A Real-Time Garbage Collection Mechanism for Flash-Memory
Storage Systems in Embedded Systems
Li-Pin Chang and Tei-Wei Kuo
{d6526009,ktw}@csie.ntu.edu.tw
Department of Computer Science and Information Engineering
National Taiwan University, Taipei, Taiwan, ROC 106
Abstract
Flash memory technology is becoming critical in building embedded systems applications because of its shock-resistant, power economic, and non-volatile na-ture. Because flash memory is a write-once and bulk-erase medium, a translation layer and a garbage col-lection mechanism is needed to provide applications a transparent storage service. In this paper, we propose a real-time garbage collection mechanism, which pro-vides a deterministic performance, for hard real-time systems. A wear-levelling method, which serves as a non-real-time service, is presented to resolve the en-durance issue of flash memory. The capability of the proposed mechanism is demonstrated by a series of ex-periments over our system prototype.
1
Introduction
Flash memory is not only shock-resistant and power economic but also non-volatile. With the recent tech-nology breakthroughs in both capacity and reliability, more and more (embedded) system applications now deploy flash memory for their storage systems. For example, the manufacturing systems in factories must be able to tolerate severe vibration, which may cause damage to hard-disks. As a result, flash memory is a good choice for such systems. Flash memory is also suitable to portable devices, which have limited en-ergy source from batteries, to lengthen their operating time.
There are two major issues for the flash memory storage system implementation: the nature of flash memory in (1) write-once and bulk-erasing, and (2) the endurance issue. Because flash memory is write-once, the existing data cannot be overwritten directly. Instead, the newer version of the data will be writ-ten to some available space elsewhere. The old ver-sion of the data is then invalidated and considered as “dead”. The latest version of the data is consid-ered as “live”. As a result, physical locations of data change from time to time because of the adoption of
the out-place-update scheme. A bulk erasing could be initiated when flash-memory storage systems have a large number of live and dead data mixed together. A bulk erasing could involve a significant number of live data copyings since the live data on the erased region must be copied to somewhere else before the erasing. That is so called garbage collection to recycle the space occupied by dead data. However, each erasable unit of flash memory has a limited cycle count in erasing, which imposes another restrictions on flash memory management strategies (the endurance issue).
In the past work, various techniques were proposed to improve the performance of garbage collection for flash memory, e.g., [1, 7, 8]. In particular, Kawaguchi, et al. proposed the cost-benefit policy [1], which uses a value-driven heuristic function as a block-recycling policy. Chiang, et al. [8] refined the above work by considering the locality in the run-time access pat-terns. Kwoun, et al. [7] proposed to periodically move live data among blocks so that blocks have more even life-times. Although researchers have proposed ex-cellent garbage-collection policies, there is little work done in providing a deterministic performance guar-antee for flash-memory storage systems. It has been shown that garbage collection could impose almost 40 seconds of blocking time on time-critical tasks with-out proper management [10]. This paper is motivated
by the needs of a predictable garbage collection mecha-nism to provide a deterministic garbage collection per-formance in time-critical systems.
The rest of this paper is organized as follows: Sec-tion 2 introduces the system architecture of a real-time flash memory storage system. Section 3 presents our real-time block-recycling policy, free-page replenish-ment mechanism, and the supports for non-real-time tasks. The proposed mechanism is analyzed in Sec-tion 4. SecSec-tion 5 summarizes the experimental results. Section 6 is the conclusion and the future research.
Non-RT task Non-RT task Time-Sharing Scheduler Real-Time Scheduler RT Garbage Collector RT Garbage Collector RT Task RT Task RT Task File System
Block Device Emulation (FTL)
Flash Memory Driver
Flash Memory
ioctl_copy ioctl_erase fread, fwrite
sector (page) read and write
read, write, erase
control signals
Figure 1: System Architecture.
2
System Architecture
This section proposes the system architecture of a real-time flash-memory storage system, as shown in Figure 1. We selected NAND flash to realize our stor-age system. There are two major architectures in flash memory design: NOR flash and NAND flash. NOR flash is a kind of EEPROM, and NAND flash is de-signed for data storage. We study NAND flash in this paper because it has a better price/capacity ra-tio, compared to NOR flash.
A NAND flash memory chip is partitioned into blocks, where each block has a fixed number of pages, and each page is of a fixed size byte array. Due to the hardware architecture, data on a flash are written in a unit of one page, and the erase is performed in a unit of one block. A page can be written only if it is erased, and a block erase will clear up all data on its pages. Logically, a page that contains live data is called a “live page”, and a “dead page” contains dead (invalidated) data. Furthermore, each block has an individual limit (theoretically equivalent in the be-ginning) on the number of erase cycles. A worn-out block will suffer from frequent write errors. The block size of a typical NAND flash is 16KB, and the page size is 512B. The endurance of each block is usually 1,000,000 under the current technology.
