基於增強式學習技術之適性化網站瀏覽推薦
67
0
0
全文
(2) 致謝 高大資管陪伴了我許多日子,感謝系上每一位充滿熱忱的教授,不論是在課 堂上還是系上大大小小的活動,都能見到老師們的身影,與老師們亦師亦友相處 使得這段日子更加可貴。也感謝口試委員戴敏育老師及楊新章老師,有您們熱心 的指導與寶貴的意見,這篇論文才能順利完成。特別感謝指導教授丁一賢老師, 從對研究毫無方向開始,一步一步帶領我完成論文,並在每次遇到瓶頸時,指出 許多往前走的路,其中非常謝謝老師對於研究給予了關心而非壓力,讓我能夠以 自己的步調,完成整篇論文。 進入碩班後的感受與大學完全不同,感謝阿珊學姐、筱萱學姐、維尼學長、 翔齡學長像是遇見老友般地歡迎我們,讓我能夠快速融入 lab211,也謝謝你們經 常為我解答問題,研究所的學習才能如此順利。再者要感謝一起奮鬥的碩士班同 學,塞轉、杰嚕米、嘉葳、小育、建任、靖雅、思妤、蕭為、東鉅,不管是討論 研究、聊天嘴砲,謝謝你們陪我寫下青春的一頁,也祝福大家在未來的路上能一 帆風順。也要感謝經常在聚在系辦的學弟妹,至哲、喬心、LuLu、Jackie、田哥, 你們為撰寫論文的期間增添了許多笑聲。另外特別感謝鮑魚和肥俠為了準備我的 口試而忙進忙出。 最後要感謝我的家人,謝謝爸爸、媽媽、姊姊、哥哥,有你們對我的鼓勵與 支持,使我能夠毫無後顧之憂地向前邁進,有你們的關心與傾聽,我才能克服各 種困難,有你們真好。. 唐銀伶 謹誌於 國立高雄大學 Lab211 資料工程與網路管理實驗室 中華民國一○二年七月. I.
(3) 基於增強式學習技術之適性化網站瀏覽推薦. 指導教授:丁一賢 博士 國立高雄大學資訊管理學系. 學生:唐銀伶 國立高雄大學資訊管理學系碩士班. 摘要 網路已經變成民眾找尋資料的重要來源,隨著網路技術的發展,造成網路上 的資訊量大且繁雜,若網站沒有良好的設計,使用者容易在瀏覽時迷失,進而浪 費許多時間。目前大部分網站並沒有提供最佳化架構,若遇到需求改變的問題, 需要了解使用者的瀏覽情況並依此調整網頁,一般稱之為適性化網站。網路上, 使用者閱讀網頁內容的時間佔 20%,因此本研究針對資訊提供型網站進行調整, 透過所提出的網頁瀏覽推薦方法,減少使用者到達目標網頁所需要的路徑長度。 本研究之瀏覽推薦方式以增強式學習技術為基礎,考量瀏覽次數、瀏覽時間、瀏 覽路徑長度、網頁所在階層以及目前排名來進行推薦,藉由增強式學習與環境互 動的特性,使網站能夠隨著使用者瀏覽情況調整,並且自動評估調整結果。本研 究以使用者到達目標網頁之路徑長度為基準來評估推薦效果。經過實驗顯示,包 含點擊次數的學習推薦,能夠確實減少找到目標網頁所需的路徑長度。. 關鍵詞:網頁使用探勘、適性化網站、增強式學習. II.
(4) Adaptive Website Navigation Recommendation Based on Reinforcement Learning Advisor: Dr. I-Hsien Ting Department of Information Management National University of Kaohsiung Student: Yin-Ling Tang Department of Information Management National University of Kaohsiung. ABSTRACT With explosive growth of the Internet, huge amount and complicate information have been aggregated on the web. Adaptive website has been considered a technique that can present the information that users needed by analyzing users’ behavior. However, users may have different needs at different times and most of recommended methods are not functioned as dynamic or time-dependent needs. In this paper, we propose a web page navigation recommendation approach which is based on reinforcement learning technique, and applies it to informational website. Five parameters are considered and included in the recommendation approach, which include clicks of the page, time that users stay at the page, paths to achieve the page, hierarchical level of the page, and the rank of the page. With reinforcement learning, the website adjusts the weight of five parameters automatically. This paper aim to reduce the paths that user needed to achieve the object page. According to the empirical evaluation results, it shows that the path length to object pages can be reduced and the recommendation that included clicks perform better performance than traditional method which only the parameter of clicks is considered. Keywords: Web Usage Mining, Adaptive Web Sites, Reinforcement Learning III.
(5) 目錄 第一章 緒論.................................................................................................................. 1 1.1 研究背景與動機............................................................................................. 1 1.2 研究目的......................................................................................................... 3 1.3 研究流程......................................................................................................... 4 1.4 論文架構......................................................................................................... 5 第二章 文獻探討.......................................................................................................... 6 2.1 網頁探勘 .................................................................................. 6 2.2 網頁使用探勘................................................................................................. 7 2.2.1 網頁使用探勘資料來源...................................................................... 8 2.2.2 網頁使用探勘常用技術.................................................................... 10 2.3 適性化網站................................................................................................... 11 2.3.1 適性化網站種類................................................................................ 11 2.3.2 人工智慧之適性化網站.................................................................... 12 2.3.3 傳統網頁探勘適性化網站的優缺點................................................ 12 2.4 增強式學習................................................................................................... 13 2.4.1 增強式學習應用領域........................................................................ 15 2.4.2 增強式學習應用於網站之相關研究................................................ 16 第三章 研究方法........................................................................................................ 18 3.1 網頁瀏覽特徵萃取....................................................................................... 19 3.1.1 資料前置處理.................................................................................... 20 3.1.2 特徵探勘............................................................................................ 22 3.2 網頁推薦權重學習....................................................................................... 23 3.2.1 參數設定............................................................................................ 25 3.2.2 參數權重學習演算法........................................................................ 26 IV.
(6) 3.3 推薦表單調整............................................................................................... 28 3.3.1 瀏覽值................................................................................................ 28 3.3.2 調整推薦............................................................................................ 29 3.4 本章小結....................................................................................................... 30 第四章 實驗................................................................................................................ 31 4.1 實驗設計....................................................................................................... 31 4.1.1. 實驗方式.......................................................................................... 32. 4.1.2. 實驗模式.......................................................................................... 33. 4.1.3 實驗環境............................................................................................ 34 4.2 實驗資料....................................................................................................... 34 4.2.1 資料來源............................................................................................ 34 4.2.2 資料庫格式........................................................................................ 36 4.3 實驗結果....................................................................................................... 38 4.3.1 平均減少路徑比較............................................................................ 39 4.3.2 最佳減少路徑比較............................................................................ 43 4.3.3 固定權重推薦.................................................................................... 45 4.3.4 單一參數推薦.................................................................................... 47 4.4 實驗小結....................................................................................................... 48 第五章 結論................................................................................................................ 49 5.1 結論............................................................................................................... 49 5.2 研究討論及研究限制.................................................................................... 51 5.2.1. 重要問題討論.................................................................................. 51. 5.2.2 研究限制............................................................................................ 52 5.3 未來研究方向............................................................................................... 53 參考文獻...................................................................................................................... 55. V.
(7) 圖目錄 圖 1-1 研究流程圖 ....................................................................................................... 4 圖 2-1 網頁使用探勘流程 ........................................................................................... 7 圖 2-2 增強式學習架構 ............................................................................................. 14 圖 3-1 本研究的概念圖 ............................................................................................. 18 圖 3-2 研究系統架構圖 ............................................................................................. 19 圖 3-3 前置處理流程 ................................................................................................. 19 圖 3-4 本研究之增強式學習模式 ............................................................................. 24 圖 3-5 增強式學習推薦流程 ..................................................................................... 25 圖 3-6 參數權重學習演算法 ..................................................................................... 27 圖 3-7 推薦階層示意圖 ............................................................................................. 29 圖 4-1 實驗流程圖 ..................................................................................................... 31 圖 4-2 網站模擬運行步驟 ......................................................................................... 32 圖 4-3 使用者存取記錄日誌檔片段 ......................................................................... 35 圖 4-4 前置處理後的日誌檔片段 ............................................................................. 36 圖 4-5 五種學習模式十二個月路徑變化圖 ............................................................. 40 圖 4-6 一年學習之路徑變化圖 ................................................................................. 42 圖 4-7 固定權重推薦效果 ......................................................................................... 46. VI.
(8) 表目錄 表 2-1 一般日誌檔格式表 ........................................................................................... 9 表 2-2 擴充日誌檔格式 ............................................................................................... 9 表 2-3 適性化網站相關研究 ..................................................................................... 12 表 2-4 增強式學習相關研究 ..................................................................................... 16 表 2-5 增強式學習之適性化網站相關研究 ............................................................. 16 表 3-1 網頁參數表 ..................................................................................................... 23 表 3-2 權重調整行動表 ............................................................................................. 26 表 3-3 增強式學習 Q 值調整資料表 ........................................................................ 28 表 4-1 學習模式 ......................................................................................................... 33 表 4-2 網頁統計分析記錄表 ..................................................................................... 37 表 4-3 增強式學習調整表 ......................................................................................... 37 表 4-4 學習記錄表 ..................................................................................................... 38 表 4-5 十二個月平均路徑減少百分比 ..................................................................... 39 表 4-6 一年學習平均路徑減少百分比 ..................................................................... 42 表 4-7 十二個月之路徑最佳減少百分比 ................................................................. 44 表 4-8 一年學習之最佳減少路徑百分比 ................................................................. 44 表 4-9 最佳調整之參數權重 ..................................................................................... 45 表 4-10 固定權重之 cp 模式推薦平均 ..................................................................... 46 表 4-11 單一參數推薦之減少路徑百分比 ............................................................... 47 表 4-12 階層搭配參數之減少路徑百分比 ............................................................... 47. VII.
