Language Support for Processing Distributed Ad Hoc Data
Kenny Q. Zhu
1Daniel S. Dantas
2Kathleen Fisher
3Limin Jia
2Yitzhak Mandelbaum
3Vivek Pai
2David Walker
21Shanghai Jiao Tong University 2Princeton University 3AT&T Labs Research
Abstract
This paper presents the design, theory and implementation of GLOVES1, a domain-specific language that allows users to specify the provenance (the derivation history starting from the origins), syntax and semantic properties of collections of distributed data sources. In particular, GLOVES specifications indicate where to locate desired data, how to obtain it, when to get it or to give up try- ing, and what format it will be in on arrival. The GLOVESsystem compiles such specification into a suite of data-processing tools in- cluding an archiver, a provenance tracking system, a database load- ing tool, an alert system, an RSS feed generator and a debugging tool. In addition, the system generates description-specific libraries so that developers can create their own applications. GLOVESalso provides a generic infrastructure so that advanced users can build new tools applicable to any data source with a GLOVESdescrip- tion. We show how GLOVESmay be used to specify data sources from two domains: CoMon, a monitoring system for PlanetLab’s 800+ nodes, and Arrakis, a monitoring system for an AT&T web hosting service. We show experimentally that our system can scale to distributed systems the size of CoMon. Finally, we provide a de- notational semantics for GLOVESand use this semantics to prove two important theorems. The first shows that our denotational se- mantics respects the typing rules for the language, while the second demonstrates that our system correctly maintains the provenance.
Categories and Subject Descriptors D.3.2 [Programming lan- guages]: Data-flow languages
General Terms Languages
1. Introduction
One of the primary tasks in developing a distributed system is keep- ing it running smoothly over long periods of time. Consequently, well-designed distributed systems include a subsystem responsi- ble for monitoring the health, security and performance of its con- stituent parts. CoMon [24], designed to monitor PlanetLab [25], is an illustrative example. CoMon operates by attempting to gather a log file from each of 800+ PlanetLab nodes every five minutes.
When all is well (which it never is) each node responds with an ASCII data file in mail-header format containing the node’s ker- nel version, its uptime, its memory usage, the ID of the user with
1We call the system GLOVESbecause it helps users get their hands on things that are difficult to handle.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
PPDP’09, September 7–9, 2009, Coimbra, Portugal.
Copyright c 2009 ACM 978-1-60558-568-0/09/09. . . $5.00.
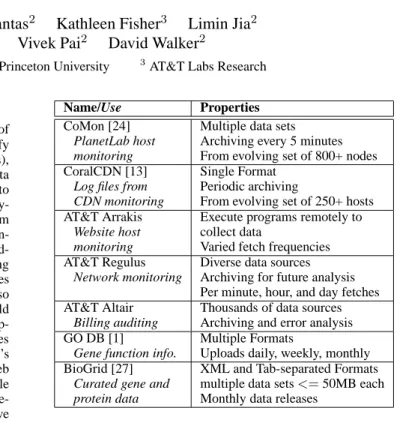
Name/Use Properties
CoMon [24] Multiple data sets PlanetLab host Archiving every 5 minutes monitoring From evolving set of 800+ nodes CoralCDN [13] Single Format
Log files from Periodic archiving
CDN monitoring From evolving set of 250+ hosts AT&T Arrakis Execute programs remotely to
Website host collect data
monitoring Varied fetch frequencies AT&T Regulus Diverse data sources
Network monitoring Archiving for future analysis Per minute, hour, and day fetches AT&T Altair Thousands of data sources
Billing auditing Archiving and error analysis
GO DB [1] Multiple Formats
Gene function info. Uploads daily, weekly, monthly BioGrid [27] XML and Tab-separated Formats
Curated gene and multiple data sets <= 50MB each protein data Monthly data releases
Figure 1. Example distributed ad hoc data sources.
the greatest CPU utilization, etc. CoMon archives this data in com- pressed form and processes the information for display to Planet- Lab users. CoMon also tracks various networking problems, main- tains lists of “problem nodes” and supports on-going time-indexed queries on the data. These features make CoMon an invaluable re- source for users who need to monitor the health and performance of their PlanetLab applications or experiments.
Almost all distributed systems should have similar monitoring infrastructure. However, the implementors of each new distributed system currently have to build “one-off” monitoring tools, which takes an enormous amount of time and expertise to do well. A sub- stantial part of the difficulty comes from the diversity, quality, and quantity of data these systems must handle. In addition, implemen- tors cannot ignore errors: they must properly handle network errors, partial disconnects and corrupted data. They also cannot ignore per- formance issues: data must be fetched before it vanishes from re- mote sites and it must be archived efficiently in ways that do not burn out hard drives by causing them to overheat. Last but not least, new monitoring systems must interact with legacy devices, legacy software and legacy data, often preventing implementers from us- ing robust off-the-shelf data management tools built for standard formats like XML and RSS.
Systems researchers are not alone in their struggles with dis- tributed collections of ad hoc data sources. Similar problems appear in the natural and social sciences, including biology, physics and economics. For example, systems such as BioPixie [21], Grifn [20]
and Golem [26], built by computational biologists at Princeton, routinely obtain data from a number of sources scattered across the net. Often, the data is archived and later analyzed or mined for information about gene structure and regulation. Figure 1 summa- rizes selected examples of distributed ad hoc data sources.
We have developed a new domain-specific language and system called GLOVESto facilitate the creation, maintenance and evolution of tools for processing ad hoc data from distributed sources. The language allows developers to describe the provenance, syntax and semantics of data sources they wish to monitor, including:
•Where the data is located. The data may be in a file on the current machine (perhaps written by another process), at some remote location, or at a collection of locations.
•When to get the data. The data may need to be fetched just once (right now!) or according to some repeating schedule.
•How to obtain it. The data may be accessible through standard protocols such ashttporftpor it may be created via a local or remote computation.
•What preprocessing the system should do when the data ar- rives. The data may be compressed or encrypted. Privacy con- siderations may require the data be anonymized.
•What format the data source arrives in. The data may be in ASCII, binary, or EBCDIC. It may be tab- or comma-separated or it may be in XML. It may be in the kind of non-standard format thatPADS[12, 16] was designed to describe or for which the user has a well-typed parser.
The GLOVESsystem compiles these high-level specifications into a collection of programming libraries and end-to-end tools for distributed systems monitoring. Our current tool suite includes a number of useful artifacts, inspired by the needs we have observed in a variety of ad hoc monitoring systems including an archiver, provenance tracking system, database loader and others.
The GLOVESsystem can generate all of these tools from declar- ative descriptions and tool configuration specifications. Thus for common tasks, users can manage distributed data sources simply by writing high-level declarative specifications. There are relatively few concepts to learn, no complex interfaces and no tricky boiler- plate to master to initialize the system or thread together tool li- braries. Because there is so little “programming” involved, we re- fer to the act of writing simple specifications and using pre-defined tools as the off-the-shelf mode of use.
