地理研究 第53期 民國99年11月
Journal of Geographical Research No.53, November 2010
台
台
台
台中市搶奪犯罪熱點與犯罪區位之空間分析
中市搶奪犯罪熱點與犯罪區位之空間分析
中市搶奪犯罪熱點與犯罪區位之空間分析
中市搶奪犯罪熱點與犯罪區位之空間分析
The Spatial Analysis of the Robbery Hot Spot and
Crime Location in Taichung city
李瑞陽
a陳勝義
bRe-Yang Lee Sheng-I Chen
Abstract
With the rapid growth in the economy and social transition in Taiwan, the phenomenon of crime is concentrated on metropolitan areas. The traditional research of the crime space is shown by the statistic data and statistic charts, it can not reveal the relationship between the crime location and space. The regression analysis is the most common method when analysis what kind of crime theories or social economic factors reveal obviously correlation with crime phenomenon. However, the traditional liner regression model does not consider the spatial heterogeneity and the phenomenon of spatial autocorrelation, it causes the explain ability of crime theory decreased because of the effects of spatial changes.
This research applies the average nearest neighbor analysis to find whether the robbery positions are aggregated and analysis the crime hotspot. And then using the kernel density estimation and spatial autocorrelation analysis to compare the distribution of the robbery in different periods and draw the crime map. With the analysis of crime location, use the criminology theory to select the variables of the social economic humanity environment and build the multiple regression models to discuss the location character of robbery hot spot and find out the fittest models and prove the spatial variation phenomenon is exist between the robbery rates and spatial character.
In the research of the spatial analysis, it proves that the phenomenon of robbery is congregate in Taichung city and the robbery hot spot is toward to west. With the analysis of crime location, finds out the variables of the social economic humanity environment and reveals that the spatial autocorrelation phenomenon which produces by the multiple regressions is eliminated, and confirmed that the spatial lag model is the best spatial model. After the reduction of smallest space unit, the analysis result is more precise.
a逢甲大學土地管理學系副教授 b
Keywords::::robbery hot spot, spatial autocorrelation, crime location analysis, spatial regressions model.
摘 要
台灣地區經濟快速成長、社會變遷,犯罪現象大多集中於大都市。以往傳統犯罪區域空間的 研究,均以統計數據、統計圖方式呈現,無法顯示犯罪地點與空間之相關性,且在分析何種社經 環境因子與犯罪現象有顯著相關性時,迴歸分析是最常使用的方法,然而,傳統的線性迴歸模式 均未考慮空間異質性和空間自相關現象,以致於犯罪理論的解釋能力會受空間變異的影響而減低。 本研究採用平均最近鄰分析,找出搶奪犯罪地點是否呈現聚集現象,再利用核密度推估法與 空間自相關分析,分析比較不同時段搶奪犯罪案件分佈變化情形,並且繪製犯罪地圖。在犯罪區 位分析方面,利用犯罪理論選取社經人文環境變項,建立多元線性迴歸模型,探討搶奪犯罪熱點 之區位特性,並尋求最合適之空間模式,驗證搶奪犯罪率與區域空間特性之間確實有空間變異之 現象存在。 在空間分析研究結果發現,台中市搶奪犯罪在空間上有聚集之現象,搶奪犯罪熱點有往西移 動之現象,且與台中市都市計畫往西發展有密切關係。在犯罪區位分析方面,找出搶奪犯罪之社 經人文環境變項,且顯示多元迴歸模型所產生的空間自相關現象已消除,證實空間落遲模型為最 佳之空間模型,且縮小最小空間單元,其分析結果將更加精確。 關鍵詞:搶奪犯罪熱點、空間自相關、犯罪區位分析、空間迴歸模型。前 言
在日常生活中,時常接收到的社會新聞消息『搶奪成性犯罪成習,台中市男子多次搶奪他人 財物,並企圖在台中市搶奪銀樓未遂。』(李錫璋,2007)、『狠心飛車行搶,81 歲老婦摔地頭 中傷。』(陳惠美等,2007)、『全台一天有 11 個人被搶,暗巷落單要小心。』(東森新聞報, 2007),這些斗大的標題,再再提醒著我們,搶奪是與我們日常生活環環相扣的犯罪行為,其中 又以機車搶奪為主,且專挑老婦、落單女子下手,使民眾對於治安的憂心,以及自身生命財產的 疑慮。 犯罪現象乃人類歷史發展過程中一直存在的社會問題,但在不同的時空背景下,犯罪行為的 性質與類別,會隨著政治制度、經濟型態、社會組織、價值判斷和倫理規範而有所差異(孟靜, 1985)。根據內政部警政署統計指標資料顯示,台灣地區搶奪發生件數占暴力犯罪總數於 1991-1994 年間約為 11.15%,到了 2001 年間,搶奪發生件數占的比例已超過 50%,至 2005 年所占的比例竟 高達 56.3%(如圖 1)。由此可知,暴力犯罪中的搶奪案發生情形日益嚴重,值得相關單位重視 與防治。4.87 3.99 5.03 7.03 31.6 31.93 21.8719.34 16.19 21.32 35 35.08 29.0131.02 35.42 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 1991 1993 1995 1997 1999 2001 2003 2005 年 件數 0 20 40 60 80 100 120 發生件數 破獲件數 破獲率 犯罪率(件/ 十萬人口) 花蓮縣 南投縣 臺東縣 高雄縣 屏東縣 臺中縣 宜蘭縣 臺北縣 臺南縣 嘉義縣 苗栗縣 新竹縣 雲林縣 桃園縣 彰化縣 臺北市 臺南市 高雄市 澎湖縣 嘉義市 基隆市 新竹市 臺中市 犯罪率 未滿10件 10-15件未滿 15-20件未滿 20件以上 花蓮縣 南投縣 臺東縣 高雄縣 屏東縣 臺中縣 宜蘭縣 臺北縣 臺南縣 嘉義縣 苗栗縣 新竹縣 雲林縣 桃園縣 彰化縣 臺北市 臺南市 高雄市 澎湖縣 嘉義市 基隆市 新竹市 臺中市 犯罪率 未滿10件 10-30件未滿 30-50件未滿 50件以上 犯罪率 犯罪率 未滿10件 10-15件未滿 15-20件未滿 20件以上 未滿10件 10-30件未滿 30-50件未滿 50件以上 花蓮縣 南投縣 臺東縣 高雄縣 屏東縣 臺中縣 宜蘭縣 臺北縣 臺南縣 嘉義縣 苗栗縣 新竹縣 雲林縣 桃園縣 彰化縣 臺北市 臺南市 高雄市 澎湖縣 嘉義市 基隆市 新竹市 臺中市 犯罪率 未滿10件 10-15件未滿 15-20件未滿 20件以上 花蓮縣 南投縣 臺東縣 高雄縣 屏東縣 臺中縣 宜蘭縣 臺北縣 臺南縣 嘉義縣 苗栗縣 新竹縣 雲林縣 桃園縣 彰化縣 臺北市 臺南市 高雄市 澎湖縣 嘉義市 基隆市 新竹市 臺中市 犯罪率 未滿10件 10-30件未滿 30-50件未滿 50件以上 犯罪率 犯罪率 未滿10件 10-15件未滿 15-20件未滿 20件以上 未滿10件 10-30件未滿 30-50件未滿 50件以上 圖 1 暴力犯罪總數與搶奪發生件數 圖 2 搶奪案發生與破獲曲線圖 資料來源:內政部警政署(2005 年) 而在台灣地區發生的搶奪案,根據內政部警政署統計顯示,1991-1994 搶奪案發生件數合計 4359 件,至 1995-1996 年間,搶奪案發生件數各高達 6700 件以上,雖然從 1997 年開始,搶奪案 發生件數有呈現減少的趨勢,至 1999 年甚至低至 3563 件。