↵Àc'x˚_«⌦xb«⌦Â↵@
©Î÷á
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
⌘«êfi6†‘|g↵èls'Ñ˙Klüø¶h A GC-aware fairness scheduler for SSD
ã∏
Lun Wang
⌥ Yà⇢ Js≤ ZÎ Advisor: Chia-Lin Yang, Ph.D.
-Ô⌘↵ 106 t 8
August, 2017
Ù Ù Ù
,÷áóÂå⇣ ñHÅ ⌥ YàJs≤Yà⇥ +⇡it∫x (
÷á⌥ ⌦@±ªÑæõ⌥Bì ®ÑY å◆ı ÛdKå _⇤|å™
õÑu™åÊ⇣ +@fàÑY®⇥ „‘5üjYà ãK-Yà -X`
YàåB¡©Yày0•óº÷á„fBf à⌥c˙p _ +⌘ x ÷
áÑØö⇥ -↵Õv'xÑÛÆYà fàx Ñ⌥ å˙p ,÷á˝
åÑ ì⌘◊ o⇢⇥ ÊW§Ñ⌅M $v/5 óå¡iÄ ÷/(
ÊW /≤m⌦˝fà´'Ñk©⇥ o Ñ∂∫⌘ '∂fà!·Ñ‹ ⌥
´ñ ì⌘ >⌃ æ4Ñ°S⇥ ÷6 /á≠&⇥Ñ ^ F‡∫ `⌘
v ;MóÂEˇ;õ (Î÷áÑ⌧·Mó dƬfi 1w Ô⌦
j4Ñ∫⌘⇥ å ≈⌥d÷á⌥⌅M⌃´⇥
ã∏ 9⌦
X X XÅ Å Å
˙Klü/vM;AÑ2X›n (⇢2↵˚q- ls«ê⌃M/ ˆ
Å⇤nÑã≈⇥ ˛ Ñlsø¶h˝- ç;_Ô 6 ↵èls'{ Ô˝⇤
‡∫˙Klü¯|É>fi6 ´4fi⇥ ⌘⌘|˛˛ Ñ;_lsø¶h&í ⇤
œ0É>fi66Üц‘ & Ù*bU⌃lüÑ«êç⌃M⇥ ⇡«÷á⇤œ
⌥ls'ˆ802X›ngË &- ↵ì↵è ⇤‘*⇢M ÑÉ>fi6
†‘⇥Ê ∫Üì;_ÔÑø¶h˝ B› É>fi6 @Õ… ⌘⌘ì˙K
lü;’JÂ;_ õ«⌦ Âøì;_ø¶h˝ c∫⌃Mlü«êf⌅↵↵
è⇥ ÊWPúo: @- Ñ_6ÔÂçT0ls'Ñ B_û† ⇣œ⇥
‹
‹‹uuuWWW - ˙˙˙KKKlllüüü øøø¶¶¶hhh ÉÉÉ>>>fififi666 lllsss''' ⇢⇢⇢222↵↵↵˚˚˚qqq
ii
Abstract
Solid-state disk (SSD) drives are the mainstream solutions for massive data stor- age today. For modern computer systems, fair resource assignment is a critical de- sign consideration and has drew great interests in recent years. Although there are several fairness I/O schedulers proposed on the host side for SSDs, process fairness could still be dramatically degraded if garbage collection (GC) is triggered in the de- vice side. We found that existing host-side I/O schedulers cannot achieve fairness because they did not consider the GC cost and update the assigned resource with GC cost too late. This paper proposed a novel device side I/O scheduling strategy in SSD controllers to achieve true fairness working with existing I/O schedulers of SSDs.
This work is the first to consider fairness down to the device level. The proposed scheduling approach can guarantee that the processes will suffer little GC overhead if the processes barely introduce GCs. Experimental results with a wide range of workloads verify that the proposed technique can achieve fairness as well as improve the throughput significantly.
keywords - solid state disk, scheduler, garbage collection, fairness, multi-task system
Contents
Abstract iii
List of Figures vi
List of Tables viii
Chapter 1 Introduction 1
Chapter 2 Background and Related Work 4
2.1 SSD storage system . . . 4 2.2 Fairness I/O Scheduling . . . 5 2.3 Garbage Collection . . . 7
Chapter 3 Motivation 11
Chapter 4 Mechanism 16
4.1 Device Side module . . . 18 4.1.1 GC-Penalty Quota Allocation . . . 18
iv
4.1.2 GC-Penalty Quota Update . . . 19
4.2 Host side module: GC-Timer Setup . . . 20
4.3 Implementation Complexity . . . 22
Chapter 5 Experiment 24 5.1 Experimental setup . . . 24
5.2 Synthetic Workload Evaluation . . . 27
5.2.1 Fairness and Throughput . . . 27
5.2.2 Request Size Sensitivity . . . 29
5.2.3 FGC vs. Preemptive GC . . . 29
5.3 Real Workload Evaluation . . . 30
Chapter 6 Conclusion 38
Bibliography 39
List of Figures
2.1 Modern SSD architecture . . . 9 2.2 SSD Resource Assignment of modern Fairness I/O Scheduler . . . 10
3.1 SSD resource assignment of modern fairness-aware I/O scheduler con- sidering GC. . . 14 3.2 The slowdown ratio of synthetic workload with 1 4KB readers and 1
4KB writers. . . 15
4.1 The design overview of Fair-GC scheduler (FGC). . . 17 4.2 Update of GC-penalty quota. . . 20
5.1 The slowdown ratio of synthetic workloads with n 4KB readers and n 4KB writers. We only show the largest slowdown ratio per case. For each case, we mark the proportional slowdown with the dotted line. . 32 5.2 The performance of synthetic workloads with n 4KB readers and n
4KB writers. Results cover three policy under each I/O scheduler. . . 33
vi
5.3 The slowdown ratio of synthetic workload with four 4KB readers and four 4KB writers. The n-KB in horizontal axis is the size of the request issued by the processes. . . 34 5.4 Worst case response time. The result is the average response time of
99.9% tail latency for the workload with 16 128KB readers and 16 128KB writers running concurrent. . . 35 5.5 Slowdown ratio for the real workload. . . 36 5.6 Throughput for the real workload. . . 37
List of Tables
5.1 System Configurations. . . 25 5.2 Characterization of real workload. . . 31
viii
Chapter 1 Introduction
NAND flash-based solid state disks(SSDs) are widely used in computer systems.
Compared to the traditional hard disk device(HDD), SSD has higher performance which has benefits for data-intensive applications. Unlike HDD, SSD is managed by complicated firmware called Flash Translation Layer(FTL) including data-mapping, garbage collection(GC), and wear-leveling. On the other hand, different I/O opera- tions(read or write, different request size) on SSD consume different SSD resource.
