SIGNAL
PROCESSING
ELSEVIER
High-speed
Signal Processing 43 (1995) 323-331
closest codeword search algorithms for vector
quantization*
Chang-Hsing Lee, Ling-Hwei Chen*
Department of Computer and Information Science, National Chiao Tung University 1001 Ta Hsueh Rd., Hsinchu, Taiwan 30050, Republic of China
Received 2 October 1992; revised 13 September 1993, 14 July 1994 and 15 December 1994
Abstract
One of the most serious problems for vector quantization is the high computational complexity involved in searching for the closest codeword through a codebook in both codebook design and encoding phases. In this paper, based on the assumption that the distortion is measured by the squared Euclidean distance, two high-speed search methods will be proposed to speed up the search process. The first one uses the difference between the mean values of two vectors to reduce the search space. The second is to find the Karhunen-Loeve transform (KLT) for the distribution of the set of training vectors and then applies the partial distortion elimination method to the transformed vectors. Experimental results show that the proposed methods can reduce lots of mathematical operations.
Zusammenfassung
Eines der schwerstwiegenden Probleme bei der Vektorquantisierung ist die hohe rechnerische Komplexitlt, die mit der Suche des ngchstliegenden Kodewortes innerhalb eines Kodebuches verbunden ist, sowohl beim Entwurf des Kodebuches, als such bei der Kodierphase. In dieser Arbeit werden unter der Voraussetzung des quadriatischen Euklidischen Abstandes als Verzerrungsmaa zwei sehr schnelle Suchmethoden vorgeschlagen, urn den Suchprozelj zu beschleunigen. Die erste Methode verwendet die Differenz zwischen den Mittelwerten zweier Vektoren, urn den Suchraum zu verkleinern. Die zweite Methode besteht darin, zunIchst die Karhunen-Loeve Transformation (KLT) fiir die Verteilung der Menge der Trainingsvektoren zu finden. Danach wird die partielle Verzerrungseliminierungsmethode auf die transformierten Vektoren angewendet. Experimentelle Ergebnisse zeigen, dal3 die vorgeschlagenen Methoden die Anzahl der mathematischen Operationen erheblich vermindern kiinnen.
L’un des problbmes les plus s6rieux dans la quantification vectorielle est la grande complexiti de calcul ntiessaire pour chercher le mot le plus proche dans un dictionnaire, ceci dans les deux phases de rkalisation du dictionnaire et d’encodage. Dans cet article, deux mtthodes de recherche rapide, bastes sur la supposition que la distortion est mesurk par la distance euclidienne quadratique, sont propos&es pour accklerer le processus de recherche. La premitre utilise la
*This research was supported in part by the National Science Council of R.O.C. under contract NSC-83-0404-EOO9-117. *Corresponding author.
016%1684/95/%9.50 0 1995 Elsevier Science B.V. All rights reserved SSDI 0165-1684(95)00009-7
324 C.-H. Lee, L.-H. Chen / Signal Processing 43 (1995) 323-331
difference entre les valeurs moyennes de deux vecteurs pour rtduire l’espace de recherche. La seconde consiste B trouver la transform& de Karhunen-Loeve (TKL) pour la distribution de l’ensemble des vecteurs d’apprentissage et ensuite applique la mtthode d’elimination partielle de distorsion aux vecteurs transform& Les rtsultats exptrimentaux montrent que les methodes proposees peuvent reduire un grand nombre d’operations mathtmatiques.
Keywords: Codebook design; Karhunen-Loeve transform; Vector quantization
1. Introduction
Vector quantization (VQ) is a well-known tech- nique for low-bit-rate image compression [6,7,13].
In VQ, the images are first decomposed into vec-
tors (i.e., blocks) and then sequentially encoded vector by vector. The aim of VQ is to find the best matching codeword in the codebook, and the key aspect of VQ is to design a good codebook contain- ing the most representative codewords. In the en- coding process, the index of the codeword that is the closest one to the input vector is transmitted or stored. The decoder uses the index to reconstruct the representative codeword. Compression is achieved by transmitting or storing the index of a codeword rather than the codeword itself.
