A Hierarchical
N-Queen Decimation Lattice and
Hardware Architecture for Motion Estimation
Chung-Neng Wang, Member, IEEE, Shin-Wei Yang, Chi-Min Liu, and Tihao Chiang, Senior Member, IEEE
Abstract—A subsampling structure, an -Queen lattice, for spatially decimating a block of pixels is presented. Despite its use for many applications, we demonstrate that the -Queen lattice can be used to speed up motion estimation with nominal loss of coding efficiency. With a simple construction, the -Queen lattice characterizes the spatial features in the vertical, horizontal, and diagonal directions for both texture and edge areas. Especially in the 4-Queen case, every skipped pixel has the minimal and equal distance of unity to the selected pixel. It can be hierarchically orga-nized for variable nonsquare block-size motion estimation. Despite the randomized lattice, we design compact data storage architec-ture for efficient memory access and simple hardware implemen-tation. Our simulations show that the -Queen lattice is superior to several existing sampling techniques with improvement in speed by about times and small loss in peak SNR (PSNR). The loss in PSNR is negligible for slow-motion video sequences and is less than 0.45 dB at worst for high-motion estimation sequences.
Index Terms—Decimation lattice, fast motion estimation, hier-archical decimation lattice, -Queen pattern, pixel decimation, video coding.
I. INTRODUCTION
S
EVERAL video coding standards including MPEG-1/2/4 and H.261/3/4 contain block motion estimation as the most computationally intensive module. Reducing the number of op-erations for block matching can speed up motion estimation. We can improve motion estimation by reducing the number of search points [1], [2], the number of pixels from a block used for matching [3]–[8], and the number of operations for mea-suring the distortion [1], [9]. The MPEG-4 reference software has provided two fast algorithms that have significantly reduced the number of search points [1], [2]. The pixel decimation ap-proaches can be easily combined with apap-proaches from there-Manuscript received April 16, 2003; revised June 26, 2003. This work was supported by the National Science Council, Taiwan, R.O.C., under Contract NSC 92-2220-E-009-016. This paper was recommended by Associate Editor X. Mouli.
C.-N. Wang is with the Department and Institute of Computer Science and Information Engineering and the Department and Institute of Electronics En-gineering, National Chiao Tung University, Hsinchu 30050, Taiwan (e-mail: cnwang@ csie.nctu.edu.tw).
S.-W. Yang is with the Department and Institute of Computer Science and Information Engineering, National Chiao Tung University, Hsinchu 30050, Taiwan. He is also with the Multimedia Technologies Laboratory, Institute for Information Industry, Taipei, Taiwan (e-mail: swyang@csie.nctu.edu.tw).
C.-M. Liu is with the Department and Institute of Computer Science and Information Engineering, National Chiao Tung University, Hsinchu 30050, Taiwan (e-mail: cmliu@csie.nctu.edu.tw).
T. Chiang is with the Department and Institute of Electronics Engi-neering, National Chiao Tung University, Hsinchu 30050, Taiwan (e-mail: tchiang@mail.nctu.edu.tw).
Digital Object Identifier 10.1109/TCSVT.2004.825550
maining categories. In this paper, we will focus on the issue of pixel decimation to achieve further improvement.
The pixel decimation can be realized with either fixed pat-terns [3]–[6] or adaptive patpat-terns [7], [8]. As shown in Fig. 1(b), Bierling used an orthogonal sampling lattice with a 4:1 subsam-pling structure [3], which is referred to as the Quarter pattern. Liu and Zaccarin achieved the pixel decimation that is similar to the Bierling’s approach with four alternating subsampling pat-terns selected for each step so that all of the pixels in the current block are visited [6]. The adaptation of a pixel decimation pat-tern can be based on the spatial luminance variation within a pic-ture [7], [8]. Adaptive techniques can achieve better coding effi-ciency than that of the uniform subsampling schemes [3]–[6] but with an overhead in selecting the most representative pattern. Due to the penalty caused by mispredicted branches, the irreg-ular or adaptive sampling structure is undesirable for pipelined implementation and efficient hardware realization.
The Quarter pattern has advantages in scheduling the opera-tions in a pipeline fashion with efficient memory access. It has a disadvantage of having pixels with irregular distances of both 1 and . It also lacks half of the coverage in the vertical, hor-izontal, and diagonal directions. To represent key features and maintain pipelined memory access, we will construct a family of lattices that retain the regularity and characterize more spatial luminance variation characteristics in all directions.
The goal is to find a sampling lattice that represents the spa-tial information in all directions and the pixels are distributed uniformly in the spatial domain. To enhance the Quarter pat-tern, we discovered that the -Queen lattice [10], [11] improves the representation since it holds exactly one pixel for each row, column, and (not necessarily main) diagonal of a block, as il-lustrated in Fig. 1(c) and (d). Thus, there are exactly pixels for each block. The experimental results show that the visual quality is maintained about the same for equal to 4 and 8. Based on the MMX single instruction multiple data (SIMD) architecture [12], we show an example of pipelined block matching using a 4-Queen pattern to speed up the con-ventional full search. As compared to the full search using the Full pattern, the proposed full search using the 4-Queen pattern shows an improvement 3.2 times in speed and occupies only 25% memory bandwidth.
This paper is organized as follows. In Section II, the -Queen pixel decimation is described. Section III shows the hardware architecture of the -Queen decimation approach. Section IV demonstrates the performance of the proposed pixel decima-tion approach versus the other pixel decimadecima-tion approaches. The paper concludes in Section V.
