行政院國家科學委員會專題研究計畫 成果報告
音質改進之語音變換系統 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-2628-E-011-107-
執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學資訊工程系
計 畫 主 持 人 : 古鴻炎
計畫參與人員: 碩士班研究生-兼任助理人員:黃崇哲 碩士班研究生-兼任助理人員:簡延庭 碩士班研究生-兼任助理人員:張世穎 碩士班研究生-兼任助理人員:林祐靖 碩士班研究生-兼任助理人員:張家維
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 100 年 10 月 19 日
行政院國家科學委員會專題研究計畫成果報告
音質改進之語音變換系統
A Voice-quality Improved Voice Conversion System 計畫編號:NSC 99-2628-E-011-107
執行期限:99 年 8 月 1 日至 100 年 7 月 31 日 主持人:古鴻炎 國立台灣科技大學資訊工程系
計畫參與人員:黃崇哲、張家維、簡延庭、張世穎、林祐靖 e-mail: [email protected]
一、中文摘要
我們提出以分段式(segmental)高斯混合 模型(GMM)的觀念,來改進語音轉換的效能,
並且發展了一個基於動態規劃之自動GMM 挑 選的演算法,以實際應用該觀念於線上(on-line) 進行的語音轉換處理。此外,為了使用單一高 斯 混 合 來 對 映(mapping) 離 散 倒 頻 譜 係 數 (DCC),我們也設計了一種高斯混合選取之演 算法。對於分段式GMM 觀念的評估,我們建 造了三個不同功能組合之語音轉換系統,然後 使 用 這 些 系 統 所 轉 換 出 的 語 音去作聽 覺測 試,實驗的結果顯示,分段式GMM 之觀念確 實可用以改進音色相似度(timbre similarity)、
及語音品質(voice quality)。
關鍵詞:語音轉換,離散倒頻譜,高斯混合模 型,音色相似度,語音品質
ABSTRACT
The idea of segmental Gaussian mixture models (GMMs) is proposed for voice conversion. To apply this idea to implement an on-line voice conversion system, we have developed a dynamic-programming based automatic GMM selection algorithm. In addition, to map a discrete-cepstrum coefficient (DCC) vector with only one Gaussian mixture, a mixture selection algorithm is also developed.
To evaluate the performance of the idea, three voice conversion systems are constructed, and used to conduct listening tests. The listening test results show that segmental GMMs proposed here can indeed help to improve the performances in both timbre similarity and voice quality.
Keywords: voice conversion, Gaussian mixture model, discrete cepstrum, timbre similarity
二、緣由與目的
在一些應用裡,把輸入的資料設定為語 音信號是比較恰當的,例如電影、電視劇人物 的自動配音。這次計畫之目標,就是要研究、
製作一個可將輸入語音的音色變換(convert)成 另一特定人音色的音色變換系統。題目裡的”
音質提升”,表示不僅是考慮變換出的語音音 色要像目標(target)語者的,並且要設法維持良 好的語音品質,不要像先前一些被提出的變換 方法,雖然音色有像目標語者的,但是信號的 品質卻衰退很多(即出現明顯的失真現象)。此 外,我們希望所研究出的技術,能夠實際地被 應用於製做系統,如前面提到的配音系統,因 此我們設定在不需知道輸入語音的內容的條 件下,來研究音色變換的方法,並且該方法能 夠被實作成具有即時(或接近即時)的處理速 度。
過去,我們對於目標語者為非特定語者 的音色變換的研究,如把女子聲音變換成男子 聲音或小孩聲音,已經有一些經驗,並且發表 了研究成果[1, 2, 3],其中兩篇[1,2]是在語音合 成系統上考慮音色變換的問題,但是使用了不 同的信號合成方法,分別是 TIPW 法(PSOLA 之變種) [1],及 HNM (harmonic plus noise model)法[4, 5];另外,第三篇[3]則是考慮輸入 為語音信號的情況下,去研究音色變換的問 題 , 我 們 經 由 作 DCC (discrete cepstrum coefficients)分析[3, 6],取得各音框的振幅頻譜 包絡(spectral magnitude envelope),然後對包絡 作調整,再用HNM 法把語音信號重新合成出 來。
