國立交通大學
資訊科學與工程研究所
博士論文
全光分波多工封包交換都會環狀網路之
高效能服務品質保證媒介存取控制技術
A High-Performance Medium Access Control
Scheme with QoS Assurance for an Optical
Packet-Switched WDM Metro Ring Network
研 究 生:趙一芬
指 導 教 授:楊啟瑞 博士
全光分波多工封包交換都會環狀網路之
高效能服務品質保證媒介存取控制技術
A High-Performance Medium Access Control
Scheme with QoS Assurance for an Optical
Packet-Switched WDM Metro Ring Network
研 究 生:趙一芬
Student: I-Fen Chao
指導教授:楊啟瑞 博士
Advisor: Dr. Maria C. Yuang
國立交通大學 資訊學院
資訊工程學系
博士論文
A Thesis
Submitted to Department of Computer Science
College of Computer Science
National Chiao Tung University
in partial Fulfillment of the Requirements
For the Degree of
Doctor of Philosophy
in
Computer Science
March 2010
Hsinchu, Taiwan, R.O.C.
全光分波多工封包交換都會環狀網路之
高效能服務品質保證媒介存取控制技術
研究生:趙一芬 指導教授:楊啟瑞 博士
國立交通大學 資訊工程學系
Abstract in Chinese
下一代全光都會型網路(Metropolitan Area Networks; MANs)旨在低成本有效 率地運用先進的光封包交換技術(Optical Packet Switching; OPS)支援各類型要求 高頻寬之網路應用程式以及訊務特性趨於動態變化之網路應用程式。此篇論文提 出一高效能服務品質保證媒介存取控制機制,應用在我們建立的高效能分波多工 光 封 包 交 換 都 會 環 狀 網 路(High-performance OPS Metro WDM slotted-ring Network, HOPSMAN)實驗平台。HOPSMAN 的設計為一可擴展性架構,所以網 路節點數目可不受光波道的數目限制。HOPSMAN 網路中包含數個服務節點, 額外配備時槽除訊器,具備時槽除訊功能,以高效率低成本的方式增加頻寬利用 率。HOPSMAN 最重要的設計為其獨一無二的媒介存取控制機制,稱為機率式 定額與額外配額(Probabilistic Quota plus Credit; PQOC);而後,我們又在其上加 入服務品質保證(Quality of Service; QoS)的功能,稱為機率式定額與額外配額服 務品質保證(Probabilistic Quota plus Credit with QoS Assurance; PQOC/QA)。藉由 機率式定額傳送資料的方式,本媒介存取控制機制可以高效率且公平的使用頻 寬。根據服務節點的數量,目標節點的訊務量分配方式,我們分析計算出該定額 分配量。除此之外,為應付極具動態變化的都會型網路的訊務量,本媒介存取控 制機制引進一時間控制機制的額外配額方式來公平使用多餘的頻寬。更甚者,為 了支援服務品質保證以及解決分波多工網路固有的存取問題,PQOC/QA 利用簡 單且具彈性的標記方法來執行時槽預訂。為了更適應動態的即時訊務(VBR),我
們不像以往其它的研究著重於估算動態訊務量;取而代之,PQOC/QA 簡單地採 用平均連線速率頻寬保留的方法在環狀網路上的每個循環(cycle)預定保留頻 寬,彈性地建立即時連線以傳送動態的即時訊務。另外,根據M/G/m 排隊理論 的分析,我們發展了一個獨特的概算方式求得平均建立連線等待時間。本分析的 伺服機數量為系統預先定義的即時訊務的最大可接受定額數,服務時間包含一指 數分佈之長度及外加一常數值。關於M/G/m 排隊理論,除了少數的服務分佈可 以得到準確結果之外;以往,針對具某些特性的一般服務分佈的概算分析,只能 達到10%的相對誤差值。但我們針對本系統內特定的服務分佈,我們提出一概算 方式,所求得的結果與模擬實驗結果完全吻合。更甚者,經由深入的模擬結果, 藉由本篇論文所提出的媒介存取控制機制,即使在各種負載或大量突發訊務之 下,HOPSMAN 可以達到更為優異的系統輸出,低延遲,以及卓越的即時訊務 表現,達到高即時訊務輸出,以及極低的VBR 延遲及延遲變化量。
A High-Performance Medium Access Control
Scheme with QoS Assurance for an Optical
Packet-Switched WDM Metro Ring Network
Student: I-Fen Chao Advisor: Dr. Maria C. Yuang
Department of Computer Science National Chiao Tung University, Taiwan
Abstract