430 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 4, APRIL 2004
Fig. 1. Pixel patterns for decimation. (a) Full pattern withN 2 N pixels selected. (b) Quarter pattern uses 4:1 subsampling. (c) A 4-Queen pattern is tiled with four identical patterns. (d) An 8-Queen pattern. (e) Hexagonal pattern adopts 4:1 subsampling. (f) Quincunx pattern uses 2:1 subsampling. (g) Rectangular pattern takes 4:1 subsampling. (h) Yu’s pattern [5] adopts 4:1 subsampling. (c) and (d) are derived from theN-Queen approach with N = 4 and N = 8, respectively.
II. -QUEENDECIMATIONAPPROACH
A. Conventional Block Matching
The motion estimation module searches for a block from the reference frame such that it has the minimal distortion as com-pared to the current block. A distortion measure is used to derive the discrepancy between each pair of pixels from the current and reference blocks. For an input frame with height and width , the best motion vector is derived from the conventional full search strategy as shown in
(1)
where is the total number of blocks
of size in a frame. indicates the search range. The is the matching criterion for computing the differ-ence between each pair of data from vectors and . The vec-tors and represent the pixels from the current and reference frames, respectively. Thus, the motion vector with the minimal value is viewed as the best candidate after the block matching and is used for motion compensation.
Finding the best motion vector from (1) is computationally expensive. In such a matching process, the computation of distortion is critical for the overall performance. Balancing the coding efficiency and the computational complexity, a simple block-matching metric, namely sum of absolute difference (SAD), is used in our experiments. To speed up the full search, various blocking matching techniques based on reduced SAD metrics have showed a significant improvement [3]–[9]. For example, the partial SAD metrics improve the motion search with a subset of the pixels in the block for finding the best motion vector [9]. The key issues are to determine how to select a representative subset of the pixels in a block and when to stop the computation of the SAD. Since a representative subset
of pixels in a block can increase the convergence speed for blocking matching based on the reduced SAD metrics. Thus, our goal is to find the most representative sampling lattice for a block in order to accomplish a fast motion estimation algorithm.
B. Rationale
The pixel decimation process is to reduce the computation in calculating distortion measuring for each pair of blocks [3]. The basic idea is to find a sampling lattice with less SAD com-putation but still the best motion vector that can be derived. The results should be equivalent with or close to the motion vector found through the standard SAD metrics. Such a sampling lat-tice, named as the most representative sampling latlat-tice, can be used to extract a subset of the pixels in a block for the reduced SAD metrics.
The most representative sampling lattice is selected based on how much the texture and edge information are preserved with a minimal number of pixels. The sampling lattice is an-alyzed with both the spatial homogeneity and directional cov-erage. The spatial homogeneity is based on the presence of sig-nificant intraframe correlations within an image [13]. The in-traframe autocorrelation function for a less detailed image is higher when the horizontal and vertical spacing (in pixels) are close to 1. Similar observations can be found for highly detailed images. That is, the correlation coefficient between the neigh-boring pixel increases as their spacing decreases. Thus, the spa-tial homogeneity is measured by the mean and variance of spatial distances from each skipped pixel to its nearest selected pixel [11].
Smaller mean and variance indicate a more spatially homoge-neous sampling lattice. The directional coverage is measured by the percentage of coverage in directions such as diagonal, ver-tical, and horizontal directions. Table I shows that the Quarter pattern has less spatial homogeneity and lacks half of the cov-erage in all directions. It also shows that the Quincunx pattern
TABLE I
COMPARISON OF THESAMPLINGLATTICES FOREACH82 8 BLOCK. INMEASURING THEDIRECTIONALCOVERAGE, FOURORIENTATIONSDESCRIBED INFIG. 1(d)
AREUSED. FORHORIZONTAL ANDVERTICALDIRECTIONS, THERE AREEIGHTPOSSIBLEEDGESWHILE FOR THEDIAGONALDIRECTIONS
THERE ARE15 POSSIBLEEDGES
[9] has the best homogeneity, but it lacks half of the coverage in both diagonal directions. To improve the spatial homogeneity and the directional coverage, we construct a new -Queen dec-imation lattice [10], [11].
As illustrated in Fig. 1(d), an edge can have four orientations in the horizontal, vertical, and diagonal directions. To fully rep-resent the spatial information of an block, it is required that at least one pixel should be selected for each row, column, and diagonal. To meet such a constraint, the solution is identical to the problem of placing queens on a chessboard, which is re-ferred to as an -Queen pattern. For an block, as shown in Fig. 1(c) and (d), each selected pixel of the -Queen pattern occupies a dominant position, which is located at the center. All of the pixels located on the four lines in the vertical, horizontal, and diagonal directions are deleted from the list of the selected pixels. With such elimination process, there is exactly one pixel selected for each row, column, and (not necessarily main) diag-onal of the block. Thus, the -Queen patterns present a subsampling lattice that can speed up the full search by approx-imately times.
The -Queen patterns are not unique. For instance, there are 92 8-Queen patterns for each 8 8 block. The remaining issue is to identify which one provides a better representation. For these 92 patterns, the mean values of spatial distances from each skipped pixel to its nearest selected pixel are distributed between 1.29 and 1.37 pixels. Thus, the maximum difference of the average distances is only 0.08 pixel. Fig. 2 shows that the 92 8-Queen patterns have almost identical performance, where the deviation in peak SNR (PSNR) is less than 0.1 dB.
