开发指南
文档版本 01
发布日期 2021-04-20
版权所有 © 华为技术有限公司 2022。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 Flink 作业开发指南... 1
1.1 流生态作业开发指引... 1
1.2 Flink 作业开发基础样例...4
1.3 使用 Flink Jar 写入数据到 OBS 开发指南... 10
2 Spark 作业开发指南... 15
2.1 使用 Spark Jar 作业读取和查询 OBS 数据... 15
2.2 在 Spark SQL 作业中使用 UDF... 25
2.3 在 Spark SQL 作业中使用 UDTF... 32
2.4 使用 Beeline 提交 Spark SQL 作业... 40
2.5 使用 JDBC 或 ODBC 提交 Spark SQL 作业...45
2.5.1 获取服务端连接地址... 45
2.5.2 下载 JDBC 或 ODBC 驱动包... 45
2.5.3 认证... 46
2.5.4 使用 JDBC 提交作业... 47
2.5.5 使用 ODBC 提交作业... 53
2.5.6 JDBC API 参考...61
2.6 在 Spark SQL 作业中使用地理空间函数... 63
2.6.1 地理空间查询基本概念...63
2.6.2 DLI 支持的地理空间查询函数分类... 63
2.6.3 地理空间查询准备工作...64
2.6.4 地理构造函数... 64
2.6.5 地理访问函数... 69
2.6.6 地理转换函数... 73
2.6.7 地理编辑函数... 74
2.6.8 地理输出函数... 75
2.6.9 地理关系函数... 76
2.6.10 地理处理函数...81
2.7 使用 Spark 作业访问 DLI 元数据... 82
2.8 使用 Spark-submit 提交 Spark Jar 作业... 96
2.9 使用 Livy 提交 Spark Jar 作业...99
2.10 使用 Spark 作业跨源访问数据源...104
2.10.1 概述...104
2.10.2 对接 CSS... 104
2.10.2.1 CSS 安全集群配置... 104
2.10.2.2 scala 样例代码...106
2.10.2.3 pyspark 样例代码... 116
2.10.2.4 java 样例代码... 122
2.10.3 对接 DWS... 127
2.10.3.1 scala 样例代码...127
2.10.3.2 pyspark 样例代码... 136
2.10.3.3 java 样例代码... 139
2.10.4 对接 HBase... 140
2.10.4.1 MRS 配置... 140
2.10.4.2 scala 样例代码...141
2.10.4.3 pyspark 样例代码... 146
2.10.4.4 java 样例代码... 151
2.10.4.5 故障处理... 154
2.10.5 对接 OpenTSDB... 155
2.10.5.1 scala 样例代码...155
2.10.5.2 pyspark 样例代码... 159
2.10.5.3 java 样例代码... 161
2.10.5.4 故障处理... 163
2.10.6 对接 RDS... 163
2.10.6.1 scala 样例代码...163
2.10.6.2 pyspark 样例代码... 172
2.10.6.3 java 样例代码... 175
2.10.7 对接 Redis... 177
2.10.7.1 scala 样例代码...177
2.10.7.2 pyspark 样例代码... 183
2.10.7.3 java 样例代码... 186
2.10.7.4 故障处理... 188
2.10.8 对接 Mongo... 188
2.10.8.1 scala 样例代码...188
2.10.8.2 pyspark 样例代码... 192
2.10.8.3 java 样例代码... 195
3 第三方 BI 工具对接 DLI... 198
3.1 永洪 BI 对接 DLI 提交 Spark 作业... 198
3.1.1 永洪 BI 对接准备工作... 198
3.1.2 永洪 BI 添加数据源... 198
3.1.3 永洪 BI 创建数据集... 201
3.1.4 永洪 BI 制作图表...204
1 Flink 作业开发指南
1.1 流生态作业开发指引
概述
流生态系统基于Flink和Spark双引擎,完全兼容Flink/Storm/Spark开源社区版本接 口,并且在此基础上做了特性增强和性能提升,为用户提供易用、低时延、高吞吐的 数据湖探索。
数据湖探索的流生态开发包括云服务生态、开源生态和自拓展生态:
● 云服务生态
DLI服务在Stream SQL中支持与其他服务的连通。用户可以直接使用SQL从这些服 务中读写数据,如DIS、OBS、CloudTable、MRS、RDS、SMN、DCS等。
● 开源生态
通过对等连接建立与其他VPC的网络连接后,用户可以在DLI的租户独享集群中访 问所有Flink和Spark支持的数据源与输出源,如Kafka、Hbase、ElasticSearch 等。
● 自拓展生态
用户可通过编写代码实现从想要的云生态或者开源生态获取数据,作为Flink作业 的输入数据。
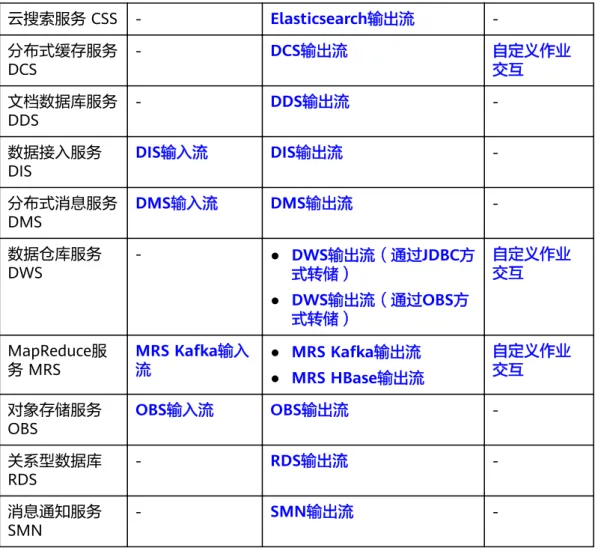
云服务生态开发
表1-1 云服务生态开发一览表
数据源 SQL 自定义作业
输入流:从其他 服务或数据库中 获取数据
输出流:将处理后的数据写入 到其他服务或数据库中
表格存储服务
CloudTable HBase输入流 ● HBase输出流
● OpenTSDB输出流
-
云搜索服务 CSS - Elasticsearch输出流 - 分布式缓存服务
DCS - DCS输出流 自定义作业
交互 文档数据库服务
DDS - DDS输出流 -
数据接入服务
DIS DIS输入流 DIS输出流 -
分布式消息服务
DMS DMS输入流 DMS输出流 -
数据仓库服务
DWS - ● DWS输出流(通过JDBC方
式转储)
● DWS输出流(通过OBS方 式转储)
自定义作业 交互
MapReduce服
务 MRS MRS Kafka输入
流 ● MRS Kafka输出流
● MRS HBase输出流
自定义作业 交互 对象存储服务
OBS OBS输入流 OBS输出流 -
关系型数据库
RDS - RDS输出流 -
消息通知服务
SMN - SMN输出流 -
开源生态开发
表1-2 开源生态开发一览表
数据源 SQL 自定义作业
输入流 输出流
Apache
Kafka 开源Kafka输入流 开源Kafka输出流 -
自拓展生态开发
表1-3 自拓展生态开发一览表
数据源 SQL 自定义作业
输入流 输出流
自拓展 自拓展输入流 自拓展输出流 -
流生态开发支持的数据格式
DLI Flink作业支持如下数据格式:
Avro,Avro_merge,BLOB,CarbonData,CSV,EMAIL,JSON,ORC,Parquet,
XML。
表1-4 数据格式和支持的输入输出流
数据格式 支持的输入流 支持的输出流
Avro - OBS输出流
Avro_merge - OBS输出流
BLOB ● DIS输入流
● MRS Kafka输入流
● 开源Kafka输入流
-
CarbonData - OBS输出流
CSV ● DIS输入流
● OBS输入流
● 开源Kafka输入流
● DIS输出流
● OBS输出流
● DWS输出流(通过OBS方式 转储)
● 开源Kafka输出流
● 文件系统输出流
EMAIL DIS输入流 -
JSON ● DIS输入流
● OBS输入流
● MRS Kafka输入流
● 开源Kafka输入流
● DIS输出流
● OBS输出流
● MRS Kafka输出流
● 开源Kafka输出流
ORC - ● OBS输出流
● DWS输出流(通过OBS方式 转储)
Parquet - ● OBS输出流
● 文件系统输出流
XML DIS输入流 -
1.2 Flink 作业开发基础样例
概述
用户可以基于Flink和Spark的API进行二次开发,构建自己的应用Jar包,提交到DLI队 列运行,实现与MRS Kafka、HBase、Hive、HDFS,DWS,DCS等数据源的交互。
本章节以通过自定义作业与MRS进行交互为例进行说明。更多样例代码请通过DLI样例 代码获取。
环境准备
1. 登录MRS管理控制台,创建MRS集群,选择“开启kerberos”,勾选“kafka”,
“hbase”, “hdfs”等。“安全组规则”开通对应UDP/TCP端口。
2. 进入MRS manager管理界面:
a. 创建机机账号,需确保该用户含有“hdfs_admin”, “hbase_admin”权 限,下载该用户认证凭据,其中包含“user.keytab” 和 “krb5.conf” 文 件。
说明
由于人机账号的keytab会随用户密码过期而失效,故建议使用机机账号进行配置。
b. 单击“服务管理”,下载客户端,单击“确定”。
c. 在MRS节点上下载配置文件,所需集群配置文件包含“hbase-site.xml”和
“hiveclient.properties”。
3. 创建DLI独享队列。
关于如何创建DLI独享队列,在购买队列时,选择“按需计费”,勾选“专属资源 模式”即可。具体操作请参见《数据湖探索用户指南》中创建队列章节。
