傳統與結合LDA之協同過濾推薦法在多樣性、新穎性和相關性指標之比較
57
0
0
全文
(2)
(3) 誌謝 本論文得以完成,首先我要感謝我的指導教授 蕭文峰老師,謝謝老師 在我就讀研究所期間的悉心指導。不管是在實驗上或是論文寫作上的困難, 都給予我許多建議,耐心的陪我解決問題。學習過程中,除了學到課業上 的知識外,更學到老師謙遜及嚴謹的態度。老師每個月也會撥專案計畫的 款項給我們,陪伴著我們到中山大學參與討論,讓我能夠順利完成本篇論 文,真的是我人生中的一大貴人。 接下來要感謝每個月陪我們一起參與討論的中山大學教授 張德民老 師,非常敬佩老師在我遇到問題時,能馬上給予我許多的建議,讓我能從 各個角度來思考,並解決問題。感謝本論文的口試委員 蔡孟琳老師,謝謝 老師抽空參加口試,提供寶貴的意見,使得我的論文能夠更完整。非常感 謝屏東大學資管系的所有老師和系辦的助教。還要感謝我的同學們,謝謝 文祥、智程和建銘,有大家彼此的打氣與陪伴,讓學習路途能夠更順遂。 謝謝宗恩在一路上的陪伴,一起參加研討會與口試。謝謝志正、世勳兩位 學弟在口試的幫忙,讓我在論文口試能夠順利。 謝謝我的女友,這段期間不厭其煩的高屏往返,一直在背後支持、鼓 勵著我,俗話說成功的男人背後一定有個偉大的女人,那這個女人就是我 的女友。也謝謝在我壓力很大時,永遠陪在身邊的歐咪。最後,感謝我親 愛的家人,因為你們的栽培與支持,得以讓我在無後顧之憂的環境下,順 利取得碩士學位,邁向人生的另一段旅程。 莊証幃 謹誌 于 國立屏東大學資訊管理學系研究所 中華民國一零六年八月. I.
(4) 摘要 傳統的推薦系統在大多數文獻中,都在研究如何改善推薦的精確度,雖 然推薦的精確度是推薦系統的關鍵層面及基礎的研究方向,但單憑精確度 並不夠用來評估推薦系統的實際效用。因此近年來許多研究紛紛提出有別 於精確度的指標,例如:多樣性(Diversity)、新穎性(Novelty)、覆蓋率 (Coverage)、偶然性(Serendipity)和非預期性(Unexpectedness)等指標。 本論文除了用 Apache Mahout 提供的工具來產生協同過濾式的推薦,還 用 JGibbLDA 工具來建構 LDA 主題模型,推導出其主題機率分布向量,經 由相似性的計算,產生 LDA 為基礎的推薦方法。過去的研究(陳登裕 2015) 僅使用總體多樣性來衡量推薦的多樣性,本論文不希望只用一種角度來衡 量推薦,於是我們從現今較多人引用的文獻中,擷取多樣性及新穎性的指 標,衡量推薦方法在指標上的表現,針對其結果來建議使用者選擇哪一種 推薦方法,最能達到使用者需求,讓使用者感到滿意。由電影資料集的實 驗結果發現,結合 LDA 的協同過濾能獲得較高的相關性,傳統協同過濾可 獲得較高的多樣性,項目為基礎之 CF 和結合 LDA 與項目為基礎之 CF 可 獲得較高的新穎性。笑話資料集的實驗結果發現,項目為基礎之 CF 可獲得 較高的相關性,結合 LDA 為基礎的協同過濾可獲得較高的多樣性,項目為 基礎之 CF 和結合 LDA 與項目為基礎之 CF 可獲得較高的新穎性。 關鍵字:推薦系統、協同過濾、主題模型、多樣性、新穎性 II.
(5) Abstract Past research on recommender systems mostly focused on improving the recommendation accuracy. Although accuracy is the key factor for the success of a recommender system, the accuracy alone is not enough to evaluate the practical utility of a recommender system. Therefore, in recent years, many measures different from accuracy have been proposed, such as diversity, novelty, coverage, serendipity and unexpectedness to compensate the accuracy measure. In this paper, we used Apache Mahout to generate the collaborative filtering recommendation. We also employed the JGibbLDA tool to construct the LDA topic model to infer the topic probability distribution of the items or the users, and further by calculating the similarities to get the LDA based recommendation. In this paper we first filtered out the indicators for diversity and novelty that currently get many citations. We then compared the performance of the recommended methods on these indicators, and suggested the corresponding recommended methods for the users that can balance accuracy, diversity, and novelty, in order to increase users’ satisfaction.According to the experimental results of the film dataset, it is found that the cooperative filtering with LDA can obtain a high correlation, and the traditional cooperative filtering can obtain higher diversity. The project based CF and the LD based on the project can get more High novelty. The experimental results of the joke dataset found that the project-based CF was highly correlated with LDA-based synergistic filtering available for higher diversity, project-based CF and LDA-based CF-based CF can get a higher novelty. Keywords: Recommender System, Collaborative Filtering , Topic Model, Diversity, Novelty. III.
(6) 目錄 第壹章 緒論 ......................................................................................................... 1 第貳章 文獻探討 ................................................................................................. 5 第一節 推薦系統 ....................................................................................................................... 5 第二節 LDA 主題模型 ........................................................................................................... 6 第三節 推薦系統評估指標 .................................................................................................. 8 一、 覆蓋率(Coverage)................................................................................. 8 二、 多樣性(Diversity) ................................................................................. 8 三、 新穎性(Novelty) ................................................................................... 9 四、 偶然性(Serendipity) ............................................................................. 9 第四節 評估指標的選擇........................................................................................................ 9 第參章 研究方法 ............................................................................................... 11 第一節 預處理 .......................................................................................................................... 11 第二節 協同過濾 ..................................................................................................................... 12 一、 使用者為基礎的推薦......................................................................... 12 二、 項目為基礎的推薦............................................................................. 12 第三節 結合 LDA 的協同過濾......................................................................................... 13 IV.
(7) 一、 協同過濾的主題分布......................................................................... 13 二、 計算相似度產生推薦......................................................................... 14 第四節 多樣性的評估指標 ................................................................................................ 15 一、 使用者間的多樣性(Inter-user Diversity) .......................................... 15 二、 使用者內部多樣性(Intra-user Diversity) .......................................... 16 三、 總體多樣性(Aggregate Diversity) ..................................................... 16 第五節 新穎性的評估指標 ................................................................................................ 17 一、 基於自信息的新穎性......................................................................... 17 二、 基於發現和距離的項目新穎性架構 ................................................ 17 第肆章 實驗結果 ............................................................................................... 20 第一節 資料集說明................................................................................................................ 20 第二節 評估指標 ..................................................................................................................... 21 第三節 推薦之相似度分析與選擇 ................................................................................. 22 第四節 LDA 主題數與字詞數的選擇........................................................................... 24 第五節 LDA 主題模型的建構 .......................................................................................... 26 一、 收集項目內容、去除停用字 ............................................................ 26 二、 參數設定 ............................................................................................. 27 V.
(8) 三、 輸入文件格式..................................................................................... 28 四、 輸出資料格式..................................................................................... 29 第六節 電影資料集之指標分析與評估 ....................................................................... 30 一、 Movielens 100k 之指標分析與評估.................................................. 31 二、 Movielens 1m 之指標分析與評估 .................................................... 34 第七節 笑話資料集之指標分析與評估 ....................................................................... 36 第伍章 結論 ....................................................................................................... 42 第一節 研究限制 ..................................................................................................................... 42 第二節 結論與貢獻................................................................................................................ 42 第三節 未來研究方向........................................................................................................... 42 第陸章 參考文獻 ............................................................................................... 43. VI.
(9) 圖目錄 圖 1 LDA 主題及字詞以顏色區分 ..................................................................... 8 圖 2 電影資料集的電影故事情節.................................................................... 27 圖 3 JESTER 所提供的笑話文字檔..................................................................... 27 圖 4 JGIBBLDA 輸入格式範例.......................................................................... 29 圖 5 MOVIELENS 100K MAE 直條圖 ................................................................. 31 圖 6 MOVIELENS 100K 多樣性指標直條圖 ....................................................... 32 圖 7 MOVIELENS 100K 新穎性指標直條圖 ....................................................... 33 圖 8 MOVIELENS 1M MAE 直條圖 ..................................................................... 34 圖 9 MOVIELENS 1M 多樣性指標直條圖........................................................... 35 圖 10 MOVIELENS 1M 新穎性指標直條圖......................................................... 36 圖 11 笑話資料集 MAE 直條圖 ....................................................................... 37 圖 12 笑話資料集多樣性指標直條圖 .............................................................. 38 圖 13 笑話資料集新穎性指標直條圖 .............................................................. 39. VII.
(10) 表目錄 表 1 資料集說明 ................................................................................................ 21 表 2 相似度在 MAE 上的結果(MOVIELENS 100K)........................................... 22 表 3 相似度在 MAE 上的結果(MOVIELENS 1M) .............................................. 23 表 4 相似度在 MAE 上的結果(笑話資料集)................................................... 23 表 5 不同的主題數與字詞數在 MAE 上的表現(MOVIELENS 100K) ............. 24 表 6 不同的主題數與字詞數在 MAE 上的表現(笑話資料集) ...................... 25 表 7 JGIBBLDA 參數說明.................................................................................. 28 表 8 JGIBBLDA 輸出檔案說明.......................................................................... 30 表 9 MOVIELENS 100K MAE 結果 ..................................................................... 31 表 10 MOVIELENS 100K 多樣性指標結果 ......................................................... 32 表 11 MOVIELENS 100K 新穎性指標結果 ......................................................... 33 表 12 MOVIELENS 1M MAE 結果 ....................................................................... 34 表 13 MOVIELENS 1M 多樣性指標結果............................................................. 35 表 14 MOVIELENS 1M 新穎性指標結果............................................................. 35 表 15 笑話資料集 MAE 結果 ........................................................................... 37 表 16 笑話資料集多樣性指標結果.................................................................. 38 表 17 笑話資料集新穎性指標結果.................................................................. 39. VIII.
