The Lightweight Genetic Search Algorithm: An Efficient Genetic
Algorithm
for
Small Search Range Problems
Chun-Hung Lin and Ja-Ling Wu
Communication and Multimedia Lab. Dept.
ofComp.
Sci,
and
Inf.
Eng.
National Taiwan University, Taipei, 106, Taiwan,
R,. 0. C.
Abstract
In this paper, the effectiveness of the genetic op- erations of the common genetic algorithms, such as crossover and mutation, are analyzed for small search range situations. As expected, the so-obtained e f l - ciency/performance of the genetic operations as quite different f r o m thut of their large search range coun- terparts. To fill this gap, a lightweight genetic search algorithm is presented t o provide an eficient way for
generating near optimal solutions for these kinds of ap-
plications.
1
INTRODUCTION
Genetic algorithms
(GAS)
have been developed andapplied to a variety of optimization and search prob-
lems [I]. In the applications with large amounts of
search points, it is impossible, due to execution time and storage space, to perform the brute-force (full) search for visiting all the points in the search space.
GAS can help to find the global optima although a
few computational overheads of the genetic evolution
are required. While compared with the computational complexity of the full search, the evolution overheads
are small and worthwhile. Nevertheless, when the
search space is very small, the genetic evolution over- heads might overtake the computational complexity of applying the full search. This implies, in this situa- t,ion, it would be better to perform the full search di- rectly. However, the time constraint for these small search range applications is usually very tight. For ex- ample, in the motion estimation stage of video cod-
ing [2], the ideal execution time for each 16 x 16 block
search must be less than 3.95 x lo-' second. The com-
putational complexity of the full search is still too high
to satisfy the above requirement. The evolution over-
heads of G.4s have to be reduced, so as to meet the
embedded strict time constraint in the above applica- tions.
GAS have been applied to these kinds of applications
in the literature [3, 41. The huge computational com-
plexity of the traditional GA-based search algorithms has made them become handicaps in real video cod-
ing applications. In this paper, a lightweight genetic
search algorithm (LGSA) will be presented. When GAS are applied in searching, the computational com- plexity comes mainly from the following two parts: ( I ) the computations of evaluating the similarity between the search points and t'he reference template; (2) the computations of the genetic evolution. The first part is dominated by the number of the evaluated search points. Fewer computa,tions would be required if the number of the evaluated points is reduced. But, this re- duction involves the risk: of finding a bad solution. The second part is controlled. by the structure of the genetic evolution. Low control overheads bring less computa-
tional complexity. In the LGSA, both the number of
the evaluated points and the control overheads of ge-
netic evolution can be reduced to meet the time con-
straint of video coding.
2
ANALYSIS
O:F CROSSOVER EFFI-CIENCY
In conventional GAS, the evolution is analyzed based
on the schema theory [l]. The crossover disruption
rates were defined as th.e probability that the schema is disrupted by crossover. For a good genetic algorithm, it is hoped that the crossover disruption rate of a highly fit schema will be very Ifow. In [l], an upper bound for
the crossover disruption rate of a schema was given.
Based on the primitive results of the schema theory, a further analysis was provided in [6]. It is concluded that at least in two situations where disruption is ad-
vantageous: (1) when th,e population is quite homoge-
provide the necessary sampling accuracy for complex search spaces. It is also known that smaller population sizes tend to become homogeneous more quickly. Be- cause population sizes are small when the search space is not large [7], the disruption will also be favorite in a small search space. The crossover productivity rate
(i.e. disruption rate) will be denoted as
Pelf.
It ishoped that the crossover productivity rate will be large enough when the population becomes homogeneous.
Besides the above two situations] disruption is also advantageous when real-time constraint is a must. In this situation, the generation number of genetic evolu- tion is not allowed t o be large. In order to probe more search points, the crossover productivity rate should be high, especially when an elitist selection is applied in the reproduction stage.
In the previous analyses] the crossover disruption rates are discussed based on schemata (chromosome patterns) while applying conventional GAS. However,
it is difficult to determine the fitness of a schema in the
applications with various kinds of search spaces. An analysis of the crossover productivity rates based on a randomly given chromosome will be provided in the following.