Linde et al. [ 1 l] proposed a clustering algorithm, which is referred to as the LBG algorithm, for VQ codebook design. The algorithm is an iterative pro- cess that minimizes the overall distortion of repres- enting the training vectors by their corresponding closest codewords. However, the LBG algorithm needs a great deal of computation time to do ex- haustive search for the closest codeword to a train- ing vector. To avoid this kind of search, many fast algorithms have been proposed. Among them, the partial distortion elimination method [l], the par- tial search partial distortion method [S], the Voronoi cells method [2,3], the k-d tree method [12,15,16], and the triangle inequality method [9,14,17-193 are more popular. However, many of these algorithms achieve the goal of decreasing the search time at the expense of the coding quality.
Equitz proposed another codebook design algo- rithm, called the pairwise nearest-neighbor (PNN) clustering algorithm [5], to accelerate the code- book design process. This algorithm begins with a separate cluster for each training vector and merges the two clusters that have the smallest dis- tance at a time until the desired codebook size or
cluster number is achieved. This algorithm signifi- cantly reduces computational complexity, but the resulting codebook is suboptimal.
Since the most effort of searching for the closest codeword to a vector is to evaluate the distance between two vectors, if those remote codewords can be rejected before evaluating their distances from the input vector, the search process will be sped up. Based on this idea, two fast search methods can be proposed under the assumption that the distortion is measured by the squared Euclidean distance. The first one uses some elim- ination rules, which are based on the difference between the means of two vectors, to avoid unnec- essary distortion calculations for those codewords which are definitely not candidates of the closest codeword to the input vector. The second is to find the Karhunen-Loeve transform (KLT) for the dis- tribution of the training vectors, and then the par- tial distortion elimination method [l] is applied to the transformed vectors.
In the next section, we will describe the proposed methods. Section 3 presents experimental results to show the effectiveness of the methods. Some con- clusions are given in Section 4.
2. The proposed methods
In this section, we will present the proposed high-speed closest codeword search algorithms. The first method is based on the difference between two mean values to reduce the search space, it is also called the mean difference method (MDM). The second one, which is referred to as the eigen- vector method (EVM), is to find the Karhunen- Loeve transform for the distribution of the training vectors. It then applies the partial distortion elim- ination method to the transformed vectors to reject those remote codewords.
2.1. The mean digerence method
In VQ, the great effort of searching for the closest codeword to an input vector is to compute the distortion of representing the input vector by every candidate codeword. Thus, if we can use a simple test to reject those codewords which are definitely not candidates for the closest codeword to the input vector before the distortions are calculated, the search process can be sped up. In practice, two vectors with large mean difference will have large distance. Based on this idea, the first search method is developed. It uses the mean difference to deter- mine the search bound of the codewords. Before describing the method, we will first give some definitions and theorems.
Definition 1. Let x = (x1, x2, . . . , xk) be a k-dimen- sional vector and y = ( y,, y2, . . . , yk) be a k-dimen- sional codeword. Define the mean values of x and Y as
1 k m, =x C xj,
j-l
(1)
Theorem 1. If the distortion measure of representing x and y is dejned to be the squared Euclidean dis-
tance, i.e.,
d2(xlY)
= i
(Xj - .Yj)'9 j=lthen d2(x,y) >, k(m, - m,)‘. (3)
Proof. Let X be a random variable and has occur-
rences xj - yj, j = 1,2, . . . , k, with probability pj = l/k. Then from the following well-known inequality in probability [4],
WX2) 2
LW)12,
where E(X) is the expected value of X, we can get
i [
j$l
txj -
Yj)”
I[ 21
,$
txj-Yj) 1 2.
(4) I-1By combining the above inequality and Eqs. (l)-(2), Inequality (3) can be easily derived. lJ
From the above theory, we can see that for a codeword y, if k(m, - m,)’ is larger than the current minimum distortion dii,, the codeword y will not be the closest codeword to the input vector x and thus can be rejected. Based on this reason, many codewords which are definitely not candidates for the closest codeword to x can be rejected without evaluating their distortions. How- ever, two vectors with similar mean values will have large distance if their components are very differ- ent. To solve this problem, an extra stage will be introduced. Assume that the size of each block (vector) is k with k = n x n, i.e. any row or column in the block contains n pixels. First, every block x is decomposed into n subvectors, X1,X2, . . . ,X,, with each subvector Xi representing the ith row or the ith column of the block. Let m,i and nt,.i be the mean values of the ith subvectors, Xi and Yi, of vectors x and y, respectively, for i = 1,2, . . . , n. Based on these notations, a definition and two corollaries will be given.
