A New Method to Forecast the TAIEX Based on Fuzzy Time Series
Chao-Dian Chen 1 and Shyi-Ming Chen 1, 2
1 Department of Computer Science and Information Engineering, National Taiwan University of Science and Technology, Taipei, Taiwan, R. O. C.
2 Department of Computer Science and Information Engineering, Jinwen University of Science and Technology, Taipei County, Taiwan, R. O. C.
Abstract—In this paper, we present a new method to forecast the Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) based on fuzzy time series, where the main factor is the TAIEX and the secondary factors are either the Dow Jones, the NASDAQ, the M 1b (Taiwan), or their combinations. First, we fuzzify the historical data of the main factor into fuzzy sets with a fixed length of intervals to form fuzzy logical relationships. Then, we group the fuzzy logical relationships into fuzzy logical relationship groups. Then, we evaluate the leverage of fuzzy variations between the main factor and the secondary factor to forecast the TAIEX. The experimental results show that the proposed method gets a higher average forecasting accuracy rate than Chen’s method [1] and Huarng et al.’s method [9] to forecast the TAIEX.
Keywords—fuzzy sets, fuzzy time series, fuzzy logical relationships, fuzzy variation
I. I NTRODUCTION
In [11], [12] and [13], Song and Chissom presented the concepts of fuzzy time series based on the fuzzy set theory [21], where the values of a fuzzy time series are represented by fuzzy sets. In recent years, some methods have been presented to handle forecasting problems based on fuzzy time series, such as enrollments forecasting [1], [2], [3], [4], [12], [13], [15], [19], temperature prediction [5], [10], [14], stock index forecasting [6], [7], [8], [9], [14], [16], [17], [18], [20] , …, etc.
In this paper, we present a new method to forecast the Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) based on fuzzy time series, where the main factor is the TAIEX and the secondary factors are either the Dow Jones, the NASDAQ, the M 1b (Taiwan), or their combinations. First, we fuzzify the historical data of the main factor into fuzzy sets with a fixed length of intervals to form fuzzy logical relationships. Then, we group the fuzzy logical relationships into “fuzzy logical relationships groups”. Then, we evaluate the leverage of fuzzy variations between the main factor and the secondary factor to forecast the TAIEX. The experimental results show that the proposed method gets a higher average forecasting accuracy rate than Chen’s method [1] and Huarng et al.’s method [9] to forecast the TAIEX.
The rest of this paper is organized as follows. In Section II, we briefly review the definition of fuzzy time series from [11], [12] and [13]. In Section III, we present a new method based on fuzzy time series to forecast the TAIEX. In Section IV, we make a comparison of the experimental results of the proposed method with the existing methods. The conclusions are discussed in Section V.
II. P RELIMINARIES
In [11], [12] and [13], Song and Chissom presented the concepts of fuzzy time series based on the fuzzy set theory [21], where the values of a fuzzy time series are represented by fuzzy sets. Let U be the universe of discourse, where U = {u 1 , u 2 , …, u n }. A fuzzy set A i in the universe of discourse U is defined as follows:
A i = f Ai (u 1 )/u 1 + f Ai (u 2 )/u 2 + …+ f Ai (u n )/u n ,
where f Ai is the membership function of the fuzzy set A i , f Ai (u j ) is the degree of membership of u j belonging to the fuzzy set A i , f Ai (u j ) ∈[0,1] and 1 ≤ j ≤ n.
Definition 2.1 [11]: Let Y(t) (t = …, 0, 1, 2, …) be the universe of discourse and be a subset of R. Assume that f i (t) (i = 1, 2, …) are defined in the universe of discourse Y(t), and assume that F(t) is a collection of f i (t) (i = 1, 2, …), then F(t) is called a fuzzy time series of Y(t) (t = …, 0, 1, 2, …).
If a fuzzy relationships R(t −1,t) exists, such that F(t) = F(t −1) D R(t−1,t), where the symbol “D” represents the max −min composition operator, then F(t) is called caused by F(t −1) [11].
Definition 2.2 [11]: Let F(t−1) = A i and let F(t) = A j . The relationship between F(t −1) and F(t) can be denoted by fuzzy logical relationship A i → A j , where A i is called the left-hand side (LHS) and A j is called the right-hand side (RHS) of the fuzzy logical relationship.
Fuzzy logical relationships having the same left-hand side can be grouped into a fuzzy logical relationship group (FLRG) [1]. For example, assume that the following fuzzy logical relationships exist:
A i → A ja , A i → A jb ,
#
A i → A jm .
then these fuzzy logical relationships can be grouped into a fuzzy logical relationship group, shown as follows:
A i → A ja , A jb , …, A jm .