For an n-point crossover, the crossover productiv-
ity rate can be derived as follows. The n crossover
points divide each chromosome into ( n
+
1) segments]i.e.,
Ca
= Ca,+
Ca2 -k . . ' $- Can+, and Cb = c b l -f Cb2+
. . .+
C b , + l . At the initial derivation, n is as- sumed to be an odd number. An n-point crossover can be identically represented as shown in Fig. l ( b ) . The corresponding crossover productivity rate can then be calculated as3
ANALYSIS
OF MUTATION
EFFI-
CIENCY
In conventional GAS, mutation is applied to probe the search points that can not be reached by the
crossover operations. The mutation probability is usu-
ally small so as not to spoil the population and ruin the
chromosomes with good fitness. When the crossover operations are taken out from the genetic evolution, due to their inefficiency in a small search space situ- ation] the task of probing new search points must be done by the mutation operations. It should be guar- anteed that every legal search point can be reached by mutating any selected chromosomes. The neces- sary generation number for a selected chromosome to be mutated into any other chromosomes should also
be small if the time constraint is an important issue.
For a selected chromosome, it is hoped that the chro-
mosome can change t o any other chromosomes with higher probability. If an efficient mutation operation is applied, the probability of transferring any given chro- mosome to the other chromosomes should be identical after a small number of iterations] such that there is not any search point which is hard to be reached from the selected chromosome.
To improve the mutation efficiency, the mutation probability has to be increased; however, the accu- mulated evolution information will also be destroyed which makes the genetic search somewhat like the ran- dom search. Unless an elitist selection is applied in the reproduction stage t o maintain the evolution infor- mation, the genetic search will degrade to the random search if the mutation probability is high. When an elitist selection is applied to avoid the disruption of population by mutation] the mutation invariance (or
unchanged) rate for a selected chromosome would be
very low. The probability of transferring one chromo-
some to other different chromosomes is proportional to the mutation efficiency.
The probability for a chromosome Ci to be mutated
into another chromosome Cjis
where P , is the mutation probability, IC the chromo-
some length, and H ( C , , Cj) the Hamming distance be-
tween Ci and Cj. A mutation efficiency matrix can
then be formed as
where t is the generation number and
mi';' = P , f f ( i , j ) (5)
Assume the selected chromosome is strong (;.e., with
high fitness value), such t h a t it and its offsprings will always be selected in the reproduction stage. When the crossover stage is disabled, the mutation efficiency can
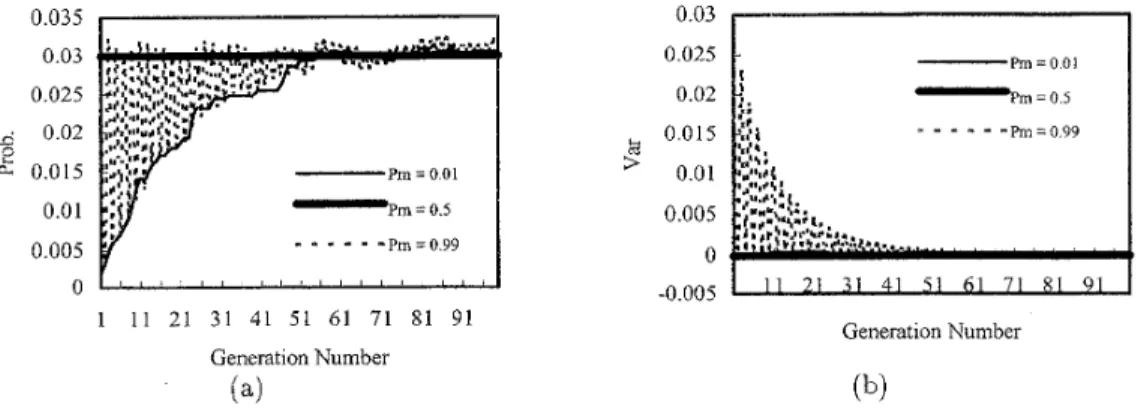
Fig. 2 shows the mutation efficiency for the case of
chromosome length k = 2. In Fig. 2(a), the average
mutation disruption rates with three different muta-
tion probabilities P, = 0.01, 0.5, and 0.99, are de-
picted, where the mutation disruption rate is defined to be the mean value of the probabilities for a selected chromosome being mutated into distinct chromosomes in the search space. The variances of the probabilities of being mutated into various chromosomes are shown in Fig. 2(b).
