The Symptoms, Causes, and Repairs of bugs inside a Deep Learning Library
Li Jiaa, Hao Zhonga,∗, Xiaoyin Wangb, Linpeng Huanga, Xuansheng Lua
aShanghai Jiao Tong University, Shanghai 200240, China
bUniversity of Texas at San Antonio, Texas, USA
Abstract
In recent years, deep learning has become a hot research topic. Although it achieves incredible positive results in some scenarios, bugs inside deep learning software can introduce disastrous consequences, especially when the software is used in safety-critical applications. To understand the bug characteristic of deep learning software, researchers have conducted several empirical studies on deep learning bugs. Although these studies present useful findings, we notice that none of them analyze the bug characteristic inside a deep learning library like TensorFlow. We argue that some fundamental questions of bugs in deep learning libraries are still open. For example, what are the symptoms and the root causes of bugs inside TensorFlow, and where are they? As the underly- ing library of many deep learning projects, the answers to these questions are useful and important, since its bugs can have impacts on many deep learning projects. In this paper, we conduct the first empirical study to analyze the bugs inside a typical deep learning library, i.e., TensorFlow. Based on our results, we summarize 8 findings, and present our answers to 4 research questions. For example, we find that the symptoms and root causes of TensorFlow bugs are more like ordinary projects (e.g., Mozilla) than other machine learning libraries (e.g., Lucene). As another example, we find that most TensorFlow bugs reside
∗Corresponding author
Email address: [email protected] (Hao Zhong)
This manuscript is an extended version of a paper [1] that is presented in the 25th Inter- national Conference on Database Systems for Advanced Applications (DASFAA), 2020.
in its interfaces (26.24%), learning algorithms (11.79%), and how to compile (8.02%), deploy (7.55%), and install (4.72%) TensorFlow across platforms.
Keywords: Deep learning, Bug analysis, TensorFlow, Empirical Study
1. Introduction
In recent years, deep learning has been a hot research topic, and researchers have used deep learning techniques to solve the problems in various research fields (e.g., computer vision [2] and software analysis [3]). When implementing deep learning applications, instead of reinventing wheels, programmers often
5
build their applications on mature libraries. Among these libraries, Tensor- Flow [4] is the most popular, and a recent study [5] shows that more than 36,000 applications of GitHub are built upon TensorFlow. As they are popular, one bug inside deep learning libraries can lead to bugs in many applications, and such bugs can lead to disastrous consequences. For example, Pei et al. [6]
10
report that a Google self-driving car and a Tesla sedan crash, due to bugs in their deep learning software.
To better understand bugs of deep learning programs, researchers have con- ducted empirical studies on such bugs. In particular, Zhang et al. [5] conduct an empirical study to understand the bugs of TensorFlow applications. Here,
15
an application of TensorFlow is a program that calls the APIs of TensorFlow.
While Zhang et al. [5] analyze only TensorFlow applications, Islam et al. [7] an- alyze the applications of more deep learning libraries such as Caffe [8], Keras [9], Theano [10], and Torch [11].
Although their results are useful to improve the quality of a specific applica-
20
tion, to the best of our knowledge, no prior studies have ever explored the bugs inside popular deep learning libraries. Although the bugs inside TensorFlow influence thousands of its applications, many questions on such bugs are still open. For example, what are the symptoms and the root causes of such bugs, and where are they? A better understanding on such bugs will improve the
25
quality of many applications, but it is challenging to conduct the desirable em-
pirical study, since TensorFlow implements many complicated algorithms and is written in multiple programming languages. In our prior work [1], we conducted the first empirical study to analyze the bugs inside TensorFlow. Compared with this work [1], our extended version has two additional contributions:
30
1. Our prior work [1] analyzed only symptoms and causes of bugs, but in this extended version, we analyzed bug fixes and multiple language bugs.
2. We compared our identified symptoms, causes, and repair patterns with those that were reported by the prior studies [7, 5, 12, 13, 14, 15, 16, 17]
(see Section 5 for details). Based on the comparison, we find that Ten-
35
sorFlow has type confusions, which are not reported by the prior studies.
In addition, we find that like deep learning applications, TensorFlow also has dimension mismatches.
Our research questions and their answers are as follows:
• RQ1. What are the symptoms and causes of bugs?
40
Motivation. The symptom and the cause of a bug are important to un- derstand and to fix the bug. For deep learning bugs, the results of the prior studies [5, 7] are incomplete, because they analyze only deep learning applications. As the prior studies do not analyze bugs inside a deep learn- ing library, the answers to the above research question are still unknown.
45
Major results. In total, we identify six symptoms and eleven root causes.
We find that root causes are more determinative than symptoms, since several root causes have dominated symptoms (Finding 1). In addition, we find that the symptoms and the root causes of TensorFlow bugs are more like those of ordinary projects (e.g., Mozilla) than other machine
50
learning libraries (Finding 2). For the symptoms, build failures have cor- relations with inconsistencies, configurations and referenced type errors, and warning-style bugs have correlation with inconsistencies, processing, and type confusions. For the root causes, dimension mismatches lead to
functional errors, and type confusions have correlation with functional
55
errors, crashes, and warning-style errors (Finding 3).
• RQ2. How do the bugs spread across different components?
Motivation. From the perspective of TensorFlow developers, the loca- tions of its bugs are important to improve the quality of TensorFlow. From the perspectives of the programmers of TensorFlow applications, they can
60
be more careful to call TensorFlow, if they know such locations. From the perspective of researchers, they can design better detection techniques for our identified bugs, after the locations of target bugs are known. The prior studies [5, 7] do not explore this research question. To explore the bug characteristics in different library components, we analyze the impacts of
65
TensorFlow bugs by their components.
Major results. We find that major reported bugs reside in deep learning algorithms (kernel, 11.79%) and their interfaces (API, 26.42%). The two categories of bugs are followed by bugs in the deployment such as compil- ing (lib, 8.02%), deploying (platform, 7.55%), and installing (tools, 4.72%).
70
The other components such as runtime (3.77%), framework (0.94%) and computation graph (0.94%) have fewer bugs.
• RQ3. What are the common repair patterns inside TensorFlow?
Motivation. Researchers have conducted empirical studies to explore the repairing patterns of bugs (see Section 7 for details), but none of them
75
have analyzed the repair patterns of deep libraries bugs. In this research question, we analyze such repair patterns. The results can be useful to determine to what degree can the prior tools repair deep learning bugs.
Major results. From TensorFlow bugs, we identify ten repair templates.
Compared with the prior studies [15, 16, 17], besides confirming known
80
templates, we find two new templates. Although it needs different ex- pertise to fix TensorFlow bugs, from the viewpoint of modifying code, we find that fixing deep learning bugs requires largely the same repair actions
with fixing bugs in other types of projects (Finding 6). The correlation of common repair patterns and their causes are also displayed (Finding 7).
85
• RQ4. Which bugs involve multiple programming languages?