To provide extensibility, GLOVESsupports two other modes of use. The second mode is for the single-minded implementer, who needs to build a new application for a specific collection of dis- tributed data sources. Such users need more than the built-in set of tools. To meet this need, the system provides support for creat- ing new tools by generating libraries for fetching data, for parsing and printing, for performing type-safe data traversal, and for stream processing using classic functional programming paradigms such asmap,foldand iterate. These generated libraries make it straightforward to create custom tools specific to particular data sources. The cost of this flexibility is a steeper learning curve be- cause the programmer must learn a variety of interfaces. Functional programmers may find these interfaces intuitive, but computational scientists may prefer to stick with off-the-shelf uses.
The third mode is for the generic programmer. Generic pro- grammers may observe that they (or their colleagues) need to per- form some task over and over again on different data sets. Rather than writing a program specific to a particular data set, they use a separate set of interfaces supplied by the GLOVES system to write a single generic program to complete the task. For exam- ple, the Round Robin Database (RRD) loader is generic because it is possible to load data from any specified source into the RRD tool [22] without additional “programming.” The generic program- ming mode is the most difficult to use as it involves learning a relatively complex set of interfaces for encoding Generalized Al- gebraic Datatypes (GADTs) [32] and Higher-Order Abstract Syn- tax (HOAS). These complexities are required to encode the depen-
dent features of GLOVESand to compensate for the lack of built- in generic programming support in OCAML. Still, the reward for building generic tools is high: as more and more such tools are built, the life of the off-the-shelf user becomes easier and easier. We used this infrastructure to build the off-the-shelf tools described earlier.
To guide the design and implementation of GLOVES, we have developed an idealized, first-order calculus and associated type sys- tem to model its core elements. We have equipped this calculus with a denotational semantics that specifies for each data source descrip- tion the set of (meta-data, data) pairs that it should produce. The semantics allows users to calculate and reason about the data that they should be receiving. We have proven the type system sound with respect to the semantics. Moreover, we have used the seman- tics to prove dependency correctness, a key theorem inspired by earlier work on provenance in databases by Cheney et al. [8]. This theorem guarantees the correct provenance meta-data is associated with every data item.
In addition to being of theoretical interest, the calculus and its meta-theory have served as a guide for our implementation infras- tructure. In particular, the compilation strategy for our surface-level language was influenced by observations about how higher-level constructs could be compiled into combinators from our calculus.
We also reorganized the way earlier versions of our system pro- cessed and propagated provenance meta-data in order to obey the principle of dependency correctness.
Contributions. The paper makes the following contributions:
• It describes the design of a domain-specific language for speci- fying provenance, syntax and semantic properties of distributed ad hoc data sources.
• It provides a formal denotational semantics for our language and proves the key properties of Type Soundness and Depen- dency Correctness.
• It describes the architecture of the system and how it enables multiple modes of use.
• It demonstrates the practicality of our architecture and its im- plementation by showing the infrastructure will scale to handle systems the size of PlanetLab.
Outline. In the rest of the paper, we describe the examples we will use throughout the paper (Section 2), show how to describe these data sources in GLOVES(Section 3), describe the generated tool in- frastructure and its modes of use (Section 4), define a denotational semantics and prove our key correctness properties (Section 5), dis- cuss the implementation and evaluate its performance (Section 6), describe related work (Section 7) and conclude (Section 8).
2. Running Examples
The CoMon [24] system, developed at Princeton, monitors the health and status of PlanetLab [25] by attempting to fetch data from each of PlanetLab’s 800+ nodes every 5 minutes. This data ranges from the node uptime to memory usage to kernel version. CoMon displays the data to users in tabular form and allows them to per- form a number of simple queries to find, for instance, lightly loaded nodes, nodes with drifting clocks or nodes with little remaining disk space. CoMon also monitors nodes for various problems and gener- ates reports of deviant machines or user programs. Finally, CoMon archives the data so PlanetLab users can perform custom analyses of historical data.
AT&T provides a web hosting service. The infrastructure for this service includes a variety of hardware components such as routers, firewalls, load balancing machines, actual web servers and databases, replicated and geographically distributed. Hence, a given web site may be distributed across a variety of machines
let sites = [
"http://pl1.csl.utoronto.ca:3121";
"http://plab1-c703.uibk.ac.at:3121";
"http://planet-lab1.cs.princeton.edu:3121"
]
feed simple_comon = base {|
sources = all sites;
schedule = every 5 min, starting now, timeout 60.0 sec;
format = Comon_format.Source;
|}
Figure 2. Simple CoMon feed (simple comon.fml).
feed comon_1 = base {|
sources = any sites;
schedule = every 5 min, lasting 2 hours;
format = Comon_format.Source;
|}
Figure 3. Description fragment for data from one of many sites (sites.fml).
running a variety of operating systems in a variety of locations.
When a customer signs up for AT&T’s hosting service, part of the contract specifies what kinds of monitoring AT&T will provide for the site. The Arrakis infrastructure provides this monitoring ser- vice. It tracks a variety of resources using a wide array of measures, including network bandwidth, packet loss, cpu utilization, disk uti- lization, memory usage, load averages, etc. For each machine in the hosting service and for each such resource, the monitoring system archives the values at regular intervals and issues alerts when the values exceed resource- and contract-specific levels. The archive is used to track long-term behavior of the service, allowing engineers to determine when more resources need to be provisioned, for ex- ample, adding cpus, memory or disk space. It also allows engineers to understand the “normal” behavior for a particular site which may include daily or seasonal cycles.
3. G
LOVES: An Informal Introduction
The GLOVESlanguage allows users to describe streams of data and meta-data that we refer to as feeds. To introduce the central features of the language, we work through a series of examples drawn from the CoMon and Arrakis monitoring systems.
3.1 CoMon Feeds
Figure 2 presents a simple CoMon statistics feed. This description specifies thesimple_comonfeed using thebasefeed construc- tor. Thesourcesfield indicates that data for the feed comes from allof the locations listed insites. Theschedulefield speci- fies that relevant data is available from each source every five min- utes, starting immediately. When trying to fetch such data, the sys- tem may occasionally fail, either because a remote machine is down or because of network problems. To manage such errors, the sched- ule specifies that the system should try to collect the data from each source for 60 seconds. If the data does not arrive within that win- dow, the system should give up.