In conventional GAS, a small mutation probability
is usually selected, for example, P, = 0.01 is suggested
in [8]. It can be seen from Fig. 2(a) that the average mutation disruption rate is very low in the early gen- erations. The average disruption rate increases slowly while the generation number increases. The average
disruption rate will reach the upper bound 0.25 after
more than one hundreds generations. In order to pro- mote the mutation efficiency, the mutation probability is increased. If the mutation probability approaches 1,
e.g. P, = 0.99, it is found that the average disruption
rate will bounce between two extreme values. More- over, by comparing Fig. 2(a) and (b), it is found that the variance of the disruption rates is very large when the average disruption rate is high. The probabilities of transferring each chromosome to all other chromosomes are still very low. Hence, increasing the mutation prob- ability will not improve the mutation efficiency well. If
a compromised value is used, e.g. P, = 0.5, the av-
erage disruption rate will retain to 0.25. Under this
condition, the mutation efficiency will be better than that of the previous two cases; however, the invariance rate will still be 1 - 0.25 x 3 = 0.25. This invariance rate is still too high to improve the mutation efficiency for each chromosome.
Fig. 3 shows the mutation efficiency for the case of
k = 5. The results are very similar to that of the case
of k = 2. Because, when the search space is larger there
are more chromosomes, the average disruption rates are therefore becoming smaller since the disruption rates
should be always less than 1. The chromosome length
is larger, in this case, so that the mutation efficiency is better (0.03 x 31
>
0.25 x 3). A smaller generation number is required for the curves of different mutationprobabilities to converge to the value 1/32. Although
the mutation efficiency is better when the chromosome length is larger, the resultant efficiency is still not high enough.
In the LGSA, each gene of a chromosome is altered by adding one of the following three values, 0 , 1, -1,
with identical probabilities, for every k generations.
In the kth generation, the mutation invariance rate is
equal to 1/2k. The mutation efficiency of the LGSA,
in the kth generation, is shown in Table. 1, where two
kinds of chromosome lengths are tested. It is found that, within a small rmmber of generations, the mu- tation efficiency of the LGSA will be better than that of the conventional ones. Moreover, the corresponding average mutation disruption rates will be higher and the variances of the disruption rates will be smaller. Notice that the mutation invariance rates of the LGSA are reasonably small as compared with that of the con-
ventional mutation approach, as shown in Figs. 2 and 3.
4
THE LIGHTWEIGHT GENETIC
SEARCH ALGORITHM
Assume the central point of the two-dimensional
search space S locates at ( 2 ,
e).
The ith chromosome,Ci for i = 0 , 1 , .
.
., N -- 1, of the population set is de-fined as
and the relative location is
( m t , .a) = (z, - 2 , YZ -
e),
0)
where ( x i , yi) denotes {,he location of the search point associated with the chromosome and the codeword sizek depends on the size of the search space. If the search spaceis{(i,j)l-w< i , j
5
w - l } , t h e v a l u e o f k w i l l b e[10g2(2w)l, where
r.1
is a ceiling function. The valuesof the genes are derived from the associated relative location, that is
where mod denotes th’e module operation and
1.1
isa floor function. The relative location can be one-to- one encoded into a series of genes with values of 0 and 1. And the relative location ( m i , n;) can be calculated
from the values of the genes by
k - I
j = O k - I
ni
j = O
Although the values of the genes might not equal 0 or
1 after mutation; however, they can be transferred to a relative location without any ambiguity.
Each chromosome has an associated fitness value which is defined as
where di is the matching value of the search point rep-
resented by the i t h chromosome, D is a difference func-
tion, and
U
and S are the unit step function and thedelta function, respectively. When the target of the
search problem is t o find a point with the minimum matching value, the difference function is defined as
D ( d i ,
JT)
= dT - d i , (13)where d, is the r t h minimum matching value among the N values, {dili = 0, 1,. .
.,
N - l}. If the target isthe global maximum, the difference function is defined
as
D ( d i , d r ) = di -
&,
(14)where
2,
is the r t h maximum matching value. Theconstant r determines how many chromosomes, a t
most: should be selected as seeds in the reproduction stage for producing a rival population. The chromo- somes with larger fitness values, in the current popula- tion set, will have higher probability to be selected as seeds for generating the rival population. This proba- bilistic scheme of selecting the seeds of the new gener- ation is known as the probabilistic reproduction. Be- cause the value of U D ( d z , z r l is either 0 or l , there needs no multiplication for computing the fitness values.