For example, a read consumes less device time than a write. A request with larger size needs more resource than a request with the smaller size. Without a good I/O scheduler, the fairness can be easily broken.
Fair I/O resource management is needed in multi-task system. Traditional I/O schedulers such as Linux CFQ [6] achieves fairness by assigning same device resource to each process. However, Linux CFQ does not consider the SSD characteristic like asymmetric read/write latency and internal parallelism. Existing fairness I/O
CHAPTER 1. INTRODUCTION 2
schedulers for SSD including FIOS [14] and FlashFQ [17] consider the characteristic of SSD but cannot maintain fairness when GCs occur. To maintain the fair resource assignment, FIOS and FlashFQ may block the process in the host. However, when GC occurs, the processes may be blocked too long that makes all processes impacted by GC.
This paper proposed an SSD scheduler, Fair-GC, which works on the device side controller of SSDs to help host-side fairness-based I/O schedulers to achieve true fairness with the consideration of GC. The key innovation of Fair-GC is to orchestrate GC operations based on the notion of GC-penalty quota which indicates the time a process can be blocked by GC in a period. The GC-penalty quota for each process is assigned based on its write intensity. The idea is to ensure that a process is penalized by GC proportionally based on the probability of invoking GC when it runs alone.
• We introduce the unfair issue in existing fairness I/O scheduler for SSDs.
Although the fair I/O schedulers assign same resource to each process, the unfair problem may be incurred by GC.
• Proposing a device side I/O scheduling in SSD to enhance the fairness of existing I/O schedulers of SSDs. The schedulers are dedicated to assigning fair resources to each process.
• Proposing a resource quota management strategy on the host. This strategy lets the host know the GC cost suffered by the process so that the host can update the maintained resource for resource quota reassignment.
CHAPTER 1. INTRODUCTION 3
The rest of the paper is organized as follows. Section 2 introduces the background and the related work. Section 3 discusses the impact of GC in the system. Section 4. Section 5 illustrates the experimental evaluation and compares different fairness I/O scheduler with Fair-GC. Section 6 concludes the paper.
Chapter 2
Background and Related Work
2.1 SSD storage system
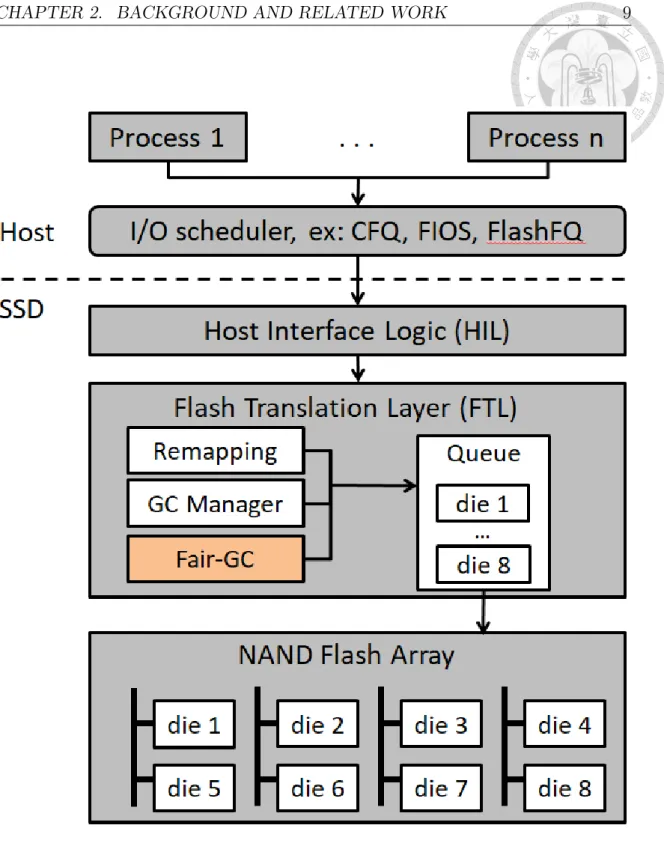
Figure 2.1 shows the overall architecture of the SSD storage system. In the host, there are multiple processes managed by block layer I/O scheduler. There are several layers in SSD, including the host interface logic(HIL), flash translation layer(FTL).
Host Interface Logic (HIL): HIL simulates the interface of HDD and parses each request into several page-sized requests.
Flash Translation Layer (FTL): FTL translates the logical page address(LPA) into physical page address(PPA) and decides which die is the request going to access.
Since FTL cannot in-place update, SSD selects a clean page to perform the write.
To manage the resource inside the SSD, FTL maintains a mapping table between LPA and PPA. There have dynamic mapping scheme and static mapping scheme for the mapping table. With dynamic mapping, a write request can be passed to
4
CHAPTER 2. BACKGROUND AND RELATED WORK 5
any chip in the SSD. But dynamic mapping scheme takes more space than static mapping scheme. On the other hand, move data from a chip to another chip has transfer cost [16]. Commercial SSD usually applies the static mapping scheme which uses a simple modulo calculation to determine the die of the LPA. After the die is determined, FTL writes data to the free space of the die.
NAND Flash Array FTL connects the NAND flash array through multiple chan- nels. Each channel consists of multiple dies which are the functional unit in SSD.
A die has several planes in which several blocks reside. A block is composed of a number of pages which is the smallest access unit for read/write request in flash memory.
2.2 Fairness I/O Scheduling
Fairness Objective:
I/O slowdown ratio= Avg I/O latencyconcurrent
Avg I/O latencyalone (2.1) Fairness means that each process gains equal access to resources [14] [17]. In multi- task system where a set of intensive I/O processes are running simultaneously, the goal of fairness is to assign equal device time for each process.
When several of I/O processes run at the same time, fairness is the case that each process is assigned an equal amount of device time. To measure the fairness, I/O slowdown ratio is introduced by the previous study [14][17]. The I/O slowdown ratio for a process is its average I/O latency normalized to that when running alone.
Formula 2.1 is the definition of I/O slowdown ratio. Suppose there are n processes
CHAPTER 2. BACKGROUND AND RELATED WORK 6
in the system. To achieve the fairness in the system, each process should experience a factor of n slowdown compared to that when running alone. This desired case is considered as the proportional slowdown.
Existing fairness I/O scheduler can be split into two group timeslice-based scheduler and fair-queuing scheduler. The former achieves fairness by assigning equal timeslice for each process. Timeslice is consumed when request complete from device. The process cannot access device with no remaining timeslice. The latter calculates the cumulative device resource used by the process. To maintain the fairness, the process is blocked in the host when more SSD resource is used up, compared to other processes.