Motivation. The implementation of TensorFlow concerns several types of programming languages. The prior study [18] shows that multiple lan- guages in software can introduce more bugs. In our study, we also explore the interaction of different languages in TensorFlow.
90
Major results. We find that only 5% TensorFlow bugs involve multi- ple programming languages, and we classify them into two categories: (1) source files and configuration files can have related bugs, and (2) the core and its applications/test cases can have related bugs (Finding 8).
Instead of analyzing deep learning applications as the prior studies [5, 7]
95
did, for the first time, our study explores the bugs and their fixes inside deep learning libraries. Our findings are useful to improve the quality of deep learning libraries, and further have positive impacts on downstream applications. We further discuss this issue in Section 6.
2. Preliminary
100
2.1. The Implementation of TensorFlow
TensorFlow uses dataflow graphs to define the computations and states of a machine learning algorithm. In a dataflow graph, each node represents an individual mathematical operator (e.g., matrix multiplication), and each edge represents a data dependency. In each edge, a tensor (n-dimensional arrays)
105
defines the data format of the information transferred between two nodes.
TensorFlow provides official APIs in different programming languages such as Python, C++, Java, JavaScript and Go. The Python interface is the most popular [19]. As unofficial APIs, open source communities also provide APIs in other programming languages such as C#, Julia, Ruby, Rust, and Scala [19].
110
TensorFlow is released under the Apache 2.0 license, and its documents are
presented in its website [19]. TensorFlow supports multiple client languages (e.g., Python and C++) and they all need to use the corresponding foreign function interface (FFI) [20] to call into a C API provided by TensorFlow to implement computational functionalities [21].
115
2.2. The Repair Process of TensorFlow Bugs
The source code of TensorFlow is maintained on GitHub [22], where its issues are reported, and commits are recorded since November 2015. Typically, if a user encounters a problem (e.g., a bug), she will submit an issue, which we call a bug report in this article. Such a report presents information to
120
diagnose the problem. The bug report includes basic information such as the OS platform, buggy TensorFlow version, and the code snippets to reproduce the buggy behavior. Besides such information, the bug report also presents a description, which introduces bug briefly. Furthermore, the reporter may suggest a feasible way to repair the bug. After receiving the bug report, the
125
developers of TensorFlow discuss the possible causes of the bug and how to repair it. Moreover, for a more complicated bug, developers can refer to related bug reports and pull requests in their discussion. Other open source communities have more advanced issue trackers (e.g., Jira), where bug reports are marked as
“resolved” or “fixed”. However, GitHub provides a much simpler issue tracker,
130
and its status is often not reliable. Meanwhile, programmers often submit pull requests without reporting their found bugs. When submitting a pull request, the submitter typically introduces the bug briefly, presents the corresponding bug report, the buggy behavior (a wrong error is thrown), submit commits to change the source code and explains the changes (fixing the bug and adding a
135
test case). After that, reviewers need to assess the fix and communicate with the submitter about the modification. Finally, if the modification is confirmed correct, other developers will approve the changes and merge the commit.
Generally, the status of a bug is not tagged by labels on bug reports, while a pull request marked as “ready to pull” indicates that the bug is solved and
140
ready to be merged. The label helps us to filter pull requests with fixed bug
simply. Some pull requests contain references to their bug reports, which is straightforward to help us identify bugs. However, some pull requests are not submitted by users, and have no corresponding bug reports. We use keywords (e.g., bug) searching to identify bug fixes from such pull requests (Section 3.1).
145
3. Methodology
3.1. Dataset
We select TensorFlow as the subject of our study, since Zhang et al. [5]
report that more than 36,000 GitHub projects call the APIs of TensorFlow. As a result, the bugs inside TensorFlow influence thousands of its applications. We
150
apply the following steps to extract approved pull requests:
Step1. Filtering pull requests by labels. To avoid superficial bugs, we start with closed pull requests with label “ready to pull ”. We notice that finished pull requests before a specific date are not tagged, so we also collect cases from earlier closed pull requests by searching keywords as described in Step 2. We manually
155
check each collected pull request to ensure that its commit is already approved by reviewers and is merged into the master branch. In this step, we collected 1,367 pull requests whose labels are “ready to pull ” and 700 closed pull requests without label. These pull requests are submitted between December 2017 and March 2019,
160
Step2. Searching pull requests by keywords. From closed pull requests, we use the keywords such as “bug”, “fix” and “error” to identify the ones that fix bugs. From bug fixes, we use the keywords such as “typo” and “doc” to remove the ones that fix superficial bugs. From the remaining bug fixes, we manually inspect them to select real ones, by reading their pull requests carefully. In total,
165
we removed 1,858 pull requests, and selected 209 bug fixes for latter analysis.
Step3. Extracting bug reports and code changes. For each one of our selected bug fixes, we extract its bug report and code changes from the posts and submitted commits. The extracted results and corresponding pull requests are used to determine their symptoms, root causes (RQ1), and locations (RQ2).
170
We introduce the details in Section 3.3. In this step, we abandoned 7 pull requests because we cannot infer their symptoms or causes. The percentage of such cases is low, and its influence is minor.
In total, we collected 202 TensorFlow bug fixes, and 84 of them have corre- sponding bugs reports. The number is comparable to other empirical studies.
175
For example, Thung et al. [14] analyze 500 bugs from machine learning projects such as Mahout, Lucene, and OpenNLP. For each project, they analyze no more than 200 bugs. As another example, Zhang et al. [5] analyze 175 bugs from Ten- sorFlow applications. Indeed, for deep learning programs, libraries are typically much larger than applications. As a result, our analyzed bugs are much more
180
complicated than the bugs in the prior studies [5, 14]. We did not analyzed bugs before 2017 because we had collected sufficient bugs for analysis, and those old bugs may not reflect the recent characteristics of deep learning bugs.
3.2. Pull Request and Commit
Core programmers have the authority to submit commits directly, and we
185
call such commits as direct commits. In our study, we did not analyze direct commits for the following considerations:
1. Pull requests reveal the important bugs from users. While direct commits are mostly submitted by core programmers, pull requests are submit- ted by users [23]. Pull requests often fix annoying bug symptoms, and users
190
would rather change the code of TensorFlow by themselves. Although they are considered as users, we notice that bugs in some pull requests are critical. For example, TensorFlow is built upon Intel MKL [24] to achieve the best perfor- mance on Intel CPUs. Compared with the core programmers of TensorFlow, the programmers of Intel MKL (considering as users) have more expertise in detect-
195
ing bugs that are related to calling Intel MKL. As it takes much time to train a real deep learning model, such bugs typically are important to many users. We notice that the programmers of Intel MKL also submitted bugs through pull requests. For example, they submitted a pull request [25] to fix a performance degradation on a wide-used image classification dataset (CIFAR-10) [26].
200
(a) A core programmer of TensorFlow
(b) A user/outsider of TensorFlow Figure 1: The mark of pull request submitter
2. Some core programmers would submit bug fixes as pull requests.
Even if they have the privilege to directly commit their changes, to collect the feedback from others, some core programmers prefer to submit pull requests [27, 28]. As shown in Figure 1, GitHub provides a label, i.e., Member, to denote the core programmers of a project. By checking the labels of programmers, we
205
find that 29.7% pull requests in our collected data are submitted by the core programmers of TensorFlow.