There are several different approaches in manag-ing flash memory for storage systems. We must point out that NAND flash prefers the block device emula-tion approach because NAND flash is a block-oriented medium (Note that a NAND flash page fits a disk sec-tor in size). “Flash memory Translation Layer” (FTL) is introduced to emulate a block device for flash mem-ory so that applications could have transparent stor-age service over flash memory. There is an alternative approach which builds a native flash memory file sys-tem over NOR flash, we refer interested readers to [5]
Page Read Page Write Block Erase
512 bytes 512 bytes 16K bytes
Performance(µs) 348 909 1,881
Symbol tr tw te
Table 1: Performance of the NAND Flash Memory (controlled through the ISA bus)
for more details.
We propose to support real-time tasks and reason-able services to non-time tasks through a real-time scheduler and a real-time-sharing scheduler, respec-tively. A real-time garbage collector is initiated for each real-time task which might write data to flash memory to reclaim free pages for the corresponding task. Real-time garbage collectors interact directly with the FTL though the special designed control ser-vices. The control services includes ioctl erase which performs the block erasing, and ioctl copy which per-forms the atomic copying. Each atomic copy, that consists of a page read then a page write, is designed to realize the live-page copying in garbage collection. The read-then-write operation is non-preemptible in order to prevent the possibility of any race condition. Note that there is no garbage collection tasks created for the non-real-time tasks. Instead, FTL must re-claim an enough number of free pages for non-real-time tasks, similar to typical flash-memory storage systems, so that reasonable performance is provided.
3
Real-Time
Garbage
Collection
Mechanism
3.1
Characteristics of Flash Memory
Op-erations
A typical flash memory chip supports three kinds of operations: Page read, page write, and block erase. The performance of the three operations measured on a real prototype is listed in Table 1. The prototype has an average read and write speed at 1.4MB/sec and 540KB/sec, respectively, if no garbage collection ac-tivities are involved. Block erases take a much longer time, compared to others. As we mentioned in Section 2, we adopted a special (ioctl copy) control services to process live-page copying for real-time garbage collec-tion. The atomic copy operation copies data from one page to another by the specified page addresses. From the perspective of FTL’s clients, the FTL is capable in processing page read, page write, block erase, and atomic copy.
Flash memory is a programmed-I/O device. In other words, flash memory operations are very CPU-consuming. As a result, the CPU is fully occupied during the execution of each flash memory operation.
W R W
Legend:
A preempible CPU computation region. A non-preemptible read request to flash memory. A non-preemptible write request to flash memory. R W t W R W t + pi
Figure 2: A task Tiwhich reads and writes flash
mem-ory.
On the other hand, flash memory operations are non-preemptible since the operations can not be inter-leaved with one another. We can treat flash memory operations as non-preemptible portions in tasks. As shown in Table 1, the longest non-preemptible opera-tion among them is a block erase, which takes 1,881
µs to complete.
3.2
Real-Time Task Model
This section illustrate how a real-time task repre-sents its requirements for flash memory storage service and timing constraint: Each periodic real-time task Ti
is defined as a triple (cTi, pTi, wTi), where cTi, pTi, and wTi denote the CPU requirements, the period, and
the maximum number of its page writes per period, respectively. The CPU requirements ci consists of the
CPU computation time and the flash memory operat-ing time: Suppose that task Tiwishes to use CPU for
ccpuTi µs, read i pages from flash memory, and write j
pages to flash memory in each period. The CPU re-quirements cTican be calculated as c
cpu
Ti + i ∗ tw+ j ∗ tr
(tw and tr can be found in Table 1). If Ti does not
wish to write to flash memory, it may set wTi = 0.
Figure 2 illustrates that a periodic real-time task Ti
issues one page read and two page writes in each pe-riod (note that the order of the read and writes does not need to be fixed in this paper).
For example, in a manufacturing system, a task T1
might periodically fetch the control codes from files, drive the mechanical gadgets, sample the reading from the sensors, and then update the status to some spec-ified files. Suppose that ccpuT1 = 1ms and pT1 = 20ms.
Let T1 wish to read a 2K-sized fragment from a data
file and write 256 bytes of machine status back to a status file. Assume that the status file already exists, and we have one-page spontaneous file system meta-data to read and one-page meta-meta-data to write. As a result, task T1can be defined as (1000+(1+2048512)∗tr+
(1+d256
512e)∗tw, 20∗1000, 1+d256512e) = (4558, 20000, 2).
Note that the time granularity is 1µs.