(9) 第一章 緒論 1.1 研究背景與動機 網路的發展改變了人們閱讀的習慣,近幾年變成民眾獲得資訊的主要來源, 2010 年網路觀看新聞的人數已經超越了報紙,隨著閱讀方式轉變,廣告管道轉 向網路,在網路廣告的花費也超越報紙(Pew Research Center, PRC, 2010),另外, 從電視獲取資訊的民眾也不斷減少,特別是年輕族群的觀眾(News Consumption Survey, 2012)。傳統報章雜誌、書籍等傳播方式呈現的資訊有限,且只能透過圖 文靜態呈現,電視傳播透過畫面能更生動地提供資訊,但資訊內容仍然由電視台 來主導,網路能夠彌補傳統傳播的不足,民眾有更高的自主權選擇資訊內容,進 而快速有效率獲得資訊。網路快速、便利及選擇性高的特性,使企業、學校以及 政府機關將資訊轉移到網路上,開始 e 化作業。 科技的進步使得傳統資訊紛紛數位化,造成網路上資訊爆炸,在面對成千上 萬的資訊中,如何找到目標資訊是一門學問,相對的,網站需要考量如何呈現訊 息,才能讓民眾快速找到目標資訊。雖然民眾擁有更高的自主權選擇想要的資訊, 但也表示需要花更多成本去找尋、去選擇。資訊 e 化後,網站不會有專業人員指 引,民眾必須靠自己的理解行動,就像問路及查地圖的差別,因此,在資料量急 速增加的環境中,網站需要作出適當的引導。 為了讓網站能夠引導使用者瀏覽,設計網站時不能忽視網站架構,但網站並 沒有最佳化架構,架構設計不當或連結錯誤,會造成找不到目標資訊的情況。任 何架構及呈現方式都可能不符合使用者需求,網站若能夠依照使用者的瀏覽特性 調整,作出合適的引導,即能夠降低資訊查詢成本,維持使用者對網站的滿意度。 現在已經有許多網站針對使用者進行不同調整,來達到各自的需求,知名網 站 Amazon 從顧客以往點選、購物等瀏覽記錄進行分析,透過其自身的推薦系統 1.
(10) 進一步推測使用者可能有興趣的資訊,並呈現在網站中,此推薦系統為 Amazon 增加不少營收,在 2012 年第二季財務總營收相較於去年同一時期成長了 29%。 呈現適合的資訊給使用者能夠提升瀏覽效率,為此網站需要能夠進行調整,調整 可以由使用者決定,也可以由網站進行。以 Google 為例,為了讓資訊更符合需 求,提供選擇工具及資訊的功能,使用者可以自行決定如何調整,並依喜好拖拉 區塊來調整呈現。雖然由使用者調整或填寫資訊能夠明確知道需求,但大多數使 用者會跳過這個階段,直接找尋資料(Schwarzkoph, 2001)。適性化網站(adaptive web site)能夠彌補這個缺點,自動分析使用者瀏覽特性,並改善網站以呈現符合 需求的內容(Perkowitz and Etzioni, 1997),調整型態分為兩種,第一種為客製化 (customization),針對個別使用者進行網頁的調整,第二種為最適化(optimization), 調整網站本身,讓整體使用者瀏覽時擁有更好的引導。 網際網路分為三類:資訊提供型(informational)、網路交易型(transactional) 及網路作業型(operational)(Koh and Baltazard, 1997),網路的快速及便利使網路交 易蓬勃發展,許多作業也進行電子化並轉移到網路,但目前多數公司及公家機關 的網站仍屬於資訊提供型,網站負責蒐集、彙整、管理特定資訊,並提供給使用 者,雖然功能簡單卻仍然會不符合使用者需求,原因可能是網站最初設計不當, 或是使用者的需求改變,最常見到的處理方式為提供動態表單快速連結到熱門頁 面。資訊提供型網站中,民眾瀏覽網站只為了找尋特定資料,而非長時間瀏覽, 較少擁有登入需求,而且使用者人數多但瀏覽頻率並不高,大多使用者並沒有足 夠的瀏覽記錄以供分析,若採用客製化調整,無法提供合適的調整。因此本研究 針對資訊提供型網站採用最適化調整,以整體使用者的需求為目標來改善網站, 雖然最適化所推薦的網頁無法完全符合所有使用者的需求,但可以改善網頁整體 的表現,幫助首次瀏覽網站或不熟悉網站架構的使用者有效率地找到資訊。 適性化調整能讓網站自動找出適合推薦的網頁,但調整之間不會相互影響, 經過長期調整也無法自行改善調整情形。本研究之網站調整不只以單次資料進行 2.
(11) 運算,而是將每次的調整連結,並從中學習,因此採用增強式學習(reinforcement learning),讓網站得知每次調整所造成的影響,並直接學習如何調整。增強式學 習起源於心理學,解釋動物及孩童的學習過程,透過與環境不斷的互動,能夠找 到正確的行為,如同嬰兒學習走路時,沒有人教導如何站立如何移動,藉由環境 的回饋訊息,例如跌倒,慢慢探索出如何使力才能夠站立及走路。由此可知增強 式學習屬於非監督式學習,不需要指導者監督及教學,透過試誤(trial-and-error) 機制,僅憑著與環境的互動進行學習,每次的行動會影響後續的狀態及行動,經 過一連串學習後,找出符合現況的最佳策略。 在資訊發達的現代,網路成為找尋資料的重要來源。由於網路上的資料量大 且繁雜,即使在一個網站中也難以快速找到想要的資訊。因此網站需要能夠依照 使用者需求提供資訊,以提升瀏覽效率。為了隨著不斷變動的使用者需求進行調 整,網站需要進一步擁有學習能力,並透過以往的經驗改善推薦。. 1.2 研究目的 本研究主要以伺服器中,記錄使用者瀏覽情況的日誌檔為依據,透過網頁探 勘從歷史資訊中分析出使用者的瀏覽特性,接著將增強式學習與網站結合,找出 各瀏覽型態對於網頁推薦的重要性,讓網站持續從每次調整中學習,自動進行網 頁推薦的最適化調整。本研究具體目的為以下所述: 1.. 透過伺服器日誌檔,分析整體使用者的瀏覽習慣及特性. 2.. 利用增強式學習使網站透過過去調整經驗學習,並依照使用者需求推薦. 3.. 透過瀏覽推薦減少找到資訊所需要的路徑長度. 4.. 瞭解網頁各瀏覽特徵對於推薦之重要性. 3.
(12) 1.3 研究流程 本研究之流程圖如圖 1-1 所示,首先闡述本研究的背景與動機,從目前網路 發展情況發現網站所面對的問題,並提出明確的目的來改善。接著探討過去相關 研究,文獻資料分別討論網頁使用探勘、適性化網站以及增強式學習,並以文獻 為基礎確定研究目標,訂定出以增強式學習為基礎的推薦模式。推薦模式中,首 先在網頁瀏覽特徵萃取階段藉由網頁使用探勘找出使用者的瀏覽習慣及特性;第 二階段,網頁瀏覽權重學習則利用增強式學習使網站能夠透過過去的經驗調整各 參數之權重;最後依照使用者之瀏覽需求推薦網頁。本研究透過模擬網站運行的 實驗方式測試此推薦模式之減少路徑效果,最後藉由實證結果與評估成果進行討 論與總結,並提供後續研究發展的方向。. 確定研究動機與目的 文獻探討. 網頁使用探勘. 適性化網站. 增強式學習. 研究方法 網頁瀏覽特性萃取. 網頁推薦權重學習. 推薦表單呈現調整. 實驗設計 實證研究與評估 評估方式 實驗結果與討論. 結論 圖 1-1 研究流程圖 4.
(13) 1.4 論文架構 本論文內容架構分為五章,依序內容如下: 第一章 緒論:說明研究背景與動機、研究目的及研究流程。 第二章 文獻探討:探討網頁探勘、適性化網頁及增強式學習的相關文獻。 第三章 研究方法:首先介紹研究系統架構,接著闡述資料採集、清理及分析的 過程,並定義增強式學習中各個參數的設定,說明調整推薦 方式,最後規劃實驗設計,並定義評估標準。 第四章 實驗:包含資料來源及處理、實驗方法、實驗環境以及分析實驗結果。 第五章 結論:確認達到本論文之研究目的,並針對重要問題進行討論,最後提 出未來發展及建議。. 5.
(14) 第二章 文獻探討 2.1 網頁探勘(Web Mining) 網頁探勘是將資料探勘應用在網頁,自動找出網路文件或服務,並從網路資 源中萃取出隱含資訊及網頁關聯(Etzioni, 1996),透過網頁探勘能夠了解網頁內容 及架構,並得知使用者型態(pattern),應用範圍廣泛,包含適性化網頁、推薦服 務系統、個人化電子商務系統、個人化搜尋引擎等。在網頁探勘中,資料可以從 伺服器端、顧客端或中介端來取得,公司的資料庫也是資料來源,每個資料來源 所獲得的資料不同,內容資料為網站頁面所包含的各個元素,例如文字、圖片等, 架構資料代表網站如何組織網頁內容,使用資料為瀏覽網站的記錄,例如 IP、 瀏覽日期及時間等,最後為使用者資料,通常是從各公司的資料庫獲得,包含註 冊資料、顧客資訊等。以上資料可做為網站引導使用者瀏覽之依據,由資料種類 可將網頁探勘分為三類,透過不同探勘類型能夠分析出不同功用的資訊。Cooley, Mobasher, Srivastava 於 1997 年將網頁探勘分為網頁內容探勘(Web Content Mining)及網頁使用探勘(Web Usage Mining)兩類(Cooley, et al., 1997),Kosala and Blockee 於 2000 年提出第三類結構探勘(Web Structure Mining)(Kosala, et al., 2000),三種探勘的介紹如下: 網頁內容探勘(Web Content Mining):針對網頁中的文字、文件等內容進行 分類解析,找出網頁內容之間的關係,主要應用在資料分類及搜尋。 網頁使用探勘(Web Usage Mining):也稱為網頁日誌探勘(Web Log Mining), 從伺服器日誌檔中萃取出有用的資訊,透過使用者的瀏覽歷史記錄,分析瀏 覽特徵,並找到使用者在找尋的目標,以提供符合使用者需求的網站。 網頁結構探勘(Web Structure Mining):利用圖型理論(graph theory)分析網站 架構中各網頁之間的連結,瞭解網頁連結狀況的合理性,並找出關鍵網頁。 6.