3. Pull requests are reviewed and approved by core programmers.
According to the guideline of TensorFlow [29], pull requests must be reviewed by core programmers. Although some pull requests are not submitted by core
210
programmers, we can analyze the discussions from core programmers and under- stand their opinions on bugs from pull requests. For example, in the discussions of a bug report [30], a core programmer and a user discussed how an unexpected graph is generated, and they determined that this bug is caused by inconsistent values of two variables. From such discussions, we can infer that its symptom
215
is an unexpected graph and its cause is the inconsistency of two values.
4. Pull requests contain more informational details than direct commits. An approved pull request contains details (e.g., discussions among programmers), and some pull requests are linked to their bug reports. Alterna- tively, the core programmers of deep learning libraries can bypass pull requests,
220
and submit their changes directly to code repositories. A direct code change has only a short message, and they seldom describe error messages and bug symptoms. Indeed, if a code change has no bug reports or pull requests, it is even difficult to determine whether the code change is a bug fix [31].
To compare code changes in pull requests with those in direct commits, we
225
manually identified 104 direct bug fixes. To ensure that the comparison is com- prehensive, we selected a code metric called the maintainability index [32]. This metric combines several metrics such as Halstead’s Volume (HV) [33], McCabe’s cyclomatic complexity (CC) [34], lines of code (LOC), and percentage of com- ments (COM). We randomly collected 104 direct bug fixes from direct commits.
230
To show the differences between these bug fixes and those in our dataset, we used one-way ANOVA [35] and compared their maintainability index. We find that all the differences are insignificant. As a result, although we agree that it can enrich our findings if the core programmers of TensorFlow are invited to analyze direct commits, as the differences between direct commits and pull
235
requests are insignificant, the new findings over our current ones can be minor.
3.3. Manual Analysis
In our study, we invite two graduate students to manually inspect all bugs.
The two students are major in computer science, and both are familiar with deep learning algorithms. In the past two years, they have developed at least two deep
240
learning application projects (e.g., mining on business data) on TensorFlow.
Following our protocols, the two students inspect the bugs independently, and compare the results. If they cannot reach a consensus on a TensorFlow bug, they discuss it on our weekly group meetings. Our initial agreement rate is 92.57%. Here, the initial agreement rate is defined as the consistent cases over
245
the total cases.
3.3.1. Protocol of RQ1
When they build their own taxonomy of bug symptoms and their root causes, they refer to the taxonomies of the prior studies [36, 12]. In particular, they
add an existing category into their taxonomy, if they find a TensorFlow bug falls
250
into this category. If a TensorFlow bug does not belong to an existing category, they try to modify a similar category of the prior studies [36, 12]. If they fail to find such a similar category, they add a new one.
For bug classifying, if a pull request has a corresponding bug report, they first read its report to identify its symptoms and root causes. If a pull request
255
does not provide a report, they manually identify its symptom and root cause from the description, bug-related discussion, code changes and comments of the pull request. For example, the pull request of #219562without report is titled
“Fix for stringpiece build failure”. Based on the title, they determine that the symptom of the bug is build failure. They notice that the only code modification
260
of this bug fix is:
1 void Append ( S t r i n g P i e c e s ) {
2 − k e y . append ( s . T o S t r i n g ( ) ) ;
3 + k e y . append ( s t r i n g ( s ) ) ;
265
4 k e y . append ( 1 , d e l i m i t e r ) ; }
TheToString()method that is called to build the key in the buggy version is removed. In the fixed version, the string(StringPiece) method should be called to build the correct key, but in the old location, the method call is not
270
updated. Considering this, they determine that the root cause of the bug is the inconsistency introduced by API change.
After the symptoms and root causes of all the bugs are extracted, the two students further classify them into categories, and use the lift function [37] to measure the correlations between symptoms and root causes. According to the
275
definition, the lift between different categories (A and B) is computed as:
lift(A, B) = P (A ∩ B)
P (A) · P (B) (1)
2In the following paragraphs, the numbers denote the ids of pull requests. Their urls can be constructed by adding the url of Tensorflow (e.g., https://github.com/tensorflow/
tensorflow/pull/21956
where P (A), P (B), P (A∩B) are the probabilities that a bug belongs to category A, category B, and both A and B. If a lift value is greater than one, a symptom is correlated to a root cause; otherwise, it is not.
3.3.2. Protocol of RQ2
280
In this research question, the two students analyze the locations of bugs. As an open source project, TensorFlow does not officially list its components, but like other projects, TensorFlow puts its source files into different directories, by their functionalities. When determining their functionalities, they refer to various sources such as official documents, TensorFlow tutorials, and forum
285
discussions. Their identified components are as following:
1. Kernel. The kernel implements core deep learning algorithms (e.g., the conv2dalgorithm), and its source files are located in thecore/kernelsdirectory.
2. Computation graph. TensorFlow uses computation graphs to define and to manage its computation tasks. The graph implements the definition,
290
construction, partition, optimization, operation, and execution of computations.
Most source files of this component are located in thecore/graphdirectory; its data operations are located in the core/ops directory; and its optimization- related source files are located in thecore/grapplerdirectory.
3. API. TensorFlow provides APIs in various programming languages,
295
which are located in thepython,c,ccandjavadirectories.
4. Runtime. The runtime implements the management of sessions, thread pools, and executors. TensorFlow has a common runtime (core/common runtime) and a distribution runtime (core/distributed runtime). Common runtime sup- ports the executions on a local machine, and distribution runtime allows to
300
deploy TensorFlow on distributed ones. We merge them into one component.
5. Framework. The framework implements basic functionalities (e.g., logging). Most source files of this component are located in core/framework directory, and the serialization is located incore/protobufdirectory.
6. Tool. The tool implements utilities. For example, tools/git and
305
tools/pip packagedirectories implement the utilities to install TensorFlow; the
core/debugdirectory provides a tool to debug TensorFlow applications; and the core/profile directory provides a tool to profile the execution of TensorFlow and its applications.
7. Platform. The platform allows to deploy TensorFlow on various plat-
310
forms. The core/platform directory contains the source files to handle hard- ware issues (e.g., CPU and GPU); thecore/tpu directory allows executing on TPU; the lite directory allows executing TensorFlow on mobile devices; and thecompilerdirectory allows compiling to native code for various architectures.
8. Contribution. The contrib directory contains extensions that are of-
315
ten implemented by outside contributors. For example, the contrib/seq2seq directory contains a sequence-to-sequence model that is widely used in neural translation. After they become mature, they can be merged into other directo- ries. In our study, we define a component for this directory.
9. Library. The library includes API libraries. Most libraries are located
320
in thethird-partydirectory, and some libraries are located in other directories (e.g,core/lib,core/utiland some files under the root directory of tensorflow).