CFQ: CFQ[6] is a time-slice based I/O scheduler which is widely used in Linux kernel. Its design principle is for hard disk drive(HDD) which tries to let the I/O with adjacent address access device at the same time to reduce the rotation latency.
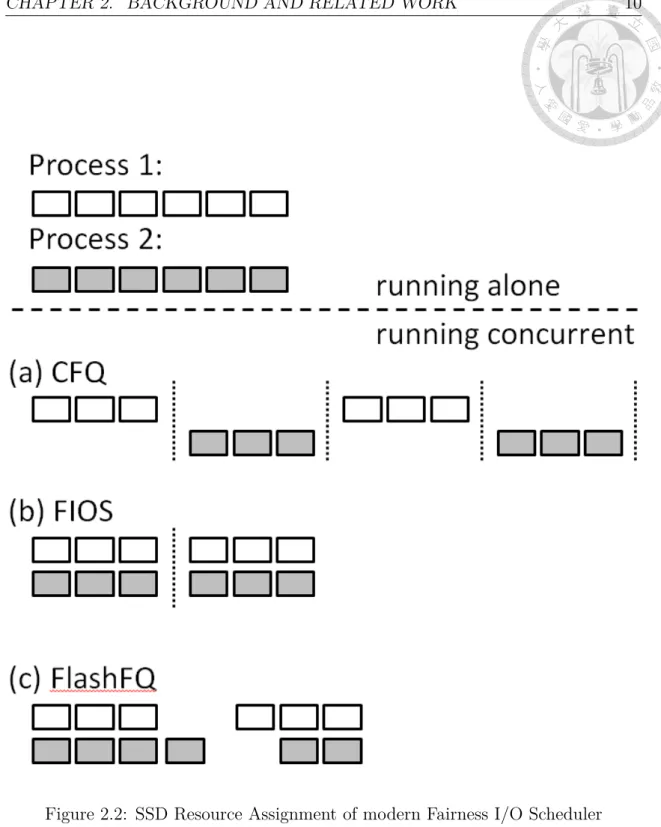
Since a process usually accesses continuous area in the HDD, different processes don’t consume their timeslices concurrently. A process can continuously issue IO, during the assigned time. CFQ switches to next process when the time is expired, there may have overlap time between the two processes. If the host directly applies CFQ on SSD which doesn’t have rotation latency, the parallelism of SSD is not fully utilized which harms the performance too much. 2.2.a is the example. Process 2 cannot consume SSD resource until CFQ expires process 1.
FIOS: FIOS [14] is a time-slice based I/O scheduler which achieves fairness by assigning equal timeslice to each process. Considering the parallelism of the SSD, FIOS allows different process can consume SSD resource at the same time.
CHAPTER 2. BACKGROUND AND RELATED WORK 7
The timeslice is decreased by the real cost of IO which is the time for the I/O spent in SSD. The timeslice for each process is the same and can be consumed non-contiguous. Considering the asymmetric read/write latency of SSD, a read I/O may be blocked by a write I/O in SSD which leads to serious slowdown on read I/O. So, FIOS blocks all write I/Os until no read I/O resides in SSD. Figure 2.2(b) illustrates the timeslice assignment. Process 2 is a write-intensive and its writes cannot consume the timeslice until no read is in SSD.
FlashFQ: FlashFQ is a fair-queuing scheduler which achieves fairness by throt- tling the process with larger progress. The progress of a process is the cumulated resource used by a process. Similar to FIOS, FlashFQ allows different process ac- cess SSD concurrently. Different to FIOS, FlashFQ calculates the SSD resource by virtual I/O cost which depends on the size and type of an I/O, and is calculated when I/O arrives the block layer. Figure 2.2(c) gives the example. When process 2 stops consuming SSD resource, FlashFQ noticed that process 1 consume too much SSD resource. Then, FlashFQ throttles process 1 until process 2 restart consuming SSD resource.
2.3 Garbage Collection
To address the erase-before-write challenge, FTL prepares a number of free blocks called update-blocks for each die. For read requests, FTL simply gets the PPA through a mapping table. For write requests, FTL forwards them to the update- block. The FTL inserts the request into the queue of the die. Usually, SSD applies
CHAPTER 2. BACKGROUND AND RELATED WORK 8
first-in-first-served scheme on each queue.
When a write request arrives FTL, FTL checks if there is sufficient space to serve the write request. When the number of update-blocks in the die is insufficient, the die (called GC-die) has to perform GC to reclaim available blocks for writing data. There have three steps for GC. (i) Select a block, which is called victim block, from the plane. A greedy algorithm is used to choose the victim block [7]. (ii) Copy the valid pages within the victim-block to the update-block of the plane. (iii) Erase the victim block and add the victim-block to the update-blocks. After the GC is performed, SSD can perform the write request. Such GC is usually called on-demand GC.
Previous research shows that GC impacts the performance [9] [13] [12] [15]. [13]
and [12] preempt GC and serve host requests as soon as possible. SSD space could run out of free space under multiple I/O intensive process. [9] and [15] predicts the idle period and perform GC. However, for I/O-intensive workload, the idle period may be not enough to perform GC. [8] [10] focus on the quality of service. They treat GC into several read/write requests and perform them in different timing to reduce the worst case response time. [11] discusses the impact of GC for multiple applica- tions. The SSD is not flexible, since they pre-partition SSD for each applications before the processes start executing.
