國立臺灣大學電機資訊學院電子工程研究所 碩士論文
Graduate Institute of Electronics Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
NewHope 二項式抽樣模板攻擊
A Template Attack on Binomial Sampling in NewHope
彭俊又
CHUNYU PENG
指導教授:鄭振牟博士
Advisor: ChenMou Cheng, Ph.D.
中華民國 108 年 7 月 July, 2019
摘要
NewHope 是一個被看好極有可能成為未來後量子密碼系統的演算 法。在分析它抵禦量子電腦攻擊的安全性之餘,密碼系統實作的安全 性也是一項重要的議題。本論文中,我們首先分析 NewHope 演算法中 可能成為旁通道分析目標的模組。接著,我們針對其二項式抽樣的實 作進行旁通道模板攻擊。實驗的結果顯示出攻擊者可以從單一次的功 率消耗波形中,以 100% 的成功率分析出二項式抽樣出的秘密參數。
關鍵字: NewHope, 後量子密碼學, 旁通道分析, 模板攻擊
Abstract
The NewHope cryptosystem is a promising candidate for the future post
quantum cryptography standard. Besides its security against the attacks from quantum and classical computers, the sidechannel security is also an impor
tant issue to the implementation of a cryptosystem. In this thesis, we first eval
uate the potential sidechannel vulnerabilities in the NewHope cryptosystem.
Then, a template attack is presented, which can reveal the secret information generated by the Binomial Sampling Function and compromise the security of the cryptosystem. The result shows a 100% success rate of recovering the secrets by only using a single sidechannel power consumption trace.
Keywords: NewHope, PQC, SideChannel Analysis, Template Attack.
Contents
摘要 iii
Abstract v
1 Introduction 1
1.1 NIST PQC Standardization Project . . . 2
1.2 Roadmap . . . 4
2 NewHope 5 2.1 Preliminaries . . . 5
2.1.1 Mathematical background . . . 5
2.1.2 Ring Learning with Errors . . . 6
2.2 Algorithm Description . . . 7
2.2.1 Key Generation . . . 8
2.2.2 Encapsulation . . . 8
2.2.3 Decapsulation . . . 8
3 SideChannel Analysis and Template Attack 11 3.1 SideChannel Analysis . . . 11
3.2 Leakage Assessment Techniques . . . 12
3.2.1 Test Vector Leakage Assessment . . . 12
3.2.2 SignaltoNoise Ratio . . . 13
3.2.3 Normalized InterClass Variance . . . 13
3.3 Template Attack . . . 14
3.3.1 Point of Interest Selection . . . 17
3.3.2 Principal Component Analysis . . . 17
3.3.3 Linear Discriminant Analysis . . . 18
3.3.4 PCA vs. LDA . . . 19
4 SideChannel Evaluation on NewHope 21 4.1 SideChannel Evaluation on the modules . . . 21
4.2 Related Works . . . 23
4.3 Evaluation on the Binomial Sampling Function . . . 24
5 Experiment 27 5.1 Experiment Setup . . . 27
5.2 Leakage Assessment on the Binomial Sampling Function . . . 28
5.3 Template Attack on the Binomial Sampling Function . . . 29
5.3.1 POIbased Template Attack . . . 29
5.3.2 LDABased Template Attack . . . 30
5.3.3 Discussion . . . 31
5.3.4 Mitigation . . . 33
6 Concolusion 35
References 37
List of Figures
2.1 NewHope Key Encapsulation Mechanism. . . 7
3.1 PCA vs. LDA . . . 20
4.1 NewHope Key Generation SideChannel Evaluation . . . 22
4.2 NewHope Encryption SideChannel Evaluation . . . 22
4.3 NewHope Decryption SideChannel Evaluation . . . 23
4.4 Implementation of the NewHope Sampling Function in pqm4 crypto library. 25 5.1 The NICV of the Binomial Sampling Function for each secret value s. . . 28
5.2 NICV of the random bytes a, b, and the output s of a single sampling operation. . . 29
5.3 The selected POIs of random byte a. . . . 30
5.4 The selected POIs of random byte b. . . . 31
5.5 The projection of the profiling traces with the first two LDAdirection of s. 32 5.6 The projection of the profiling traces with the first two LDAdirections. . 32
5.7 The 1st and 2ndLDAdirection of s. . . . 33
List of Tables
5.1 The success rate of the POIbased template attack of 12800 sampling op
erations. . . 30 5.2 The success rate of the LDAbased template attack of 12800 sampling
operations. . . 31
Chapter 1 Introduction
Cryptographic primitives are the foundation of information security. However, the world of cryptography is constantly under the threat of newer and better cryptanalysis techniques.
At the end of the 1990s, the exponential growth of the computing power prompted the Na
tional Institute of Standards and Technology (NIST) to migrate the symmetric encryption standard from DES to AES. Later, the discovery of sidechannel analysis opens a new area of cryptanalysis and completely revolutionizes the implementation aspect of cryp
tosystems. Recently, as the development of quantum computers once again threatens the security of the public key cryptosystems, NIST initiated the PostQuantum Cryptography (PQC) Standardization Project in response and trying to find a new set of public key cryp
tosystems that can withstand the attacks from quantum computers. The standardization project brings new energy into the community of cryptographic research, which has come up with a large number of proposals. While evaluating the mathematical soundness of the candidates against both classical and quantum computers, it is also important to investigate whether the implementations are secure against the uprising sidechannel attacks.
NewHope is one of the latticebased keyexchange protocol, which was submitted to the NIST PQC project. Because of the simple scheme and good performance, it is considered a promising candidate. In this work, we will discuss the potential risk of the straightforward implementation of the NewHope cryptosystem. We will show a single trace attack on a microprocessor, based solely on the sidechannel information. The attack can compromise the security of NewHope by extracting the secret information, including
the secret key, generated by the Binomial Sampling Function.
1.1 NIST PQC Standardization Project
Twenty years ago, Shor discovered a quantum algorithm that can exponentially speed up the integer factorization and discrete logarithm problems, which are the mathematical hard problem behind the RSA and ECCbased cryptosystem. At the time, it was not clear whether or not building a large scale quantum computer is possible. Therefore, these public key cryptosystems were not considered vulnerable in practice.
In the past decade, a large amount of research energy has been put into developing quantum computers. This type of computer can use the quantum mechanical phenomena to solve problems that are unmanageable for classical computers. Large tech companies such as Google, Intel, and IBM are all developing their own quantum computers ranging from 20qubits to 72qubits. It is estimated that significantly largescale quantum comput
ers will come to reality within 20 years. As a result, it will compromise the confidentiality and integrity of the digital world, and shatter the security of the public key cryptosystems that are currently in used, including the RSA, DSA, and ECCbased public key crypto
graphic schemes. To prepare for the upcoming threat to the public key cryptosystems in the near future, NIST initiated the PostQuantum Cryptography Standardization Project in February 2016. The goal is to develop new cryptographic systems that are secure against both quantum and classical computers.
The postquantum cryptosystems can be categorized into several families, includ
ing the latticebased cryptosystem, multivariate cryptosystem, codebased cryptosystem, hashbased signature schemes, and Supersingular isogeny key exchange. Some of the schemes have even been around for several decades, without any known attacks. How
ever, it is stated in the Report on PostQuantum Cryptography by NIST [8], that more research and analysis are required before selecting any of the algorithms as standard.