10. Documentation. The documentation includes samples, which are located in theexamplesandcore/exampledirectories. It also includes other types of documents. For example, thesecuritydirectory stores security guidelines.
325
We use the lift metric as defined in Equation 1 to measure the correlation between a bug location and a symptom or a root cause. Here, if a bug involves more than one directory, we count them once for each directory to ensure that each location does not lose a symptom and a root cause.
3.3.3. Protocol of RQ3
330
We find that some bug fixes are repetitive, i.e., appearing at least twice, so we follow next steps to analyze such fixes:
1. Inspecting symptoms and root causes. We inspect the symptom, root cause and location information obtained from previous sections to outline the general situation of a bug.
335
2. Locating related code modifications. We determine the fix scale of
a bug from the code changes including the number of related files, changed lines and commit frequency. If a commit contains modifications that are irrelevant to repair bugs (e.g., test case modifications), we ignore such modifications. If a pull request fixes more than one bug, we consider them as individual bugs, and
340
analyze them respectively, but such cases are rare in our observation. Generally, it is easier to find specific templates in fixes with small scale.
3. Analyzing the characteristics of modifications. We focus on several characteristics of a bug fix to describe the repair process in detail including scope of buggy code (in a method, in a constructor or global), modified code elements
345
(variables, methods or classes), and modification intention (e.g., changing a value, and modifying conditions of if-statements).
4. Extracting fix templates. We suppose that bug fixes with similar characteristics mentioned above are possible to share the same repair template.
We define repair patterns according to these characteristics and extract instances
350
appearing multiple times as templates.
When we design our protocol, we refer to the ones used in the prior stud- ies [15, 16, 17]. When we analyze repair patterns in TensorFlow, if a pattern is not identified by the prior studies [15, 16, 17], we then create a new category to define its pattern.
355
3.3.4. Protocol of RQ4
For simplicity, we use build script languages to denote the languages of configuration files, batch files, and build files.
To study the impact of language overlap, we investigate all bugs which con- cern multiple files belonging to different languages, which can be identified by
360
their extensions. For bugs with both programming and build script languages, we check their symptoms and root causes to make sure whether they contain con- figuration errors and extra defects. For bugs with only programming languages, we further inspect relative reports and fixes to determine their fix objectives in corresponding files to summarize main pattern of these bugs.
365
4. Empirical Result
This section presents the results of our study. More details are listed on our project website: https://github.com/fordataupload/tfbugdata/
4.1. RQ1. Symptoms and Root Causes 4.1.1. The categories of symptoms
370
Our identified symptoms are as follows:
1. Functional error (35.64%). If a program does not function as designed, we call it a functional error. For example, we find that the bug report of #20751 complains the functionality of thetf.Print method:
If you print a tensor of shape [n, 4] with tf.Print, by default (summarize=3 is the default value),
375
you get: [[9 21 55]...], which wrongly looks like your tensor is of shape [n, 3]. The correct output
should be: [[9 21 55...]...].
The method is designed to print the details of tensors. The bug report complains that it prints incorrect output, when the shape is [n, 4]. As the result is not as expected, it is a functional error.
380
2. Crash (26.73%). A crash occurs, when a program exits irregularly.
When it happens, the program often throws an error message. For example, the bug report of #16100 describes a crash caused by an unsupported operand type:
Using a TimeFreqLSTMCell in a dynamic rnn without providing optional parameter frequency skip
385
results in an exception: TypeError: unsupported operand type(s) for /: ‘int’ and ‘NoneType’.
3. Hang (1.49%). A hang occurs, when a program keeps running without stopping or responding. The bug report of #11725 is an example:
When running the above commands (Inception V3 synchronized data parallelism training with 2
workers and 1 external ps), the tf cnn benchmarks application hangs forever after some iterations
390
(usually in warm up).
4. Performance degradation (1.49%). A performance degradation oc- curs, when a program does not return results in expected time. For example, we find a performance degradation in the bug report of #17605:
There is a performance regression for TF 1.6 comparing to TF 1.5 for cifar 10.
395
5. Build failure (23.76%). A build failure occurs in the compiling process.
For example, we find that the bug report of #16262 describes a build failure, which is caused by a missing header file:
Build failing due to missing header files “tensorflow/contrib/tpu/proto/tpu embedding config.pb.h”.
400
6. Warning-style error (10.89%). Warning-style error means the run- ning of a program is not disturbed, but modifications are still needed to get rid of risk or improve code quality, including interfaces to be deprecated, redun- dant code and bad code style. Most bugs in this category are shown by warning messages, while a few others do not provide visible messages which are found
405
by code review or other events. For example, we find a bug in such category in the pull request of #18558, since it calls a method with a deprecated argument:
According to tf.argmax, dimension argument was deprecated, it will be removed...
4.1.2. The categories of root causes Our identified causes are as follows:
410
1. Dimension mismatch (3.96%). We put a bug into this category if it is caused by dimension mismatch in tensor computations and transformations.
The pull request of #22822 describes the cause of a bug in this category as:
Wrongly ”+1” for output shape, that will cause CopyFrom failure in MklToTf op because of tensor
size and shape mismatch.
415
The buggy code sets the dimension of an output tensor:
1 o u t p u t t f s h a p e . AddDim ( ( o u t p u t p d −>g e t s i z e ( ) / s i z e o f(T) ) + 1 ) ;
The fixed code sets the correct dimension:
420
1 o u t p u t t f s h a p e . AddDim ( ( o u t p u t p d −>g e t s i z e ( ) / s i z e o f(T) ) ) ;
2. Type confusion (12.38%). Type confusions are caused by the mis- matches of types. The pull request of #21371 is a sample as below:
425
CRF decode can fail when default type of ”0” (as viewed by math ops.maximum) does not match
the type of sequence length.
After the bug was fixed, programmers modified a test case to ensure that the method accepts more types of input values:
430
1 np . a r r a y ( 3 , d t y p e=np . i n t 3 2 ) ,
2 − np . a r r a y ( 1 , d t y p e=np . i n t 3 2 )
3 + np . a r r a y ( 1 , d t y p e=np . i n t 6 4 )
3. Processing (22.28%). We put a bug into this category, if it is caused
435
by wrong assignment or initialization of variables, wrong formats of variables, or other wrong usages that are related to data processing. For example, we find a bug in such category reported in the pull request of #17345 as follow:
ConvNDLSTMCell class in tensorflow.contrib.rnn cannot pass the name attribute correctly when
created, because of the missing parameter in constructor.
440
The constructor ofConvNDLSTMCellhas no parameters to define their names:
1 s u p e r ( Conv1DLSTMCell , s e l f ) . i n i t ( c o n v n d i m s =1 , ∗∗ k w a r g s )
The bug is fixed in a latter version:
445
1 s u p e r ( Conv1DLSTMCell , s e l f ) . i n i t ( c o n v n d i m s =1 , name=name , ∗∗
k w a r g s )
4. Inconsistency (16.83%). We put a bug into this category, if it is
450
caused by incompatibility due to API change or version update. For example, the pull request of #17418 complains that a removedopsis called:
Op type not registered ’KafkaDataset’ in binary. is returned from kafka ops. The issue was that
the inclusion of kafka ops was removed due to the conflict merge from the other PR.