但從 2000 年開始,台灣地區搶奪案發 生件數從 4729 件大幅攀升至 2005 年的 8052 件,而犯罪率也從 1991 年的 4.87 件,提高至 2005 年的 35.42 件;破獲率也從最高的 1993 年 95.53%,降至 2005 年的 39.9%(圖 2)。由此可知, 搶奪犯罪率的提升、破獲率的降低與搶奪案發生件數的激增,導致台灣地區近年來,破獲率不及 搶奪案發生件數的速度,使搶奪案的犯罪率居高不下,搶奪犯罪日益嚴重情形值得深入研究。 根據內政部警政署(2005)統計資料顯示,分析自 1999-2003 年,台灣近五年來,各縣市強 盜、搶奪案犯罪率平均值觀察,並且以繪製犯罪地圖方式,視覺化呈現出台灣地區各縣市強盜、 搶奪案平均犯罪率:強盜犯罪率以台中市每十萬人口發生 25.04 件最高,基隆市 23.96 件次之, 新竹市 20.91 件第三;而搶奪案犯罪率以高雄市每十萬人口發生 91.92 件最高,台中市 73.31 件次 之,高雄縣 37.84 件第三(圖 3)。從 1999-2003 年各縣市的強盜與搶奪犯罪率得知,台中市強盜 與搶奪案犯罪情形遠超過其它縣市,幾乎居強盜與搶奪案犯罪率之首,可見台中市搶奪犯罪問題 之嚴重性。 圖 3 台灣地區 1999-2003 年強盜與搶奪犯罪率分佈圖 資料來源:內政部警政署(專題分析,2005) 暴力犯罪總數 搶奪發生件數 0 2000 4000 6000 8000 10000 12000 14000 16000 18000 1991 1993 1995 1997 1999 2001 2003 2005 年 件數 暴力犯罪總數 搶奪發生件數
從有人類社會開始,即有犯罪問題存在。犯罪統計向來被視為評論治安好壞的重要依據,傳 播媒體或官方機構更常以犯罪統計作為訴求的重點。管理犯罪統計資料的機構,往往自限於機密 資料之保護,不對外開放提供參考研究,亦未能與國外犯罪統計資料機構進行交流;而學術界不 易取得犯罪統計資料,更造成無法對犯罪問題深入剖析,甚至無法提供良好之犯罪預防政策(李 湧清等,2003),因此,本研究克服此問題,利用學術研究之觀點,向台中市警察局刑警隊取得 犯罪相關資料,進行犯罪問題之研究。 有關犯罪相關理論,大致上可分為解釋犯罪者如何形成以及解釋犯罪事件如何發生兩種類 型,直到近來的研究焦點,才逐漸轉移到犯罪事件上,不像過去多集中在犯罪人的特質上(孟維 德,1998)。而在犯罪的議題上,犯罪熱點(hot spot)亦是研究的重點之一,犯罪熱點是顯示出 一個更高犯罪集中的地理區域(Grubesic, 2006)。在國內過去研究犯罪事件中,學者多以研究犯 罪者作為研究對象,或是再加入犯罪者與執法人員做深入的瞭解,比較執法人員與犯罪者對犯罪 情境之差異,此方法在犯罪預防觀點上譽為治本之作法,但隨著犯罪率節節升高的趨勢下,卻顯 得不切實際,並未能真正降低犯罪率(吳芳富,2003)。因此,近年來相關犯罪議題,已開始由 加害人研究,轉向被害人與犯罪地點進行觀察研究(賴致瑜,2006)。在國外 Andresen(2006) 利用社會解組論、日常生活理論與犯罪之多變量,且不同於以往犯罪率之算法,是利用住宅與周 遭人口當作分母,並且利用空間迴歸技術去探討各種犯罪類型與各種因子之間之關係;Grubesic (2006)說明模糊群集提供一個較詳細的資料結構,且不同於硬式分群方法,可以探索犯罪熱點 在空間模式特性的瞭解,結論也證實模糊群集在都市環境犯罪熱點的描述上,是較佳之方法。 在暴力犯罪事件中,搶奪案發生情形已佔據一半以上(如圖 1),搶奪案件型態已備受矚目。 而其中以街頭搶奪案,讓民眾對治安有不安全的懼怕感,且對其自身財產與生命構成嚴重威脅(陳 國恩,2004)。傳統犯罪區域空間的研究,在研究方法上採各區域量化統計輔以文字敘述來呈現 為主,無法顯示犯罪地點與空間之相關性,且在分析何種犯罪理論或社經因子與犯罪現象有顯著 相關性時,迴歸分析是最常使用的方法,然而,區域內的社經條件並非均質一致,傳統的線性迴 歸模式均未考慮空間異質性1和空間自相關2現象,以致於犯罪理論的解釋能力會受空間變異的影 響而減低(賴致瑜,2006)。近年來,隨著地理資訊系統技術發展,得以處理與分析空間資料, 以圖層方式將搶奪犯罪資料加以視覺化;同時,若假設區域之間在空間上具有異質性可能更符合 現實,空間計量經濟學方法可以有效地解決這個問題(吳玉鳴,2007)。因此,本研究以台中市 為研究範圍,利用空間分析技術,分析比較不同時期搶奪犯罪地圖分佈變化情形,並且繪製犯罪 地圖。在犯罪區位分析方面,利用犯罪理論選取社經人文環境變項,建立多元線性迴歸模型,找 出搶奪犯罪的區位因子,進而探討搶奪犯罪熱點之區位特性,並比較不同之空間迴歸模型,尋求 出最合適之空間模式,並且驗證搶奪犯罪率與區域的空間特性之間確實有空間變異之現象存在。
研究材料與方法
1 空 間 異 質 性 主 要 原 因 所 在 的 地 理 的 環 境 、 空 間 區 位 這 些 屬 性 是 有 所 不 同 , 變 異 的 不 穩 定 性 (non-stationarity)使得模型產生空間異質的問題。 2 空間中,某空間單元與其周圍單元間,就某種特徵值,透過統計方法,進行空間自相關性程度的計 算,以分析這些空間單元在空間上分佈現象的特性。(一)資料蒐集與處理
本研究「犯罪資料」為台中市警察局刑警隊所提供,時間範圍為 2004、2005 兩年,空間範圍 為台中市。此外,台中市 2004、2005 搶奪案件文字資料內容包括:案類、發生日期(年、月、日、 時、分)、發生地點及發生地管轄。「圖層資料」由逢甲大學地理資訊系統研究中心、台中市政 府所提供,其中包括:台中市行政區圖層、台中市鄰里圖層、台中市門牌點位圖層(2005 年)、 台中市街道圖層、台中市休閒設施、金融機構、警消設施、便利商店、購物場所等圖層(2005 年)。 「相關統計資料與圖層」由台中市政府民政局、主計處所提供,其中包括:台中市 2005 年各里、 各區之土地面積、人口數、人口密度、男女人口數、教育程度、年齡結構等。(二)犯罪地圖製作
在空間型態分析中,主要目的於瞭解點資料於空間上分佈型態,常用方法為 Nearest NeighborAnalysis 與 Density Map 等方式,該分析方法基於座標位置,只能分析是否呈現群集狀況,因此是
屬於全域分析;另外礙於座標提供資訊有限,故需要配合屬性資料進行進階分析,使之能夠更充 分掌握空間點型態分散情形,該類型分析方法包括:Density Map、Moran’s I、Geary’s C、
Autocorrelation、Anselin’s LISA、Getis-Ord Gi*: Statistic…等,但各類型方法有不同之適用範圍與
條件,根據其方法與特性,將上述分析方法區分成全域分析(Global analysis)與區域分析(Local
analysis)(林美君等,2005),利用下圖四表示與簡述。由於進行犯罪熱點分析前,必須先確定犯 罪地點是否呈現聚集現象(Chainey et al. ,2002),因此,本研究採用平均最近鄰分析(Average
Nearest Neighbor)、核密度推估法(Kernel Density Estimation)去初步探討空間點資料是否呈現
群集現象,一旦呈現是群集,則需要進一步做區域分析,經由(朱健銘,2000、陳慈仁,2001) 發現 Getis-Ord Gi*演算法得以瞭解區域內相關程度大小,進而去探求犯罪熱點分析成果。 點資料 座標分析 屬性分析 1.Quadrat Analysis 2.Nearest Neighbor Analysis 3.Density Map
●Kernel density estimates
全域分析 (Global analysis ) 區域分析 (Local analysis ) ●Density Map ●Moran’s I ●Geary’s C Anselin’s LISA ●Local Moran’s I ●Local Geary’s C ●Getis 全域分析 圖 4 空間點型態群集分析方法圖 資料來源:林美君等,2005