Definition 2. Let M, = ( mXI, mX2, . . . , m,,) and My = (myl,my2, . . . ,myn), the squared distance between M, and M, is defined to be
dz(~,y) = d2(M,, My) = i (m,, - m,i)2.
i=l
From Definition 2 and Theorem 1, we have the following corollary.
Corollary 1. d2(x,y) 2 nd:(x,y) > k(m, - my)2. (5)
Proof. Since m, and my are the mean values of M, and My, respectively, from Definition 2 and Theorem 1, we have
dz(X,y) = i (t&i - t?lyi)2 > n(m, - my)‘. i=l
Since k = n x n, we have
326 C.-H. Lee, L.-H. Chen / Signal Processing 43 (1995) 323-331
Since mxi and myi are the mean values Of Xi and Yi, values of codewords, then the sorted codebook
from Theorem 1, we can get C,, is
C,, = {y’i’lmi < mi+l, 1 d i 6 N - i}.
i=l j=i i=l
= n&x,y), (7)
where Xii and Yij represent the jth pixels of Xi and Yi, respectively. Combining Inequalities (6) and (7), we finally obtain Inequality (5). 0
From Theorem 1 and Corollary 1, we can obtain the following corollary immediately.
Step 2. For each training vector x,, find the closest codeword yi(‘) in the codebook C,, and assign x, to class i(t). This procedure includes the following substeps:
Step 2.1. Input a training vector x, = (x,r , xt2, . . . , xtk), compute the mean values of all subvectors ofx, and the mean value mXt of x,.
Step 2.2. Find the codeword ytp) that has the minimum mean difference from x, (using binary search), i.e.,
Corollary 2. Let x be a training vector and d$” be the current candidate minimum distortion. For any codeword y, if k(m, - my)’ 2 d&n or n&x,y) > d&y then d2(~,y) 2 dkin e
lm,, - m,l< lmxr - VIil for all i #p,
where mP is the mean value of y(P). Set i(t) = p and the current minimum distortion &ii” = &(x,,y’“‘).
From Corollary 2, we know that for a training vector x and a codeword y, if k(m, - m,,)’ > dzi” or ndi(x,.Y) 2 d$“,y will not be the closest code- word to x and can be rejected with calculating d2(x,y).
With the above theorem and corollaries in hand, we now turn to describe the MDM. For a training vector x, we first calculate the mean values of all subvectors of x and the mean value of x. For every codeword y, if k(m, - my)’ is larger than the cur- rent minimum distortion d~i,, the codeword y will be rejected. Otherwise, if nd:(x,y) 2 d&n, the codeword y is rejected. If y is not rejected, the distortion d’(x,y) is calculated, and if d2(x9y) < d5”, the current minimum distortion dii” is replaced by d2(x,y).
Step 2.3. Find the closest codeword y’(‘) in C,, and assign x, to class i(t). The procedure is as follows:
Setd= 1;
while ((p + d 6 N and k(m,, - mp+d )2 < diin) or
A detailed description of how to employ the MDM to the codebook design of the LBG algo- rithm is given below.