III. A N EW M ETHOD FOR F ORECASTING THE TAIEX B ASED ON F UZZY T IME S ERIES
In this section, we present a new method to forecast the TAIEX from 2000 to 2004 based on fuzzy time series, where Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics
San Antonio, TX, USA - October 2009
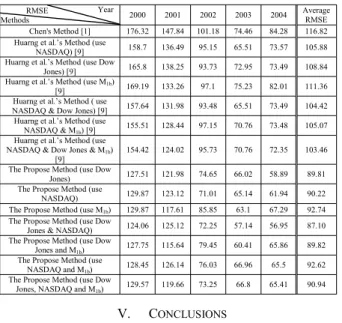
the historical data are divided into two parts, i.e., the training data set and the testing data set. The training data set consists of the historical data from January to October for each year, and the testing data set consists of the historical data from November to December for each year. Table I [9] shows the TAIEX, the Dow Jones, the NASDAQ, and the M 1b from January 2004 to December 2004. In this paper, the TAIEX is the main factor, where the secondary factors Dow Jones, NASDAQʳ and M 1b are used to forecast the TAIEX. The proposed method is now presented as follows:
Step 1: Define the universe of discourse U, U = [D min −D 1 , D max +D 2 ], where D min and D max are the minimum and the maximum values of the historical data of the main factor, respectively; D 1 and D 2 are two proper positive real values to partition the universe of discourse U into n intervals u 1 , u 2 , …, and u n of equal length. For example, from Table I, we can see that the minimum and the maximum values of the training data of the TAIEX of the year 2004 are 5316.87 and 7034.1, respectively. If we let D 1 = 16.87 and D 2 = 65.9, then the universe of discourse U = [5300, 7100]. Let the length of each interval in the universe of discourse U be 100. Then, the universe of discourse U can be divided into 18 intervals, which is defined as follows:
u i = [5300 + (i − 1) × 100, 5300 + (i) × 100], (1) where i = 1, 2, …, 18.
TABLE I. H ISTORICAL D ATA OF THE TAIEX, THE D OW J ONES , THE
NASDAQ, AND THE M1 B OF 2004 [9]
Date TAIEX Dow Jones NASDAQ M
1b2004/1/2 6041.56 10409.85 2006.68 6491205 2004/1/5 6125.42 10544.07 2047.36 6487349 2004/1/6 6144.01 10538.66 2057.37 6497906
# # # # #
2004/11/1 5656.17 10054.39 1979.87 7040767 2004/11/2 5759.61 10035.73 1984.79 7054955
# # # # #
2004/12/31 6139.69 10783.01 2175.44 7370450
Step 2: Define the linguistic terms A i represented by fuzzy sets, shown as follows:
A 1 = 1/u 1 + 0.5/u 2 + 0/u 3 + … + 0/u n −2 + 0/u n −1 + 0/u n , A 2 = 0.5/u 1 + 1/u 2 + 0.5/u 3 + … + 0/u n −2 + 0/u n −1 + 0/u n ,
#
A n = 0/u 1 + 0/u 2 + 0/u 3 + … + 0/u n−2 + 0.5/u n−1 + 1/u n . where A 1 , A 2 , …, and A n are linguistic terms. For example, based on the obtained 18 intervals, we can define the linguistic terms A 1 , A 2 , …, and A 18 , shown as follows:
A 1 = 1/u 1 + 0.5/u 2 + 0/u 3 + … + 0/u 16 + 0/u 17 + 0/u 18 , A 2 = 0.5/u 1 + 1/u 2 + 0.5/u 3 + … + 0/u 16 + 0/u 17 + 0/u 18 ,
#
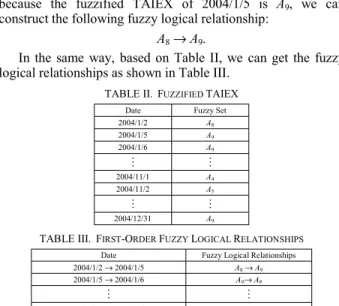
A 18 = 0/u 1 + 0/u 2 + 0/u 3 + … + 0/u 16 + 0.5/u 17 + 1/u 18 . Step 3: Fuzzify each historical datum of the main factor into a fuzzy set defined in Step 2. If the historical datum of the main factor belongs to u i and the maximum membership value of the fuzzy set A i occurs at u i , where 1 ≤ i ≤ n, then the historical datum of the main factor is fuzzified into A i . For example, from Table I, we can see that the TAIEX of 2004/1/2 is 6041.56, which can be fuzzified into A 8 . Table II shows the fuzzified TAIEX of the data shown in Table I, respectively.