(15) 本研究要讓網站自動調整以符合使用者需求,首先必須了解目前網站的瀏覽 狀況,因此本研究利用網頁使用探勘從日誌檔中找出使用者的瀏覽特徵,作為接 下來網站學習的依據。. 2.2 網頁使用探勘(Web Usage Mining) 網路快速及便利的特性,讓許多企業朝網路發展,在無法面對面觀察使用者 的情況下,難以知道顧客的需求,透過網頁使用探勘,能夠自動從網站伺服器中 追蹤使用者的瀏覽行為(例如:滑鼠點擊),並加以分析使用者特性,藉此提供 適當的資訊給顧客,拉近雙方的距離。網頁使用探勘最廣泛應用在商業網站中, 透過使用者的點擊、購買紀錄等,個人化推薦適合的商品,以提高購買率,而藉 由分析顧客瀏覽資料,還能了解促銷活動的成效、目前市場的趨勢等影響公司策 略的資訊,甚至找到新的客戶。另外,分析出的使用者瀏覽型態能做為改善網站 的依據,讓網站內容更有效率地呈現,也使得公司與顧客之間的互動更為順暢。 網頁使用探勘包含三個階段(Srivastava, Cooley, Deshpande, Tan, 2000):前置 處理(preprocessing)、特徵發掘(pattern discovery)及特徵分析(pattern analysis),如 圖 2-1 所示。. 特徵發覺. 前置處理. 日誌檔. 已處理資料. 特徵分析. 規則、特徵及統計資料. 有興趣的規則、 特徵及統計資料. 圖 2-1 網頁使用探勘流程. 7.
(16) 探勘流程最初會從網站伺服器中取出日誌檔,並將日誌檔資料進行前置處理, 處理過程為資料過濾、資料清理、使用者定義、session 定義,若不符合分析需 求的記錄會將之刪除,每筆資料只留下所需要的部分,其餘將予以清除,以便之 後的分析。保留所需的資訊後,定義區分不同使用者的條件,接著定義 session 的分界點來區分不同次的瀏覽紀錄,一般以 30 分鐘為間隔(Catledge and Pitkow, 1995),經過以上的處理能夠獲得使用者整個瀏覽歷程,而非單一一筆要求網頁 的記錄;處理完的資料經過統計分析,找出瀏覽規則及特徵,最後從分析出的特 徵中選出所需要的資料。. 2.2.1 網頁使用探勘資料來源 日誌檔(Log)是網頁使用探勘主要的資料來源,伺服器在使用者瀏覽全球資 訊網時,將瀏覽及存取動作紀錄到日誌檔中,伺服器預設的日誌格式為 NCSA 的 ASCII 一般日誌格式(Common Log File Format),紀錄資訊包含 IP、主機名稱、 使用者名稱、時間、存取檔案名稱及大小等,另一種常用格式為擴充日誌檔格式 (Extended Log File Format),此種格式增加紀錄使用者帳號、Cookie、瀏覽器版 本以及主機的作業系統等(Kosala, et al., 2000)。. 一般日誌格式的內容如下,本研究以日誌檔中的一筆資料來進行解釋,並對 照表 2-1 來說明各欄位所代表的意思。 [userIP][timestamp][method][url][httpversion][httpresult][size] 66.249.69.118 - - [01/Jan/2012:00:02:33 +0800] "GET /index.php?tid=238 HTTP/1.1" 200 2755. 8.
(17) 表 2-1 一般日誌檔格式表 欄位名稱. 說明. 例子. 使用者的主機 IP 或 DNS 名稱 使用者登入名稱. 66.249.69.118 - (代表空值). 以認證過的使用者名稱. - (代表空值). 使用者對伺服器送出要求的日期. 01/Jan/2012. 使用者對伺服器送出要求的時間. 00:02:33. 使用者所在的時區. +0800. method. 使用者使用的 HTTP 方法. GET. url. 使用者的瀏覽路徑. /index.php?tid=238. httpversion. 使用的 HTTP 通訊協定版本. HTTP/1.1. httpresult. HTTP 的狀態. 200. size. 伺服器傳送的檔案大小. 2755. userIP. timestamp. W3C 擴充日誌檔格式中,各欄位的介紹如表 2-2。在此格式中,除了日期及 時間欄位之外,可以自訂要擴充的欄位,選擇重要的欄位並略過不需要的欄位能 夠控制日誌的大小,節省不必要的空間及減少後續的處理。. 表 2-2 擴充日誌檔格式 欄位名稱. 欄位說明. 欄位名稱. 欄位說明. Data. 請求發出日期(固定). sc-status. 伺服器通訊協定狀態. Time. 請求發出時間(固定). sc-substatus. 伺服器通訊協定子狀態. c-ip. 用戶端 IP 位址. sc-win32-status. 伺服器 Win32 狀態. cs-usename. 用戶端名稱. sc-bytes. 伺服器已傳送資料位元組. s-sitename. 伺服器服務名稱. cs-bytes. 用戶端已接受資料位元組. s-computername. 伺服器電腦名稱. time-take. 傳送資料花費時間. s-ip. 伺服器 IP 位址. cs-version. 用戶端通訊協定版本. s-port. 伺服器連接埠. cs-host. 用戶端主機名稱. cs-method. 用戶端方法. cs(UserAgent). 用戶端使用的瀏覽器類型. cs-uri-stem. 用戶端存取網址. cs(Cookie). 送出或接收的 Cookie 資訊. cs-uri-query. 用戶端查詢網址參數. cs(Referer). 用戶端上一個造訪網站. 資料來源:W3C 9.
(18) 2.2.2 網頁使用探勘常用技術 網頁使用探勘過程中最重要的是分析階段,必須從眾多資料及記錄中找出使 用者的瀏覽型態,在特徵發掘(pattern discovery)階段有許多不同的分析方式,常 用的技術如下:(Srivastava, et al., 2000) 統計分析(Statistical Analysis ):統計分析是萃取網站知識中最常見的方法, 可將點擊次數、停留時間、路徑長度等作敘述統計分析。 關聯法則(Association Rule):計算網頁與網頁或是網頁項目之間的相關程度, 以建立關聯規則,其中分析出的相關網頁不一定是相互連結的。 分類分析(Classification):建立可能的類別,以資料特徵來做分類標準,若 相關程度高,則歸入此類別中,經常用來對新的資料做預測。 群集分析(Clustering Analysis):計算網頁與網頁或是網頁項目之間的相似程 度,或互相影響的關係,將特性相似的資料聚集為同一群組。 序列型樣(Sequence Pattern):以時間軸找出網頁在瀏覽中相關項目之間的 關係,來找出使用者瀏覽順序,並預測使用者下一步瀏覽的網頁。. 2.2.3 本研究之網頁使用探勘應用 本研究依據使用者瀏覽情況調整網站推薦,因此利用網頁使用探勘找出使用 者瀏覽網站的瀏覽歷程,並透過探勘中的統計分析方法取得整體使用者瀏覽各網 頁的次數、停留於各網頁的時間、以及到達各網頁所花的路徑長度,藉由以上所 找出的資訊來了解使用者之瀏覽情況,再依此調整網站推薦。. 10.
(19) 2.3 適性化網站(Adaptive Web Site) 資訊豐富的網站,頁面之間的鏈結往往也越趨複雜,若能針對使用者的特性 及需求提供不同的資料及呈現方式,可以提升瀏覽效率,讓使用者能夠更快速找 到所需要的資料,進一步提升使用者對網站的滿意度。適性化網站能夠從使用者 存取網頁的型態學習,自動改善網站的組織及呈現(Perkowitz and Etzioni, 1997)。 適性化流程分為兩個階段,第一階段為行為觀察,透過網頁使用探勘從記錄中找 出使用者瀏覽特性,並將特性模組化,以便往後快速比對;第二階段為網站調整, 通常會事先寫出多個網頁模組,依照瀏覽特性找出對應的模組呈現給使用者 (Perkowitz and Etzioni, 1998)。. 2.3.1 適性化網站種類 適性化網站依照調整目標不同分為內容適性化(content-level adaptation) 及 鏈結適性化(link-level adaptation) (Brusilovsky, 1996)。內容適性化又稱為適性化呈 現(adaptive presentation),主要針對網站頁面呈現做調整,目的是給予不同種類 的使用者差異化的內容,其中內容呈現又細分為文字及多媒體適性化,目前以文 字適性化為主;鏈結適性化又稱為適性化瀏覽支援(adaptive navigation support), 主要針對網頁之間的鏈結進行調整,目的在於提供網站導覽以避免使用者在網站 中迷失,能夠快速找到所需資訊。 網站的適性化調整又可以依照調整方式的不同分為兩個方向 (Perkowitz, Etzioni, 1997),第一種是個人化(customization),網頁立即調整以符合個別使用者 的需求,使用者可以依照自己的瀏覽方式選擇呈現的畫面,或是由網站從過去的 瀏覽記錄中,自動預測使用者的下一步及目標,並提供導覽讓瀏覽能夠更快速; 第二種是最適化(optimization),最適化調整不會為個別使用者調整,而是根據所 有使用者的資訊調整網站,讓整個網站更容易使用,舉例來說:當最常觀看的頁 11.