Step 0. Initialization: Given N = codebook size, M= the number of training vectors, k = n x n = the dimension of a training vector, Co = initial codebook, E = distortion threshold. Set iteration counter r = 0, initial total distortion D- 1 = co . Step 2. Compute the mean values of all subvec- tors and the mean value, mi, of each codeword y”’ in the codebook C,, for i = 1,2, . . . , N. Sort
C, according to the increasing order of the mean
(p - d 2 1 and k(mXt - mp_d)2 < Ai,) begin if (p + d < N and k(m,, - m,+d)’ < d,$,)
begin /* first stage */
if (nd$(x,,y”‘d) < &ii”) begin /* second stage */
if(d2(x,,yp’d) < diin) begin dii” = d2(X,,yp+d); i(t) = p + d; end; end; end; if (p - d 2 1 and k(m, - mP_d)2 -C A,$,,) begin /* first state */
if(ndf(x,,yPed) < d&) begin /* second stage */ if(d2(x,,ypdd) < &ii”) begin
dii” = d2(X~pyp-d); i(t) = p - d; end; end; end; d=d+l; end; (of while}
Step 3. Compute the overall distortion for the rth iteration, D,. Here D, is defined to be
D, = f 4P(x,,y”“).
r=1
Step 4. If (O,_ 1 - D,)/Dr < E, halt with final code- book being C,,. Otherwise go to Step 5.
Step 5. Compute the centroid of every class. The centroids are regarded as the codewords of the new codebook. Set r = I + 1 and go to Step 1 for next iteration,
The MDM contains two stages. The first one compares the mean value of a codeword with that of the training vector; the second compares the mean values of the n subvectors of the codeword with those of the training vector. Note that the second stage will be very effective when every vec- tor is normalized so that it has zero mean or when two compared vectors with similar means have variant block types (for example, if one vector rep- resents a homogeneous block and the other is a block with edge pixels).
The encoder has to find the closest codeword in a predesigned codebook for each input vector and then uses the codeword as the reproduction one of the corresponding input vector. Therefore, it can use the MDM to find the closest codeword to each input vector. The details of this procedure are sim- ilar to those in Step 2 of the codeword design algorithm described above.
2.2. The eigenvector method
As mentioned previously, the most effort in searching for the closest codeword to a training vector is to evaluate the distance between two vec- tors. The lower the vector dimension is, the less the effort of the distance evaluation is. If we can find a lower-dimensional subspace S and for every vec- tor u, its projection vector on S can approximate u very well, the distance between two projected vectors will approach to that between two original vectors. Thus, those remote codewords can be re- jected only through testing the distance between
their projected vectors and the projected vector of the input vector. The first stage of the MDM
is such an example, the mean value of a vector represents the point of projecting the vector onto the subspace S1 spanned by the unit.vector (l/G,
lJJst, . . . , l/G). This means that in order to lower the complexity of the distance evaluation, we have projected every vector onto the one-dimen- sional subspace Si to approximate the vector. Since the rate of rejecting codewords before evaluating their distortions depends on the approximation accuracy, how to find a projection subspace with proper dimension becomes an important topic. In fact, the Karhunen-Loeve transform (KLT) for the distribution of the training vectors can be used to find the best subspace [lo]. Based on this trans- form and the above idea, the eigenvector method (EVM) is developed. It will first use KLT to find the best lower-dimensional subspace and projects every training vector and codeword onto the sub- space to get the projected vectors. Then the partial distortion elimination method [l] is applied to quickly reject those codewords which are definitely not candidates for the closest codeword match. The detail is described as follows.
Let C, be the covariance matrix of the training vectors x’s and be represented by
C, = E((x - m,) (x - mJT),
where m, = E(x), and T indicates vector transposi- tion. For all training vectors, under the mean square error sense, the best p-dimensional projec- tion subspace, S,, is spanned by the p orthonormal eigenvectors associated with the p largest eigen- values of C,, the reason can be found in [lo]. Let A be the matrix whose rows are formed by the orthonormal eigenvectors of C, and are ordered such that the first row of A is the eigenvector associated with the largest eigenvalue, and the last row is the eigenvector associated with the smallest eigenvalue. If we use the eigenvectors as the coordinate axes, then the new coordinates x’ = (xi,&, . . . ) xi) of each vector x can be ob- tained by the following equation:
x’=Ax.