The above compilation error was caused by a conflict merge of two commits.
455
One removedkafka ops, but the other added a call to the operator.
5. Algorithm (2.97%). We put a bug into the algorithm category, if it is caused by wrong logic in algorithms. For example, the pull request of #16433 complains that a method returns wrong values:
Input labels = tf.constant([[0., 0.5, 1.]]), predictions = tf.constant([[1., 1., 1.]]), the result of
460
tf.losses.mean pairwise squared error(labels, predictions) should be [(0 − 0.5)2+ (0 − 1)2+ (0.5 −
1)2]/3 = 0.5, but TensorFlow returns different value 0.333333.
According to the code document, the mean pairwise squared error is incor- rectly calculated. In the process of deduction, the denominators of two inter- mediate variables are wrong. A developer replaces an assignment and changes
465
a method with corresponding parameters to fix denominators as below:
1 − n u m p r e s e n t p e r b a t c h )
2 + n u m p r e s e n t p e r b a t c h −1)
3 . . .
470
4 + m a t h o p s . s q u a r e ( n u m p r e s e n t p e r b a t c h ) )
5 − m a t h o p s . m u l t i p l y ( n u m p r e s e n t p e r b a t c h , n u m p r e s e n t p e r b a t c h −1) )
6. Corner case (15.35%). We put a bug into this category, if it is caused
475
by erroneous handling of corner cases. A bug of this kind is reported in the pull request of #21338 as:
When batch size is 0, max pooling operation seems to produce an unhandled cudaError t status.
It may cause subsequent operations fail with odd error message.
As the reporter says, a crash happens when batch size of the input is 0,
480
which belongs to corner cases.
7. Logic error (9.90%). We put a bug into this category, if it occurs in the logic of a program. A logic error indicates an incorrect program flow or a wrong order of actions. The pull request of #19894 provides the description as:
When a kernel Variable is shared by two Conv2Ds, ... there will be only one Conv2D getting the
485
quantized kernel.
TensorFlow implements a mechanism called quantization to shrink tensors.
The reporter complains that when a tensor shares two Conv2D, the second one cannot obtain the right quantized kernel. The logic of the code is flawed, in that the program in complex flow does not behave as expected.
490
8. Configuration error (7.43%). We put a bug into this category, if it is caused by a wrong configuration. A pull request #16130 is an example:
Linking of rule ’...toco’ fails because LD LIBRARY PATH is not configured.
To repair the bug, in a configuration file, programmers add the following statement to initiateLD LIBRARY PATH:
495
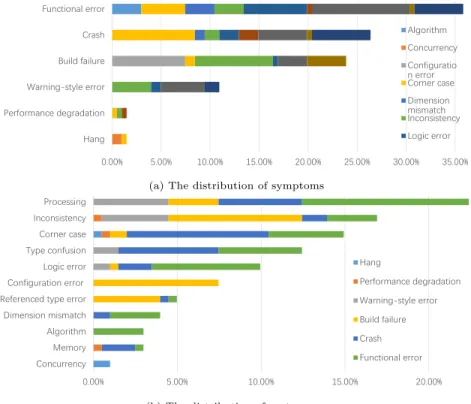
0.00% 5.00% 10.00% 15.00% 20.00% 25.00% 30.00% 35.00%
Hang Performance degradation Warning-style error Build failure Crash Functional error
Algorithm Concurrency Configuratio n error Corner case Dimension mismatch Inconsistency Logic error
(a) The distribution of symptoms
0.00% 5.00% 10.00% 15.00% 20.00%
Concurrency Memory Algorithm Dimension mismatch Referenced type error Configuration error
Logic error Type confusion Corner case Inconsistency Processing
Hang
Performance degradation Warning-style error Build failure Crash Functional error
(b) The distribution of root causes
Figure 2: Distribution of bug symptoms and root causes
1 i f ’LD LIBRARY PATH ’ i n e n v i r o n c p and e n v i r o n c p . g e t ( ’ LD LIBRARY PATH ’ ) != ’ 1 ’ :
2 w r i t e a c t i o n e n v t o b a z e l r c ( ’LD LIBRARY PATH ’ , . . . )
500
9. Referenced types error (4.95%). We put a bug into this category, if it is caused by missing or adding unnecessaryincludeorimport statements. A bug in the pull request of #21017 triggers the following error message:
The compiler couldn’t find std::function, because header file #include <functional> is missing.
Programmers forget to add theinclude statement, which causes the bug.
505
10. Memory (2.97%). We put a bug into the memory category, if it is caused by incorrect memory usages. For example, the pull request of #21950 de- scribes a possible memory leak, which can be triggered by an exception, because of missing deconstruction operation.
11. Concurrency (0.99%). We put a bug into this category, if it is caused
510
by synchronization problems. The pull request of #13684 describes a deadlock:
notify one was used to notify inserters and removers waiting to insert and remove elements into
Staging Areas. This could result in deadlock when many removers were waiting for different keys.
As the reporter says, when multiple removers wait for keys but notify one only notifies one of them, a deadlock may occur.
515
4.1.3. Distribution
Figure 2a shows the distribution of symptoms. Its horizontal axis shows symptom categories, and its vertical axis shows the percentage of corresponding symptom. For each symptom, we refine its bugs by their root causes. Tan et al. [12] report the distributions of Mozilla, Apache, and the Linux kernel. We
520
find that the distribution of TensorFlow is close to their distributions. Figure 2a shows that functional errors account for 39%, which are the most common bugs of TensorFlow. Tan et al. [12] show that in Mozilla, Apache, and the Linux kernel, function errors vary from 50% to 70%. We find that crashes account for 26.5% TensorFlow bugs, which are close to Linux (27.2%), and hangs account
525
for 1% bugs, which are close to Mozilla (2.1%).
Figure 2b shows the distribution of root causes. Its horizontal axis shows cause categories, and its vertical axis shows the percentage of corresponding causes. For each root cause, we refine its bugs by symptoms. We find that all the symptoms have multiple and evenly distributed root causes, but the
530
distribution of root causes are not so evenly. For example, as shown in Figure 2b, the bugs in processing mainly cause the symptoms such as warning-style errors, build failures, crashes and functional errors can be caused by processing, but as shown in Figure 2a, a symptom typically has more fragmented causes.
Finding 1. Compared to symptoms, root causes are more determinative, since several root causes have dominated symptoms.