(11) 第壹章 緒論 隨著資訊科技的發展,資訊量時時刻刻的增加,讓推薦系統在我們日常 生活中日漸重要。推薦系統(Recommendation systems)是一種幫助使用者過 濾資訊的系統(Resnick et al. 1997; Schafer et al. 1999; Chesani 2002),能夠將 受喜好的資訊或是實物推薦給使用者,透過使用者的個人資訊,包括喜好、 點閱內容、評分等等,幫助使用者快速找出有用的資訊,如:Amazon.com、 Netflix、eBay、LinkedIn 和淘寶,都是一些成功的案例。 傳統的推薦系統在大多數文獻中,都在研究如何改善推薦的精確度,雖 然推薦的精確度是推薦系統的關鍵層面及基礎的研究方向,但單憑精確度 並不夠用來評估推薦系統的實際效用。因此近年來許多研究提出其他不同 的指標,例如:覆蓋率(Coverage)、多樣性(Diversity)、新穎性(Novelty)、偶 然性(Serendipity)、驚奇性(Surprise)和非預期性(Unexpectedness),藉由這些 指標使得推薦系統的表現更人性化,讓使用者得到的推薦不僅僅是熱門的 頭項目(Head items),還可以得到一些令使用者覺得驚奇或新穎的長尾項目 (Long-tail items) (Castells et al. 2011)。 協同過濾(Collaborative Filtering, CF)是較普遍被使用的推薦方法,主要 又分成使用者為基礎(User-Based)的協同過濾法(Resnick 1994)和項目為基 礎(Item-Based)的協同過濾法(Sarwar 2001)。這兩種方法利用使用者對於項 目的評分矩陣,透過使用者之間和項目之間的關係,計算出相似度產生推 1.
(12) 薦。但是傳統的推薦方法沒有充分考慮潛在的語意訊息,大多推薦較熱門 的項目給使用者,而忽略了多樣性和新穎性的推薦。 為克服上述問題,陳登裕(2015)提議結合隱含迪利克雷分佈(Latent Dirichlet Allocation, LDA)主題模型與傳統的協同過濾,從文件中找出潛在的 主題分布,藉由推薦不同主題之項目,達到多樣性的推薦。例如:麥芽牛 奶主要的主題是麥芽與牛奶,可以推薦巧克力牛奶、或麥芽紅茶等。本論 文認為 LDA 主題模型除了可以幫助多樣性的推薦之外,也可能對新穎性的 推薦有幫助。Zhang (2013)第三章節提到新穎性指的是使用者沒看過的項目。 但如果僅注重多樣性的推薦,可能會令使用者感到不夠新穎或新鮮,而造 成使用者滿意度下降,所以本論文將加入新穎性指標,從另一個面向來衡 量推薦系統。 陳登裕(2015)從精確度、召回率、F1、MAP、MAE 和總體多樣性這些 指標,衡量協同過濾和結合 LDA 之協同過濾的表現。總體多樣性指的是所 有使用者中獲得的推薦項目彼此不同。假設推薦系統可以推薦的項目很少, 很容易因為使用者人數較多或推薦給使用者的項目數很多時,造成總體多 樣性很高的結果,因此本論文認為只用一種多樣性指標來衡量是不夠的。 綜合上述,本論文的具體研究目的如下: 1. 本論文從較多人引用的文獻中,擷取多樣性和新穎性指標,探討推 薦的表現。以多樣性指標為例,陳登裕(2015)使用的總體多樣性是. 2.
(13) 用來衡量使用者之間推薦清單整體的差異,本論文不希望僅從使用 者之間的單一面向來衡量,於是我們加入使用者內部多樣性指標, 它是用來衡量單一位使用者推薦清單的項目差異性,由此指標的加 入,得以從另一個面向來衡量不同推薦方法上的表現。另外,新穎 性指標在現今也已經是推薦系統所要探討的主要議題之一,該研究 並沒有關於新穎性的衡量指標,因此本論文將加入新穎性指標,從 其他面向來衡量推薦系統。 2. 一般協同過濾的推薦又分為使用者為基礎和項目為基礎的推薦,本 論文還結合 LDA 主題模型與協同過濾延伸出兩種 LDA 為基礎的協 同過濾推薦。再利用多樣性、新穎性和相關性指標,觀察四種推薦 方法在各指標上的表現,建議使用者該使用哪種推薦方法。 過去也有類似的研究,Niemann and Wolpers (2013)提出一個新的協同過 濾推薦法為 Usage Context-Based Collaborative Filtering,該研究的使用情境 不考慮任何的語意訊息,而是透過項目共同出現的概念(例如:項目 A、B 和 C 這個項目組合很常被使用者所選取,而項目 A、B 和 D 的項目組合也 是如此,我們就可以假設項目 C 與項目 D 是高度相關的項目),創造特徵向 量來計算相似度,希望不犧牲精確度而達到多樣且新穎的推薦。該研究與 本論文有些不同之處,我們有加入 LDA 主題模型來考慮項目的語意訊息, 另外新穎性指標的部份,該論文使用自己提出的流行度算法來計算新穎性,. 3.
(14) 但基於流行度真正的算法還尚未被提出,因此本論文並沒有採用基於流行 度的新穎性指標來衡量推薦。Kibeom and Kyogu (2015)主張基於協同過濾的 推薦系統,在準確性方面表現良好,但缺乏找到新鮮和新奇物品的能力。 因此該研究提出一種以圖形為基礎的推薦系統,在使用者個人檔案中,針 對正評價的項目建構一個高度連結,其中將項目作為節點以及正相關作為 邊。在圖形為基礎的推薦系統上又以 entropy 和 linked items 的概念,找到 既新穎又有相關的推薦。最後依據該研究在 Last.fm 資料集上的實驗結果, 發現圖形為基礎的推薦表現,優於矩陣分解為基礎的推薦,且確實能帶來 新穎和相關的推薦。Kunaver and Požrl (2017)提到多樣性在 2001 年時第一次 被提出探討,至今已經成為推薦系統研究的主要議題之一。其主要目的為 整理出歷年來多樣性的相關研究,例如:多樣性的定義及評估、多樣性對 推薦結果品質的影響、多樣性算法發展等。讓尋求多樣性這類主題的研究 人員,能夠更好了解多樣性領域的工作。 本論文第二章會介紹典型的推薦系統架構、LDA 主題模型以及推薦系 統所使用的評估指標;第三章詳細說明本論文提出的研究方法及架構;實 驗結果在第四章;第五章為研究結論。. 4.
(15) 第貳章 文獻探討 根據上述的研究動機與目的,本論文主要探討的方向為衡量不同推薦方 法在各指標上的表現,針對結果來建議使用者該使用哪種推薦方法,能讓 推薦結果更令人感到滿意。因此本章節會先介紹幾種常見的推薦方法以及 LDA 主題模型,最後再介紹目前已經被提出的推薦系統評估指標。. 第一節 推薦系統 推薦系統通常又分為三類,第一類為內容為基礎(Content-Based)的推薦 系統,內容為基礎的推薦系統是由資訊檢索(Information Retrieval, IR)衍生而 來(Ansari et al. 2000; Linden et al. 2003),主要是針對物品內容的分析,依據 使用者過去的興趣、點閱內容、對物品的評價等資訊,建立一個使用者的 個人檔案(Profile),經由推薦系統將個人檔案與物品做比對後,相似度較為 高者,就是使用者可能會喜歡或有興趣的物品。例如:顧客在個人檔案中 註記自己對牛奶類商品有興趣,於是當顧客在挑選商品時,推薦系統便會 建議顧客挑選木瓜牛奶和紅茶牛奶這一類型的牛奶商品。 第二類為協同式過濾(Collaborative Filtering)的推薦系統,協同過濾 (Candillier 2007)會尋找有相同喜好或是相似行為的使用者,將這些使用者 列為同一群體,然後依據其他使用者之前對物品的評分高低,來推測使用 者可能會喜歡什麼物品。協同過濾通常又分為兩種,第一種是使用者為基. 5.
(16) 礎(User-Based)的方法(Resnick 1994),它透過相似性統計,找到與使用者喜 好相鄰的使用者。使用者為基礎的協同過濾,隨著使用者數量增多,計算 的時間就會變長,因此衍伸出第二種項目為基礎(Item-Based)的方法(Sarwar 2001)。項目為基礎的協同過濾,是計算項目之間的相似度,不須透過使用 者的歷史資料,找出鄰近的使用者。使用者的特徵檔案(profile)會隨著時間 而變,但項目本身的特徵並不會改變(例如:導演、演員、類別等),一旦將 項目與項目間的相似度計算完成後,就可以直接在推薦階段使用,因此項 目為基礎的協同過濾執行速度較快。 第三類為混合為基礎(Hybrid-Based)的推薦系統,混合為基礎的方法(Li & Kim 2003)結合內容為基礎與協同過濾的推薦,內容為基礎的推薦主要原 理是針對項目的資訊與使用者個人檔案產生推薦,需要先對項目進行定義, 但並不考慮使用者之間的關係。而協同過濾的概念是考慮使用者之間的互 動或是項目的相似度關係產生推薦,但受限於需要對商品進行評分的動作, 將兩個推薦方法結合,獲得更好的預測結果。. 第二節 LDA 主題模型 傳統協同過濾著重於找出最相似的項目,但這樣的推薦造成多樣性降低。 所以一些研究採用犧牲推薦準確度的方式,將其他相似度較低的項目給予 使用者,進而達到多樣性的推薦。而結合 LDA 主題模型的協同過濾恰好能 夠彌補這樣的問題,在不失準確度的前提下,達到更多樣的推薦,因此以 6.