Future optical Metropolitan Area Networks (MANs) have been expected to exploit advanced Optical Packet Switching (OPS) technologies to cost-effectively satisfy a wide range of applications having time-varying and high bandwidth demands and stringent delay requirements. In this thesis, we present a high-performance real-time medium access control scheme for our experimental high-performance OPS metro WDM slotted-ring network (HOPSMAN). HOPSMAN has a scalable architecture in which the node number is unconstrained by the wavelength number. It encompasses a handful of nodes (called server nodes) that are additionally equipped with optical slot erasers capable of erasing optical slots resulting in an increase in bandwidth efficiency. In essence, HOPSMAN is governed by a novel medium access control (MAC) scheme, called Probabilistic Quota plus Credit (PQOC), which is further enhanced with QoS assurance, called Probabilistic Quota plus Credit with QoS Assurance (PQOC/QA). The proposed MAC scheme embodies a highly efficient and fair bandwidth allocation in accordance with a quota being exerted probabilistically. The probabilistic quota is then analytically derived taking the server-node number and destination-traffic distribution into account. Besides, the MAC scheme introduces a time-controlled credit for regulating a fair use of remaining bandwidth particularly in the metro environment with traffic of high burstiness. Moreover, PQOC/QA adopts slot-basis reservation through a simple and flexible marking mechanism to support QoS and to resolve the intrinsic access problem in WDM network. Instead of focusing on estimation of the bandwidth requirements, PQOC/QA sets up real-time connections by employing constant mean rate reservation on each cycle of the ring
and effectively accommodates bursty real-time traffic (VBR). Furthermore, we develop a novel approximation to acquire the accurate results of the expected connection setup queueing delay by means of an M/G/m queueing analysis. In the analysis, the maximum admissible quota of real-time traffic is regarded as the number of servers and the service time has a duration that follows an exponential form with an added constant. In M/G/m queueing analysis, the accurate results have only been attained for a limited number of special service distributions, while most of the proposed approximation only maintained a less than 10% relative error for certain properties of service distributions. Our approximation results, which are derived under the particular general service distribution in our system, show that the mean setup queueing time is in profound agreement with the analytic result. Additionally, extensive simulation results show that HOPSMAN with the proposed MAC scheme achieves exceptional delay-throughput performance and remarkable real-time traffic performance (high statistical multiplexing gain for real-time traffic, exceedingly low VBR delay and jitter) under a wide range of traffic loads and burstiness.