535
Tan et al. [12] show that in Mozilla, Apache, and the Linux kernel, the dominant root cause is semantic (80%). In our taxonomy, memory, configuration and referenced types errors belong to semantic bugs (85%). Meanwhile, Tan et al. Thung et al. [14] show that in machine learning systems, algorithm errors are the most common bugs (22.6%). The above observations lead to a finding:
540
Algorithm
Dimension mismatch Functional
error
Crash
Type confusion Build failure
Processing
Warning- style error 2.79
2.21
1.82 1.12 0.56
0.84 1.24
Corner cases
Inconsistency
Memory
Logic error Configuration
error
Referenced types error 0.63
1.95
0.76
0.49 0.33
1.97
2.15 2.53
1.81
0.76 4.19
3.35 1.10
1.83
Figure 3: Correlation between symptoms and root causes
Finding 2. The symptoms and causes of TensorFlow are more like an ordinary software system (e.g., Mozilla) than a machine learning system (e.g., Lucene).
A machine learning system typically provide many algorithms for users to invoke. For example, although Lucene has 554,036 lines of code, the symptoms and root causes of its bugs are more different from TensorFlow than ordinary software systems like Mozilla. We find that Lucene provides numerous APIs
545
to handle natural language texts in different ways (e.g., tokenization). In the contrast, TensorFlow provides much fewer interfaces to invoke, which is more like a traditional software system.
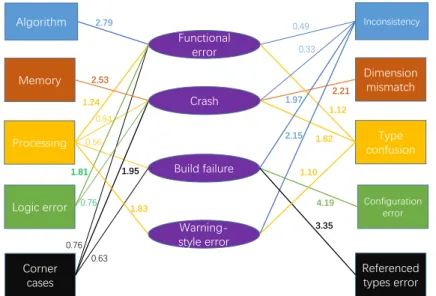
4.1.4. Correlation of bug categories
Figure 3 shows the correlation of bug categories. The rectangles on the
550
left side denote symptoms, the ovals on the right side denote root causes. We choose different colors to distinguish the correlations, and the root causes of the same color are not related. We ignore categories whose bugs are fewer than three, since they are statistically insignificant (e.g., hangs). The lines denote correlations, and we highlight correlations whose values are greater than one.
555
Both Tan et al. [12] and we find that crashes have correlations with memory bugs and corner cases. Tan et al. [12] find that crashes also have correlations with concurrency, but we do not consider it, since only two of our analyzed bugs are related to concurrency. Instead, our study shows that crashes of TensorFlow have correlations with type confusions, which are not identified by Tan et al.
560
In addition, Tan et al. [12] and we find that function errors have correlations with processing and logic errors. Tan et al. [12] find that function errors have correlations with missing features by defining a missing feature as a feature is not implemented yet. As we find that TensorFlow programmers seldom write their unimplemented features in their code, we eliminate this subcategory. We
565
find that build failures have correlation with inconsistencies, configurations and referenced type errors, and warning-style bugs have correlation with inconsis- tencies, processing, and type confusions. We believe that other open source projects (e.g., Mozilla) also have the two types of symptoms, but are ignored by Tan et al. [12]. We identify the correlations of build failures and warning-style
570
bugs, complementing the study of Tan et al. [12]. For our identified root causes and symptoms of TensorFlow, our observations lead to the following finding:
Finding 3. Build failures have correlation with inconsistencies, configura- tions and referenced type errors. Warning-style bugs have correlation with inconsistencies, processing, and type confusions. Dimension mismatches lead to crashes, and type confusions lead to functional errors, crashes and warning-style errors.
In summary, for those common symptoms and root causes between Tan et al. [12] and ours, the correlations are largely consistent. For TensorFlow, we
575
discover the correlations between symptoms and root causes, which are not reported by the prior study.
4.2. RQ2. Bug Locations 4.2.1. Distribution
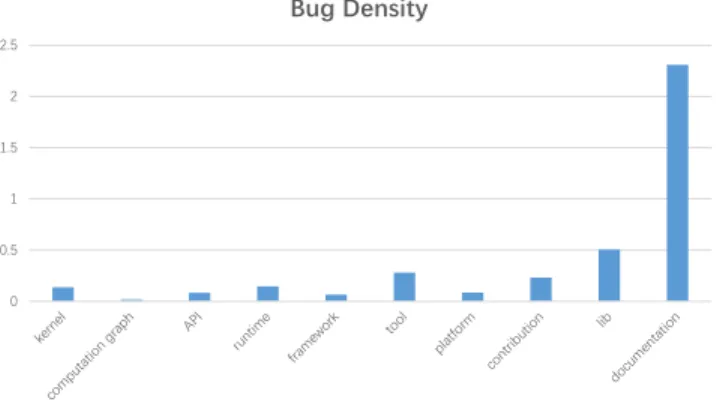
Figure 4 shows the distribution of bug locations. Some components have
580
more bugs because they are larger. To reduce the bias, we define the bug
0 0.5 1 1.5 2 2.5
Bug Density
Figure 4: The bug locations
density as the number of bugs per 1,000 lines of code (LoC). The densities of documentation is much larger than others. As described in Section 3.1, we have ignored superficial bugs (e.g., textual errors in documents). However, the documentation module contains illustrative code samples, and their modifica-
585
tions appear in Figure 4. When programmers fix bugs, they often modify the corresponding samples, which can partially explain its high ratio in Figure 4.
Finding 4. The documentation of TensorFlow is the most frequently mod- ified component.
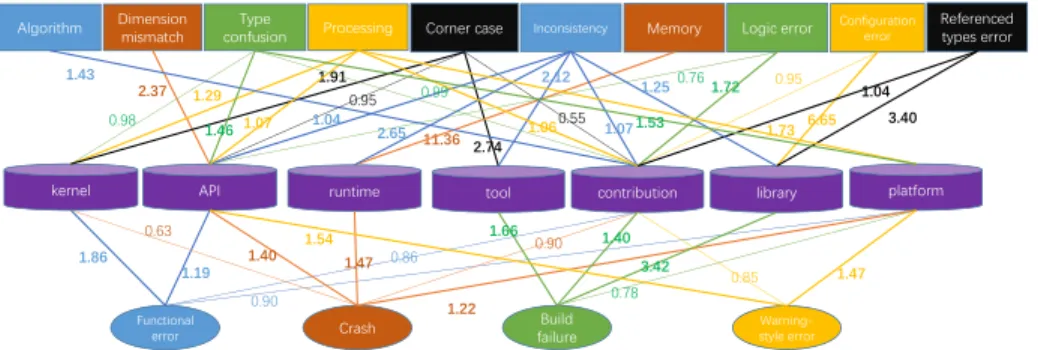
4.2.2. Correlation of bug categories
Figure 5 shows the correlations among symptoms, root causes, and bug
590
locations. In this figure, the rectangles denote root causes; the ovals denote symptoms; and the cylinders denote bug locations. We ignore bug locations, if their bugs are fewer than three. The lines denote correlations, and we highlight correlations whose values are greater than one.