The last field in a base feed constructor is theformatfield, which specifies the syntax of the fetched data by supplying a parser for it. In this case, Comon_format.Source is actu- ally a parser generated from a PADS/ML [16] specification file (comon_format.pml), which we have omitted because of space
(* Ocaml helper values and functions *) let config_locations =
["http://summer.cs.princeton.edu/status/ \ tabulator.cgi?table=slices/ \
table_princeton_comon&format=nameonly"]
(* Feed of nodes to query *) feed nodes =
base {|
sources = all config_locations;
schedule = every 5 min;
format = Nodelist.Source;
|}
let makeURL (Nodelist.Data x) =
"http://" ˆ x ˆ ":3121"
let old_locs = ref []
let current list_opt = match list_opt with
Some l -> old_locs := l; l
| None -> !old_locs
(* Dependent CoMon feed of node statistics *) feed comon =
foreach nodelist in nodes create
base {|
sources = all (List.map makeURL
(List.filter Nodelist.is_node (current (value nodelist))));
schedule = once, timeout 60.0 sec;
format = Comon_format.Source;
|}
Figure 4. Node location feed drives data collection (comon.fml).
constraints. While it is not strictly necessary for GLOVESprogram- mers to usePADS/MLspecifications in their descriptions, and the key ideas in this paper can be understood without a deep knowl- edge of PADS/ML, the two languages have been designed to fit together elegantly. Moreover, several of our generated tools exploit the common underlying infrastructure to enable useful data analy- ses and transformations over feeds whose formats are specified by
PADS/MLdescriptions.
A simple variation of our first description appears in Figure 3. In contrast tosimple_comon, which returns data from all sites per time slice,comon_1returns data from just one site per time slice.
This difference between the two is specified using theanycon- structor instead of theall. This feature is particularly useful when monitoring the behavior of replicated systems, such as those us- ing state machine replication, consensus protocols, or even loosely- coupled ones such as Distributed Hash Tables (DHTs) [5]. In these systems, the same data will be available from any of the function- ing nodes, so receiving results from the first available node is suffi- cient. The schedule forcomon_1indicates the system should fetch data every five minutes for two hours, using thelastingfield to indicate the duration of the feed. It omits thestartingand timeoutspecifications, causing the system to use default settings for the start time and the timeout window.
So far, our examples have hard-coded the set of locations from which to gather data. In reality, however, the CoMon system has an Internet-addressable configuration file that contains a list of hosts to be queried, one per non-comment line. This list is periodically up- dated to reflect the set of active nodes in PlanetLab. Figure 4 spec- ifies a version of thecomonfeed that depends upon this configu- ration information. To do so, the description includes an auxiliary feed callednodesthat describes the configuration information: it
ptype nodeitem =
Comment of ’#’ * pstring_SE(peor)
| Data of pstring_SE(peor)
let is_node item = match item with Data _ -> true
| _ -> false
ptype source =
nodeitem precord plist (No_sep, No_term)
Figure 5. PADS/ML description (nodelist.pml) for CoMon configs, with one host name per uncommented line.
is available from theconfig_location, it should be fetched every five minutes, and its format is described by thePADS/MLde- scriptionsourcegiven in the file nodelist.pml, which ap- pears in Figure 5.
ThePADS/MLdescription in Figure 5 specifies thatsource is a list (plist) of new-line terminated records (precord) each containing anodeitem. In turn, anodeitemis either a’#’
character followed by a comment string, which should be tagged with theCommentconstructor, or a host name, which should be tagged asData. The description also defines a helper function is_node, which returns true if the data item in question is a host name rather than a comment. Given this specification, the nodesfeed logically yields a list of host names and comments every five minutes. In fact, because of the possibility of errors, the feed actually delivers a list option every five minutes:Someif the list is populated with data,Noneif the data was unavailable at the given time-slice. Furthermore, to record provenance information, each element in the feed is actually a pair of meta-data and the payload value.
Given thenodesspecification, we can define thecomonfeed using the notation foreach nodelist in nodes create .... In this declaration, each element ofnodesis bound in turn to the variablenodelistfor use in generating the new feed declared in “...” The final result of theforeachis the union of all such newly generated feeds. Both the payload data and the provenance meta-data ofnodelistmay be used in creating the dependent feed. In this example, we use the functionvalueto select only the payload portion, ignoring the meta-data. The complementary functionmetaprovides access to the provenance information.
To complete the construction of the comon feed, a small amount of functional programming allows the user to manage er- rors and strip out comment fields. Any such simple transformations may be written directly in OCAML, the host language into which we have embedded GLOVES. In particular, thecurrentfunction checks if thenodelistvalue isSome l, in which case it caches lbefore returning it as a result. Otherwise, if thenodelistvalue isNone(indicating an error), the most recently cached list of nodes is used instead. The rest of thesourcesspecification filters out comment fields and converts the host names to URLs with the re- quired port using the auxiliary functionmakeURL.
With this specification, we expect to get data from all the active machines listed in the configuration file every five minutes. We further expect the system to notices changes in the configuration file within five minutes.
The previous examples all showcased feeds containing a single type of data. GLOVESalso provides a datatype mechanism so we may construct compound feeds containing data of different sorts.
As an example of where such a construct is useful, the CoMon system includes a number of administrative data sources. One such source is a collection of node profiles, collecting the domain name, IP address, physical location, etc., for each node in the cluster.
A second such source is a list of authentication information for logging into the machines. These two data sources have different formats, locations, and update schedules, but system administrators want to keep a combined archive of the administrative information present in these sources. Ifsites_mimeis a feed description of the profile information andsites_keyscan_mimeis a feed of authentication information, then the declaration
feed sites =
Locale of sites_mime
| Keyscan of sites_keyscan_mime
creates a feed with elements drawn from each of the two feeds.
The constructors Localeand Keyscantag each item in the compound feed to indicate its source.
3.2 Arrakis Example
We now shift to an example drawn from AT&T’s Arrakis project.
Like the earlier CoMon example, the stats feed in Figure 6 monitors a collection of machines described in a configuration file.
Before we discuss thestats feed itself, we first explain some auxiliary feeds that we use in its definition.
Theraw_hostListsdescription has the same form as the nodesfeed we saw earlier, except it draws the data from a local file once a day. We use a feed comprehension to define a clean ver- sion of the feed,host_lists. In the comprehension, the built-in predicateis_goodverifies that no errors occurred in fetching the current list of machineshl, as would be expected for a local file.
The functionget_hoststakeshland uses the built-in function get_goodto extract the payload data from the provenance and error infrastructure, an operation that is guaranteed to succeed be- cause of theis_goodguard. The functionget_hoststhen se- lects the non-comment entries and unwraps them to produce a list of unadorned host names.
We next define a feed generator gen_statsthat yields an integrated feed of performance statistics for each supplied host.
When given a hosth,gen_statscreates an every-five-minute schedule lasting twenty-four hours with a one minute timeout. It uses this schedule to describe a compound feed that pairs two base feeds: the first uses the Unix commandpingto collect network statistics about the route tohwhile the second performs a remote shell invocation usingsshto gather statistics about how long the machine has been up. Both of these feeds use theprocconstructor in thesourcesfield to compute the data on the fly, rather than reading it from a file. The argument to proc is a string that the system executes in a freshly constructed shell. The pairing constructor for feeds takes a pair of feeds and returns a feed of pairs, with elements sharing the same scheduled fetch-time being paired.
