國立臺灣大學電機資訊學院資訊工程學研究所 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
非中文母語學習者中文寫作用詞錯誤偵測及更正之研究 Detection and Correction of Chinese Word Usage Errors for
Learning Chinese as a Second Language
薛祐婷 Yow-Ting Shiue
指導教授:陳信希 博士 Advisor: Hsin-Hsi Chen, Ph.D.
中華民國 106 年 7 月
July 2017
口試委員會審定書
誌謝
能夠完成這篇論文,首先要感謝我的指導教授陳信希老師。我從大學時開始和 老師做專題,老師總是非常有耐心地引導我,在我遇到瓶頸時給予有用的建議,往 往我自己研究了一個禮拜沒有任何進展,和老師討論後便豁然開朗,可以往自己沒 有想過的方向努力看看。此外,也非常感謝博士後黃瀚萱學長,不僅在討論的時候 提出許多想法,關於程式實作細節的問題、以及研究生活的壓力適應等等,也不厭 其煩地幫助我。感謝學長姐:昂穎、安孜、重吉、衍綺、聖倫、文俊、文立、長睿、
葛浩、鈺瑋,你們是我的楷模,我從你們身上學到很多。感謝同屆的夥伴宇祥、仕 弘、勤和、微涓,這兩年來我們總是相互激勵,不僅在研究上有所交流,也建立了 深刻的情誼,多麼幸運能與你們相遇。感謝學弟妹們:傳恩、瑋柔、佳文、博政、
子軒、宗翰、斯文,你們新穎的想法和積極的態度也給我許多啟發。感謝口試委員 蔡宗翰教授、林川傑教授、禹良治教授,指出我論文的不足之處,給我許多修改的 建議,讓這篇論文可以更清楚完整。
感謝我的父母,從小讓我自由探索自己喜愛的事物,在我就讀研究所期間仍然 無怨無悔地給予經濟及生活上的支持,讓我可以無後顧之憂地撰寫論文。感謝男友,
在服役中仍然花時間陪伴我,在我壓力極大、幾乎要放棄的時候也沒有責備我,反 而耐著性子聽我抱怨。感謝我的朋友們,在我感到無助時,適時拉我一把,讓我有 繼續前進的動力。只靠我自己一個人,沒有許許多多人的幫助,我是絕對沒辦法通 過種種考驗、完成學位論文的。真心謝謝大家。
中文摘要
近年來,世界上越來越多人選擇學習中文,中文文法錯誤偵測及更正工具的需
求因而增加。在HSK 動態作文語料庫中,用詞錯誤是最頻繁的詞層級錯誤。然而,
針對用詞錯誤偵測的研究並不多;在更正方面則只有處理特定詞類,如介係詞等。
在這篇碩士論文中,我們提出中文用詞錯誤偵測及更正的方法。據我們所知,這是 第一篇處理所有詞類之中文用詞錯誤更正之研究。
我們分三個階段處理中文用詞錯誤:(1) 子句層級之偵測、(2)詞層級之偵測、
(3)更正,使用了中文字、詞、詞性和依存關係等等資訊。在第一階段中,我們訓練 二元分類器來判斷一個子句是正確的、還是含有用詞錯誤,最好的模型準確率達 0.84、精確率達 0.95。在第二階段,我們使用雙向長短期記憶神經網路建立序列標 記模型,預測每一個詞的錯誤程度。這個模型可以考慮錯誤的詞和其他上下文詞彙
的關係,在超過80%的測試資料中,可以將標準答案排在前兩名。在第三階段,我
們建立神經網路模型,輸入上下文以及需要被更正的詞之特徵,產生一個更正向量,
這個向量可以和候選詞彙集合比較以選出適合的更正。由於可能存在不只一種更 正,我們對系統的前五名候選更正進行人工標記。根據人工評估的結果,對於超過 91%的測試資料,前五名中至少有一個是可接受的更正。非母語中文學習者可以使 用我們的系統,在沒有語言教師指導的情況下檢查並修正自己所寫的句子。
關鍵字:文法錯誤、中文用詞錯誤、用詞錯誤偵測、用詞錯誤更正、電腦輔助語言 教學、HSK 語料庫
ABSTRACT
Recently, more and more people around the world choose to learn Chinese as a second language. The need of Chinese grammatical error detection and correction tools is therefore increasing. In the HSK dynamic composition corpus, word usage error (WUE) is the most common type of errors at the lexical level. However, few studies focus on WUE detection, and for correction only specific types of words such as prepositions are investigated. In this thesis, we propose methods to detect and correct Chinese WUEs. To the best of our knowledge, this is the first research addressing general-type Chinese WUE correction.
We deal with Chinese WUE with three stages: (1) segment-level detection, (2) token- level detection, and (3) correction. Information of character, word, POS and dependency are utilized. In the first stage, we train binary classifiers to tell whether a segment is correct, or contains some WUE. The best model achieves accuracy 0.84 and precision 0.95. In the second stage, we use bidirectional Ling-Short Term Memory to build sequence labeling model that can predict the level of incorrectness of each token. The model can consider the dependency of the erroneous token on context words and rank the ground-truth position within the top two in more than 80% of the cases. In the third stage, we build a neural network model that takes context and target erroneous token features as
input and generates a correction vector, which can be compared against a candidate vocabulary to select suitable corrections. To deal with potential alternative corrections, the top five candidates are judged by human annotators. According to the human evaluation results, for more than 91% of the cases our system can propose at least one acceptable correction within a list of five candidates. With the help of our system, non- native Chinese learners can check and revise their sentences by themselves without the help of language teachers.
Keywords: Grammatical error, Chinese word usage error, Word usage error detection, Word usage error correction, Computer-assisted language learning, HSK corpus
CONTENTS
口試委員會審定書 ... i
誌謝 ... iii
中文摘要 ... v
ABSTRACT ... vii
CONTENTS ... ix
LIST OF FIGURES ... xv
LIST OF TABLES ... xvi
Chapter 1 Introduction ... 1
1.1 Motivation... 1
1.2 Chinese Word Usage Error (WUE) ... 2
1.3 Overview... 5
1.4 Thesis Organization ... 6
Chapter 2 Related Work ... 7
2.1 Grammatical Error Detection and Correction in English ... 7
2.2 Grammatical Error Detection and Correction in Chinese ... 10
2.3 Distributed Word Representations ... 11
2.3.1 CBOW/Skip-gram Word Embeddings ... 12
2.3.2 CWINDOW/Structured Skip-gram Word Embeddings ... 13
2.3.3 Character-enhanced Word Embedding (CWE) ... 14
Chapter 3 The HSK Word Usage Error Dataset ... 17
3.1 Data Collection ... 17
3.1.1 Split Sentences ... 17
3.1.2 Convert Multiple-error Sentences into Single-error Ones ... 17
3.2 Linguistic Processing ... 18
3.3 Splitting Sentences into Sentence Segments ... 19
3.4 Data Filtering ... 20
Chapter 4 Segment-level Chinese WUE Detection... 21
4.1 Task Description ... 21
4.2 Dataset ... 21
4.3 Features ... 22
4.3.1 Google N-gram Features ... 22
4.3.2 Dependency Count Features ... 23
4.3.3 Dependency Bigram Features ... 26
4.3.4 Single-character Features ... 26
4.3.5 Word Embedding Features ... 28
4.4 Machine Learning Classifiers ... 28
4.5 Results and Discussion ... 29
4.5.1 Overall Results on the 15000s Dataset ... 29
4.5.2 Results on Different Sub-types of WUEs... 33
4.6 Conclusion for Segment-level Detection ... 36
Chapter 5 Token-level Chinese WUE Detection ... 37
5.1 Task Description ... 37
5.2 Dataset ... 38
5.3 WUE Detection Based on Bidirectional LSTM ... 38
5.4 Sequence Embedding Features ... 42
5.4.1 Word Embeddings ... 42
5.4.2 POS Embeddings ... 42
5.5 Token Features ... 42
5.5.1 Out-of-Vocabulary Indicator ... 43
5.5.2 N-gram Probability Features ... 43
5.6 Evaluation ... 44
5.6.1 Accuracy ... 44
5.6.2 Mean Reciprocal Rank (MRR) ... 44
5.6.3 Hit@k Rate ... 44
5.6.4 Hit@r% Rate ... 45
5.7 Results and Analysis ... 46
5.7.1 Overall Results ... 47
5.7.2 LSTM v.s. Bi-LSTM on Segments with Different Length ... 48
5.7.3 Relationship between Top Two Candidates ... 48
5.7.4 Effectiveness of POS Features ... 50
5.7.5 Effectiveness of N-gram Features ... 51
5.7.6 Performance on Commonly Misused Words... 53
5.8 Conclusion for Token-level Detection ... 54
Chapter 6 Chinese WUE Correction ... 55
6.1 Task Description ... 55
6.2 Dataset ... 56
6.3 Neural Network-based Correction Generation Model ... 58
6.3.1 Model Overview ... 58
6.3.2 Model Output ... 59
6.3.3 Candidate Vocabulary... 60
6.3.4 Model Parameters ... 60
6.4 Features ... 61
6.4.1 Target CWE+P Word Embedding ... 61
6.4.2 Target CWE Position-Insensitive Character Embedding ... 62
6.4.3 Context2vec Features ... 63
6.4.4 Target POS Feature ... 66
6.5 Language Model Re-ranking ... 68
6.5.1 Traditional N-gram Language Model (N-gram LM) ... 68
6.5.2 Recurrent Neural Network Language Model (RNNLM) ... 69
6.5.3 Re-ranking Method ... 70
6.6 Automatic Evaluation ... 71
6.6.1 Overall Results ... 71