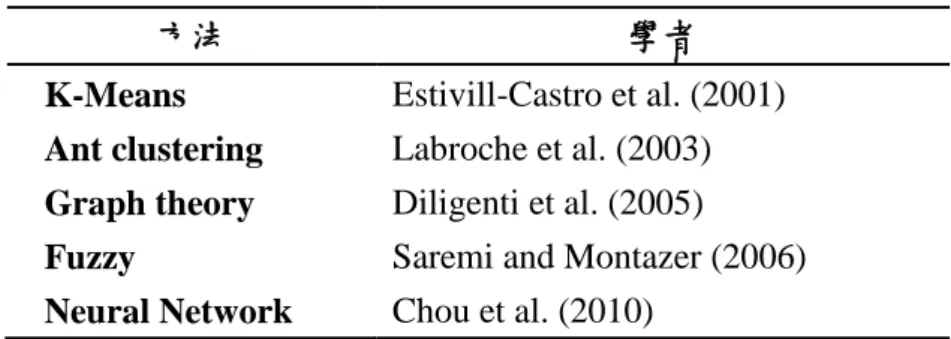
(20) 面離首頁相隔很遠,就應該建一個連結直達此頁,當重要訊息公布時,將訊息以 較大的版面呈現來提高使用者的注意。最適化網站以整體使用者的需求來做調整, 能夠幫助新進使用者瀏覽。. 2.3.2 人工智慧之適性化網站 為了讓網站有更好的調整,許多研究將人工智慧加入適性化網站中,表 2-3 為過去的相關研究。Estivill-Castro et al. (2001) 使用 k-means 來將使用者分群, 透過相似使用者之瀏覽來推薦相關網頁;Labroche et al. (2003) 將 k-means 與螞 蟻演算法(ant algorithm)結合,提升分群的效果;Diligenti et al. (2005) 以圖論來 分析使用者的瀏覽順序,預測出下一個瀏覽頁面;Saremi and Montazer (2006) 使 用模糊理論(fuzzy)來分析網頁內容與網頁標題的相關性,再依此調整網站;Chou et al. (2010)使用神經網路(neural network)分析使用者的瀏覽序列,並加上使用者 分群,提供個人化的網站。由過去研究可發現,多數研究將人工智慧加入到適性 化網站中的行為觀察階段,讓網頁所探勘出的特性能夠更加符合使用者需求。. 表 2-3 適性化網站相關研究 方法. 學者. K-Means Ant clustering Graph theory Fuzzy. Estivill-Castro et al. (2001) Labroche et al. (2003) Diligenti et al. (2005) Saremi and Montazer (2006). Neural Network. Chou et al. (2010). 2.3.3 傳統網頁探勘適性化網站的優缺點 網站可能遇到的問題有以下四種:第一,不同的使用者有不同的目標,第二, 同一個使用者依時間的改變有不同的需求,第三,原始設計不再適合目前的網站, 12.
(21) 第四,網站的使用方式與原本預計的不同(Perkowitz and Etzioni, 1997)。使用網頁 探勘能夠得知目前網站的瀏覽狀況,從眾多資料及記錄中,找出使用者真正的需 求,透過適性化調整能夠讓網站進行改善,來解決以上的問題。除了讓網站提供 符合需求的資訊之外,適性化網站自動調整的特性也能夠減少人員參與。 傳統的適性化網站雖然能夠得知使用者需求,並依此調整呈現,但網站的調 整為一次性,每次的調整為獨立事件,彼此之間無法互相影響,其中調整的條件 及方式皆由設計者訂定,如此會造成調整不當的情況。想要讓網站能夠正確改善, 調整所造成的影響,依然需要人員來判斷是否合適,並適時修正調整。為了改善 傳統適性化網站的問題,調整若能加入機器學習,將可讓網站透過每次學習,找 出最適合的調整。. 2.4 增強式學習(Reinforcement Learning) 增強式學習源自於心理學實驗,實驗內容為訓練鴿子啄擊綠色按鍵,每當啄 擊綠色按鍵時給與飼料,飼料為實驗中的增強物,藉由訓練,鴿子可以學習到辨 別按鈕,進階實驗讓飼料只有在燈亮時啄擊才會掉落,鴿子可以學到何時應該啄 擊(Skinner, 1953),將此實驗轉換到增強式學習的架構中,鴿子代表代理人,是 否亮燈為狀態,飼料為回饋值,經過不斷的訓練學習,能夠讓鴿子學會複雜的行 為。但在學習過程中,鴿子可能會做出與學習目標無關的行為,例如:燈亮時, 鴿子邊拍翅膀邊啄擊綠色按鍵,由於達到學習目標,鴿子會得到飼料,因此誤以 為拍翅膀也是需要的行為,以至於後來的學習會不斷重複這個無意義的動作。. 13.
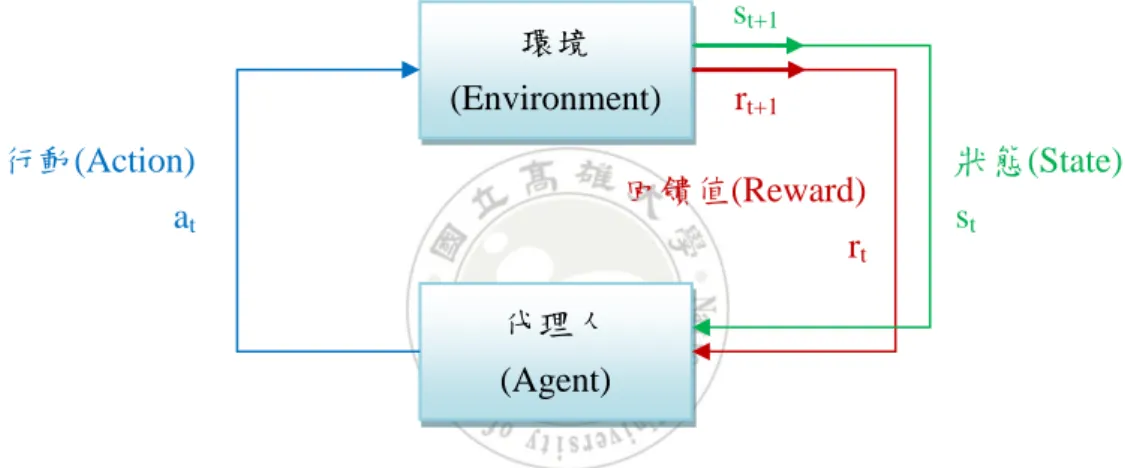
(22) 增強式學習模擬生物學習的方式,透過失敗吸收教訓,再反覆練習強化自身 能力,是一種非監督式學習(Unsupervised Learning)。學習中包含環境(environment) 及代理人(agent)兩個項目,環境代表需要改變的問題,代理人則負責學習,代理 人下達動作(action)命令後,會改變環境的狀態(state),在不同狀態之下,代理人 依照獎懲值(reward)調整下一次動作(Sutton and Barto, 1998)。增強式學習只需要 輸入資料,代理人即自動學習,代理人會依據累積的經驗選擇下一次行動,因此 適用於動態環境,在與環境互動中,利用試誤(trial-and-error)和延遲獎懲(delay reward)機制找尋最佳策略 (Sutton and Barto, 1998),其架構如圖 2-2 所示。. st+1. 環境 (Environment) 行動(Action). rt+1. 回饋值(Reward). at. rt. 狀態(State) st. 代理人 (Agent). 圖 2-2 增強式學習架構. 增強式學習過程中,代理人在時間點 t 收到環境狀態(st),代理人依據狀態選 擇行動(at)並送給環境,環境採取行動後會改變目前狀態(st+1), 狀態的改變會依 照對目標的影響產生獎懲值(rt+1),並傳回給代理人,代理人會根據收到的新狀態 (st+1)和獎懲值(rt+1)來修改價值函數(value function),並依照函數變化再次為新的 狀態選擇行動,繼續執行以上的步驟。學習過程中,每次行動所產生的變化都會 做為後續選擇行動時的依據,藉由學習經驗的累積,得知不同狀況下所應該採取 的最佳行動,進而接近目標。 增強式學習分為主動式(active)與被動式(passive)兩種,被動式增強式學習的 代理人用固定策略去學習,主動式學習則需要不停探索環境來找到適合的策略 14.
(23) (Melenchuk, 2000) 。 本研究利用主動式增強式學習中 Q-Learning 演算法, Q-Learning 是由 Watkins 在 1989 年提出的一種無策略演算法,其演算法建立在 被動式演算法 TD 方法基礎之上,藉由試誤及延遲獎懲不斷計算 Q-value (也稱為 state-action-value),Q-value 為狀態與行動對目標的比較值,值越大代表達到目標 的機會越大,代理人依過往經驗來選擇最佳的行動(Watkins, 1989),其公式如公 式 1(Sutton and Barto, 1998): Q(s, a) Q(s, a) + α(R(s) + γmax Q(s', a' ) - Q(s, a) ). --公式 1. s 代表目前的環境狀態,a 為代理人的行動,s'是下一時間點的狀態,a'是下 一時間點的動作,α 為學習函數,γ 為獎懲的折扣值,R(s)代表狀態 s 下的實際價 值,Q(s, a)代表在狀態 s 下進行行動 a 的期望價值,maxQ(s', a')代表下一時間所 有 Q-value 的最大值,Q-Learning 必須計算下一次行動中最大的 Q-value。. 2.4.1 增強式學習應用領域 目前已經有許多研究加入增強式學習,並且應用在各種領域,表 2-4 為過去 相關研究,在金融上,Lee(2001) 利用增強式學習預測股票價格,做為股票買賣 的指標;在語言學習上,Branavan et al.(2009) 透過增強式學習將自然語言所下 的指令與系統實際動作進行比對,讓系統減少導覽的需求;最常應用的領域為機 器學習及控制,Ipek et al.(2008) 將增強式學習應用在電腦記憶體的自我最佳化 調整,透過學習來改善排程,Bar-Hillel et al.(2007) 使用增強式學習來調整工作 站的工作量,使之能進行最小的改變來達到最大的效能;在 2009 年 Bu et al. 將 增強式學習應用在網站中,選出影響網站效率的參數,調整每種參數的重要性, 使系統資源接近最優化的配置;Fang and Ting(2010)在遊戲中加入增強式學習, 讓 NPCs(non-player characters)能夠透過玩家學習該走的路徑,並加上模糊理論來 改善每次學習時的獎懲值。 15.
(24) 表 2-4 增強式學習相關研究 領域. 目標. 學者. 金融業 自然語言 機器控制 機器控制 機器控制 遊戲. 預測股票價格 比對自然語言與系統實作 調整工作站的工作量 電腦記憶體調整 調整網站系統資源配置 讓 NPCs 學習該走的路徑. Lee(2001) Branavan et al.(2009) Bar-Hillel et al.(2007) Ipek et al.(2008) Bu et al.(2009) Fang, and Ting (2010). 2.4.2 增強式學習應用於網站之相關研究 網站中使用者瀏覽的習慣及需求會不斷變動,藉由增強式學習能與環境互動 的特性,讓網站隨著環境的變動來調整後續動作,因此過去有許多學者將增強式 學習應用在網站的調整中,如表 2-5,其中透過增強式學習調整的呈現方式,多 數研究以推薦為學習結果的呈現方式。. 表 2-5 增強式學習之適性化網站相關研究 學者 Rojanavasu et al. (2005) Taghipour et al. (2007) Mahmood et al. (2007) Mahmood et al. (2009). 目標 預測使用者會購買的相關商品 預測使用者下一個瀏覽頁面 學習網頁適合推薦的情況 學習網頁在不同情況下的對應動作. Rojanavasu et al. (2005) 研究中,商品網頁為學習的狀態,推薦相關商品網 頁為學習的行動,評估結果之回饋會直接調整學習中的 Q 值,當使用者點擊推 薦時增加 1,而購買推薦商品時則增加 3,透過學習得知各商品適合的相關推薦。 Taghipour et al. (2007) 在目前瀏覽頁面之外,進一步將使用者的瀏覽歷程視為網 頁學習的狀態,並以推薦不同網頁作為學習中的行動,其回饋值透過目前網頁到 16.