Molano, et al. [2] pointed out that the access of
sym- Description
bol
Λ the total number of live pages currently on flash
∆ the total number of dead pages currently on flash
Φ the total number of free pages currently on flash
π the number of pages in each block
Θ the total number of pages on flash (=Λ + ∆ + Φ)
α the constant lower-bound of the number of
reclaimed free pages after each block recycling
ρ the total number of tokens in system
ρf ree the number of unallocated tokens in system ρTi the number of tokens given to Ti
ρGi the number of tokens given to Gi
ρnr the number of tokens given to non-real-time tasks Table 2: Symbol Definitions.
file system meta-data may introduce unbounded delay. They proposed a meta-data pre-fetch scheme which loads necessary meta-data into RAM to provide a de-terministic behavior in accessing meta-data. In this paper, we assume that each real-time task has a de-terministic behavior in accessing meta-data so that we can focus on the real-time support issue for the flash memory storage systems.
3.3
Real-Time Garbage Collection
In this section, we shall present our real-time garbage collection mechanism. We shall first propose the idea of real-time garbage collectors and the free-page replenishment mechanism for garbage collection. We will then present a block-recycling policy to choose appropriate blocks to recycle.
3.3.1 Real-Time Garbage Collectors
For each real-time task Tiwhich may write to flash
memory (wTi> 0), we propose to create a
correspond-ing real-time garbage collector Gi. Girecycles a block
in each period, and it should reclaim and supply Ti
with enough free pages. Let a constant α denote a lower-bound on the number of free pages that can be reclaimed for each block recycling (we will show how to derive the lower-bound in Section 4.1). Let π denote the number of pages per block. Given a real-time task
Ti = (cTi, pTi, wTi) with wTi > 0, the corresponding
real-time garbage collector is created as follows:
cGi = (π − α) ∗ (tr+ tw) + te+ c cpu Gi pGi= ( pTi/d wTi α e , if wTi > α pTi∗ b α wTic , otherwise . (1)
The CPU demand cGi consists of at most (π − α)
live-page copyings, a block erase, and computation re-quirements ccpuG
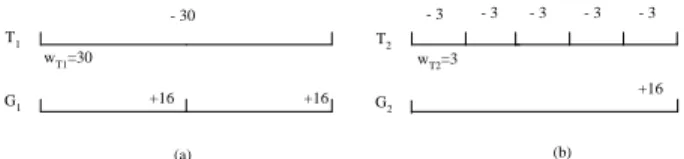
- 30 T1 G1 +16 +16 T2 G2 +16 - 3 - 3 - 3 - 3 - 3 (a) (b) wT1=30 wT2=3
Figure 3: Creation of the Corresponding Real-Time Garbage Collectors.
all real-time garbage collectors are the same since α is a constant lower-bound. Obviously, the estimation is conservative, and Gi might not consume the entire
CPU requirements in each period. The period pGi is
set under the guideline in supplying Ti with enough
free pages. The length of its period depends on how fast Ti consumes free pages. We let Gi and Ti arrive
the system at the same time.
Figure 3 provides two examples for real-time garbage collectors, with the system parameter α = 16. In Figure 3.(a), because wT1 = 30, pG1 is set as one
half of pT1 so that G1can reclaim 32 free pages for T1
in each pT1. As astute readers may point out, more
free pages may be unnecessarily reclaimed. We will address this issue in the next section. In Figure 3.(b), because wT2 = 3, pG2 is set to five-times of pT2 so
that 16 pages are reclaimed for T2 in each pG2. The
reclaimed free pages are enough for T1and T2to
con-sume in each pT1 and pG2, respectively. We define the
meta-period σiof Tiand Gias pTiif pTi≥ pGi;
oth-erwise, σi is equal to pGi. In the above examples, σ1
= pT1 and σ2= pG2. The meta-period will be used in
the later sections.
3.3.2 Free-Page Replenishment Mechanism The consuming and reclaiming of free pages dur-ing run-time usually do not behave in the worst-case. In this section, we provide a token-based “free-page replenishment mechanism” to manage the free pages and their reclaiming more efficiently and flexibly:
Consider a real-time task Ti = (cTi, pTi, wTi) with wTi > 0. Initially, Ti is given (wi∗ σi/pTi) tokens, and
one token is good for executing one page-write (Please see Section 3.3.1 for the definition of σi). We require
that each (real-time) task could not write any page if it does not own any token. Note that a token does not correspond to any specific free page in the sys-tem. Several counters of tokens are maintained: ρinit
denotes the total number of available tokens when sys-tem starts. ρ denotes the total number of tokens that are currently in system (regardless of whether they are allocated and not). ρf reedenotes the number of
unal-located tokens currently in system, ρTiand ρGi denote
the numbers of tokens currently given to task Ti and
Gi() {
if( ) {
// create tokens from the // existing free pages
} else {
// Recycle a block recycleBlock();
// Note that change }
// Supply Ti with tokens
// Give up the residual tokens
} ; ; Gi Gi ρ α ρ ρ α ρ = + = + Gi , ,ρρ Φ ; ; Gi Gi Ti Ti ρ αρ ρ α ρ = + = − ; z ; z ); ( z=ρGi−π−α ρGi=ρGi− ρ=ρ− α ; x ; x Ti Ti=ρ − ρ=ρ− ρ Ti() { if(beginningOfMetaPeriod()) {
// give up the extra tokens
} ... /* job of Ti */ } α ρ Φ− )≥ ( ; p ) * w ( x Ti i Ti Ti σ ρ − =
Figure 4: The Algorithm of the Free-Page Replenish-ment Mechanism.