CHAPTER 2. BACKGROUND AND RELATED WORK 9
Figure 2.1: Modern SSD architecture
CHAPTER 2. BACKGROUND AND RELATED WORK 10
Figure 2.2: SSD Resource Assignment of modern Fairness I/O Scheduler
Chapter 3 Motivation
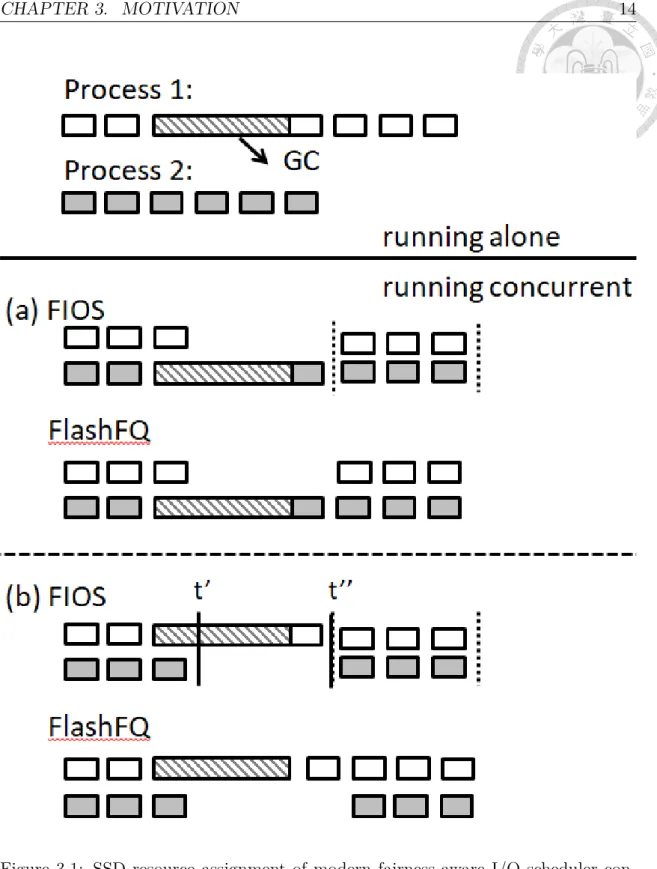
Section 2.3 mentions that GC is triggered when the number of free pages is below a predefined threshold. It is hard to predict when GC occurs and its performance impact on the individual process. Figure 3.1 how GC impacts the fair I/O scheduler for SSD described in Section 2.2. We assume process 1 triggers GC when running alone while process 2 does not. We show two scenarios for the processes running concurrently: Figure 3.1(a) shows the case when process 2 triggers GC while process 1 does not and Figure 3.1(b) shows an opposite way in which process 1 triggers GC while process 2 does not.
In the first scenario in Figure 3.1(a), for FIOS, process 2 wastes its timeslice on GC. Similarly, for FlashFQ, the progress of process 2 is blocked due to GC. Although process 2 does not incur GC when running alone, it may trigger GC when running concurrently. Its performance is degraded significantly by GC and fails to meet the fairness criteria. In this scenario, the system is unfair because GC is unfairly
CHAPTER 3. MOTIVATION 12
attributed to process 2 when running concurrently with process 1. From these two examples, we could also observe that the SSD utilization is impaired due to tje fair I/O scheduler trying to assign same SSD resource to each process and blocking some process in the host.
In the second scenario, for FIOS, process 1 is blocked in SSD due to GC, and process 1’s timeslice is updated at t” when request 3 returns. For process 2, it runs out of its timeslice at t’. To maintain the fairness, FIOS doesn’t allow process 2 accesses SSD until FIOS refreshes the timeslices. In this case, process 2 experiences significant slowdown compared to running alone. Therefore, it is very likely to fail the fairness criteria described in Section 2.2. For FlashFQ, process 1’s progress is delayed due to GC. Therefore, FlashFQ throttles process 2 to maintain fairness. So, process 2 could also fail to meet the fairness criteria.
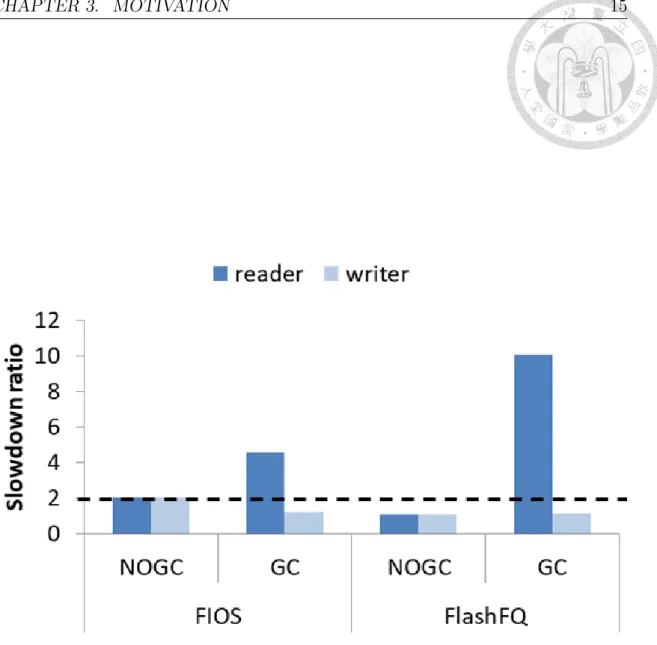
Figure 3.2 analyzes the fairness of two SSD fair I/O schedulers described in Sec- tion 2.2 with and without GC. The workloads contain two processes: the reader/writer process, which issues 4KB read/write requests. The details of the workload and sim- ulator are described in Section 5. Without the intervention of GC, both FlashFQ and FIOS achieve fairness. However, when GC is involved, the reader process ex- periences 4x and 9x slowdown on FIOS and FlashFQ, respectively. Based on the above observation, we derive two key principles to design a fair I/O scheduler for SSD considering GC:
• When multiple processes running concurrently, the GC overhead should be distributed to the processes in the system in the same degree as they run alone.
CHAPTER 3. MOTIVATION 13
This design principle is to solve the issue showed in Figure 3.1(a); On another saying, the process, which triggers less GC, should suffer less GC overhead when running concurrently with other processes.
• The fair I/O scheduler needs to be aware of GC inside SSD such that the SSD resource quota of a process could be updated in a timely manner.
This design principle is to solve the issue showed in Figure 3.1(b). The SSD resource quota maintained by the I/O scheduler should contain the time of a process is blocked by GC in SSD.
CHAPTER 3. MOTIVATION 14
Figure 3.1: SSD resource assignment of modern fairness-aware I/O scheduler con- sidering GC.
CHAPTER 3. MOTIVATION 15
Figure 3.2: The slowdown ratio of synthetic workload with 1 4KB readers and 1 4KB writers.
Chapter 4 Mechanism
In this section, we present the proposed GC-aware fair I/O scheduling framework which contains device side design and host side design.
The main idea of device side FGC is to orchestrate GC operations to ensure that a process’s performance is degraded by GC to the same degree as when it runs alone. To achieve this goal, we introduce a new concept, GC-penalty quota, which corresponds to the time that a process could be blocked by GC in an epoch.
An epoch ends when all processes run out of their GC-penalty quotas. Processes with higher write frequency contribute makes more contribution to the cause of GC.
Therefore, they should be penalized more by GC. So, FGC assigns each process’s GC-penalty quota based on their write intensity.