4. 使用该DLI独享队列与MRS集群建立增强型跨源连接,且用户可以根据实际所需设 置相应安全组规则。
如何建立增强型跨源连接,请参考《数据湖探索用户指南》中增强型跨源连接章 节。
如何设置安全组规则,请参见《虚拟私有云用户指南》中“安全组”章节。
5. 获取MRS集群全部节点的ip和域名映射,在DLI跨源连接修改主机信息中配置host 映射。
如何添加IP域名映射,请参见《数据湖探索用户指南》中“修改主机信息”章 节。
说明
Kafka服务端的端口如果监听在hostname上,则需要将Kafka Broker节点的hostname和IP 的对应关系添加到DLI队列中。Kafka Broker节点的hostname和IP请联系Kafka服务的部署 人员。
前提条件
● 确保已创建独享队列。
● 用户运行Flink Jar作业时,需要将二次开发的应用代码构建为Jar包,上传到已经 创建的OBS桶中。并在DLI“数据管理”>“程序包管理”页面创建程序包,具体 请参考创建程序包。
说明
DLI不支持下载功能,如果需要更新已上传的数据文件,可以将本地文件更新后重新上传。
● 由于DLI服务端已经内置了Flink的依赖包,并且基于开源社区版本做了安全加固。
为了避免依赖包兼容性问题或日志输出及转储问题,打包时请注意排除以下文 件:
– 系统内置的依赖包,或者在Maven或者Sbt构建工具中将scope设为provided – 日志配置文件(例如:“log4j.properties”或者“logback.xml”等)
– 日志输出实现类JAR包(例如:log4j等)
使用方法
创建并提交Flink jar作业,详细操作步骤请参见《数据湖探索用户指南》中创建Flink Jar作业章节。
步骤1 在DLI管理控制台的左侧导航栏中,单击“作业管理”>“Flink作业”,进入“Flink作 业”页面。
步骤2 在“Flink作业”页面右上角单击“新建作业”,弹出“新建作业”对话框。
图1-1 新建 Flink Jar 作业
步骤3 配置作业信息。
表1-5 作业配置信息
参数 参数说明
类型 选择Flink Jar。
名称 作业名称,只能由英文、中文、数字、中划线和下划线组成,并且长度 为1~57字节。
说明
作业名称必须是唯一的。
描述 作业的相关描述,且长度为0~512字节。
参数 参数说明
标签 使用标签标识云资源。包括“标签键”和“标签值”。如果您需要使用 同一标签标识多种云资源,即所有服务均可在标签输入框下拉选择同一 标签,建议在标签管理服务(TMS)中创建预定义标签。具体请参考
《标签管理服务用户指南》。
说明
● 最多支持10个标签。
● 一个“键”只能添加一个“值”。
● 标签键:在输入框中输入标签键名称。
说明
– 标签键的最大长度为36个字符 ,不能包含“=”,“*”,“,”,“<”,“>”,
“\”,“|”,“/”,且首尾字符不能为空格。
– 若有预定义标签,可在输入框的下拉列表中进行选择。
● 标签值:在输入框中输入标签值。
说明
– 标签值的最大长度为43个字符,不能包含“=”,“*”,“,”,“<”,“>”,
“\”,“|”,“/”,且首尾字符不能为空格。
– 若有预定义标签,可在输入框的下拉列表中进行选择。
步骤4 单击“确定”,进入“编辑”页面。
步骤5 选择队列。Flink Jar作业只能运行在通用队列上。
说明
● Flink Jar作业只能运行在预先创建的独享队列上。
● 如果“所属队列”下拉框中无可用的独享队列,请先创建一个独享队列并将该队列绑定到当 前用户。
图1-2 选择队列
步骤6 上传Jar包。
图1-3 上传 Jar 包
表1-6 参数说明
名称 描述
应用程序 用户自定义的程序包。在选择程序包之前需要将对应的Jar包上传至 OBS桶中,并在“数据管理>程序包管理”中创建程序包,,具体请 参考创建程序包。
主类 指定加载的Jar包类名,如KafkaMessageStreaming。
● 默认:根据Jar包文件的Manifest文件指定。
● 指定:必须输入“类名”并确定类参数列表(参数间用空格分 隔)。
说明
当类属于某个包时,需携带包路径,例如:
packagePath.KafkaMessageStreaming
参数 指定类的参数列表,参数之间使用空格分隔。
依赖jar包 用户自定义的依赖程序包。在选择程序包之前需要将对应的Jar包上 传至OBS桶中,并在“数据管理>程序包管理”中创建程序包,包类 型选择“jar”,具体请参考创建程序包。
名称 描述
其他依赖文件 用户自定义的依赖文件。在选择依赖文件之前需要将对应的文件上 传至OBS桶中,并在“数据管理>程序包管理”中创建程序包,包类 型没有限制,具体请参考创建程序包。
通过在应用程序中添加以下内容可访问对应的依赖文件。其中,
“fileName”为需要访问的文件名,“ClassName”为需要访问该 文件的类名。
ClassName.class.getClassLoader().getResource("userData/fileName")
作业特性 队列为CCE队列时,显示该参数。
● 基础型
● 自定义镜像:选择镜像名称和镜像版本。用户可在“容器镜像服 务”设置的镜像。具体操作请参考《容器镜像服务用户指南》。
Flink版本 选择Flink版本前,需要先选择所属的队列。当前支持“1.10”和
“1.11”版本。
步骤7 配置作业参数。
图1-4 配置参数
表1-7 参数说明
名称 描述
CU数量 一个CU为1核4G的资源量。CU数量范围为2~400个。
管理单元 设置管理单元的CU数,支持设置1~4个CU,默认值为1个CU。
名称 描述
最大并行数 作业中每个算子的最大并行数。
说明
● 并行数不能大于计算单元(CU数量-管理单元CU数量)的4倍。
● 并行数最好大于用户作业里设置的并发数,否则有可能提交失败。
TaskMana
ger配置 用于设置TaskManager资源参数。
勾选后需配置下列参数:
● “单TM所占CU数”:每个TaskManager占用的资源数量。
● “单TM Slot”:每个TaskManager包含的Slot数量。
保存作业日
志 设置是否将作业运行时的日志信息保存到OBS。
勾选后需配置下列参数:
“OBS桶”:选择OBS桶用于保存用户作业日志信息。如果选择的 OBS桶是未授权状态,需要单击“OBS授权”。
作业异常告 警
设置是否将作业异常告警信息,如作业出现运行异常或者欠费情况,
以SMN的方式通知用户。
勾选后需配置下列参数:
“SMN主题”:
选择一个自定义的SMN主题。如何自定义SMN主题,请参见《消息通 知服务用户指南》中“创建主题”章节。
异常自动重 启
设置是否启动异常自动重启功能,当作业异常时将自动重启并恢复作 业。
勾选后需配置下列参数:
● “异常重试最大次数”:配置异常重试最大次数。单位为“次/小 时”。
– 无限:无限次重试。
– 有限:自定义重试次数。
● “从Checkpoint恢复”:从保存的checkpoint恢复作业。
勾选该参数后,还需要选择“Checkpoint路径”。
“Checkpoint路径”:选择checkpoint保存路径。必须和应用程序 中配置的Checkpoint地址相对应。且不同作业的路径不可一致,否 则无法获取准确的Checkpoint。
步骤8 单击右上角“保存”,保存作业和相关参数。
步骤9 单击右上角“启动”,进入“启动Flink作业”页面,确认作业规格和费用,单击“立 即启动”,启动作业。
启动作业后,系统将自动跳转到Flink作业管理页面,新创建的作业将显示在作业列表 中,在“状态”列中可以查看作业状态。作业提交成功后,状态将由“提交中”变为
“运行中”。运行完成后显示“已完成”。
如果作业状态为“提交失败”或“运行异常”,表示作业提交或运行失败。用户可以 在作业列表中的“状态”列中,将鼠标移动到状态图标上查看错误信息,单击 可以 复制错误信息。根据错误信息解决故障后,重新提交。
说明
其他功能按钮说明如下:
另存为:将新建作业另存为一个新作业。
----结束
1.3 使用 Flink Jar 写入数据到 OBS 开发指南
概述
DLI提供了使用自定义Jar运行Flink作业并将数据写入到OBS的能力。本章节JAVA样例 代码演示将kafka数据处理后写入到OBS,具体参数配置请根据实际环境修改。
环境准备
已安装和配置IntelliJ IDEA等开发工具以及安装JDK和Maven。
说明
● Maven工程的pom.xml文件配置请参考JAVA样例代码中“pom文件配置”说明。
● 确保本地编译环境可以正常访问公网。
JAVA 样例代码
● pom文件配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/
maven-4.0.0.xsd">
<parent>
<artifactId>Flink-demo</artifactId>
<groupId>com.huaweicloud</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-kafka-to-obs</artifactId>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--Flink 版本-->
<flink.version>1.10.0</flink.version>
<!--JDK 版本-->
<java.version>1.8</java.version>
<!--Scala 2.11 版本-->
<scala.binary.version>2.11</scala.binary.version>
<slf4j.version>2.13.3</slf4j.version>