Step 4: Construct fuzzy logical relationships from the fuzzified historical data of the main factor obtained in Step 3. For example, from the fuzzified TAIEX of the training data shown in Table II, we can construct fuzzy logical relationships. For example, because the fuzzified TAIEX of 2004/1/2 is A 8 and because the fuzzified TAIEX of 2004/1/5 is A 9 , we can construct the following fuzzy logical relationship:
A 8 → A 9 .
In the same way, based on Table II, we can get the fuzzy logical relationships as shown in Table III.
TABLE II. F UZZIFIED TAIEX
Date Fuzzy Set
2004/1/2 A
82004/1/5 A
92004/1/6 A
9# #
2004/11/1 A
42004/11/2 A
5# #
2004/12/31 A
9TABLE III. F IRST -O RDER F UZZY L OGICAL R ELATIONSHIPS Date Fuzzy Logical Relationships 2004/1/2 → 2004/1/5 A
8→ A
92004/1/5 → 2004/1/6 A
9→ A
9# #
2004/10/28 → 2004/10/29 A
4→ A
5Step 5: Fuzzify the variation between the adjacent historical data of the main factor and the secondary factors, respectively, and then group the fuzzy logical relationships of the main factor. The sub-steps are shown as follows:
Step 5.1: Calculate the variation of the close index between the adjacent historical data, where the variation Var t on day t is calculated as follows:
Close % Close Close Var
t t t
t
100
1 1
×
= −
−
−
, (2)
where the terms Close t and Close t −1 are the close indices on the trading day t and trading day t −1, respectively, and the unit of the variation is the percentage. For example, from Table I, we can see that the TAIEX of 2004/1/2 and 2004/1/5 are 6041.56 and 6125.42, respectively. Based on Eq. (2), we can see that the variation of the TAIEX on 2004/1/5 is equal to
. % .
. 100
56 6041
56 6041 42
6125 − × = 1.388052 %. Table IV and Table V show the variation of the TAIEX, the Dow Jones, the NASDAQ and the M 1b of the training data and the testing data.
TABLE IV. T HE V ARIATION OF THE T RAINING D ATA OF TAIEX, THE
D OW J ONES , THE NASDAQ, AND THE M
1B(U NIT : %)
Date Variation of the TAIEX
Variation of the Dow Jones
Variation of the NASDAQ
Variation of the M
1b2004/1/5 1.388052 % 1.289356 % 2.027229 % -0.059403 % 2004/1/6 0.303489 % -0.051308 % 0.488922 % 0.162732 %
# # # # #
2004/10/29 0.182072 % 0.229196 % -0.037960 % 0.639198 %
TABLE V. T HE V ARIATION OF THE T ESTING D ATA OF TAIEX, THE D OW J ONES , THE NASDAQ AND THE M
1B(U NIT : %)
Date Variation of the TAIEX
Variation of the Dow Jones
Variation of the NASDAQ
Variation of the M
1b2004/11/1 -0.872075 % 0.268463 % 0.247090 % -0.348530 % 2004/11/2 1.828799 % -0.185591 % 0.248501 % 0.201512 %
# # # # #
2004/12/30 0.203170 % -0.266779 % 0.061553 % 0.979241 %
Step 5.2: Define the universe of discourse V, V = [E min , E max ], where E min and E max are the minimum and the maximum variation of the main factor and secondary factors, respectively.
It should be noted that the minimum and the maximum limited variations of the TAIEX are -7% and 7%, respectively, and the minimum and the maximum limited variations of the Dow Jones, the NASDAQ and the M 1b are not limited, respectively.
The universe of discourse V is defined as [- ∞, ∞]. We let the length of each interval between -6% and 6% be equal to 1.
Then, the universe of discourse V can be divided into 14 intervals v 1 , v 2 , …, and v 14 , where v 1 = [-∞, -6], v 2 = [-6, -5], …, and v 14 = [6, ∞], as shown in Table VI.