6.6.2 Effect of LM Re-ranking ... 73
6.7 Human Evaluation ... 75
6.7.1 Motivation for Human Evaluation ... 75
6.7.2 Annotation Guideline ... 76
6.7.3 Annotation Agreement ... 80
6.7.4 Evaluation with Human Annotation ... 81
6.8 Error Analysis ... 83
6.8.1 Performance on Different POS Tags ... 83
6.8.2 Error Cases ... 84
6.9 Conclusion for WUE Correction ... 88
Chapter 7 Conclusion and Future Work... 91
7.1 Conclusion ... 91 7.2 Future Work ... 93 REFERENCE ... 96
LIST OF FIGURES
Figure 1-1 Workflow of our Chinese WUE detection and correction system. ... 6
Figure 2-1 The architecture of CBOW and Skip-gram (Mikolov et al., 2013a). ... 13
Figure 2-2 The architecture of CWINDOW and Structured Skip-gram (Ling et al., 2015). ... 14
Figure 2-3 Comparison between CBOW and CWE (Chen et al., 2015). ... 15
Figure 4-1 Accuracy v.s. dataset size. ... 35
Figure 5-1 LSTM-based WUE detection model. ... 40
Figure 5-2 Bidirectional LSTM-based WUE detection model. ... 41
Figure 5-3 An example of undirected dependency graph. ... 49
Figure 6-1 A high-level view of our correction generation model. ... 59
Figure 6-2 The architecture of Context2vec. ... 64
Figure 6-3 The effect of parameter α in LM re-ranking. ... 75
Figure 6-4 The annotation guideline presented to the annotators. ... 79
LIST OF TABLES
Table 1-1 Sub-types of WUE (with error tag CC) defined in the HSK corpus. ... 3
Table 1-2 Sub-types of WUE defined in this thesis. ... 4
Table 3-1 Example sentences in our dataset. ... 17
Table 4-1 The statistics of the balanced dataset “15000s” ... 21
Table 4-2 Hyperparameters of the CBOW/SG embeddings ... 28
Table 4-3 Performance of Decision Tree on the 15000s dataset ... 30
Table 4-4 Performance of Random Forest on the 15000s dataset. ... 30
Table 4-5 Performance of Support Vector Machine on the 15000s dataset. ... 31
Table 4-6 Performance of Deep Neural Network on the 15000s dataset. ... 31
Table 4-7 Performance of Random Forest on the 4000s_W and 4000s_U dataset. ... 33
Table 5-1 Parameters of the LSTM-based WUE detection model... 39
Table 5-2 Performance of the LSTM/Bi-LSTM sequence labeling models with different sets of features. ... 46
Table 5-3 Hit@20% rates of LSTM and Bi-LSTM on segments with different lengths. ... 48
Table 5-4 Summary of the analysis of the dependency between the top two candidates. ... 50
Table 5-5 Hit@20% rates of Bi-LSTM models with or without POS features on three
most frequent POS tags of the erroneous token... 50
Table 5-6 Precision/recall on four most commonly misused words. ... 53
Table 6-1 Statistics of the dataset used in the WUE correction stage. ... 57
Table 6-2 Correction generation model parameters. ... 61
Table 6-3 POS transitions that occurs at least 10 times in the validation set... 66
Table 6-4 Hyperparameters of RNNLM. ... 70
Table 6-5 Performance of the correction generation model with various target and context features. ... 72
Table 6-6 Correction performance with LM re-ranking. ... 73
Table 6-7 An example of alternative corrections. ... 76
Table 6-8 WUE correction annotation instructions. ... 78
Table 6-9 Average κ of the annotation. ... 80
Table 6-10 Proportion of candidates that meet the correctness criterion. ... 81
Table 6-11 Correction performance with human evaluation. ... 83
Table 6-12 System performance on most frequent POS tags of the erroneous token... 83
Table 6-13 Example in which segmentation error is the source of error. ... 85
Table 6-14 Comparison of n-gram LM base 10 log probabilities of correct and wrong segmentation results... 85
Table 6-15 Example in which the similarity between the target and the correction is context-dependent. ... 87 Table 7-1 Summary of information used in each stage... 91 Table 7-2 Summary of the best performance of each stage. ... 92
Chapter 1 Introduction
1.1 Motivation
Nowadays, more and more people around the world choose to learn Chinese as their second language. The need for automatic Chinese grammatical error detection and correction (GEC) tools, which facilitate learners in recognizing the errors and revising their sentences, is therefore increasing. Although the techniques for building GEC tools have been studied for decades, most of the studies are based on English learner data. The method of correcting sentences in Chinese, a language which differs substantially from English, has not yet been fully developed.
Leacock et al. (2014) pointed out that the mistakes made by non-native language learners differ from those made by native speakers in types and distribution. For example, native English speakers seldom make a verb tense error, which is one of the most common mistakes made by non-natives. Therefore, learner data should be considered when designing or training a correction system for non-native users. Moreover, such data is required to perform realistic evaluation on GEC systems targeting language learners.
However, since the ground-truth of the correction must be manually annotated by trained annotators, the available amount of data is limited. Compared to English ones, annotated Chinese learner corpora are even fewer. At the time of this study, the largest
available learner corpus was the HSK dynamic composition corpus built by Beijing Language and Culture University1. According to the analysis of the corpus, word usage error (WUE) is the most frequent lexical-level error2. Given this fact, a WUE detection and correction tool is worth developing.
1.2 Chinese Word Usage Error (WUE)
This research deals with the detection and correction of Chinese WUE. In Chinese sentences, a WUE is a grammatically or semantically incorrect token in which either the word itself is written in a wrong form, or the word is a correct existent word but is improper for its context.
On the website of the HSK corpus, WUE, whose error tag is CC, is divided into four sub-types, as shown in Table 1-1.
1 http://202.112.195.192:8060/hsk/index.asp
2 http://202.112.195.192:8060/hsk/tongji2.asp
Sub-type Example (correct_word{CC incorrect_word})3 (1) Character disorder within a
word
首先{CC 先首} (first of all)
眾所周知{CC 眾所知周} (as we all know) (2) Incorrect selection of a word 雖然現在還沒有實現{CC 實踐},……
(While it is not yet implemented, …) (3) Non-existent word 殘留量{CC 潛留量} (amount of residue)
農產品{CC 農作品} (agricultural product)
(4) Word collocation error 最好的辦法是兩個都保持{CC 走去}平衡。
(The best way is to keep both balanced.) Table 1-1 Sub-types of WUE (with error tag CC) defined in the HSK corpus.
However, the error annotation does not contain information about which sub-type a WUE belongs to, and the divisions between some sub-types are not very clear. More specifically, CC (1) and (3) are similar in that the misused form is a non-existent word.