(17) 下將簡單介紹 LDA 主題模型的概念。 Blei et al. (2003)提出隱含狄利克雷分布(Latent Dirichlet Allocation, LDA),是一種廣泛使用的機率主題模型,同時也是一種非監督式學習的演 算法,目前在文件探勘領域都可以看到 LDA 主題模型的應用。LDA 主題模 型是通過對每個文件進行建模,挖掘出文件中的潛在主題,將文件集中每 篇文件的主題按照機率分布的形式產生。如圖 1 所示,一個主題當中包含 許多字詞,同時一個文件是由主題的分布所組合,範例中分別以不同顏色 做區別。. 7.
(18) 圖 1 LDA 主題及字詞以顏色區分 資料來源(Blei et al. 2003). 第三節 推薦系統評估指標. 一、 覆蓋率(Coverage) 覆蓋率(Coverage)指的是推薦系統向使用者推薦的項目占全部項目的比 例(Herlocker et al. 2004),經常用來評推薦系統對長尾項目的發掘能力。一 般來說,當覆蓋率較高時,表示使用者可以選擇的項目很多,反之覆蓋率 較小時,則代表使用者可以選擇的商品很少。覆蓋率在本論文中沒有被探 討,為了補足指標的完整性,故在此做介紹。. 二、 多樣性(Diversity) 推薦系統除了需要準確推薦使用者有興趣的項目之外,還必須提供更多 樣性的推薦(Mcnee et al. 2006),若推薦清單一成不變,只能涵蓋使用者少數 幾項興趣點,推薦項目可能就無法讓使用者感到滿意。相反的,推薦如果 是非常多樣化,滿足了使用者大部分的興趣點,則會增加使用者找到滿意 推薦的機率。除此之外,若是要高準確度的推薦,多樣性有可能會跟著降 低,造成推薦不夠多樣性。若是高多樣性的推薦,準確度則有可能會降低, 造成推薦給使用者的項目不是那麼準確。因此如何取捨這兩個評估指標, 讓推薦系統的表現能達到最佳狀態,是本論文要探討的問題。. 8.
(19) 三、 新穎性(Novelty) 新穎性(Castells et al. 2011; Vargas et al. 2011)指的是推薦系統推薦使用 者之前所沒看過的項目。傳統推薦系統都傾向於推薦熱門度高的項目,可 能使得推薦準確度非常高,但這些項目也許使用者都已經關注過或已經購 買了,若再推薦同樣類型的項目,便沒有推薦價值。這時候我們就能利用 長尾理論(The long tail),不再推薦那些熱門度高的頭項目(Head items),而 推薦較冷門的長尾項目(Long-tail items),若能滿足不同使用者個人在長尾中 的需求,或許可以產生和頭項目一樣的價值或效益。. 四、 偶然性(Serendipity) 偶然性(Murakami et al. 2007; Ge et al. 2010)又稱為驚奇性(Surprise)和非 預期性(Unexpectedness),指的是使用者感到意外但是有興趣的推薦項目。 Murakami et al. (2007)提到偶然性高的推薦會讓使用者覺得新鮮,但反之則 不一定;具有新穎性的項目可能不具偶然性。舉例來說,音樂網站裡原本 就涵蓋有搖滾、抒情、舞曲等等類型的音樂,但消費者平時只聽抒情樂, 沒注意到其他類型的音樂,直到某一天消費者偶然發現到了搖滾樂,並且 感到很有興趣,這樣的情況稱之為偶然性。. 第四節 評估指標的選擇 本論文並沒有採用覆蓋率及偶然性指標,原因是覆蓋率早在過去就已被. 9.
(20) 提出探討(Good et al. 1999, Herlocker et al. 1999, Sarwar et al. 1998)。而偶然 性雖然已被提出,但因為研究範圍不想太過發散。因此本論文僅討論新穎 性及多樣性指標,使用此兩種指標除了彌補準確度的不足之外,還要探討 多樣性和新穎性對於準確度的相互關係。. 10.
(21) 第參章 研究方法 本論文除了使用一般的協同過濾法來產生推薦,還將 LDA 主題模型方 法與協同過濾做結合,並從較多人引用的研究文獻中,擷取不同的多樣性 和新穎性指標,針對各個指標結果來比較不同推薦方法之間的表現,最後 選擇表現最好的推薦方法,推薦給使用者使用。因此本章節將介紹四種推 薦方法和評估指標的詳細架構與定義。. 第一節 預處理 本論文採用的預處理包括過濾資料集和切割資料集兩個步驟。實驗開始 前,我們必須檢查資料集有無需過濾的雜訊,例如:使用者對電影或笑話 的評分,有 90%都是 1 分或 5 分,就將之視為雜訊。並將評分未滿 5 次的 項目以及超過平均字數太多的項目移除,此步驟與陳登裕(2015)預處理的方 式不同,原因是項目評分若未滿 5 次,其評分通常比較不可靠,在計算自 信息(Self-Information)(Zhou et al. 2010)時可能會出現問題。而超過平均字數 太多的項目則會造成 LDA 計算時間過久的問題,故應予移除。接著我們使 用過濾完的資料集,將資料集的 80%作為訓練資料集,剩下的 20%做為測 試資料集。最後我們必須決定產生推薦時所需要的鄰居數和相似度方法, 因此我們根據(Herlocker et al. 2002)的實驗分析,選擇 20 作為鄰居數。相似 度的選擇,則以實驗來決定我們要採用的相關量測。. 11.
(22) 第二節 協同過濾. 一、 使用者為基礎的推薦 使用者為基礎的協同過濾是根據使用者對項目的評分,計算出使用者對 項目評分之間的相似度(皮爾森相關係數、餘弦相似性、修正的餘弦相似性 等等)(Bobadilla et al. 2013),然後搜索目標使用者的最近鄰居,根據最近鄰 居的評分向目標使用者產生推薦。實現使用者為基礎的推薦,我們用以下 公式來預測結果,產生推薦清單給使用者: Pu,i = r̅u +. ∑v∈Nu sim(u, v)(rvi − r̅v ) ∑v∈Nu|sim(u, v)|. Pu,i 為使用者 u 對於項目 i 的預測評分,r̅u 為使用者 u 對所有項目的平均評 分值,v 為使用者 u 的最近鄰居,Nu 為使用者 u 的最近鄰居集合,sim(u,v) 為使用者 u 對使用者 v 的相似度,rvi 為使用者 v 對項目 i 的評分值,r̅v 為使 用者 v 對所有項目的平均評分值。. 二、 項目為基礎的推薦 項目為基礎的協同過濾是計算預測項目與使用者評分的項目之間的相 似度(皮爾森相關係數、餘弦相似性、修正的餘弦相似性等等)(Bobadilla et al. 2013),然後經由計算與項目 i 相似項目的評分總和來預測使用者 u 對項目 i 的評分,我們使用以下公式來預測結果,最後產生推薦清單:. 12.
(23) Pu,i =. ∑j∈Ni sim(i, j)ruj ∑j∈Ni|sim(i, j)|. Pu,i 為使用者 u 對於項目 i 的預測評分,j 為項目 i 的最近鄰居,Ni 為項目 i 的最近鄰居的集合,sim(i,j)為項目 i 和項目 j 的相似度,ruj 為使用者 u 對項 目 j 的評分值。. 第三節 結合 LDA 的協同過濾. 一、 協同過濾的主題分布 本論文使用的 LDA 工具為 JGibbLDA,它是利用 Gibbs sampling 的方 式進行主題模型的建構與分析。首先我們除了需要使用者的評分資料,還 需要所有項目的內容,因此我們從 IMDB 來抓取電影資料集的電影情節, 而笑話資料集是使用 Jester 所提供的笑話文字檔。接著,從這些項目內容 中,有許多與文章主題較無相關的字,例如:"a"、"and"、"is" 及 "the" 等 字,我們要先去除這些停用字後,才可以利用 JGibbLDA 對電影和笑話資 料集找出主題分布 T。T 是由 k 個主題所組成,即𝐓 = (𝒕⃗𝟏 , 𝒕⃗𝟐 , … 𝒕⃗𝒌 ),而每 個主題中又有代表該主題的字詞組成,即𝒕⃗𝒌 = (𝒘𝒌𝟏 , 𝒘𝒌𝟐 , … 𝒘𝒌𝒏 )。但此時 得到的主題分布 T 並不代表就是使用者或項目為基礎的主題分布,只是 主題字詞的分布。因此我們採用(陳登裕 2015)的作法,推導出協同過濾 的主題分布。以項目為基礎的主題分布為例,其步驟如下: (1) 將項目 i 的內容對應第 k 個主題中的字,紀錄對應到的次數 c,除上 13.
(24) 項目 i 的總字數 s,會得到項目 i 在第 k 個主題中的第 n 個字的權重, 即𝒑𝒊,𝒌𝒏 = 𝒄𝒘𝒌𝒊 /𝒔𝒊 。 (2) 將主題 k 中所有字得到的權重加總,會得到項目 i 中 k 主題的值,即 𝒗𝒊,𝒌 = 𝒑𝒊,𝒌𝟏 + 𝒑𝒊,𝒌𝟐 + ⋯ + 𝒑𝒊,𝒌𝒏,所以會得到該項目 i 的每個主題 k 的 v 值。如此我們就會得到每個項目的主題分布。 同上述,項目得到的分布只是主題字詞的分布,並不代表就是使用者 為基礎的主題分布,我們必須以使用者看過之項目來推導,最後的結果才 是使用者為基礎的主題分布。其步驟如下: (1) 同項目為基礎的方法,第一步須算出項目 i 在第 k 個主題中的第 n 個 字的權重,即𝒑𝒊,𝒌𝒏 = 𝒄𝒘𝒌𝒊 /𝒔𝒊 。 (2) 將得到的主題分布乘上評分標準化,評分標準化是將使用者 u 對項目 i 的評分𝒓𝒖,𝒊,除上使用者 u 對所有項目的評分總分𝑹𝒖。那該項目的第 k 個主題分布向量就可以被表示為𝒕𝒖,𝒊𝒌 =. 𝒓𝒖,𝒊 𝑹𝒖. ∗ (𝒑𝒊,𝒌𝟏 , 𝒑𝒊,𝒌𝟐 , … , 𝒑𝒊,𝒌𝒏 )。. (3) 最後將該使用者對 n 個評分過的項目主題分布向量加總,即 𝒕𝒖,𝒌 = 𝒕𝒖,𝒌𝟏 + 𝒕𝒖,𝒌𝟐 + ⋯ + 𝒕𝒖,𝒌𝒏,最後就可以得到使用者 u 的主題分布 向量。. 二、 計算相似度產生推薦 有了每個項目和使用者的主題分布向量後,我們利用餘弦相似性方法來 計算向量之間的相似度,假設兩個項目 i 和 j 利用 LDA 主題模型所得到的 14.