(25) 達最終目標網頁的距離及時間來計算,此研究透過使用者目前所瀏覽過的網頁序 列,來預測使用者的下一個瀏覽頁面,並進行適合的推薦。 Mahmood et al. (2007) 以旅遊網站為研究目標,學習的狀態由瀏覽網頁種類 以及使用者動作兩個參數組成,利用增強式學習讓網站學習各種狀態下適合的動 作(例如:呈現查詢結果、增加查詢參數等),當到達目標頁面時,回饋值增加 1,其餘皆給予負值。Mahmood et al. (2009) 同樣以旅遊網站為目標,狀態由 12 個變數組成,包含使用者要求、選擇的行程、以及過去經驗等,可執行的對應動 作共有 30 種,其回饋值在使用者加入推薦商品或行程時增加 5,點擊推薦時增 加 1,其餘情況不給予回饋值,目標要學習各狀態下網站應該回應的動作。 由過去文獻中顯示,增強式學習之推薦研究皆以商業性網站為實驗對象,各 網站擁有會員機制,因而對顧客進行個人化推薦,但在學習過程中,缺少時間性, 以 Rojanavasu et al. (2005)的研究為例,代理人無法判斷是否到達冬天,來推薦保 暖商品,只能透過使用者點擊了圍巾之後,才進一步推薦手套,無法以環境傳回 的狀態來判斷出時間性的推薦。 目前民眾花在網路上的時間中,觀看資訊內容佔了 20%,因此本研究不同於 以往的研究,選擇資訊提供型網站進行改善,由於從資訊提供型網站所能獲得的 使用者資訊有限,本研究以整體使用者為目標,提供最適化推薦。在本研究之增 強式學習中,狀態會受使用者瀏覽情形所影響,舉例來說,開學期間由瀏覽情形 可得知一般公告為最重要的類別,而暑假時,最重要的類別則變為活動資訊,因 此能夠反應出時間性。. 17.
(26) 第三章 研究方法 本研究的概念如圖 3-1,系統追蹤使用者瀏覽網頁的情況,透過網頁探勘分 析出網頁的瀏覽次數、停留時間及到達網頁的路徑長度,並從資料庫中抓取各網 頁在網站中所在階層以及目前排名等配置狀況,經過增強式學習獲得以上五個影 響網頁重要程度的參數之權重後,將探勘分析出的資料與學習所獲得的權重放入 推薦機制中,求出各個網頁的瀏覽值(surf value),並依照瀏覽值將所有網頁進行 排名,最後選出推薦網頁。. 網頁瀏覽情況 (瀏覽次數、停留時間、路徑長度). 網頁瀏覽值. 網頁配置情況 (網頁目前層級、網頁目前排名). 圖 3-1 本研究的概念圖. 本研究利用增強式學習調整網站推薦,以利使用者快速找到目標資訊。網站 採取最適化調整,以整體使用者為目標,統整網站所有瀏覽紀錄,提供適性化推 薦,減少不熟悉網站架構之使用者找尋資料的時間,也讓新的使用者對網站更容 易上手,如此可以提升使用者對網站的滿意度;另外,本研究除了網頁瀏覽次數 及停留時間外,增加了三個輔助資訊,分別為到達網頁路徑長度、網頁所在階層 以及網頁目前排名,其中,減少路徑為本研究的目標,而後兩項參數代表先前調 整的狀況,因此將此三項参數加入考量中。本研究系統主要分為三部分:網頁瀏 覽特徵萃取、網頁推薦權重學習及推薦表單調整,其系統架構如下圖: 18.
(27) 網頁瀏覽 特性萃取 使用者 瀏覽網頁. 1.日誌檔. 2.瀏覽特徵. 前置處理 特徵探勘. 5.推薦網頁 推薦表單 呈現調整 計算瀏覽值. 3.瀏覽特徵 4.權重. 網頁配置. 網頁推薦 權重學習. 資料庫 Database. 4.權重. 調整推薦. 圖 3-2 研究系統架構圖. 圖 3-2 為本研究之系統架構,使用者在瀏覽網站時,Apache server 會自動將 使用者所發出的要求記錄成日誌檔(log),為了分析使用者的瀏覽情況,首先會將 此伺服器的日誌檔擷取出來,經過前置處理會過濾掉不必要的資料後,本研究將 此視為原始資料,並進行格式化,記錄到資料庫;接著透過資料探勘找出整體使 用者的瀏覽特徵,一樣將此存入資料庫中。從資料庫抓取出瀏覽特徵後,透過增 強式學習,系統會學習到調整推薦需要改變的參數權重,將此加入計算中,各個 網頁都會獲得一個瀏覽值(surf value),網站之瀏覽推薦會依學習後的瀏覽值進行 調整,最後呈現給使用者。當使用者再次瀏覽網頁,所產生的日誌檔會再次進行 計算,將推薦的網頁不斷調整,以符合當時大多數使用者的需求。. 3.1 網頁瀏覽特徵萃取 資料 擷取. 資料 切割. 資料 過濾. 資料 清理. 資料 格式化. 圖 3-3 前置處理流程 19. 使用者 定義. Session 定義.
(28) 圖 3-3 為本研究之實驗中前置處理的流程,首先會對抓取的資料進行基本的 整理,包含資料擷取、資料切割、資料過濾、資料清理及資料格式化,接著定義 使用者及 Session,並將處理完的資料存入資料庫。經過上述的步驟,可以從日 誌檔中了解使用者的特性以及網頁的架構,並得知使用者所需要的目標網頁,網 頁即可藉此調整架構。. 3.1.1 資料前置處理 在分析資料之前,本研究將對所得到的使用者日誌檔進行前置處理,本節將 會針對各程序進行詳細敘述。 資料切割 由於直接處理過大的日誌檔容易產生多餘的處理,造成分析時間變長,因此 截取日誌檔之後,首先將資料切成適合分析的大小以利分析。本研究目的要找出 目前網站使用者的瀏覽趨勢,分析時段間隔越小越好,因此本實驗以一天為切割 單位,經過後續前置處理步驟後,每天所累積的記錄大小皆保持在 40KB 左右。 資料過濾 資料過濾會將研究中不需要的紀錄過濾掉,本研究實驗所使用的網頁是由 PHP 所撰寫,為了瞭解使用者瀏覽網頁的路徑,我們截取日誌檔中要求 php 檔的 記錄,其他如圖檔(*.jpg、*.png)或執行檔(*.js)等將予以清除,並將功能性的網頁 紀錄刪除,只保留含有網頁本體的記錄(含有 index.php)。由於伺服器中架有多個 網站,必須刪除其他資料夾的記錄,僅僅保留此網站頁面的記錄(只有/index.php)。 而目前 PHP 網頁多由參數來傳遞,而非網頁之間直接連結,實驗網頁也採用依 參數來呈現網頁的方式,因此在過濾完不必要的頁面之後,將傳遞的參數視為網 頁,以便接下來的分析。 20.
(29) 資料清理 對於資料過濾後的日誌檔,透過資料清理能將記錄中不需要的部分刪除,僅 留下後續研究中會使用到的欄位,本研究主要針對瀏覽頁面來做分析,分析前會 依瀏覽的日期、時間來進行整理,找出同一次瀏覽網頁的路徑,所以後續分析會 使用到的資料欄位為使用者 IP、timestamp 以及 url。 資料格式化 為了方便將使用者資料匯入資料庫,資料格式化的步驟會將資料轉換為資料 庫所需要的格式,我們將資料中 timestamp 中的日期及時間分成兩個欄位,在 url 中由於都是同一個頁面(index.php),因此用傳遞的參數來代替,並且在每個欄位 之 間 加 入 "," 來 區 隔 , 方 便 接 下 來 處 理 及 匯 入 資 料 庫 的 動 作 , 格 式 呈 現 為 [userIP],[date],[time],[url]。 使用者及 Session 定義 使用者定義一般以 Cookie、使用者帳號及 IP 等方法來定義,但公告性網站 的使用者不需登入即可查詢所需資料,造成取得的資料有先天上的限制,在網站 沒有登入資訊的情況下,區分使用者最常使用的方式為 IP 位置(Pierrakos, et al., 2003),所以本研究將同個 IP 視為一個使用者,並以 30 分鐘做為 Session 的分界 點,利用使用者 IP 及網頁瀏覽間隔時間來整理日誌檔,將同一次瀏覽紀錄整理 一起,得到完整瀏覽歷程。以使用者 IP 做為使用者定義可能會忽略掉的情況, 但本研究主要是分析整體使用者的瀏覽行為,此階段目的在於整理出單次瀏覽中 經過的頁面,同一使用者使用不同 IP 及不同使用者使用同一個 IP 的情形對結果 的影響並不大。. 21.
(30) 3.1.2 特徵探勘 本節要從使用者瀏覽行為中找出瀏覽特性及趨勢以利後續的學習,日誌檔在 經過前置處理之後,利用統計分析來找出瀏覽目標。 網頁參數 本研究會將網站中各個網頁的重要程度進行衡量,在衡量中會考量使用者的 停留時間及網頁的瀏覽次數,藉此資訊瞭解各網頁的重要性,並找出當時網站中 使用者的目標網頁。在此階段會計算出各個網頁在期間內的點擊次數、停留時間, 網頁停留的時間為此次要求時間與下一次網頁要求之時間的間隔,而最後要求的 網頁停留時間則採用所有網頁的平均停留時間;此階段同時會計算出網頁的到達 路徑長度,網頁的到達路徑為當次瀏覽所發出的第一個網頁要求到目前的頁面之 間總共要求過幾個網頁,第一個網頁的路徑長度為 1,路徑長度的增加或減少會 做為之後增強式學習中網站狀態與動作配對的回饋值。以上網頁的各項參數經過 計算後,會獲得網頁的瀏覽值(surf value),做為最後調整時的依據。 網頁資料庫 在網頁探勘過程中,本研究所追蹤的網頁資料包含瀏覽次數、停留時間及到 達網頁的路徑長度,記錄此三項資料的同時,也抓取出網頁的所在階層及排名, 來代表網頁的配置情形,以上五個參數將會匯入資料庫,參數介紹如表 3-1。在 匯入資料庫的階段,資料保持原始數據以供未來查詢,因此將直接存入統計過後 的數值,往後的計算中,為了讓資料能夠以相同標準比較,會將五項參數標準化, 每個資料所代表的值為此網頁佔全部網頁中的比例。 表示方式為 Page(Click, Stay, Path, Level, Rank). 22.