回顧前人在語音變換(voice conversion)
方面的研究成果,所提出的語音變換技術,大 體上可分成 6 類,分別是: (a)向量量化對映 (mapping)[7,8]、(b)共振峰(formant)頻率對映 [9,10]、(c)GMM (Gaussian mixture model)對映 [11,12]、(d)ANN (artificial neural network)對映 [13] 、 (e) 單 元 挑 選 (unit selection)[14,15] 、 (f)HMM (hidden Markov model)對映[16,17]。
三、研究方法
3.1 四個因素
一般來說,語音變換系統的製作需考慮到 四個因素,分別是語料因素、頻譜特徵參數、
音色變換方法、信號合成方法。
關於語料因素,我們採取平行語料的方 式,就是要求來源語者和目標語者都對同一份 文句內容發音,如此在作系統訓練時,比較方 便建立兩語者之間的頻譜參數的對應關係。
關於頻譜特徵參數,過去常被採用的包括 了LPC 導出的 LSF (line spectrum frequency)線 頻譜頻率係數[18],LPC 導出的倒頻譜係數 [19],由 STRAIGHT[20]頻譜計算出的 MFCC (mel-frequency cepstrum coefficient)梅爾倒頻 譜係數,及 DCC 離散倒頻譜係數。在本計畫 裡,我們採用了 DCC 係數來作為頻譜特徵參 數。
關 於 信 號 合 成 的 方 法 , 雖 然 使 用 STRAIGHT [20] 來對修改過的頻譜參數作合 成,可以得到非常高品質的合成語音信號,但 是 STRAIGHT 作信號合成的計算量非常大,
而無法在一般個人電腦上達成接近即時處理 的要求,因此我們採用了基於HNM 之合成方 法。
關於音色變換的處理,觀察近期許多語音 變換的研究,都採取以GMM 作為基本的對映 機制,因此我們也決定以GMM 對映機制為基 礎,再加以改進。GMM 對映機制的一個重要 問題,就是變換出的頻譜參數會有頻譜包絡 (spectral envelope)過於平滑(over-smoothed)的 現象[21, 22],所以會有語音品質退化的感覺。
一個典型的基於GMM 的對映函數,其公 式如下[11]:
( ; , ) y F x
11 1
( ; , )
( )
( ; , )
x xx
M m m m y yx xx x
m m m m
M x xx
m m m m
m
w N x
x w N x
(1) 其中x 表示來源語者的頻譜特微向量,y 表示 變換後得到的頻譜特微向量,M 是高斯混合 N(,,)的總數,而 μ及 Ψ分別表示平均向量 與共變異矩陣的集合。我們認為把全部語料放 在一起,去訓練一個GMM 模型的 M (如 128) 個高斯混合的參數,容易發生一種現象,就是 一 個 高 斯 分 佈 為 了 照 顧 兩 種 音素的頻譜特 性 , 而 使 得 高 斯 分 佈 的 中 心 落 在 兩 音 素 (phoneme)之間,也使得高斯分佈變得平緩。
因此,我們提出一個解決辦法,就是先把訓練 語料裡的各個音框依其來源發音的韻母作分 群 , 然 後 再 分 別 對 各 群 去 訓 練 出 自 己 的 GMM,如此各個 GMM 就可忠實地代表它所 對應韻母的頻譜特性。
3.2 模型訓練階段
在訓練階段的主要處理步驟如圖 1 所 示。我們邀請了三位錄音者,分別到隔音錄音 室來錄製 375 句之平行語料,取樣率設為 22,050Hz,其中二位是男性,在此以 M1 和 M2 作代號,而另一位是女性,以 F1 作代號。
在本計畫裡,我們把M1 當作來源語者,而把 M2 和 F1 分別作為目標語者,也就是要把 M1 的語音變換成M2 及 F1 的語音。375 個訓練語 句共可擷取出2,926 個音節音檔,我們再依音 檔檔名中的韻母拼音符號,將這些音節音檔分 成37 群。
3.2.1 DCC 係數計算
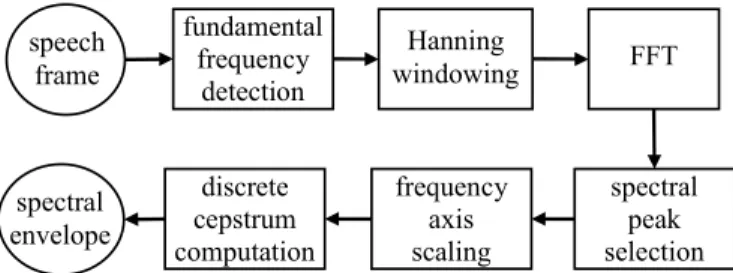
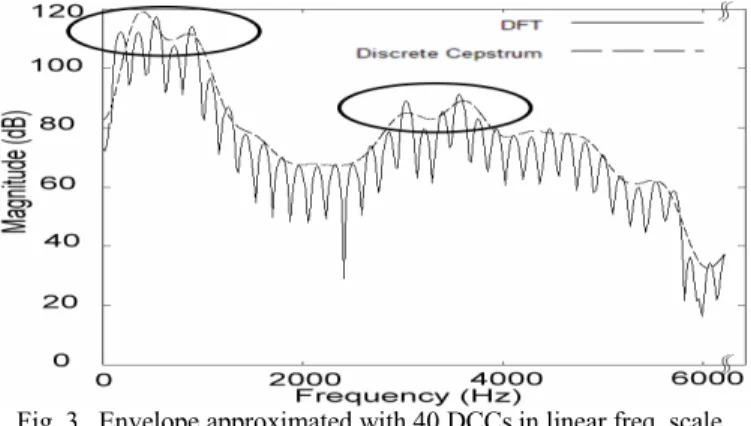
在本計畫裡,我們採用離散倒頻譜之頻譜 包絡估計方法,並且以離散倒頻譜係數(DCC) 作為頻譜參數。對於一個語音音框,我們使用 先前發展的 DCC 估計程式來計算出 40 維的 DCC 係數,在此一個音框的長度設為 512 個樣 本點(23.2ms),而音框位移則設為 110 個樣本 點(5ms)。
3.2.2 分段式 GMM 之訓練
在圖 1 中經由方塊 ”Grouping into 37 classes” 的處理之後,對於各群的音節片段 (segment),我們就分別拿去訓練出一個由 16
Training Segmental
GMMs Labeling and
segmenting Training sentences of
source speaker Training sentences of target speaker
Labeling and segmenting Grouping into
37 classes
Grouping into 37 classes
DTW alignment Estimating
DCC Estimating
DCC
Param. of 37 GMMs
Estimating pitch param.