1. 平均最近鄰分析 ( Average Nearest Neighbor ) 在最近鄰分析的演算法中,
l
mean是最近鄰距離的平均值,d
是指點i
到與其最近鄰點j
之間 的距離,n
是指研究區的事件點數。而單就只看l
mean,此數值是沒有意義,其所代表的是最近鄰 距離的平均數,此指數在點符號形式的資料無法提供其他表示含意。R
是表示最近鄰指數,l
theory 為在最近鄰與點間的距離平均值,表示此研究區範圍除以總點數(湯巧君,2007)。公式如下(1):n
d
l
mean=
∑
ij theory meanl
l
R
=
(1) meanl
:最近鄰距離的平均數 R:最近鄰指數, theoryl
:在最近鄰與點間的距離平均值平均最近鄰分析(Average Nearest Neighbor)是最近鄰距離分析中最簡單的量測方法,概念 類 似 於 平 均 。 平 均 最 近 鄰 分 析 可 檢 視 最 近 鄰 距 離 的 累 加 次 數 分 配 ( cumulative frequency distribution)。觀察平均最近鄰指標的函數圖形可以發現,若事件呈現群聚現象,平均最近鄰指標 會在短距離內快速增加;反之,若事件是均勻分佈在空間中,平均最近鄰指標會穩定增加 ( Bailey & Gatrell, 1995 )。因此,透過犯罪熱點分析,以平均最近鄰分析方式,瞭解犯罪事件發生有無群 集現象發生。公式如下(2):
( ) (
)
n
w
w
w
iG
=
≤
∧#
(2)w
:兩事件間最短距離,n
:研究區的事件數 #:在指定最短距離間之事件數量 平均最近鄰分析是用來計算點資料分佈狀況的指數,假若計算數值大於1,則此資料是屬於分 散的分佈;假若計算分析結果的數值小於1,則此資料是屬於具有群集的分佈;假若計算分析結果 數值接近於1,則此資料是屬於隨機的分佈情形(湯巧君,2007)。2. 核密度推估法(Kernel Density Estimation)
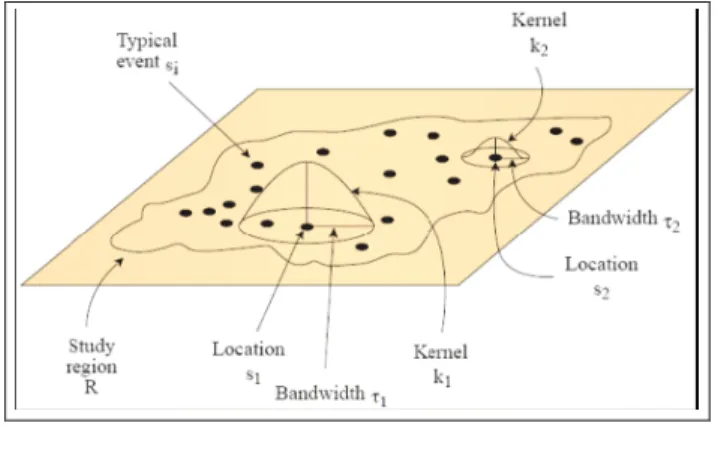
這個方法是設計核心區
k
1、k
2,以點s
1、s
2為核心計算半徑範圍內的事件數,會將多數的事件分配至不同的事件群中,產生密度表面,核心區的半徑長度
τ
1、τ
2會影響估計的精確度。這個分析點空間型態的方法有助於找出犯罪熱點所在,且可連結經轉換成密度表面的地理資料, 如犯罪密度、人口密度、失業率密度,進行加權計算(Bailey & Gatrell, 1995)。
若
s
代表研究區R
中的一定點,s
1…s
n為n
個觀測事件的位置,則在s
點的核密度λ
( )
s
∧
可 以估計為:
∑
= ∧
−
=
n i is
s
k
s
s
1 21
)
(
1
)
(
τ
τ
δ
λ
τ τ (3) k ( ):雙變量的概率密度函數,稱為核心(kernel)參數τ> 0 ,帶寬( bandwidth) ,它是用來定義平滑量( the amount of smoothing)的大小
圖 5 核密度推估法
資料來源:Bailey & Gatrell, 1995
本研究參照賴致瑜(2006)、湯巧君(2007),因空間範圍與大小相近,且都是以單一縣市 為例,因此,本研究以搶奪犯罪地點作為定點核心,搜索半徑為 1000 公尺,網格尺寸為 100 平方 公尺,計算半徑範圍內的事件數,產生搶奪犯罪機率密度趨勢面。
3. Getis-Ord Gi*演算法
本研究以 ArcMap9.2 軟體之 ArcToolbox 模組,採用其空間統計工具(spatial statistic tools) 中群聚量測(mapping clusters)之熱點分析(hot spot analysis—Getis-Ord Gi*)計算功能進行分析。 首先,將犯罪地點利用地理資訊系統分派至台中市各里,再將各里犯罪數除以各里人口數,計算 出各里的犯罪率。最後將各里的犯罪率代入 Getis-Ord Gi*的公式,若某里與其鄰近里的犯罪率同 樣偏高,該里的 Getis-Ord Gi*值就會高,Getis-Ord Gi*值是代表具有統計顯著性的空間聚集程度,
Getis-Ord Gi*值高表示該里為犯罪高度集中處,即為犯罪熱點。 在 Gi*統計量中,以一分為 n 個空間單元的研究區域中,每個空間單元 i 以其範圍內的一個 點(通常為空間單元之中心點)為代表,而每個點也代表一個取自隨機變數 X 的值 xi,若給定一 個半徑距離 d,以每個空間單元 i 的代表點為圓心分別向外畫出半徑距離 d 的圓,則包含在每個 圓中的點所代表的其他空間單元 j 即為空間單元 i 的鄰近空間單元,如此即可定義出 n 個子區 域;對於每個子區域,Gi*統計量可以量測其中隨機變數 X 相對於其他子區域的 X 值之空間聚集 程度。公式如下:
( )
∑
∑
= ==
∗
n j ij n j j ijX
X
d
W
G
1 1i
(4) d:距離 Wij:加權矩陣,當 j 在以 i 為圓心,d 為半徑的範圍內,Wij=1,當 j 在以 i 為圓心,d 為半 徑的範圍外,Wij=0。 xi and xj:X 在位置 i 和 j 的值(三)犯罪區位分析
本研究犯罪區位分析以統計分析軟體 SPSS 進行分析,以單一樣本 T 檢定、相關分析、多元 線性迴歸分析去探討犯罪熱點的社經環境,以預測或解釋環境社經變項對地區犯罪率的影響程 度。然而,傳統的線性迴歸模式均未考慮空間異質性和空間自相關現象,以致於各變項的解釋能 力會受空間變異的影響而減低,因此,本研究運用空間統計軟體 Geoda,,以不同空間迴歸模型去 尋求出最合適之空間模式,並且驗證搶奪犯罪率與區域的空間特性之間確實有空間變異之現象存 在。 1. 單一樣本 T 檢定 以統計分析軟體 SPSS 進行單一樣本 T 檢定,其檢定某個變數的母體平均數和某指定值之間 是否存在顯著差異。統計的前提樣本母體需服從常態分配,即單樣本本身無法比較,進行的是其 平均數與已知母體均數間的比較(林傑斌等,2005)。 在進行單一樣本 T 檢定前,先將搶奪犯罪點合併至各里空間,再將各里犯罪數除以各里人口 數,計算出各里的犯罪率。本研究以台中市 2005 年搶奪案犯罪率(搶奪案件數/人口數)視為母 體平均數,各里為樣本數。透過單一樣本 T 檢定方式,得到台中市 214 個里的犯罪率平均數及標 準差,並以平均數與正負三個標準差範圍外的樣本數予以剔除,以有效樣本數進行後續分析。 2. 相關分析 相關分析是用來分析兩個變數間相關程度的強弱與正負方向。而衡量兩變數間相關程度的指 標有很多個,其中以皮爾森 ( Pearson ) 簡單相關係數( r )為最常見,主要是用來衡量兩個變 數間線性關係之強弱程度與方向的指標,其範圍為 -1≦ r ≦1 表示相關係數之大小與意義。去除 變數單位的影響,以兩變數之標準差為分母所計算標準化關聯係數。其公式為:∑
∑
−
−
−
−
=
=
2 2)
(
)
(
)
)(
(
)
,
cov(
Y
Y
X
X
Y
Y
X
X
S
S
y
x
r
y x (5) cov(x,y):樣本共變異數,Sx:x 的樣本標準差,Sy:y 的樣本標準差3. 多元線性迴歸分析 多元線性迴歸是使用甚廣的一種多變量分析技術,其主要用途有二:一為解釋,二為預測。 解釋的功能主要在於說明預測變項與效果變項間的關聯強度及關聯方向;預測的功能則是使用迴 歸方程式,利用已知的自變數來預測未知的依變數。所以為了增加迴歸分析的預測力,所有的預 測變數之間的相關要愈低愈好,而每個預測變數與依變數的相關則要愈高愈好(陳正昌,2005)。 此外,進行迴歸分析前,需讓犯罪地點資料、戶口及住普查資料及其他相關資料的空間單元 一致,本研究以里作為最小空間單元,根據里的範圍,合併各項資料。
4. 空間落遲模型(spatial lag model)
空間落遲模型包含了用一個空間上「落遲」的被解釋變數作為一般的解釋變數,類似於時間 序列模型中上期、本期的概念,此「落遲」的意義是來自於空間上的鄰近可類比為時間上的先後。 空間落遲模型常用於「一地的某活動同時影響鄰近地區某活動,也受鄰近地區某活動的影響」, 由相關經濟變數來補抓且通常只考慮被解釋變數的空間落遲效果。 i i i i
Wy
X
Y
=
α
+
ρ
+
β
+
ε
,ε
i~
iid
(6) 式中:其中被解釋變數搶奪犯罪率取自然對數Wy
表被解釋變數乘上空間上的鄰近矩陣ρ
表被解釋變數的空間落遲係數 由上式可知,空間落遲迴歸模型與一般 OLS 迴歸模型不同的地方,即是多加一個被解釋變數 乘上空間的鄰近矩陣當作解釋變數,透過檢定被解釋變數的空間落遲係數ρ
,是否顯著異於零,0
≠
ρ
即表示空間落遲模型確實具有鄰近區域上的空間關係。5. 空間誤差模型(spatial error model)
空間誤差模型適合用於修正因空間自相關的存在,使原來的模型產生誤差(郭迺鋒,2004), 誤差項是將干擾因子考慮進來,考慮到此模型裡較不重要的變數,代表空間自相關存在於誤差項 中。當空間相關依性存在於誤差項時,殘差將不是 white noise3 而是有空間自我相關。