Gi, respectively. The symbols for token counters are
summarized in Table 2.
Initially, Ti and Gi are given (wTi ∗ σi/pTi) and
(π − α) tokens, respectively. It is to prevent Tiand Gi
from being blocked in their first meta-period. Dur-ing their executions, Ti and Gi are more like a pair
of consumer and producer for tokens. Gi creates and
provides tokens to Ti in each of its period pGi because
of its reclaimed free pages in block-recycling. The re-plenishment of tokens are enough for Tito write pages
in each of its meta-period σi. When Ticonsumes a
to-ken, both ρTi and ρ are decreased by one. When Gi
reclaim a free page and, thus, create a token, ρGi and ρ are both increased by one. Basically, by the end
of each period (of Gi), Gi provides Ti the created
to-kens in the period. When Ti and Gi terminates, their
tokens must be returned to the system.
The above replenishment mechanism has some problems: First, real-time tasks might consume free pages slower than what they declared. Secondly, the real-time garbage collectors might reclaim too many free pages than what we estimate in the worst-case. Since Gi always replenish Ti with at least α created
tokens, tokens would gradually accumulate at Ti. The
other problem is that Gi might unnecessarily reclaim
free pages even though there are already sufficient free pages in the system. Here we propose to refine the ba-sic replenishment mechanism as follows:
In the beginning of each meta-period σi, Ti gives
up ρTi− (wTi∗ σi/pTi) tokens and decreases ρTi and ρ
by the same number because those tokens are beyond the needs of Ti. In the beginning of each period of
Gi, Gi also checks up if (Φ − ρ) ≥ α, where a variable
Φ denotes the total number of free pages currently in the system. If the condition holds, then Gi takes α
free pages from the system, and ρGi and ρ is
recycling. Otherwise (i.e., (Φ − ρ) < α), Gi initiates
a block recycling to reclaim free pages and create to-kens. Suppose that Gi now has y tokens (regardless
of whether they are done by a block erasing or a gift from the system) and then gives α tokens to Ti. Gi
might give up y − α − (π − α) = y − π tokens be-cause they are beyond its needs, where (π − α) is the number of pages needed for live-page copyings (done by Gi). Figure 4 provides the algorithm of the refined
free page replenishment mechanism. Again, readers could find all symbols used in this section in Table 2. 3.3.3 A Block-Recycling Policy
A block-recycling policy should make a decision on which blocks should be erased during garbage collec-tion. The previous two sections propose the idea of real-time garbage collectors and the free-page replen-ishment mechanism for garbage collection. The only thing missing is a policy for the free-page replenish-ment mechanism to choose appropriate blocks for re-cycling. The purpose of this section is to propose a greedy policy that delivers a predictable performance on garbage collection:
We propose to recycle a block which has the largest number of dead pages. Obviously the worst-case in the number of free-page reclaiming happens when all dead pages are evenly distributed among all blocks in the system. The number of free pages reclaimed in the worst-case after a block recycling can be denoted as:
dπ ∗∆
Θe, (2)
where π, ∆, and Θ denote the number of pages per block, the total number of dead pages on flash, and the total number of pages on flash, respectively. We refer readers to Table 2 for the definitions of all symbols used in this paper.
Formula 2 denotes the worst-case performance of the greedy policy, which is proportional to the ratio of the numbers of dead pages and pages on flash memory. That is an interesting observation because we can not obtain a high garbage collection performance by sim-ply increasing the flash memory capacity. We must emphasize that π and Θ are constant in a system. A proper greedy policy which properly manages ∆ would result in a better lower-bound on the number of free pages reclaimed in a block recycling.
Because Θ = ∆ + Φ + Λ. Equation 2 could be re-written as follows:
dπ ∗ Θ − Φ − Λ
Θ e, (3)
where π and Θ are constants, and Φ and Λ de-note the numbers of free pages and live pages,
respec-tively, when the block-recycling policy is activated. As shown in Equation 3, the worst-case performance of the block-recycling policy can be controlled by bound-ing Φ and Λ.