There are several reasons why NIST decided to start the standardization project. First, the progress of the development of quantum computers has increased drastically in recent years. Second, the transition from the current public key cryptosystems to postquantum
ones might be tricky, since most of the postquantum schemes have a significantly larger key size than the currently used systems. Therefore, it might take a few years to transition to the new systems. Third, the evaluation process of the postquantum schemes is ex
pected to be more complicated than the previous SHA3 and AES competitions, since the algorithms themselves are more complex. Also, there has not been a sufficient amount of research energy until now. Since the mathematical foundation of the different post
quantum families is quite different, it is hard to directly compare some of the schemes.
As a result, it is expected to have several candidate cryptosystems being selected as the standard, and serve as replacements for the current public key cryptosystems, including the digital signature, public key encryption, and key establishment algorithms.
The formal call for proposal was announced on December 20, 2016. Upon the sub
mission deadline on November 30, 2017, there were 82 proposals submitted to the com
petition. 69 of the submissions were deemed “complete and proper”, meaning they have met the minimum acceptance criteria and the submission requirements given by NIST.
Three weeks after the submissions were made public, 12 schemes were found insecure or even broken, and some were withdrawn. After a year of evaluation, the secondround candidates were announced on January 30, 2019, and there are 26 candidates left in the competition, including 17 public key encryption and key establishment schemes, and 9 digital signature schemes.
The selection criteria in the first round are security, cost and performance, and al
gorithm and implementation characteristics, in the order of importance. For the twelve to eighteen months following the secondround candidates announcement, the remaining candidates, with their updated parameters and implementations, will once again be kept under a thorough inspection both by NIST and the cryptographic community. In the later stage of the selection process, the implementation aspect will play a larger role in the evalu
ation process. NIST is hoping to see the performance data on both software and hardware, such as on the CortexM4 microprocessor and the Artix7 FPGA, as well as the optimized implementation, including using the assembly code and the instruction set extension. The resistance to sidechannel attacks is also an important issue in both algorithmic design and
implementations [1].
1.2 Roadmap
This thesis is composed of six chapters.
Chapter 2 introduces some notations and the mathematical hard problem behind the NewHope key establishment scheme. Then, a brief description of the algorithm is given in the following section.
Chapter 3 presents several leakage assessment techniques that can be used to evaluate sidechannel characteristics. Then, the framework of the template attack is described, and different data reduction methods are presented.
Chapter 4 gives a detailed evaluation of the NewHope key encapsulation mecha
nism. Then, we analyze the sidechannel properties of the Binomial Sampling Function in NewHope and identify the weakness in the implementation.
Chapter 5 shows the template attacks on an ARM CortexM4 microprocessor. The result supports our analysis on the Binomial Sampling Function that the implementation is indeed vulnerable to the template attack.
Chapter 6 concludes the template attack on NewHope.
Chapter 2 NewHope
The NewHope cryptosystem is a keyencapsulation mechanism (KEM) based on the con
jectured quantum hardness of the RingLWE problem [20]. It was submitted to the NIST postquantum cryptography standardization project, and remaining a candidate algorithm in the second round evaluation process [1]. The parameter choice of NewHope allows the utilization of Number Theoretic Transform (NTT), making the computation efficient in both time and memory usage. An experiment conducted by Google had shown no problem integrating NewHope into the TLS key agreement in a development version of the Chrome browser, with only a slight increase of the latency by milliseconds, which is caused by the larger message size of the postquantum cryptography scheme. Another one of the largest security chip company in the world, Infineon, has also claimed to have al
ready deployed a variant of NewHope on their commercially available contactless security chip product.
2.1 Preliminaries
2.1.1 Mathematical background
In the NewHope cryptosystem, all elements are polynomials over the ring structure:Rq = Zq[X]/(Xn+ 1), which is the ring of integer polynomials modulo Xn+ 1, where each coefficient is in the field of modulus q. In other words, each of the elements in the cryp
tosystem is a polynomial with n coefficients, and all the coefficients are integers within the range [0, q− 1]. In the following, the bold letters are used to refer to the elements in Rq. There are two parameter settings, (n, q) = (512, 12289) and (n, q) = (1024, 12289), matching the NIST security level 1 and 5 respectfully.
2.1.2 Ring Learning with Errors
The original Learning with Errors (LWE) problem was introduced in [22], and the prob
lem is describe as follows:
There is a secret vector s, chosen randomly inZq. Given a set of random linear equa
tions on s with ‘errors’, the goal is to recover the secret vector s. For instance, given the following set of ‘errored linear equations’:
8s1+ 6s2+ 5s3+ 10s4 + e0 = 7 (mod 17) 5s1+ 7s2+ 4s3+ 6s4 + e1 = 5 (mod 17) 6s1+ 3s2+ 3s3+ 2s4 + e2 = 15 (mod 17) 4s1+ 1s2+ 9s3+ 7s4 + e3 = 10 (mod 17)
...
3s1+ 6s2+ 2s3+ 7s4+ en= 15 (mod 17)
with the errors ei within the range±1. The objective is to find the secret vector s, which in this case is (s1, s2, s3, s4) = (1, 9, 8, 4).
Without the errors, finding the secret s would be as simple as solving a set of linear equations, which can be done using Gaussian elimination, as long as the number of equa
tions exceeds the number of variables in s. However, in the problem of Learning with Errors, with each new equation, a new variable eiis introduced. Therefore, the number of equations would never exceed the number of variables, making the problem impossible to solve with Gaussian elimination.
In the RingLWE problem, all the elements are in the polynomial ringRq. The problem is to find the secret s, given two polynomials (a, b = a◦ s + e), where a is uniformly
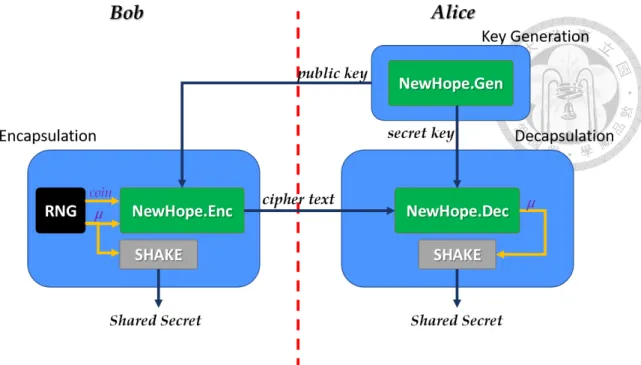
Figure 2.1: NewHope Key Encapsulation Mechanism.
distributed inRq, and (s, e) are randomly sampled following an error distribution. It is shown in [14], that the hardness of RingLWE is similar to solving the Shortest Vector Problem (SVP) on an ideal lattice.
2.2 Algorithm Description
NewHope is a RingLWE based key encapsulation mechanism and is a variant of the NewHopeSimple scheme [2]. Different from the earlier NewHopeUsenix scheme [3], NewHope uses encryptionbased key exchange method rather than the reconciliation method.