On the other hand, in both CC (2) and (4) the misused form is an existent word. Therefore, in this thesis, CC (1) along with (3), and CC (2) along with (4) are merged into morphological errors (W) and usage errors (U) respectively.4 The WUE sub-types defined by this thesis are summarized in Table 1-2.
3 The example sentences/phrases extracted from the HSK corpus are originally written in simplified Chinese. In this thesis, they are manually converted to traditional Chinese versions by the author.
4 Strictly speaking, the result of a CC (1) error might not be a non-existent word. For example, “產 生”(generate) can be a misused form of “生產”(produce). However, we define sub-types only based on the “result” of the error. Thus, a WUE is categorized as U-error as long as the misused form is an existent word.
Sub-type Corresponding HSK CC Sub-types # instances
Morphological errors (W) (1) & (3) 4,010
Usage errors (U) (2) & (4) 13,314
Table 1-2 Sub-types of WUE defined in this thesis.
To determine whether the misused form is an existent word, we query the Beijing University Dictionary (北京大學辭典)5 . If the misused form cannot be found in the dictionary, the instance is marked as W-error; otherwise it is marked as U-error.
In morphological errors, the Chinese characters within a word are wrongly selected or permuted. Character usage within a word is considered an aspect of word usage, since most of the Chinese characters are able to form meaningful words by themselves. For usage errors, the problem may lie in collocational combination, or a discrepancy between the intended meaning (inferred from the context by annotators) and the literally expressed semantics. According to Table 1-2, the non-native Chinese learners contributing the HSK corpus misuse an existent Chinese word more frequently than writing a word in an incorrect form.
In both cases of WUEs, the error can be corrected by replacing the erroneous token with an appropriate word. However, in morphological errors, a non-existent word is likely to be segmented into a sequence of single characters by a dictionary-based segmentation
5 〈現代漢語語法信息詞典的開發與應用〉,《中文與東方語言信息處理學會通訊》,pp. 81-86
system, which makes the determination of the start and end offset a difficult aspect for automatic correction. On the other hand, to correct usage errors, how to derive the intended semantics is the major issue.
1.3 Overview
This research divides the WUE detection and correction task into three stages.
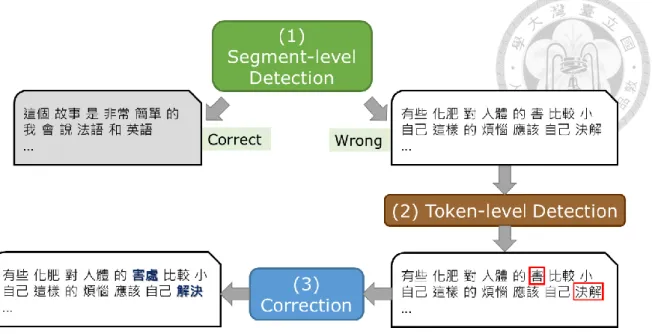
Stage 1: Segment-level detection Stage 2: Token-level detection Stage 3: Correction
In stage 1, the detection task is formulated as a binary classification problem. Given a Chinese segment, typically delimitated by punctuation marks like comma (,), we determine whether the segment is erroneous or not. The incorrect segments can then be passed to Stage 2, in which we build a sequence labeling model to estimate the level of incorrectness of each token. The tokens with the highest score of incorrectness are proposed to be potentially erroneous ones. In Stage 3, we assume the error position is known and rank candidate corrections based on both the context and the original (erroneous) token written by the language learner. The workflow of our system is shown in Figure 1-1.
Figure 1-1 Workflow of our Chinese WUE detection and correction system.
1.4 Thesis Organization
The remainder of this thesis is organized as follows. Chapter 2 reviews the related work. Chapter 3 introduces the dataset adopted in this research and describes the pre- processing steps. Chapters 4 and 5 deals with segment-level and token-level WUE detection respectively. Chapter 6 presents our method of WUE correction. Chapter 7 concludes the thesis and discusses possible future directions.
Chapter 2 Related Work
2.1 Grammatical Error Detection and Correction in English
Leacock et al. (2014) give a very comprehensive survey of past studies in automated GEC. They also point out that despite the importance of learner data, the limited amount of annotated learner corpora could make it difficult to build a robust statistical model.
Therefore, researchers have also explored to combine statistical models with traditional rule-based approaches. Other methods of overcoming the limitation of the amount of data include constructing artificial error corpora and making use of large “grammatical” text corpora.
A disadvantage of using artificial data for machine learning models is that the distribution of the training data (artificially-made erroneous text) could differ a lot from that of the test data (real text written by language learners). In addition, it is possible that the model ends up learning the way of synthesizing data, instead of language learners’
pattern of making mistakes.
On the other hand, the use of well-formed text may suffer from the difference in domain and style. For example, large corpora which are composed of newspaper or Wikipedia text can be much more formal than the essays written by language learners.
Also, the topics can be different, since language learners, especially beginners, are more
likely to write essays about themselves and their daily lives. Moreover, it is hard to determine whether an expression is grammatical based solely on corpus frequencies, since the language leaners’ way of expressing a meaning might differ from the typical way of native speakers. As a result, it would be difficult to draw a line between rare usage and wrong usage.
Another difficult aspect in GEC research pointed out by Leacock et al. (2014) is evaluation. Different research teams tend to adopt different typology of errors and evaluate on different datasets, so it might be hard to compare various systems and conclude which one is better. To measure the performance of GEC systems in a standardized manner, several shared tasks have been conducted, including Helping Our Own (HOO) 2011 (Dale and Kilgarriff, 2011), HOO 2012 (Dale et al., 2012), CoNLL 2013 (Ng et al., 2013) and CoNLL 2014 (Ng et al., 2014). Different types of grammatical errors were investigated. For example, five error types: article/determiner, preposition, noun number, verb form and subject-verb agreement, are evaluated in the CoNLL 2013 Shared Task on GEC. In CoNLL 2014, it is extended to 28 error types. Language models, machine learning-based classifiers, rule-based classifiers, and machine translation models have been explored.
The machine translation approach to GEC, which aims to model a transformation from incorrect text to its correction, has the major advantage that there is no need to
explicitly formulate the types of the errors. Based on the phrase-based statistical machine translation (SMT) framework, Dahlmeier and Ng (2011) add phrase table entries to handle semantic collocation errors resulting from the influence of the writer’s first language (L1). Chollampatt et al. (2016b) explore neural network-based translation models, including Neural Network Global Lexicon Model (NNGLM) and Neural
Network Joint Model (NNJM) for GEC. By incorporating features generated by neural network models into the phrased-based SMT model, they achieve substantial improvement over the top systems proposed in the CoNLL 2014 Shared Task.
Chollampatt et al. (2016a) adapt a general NNJM with L1-specific text to capture the different regularities of errors made by learners with different L1. A Kullback-Leibler divergence regularization term is introduced to prevent overfitting to the relatively small L1-specific data. Improvements are shown on the data of three L1s: Chinese, Russian and Spanish.
Rei and Yannakoudakis (2016) argue that the evaluation of error correction can be subjective and focus only on error detection. The detection is performed with a sequence labeling framework, where the probability of being correct/incorrect is predicted at token level based on the word representation of each input token. They compare different composition architectures such as Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Long-Short Term Memory (LSTM), and conclude that
LSTM is the most suitable model for this task.
2.2 Grammatical Error Detection and Correction in Chinese
For Chinese, spelling check evaluations were held at SIGHAN 2013 Bake-off (Wu et al., 2013) and SIGHAN 2014 Bake-off (Yu et al., 2014). The task is to detect and correct character errors in the given sentence. Similar character sets are provided. Two Chinese characters can be orthographically similar, such as ”間” and ”門”, or phonetically similar, such as ”惕” and ”悌”.
The Shared Task for Chinese Grammatical Error Diagnosis (Yu et al., 2014; Lee et al., 2015, 2016) extends the above task to word errors. Four kinds of errors, including redundant word, missing word, word disorder and word selection, are defined. The performance of the participants are reported on the whole dataset, so it is unclear whether some systems are better at certain error types. Besides, these tasks only deal with the detection but not the correction.