(31) 表 3-1 網頁參數表 代碼. 參數名稱. Click. 網頁瀏覽次數. Stay. 網頁停留時間. Path. 到達網頁路徑長度. Level. 網頁目前所在階層. Rank. 網頁目前排名. 3.2 網頁推薦權重學習 分析網站採用的衡量指標有內容指標及商業指標,本研究的目標網頁與商業 交易無關,因此採用網站內容指標來衡量,衡量網站需要瞭解使用者與網站內容 的互動情況,一般會追蹤進站與離站的網頁、瀏覽各別網頁的次數、瀏覽各別網 頁的時間長度等資料,每個衡量指標能夠知道網站的不同特性,但彼此之間是無 法比較,目前不能肯定哪項指標是最佳的衡量的方式,因此,本研究希望透過自 動學習,讓網站能夠學到各資料在排名計算中最適合的權重,增強式學習讓網站 不是一次就決定權重配置,而是經過長期學習,參考以往權重調整後對瀏覽狀態 的影響,進行之後的調整。 追蹤資料除了點擊次數及停留時間之外,本研究增加了到達網頁的路徑長度、 網頁目前所在的層級以及網頁目前的排名來當作計算排名時的輔助資料,當兩個 網頁之間的瀏覽次數及停留時間相近時,我們推測到達路徑長度比較長的網頁優 先推薦能夠使整體平均瀏覽長度減少較多,在底層的網頁也因為相同原因會比高 層的網頁優先推薦,而網頁單次的點擊次數及停留時間減少並不一定代表它的重 要性降低,因此先前的排名也會加到學習中。. 23.
(32) 本研究使用增強式學習的模式如圖 3-4,環境代表網頁的瀏覽狀況,環境會 將先前由網頁探勘所分析出的資料傳給代理人,讓代理人知道目前網頁的瀏覽狀 態。根據同時由環境傳回的回饋值(reward),衡量前一次調整對網頁表現的影響, 並採用 SARSA 演算法計算其 Q-value 值,再更新學習資料,接著依照新的狀態 採取合適的行動,Q-value 值越大代表選到該行動的機率越大。學習各參數的權 重後,透過推薦機制會將所有網頁進行排名,最後,系統直接抓取排名在前面的 網頁來推薦,並呈現在動態表單中,代理人以一天為間隔,處理累積的資料,再 次進行學習調整。 SARSA 演算法的公式如公式 2: Q(s, a) Q(s, a) + α(R(s) + γQ(s', a' ) - Q(s, a) ). --公式 2. 將 α 及 γ 設為 1,本實驗將 SARSA 演算法減化如公式 3: Q(s, a) R(s) + Q(s', a' ). --公式 3. 推薦. 環境. 計算瀏覽值 排名並推薦. 回饋值 路徑長度. 推薦機制. (過去-現在). 停留時間的權重增加. 網站中的類別 1) 一般公告 2) 活動資訊. 行動. 點擊次數的權重增加. 狀態. 3) 固定資訊. 代理人. 路徑長短的權重增加 目前層級的權重增加. 狀態(State):網站中最重要的類別項目。. 目前排名的權重增加. 行動(Action):選擇其中一個參數,增加其權重。. 所有參數的權重不變. 回饋值(Reward):到達目標網頁的平均路徑長度變化。. 圖 3-4 本研究之增強式學習模式. 24.
(33) 本研究網站於學習網頁參數權重階段,使用增強式學習的流程如圖 3-5。. 1.. 初始推薦 -為了不讓最初的效率太差,會先計算第一次排名,並推薦. 2.. 代理人根據 Q-value 選擇增加權重的參數(action) -第一次由於 Q-value 都相同,隨機選取. 3. 4.. 推薦機制依照行動所調整的權重來計算排名,並推薦 環境傳回新推薦所造成的狀態(state) -透過網頁探勘找出最重要的類別作為狀態. 5.. 環境傳回狀態與行動配對的回饋值(reward) -回饋值為過去路徑長度減去目前路徑長度. 6. 7.. 重新計算增加各參數之權重的 Q-value 回到第二步驟 圖 3-5 增強式學習推薦流程. 3.2.1 參數設定. 狀態(State):以最重要的網站分類代表目前網站中的瀏覽狀況。 為了控制增強式學習中狀態的數量以確保狀態學習次數,本研究將網站分類 視為瀏覽狀態,分別為一般公告(news)、活動資訊(activity)、固定資訊(info),所 佔的瀏覽比例各為 1/3,其中固定資訊包含系所資訊、教師資訊、畢業資格等。 每次學習透過網頁探勘找出目前最重要的類別,讓網站依照此狀態進行學習。. 行動(Action):代理人所選擇要增加權重的參數。 代理人能夠選擇的動作有六種(如表 3-2),每個行動針對不同參數的權重進 行調整,對於各項參數權重的調整皆為固定的值,當選擇增加某一參數時,另外 四種參數將會同時減少對應的值,讓所有權重的加總保持在一定的值。每次行動 25.
(34) 所選擇的參數權重增加 4,其餘參數的權重皆減少 1,使所有參數之權重總和保 持為 100,代理人也可選擇不調整任何參數的權重。. 表 3-2 權重調整行動表 權重. 瀏覽 次數. 停留 時間. 到達 路徑. 所在 階層. 目前 排名. 行動 A. +4. -1. -1. -1. -1. 行動 B. -1. +4. -1. -1. -1. 行動 C. -1. -1. +4. -1. -1. 行動 D. -1. -1. -1. +4. -1. 行動 E. -1. -1. -1. -1. +4. 行動 F. 0. 0. 0. 0. 0. 回饋值(Reward):過去目標網頁到達路徑長度減去現在目標網頁到達路徑長度。 本研究的目標是要減少使用者找尋目標所需要經過的頁面,因此以網頁到達 路徑的長度變化作為評估此次狀態與行動配對的標準,計算到達路徑長短的網頁 只侷限在目標網頁,其餘的網頁並非我們所要減少的目標。回饋值的計算由過去 平均網頁到達路徑長度減去此次網頁到達路徑長度,路徑長度增加,意味著此次 調整的權重所帶來的影響不好,反之亦然。. 3.2.2 參數權重學習演算法 權重學習階段我們會抓取各網頁的瀏覽次數、瀏覽時間、到達網頁的路徑長 度、以及網頁所在階層和排名五項參數作為輸入值,並依照圖 3-6 之演算法學習。. 26.
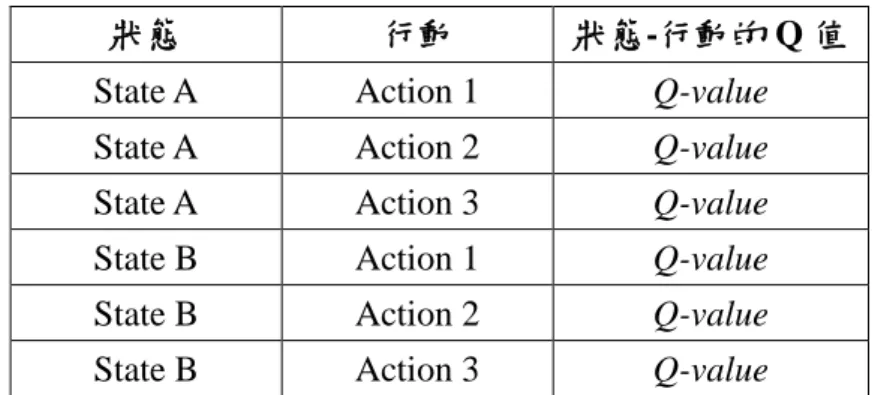
(35) Reinforcement Learning Recommendation Algorithm 1. TotalPathnow ΣPath 2. R TotalPathpast - TotalPathnow 3. Update Q 4. S Top Website Category 5. Match S in RLmatrix. 6. 7.. Select A Where Q = Max Q Return A. 圖 3-6 參數權重學習演算法. 在系統每次更新推薦中,step 1 將所有網頁的到達路徑長度加總(ΣPath),獲 得目前總目標網頁路徑長度(TotalPathnow),step 2 將目前網頁之路徑長度與前一 次之總路徑長度(TotalPathpast)相減,得知的路徑長度變化視為獎懲值(R),代表前 一次調整之評估結果,step 3 透過此獎懲值帶入增強式學習之公式,再次更新 Q 值。step 4 以當時網站分類中最重要的類別作為學習狀態(S),step 5 接著在增強 式學習之學習矩陣(RLmatrix)中比對出相同的狀態(S),step 6 從符合的狀態中選 出 Q 值最高的行動(A),step 7 將此行動(A)回傳並執行。 系統在執行動作後會改變目前各項參數之權重,並以此權重進行接下來的網 頁調整推薦,一天過後,會再次分析網頁以獲得五項參數值,並執行此演算法。. 3.2.3 增強式學習資料庫 增強式學習表中包含狀態、行動、以及 Q 值三個欄位,在獲得網站狀態後, 將於學習表找出此狀態中 Q 值最大的行動,若 Q 值相同,則隨機選取一個行動, 網站狀態會隨採取的行動而改變,在獲得獎懲值後,更新此次選取的狀態-行動 27.