(25) 主題分布向量分別為i⃗和j⃗,我們將可透過以下公式得到他們的相似度,然後 再利用項目及使用者為基礎的協同過濾法來完成最後的推薦。 𝐬𝐢𝐦(𝐢, 𝐣) = 𝐜𝐨𝐬(𝒊⃗, 𝒋⃗) =. 𝒊⃗ ∙ 𝒋⃗ ‖𝒊⃗‖ × ‖𝒋⃗‖. 第四節 多樣性的評估指標. 一、 使用者間的多樣性(Inter-user Diversity) 使用者與使用者之間的多樣性(Inter-user Diversity)之衡量是由(Zhou et al. 2008)所提出,它是用來衡量推薦系統對使用者推薦不同項目的差異性。 首先,我們可以使用漢明距離(Hamming Distance)來衡量這兩個使用者推薦 清單中重複項目的數目,其公式為: Hij = 1 −. Q L. 公式中,L 表示為推薦清單的長度(也就是對每個使用者推薦項目的數 目),使用者Ui 與使用者Uj 的推薦清單中重複之項目數目則為 Q。若使用者 的兩個推薦清單一樣,則漢明距離會為 0;反之若兩個推薦清單完全不同, 則漢明距離會為 1,因此漢明距離越大越好。 S=. 1 ∑ Hij m(m − 1) i≠j. 上面式子中,m 為所有使用者,我們可以對漢明距離(兩兩成對的使用 者推薦清單)取平均,來測量整個推薦的多樣性,得到的結果越大,推薦的. 15.
(26) 多樣性越好。. 二、 使用者內部多樣性(Intra-user Diversity) Ziegler et al. (2005)提出推薦清單的內部多樣性的方法,用來衡量單一個 推薦清單中項目的差異性,其公式如下: IntralistDiversity@N =. 2 ∙∑ |U| ∙ N(N − 1). ∑. d(i, j). ∑. u i∈RS(u,N) j≠i∈RS(u,N). 上面式子中,U 為所有使用者,N 為推薦給使用者的項目數目,d(i,j) 通常是以 1-sim(i,j)來計算,並且正規化讓所得到的值為 0 到 1 之間。而 sim(i,j) 則是透過下面的相似性公式,來計算項目 i 和項目 j 的差異。 ∑u∈S(i,j)(ru,i − r̅u ) ∙ (ru,j − r̅u ). Sim(i, j) =. 2. √∑u∈S(i,j)(ru,i − r̅u ) √∑u∈S(i,j)(ru,j − r̅u ). 2. 三、 總體多樣性(Aggregate Diversity) Adomavicius and Kwon (2012)提出衡量總體多樣性的方法,總體多樣性指的 是所有使用者中獲得的推薦項目差異性,其公式為: AggDiversity@N = |⋃ RS(u, N)| u∈U. 上面公式中,U 為所有使用者,RS(u, N)代表使用者 u 的 N 個推薦,每 個使用者的差異越大,總體多樣性也會越大;反之每個使用者差異越小, 總體多樣性也會越小。. 16.
(27) 第五節 新穎性的評估指標. 一、 基於自信息的新穎性. Zhou et al. (2010)提出自信息(self-information)是一個可以用來衡量新穎 性的指標。假設給定一個項目為 a 以及使用者總數 u,則隨機一位使用者選 取到此項目的機率可表示為𝒌𝒂 /𝒖,那麼我們可以得到自信息的算法如下: 𝑰𝒂 = 𝐥𝐨𝐠 𝟐 (𝒖/𝒌𝒂 ) 上面式子中,𝒌𝒂 為選到 a 項目的使用者人數,u 為使用者總數。在符合 one deleted link 的前提之下(Zhou et al. 2010),我們藉由自信息來計算出單一 使用者推薦清單的新穎性𝑰𝒖 (𝑳),其中 L 為某位使用者的推薦清單長度。One deleted link 的概念是由某位使用者的 top-N 推薦中,至少要有一筆推薦的項 目能與測試資料集中互相對應,否則該使用者的新穎性則不列入計算。如 此,才能將所有使用者的新穎性加總後取平均,得到整個推薦清單的新穎 性結果𝐈(𝐋)。. 二、 基於發現和距離的項目新穎性架構 de Máster, T. F. (2012)提出一個架構來分析使用者和項目之間的三個關 係,分別為:(1)發現(Discovery):一個項目被使用者看過或是對使用者來 說是熟悉的項目。(2)相關性(Relevance):一個項目被使用者所使用、挑選、 17.
(28) 選擇、消費或購買等等。(3)選擇(Choice):一個項目被使用者所喜歡、享受 或有用的等等。另外該研究也提出情境的概念,一個通用的情境變數 θ,可 以經由不同角度來定義:某個人(目標使用者、一個集合的使用者、所有使 用者)、某個時間點(過去特定的一段時間、正在進行的會話、從來沒有)、 某個地方看過(過去的推薦、現有的推薦、其他系統的推薦、任何地方)。依 據此架構及概念提出了兩種不同的新穎性衡量: 1. 發現為基礎的項目新穎性,其公式為: nov(i|θ) = 1 − p(seen|i, θ) 一般來說,p(seen|i, θ)表示使用者在 θ 的情境之下,會看到項目的機率。 得到的結果若為高新穎值,表示很少使用者會選擇到的長尾項目,而低新 穎值就是使用者常常選擇到的受歡迎頭項目。Vargas(2014)提到,θ 的定義 取決於我們使用的資料類型,若將 θ 作為使用者與項目之間的交互集合, 並且我們使用的資料是由使用者對項目評分所組成,如此就可以使用以下 式子來做計算: p(seen|i, r)~. |𝐢| |{u ∈ 𝒰|r(u, i) ≠ ∅}| = |𝒰| |𝒰|. 其中 i 為曾經評過項目 i 的使用者所形成的集合,r(u, i) ≠ ∅為使用者 u 對項目 i 的評分是已知的。 2. 距離為基礎的項目新穎性,其公式如下: nov(i|θ) =. ∑j∈θ p(choose|j, θ, i)d(i, j) ∑j∈θ p(choose|j, θ, i) 18.
(29) 式子中,p(choose|j, θ, i)表示為當使用者已選擇項目 i,在 θ 的情境之下, 使用者會選擇項目 j 的機率。d(i,j)通常是以 1-sim(i,j)來計算(公式 4),並且 正規化讓所得到的值為 0 到 1 之間。. 19.
(30) 第肆章 實驗結果 本論文使用三個不同的資料集完成三組實驗,第一組實驗使用 MovieLens 100k 的電影資料集,第二組實驗使用 MovieLens 1m 的電影資料 集,第三組實驗使用 Jester 笑話資料集,我們將這三個資料集的 80%當訓練 集,20%當測試集,做 5 等分交叉驗證。利用 Apache Mahout 提供的工具, 實現項目為基礎和使用者為基礎的協同過濾,並加上 LDA 主題模型實現另 外兩種推薦,分別為結合 LDA 與項目為基礎之 CF 和結合 LDA 與使用者為 基礎之 CF,共四種推薦方法。 最後,我們沒有使用精確度及召回率來衡量推薦的正確性,原因是因為 精確度及召回率通常是用於 0/1(沒購買/有購買)的情境,電影和笑話資料集 具有評分等級上的差異,因此我們使用 MAE 來衡量。除此之外,本論文還 加入多樣性(Diversity)和新穎性(Novelty)指標,希望能由不同構面的指標衡 量,針對其結果來建議使用者選擇較好的推薦方法,讓使用者對推薦感到 更滿意。. 第一節 資料集說明 MovieLens 100k1和 MovieLens 1m2電影資料集是由 GroupLens 研究小組 公佈的資料集3。MovieLens 100k 有 943 位使用者以及 1682 部電影,每位使 1 2 3. http://files.grouplens.org/datasets/movielens/ml-100k.zip http://files.grouplens.org/datasets/movielens/ml-1m.zip https://grouplens.org/datasets/movielens/ 20.
(31) 用者至少對 20 部電影進行評分,共有 100,000 筆介於 1 分至 5 分的評分。 其電影內容平均字數為 518 個字,最多字數為 2007 個字,最少字數為 124 個字。MovieLens 1m 有 6040 位使用者以及 3952 部電影,共有 1,000,209 筆介於 1 分至 5 分的評分。笑話資料集是由 Jester 提供的資料集4,有 24938 位使用者以及 100 個笑話,每位使用者都至少評過 15 到 35 個笑話,共有 615,091 筆介於介於-10 分至 10 分的評分,這邊我們將評分比例調整為 0 分 至 5 分之間。其笑話內容平均字數為 318 個字,最多字數為 1208 個字,最 少字數為 61 個字。 表 1 資料集說明 Dataset MovieLens 100k. Users 943. Items 1682. Ratings 100,000. Rating Scale [1-5]. Movielens 1M. 6040. 3952. 1,000,209. [1-5]. JokeData. 24938. 100. 615,091. [0-5]. 第二節 評估指標 平均絕對誤差(Mean Absolute Error, MAE)是用來比對預測分數以及實 際評分之間的差距,其公式如下: ∑𝑁 u=1|Pu,i − R u,i | MAE = N Pu,i 表示系統預測使用者 u 對於項目 i 的評分,R u,i 表示使用者 u 對於項 目 i 的實際評分,N 為推薦項目對應到測試集項目的個數,其 MAE 值越低,. 4. http://eigentaste.berkeley.edu/dataset/ 21.