C. Recursive Structure
The -Queen lattice can also be used recursively to segment a frame into hierarchical layers. Each layer consists of blocks of equal size . As shown in Fig. 3, we can se-lect these blocks using one of the sampling lattices at each
Fig. 2. Performances of the two techniques [1], [2] using 92 8-Queen patterns for theY component of the Foreman sequence in CIF format. The bit rate is 112 kb/s and the frame rate is 10 fps. The block size is 162 16 and the search range is 322 32.
Fig. 3. Recursive structure of pixel decimation using various patterns at each layer.
432 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 4, APRIL 2004
Fig. 4. Architecture example of the 4-Queen pattern motion estimation. For the compact storage, the row-alignment approach [10], [11] for transforming a two-dimensional 42 4 block in Memory 3 into a one-dimensional vector of 4 pixels in Memory 4 is illustrated.
layer except for layer . For each selected block, the same pixel decimation process can be applied recursively. A combination of various lattices offers great flexibility in performing motion estimation especially when global motion estimation at a frame level is considered. In addition, the -Queen lattice is appli-cable for motion search using nonsquare blocks, which are used in H.26L (H.264 or Advanced Video Coding) [14]. To fit vari-able block size motion search in H.26L, multiple small 4-Queen patterns are tiled to construct the final pattern.
III. HARDWAREARCHITECTURE: CASESTUDY
The proposed motion estimation architecture using the -Queen lattice is shown in Fig. 4. The architecture based on the -Queen lattice consists of three parts: the reshuffling, data accessing, and pipelined matching modules. In the reshuffling module, we rearrange the pixels into smaller buffers for com-pact storage. Prior to the matching process, the pointers that store the starting addresses of the relevant pixels are computed and initialized for all buffers. With the starting addresses, we can overlap the memory access and block-matching pipelines. In this paper, we use the 4-Queen lattice to explain the ar-chitecture implementation based on the -Queen lattice. A case study of the practical realization that adopts the Intel SIMD architecture using MMX technology [12] is provided for
facilitating the speedup by parallel processing using -Queen lattices.
A. Compact Storage
For each block within a macroblock, the -Queen subsampling process transforms a two-dimensional (2-D)
block to a one-dimensional (1-D) vector of pixels in a se-quential manner, which is desirable for both the software and hardware implementation. The row or column alignment ap-proaches are used to transform a 2-D block into a 1-D vector of pixels. For the -Queen lattice, the row alignment approach moves the selected pixels into a 1-D row vector and the column alignment approach moves the selected pixels into a 1-D column vector. A 4-Queen motion estimation architecture with the compact storage through the row alignment approach [10], [11] is shown in Fig. 4. The column alignment approach can be constructed similarly with this architecture. Applying either alignment approach periodically to every block in a raster scan-ning order, we can group the pixels that are located at nonover-lapping search points within a frame together. Consequently, the pixels of a frame can be split into groups using either the row or column alignment approach for advanced processing.
To minimize the memory access bandwidth, a group number (1–4) is used to index each group of pixels that are placed in
a separate memory buffer, as shown in Fig. 4. There is a sep-arate frame memory buffer allocated for each of the groups based on the -Queen lattice. For example, the 4-Queen lattice stores the nonoverlapping search positions pixels in four smaller buffers.
One of the special properties of this storage technique is that a macroblock resides in a continuous memory space for easy access. If we use a pipelined memory access strategy, a shift of one pixel in each frame buffer represents a spatial shift in pixels in the original frame. Thus, this data storage ar-chitecture can facilitate a search strategy easily. Another interesting observation is that each pixel is sequentially acces-sible even though the search strategy is hierarchical. This pro-vides an elegant solution to improve both search strategy and memory access.
B. Data Access
In each buffer, the selected pixels can be accessed in two steps. The first step is to compute the buffer indices and the second step is to compute the starting addresses of the pixels that will be accessed first. In the first step, the buffer index can be retrieved from a lookup table. The table is predetermined based on the specific -Queen patterns. For example, the 4 4 block at the upper left corner in the reference frame buffer of Fig. 4 is used to construct such an index table defined as follows:
(2) The buffer index is computed as
(3) where is the index of the th group with for the 4-Queen case. The symbol “mod” denotes the arithmetic modulo operation. Let the coordinate of the pixel on the upper left corner of a frame be (0, 0) and the coordinates rep-resent the offset from (0, 0). The entries of the matrix represent the offsets of the selected pixels from the position (0, 0) of the 4 4 subblock on the upper left corner as shown in the reference frame buffer of Fig. 4. The matrix of the offsets is defined as
(4) For each row of the matrix, the first number represents the offset in the vertical direction and the second number means the offset in the horizontal direction. In the second step, the starting addresses for the pixels of the indexed buffer are com-puted as follows. For the column- and row-alignment buffers, the addresses are computed as
(5) (6) and (7) (8) respectively.
The symbol denotes the row number within the th aligned memory buffer and the symbol denotes the column
number in the same buffer, where the value of ranges from 0 to 3 for the 4-Queen pattern.