This semantics produces a compound feed that for each host returns a pair of its ping and uptime statistics, conveniently grouping the information for each host. Of course, the full Arrakis monitoring application uses many more tools than justpinganduptimeto probe remote machines so the full feed description has many more components than this simplified version.
Finally, we define the feedstats. The most interesting piece of this declaration is the list feed comprehension, given in square brackets, that we use to generate a feed of lists. Given a host list element hl, the right-hand side of the comprehension uses the valuefunction to extract the payload from the meta-data and then considers each hosthfrom the resulting list in turn. The left-hand side of the comprehension uses thegen_statsfeed generator to construct a feed of the statistics forh. The list feed comprehension then takes this collection of statistics feeds and converts them into a single feed, where each entry is a list of the statistics for the machines inhlat a particular scheduled fetch-time. We call each such entry a snapshot of the system. The resulting feed makes
let config_locations =
[("file:///arrakis/config/machine_list")];
feed raw_hostLists = base {|
sources = all config_locations;
schedule = every 24 hours;
format = Hosts.Source; |}
let get_host (Hosts.Data h) = h let get_hosts hl =
List.map get_host
(List.filter Hosts.is_node hl)
feed host_lists =
{| get_hosts (get_good hl) |
hl <- raw_hostLists, is_good hl |}
feed gen_stats (string h) = let s = every 5 mins,
timeout 1 min, lasting 24 hours in (
base {|
sources = proc ("ping -c 1 " ˆ h);
format = Ping.Source;
schedule = s; |}, base {|
sources = proc ("ssh " ˆ h ˆ " uptime");
format = Uptime.Source;
schedule = s; |}
)
feed stats =
foreach hl in host_lists create [ gen_stats (h) | h <- value hl ]
Figure 6. Simplified version of Arrakis feed (arrakis.fml).
it easy for down-stream users to perform actions over snapshots, relieving them of the burden of having to implement their own multi-way synchronization. Given the list feed comprehension, the foreach...createconstruct generates a feed of snapshots from the feed of host lists.
4. Working with Feeds
4.1 The “Off the Shelf” User
The GLOVESsystem provides a suite of “off-the-shelf” tools to help users cope with standard data administration needs. After writ- ing a GLOVESdescription, users can customize these tools by writ- ing simple configuration files, such as shown in Figure 7. Each con- figuration file includes a feed declaration header and a sequence of tool specifications. The header specifies the path to the feed de- scription file (comon.fml) and the name of the feed to be created (comon). Each tool specification starts with the keywordtoolfol- lowed by the name of the tool (e.g.,provtrackandrss). The body of each tool specification lists name-value pairs, where val- ues are OCAMLexpressions. Some attributes are optional, and the compiler fills in a default value for every omitted attribute. GLOVES
compiles a configuration file into an OCAMLprogram that creates and archives the specified feed, configures the specified tools, and applies them to the feed in parallel. In the following paragraphs, we describe some of the tools we have implemented.
Archiver. The archiver saves the data fetched by a feed in the local file system, organizing it according to the structure of the feed, with one directory per base feed. It places a catalog in each directory documenting the source of the data, its scheduled
feed comon.fml/comon
tool provtrack {
minalert = true; maxalert = true;
lesssig = 3; moresig = 3;
slicesize = 10;
slicefile = "slice.acc";
totalfile = "total.acc";
}
tool rss {
title = "CoMon Memory RSS";
link = "http://www.comon.org/memory-rss.xml";
desc = "CoMon Memory Usage Information";
path = "<top>.[?].Mem_info";
}
Figure 7. Example tool configuration file (comon.tc).
======================================================
Summary of network transmission errors
======================================================
ErrCode: 1 ErrMsg: Misc HTTP error Count: 12 ErrCode: 5 ErrMsg: Bad message Count: 27 ErrCode: 6 ErrMsg: No reply Count: 2
======================================================
Top 10 locations with most network errors
======================================================
Loc: http://planetlab01.cnds.unibe.ch:3121 Count: 2 Loc: http://pepper.planetlab.cs.umd.edu:3121 Count: 2 ... omitted ...
Figure 8. Fragment of provenance tracker output (comon.acc).
arrival time and the actual arrival time. The archiver will optionally compress files.
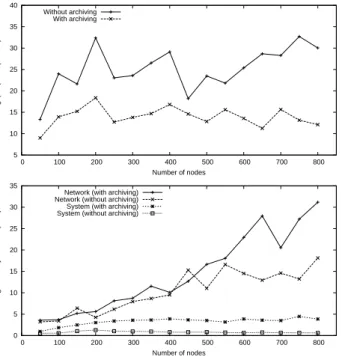
Profiler. The profiler monitors performance, reporting through- put, average network latency and average system latencies over a period of time. Users can specify in the configuration when to pro- file and for how long. We used this tool to produce some of the experimental results in Section 6.
Provenance tracker. The provenance tracker maintains statisti- cal profiles for feeds. These include error rates, most common er- rors and their source locations and times. For numeric data, the tracker keeps aggregates such as averages, max/min values and standard deviations. For other data (e.g., strings, URLs and IP ad- dresses), it keeps the frequency of the top N most common values.
The user can configure the tracker to profile entire feeds at once, or incrementally. The latter is useful for infinite feeds, because it allows users to continuously monitor feeds and compare their cur- rent behavior with historical statistics. The tracker can output either plain text or XML. Figure 8 shows portions of provenance tracker output for the CoMon example.
Alerter. The alerter allows users to register boolean functions which generate notifications when they evaluate to false on feed items. The tool appends these notifications to a file, which can be piped into other tools. The system provides a library of common alerters such as exceeding max/min thresholds or deviating from the norm (i.e., trigger an alert when a selected value strays more than k standard deviations from its historical value). Users can supply their own conditions by giving arbitrary OCAMLpredicates in the configuration file.
Database loader. This tool allows users to load numerical data from a feed into an RRD. Users specify a function to transform feed items into numeric values and RRD parameters such as data source type and sampling rate. RRD indexes the data by arrival time. It periodically discards old data to make space for new. The tool supports time-indexed queries and graphing of historical data.
let (sample, _) = Feed.split_every 600. comon in let select_load = function
Some {Comon_format.Source.
loads = (_, load::_)} -> Some load
| None -> None in
let loads = Feed.map select_load sample in let load_tbl = Feed.fold update empty_tbl loads in print_top 10 load_tbl
Figure 9. Code fragment finding least loaded PlanetLab nodes.
let update_m tbl adata =
let meta = Feed.get_meta adata in let data = Feed.get_contents adata in match meta, data with
(h, Some basemeta), Some load ->
let location = Meta.get_link basemeta in update tbl (location, data)
| _ -> tbl (* no change to tbl *) in
let load_tbl = Feed.fold_m update_m empty_tbl loads in print_top_with_loc 10 load_tbl
Figure 10. Revised code fragment with provenance meta-data.