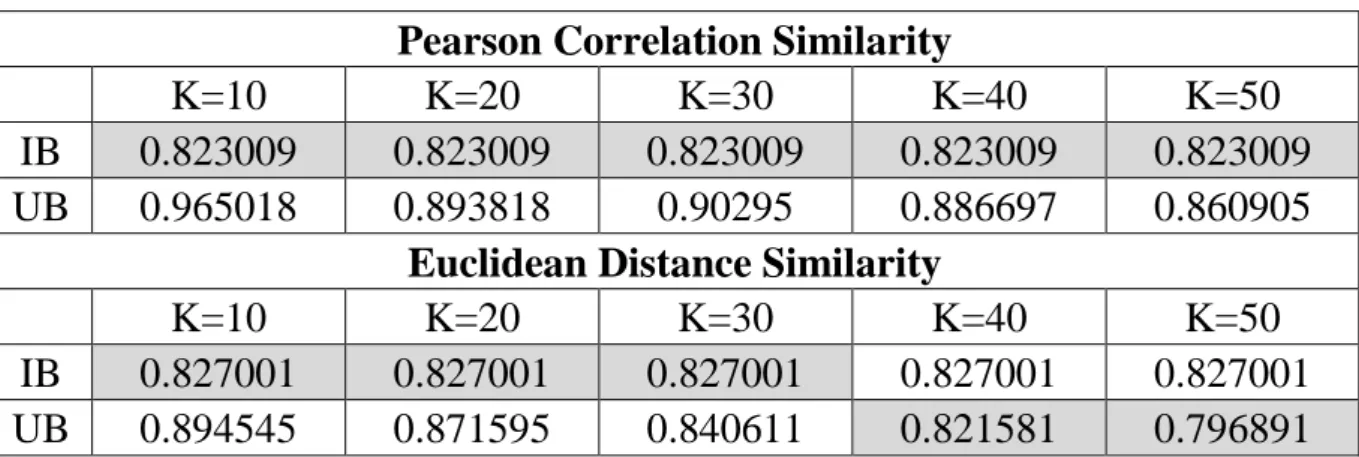
(32) 表示誤差低,也代表有越佳的推薦精確度。. 第三節 推薦之相似度分析與選擇 利用 Apache Mahout 來實現傳統的協同過濾,除了需要決定鄰居數之外, 還必須決定需要使用哪種相似度方法來計算。因此本論文將電影和笑話資 料集分割為 80%訓練集和 20%測試集,做五等份交叉驗證,再透過 Apache Mahout 提供的 Pearson Correlation Similarity、Uncentered Cosine Similarity 和 Euclidean Distance Similarity 三種相似度方法來觀察 MAE 值的結果,最 後採用誤差最小的相似度方法做為我們推薦所需的參數。沒有使用 LogLikelihood Similarity 和 Tanimoto Coefficient Similarity 的原因,是因為此 兩種方法著重於使用者與項目之間的關係,用於 0/1(不喜歡/喜歡)的情境, 較不關心使用者對項目具體評分為多少,因此我們將不對此兩種方法做實 驗與分析。 表 2 相似度在 MAE 上的結果(Movielens 100k). IB UB. K=10 0.823009 0.965018. IB UB. K=10 0.827001 0.894545. Pearson Correlation Similarity K=20 K=30 K=40 0.823009 0.823009 0.823009 0.893818 0.90295 0.886697 Euclidean Distance Similarity K=20 K=30 K=40 0.827001 0.827001 0.827001 0.871595 0.840611 0.821581. 22. K=50 0.823009 0.860905 K=50 0.827001 0.796891.
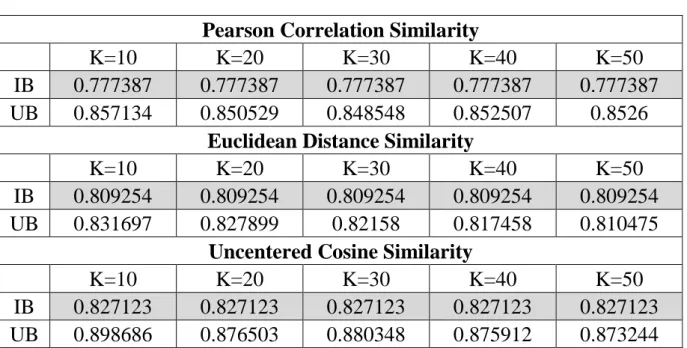
(33) IB UB. K=10 0.833317 0.950981. Uncentered Cosine Similarity K=20 K=30 K=40 0.833317 0.833317 0.833317 0.91922 0.91205 0.91105. K=50 0.833317 0.882999. 表 3 相似度在 MAE 上的結果(Movielens 1m). IB UB. K=10 0.777387 0.857134. IB UB. K=10 0.809254 0.831697. IB UB. K=10 0.827123 0.898686. Pearson Correlation Similarity K=20 K=30 K=40 0.777387 0.777387 0.777387 0.850529 0.848548 0.852507 Euclidean Distance Similarity K=20 K=30 K=40 0.809254 0.809254 0.809254 0.827899 0.82158 0.817458 Uncentered Cosine Similarity K=20 K=30 K=40 0.827123 0.827123 0.827123 0.876503 0.880348 0.875912. K=50 0.777387 0.8526 K=50 0.809254 0.810475 K=50 0.827123 0.873244. 表 4 相似度在 MAE 上的結果(笑話資料集). IB UB. K=10 0.944631 1.118269. IB UB. K=10 0.977111 0.963328. IB UB. K=10 0.987635 1.082924. Pearson Correlation Similarity K=20 K=30 K=40 0.944631 0.944631 0.944631 1.075068 1.064281 1.052144 Euclidean Distance Similarity K=20 K=30 K=40 0.977111 0.977111 0.977111 0.9356 0.935143 0.924996 Uncentered Cosine Similarity K=20 K=30 K=40 0.987635 0.987635 0.987635 1.063951 1.047694 1.03953. K=50 0.944631 1.04623 K=50 0.977111 0.917685 K=50 0.987635 1.036633. 根據表 2、表 3 和 表 4 的實驗結果,Uncentered Cosine Similarity 的誤差明顯偏高。 23.
(34) Euclidean Distance Similarity 的結果,UB 表現優於 IB,不符合我們一般對 協同過濾的認知。因此我們將採用誤差最小的 Pearson Correlation Similarity 來進行後續的實驗推薦。. 第四節 LDA 主題數與字詞數的選擇 本論文主題與字詞的參數設定需視資料集的大小而定。由於 Movielens 100k 只有 1682 部電影,笑話資料集只有 100 篇笑話,故主題數與字詞數不 宜設定太多。此節,我們將會比較主題數與字題數分別設定在 5、10、15、 20 的 MAE 結果,來決定最後的參數值。 表 5 不同的主題數與字詞數在 MAE 上的表現(MovieLens 100k) 主題數. 字詞數. 5 10 15 20 5 10 15 20 5 10 15 20 5 10 15 20. 5 5 5 5 10 10 10 10 15 15 15 15 20 20 20 20. LDA-IB 0.63968 0.63334 0.64239 0.66846 0.62034 0.6342 0.63799 0.62619 0.64044 0.63271 0.64073 0.64237 0.64737 0.63589 0.6493 0.64225 24. LDA-UB 0.74381 0.732 0.73954 0.73024 0.7331 0.74517 0.73627 0.73351 0.73276 0.73414 0.7276 0.73349 0.7353 0.73514 0.73422 0.73563.
(35) 根據表 5 可以發現 LDA-IB 在字詞數 10 的 MAE 表現比較好,若將字 詞數增加至 15、20 時,誤差反而造成些許的提升。若將字詞數減少至 5 時, 其表現也沒有字詞數 10 來的好。最後我們由字詞數 10 的組合來看,其中 主題數 5、字詞數 10 的組合與主題數 20、字詞數 10 的組合表現較為相近, 但還是主題數 5、字詞數 10 的表現較為優異。因此我們選擇主題數 5、字 詞數 10 的組合,做為 MovieLens 100k 在建構 LDA 時的參數設定。 表 6 不同的主題數與字詞數在 MAE 上的表現(笑話資料集) 主題數. 字詞數. 5 10 15 20 5 10 15 20 5 10 15 20 5 10 15 20. 5 5 5 5 10 10 10 10 15 15 15 15 20 20 20 20. LDA-IB 0.75093 0.69388 0.68025 0.67975 0.7617 0.71848 0.71914 0.72602 0.77436 0.75089 0.74768 0.75808 0.79296 0.7704 0.77108 0.7759. LDA-UB 0.9437 0.88939 0.8629 0.84871 0.93341 0.87393 0.84647 0.83032 0.93512 0.87237 0.83783 0.83224 0.93146 0.86925 0.84736 0.87771. 根據表 6 可以明顯看出笑話資料集在字詞數 5 的時候,誤差比在字詞 數 10、15、20 的時候還要低。因此我們從字詞數 5 的組合中,選擇主題數. 25.