Estimating pitch param.
Pitch param.
of target Pitch param.
of source
Framing Framing
圖1 訓練階段之主要處理流程 個高斯混合所形成的GMM 模型,所以這樣得
到 的 37 個 GMM , 就 稱 為 37 個 分 段 式 (segmental) GMM。
由於我們使用的是平行語料,每一個來源 語者音節和它對應的目標語音音節,可先以動 態時間校正(dynamic time warping)作時間軸對 齊的處理,這由圖1 裡的 ”DTW alignment” 方 塊負責。然後,一個來源語音音框和它所對齊 的目標語音音框,兩音框算出的 DCC 係數就 可被合併成一個 80 維的頻譜特徵向量,接著 我 們 使 用 基 於 MLE (maximum likelihood estimate)的 GMM 訓練方法[23],來對各群合 併後DCC 向量進行 MLE 訓練,如此就可得到 各群的聯合機率密度之GMM 模型。
3.2.3 音高參數
我們使用一種基於自相關函數及 AMDF 的基週偵測方法[24],來偵測各音框的音高頻 率,然後將一個語者發音中有聲(voiced)音框 偵測出的音高頻率值收集起來,據以求出他們 的平均值及標準差,這就是我們所需要的音高 參數。
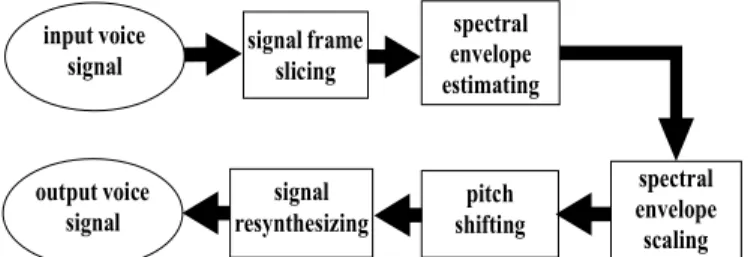
3.3 語音變換階段
我們研究的語音變換方法,其主要的處理 流程如圖2 所示。當一句未知內容的語句輸入 後,它首先會被切割成一序列的音框,而音框 長度(512 點)和位移(110 點)則和 3.2.1 節裡使
用的一樣。然後,在圖2 的左邊流程,會對各 音框的音高頻率作偵測,當一個音框被偵測為 無聲時,圖 2 中的三個灰色方塊就被直接跳 過,也就是不需作音高頻率的調整,且 DCC 頻譜參數也未被變換。
相對地當一個音框被偵測為有聲時,我們 在此採用一種簡便的音高調整公式來調整音 高頻率,
( )
y y x
t x t
q p
(2)
其中pt表示偵測出的音高頻率值,μx和σx分別 表示來源語者的音高頻率平均值和標準查,而 μy和σy是目標語者的。
在圖2 裡的右邊流程,基本上是一個音框 接著一個音框來作處理,但是在 “Selecting a GMM” 之方塊裡,我們提出一種 GMM 自動 挑選之演算法,該演算法是以每 20 個有聲音 框為一個批次(batch)來作 GMM 的挑選,以便 為各個有聲音框從 37 個 GMM 中選出正確的 (或鄰近的)一個 GMM。之後,在 “Mapping with single mixture” 之方塊裡,我們再從一個 音框所選取到的GMM 裡,選取出一個高斯混 合來作單一高斯混合之 DCC 係數對映,以便 避免頻譜曲線過度平滑的情形發生。不過,我 們不能只依據加權值的大小來分別為各個音 框挑選出單一個高斯混合,因為相鄰音框的變 換後頻譜的連續性也必需被考慮,以避免怪音 被產生出來。對於單一高斯混合選取的問題,
我們也發展了一個基於DP 的演算法,基本上 是把一序列的有聲音框(左、右兩邊被無聲音
HNM based speech synthesis Pitch
adjusting
Selecting a GMM
Mapping with single mixture Estimating DCC
Converted voice Detect pitch freq.