During the execution of the process, the GC-penalty quota is decremented with the additional access latency induced by GC, called GC cost. When a request of the process with zero GC-penalty quota is blocked by GC, the GC needs to be
16
CHAPTER 4. MECHANISM 17
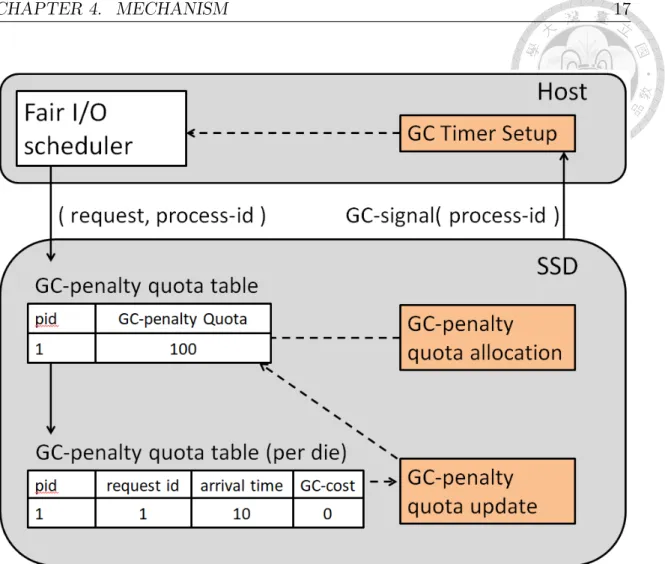
Figure 4.1: The design overview of Fair-GC scheduler (FGC).
preempted. Once all processes’ GC-penalty quotas reach zero, it marks the end of an epoch, and GC-penalty quota is reset. To ensure the host I/O scheduler updates the SSD resource quota with GC cost at the right time period, in our framework, the SSD informs the host when a process is blocked by GC. With this information, the host I/O scheduler can update their SSD resource quota considering the GC factor.
The proposed framework is showed in Figure 4.1. There are two modules in SSD
CHAPTER 4. MECHANISM 18
and one module in the host. The GC-penalty quota allocation module decides the GC-penalty quota of the processes for a new epoch. The GC-penalty quota update module estimates the GC cost for each process and updates the GC-penalty quota.
The interface between the host and SSD device is enhanced to pass the process ID along with a request from the host to SSD, and also allows the SSD to signal the host when a process is blocked by GC. Then, the GC timer setup module can estimate the GC cost of the processes and give the information to the fair I/O scheduler. The following sections describe each module.
4.1 Device Side module
This section describes the device side module of FGC showed in Figure 4.1.
4.1.1 GC-Penalty Quota Allocation
The GC-penalty quota for each process should be allocated based on process write intensity. Let qmax represents the GC time the SSD could take in an epoch. The GC-penalty quota for each process (Qi) is formulated as follows:
Qi = qmaxú Wi
(W1+ W2+ ...Wn) (4.1)
where Qi and Wi are the allocated quota and the number of write operations for process i. To accurately reflect the write behavior of processes during the execution, FGC periodically calculates the number of write operations for each process. Write frequencies from the past period are used, when a new epoch begins and GC-penalty
CHAPTER 4. MECHANISM 19
quota has to be recalculated.
4.1.2 GC-Penalty Quota Update
Once the GC-penalty quota is allocated, it is updated based on the GC cost of different processes. GC cost of the process is the time that host request from the process is blocked by the GC process. We maintain GC cost table per die, since each host request may access multiple dies.
When a host request is issued to SSD, it is divided into several sub-requests to different dies, and the request-ID, process-ID, request arrival time are recorded in the GC cost table as showed in Figure 4.1. The GC cost for each sub-request is collected when the sub-request is blocked. The GC cost is added after each GC operation (GC process includes several valid page reads/writes and a block erase) by formula 4.2.
GCcost = GCcost+ GCop end≠ MAX(request arrival, GCop start) (4.2) There are two cases for the GC-penalty quota updates based on the GC cost. Figure 4.2 shows an example for the two cases.
The first case: The counted GC cost is smaller than the GC-penalty quota when the current GC process is completed. The GC-penalty quota is updated by decreasing the counted GC cost of the last completed sub-request. When a sub- request completes, FGC detached the corresponding information from the GC-table.
When the last completed sub-request is complete, the GC-penalty quota can easily
CHAPTER 4. MECHANISM 20
get the GC-cost of the request. In the example, at T0, request R0 from process 1 (P1) is blocked by GC and the GC-penalty quota of P1 is 100ms. When all of the sub-requests from R0 are completed at T1, the GC cost with 40ms is acquired, which is decreased from the GC-penalty quota.
The second case: The counted GC cost is larger than the GC-penalty quota before the current GC process is completed. The GC-penalty quota is set to 0 once the GC cost is increased to larger than the remaining GC-penalty quota. After that, the current GC process is preempted right now. In the example, the GC-penalty quota is reduced to 60ms. At T2, request R1 from P1 is blocked by another GC, and at T3, the GC cost is increased to 60ms before the current GC completed. Then, the GC-penalty quota is set to 0 and the current request can preempt the GC right at T3.
T0
Quota: 100ms
R1 R0
T1 GC Cost: 40ms
Quota: 60ms
T3 GC Cost: 60ms T2
Quota: 0ms GC Preempt
Figure 4.2: Update of GC-penalty quota.
4.2 Host side module: GC-Timer Setup
This section describes the host side module of FGC (GC-Timer Setup module) showed in Figure 4.1.
CHAPTER 4. MECHANISM 21
When a request for a process is blocked by GC inside SSD, the SSD sends a GC-signal to the host which contains the process-ID of this request. When the host receives the GC-signal, the host sets a timer for the process. The timer of the process is introduced to record how much time will be spent on GC by the process at the host and to notify the host I/O scheduler the SSD resource quota is consumed by GC.
For FIOS, the timeout value of the timer is set to the remaining timeslice of the process. There are two cases to work with the timer:
Case 1: If the timer is triggered, it means the GC procedure cannot be com- pletely handled within the timeslice left for the process. In this case, the timeslice will be updated with the timeout value. Since the request is still blocked inside SSD, the timeout value of the timer should be reset;
Case 2: If the request of the process completes from SSD before the timer is triggered, the timer will be cleared.
For FlashFQ, the only difference is the setting of the timeout value of the timer.
In FlashFQ, two processes cannot have progress difference larger than a progress threshold. The timeout value can be calculated based on the process’ progress and the progress threshold. The setting of the timeout value for the timer may be different but all I/O schedulers follow the same principle to set the timeout value which is the remaining SSD resource quota can be used for GC.
CHAPTER 4. MECHANISM 22
4.3 Implementation Complexity
The implementation of FGC needs several technologies to support, including process- ID transferring to SSD, and SSD notifying host the blocked process.