This is the well-known KLT. Let x and y be two k-dimensional vectors, and x’ and y’ be the new coordinates of x and y projected on the eigenvector coordinate system, respectively, then x’ = Ax and
328 C.-H. Lee, L.-H. Chen / Signal Processing 43 (1995) 323-331
y’ = Ay. Since A is an orthonormal transform matrix, the distance between x and y is equal to the distance between x’ and y’, i.e., d’(x’,y’) = d2(x,y). Let A, be the p x k matrix whose rows are formed by the first p rows of A. Let x; = (x;,x;, . . . ,xk) and Y; = (Y’I,Y;, . . . ,Y;) be two p-dimensional vectors of x and y projected on the subspace, S,, spanned by A,, i.e., xb = A& and yb = Apv. Therefore, we can get
d2(x,y) = &(x’,y’) = i (XI - y;)2
j=l
> i (XJ - y>)’ = d’(x;,yy).
j=l
Having the above result, we will begin describing the EVM.
Let x be a training vector and the current candi- date minimum distortion be dii”. For any code- wordy, if d2(x”,yk) is larger than dzi,, y will not be the closest codeword to x and can be rejected without calculating its distortion. To test whether d’(xb,yb) is larger than d:i”, the partial distortion elimination method [l] is applied to speed up the testing process.
Note that the EVM needs some overhead to obtain the covariance matrix of the training vec- tors, the eigenvectors and the projected vectors. As contrasted with the MDM, the EVM has a higher rejection rate but needs more overhead. Therefore, for codebooks with smaller codebook sizes, the MDM may outperform the EVM, and the EVM is proper for those codebooks with larger codebook sizes.
3. Experimental results
To examine the efficiency of the proposed two methods, experiments were performed on a Sun SPARC-station-IPC using several 512 x 512 mono- chrome images with 256 gray levels. Each image is divided into 4 x 4 blocks, so that the training se- quence contains 16 384 16-dimensional vectors. The proposed algorithms were compared with the LBG algorithm and the fast nearest-neighbor search (FNNS) algorithm 1143, which is based on the triangle inequality, in terms of the numbers of
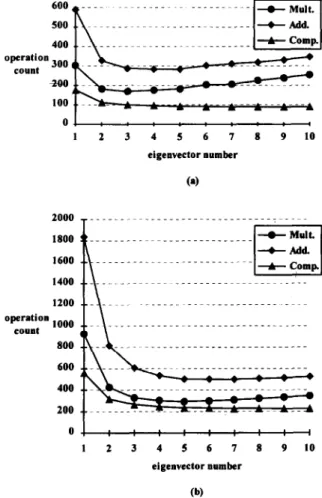
ol : : : : : : : , 1 2 3 4 5 6 7 8 9 10 eigenveetor number oy;;;to” 1000 . 800 Eli--- __ ___. .___________________----_.. 1 2 3 4 5 6 7 8 9 IO eigenveetor number (b)
Fig. 1. The average numbers of mathematical operations (over- head included) required per vector in codebook design using the EVM with variant codebook sizes versus selected eigenvector number p. (a) Codebook size 128, (b) codebook size 512.
multiplication, addition, and comparison opera- tions required in codebook design as well as image encoding.
Fig. 1 shows the average numbers of multiplica- tion, addition, and comparison operations required per vector in codebook design using the EVM algorithm versus the number of selected eigenvec- tors. From this figure, we can see that selecting more eigenvectors does not guarantee to result in better performance. For example, when codebook sizes of 128 and 512 are chosen, selecting 3 and 5 eigenvectors, respectively, will perform best. In practice, the more eigenvectors are selected, the more codewords can be rejected. However, the
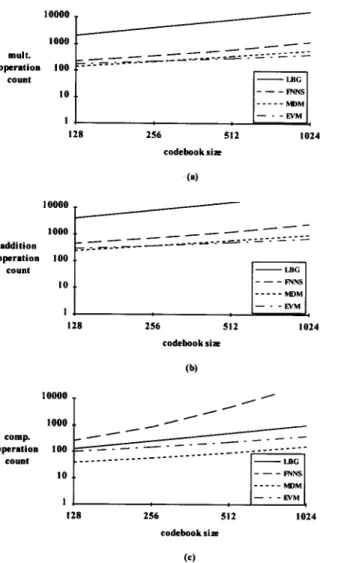
---MNS _-_-_&Q&j -_ -WM 256 512 1024 codebooksirr 128 256 512 1024 W 10000 T /’ 10 . . 1, 128 ---FNNS _____hDM -. -EvM 256 512 1024 codebooksia (f)
Fig. 2. The average numbers of mathematical operations (over- head included) required per vector in codebook design versus codebook sizes. (a) Multiplication, (b) addition, (c) comparison.
overhead will increase in proportion to the number of selected eigenvectors. From this figure, we can see that the more the codewords are, the more the eigenvectors we need.