TABLE VI. 14 I NTERVALS IN THE U NIVERSE OF D ISCOURSE V (U NIT : %)
v
1= [-∞, -6] v
4= [-4, -3] v
7= [-1, 0] v
10= [2, 3] v
13= [5, 6]
v
2= [-6, -5] v
5= [-3, -2] v
8= [0, 1] v
11= [3, 4] v
14= [6, ∞]
v
3= [-5, -4] v
6= [-2, -1] v
9= [1, 2] v
12= [4, 5]
Step 5.3: Define the linguistic term B j represented by fuzzy sets, shown as follows:
B 1 = 1/v 1 + 0.5/v 2 + 0/v 3 +…+ 0/v m −2 + 0/v m −1 + 0/v m , B 2 = 0.5/v 1 + 1/v 2 + 0.5/v 3 +…+ 0/v m −2 + 0/v m −1 + 0/v m ,
#
B m = 0/v 1 + 0/v 2 + 0/v 3 +…+ 0/v m −2 + 0.5/v m −1 + 1/v m . where B 1 , B 2 , …, and B m are linguistic terms. For example, based on Table VI, we can define the linguistic terms B 1 , B 2 ,
…, and B 14 , shown as follows:
B 1 = 1/v 1 + 0.5/v 2 + 0/v 3 +…+ 0/v 12 + 0/v 13 + 0/v 14 , B 2 = 0.5/v 1 + 1/v 2 + 0.5/v 3 +…+ 0/v 12 + 0/v 13 + 0/v 14 ,
#
B 14 = 0/v 1 + 0/v 2 + 0/v 3 +…+ 0/v 12 + 0.5/v 13 + 1/v 14 .
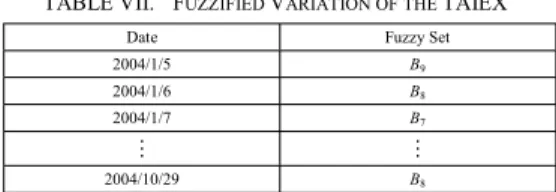
Step 5.4: Fuzzify each historical variation of the main factor into a fuzzy set defined in Step 5.2. If the historical variation of the main factor on day t belongs to v j , where 1 ≤ j ≤ m, then the historical variation of the main factor on day t is fuzzified into B j . For example, from Table IV, we can see that the variation of the TAIEX on 2004/1/5 is 1.388052%, which is fuzzified into B 9 . Table VII shows the fuzzified variation of the TAIEX of the training data.
TABLE VII. F UZZIFIED V ARIATION OF THE TAIEX
Date Fuzzy Set
2004/1/5 B
92004/1/6 B
82004/1/7 B
7# #
2004/10/29 B
8Step 5.5: Based on the linguistic terms of the fuzzified variations, group the fuzzy logical relationships having the same linguistic term of the fuzzified variation into a fuzzy logical relationship group. For example, let us consider the following fuzzy logical relationships: “A a1 → A aa ”, where the fuzzified variation is B z ; “A a1 → A ab ”, where the fuzzified variation is B z ; “A a1 → A ac ”, where the fuzzified variation is B z ; …; “A a1 → A ak ”, where the fuzzified variation is B z . Then, these fuzzy logical relationships can be grouped into the same fuzzy logical relationship group in which the fuzzified variation
of each fuzzy logical relationship in this group is B z , shown as follows:
A a1 → A aa , A ab , A ac , …, A ak .
For example, from Table III, we can see that the fuzzy logical relationship between the trading days 2004/1/2 and 2004/1/5 is A 8 → A 9 , from Table VII, we can see that the fuzzified variation on 2004/1/5 is B 9 ; so we can group the fuzzy logical relationship “A 8 → A 9 ” into the fuzzified variation B 9 group.
Table VIII shows the fuzzy logical relationship groups with respect to different fuzzified variations, respectively.
TABLE VIII. F UZZY L OGICAL R ELATIONSHIP G ROUPS B
1Group A
16→ A
11B
2Group A
5→ A
2A
9→ A
6B
3Group A
12→ A
9B
4Group A
6→ A
4A
8→ A
6B
5Group A
2→ A
1A
9→ A
7A
5→ A
3A
11→ A
9A
6→ A
5A
13→ A
12A
7→ A
5, A
6A
16→ A
14, A
15B
6Group A
2→ A
1A
9→ A
8A
4→ A
3, A
3, A
4, A
3A
11→ A
11, A
10A
5→ A
4, A
4, A
4A
14→ A
13, A
13A
6→ A
5, A
5, A
5, A
6A
16→ A
16, A
15A
7→ A
6, A
6A
17→ A
16A
8→ A
7A
18→ A
17B
7Group A
1→ A
1, A
1, A
1, A
1, A
1, A
1, A
1, A
1, A
1A
10→ A
10, A
10, A
10, A
10, A
9A
2→ A
1, A
1A
11→ A
11A
3→ A
3, A
3, A
2A
12→ A
12, A
12A
4→ A
4A
13→ A
13A
5→ A
5, A
5, A
5, A
5, A
5, A
5A
14→ A
14, A
13, A
14, A
14A
6→ A
6, A
6, A
5, A
6, A
6, A
6, A
6, A
6, A
6, A
5,
A
5A
15→ A
15, A
14A
7→ A
7, A
7, A
7, A
7, A
6, A
7, A
6, A
7A
16→ A
15A
8→ A
8A
17→ A
17, A
17A
9→ A
9, A
9, A
9, A
8B
8Group A
1→ A
1, A
1, A
1, A
1A
10→ A
10, A
10A
4→ A
5, A
4, A
4, A
4, A
5A
11→ A
11, A
11A
5→ A
5, A
6, A
5, A
5, A
6, A
5A
12→ A
12, A
12, A
13A
6→ A
7, A
6, A
6, A