The concept of the NewHope key encapsulation mechanism is shown in Figure 2.1, where Bob takes Alice’s public key to encrypt a randomly generated key material. Alice then uses her secret key to recover the key material. The shared secret is then derived from the key material using SHAKE256. The algorithm can be separated into three steps: Key Generation, Encapsulation, and Decapsulation. In this section, we will describe a simpli
fied version of these three operations, where the details such as the NTT and the message encode/decode are omitted.
2.2.1 Key Generation
A public and secret key pair is generated in the key generation process. The algorithm is shown in Algorithm 1, where a ‘large’ polynomial a is generated by the GenA function, which generates a polynomial with the coefficients uniformly distributed in [0, q − 1].
Another two ‘small’ polynomials s and e are generated by the Sample function, shown in Algorithm 3, where the coefficients are binomial distributed in the range [−8, 8]. The public key is the two polynomials (a, b = a◦ s + e), and the secret key is s.
Algorithm 1 NewHope Key Generation
1: function NEWHOPEKEYGEN()
2: seed←− {0, . . . , 255}$ 32
3: publicseed||noiseseed ← SHAKE256(64, seed) ∈ {0, . . . , 255}32+32
4: a← GenA(publicseed)
5: s← Sample(noiseseed, 0)
6: e← Sample(noiseseed, 1)
7: b← a ◦ s + e
8: return (publickey = (a, b), secretkey = s)
2.2.2 Encapsulation
A randomly generated key material is encrypted and sent to Alice in the encapsulation process. The function is described in Algorithm 2. A 256bit random key material µ is encoded into a polynomial K with coefficients either 0 or q/2 depending on the random key bit, shown in Algorithm 4. Another three ‘small’ polynomials s′, e′and e′′are again generated by the Sample function. The message is consist of two polynomials (c1, c2), where c1 = a◦ s′+ e′, and c2 = b◦ s′+ e′′+ K. The message c is then sent to Alice, while the 32byte shared secret ss is derived from the key material µ with SHAKE256.
2.2.3 Decapsulation
In the decapsulation process, the key material is recovered by decoding c2− c1◦ s , and the shared secret is then derived from the key material with SHAKE 256. The function is shown in Algorithm 5. It is shown below that with the help of the secret polynomial s,
Algorithm 2 NewHope Encapsulation
1: function NEWHOPEENCAPS(publickey)
2: coin←− {0, . . . , 255}$ 32
3: µ||coin′ ← SHAKE256(64, coin) ∈ {0, . . . , 255}32+32
4: a, b← publickey
5: s′ ← Sample(coin′, 0)
6: e′ ← Sample(coin′, 1)
7: e′′ ← Sample(coin′, 2)
8: c1 ← a ◦ s′+ e′
9: K ← Encode(µ)
10: c2 ← b ◦ s′+ e′′+ K
11: ss← SHAKE256(32, µ)
12: return (ss, c = (c1, c2))
Algorithm 3 NewHope Binomial Sampling Function
1: function NEWHOPESAMPLE(seed∈ {0, . . . , 255}32, nonce)
2: r ← Rq
3: extseed← {0, . . . , 255}34
4: extseed[0 : 32]← seed||nonce
5: for i from 0 to (n/64)− 1 do
6: extseed[33]← i
7: buf ← SHAKE256(128, extseed)
8: for j from 0 to 63 do
9: a← buf[2 ∗ j]
10: b← buf[2 ∗ j + 1]
11: r64∗i+j ← HW(a) − HW(b) mod q
12: return r ∈ Rq
Algorithm 4 NewHope Message Encoding Function
1: function NEWHOPEENCODE(µ∈ {0, . . . , 255}32)
2: r ← Rq
3: for i from 0 to 31 do
4: for j from 0 to 7 do
5: mask← −((µ[i] ≫ j)&1)
6: r8∗i+j+0← mask&(q/2)
7: r8∗i+j+256 ← mask&(q/2)
8: if n equals 1024 then
9: r8∗i+j+512 ← mask&(q/2)
10: r8∗i+j+768 ← mask&(q/2)
11: return r ∈ Rq
Alice can recover K with a relatively small error e′′′.
c2− c1◦ s
=(b◦ s′+ e′′+ K)− (a ◦ s′+ e′)◦ s
=((a◦ s + e) ◦ s′+ e′′+ K)− (a ◦ s′+ e′)◦ s
=(a◦ s ◦ s′+ e◦ s′+ e′′+ K)− (a ◦ s′◦ s + e′◦ s)
=e◦ s′+ e′′+ K + e′◦ s = K + e′′′
The decoding step can then remove the remaining errors e′′′and recover the encapsulated key material µ as shown in Algorithm 6.
Algorithm 5 NewHope Decapsulation
1: function NEWHOPEDECAPS(c, secretkey)
2: (c1, c2), s← c, secretkey
3: µ← Decode(c2− c1◦ s)
4: ss← SHAKE256(32, µ)
5: return ss
Algorithm 6 NewHope Message Decoding Function
1: function NEWHOPEDECODE(r ∈ Rq)
2: µ← {0, . . . , 255}32
3: for i from 0 to 255 do
4: t← |(ri+0 mod q)− (q − 1)/2|
5: t← t + |(ri+256 mod q)− (q − 1)/2|
6: if n equals 1024 then
7: t← t + |(ri+512 mod q)− (q − 1)/2|
8: t← t + |(ri+768 mod q)− (q − 1)/2|
9: t← t − q
10: else
11: t← t − q/2
12: t← t ≫ 15
13: µ[i≫ 3] ← µ[i ≫ 3]|(t ≪ (i&7))
14: return µ∈ {0, . . . , 255}32
Chapter 3
SideChannel Analysis and Template Attack
3.1 SideChannel Analysis
Sidechannel analysis is the type of attack that exploits the physical information acquired from an operating cryptographic device to reveal the secrets within the device. This type of attack does not require a deep mathematical understanding of cryptographic systems, but rather a wide range of knowledge from hardware designs to signal processing and sta
tistical analysis techniques. Throughout the years, different types of side channels have been found to leak the information that can weaken the security of a cryptosystem, includ
ing computational time, power consumption, EM radiation, acoustic wave, or even the heat signal generated by the device. The compromising sidechannel information is also called leakages.
Since the cryptographic algorithms need to be run on an electrical device, such as a microprocessor or a specialized hardware circuit, it is common to have information re
lated to the cryptosystem leaked through different physical channels. Different types of countermeasures have been proposed to minimize or avoid sidechannel leakages. For in
stance, using a constant time computation algorithm to avoid timing leakage, or applying the masking and hiding countermeasures to break the relation between power consump
tion and the processing data. To better understand how a countermeasure affects the side
channel characteristics and to gain more confidence in its effectiveness, it is common to utilize statistical tools to quantify the leakages. This process is also known as leakage assessment.