First, for the process-ID transferring to SSD, this function has been supported by NVMe SSD, where the read/write commands have reserved area [1] which can be used to transfer the process-id of the request. Once the process-ID is transfered, it is first decoded and recorded in the two tables if it is the first time added.
Second, the process-id of the process blocked by GC should be notified to the host side. To let the device pro-actively send signals to the host machine, the NVMe [19] protocol should be applied. NVMe is a protocol designed for SSD, which has completion queues. The complete commands from SSD are resided in the completion queues. In order to notify the host that which process is blocked by GC, a new command is needed to pass the process-ID of the process blocked by GC. After the command is activated, the blocked process-ID is put into the completion queue.
Then, the controller will notify the host that there is request to be handled in the completion queue. In this case, the host gets the process-ID of the process blocked by GC and sets the timer.
There are two types of tables required in the controller. For the GC-penalty quota table, it only needs several bytes to record the process-ID and the GC-penalty quota for each processes. Assume there are 100 processes and each entry is 8B, the memory cost is smaller than 1KB. For the GC cost tables, it has to record the request-ID, process-ID, request arrival time and GC-cost. The number of entries in
CHAPTER 4. MECHANISM 23
the GC-cost table is same as the size of the I/O queue which is not large. Assume that there are 64 entries and each entry is 16B. The memory cost is only 512B. We can find that the memory cost for FGC is small.
Chapter 5 Experiment
In this section, the experimental setup is first presented. Then we present results with synthetic workload, followed by real workloads.
5.1 Experimental setup
Experiment Platform: Fair-GC is implemented inside the controller of the SSD.
However, it is hard to acquire the inside organization of real production for most of the SSDs. In order to efficiently evaluate the proposed scheme, we implemented Fair-GC on a widely used event-driven simulator, Disksim [3]. Disksim contains a full-functioned controller simulation of SSD, including host interface logic, flash translation layer, garbage collection and so on. To evaluate the proposed scheme, we add a new layer above Disksim to simulate the block layer of operating systems, where several advanced fair I/O schedulers are implemented.
24
CHAPTER 5. EXPERIMENT 25
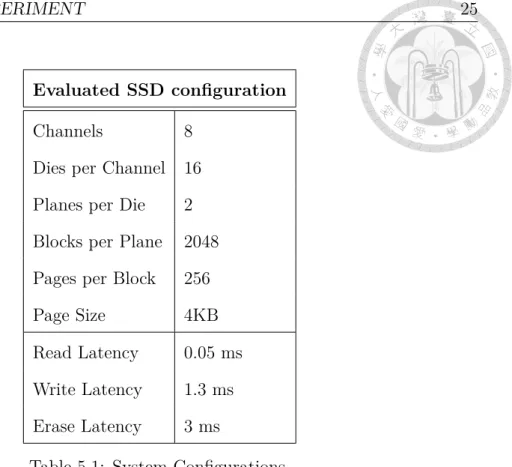
Evaluated SSD configuration
Channels 8
Dies per Channel 16 Planes per Die 2 Blocks per Plane 2048 Pages per Block 256
Page Size 4KB
Read Latency 0.05 ms Write Latency 1.3 ms Erase Latency 3 ms
Table 5.1: System Configurations.
System Configuration: Table 5.1 is the parameters for the simulated SSD. The evaluated SSD is configured with 8 channels which adopt Micron MT29F512G08CUAAA NAND Flash packages [2]. The total size of the SSD is 512GB. A GC threshold is set in SSD for GC activation: on-demand GC (5% of the free pages). When the free space on each SSD die is smaller than 5%, on-demand GC is activated.
To evaluate the effectiveness of the proposed Fair-GC scheme, several existing schemes are implemented, including the host side scheduling, such as CFQ, FIOS and FlashFQ. Since CFQ does not take the specific characteristics of SSD into consideration, it is not evaluated in the experiment. In this work, the timeslice in FIOS is set to be 100ms and the progress threshold in FlashFQ is set to be 100ms which are the default parameters from FIOS and FlashFQ.
CHAPTER 5. EXPERIMENT 26
Inside SSD, Fair-GC is implemented. In the experiments, the following 4 schemes are evaluated separately for the different host I/O scheduler:
• NOGC: The GC process is removed from the critical path;
• GC: The GC process is activated if the on-demand GC threshold is reached;
• FGC1: The Fair-GC scheduler in SSD is deployed, where the quota is set to 100ms in default;
• FGC2: This represents the complete GC-aware I/O scheduling framework, including the device-side fair-GC scheduler and the host I/O scheduler support described in 4.2.
Evaluation Metrics: Two metrics are used to evaluate the proposed scheme: Fair- ness and Throughput.
• Fairness: The slowdown ratio, described in Formula 2.1, is used to evaluate the fairness. The slowdown ratio represents the average I/O latency of a process normalized to that when running alone. Note that we calculate the slowdown ratio under the same GC policy for the processes running concurrently and alone;
• Throughput: Throughput is a critical metric in evaluating overall system per- formance. The throughput is the amount of the data completes from/to SSD.
Workload: To measure the advantages of Fair-GC, first, a wide range of synthetic workloads which contain readers and writers to represent the processes suffering
CHAPTER 5. EXPERIMENT 27
little or large GC overhead when running alone. The reader and writer continuously issues the next request when the previous request completes at SSD. To test the scalability of the scheme, the number of processes is varied from “1 reader” vs. “1 writers to 32 readers vs. 32 writers”. In addition, preemption GC is also compared against Fair-GC in term of tail latency since pure preemption GC will introduce high tail latency. Furthermore, a set of real workloads is used in the experiment, which are collected from enterprise servers.