RSS feed generator. The RSS feed generator converts a GLOVES
feed to an RSS feed. Users specify the title, link (source), descrip- tion, update schedule and contents of the RSS feed. Content speci- fications are written in the path expression language.
4.2 The Single-Minded Implementer
In addition to the off-the-shelf tools, GLOVESincludes an API for manipulating generated feeds. The API provides users with a feed abstraction representing a potentially infinite series of elements.
This abstraction is related to that of a lazy list, but extends it with support for provenance information. Therefore, we model the feed API on the list APIs of functional languages but provide two levels of abstraction. One level allows users to manipulate feeds like any lazy list of data elements (ignoring where they come from), while the other exposes the meta-data as well.
For example, consider PlanetLab users looking for a desirable set of nodes on which to run their experiments. They can use the API generated from the CoMon description to monitor PlanetLab for a few minutes to find the least loaded nodes. Figure 9 shows an OCAMLcode fragment that collects the nodes with the low- est average loads over 10 minutes and then prints them. We omit the details for maintaining the table of top values, as it is orthogo- nal to our discussion. First, we useFeed.split_everyto split the feed when 600 seconds (10 minutes) have elapsed. Then, we useFeed.mapto project the load data from the CoMon elements.
Finally, we useFeed.foldto collect the data into a table. Func- tionupdateadds an entry to the table, andempty_tblis the initially empty table. After filling the table,print_top 10pro- cesses each node’s loads and prints the ten lowest average loads.
However, if we want a report of the names of the nodes that have the lowest average loads, the above solution is not good enough because the CoMon data format does not include the node location in the data. In such situations, provenance meta-data is essential. We therefore replace the last two lines of Figure 9 with the code in Figure 10 that exploits the meta-data. First, we give theupdate_m(update with meta) function that uses meta-data to associate a location with every load in the table. It relies on the Metamodule, which GLOVESprovides to facilitate management of meta-data. Next, we show a call to the meta-aware foldfold_m, which passes the payload and its meta-data to the folding function.
Last, the callprint_top_with_loc 10prints the ten lowest average loads and their locations.
It should be clear from these examples that the single-minded implementer has a number of new interfaces to master relative to
the off-the-shelf user, but gains a correspondingly higher degree of flexibility and can still write relatively concise programs.
4.3 The Generic Programmer
Occasionally, users might want to develop functions that can ma- nipulate any feed. Often, such functions can be written parametri- cally in the type of the feed element, much like the feed library functions discussed above. However, the behavior of many feed functions depends on the structure of the feed and its elements.
Such functions can be viewed as interpretations of feed descrip- tions. To support their development, we provide a framework for writing feed interpreters.
Two core examples of feed interpretation are the feed creator and the provenance tracker. The behavior of these tools depends on the structure of the feed. Functions like these require as input a run- time representation of the feed, complete with the details of the feed description that they represent. The obvious choice for represent- ing feed descriptions in OCAMLis a datatype. However, standard OCAMLdatatypes are not sufficiently typeful to express the types of many generic feed functions. For example, the feed creation function has the type: feed_create : ’a prefeed ->
’a feed where the type ’a prefeed is an AST of a feed description and feed elements have type’a. This limitation of datatypes has been widely discussed in the literature, and vari- ous solutions have been proposed [11, 31, 32]. We have chosen to represent our AST using a variant of the Mogensen-Scott encod- ing [18, 30] which exploits higher-order abstract syntax to encode variable binding in feed descriptions. This implementation strategy exploits OCAML’s module system to type the encodings in Fω. Our earlier work onPADS/ML[11] exploited a similar strategy, but there we only sought to encode the OCAMLtype of the data, not the entirePADS/MLdescription, which is where higher-order abstract syntax becomes useful.
The result of our work is that developers can interpret feed- description representations by case analysis on their structure, while still achieving the desired static guarantees. Moreover, we have successfully used this framework to develop all of the tools presented in this paper, including the feed creator. The compiler only infers appropriate type declarations from feed descriptions and compiles the feed syntax into our representations. However, as one might expect, interfaces using higher-order abstract syntax and Mogensen-Scott encodings are one step more complex than those involving the more familiar maps and folds. Consequently, the learning curve for the generic programmer is one step steeper than the curve for the single-minded implementor, and two (or perhaps ten) steps steeper than the curve for the off-the-shelf user.
5. G
LOVESSemantics
Developing a formal semantics for GLOVEShas been an integral part of our language design process. The semantics helps commu- nicate our ideas precisely and explore the nuances of design deci- sions. Moreover, the semantics provides users with a tool to reason about the feeds resulting from GLOVESdescriptions, including sub- tleties related to synchronization, timeouts, errors and provenance.
To express locations, times, schedules and constraints, the feed calculus depends upon a host language, which we take to be the simply-typed lambda calculus. Figure 11 presents its syntax, which includes a collection of constants to simplify the semantics: strings (w), times (t) and locations (ℓ). We assume times may be added and compared and we let∞ represent a time later than all others.
We assume that the set of locations includes the constant nowhere, indicating the associated data was computed rather than fetched.
We treat schedules as sets of times and use the notation t∈ s to refer to a time t drawn from the set s. We use a similar notation to refer to elements of a list. The host language also includes standard
(host-language base types) b ::= bool | string | time | loc (host-language types)
τ ::= b | τ option | τ1∗ τ2| τ1+ τ2| τ list | τ set | τ1→ τ2
(host-language values) v ::=
false| true booleans
| w| t | ℓ strings, times, locations
| None| Some v optional values
| (v1, v2) pairs
| inl v| inr v sum values
| [v1, . . . , vn] list values
| {v1, . . . , vn} set values
| λx:τ.e function values (host-language expressions) e ::=
x variables
| v data values
| None| Some e option expressions
| ... more typed lambda expressions Figure 11. Host Language Syntax.
(feed payload types)
σ ::= τ | τ option | σ1∗ σ2| σ1+ σ2| σ list (core feeds)
C ::=
{ src = e1; source specification sched= e2; schedule specification win= e3; time-out window specification pp= e4; pre-processor
format= e5; } format specification (feeds)
F ::=
all C all sources
| any C one of multiple sources
| ∅ empty feed
| One(ev, et) singleton feed
| SchedF(e) schedule to feed
| F1∪ F2 union feed
| F1+ F2 sum feed
| (F1, F2) pair feed
| [F | x ← e] list comprehension feed
| {|F2 | x ← F1|} feed comprehension
| filter F with e filter feed
| let x= e in F let feed
Figure 12. Feed Language Syntax.
structured types such as options, pairs, sums, lists and functions.