3.2 Leakage Assessment Techniques
Leakage assessment techniques are used to assess whether a device leaks exploitable side
channel information while performing cryptographic operations. There are several differ
ent assessment techniques utilize different statistical tools to quantify the leakages, such as the Test Vector Leakage Assessment (TVLA) methodology [11], SignaltoNoise Ratio (SNR), Normalized InterClass Variance (NICV) [6], and Mutual Information Analysis (MIA). These techniques can be useful to both the attackers and the designers of cryp
tographic systems. For an attacker, performing a standard sidechannel attack is often computationally heavy and timeconsuming. Leakage assessment tools can help confirm possible leakages and identify the location of the leakage information. By only focus
ing on the part where the device leaks the secret information, it is useful to lower the cost of an attack. For the designers, leakage assessment techniques can be used to test the effectiveness of different countermeasures and finding the desired tradeoff between the sidechannel resistance and performance efficiency. These assessment techniques can also provide a certain level of confidence that no detectable information is leaked through the sidechannels during the cryptographic operations.
3.2.1 Test Vector Leakage Assessment
The Test Vector Leakage Assessment methodology is a popular leakage detection tool in both academic research and the industry. TVLA uses the Welch ttest to assess whether the changes in the sensitive data can be detected in the measurement data. There are several settings designed to detect different specific types of data leakage. The most common setting is the general test, which tests whether the fixed and random input data cause
differences in the sidechannel measurement.
The ttest statistics can be calculated by the following formula:
t = √L¯A− ¯LB
SA2 NA + SB2
NB
where ¯LA and ¯XB are the leakage sample means, the SAand SB are the standard devia
tions, and NAand NB are the number of measurement in each set. The threshold of±4.5 is often set as the pass criteria. If two separate tests exceed the threshold in the same di
rection, then the implementation is considered leaking sidechannel information, and fail the TVLA test.
3.2.2 SignaltoNoise Ratio
Signaltonoise ratio is a popular measure used in electrical engineering, that shows the ratio of the desired signal to the unwanted background noise. In power analysis, SNR quantifies the amount of information that is leaking through the sidechannel, where the information is the variation in the sidechannel signal caused by the different processing data. A high SNR value indicates a large leakage information [15]. The SNR value can be calculated by the following formula:
SNR = Var(signal)
Var(noise) = Var(E[L|X]) E[Var(L|X)]
where the leakage traces L are first separated into groups by the intermediate data value.
Then, the signal is the variance of the means from each group, and the noise is the variance within the same group.
3.2.3 Normalized InterClass Variance
The NICV leakage detection tool was proposed in [6], which has the advantage of relying only on the publicly known information, such as the plaintext or the ciphertext information.
The idea of the NICV is to quantify how much of the total variance in the measurement is
contributed by the variation of the input data. The calculation of the NICV value can be done by the following:
NICV = Var(E[L|X])
Var(L) = 1
1 + 1 SNR
where the numerator denotes the variation from the input data, and the denominator de
notes the total variation of the data set. If the NICV value reaches 1, it means that all the variation of the measurement is caused by the datadependent power consumption, which indicates a significant leakage was found in the sidechannel measurement. Because of not having an assumption on the power model, it is shown to be an upper bound to the correlationbased leakage detection method and can be directly related to the SNR. One detail of the calculation of NICV is that the number of traces in each group is assumed to be roughly the same, otherwise the computation may result in the NICV value exceeds 1.
In the case where the number of traces in each group is highly unbalanced, one can simply calculate the SNR, then transform the result into NICV.
3.3 Template Attack
Among the different kinds of sidechannel analysis techniques, template attack, which was first introduced in [7], is believed to be the most powerful form of an attack in an informationtheoretic sense. The commonly used Differentialbased Power Analysis (DPA) [13] techniques focus on the instantaneous power consumption at a certain point during the cryptographic operation, while in reality, the leakage often lies in several parts of the recorded trace. Template attack, on the other hand, utilizes all the information avail
able in the leakage traces and builds a profile linking the traces to the secret information.
As a result, the number of traces required during an attack can be significantly lower than the differentialbased power analysis techniques.
It is shown in [15], that the instantaneous power consumption can be modeled as the combination of the operation dependent signal and the random noise. Where we can use a power model to map the processing data to the instantaneous power consumption, and
the noise can be seen as a Gaussian distribution. As a result the instantaneous power consumption can also be modeled as a Gaussian distribution, where the means depends on the processing data and the variance is caused by the noise.
Ptotal = Psignal+ Pnoise
= P owerM odel(data) +N (0, σ2)
=N (P owerModel(data), σ2)
The power trace recorded from a cryptographic device is a time series of instantaneous power consumption samples. In order to describe the correlation between each sample, the multivariate Gaussian model is commonly used to characterize the power trace. The multivariate Gaussian model can be seen as the extension of the Gaussian model, where the mean is now a mean vector, and the variance is now a covariance matrix denoting the correlation between each sample. For example, a power trace consist of 10 sample points, can be modeled as a 10dimensional multivariate Gaussian model, with a mean vector of size 10 and a covariance matrix of size 10x10.
In the profiling phase, the attacker is assumed to have access to an identical device and have full control over it. For example, being able to change the internal secret in
formation or sending different input data. To build the templates using the multivariate Gaussian model, the following steps are required:
1. Record a large amount of traces, with different input data or secret values.
2. Separate the traces into different groups according to the secret values.
3. Calculate the mean vector tkand the covariance matrix Ckof each group k.
tk = 1 np
np
∑
i=1
tk,i
Ck = 1 np− 1
np
∑
i=1
(tk,i− tk)(tk,i− tk)T
To estimate the mean vector of the model for each group, it is common to use the av
erage of the traces in the same group. The estimated covariance matrix comes from the
pairwise covariance between each sampling point within the group. The more data are col
lected to build the model, the more accurate the model is to represent the real distribution of the traces.
In the attack phase, the goal is to infer the secret value being processed by the device.
Using the multivariate Gaussian models that are built during the profiling phase, the prob
ability density function of the leakage trace t, given the mean and covariance matrix of the secret value k is as follows
Pr(t|tk, Ck) = 1
√(2π)n|Ck|exp (
−1
2(t− tk)TCk−1(t− tk) )
.
During the attack, the adversary would collect a set of tracesLafrom the target device with the unknown secrets. Then, the secret value is extracted by selecting the model that maximize the product of the posterior probabilities
k∗ = argmax
k
∏
ti∈La
Pr (ti|tk, Ck) Pr (k) Pr (ti) .
When performing the template attack using the multivariate Gaussian model, several problems can arise during the implementation. First, the required memory of the covari
ance matrix and the computational time grows quadratically to the number of samples in each trace. As the sidechannel leakages usually contain thousands, sometimes millions of samples per trace, it is impractical to build the template based on the raw sidechannel trace directly acquired from the device. Second, the number of traces used for profiling is necessary to be larger than the number of samples in each power trace, otherwise, the covariance matrix Ckcould become singular [9], and causing problems when calculating the probability density function. Third, as the number of traces and samples grows, the computation may reach the floatingpoint limits, and increase the error in the templates.
To fix these problems, in practice, it is common to reduce the number of samples in the traces either by only selecting some point of interest or apply some datadimension reduc
tion techniques, such as the Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA).
3.3.1 Point of Interest Selection
The goal of selecting the point of interest is to reduce the number so that building the templates and calculating the probability density function can be practical and efficient.