<log4j.version>2.10.0</log4j.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- logging -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-jcl</artifactId>
<version>${log4j.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
<mainClass>com.huaweicloud.dli.FlinkKafkaToObsExample</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
<resources>
<resource>
<directory>../main/config</directory>
<filtering>true</filtering>
<includes>
<include>**/*.*</include>
</includes>
</resource>
</resources>
</build>
</project>
● 示例代码
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import
org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import
org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.OnCheckpointRollingPolicy;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
/** * @author xxx * @date 6/26/21
*/ public class FlinkKafkaToObsExample {
private static final Logger LOG = LoggerFactory.getLogger(FlinkKafkaToObsExample.class);
public static void main(String[] args) throws Exception {
LOG.info("Start Kafka2OBS Flink Streaming Source Java Demo.");
ParameterTool params = ParameterTool.fromArgs(args);
LOG.info("Params: " + params.toString());
// Kafka连接地址 String bootstrapServers;
// Kafka消费组 String kafkaGroup;
// Kafka topic String kafkaTopic;
// 消费策略,只有当分区没有Checkpoint或者Checkpoint过期时,才会使用此配置的策略;
// 如果存在有效的Checkpoint,则会从此Checkpoint开始继续消费 // 取值有: LATEST,从最新的数据开始消费,此策略会忽略通道中已有数据 // EARLIEST,从最老的数据开始消费,此策略会获取通道中所有的有效数据 String offsetPolicy;
// OBS文件输出路径,格式obs://ak:sk@obsEndpoint/bucket/path String outputPath;
// Checkpoint输出路径,格式obs://ak:sk@obsEndpoint/bucket/path String checkpointPath;
bootstrapServers = params.get("bootstrap.servers", "xxxx:9092,xxxx:9092,xxxx:9092");
kafkaGroup = params.get("group.id", "test-group");
kafkaTopic = params.get("topic", "test-topic");
offsetPolicy = params.get("offset.policy", "earliest");
outputPath = params.get("output.path", "obs://ak:[email protected]:
443/bucket/output");
checkpointPath = params.get("checkpoint.path", "obs://ak:[email protected] north-1.huaweicloud.com:443/bucket/checkpoint");
try {
// 创建执行环境
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
RocksDBStateBackend rocksDbBackend = new RocksDBStateBackend(new FsStateBackend(checkpointPath), true);
streamEnv.setStateBackend(rocksDbBackend);
// 开启Flink CheckPoint配置,开启时若触发CheckPoint,会将Offset信息同步到Kafka streamEnv.enableCheckpointing(300000);
// 设置两次checkpoint的最小间隔时间
streamEnv.getCheckpointConfig().setMinPauseBetweenCheckpoints(60000);
// 设置checkpoint超时时间
streamEnv.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置checkpoint最大并发数
streamEnv.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 设置作业取消时保留checkpoint
streamEnv.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// Source: 连接kafka数据源
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", bootstrapServers);
properties.setProperty("group.id", kafkaGroup);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, offsetPolicy);
String topic = kafkaTopic;
// 创建kafka consumer
FlinkKafkaConsumer<String> kafkaConsumer =
new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties);
/**
* 从 Kafka brokers 中的 consumer 组(consumer 属性中的 group.id 设置)提交的偏移量中开始 读取分区。
* 如果找不到分区的偏移量,那么将会使用配置中的 auto.offset.reset 设置。
* 详情 https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/connectors/
datastream/kafka/
*/
kafkaConsumer.setStartFromGroupOffsets();
//将kafka 加入数据源 DataStream<String> stream =
streamEnv.addSource(kafkaConsumer).setParallelism(3).disableChaining();
// 创建文件输出流
final StreamingFileSink<String> sink = StreamingFileSink // 指定文件输出路径与行编码格式
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")) // 指定文件输出路径批量编码格式,以parquet格式输出
//.forBulkFormat(new Path(outputPath), ParquetAvroWriters.forGenericRecord(schema)) // 指定自定义桶分配器
.withBucketAssigner(new DateTimeBucketAssigner<>()) // 指定滚动策略
.withRollingPolicy(OnCheckpointRollingPolicy.build()) .build();
// Add sink for DIS Consumer data source
stream.addSink(sink).disableChaining().name("obs");
// stream.print();
streamEnv.execute();
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
} }
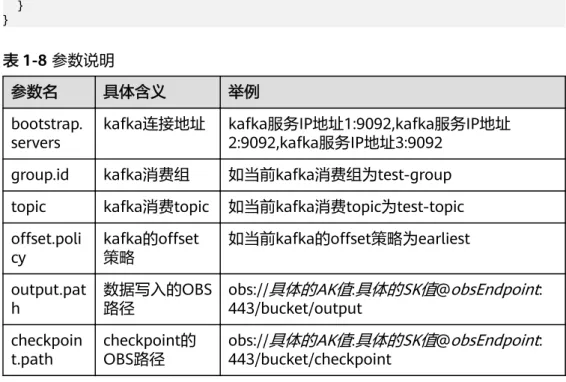
表1-8 参数说明
参数名 具体含义 举例
bootstrap.