Huang and Wang (2016) use LSTM for Chinese grammatical error diagnosis. Each word in the sentence is represented by a randomly initialized real-valued vector. Their models are trained only on learner data. Without incorporating information derived from external well-formed text, the performance might be limited by the relatively small number of annotated sentences written by non-native learners.
The HSK corpus used in this research has been adopted by Yu and Chen (2012) to study word ordering errors (WOEs) in Chinese. They propose syntactic features, web corpus features and perturbation features for WOE detection. Cheng et al. (2014) identify sentence segments containing WOEs, and further recommend the candidates with correct word orderings by using ranking support vector machine (SVM).
Huang et al. (2016) also use the HSK corpus to study the Chinese preposition selection problem. They propose gated recurrent unit (GRU)-based models to select the most suitable one from a closed set of 43 Chinese prepositions given the sentential context.
Their approach can be utilized to both detect and correct preposition errors.
Nevertheless, it is still worth investigating how to handle WUEs involving other types of words such as verbs and nouns. Recognizing and correcting errors of such open-set types could be much more difficult since the set of candidates can be huge. To the best of our knowledge, this is the first research dealing with general-type Chinese WUE correction.
2.3 Distributed Word Representations
In the past few years, distributed word representations (word embeddings) derived from neural network models (Mikolov et al., 2013a; Pennington et al., 2014) have become popular among various studies in natural language processing. Based on the assumption
that similar words should share similar context, the representations can be trained on large text corpora in an unsupervised manner. Typically, these representations are in the form of real-valued vectors, whose dimensionality is low compared to the size of the vocabulary. Beyond surface forms, these low-dimensional vector representations can encode syntactic and semantic information implicitly (Mikolov et al., 2013b).
Because WUEs involve syntactic or semantic problems, vector representations could be promising for the detection/correction task. In this research, we experiment with three major types of word embeddings.
2.3.1 CBOW/Skip-gram Word Embeddings
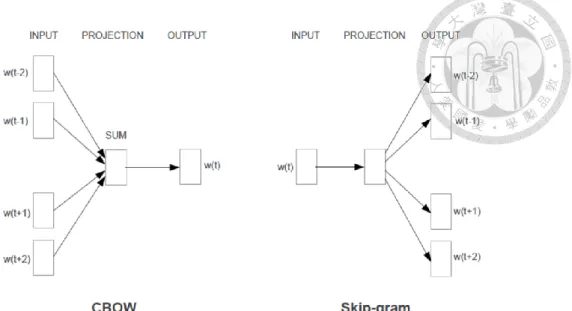
These are the two architectures included in the Word2vec software (Mikolov et al., 2013a). The continuous bag-of-words model (CBOW) uses the words in a context window to predict the target word, while the skip-gram model (SG) uses the target word to predict every word in the context window. The two architectures are shown in Figure 2-1. In these two models, every context word is treated equally, so the information of word order is not preserved.
Figure 2-1 The architecture of CBOW and Skip-gram (Mikolov et al., 2013a).
2.3.2 CWINDOW/Structured Skip-gram Word Embeddings
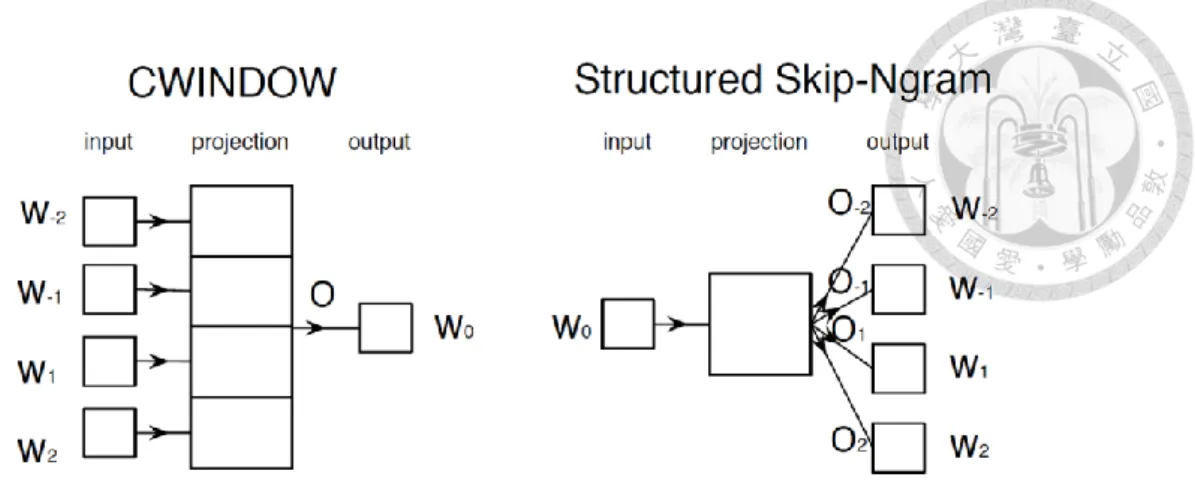
The continuous window model (CWIN) and the structured skip-gram model (Struct- SG) (Ling et al., 2015) are extensions of CBOW and SG respectively, which take the order of context words into consideration. The former replaces the summation of context word vectors in CBOW with a concatenation operation, and the latter applies different projection matrices for predicting context words in different relative position with the target word. Figure 2-2 illustrates the two models.
In their paper, Ling et al. (2015) show that by using CWIN and Struct-SG embeddings, the performance of syntactic tasks such as part-of-speech (POS) tagging and dependency parsing can be enhanced. For Chinese WUE, the incorrect selection of a word might cause syntactic anomaly, so we examine whether these embeddings can help.
Figure 2-2 The architecture of CWINDOW and Structured Skip-gram (Ling et al., 2015).
2.3.3 Character-enhanced Word Embedding (CWE)
One of the most idiosyncratic aspect of the Chinese writing system is that the components of words, the Chinese characters, usually take on their own meanings. The meanings of individual characters usually contribute to the meaning of the word. For example, one familiar with Chinese can easily infer that “公車”(bus) is very likely to be a kind of “車”(vehicle), even without any context. Also, the character “公”(public) indicates that “公車” is a kind of public transportation.
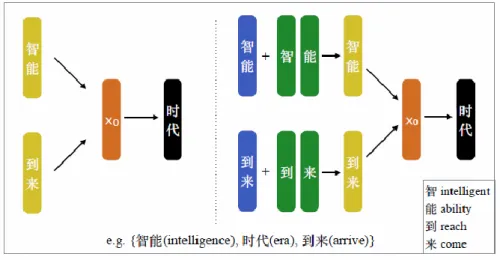
Based on this characteristic of Chinese, Chen et al. (2015) proposed character- enhanced word embedding model (CWE), in which word vectors and character vectors are learned jointly. The model is based on CBOW. Figure 2-3 compares CWE with CBOW.
In CWE, the representation of a context word is a combination of its own vectors and the
vectors of its constituent characters. The combination is done with vector addition.
Throughout the process of training, both word and character vectors are updated.
As discussed in Chapter 1, one case of Chinese WUE is that the characters within a word is wrongly chosen or permuted. For instance, “決解” is a misused form of “解決”
(solve). Though the misused form is a non-existent word, its character components serve as an important clue for discovering what the writer originally means and help provide more suitable correction. Therefore, we study how to utilize the CWE vectors, which encode both character and word information, to cope with the WUE correction task.
Figure 2-3 Comparison between CBOW and CWE (Chen et al., 2015).
Chapter 3 The HSK Word Usage Error Dataset
3.1 Data Collection
3.1.1 Split Sentences
We extract correct and wrong sentences from the HSK corpus, which contains essays written by non-native Chinese learners. The punctuation marks “。”, “?” and “!” are used to split the sentences. The sentences containing no error annotation are regarded as correct. To study the WUE correction task, we also include the correction of the wrong sentences in our dataset. Example sentences are shown in Table 3-1.
Correct sentence 我曾經到台灣讀書交了很多外國朋友,我們是用漢語說話的。
Wrong sentence 可想而知,他們長大以後會遇到很多的麻煩,甚至不適應生
活,造成不甚後果。
Correction of the wrong sentence
可想而知,他們長大以後會遇到很多的麻煩,甚至不適應生 活,造成不良後果。
Table 3-1 Example sentences in our dataset.