y
i=
α
+
β
x
i+
ε
i (7) 式中:β
表迴歸係數ε
表誤差項 修正後之誤差項,如下所示: i i iλ
W
ε
ξ
ε
=
+
,ξ
~
iid
N
( )
0
,
σ
2 (8) 式中:λ
表空間誤差係數W
表空間矩陣 空間誤差模型是將迴歸模型中的殘差項裡,多加上一個殘差項自己本身乘上空間上的鄰近矩 陣,若其中空間誤差係數λ
顯著異於零,λ
≠
0
即表示空間誤差迴歸模型中確實有干擾因子造成 3 在時間數列模型當中,殘差項具有常態,同質變異,無自相關者,稱為白噪音的隨機過程。空間自相關。
在使用空間迴歸模型的方法上,可以用空間落遲模型(Spatial Lag Model)與空間誤差模型 (Spatial Error Model)兩種模型來分析,這二種模型何者才是最適模型,可從以下四個檢定方法 來判斷(艾兆蕾,2005;黃雅燕,2006)。
1. 空間異質性檢定(Breusch-Pagan test)
透過 Breusch-Pagan 檢定進行異質檢定,虛無假設為無異質變異,若結果顯著為拒絕虛無假 設,則表示迴歸模型中的殘差項具有異質差異。
2. 殘差項空間相依性檢定
Lagrange Multiplier 檢定(LM test),以 LM 測試方法檢定空間模型之誤差項,虛無假設為空
間模型之誤差項無空間相依性存在,依據 LM test 的判斷準則,若 LM-Lag 較 LM-Error 顯著,則
LM-Lag 為適合的模型。反之,若 LM-Error 較 LM-Lag 顯著,則 LM-Error 是為適合的模型。 3. 空間相依性檢定
由上述殘差項空間相依性檢定顯示誤差項有空間自我相關,因此,需進一步採用空間落遲模 型(Spatial Lag Model)與空間誤差模型(Spatial Error Model),以概似比檢定來測試該二模型是
否具有空間相依性,虛無假設為空間落遲變數無相依存在,即
H
0:ρ
= 0;與空間誤差變數無相依性存在,即
H
0:λ
= 0,所以要進一步利用 Robust LM(Lag)與 Robust LM(Error)來判斷該二模型中,哪一個空間迴歸模型較適合本研究使用。
4. 配適度檢定
就整體的配適度而言,在空間落遲模型和空間誤差模型之下不能使用
R
2衡量,因為空間落遲模型和空間誤差模型是使用最大概似法估計,故其模型中可得出最大相似且非線性的檢定值,
並極大化其係數,所以對數概似值 Log Likelihood(LIK)、Akaike Information Criterion(AIC)4
等依據非線性原則的配適檢定才能拿來檢定配適度,而最大的 Log Likelihood 值或是最小的 AIC 值才是最佳模型。
實證分析
(一)搶奪犯罪地圖製作
經由地址對位程式將地址資料轉換成空間座標,即可繪製 2004 年、2005 年搶奪犯罪地點分 佈圖(圖 6、圖 7),圖上每個點都代表一個犯罪地點,因此,從點的疏密程度,便可粗略得知犯 罪集中地區。從搶奪犯罪地點分佈圖中,可以初步得知搶奪案件大致集中在台中市中間區域,而 在台中市行政邊界,搶奪案件呈現零星件數分佈。且從搶奪犯罪地點分佈圖與道路圖層來看,搶 奪犯罪地點是沿著幾條主要道路,如:台中港路、大雅路、中清路、精誠路、公益路、進化北路、 美村路、西屯路、福星路等,成線狀排列。 4 屬於一種判斷時間序列模型是否恰當的訊息準則,一般來說數值愈小,時間序列模型的配適較好。圖 6 2004 年台中市搶奪案分佈圖 圖 7 2005 年台中市搶奪案分佈圖
(二)空間分析
1. 平均最近鄰分析( Average Nearest Neighbor )
本研究對於 2004 年與 2005 年台中市搶奪犯罪地點分佈圖進行平均最近鄰分析,計算搶奪案 犯罪點分佈狀況指數。2004 年的 R 值為 0.5560 且 Z-score 為-27.2227(P=0.01),2005 年的 R 值 為 0.6047 且 Z-score 為-25.6453(P=0.01)。由於 2004 年與 2005 年的 R 值均小於 1 且 Z-score 大 於-2.58,由分析結果得知,此資料是屬於具有群集的分佈,即 2004 年與 2005 年台中市搶奪案件 分佈有呈現聚集現象,得以進行犯罪熱點分析。
2. 核密度推估法(Kernel Density Estimation)
利用核密度推估法可針對點圖層進行空間的核密度分佈分析,找出犯罪熱點所在,且可清楚 地判別搶奪犯罪的變遷趨勢。而圖中顏色分別代表不同密度,紅色為搶奪密度最高區域,白色為 搶奪密度最低區域。2004 年台中市搶奪案核密度分佈圖(圖 8),犯罪密度最高的區域,東至雙十 路一段、南至建國路、西至柳川東路四段、北至健行路之間,搶奪案密度分佈次高區域有兩個區 域,一處位於搶奪密度分佈最高之附近周圍;另一處位於東至美村路、南至忠誠街、西至東興路 三段、北至博館路,並且大致上有三個犯罪熱點區域,分別為中區與北區、西區、西屯區。而 2005 年台中市搶奪案核密度分佈圖(圖 9),犯罪密度最高的區域,東至精美街、南至大墩十一街、西 至大光街、北至大業路之間,搶奪案密度分佈次高區域有兩個區域,一處位於搶奪密度分佈最高 之附近周圍;另一處位於東至一中街、南至太平路、西至中華路二段、北至五權路,大致上有兩 個犯罪熱點區域,分別為北區與西區、西屯區和南屯區交接處。 此外,西區與南屯區交接處,大業路、東興路三段、大墩十一街、大墩路之間形成新的犯罪 熱點。其中中區雙十路一段、自由路二段、三民路三段、中山路之間的犯罪熱點有消散跡象,因 此,從這 2 年的變遷可得知犯罪熱點有往西移動之現象,且由犯罪相關理論得知,人口密度高相 對犯罪率亦高,台中市第十二期福星市地重劃區,除促進西屯地區之繁榮外,將連接七期重劃區, 使本區發展成一多核心之都市,由單核心轉變為雙核心,有往西發展之計畫(張雅華,2007),人 口的大量移動也帶動地方的經濟發展,例如:百貨公司、量販店、便利商店、金融機構、商業區、 圖 圖 圖 圖例例例例 2004_搶奪案件 道路路線 臺中市 圖 圖圖 圖例例例例 2005_搶奪案件 道路路線 臺中市
八大行業5 …等也大量往西發展與建設,因此,犯罪熱點也隨著人口的大量移動與促使搶奪犯罪的 一些社經環境變項,隨之移動變遷。 圖 8 2004 年台中市搶奪案核密度分佈圖 圖 9 2005 年台中市搶奪案核密度分佈圖 3. 熱區分析 利用空間分派技術,將犯罪事件分配至各里,即可得各里犯罪數;再將各里犯罪數除以各里 人口數,計算出各里的犯罪率。Getis-Ord Gi*值是代表具有統計顯著性的空間聚集程度,若某地 區與其鄰近地區的犯罪率同是高值,該地區的 Getis-Ord Gi*值即為高值,顯示該地區為犯罪集中 處,即為犯罪熱點。2004 年台中市搶奪犯罪率 Getis-Ord Gi*值超過 2.5 個標準差的里有:北區五 常里、大湖里、錦平里、育德里、新北里、樂英里、邱厝里、東區新庄里,共 8 個里(圖 10)。 而 2005 年台中市搶奪犯罪率 Getis-Ord Gi*值超過 2.5 個標準差的里有:北區錦平里、樂英里、新 北里、大湖里、五常里、邱厝里,共 6 個里(圖 11)。從這 2 年的變遷中值得注意的是,在北區 的搶奪犯罪熱點有其消散之情形,且搶奪犯罪熱點有往西擴散之現象,此與核密度推估法有密切 吻合之處,亦與台中市都市計畫發展第十二期福星市地重劃區,且與人口大量從中區、北區向西 移動的趨勢有關。
(三)犯罪區位分析
因為賴致瑜(2006)中有提到,社經環境變項資料蒐集不易,社會解組論的各里重要變項資 訊無法取得,因此,本研究利用不同最小空間單元去獲取社會解組論之重要因子。首先,利用里 作為最小空間單元,根據日常活動理論與社會解組論,以 2005 年台中市人口統計資料及其它相關 資料,產生社經人文環境變項(表 1),進行相關分析與迴歸分析。再來,根據里的相關分析把不 顯著因子在去和最小空間單元-區,以 2005 年台中市人口統計資料及其它相關資料,產生社經人 文環境變項(表 2),進行相關分析與迴歸分析。最後,找出可能影響搶奪犯罪熱點的社經環境因 子,提供搶奪犯罪防治工作之決策參考。 5 依據 82 年 3 月 18 日行政院第二三二三會議暨入 85 年 9 月 12 日行政院第二四九六次會議院長提示, 將視聽歌唱業、理髮業、三溫暖業、舞廳業、舞場業、酒家業、酒吧業、特種咖啡茶室業等八種行 業列為影響治安行業。
圖 10 2004 年台中市各里 Getis-Ord Gi*值 圖 11 2005 年台中市各里 Getis-Ord Gi*值 表 1 本研究所使用之各里社經人文環境變項 犯罪理論 犯罪理論 犯罪理論 犯罪理論 變項變項變項變項 定義定義定義定義 1.金融機構密度 金融機構數
÷
總面積(km
2) 2.便利商店密度 便利商店數÷
總面積(km
2) 3.道路密度 道路總長÷
總面積(km
2) 4.警消密度 警消總數÷
總面積(km
2) 5.人口密度 總人口數÷
總面積(km
2) 6.購物場所密度 購物場所數÷
總面積(km
2) 日常活動理論 7.八大行業密度 八大行業數÷