C. Parallel Block Matching
Based on our storage architecture, the continuous pixels in a row can be moved in a batch fashion from the buffer into a wide register of multiple bytes depending on the specific pro-cessor used. For example, two registers of 64 b can store four pixels from the current and reference blocks. Upon completion of the distortion computation, the reference register only needs to access next 64 b that are sequentially located to implement a shift of four pixels in search points. Thus, our data storage structure can easily support pipelined memory access and the register with the four pixels can be processed in parallel. With the sequential nature of the storage, the data retrieval and the matching can be overlapped in a pipelined fashion.
A parallel matching algorithm is presented for a group of the pixels within the search window. Assume that the search range is 32 32 and the block size is 16 16. To sequentially per-form block matching, the SAD of each search point is derived in a row-first manner. Assume that several 64-b or 32-b regis-ters are available and each pixel is stored in 16-b-wide register. Using a 64-b register, four pixels are retrieved sequentially from the same row or the same column within the search window and then the matching are simultaneously performed. In the row-aligned buffer 1 within Memory 4 of Fig. 4, the 16 pixels starting from the coordinate (0, 0) at the same row can be placed into multiple 64-b registers, where each register contains four pixels. To process the next search point starting at (0, 4), the con-tents inside the overlapping three registers can be kept and the content of the first register is updated with the next successive four pixels with the starting coordinate (0, 16) at the same row. The same procedures can be employed for each row within the search window. Similarly, we can transpose the column-aligned buffers into the row-aligned buffers and identical method can be used for the row-aligned buffers. Both the row-aligned and the column-aligned buffers have high reusability and no overhead for collecting pixels in each step. Thus, either approach can pro-vide a pipelined memory access for parallel block matching.
In Fig. 4, we illustrate the architecture for compact storage, data access, and parallel block matching. For compact storage, the pixels from the original and reference frame buffers are reshuffled into the row-aligned buffers 0–4 separately. The reshuffled location for each pixel is controlled by the three modules, namely Data Addressing 1–3. To efficiently move the 4-Queen sampled pixels within the reference frame, a 32-b-wide bus is connected to each row of Memory 3. Sub-sequently, the pixels with the same buffer index are moved to the specified row-aligned buffer via a multiplexer MUX1. As shown in the block matching module, the number of bits per data fetch varies among various architectures. A large can increase the execution speed by reducing the time in computing the distortion in the parallel block matching module. The pixels from the current frame and the pixels from the reference frame are retrieved by the module Data Indexing 1 and 2, respectively. Since there are four aligned buffers from the reference frame, a multiplexer MUX2 is used to select the pixels from one of the four buffers for block matching.
434 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 4, APRIL 2004
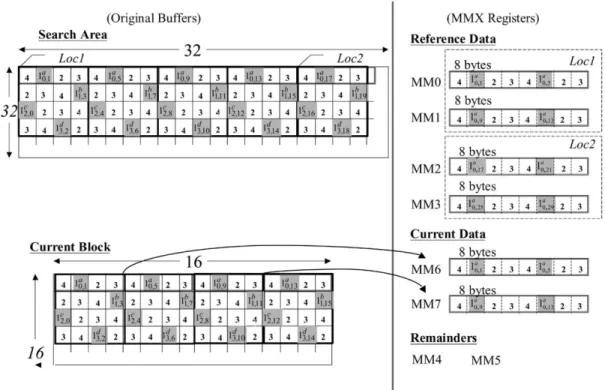
Fig. 5. Illustration of data loading into the MMX registers from the original buffers for the Full pattern block matching. The Registers MM0-MM3 are used for storing the reference data that from the search area. The current data is uploaded into Registers MM6 and MM7. The remaining registers are used for intermediate results.
D. MMX Pipelined Implementation for Full Search
We now describe an implementation for the full search, which will be used to compare against the case for the 4-Queen pattern. Assume the search range is 32 32 and the block size is 16 16. The absolute value of the difference signal can be stored in 8 b. For the MMX SIMD architecture [12], each 64-b register can store eight pixels.
As shown in Fig. 5, the Full pattern block matching uses a 16 16 block where each row has 16 pixels stored in 8-b bins. Two MMX registers are used to store pixels from a row of the target block and four MMX registers are used to store the 32 pixels of the row from the reference frame. The first eight pixels of the row from the target block are loaded in Register MM6 and the remaining pixels in the same row are stored in Register MM7. Each group of nonoverlapping eight pixels from the row within the search area is simultaneously loaded into four MMX Regis-ters MM0-MM3. The other regisRegis-ters are reserved for temporary storage. The parallel computation of the SAD’s is performed in a row-by-row fashion for each block.
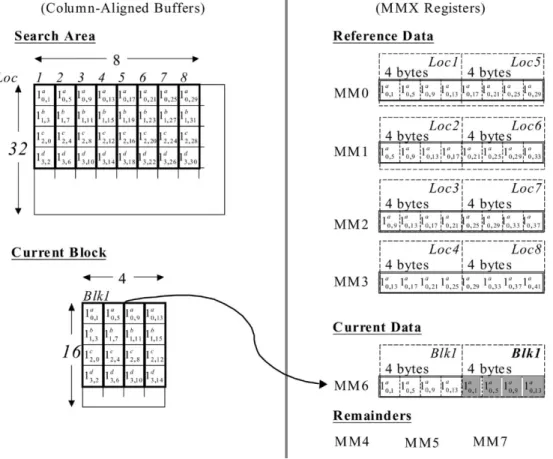
E. MMX Pipelined Implementation for 4-Queen Search Now we introduce the block-matching algorithm and the pipelined scheme based on a 4-Queen pattern. Since the row-and column-alignment approaches are similar, our discussions only focus on the improved parallel block matching using the column-aligned buffer. As shown in Fig. 6, the block matching using a 4-Queen pattern adopts a 16 4 block that has four pixels in each row, where each pixel is stored in an 8-b bin. To minimize the memory access, we take one MMX register to store the pixels at every row of the current block and their dupli-cated pixels. We use four MMX registers to store the 32 pixels
from the reference frame. Initially, we load the successive 32 pixels into the four MMX Registers MM0-MM3 and compute the two SADs concurrently for these 32 pixels. Next, we move to the next location in the same row within the search area by right-shifting one pixel and loading the next consecutive 32 pixels into the MMX registers. The same steps are repeated until all of the search positions are visited. The remaining registers are reserved for temporary storage. Consequently, the parallel computation of the SADs is performed in a row-by-row manner for each block.