3.1.2 Convert Multiple-error Sentences into Single-error Ones
A sentence may contain multiple errors, including errors of types other than WUE.
To focus on WUEs and enable systematic analysis, we convert a sentence containing n errors into n sentences, each of which only contains one error. That is, the following sentence with three errors:
○ ○ E1 ○ ○ ○ ○ ○ ○ E2 ○ ○ ○ ○ E3 ○
will be converted into three sentences:
○ ○ E1 ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○
○ ○ ○ ○ ○ ○ ○ ○ ○ E2 ○ ○ ○ ○ ○ ○
○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ○ E3 ○
After conversion, only wrong sentences in which the error is a WUE are considered. We got a total of 33,851 wrong sentences, each of which contains exactly one WUE.
3.2 Linguistic Processing
We process the extracted sentences with the Stanford CoreNLP toolkit (Manning et al., 2014). The following annotators are applied.
Word Segmentation
POS Tagging
Dependency Parsing
The length of a sentence is defined to be the number of tokens in its word segmentation result. The POS tagging set of CoreNLP is that of the Chinese Penn Treebank. The tagging guideline can be found in (Xia 2000).
In each stage, we will extract features based on these three levels of information. The details will be provided in subsequent chapters.
3.3 Splitting Sentences into Sentence Segments
In our pilot experiments, we randomly sampled 1,000 correct and wrong sentences respectively and found out that we can achieve nearly 80% binary classification accuracy simply using a threshold on the length of the sentences. The reason is that a Chinese sentence is usually composed of several segments, mostly separated by comma “,”.
For example, the following sentence is composed of three segments:
如果我當推銷員的話,為了早點兒習慣,打算盡可能努力。
The longer a sentence is, the more likely a learner would make some grammatical errors somewhere. In fact, among the 2,000 selected sentences, the average length of the correct sentences is 7.8, while that of the wrong sentences is 25.6. If we mark the whole sentence as “wrong” only because one of the segments contains WUE, the benefit to the learner will be limited. Therefore, in the first stage, we consider a sentence segment as a unit of detection. We use the tokens with POS tag “PU” (punctuation mark) to split the segments.
3.4 Data Filtering
The raw essay text contains metadata such as serial number, title, or total number of words. In addition, after splitting with punctuation marks we get short segments such as the ones in “您好!”, “不過,…” and “那時,…”. It is nearly impossible to determine the correctness of these single-word segments individually. To conduct experiments on valid instances, we filter out segments:
That contain digits or English alphabets
Whose length is less than five
Finally, our dataset contains 63,612 correct segments and 17,324 segments with WUEs.
In each of the three stages, a subset of data is extracted from this complete dataset. The details will be described in the corresponding chapters.
Chapter 4 Segment-level Chinese WUE Detection
4.1 Task Description
In this stage, we formulate WUE detection as a binary classification problem. Given a Chinese sentence segment, we build models to tell whether there is any WUE in the segment.
4.2 Dataset
According to Section 3.4, the number of the correct segments are much more than that of the wrong segments in our complete dataset. Therefore, a model can reach high performance by always guessing the majority class, yet this kind of system would not be helpful for language learners. To avoid this problem, we build a balanced dataset. We randomly select 15,000 correct and WUE segments respectively, and combine them into a dataset with 30,000 segments in total. This dataset is called “15000s”. The statistics of the dataset is summarized in Table 4-1.
Correct Segments Wrong Segments
# segments 15,000 15,000
# tokens 115,597 136,666
# types 8,532 11,187
Table 4-1 The statistics of the balanced dataset “15000s”
4.3 Features
In Section 1.2 we divided WUE into two sub-types, i.e., morphological errors (W) and usage errors (U). Based on this division, several properties of the Chinese WUE detection problem are worth noticing. W-errors can be identified almost at first sight, but for U-errors, even native speakers may have to “ think twice ” . For example, to determine if “體會” (realize) is a misuse of the word “體驗” (experience) in the sentence “ 親 身 體 會 了 一 場 永 遠 難 忘 的 電 單 車 意 外 ” (personally realize an accident which was never forgotten), we have to consider its collocation with “意外”
(accident). On the other hand, any error with a non-existent word such as “農作品”
can be detected solely by its extremely low frequency in a Chinese corpus.
To detect the existence of WUE, we experiment with several sets of features. All the following features are utilized in combination with segment length (s_len), which is defined to be the number of tokens in the segment.
4.3.1 Google N-gram Features
We adopt the Chinese version of Google Web 5-gram (Liu et al., 2010) to generate n- gram features. For every word sequence of length 𝑛 (𝑛 = 2, 3, 4, 5) in a segment, we calculate the n-gram probability by Maximum Likelihood Estimation (MLE). For example, the tri-gram probability is defined as follows.
p(𝑤𝑖|𝑤𝑖−2, 𝑤𝑖−1) = 𝑐(𝑤𝑖−2, 𝑤𝑖−1, 𝑤𝑖)
, where c(‧) is the frequency of the word sequence in the Google Web 5-gram corpus.
For a segment 𝑤1𝑤2… 𝑤𝐿 , all n-gram features are concatenated into a feature vector 𝐆 = (𝑔2, 𝑔3, 𝑔4, 𝑔5), where
𝑔𝑛 = ∑ p(𝑤𝑖|𝑤𝑖−𝑛+1, … , 𝑤𝑖−1)
𝐿
𝑖=𝑛
The reason for using the summation of probabilities, instead of average probability, is that the relationship between segment length and probability sum might not be linear. Since this set of features is combined with s_len, the model is expected to capture more complex relationship.
To query the n-gram counts efficiently, we utilized marisa-trie6, a data structure that can save memory usage and enable fast search by grouping keys (n-grams) that share the same prefixes.
4.3.2 Dependency Count Features
Errors in a sentence affect the result of segmentation and parsing. We postulate that there is a certain distribution of dependency counts in normal sentences, and the counts of error sentences deviate from the distribution. An example is shown below.
6 https://github.com/pytries/marisa-trie
Correct segment Wrong segment 以下 介紹 一下 我 的 簡歷 和 經
驗 。
以下 紹 介 一下 我 的 簡歷 和 經 驗 。
nsubj(介紹-2, 以下-1) root(ROOT-0, 介紹-2) advmod(介紹-2, 一下-3) assmod(經驗-8, 我-4) case(我-4, 的-5) conj(經驗-8, 簡歷-6) cc(經驗-8, 和-7) dobj(介紹-2, 經驗-8)
nsubj(介-3, 以下-1) advmod(介-3, 紹-2) root(ROOT-0, 介-3) advmod(介-3, 一下-4) assmod(經驗-9, 我-5) case(我-5, 的-6) conj(經驗-9, 簡歷-7) cc(經驗-9, 和-8) dobj(介-3, 經驗-9)
By comparing the two dependency parsing results, we can find out that ”紹介”, a misused form of “介紹” (introduce), is (incorrectly) segmented into two words and results in an additional, unreasonable dependency relation advmod(介-3, 紹-2).
Therefore, we take the count of each type of dependency as a set of features. Let dep be the type of dependency such as nsubj and dobj. For each dependency, we compute two types of count:
(1) internal count (dep_int_cnt): counts the occurrence if the two words are both in the target segment.
(2) external count (dep_ext_cnt): counts as long as one of the words is in the target segment.
The total internal (all_int_cnt) and external counts (all_ext_cnt) are also considered.
An example of the calculation of this set of features is shown below.
聽說 貴 公司 在 國內 很 有名 , 外國 顧客 也 很多 。 root(ROOT-0, 聽說-1)
nn(公司-3, 貴-2) nsubj(有名-7, 公司-3) case(國內-5, 在-4) prep(有名-7, 國內-5) advmod(有名-7, 很-6) ccomp(聽說-1, 有名-7) nn(顧客-10, 外國-9) nsubj(很多-12, 顧客-10) advmod(很多-12, 也-11) conj(有名-7, 很多-12)
The corresponding feature values of the shaded segment are:
nn_int_cnt 1 nn_ext_cnt 1
nsubj_int_cnt 1 nsubj_ext_cnt 1
case_int_cnt 1 case_ext_cnt 1
prep_int_cnt 1 prep_ext_cnt 1
advmod_int_cnt 1 advmod_ext_cnt 1
ccomp_int_cnt 1 ccomp_ext_cnt 1
conj_int_cnt 0 conj_ext_cnt 1
all_dep_int_cnt 6 all_dep_ext_cnt 7
For all other dependency types that do not appear, the feature value is 0. Note that though the unit of detection is a segment, the external count features can introduce information across segments.