(36) 20、字詞數 5 的組合,做為笑話資料集在建構 LDA 時的參數設定。. 第五節 LDA 主題模型的建構 本論文實驗是用 JAVA 語言撰寫,因此我們選擇使用同樣由 JAVA 語言 撰寫而成的 LDA 工具 JGibbLDA5,同時它也是一種開放原始碼的工具,如 此一來也較容易從原始碼中理解及應用在本論文架構上。JGibbLDA 工具是 採用 Gibbs sampling 的方式進行主題模型的建構與分析,其詳細步驟如下:. 一、 收集項目內容、去除停用字 我們使用的資料集為電影及笑話資料集。首先,電影資料集除了需要 使用者對電影的評分資料外,還需要所有電影項目的內容,因此我們從 IMDB6擷取所有電影項目的故事情節如圖 2;笑話資料集是使用 Jester7所提 供的笑話文字檔8如圖 3。最後從這些項目內容中,將文章裡常常出現卻與 文章主題較無相關的停用字剔除,例如:"a"、"and"、"is" 及 "the" 等字。. 5 6 7 8. http://jgibblda.sourceforge.net/ http://www.imdb.com/ http://eigentaste.berkeley.edu/ http://eigentaste.berkeley.edu/dataset/jester_dataset_1_joke_texts.zip 26.
(37) 圖 2 電影資料集的電影故事情節. 圖 3 Jester 所提供的笑話文字檔. 二、 參數設定 主題模型建構時的各項參數說明如表 7,本論文主題與字詞的參數設定 需視資料集的大小而定。由於 Movielens 100k 只有 1682 部電影,笑話資 料集只有 100 篇笑話,故主題數與字詞數不宜設定太多,我們會比較主題. 27.
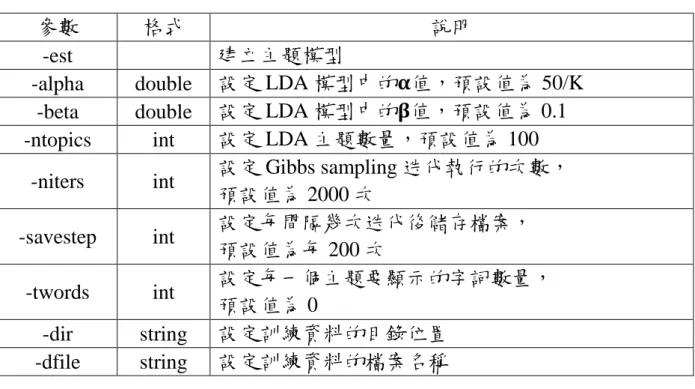
(38) 數與字題數設定在 5、10、15、20 的效果,決定最後的參數值。其餘參數 設定則保留預設值來進行建構。 表 7 JGibbLDA 參數說明 參數 -est -alpha -beta -ntopics. 格式 double double int. -niters. int. -savestep. int. -twords. int. -dir -dfile. string string. 說明 建立主題模型 設定 LDA 模型中的𝛂值,預設值為 50/K 設定 LDA 模型中的𝛃值,預設值為 0.1 設定 LDA 主題數量,預設值為 100 設定 Gibbs sampling 迭代執行的次數, 預設值為 2000 次 設定每間隔幾次迭代後儲存檔案, 預設值為每 200 次 設定每一個主題要顯示的字詞數量, 預設值為 0 設定訓練資料的目錄位置 設定訓練資料的檔案名稱. 三、 輸入文件格式 輸入文件的統一格式如下圖 4 所示,第一列代表所有項目的數量,從第 二列開始後之每一列代表著每個項目中的字詞。. 28.
(39) 圖 4 JGibbLDA 輸入格式範例. 四、 輸出資料格式 透過 Gibbs sampling 的方式進行主題模型分析後,我們會得到以下六個檔 案,其檔案紀錄了主題在各文件上的主題與字詞分布的資訊,詳細檔案說 明如下表 8 所示:. 29.
(40) 表 8 JGibbLDA 輸出檔案說明 檔案名稱 <model-name>.others <model-name>.phi <model-name>.theta <model-name>.tassign <model-name>.twords Wordmap.txt. 說明 紀錄主題模型建立時的參數及設定 儲存每個字詞被指定到某個主題的機率分布 儲存每個文件所包含主題的機率分布 儲存訓練資料字詞對特定主題的對應 儲存每個主題下選出的字詞及對應的權重 每個字詞與系統自動編號的對應. 第六節 電影資料集之指標分析與評估 本節涵蓋兩個實驗,實驗一使用 Movielens 100k 資料集來進行,經由四 種推薦方法分別為項目為基礎之 CF、使用者為基礎之 CF、結合 LDA 與項 目為基礎之 CF 和結合 LDA 與使用者為基礎之 CF 來產生前 20 名的推薦清 單,並利用相關性、多樣性和新穎性指標來評估四種推薦方法的表現。實 驗二使用 Movielens 1m 資料集,經由兩種推薦方法分別為項目為基礎之 CF、 使用者為基礎之 CF 來產生前 20 名的推薦清單,並利用相關性、多樣性和 新穎性指標來評估四種推薦方法的表現。實驗二沒有結合 LDA 與協同過濾 來產生推薦,因為本論文 MovieLens 1m 資料集的電影項目內容仍持續收集 中,未來收集完畢可能會由學弟來完成。 進行實驗前,我們必須考慮使用者的情境。假設某位使用者是個愛看電 影的人,以往推薦系統都準確推薦符合他個人興趣的電影,而忽略了一些 新奇且新穎的電影。於是他希望能利用週末不用上班的時間,看任何一部 之前沒有看過的電影,紓解平日上班的壓力,因此我們必須根據此情境來 30.
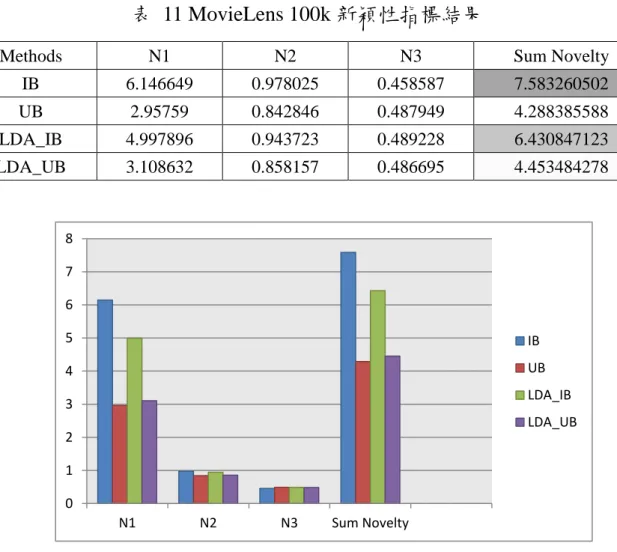
(41) 建議最適合推薦方法給予使用者。. 一、 Movielens 100k 之指標分析與評估 表 9 MovieLens 100k MAE 結果 MAE IB. 0.823009. UB. 0.893818. LDA_IB. 0.620341. LDA_UB. 0.733101. 1 0.9 0.8 0.7 0.6. IB. 0.5. UB. 0.4. LDA_IB. 0.3. LDA_UB. 0.2 0.1. 0 MAE. 圖 5 MovieLens 100k MAE 直條圖 本論文使用 MAE 來比較四種推薦方法在預測評分資料和真實評分資料 之間的差距,得到的結果值越大代表誤差越高表現越不好,反之結果越小, 表現越好。由結果來看,LDA-IB 的誤差最小,LDA-UB 的誤差則略大於 LDA-IB, UB 的誤差最大, IB 的誤差則比 UB 小一點,但略大於 LDA-UB 和 LDA-IB。 31.
(42) 表 10 MovieLens 100k 多樣性指標結果 D1. D2. D3. Sum Diversity. IB. 0.480236. 0.812454. 0.215114. 1.5078035. UB. 0.454448. 0.550185. 0.425776. 1.430409996. LDA_IB. 0.484498. 0.863158. 0.386005. 1.733660891. LDA_UB. 0.455643. 0.547813. 0.399934. 1.403390126. 2 1.8 1.6 1.4 1.2. IB. 1. UB. 0.8. LDA_IB. 0.6. LDA_UB. 0.4 0.2 0 D1. D2. D3. Sum Diversity. 圖 6 MovieLens 100k 多樣性指標直條圖 表 10 為多樣性指標的結果,在 D1 四種推薦方法雖然差異不大,但 IB 的表現最好,接著是 LDA-IB,再來是 UB,LDA-UB 的表現最差。IB 在 D2 的部分最好,LDA-IB 比 IB 差了一點,LDA-UB 又比 LDA-IB 差,表現 最差的為 UB。D3 的部分,LDA-IB 表現最差,UB 表現最好。最後我們將 D1、D2 及 D3 指標相加,從最後相加的結果可以得知 IB 在多樣性指標表 現最好,接著是 UB,再來是 LDA-UB,最後一名則是 LDA-IB。. 32.
(43) 表 11 MovieLens 100k 新穎性指標結果 Methods. N1. N2. N3. Sum Novelty. IB. 6.146649. 0.978025. 0.458587. 7.583260502. UB. 2.95759. 0.842846. 0.487949. 4.288385588. LDA_IB. 4.997896. 0.943723. 0.489228. 6.430847123. LDA_UB. 3.108632. 0.858157. 0.486695. 4.453484278. 8 7 6. 5. IB. 4. UB LDA_IB. 3. LDA_UB 2 1 0 N1. N2. N3. Sum Novelty. 圖 7 MovieLens 100k 新穎性指標直條圖 表 11 為新穎性指標的結果,N1 的部分,LDA-IB 表現明顯高於其他三 種推薦。N2 表現最好的是 IB,LDA-IB 略比 IB 差了一點,LDA-UB 又比 LDA-IB 差,表現最差的為 UB。從 N3 的結果來看,LDA-IB 的表現最差, 其他三指推薦表現較為相近。最後我們將 N1、N2 及 N3 指標相加比較,我 們可以得知 LDA-IB 在新穎性指標表現最好,然後是 IB,而 LDA-UB 和 UB 的結果分別為第三與第四名。 依據以上指標評估與分析,因為 LDA 主題模型的結合,LDA-IB 雖然沒 有很好的多樣性表現,但在新穎性和相關性上的表現是最好的,所以在此 33.