We omit the typing annotations from lambda expressions when they can be reconstructed from the context and we use pattern matching where convenient (e.g., λ(x, y).e is a function over pairs).
5.1 Feed Syntax and Typing
The abstract syntax for our feed calculus and its typing rules appear in Figures 12 and 13, respectively. The feed typing judgment has the formΓ ⊢ F : σ feed, which means that in the context Γ mapping variables to host language types τ , F is a feed of σ values.
The core typing judgment, which has the formΓ ⊢ C : σ core, conveys the same information for core feeds.
Intuitively, a feed carrying values of type σ is a sequence of pay- load values of type σ. However, to record provenance information, we pair each payload value with meta-data, so a feed is actually a sequence of (meta-data, payload) pairs. At the top-level, meta-data consists of a triple of the scheduled time for the payload, a depen- dency set that records the origin and scheduled time of any data that contributed to the payload, and a nested meta-data field whose form depends upon the type of the payload.
Formally, we let m range over top-level meta-data, ds range over dependency sets, and n range over “nested” meta-data:
m ::= (t, ds, n) top-level meta-data ds ::= {(t1, ℓ1), . . . , (tn, ℓn)} dependency set
n ::= (t, ℓ, None) base meta-data (timeout)
| (t, ℓ, Some t) base meta-data (success)
| (n1, n2) pair meta-data
| inl n sum meta-data
| inr n sum meta-data
| [n1, . . . , nk] list meta-data
Given meta-data m, we write m.t, m.ds and m.nest for the first, second and third projections (respectively) of m. Base meta-data is a triple of the scheduled time, the location of origin and an optional arrival time whereNoneindicates the data did not arrive in time.
As shown in Figure 12, we define the feed payload type σ in terms of host language types, stratified to facilitate the proof of semantic soundness. We use the function meta(σ) to define the type of meta-data associated with payload of type σ:
meta(σ) = time∗ ds ∗ nest(σ)
ds = (time ∗ loc) set
nest(τ ) = time∗ loc ∗ (time option) nest(τ option) = time∗ loc ∗ (time option) nest(σ1∗ σ2) = nest(σ1) ∗ nest(σ2) nest(σ1+ σ2) = nest(σ1) + nest(σ2) nest(σ list) = nest(σ) list
Feed typing depends upon a standard judgment for typing lambda calculus expressions:Γ ⊢ e : τ .
Having covered these preliminaries, we can now discuss the syntax and typing for each of the feed constructs in Figure 12.
Core feeds express the structure of base feeds, describing the data sources (src), schedule (sched), window (win), preprocessing function (pp) and file format (format). The source field describes the set of locations from which to fetch data. It may contain pseudo- locations that model the proc form found in the implementation.
Instead of having timeouts specified as part of schedules, as we did in the surface language, the calculus separates these two concepts into distinct fields, which simplifies the semantics. If an item spec- ified to arrive at time t by schedule e2 fails to arrive within the window e3, the feed pretends it received the valueNone. Other- wise, it wraps the received data string in an option. As a result, the preprocessor e4maps a string option to a string option, where a result ofNoneindicates either a network or preprocessing error.
Finally, the formatting function e5parses the output of the prepro- cessor to produce a value of type τ option, where aNoneresult in- dicates a network, preprocessing or formatting error. (For the sake of simplicity, we do not model the variety of error codes that the implementation supports.)
The feed all C selects all the data from the core feed C. The feed any C selects for each time in the schedule for C the first good value to arrive from any location. It returnsNonepaired with appropriate meta-data if no such good value exists.
Γ ⊢ e1: loc list Γ ⊢ e2: time set Γ ⊢ e3: time Γ ⊢ e4: string option → string option
Γ ⊢ e5: string option → τ option Γ ⊢ {src =e1; sched =e2; win =e3;
pp=e4; format =e5; } : τ option core
(t-core)
Γ ⊢ C : σ core
Γ ⊢ all C : σ feed (t-all) Γ ⊢ C : σ core
Γ ⊢ any C : σ feed (t-any)
Γ ⊢ ∅ : σ feed (t-empty) Γ ⊢ ev: τ Γ ⊢ et: time
Γ ⊢ One(ev, et) : τ feed (t-one) Γ ⊢ e : time set
Γ ⊢ SchedF(e) : time feed (t-schedule) Γ ⊢ F1: σ feed Γ ⊢ F2: σ feed
Γ ⊢ F1∪ F2: σ feed (t-union) Γ ⊢ F1: σ1feed Γ ⊢ F2: σ2feed
Γ ⊢ F1+ F2: σ1+ σ2feed (t-sum) Γ ⊢ F1: σ1 feed Γ ⊢ F2: σ2feed
Γ ⊢ (F1, F2) : σ1∗ σ2feed (t-pair) Γ ⊢ e : τ list Γ, x:τ ⊢ F : σ feed
Γ ⊢ [F | x ← e] : σ list feed (t-list) Γ ⊢ F1: σ1feed Γ, x:meta(σ1) ∗ σ1⊢ F2: σ2feed
Γ ⊢ {|F2| x ← F1|} : σ2feed (t-comp)
Γ ⊢ F : σ feed Γ ⊢ e : (meta(σ) ∗ σ) → bool
Γ ⊢ filter F with e : σ feed (t-filter) Γ ⊢ e : τ Γ, x:τ ⊢ F : σ feed
Γ ⊢ let x = e in F : σ feed (t-let) Figure 13. Feed Language Typing.
The empty feed (∅) contains no elements and may be ascribed any feed type. The singleton feed One(ev, et) constructs a feed containing a single value ev at a single time et. The schedule feed SchedF(e) builds a feed whose elements are the times in the schedule e. The union feed merges two feeds with the same type into a single feed. In contrast, the sum feed takes two feeds with (possibly) different types and injects the elements of each feed into a sum before merging the results into a single feed. The pair feed, written(F1, F2), combines the elements of the two nested feeds synchronously, matching elements that have the same scheduled time, regardless of when those elements actually arrive. The list feed[F | x ← e], in contrast, provides n-way synchronization, where n is the length of the input list e. Each element eiin e defines
a feed Fi = F [x 7→ ei]. For each time t with a value viin each feed Fi, the list feed returns the list[v1, . . . , vn] (and appropriate meta-data). Note that if the Fifeeds share a schedule s, then each feed will have a value for every time in the schedule s, even in the presence of errors, so the synchronization will succeed at each time in the schedule s.
The feed comprehension{|F2 | x ← F1|} creates a feed with elements F2[x 7→ v] when v is an element of F1. Note that the entry v is a pair of meta-data (with type meta(σ)) and payload data (with type σ). The feed filter F with e eliminates elements v from F when e v is false. Finally, let feeds let x= e in F provide a convenient mechanism for binding intermediate values.