There are 45 types of dependencies in our dataset, and we also include total internal and external counts. The result feature vector D has 92 dimensions.
4.3.3 Dependency Bigram Features
Long distance dependency is common in Chinese sentences. In the example, “親 身 體會 了 一場 永遠 難忘 的 電單車 意外”, “意外” is the object of “體 會”, but there are 6 words in-between, falling out of the range of n-gram features. To cope with the problem, we generate dependency bigrams. The above sentence contains dependencies such as nsubj(體會-2, 親身-1) and dobj(體會-2, 意外-9). We compose the two words in each dependency, i.e. (親身, 體會) and (體會, 意外), query the Google n-gram corpus, and calculate the bigram probabilities. Below is an example showing that the frequency of the bigram composed of correct collocation is higher than that composed of wrong collocation.
Bigram Frequency
Wrong 體會 意外 0
Correct 經歷 意外 167
Since the collocating behavior may vary with dependency type, we sum the bigram probabilities of each type respectively. Similar to the dependency count features, we calculate both internal sum (dep_int_sum_prob) and external sum (dep_ext_sum_prob).
The probability sums of all dependency types are also included (all_int_sum_prob, all_ext_sum_prob). This set of features, denoted by feature vector B, has 92 dimensions.
4.3.4 Single-character Features
A non-existent Chinese word (W-error) is usually separated into several single-
character words after segmentation, so the occurrence of single-character words is an important indicator of WUEs. We define the following features:
(1) seg_cnt: number of contiguous single-character blocks
(2) len2above_seg_cnt: number of contiguous single-character blocks with length no less than 2
(3) max_seg_len: length of the maximum contiguous single-character block (4) sum_seg_len: sum of the lengths of all contiguous single-character blocks Consider the following segment as an example:
而且 我 認為 貴 公司 是 我國 最 大 的
(…, and I thought that your company is the biggest in our country.)
The feature values are 4, 1, 3, and 6, respectively. The proposed features are concatenated into a vector S.
4.3.5 Word Embedding Features
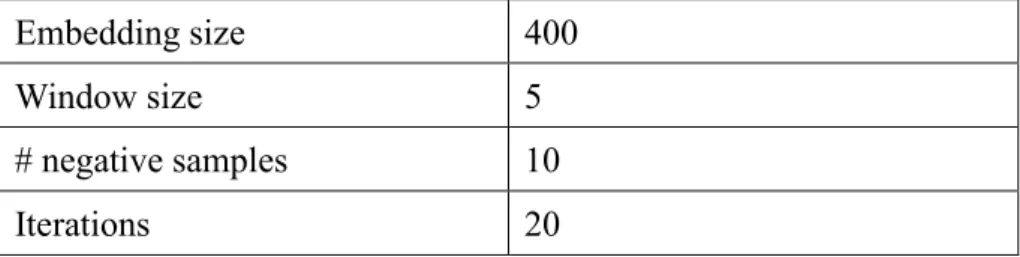
We train CBOW/SG word embeddings on the Chinese part of the ClueWeb09 dataset7. The Chinese part was extracted and segmented by Yu et al. (2012). The negative sampling objective is adopted. The hyperparameter settings are shown in Table 4-2. All other hyperparameters not mentioned are left default.
Embedding size 400
Window size 5
# negative samples 10
Iterations 20
Table 4-2 Hyperparameters of the CBOW/SG embeddings
For each segment, we sum the vectors of all the words in it. We concatenate CBOW and SG embeddings into a feature vector W. The dimensionality of W is therefore 800.
4.4 Machine Learning Classifiers
We experiment with four kinds of machine learning classifiers, including Decision Tree (DT), Random Forest (RF), Support Vector Machine with RBF kernel (SVM), and Feed-forward Neural Network (Deep Neural Network, DNN). For the first three models,
7 http://lemurproject.org/clueweb09.php
we use the implementation of scikit-learn8; for DNN, we use libdnn9.
For SVM and DNN, we scale the feature vector to zero mean and unit variance, since the range of the feature values can affect the performance of these two models.
4.5 Results and Discussion
4.5.1 Overall Results on the 15000s Dataset
The performance of each kind of classifiers on different sets of features are shown in Table 4-3 ~ Table 4-6. The s_len feature is included in every feature combination. For each combination, we report the performance metrics of the model with best accuracy among various parameter settings. All the reported performance values are the average of 10-fold cross validation. The metrics are computed as follows.
Model Prediction
Wrong (with WUE) Correct (no WUE) Ground-truth Wrong (with WUE) True Positive (TP) False Negative (FN)
Correct (no WUE) False Positive (FP) True Negative (TN)
accuracy = TP+TN
TP+FN+FP+TN precision = TP
TP+FP recall = TP TP+FN
8 http://scikit-learn.org/stable/
9 https://github.com/botonchou/libdnn
Feature Accuracy Precision Recall F1
G 0.8354 0.9268 0.7285 0.8158
D 0.6430 0.6586 0.5955 0.6254
B 0.6437 0.6311 0.6960 0.6620
S 0.5931 0.6009 0.5560 0.5776
W 0.6018 0.6159 0.5446 0.5780
GD 0.8311 0.9557 0.6945 0.8044
GB 0.8311 0.9569 0.6935 0.8042
GS 0.8301 0.9201 0.7230 0.8097
GW 0.8123 0.8687 0.7359 0.7968
All 0.8299 0.9499 0.6968 0.8039
Table 4-3 Performance of Decision Tree on the 15000s dataset
Feature Accuracy Precision Recall F1
G 0.8398 0.9620 0.7075 0.8154
D 0.6636 0.6767 0.6267 0.6507
B 0.7026 0.7211 0.6611 0.6898
S 0.5970 0.6065 0.5557 0.5800
W 0.6623 0.6779 0.6187 0.6469
GD 0.8376 0.9324 0.7281 0.8177
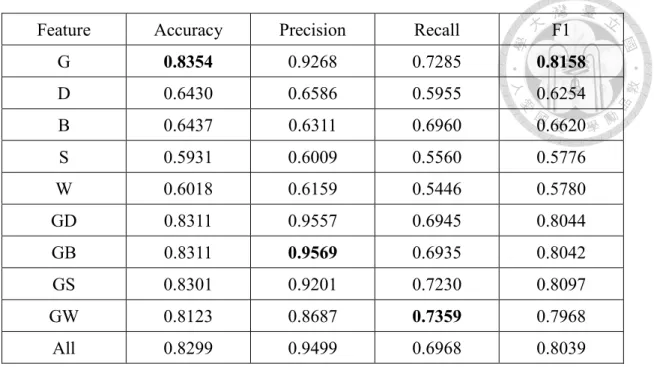
GB 0.8425 0.9450 0.7274 0.8220
GS 0.8342 0.9571 0.6998 0.8085
GW 0.8281 0.8551 0.7901 0.8213
All 0.8315 0.8405 0.8185 0.8293
Table 4-4 Performance of Random Forest on the 15000s dataset.