Unknown spoken sentence
Framing
圖2 變換階段之主要處理流程 框包夾),當作一個批次來作單一高斯混合選
取的處理。接著在圖 2 裡左右流程合併之方 塊 ”HNM based speech synthesis”,我們使用一 個基於HNM 的信號合成方法,去依據變換出 的 DCC 係數及音高頻譜,把語音信號再合成 出來。
3.3.1 分段 GMM 之選取方法
對 於 一 個 線 上 處 理 的 語 音 變 換 系 統來 說,輸入語音的說話內容是事先不知道的,因 此當要對一個音框的 DCC 係數作對映時,我 們如何知道37 個 GMM 當中的那一個應被選 取?這樣的問題必須先被解決,而該問題是一 種語音辨識的問題,不過它不需要像語音辨識 那樣嚴厲地被對待,因為選取到錯誤但近似的 GMM 是可以容忍的。
在 語 音 辨 識 領 域 , 隱 藏 式 馬 可 夫 模型 (hidden Markov model, HMM)是最常被採用的 統計模型,不過在此我們希望以所訓練出的37 個GMM 來取代 HMM 的角色,如此就不需另 外去訓練HMM。此外,我們觀察到一個非常 接近真實的現象是,一個人不可能在一個很短 暫的時間如100ms 之內,發出多於 2 個的語音 片段(在此語音片段指的是音節)。所以,我們 決定把每20 個連續的有聲音框(含蓋 100ms 之 時間範圍)作為一個批次,去作 20 個音框整批 的GMM 選取之處理,如此一個批次裡就只需 選出一個或二個的GMM。本論文研發了一個 DP 為基礎的 GMM 挑選之演算法,該演算法 會依據最大似然率(maximum likelihood)去選
出一個或二個GMM。
令第 t 個輸入音框的 DCC 係數是由第 s 個GMM 所產生的機率是 Gt(s),其詳細計算公 式為
1
( ) = ( ) ; ( ), ( ) ,
M x xx
t m t m m
m
G s w s N x s s (3)
其中 Wm(s)表示第 m 個高斯混合的加權,xt表 示第 t 個音框的 DCC 向量。此外,令 R(t, s) 表示從時刻 1 到時刻 t 的音框都是由第 s 個 GMM 所產生的似然率對數值,而令 D(t, s)表 示從時刻1 到時刻 t 的音框是由 2 個 GMM 所 產生,並且第t 個音框是由第 s 個 GMM 所產 生的似然率對數值。依據前述的定義,我們可 以推導出如下的兩個遞迴公式:
( , ) log t( ) ( 1, ) ,
R t s G s R t s (4)
( , ) log t( ) D t s G s
0 37,
max max ( 1, ) , ( 1, ) ,
v v s R t v D t s
(5)
其所需設定的邊界值是,D(1, s)=0 和 R(1, s)=G1(s),s=0, 1, ..., 36。接著,依據公式(4)和 (5),我們可得到 T 個音框整體的最大似然率為
0 37 0 37
( ) max max ( , ) , max ( , ) ,
v v
A T R T v D T v
(6)
其中 T 在本論文裡設為 20。在依據公式(4),
(5)和(6)得到 A(20)之最大似然率數值之後,我 們可作回溯(backtrack)處理,去找出 A(20)數值 的最佳行走路徑,而得到 20 個音框各自所被 指派的GMM 編號。
3.3.2 單一高斯混合之對映
所謂使用單一高斯混合來對映一個輸入 音框的DCC 係數,其實際作法是把公式(1)裡 的累加符號及加權項移除,如此變換出的DCC 向量y 就變成以下列公式來計算,
1( ) y yx ( ) ,
k xx x
k k
k k
y F x x (7) 其中x 表示輸入音框的 DCC 係數,Fk(x)表示 使用第k 個高斯混合所建立的對映函數。
關於公式(7)裡 k 值(即高斯混合之編號) 的選取的問題,我們設計了一個基於DP 的高 斯混合選取之演算法。首先令3.3.1 節中為第 t 個音框自動挑出之 GMM 編號為 I(t),接著以
( )( )
I tk t
F x 表示使用第k 個高斯混合來對第 t 個 音框之DCC 向量 xt作對映,此外以C(t, k)表 示從時刻1 到時刻 t 的累積距離,但是限定在 時刻t 時使用編號為 k 的高斯混合,如此我們 設計的遞迴公式就可寫成
( ) ( 1) 1
0 ,
( ( 1))
( ), ( )
( , ) min ,
( 1, )
m
k m
I t t I t t
w I tm M H
dist F x F x C t k
C t m
(8) 其中dist(, )表示對兩 DCC 向量之間作幾何 距離的量測,H 是一個門檻參數,我們依經驗 設定它的值為 0.3,而 Wm(I(t-1))表示第 I(t-1) 個GMM 的第 m 個混合的加權。
公式(8)的意義是,在各個時刻 t 先依 Wm(I(t)) > H 之條件篩選出加權夠大的幾個高 斯混合,然後從各時刻篩選出的高斯混合中,
以DP 的觀念去串接出行走的路徑,最後在結 束的時刻T 時,以下列公式找出最小的累積距 離B(T),
0 , ( ( ))
( ) min ( , ) ,
k M w I Tk H
B T C T k
(9)
所以依據公式(8)和(9),我們可求得最小的累 積距離,然後經由回溯的程序找出行走的路 徑,如此就可決定時刻1 到時刻 T 各個音框所 應選取的高斯混合。至於公式(8)裡 C(t, k)在 t=0 時的邊界數值,我們可直接設定成 C(0, k)=0,0k < M。
3.3.3 基於 HNM 之語音信號合成