Several of the surface language constructs presented in Sec- tion 3 may be modeled as derived constructs in the calculus. For instance, (foreachx in F1 createF2) can be modeled as a {|F2 | x ← F1|}. Likewise, the surface language comprehension {|e2 | x ← F1, e1|} can be modeled as {|One(e2, x.1.t) | x ← filter F1 with e1|}. When esis a schedule and etis a function over times, purely artificial “computed” feeds may be modeled as {|One(etx.1.t, x.1.t) | x ← SchedF(es)|}.
5.2 Feed Semantics
We give a denotational semantics for our formal feed language in Figure 14. The principal semantic functions areC[[C]]E U and F[[F ]]E U, defining core feeds and feeds, respectively. In these definitions, E is an environment mapping variables to values and U is a universe mapping pairs of schedule time and location to arrival time and a string option representing the actual data. Intuitively, the universe models the network. When U(ts, ℓ) = (ta, Some w), the interpretation is that if the run-time system requests data from location ℓ at time ts then string data w will be returned at time ta. The time ta must be no earlier than ts. When U(ts, ℓ) = (∞, None), networking errors have made location ℓ unreachable.
The semantic definitions for C and F use conventional set- theoretic notations. They depend upon a semantics for the simply- typed host language, writtenE[[e]]E, whose definition we omit. We assume that given environment E with typeΓ and expression e with type τ inΓ, E [[e]]E= v and ⊢ v : τ .
The meaning of core feed C is the set of (meta-data, payload) pairs for the feed. To construct this set, we first compute the list of source locations L, the set of times in the schedule S and the length of the window W . Thetimeoutfunction checks whether the item arrival time xat is within the window W of the sched- uled time xt, returningNoneif not. Otherwise,timeoutreturns its data argument xs, which may be Nonebecause of other net- working errors. Similarly, thearrivalfunction returns the ar- rival timeSome xat if the item arrived within the window and Noneotherwise. The functionmetauses thearrivalfunction to construct the meta-data for the item, consisting of the sched- uled time t, the dependency set containing the scheduled time and source location{(t, ℓ)}, and the nested meta-data, which includes the scheduled time t, the source location ℓ, and the actual arrival timearrival(t, U (t, ℓ)). (This apparent redundancy goes away with non-core feeds.) Using thetimeoutfunction, we define an alternate universe U′that retrieves data from the outside world us- ing the original universe U , checks for a timeout, and applies the preprocessor (E[[epp]]E). To compute the payload, thevalfunction applies the formatting functionE[[ef]]Eto the value returned by the alternative universe U′at time t for location ℓ. Finally, the result is the set of all pairs of meta-data and payload produced for each location ℓ in the list L and time t in the schedule S.
The semantics of the all C feed is simply the semantics of the underlying core feed. The semantics of the any C feed selects for each time t in the schedule S of the core feed C the earliest good payload value from any location if one exists, orNoneotherwise.
C[[{src =esrc; = {(meta(t, ℓ), payload(t, ℓ)) | ℓ ∈ L and t ∈ S}
sched=esched; where
win=ewin; L= E [[esrc]]E
pp=epp; S= E [[esched]]E
format=ef; }]]E U W = E [[ewin]]E
timeout= λ(xt,(xat, xs)).if xat≤ xt+ W then xselse None arrival= λ(xt,(xat, xs)).if xat≤ xt+ W then Some xatelse None meta= λ(t, ℓ).(t, {(t, ℓ)}, (t, ℓ, arrival(t, U (t, ℓ))))
U′= λ(t, ℓ).E [[epp]]E(timeout (t, U (t, ℓ))) payload= λ(t, ℓ).E [[ef]]E(U′(t, ℓ))
F[[all C]]E U = C[[C]]E U
F[[any C]]E U = {((t, DSt, nestt), vt) | t ∈ S}
where A = C[[C]]E U
S = {m.t | (m, v) ∈ A}
At = {(m, v) | (m, v) ∈ A and m.t = t}
DSt = S
(m,v)∈Atm.ds
Gt = {(m, Some v) | (m, Some v) ∈ At} (nestt, vt) =
(m.nest, v) where (m, v) = earliest(Gt) if |Gt| > 0 ((t, nowhere, None), None) if |Gt| = 0
F[[∅]]E U = { }
F[[One(ev, et)]]E U = {((E[[et]]E,{ }, (E[[et]]E, nowhere, SomeE[[et]]E)), E [[ev]]E)}
F[[SchedF(e)]]E U = {((t, { }, (t, nowhere, Some t)), t) | t ∈ E[[e]]E} F[[F1∪ F2]]E U = F[[F1]]E US F[[F2]]E U
F[[F1+ F2]]E U = {((m.t, m.ds, inl m.nest), inl v) | (m, v) ∈ F[[F1]]E U}S {((m.t, m.ds, inr m.nest), inr v) | (m, v) ∈ F[[F2]]E U} F[[(F1, F2)]]E U = {((m1.t, m1.ds∪ m2.ds,(m1.nest, m2.nest)), (v1, v2)) |
(m1, v1) ∈ F[[F1]]E Uand(m2, v2) ∈ F[[F2]]E Uand m1.t= m2.t}
F[[[F | x ← e]]]E U = {((t,S
i=1...kmi.ds,[m1.nest, . . . , mk.nest]), [v1, . . . , vk]) |
∀i : 1 . . . k.(mi, vi) ∈ F[[F ]](E,x7→zi) Uand mi.t= t}
where [z1, . . . , zk] = E [[e]]E
F[[{|F2| x ← F1|}]]E U = {((m2.t, m1.ds∪ m2.ds, m2.nest), v2) | (m1, v1) ∈ F[[F1]]E U and(m2, v2) ∈ F[[F2]](E,x7→(m
1,v1)) U} F[[filter F with e]]E U = {(m, v) | (m, v) ∈ F[[F ]]E UandE[[e (m, v)]]E= true}
F[[let x = e in F ]]E U = F[[F ]](E,x7→E[[e]]E) U
Figure 14. Feed Language Semantics.
It returns the set of all such values vt, paired with the appropriate meta-data. To compute this set, the function first computes the meaning A of the core feed C. It extracts the schedule S from the meta-data in A. For each time t in the schedule, it computes the set Atof (meta-data, payload) pairs fetched at time t. For each such set, it computes the dependency set DSt, which collects the dependencies of all the items fetched at time t. The set Gtcollects all the good items from At. If this set is non-empty, we use the function earliest to choose the (meta-data, payload) pair(m, v) with the earliest arrival time from Gt. (We assume that there is always one such earliest item.) In this case, we set the nested meta- data nesttto be the nested meta-data of m, and the payload value vt to be v. If the set of good values is empty, then we set the nested meta-data to indicate that at time t, we created (location =
nowhere) a payload value that had no actual arrival time. In this case, the payload value vtis justNone.