There are two main reasons why we can build the templates by only using part of the traces. First, during the whole cryptographic operation, usually, there are only a few parts of the operation are related to the secret information. Take the power trace of an 8bit microprocessor running an AES encryption for example, the information directly related to the secret key can only be found in the first round of the encryption process because of the diffusion property of the permutation layer. When taking a closer look at the power trace during the first round operation, the power consumption related to the byte 0 subkey will only appear at the beginning of the Add Round Key, Byte Substitution, and the Mix Columns operations. There will not be any information related to the byte 0 subkey in the Shift Rows operation since the byte 0 does not take part in the operation. Second, the samples that are close together in the power trace usually contain similar information, especially when they are in the same clock cycle.
Based on the above observations, there are several proposals for selecting the point of interest. The most common one is to use the pairwise difference between the average trace of each group [7]. Sometimes an additional condition of not picking the samples within the same clock cycle may be used to reduce the samples.
3.3.2 Principal Component Analysis
Principal Component Analysis is a popular dimension reduction tool, which projects a highdimensional data into a lowdimensional subspace while preserving the maximum information within the data [4]. The PCAbased template attack first projects the traces onto the lowerdimensional principal subspace, then perform the template attack on the principal subspace.
To find the principal components, we first calculate the empirical covariance matrix.
S = 1 K
∑K k=1
(tk− ¯t)(tk− ¯t)T
Where tk is the mean trace for each class, and ¯t is the average of the mean traces. The principal directions can then be found by calculating the eigenvectors of the empirical covariance matrix. However, the size of the covariance matrix S is normally quite large, and difficult to compute. It is shown in [4], that the computation can be done with the following alternative method. Let T = (t1 − ¯t, t2 − ¯t, ..., tK − ¯t), and the covariance matrix can be rewritten as S = 1
KT TT. First, let us perform the eigendecomposition of 1
KTTT , and we will have(1
KTTT )U = U ∆, where U and ∆ are the eigenvectors and the eigenvalues. Then, left multiply T on both sides, and we now have S(T U ) = (T U )∆, where T U is the eigenvectors of S. Finally, the projection matrix W is built by selecting the M eigenvectors with the largest eigenvalues. After projecting all the traces onto the principal subspace, we can continue the template attack with only M samples in each trace.
3.3.3 Linear Discriminant Analysis
Similar to the PCAbased template attack, the LDAbased template attack also projects the traces into a lowerdimensional subspace and performs the template attack with a lower number of samples. The objective of the Linear Discriminant Analysis is to find the axes where the ratio of the betweenclass variance and the withinclass variance is maximized:
J (w) = V ar(wTTbetween)
V ar(wTTwithin) = wTSBw wTSWw.
The SBand SW denotes the betweenclass scatter matrix and withinclass scatter matrix.
This objective function matches the calculation of the leakage assessment tool SNR, where the betweenclass variance can be related to the datadependent signal in the traces, and the withinclass variance indicates the noise. In other words, LDA projects the traces onto a lowerdimensional space where the SNR is maximized.
To calculate the LDA directions, the first step is to calculate the betweenclass scatter matrix SB and the withinclass scatter matrix SW.
SB =
∑K k=1
Nk(tk− ¯t)(tk− ¯t)T
SW =
∑K k−1
Nk
∑
i=1
(tk,i− tk)(tk,i− tk)T
Then, the LDA directions can be found by performing the eigendecomposition (SW−1SB).
Similar to the PCAbased template attack, the last step is to build the projection matrix W by selecting the M eigenvectors with the largest eigenvalues, and project the traces into the subspace with only M samples in each trace.
3.3.4 PCA vs. LDA
In the case of sidechannel analysis, where the number of samples in each trace is much larger than the number of classes, PCA is excellent at reducing the number of samples.
PCA provides us with a way to systematically lower the number of samples in each trace.
It can achieve a small sample size even when the raw data trace contains a large number of samples. However, the PCAbased template attack only takes the betweenclass dif
ferences into account, thus, it may not be optimal since the noise within each class is not considered.
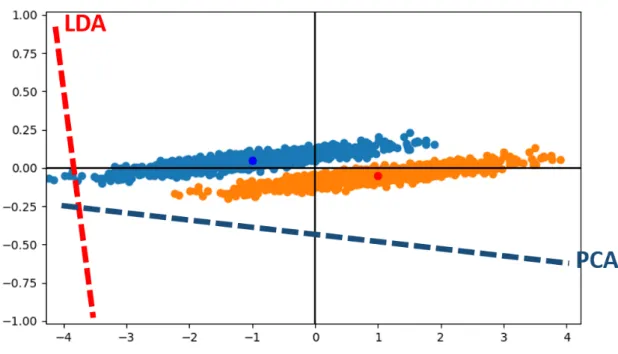
The LDAbased template attack, on the other hand, takes the noise distribution into account and tries to find the projection that maximizes the class separability. The ad
vantage of LDA over PCA can be illustrated in Figure 3.1, where the red LDA direction shows a better separability between the blue group and the orange group. However, the limitation of Linear Discriminant Analysis arises when the sample size is large in the side
channel traces. The withinclass scatter matrix SW becomes singular and not invertible when the number of traces Nk is fewer than the number of time samples in each trace. In other words, LDA is not suitable when a large number of samples are in the measurement traces.
Figure 3.1: PCA vs. LDA
Chapter 4
SideChannel Evaluation on NewHope
4.1 SideChannel Evaluation on the modules
From the aspect of sidechannel analysis, while implementing a cryptographic system, it is important to not leak any information related to the secret key or some other intermediate values that could lead to the secrets and compromise the security of the system. For exam
ple, in the symmetric block cipher, such as AES, the encryption key is usually considered the information that should be kept a secret, and only known by the authorized party. If the Hamming weight of the firstround Sbox output is leaked through the power consump
tion, which is common in the case of an unprotected AES software implementation, an attacker can easily recover the secret key using Differential Power Analysis.
In the case of public key cryptosystems, or more specifically the NewHope key en
capsulation mechanism, the secret information includes both the secret key of NewHope and the 256bit key material, which could be derived into the shared secret on both sides.
Therefore, it is important to implement the functions processing these secrets in a way that doesn’t leak information through the sidechannels. To further evaluate the design of the NewHope cryptosystem, we now look into the three main functions of the public key encryption scheme, including the key generation, encryption, and decryption process in NewHope, and point out the functions that may be a security risk of the sidechannel attacks.
(a) NewHope Key Generation (b) Secrets in Key Generation Figure 4.1: NewHope Key Generation SideChannel Evaluation
(a) NewHope Encryption (b) Secrets in Encryption Figure 4.2: NewHope Encryption SideChannel Evaluation
Key Generation
A simplified version of the key generation process is shown in the Figure 4.1(a). If we remove the modules that only process the publicly known information, the remaining mod
ules, shown in Figure 4.1(b), are the ones that should be carefully implemented such that they won’t leak sidechannel information and compromise the security of the system. The modules are the True Random Number Generator, SHAKE256, Binomial Sampling Func
tion, Polynomial Encoding, and the polynomial arithmetic modules, such as the Number Theoretic Transform (NTT), and polynomial addition and subtraction.
Encryption
A simplified version of the encryption process is shown in Figure 4.2(a), and the modules processing the secret information are shown in Figure 4.2(b). These modules include Message Encoding, Binomial Sampling Function, and polynomial arithmetic modules.