Because it is not necessary to perform garbage col-lection if there are already sufficient free pages in sys-tem. The block-recycling policy could be activated only when the number of free pages is less than a threshold value (a bound for Φ). Furthermore, in order to bound the number of live pages in system (i.e., Λ), we propose to reduce the total number of the FTL-emulated LBA’s (where LBA stands for “Logical Block Address” of a block device). For example, we can emulate a 48MB block device by using a 64MB NAND flash memory. We argue that this intuitive ap-proach is affordable since the capacity of flash mem-ory chip is increasing very rapidly. 1 For example,
suppose that the block-recycling policy is always ac-tivated when Φ ≤ 100, and there are 32 pages in a block, the worst-case performance of the greedy pol-icy is d32 ∗131,072−100−98,304131,072 e = 8. The major chal-lenge in guaranteeing the worst-case performance is how to properly set a bound for Φ for each block recy-cling since the number of free pages in system might grow and shrink from time to time. We shall further
discuss this issue in Section 4.1.
3.4
Supports for Non-Real-Time Tasks
The objective of the system design aims at the si-multaneous supports for both real-time and non-real-time tasks. In this section, we shall extend the token-based free-page replenishment mechanism in the pre-vious section to supply free pages for non-real-time tasks. A non-real-time wear-leveller will then be pro-posed to resolve the endurance issue.
3.4.1 Free-Page Replenishment for Non-Real-Time Tasks
Different from real-time tasks, let all non-real-time tasks share a collection of tokens, denoted by ρnr.
π tokens are given to non-real-time tasks (ρnr = π)
initially for the purpose of live-page copying during garbage collection for non-real-time tasks. Before a non-real-time task issues a page write, it should check up if ρnr > π. If the condition holds, the page write
is executed, and one token is consumed (ρnr and ρ
are decreased by one). Otherwise (i.e., ρnr ≤ π), the
system must replenish itself with tokens for non-real-time tasks. The token creation for non-real-non-real-time tasks is similar to the strategy adopted by real-time garbage collectors: If Φ ≤ ρ, a block recycling is initiated to reclaim free pages, and tokens are created. If Φ > ρ,
1The capacity of a single NAND flash memory chip had
then there might not be any needs for any block recy-cling.
3.4.2 A Non-Real-Time Wear-Leveller
As we mentioned in Section 2, each block has an in-dividual limit on the number of erase cycles. In order to lengthen the overall life-time of flash memory, the management software should try to wear each block as evenly as possible. It is so-called ”wear-levelling”. In the past work, researchers tend to resolve the wear-levelling issue in the block-recycling policy. A typi-cal wear-levelling-aware block-recycling policy might sometimes recycle the block which has the least erase count, regardless of how many free pages can be re-claimed. Note that the erase count denotes the num-ber of erases had been performed on the block so far. This approach is not suitable to a time-critical appli-cation, where predictability is an important issue.
We propose to use non-real-time tasks for wear-levelling and separate the wear-wear-levelling policy from the block-recycling policy. We could create a non-real-time wear-leveller, which sequentially scans a given number of blocks to see if any block has a relatively small erase count. We say that a block has a rela-tively small erase count if the count is less than the average by a given number, e.g., 2. One of the main reasons why some blocks have relatively small erase counts is because the blocks contain many live-cold data (which had not been invalidated / updated for a long period of time). Those blocks obviously are not good candidates for recycling, hence they are seldom erased. When the wear-leveller finds a block with a rel-atively small erase count, the wear-leveller first copy live pages from the block to some other blocks and then sleeps for a while. As the wear-leveller repeats the scanning and live-page copying, dead pages on the target blocks would gradually increase. As a result, those blocks will be selected by the block-recycling policy sooner or later. The idea is to ”defrost” the blocks by moving live-cold data away.
4
System Analysis
The purpose of this section is to provide a sufficient condition to guarantee the worst-case performance of the block-recycling policy. As a result, we can jus-tify the performance of the free-page replenishment mechanism. An admission control strategy is also in-troduced.
