會對於辨識的正確 率造成過多的影響。. 校正手部物件偏移角度演算法如下: Stage1:Intput:輸入手部物件。 Step1:計算 Scenter:整體畫面的中心點(xs,ys),xs = 整體畫面的寬÷2, ys = 整體畫面的長÷2。 Step2:計算 Ocenter:手部物件的中心(xo,yo),xo = 整體畫面的寬÷2, yo = 整體畫面的寬÷2。 Step3:將 Scenter(xs,ys)與 Ocenter(xo,yo)相減,得出△X、△Y。 Step4:△X、△Y 與物件的每一點像素點座標做運算。 Step5:進行物件偏移角度的調整。 Stage2:Output:輸出校正偏移角度的手部物件。. 38.
(50) 圖 61: 輸入手部物件(示意). 圖 62: 計算出畫面的中心(示意). 39.
(51) 圖 63: 計算出手部物件的中心(示意). 圖 64: 進行手部物件偏移角度的調整(示意). 40.
(52) 圖 65: 輸入手部物件(實際). 圖 66: 計算出畫面的中心(實際). 41.
(53) 圖 67: 計算出手部物件的中心(實際). 圖 68: 進行手部物件偏移角度的調整(實際) 圖 69~圖 70 為校正手部物件偏移角度演算法執行步驟之示意圖,圖 71 為實際執 行輸入的手部物件,圖 72 為計算出整體畫面的中心(xs,ys),紅色標記線為水平軸、綠 色標記線為垂直軸,圖 73 為計算出手部物件的中心(xo,yo),圖 74 為整體畫面的中心 (xs,ys 與手部物件的中心(xo,yo)相減之後,運用△X、△Y 與手部物件的每一點像素點座 標做運算之後的校正偏移角度輸出。. 42.
(54) 八、正規化 由於每次拍攝的攝影器材,不盡相同,所以將每ㄧ張經過數位影像前處理的手部物 件,進行正規化,將其縮放為同一大小比例修正,如此才不會對於辨識的正確率造成過 多的影響。本論文所縮放的手部物件圖像,長、寬為 32x32,圖像像素點一共為 1024 點,如此一來就可以降低手部物件進行 SVM 特徵向量抽取的運算時間。NRangemax:正 規化範圍的最大值。NRangemix:正規化範圍的最小值。ORangemax:物件範圍的最大值。 ORangemax:物件範圍的最小值。O:物件當前的範圍值。正規化(Normalization)的公 式如下:. Normalization =. (( NRange max − NRange min) * (O − ORange min)) + NRange min (10) (ORange max − ORange min). 圖 75: 正規化前 1024x768 的手部物件. 43.
(55) 圖 76: 正規化後 32x32 的手部物件. 第四節 轉換特徵向量 應用 SVM 做分類辨識時,一個限制的條件,就是必須將物件特徵轉換為 SVM 所支持 的特徵向量,如此 SVM 才能順利進行分類,而特徵向量對於 SVM 的正確辨識率具有一定 程度的影響。所以,本論文提出抽取正規化後的手部物件特徵轉換為 SVM 特徵向量的演 算法,進行轉換。轉換 SVM 特徵向量演算法如下: Stage1:Intput:輸入正規化後的手部物件特徵。 Step1:因輸入辨識總共 10 類,故設定物件類別為[+1~+10]。 Step2:轉換為 1024 維度向量(32x32)。 Step3:每一維度特徵向量值為[0~1]。 (1) 手部物件特徵該點像素的像素值為暗點時,特徵向量值為 1。 (2) 手部物件特徵該點像素的像素值為亮點時,特徵向量值為 0。 Stage2:Output:輸出 SVM 特徵向量。. 44.
(56) 圖 77: SVM 特徵向量表 圖 78 為將正規化之後的手部物件以轉換 SVM 特徵向量演算法進行轉換的輸出,因 使用圖 79 正規化後 32x32 的手部物件,因此輸出為具有 1024 維度的 SVM 特徵向量表, 而其功用在於,這是 SVM 所支持的格式,如此 SVM 才能順利進行分類,而其中的特徵向 量選擇則是由使用者需求而定,因此格式相同,若選取的特徵向量不同,則辨識結果可 能也不盡相同。. 第五節 實驗結果 本論文收集了 ASL 手語樣板阿拉伯數字 0~9 的部份,一共收集了 17 份由真人參照 圖 19 所建立的真人手語手勢樣本,每一份樣本皆是一個人擺出 ASL 手語樣板阿拉伯數 字 0~9 的手勢,所以,每一份樣本共有 10 種不同 ASL 手語手勢,總共有 170 張 ASL 手 語樣本。將隨機抽取的 6 份樣本做為 SVM 訓練樣本,其餘的 11 份樣本做為測試樣本。 由於 ASL 手語樣板阿拉伯數字 0~9 的部份,一共有十種不同的手勢,所以將訓練樣本分 別為十個類別代表不同的數字,ASL 手語手勢 0 代表第ㄧ類、手勢 1 代表第二類,以此 類推。訓練樣本每ㄧ類下有 6 個樣本,所以總共是 60 個樣本,測試樣本每ㄧ類下有 11 個樣本,所以總共是 110 個樣本。. 表 3:系統開發環境與硬體設備 Operating system. Windows 7. Software Development Environment. Microsoft Visual Studio 2008. Programming language. C#. Photographic lens. Digital Cameras(8,000,000 pixels). 45.