(a) NewHope Decryption (b) Secrets in Decryption Figure 4.3: NewHope Decryption SideChannel Evaluation
Decryption
A simplified version of the decryption in NewHope is shown in Figure 4.3(a), and the modules that are processing the secret information are the polynomial arithmetic modules, and the Message Decoding, shown in Figure 4.3(b).
To summarize, the following modules in NewHope may require more attention and a careful evaluation of their implementation to prevent sidechannel attacks: True Ran
dom Number Generator, SHAKE256, Binomial Sampling Function, Polynomial Encode, Polynomial Decode, Message Encode, Message Decode, and the polynomial arithmetic modules.
4.2 Related Works
Several works have already discussed the sidechannel properties of the latticebased prim
itives. Simple power analyses targeting the modular addition operation and the NTT op
eration was proposed in [19] and [21]. To protect against sidechannel attacks, masking schemes on the NTT operation and the other RingLWE primitives were introduced in [23] and [16]. While some of the primitives in NewHope have been discussed in the pre
vious work, other subroutines, such as the encoding process and the Binomial Sampling Function, are less explored. Although these operations have already been implemented in a constanttime fashion, the leakage information in the power consumption may still compromise the security of the cryptosystem.
Depending on the threat model and the situation where the NewHope scheme is used, the definition of sidechannel vulnerability may vary in different scenarios. For exam
ple, in the case of the NewHopeCPA secure mode, the generated key pair is meant to be ephemeral. Therefore, the differentialbased sidechannel attacks and the masking coun
termeasures are irrelevant in the scenario. And the reuse of the key pair may lead to other types of attacks [5]. On the other hand, if the attacker is powerful enough to recover the secret information within a single trace, such as mentioned in [21], the masking coun
termeasure may also fail, since the attacker can simply recover the different shares of the secret information and combine the results.
4.3 Evaluation on the Binomial Sampling Function
Of all the modules processing the secret information, the Binomial Sampling Function is found to be the most important subroutine for several reasons. First, this function is used multiple times in the whole scheme, including the key generation and the encryption pro
cess in NewHope. Second, the sampling function, which generates a ‘small’ polynomial with coefficients that are binomially distributed within the range of [−8, 8], is the sole provider of the confidentiality for the whole encryption scheme. Third, during the key generation process, the secret key is also generated by the Binomial Sampling Function.
Therefore, if an attacker is able to recover the output of this function, the NewHope key encapsulation mechanism will then be completely compromised and provide no protection to the secret information at all.
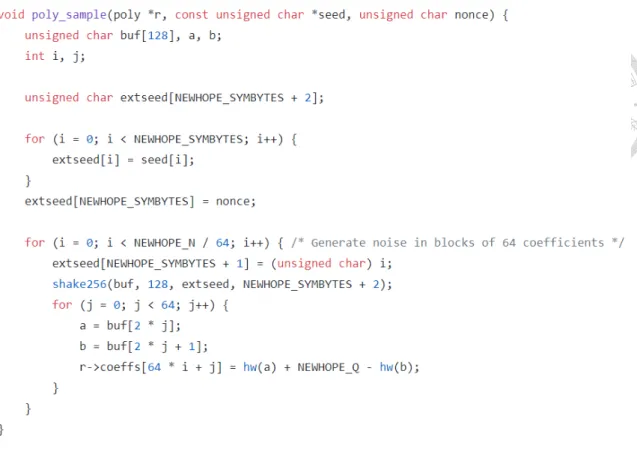
To further evaluate the Binomial Sampling process, we now take a closer look at the implementation of NewHope in the pqm4 crypto library [12]. In Figure 4.4, we can see that the Sampling function first takes in a 32byte seed and a nonce. Then, it uses SHAKE256 to generate a series of random bytes. In the last step, the binomial distributed random numbers are generated by subtracting the Hamming weight of two random bytes.
If an attacker can gather the Hamming weight information of the two random bytes through the sidechannel information, then recovering the output of this function would be as sim
ple as subtracting the two Hamming weight values.
Figure 4.4: Implementation of the NewHope Sampling Function in pqm4 crypto library.
Although getting the Hamming weight information of processing data is a commonly used assumption in literature [10], it may not be easy to attain on a real device. First, the leakage model of a device may be very different from the Hamming weight model.
Second, the noise in the sidechannel measurement may cause errors in the template attack.
In the case of the sampling process, we only get a single shot at recovering the information, since the sampling function generates a new set of outputs each time it is used. Also, the success rate of the identification needs to be high enough to ensure the correctness of recovering the full 1024 coefficients in a secret polynomial. To achieve a single trace sidechannel attack, it is important to minimize the noise during the acquisition phase and try to maximize the difference in the signal during the template building phase. In our experiment, the synchronized sampling equipment is used to reduce the noise during the acquisition, and the POI selection criteria and the LDAbased template are used to maximize the separability of the sidechannel measurements.
Chapter 5 Experiment
5.1 Experiment Setup
In the experiment, the NewHope submitted reference C program and the pqm4 crypto library [12] are used as the target implementation for the sidechannel analysis. The pqm4 crypto library contains implementations of the postquantum cryptographic schemes targeting the ARM CortexM4 family of microprocessors. The implementation includes the CortexM4 specific optimization using the assembly code. However, the binomial sampling function in NewHope is still implemented in the C language. The target platform in our experiment is the STM32F3 microprocessor, which is also in the ARM CortexM4 family.
The ChipWhisperer toolchain is used as the acquisition device, including the Chipwhisperer
Pro hardware capture device and the ChipWhisperer Capture 4.0.2 software program. The ADC in the ChipWhispererPro has a 10bit resolution, and the analog amplifier is of a maximum 60dB gain. ChipWhisperer is an opensource toolchain for sidechannel anal
ysis [18]. One of the main attractions, other than being lowcost equipment, is the syn
chronized sampling feature, which lowers the samples required during the acquisition and decreases the noise introduced by the phase shift [17]. In this setup, the clock rate of the microprocessor is 7.38 MHz, and the sampling rate is 29.52MS/s, four times the micro
processor’s clock frequency.
Figure 5.1: The NICV of the Binomial Sampling Function for each secret value s.
5.2 Leakage Assessment on the Binomial Sampling Func
tion
To confirm our suspicion that the Binomial Sampling Function is indeed leaking the in
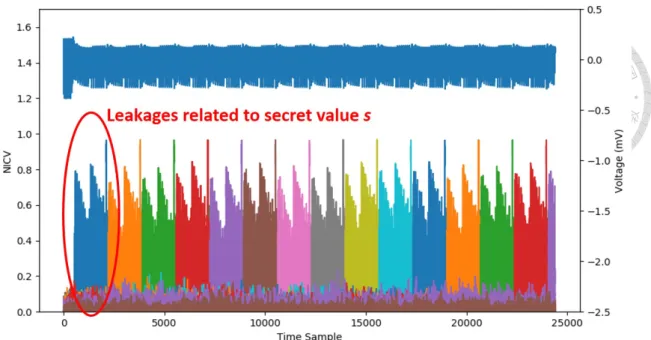
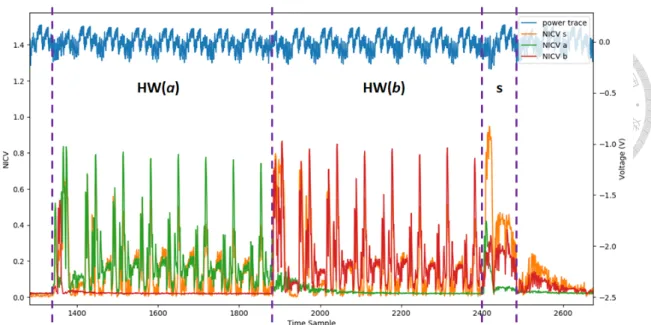
formation related to its output, we use the NICV leakage detection tool to test the power traces, and the result is shown in Figure 5.1. The power trace is shown in the upper half of the figure with a blue line, and the lower half shows the result of the NICV value for each sampled output s. We can see that the leakage information for each output s can be detected in the repeated pattern in the captured power trace.