4.1
The
Performance
of
the
Block-Recycling Policy
The performance guarantees of real-time garbage collectors and the free-page replenishment mechanism are based on a constant α, i.e., a lower-bound on the number of free pages that can be reclaimed for each
block recycling. As shown in Section 3.3.3, guaran-teeing the performance of the block-recycling policy is not trivial since the number of free pages on flash, i.e., Φ, may grow or shrink from time to time. In this sec-tion, we will derive the relationship between α and Λ (the number of live pages on the flash) as a sufficient condition for engineers to guarantee the performance of the block-recycling policy for a specified value of α. As indicated by Equation 2, the system must satisfy the following condition:
d∆
Θ∗ πe ≥ α. (4) Since ∆ = (Θ − Λ − Φ), and (dxe ≥ y) implies (x > y − 1) if y is an integer, Equation 4 can be re-written as follows:
Φ < Θ ∗ (1 −(α − 1)
π ) − Λ. (5)
The formula shows that the number of free pages, i.e., Φ, must be controlled under Equation 5 if α has to be guaranteed (under the utilization of the flash, i.e., Λ). Because real-time garbage collectors would initiate block recyclings only if Φ − ρ < α (please see Section 3.3.2), the largest possible value of Φ on each block recycling is (α − 1) + ρ. Now let Φ = (α − 1) + ρ, Equation 5 can be again re-written as follows:
ρ < Θ ∗ (1 −(α − 1)
π ) − Λ − α + 1. (6)
Note that given a specified bound α and the (even conservatively estimated) utilization Λ of the flash, the total number of tokens ρ in system should be con-trolled under Equation 6. In the next paragraphs, we will first derive ρmax which is the largest possible
number of tokens in the system under the proposed garbage collection mechanism. Because ρmax should
also satisfy Equation 6, we will derive the relationship between α and Λ (the number of live pages on the flash) as a sufficient condition for engineers to guaran-tee the performance of the block-recycling policy for a specified value of α. Note that ρ may go up and down, as shown in Section 3.3.1.
We shall consider the case which has the maximum number of tokens accumulated: The case occurs when non-real-time garbage collection recycled a block with-out any live-page copying. As a result, non-real-time tasks could hold up to 2 ∗ π tokens, where π tokens are reclaimed by the block recycling, and the other π to-kens are reserved for live-page copying. Now consider real-time garbage collection: Within a meta-period σi
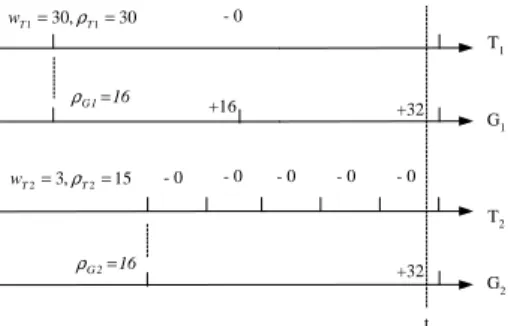
T1 G1 +16 T2 G2 - 0 - 0 - 0 - 0 - 0 - 0 +32 +32 30 , 30 1 1= T = T w ρ 15 , 3 2 2= T = T w ρ 16 1 G= ρ 16 2 G = ρ t
Figure 5: An Instant of Having the Largest Number of Tokens in System (Based on the Example in Figure 3.)
reserved (wTi ∗ σi/pTi) tokens. On the other hand, Gireplenishes Tiwith (α ∗ σi/pGi) tokens. In the best
case, Girecycles a block without any live-page copying
in the last period of Gi within the meta-period. As a
result, Ticould hold up to (wTi∗ σi/pTi) + (α ∗ σi/pGi)
tokens, and Gi could hold up to 2 ∗ (π − α) tokens,
where (π − α) tokens are the extra tokens created, and the other (π − α) tokens are reserved for live page copying. If all real-time tasks Tiand their
correspond-ing real-time garbage collectors Gibehave in the same
way, as described above. Figure 5 illustrates the above example based on the task set in Figure 3. The largest potential number of tokens in system ρmax could be
as follows, where ρf ree is the number of un-allocated
tokens: ρmax= ρf ree+ 2π + n X i=1 µ wTi∗ σi pTi +α ∗ σi pGi + 2(π − α) ¶ . (7) When ρ = ρmax, we have the following equation by
combining Equation 6 and Equation 7:
ρf ree+ 2π + n X i=1 µ wTi∗ σi pTi +α ∗ σi pGi + 2(π − α) ¶ < Θ ∗ (1 −(α − 1) π ) − Λ − α + 1 (8)
Equation 8 shows the relationship between α and Λ. We must emphasize that this equation serves as as a sufficient condition for engineers to guarantee the performance of the block-recycling policy for a speci-fied value of α, provided the number of live pages in the system Λ, i.e., the utilization of the flash. We shall address the admission control of real-time tasks in the next section, based on α.
4.2
Admission Control
The admission control of a real-time task must con-sider its resource requirements and the impacts on other tasks. The purpose of this section is to derive a formula for admission control. Given a set of real-time tasks {T1, T2, ..., Tn} and their corresponding real-time
garbage collectors {G1, G2, ..., Gn}, let cTi, pTi, and wTi denote the CPU requirements, the period, and the
maximum number of page writes per period of task
Ti, respectively. Suppose that cGi = pGi = 0 when wTi = 0 (it is because no real-time garbage collector
is needed for Ti). Since the focus of this paper is on
flash-memory storage systems, the admission control of the entire real-time task set must consider whether the system could give enough tokens to all tasks ini-tially. The verification could be done by evaluating the following formula:
n X i=1 µ wTi∗ σi pTi + (π − α) ¶ ≤ ρf ree. (9)
Note that ρf ree = ρinit when the system starts,
where ρinit is the number of initially reserved tokens
in the system. Beside the test, engineers should also verify the relationship between α and Λ by means of Equation 8. These verifications can be done in a linear time.