5.2 Synthetic Workload Evaluation
5.2.1 Fairness and Throughput
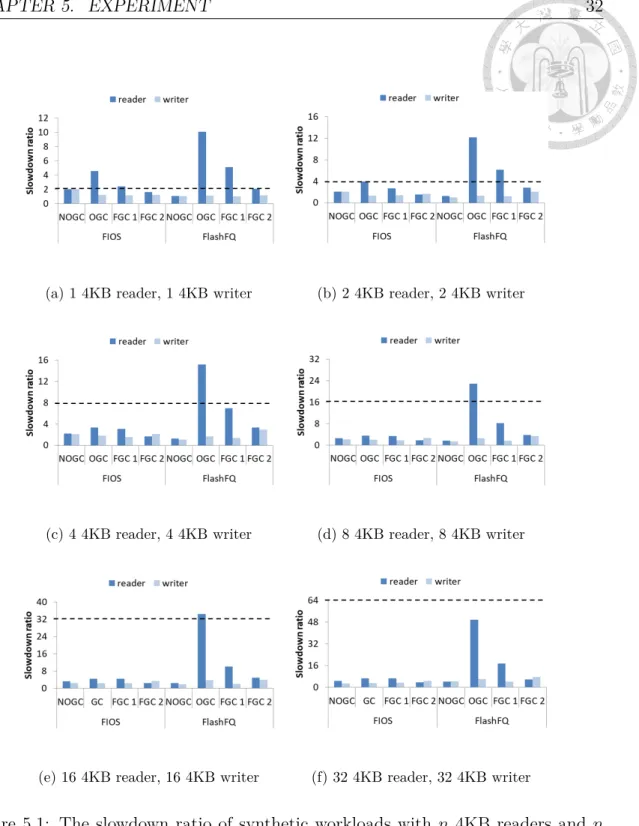
Figure 5.1 plots the fairness results for n 4KB readers and n 4KB writers. From the results, we have following observations. First, FIOS and FlashFQ are able to achieve fairness at different cases when there are no GC activated. These results are consistent with the data presented in previous work. The reason comes from that both FIOS and FlashFQ are designed to full aware of the read and write asymmetry and parallelism of SSDs. Second, when GC involves to the system, both FIOS and FlashFQ may break the fairness. For example, when there are only 1 4KB reader and 1 KB writer, the reader in both of the two schemes cannot achieve the proportional slowdown. The system cannot achieve the fairness. The reasons have been explained in Section 3, where GC may significantly delay reader. Note that FIOS is able to achieve fairness when there are more processes, but FlashFQ does not achieve fairness for all cases. The reasons come from the design principles
CHAPTER 5. EXPERIMENT 28
of these two schemes. FIOS is designed based on time slice, which allows each process to issue requests during the timeslice. However, FlashFQ only counts the virtual time as progress. In this case, if GC is activated, readers can be significantly delayed. Third, FGC1 is able to achieve fairness in most cases. For example, when FIOS is deployed, FGC1 is able to achieve fairness with significant reduction on read slowdown ratio. The reason comes from that the GC-penalty quota of readers is zero since there are no writes in readers. In this case, read requests from readers will not be blocked by GC. However, FGC1 is not able to achieve fairness with a small number of processes when FlashFQ is implemented. The reason comes from that when writers are blocked by GC, readers need to wait at the host side. When the number of processes is increased, FGC1 with FlashFQ is still able to achieve fairness. We also note that readers have much higher slowdown ratio compared with writers. This problem is solved by the host I/O scheduler support of Fair-GC Fourth, FGC2, which combines the two schemes proposed in the paper, is able to achieve fairness for all cases. Notably, we find that FGC2 is able to improve readers significantly since readers will not be blocked at host if writers are blocked by GC in the controller anymore. In this case, readers’ performance can be improved and fairness can be achieved.
The proposed scheme not only achieves fairness. Another key contribution of the proposed scheme is to improve storage performance by fairly control the concurrently running processes. Figure 5.2 presents the throughput results for the evaluated schemes. From the results, we find that FGC1 is able to significantly improve the throughput. The reason is simple. Since readers are able to preempt GC, readers
CHAPTER 5. EXPERIMENT 29
are processed quickly. In this case, the throughput will be significantly improved.
However, we notice that FGC2 will reduce the throughput compared with FGC1, but still has great improvement over on-demand GC cases. This is because FGC2 is added with the host I/O scheduler support of Fair-GC, which is designed to further improve read performance. However, in this case, writers may be blocked by the readers in SSD.
These results confirm that with the fully awareness of GC and the design of the Fair-GC scheduler, we are not only able to achieve fairness no matter what fair scheduler is used on the host side, but also improve the throughput.
5.2.2 Request Size Sensitivity
Figure 5.3 plots the fairness of the schemes with different request sizes. In the experiment, the size of the request varies from 4KB to 128KB. Both the number of readers and writers are set to four. From the results, we can find that the proposed scheme can achieve fairness in most cases.
5.2.3 FGC vs. Preemptive GC
Modern SSD usually applies preemptive GC (PGC) [18] to reduce the impact of GC. The basic idea of preemptive GC is to postpone GC when the host requests competes the resource with GC. To make sure the free space of SSD is enough for write requests, SSD usually set another preemption GC threshold. (3% of the free pages). SSD performs on-demand GC when the free space of SSD is less than
CHAPTER 5. EXPERIMENT 30
preemptive GC threshold. Otherwise, SSD preempts GC to serve the host requests.
In this work, FGC adopts PGC to avoid processes blocking from GC for a long time. FGC doesn’t postpone GC and performs some GC in each epoch. In contrast, in the multi-task system, PGC consumes free space fast when the write requests burst in a short period of time. Finally, the SSD has no free space to serve the write requests. We implement preemptive GC on the simulator [12]. To simulate the scenario to activate PGC, we run the workload with 16 128KB readers and 16 128KB writers to reach the preemptive GC threshold. Figure 5.4 is the result for 99.9% tail latency. FGC has smaller tail latency than PGC for all I/O schedulers.
5.3 Real Workload Evaluation
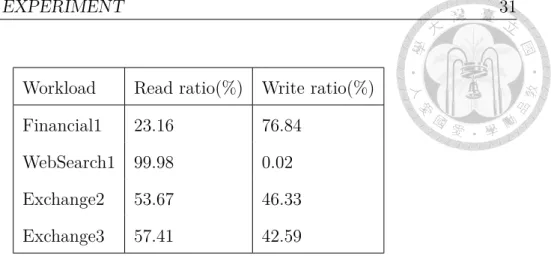
We evaluate the fairness for the real workloads in this section. Table 5.2 plots the read/write ratios of the selected workloads. WebSearch1 and Financial1 are OLTP workloads [4]. The former one is a read-intensive workload which is collected from a popular search engine. The latter one [4] is an on-line transaction processing workload. The Exchange workloads [5] are collected from different Microsoft servers.
The requests in OLTP workloads spread evenly into whole time while the exchange workloads burst the requests at a small time period. To build the workload with multi-processes, we assume one workload represents one process. Then, we select the same amount of requests in each workload and mix these requests into a new workload.
Figure 5.5 is the results of fairness for the real workloads. From the results, we
CHAPTER 5. EXPERIMENT 31
Workload Read ratio(%) Write ratio(%)
Financial1 23.16 76.84
WebSearch1 99.98 0.02
Exchange2 53.67 46.33
Exchange3 57.41 42.59
Table 5.2: Characterization of real workload.
find that when there is no GC, both FIOS and FlashFQ are able to achieve fairness.