(44) 情境中,我們建議使用者可以選擇 LDA-IB 來產生推薦。我們也可以建議使 用者選擇項目為基礎的協同過濾,雖然相關性比起 LDA-IB 還要低,卻可以 換取更高多樣性的表現,且在新穎性表現排名為第二名,與 LDA-IB 還要差 一點,但較無明顯的差異。因此,在此情境中也是可以納入考慮的好選擇。. 二、 Movielens 1m 之指標分析與評估 表 12 MovieLens 1m MAE 結果 MAE IB. 0.777386517. UB. 0.850529114. 0.86 0.84 0.82 IB. 0.8. UB 0.78 0.76 0.74 MAE. 圖 8 MovieLens 1m MAE 直條圖 在 MAE 的部分,IB 的誤差比 UB 還低,表示 IB 與實際評分的差異相 差不大,其結果算是符合我們一般對協同過濾的認知。. 34.
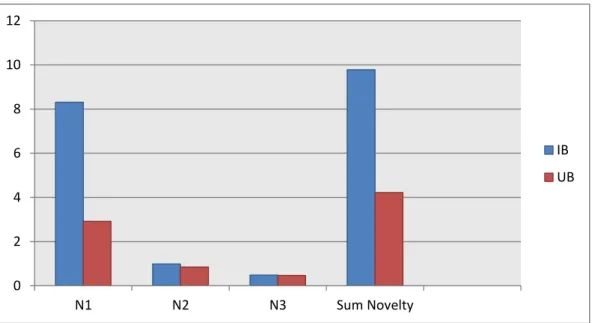
(45) 表 13 MovieLens 1m 多樣性指標結果 D1. D2. D3. Sum Diversity. IB. 0.488446634. 0.674544534. 0.211060799. 1.374051968. UB. 0.467414535. 0.460172065. 0.388437169. 1.316023769. 1.6 1.4 1.2 1 IB. 0.8. UB. 0.6. 0.4 0.2 0 D1. D2. D3. Sum Diversity. 圖 9 MovieLens 1m 多樣性指標直條圖 表 13 為多樣性指標結果,IB 在 D1 和 D2 的表現都比 UB 好,由此得 知 IB 在使用者彼此之間的推薦清單差異較大,總體多樣性上的表現也比較 突出。D3 的部分,在衡量單一為使用者推薦清單的差異性時,反而是 UB 比 IB 好,這可能表示使用 UB 來產生多樣的推薦時,應該站在單一使用者 的角度,而不是全部使用者的角度。最後我們將多樣性指標相加,整體來 看 IB 的表現比 UB 好。 表 14 MovieLens 1m 新穎性指標結果 N1. N2. N3. Sum Novelty. IB. 8.30875329. 0.990491168. 0.481063853. 9.780308311. UB. 2.91383397. 0.845844027. 0.462922892. 4.222600889. 35.
(46) 12 10 8 IB. 6. UB 4 2 0 N1. N2. N3. Sum Novelty. 圖 10 MovieLens 1m 新穎性指標直條圖 表 14 為新穎性指標結果,在每個新穎性指標上,IB 表現都比 UB 還要 好。將各個新穎性指標加總後,整體來看也當然是 IB 表現較好。N1 的部 分,我們推測 UB 有較多為不符合 one deleted link 的推薦,未滿足該條件之 下,不能將使用者列入計算,因此 IB 的表現比 UB 優異許多。N2 的結果則 代表 IB 獲得較多長尾項目的推薦。 依據以上指標評估與分析,項目為基礎之協同過濾在相關性、多樣性和 新穎性的整體表現皆優於使用者為基礎之協同過濾,所以在此情境中,我 們可以很強烈的建議使用者可以選擇項目為基礎之協同過濾來產生推薦。. 第七節 笑話資料集之指標分析與評估 本節對 Jester 所提供的笑話資料集進行一次實驗,經由四種推薦方法分 別為項目為基礎之 CF、使用者為基礎之 CF、結合 LDA 與項目為基礎之 CF 的和結合 LDA 與使用者為基礎之 CF 來產生前 20 名的推薦清單並利用 36.
(47) 相關性、多樣性和新穎性指標來評估四種推薦方法的表現。 進行實驗前,我們必須考慮使用者的情境。下個禮拜系上要舉行每年度 的機智笑話王競賽,比賽的規則為抽到某個主題,就必須在限制時間內, 講出符合該主題的笑話,且不能與別的參賽者重複,即可過關。評分的方 式則是由每場比賽觀眾給予參賽者的評分進行累加,最後存活者且評分最 高者獲勝。假設某位使用者想要獲得不同主題,且不會與其他人撞題的笑 話題材推薦,依據此情境,我們在本節最後面來分析哪種推薦方法較適合 該使用者。 表 15 笑話資料集 MAE 結果 MAE IB. 0.823009. UB. 0.893818. LDA_IB. 0.679752. LDA_UB. 0.848709. 1 0.9 0.8 0.7 0.6. IB. 0.5. UB. 0.4. LDA_IB. 0.3. LDA_UB. 0.2 0.1 0 MAE. 圖 11 笑話資料集 MAE 直條圖 37.
(48) 在 MAE 的部分,IB 的誤差結果最低,表示它與實際值差距最小,UB 又比 IB 高一些,再來是 LDA-UB,最高的為 LDA-IB。會造成這樣的結果, 我們推測可能是因為笑話資料集的內容,通常只是簡短的一句話,而電影 資料集通常使用較多文字來描述其電影情節(4.1 顯示笑話資料集平均字數 為 318 個字),造成 LDA 主題模型在笑話資料集中,不易找出代表性的主題, 使得 LDA 的結合讓相關性表現較差。 表 16 笑話資料集多樣性指標結果 D1. D2. D3. Sum Diversity. IB. 0.338704. 0.988. 0.357824. 1.684527757. UB. 0.350447. 0.986. 0.389764. 1.726211637. LDA_IB. 0.345074. 0.97. 0.412893. 1.727966386. LDA_UB. 0.362607. 0.958. 0.416087. 1.736694255. 2 1.8 1.6 1.4 1.2. IB. 1. UB. 0.8. LDA_IB. 0.6. LDA_UB. 0.4 0.2 0 D1. D2. D3. Sum Diversity. 圖 12 笑話資料集多樣性指標直條圖 表 16 為多樣性指標結果,LDA-UB 在 D1 的表現最好,接著是 LDA-IB,. 38.
(49) 然後是 UB,IB 則表現最差。D2 的部分,IB 和 UB 分別為第一、二名,LDA-IB 和 LDA-UB 則為第三、四名,由此得知,結合 LDA 的協同過濾在總體多樣 性的表現反而沒有傳統協同過濾來的好。D3 表現最好的為 LDA-UB, LDA-IB 比 LDA-UB 差,UB 又比 LDA-IB 差,而最差是 IB。最後將新穎性 指標加總後,整體來看,LDA-UB 的表現為第一名,LDA-IB 為第二名,接 著 UB 為第三名,最後一名為 IB。 表 17 笑話資料集新穎性指標結果 N1. N2. N3. Sum Novelty. IB. 4.823282. 0.863714. 0.418532. 6.105529105. UB. 2.913342. 0.780188. 0.428988. 4.122517636. LDA_IB. 4.186235. 0.869574. 0.434321. 5.490129758. LDA_UB. 2.743308. 0.767769. 0.422827. 3.933904144. 7 6 5 IB. 4. UB 3. LDA_IB. 2. LDA_UB. 1 0 N1. N2. N3. Sum Novelty. 圖 13 笑話資料集新穎性指標直條圖 表 17 為新穎性指標結果,IB 在 N1 的部分表現最好,LDA-IB 比 IB 差. 39.
(50) 一點,UB 又比 LDA-IB 差,最差的是 LDA-UB。N1 的結果普遍偏高,我 們推測是因為笑話資料集只有 100 則笑話,其中 IB 評分次數高於 5000 的 項目有 29 筆,換句話說有 71 筆都是自信息較高的項目,所以才會有此結 果產生。 N2 的部分,LDA-IB 表現最好,接著是 IB,再來是 LDA-UB,表現最 差的是 UB,可以發現 IB 和 LDA-IB 都比 UB 和 LDA-UB,還要容易推薦 長尾項目。N3 的結果,LDA-IB 表現是最好,LDA-UB 表現略比 LDA-IB 差,UB 又比 LDA-UB 差,但比 IB 的表現好一點。最後將新穎性指標加總 後,整體來看 IB 在新穎性指標表現最好,LDA-IB 為第二名,UB 為第三名, 最後 LDA-UB 為第四名。 依據此情境,我們必須著重於多樣性和新穎性之間的取捨,因為高多樣 性的推薦,代表推薦的項目差異性大,有不同類型的笑話推薦,而高新穎 的推薦,則代表得到較少人看過的長尾項目,如此可以避免參賽者與其他 人撞題。IB 雖然有高新穎的表現,但在多樣性的表現上為最後一名,而且 因為有高相關性的表現,也許會常常得到熱門的頭項目,容易與其他參賽 者講了重複的笑話,所以我們建議排除使用 IB。LDA-UB 則是有著高多樣 性,但新穎性的表現卻是最後一名,所以我們也將之排除。因上述結果, 我們退而求其次,建議使用者使用 LDA-IB 來產生推薦,其多樣性及新穎性 表現皆為第二名,希望使用者能夠得到不同類型且較少人看過的笑話推. 40.
(51) 薦。. 41.