For root causes, we find that inconsistencies are popular, and for symp-
595
toms, crashes and build failures are popular among the components. From the perspective of components, we find that kernel has strong correlation with func- tional errors and corner cases, which indicates semantic bugs are dominant in this component. Meanwhile, we find that API has strong correlation with root causes related to tensor computations such as dimension mismatches and type
600
Algorithm Dimension mismatch
kernel runtime
Type confusion
API
Processing
contribution tool
11.36
0.76
1.07 1.06 6.65
Corner case Inconsistency Memory Logic error Configuration error
Referenced types error
2.74 0.95 1.04
1.43 1.91
2.37 1.72 0.95
1.29
0.55 3.40
platform library
1.04 1.07
1.25 2.65
2.12
1.73 1.46
0.99 0.98
Functional
error Crash Build
failure style errorWarning- 1.19
0.90
1.86 0.63 1.40 0.86 0.90
1.22
1.40 3.42 0.78 1.66
1.47 1.54
0.85 1.47
1.53
Figure 5: Correlation between locations
confusions. For library and tool, their symptoms have strong correlations with build failures, and their root causes have strong correlations with inconsistences.
The above observations lead to a finding:
Finding 5. As core components, kernel contains many sematic bugs, and API bugs are often caused by tensor computation problems such as dimen- sion mismatches and type confusions. In library and tool, build failures are popular, and most bugs are caused by inconsistencies.
In summary, most TensorFlow bugs reside in deep learning algorithms, API
605
interfaces, and platform-related components. Furthermore, the correlations be- tween their locations and symptoms or root causes follow specific patterns.
4.3. RQ3. Repair Patterns
4.3.1. The categories of repair patterns
We find several recurring repair templates as following:
610
1. Parameter modifier (21.85%). This repair pattern adds, removes, or replaces a parameter input. The pull request #18674 is an example:
1 − v s . g e t v a r i a b l e ( o p a q u e k e r n e l , . . . )
2 + v s . g e t v a r i a b l e ( o p a q u e k e r n e l , d t y p e= s e l f . p l a i n d t y p e , . . . )
615
Forfloat16data type, reusingopaque kernelin CudnnLSTM throws a ValueEr- ror. The issue is fixed by passing the data type.
2. Method replacer (16.81%). This repair pattern replaces a method with another method whose parameters and return type are compatible. A pull
620
request #25427 is an example:
1 − return l o g ( 1 + exp(−y wx ) ) ∗ e x a m p l e w e i g h t ;
2 + return l o g 1 p ( exp(−y wx ) ) ∗ e x a m p l e w e i g h t ;
625
Thelog(1+x)method is replaced with thelog1p(x) method, since the latter is more precise.
3. Value checker (14.29%). This repair pattern checks the value of a variable. A sample fix in the pull request of #16051 is as follows:
630
1 + i f( l o g i t s i n . d i m s i z e ( 0 ) >0) { . . .
This a crash caused by corner cases. According to the fix description, if the first dimension of logits inis 0, a crash on GPU will be triggered. Adding a value check fixes this issue.
635
4. Type replacer (11.76%). This repair pattern replaces the type of a variable. A fix in the pull request of #17148 in this pattern is shown below:
1 −o n v a l u e = 0 . ,
2 +o n v a l u e=o p s . c o n v e r t t o t e n s o r ( 0 . , d t y p e=p r o b s . d t y p e ) ,
640
This is a crash caused by a type error. When float16 values are fed into the method, it crashes, since the data type of on value is inferred from value 0., which isfloat32. As a result, converting “0.” to a tensor fixes this bug.
5. Referenced type modifier (11.76%). This pattern adds, removes, or
645
replaces referenced types. The pull request of #21017 shows this pattern:
1 + #i n c l u d e <f u n c t i o n a l >
This is a build failure caused by referenced type errors. As the reporter says,
650
the compiler cannot findstd::function, and including<functional>fixes it.
6. Initializer modifier (6.72%). This repair pattern modifies the initial value of a variable. A fix in the pull request of #25909 in this pattern is provided:
1 − i n t 6 4 n e w s i z e ;
655
2 + i n t 6 4 n e w s i z e = −1;
This a warning-style error caused by procesing problem. A warning message complains that thenew sizevariable is not initialized, and adding an initializer fix this problem.
660
7. Variable replacer (5.88%). This repair pattern replaces a variable with a compatible one. For example, to fix a functional error, the pull request of #16081 is as follows:
1 − . . . c o n c a t d i m = N + c o n c a t d i m ;
665
2 + . . . c o n c a t d i m = e x p e c t e d d i m s + c o n c a t d i m ;
If concat dimis negative, its value is wrongly updated. To repair the bug, Nis replaced withexpected dim.
8. Format checker (5.04%). This repair pattern checks the data format
670
of a variable. The pull request of #18481 shows this repair pattern:
1 +i f i s i n s t a n c e( t y p e v a l u e , (type, np . d t y p e ) ) : f o r key . . .
This is a crash caused by type error. Crash happens when an invalid dtype
675
(e.g.,[,]) is given, and adding a format checker can fix this.
9. Condition replacer (2.52%). This repair pattern replaces the pred- icate of a branch with a compatible one. A fix example in the pull request of
#18183 is shown as follows:
680
1 − i f not module or ’ t e n s o r f l o w . ’ not i n module . n a m e :
2 + i f (not module or not h a s a t t r( module , ” n a m e ” ) or ’ t e n s o r f l o w . ’ not i n module . n a m e ) :
This is a crash caused by corner cases. An object in program does not have
685
name attribute and leads to crash, so ahasattr()checker is added to check whether the attribute is contained.
10. Exception adder (1.68%). This repair pattern handles exceptions locally. A sample in the pull request of #20479 is as follow:
690
1 +try:
2 . . .
3 o r i g r e s t , r e s t = c o n t e x t t . BuildCondBranch ( t r u e f n )
4 i f o r i g r e s t i s None : r a i s e V a l u e E r r o r ( ” t r u e f n must have a r e t u r n v a l u e . ” )
695
5 c o n t e x t t . E x i t R e s u l t ( r e s t )
6 +f i n a l l y:
7 + c o n t e x t t . E x i t ( )
Type confusion Processing Corner case Inconsistency Referenced types error
Initializer modifier Method
replacer Parameter
adder/remover/
replacer
Referenced type adder/remover/
replacer Type
replacer
Value checker Variable
replacer
1.70 3.50
1.49 1.98
0.79
4.85 0.96
2.82
1.34
8.50
Figure 6: Correlation between repair patterns
This is a crash caused by corner case. If an exception occurred in tf.cond(),
700
CondContext is left uncleaned, which will be passed to context t, then causes crash. So a way to fix this bug is adding a try statement to catch exception.
11. Syntax modifier (1.68%). This repair patternremoves syntax errors.
A fix in the pull request of #25962 of this pattern is shown as below:
705
1 −EIGEN STATIC ASSERT ( ( n r==4) , YOU MADE A PROGRAMMING MISTAKE) ;
2 +EIGEN STATIC ASSERT ( ( n r ==4) , YOU MADE A PROGRAMMING MISTAKE)
A warning message complains that there is an unnecessary semicolon at the end of the code, and removing it fixes this issue.
710
Our found fix patterns are largely overlapped with the prior ones [15, 16, 17].
This observation lead to a finding:
Finding 6. From the viewpoint of modifying code, fixing TensorFlow bugs is largely consistent with fixing bugs in other types of projects.