Feature Accuracy Precision Recall F1
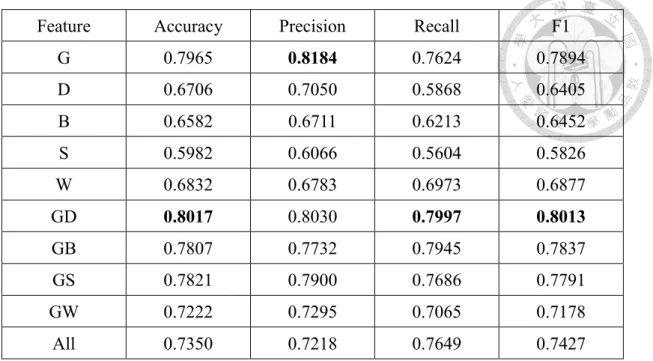
G 0.7965 0.8184 0.7624 0.7894
D 0.6706 0.7050 0.5868 0.6405
B 0.6582 0.6711 0.6213 0.6452
S 0.5982 0.6066 0.5604 0.5826
W 0.6832 0.6783 0.6973 0.6877
GD 0.8017 0.8030 0.7997 0.8013
GB 0.7807 0.7732 0.7945 0.7837
GS 0.7821 0.7900 0.7686 0.7791
GW 0.7222 0.7295 0.7065 0.7178
All 0.7350 0.7218 0.7649 0.7427
Table 4-5 Performance of Support Vector Machine on the 15000s dataset.
Feature Accuracy Precision Recall F1
G 0.8106 0.8621 0.7399 0.7963
D 0.6398 0.6520 0.6014 0.6257
B 0.6200 0.6342 0.5731 0.6021
S 0.6050 0.6230 0.5403 0.5787
W 0.6800 0.6960 0.6399 0.6668
GD 0.8087 0.8763 0.7203 0.7907
GB 0.7524 0.7683 0.7273 0.7472
GS 0.8123 0.8802 0.7243 0.7947
GW 0.7285 0.7221 0.7469 0.7343
All 0.7955 0.8288 0.7461 0.7853
Table 4-6 Performance of Deep Neural Network on the 15000s dataset.
Since we use a balance dataset, the baseline accuracy is 50%. As can be seen, all the models with each of the proposed set of features outperform the baseline. Google n-
gram(G) is the most effective set of features, reaching 0.8398 accuracy and 0.9620 precision on its own with the RF model. The best accuracy of Dependency count (D) and Dependency bigram (B) features are about 0.67 and 0.70, with SVM and RF respectively.
For single character features (S), the accuracy is only around 0.6. The word embedding features (W) work better with SVM and DNN, with accuracy about 0.68.
Because G is the strongest set of features, we try to combine it with others. Although individual sets of features cooperate better with different classifiers, generally DT and RF handle feature combinations better. Note that RF is a model that ensembles many DTs, so RF is usually better than a single DT. We focus our discussion on RF below. The best accuracy on the 15000s dataset is 0.8425, achieved by the GB feature combination. While the accuracy is better than that of RF only with G features, the precision slightly decreases to 0.945. W features increase the recall by about 9% when used with the G features, but at the expense of precision. D and B features also help increase the recall when used with G. With all sets of features, precision and recall are balanced, which are 0.8405 and 0.8185 respectively, and the best F1 score 0.8293 is achieved.
By utilizing suitable combination of features, we can construct a system that favors precision or recall, according to specific application purposes. Especially, the precision as high as 0.96 we achieved indicates that our system is highly reliable and seldom produces misleading results.
4.5.2 Results on Different Sub-types of WUEs
To test the performance of our system on different WUE sub-types, we sample 4,000 segments from each subtype and combine them with 4,000 correct segments respectively.
The generated dataset, called 4000s_W and 4000s_U, contains 8,000 segments respectively. We use RF to conduct the experiments. The experimental results of the two datasets are shown in Table 4-7.
Feature 4000s_W 4000s_U
Acc. P R F1 Acc. P R F1
G 0.7969 0.8425 0.7313 0.7829 0.6355 0.6321 0.6515 0.6417 D 0.6420 0.6370 0.6608 0.6486 0.6211 0.6151 0.6528 0.6334 B 0.6210 0.6205 0.6235 0.6220 0.6299 0.6486 0.5678 0.6055 S 0.6330 0.6172 0.7008 0.6563 0.5998 0.5872 0.6725 0.6270 W 0.6095 0.6110 0.6038 0.6074 0.6139 0.6321 0.5453 0.5855 GD 0.8213 0.8630 0.7640 0.8105 0.6813 0.6981 0.6388 0.6671 GB 0.8091 0.8790 0.7188 0.7908 0.6935 0.6906 0.7010 0.6958 GS 0.8226 0.8920 0.7345 0.8056 0.6396 0.6586 0.5805 0.6171 GW 0.7714 0.7722 0.7705 0.7714 0.6529 0.6563 0.6420 0.6491 All 0.8056 0.7757 0.8608 0.8160 0.6881 0.6956 0.6700 0.6826 Table 4-7 Performance of Random Forest on the 4000s_W and 4000s_U dataset.
Detecting U-errors is generally harder than detecting W-errors. The best accuracy of W-errors is above 0.82, but the best of U-errors is less than 0.7. On both sub-types, G is the most effective. However, for U-errors the difference in performance between G and other individual sets is smaller. This is consistent with what we previously discussed, that
compared to W-errors, U-errors cannot be easily detected by low corpus frequency.
Considering the combination of G with the others, we can observe different functionalities of different feature sets. The single-character features (S) designed for W- errors improve the accuracy when used with G on the 4000s_W dataset. S feature is not very effective on its own, probably because the existence of single-character words is not sufficient to conclude that there is something wrong with the segment. For example, the following “correct” sentence contains many single character words due to its grammatical structure:
有 人 對 她 說
In contrast, the following segment contains a short problematic sequence of single characters “共 敬” whose bigram probability is less than 0.0001. (To correct the error, the two tokens “共 敬” should be replaced by a single word “尊敬”)
他們 應該 共 敬 父母
Therefore, G and S features can together provide useful information for the model in such cases.
On the other hand, D and B, the features derived from the result of dependency parsing, are helpful on the 4000s_U dataset. The accuracy both improves when D or B is used with G. This indicates that dependency information can help the models handle collocation errors better, especially those involve long-distance dependency. While GD
results in slightly lower recall compared to G, GB increases the recall a lot over G.
W features also have different effects for two different sub-types of WUE. GW leads to better recall over G on the 4000s_W dataset, and better precision and accuracy on the 4000s_U dataset.
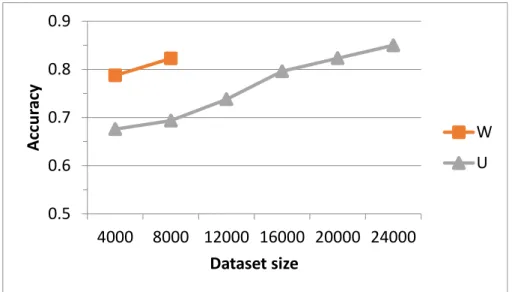
Figure 4-1 Accuracy v.s. dataset size.
Figure 4-1 shows the relationship between the best accuracy and the dataset size in the experiments of RF. Due to the amount of available data for W-errors, only two datasets are generated. The dataset size is the total number of segments, including both wrong and correct ones. Therefore, the datasets with size 8000 are just 4000s_W and 4000s_U we used previously.
With the largest dataset, the accuracy for U-errors reaches 0.8499. The accuracy of two sub-types both increases with the amount of training data. To reach the same level of
0.5 0.6 0.7 0.8 0.9
4000 8000 12000 16000 20000 24000
Accuracy
Dataset size
W U
accuracy, more training data are needed for U-errors, which also indicates that handling U-errors is more difficult.
4.6 Conclusion for Segment-level Detection
In this stage, we deal with the Chinese WUE detection task with n-gram features, dependency count features, dependency bigram features, single-character features and word embedding features. The best model achieves 0.8425 accuracy, 0.9450 precision, 0.7274 recall, and 0.8220 F1 on the 15000s balanced dataset. Among the tested machine learning classifiers, random forest is the most suitable model for the proposed features.
The single-character features in combination with n-gram features are effective for morphological errors (W), while dependency-derived features help better capture usage errors (U). The detection of usage error is harder and need more training data.
By utilizing suitable model and combination of features, we can also construct a WUE detection system that favors precision, up to 96.2%. If a segment is classified as wrong by our high-precision model, it is very likely that there is indeed some WUE in the segment. Therefore, in our next stage, we consider those segments known to contain WUE and design models to locate the specific erroneous token.
Chapter 5 Token-level Chinese WUE Detection
5.1 Task Description
The goal of this stage is to locate the specific location of WUE given known incorrect segments. We formulate the Chinese WUE detection task as a sequence labeling problem.