The meaning of the empty feed is the empty set. The meaning of the singleton feed One(ev, et) is a single pair, the payload portion of which is the meaning of ev. The meta-data indicates the sched- uled time is the meaning of et, the dependency set is empty, the data came from nowhere (a dummy location indicating the value was generated internally), and the arrival time matched the scheduled time. A schedule feed SchedF(e) yields a feed with one payload value for each t in the meaning of the schedule e. The correspond- ing meta-data follows the same pattern as for the singleton feed.
The union feed is the set-theoretic union of its constituent feeds.
The sum feed injects the elements of its constituent feeds into a sum and likewise takes their union. It constructs compound meta- data from the meta-data of the constituent feeds in the obvious way.
The pair feed(F1, F2) is formed by finding for each time t all elements of F1 at a time t (including erroneous elements) and all elements of F2at time t (again including erroneous elements) and generating their Cartesian product. Notice that if the schedules do not intersect, the pair feed will empty. The meta-data is constructed by combining the meta-data for the paired feeds. The semantics of the list feed[F | x ← e] is similar to that of the pair feed except the synchronization is n-way instead of pairwise, where n is the length of the list e.
The feed comprehension {|F2 | x ← F1|} contains payload values v2 taken from the meaning of feed F2 when x is mapped to (meta-data, payload) pairs drawn from the meaning of feed F1. The dependency set for the feed comprehension includes the de- pendency sets of both F1and F2. The filter feed filter F with e selects those (meta-data, payload) pairs from the meaning of F that satisfy the predicate e. Finally, the let feed let x= e in F returns the meaning of feed F when x is mapped to the meaning of e.
5.3 Feed Properties
We have used our semantics to prove two key properties of our cal- culus. The first property, Type Soundness, serves as an important check on the basic structure of our definitions: Do the sets of val- ues given by the denotational semantics have the types ascribed by our typing rules? The second property, Dependency Correctness, guarantees the semantics adequately maintains provenance meta- data. To be more specific, it demonstrates that a feed item depends exclusively on the locations and times mentioned in its dependency set. This theorem is crucial for users who need to track down prob- lems in their distributed system – when they find their incoming data is bad, they need to know exactly where (and when) to look to find malfunctioning equipment or software.
Type Soundness. The type soundness theorem states that values contained in the semantics of each feed are (meta-data, payload) pairs with the appropriate type. More specifically, if the feed typing rules give feed F type σ feed, then its data has type σ and its meta- data has type meta(σ). A similar statement is true of core feeds.
Theorem 1 (Type Soundness)
•IfΓ ⊢ C : σ core and for all x in dom(Γ), ⊢ E(x) : Γ(x) and⊢ U : time ∗ loc → time ∗ (string option) then for all (m, v) ∈ C[[C]]E U,⊢ (m, v) : meta(σ) ∗ σ.
•IfΓ ⊢ F : σ feed and for all x in dom(Γ), ⊢ E(x) : Γ(x) and⊢ U : time ∗ loc → time ∗ (string option) then for all (m, v) ∈ F[[F ]]E U,⊢ (m, v) : meta(σ) ∗ σ.
We have proven the theorem by induction on the structure of feeds.
Dependency Correctness. In order to make the principle of De- pendency Correctness precise, we must define what it means for two universes to be equal relative to a dependency set ds. Intu- itively, this definition simply states that the universes are equal at the times and locations in ds and unconstrained elsewhere.
Definition 2 (Equal Universes Relative to a Dependency Set) U1=dsU2if and only if for all(t, ℓ) ∈ ds, U1(t, ℓ) = U2(t, ℓ).
Now, we need a similar definition of feed equality. In the following definitions, let S1, S2 range over denotations of core feeds and feeds.
Definition 3 (Feed Subset Relative to a Dependency Set) S1 ⊆dsS2if and only if for all(m, v) ∈ S1such that m.ds⊆ ds, (m, v) ∈ S2.
Definition 4 (Feed Equality Relative to a Dependency Set) S1 =dsS2if and only if S1⊆dsS2and S2⊆dsS1
Finally, Dependency Correctness states that if two universes U1
and U2 are identical at locations and times in ds (but arbitrarily different elsewhere) then the elements of any feed F that depend upon the locations and times in ds do not change when F is inter- preted in universe U1as opposed to in U2. We prove Dependency Correctness by induction on the structure of feeds.
Theorem 5 (Dependency Correctness)
• If U1=dsU2thenC[[C]]E U
1 =dsC[[C]]E U
2.
• If U1=dsU2thenF[[F ]]E U
1 =dsF[[F ]]E U
2.
6. G
LOVESImplementation and Evaluation
The GLOVES implementation has three parts: the compiler, the runtime system, and the built-in tools library. We describe these parts in turn and then evaluate the overall system performance and design.
The Compiler. The GLOVEScompiler consists oftcc, the tool configuration compiler for .tc files, andfmlc, the compiler for feed declarations (.fml files). Both compilers convert their sources into OCAMLcode, which is then compiled and linked to the runtime libraries. We implemented both tools withCamlp4, the OCAML
preprocessor.
The fmlc compiler performs code generation in two steps.
First, the code generator emits the type declarations for each feed.
Second, it generates representations for each feed description. The compiler constructs these representations by extracting elements from the concurrently generatedPADS/MLlibraries and using poly- morphic combinators to build structured descriptions.
The Runtime System. We implement each GLOVESfeed as a lazy list of feed items. Following the semantics in Section 5, a feed item is a (meta-data, payload) pair, although the implementation has a more refined notion of meta-data that includes more detailed error information.
The GLOVES runtime system is a multi-threaded concurrent system that follows the master-worker implementation strategy.
Each worker thread either fetches data from a specified location and parses the data into an internal representation (the rep), or synthesizes its data by calling a generator function. Using error conditions, location, scheduled time and arrival time, the worker generates the appropriate meta-data, pairs it with the rep and pushes the feed item onto a queue. The master thread pops the feed item from the queue on demand, i.e., when the user program requests the data. The worker thread is eager, which guarantees that all data will be fetched and archived, but the master thread is lazy, which allows application programs to process only relevant data.
We used theOcamlnet 2library [28] to implement the fetch- ing engine. It batches concurrent fetch requests into groups of 200, a size which balances maximizing throughput with avoiding over- whelming the operating system with too many open sockets.
Tools Library. As explained in Section 4, we implemented the GLOVESoff-the-shelf tool suite using our generic tool framework.
Some tools depend upon auxiliary tools. For instance, the feed se- lector calls a data selector built using thePADS/MLgeneric tool framework [11] for base feeds. Other tools depend upon external li- braries. For instance, thefeed2rrdtool requires the RRD round- robin database [22] and thefeed2rsstool uses the XML-Light package [19] for parsing and printing XML.
Experiments. To assess performance, we measure the average time to fetch a data item (termed network latency), the average time to prepare the data item for consumption after fetching it (termed system latency), and the throughput of the system for the CoMon feed description in Figure 4. The throughput measures the average number of items fetched and processed per second.