6, A
6A
13→ A
13, A
14, A
14, A
13, A
13A
7→ A
7, A
7, A
7, A
7A
14→ A
14, A
14, A
14, A
15, A
14, A
14A
8→ A
8, A
8, A
9A
15→ A
16, A
15, A
15, A
16, A
15A
9→ A
9, A
9, A
10, A
10A
16→ A
16B
9Group A
1→ A
2, A
1, A
2, A
2A
10→ A
10, A
11, A
11A
2→ A
3A
11→ A
12A
3→ A
4, A
4A
12→ A
13A
4→ A
5A
14→ A
14A
5→ A
6, A
5, A
6, A
6A
15→ A
16, A
16A
6→ A
6, A
7, A
7, A
7, A
7A
16→ A
17A
7→ A
8A
17→ A
18, A
17A
8→ A
9, A
9B
10Group A
1→ A
2A
8→ A
9A
4→ A
6A
13→ A
14A
6→ A
7A
14→ A
15A
7→ A
8, A
8A
15→ A
16B
11Group A
2→ A
4A
5→ A
7A
3→ A
5A
13→ A
15B
13Group A
3→ A
6A
9→ A
12Step 6: Fuzzify the variation of the secondary factors and evaluate the linguistic terms of the main factor and the secondary factors, respectively, where the sub-steps are shown as follows:
Step 6.1: Select the secondary factors to fuzzify the
variation, such as singular kinds “the Dow Jones”, “the
NASDAQ” and “the M 1b ”; double kinds like “the Dow Jones
and the NASDAQ”, “the NASDAQ and the M 1b ” and “the
Dow Jones and M 1b ”; triple kinds like “the Dow Jones, the
NASDAQ and the M 1b ”. We let the variations of the Dow
Jones, the NASDAQ and the M 1b be denoted by Var Dow Jones ,
Var NASDAQ and Var M1b , respectively. The variation of the secondary factor Var s is calculated as follows:
Situation 1: If we use one secondary factor for prediction, the variation of the secondary factor Var s is calculated as follows:
(i) When using “the Dow Jones” for prediction, the variation of the secondary factor Var s = Var Dow Jones .
(ii) When using “the NASDAQ” for prediction, the variation of the secondary factor Var s = Var NASDAQ .
(iii) When using “the M 1b ” for prediction, the variation of the secondary factor Var s = Var M1b .
Situation 2: If we use two secondary factors for prediction, the variation of the secondary factor Var s is calculated as follows:
(i) When using “the Dow Jones and the NASDAQ” for prediction, the variation of the secondary factor Var s =
2
NASDAQ Dow JonesVar
Var + .
(ii) When using “the Dow Jones and the M 1b ” for prediction, the variation of the secondary factor Var s = Var
Dow Jones2 + Var
M1b.
(iii) When using “the NASDAQ and the M 1b ” for prediction, the variation of the secondary factor Var s = Var
NASDAQ2 + Var
M1b.
Situation 3: If we use three secondary factors “the Dow Jones, the NASDAQ and the M 1b ” for prediction, the variation of the secondary factor Var s = Var
Dow Jones+ Var 3
NASDAQ+ Var
M1b.
In the following, we use “the Dow Jones and the NASDAQ” as the secondary factor for prediction. For example, from Table IV, we can see that the variations of the Dow Jones and the NASDAQ of the trading day 2004/1/5 are 1.289356 % and 2.027229 %, therefore, the variation of the secondary factor Var s is equal to
2
NASDAQ Dow JonesVar
Var + = 1 . 289356 % + 2 2 . 027229 % =
2 316585
3 . % = 1.658292 %. Table IX shows the variation of the secondary factor Var s “the Dow Jones and the NASDAQ”.
TABLE IX. T HE V ARIATION OF THE S ECONDARY F ACTOR “ THE D OW J ONES AND THE NASDAQ”
Date t Var
t2004/1/5 1.658292 %
2004/1/6 0.218807 %
2004/1/7 0.447902 %
# #
2004/10/29 0.095618 %
Step 6.2: Fuzzify each variation of the secondary factor Var s into a fuzzy set defined in Step 5.2. If the variation of the secondary factor Var s belongs to v j , where 1 ≤ j ≤ m, then the variation of the secondary factor Var s is fuzzified into B j . For example, from Table IX, we can see that the variation of the secondary factor Var s of the secondary factor “the Dow Jones and the NASDAQ” on 2004/1/5 is 1.658292 %, which is fuzzified into B 9 . Table X shows the fuzzified variation Var s of the secondary factor “the Dow Jones and the NASDAQ”.