Other than the above tests, readers might want to verify the schedulability of real-time tasks in terms of CPU utilization. Suppose that the earliest dead-line first algorithm (EDF) [3] is adopted to sched-ule all time tasks and their corresponding real-time garbage collectors. Since all flash-memory op-erations are non-preemptive, and block erasing is the most time-consuming operation, the schedulability of the real-time task set can be verified by the following formula, provided that other system overheads are ig-norable: te min p()+ n X i=1 µ cTi pTi + cGi pGi ¶ ≤ 1, (10) where min p() denotes the minimum period of all
Ti and Gi, and te is the duration of a block erase.
Because every real-time task might be blocked by a block erase issued by either real-time garbage collec-tion or non-real-time garbage colleccollec-tion, as a result, the longest blocking time of every task is the same, i.e., te. We could derive Equation 10 from Theorem
2 in T. P. Baker’s work [9], which presents a suffi-cient condition of the schedulability of tasks which have non-preemptible portions. We must emphasize
Task ccpu page page c p c/p
reads writes(w)
T1 3ms 4 2 6,354 µs 20ms 0.32
T2 5ms 2 5 8,738 µs 200ms 0.05
Table 3: The Basic Simulation Workload
Task ccpu page page c p c/p
reads writes
T1 3ms 4 2 6,354 µs 20ms 0.32
T2 5ms 2 5 8,738 µs 200ms 0.05
G1 10 µs 16 16 22,003 µs 160ms 0.14
G2 10 µs 16 16 22,003 µs 600ms 0.04
Table 4: The Simulation Workload for Evaluating The Real-Time Garbage Collection Mechanism . (α = 16, Capacity Utilization = 50%)
that the above formula only intends to deliver the idea of blocking time, due to flash-memory operations.
5
Performance Evaluation
In this section, we compare the behaviors of a sys-tem prototype with or without the proposed real-time garbage collection mechanism. We also show the effec-tiveness of the proposed wear-levelling method, which is executed as a non-real-time service.
5.1
Simulation Workloads
A series of experiments were done over a real sys-tem prototype. A set of tasks was created to emulate the workload of a manufacturing system which stored all files on flash memory to avoid vibration from dam-aging the system. The basic workload consisted of two real-time tasks T1 and T2 and one non-real-time
task. T1and T2sequentially read the machine control
files, did some computations, and updated their own (small) status files. The non-real-time task emulated a file downloader, which downloaded the machine con-trol files continuously over a local-area-network and then wrote the downloaded file contents onto flash memory. The flash memory used in the experiments was a 16MB NAND flash [6]. The block size was 16KB, and the page size was 512B (π = 32). The traces of T1, T2, and the non-real-time file downloader
were synthesized to emulate the necessary requests for the file system. The basic simulation workload is de-tailed in Table 3. The duration of each experiment was 20 minutes.
5.2
The Evaluation of Garbage Collection
Mechanisms
In order to observe the behavior of a non-real-time garbage collection mechanism in a time-critical sys-tem, we evaluated a system which adopted a non-real-time garbage collection mechanism under the basic workload and a 50% flash memory capacity utiliza-tion. The non-real-time garbage collection mechanism
1 10 100 1,000 10,000 100,000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Number of Garbage Collection Instances Invoked So Far (K)
Blocking Time (ms)
Figure 6: The Blocking Time Imposed on each Page Write by a Non-Real-Time Garbage Collection In-stance.
basically followed the well-known cost−benef it block-recycling policy [1], but it might recycle a block which had an erase count less than the average erase count by 2 in order to perform wear-levelling. Note that garbage collection was activated on demand. We de-fined that an instance of garbage collection consisted of all of the activities which started when the garbage collection was invoked and ended when the garbage collection returned control to the blocked page write. We measured the blocking time imposed on a page write by each instance of garbage collection. The re-sults in Figure 6 show that the blocking time could even reach 21.209 seconds in the worst-case. The lengthy and un-predictable blocking time was mainly caused by wear-levelling. As astute readers may no-tice, an instance of garbage collection might consist of recycling several blocks consecutively, because a block without dead pages might be recycled due to wear-levelling. The block recycling-policy continued recy-cling blocks until at least one free page was reclaimed. We also observed that if the real-time tasks were ever been blocked due to an insufficient number of tokens, under the adoption of the proposed real-time garbage collection mechanism. The same basic con-figurations were used in this experiment. The corre-sponding real-time garbage collectors were created ac-cording to the method described in Section 3.3.1, and the workload is summarized in Table 4. T1 and T2
generated 12,000 and 3,000 page writes, respectively, in the 20-minute experiment. The results are shown in Figure 7. We observed no blocking time being im-posed on page writes of T1 and T2(as we expected).