總面積(km
2) 1.人口密度 總人口數÷
總面積(km
2) 2.商業區密度 商業區面積(km
2)÷
總面積(km
2) 3.男性人口比例 男性人口數÷
總人口數*100% 社會解組論 4.女性人口比例 女性人口數÷
總人口數*100% 表 2 本研究所使用之各區社經人文環境變項 犯罪 犯罪 犯罪 犯罪 理論 理論 理論 理論 變項變項 變項變項 定義定義定義定義 1.警消密度 警消總數÷
總面積(km
2) 2.人口密度 總人口數÷
總面積(km
2) 3.公園密度 公園面積÷
總面積(km
2) 日常活動理論 4.學校密度 學校面積÷
總面積(km
2) 1.人口密度 總人口數÷
總面積(km
2) 2.男性人口比例 男性人口數÷
總人口數*100% 3.女性人口比例 女性人口數÷
總人口數*100% 4.20 歲以下人口比例 20 歲以下人口數÷
總人口數*100% 5.20~39 歲人口比例 20~39 歲人口數÷
總人口數*100% 6.40~59 歲人口比例 40~59 歲人口數÷
總人口數*100% 7.60 歲以上人口比例 60 歲以上人口數÷
總人口數*100% 8.高教育人口比例 大學以上教育人口數÷
總人口數*100% 9.低教育人口比例 小學以下教育人口數÷
總人口數*100% 社會解組論 10.人口增減率 人口增減數÷
前年人口數*100%1. 搶奪案之區位分析(里) (1)單一樣本 T 檢定 將 2005 年台中市各里搶奪案件數除以各里的總人口數,即是各里犯罪率。利用單一樣本 T 檢定方式,得到 214 個里的平均數與標準差,並以 95%信賴區間為範圍,為異常值樣本予以刪除。 結果顯示如表 3、圖 12。此無效樣本數有 3 個,分別為南屯區大業里、北區錦平里、北區新北里, 其數值超過正三個標準差以外範圍 0.00489662,故本研究僅以台中市 211 里為樣本,進行相關分 析及迴歸分析。 表 3 單一樣本 T 檢定(里) 個數 個數 個數 個數 平均數平均數平均數平均數 標準差標準差標準差標準差 平均數的標準誤平均數的標準誤平均數的標準誤平均數的標準誤 里犯罪率 214 0.00119261 0.00123467 0.00008440 圖 12 里犯罪率次數分佈圖 (2)相關分析 本研究先針對社經人文環境變項及犯罪率進行相關係數分析,以瞭解犯罪熱點與周遭社經人 文環境因素相關程度。根據分析變項相關係數(表 4)顯示,金融機構密度、便利商店密度、道 路密度、購物場所密度、八大行業密度、商業區密度等六個變項呈現相關性,且帶入迴歸分析進 行後續分析。
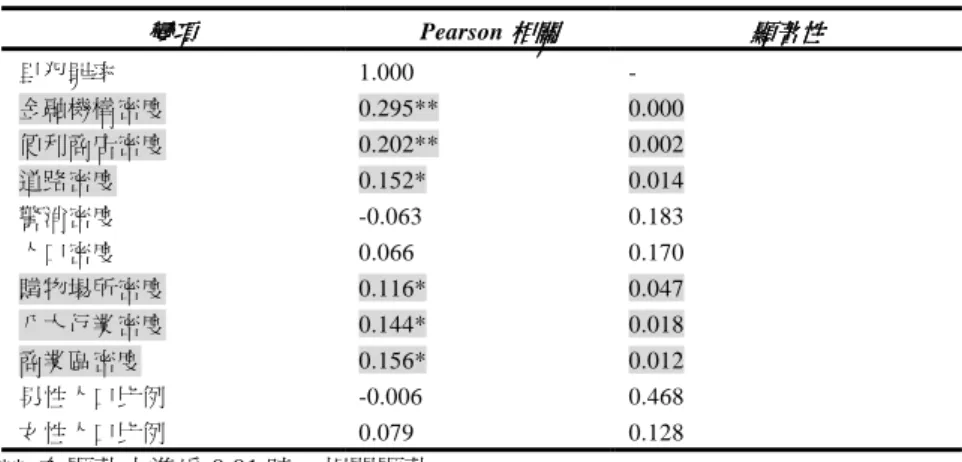
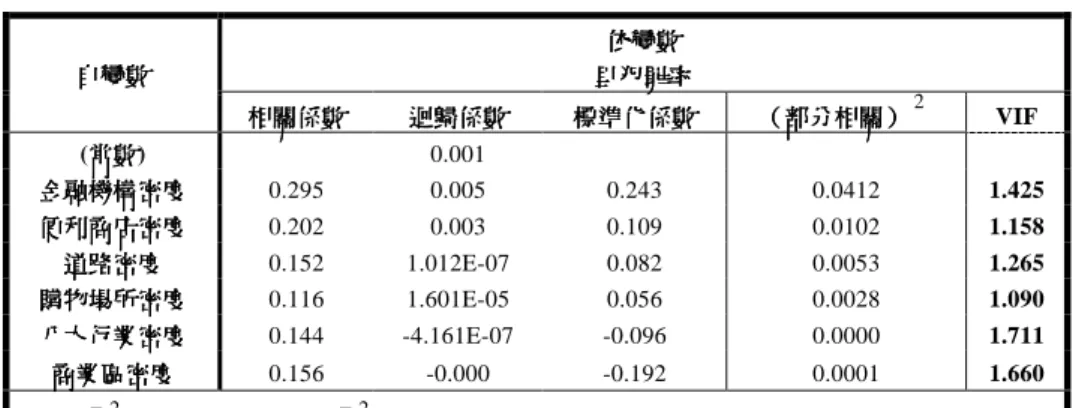
表 4 分析變項相關係數表(里) 變項 變項 變項 變項 Pearson 相關相關相關相關 顯著性顯著性顯著性顯著性 里犯罪率 1.000 - 金融機構密度 0.295** 0.000 便利商店密度 0.202** 0.002 道路密度 0.152* 0.014 警消密度 -0.063 0.183 人口密度 0.066 0.170 購物場所密度 0.116* 0.047 八大行業密度 0.144* 0.018 商業區密度 0.156* 0.012 男性人口比例 -0.006 0.468 女性人口比例 0.079 0.128 ** 在顯著水準為 0.01 時,相關顯著。 * 在顯著水準為 0.05 時,相關顯著。 (3)(傳統)多元迴歸分析 在進行(傳統)多元迴歸模式前,由表五觀察出自變項與自變項間的相關性皆小於 0.8,而 Durbin-Watson 檢定介於 2 之間,且 VIF 檢測迴歸方程式皆小於 10,而各變數的條件指標皆小於 30,顯示變項間的共線性將不足以影響迴歸模式的預測與解釋能力。由以上的預測變項,可以得 到 以 下 的 迴 歸 方 程 式 :『『『『 里 犯 罪 率里 犯 罪 率里 犯 罪 率里 犯 罪 率 =0.001+0.005 (((( 金 融 機 構 密 度金 融 機 構 密 度 )金 融 機 構 密 度金 融 機 構 密 度)) +0.003 () ((( 便 利 商 店 密 度便 利 商 店 密 度便 利 商 店 密 度便 利 商 店 密 度 )))) +0.0000001012((((道路密度道路密度道路密度)道路密度)))+0.00001601((((購物場所密度購物場所密度)購物場所密度購物場所密度))-0.0000004161() (((八大行業密度八大行業密度八大行業密度)八大行業密度)))+0.000 ( ( ( (商業區密度商業區密度商業區密度)』商業區密度)』)』 )』 分析結果顯示,整體的解釋率為 10.9%,而「金融機構密度」、「便利商店密度」與「里犯罪 率」呈現正相關,且為六個變項中相關係數最高與次高,大於 0.2。由於搶奪犯主要搶奪動機就 是「獲取金錢」,而「獲取金錢」的主要理由,包括:要錢去買毒品、要錢去解決朋友的困難、要 錢去解決自己與家庭生活的困境等(謝文彥,2004),而金融機構與便利商店就是較多金錢往來的 地方,且在金融機構附近較好行搶、較有錢可拿;搶奪犯罪通常發生在夜晚,發生時間約在 20 時至 24 時(吳芳富,2003),便利商店更是 24 小時營業,因此成為搶奪犯之首選。六個變項之間 的相關係數中,「八大行業密度」與「商業區密度」相關係數最高,為 0.542;「八大行業密度」 與「道路密度」相關係數次高,為 0.443。由於八大行業大部分都位於商業區裡面,而八大行業 根據日常生活理論,更是搶奪犯最主要出入的地方,打電動、唱歌、撞球、喝酒是搶奪犯常有的 娛樂活動(陳國恩,2004),這些活動形成他們的生活模式,更是構成了他們犯罪的溫床。且搶奪 犯在行搶時會顧慮到行搶後能否順利脫逃,因此會選擇能易於行搶並且容易脫逃之場所,且因搶 奪犯犯案工具多以機車為主,因此道路對於搶奪犯而言,為其犯案後具有高移動性、可及性與易 達性高的街道上,以上這些行為與文獻回顧中,理性選擇理論與日常活動理論相符合。
表 5 迴歸係數分析表(里) 依變數 依變數依變數 依變數 里犯罪率 里犯罪率里犯罪率 里犯罪率 自變數 自變數 自變數 自變數 相關係數 相關係數 相關係數 相關係數 迴歸係數迴歸係數 迴歸係數迴歸係數 標準化係數標準化係數標準化係數標準化係數 (部分相關(((部分相關部分相關)部分相關)))2 VIF (常數常數常數常數) 0.001 金融機構密度 金融機構密度金融機構密度 金融機構密度 0.295 0.005 0.243 0.0412 1.425 便利商店密度 便利商店密度便利商店密度 便利商店密度 0.202 0.003 0.109 0.0102 1.158 道路密度 道路密度 道路密度 道路密度 0.152 1.012E-07 0.082 0.0053 1.265 購物場所密度 購物場所密度購物場所密度 購物場所密度 0.116 1.601E-05 0.056 0.0028 1.090 八大行業密度 八大行業密度八大行業密度 八大行業密度 0.144 -4.161E-07 -0.096 0.0000 1.711 商業區密度 商業區密度 商業區密度 商業區密度 0.156 -0.000 -0.192 0.0001 1.660 2
R
=0.109,,,,AdjustedR
2=0.083,,,,F
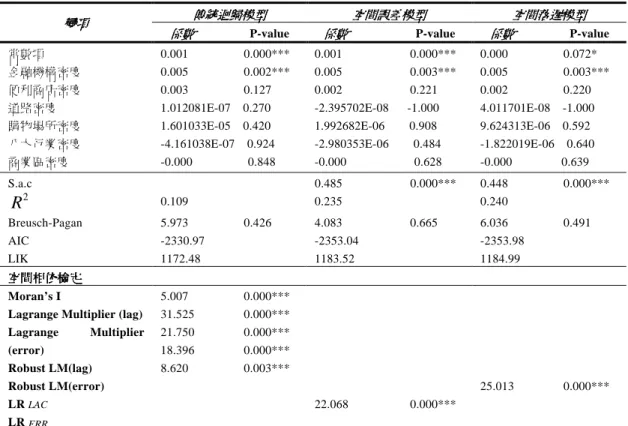
(6,204)=4.151,,,P<0.05,, ,,,Durbin-Watson=1.498 (4)(傳統)迴歸模型殘差值分析 圖 13 顯示傳統迴歸模型殘差值分佈情形,有些地區呈現聚集現象。經由空間自相關分析,得 到 Moran’s I Index = 0.031420,Z score = 5.912501,顯示傳統迴歸模型殘差值具有空間自相關 現象(圖 14)。由於在空間均質的假設下,傳統迴歸模型的分析結果無法反映空間變異情形。 圖 13 傳統迴歸模型殘差值分佈圖(里) 圖 14 傳統迴歸模型殘差值空間自相關 分析圖(里) 資料來源:Arc GIS 軟體畫面 (5)空間落遲、空間誤差模型分析 經由上述傳統迴歸模型殘差值分析得知,傳統迴歸模型殘差值具有空間自相關現象,且傳統 迴歸模型的分析結果無法反映空間變異情形,且經由傳統迴歸模型配適度 10.9%,其 Moran’s I 為 5.007,p 值顯著代表有空間自我相關,因此,需要用一階空間模型檢定,根據空間模型判定效 果而言,LIK 越大模型配適度越高;AIC(AKaike Information Criterion)越小模型配適度越高為準則。研究結果顯示(表 6),LM-Lag 與 LM-error 皆顯著,Roust LM-Lag 與 Roust LM-error 亦顯
著,所以再進一步比較空間誤差與空間落遲的估計結果,空間誤差模型的 LIK 為 1183.52,AIC 為-2353.04;空間落遲模型的 LIK 為 1184.99,AIC 為-2353.98。因為 LIK 越大模型配適度越高,