If we take a closer look at a single sampling operation, shown in Figure 5.2. The power trace can be roughly separated into three parts. With the help of the NICV leakage assessment, we can confirm that the first and second parts correspond to the calculation of the Hamming weight of the two random bytes. The last part is the operation where the two Hamming weight values are subtracted into the output s. At the end of the sampling operation, the NICV value reaches 9.5, which is high enough to possibly extract the secret with a single trace in our experience.
Figure 5.2: NICV of the random bytes a, b, and the output s of a single sampling operation.
5.3 Template Attack on the Binomial Sampling Function
In this section, we are going to present the result of the two types of template attacks, the POI selection and the LDAbased template attack. In the profiling stage, we recorded 25,600 traces of the Binomial Sampling Function with random input seeds, and another 200 traces were recorded for testing. Each trace contains 64 sampling operations, which covers one inner for loop in the Sampling Function. To increase the number of traces for profiling, we separate each trace into 64 single sampling operation. As a result, we have a total number of 1,628,400 traces for profiling.
5.3.1 POIbased Template Attack
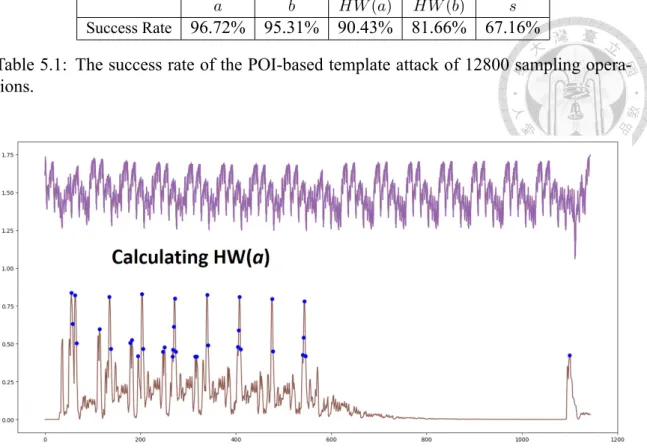
In our experiment, it is found that the following selection process yields a better result.
First, use the NICV leakage detection technique to find the samples that contain the most information related to the secrets in the power trace. Then, find the correlation coefficients between the selected samples, and remove the ones that are highly related to others. Be
cause the highly correlated samples do not bring much extra information, removing those samples can reduce the computational complexity without losing much information. The thresholds for NICV and the correlation coefficient were set to 0.5 and 0.99, and the se
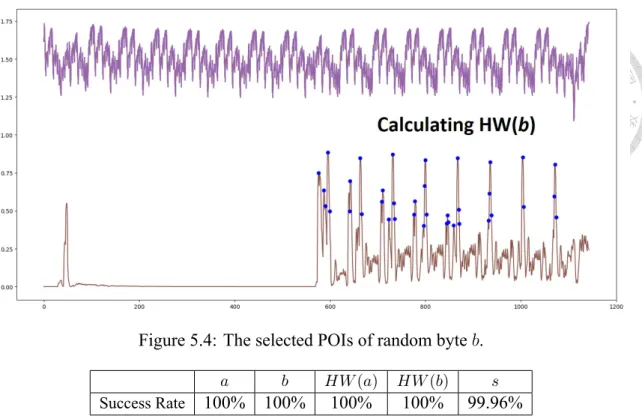
lected POIs of the random bytes a and b are shown as the blue dots in Figure 5.3 and
a b HW (a) HW (b) s Success Rate 96.72% 95.31% 90.43% 81.66% 67.16%
Table 5.1: The success rate of the POIbased template attack of 12800 sampling opera
tions.
Figure 5.3: The selected POIs of random byte a.
Figure 5.4.
200 traces, each contains 64 sampling operations, are used in the evaluation process.
The success rate is calculated by the correct identification of the secret value with a total of 12,800 trials. The result of the POIbased template attack is shown in Table 5.1.
Even though the success rate of identifying the random number a and b is quite high, the 96% success rate is not good enough to threaten the security of NewHope, since there are 1024 coefficients in the secret polynomial s.
5.3.2 LDABased Template Attack
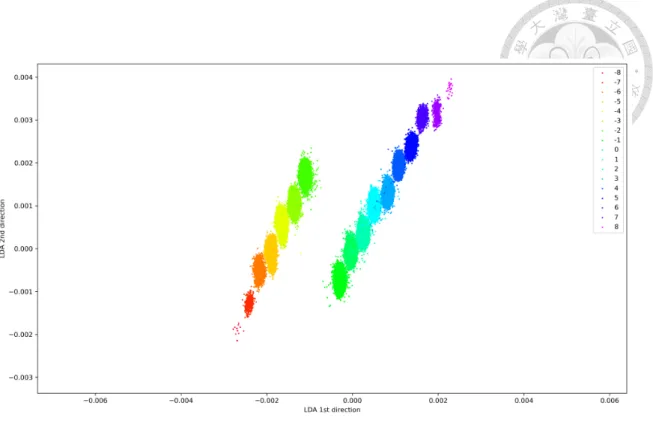
Figure 5.5 shows the projection of the profiling traces using the first two LDAdirections.
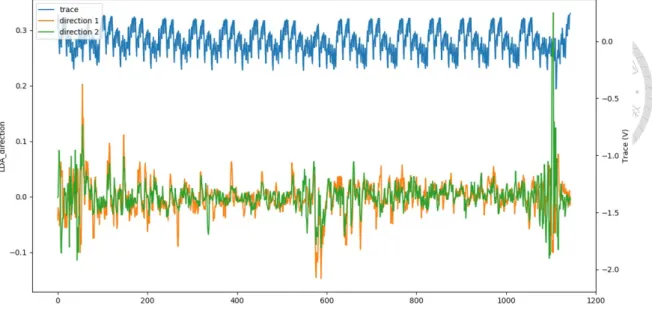
Each dot in Figure 5.5 represents a trace in the profiling data set. Traces with different s value were projected onto a different location in the subspace. The 17 groups of dots were well separated in the LDA subspace. And we can observe the binomial distributed s by the fact that the number of dots in the group−8 and 8 are both significantly lower than the others. Figure 5.6(a) and Figure 5.6(b) also shows a highly separated traces by the
Figure 5.4: The selected POIs of random byte b.
a b HW (a) HW (b) s
Success Rate 100% 100% 100% 100% 99.96%
Table 5.2: The success rate of the LDAbased template attack of 12800 sampling opera
tions.
values of HW(a) and HW(b) in the LDA subspace. The good performance of the LDA
based template attack is shown in Table 5.2, where the attack achieves a 100% success rate with 12,800 trials when extracting the Hamming weight information of the random bytes a and b. The result provides the evidence for our analysis in Section 4.3, that an attacker can recover the Hamming weight information of the two random bytes and calculate the secret information s. With the success rate reaching 100%, there should be no problem recovering the full 1024 coefficients of the secret polynomial s.