Each token, the fundamental unit after word segmentation, is labeled either correct (0) or incorrect (1).
As we mentioned in Chapter 1, U-errors are much more than W-errors in the HSK dataset. In fact, many Chinese WUEs result from subtle semantic unsuitability instead of violation of syntactic constraints. In (S5-1), both “權力” (power) and “權利” (right) are existent nouns in Chinese, and both versions are grammatically correct.
(S5-1) 人們有(*權力,權利)吃安全的食品。
(People have the (*power, right) to enjoy safe food. )
To recognize the WUE, we have to understand the meaning of “吃安全的食品”, so that we can determine whether it is a kind of right, or a kind of power. If the context changes, which word is the correct choice is very likely to be different.
The above example can shed light on one of the challenging aspects of this task. The errors usually do not stand on their own, but the problems lie in their relationship with their context. If a model examines the sentence segment token by token, it would not be able to detect this kind of WUEs. Therefore, we need a model that considers the sequence
of words as a whole to determine which position needs correction.
5.2 Dataset
We extract the wrong segments in the 15000s balanced dataset used in the previous stage. Each sentence segment has exactly one token-level position that is erroneous. We filter out any sentence segment whose corrected version differs from it by more than one token due to segmentation issues. Some W-error instances are filtered out since the erroneous token is segmented into several words. We only focus on the cases in which the error can be corrected by replacing one single token.
After filtering, we end up with 10,510 sentence segments. We use 10% data for validation and testing respectively, and the remaining 80% data as the training set.
5.3 WUE Detection Based on Bidirectional LSTM
We previously discuss the challenge of token-level WUE detection and conclude that a model suitable for this task needs to consider the whole sequence words. One possible model is the Long Short-Term Memory (LSTM) model (Hochreiter and Schmidhuber, 1997), which processes sequential data and generates the output based not only on the information of the current time step, but also on the past information stored in the memory layer. Therefore, we utilize LSTM as our sequence labeling model.
LSTM handles long sequences better than simple recurrent neural network (RNN) does, since it is equipped with input, output and forget gates to control how much information is used. The ability of LSTM to capture longer dependencies among time steps makes it suitable for modeling the complex dependencies of the erroneous token on the other parts of the sentence.
We train the LSTM model with the Adam optimizer (Kingma and Ba, 2014) implemented in Keras10. The parameters are shown in Table 5-1. The training process is stopped when the validation accuracy does not increase for two consecutive epochs. The model with the highest validation accuracy is selected as the final model.
LSTM layer size 400
Cost function binary_crossentropy
Optimizer Adam
Batch size 32
Initial learning rate 0.001
Table 5-1 Parameters of the LSTM-based WUE detection model.
We apply a sigmoid activation function before the output layer, so the output score of each token, which is between 0 and 1, can be interpreted as the predicted level of incorrectness. With these scores, our system can output a ranked list of candidate error
10 https://keras.io/
positions. The positions with the highest incorrectness scores will be marked as incorrect.
We show an example labeling result of our system with segment (S5-2). The tokens
“差” (bad) and “知識”(knowledge), which are given the highest scores, are most likely to be incorrect. We also use (S5-2) to illustrate the LSTM-based WUE detection model in Figure 5-1. The darkness of the blocks in the bottom indicates the level of incorrectness predicted by the model.
(S5-2) 學習 的 知識 也 很 差
Incorrectness score 0.056 0.035 0.153 0.039 0.030 0.429 ( The knowledge learned is also very bad. )
Figure 5-1 LSTM-based WUE detection model.
Bidirectional LSTM (Schuster and Paliwal, 1997) is an extension of LSTM which includes a backward LSTM layer. Both information before and after the current time step
are taken into consideration. Figure 5-2 illustrates a bidirectional LSTM-based WUE detection model. In segment (S5-3), we need the “future” information to detect the error.
The incorrectness of the token 留在(left at) cannot be determined without considering its object 我們(us).
(S5-3) 店是爸爸(*留在,留給) 我們的。
( The store is our father left (*at,to) us. )
Figure 5-2 Bidirectional LSTM-based WUE detection model.
5.4 Sequence Embedding Features
We consider the word sequence in a sentence segment and the corresponding POS tag sequence. They are mapped to sequences of real-valued vectors through an embedding layer. These vectors are also updated during the training process.
5.4.1 Word Embeddings
We set the word embedding size to 400. Besides randomly initialized embedding, we also try several types of pre-trained word vectors.
1. CBOW/Skip-gram Word Embeddings: two basic architectures of Word2vec
2. CWINDOW/Structured Skip-gram Word Embeddings: take the order of the context words into consideration
The training corpus and the hyperparameter settings are the same as those used for obtaining W features in the previous stage.
5.4.2 POS Embeddings
The POS embeddings are randomly initialized. We set the embedding size to 20, which is slightly smaller than the number of different POS tags (30) in our dataset.
5.5 Token Features
In addition to representing each token as a real-valued vector, we also incorporate some abstract features. These features are derived from the Google Chinese Web 5-gram
corpus and will be referred to as “n-gram features”.
5.5.1 Out-of-Vocabulary Indicator
This feature is simply a bit indicating whether a word is an out-of-vocabulary (OOV) word or not. If a token never appears in the Web 5-gram corpus, the bit is set to 1;
otherwise it is set to 0. A W-error token which is not segmented into several words is expected to be captured with the help of this binary indicator.
5.5.2 N-gram Probability Features
We compute the n-gram probability of each token using the occurrence count in the Web 5-gram corpus. We consider only up to trigrams since the probabilities are mostly zero when 𝑛 > 3. For boundary cases such as the first token for bigram, and the first and second token for trigram, a special value -1 is given.
In fact, this is similar to the Google n-gram features we used in the previous segment- level detection task. The difference is that we preserve the sequence of probabilities.
Given the limited amount of available learner data, these probabilities may serve as useful features indicating how likely an expression is valid in Chinese.
5.6 Evaluation
5.6.1 Accuracy
We use the detection accuracy as our main evaluation metric. A test instance is regarded as correct only if our system gives the highest score of incorrectness for the ground-truth position. This metric is relatively strict as the average length of the sentence segments in our dataset is 9.24. The McNemar’s test (McNemar, 1947) is adopted to perform statistical significance test.
5.6.2 Mean Reciprocal Rank (MRR)
The mean reciprocal rank rewards the test instances for which the model ranks the ground-truth near the top of the candidate list. The definition of MRR is:
𝑀𝑅𝑅 = ∑ 1
𝑟𝑎𝑛𝑘(𝑖)
𝑁
𝑖=1
, where 𝑁 is the total number of test instances and 𝑟𝑎𝑛𝑘(𝑖) is the rank of the ground- truth position of test instance 𝑖.
5.6.3 Hit@k Rate
The Hit@k rate regards a test instance as correct if the answer is ranked within the top k places. In the experiments, k is set to 2. We report this metric since one of the most common types of WUEs is collocation error. In example (S5-2), the problem involves a pair of words, i.e., the adjective “差” (bad) is not a suitable modifier of the noun “知識”
(knowledge). (S5-4) and (S5-5) are both acceptable.
(S5-4) 學習 的 知識 也 很 不足
( The knowledge learned is also insufficient. ) (S5-5) 學習 的 態度 也 很 差
( The attitude of learning is also very bad. )
Which correction is better highly depends on the context or even the intended meaning in the writer’s mind. If the model proposes two potentially erroneous tokens which are closely related to each other, it can be useful for Chinese learners.
5.6.4 Hit@r% Rate
Finding the exact position of the error could be more challenging in a longer sentence segment. Therefore, we propose another hit rate measure which takes the segment length (𝑠_𝑙𝑒𝑛) into account. Specifically, we regard one test instance as correct if the answer is ranked within the top max(1, ⌊𝑠_𝑙𝑒𝑛 ∗ 𝑟%⌋) candidates. We report hit@20%. That is, for segments shorter than 10 tokens, the system is allowed to propose one candidate; for those whose length is between 10 and 14, the system is allowed to propose two, and so on.
Equivalently, this measure judges whether our system can rank the ground-truth error position within the top 20% of the candidate list. This metric compromises Accuracy and Hit@k.