表 6 2005 年里犯罪率空間迴歸模型估計 傳統迴歸模型 傳統迴歸模型 傳統迴歸模型 傳統迴歸模型 空間誤差模型空間誤差模型 空間誤差模型空間誤差模型 空間落遲模型空間落遲模型空間落遲模型空間落遲模型 變項 變項 變項 變項 係數 係數 係數
係數 P-value 係數係數 P-value 係數係數 係數係數係數係數 P-value 常數項 0.001 0.000*** 0.001 0.000*** 0.000 0.072* 金融機構密度 0.005 0.002*** 0.005 0.003*** 0.005 0.003*** 便利商店密度 0.003 0.127 0.002 0.221 0.002 0.220 道路密度 1.012081E-07 0.270 -2.395702E-08 -1.000 4.011701E-08 -1.000 購物場所密度 1.601033E-05 0.420 1.992682E-06 0.908 9.624313E-06 0.592 八大行業密度 -4.161038E-07 0.924 -2.980353E-06 0.484 -1.822019E-06 0.640 商業區密度 -0.000 0.848 -0.000 0.628 -0.000 0.639 S.a.c 0.485 0.000*** 0.448 0.000*** 2
R
0.109 0.235 0.240 Breusch-Pagan AIC LIK 5.973 0.426 -2330.97 1172.48 4.083 0.665 -2353.04 1183.52 6.036 0.491 -2353.98 1184.99 空間相依檢定 空間相依檢定 空間相依檢定 空間相依檢定 Moran’s ILagrange Multiplier (lag) Lagrange Multiplier (error) Robust LM(lag) Robust LM(error) LRLAC LRERR 5.007 0.000*** 31.525 0.000*** 21.750 0.000*** 18.396 0.000*** 8.620 0.003*** 22.068 0.000*** 25.013 0.000***
註:1.樣本數為 211 里,p-value 小於 0.1“*”, p-value 小於 0.05“**”,p-value 小於 0.01“***”。
(6)空間模型殘差值分析 圖 15 顯示空間誤差模型殘差值分佈情形,經由空間自相關分析,得到 Moran’s I Index = 0.005988,Z score = 1.697577,顯示空間誤差模型殘差值介於聚集與隨機中間(圖 16),可見空間 誤差模型尚未能消除空間自相關現象,反映空間變異情形。 圖 15 空間誤差模型殘差值分佈圖(里) 圖 16 空間誤差模型殘差值空間自相關 分析圖(里) 資料來源:Arc GIS 軟體畫面
反觀,圖 17 顯示空間落遲模型殘差值分佈情形,經由空間自相關分析,得到 Moran’s I Index = 0.004884,Z score = 1.523602,顯示空間落遲模型殘差值是呈現隨機分佈(圖 18),可見空間落 遲模型的分析結果確實能消除空間自相關現象,反映空間變異情形。 圖 17 空間落遲模型殘差值分佈圖(里) 圖 18 空間落遲模型殘差值空間自相關分析圖(里) 資料來源:Arc GIS 軟體畫面 2. 搶奪案之區位分析(網格式) 由於用「里」做為最小空間單元,里的面積有大有小,且雖然利用空間迴歸模式可以有效地 提升解釋能力,但最佳亦僅有 24%的解釋能力,因此本研究再將最小空間單元縮小且網格化,進 行空間迴歸分析。 (1)取決網格大小 以「里」為最小空間單元,里的面積有大有小,且並不是每個里都是處於犯罪熱點區域,因 此,本研究配合空間分析(核密度分佈圖)(圖 9),在犯罪熱點區域內,取各里(忠誠里、公平 里、公正里、公德里、溝墘里、惠中里…等共 13 個里)面積大小總和之平均,視為網格大小。本 研究利用 Arc GIS9.1 將平均網格大小視為 550*550 平方公尺,以 634 個平均網格為樣本(圖 19), 進行空間迴歸分析。且各項變數與各里犯罪率,是由各里之統計量去轉換,並且依照網格大小, 依面積比例重新分配,利用 Arc GIS 呈現在平均網格上。 (2)空間落遲、空間誤差模型分析 由於利用「里」為最小空間單元,空間迴歸模型僅有「金融機構密度」呈現顯著性,且整體 解釋率從傳統迴歸模型的 10.9%,上升至空間落遲模型的 24%,但整體解釋率還是偏低,因此, 本研究利用上述之相關分析,將金融機構密度、便利商店密度、道路密度、購物場所密度、八大 行業密度、商業區密度等六個變項,再一次進行平均網格之空間迴歸分析(如表 7)。 經由傳統迴歸模型配適度 54.8%,其 Moran’s I 為 10.502,p 值顯著代表有空間自我相關,因 此,需要用一階空間模型檢定,根據空間模型判定效果而言,LIK 越大模型配適度越高;AIC (AKaike Information Criterion)越小模型配適度越高為準則。研究結果顯示(表 7),LM-Lag 與
LM-error 皆顯著,Roust LM-Lag 與 Roust LM-error 亦顯著,所以再進一步比較空間誤差與空間落
遲的估計結果,空間誤差模型的 LIK 為 6535.11,AIC 為-13056.2;空間落遲模型的 LIK 為 6561.65,
間落遲模型解釋力較佳。 利用「634 平均網格」為最小空間單元,由空間迴歸模式得知,傳統迴歸模型解釋率為 54.8 %,空間誤差模型解釋率為 69%,空間落遲模型解釋率為 70.5%,故各方面都顯示比利用「里」 為最小空間單元,傳統迴歸模型解釋率為 10.9%,空間誤差模型解釋率為 23.5%,空間落遲模型 解釋率為 24%為佳,因此,可證實縮小最小空間單元,其分析結果將更加精確。 圖 19 進行分析的 634 平均網格犯罪率分佈圖 表 7 2005 年平均網格犯罪率空間迴歸模型估計 傳統迴歸模型 傳統迴歸模型傳統迴歸模型 傳統迴歸模型 空間誤差模型空間誤差模型 空間誤差模型空間誤差模型 空間落遲模型空間落遲模型空間落遲模型空間落遲模型 變項 變項 變項 變項 係數 係數係數
係數 P-value 係數係數 P-value 係數係數 係數係數係數係數 P-value 常數項 8.264251E-07 0.055** 2.588702E-06 0.0025*** 5.224073E-08 0.8815 金融機構密度 0.827 0.000*** 0.694 0.000*** 0.595 0.000*** 便利商店密度 1.145 0.000*** 0.097 0.000*** 0.652 0.000*** 道路密度 1.375171E-07 0.7945 -5.571258E-08 0.8924 -8.86717E-08 0.8344 購物場所密度 0.355 0.0982* 0.049 0.7734 0.003 0.9848 八大行業密度 0.054 0.000*** 0.155 0.0022** 0.056 0.2145 商業區密度 5.027309E-06 0.2855 5.31169E-06 0.2031 -2.662293E-07 0.9441 S.a.c 2
R
0.548 0.690 0.705 Breusch-Pagan AIC LIK 1111.217 0.000*** -12905.3 6459.66 -13056.2 6535.11 -13107.3 6561.65 空間相依檢定 空間相依檢定 空間相依檢定 空間相依檢定 Moran’s ILagrange Multiplier (lag) Lagrange Multiplier (error) Robust LM(lag) Robust LM(error) LRLAC LRERR 10.502 0.000*** 177.007 0.000*** 107.229 0.000*** 73.3410 0.000*** 3.5628 0.059* 150.898 0.000*** 203.9885 0.000***