Step 6.3: Based on the linguistic terms of the fuzzified variations, group the fuzzy variation of the main factor on trading day t having the same linguistic term of the fuzzy variation of the secondary factor on trading t − 1. For example, let us consider the following fuzzy variation between the
secondary factor on trading day t − 1 and the main factor on trading day t: the fuzzy variation of the main factor on trading day t is “B b1 ” and the fuzzy variation of the secondary factor on trading day t − 1 is B z ; the fuzzy variation of the main factor on trading day t + m is “B b2 ” and the fuzzy variation of the secondary factor on trading day t + m − 1 is B z ; …; the fuzzy variation of the main factor on trading day t + n is “B bk ” and the fuzzy variation of the secondary factor on trading day t + n − 1 is B z . Then, these fuzzy variations of the main factor can be grouped into the same fuzzy variation group of the secondary factor in which each fuzzy variation of the secondary factor in this group is B z , shown as follows:
B b1 , B b2 , …, B bk .
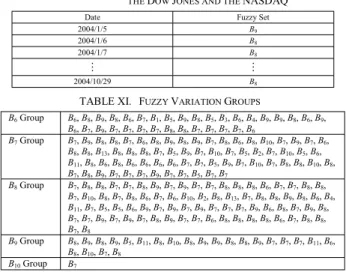
For example, from Table X and Table VII, we can see that the fuzzy variation of the secondary factor on 2004/1/5 is B 9 and the fuzzy variation of the main factor on 2004/1/6 is B 8 . We can then group the fuzzy variation of the main factor “B 8 ” into the fuzzified variation of the secondary factor B 9 group. Table XI shows the fuzzy variation groups with respect to different fuzzified variations of the secondary factor.
TABLE X. F UZZIFIED V ARIATIONS OF THE S ECONDARY F ACTOR
“ THE D OW J ONES AND THE NASDAQ”
Date Fuzzy Set
2004/1/5 B
92004/1/6 B
82004/1/7 B
8# #
2004/10/29 B
8TABLE XI. F UZZY V ARIATION G ROUPS
B
6Group B
6, B
8, B
9, B
8, B
6, B
7, B
1, B
5, B
9, B
8, B
5, B
3, B
6, B
4, B
9, B
9, B
8, B
6, B
9, B
6, B
7, B
9, B
7, B
7, B
7, B
7, B
8, B
8, B
7, B
7, B
7, B
7, B
6B
7Group B
7, B
9, B
8, B
8, B
7, B
6, B
8, B
9, B
8, B
9, B
7, B
8, B
6, B
8, B
10, B
7, B
9, B
7, B
6, B
8, B
8, B
13, B
8, B
8, B
8, B
7, B
5, B
9, B
7, B
10, B
7, B
5, B
2, B
7, B
10, B
5, B
6, B
11, B
8, B
6, B
8, B
6, B
6, B
6, B
6, B
7, B
7, B
5, B
9, B
7, B
10, B
7, B
8, B
8, B
10, B
8, B
7, B
8, B
9, B
7, B
7, B
7, B
9, B
7, B
7, B
5, B
7, B
7B
8Group B
7, B
8, B
8, B
7, B
7, B
8, B
9, B
7, B
9, B
7, B
7, B
8, B
8, B
8, B
6, B
7, B
7, B
8, B
8, B
7, B
10, B
8, B
7, B
8, B
6, B
7, B
6, B
10, B
2, B
8, B
13, B
7, B
8, B
8, B
9, B
8, B
6, B
4, B
11, B
7, B
5, B
5, B
6, B
9, B
7, B
9, B
7, B
9, B
7, B
7, B
7, B
9, B
6, B
8, B
7, B
9, B
8, B
7, B
7, B
9, B
7, B
9, B
7, B
8, B
9, B
7, B
7, B
6, B
8, B
8, B
8, B
8, B
6, B
7, B
8, B
8, B
7, B
8B
9Group B
8, B
9, B
8, B
9, B
5, B
11, B
8, B
10, B
8, B
9, B
9, B
8, B
8, B
9, B
7, B
7, B
7, B
11, B
6, B
8, B
10, B
7, B
8B
10Group B
7Step 6.4: Evaluate the linguistic terms of the fuzzy variation groups between the secondary factor and the main factor. Let the fuzzy variations of the main factor and the secondary factor be B M and B S , respectively, where M and S are positive numbers, 1 ≤ M ≤ 14 and 1 ≤ S ≤ 14. Let B S,1 be the static counter denoting the number of fuzzy variations in the B S
Group and M < S; let B S,2 be the static counter denoting the number of fuzzy variations in the B S Group and M = S; let B S,3
be the static counter denoting the number of fuzzy variations in the B S Group and M > S, where B S,1 , B S,2 and B S,3 are integers whose initial values are 0. Evaluate the fuzzy variation B S
groups in which the effect between the secondary factor and the main factor appear, described as follows:
Situation 1: In the B S Group, if M < S, then we can see that when the secondary factor is B S , the index M of the fuzzy variation of the main factor is less than S. We add one to the B S,1 when the secondary factor is B S and M < S.