誌謝
首先我要對我的指導老師楊啟瑞教授致上最誠摯的謝意與敬意。 感謝她在 我博士班期間不厭其煩地給我指導與協助,以及研究理念上的薰陶。同時也在老 師身上看到了她對做研究的熱忱和堅持,這樣的精神讓我深受感動以及深刻地影 響我。 接著,我要特別感謝我的先生 鍾勇輝,沒有他全力的支持和鼓勵,我想我 不會走完這一程。每每氣餒時,他總是對我仍然信心十足,讓我有勇氣去面對每 個時候的難題。 我還要感謝實驗室的學長學弟,他們在這幾年間給予我許多的指導與關 照。感謝羅志鵬、施汝霖先生在研究過程中不吝給予幫助指導,感謝與王雅纖學 姐互相砥礪扶持。 此外,我還要感謝我的家人,因為你們的支持與鼓勵,使我有動力完成這 份研究,在此衷心地感謝他們。特別是我婆婆,由於她無私的照料,讓我完全無 後顧之憂,可以全心的專注在研究上。感謝我的女兒鍾若昀,讓我在研究之餘, 感覺生命的美好。 最後僅將我的論文獻給我最摯愛的父母,感謝他們無條件的愛以及支持。 趙一芬 國立交通大學 中華民國九十九年五月CONTENTS
ABSTRACT IN CHINESE ... I ABSTRACT... III ACRONYMS... IX CHAPTER 1. INTRODUCTION...1 1.1OPTICAL WDMNETWORKS...11.2MOTIVATION AND OBJECTIVES...11
1.3ORGANIZATION OF THE THESIS...13
CHAPTER 2. GENERAL NETWORK AND NODE ARCHITECTURES ...15
2.1NETWORK ARCHITECTURE...15
2.2NODE ARCHITECTURE...16
CHAPTER 3. MAC SCHEME– PROBABILISTIC QUOTA PLUS CREDIT ...19
3.1DESIGN PRINCIPLES AND THE DETAILED ALGORITHM...19
3.2BANDWIDTH ALLOCATION-PROBABILISTIC QUOTA DETERMINATION...25
3.3SIMULATION RESULTS...30
3.4TESTBED IMPLEMENTATION AND EXPERIMENTAL RESULTS...40
CHAPTER 4. MAC SCHEME WITH QOS ASSURANCE ...50
4.1DESIGN PRINCIPLES AND THE DETAILED ALGORITHM...50
4.2EXPECTED QUEUEING TIME ANALYSIS...64
4.3SIMULATION RESULTS...71
CHAPTER 5. CONCLUSIONS...84
List of Figures
Figure 1. HOPSMAN: network architecture... 15
Figure 2. HOPSMAN node architecture. ... 16
Figure 3. Cycle and slot structures ...21
Figure 4. Detailed PQOC algorithm...23
Figure 5. Quota determination...26
Figure 6. Bandwidth efficiency of HOPSMAN ...32
Figure 7. Analytic and simulation results on system throughput under different S-node ... 33
Figure 8. Throughput performance of HOPSMAN... 34
Figure 9. Delay performance of HOPSMAN...35
Figure 10. Credit window size under various burstiness...37
Figure 11. Credit impact on delay for network with malicious nodes (nodes 5 and 15) ...37
Figure 12. The impact of probabilistic exertion of quota under various loads and burstiness...38
Figure 13. Hardware implementation of the HOPSMAN testbed system. ...41
Figure 14. Synchronization of control and data channels ...43
Figure 15. Experimental results with fast optical devices...46
Figure 16. Feasibility test and demonstration of HOPSMAN testbed ... 48
Figure 17. Cycle and slot and reservation structures... 51
Figure 18. Quota distribution in PQOC/QA... 53
Figure 19. An example of connections set up ...56
Figure 20. Data flow of the real-time connections...57
Figure 21. Detailed PQOC/QA algorithm ...62
Figure 22. Occupancy distribution analysis for M/G/m under FCFS ... 68
Figure 23. Connections setup performance... 74
Figure 24. Throughput performance of high priority data. ...76
Figure 25. Mean delay and jitter performance of VBR traffic ...77
Figure 27. Delay bound of VBR traffic...79 Figure 28. The impact on VBR mean delay under various ABR loads and the ABR
delay comparison ... 80 Figure 29. Mean delay comparison between ABR and VBR traffic under equivalent
loads ... 82 Figure 30. The impact on ABR delay under various burstiness and loads of VBR traffic...82
Acronyms
ABR Available Bit Rate
ADM Add/Drop Multiplexer
AOTF Acousto-Optic Tunable Filter ATMR Asynchronous Transfer Mode Ring AWG Arrayed Waveguide Gratings
BMR Burst-Mode Receiver
CAC Call Admission Control CBR Constant Bit Rate
CSMA/CA Carrier Sense Multiple Access with Collision Avoidance DAVID Data And Voice Integration over DWDM
DQDB Distributed Queue Dual Bus
DQBR Distributed Queue Bidirectional Ring DWDM Dense Wavelength Division Multiplexing EOTF Electro-Optic Tunable Filter
FBG Fiber Bragg Gratings FCFS First Come First Serve FIFO First In First Out
FPGA Field Programmable Gate Array
FR Fixed-Tuned Receiver
FT Fixed-Tuned Transmitter
FWM Four Wave Mixing
HORNET Hybrid Optoelectronic Ring Network
IP Internet Protocol
MAN Metropolitan Area Network
M-ATMR Multiple Asynchronous Transfer Mode Ring MMPP Markov Modulated Poisson Process
MMR Muliple MetaRing MPU MAC Processing Unit
MPEG Moving Picture Experts Group MTIT Multitoken Interarrival Time M/G/m Multi-Server Queueing System OCS Optical Circuit Switching
OPS Optical Packet Switching O-Node Ordinary Node