(3)搶奪案之區位分析(區) a.相關分析 由於賴致瑜(2006)無法取得各里的社會解組程度的變項,導致社會解組論未對迴歸模式產 生顯著地影響,Andresen(2006)社會解組論在統計模型上發展不好,資料取得有困難,因此, 本研究將各里沒有顯著的變項加上新的變項,進行各區之相關分析。根據分析變項相關係數(表 8)顯示,40~59 歲人口比例、60 歲以上人口比例、低教育人口比例、人口增減率等四個變項呈 現相關性,且帶入迴歸分析進行後續分析。 表 8 分析變項相關係數表(區) 變項 Pearson 相關 顯著性顯著性顯著性顯著性 區犯罪率 1.000 - 警消密度 0.290 0.243 人口密度 0.387 0.172 男性人口比例 0.456 0.128 女性人口比例 -0.456 0.128 20 歲以下人口比例 -0.417 0.152 20~39 歲人口比例 -0.353 0.196 40~59 歲人口比例 0.626* 0.048 60 歲以上人口比例 0.671* 0.034 高教育人口比例 高教育人口比例 高教育人口比例 高教育人口比例 -0.431 0.143 低教育人口比例 低教育人口比例 低教育人口比例 低教育人口比例 0.711* 0.024 公園密度 公園密度 公園密度 公園密度 -0.303 0.233 學校密度 學校密度 學校密度 學校密度 -0.228 0.294 人口增減率 人口增減率 人口增減率 人口增減率 -0.792** 0.010 ** 在顯著水準為 0.01 時,相關顯著。* 在顯著水準為 0.05 時,相關顯著。 b.(傳統)多元迴歸分析 由以上的預測變項,可以得到以下的迴歸方程式: 『 『 『 『區犯罪率區犯罪率區犯罪率區犯罪率=-0.002+0.00007766((((40~~~~59 歲人口比例歲人口比例)歲人口比例歲人口比例)))-0.00003208((((60 歲以上人口比例歲以上人口比例歲以上人口比例歲以上人口比例)))) +0.00005951((((低教育人口比例低教育人口比例低教育人口比例低教育人口比例))+0.000()) ((人口增減率(人口增減率人口增減率人口增減率)』)』)』)』 表 9 迴歸係數分析表(區) 依變數 依變數 依變數 依變數 里犯罪率 里犯罪率 里犯罪率 里犯罪率 自變數 自變數 自變數 自變數 相關係數 相關係數 相關係數 相關係數 迴迴歸係數迴迴歸係數歸係數歸係數 標準化係數標準化係數標準化係數標準化係數 (部分相關(((部分相關部分相關)部分相關)))2 VIF (常數常數常數常數) -0.002 40~~~59 歲人口比例~ 歲人口比例歲人口比例歲人口比例 0.626 7.766E-05 0.312 0.0350 2.766 60 歲以上人口比例歲以上人口比例歲以上人口比例 歲以上人口比例 0.671 -3.208E-05 -0.276 0.0216 3.525 低教育人口比例 低教育人口比例 低教育人口比例 低教育人口比例 0.711 5.951E-05 0.579 0.1840 1.820 人口增減率 人口增減率 人口增減率 人口增減率 -0.792 0.000 -0.502 0.0671 3.757 2
R
=0.819,,,Adjusted ,R
2=0.578,,,,F
( )4,3 =3.394,,,,P<0.05,,,Durbin-Watson=1.547 ,由以上分析結果得知,「人口增減率」與「區犯罪率」呈現負相關,「低教育人口比例」與「區 犯罪率」呈現正相關,且四個變項中相關係數最高與次高,均大於 0.7。人口增減率高,代表人 口移動率高,組成份子複雜,文化差異甚大,較難以凝聚社區意識,倫理道德亦無法規範個體行 為,因此犯罪率較高。而低教育程度的人或是家庭,其收入相對而言是較低的,高犯罪率被認為 與低經濟條件有關,且搶奪犯以國中教育程度居多,教育程度低者,其對搶奪犯罪的刑度、嚴重 性都不甚瞭解,也比較不會考量行為後果(吳芳富,2003),此與孟靜(1985)、賴致瑜(2006) 的研究顯示住宅竊盜發生區位的環境特質是在平均所得較高之地區,也就是高教育人口之地區有 所不同,由於家庭收入高的地區可提供較佳的犯罪獲利機會,吸引竊盜犯侵入作案,因此,造成 研究結果不同的主要原因是犯罪型態的不同。由此可見,本研究的結論較吻合台灣地區搶奪犯罪 的實證研究,犯罪率與人口增減率和低教育人口比例具有相關性。 而四個變項之間的相關係數,「人口增減率」與「60 歲以上人口比例」相關係數最高,為-0.788。 人口移動率較高之區域,較難以凝聚社區意識,使得大家只關心自己個人與財產的安全,社區外 的潛在犯罪者視這個社區是犯罪有利場所,他們侵入這個社區犯罪,並認為在這裡犯罪不易被查 察或發現,這個社區犯罪比率就逐漸增加。近年來,人口老化對台灣的社會和經濟犯罪問題帶來 莫大的衝擊,因為扶養負擔增加,少量的青壯年人口所要負擔比例相當高的老年人口,因此,產 生一些社會犯罪問題。其中,根據張雅華(2007)在空間上人口老化區有向外擴展趨勢,集中於 東區、西區、西屯區與北區,此與本研究搶奪犯罪熱點區域有密切吻合之處。由於 60 歲以上人口 大部分處於沒工作狀態,且根據林進發(2005)與湯巧君(2007)搶奪犯罪發生時段主要是以下 午、夜晚時段發生最多,下午時段更是老人家外出運動與最佳的活動時間,因此,此時段時常暴 露在外,又加上搶奪犯經常是臨時起意,看容易下手之目標,故「60 歲以上人口比例」與「人口 增減率」產生顯著的影響關係。 c.(傳統)迴歸模型殘差值分析 圖 20 顯示傳統迴歸模型殘差值分佈情形,呈現隨機分佈情形。經由空間自相關分析,得到
Moran’s I Index = -0.177219,Z score = -0.398960,顯示傳統迴歸模型殘差值呈現隨機分佈(圖
21)。即代表傳統迴歸模型沒有空間自相關現象,可能由於「區域」資料庫的資料是比較一致,且 比「里」的屬性變異來的低之緣故。因此,無須進行空間誤差、空間落遲模型之分析。 圖 20 (傳統)迴歸模型殘差值分佈圖(區) 圖 21 傳統迴歸模型殘差值空間自相關分析圖(區) 資料來源:Arc GIS 軟體畫面
結 論
本研究以台中市為研究範圍,採用平均最近鄰分析(Average Neareast Neighbor),找出空間 聚集現象,再利用核密度推估法(Kernel Density Estimation)與空間自相關分析 Getis-Ord Gi*演 算法,找出犯罪熱點的空間分佈,分析比較不同時期搶奪犯罪地圖分佈變化情形,並且繪製犯罪 地圖。在犯罪區位分析方面,利用犯罪理論選取社經人文環境變項,建立多元線性迴歸模型,找 出搶奪犯罪的區位因子,進而探討搶奪犯罪熱點之區位特性,並比較傳統迴歸模型、空間落遲模 型與空間誤差模型作分析比較,尋求出最合適之空間模式,並且驗證搶奪犯罪率與區域的空間特 性之間確實有空間變異之現象存在。 然而,由於「平均最近鄰分析」與「核密度推估法」是屬於座標分析,只能分析是否呈現群 集狀況;另外礙於座標提供資訊有限,故需要配合屬性資料進行進階分析,使之能夠更充分掌握 空間點型態分散情形。而「空間自相關分析」是屬於屬性分析,本研究採用 Getis-Ord Gi*演算法, 主要是因為空間中的次區域,若 Xi 值小的次區域被同樣 Xj 值小的次區域所環繞的時候,I 值仍 然會呈現高度正相關,而 G 呈現高度負相關(Getis & Ord, 1992),如表 10。然而在犯罪點位空 間聚集的研究中,本研究所關心的在於犯罪點位聚集的狀態,因此若在 Xi 與其周圍 Xj 都很小, 卻發生很高的聚集現象,顯然不合理,因此本研究以 Getis 統計方法進行最為適當(朱健銘,2000、 陳慈仁,2001)。 表 10 Moran's I 與 Getis 統計之比較 Situation Getis Z((((G)))) Moran’s I Z((((I)))) H-H + + + + H-M + + M-M 0 0 Random 0 0 H-L - - - M-L - # - L-L - - + + Key:::: H =數值高的空間單元數值高的空間單元數值高的空間單元數值高的空間單元 M =數值中的空間單元數值中的空間單元數值中的空間單元數值中的空間單元 L =數值低的空間單元數值低的空間單元數值低的空間單元 數值低的空間單元 Random =空間單元中的數值是隨機的空間單元中的數值是隨機的空間單元中的數值是隨機的空間單元中的數值是隨機的 + + =強度高的空間正相關強度高的空間正相關強度高的空間正相關強度高的空間正相關(((Z 值很高( 值很高值很高值很高)))) + =中度的空間正相關中度的空間正相關中度的空間正相關中度的空間正相關 0 =無空間自相關無空間自相關無空間自相關無空間自相關 # =比比 HL 組合的空間正相關值比比 組合的空間正相關值組合的空間正相關值還組合的空間正相關值還還還小小小 小 資料來源:朱健銘,2000、陳慈仁,2001 以下分別依搶奪犯罪地圖、空間分析、犯罪區位分析所得之具體結果如下:
(一)搶奪犯罪地圖
本研究將 2004、2005 年台中市搶奪案件犯罪地點與地理資訊系統技術結合,利用地址對位與 找尋交叉路口,使犯罪地點文字資料轉換成具有空間性的犯罪地圖,以視覺化方式呈現了搶奪犯 罪地圖,製作「搶奪案分佈圖」,可發現犯罪地點並不是隨機分佈,而是集中在台中市中間區域, 且搶奪犯罪地點是沿著幾條主要道路成線狀排列。(二)空間分析