Situation 2: In the B S Group, if M = S, then we can see that
when the secondary factor is B S , the index M of the fuzzy
variation of the main factor M is equal to S. We add one to the B S,2 when the secondary factor is B S and M = S.
Situation 3: In the B S Group, if M > S, then we can see that when the secondary factor is B S , the index M of the fuzzy variation of the main factor is bigger than S. We add one to the B S,3 when the secondary factor is B S and M > S.
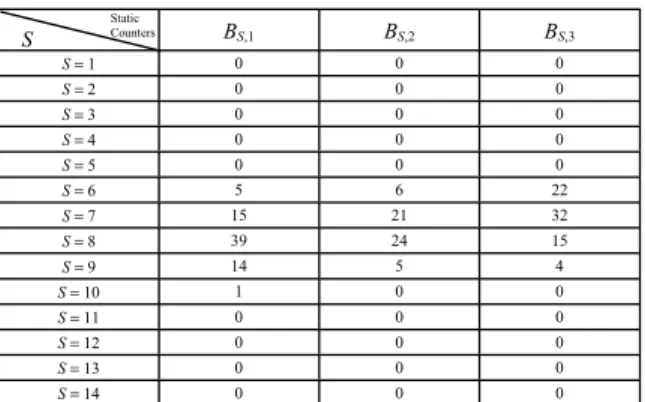
For example, we let the TAIEX be the main factor and let “the Dow Jones and the NASDAQ” be the secondary factor. From the B 6 Group shown in Table XI, we can see that the fuzzy variations of the main factor are B 6 , B 8 , B 9 , B 8 , B 6 , B 7 , B 1 , B 5 , B 9 , B 8 , B 5 , B 3 , B 6 , B 4 , B 9 , B 9 , B 8 , B 6 , B 9 , B 6 , B 7 , B 9 , B 7 , B 7 , B 7 , B 7 , B 8 , B 8 , B 7 , B 7 , B 7 , B 7 and B 6 . Because S is 6 and the situation when M < S are B 1 , B 5 , B 5 , B 3 and B 4 , the total number of fuzzy variations is 5, i.e., B 6,1 = 5. In the same way, the situation when M = S are B 6 , B 6 , B 6 , B 6 , B 6 and B 6 , the total number of fuzzy variations number is 6, i.e., B 6,2 = 6. In the same way, the situation when M > S are B 8 , B 9 , B 8 , B 7 , B 9 , B 8 , B 9 , B 9 , B 8 , B 9 , B 7 , B 9 , B 7 , B 7 , B 7 , B 7 , B 8 , B 8 , B 7 , B 7 , B 7 and B 7 , the total number of fuzzy variations is 22, i.e., B 6,3 = 22.
Table XII shows the statistics of the fuzzy variations of the secondary factor “the Dow Jones and the NASDAQ”, where the main factor is the TAIEX.