For each block, we use the table lookup approach to com-pute the buffer index to retrieve the pixels. The table of indexing buffer is derived from (3), where the arithmetic modulo opera-tion can be implemented as a logicalAND(“&”) operation with reduced complexity as follows:
(9) Thus, the operation “mod 4” is replaced by the operation
ANDwith a constant of value 3. The indices can be found by directly searching the lookup tables as illustrated in Table II. Each indexing approach needs operations, where the symbol denotes the total number of operations required for loading the data from memory according to the MMX tech-nology [12]. In addition, we need to compute the starting ad-dresses for loading the reference data into the MMX registers prior to blocking matching. The starting addresses at the speci-fied buffer are defined in (7) and (8) for column-aligned buffers, which can be realized by replacing the division with a right-shift
operation as follows:
(10) (11)
Fig. 6. Illustration of data loading from the column-aligned buffers into the MMX registers for the 4-Queen pattern blocking matching. The Registers MM0-MM3 are used for storing the reference data from the search area. The current data is loaded into the Register MM6. The remaining registers are used for intermediate results.
TABLE II
BUFFERINDEXING FORCOLUMN-ALIGNEDSTORAGE. THECOORDINATE(x; y)
INDICATES THEPOSITION OF THEUPPERLEFTCORNER OF THEBLOCK
Thus, the address computation needs (2 1) operations.
F. Computational Complexity
The computational complexity is compared based on the total operations used per block. Thus, for an block and an
TABLE III
CYCLECOUNTS FOR THEBLOCKMATCHINGUSING THEFULLPATTERN AND THE4-QUEENPATTERN
Fig. 7. Decimation patterns at the block layer. The marked block means the selected 42 4 block.
search area, the pipelined block matching using the Full pattern takes
(12) operations per macroblock in total.
For the 4-Queen pattern using the column-aligned storage, the migration of the pixels from the frame buffers to the aligned buffers for both the current and reference images needs
436 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 4, APRIL 2004
Fig. 8. ReconstructedY components for the 102nd frame of the Foreman sequence in CIF format. (a) The original frame. (b)–(d) Constructed pictures with Full Search and N-Queen patterns.
operations. With the aligned buffer, the block matching takes (14) operations. Additional buffer address computation and memory access require
(15) operations for each marcoblock. Consequently, the overall com-putational complexity for the pipelined block matching using a
4-Queen pattern is .
The comparison of the computational costs for the pipelined schemes using the Full and 4-Queen patterns is shown in Table III, where the block size is 16 16 and the search area is 32 32. Based on the MMX technology, the 4-Queen scheme has improved the motion estimation by about 3.2 times in speed. The reason for not achieving the theoretic improvement of four times comes from the fact that extra buffer indexing and pixel address computations are required.
G. Memory Bandwidth
In this section, we analyze total memory bandwidth for loading the current and reference frames. For the Full pattern, the total bandwidth consumption in bytes per second is
(16) where the symbol denotes the bandwidth to access the data from the current frame and is the bandwidth for loading the data from the search window of the reference frame.
Let the symbol be the frame rate. Assume that the pro-cessing pixels of the current block are loaded simultaneously into an on-chip memory with data bins. Thus, to access the data from the current frame of size requires
(17) bytes.
For an block and a search area, assume the reference data are simultaneously loaded into the on-chip
memory with size . Since the
over-lapped data can be reused for the next location, only partial data are reloaded. Specifically, there are data need to be updated. Thus, the memory consumption for storing the ref-erence data from the whole search area needs additional
(18) bytes. The first term in the parenthesis accounts for the first search point, which takes more operations due to the memory stall in the initialization stage of pipelining. Less access is needed since the neighboring search windows overlap in area.