servers kafka连接地址 kafka服务IP地址1:9092,kafka服务IP地址 2:9092,kafka服务IP地址3:9092
group.id kafka消费组 如当前kafka消费组为test-group topic kafka消费topic 如当前kafka消费topic为test-topic offset.poli
cy kafka的offset
策略 如当前kafka的offset策略为earliest output.pat
h 数据写入的OBS
路径 obs://具体的AK值:具体的SK值@obsEndpoint: 443/bucket/output
checkpoin
t.path checkpoint的
OBS路径 obs://具体的AK值:具体的SK值@obsEndpoint: 443/bucket/checkpoint
编译运行
应用程序开发完成后,参考Flink作业开发基础样例将编译打包的JAR包上传到DLI运 行,查看对应OBS路径下是否有相关的数据信息。
2 Spark 作业开发指南
2.1 使用 Spark Jar 作业读取和查询 OBS 数据
操作场景
DLI完全兼容开源的Apache Spark,支持用户开发应用程序代码来进行作业数据的导 入、查询以及分析处理。本示例从编写Spark程序代码读取和查询OBS数据、编译打包 到提交Spark Jar作业等完整的操作步骤说明来帮助您在DLI上进行作业开发。
环境准备
在进行Spark Jar作业开发前,请准备以下开发环境。
表2-1 Spark Jar 作业开发环境
准备项 说明
操作系统 Windows系统,支持Windows7以上版本。
安装JDK JDK使用1.8版本。
安装和配置IntelliJ
IDEA IntelliJ IDEA为进行应用开发的工具,版本要求使用2019.1 或其他兼容版本。
安装Maven 开发环境的基本配置。用于项目管理,贯穿软件开发生命周 期。
开发流程
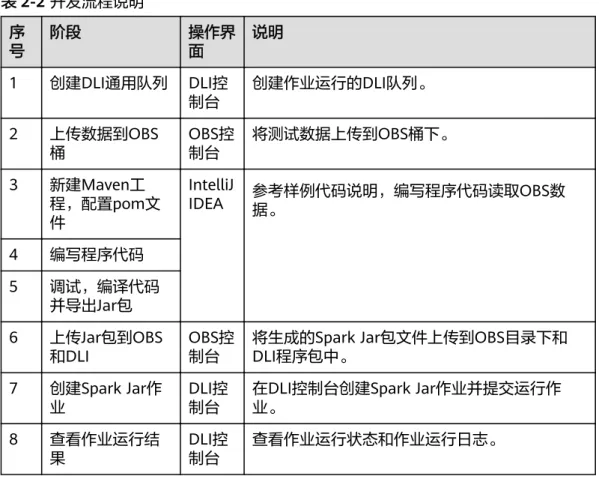
DLI进行Spark Jar作业开发流程参考如下:
图2-1 Spark Jar 作业开发流程
表2-2 开发流程说明 序
号
阶段 操作界
面
说明
1 创建DLI通用队列 DLI控
制台 创建作业运行的DLI队列。
2 上传数据到OBS
桶 OBS控
制台 将测试数据上传到OBS桶下。
3 新建Maven工 程,配置pom文 件
IntelliJ
IDEA 参考样例代码说明,编写程序代码读取OBS数 据。
4 编写程序代码 5 调试,编译代码
并导出Jar包 6 上传Jar包到OBS
和DLI OBS控
制台
将生成的Spark Jar包文件上传到OBS目录下和 DLI程序包中。
7 创建Spark Jar作 业
DLI控 制台
在DLI控制台创建Spark Jar作业并提交运行作 业。
8 查看作业运行结 果
DLI控 制台
查看作业运行状态和作业运行日志。
步骤 1:创建 DLI 通用队列
第一次提交Spark作业,需要先创建队列,例如创建名为“sparktest”的队列,队列类 型选择为“通用队列”。
1. 在DLI管理控制台的左侧导航栏中,选择“队列管理”。
2. 单击“队列管理”页面右上角“购买队列”进行创建队列。
3. 创建名为“sparktest”的队列,队列类型选择为“通用队列”。创建队列详细介 绍请参考创建队列。
4. 单击“立即购买”,确认配置。
5. 配置确认无误,单击“提交”完成队列创建。
步骤 2:上传数据到 OBS 桶
1. 根据如下数据,创建people.json文件。
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2. 进入OBS管理控制台,在“桶列表”下,单击已创建的OBS桶名称,本示例桶名 为“dli-test-obs01”,进入“概览”页面。
3. 单击左侧列表中的“对象”,选择“上传对象”,将people.json文件上传到OBS 桶根目录下。
4. 在OBS桶根目录下,单击“新建文件夹”,创建名为“result”的文件夹。
5. 单击“result”的文件夹,在“result”下单击“新建文件夹”,创建名为
“parquet”的文件夹。
步骤 3:新建 Maven 工程,配置 pom 依赖
以下通过IntelliJ IDEA 2020.2工具操作演示。
1. 打开IntelliJ IDEA,选择“File > New > Project”。
图2-2 新建 Project
2. 选择Maven,Project SDK选择1.8,单击“Next”。
3. 定义样例工程名和配置样例工程存储路径,单击“Finish”完成工程创建。
如上图所示,本示例创建Maven工程名为:SparkJarObs,Maven工程路径为:
“D:\DLITest\SparkJarObs”。
4. 在pom.xml文件中添加如下配置。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
</dependencies>
图2-3 修改 pom.xml 文件
5. 在工程路径的“src > main > java”文件夹上鼠标右键,选择“New >
Package”,新建Package和类文件。
Package根据需要定义,本示例定义为:“com.huawei.dli.demo”,完成后回 车。
在包路径下新建Java Class文件,本示例定义为:SparkDemoObs。
步骤 4:编写代码
编写SparkDemoObs程序读取OBS桶下的1的“people.json”文件,并创建和查询临时 表“people”。
完整的样例请参考完整样例代码参考,样例代码分段说明如下:
1. 导入依赖的包。
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
2. 通过当前帐号的AK和SK创建SparkSession会话spark 。
SparkSession spark = SparkSession .builder()
.config("spark.hadoop.fs.obs.access.key", "xxx") .config("spark.hadoop.fs.obs.secret.key", "yyy") .appName("java_spark_demo")
.getOrCreate();
– "spark.hadoop.fs.obs.access.key"参数对应的值"xxx"需要替换为帐号的AK 值。
– "spark.hadoop.fs.obs.secret.key"参数对应的值“yyy”需要替换为帐号的SK 值。
AK和SK值获取请参考:如何获取AK和SK。
3. 读取OBS桶中的“people.json”文件数据。
其中“dli-test-obs01”为演示的OBS桶名,请根据实际的OBS桶名替换。
Dataset<Row> df = spark.read().json("obs://dli-test-obs01/people.json");
df.printSchema();
4. 通过创建临时表“people”读取文件数据。
df.createOrReplaceTempView("people");
5. 查询表“people”数据。
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
6. 将表“people”数据以parquet格式输出到OBS桶的“result/parquet”目录下。
sqlDF.write().mode(SaveMode.Overwrite).parquet("obs://dli-test-obs01/result/parquet");
spark.read().parquet("obs://dli-test-obs01/result/parquet").show();
7. 关闭SparkSession会话spark。
spark.stop();
步骤 5:调试、编译代码并导出 Jar 包
1. 单击IntelliJ IDEA工具右侧的“Maven”,参考下图分别单击“clean”、
“compile”对代码进行编译。
编译成功后,单击“package”对代码进行打包。
打包成功后,生成的Jar包会放到target目录下,以备后用。本示例将会生成到:
“D:\DLITest\SparkJarObs\target”下名为“SparkJarObs-1.0- SNAPSHOT.jar”。
步骤 6:上传 Jar 包到 OBS 和 DLI 下
1. 登录OBS控制台,将生成的“SparkJarObs-1.0-SNAPSHOT.jar”Jar包文件上传到 OBS路径下。
2. 将Jar包文件上传到DLI的程序包管理中,方便后续统一管理。