4.3.2. Correlation of bug categories
Figure 6 shows the correlations between root causes and repair patterns. In
715
this figure, the rectangles denote root causes, and the rounded rectangle denote repair patterns. We ignore repair patterns, if their bugs are fewer than three.
The lines denote correlations, and we highlight correlations whose values are greater than one. Since not all bug fixes can be classified by a repair pattern, we exclude the isolated fixes. From Figure 6, we find the following correlations:
720
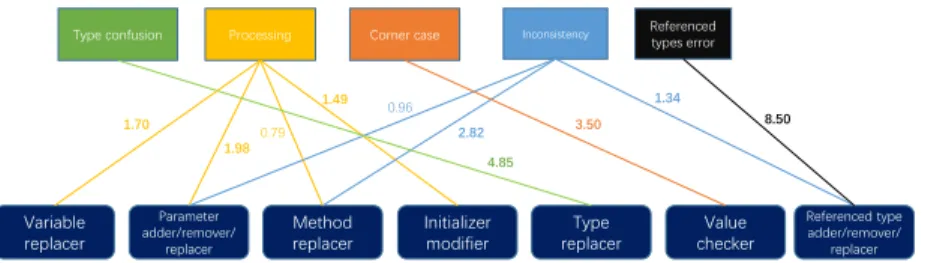
Finding 7. Parameter modifiers, method replacers, value checkers, type replacers and referenced type modifiers are common repair patterns in Ten- sorFlow. They are often introduced to fix bugs caused by inconsistency, type confusion and corner cases.
In summary, we find ten repair templates from our collected fixes. Compared with the prior studies, we find two new templates, but the majority of our found templates are overlapped with existing ones.
4.4. RQ4. Multi-language Programming
725
Figure 7 shows the distribution. In total, we find ten multiple-language bugs, and we classify them into two categories:
1. In total, six bugs are configuration bugs. For example, a pull request #17005 says that theCmakefile does not work on MacOS. This file is a build configuration file. To fix the bug, programmers modified theCmakefile:
730
1 −s e t ( p y w r a p t e n s o r f l o w l i b ” $ {CMAKE CURRENT BINARY DIR}/
l i b p y w r a p t e n s o r f l o w i n t e r n a l . s o ” )
2 +s e t ( p y w r a p t e n s o r f l o w l i b ” $ {CMAKE CURRENT BINARY DIR}/
l i b p y w r a p t e n s o r f l o w i n t e r n a l $ {CMAKE SHARED LIBRARY SUFFIX} ” )
735
However, modifying this file alone does not fully repair the bug. Program- mers also modified aCheader file as follows:
1 − #i n c l u d e <m a l l o c . h>
740
2 + #i n c l u d e < s t d l i b . h>
2. The other four bugs modify test cases in other languages. For ex- ample, the pull request of #16168 complains that the Python interface wrongly converts a unicode string. To fix the bug, programmers modified thepy func.cc
745
file in C, and a test case in Python.
The above observations lead to a finding:
Finding 8. Only ten out of 202 bugs involve multiple languages, and their reasons are simple: (1) source files and configuration files can have related bugs, and (2) the core and its applications/test cases can have related bugs.
C++
79 Python
87
Build script languages
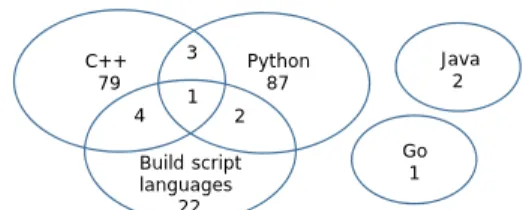
22
Java 2
Go 1 1
3
4 2
Figure 7: The distribution of programming languages
In summary, we find that only ten TensorFlow bugs involve multiple lan- guages, and their reasons are simple.
750
4.5. Threats to validity
The internal threats to validity include the possible errors of our manual inspection. To reduce the threat, we ask two students to inspect our bugs.
When they encounter controversial cases, they discuss them with others on our group meeting, until they reach an agreement. The threat can be mitigated
755
with more researchers, so we release our inspection results on our website. The threats to external validity include our subject, since we analyzed the bugs inside only TensorFlow. Although our analyzed bugs are comparable with the prior studies and other studies (e.g. [5]) also analyzed only TensorFlow bugs, they are limited.
760
5. The Comparison with Prior Studies
Table 1 summarizes the subjects, protocols, and findings of the prior stud- ies [12, 5, 14, 7, 15]. We next introduce their details and our new findings.
5.1. Symptoms
Tan et al. [12] classify bugs in open source projects by their symptoms as
765
shown in Table 1. Comparing with their taxonomy, we do not find data cor- ruptions as they did. As shown in their example, data corruptions are related to databases. As TensorFlow does not use databases, we do not find such bugs. Meanwhile, we find build failures and warning-style errors, which are not reported by Tan et al. They did not find build failures, since they focus
770
Tanetal.[12]
Subject: 2,060 bugs that were collected from the issue trackers and the NVD of Mozilla, Apache, and Linux.
Protocol: They read bug reports to identify bugs, and use the existing categories of NVD as a reference.
Finding: They identified six symptoms and three causes, and they further re- fined them into more subcategories. They find that incorrect functionality is the dominant symptom, and semantic bugs are the dominant causes.
Thungetal.[14]
Subject: 200 Mahout bugs, 200 Lucene bugs, and 100 OpenNLP bugs that were collected from issue trackers.
Protocol: They read bug reports to classify bugs, and use the categories proposed by Seaman et al. [13] as a reference.
Finding: The most bugs are categorized as algorithm/method, followed by non- functional and assignment/initialization.
Zhangetal.[5]
Subject: 175 TensorFlow application bugs were collected from GitHub commits and Stack Ovrerflow threads.
Protocol: Then they manually inspect bugs to classify them.
Finding: They find seven causes and four symptoms. Among them, incorrect model parameters/structures, API breaking changes and API misuses are the dominant causes, and crashes and exceptions are the dominant symptoms.
Islametal.[7]
Subject: 415 Stack Overflow discussions and 555 bugs from GitHub commits of Caffe, Keras, Tensorflow, Theano, and Torch applications.
Protocol: They formulate a set of classification criteria, and use Zhang et al. [5]
as a reference.
Finding: They find ten causes and six symptoms. Among them, incorrect model parameters/structures are the most common root cause, followed by structure inefficiency and unaligned tensors, and for symptoms, crashes are the most com- mon, followed by bad performance and incorrect functionality.
Kimetal.[15]
Subject: 62,656 human-written patches were collected from Eclipse JDT.
Protocol: They implement a tool to build graphs from patches, but deeper anal- yses are still manual.
Finding: They derived ten repair patterns, but did not present the percentage of repair patterns.
Table 1: The comparison to the prior studies
on runtime bugs. They also ignore warning-style errors, possibly because their symptoms are trivial. In the study of Thung et al. [14], they did not classify bugs by their symptoms.