(57) 表 4:正規化維度辨識率 訓練樣本數. 測試樣本數. 辨識錯誤數. 正規化維度. 總體辨識率. 60. 110. 58. 8x8. 47.27%. 60. 110. 36. 16x16. 67.27%. 60. 110. 10. 32x32. 90.90%. 60. 110. 2. 64x64. 98.18%. 60. 110. 2. 128x128. 98.18%. 圖 80:正規化維度參數與總體正確辨識率. 表 5:3、5、7、9 類別各辨識率 類別. 訓練樣本數. 測試樣本數. 辨識錯誤數. 正規化維度. 正確辨識率. 0~2. 18. 33. 0. 64x64. 100%. 0~4. 30. 55. 0. 64x64. 100%. 0~6. 42. 77. 3. 64x64. 96.10%. 0~8. 54. 99. 2. 64x64. 97.97%. 46.
(58) 表 6:FFT 三種辨識法手勢目標成功率測試影像訓練資料與整體成功率 Hand-Pose No. Overall 1. 2. 3. 4. 5. 6. 7. Shift-Distance. 88%. 66%. 83%. 100%. 100%. 100%. 77%. 88%. FFT Feature. 89%. 89%. 78%. 44%. 89%. 67%. 100%. 80%. Combined. 85%. 71%. 100%. 100%. 100%. 100%. 100%. 95%. 資料來源:(陳,2007). 表 4 為測試不同正規化維度之正確辨識率,從圖 81 觀察發現正規化維度的參數 值,維度越高的時候,對於辨識率具有正向的助益,因為能保留的特徵越多,可是,會 增加其 SVM 於分類的運算時間,對於系統執行時的即時反應率會有所折扣,由於常人的 手指頭數量與指關節活動的範圍,對於手勢所需擷取的特徵有限,所以,最佳的正規化 參數為 64x64,可以保留足夠的特徵,相比於維度 128x128 亦可減少 4 倍的資訊量。表 7 為測試不同類別數之正確辨識率,依照人機介面溝通的指令需求,可以依照表 4 之辨 識結果,作為選取合適的類別數,以此作為指令需求的依據。表 8 為距離特徵辨識法、 FFT 特徵辨識法與綜合兩者以權重值的組合辨識法。表 4、表 5、表 6 比較,若人機介 面溝通的指令需求不需要使用到 10 種手勢,則表 4、表 6 之部分類別辨識率優於表 5 整體類別的辨識率,觀察測試結果之後,發現其此部分類別辨識率優於其他類別的因素 為前面的類別手勢簡單,因此減少了手指、手掌與擺放角度的影響因素,即使是不同測 試樣本也無太大的改變。若以整體辨識結果而論,則表 5 的 10 種手勢類別辨識優於表 6 的 7 種手勢類別,表 4~6 皆為影像訓練過後的辨識結果。. 47.
(59) 第四章:結論與未來研究方向 第一節 結論 本論文以 SVM 作為辨識基礎,使用 ASL 手語樣板,應用數位影像處理的方法,設計 一套辨識系統,做為人機介面溝通的一種方式。透過此次實驗結果發現,SVM 經由超平 面所分類的結果,是可以期待的。SVM 的正確辨識率受到數位影像前處理與 SVM 特徵向 量抽取的方式影響,正規化維度越高,則可以保證 ASL 手語樣板的特徵維持,而如何提 升 SVM 正確辨識率的要素就落在多餘資訊量的剔除與特徵的維持之上,透過本論文所提 出的"手部物件特徵轉換為 SVM 特徵向量演算法",對於 SVM 提升正確辨識率,是具有正 面助益的。 在本系統辨識之擷取的數位影像測試樣本有著下列的限制: 1.. 拍攝的測試樣本須符合 ASL 手語樣板阿拉伯數字 0~9 的部份。. 2.. 拍攝的測試樣本距離遠近,依照攝影鏡頭規格須不能超過 1 公尺。. 3.. 辨識畫面須為單手影像。. 4.. 拍攝的測試樣本,其環境光線必須充足。. 5.. 手部部分不能穿戴手套等遮蔽。. 第二節 未來研究方向 本論文使用的攝影鏡頭,僅能捕捉平面影像二維空間,無法對於深度資訊做進一步 的處理,建議可以提升硬體規格,例如使用 Microsoft Kinect 感測器,具有捕捉深度 資訊與人體偵測的功能,應用影像感測器感測辨識,可以減少許多手勢辨識所需要做的 數位影像前處理,並且針對於特徵向量的選取,做深度資訊與人體動態偵測等,更進ㄧ 步的研究探討。並且結合網路雲端技術,提升即時運算效能,進而減少辨識時間。等... 都是值得我們思考的未來研究方向。. 48.