a. 登录DLI管理控制台,单击“数据管理 > 程序包管理”。
b. 在“程序包管理”页面,单击右上角的“创建”创建程序包。
c. 在“创建程序包”对话框,配置以下参数。
i. 包类型:选择“JAR”。
ii. OBS路径:程序包所在的OBS路径。
iii. 分组设置和组名称根据情况选择设置,方便后续识别和管理程序包。
d. 单击“确定”,完成创建程序包。
步骤 7:创建 Spark Jar 作业
1. 登录DLI控制台,单击“作业管理 > Spark作业”。
2. 在“Spark作业”管理界面,单击“创建作业”。
3. 在作业创建界面,配置对应作业运行参数。具体说明如下:
– 所属队列:选择已创建的DLI通用队列。例如当前选择步骤1:创建DLI通用队 列创建的通用队列“sparktest”。
– 作业名称(--name):自定义Spark Jar作业运行的名称。当前定义为:
SparkTestObs。
– 应用程序:选择步骤6:上传Jar包到OBS和DLI下中上传到DLI程序包。例如 当前选择为:“SparkJarObs-1.0-SNAPSHOT.jar”。
– 主类:格式为:程序包名+类名。例如当前为:
com.huawei.dli.demo.SparkDemoObs。
其他参数可暂不选择,想了解更多Spark Jar作业提交说明可以参考创建Spark作 业。
图2-4 创建 Spark Jar 作业
4. 单击“执行”,提交该Spark Jar作业。在Spark作业管理界面显示已提交的作业运 行状态。
步骤 8:查看作业运行结果
1. 在Spark作业管理界面显示已提交的作业运行状态。初始状态显示为“启动中”。
2. 如果作业运行成功则作业状态显示为“已成功”,单击“操作”列“更多”下的
“Driver日志”,显示当前作业运行的日志。
图2-5 “Driver 日志”中的作业执行日志
3. 如果作业运行成功,本示例进入OBS桶下的“result/parquet”目录,查看已生成 预期的parquet文件。
4. 如果作业运行失败,单击“操作”列“更多”下的“Driver日志”,显示具体的报 错日志信息,根据报错信息定位问题原因。
例如,如下截图信息因为创建Spark Jar作业时主类名没有包含包路径,报找不到 类名“SparkDemoObs”。
可以在“操作”列,单击“编辑”,修改“主类”参数为正确的:
com.huawei.dli.demo.SparkDemoObs,单击“执行”重新运行该作业即可。
后续指引
● 如果您想通过Spark Jar作业访问其他数据源,请参考《使用Spark作业跨源访问 数据源》。
● 如果您想通过Spark Jar作业在DLI创建数据库和表,请参考《使用Spark作业访问 DLI元数据》。
完整样例代码参考
package com.huawei.dli.demo;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
public class SparkDemoObs {
public static void main(String[] args) { SparkSession spark = SparkSession .builder()
.config("spark.hadoop.fs.obs.access.key", "xxx") .config("spark.hadoop.fs.obs.secret.key", "yyy") .appName("java_spark_demo")
.getOrCreate();
// can also be used --conf to set the ak sk when submit the app // test json data:
// {"name":"Michael"}
// {"name":"Andy", "age":30}
// {"name":"Justin", "age":19}
Dataset<Row> df = spark.read().json("obs://dli-test-obs01/people.json");
df.printSchema();
// root
// |-- age: long (nullable = true) // |-- name: string (nullable = true)
// Displays the content of the DataFrame to stdout df.show();
// +----+---+
// | age| name|
// +----+---+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+---+
// Select only the "name" column df.select("name").show();
// +---+
// | name|
// +---+
// |Michael|
// | Andy|
// | Justin|
// +---+
// Select people older than 21 df.filter(col("age").gt(21)).show();
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show();
// +----+---+
// | age|count|
// +----+---+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+---+
// Register the DataFrame as a SQL temporary view df.createOrReplaceTempView("people");
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
// +----+---+
// | age| name|
// +----+---+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+---+
sqlDF.write().mode(SaveMode.Overwrite).parquet("obs://dli-test-obs01/result/parquet");
spark.read().parquet("obs://dli-test-obs01/result/parquet").show();
spark.stop();
} }
2.2 在 Spark SQL 作业中使用 UDF
操作场景
DLI支持用户使用Hive UDF(User Defined Function,用户定义函数)进行数据查询 等操作,UDF只对单行数据产生作用,适用于一进一出的场景。
约束限制
● 在DLI Console上执行UDF相关操作时,需要使用自建的SQL队列。
● 跨账号使用UDF时,除了创建UDF函数的用户,其他用户如果需要使用时,需要 先进行授权才可使用对应的UDF函数。授权操作参考如下:
登录DLI管理控制台,选择“ 数据管理 > 程序包管理”页面,选择对应的UDF Jar 包,单击“操作”列中的“权限管理”,进入权限管理页面,单击右上角“授 权”,勾选对应权限。
环境准备
在进行UDF开发前,请准备以下开发环境。
表2-3 UDF 开发环境
准备项 说明
操作系统 Windows系统,支持Windows7以上版本。
安装JDK JDK使用1.8版本。
安装和配置IntelliJ
IDEA IntelliJ IDEA为进行应用开发的工具,版本要求使用2019.1 或其他兼容版本。
安装Maven 开发环境的基本配置。用于项目管理,贯穿软件开发生命周 期。
开发流程
DLI下UDF函数开发流程参考如下:
图2-6 开发流程
表2-4 开发流程说明 序
号
阶段 操作界
面
说明
1 新建Maven工 程,配置pom文 件
IntelliJ
IDEA 参考操作步骤说明,编写UDF函数代码。
2 编写UDF函数代码 3 调试,编译代码并
导出Jar包
4 上传Jar包到OBS OBS控 制台
将生成的UDF函数Jar包文件上传到OBS目录 下。
5 创建DLI的UDF函 数
DLI控 制台
在DLI控制台的SQL作业管理界面创建使用的 UDF函数。
6 验证和使用DLI的
UDF函数 DLI控 制台
在DLI作业中使用创建的UDF函数。
操作步骤
1. 新建Maven工程,配置pom文件。以下通过IntelliJ IDEA 2020.2工具操作演示。
a. 打开IntelliJ IDEA,选择“File > New > Project”。
图2-7 新建 Project
b. 选择Maven,Project SDK选择1.8,单击“Next”。