在諧波加雜音模型(HNM)中,一個有聲音 框的頻譜被分割成低頻的諧波部分和高頻的 雜音部分,而分割這兩部分的邊界頻率稱為最 大 有 聲 頻 率(maximum voiced frequency , MVF)。關於 MVF 值的偵測,在 Stylianou 的 博士論文裡[11],提出了一個對各個音框逐一
作偵測的方法,不過為了簡化語音信號合成處 理的程序,在此我們把各個有聲音框的 MVF 值都直接設為6,000Hz。
假設第i 和第 i+1 個音框都是有聲的,並 且 分 別 有 Li 和 Li+1 個 諧 波 成 分(harmonic partials),Li的值以MVF / qi作計算,qi表示第 i 個音框的變換過的基頻值。當要對這兩個音 框之間的第t 個樣本點產生出信號樣本值,首 先我們以線性內插來計算第t 個樣本點上的各 個諧波成分的頻率值 f tk( )和振幅值a tk( ),計 算方式如公式(10)所示,
1
1
( ) , 1, 2,..., ,
( ) , 1, 2,...,
i i
i k k
k k
i i
i k k
k k
f f
f t f t k L
N
a a
a t a t k L
N
(10)
其中 N 表示兩相鄰音框之間的樣本點總數(在 此設為 110,即音框位移的點數),L 表示 Li 和Li+1兩者的較大值,此外fki和aki分別表示第 i 個音框的第 k 的諧波成分的頻率值和振幅 值,fki可以fki k qi作計算,而aki則必需依據 第 i 個音框對映得到的 DCC 係數,變換成頻 譜包絡後再去求取它的數值,關於aik數值求取 的細節請參考我們先前發表的論文[25]。另 外,如果Li小於Li+1,我們就直接設定aik= 0,
1, ..., 1
i i
k L L。然後,第t 個樣本點上的諧 波信號h(t)就可以公式(11)來作計算,
1
( ) ( ) cos( ( )), 0 , ( ) ( 1) 2 ( ) / 22, 050
L
k k
k
k k k
h t a t t t N
t t f t
(11)
其中k( )t 表示第k 個諧波成分在樣本點 t 時的 累積相位,22,050 是取樣率。至於k( )t 的初值
) (1
k ,我們可令它等於前一個音框最後一個 樣本點時的累積相位(即k(N1)),以保持相 位的連續性。如果本音框是第一個音框(即沒 有前一個音框),則可令k(1)的值為一個隨機 值,使用隨機值是符合語音信號特性的。
四、系統製作 與 聽測實驗
為了評估所提出的變換方法,我們建造了 三個語音變換系統,分別以SOG,SSG 和 SLG 作為代號,在代號SOG (system using original GMM for mapping)的系統裡,我們使用 350 個 訓練語句來訓練出一個由256 個高斯混合形成 的GMM,然後使用公式(1)來對各個輸入音框
的DCC 係數作對映。另外,在代號 SSG (system using single Gaussian mixture for mapping)的系 統裡,我們仍然使用350 個語句所訓練出的一 個具有256 個高斯混合的 GMM,不過在變換 階段,3.3.2 節裡說明的高斯混合選取方法被用 來為一序列的輸入音框選取出各音框的單一 高斯混合,然後各輸入音框的 DCC 係數就使 用所選出的單一高斯混合及公式(7)來作對 映。至於在代號 SLG (system using selected GMM for mapping)的系統裡,我們首先以 350 個語句來訓練出37 個分段式 GMM,而各分段 式GMM 都只有 16 個高斯混合,然後在變換 階段,我們採用3.3.1 節裡說明的 GMM 選取 方法,來為每 20 個有聲音框選取出最大似然 率的一個或兩個分段 GMM,接著採用 3.3.2 節裡的高斯混和選取方法,來為各輸入音框選 取出單一個高斯混合,再依據公式(7)作對映。
當把一個來源語者的發音檔,分別輸入到 前述的三個語音變換系統,我們就可得到三個 變換出語音檔。然後使用變換出的音檔,我們 進行了兩種類型的聽測實驗,分別是音色相似 度之聽測、和語音品質之聽測。在這二類型的 聽測實驗裡,我們都邀請了 25 位人士來聆聽 音檔並給予相對分數,而在這 25 位人士中,
有20 位是不熟悉語音變換之研究的。
4.1 音色相似度測試
首先我們準備了5 個音檔,它們的代號分 別是VS(由來源語者發音),VT(由目標語者發 音),VX1(經由 SOG 系統變換得到),VX2(經 由 SSG 系統變換得到),VX3(經由 SLG 系統 變換得到),其中 VS 與 VT 具有相同的說話內 容,而VX1、VX2 和 VX3 三者也有相同的內 容,但不同於VS 和 VT 的,這 5 個音檔可從 網頁http://guhy.csie.ntust.edu.tw/VoiceConv/去 下載。在進行聽測實驗時,我們以 ABX 的次 序來撥放前述的音檔,在此 A 固定為 VS,B 固定為VT,而 X 則隨機由 VX1、VX2 和 VX3 三者中選出,每次以 ABX 次序播放完音檔 後,受測者就被要求給一個分數。在此分數的 定義是,9 分(或 1 分)表示 X 的音色確定就是 B(或 A)的音色,7 分(或 3 分)表示 X 的音色比 較接近B(或 A)的音色,而 5 分表示 X 的音色 無法判斷是接近A 或接近 B。
做完聽測實驗之後,25 位受測者所給的 分數被用來計算出三個系統各自的平均分數 (AVG)和標準差(STD),所得到的分數數值就