The reproduction method used in this work is similar
to the weighted roulette wheel method [l]. For each
chromosome Ci, an incidence range ri is calculated as
(151
r i =
[
f kE",=,
f k)
cfcr
fk'
fk 'where fk is the fitness value of the kth chromosome in
the population, and '[' and ')' denote closing and open- ing boundaries, respectively. When the incidence range
of each chromosome has been determined, N real num-
bers ai for i = 0 , 1 , . . . , iV- 1, are randomly generated, where 0
5
ai<
1. T h e value of ai will be bounded bysome incidence range r j , that is, aiE r j . The j t h chro-
mosome Cj is then selected as a seed to generate the
rival population. It is possible that one chromosome
can be selected twice or more. Because N real random
numbers are generated, N seeds will be selected and
placed in the mating pool.
After the reproduction stage, the seeds in the mating
pool are transferred into candidate chromosomes of the
new population set by mutation. Assume the current
chromosome t o be processed is [mi nilt, where mi =
[ ~ l i , k - l a i , k - 2 . . .Ui,o] and ni = [ b i , k - l b i , k - % . . . bi,o]. In
the j t h generation, two genes ai,= and bi,z are varied, where z = k - 1 - ( j mod I C ) .
There are eight mutation operators,
{(G,
y p ) j p =0 , 1 , . . ., 7}, which can be adopted in our implementa- tion, that is
where p is a random integer whose value is between
0 and 7. Because the chromosomes are randomly se-
lected and put on the mating pool, it is not necessary to generate a random number for determining the value of p . We simply set p t o be ( i mod 8). The mutation operators are therefore defined as,
c p = (-l)"([p
+
1-
1(1+ l)]V P - - ( - l ) q P + 1 - 1(Z+ l)]
N chromosomes are selected from the union of the
original population set and the rival population set ( 2 N
chromosomes in total) according t o the fitness values. Each chromosome can only be selected once. T h e chro- mosomes with larger fitness values will be picked u p as the members of the new population set and go through the next iteration of the genetic evolution. Although the chromosomes have to be sorted in this survival com- petition stage, the overhead is not high because the
population size is usually not large in the LGSA. In
GA, the new chromosomes generated from the original
ones are not guaranteed t o have larger fitness values. The survival competition stage is included in the LGSA to prevent the chromosomes from being replaced by the new ones with poorer fitness values because the maxi- mum generation number will be restricted to be quite small so as t o cope with the tight time constraint.
The chromosome with the maximum fitness value is selected from the current population as a possible solution. The possible solution might be replaced by the other ones from one generation t o the others. The iteration will be terminated when the termination con- ditions are satisfied. There are three termination con-
ditions in the LGSA: (1) the possible solution is not
updated for a predetermined period of generations; (2)
the matching value of the possible solution is better
than a predefined threshold; ( 3 ) the iteration number
reaches the given maximum generation bound. The computational cost of generating a random
tions, the search space is usually large and the time con- straint is not an important issue, hence the computa- tional cost required t o generate random numbers is tol- erable. However, when GAS are applied to time critical applications, such as the block matching of video cod- ing, the cost of generating random numbers becomes a critical issue because the search space is relatively small and the time constraint is extremely tight. In con- ventional GAS, random numbers have to be generated in the reproduction, the crossover, and the mutation stages. Nevertheless, the random number generator is only called in the reproduction stage of the LGS.A.
In conventional GAS, crossover is usually applied.
The purpose of performing crossover is t o randomly
exploit new search points. Because the search space is not large in the LGSA, there are no large amounts of local optima in the search space. The effectiveness of crossover is not prominent; therefore, the crossover stage is not included in the LGSA for complexity re- duction.
Because weaker chromosomes might propagate stronger chromosomes, they are not excluded in the
new population set of the conventional GAS. The pop-
ulation will be gradually mature after a long period of generations. T h a t is, weaker chromosomes will not hin- der the population from being mature; however, they will bring large harms to the LGSA in which the gen-
eration number of evolution is restricted to be small.
To solve this problem, in the LGSA, a survival com- petition stage is included. It ensures that the quality of each chromosome in the current population set is better than the old ones.