Fig. 2 shows the average numbers of multiplica- tion, addition, and comparison operations required per vector in codebook design using the LBG, the FNNS, the MDM and the EVM algorithms. The MDM uses a column of a block to represent a sub- vector. The image Lena was used to design the codebook. From this figure, we can see that the MDM and EVM algorithms require much fewer
12 3 4 5 6 7 8 9 10 eigeavectornumber (8) 1800 1600 1400 1200 operation 1000 couat 800 600 400 200 0 12 3 4 5 6 7 8 9 10 eigcnvectornumber W
Fig. 3. The average numbers of mathematical operations re- quired per vector in image encoding using the EVM with variant codebook sizes versus selected eigenvector number p. (a) Code- book size 128, (b) codebook size 512.
multiplication and addition operations needed by the LGB algorithm and outperform the FNNS algorithm. The overhead required in the MDM and the EVM algorithms and that in the FNNS algo- rithm are included in this figure.
Fig. 3 shows the average numbers of multiplica- tion, addition, and comparison operations required per vector in image encoding using the EVM algo- rithm versus the number of selected eigenvectors. In the simulation, the image Lena was used to design a codebook, and the resulting codebook was then used to encode the four images (Lena, Peppers, Jet
330 C.-H. Lee, L.-H. Chen J Signal Processing 43 (1995) 323-331
l0000 _
1000 ., -__~__z_z_--~ mult. .__zz=-- -_TI_y_yrs_z--- _ _ _ _ ___- - - _-e--
operation 100.7 - _ - count - F",laarrh 10 ---FN~zj --___MDM -_ 1. -GYM 128 256 512 1024 w operation coUnt ',I : ~~~ 128 256 512 1024 codelmoksize (‘9 -_--- _______----. ._____---_F”,,,.,,.L 10 I f-l ---FNNNS --_-_&Q&q -. I -WM I 128 256 512 1024 codcbooksize w
Fig. 4. The average numbers of mathematical operations re- quired per vector in image encoding of four images (Lena, Peppers, Jet and Baboon) versus codebook sizes: (a) multiplica- tion, (b) addition, (c) comparison.
and Baboon). The overhead is excluded in this figure, since the eigenvectors and the projection of each codeword onto the subspace spanned by the selected eigenvectors can be calculated in advance and stored for image encoding.
Fig. 4 shows the average numbers of mathe- matical operations required per vector for image encoding by giving a predesigned codebook using the full search, the FNNS, the MDM and EVM algorithms. From this figure, we can see that the
EVM results in the best performance, since much of its overhead has been calculated in advance and is not included in this figure.
From these figures, we can see that in the code- book design process, the MDM performs best when a codebook has a smaller size (e.g., 128 and 256), while the EVM performs best for codebooks with larger size (eg., 512 and 1024). Both methods outperform the FNNS algorithm. In image encod- ing, the EVM results in the best performance be- cause the overhead required in evaluating the eigenvectors and the projection vectors of all code- words can be done in advance.
4. Conclusions
In this paper, based on the assumption that the distortion is measured by the squared Euclidean distance, two high-speed closest codeword search algorithms: the MDM and the EVM, for vector quantization have been proposed. The proposed algorithms can speed up the search process in VQ codebook design as well as image encoding. The MDM uses the difference between the mean values of two vectors to reduce the search space. The EVM projects each vector onto the subspace span- ned by the Karhunen-Loeve transform. It then calculates the distance between a training vector and every codeword in the projected subspace to reject those codewords which are definitely not candidates for the closest codeword to the training vector. The performance of the proposed algo- rithms has been evaluated in both codebook de- sign as well as image encoding. Simulation results show that the proposed algorithms can save a great number of mathematical operations required in the LBG algorithm and outperform the FNNS algorithm.