如表1 所列出的。由表 1 的平均分數可知,不 同性別之間的語音變換(即從 M1 到 F1),會比 同性別之間的(即從 M1 到 M2)獲得明顯較高 的分數。此外,拿三個系統的平均分數作比 較,可從表一的數值得知,SLG 系統的表現明 顯比SSG 系統的好許多(7.05 vs 6.24,7.60 vs 7.24),而 SSG 系統的表現則是比 SOG 系統的 稍微好一些(6.24 vs 6.08,7.24 vs 6.92)。所以 本計畫提出的分段式 GMM 之觀念及自動 GMM 挑選之演算法,的確可幫忙改進所變換 出語音的音色相似度。
表 1、音色相似度聽測之平均分數與標準差
SOG SSG SLG
AVG 6.08 6.24 7.05
M1=>M2
STD 1.11 1.09 0.93
AVG 6.92 7.24 7.60
M1=>F1
STD 1.13 1.07 1.10
4.2 語音品質測試
在此我們使用三個系統變換出的語音檔 VX1、VX2 和 VX3,來進行語音品質的聽測 實驗。音檔撥放的次序為 AX,A 固定設為 VX1,而 X 則隨機由 VX2 和 VX3 兩者中取 出,每次以AX 次序播放完音檔後,受測者就 被要求給一個分數。在此分數的定應是,9 分 (或 1 分)表示 X 的語音品質明顯比 A 的好(或 差),7 分(或 3 分)表示 X 的品質比 A 的稍微好 (或差)一些,5 分則表示 X 和 A 的語音品質無 法分辨優劣。
作完聽測實驗之後,我們收集 25 位受測 者所給的分數,來計算出SSG 和 SLG 兩系統 各自的平均分數和標準差,結果得到的數值如 表2 裡列出的。依據表 2 的平均分數可看出,
同性別之間(即從 M1 到 M2)的變換語音的品 質,會比不同性別之間(即從 M1 到 F1)的較好 約0.5 分,這顯示不同性別之間的變換語音的 品質,是比較難作改進的。此外,依據 SLG 和 SSG 兩系統的平均分數作比較,我們可看 出SLG 的分數都比 SSG 的高約 0.7 分,並且 SLG 的平均分數都高於 5 分,所以分段式 GMM 之觀念及自動挑選 GMM 之演算法,確 實可用以改進所變換出語音的語音品質。
表 2、語音品質聽測之平均分數與標準差 SSG vs SOG SLG vs SOG
AVG 5.23 6.04
M1=>M2
STD 1.43 1.45
AVG 4.89 5.55
M1=>F1
STD 1.50 1.47
4.3 倒頻譜距離量測
在所錄音的 375 句平行語料中,最後 25 句並未被用於訓練 GMM 模型,因此這 25 句 來源語者發音的語音檔,在此就分別被輸入到 三個語音變換系統 SOG、SSG 和 SLG,去作 語音變換的處理,以便量測變換出語音和目標 語音(目標語者發音)之間的倒頻譜距離,用以 作為變換後頻譜和目標頻譜之間的接近程度 的客觀量測。
對於變換出的語音音檔的每一個有聲音 框,我們先依先前作DTW 時間對齊的資料,
來找出目標語者發音檔中對應的音框,然後將 兩對應音框的 DCC 係數,拿去計算幾何距 離,接著再依所有有聲音框量測到的距離去計 算出平均距離,結果對於三個語音變換系統,
我們計算出的平均距離就如表3 裡所列出的。
表 3、變換後語音的平均倒頻譜距離
SOG SSG SLG
M1=>M2 0.543 0.609 0.601
M1=>F1 0.598 0.634 0.612
依據表3 列出的數值,可發現 SOG 系統 會得到最小的平均距離,然而由聽測實驗的結 果可知,SOG 系統在音色相似度方面是最差 的,並且在語音品質方面也是比SLG 系統差,
如此的不一致性,其原因尚需進一步去了解。
另一方面,SLG 系統比起 SSG 系統所表現出 的效能改進,則是有反應在所量測出的平均距 離上,SLG 比 SSG 多增加了選取分段式 GMM 之處理步驟。
五、成果與討論
經由本計畫的執行,我們提出以分段式 GMM 之觀念,來解決傳統 GMM 語音變換方 法,因使用數量很多的高斯混合,造成頻譜過 於平滑,而導致語音音質衰退的問題。此外為 了在線上處理的實際語音變換系統中,使用分 段式 GMM 之觀念,我們也發展了一個自動
GMM 挑選的演算法。
為了驗證所提出的方法,我們實際建造了 三個不同功能組合之語音變換系統,然後進行 聽測實驗,其結果顯示 SLG 系統是三個系統 之中效能最好的,不管是在音色相似度、還是 在語音品質上都表現得最好,而 SLG 系統所 採用的處理方法,就是本計畫提出的分段式 GMM 之觀念及自動 GMM 挑選之演算法。
另一方面,依據客觀量測出的平均倒頻譜 距離,可知使用原始 GMM 變換方法之 SOG 系統,可得到三個系統中最小的平均距離,然 而由聽測實驗的結果可知,SOG 系統在音色相 似度方面是最差的,並且在語音品質方面也是 比 SLG 系統差,如此的不一致性,其原因尚 需進一步去探討。目前我們僅根據韻母來作語 音的分段與分群,將來可再考慮把有聲聲母 (如/m/, /n/, /l/)的部分獨立切成語音段,這樣應 可進一步改進語音變換的效能。
六、參考文獻
[1] Hung-Yan Gu and Wen-Lung Shiu, "A Mandarin-syllable Signal Synthesis Method with Increased Flexibility in Duration, Tone and Timbre Control", Proceedings of the National Science Council, Republic of China, Part A:
Physical Science and Engineering, Vol. 22, No.