(60) 參考文獻 李健銘(2008)。即時手語辨識。國立成功大學工程科學系碩士班,碩士論文 沈群景(2009)。基於視覺的手寫軌跡注音符號組合辨識系統。中央大學資訊工程學研究 所,碩士論文 陳佳源(2005)。結合平移距離與傅立葉特徵之手勢辨識系統。中原大學資訊工程研究所, 碩士論文 Tsai Bo-Lin. (2009)。Vision-based Sign Language Recognition System。清華大學電機工 程研究所,碩士論文 A Library for Support Vector Machines,http://www.csie.ntu.edu.tw/~cjlin/libsvm/。 Chang Chuehwei, Chang Chunhao, Chung Yihao. (2011), A Two-Hand Multi-Point Gesture Recognition System Based on Adaptive Skin Color Model, Scientific Journal of Information Engineering, Vol. 1 , pp. 1101–1102. Stergiopoulou, E. , Papamarkos*, N. (2009), Hand gesture recognition using aneural network shape fitting technique, Engineering Applications of Artificial Intelligence ,Vol. 20 , pp. 1141–1158. Yang, H. D., Sclaroff, S. , Lee, S. W. (2009), Sign Language Spotting with a Threshold Model Based on Conditional Random Fields, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 31, pp.1264–1277. Hideki Nodaכ, Michiharu Niimi. (2007), Colorization in YCbCr color space and its ap plication to JPEG images, Pattern Recognition ,Vol. 40, pp. 3714–3720. Han, J.W. , Awad, G. , Sutherland, A. (2009), Modelling and segmenting subunits for sign language recognition based on hand motion analysis, Pattern Recognition Lett,Vol. 30, pp.623–633. Jose, M. Chaves-Gonzálezכ, Miguel, A. , Vega Rodríguez, Juan, A. Gómez Pulido, Juan, M. Sánchez Pérez. (2010), Detecting skin in face recognition systems: A colour spaces study,. 49.
(61) Digital Signal Processing ,Vol. 20, pp. 806–823. Cho Kyung-Min, Jang Jeong-Hun, Hong* Ki-Sang. (2001), Adaptive skin-color , Pattern Recognition ,Vol. 34, pp. 1067–1073. Cho Kyung-Min, Jang Jeong-Hun, Hong* Ki-Sang. (2011), Face Localization Based On Edge Information Of Skin Color And Eye, Energy Procedia, Vol. 13, pp. 3678–3683. Flasin´Mariusz , lin´ SzymonMys´. (2010),On the use of graph parsing for recognition of isolated hand postures of Polish Sign Language, Pattern Recognition,Vol. 43 , pp.2249–2264. Otsu, N. (1979 ,January), "A Threshold Selection Method from gray-level Histograms. IEEE International Conference on System, Man, and Cybernetics. vol. 9, pp. 62–66. Khan* Rehanullah , Hanbury Allan, Stöttinger Julian, Bais Abdul. (2012), Color based skin classification, Pattern Recognition ,Vol. 33, pp. 157–163. Vinayak, a. , Sundar Murugappana, Liu HaiRong, a, Karthik Ramania, b. (2013), Shape-It-Up: Hand gesture based creative expression of 3D shapes using intelligent generalized cylinders, Pattern Recognition,Vol. 45 , pp. 277–287.. 50.
(62)
數據




+7





Outline
相關文件
We have provided alternative proofs for some results of vector-valued functions associ- ated with second-order cone, which are useful for designing and analyzing smoothing and
“Transductive Inference for Text Classification Using Support Vector Machines”, Proceedings of ICML-99, 16 th International Conference on Machine Learning, pp.200-209. Coppin
Machine Translation Speech Recognition Image Captioning Question Answering Sensory Memory.
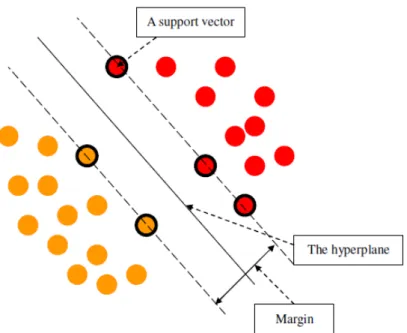
Lecture 1: Large-Margin Linear Classification Large-Margin Separating Hyperplane Standard Large-Margin Problem Support Vector Machine.. Reasons behind
時值知識經濟時代的來臨,台灣已加入了 WTO ( World Trade Organization,WTO ),企業面臨劇變之環境及廣闊的物料採購市 場,若能善用「知識管理」( Knowledge
Mutual information is a good method widely used in image registration, so that we use the mutual information to register images.. Single-threaded program would cost
Our preliminary analysis and experimental results of the proposed method on mapping data to logical grid nodes show improvement of communication costs and conduce to better
Jones, "Rapid Object Detection Using a Boosted Cascade of Simple Features," IEEE Computer Society Conference on Computer Vision and Pattern Recognition,