c. 定义样例工程名和配置样例工程存储路径,单击“Finish”完成工程创建。
d. 在pom.xml文件中添加如下配置。
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
图2-8 pom 文件中添加配置
e. 在工程路径的“src > main > java”文件夹上鼠标右键,选择“New >
Package”,新建Package和类文件。
Package根据需要定义,本示例定义为:“com.huawei.demo”,完成后回 车。
在包路径下新建Java Class文件,本示例定义为:SumUdfDemo。
2. 编写UDF函数代码。UDF函数实现,主要注意以下几点:
a. 自定义UDF需要继承org.apache.hadoop.hive.ql.UDF。
b. 需要实现evaluate函数,evaluate函数支持重载。
详细UDF函数实现,可以参考如下样例代码:
package com.huawei.demo;
import org.apache.hadoop.hive.ql.exec.UDF;
public class SumUdfDemo extends UDF { public int evaluate(int a, int b) { return a + b;
} }
3. 编写调试完成代码后,通过IntelliJ IDEA工具编译代码并导出Jar包。
a. 单击工具右侧的“Maven”,参考下图分别单击“clean”、“compile”对 代码进行编译。
编译成功后,单击“package”对代码进行打包。
打包成功后,生成的Jar包会放到target目录下,以备后用。本示例将会生成 到:“D:\DLITest\MyUDF\target”下名为“MyUDF-1.0-SNAPSHOT.jar”。
4. 登录OBS控制台,将生成的Jar包文件上传到OBS路径下。
说明
Jar包文件上传的OBS桶所在的区域需与DLI的队列区域相同,不可跨区域执行操作。
5. (可选)可以将Jar包文件上传到DLI的程序包管理中,方便后续统一管理。
a. 登录DLI管理控制台,单击“数据管理 > 程序包管理”。
b. 在“程序包管理”页面,单击右上角的“创建”创建程序包。
c. 在“创建程序包”对话框,配置以下参数。
i. 包类型:选择“JAR”。
ii. OBS路径:程序包所在的OBS路径。
iii. 分组设置和组名称根据情况选择设置,方便后续识别和管理程序包。
d. 单击“确定”,完成创建程序包。
6. 创建UDF函数。
a. 登录DLI管理控制台,单击“SQL编辑器”,执行引擎选择“spark”,选择 已创建的SQL队列和数据库。
图2-9 选择队列和数据库
b. 在SQL编辑区域输入下列命令创建UDF函数,单击“执行”提交创建。
CREATE FUNCTION TestSumUDF AS 'com.huawei.demo.SumUdfDemo' using jar 'obs://dli-test- obs01/MyUDF-1.0-SNAPSHOT.jar';
7. 重启原有SQL队列,使得创建的Function生效。
a. 登录数据湖探索管理控制台,选择“队列管理”,在对应“SQL队列”类型 作业的“操作”列,单击“重启”。
b. 在“重启队列”界面,选择“确定”完成队列重启。
8. 使用UDF函数。
在查询语句中使用6中创建的UDF函数:
select TestSumUDF(1,2);
图2-10 执行结果
9. (可选)删除UDF函数。
如果不再使用UDF函数,可执行以下语句删除该函数:
Drop FUNCTION TestSumUDF;
2.3 在 Spark SQL 作业中使用 UDTF
操作场景
DLI支持用户使用Hive UDTF(User-Defined Table-Generating Functions)自定义表 值函数,UDTF用于解决一进多出业务场景,即其输入与输出是一对多的关系,读入一 行数据,输出多个值。
约束限制
● 在DLI Console上执行UDTF相关操作时,需要使用自建的SQL队列。
● 跨账号使用UDTF时,除了创建UDTF函数的用户,其他用户如果需要使用时,需 要先进行授权才可使用对应的UDTF函数。授权操作参考如下:
登录DLI管理控制台,选择“ 数据管理 > 程序包管理”页面,选择对应的UDTF Jar包,单击“操作”列中的“权限管理”,进入权限管理页面,单击右上角“授 权”,勾选对应权限。
环境准备
在进行UDTF开发前,请准备以下开发环境。
表2-5 UDTF 开发环境
准备项 说明
操作系统 Windows系统,支持Windows7以上版本。
安装JDK JDK使用1.8版本。
安装和配置IntelliJ
IDEA IntelliJ IDEA为进行应用开发的工具,版本要求使用2019.1 或其他兼容版本。
安装Maven 开发环境的基本配置。用于项目管理,贯穿软件开发生命周 期。
开发流程
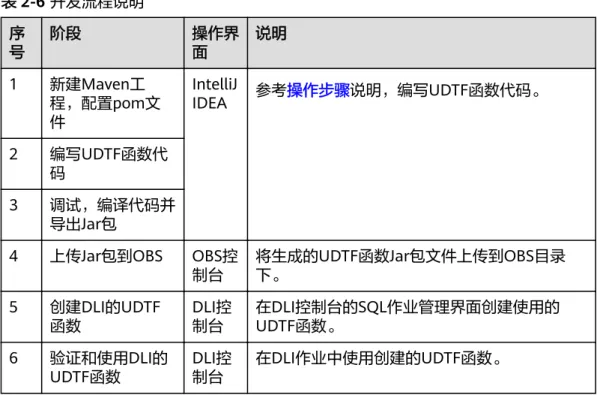
DLI下UDTF函数开发流程参考如下:
图2-11 UDTF 开发流程
表2-6 开发流程说明 序
号
阶段 操作界
面
说明
1 新建Maven工 程,配置pom文 件
IntelliJ
IDEA 参考操作步骤说明,编写UDTF函数代码。
2 编写UDTF函数代 码
3 调试,编译代码并 导出Jar包
4 上传Jar包到OBS OBS控
制台 将生成的UDTF函数Jar包文件上传到OBS目录 下。
5 创建DLI的UDTF 函数
DLI控 制台
在DLI控制台的SQL作业管理界面创建使用的 UDTF函数。
6 验证和使用DLI的
UDTF函数 DLI控 制台
在DLI作业中使用创建的UDTF函数。
操作步骤
1. 新建Maven工程,配置pom文件。以下通过IntelliJ IDEA 2020.2工具操作演示。
a. 打开IntelliJ IDEA,选择“File > New > Project”。
图2-12 新建 Project
b. 选择Maven,Project SDK选择1.8,单击“Next”。
c. 定义样例工程名和配置样例工程存储路径,单击“Finish”完成工程创建。
d. 在pom.xml文件中添加如下配置。
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
图2-13 pom 文件中添加配置
e. 在工程路径的“src > main > java”文件夹上鼠标右键,选择“New >
Package”,新建Package和类文件。
Package根据需要定义,本示例定义为:“com.huawei.demo”,完成后回 车。
在包路径下新建Java Class文件,本示例定义为:UDTFSplit。
2. 编写UDTF函数代码。完整样例代码请参考样例代码。
UDTF的类需要继承“org.apache.hadoop.hive.ql.udf.generic.GenericUDTF”,实 现initialize,process,close三个方法。
a. UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息,如,返 回个数,类型等。
b. 初始化完成后,会调用process方法,真正处理在process函数中,在process 中,每一次forward()调用产生一行。
如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到 forward()函数。
public void process(Object[] args) throws HiveException { // TODO Auto-generated method stub
if(args.length == 0){
return;
}
String input = args[0].toString();
if(StringUtils.isEmpty(input)){
return;
}
String[] test = input.split(";");
for (int i = 0; i < test.length; i++) { try {
String[] result = test[i].split(":");
forward(result);
} catch (Exception e) { continue;
} } }
c. 最后调用close方法,对需要清理的方法进行清理。
3. 编写调试完成代码后,通过IntelliJ IDEA工具编译代码并导出Jar包。
a. 单击工具右侧的“Maven”,参考下图分别单击“clean”、“compile”对 代码进行编译。
编译成功后,单击“package”对代码进行打包。