Acknowledgements
The authors would like to thank the anonymous reviewers for their many valuable suggestions which have greatly improved the presentation of the paper.
References
[l] C.D. Bei and R.M. Gray, “An improvement of the min- imum distortion encoding algorithm for vector quantiz- ation”, lEEE Trans. Commun., Vol. COM-33, No. 10, October 1985, pp. 1132-l 133.
[2] D.Y. Cheng, A. Gersho, B. Ramamurthi and Y. Shoham, “Fast search algorithms for vector quantization and pat- tern matching”, Proc. IEEE Internat. Conf Acoust. Speech Signal Process., 1984, pp. 9.11.1-9.11.4.
[3] D.Y. Cheng and A. Gersho, “A fast codebook search algorithm for nearest neighbour pattern matching”, Proc. IEEE Internat. Conf Acoust. Speech Signal Process., 1986,
pp. 2655268.
[4] E.R. Dougherty, Probability and Statisticsfor the Engineer- ing, Computing and Physical Sciences, Prentice-Hall, Englewood Cliffs, NJ, 1990.
[S] W.H. Equitz, “A new vector quantization clustering algo- rithm”, IEEE Trans. Acoust. Speech Signal Process., Vol.
37, No. 10, October 1989, pp. 1568-1575.
[6] A. Gersho and R.M. Gray, Vector Quantization and Signal Compression, Kluwer, Boston, 1992.
[7] R.M. Gray, “Vector quantization”, IEEE ASSP Magazine,
Vol. 1, April 1984, pp. 429.
[S] C.H. Hsieh, P.C. Lu and J.C. Chang, “Fast codebook generatioin algorithm for vector quantization of images”,
Pattern Recognition Lett., Vol. 12, 1991, pp. 6055609. [9] C.M. Huang, Q. Bi, G.S. Stiles and R.W. Harris, “Fash full
search equivalent encoding algorithms for image compres- sion using vector quantization”, IEEE Trans. Image Pro- cess., Vol. 1, No. 3, July 1992, pp. 413416.
[lo] A.K. Jain, Fundamentals of Digital Image Processing, Pren- tice-Hall, Englewood Cliffs, NJ, 1988.
[11] Y. Linde, A. Buzo and R.M. Gray, “An algorithm for vector quantizer design”, IEEE Trans. Commun., Vol. COM-28, No. 1, January 1980, pp. 8495.
[12] A. Lowry, S. Hossain and W. Millar, “Binary search trees for vector quantization”, Proc. IEEE Internat. Conf Acoust. Speech Signal Process., 1987, pp. 2205-2208. [13] N.M. Nasrabadi and R.A. King, “Image coding using
vector quantization: A review”, IEEE Trans. Commun.,
Vol. COM-36, No. 8, August 1988, pp. 957-971. [14] M.T. Orchard “A fast nearest-neighbor search algorithm”,
Proc. IEEE Internat. Conf Acoust. Speech Signal Process., 1991, pp. 2297-2300.
[15] V. Ramasubramanian and K.K. Pahwal, “An optimized
k-d tree algorithm for fast vector quantization of speech”,
Proc. European Signal Processing Conf, 1988, pp. 875-878.
[16] V. Ramasubramanian and K.K. Paliwal, “Fast k-dimen- sional tree algorithms for nearest neighbor search with application to vector quantization encoding”. IEEE Trans. Signal Process., Vol. 40, No. 3, March 1992, pp. 518-531.
[17] V. Ramasubramanian and K.K. Paliwal, “An efficient ap- proximation elimination algorithm for fast nearest-neigh- bor search based on a spherical distance coordinate for- mulation”, Pattern Recognition Lett., Vol. 13, 1992, pp. 471480.
[18] M.R. Soleymani and S.D. Morgera, “An efficient nearest neighbor search method”, IEEE Trans. Commun., Vol. COM-35, No. 6, June 1987, pp. 677-679.
[19] E. Vidal “An algorithm for finding nearest neighbors in (approximately) constant average time complexity”, Pat- tern Recognition Lett., Vol. 4, 1986, pp. 145-157.