本研究使用點型態分析的平均最近鄰分析、核密度分析與空間自相關分析 Getis-Ord Gi*演算 法,製作 2004 年與 2005 年台中市搶奪犯罪熱點分佈圖。從平均最近鄰分析可發現,台中市搶奪 犯罪在空間上有聚集之現象。從核密度分析與空間自相關分析 Getis-Ord Gi*演算法可發現,搶奪 犯罪地圖之熱點與變化情形,且在 2 年內有明顯轉移之現象。從核密度分佈圖顯示,原本在西區 與西屯區之犯罪熱點有擴散之現象,西區與南屯區交接處有新的犯罪熱點產生,而北區與中區的 犯罪熱點在 2005 年有消散之跡象,可初步得知,犯罪熱點有往西移動之現象。從 Getis-Ord Gi* 值犯罪分佈圖顯示,原本在北區與東區之犯罪熱點有消散之現象,西區、西屯區與南屯區交接處 形成新的犯罪熱點,此與先前的核密度分析有共同之趨勢,亦可發現犯罪熱點有往西移動之現象。 本研究兼顧座標分析與屬性分析,由分析結果得知,搶奪犯罪熱點有往西移動變遷之趨勢, 且由社會解組論得知,人口密度高造成空間上過於擁擠,組成份子複雜,文化差異甚大,容易造 成高犯罪率發生,此與台中市第十二期福星市地重劃區,除促進西屯地區之繁榮外,將連接七期 重劃區,使本區發展成一核心都市,且與台中市都市計畫發展由單核心轉變為雙核心,往西發展 之計畫有關。人口的大量移動也帶動地方的經濟發展,例如:百貨公司、量販店、便利商店、金 融機構、商業區、八大行業…等也大量往西發展與建設,因此,犯罪熱點也隨著人口的大量移動 與促使搶奪犯罪的一些社經環境變項,隨之移動變遷。(三)犯罪區位分析
(1)多元線性迴歸分析 由實證結果證實「金融機構密度」、「便利商店密度」、「八大行業密度」、「商業區密度」這四 個環境因子確實存在於搶奪犯罪熱點區域周遭。由於搶奪犯主要搶奪動機就是「獲取金錢」,而金 融機構與便利商店是較多金錢往來的地方,且在金融機構附近較好行搶、較有錢可拿;搶奪犯罪 通常發生在夜晚,發生時間約在 20 時至 24 時(吳芳富,2003),便利商店更是 24 小時營業,因 此成為搶奪犯之首選。而八大行業根據日常生活理論,更是搶奪犯最主要出入的地方,且大都位 於商業區內,而打電動、唱歌、撞球、喝酒是他們常有的娛樂活動(陳國恩,2004),這些活動形 成他們的生活模式,更構成了犯罪的溫床。且搶奪犯在行搶時會顧慮到行搶後能否順利脫逃,因 此會選擇易於行搶並且容易脫逃之場所,且因搶奪犯犯案工具多以機車為主,因此道路對於搶奪 犯而言,為其犯案後具有高移動性、可及性與易達性高的街道上。 人口增減率高,代表人口移動率高,組成份子複雜,文化差異甚大,較難以凝聚社區意識, 倫理道德亦無法規範個體行為,因此犯罪率較高。而低教育程度的人或是家庭,其收入相對而言 是較低的,高犯罪率被認為與低經濟條件有關,且搶奪犯以國中教育程度居多,教育程度低者, 其對搶奪犯罪的刑度、嚴重性都不甚瞭解,也比較不會考量行為後果(吳芳富,2003)。近年來, 人口老化對台灣的社會和經濟犯罪問題帶來莫大的衝擊,因為扶養負擔增加,少量的青壯年人口 所要負擔比例相當高的老年人口,因此,產生一些社會犯罪問題。其中,根據張雅華(2007)在 空間上人口老化區有向外擴展趨勢,集中於東區、西區、西屯區與北區,此與本研究搶奪犯罪熱 點區域有密切吻合之處。由於 60 歲以上人口大部分處於沒工作狀態,且根據林進發(2005)與湯巧君(2007)搶奪犯罪發生時段主要是以下午、夜晚時段發生最多,下午時段更是老人家外出運 動與最佳的活動時間,因此,此時段時常暴露在外,又加上搶奪犯經常是臨時起意,找容易下手 之目標,成為高犯罪率之變項。 (2)空間迴歸分析 利用「634 平均網格」為最小空間單元,其傳統迴歸模型解釋率為 54.8%,空間誤差模型解 釋率為 69%,空間落遲模型解釋率為 70.5%,各方面都顯示比利用「里」為最小空間單元,傳統 迴歸模型解釋率為 10.9%,空間誤差模型解釋率為 23.5%,空間落遲模型解釋率為 24%為佳,因 此,可證實縮小最小空間單元,其分析結果將更加精確。 (3)空間迴歸模型殘差值分析 經由空間自相關檢驗,各「里」的多元迴歸殘差值存在顯著的空間自相關現象,迴歸模式受 到空間變異的影響無法充分解釋變異量。因此,本研究採用空間誤差、空間落遲模型,以反映里 犯罪率與社經人文環境變項間關係的空間變異情形。結果顯示空間誤差、空間落遲模型確實能提 高模式的解釋能力,從傳統迴歸模型的 10.9%,提升至空間誤差模型 23.5%,最高至空間落遲模 型的 24%。 空間誤差、空間落遲模型的殘差值經由空間自相關檢驗呈現隨機分佈,顯示多元迴歸模型所 產生的空間自相關現象已消除,且證實空間落遲模型為最佳之空間模型。 在各「區」的傳統迴歸殘差值空間自相關分析,呈現隨機分佈情形。即代表傳統迴歸模型沒 有空間自相關現象,可能由於「區域」資料庫的資料是比較一致,且比「里」的屬性變異來的低 之緣故。
參考文獻
內政部警政署(2005):〈強盜及搶奪案件分析〉,《專題分析》。 艾兆蕾(2005):《影響住宅區地價因素之空間分析-以鄉鎮與縣市為例》。台北:世新大學經濟學 研究所碩士論文。 朱健銘(2000):《土地利用空間型態之研究》。國立台灣大學地理學研究所碩士論文。 吳玉鳴(2007):〈大學、企業研發與區域創新的空間統計與計量分析〉,《數理統計與管理》,27 (2):318-324。 吳芳富(2003):〈搶奪犯罪成因與犯罪模式之實證研究-以高雄地區為例〉,《中央警察大學犯罪防 治學報》,4:241-260。 李湧清、王靜宜、陳怡樺、黃啟賓(2003):〈犯罪統計形成之問題與研究〉,《中央警察大學警政 論叢》,3:45-80。 李錫璋(2007):〈搶奪成性犯罪成習,台中市男子多次搶奪他人財物,並企圖在台中市搶奪銀樓 未遂〉,中央社。 林美君、蘇明道、溫在弘(2005):〈空間點型態分析-台北市照護分析〉,2005 年台灣地理資訊學 會年會暨學術研討會論文集。 孟維德(1998):〈社區警政與預防犯罪〉,《中國行政評論》,1:181-210。孟靜(1985):〈台灣的犯罪現象與地區環境之空間分析〉,《國立台灣師範大學地理研究報告》,11: 73-100。 東森新聞報(2007):〈全台一天有 11 個人被搶,暗巷落單要小心〉,東森新聞報。 林傑斌、林川雄、劉明德(2005):《SPSS12 統計建模與分析程序》。台北:文魁資訊。 林進發(2005):《台中市搶奪犯罪熱點之空間分析》。彰化:國立彰化師範大學地理學研究所碩士 論文。 張雅華(2007):《台中市老年人口與醫療資源空間相關性研究》。台中:逢甲大學土地管理研究所 碩士論文。 郭迺鋒、詹立宇、朱真慧(2004):〈專利活動國際化與第三波民主化關係之探討:空間計量分析〉 陳正昌、陳新豐、程炳林、劉子鍵(2005),《多變量分析方法-統計軟體應用》,台北:五南圖書 出版有限公司。 陳國恩(2004):〈街頭搶奪犯罪之質性研究〉,《中央警察大學犯罪防治學報》,5:81-108。 陳惠美等(2007):〈狠心飛車行搶,81 歲老婦摔地頭中傷〉,東森新聞報。 陳慈仁(2001):《台北市資訊軟體業與網際網路服務業》,台北:國立台灣大學建築與城鄉研究所 碩士論文。 湯巧君(2007):《利用犯罪地圖分析台中市 2005 年搶奪案之時空差異》。高雄:國立高雄師範大 學地理學研究所碩士論文。 黃雅燕(2006):《中國大陸地級城市經濟成長收斂性假說驗證-空間 Panel 計量的應用》。台北: 世新大學財務金融學研究所碩士論文。 賴致瑜(2006):《台北市住宅竊盜犯罪地圖製作與犯罪區位分析》。台北:國立台灣大學地理環境 資源研究所碩士論文。 謝文彥(2006):〈街頭搶奪犯罪動機與決意歷程之研究〉,《中央警察大學警學叢刊》,36(5):93-122。
Andresen, M. A.(2006): Crime measures and the spatial analysis of criminal activity, Brit.J. criminol., 46: 258-285.
Anselin, L.(2003): GeoDaTM 0.9 User’s Guide, Spatial Analysis Laboratory. Anselin, L.(2004): GeoDaTM 0.9.5-I Release Notes, Spatial Analysis Laboratory.
Bailey, T. C. and A. C. Gatrell(1995): Interactive Spatial Data Analysis, Essex and New York: Longman
Scientific & Technical.
Chainey, S. P. , S. Reid, and N. Stuart, (2002): When Is a Hotspot ? A Procedure for Creating Statistically Robust Hotspot Maps of Crim, Innovations in GIS 9, London: Taylor & Francis. Grubesic, T. H.(2006): On The Application of Fuzzy Clustering for Crime Hot Spot Detection, Journal
of Quantitative Criminology, 22(1) , 77-105.
Getis, A. and J. K. Ord, (1992): The Analysis of Spatial Association by Use of Distance Statistics,
投稿日期:99 年 5 月 12 日 修稿日期:99 年 9 月 20 日 接受日期:99 年 11 月 30 日