5.3.3 Discussion
In the experiment, we showed that not only is it possible to extract the Hamming weight information directly from the sidechannel information, in the case of Binomial Sampling Function, we can also extract the exact value of the processed data. From the result of the two types of template attacks, we can conclude that the LDAbased template attack performs better than the POIbased method. The main difference between the two ap
proaches is that the POIbased template only utilizes part of the leakage sample while the
Figure 5.5: The projection of the profiling traces with the first two LDAdirection of s.
(a) Hamming Weight of a (b) Hamming Weight of b Figure 5.6: The projection of the profiling traces with the first two LDAdirections.
Figure 5.7: The 1stand 2nd LDAdirection of s.
LDA method combines all the available information to maximize the differences between each group.
One interesting observation we made in our experiment is that the projected traces of the value−8 to 8 on the first direction are arranged in order from left to right in Figure 5.5.
If we take a look at the first LDAdirection, which was shown as the orange line in Fig
ure 5.7, we can see that there is a positive peak in the beginning of the trace, and a negative peak in the middle of the traces. It is shown in Figure 5.2 that these two locations are the beginning of the two Hamming weight calculations, which makes it highly possible to leak the Hamming weight information of the 2 random bytes a and b. The ‘projection’ of traces is essentially performing some linear combination of the samples in each trace, such that the traces from the different groups are best separated. What the first LDA direction does is to find the two Hamming weight information in the power trace and subtract the two values to get the maximum separability of the traces, which matches the actual calculation of the secret value s.
5.3.4 Mitigation
A parallel implementation of the Hamming weight function, calculating four Hamming weight at once, can not only speed up the performance but also increase the noise in the
power leakage, which making the ‘single trace’ attack more difficult. However, with a higher resolution oscilloscope and a localized EM measurement, an attacker may still be able to identify the secrets and perform the attack. A masking countermeasure is pro
posed in [16]. However, if an attacker can identify the two shares with a single trace, the masking scheme may fail as a countermeasure. A better way is to apply the shuffling countermeasure by randomizing the sequence of the sampling operation. The shuffling countermeasure should be secure against the singletrace attack as long as the sequence is unknown to the attacker.
Chapter 6 Concolusion
The sidechannel characteristics of the NIST PQC candidates are becoming more and more important since the report form NIST stated that the performance will play more of a role in the later selection process. It is important to investigate whether the implementations are secure against sidechannel attacks.
In this work, we analyzed the design of the NewHope cryptosystem, and identified the modules that may be the targets of sidechannel analysis. We then showed that it is possi
ble to extract the secret information generated by the Binomial Sampling Function. First, the NICV leakage assessment tool is used to confirm and identify leakages during the sam
pling operation. Then, we implemented different types of template attacks, and achieve a single trace attack on an ARM CortexM4 microprocessor with a 100% success rate.
The result shows that the straightforward implementation of the NewHope cryptosystem is vulnerable to sidechannel analysis. While this work focuses on the implementation of NewHope, some other RingLWE based encryption schemes also use the same method to sample from the binomial distribution. Therefore, the attack may also apply to other RingLWE based candidates with similar implementation.
References
[1] G. Alagic, G. Alagic, J. AlperinSheriff, D. Apon, D. Cooper, Q. Dang, Y.K. Liu, C. Miller, D. Moody, R. Peralta, et al. Status Report on the First Round of the NIST PostQuantum Cryptography Standardization Process. US Department of Com
merce, National Institute of Standards and Technology, 2019.
[2] E. Alkim, L. Ducas, T. Pöppelmann, and P. Schwabe. Newhope without reconcilia
tion. IACR Cryptology ePrint Archive, 2016:1157, 2016.
[3] E. Alkim, L. Ducas, T. Pöppelmann, and P. Schwabe. Postquantum key exchange—
a new hope. In 25th{USENIX} Security Symposium ({USENIX} Security 16), pages 327–343, 2016.
[4] C. Archambeau, E. Peeters, F.X. Standaert, and J.J. Quisquater. Template attacks in principal subspaces. In International Workshop on Cryptographic Hardware and Embedded Systems, pages 1–14. Springer, 2006.
[5] A. Bauer, H. Gilbert, G. Renault, and M. Rossi. Assessment of the keyreuse re
silience of newhope. In Cryptographers'Track at the RSA Conference, pages 272–
292. Springer, 2019.
[6] S. Bhasin, J.L. Danger, S. Guilley, and Z. Najm. Nicv: normalized interclass vari
ance for detection of sidechannel leakage. In 2014 International Symposium on Electromagnetic Compatibility, Tokyo, pages 310–313. IEEE, 2014.
[7] S. Chari, J. R. Rao, and P. Rohatgi. Template attacks. In International Workshop on Cryptographic Hardware and Embedded Systems, pages 13–28. Springer, 2002.
[8] L. Chen, L. Chen, S. Jordan, Y.K. Liu, D. Moody, R. Peralta, R. Perlner, and D. SmithTone. Report on postquantum cryptography. US Department of Com
merce, National Institute of Standards and Technology, 2016.
[9] O. Choudary and M. G. Kuhn. Efficient template attacks. In International Confer
ence on Smart Card Research and Advanced Applications, pages 253–270. Springer, 2013.
[10] C. Clavier, D. Marion, and A. Wurcker. Simple power analysis on aes key expansion revisited. In International Workshop on Cryptographic Hardware and Embedded Systems, pages 279–297. Springer, 2014.
[11] B. J. Gilbert Goodwill, J. Jaffe, P. Rohatgi, et al. A testing methodology for side
channel resistance validation. In NIST noninvasive attack testing workshop, vol
ume 7, pages 115–136, 2011.
[12] M. J. Kannwischer, J. Rijneveld, P. Schwabe, and K. Stoffelen. PQM4: Post
quantum crypto library for the ARM CortexM4. https://github.com/mupq/
pqm4.
[13] P. Kocher, J. Jaffe, and B. Jun. Differential power analysis. In Annual International Cryptology Conference, pages 388–397. Springer, 1999.
[14] V. Lyubashevsky, C. Peikert, and O. Regev. On ideal lattices and learning with errors over rings. In Annual International Conference on the Theory and Applications of Cryptographic Techniques, pages 1–23. Springer, 2010.
[15] S. Mangard, E. Oswald, and T. Popp. Power analysis attacks: Revealing the secrets of smart cards, volume 31. Springer Science & Business Media, 2008.
[16] T. Oder, T. Schneider, T. Pöppelmann, and T. Güneysu. Practical cca2secure and masked ringlwe implementation. IACR Transactions on Cryptographic Hardware and Embedded Systems, pages 142–174, 2018.