However, when there are GC activated, both of them are not able to achieve fairness.
Notably, Websearch1 has the worst slowdown ratio among these workloads, because Websearch1 is a read-intensive workload. When GC is activated inside SSD, it will be significantly delayed and this cannot be solved by the host side fair scheduler.
For the proposed scheme FGC, we find that it is able to achieve fairness no matter FIOS or FlashFQ is implemented at the host side.
Figure 5.6 is the results on throughput for the real workloads. FGC is able to significantly improve the throughput of the storage systems.
These results further confirm that GC aware fairness scheduling presented in this work is able to achieve both fairness and improve performance.
CHAPTER 5. EXPERIMENT 32
(a) 1 4KB reader, 1 4KB writer (b) 2 4KB reader, 2 4KB writer
(c) 4 4KB reader, 4 4KB writer (d) 8 4KB reader, 8 4KB writer
(e) 16 4KB reader, 16 4KB writer (f) 32 4KB reader, 32 4KB writer
Figure 5.1: The slowdown ratio of synthetic workloads with n 4KB readers and n 4KB writers. We only show the largest slowdown ratio per case. For each case, we mark the proportional slowdown with the dotted line.
CHAPTER 5. EXPERIMENT 33
Figure 5.2: The performance of synthetic workloads with n 4KB readers and n 4KB writers. Results cover three policy under each I/O scheduler.
CHAPTER 5. EXPERIMENT 34
Figure 5.3: The slowdown ratio of synthetic workload with four 4KB readers and four 4KB writers. The n-KB in horizontal axis is the size of the request issued by the processes.
CHAPTER 5. EXPERIMENT 35
Figure 5.4: Worst case response time. The result is the average response time of 99.9% tail latency for the workload with 16 128KB readers and 16 128KB writers running concurrent.
CHAPTER 5. EXPERIMENT 36
Figure 5.5: Slowdown ratio for the real workload.
CHAPTER 5. EXPERIMENT 37
Figure 5.6: Throughput for the real workload.
Chapter 6 Conclusion
This paper proposed Fair-GC which is a scheduler in SSD that helps modern host I/O scheduler achieves fairness when GC occurs. The design of Fair-GC is motivated by the execution of GC. GC indirectly reduce the fairness while the host I/O scheduler try to assign same SSD resource to each process. To minimize the GC impact on the system, Fair-GC distributes the GC overhead to each process in SSD and try to let the processes execute concurrently with GC. We evaluate fairness under different workloads and discuss the impact of the size of GC-quota. Since Fair-GC adopts the preemption technology, we compare preemption GC as well. Compared to PGC, existing I/O scheduler for SSDs can achieve fairness with FGC. For the I/O scheduler for HDDs, Fair-GC reduces the GC impact on the processes.
38
Bibliography
[1] NVM Express. http://www.nvmexpress.org/. Accessed: 2017-09-26.
[2] Micron Technology. MT29F512G08CUAAA NAND Flash Memory Datasheet, 2009.
[3] N. Agrawal, V. Prabhakaran, T. Wobber, J. D. Davis, M. S. Manasse, and R. Pani- grahy. Design tradeoffs for ssd performance. In USENIX Annual Technical Confer- ence, volume 8, pages 57–70, 2008.
[4] O. Application. I/o. umass trace repository, 2007.
[5] S. N. I. Association et al. Snia iotta repository. Microsoft Enterprise Traces, Colorado Springs, Colorado (iotta. snia. org/traces/130), 2011.
[6] J. Axboe. Linux block io—present and future. In Ottawa Linux Symp, pages 51–61, 2004.
[7] L.-P. Chang, T.-W. Kuo, and S.-W. Lo. Real-time garbage collection for flash- memory storage systems of real-time embedded systems. ACM Transactions on Embedded Computing Systems (TECS), 3(4):837–863, 2004.
[8] M. Jung, W. Choi, S. Srikantaiah, J. Yoo, and M. T. Kandemir. Hios: A host interface i/o scheduler for solid state disks. ACM SIGARCH Computer Architecture News, 42(3):289–300, 2014.
[9] M. Jung, R. Prabhakar, and M. T. Kandemir. Taking garbage collection overheads
BIBLIOGRAPHY 40
off the critical path in ssds. In Proceedings of the 13th International Middleware Conference, pages 164–186. Springer-Verlag New York, Inc., 2012.
[10] B. S. Kim and S. L. Min. Qos-aware flash memory controller. In Real-Time and Embedded Technology and Applications Symposium (RTAS), 2017 IEEE, pages 51–
62. IEEE, 2017.
[11] J. Kim, D. Lee, and S. H. Noh. Towards slo complying ssds through ops isolation.
In FAST, pages 183–189, 2015.
[12] J. Lee, Y. Kim, G. M. Shipman, S. Oral, and J. Kim. Preemptible i/o scheduling of garbage collection for solid state drives. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 32(2):247–260, 2013.
[13] J. Lee, Y. Kim, G. M. Shipman, S. Oral, F. Wang, and J. Kim. A semi-preemptive garbage collector for solid state drives. In Performance Analysis of Systems and Software (ISPASS), 2011 IEEE International Symposium on, pages 12–21. IEEE, 2011.
[14] S. Park and K. Shen. Fios: a fair, efficient flash i/o scheduler. In FAST, pages 1–1, 2012.
[15] S.-H. Park, D.-g. Kim, K. Bang, H.-J. Lee, S. Yoo, and E.-Y. Chung. An adaptive idle-time exploiting method for low latency nand flash-based storage devices. IEEE Transactions on Computers, 63(5):1085–1096, 2014.
[16] N. Shahidi, M. Arjomand, M. Jung, M. T. Kandemir, C. R. Das, and A. Sivasubra- maniam. Exploring the potentials of parallel garbage collection in ssds for enterprise storage systems. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–1. IEEE Press, 2016.
[17] K. Shen and S. Park. Flashfq: A fair queueing i/o scheduler for flash-based ssds. In USENIX Annual Technical Conference, pages 67–78, 2013.
[18] W. Wu, S. Traister, J. Huang, N. D. Hutchison, and S. Sprouse. Pre-emptive garbage collection of memory blocks, Jan. 7 2014. US Patent 8,626,986.
[19] Q. Xu, H. Siyamwala, M. Ghosh, T. Suri, M. Awasthi, Z. Guz, A. Shayesteh, and V. Balakrishnan. Performance analysis of nvme ssds and their implication on real world databases. In Proceedings of the 8th ACM International Systems and Storage Conference, page 6. ACM, 2015.