For the proposed 4-Queen algorithm, the total memory bandwidth (in bytes) is
(19) Obviously, only a quarter of the reference and current data are needed for block matching. Thus,
TABLE IV
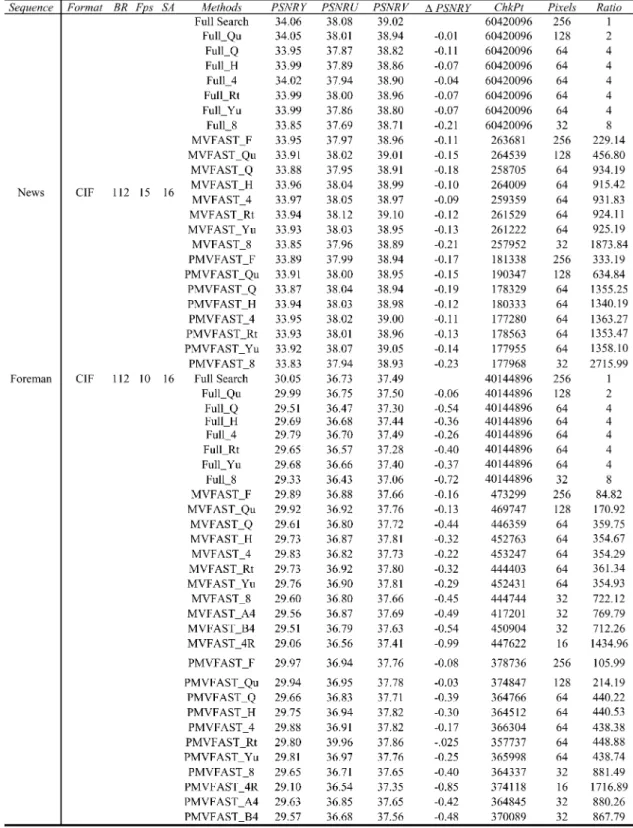
PERFORMANCE OF THEFOURPIXELPATTERNS ANDRECURSIVESTRUCTURE,THETHREESEARCHSTRATEGIES FORVARIOUSVIDEOSEQUENCESUNDER
DIFFERENTTESTINGCONDITIONS
For each method, the first symbol denotes the search strategy and the remaining symbols denote the sampling patterns. For example, the notation “PMVFAST_8” represents the motion estimation using the PMVFAST approach and 8-Queen pattern. “BR” indicates the bit rate in kb/s, the frame rates are represented in frames per second “Fps”, and the search range is denoted as “SA”. The column “PSNRY” denotes the average PSNR for the luminance component
and the “ChkPt” indicates the actual number of search points used. The “Pixels” means the number of pixels per search point. The final column “RatioO” is the improvement in speed as compared to the full search.
IV. EXPERIMENTALRESULTS
In our simulation, we use the MPEG-4 reference software [15] and the distortion measure is SAD. Only the 16 16 motion
vector mode is enabled for demonstrating the performance. The coding efficiency is analyzed based on the three parameters: sampling patterns, search strategies, and testing conditions.
438 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 4, APRIL 2004
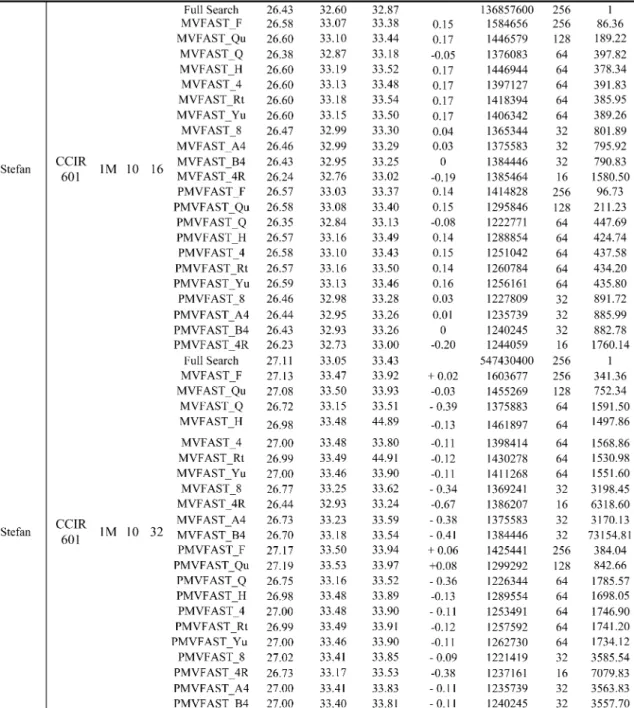
TABLE IV (Continued.)
PERFORMANCE OF THEFOURPIXELPATTERNS ANDRECURSIVESTRUCTURE,THETHREESEARCHSTRATEGIES FORVARIOUSVIDEO
SEQUENCESUNDERDIFFERENTTESTINGCONDITIONS
For each method, the first symbol denotes the search strategy and the remaining symbols denote the sampling patterns. For example, the notation “PMVFAST_8” represents the motion estimation using the PMVFAST approach and 8-Queen pattern. “BR” indicates the bit rate in kb/s, the frame rates are represented in frames per second “Fps”, and the search range is denoted as “SA”. The column “PSNRY” denotes the average PSNR for the luminance component
and the “ChkPt” indicates the actual number of search points used. The “Pixels” means the number of pixels per search point. The final column “RatioO” is the improvement in speed as compared to the full search.
As for the sampling patterns, we use eight patterns as de-scribed in Fig. 1. The Full pattern (“F”) selects all pixels in the current block. The Quarter pattern (“Q”) is described in [3] and Quincunx pattern (“Qu”) is from [9]. The Hexagonal pat-tern (“H”) and the Yu’s patpat-tern (“Yu”) are described in [4] and [5], respectively. The 4-Queen (“4”) pattern is constructed by tiling multiple small 4-Queen patterns for each 16 16 mac-roblock. The 8-Queen (“8”) pattern and Rectangular (“Rt”) pat-tern are similarly tiled. Additionally, in order to examine the performance of the pixel decimation using recursive structure,
Fig. 7 demonstrates three patterns used for two-layer recursive sampling. The two-layer recursive scheme (“4R”) employs the same 4-Queen pattern at both the block and pixel layers. The second two-layer recursive sampling approach (“A4”) adopts the pattern “A” and the last approach (“B4”) takes the pattern “B” in Fig. 7 at the block layer. At the pixel layer, the 4-Queen pattern is applied for each subblock.