图2-14 编译打包
打包成功后,生成的Jar包会放到target目录下,以备后用。本示例将会生成 到:“D:\MyUDTF\target”下名为“MyUDTF-1.0-SNAPSHOT.jar”。
4. 登录OBS控制台,将生成的Jar包文件上传到OBS路径下。
说明
Jar包文件上传的OBS桶所在的区域需与DLI的队列区域相同,不可跨区域执行操作。
5. (可选)可以将Jar包文件上传到DLI的程序包管理中,方便后续统一管理。
a. 登录DLI管理控制台,单击“数据管理 > 程序包管理”。
b. 在“程序包管理”页面,单击右上角的“创建”创建程序包。
c. 在“创建程序包”对话框,配置以下参数。
i. 包类型:选择“JAR”。
ii. OBS路径:程序包所在的OBS路径。
iii. 分组设置和组名称根据情况选择设置,方便后续识别和管理程序包。
d. 单击“确定”,完成创建程序包。
6. 创建DLI的UDTF函数。
a. 登录DLI管理控制台,单击“SQL编辑器”,执行引擎选择“spark”,选择 已创建的SQL队列和数据库。
图2-15 选择队列和数据库
b. 在SQL编辑区域输入下列命令创建UDTF函数,单击“执行”提交创建。
CREATE FUNCTION mytestsplit AS 'com.huawei.demo.UDTFSplit' using jar 'obs://dli-test-obs01/
MyUDTF-1.0-SNAPSHOT.jar';
7. 重启原有SQL队列,使得创建的UDTF函数生效。
a. 登录数据湖探索管理控制台,选择“队列管理”,在对应“SQL队列”类型 作业的“操作”列,单击“重启”。
b. 在“重启队列”界面,选择“确定”完成队列重启。
8. 验证和使用创建的UDTF函数。
在查询语句中使用6中创建的UDTF函数,如:
select mytestsplit('abc:123\;efd:567\;utf:890');
图2-16 执行结果
9. (可选)删除UDTF函数。
如果不再使用该Function,可执行以下语句删除UDTF函数:
Drop FUNCTION mytestsplit;
样例代码
UDTFSplit.java完整的样例代码参考如下所示:
package com.huawei.demo;
import java.util.ArrayList;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class UDTFSplit extends GenericUDTF { @Override
public void close() throws HiveException { // TODO Auto-generated method stub }
@Override
public void process(Object[] args) throws HiveException { // TODO Auto-generated method stub
if(args.length == 0){
return;
}
String input = args[0].toString();
if(StringUtils.isEmpty(input)){
return;
}
String[] test = input.split(";");
for (int i = 0; i < test.length; i++) { try {
String[] result = test[i].split(":");
forward(result);
} catch (Exception e) { continue;
} } }
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException { if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
} }
2.4 使用 Beeline 提交 Spark SQL 作业
DLI Beeline 简介
DLI Beeline是一个用于连接DLI服务的客户端命令行交互工具,该工具基于DLI JDBC实 现,提供SQL命令交互和批量SQL脚本执行的功能。
准备工作
在使用DLI Beeline前,需要进行如下操作:
1. 授权。
DLI使用统一身份认证服务(Identity and Access Management,简称IAM)进行 精细的企业级多租户管理。该服务提供用户身份认证、权限分配、访问控制等功 能,可以帮助您安全地控制华为云资源的访问。
通过IAM,您可以在华为云账号中给员工创建IAM用户,并使用策略来控制他们对 华为云资源的访问范围。
目前包括角色(粗粒度授权)和策略(细粒度授权)。具体的权限介绍和授权操 作请参考《数据湖探索用户指南》。
2. 创建队列。在“队列类型”中选择“SQL队列”,即SQL作业的计算资源。
DLI管理控制台中,创建队列的操作入口有三个,分别在“总览”页面、“SQL编 辑器”页面和“队列管理”页面。
– 单击总览页面右上角 进行创建队列。
– 在“队列管理”页面创建队列。
i. 在DLI管理控制台的左侧导航栏中,选择“队列管理”。
ii. 在“队列管理”页面右上角 进行创建队列。
– 在“SQL编辑器”页面创建队列。
i. 在DLI管理控制台的顶部菜单栏中,选择“SQL编辑器”。
ii. 在左侧导航栏的 页签,单击“队列”右侧的 创建队列。
说明
如果创建队列的用户不是管理员用户,在创建队列后,需要管理员用户赋权后才可使用。
关于赋权的具体操作请参考《数据湖探索用户指南》。
DLI 客户端工具下载
您可以在DLI管理控制台下载DLI客户端工具。
步骤1 登录DLI管理控制台。
步骤2 单击总览页右侧“常用链接”中的“SDK下载”。
步骤3 在“DLI SDK DOWNLOAD”页面,单击“huaweicloud-dli-clientkit-<version>”即 可下载DLI客户端工具。
说明
DLI客户端空间命名为“huaweicloud-dli-clientkit-<version>-bin.tar.gz”,支持在Linux环境中 使用,且依赖JDK 1.8及以上版本。
----结束
使用 DLI Beeline 连接服务端
使用DLI Beeline的机器安装JDK 1.8或以上版本并配置环境变量,推荐在Linux环境下 使用Beeline工具。
步骤1 下载并解压工具包“huaweicloud-dli-clientkit-<version>-bin.tar.gz”,其中version为 版本号,以实际版本号为准。
步骤2 进入解压目录,里面有三个子目录bin、conf、lib,分别存放了Beeline相关的执行脚 本、配置文件和依赖包。
步骤3 进入配置文件conf目录,将“connection.properties.template”重命名成
“connection.properties”,并配置连接参数。
说明
具体连接参数请参考“使用JDBC提交作业”中的“表2-数据库连接参数”和“表3-属性项”。
步骤4 进入执行脚本bin目录,启动beeline脚本,执行连接命令即可执行SQL语句,如下所 示:
%bin/beeline Start Beeline
Welcome to DLI service ! beeline> !connect
Connecting from the default connection.properties
Connecting to jdbc:dli://dli.cn-north-1.myhuaweicloud.com/8fc20d97a4444cafba3c3a8639380003 Connected to: DLI service
jdbc:dli://dli.cn-north-1.myhuaweicloud... (not set)> show databases;
+---+
| databaseName | +---+
| bjhk |
| db_xd |
| dimensions_adgame |
| odbc_db |
| sdk_db |
| tpch_csv_1024 |
| tpch_csv_4g_new |
| tpchnewtest |
| tpchtest |
| xunjian | +---+
10 rows selected (0.338 seconds)
用户也可以在启动beeline脚本时通过命令行选项设置连接参数,如下所示,如果连接 参数不全,Beeline会提示补全相关信息。
%bin/beeline -u 'jdbc:dli://dli.cn-north-1.myhuaweicloud.com/8fc20d97a4444cafba3c3a8639380003?