3, pp. 385-395, 1998.
[2] Hung-Yan Gu, Chen-Lin Cai, and Song-Fong Cai, “An HNM-based Speaker-nonspecific Timbre Transformation Scheme for Speech Synthesis”, International Congress on Image and Signal Processing (CISP 2009), Tianjin, China, pp. 4304-4308, Oct. 2009.
[3] 古鴻炎、蔡松峰,「基於離散倒頻譜之頻譜 包絡估計架構及其於語音變換之應用」,第 二 十 一 屆 自 然 語 言 與 語 音 處 理 研 討 會 (ROCLING 2009),台中,第 151-164 頁,2009。
[4] Yannis Stylianou, Harmonic plus Noise Models for Speech, combined with Statistical Methods, for Speech and Speaker Modification, Ph.D.
Dissertation, Ecole Nationale Supèrieure des Télécommunications, Paris, France, 1996.
[5] Hung-Yan Gu and Yan-Zuo Zhou, “An HNM Based Scheme for Synthesizing Mandarin Syllable Signal”, International Journal of Computational Linguistics and Chinese Language Processing, Vol. 13, No. 3, pp.
327-341, 2008.
[6] O. Cappe and E. Moulines, "Regularization
Techniques for Discrete Cepstrum Estimation", IEEE Signal Processing Letters, Vol. 3, No. 4, pp. 100-102, April 1996.
[7] M. Abe, S. Nakamura, K. Shikano, and H.
Kuwabara, “Voice Conversion through Vector Quantization,” International Conference on Acoustics, Speech, and Signal Processing, New York, Vol. 1, pp. 655-658, Apr. 1988.
[8] S. Nakamura and K. Shikano, “Spectrogram Normalization Using Fuzzy Vector Quantization”,J. Acoust. Soc., Japan, Vol. 45, pp. 107-114, 1989.
[9] H. Mizuno and M. Abe, “Voice Conversion Algorithm Based on Piecewise Linear Conversion Rules of Formant Frequency and Spectrum Tilt”,Speech Communication, Vol. 16, No. 2, pp. 153-164, 1995.
[10] 吳嘉彧、王小川,”不需平行語料而基於共振
峰與線頻譜頻率映對之語者特質變換系統”,
第 二 十 一 屆 自 然 語 言 與 語 音 處 理 研 討 會 (ROCLING 2009),台中,第 319-332 頁,2009。
[11] Stylianou Y., Capp´e O., Moulines E, ”Continuous Probabilistic Transform for Voice Conversion,” IEEE trans. Speech and Audio Processing, Vol. 6, No. 2, pp.131–142, 1998.
[12] Min Chu, “Voice Conversion with Smoothed GMM and MAP Adaptation”, Proc. of EuroSpeech, Geneva, Switzerland, pp.
2413-2416, 2003.
[13] Srinivas Desaiy, et al., “VoiceConversion Using Artificial Neural Networks,” ICASSP, Taipei, Taiwan, pp.3893–3896, 2009.
[14] Zhiwei Shuang, Fanping Meng, and Yong Qin,
“Voice Conversion by Combining Frequency Warping with Unit Selection”, ICASSP, Las Vegas, U.S.A , pp.4661-4664, 2008.
[15] D. Sundermann, et al.,“TextIndependentVoice Conversion Based on UnitSelection”,ICASSP, pp. 81-84, Toulouse, France, 2006.
[16] 劉德賢,應用雙可夫模型與聲音變換於情緒 語音合成之研究,碩士論文,國立成功大學 資訊工程研究所,2005。
[17] E. K. Kim, S. Lee, and Y. H. Oh, “Hidden
Markov Model Based Voice Conversion Using Dynamic Characteristics of Speaker”, Proc.
EuroSpeech, Vol. 5, Rhodes, Greece, 1997.
[18] A. Kain and M.W. Macon, “Spectral Voice Conversion for Text-to-speech Synthesis”,IEEE ICASSP, Seattle, Vol. 1, pp. 285-288, May 1998.
[19] K. S. Lee, “Statistical Approach for Voice Personality Transformation,”IEEE trans. Audio, Speech, and Language Processing, Vol. 15, No.