TABLE XII. T HE S TATISTICS OF THE F UZZY V ARIATIONS OF THE
S ECONDARY F ACTOR “ THE D OW J ONES AND THE NASDAQ”,
WHERE THE M AIN F ACTOR IS THE TAIEX
B
S,1B
S,2B
S,3S = 1 0 0 0
S = 2 0 0 0
S = 3 0 0 0
S = 4 0 0 0
S = 5 0 0 0
S = 6 5 6 22
S = 7 15 21 32
S = 8 39 24 15
S = 9 14 5 4
S = 10 1 0 0
S = 11 0 0 0
S = 12 0 0 0
S = 13 0 0 0
S = 14 0 0 0
Step 7: Define the weights of the fuzzy variation B s of the secondary factor when S > M, S = M, and S < M. According to Step 6.4 , we let B S,1 be the total number of times when the secondary factor is B S and S > M; let B S,2 be the total number of times when the secondary factor is B S and S = M; let B S,3 be the total number of times when the secondary factor is B S and S <
M. Let W Bs,1 , W Bs,2 and W Bs,3 be the weights of the fuzzy set B S at different situations, where W Bs,1 denotes the weight of B S when S > M; W Bs,2 denotes the weight of B S when S = M; W Bs,3 denotes the weight of B S when S < M. The weight of the fuzzy variation B S,k is calculated as follows:
,3 s ,2 s ,1 s
k , s k ,
Bs
B B B
W B
+
= + , (3)
where k is a positive integer and k = 1, 2, 3. For example, from Table XII, we can see that the number of times is 5 when the fuzzy variation is B 6 and S > M; the number of times is 6 when the fuzzy variation is B 6 and S = M; the number of times is 22 when the fuzzy variation is B 6 and S < M. Therefore, the weight W B6,1 is equal to
22 6 5
5 +
+ = 0.151515, the weight W B6,2 is equal to
22 6 5
6 +
+ = 0.181818, and the weight W B6,3 is equal to
22 6 5
22 +
+ =
0.666667. In summary, the weights of the fuzzy variation B j of the secondary factor are shown in Table XIII, where 1 ≤ j ≤ 14.
Step 8: Assume that the main factor F(t −1) = A i and assume that we want to predict the main factor F(t), where A i is a fuzzy set. Based on the fuzzy variation of the secondary factor F(t −1)
= B j , we choose the corresponding fuzzy variation B j of the weight of the secondary factor of the fuzzy logical relationship groups for prediction. Assume that the fuzzy variation of the secondary factor of the trading day t −1 is B j . We then choose the fuzzy logical relationship: “A i → A i1 , A i2 , …, A iz ” in the Group B j . Let u i1 L
, u i2 L
, …, and u iz L
be the minimum value of the intervals u i1 , u i2 , …, and u iz , respectively; let u i1 M
, u i2 M
, …, and u iz M
be the midpoints of the intervals u i1 , u i2 , …, and u iz , respectively; let u i1 R
, u i2 R
, …, and u iz R
be the maximum value of the intervals u i1 , u i2 , …, and u iz , respectively. The new value u a * of u a is calculated as follows:
u a * = W Bj,1 × u a L
+ W Bj,2 × u a M
+ W Bj,3 × u a R
, (4) where a = i1, i2, …, iz, and the forecasted value FV of day t is calculated as follows:
z
* u FV
iz i a ¦ a
= = 1 . (5)
TABLE XIII. T HE W EIGHTS OF THE F UZZY V ARIATION B
S,KOF THE
S ECONDARY F ACTOR
k = 1 k = 2 k = 3
W
B1,k0 0 0
W
B2,k0 0 0
W
B3,k0 0 0
W
B4,k0 0 0
W
B5,k0 0 0
W
B6,k0.151515 ʳ 0.181818 0.666667
W
B7,k0.220588 0.308824 0.470588
W
B8,k0.5 0.307692 0.192308
W
B9,k0.608696 0.217391 0.173913
W
B10,k1 0 0
W
B11,k0 0 0
W
B12,k0 0 0
W
B13,k0 0 0
W
B14,k0 0 0
For example, assume that we want to forecast the TAIEX of 2004/11/2 by the first order fuzzy logical relationships. From Table I and Table XIII we can see that because the TAIEX on 2004/11/1 is 5656.17 (Note: Its fuzzified TAIEX is A 4 ) and because from Table V, we can see that the variation of the Dow Jones and the NASDAQ on 2004/11/1 are 0.268463 % and 0.247090 %, respectively, based on Step 6.1, the variation of the secondary factor is
2
% 247090 0
% 268463
0 . + . = 0 . 515553 2 % = 0.257777
% and based on Table VI, we can see that the fuzzy variation of the secondary factor is B 8 . We choose the B 8 group shown in Table VIII, where the left-hand side of the fuzzy logical relationship “A 4 → A 5 , A 4 , A 4 , A 4 , A 5 ” is A 4 . The given weights u 5 and u 4 become u 5 * and u 4 *, respectively, for forecasting. The minimum value of the interval u 5 is 5700, the midpoint of the interval u 5 is 5750 and the maximum value of the interval u 5 is 5800. Based on Eq. (3), we can get the weight of B 8,1 = 0.5, the weight of B 8,2 = 0.307692 and the weight of B 8,3 = 0.192308.
Based on Eq. (4), the new value u 5 * of u 5 for prediction is calculated as follows: 5700 × 0.5 + 5750 × 0.307692 + 5800 × S
Static Counters
Weight of Fuzzy Set