5.3
Effectiveness of the Wear-Levelling
Method
The second part of experiments evaluated the the effectiveness of wear-levelling, which was evaluated in terms of the standard deviation of the erase counts of all blocks. A lower value indicated that all blocks were
0.00 1.00
0 20 40 60 80 100 120
Page Writes Processed So Far (K)
Blocking Time (ms)
T1 T2
Figure 7: The Blocking Time Imposed on each Page Write of a Real-Time Task by Waiting for Tokens (Un-der the Real-Time Garbage Collection Mechanism).
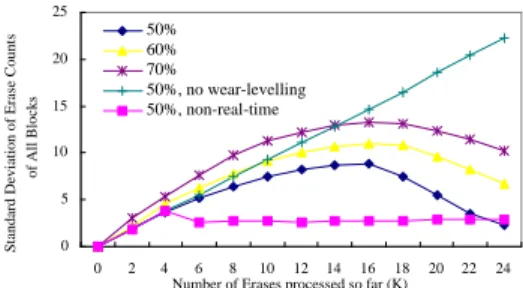
erased more evenly. The objective of wear-levelling is to maintain a small value of the standard deviation.
The non-real-time wear-leveller was configured as follows: It performed live-page copyings whenever the erase count of a block was less than the average erase count by 2. The wear-leveller slept for 50ms between every two consecutive live-page copyings. Since the past work showed that the overheads of garbage col-lection highly depend on the flash-memory capacity utilization [1, 8, 4], we evaluated the experiments un-der different capacity utilizations: 50%, 60% and 70%. As the results shown in Figure 8, the non-real-time wear-leveller gradually levelled the erase count of each block. The results also pointed out that the effective-ness of wear-levelling was better when the capacity utilization was low, since the system was not heavily loaded by the overheads of garbage collection. The standard deviation increased very rapidly when wear-levelling was disabled. We also observed that the the standard deviation was stringently controlled under the non-real-time block-recycling policy.
6
Conclusion
This paper is motivated by the needs of a garbage collection mechanism which is capable of providing a deterministic performance for time-critical systems. We propose a real-time garbage collection mechanism with a guaranteed performance. The endurance issue is also resolved by the proposing of a wear-levelling method. We demonstrate the performance of the pro-posed methodology in terms of a system prototype. However, there are some issues not addressed in this work: We should observe the overheads and perfor-mance of the proposed mechanism when the system is highly stressed. Furthermore, we shall extend the pro-posed mechanism to support time-critical applications over a NOR flash-based storage system.
0 5 10 15 20 25 0 2 4 6 8 10 12 14 16 18 20 22 24 Number of Erases processed so far (K)
Standard Deviation of Erase Counts
of All Blocks 50% 60% 70% 50%, no wear-levelling 50%, non-real-time
Figure 8: Effectiveness of the Wear-Levelling Method.
References
[1] A. Kawaguchi, S. Nishioka, and H. Motoda,“A Flash Memory based File System,” Proceedings of the USENIX Technical Conference, 1995. [2] A. Molano, R. Rajkumar, and K. Juvva,
“Dy-namic Disk Bandwidth Management and Meta-data Pre-fetching in a Real-Time Filesystem,” Proceedings of the 10th Euromicro Workshop on Real-Time Systems , 1998.
[3] C. L. Liu and J. W. Layland, “Scheduling Al-gorithms for Multiprogramming in a Hard Real-Time Environment,” Journal of the ACM , 1973. [4] F. Douglis, R. Caceres, F. Kaashoek, K. Li, B. Marsh, and J.A. Tauber, “Storage Alterna-tives for Mobile Computers,” Proceedings of the USENIX Operating System Design and Imple-mentation, 1934.
[5] Journaling Flash File System, http://sources. redhat.com/jffs2/jffs2-html/
[6] “K9F2808U0B 16Mb*8 NAND Flash Memory Data Sheet,” Samsung Electronics Company. [7] K. Han-Joon, and L. Sang-goo, “A New Flash
Memory Management for Flash Storage System,” Proceedings of the Computer Software and Appli-cations Conference, 1999.
[8] M. L. Chiang, C. H. Paul, and R. C. Chang, “Manage flash memory in personal communi-cate devices,” Proceedings of IEEE International Symposium on Consumer Electronics, 1997. [9] T. P. Baker, “A Stack-Based Resource Allocation
Policy for Time Process,” IEEE 11th Real-Time System Symposium, Dec 4-7, 1990. [10] Vipin Malik, “JFFS2 is Broken,” Mailing List of
Memory Technology Device (MTD) Subsystem for Linux, June 28th 2001.