As for the search strategies, we tested the full search and two approaches adopted by the MPEG-4 committee. These approaches are often referred to as motion vector field adaptive
search technique (MVFAST) [1] and predictive MVFAST (PMVFAST) [2]. The component of the 102nd reconstructed frame of the Foreman sequence encoded using Full search with -Queen decimation patterns and constant quantization is illustrated in Fig. 8. The bit rate is around 125 kb/s at 10 Hz. The quantization parameter (QP) of the intracoded video object plane (I-VOP) is 16. The QPs of the predicted video object planes (P-VOPs) are 16, 17, and 18 for the Full, 4-Queen, and 8-Queen patterns, respectively. The respective average PSNRs are 31.77, 31.33, and 30.93 dB.
We follow the recommended testing conditions as prescribed by the MPEG committee [16]. As shown in Table IV and our previous work presented in [10] and [11], we reach the following conclusions.
1) The -Queen patterns have negligible video quality degradation. With PMVFAST, the loss in PSNR is less than 0.23 dB for slow motion video such as the “News” sequence. The loss in PSNR is less than 0.45 dB at worst for fast motion video. The 4-Queen pattern is better than the Quarter, Quincunx, Rectangular, Yu’s, and Hexagonal patterns by about 0.01–0.28 dB for the noninterlaced coded sequences.
2) When various search strategies are compared for the same pattern, the degradation using Full Search is more for the -Queen, Quincunx, and Quarter patterns. Such a phenomenon may be caused by the predictive vector technique used by MVFAST and MVFAST that yield smoother vector fields.
3) It is advantageous to use the recursive structure “4R” for larger picture sizes such as CCIR-601 format because the 16 16 block corresponds to 32 32 block at CCIR-601 resolution. For the same content, there is less spatial lu-minance variation at larger picture sizes.
4) Observing the performance of the two-layer subsampling approaches, namely “A4” and “B4,” the recursive struc-tures of pixel decimation perform better when the picture size is increased to a format such as CCIR-601 format. For the video with higher resolution such as the “Stefan” se-quence, the worst-case loss in PSNR is less than 0.41 dB. The improved performance of the two-layer decimation for larger frame sizes may be attributed to the stronger spatial correlations at larger picture sizes.
5) When we compare the 4-Queen pattern and the Quin-cunx pattern, which have the same spatial homogeneity but different directional coverage, as shown in Table I, the 4-Queen pattern has about twice the speedup than the Quincunx pattern with a video quality degradation of less than 0.2 dB in PSNR. Such a result shows that the direc-tional coverage of the sampling lattice is useful.
V. CONCLUSION
This paper has presented a novel and simple pixel decima-tion technique using an -Queen lattice with an application for
block-based motion estimation. The complexity and memory bandwidth can be arbitrarily reduced by a factor of . It is su-perior in terms of spatial homogeneity and directional coverage. It is advantageous that such a randomized lattice can be stored compactly with a sequential pipelined buffer access as demon-strated in this paper. In our approach, search can be im-plemented sequentially. The recursive nature of the -Queen sampling lattice is flexible when the block size is variable in-cluding a full picture size and nonsquare block for applications such as global motion estimation and sprite generation. With im-provement in speed by a factor of , our experimental results show no significant degradation in PSNR and have consistent performance for extensive tests as recommended by the MPEG committee.
ACKNOWLEDGMENT
The authors wish to thank the anonymous reviewers for their insightful comments to improve the initial draft of this paper.
REFERENCES
[1] A. M. Tourapis, O. C. Au, M. L. Liou, G. Shen, and I. Ahmad, “Opti-mizing the MPEG-4 encoder- advanced diamond zonal search,” in Proc.
2000 Int. Symp. Circuits Systems, vol. 3, Geneva, Switzerland, May
2000, pp. 674–677.
[2] S. Zhu and K.-K. Ma, “A new diamond search algorithm for fast block-matching motion estimation,” IEEE Trans. Image Processing, vol. 9, pp. 287–290, Feb. 2000.
[3] M. Bierling, “Displacement estimation by hierarchical block matching,” in Proc. SPIE Conf. Visual Commun. Processing, vol. 1001, 1988, pp. 942–951.
[4] K. T. Choi, S. C. Chan, and T. S. Ng, “A new fast motion estimation algorithm using hexagonal subsampling pattern and multiple candidate search,” in Proc. IEEE Int. Conf. Image Processing, 1996, pp. 497–500. [5] Y. Yu, J. Zhou, and C. W. Chen, “A novel fast block motion estimation algorithm based on combined subsamplings on pixels and search can-didates,” J. Vis. Commun. Image Representation, vol. 12, pp. 96–105, 2001.
[6] B. Liu and A. Zaccarin, “New fast algorithms for the estimation of block motion vector,” IEEE Trans. Circuits Syst. Video Technol., vol. 3, pp. 148–157, Apr. 1993.
[7] Y.-L. Chan and W.-C. Siu, “New adaptive pixel decimation for block motion vector estimation,” IEEE Trans. Circuits Syst. Video Technol., vol. 6, pp. 113–118, Feb. 1996.