authenticationmode=aksk' Start Beeline
Connecting to jdbc:dli://dli.cn-north-1.myhuaweicloud.com/8fc20d97a4444cafba3c3a8639380003?
usehttpproxy=true;proxyhost=10.186.60.154;proxyport=3128;authenticationmode=aksk Enter region name: cn-north-1
Enter service name: DLI
Enter access key(AK): <real access key>
Enter secret key(SK): ****************************************
Enter queue name: default
Connected to: DLI service Welcome to DLI service !
jdbc:dli://dli.cn-north-1.myhuaweicloud... (not set)>
----结束
DLI Beeline 支持的命令
DLI Beeline支持一系列命令,每个命令以“!” 这个符号开始,例如“!connect”。具 体请参考表2-7。
表2-7 DLI Beeline 支持的命令
命令 描述
!connect 通过输入连接参数的方式连接到DLI服务,若不输入参数,则加载默认 的“connection.properties”文件连接。
!help 打印命令行的帮助文档。
!history 展示命令行执行历史。
!outputfor mat
设置查询结果的输出格式,支持
table,vertical,csv2,dsv,tsv2,xmlattr,xmlelements,每一种格式的具体说 明详参见查询输出格式。
!propertie s
通过加载“connection.properties”文件连接到DLI服务。该功能与!
connect相同,但是可以指定连接配置文件。
!quit 退出beeline会话。
!run 执行一个SQL脚本。使用方法:
!run <scriptfile>
!save 将当前的会话属性保存至beeline.properties中,下次开启beeline时会 自动加载这些属性。
!script 将执行的命令保存至一个文件中。例如:
!script /tmp/mysession.script
执行该语句之后,后续的命令将被保存至“/tmp/mysession.script”。
再次执行!script,结束脚本记录。执行如下语句,将会重新执行记录下 来的命令。
!run /tmp/mysession.script
!set 设置Beeline变量,例如:
!set color true
!set后面不接参数则显示所有变量值。
!sh 执行一个Shell脚本。例如:
!sh <shellscript>
命令 描述
!sql 显性地执行一条SQL语句,beeline中不带命令的语句默认会转换成!sql 命令,sql语句必须以分号结尾。例如:
!sql <sql>
!dliconf 查看DLI 自定义配置。
DLI Beeline 支持的命令行选项
DLI Beeline支持的启动命令行选项请参考表2-8。
表2-8 DLI Beeline 支持的启动命令行选项
命令行选项 描述
-u <database URL> 连接DLI JDBC的url,其中url需要采用单 引号括起来。使用方式:
beeline –u db_URL
-e <query> 需要执行的SQL语句,可以输入多条语 句,以分号间隔,语句需要采用单引号 括起来。
-f <file> 需要执行的脚本文件。
--dliconf property=value 待设置的DLI属性。
--property-file=<property-file> 通过指定的方式获取连接属性文件并连 接到DLI服务。
--help 打印命令行选项帮助。
查询输出格式
DLI Beeline支持多种查询结果输出格式,输出格式可以通过!outputformat指定。DLI Beeline支持的输出格式包括:table,vertical,csv2,dsv,tsv2,xmlattr,
xmlelements。
● table
table格式输出的结果以表的形式展示,例如:
!outputformat table
select id, value, comment from test_table;
+---+---+---+
| id | value | comment | +---+---+---+
| 1 | Value1 | Test comment 1 |
| 2 | Value2 | Test comment 2 |
| 3 | Value3 | Test comment 3 | +---+---+---+
● vertical
以行为单元组织数据,每一个属性以key-value的形式展示,例如:
!outputformat vertical
select id, value, comment from test_table;
id 1 value Value1
comment Test comment 1 id 2
value Value2
comment Test comment 2 id 3
value Value3
comment Test comment 3
● csv2
以纯文本形式存储表格数据(数字和文本),使用逗号(,)作为分隔符,例如:
!outputformat csv2
select id, value, comment from test_table;
id,value,comment 1,Value1,Test comment 1 2,Value2,Test comment 2 3,Value3,Test comment 3
● dsv
每一行储存一条记录, 每条记录的各个字段间以制表符作为分隔,例如:
!outputformat dsv
select id, value, comment from test_table;
id|value |comment 1 |Value1|Test comment 1 2 |Value2|Test comment 2 3 |Value3|Test comment 3
● tsv2
每一行储存一条记录, 每条记录的各个字段间以空格作为分隔,例如:
!outputformat tsv2
select id, value, comment from test_table;
id value comment 1 Value1Test comment 1 2 Value2Test comment 2 3 Value3Test comment 3
● xmlattr
用于在SQL查询返回的 XML 元素中设置属性的函数,例如:
!outputformat xmlattr
select id, value, comment from test_table;
<resultset>
<result id="1" value="Value1" comment="Test comment 1"/>
<result id="2" value="Value2" comment="Test comment 2"/>
<result id="3" value="Value3" comment="Test comment 3"/>
</resultset>
● xmlelements
将一个关系值转换为XML元素的函数,格式为<elementName>值</
elementName>,例如:
!outputformat xmlelements
select id, value, comment from test_table;


![表 2-30 创建表参数 参数 说明 url ● url的格式为: "IP:PORT[,IP:PORT]/[DATABASE][.COLLECTION] [AUTH_PROPERTIES]" 例如: "192.168.4.62:8635/test?authSource=admin" ● url需要在mongo(DDS)的连接地址的截取得到。 说明 获取到的mongo的连接地址格式为:"协议头://用户名:密码@访问地址: 访问端口/数据库名?authSource=ad](https://thumb-ap.123doks.com/thumbv2/9libinfo/9641182.664553/193.892.271.819.143.912/创建表参参数说明●格式IPPORTIPPORTDATABASECOLLECTION例如●需要连接地址截取得到说明.webp)