(52) 第伍章 結論 第一節 研究限制 達到良好的使用者滿意度必須滿足許多面向(新穎性、多樣性、相關性 和驚奇性等),即使本論文達到多樣、新穎且相關的推薦,也難以保證能讓 使用者感到滿意,因此本論文沒有考慮使用者滿意度的問題。. 第二節 結論與貢獻 陳登裕(2015)所採用的多樣性指標,如模擬使用者情境時,無法從各個 面向來衡量該選擇哪種推薦方法,因此本論文使用多樣性、新穎性和相關 性三種指標,探討傳統協同過濾及結合 LDA 的協同過濾在各個指標上的表 現。本論文實驗結果證明,結合 LDA 的協同過濾不只會帶來更多樣的推薦, 也能帶來更新穎的推薦。從三種指標不同的面向,更有助於分析其推薦結 果,依據結果建議使用者選擇適當的推薦方法,獲得使用者想要的推薦。. 第三節 未來研究方向 現今用來衡量推薦的指標非常眾多,如何選擇適當的指標來衡量推薦, 實際上是相當困難的。因為某些指標表現的好,相對的另一個指標就會表 現得比較差。若未來能加入一種綜合評估的指標,幫助指標之間的取捨, 在任何情境中都能判斷推薦的好壞,就能提升使用者滿意度。. 42.
(53) 第陸章 參考文獻 王錦坤、姜元春、孫見山、孫春華(2016)。考慮用戶活躍度和項目流行度的 基於項目最近鄰的協同過濾演算法。計算機科學,43(12),158-162。 陳登裕(2015)。以主題模式進行多樣且相關的線上課程推薦(未出版之碩士 論文)。國立屏東大學,屏東。 Adamopoulos, P., & Tuzhilin, A. (2011). On Unexpectedness in Recommender Systems: Or How to Expect the Unexpected. In Workshop on Novelty and Diversity in Recommender Systems, 11-18. Adomavicius, G., & Kwon, Y. (2012). Improving aggregate recommendation diversity using ranking-based techniques. IEEE Transactions on Knowledge and Data Engineering, 24(5), 896-911. Ansari, A., Essegaier, S., and Kohli, R. (2000). Internet Recommendation Systems. Journal of Marketing Research, 37(3), 363-375. Arsan, T., Köksal, E., & Bozkuş, Z. (2016). Comparison of collaborative filtering algorithms with various similarity measures for movie recommendation. International Journal of Computer Science, Engineering and Applications (IJCSEA), 6(3). Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. The Journal of machine Learning research, 3, 993-1022. Bobadilla, J., Ortega, F., Hernando, A., & Gutiérrez, A. (2013). Recommender systems survey. Knowledge-based systems, 46, 109-132. Bradley, K., & Smyth, B. (2001). Improving recommendation diversity. In Proceedings of the Twelfth Irish Conference on Artificial Intelligence and 43.
(54) Cognitive Science, 85-94. Candillier, L., Meyer, F., and Boullé, M. (2007). Comparing state-of-the-art collaborative filtering systems. In Machine Learning and Data Mining in Pattern Recognition, Springer Berlin Heidelberg, 548-562. Castells, P., Vargas, S., and Wang, J. (2011). Novelty and diversity metrics for recommender systems: Choice, discovery and relevance. Proceedings of International Workshop DDR, 29-37. Chang, T. M., & Hsiao, W. F. (2013). LDA-based Personalized Document Recommendation. In PACIS. Retrieved from http://aisel.aisnet.org/cgi/viewcontent.cgi?article=1012&context=pacis2013 Chesani, F. (2002). Recommendation Systems. Corso di laurea in Ingegneria Informatica, 1-32. de Máster, T. F. (2012). Novelty and Diversity Enhancement and Evaluation in Recommender Systems. Retrieved from http://nlp.uned.es/ma2vicmr/docs/tfm-vargas-sandoval.pdf Ge, M., Delgado-Battenfeld, C., and Jannach, D. (2010). Beyond accuracy: evaluating recommender systems by coverage and serendipity. Proceedings of the fourth ACM conference on Recommender systems, ACM, 257-260. Good, N., Schafer, J. B., Konstan, J. A., Borchers, A., Sarwar, B., Herlocker, J., & Riedl, J. (1999). Combining collaborative filtering with personal agents for better recommendations. In AAAI/IAAI, 439-446. Guo, S. (2014). Analysis and evaluation of similarity metrics in collaborative filtering recommender system. Retrieved from https://www.theseus.fi/bitstream/handle/10024/80193/Shuhang%20Guo_BI T10_K0951349_FinalThesis.pdf?sequence=1 Herlocker, J. L., Konstan, J. A., Borchers, A., & Riedl, J. (1999). An algorithmic 44.
(55) framework for performing collaborative filtering. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, ACM, 230-237. Herlocker, J. L., Konstan, J. A., Terveen, L. G., and Riedl, J. T. (2004). Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems (TOIS), 22(1), 5-53. Herlocker, J., Konstan, J. A., and Riedl, J. (2002). An empirical analysis of design choices in neighborhood-based collaborative filtering algorithms. Information retrieval, 5(4), 287-310. Kunaver, M., & Požrl, T. (2017). Diversity in recommender systems–A survey. Knowledge-Based Systems, 123, 154-162. Lee, K., & Lee, K. (2015). Escaping your comfort zone: A graph-based recommender system for finding novel recommendations among relevant items. Expert Systems with Applications, 42(10), 4851-4858. Li, Q. and Kim, B. M. (2003). Clustering Approach for Hybrid Recommender System. Proceedings of the IEEE/WIC International Conference on Web Intelligence, 33-38. Linden, G., Smith, B., and York, J. (2003). Amazon.com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Computing, 7(1), 76-80. Mcnee, S. M., Riedl, J., and Konstan, J. A. (2006). Being Accurate is Not Enough: How Accuracy Metrics Have Hurt Recommender Systems. Conference on Human Factors in Computing Systems, 1097-1101. Morozov, S., & Zhong, X. (2013). The Evaluation of Similarity Metrics in Collaborative Filtering Recommenders. Hawaii University International Conferences. 45.
(56) Murakami, T., Mori, K., and Orihara, R. (2007). Metrics for evaluating the serendipity of recommendation lists. Newfrontiers in artificial intelligence: JSAI, 40-46. Niemann, K., & Wolpers, M. (2013). A new collaborative filtering approach for increasing the aggregate diversity of recommender systems. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, 955-963. Resnick, P., and Varian, Hal R. (1997). Recommendation systems. Communication of ACM, 40(3), 56-58. Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., and Riedl, J. (1994). Grouplens: An open architecture for collaborative filtering of netnews. Proceedings of the ACM CSCW’94 Conference on Computer-Supported Cooperative Work, 175-186. Sarwar, B. M., Konstan, J. A., Borchers, A., Herlocker, J., Miller, B., & Riedl, J. (1998). Using filtering agents to improve prediction quality in the grouplens research collaborative filtering system. In Proceedings of the 1998 ACM conference on Computer supported cooperative work, 345-354. Sarwar, B., Karypis, G., Konstan, J., and Riedl, J. (2001). Item-Based collaborative filtering recommendation algorithms. Proceedings of the 10th International World Wide Web Conference, 285-295. Schafer, J.B., Konstan, J., and Riedl, J. (1999). Recommender systems in e-commerce. Proceedings of the 1st ACM Conference on Electronic Commerce, New York, 158−166. Vargas, S. (2011). New approaches to diversity and novelty in recommender systems. In Fourth BCS-IRSG symposium on future directions in information access (FDIA 2011), 31. 46.
(57) Wilson, J., Chaudhury, S., & Lall, B. (2014). Improving collaborative filtering based recommenders using topic modelling. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), 1, 340-346. Zhang, L. (2013). The Definition of Novelty in Recommendation System. Journal of Engineering Science & Technology Review, 6(3). Zhang, Y. C., Séaghdha, D. Ó ., Quercia, D., and Jambor, T. (2012). Auralist: introducing serendipity into music recommendation. Proceedings of the fifth ACM international conference on Web search and data mining, ACM, 13-22. Zheng, Q., Chan, C. K., & Ip, H. H. (2014). IURA: An Improved User-based Collaborative Filtering Method Based on Innovators. In Proceedings of the International MultiConference of Engineers and Computer Scientists, 1. Zhou, T., Jiang, L. L., Su, R. Q., and Zhang, Y. C. (2008). Effect of initial configuration on network-based recommendation. EPL (Europhysics Letters), 81(5). Zhou, T., Kuscsik, Z., Liu, J. G., Medo, M., Wakeling, J. R., and Zhang, Y. C. (2010). Solving the apparent diversity-accuracy dilemma of recommender systems. Proceedings of the National Academy of Sciences, 107(10), 4511-4515. Zhou, T., Su, R. Q., Liu, R. R., Jiang, L. L., Wang, B. H., & Zhang, Y. C. (2009). Accurate and diverse recommendations via eliminating redundant correlations. New Journal of Physics, 11(12), 123008. Ziegler, C. N., McNee, S. M., Konstan, J. A., & Lausen, G. (2005). Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web, 22-32. 47.
(58)
數據

+5

Outline
相關文件
• Content demands – Awareness that in different countries the weather is different and we need to wear different clothes / also culture. impacts on the clothing
Based on “The Performance Indicators for Hong Kong Schools – Evidence of Performance” published in 2002, a suggested list of expected evidence of performance is drawn up for
We have made a survey for the properties of SOC complementarity functions and theoretical results of related solution methods, including the merit function methods, the
We have made a survey for the properties of SOC complementarity functions and the- oretical results of related solution methods, including the merit function methods, the
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
• Formation of massive primordial stars as origin of objects in the early universe. • Supernova explosions might be visible to the most
“information literacy” education at school recommended?. What is the suggested learning and teaching hours across
(Another example of close harmony is the four-bar unaccompanied vocal introduction to “Paperback Writer”, a somewhat later Beatles song.) Overall, Lennon’s and McCartney’s