PDF Probability Desnsity Function PQOC Probabilistic Quota plus Credit
PQOC/QA Probabilistic Quota plus Credit with QoS Assurance QoS Quolity of Service
RAM Random Access Memory
RingO The Italian Ring Optical Network RPR IEEE 802.17 Resilient Packet Ring SDH Synchronous Digital Hierarchy
SGDBR Sampled-Grating Distributed-Bragg-Reflector SOA Semiconductor Optical Amplifier
SONET Synchronous Optical Network SRR Synchronous Round Robin
SR3 Synchronous Round Robin with Reservations
STE SYNC Timing Extractor
S-Node Server Node
TDM Time Division Multiplexing
TR Tunable Receiver
TT Tunable Transmitter
VBR Variable Bit Rate
WDM Wavelength Division Multiplexing WDMA WDM Access Protocol
Chapter 1. Introduction
1.1 Optical WDM Networks
1.1.1 An Overview
For long-haul backbone networks, optical wavelength division multiplexing (WDM) [1,2] has been shown successful in providing virtually unlimited bandwidth to support a large amount of steady traffic based on the optical circuit switching (OCS) paradigm. Future optical metropolitan area networks (MANs) [3,4], on the other hand, are expected to cost-effectively satisfy a wide range of applications having time-varying and high bandwidth demands and stringent delay requirements. Nevertheless, today’s metropolitan area networks are mostly SONET/SDH ring networks. These networks are circuit-switched networks. The SONET/SDH technology offers data transmission only at specific rates from a prescribed set of rates. The main drawback of SONET/SDH networks is that due to their time-division multiplex operation in conjunction with a circuit set-up time on the order of several weeks or months [5], they accommodate packet traffic only inefficiently [6], especially when the traffic is highly variable, giving rise to the so called metro gap. Such facts bring about the need of exploiting the optical packet-switching (OPS) [4,7,8] paradigm that takes advantage of statistical multiplexing to efficiently share wavelength channels among multiple users and connections. Note that the OPS technique studied here excludes the use of optical signal processing and optical buffers, which are current technological limitations OPS faces. Numerous topologies and architectures [3,4,7-16] for OPS-based WDM metro networks have been proposed. Of these proposals, the structure of slotted rings [9-16] receives the most attention. Essentially, these slotted-ring networks offer high-performance access and
efficient bandwidth allocation by means of medium access control (MAC) [17-20] schemes.
Regarding the design of the WDM networks, we first consider two of the important issues: node architectures [21,22] and bandwidth reuse [14,16]. In the WDM networks, the nodes are equipped with number of transmitters and receivers to transmit and receive data. The transmitters and receivers are either fixed-tuned to a particular wavelength (denoted as FT/FR) or tunable to any wavelength (denoted as TT/TR). The systems are first designed by a non-scalable architecture which is equipped with the same number of FT/FR as that of the wavelengths [23]. The main advantage of this system is that concurrent transmissions on distinct channels are possible at a given node. While this architecture requires as many wavelengths as there are nodes in the network, and this severely limits the scalability of such a network. Further, the nodes are further designed with advanced optical devices, such as TT-FR and TT-TR structures. Systems based on TT-FR is still incurred a scalability problem, since each node or a group of nodes is assigned a home channel to receive data. Once there is no data to transmit to a particular node, the bandwidth of its home channel is then wasted. Except the throughput degrades due to the static assignment (poor statistic multiplexing gain), the maximum number of nodes is also limited by the number of available channels. While systems based on the TT-TR structure are the most flexible in accommodating a scalable user population but with a most challenging issue in designing and implementing a high-speed photonic hardware component (TR).