(36) 配對之 Q 值。當學習遇到尚未出現在表中的新狀態時,也能夠直接新增狀態以 及其對應的所有行動,並隨機選擇一項行動執行。增強式學習表之內容如表 3-3。. 表 3-3 增強式學習 Q 值調整資料表 狀態. 行動. 狀態-行動的 Q 值. State A. Action 1. Q-value. State A. Action 2. Q-value. State A. Action 3. Q-value. State B. Action 1. Q-value. State B. Action 2. Q-value. State B. Action 3. Q-value. 3.3 推薦表單調整 透過網頁瀏覽特徵萃取及網頁權重學習兩個步驟,我們獲得五個參數值以及 其相對權重,接著進入推薦調整階段,在此階段中將計算出瀏覽值(surf value)作 為推薦的依據。. 3.3.1 瀏覽值(Surf Value) 瀏覽值計算所使用到的參數為網頁瀏覽次數(click)、網頁停留時間(stay) 、 到達網頁路徑長度(path)、網頁目前所在階層(level)、網頁目前排名(rank)五個參 數及其各自的權重,各個參數在計算之前會經過標準化,讓資料以相同的標準比 較,而接下來的計算不再進行其他處理,直接將各參數的數值與權重相乘並加總, 即獲得此網頁的瀏覽值,如公式 4,由於參數的數值及權重沒有經過其他的處理, 因此權重的變化也就代表各個參數的重要性。 Surf Value = Click*WClick + Stay*WStay + Path*WPath + Level*WLevel + Rank*WRank --公式 4. 28.
(37) 3.3.2 調整推薦 所有網頁經過計算皆會得到各自的瀏覽值,網站會依此排名並選出推薦網頁, 選擇的方式第一步會過濾掉呈現頁面,也就是首頁,第二步將首頁直接連結的網 頁從排名中刪除,以圖 3-7 解釋,推薦的連結會呈現在首頁,紅色圓圈代表推薦 的網頁,而第二層的 A1、B1 及 C1 三個網頁,能夠從首頁直接連結,即使推薦 也無法減少路徑長度,因此將這種網頁也過濾掉,推薦所能選取的範圍即為圖中 紅色虛線框中的所有網頁。在過濾掉不適合的網頁後,第三步系統會抓取剩下排 名中的前三名作為推薦網頁,最後將推薦網頁呈現在首頁之動態表單,並給予連 結以直接到達目標網頁,在圖 3-7 中,若推薦網頁選到 A3-11、B3-12 和 B4-313, 此三頁之連結會出現在首頁的紅色圓圈中,而在架構圖中,三個頁面與首頁之間 皆會增加一條線(圖中為橘線)代表能夠直接連結。. 首頁. A1. A2-1. A3-11. B1. A2-1. B2-1. B3-11. B3-11. B2-2. B3-12. B4-311. C1. B3-31. B3-32. B4-312. B4-313. 圖 3-7 推薦階層示意圖. 29. C2-1. B2-3. C2-2. C3-21.
(38) 3.4 本章小結 本研究之網站調整方式以增強式學習技術為基礎,考量瀏覽次數、停留時間、 瀏覽路徑長度、網頁所在階層以及目前排名來進行瀏覽推薦。藉由增強式學習與 環境互動的特性,網站能夠隨著使用者瀏覽情況調整,並且自動評估調整結果, 評估基準為使用者到達目標網頁之路徑長度。研究系統主要分為以下三部分: 1. 網頁瀏覽特徵萃取 (採用技術:網頁使用探勘) 本研究將使用者瀏覽情形考慮至推薦中,採用網頁使用探勘從日誌檔中找出 使用者瀏覽歷程,並分析出網頁瀏覽次數、網頁停留時間、及到達路徑長度。 2. 網頁推薦權重學習 (採用技術:增強式學習) 取得使用者瀏覽特徵及網頁配置情形的參數後,本研究透過增強式學習取得 各參數之權重,作為接下來瀏覽推薦的依據。增強式學習之各項設定如下: 狀態:以網站最重要的分類代表目前瀏覽狀況,分別為一般公告(news)、 活動資訊(activity)、固定資訊(info)。 行動:代理人選擇單一參數增加其權重,並減少其他參數之權重,使權 重總和維持在 100;代理人也可以選擇不調整任何參數之權重。 回饋值:以到達目標網頁之路徑變化評估學習效果,計算方式為過去目 標網頁到達路徑長度減去現在目標網頁到達路徑長度。 3. 推薦表單調整 (採用技術:適性化網站) 經過前兩步驟獲得網頁之參數及其權重,將參數與相對應的權重相乘並加總 後,各網頁皆獲得瀏覽值,網站將依此瀏覽值調整推薦,並給予推薦之網頁 直接連結。. 30.
(39) 第四章 實驗 此章節將說明本研究之實驗設計,並介紹實驗中各資料的處理過程,接著以 減少的路徑長度為標準,探討不同參數加入學習對於推薦效果的影響,除此之外, 也與單純使用點擊來推薦的方式比較,並分析學習後各參數之權重比例。. 4.1 實驗設計 本研究之實驗流程如圖 4-1,實驗最初擷取目標網站的日誌檔,並將此資料 進行過濾整理,接著模擬網站擁有推薦機制時的運行情況,實驗中包含五種學習 模式的推薦(詳見 4.1.2),分別進行為期一個月的短期學習,以及長達一年的學習, 短期學習會將 1 到 12 月的資料依不同月份分開進行模擬,本研究同時也模擬一 般依照點擊次數的推薦情形,來與本研究之方法比較。驗證部分分為兩部分,第 一部分比較學習後所減少的平均路徑長度,並觀察短期學習在 12 個月的路徑減 少趨勢,第二部分則比較五種學習以及點擊方式在最佳推薦時路徑的減少效果, 並找出各參數組合最佳推薦時的權重,接著以此固定的權重再次模擬網站推薦, 最後比較其路徑減少效果。 短期 學習 資料 蒐集. 驗證 -平均. 資料 整理. 驗證 -最佳. 長期 學習 權重 推薦. 點擊 推薦 圖 4-1 實驗流程圖 31. 驗證 -平均.
(40) 4.1.1 實驗方式 為了比較不同參數組合之下學習的推薦效果,本研究希望將環境控制在相同 的情況,因此採取模擬的方式進行實驗,利用過去日誌檔中的紀錄模擬網站加入 推薦後的瀏覽情形。在模擬網站運行中,事先訂定一個假設,當使用者的目標網 頁出現在推薦之中,會直接點擊此推薦連結,而不會出現錯過的情形。. Step 1 記錄 1 記錄 2. 網頁 A. 記錄 3 記錄 4 記錄 5. 推 薦 網 頁. 網頁 B. 網頁 E. 記錄 6. IP_x IP_x IP_x IP_x IP_x IP_x. 網頁 A 網頁 B 網頁 E 網頁 F 網頁 G 網頁 D. --- 1 --- 2 --- 3 --- 4 --- 5 --- 6. IP_x IP_x IP_x. 網頁 A 網頁 B 網頁 E. --- 1 --- 2 --- 3. IP_x IP_x IP_x. 網頁 F --- 4 網頁 G --- 5 網頁 D --- 6. IP_x IP_x. 網頁 A 網頁 D. Step 2 記錄 1. 網頁 C. 記錄 2. 網頁 F. D. 記錄 3 記錄 4. 網頁 D. 記錄 5. 網頁 G. 記錄 6. Step 3 記錄 1 記錄 2. --- 1 --- 2. 圖 4-2 網站模擬運行步驟. 模擬網站運行中,日誌檔的處理方式如圖 4-2,左半圖為網站之架構,推薦 結果呈現在網頁 A,右半圖為日誌檔之變化;在 step 1 首先獲得使用者的瀏覽記 錄,圖中為簡化後的日誌檔,從中可得知 IP_x 使用者的瀏覽歷程為 A-B-E-F-G-D, D 為目標網頁,對照至左圖為藍色箭頭經過之路徑;當網頁 D 為推薦網頁時, 網頁 A 會增加連結至網頁 D,如左圖架構之紅色虛線,代表兩個網頁能夠直接 連結,此時不需要再經過 BEFG 來到達目標網頁,因此 step 2 將 BEFG 的記錄刪 32.
(41) 除,讓日誌檔呈現網頁 A 直接連結到 D 的瀏覽情形;在刪除不必要的網頁記錄 之後,進入 step 3,重新計算網頁的到達路徑長度,使得 A 網頁路徑不變,D 網 頁路徑從 6 變為 2,後續學習流程以此整理過的日誌檔,視為新的瀏覽紀錄。. 4.1.2 實驗模式 本研究在參考網頁目前瀏覽情況之外,增加網頁配置的參數,全部包含瀏覽 次數、停留時間、到達路徑、所在階層以及目前排名五個參數(詳情參考 3.1.3 網 頁參數),以供實驗進行學習及推薦。為了找出對推薦最有影響力的參數,實驗 中分別採用兩個參數、三個參數(f3)、以及五個參數(f5)的組合,其中考量三個參 數的學習模式只選取目前網站瀏覽情形,包含瀏覽次數、停留時間、到達路徑; 而兩個參數的學習則是從三參數中挑出兩個來進行學習,因此又分為三種,分別 為瀏覽次數搭配停留時間(cs)、瀏覽次數搭配到達路徑(cp)、以及停留時間搭配 到達路徑(sp)。五種學習模式整理如表 4-1。. 表 4-1 學習模式 學習模式代號. 考量參數. cs (Click, Stay ). 瀏覽次數、停留時間. cp (Click, Path). 瀏覽次數、到達路徑. sp (Stay, Path). 停留時間、到達路徑. f3 (Click, Stay, Path). 瀏覽次數、停留時間、到達路徑. f5 (Click, Stay, Path, Level, Rank). 瀏覽次數、停留時間、到達路徑、 所在階層、目前排名. 33.
(42) 4.1.3 實驗環境 本研究實驗平台軟硬體設備如下: OS:Windows Win7 CPU:Intel(R)Core(TM) i7-2600CPU @3.40GHz RAM:16GB 程式語言:PHP 5. 4.2 實驗資料 本研究以台灣學術網站為實驗平台,選擇以資訊提供型網站為目標,這也是 本研究的限制,本節將呈現資料來源及資料存入資料庫中的格式,並介紹學習中 會使用到的資料表。. 4.2.1 資料來源 本研究以實際運作的網站為資料來源,採用國立高雄大學資訊管理學系系網 頁使用者瀏覽日誌檔,該網站為學術網站,公布訊息為主要功能,日誌檔格式為 NCSA 的 ASCII 一般日誌檔格式(詳細內容請參考 2.2.1 節)。本研究於 2012 年 10 月擷取網站伺服器運作以來的歷年資料,期間自西元 2008 年 5 月至 2012 年 9 月,原始檔案大小為 2.67GigaByte。為了瞭解網站架構及內容,我們在 2012 年 期間不斷瀏覽此網站,如此造成日誌檔產生許多雜訊,所以暪研究採用往前兩年 的歷史資料進行實驗。圖 4-3 為高大資管系網站使用者的瀏覽紀錄日誌檔片段, 格式為[userIP][timestamp][method][url][httpversion][httpresult][size]。. 34.