There are two kinds of mutation operators used in the traditional GA-based implementation: changing a gene’s value (i) from 0 to 1, or (ii) from 1 t o 0. Gen- erally, the mutation probability is very low so as not
to impair the overall quality of a given population. In
the LGSA, the mutation probability is relatively high
so the evolution of chromosomes is relatively violent.
Fortunately, the bad effect of high mutation rate will be totally controlled by the survival competition. In- terestingly, lots of search points will be explored due to high mutation rate although there is no crossover stage in the LGSA.
Because the evolution of chromosomes is slow, the maximum and the average generation numbers are
la,rge in conventional GAS, and so are the required
average computations for finding the extreme value. Therefore, both the control overheads and the cost of performing extreme value finding are tremendous. In the LGSA, the evolution is relatively violent and the
quality of chromosomes is well controlled by the sur-
vival competition stage, so the maximum generation
number is small and the control overheads of chromo- some evolution are also reduced. Moreover, the cost for extreme value finding of the
LGSA
i s relatively small because most of the irrelevant search points have been excluded.5
CONCLUSION
In this paper, some important issues of the genetic evolution, such as the efficiency of crossover and muta- tion operations and the global convergence property are analyzed. It follows froiii the analyses, when the search space is small, the efficiency of the crossover operation is not good enough for deserving the required computa- tions. It is also hard t o adjust the mutation probability t o promote the efficiency of the conventional mutation operations. In the proposed LGSA, the computational complexity is well controlled by taking the characteris- tics of smaller search space into account.
References
[I] D. E. Goldberg, Genetic Algorithms i n Search, Op- timization t4 Machane Learning. Reading: Addison- Wesley, 1989.
[a]
J. R. Jain and A. K. .Jain, “Displacement measurement and its application in interframe image coding,” IEEETrans. Commun., vol. COM-29, Dec. 1981, pp. 1799- 1808.
[3] Keith Hung-Kei Chow and Ming L. Liou, “Genetic
motion search algorithm for video compression,” IEEE
Trans. Circuits and 5”ystems f o r Video Technology, vol.
3, no. 6, Dec. 1993: lpp. 440-445.
[4] In Kwon Kim and Rae-Hong Park, “Block matching algorithm using a ge.netic algorithm,” in S P I E Sympo-
sium on Visual Communications and Image Process- ing, Taipei, Taiwan, May 1995, pp. 1545-1552.
151 M. Wollborn, “Prototype prediction for colour up-
date in object-based analysis-synthesis coding,” IEEE Trans. Circuits and Systems for Video Technology, vol.
4, no. 3 , June 1994, pp. 236-245.
[6] K. A. De Jong and SY. M. Spears, “An analysis of the interacting roles of population size and crossover in
genetic algorithms,” in Parallel Problem Solving from
Nature, H. P. Schwefel and R. MGnner, Eds. Springer, Berlin and Heidelberg, 1991, pp. 38-47.
[7] D. E. Goldberg, “Sizing populations for serial and par- allel genetic algorithms,” in Proc. 3rd Int. Conf, Ge- netic Algorithms and Applications, San Mateo, CA,
1989.
[8] J. J. Greffenstette, “Optimization of control param-
eters for genetic algorithms,” IEEE Trans. Systems
Man and Cybernetic:a, vol. 16, no. 1, 1986, pp. 122-
2 0.2963 0.0027 0.1111
Figure 1. (a) T h e N-point crossover, (b) an equivalent representation of an n-poznt crossover
3
4
5 0.35 1 0.1376 0.0017 0.0370 0.0661 0.0006 0.0123 0.0041 0.0321 0.0002 0 F ' ' ' ' ' ' ' ' ' ' ' ' ' ' ' ' ' ' " 1 11 21 31 41 51 6 1 71 81 91 Generation Number(4
Y m= 0.5 -Pm=0.99~ _ _ _ _
Generation NumberFigure 2. Mutation eficiency of chromosome length b = 2 : (a) the average mutation disruption rates, (b) the variances of the disruption rates for different chromosomes.
0.035 1 I Pm=OOl 0.025 r m= 0.5 -Pm=0.99
I
- . . - -
0.005 0 . . . 1 1 1 2 1 31 41 5 1 61 71 81 91 Generation Number (a) Generation Number (b)Figure 3. Mutation eflciency of chromosome length k = 5: (a) the average mutation disruption rates, (b) the