[8] Y. K. Wang, Y. Q. Wang, and H. Kuroda, “A globally adaptive pixel-dec-imation algorithm for block-motion estpixel-dec-imation,” IEEE Trans. Circuits
Syst. Video Technol., vol. 10, pp. 1006–1011, Sept. 2000.
[9] K. Lengwehasatit and A. Ortega, “Probabilistic partial-distance fast matching algorithms f or motion estimation,” IEEE Trans. Circuits
Syst. Video Technol., vol. 11, pp. 139–152, Feb. 2001.
[10] S.-W. Yang, C.-N. Wang, C.-M. Liu, and T. Chiang, “Fast motion estima-tion using N-Queen pixel decimaestima-tion,” in Proc. 2nd IEEE Pacific-Rim
Conf. Multimedia, Beijing, China, Oct. 24–26, 2001.
[11] C.-N. Wang, S.-W. Yang, C.-M. Liu, and T. Chiang. (2003, Aug.) A hierarchical decimation lattice based onN-Queen with an application for motion estimation. IEEE Signal Process Lett., pp. 228–231 [12] Intel Architecture Software Developer’s Manual, vol. 1–3, Intel Corp.,
1999.
[13] N. S. Jayant and P. Noll, Digital Coding of Waveforms—Principles and
Applications to Speech and Video. Englwood Cliffs, NJ: Prentice-Hall, 1984.
[14] Text of ISO/IEC FDIS 14496-10: Information Technology—Coding of
Audio-Visual Objects—Part 10: Advanced Video Coding, Mar. 2003.
[15] ISO/IEC 14 496-5:2001/FPDAM1, July 2001.
[16] Experimental Conditions for Evaluating Encoder Motion Estimation
440 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 4, APRIL 2004
Chung-Neng Wang (M’03) was born in PingTung, Taiwan, R.O.C., in 1972. He received the B.S. degree and Ph.D. degree in computer science and informa-tion engineering from Nainforma-tional Chiao-Tung Univer-sity (NCTU), Hsinchu, Taiwan, in 1994 and 2003, re-spectively.
He joined the faculty at NCTU in January 2003. Since 2001, he has actively parcticipated in ISO’s Moving Picture Experts Group (MPEG) digital video coding standardization process, and he has made more than 18 contributions to the MPEG committee over the past four years. He has published over 20 technical journal and conference papers in the field of video and signal processing. His current research interests are video/image compression, motion estimation, video transcoding, and streaming.
Shin-Wei Yang was born in TaoYuan, Taiwan, R.O.C., in 1977. He received the B.S. degree in computer science and information engineering and the M.S. degree from National Chiao-Tung University, Hsinchu, Taiwan, in 2000 and 2002, respectively.
He is currently with the Institute for Information Industry, Taipei, Taiwan.
Chi-Min Liu received the B.S. degree in electrical engineering from Tatung Institute of Technology, Taiwan, R.O.C., in 1985 and the M.S. degree and Ph.D. degree in electronics from National Chiao Tung University (NCTU), Hsinchu, Taiwan, in 1987 and 1991, respectively.
He is currently a Professor with the Department of Computer Science and Information Engineering, NCTU. His research interests include video/audio compression, speech recognition, radar processing, and application-specific VLSI architecture design.
Tihao Chiang (S’91–M’95–SM’99) was born in Cha-Yi, Taiwan, R.O.C., in 1965. He received the B.S. degree in electrical engineering from the National Taiwan University, Taipei, in 1987, and the M.S. and Ph.D. degrees in electrical engineering from Columbia University, New York, NY, in 1991 and 1995, respectively.
In 1995, he joined the David Sarnoff Research Center, Princeton, NJ, as a Member of Technical Staff. Later, he was promoted to technology leader and a program manager at Sarnoff. While at Sarnoff, he led a team of researchers and developed an optimized MPEG-2 software encoder. For his work in the encoder and MPEG-4 areas, he received two Sarnoff achievement awards and three Sarnoff team awards. Since 1992, he has actively participated in ISO’s Moving Picture Experts Group (MPEG) digital video coding standardization process with particular focus on the scalability/compatibility issue. He is currently the co-editor of part 7 on the MPEG-4 committee. He has made more than 90 contributions to the MPEG committee over the past 11 years. His main research interests are compatible/scalable video compression, stereoscopic video coding, and motion estimation. In September 1999, he joined the faculty at National Chiao-Tung University, Hsinchu, Taiwan. He has published over 50 technical journal and conference papers in the field of video and signal processing. He holds 13 U.S. patents and 30 European and worldwide patents.
Dr. Chiang was a co-recipient of the 2001 best paper award from the IEEE TRANSACTIONS ONCIRCUITS ANDSYSTEMS FORVIDEOTECHNOLOGY.
![Fig. 2. Performances of the two techniques [1], [2] using 92 8-Queen patterns for the Y component of the Foreman sequence in CIF format](https://thumb-ap.123doks.com/thumbv2/9libinfo/7635586.136340/3.918.457.827.874.1095/performances-techniques-queen-patterns-component-foreman-sequence-format.webp)
![Fig. 4. Architecture example of the 4-Queen pattern motion estimation. For the compact storage, the row-alignment approach [10], [11] for transforming a two-dimensional 4 2 4 block in Memory 3 into a one-dimensional vector of 4 pixels in Memory 4 is illust](https://thumb-ap.123doks.com/thumbv2/9libinfo/7635586.136340/4.918.68.818.97.611/architecture-estimation-alignment-approach-transforming-dimensional-memory-dimensional.webp)