(43) 220.181.108.162 - - [01/Jan/2011:01:47:32 +0800] "GET /?tid=197&act=shownotic&cid=1052 HTTP/1.1" 200 40918 95.108.240.252 - - [01/Jan/2011:01:47:57 +0800] "GET /?tid=238&act=shownotic&cid=1485 HTTP/1.1" 200 45383 139.18.2.209 - - [01/Jan/2011:01:48:14 +0800] "GET /act_showimage.php?actid=19&actpid=205 HTTP/1.1" 200 196063 140.122.72.58 - - [01/Jan/2011:01:50:21 +0800] "GET /admin/schedule.php HTTP/1.0" 200 8 66.249.68.22 - - [01/Jan/2011:01:50:41 +0800] "GET /index.php?tid=338 HTTP/1.1" 200 15550 221.183.16.137 - - [01/Jan/2011:01:51:35 +0800] "GET /index.php?tid=197&act=shownotic&cid=662 HTTP/1.1" 200 26139 139.18.2.209 - - [01/Jan/2011:01:52:40 +0800] "GET /?tid=196 HTTP/1.1" 200 20794 139.18.2.209 - - [01/Jan/2011:01:52:41 +0800] "GET /?tid=196 HTTP/1.1" 200 20794 66.249.68.168 - - [01/Jan/2011:01:53:52 +0800] "GET /robots.txt HTTP/1.1" 404 1207. 圖 4-3 使用者存取記錄日誌檔片段. 在前置處理過程,本論文將日誌檔中非瀏覽本網站之記錄以及瀏覽功能性網 頁的記錄刪除,並過濾掉網路蜘蛛。接著以 IP 為使用者定義,不同 IP 代表不同 個使用者,並以 30 分鐘做為 session 的分界點,超過此間隔,視為不同次的瀏覽 紀錄,經過以上整理步驟可獲得多組瀏覽歷程。 記錄中,本論文僅保留實驗所需的欄位,並將其中的 timestamp 再切分為 date 及 time 兩個欄位,除了原本記錄中資料之外,另外增加兩個欄位,停留時間(stay) 以及到達路徑(path),並在每個欄位之間使用「,」分隔,經過前置處理的資料儲 存格式為[userIP],[date],[time],[url],[stay],[path]。stay 代表停留在要求網頁的時間, 計算方式為瀏覽歷程中兩次請求之間的間隔,若要求網頁為目標網頁,則暫時以 「ObjectPage」來代表時間,在計算出平均時間後,即以平均瀏覽時間來取代; 另外,path 是到達要求網頁所經過的網頁個數,第一個要求頁面的路徑長度為 1, 每多瀏覽一個網頁,其路徑長度會增加 1,整理後的資料片段如圖 4-4。. 35.
(44) 66.249.68.168,2011/Jan/01,4313,/index.php?tid=238&act=shownotic&cid=1908,7,1 66.249.68.168,2011/Jan/01,4320,/index.php?tid=189&act=showGroup&trid=10,ObjectPage,2 66.249.68.22,2011/Jan/01,6641,/index.php?tid=338,1129,1 66.249.68.22,2011/Jan/01,7770,/index.php?tid=196&rid=25&act=showadmission_at&cid=1260,1129,2 66.249.68.22,2011/Jan/01,8899,/index.php?tid=196&act=showadmission_at&rid=25&cid=1260,806,3 66.249.68.22,2011/Jan/01,9705,/index.php?tid=183&year=1651&semester=1,1,4 66.249.68.22,2011/Jan/01,9706,/index.php?tid=183&year=708&semester=1,ObjectPage,5 67.195.37.165,2011/Jan/01,10267,/index.php?tid=259&actid=,1170,1 67.195.37.165,2011/Jan/01,11437,/index.php?tid=238&pg=2,ObjectPage,2. 圖 4-4 前置處理後的日誌檔片段. 以圖 4-4 中第三筆到第七筆紀錄解釋,經過整理, 本論文獲得 IP 為 66.249.68.22 之使用者瀏覽歷程中有五筆紀錄,代表此次瀏覽了五個網頁,要求 第一頁的時間為 6641(早上 01:52:41),第二頁的要求時間為 7770(早上 02:09:30), 其停留時間為此兩要求之間隔為 1129 秒;而此歷程中第一筆記錄到達網頁的路 徑設為 1,下一筆紀錄則會再增加 1,直到最後一筆記錄時由於瀏覽了 5 頁,因 此到達路徑長度為 5,而此網頁之停留時間在計算完所有記錄後,以平均停留時 間取代,並將此記錄所要求之網頁設為目標網頁。. 4.2.2 資料庫格式 日誌檔經過前置處理後會存入資料庫,並進行統計分析,計算各網頁的點擊 次數、停留時間、到達路徑長度、及所在階層,而網頁的排名是從前一次學習所 產生的排名獲得,因此第一次推薦時所有網頁的排名皆為 0,表 4-2 為分析後所 產生的資料表格式。. 36.
(45) 表 4-2 網頁統計分析記錄表 日期. 網頁. 點擊次數. 停留時間. 路徑長度. 所在階層. 目前排名. 2011/1/1. tid=196. 10. 351.0380. 3.60. 3. 13. 20111/1. /index.php. 4. 143.1488. 1.25. 1. 10. 2011/1/1. tid=183. 11. 585.0714. 2.09. 3. 3. 2011/1/1. tid=197. 19. 682.9240. 2.05. 3. 2. 2011/1/1. tid=217. 3. 535.1984. 1.60. 3. 20. 增強式學習為實驗中最主要的階段,以下為學習中操作流程,當網站分析目 前瀏覽狀況後,在增強式學習調整表(如表 4-3)中比對第一欄的狀態,並從相同 狀態中找出 Q 值最大的行動執行,網頁的狀態有三種,公告(news)、活動(activity)、 資訊(info),而行動會由考慮的參數不同而有所調整,當學習中考慮兩個參數時, 其行動為(2, -2)、(-2, 2)、以及(0, 0)三種,變為三參數的行動包含(2, -1, -1)、(-1, 2, -1)、(-1, -1, 2)、及(0, 0, 0)四種,五參數所能選擇的行動則有六種,如表 4-3,以 表中資料解說學習情形,當遇到的狀態為 news,最高 Q 值為 23.5385,其相對應 的動作即為 4, -1, -1, -1, -1,網站將會執行此動作,改變原本的權重,分別為點擊 次數+4、停留時間-1、到達路徑-1、所在階層-1、目前排名-1。並在下一次獲得 狀態時,同時透過路徑的變動,取得回饋值, 並更新狀態「news」與行動 「4,-1,-1,-1,-1」配對之 Q 值。. 表 4-3 增強式學習調整表 狀態. 行動. News. 4, -1, -1, -1, -1. 23.5385. News. -1, 4, -1, -1, -1. 7.3496. News. -1, -1, 4, -1, -1. 1.8648. News. -1, -1, -1, 4, -1. -0.5445. News. -1, -1, -1, -1, 4. 2.0283. 37. Q值.
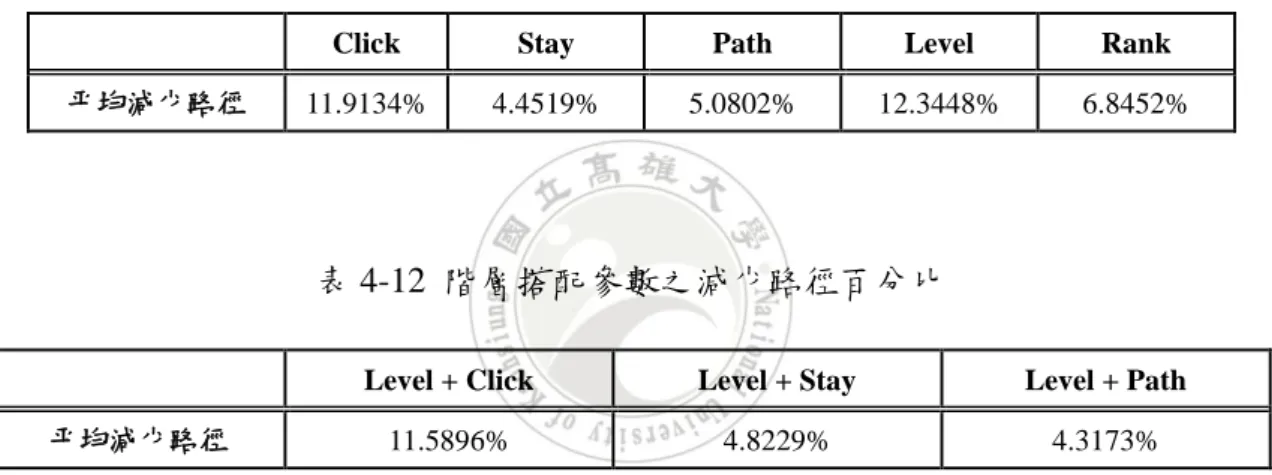
數據


+3
相關文件
In this paper, by using the special structure of circular cone, we mainly establish the B-subdifferential (the approach we considered here is more directly and depended on the
This paper is based on Tang Lin’ s Ming Bao Ji (Retribution after Death), which is written in the Early Tang period, to examine the transformation of the perception of animal since
Therefore, in this research, we propose an influent learning model to improve learning efficiency of learners in virtual classroom.. In this model, teacher prepares
¾ To fetch a Web page, browser establishes TCP connection to the machine where the page is and sends a message over the connection asking for the
Reinforcement learning is based on reward hypothesis A reward r t is a scalar feedback signal. ◦ Indicates how well agent is doing at
In this chapter, we have presented two task rescheduling techniques, which are based on QoS guided Min-Min algorithm, aim to reduce the makespan of grid applications in batch
In this paper, a decision wandering behavior is first investigated secondly a TOC PM decision model based on capacity constrained resources group(CCRG) is proposed to improve
Therefore, a new method, which is based on data mining technique, is proposed to classify driving behavior in multiclass user traffic flow.. In this study, driving behaviors