2, pp. 641-651, Feb. 2007.
[20] H. Kawahara, I. Masuda-katsuse and A. De Cheveign, “Restructuring Speech Represen- tations Using a Pitch-adaptive Time-frequency Smoothing and an Instantaneous-frequency- based F0 Extraction: Possible Role of a Repetitive Structure in Sounds”, Speech Communication, Vol. 27, pp. 187-207, 1999.
[21] T. Toda, H. Saruwatari,and K.Shikano,“Voice Conversion Algorithm Based on Gaussian Mixture Model with Dynamic Frequency Warping of STRAIGHT Spectrum”, ICASSP, Salt Lake City, pp. 841-844, May 2001.
[22] M. Zhang, J. Tao, H. Jia, and X.
Wang, ”Improving HMM Based Speech Synthesis by Reducing Over-Smoothing Problems”,International Symposium on Chinese Spoken Language Processing (ISCSLP), Kunming, China, Dec. 2008.
[23] R. A. Redner and H. F. Walker, “Mixture densities, maximum likelihood and the EM algorithm,” SIAM Review, vol. 26, no. 2, pp.
195-239, 1984.
[24] H.Y.Kim,etal.,“Pitch detection with average magnitude difference function using adaptive threshold algorithm for estimating shimmer and jitter,” 20-th Annual Int. Conf. of the IEEE Engineering in Medicine and Biology Society, Hong Kong, China, 1998.
[25] H.Y.Gu and S.F.Tsai,“A discrete-cepstrum based spectrum-envelope estimation scheme and itsexampleapplication ofvoicetransformation,” International Journal of Computational Linguistics and Chinese Language Processing, vol. 14, no. 4, pp. 363-382, 2009.
1
出席國際學術會議心得報告
計畫編號 NSC 99-2628-E-011-107 計畫名稱 音質改進之語音變換系統
出國人員姓名 服務機關及職稱
古鴻炎
台灣科技大學資訊工程系副教授 會議時間地點 2010/10/21 ~ 2010/10/23, 中國蘇州
會議名稱 International Conference on Wireless Communications and Signal Processing (WCSP 2010)
發表論文題目 A Discrete-cepstrum Based Spectral-envelope Estimation Scheme with Improvements
一、參加會議經過
WCSP 2010 國際研討會,由上海交通大學、
東南大學、中國人民解放軍理工大學所共同主 辦,而由 IEEE 通信學會(Communication Society) 與信號處理學會(Signal Processing Society)的南京 支會等協辦,接受的論文將收錄於 IEEE Xplore 資料庫。WCSP 2010 研討會接受投稿的領域包含 了無線通信與信號處裡之相關領域。個人投稿的 論文,屬於語音信號處理,研究的成果是,在離 散 倒 頻 譜(discrete cepstrum) 為 基 礎 的 頻 譜 包 絡 (spectral envelope)估計上,提出頻譜峰點之找尋 方法、和提出頻率軸尺度的轉換函數,以改進頻 譜包絡估計之準確性。
WCSP 2010 研討會共有 571 篇論文投稿,而 被接受的論文有 243 篇(接受率 42%),分別來自 25 個 國 家 和 地 區 。接 受 的 論 文 , 分 成 30 個 sessions 進行口頭發表,30 個 sessions 之中有 8 個屬於信號處理之領域,我的論文排於 10 月 21 日 16:00~18:00 的 Speech and Audio Signal Processin Session 進行口頭發表,右邊上圖就是在
發表會場所拍攝的照片,而右邊下圖,則是在晚宴會場所拍攝的照片。
2
除了前述的論文發表session 之外,我還參加了另外兩個 sessions,即 Array & Multi-channel Signal Processing、Blind and Adaptive Signal Processing,其它信號處理的相關 sessions,則由於 平行session 之安排方式而無法參與。
在行程方面,於 10 月 20 日搭乘 11:45 由松山機場直飛上海浦東機場的班機,然後搭乘長 途巴士前往位於蘇州城內的會場(即國際會議中心飯店),到達會場時大約是 17:40。參加研討會 後,則於 23 日中午搭乘巴士前往上海虹橋機場第一航站,並且在航站附近的旅館住宿一晚,然 後在隔日清晨8:05,趕搭由虹橋機場直航台北松山機場的班機。
二、與會心得
雖然WCSP 2010 研討會接受投稿的領域包含了無線通信與信號處裡之相關領域,但是所邀 請的五位 keynote speaker 的演講題目,都集中於通信領域的議題。所以,個人感覺信號處理與 語音處理並不是此次研討會的焦點,不過投稿信號處理領域的論文數量相對地少很多,應也是 一個重要的原因 。
在Speech and Audio Signal Processing 場次,共有 8 篇論文發表,其中有 7 篇是屬於語音處 理的。除了我的論文之外,其它論文中有兩篇是作語音編碼(speech coding)的,有一篇是作語音 強化(speech enhancement)的,一篇是作基週偵測的,及語者辨識等。雖然語音處理方面的篇數 不多,但是也含蓋了幾個語音研究的子領域,因此仍可相互了解不同子領域裡的研究情況。