We further observe that a ring network with spatial bandwidth reuse achieves much better throughputs than in star topology [24,25], where bandwidth reuse is not possible. Indeed, the advantage of spatial bandwidth reuse is one of the main reasons why the structure of slotted rings receives the most attention. Generally, the spatial
reuse includes source- and destination-stripping schemes. In the case of source-stripping operation, the transmitting node is responsible for marking the slot empty after it has completed an entire ring loop. With destination stripping, the destination node receives the packets and removes them from the ring, making the slot reusable earlier than in the previous scheme. The network capacity of unidirectional ring networks can be increased with destination stripping where multiple simultaneous transmissions can take place on each wavelength. For uniform traffic, the mean distance between source and destination is half the ring circumference. As a consequence, two simultaneous transmissions can take place at each wavelength on average, resulting in a network capacity that is twice as large as that of unidirectional rings with source stripping. However, in this thesis, we propose a new notion which is referred to as server-stripping. Only a few numbers of nodes in the network is capable of removing the data from the ring. The associated network architecture will be shown to be most cost-effective for bandwidth reuse.
1.1.2 Existing MAC Schemes on Single-Channel Rings
Before assessing the OPS WDM slotted-ring networks, we first examine some formerly proposed MAC schemes for ring networks. These schemes can generally be categorized as quota-based or rate-based. In the quota-based schemes, each node is allocated a quota that is the maximum transmission bound within a variable-length cycle. Most of the research work focuses on the dynamic adjustment of the cycle length. In the following, we introduce two of the well-known quota-based schemes: ATMR [3,26] and MetaRing [3,27]. And, we also introduce a rate-based scheme: RPR (IEEE 802.17 Resilient Packet Ring) [28].
The ATMR protocol adopts a quota-based scheme on single/dual- ring network. It provides fairness control with a cycle reset mechanism. The mechanism allocates
each node a maximum transmission bound (quota) within a cycle, and it re-starts a new cycle by sending a reset signal from the last active node. If the last active node detects inactivity of all other nodes, it generates a reset which is sent to all nodes as soon as the node itself stops sending. Monitoring of inactivity is performed as each active node overwrites a busy address field in the header of each cell with its own address. So any node which receives a slot with its own busy address assumes that all other nodes are inactive because none of them has overwritten the field. The reset is responsible for the distributed fairness control and causes a node to set up its window counter to the initial window size. The counter is decremented each time the node fills a free slot with data. By counting it down to zero it is guaranteed that within a reset period, i.e. the time between two consecutive resets, each station uses a maximum number of cells. As the window counter expires, the node is forced into the inactive state. In this state it cannot send any data until the next reset activates once more. If a station has no more data to send the node will pass over to the inactive state, but it may become active again without receiving the next reset on arriving data at the transmit queue. The primary disadvantage of this scheme is that a node cannot send any packet before receiving the reset signal. In other words, there is an idle gap between two consecutive reset periods. Therefore, the bandwidth is waste and system utilization downgrades. Another disadvantage is the determination of the value of quota, which relates to the network throughput and the maximum delay time. Since the reset signal has to run at least one round trip time, the quota can not be set too small causing the maximum delay time is above one round trip time.
MetaRing deploys a quota-based fairness scheme on dual-ring network. This mechanism works with a hardware control message, called SAT-signal. This is very short, and on a dual counter rotating ring it circulates in the opposite direction to the data which it controls. The signal has preemptive resume priority, i.e. at any time it
can be inserted into the data flow. If a station gets the SAT-signal and it is satisfied, it sends the signal immediately to the neighboring node. Otherwise it keeps the signal until it becomes satisfied. A node can transmit its local traffic whenever it has not exhausted its quota. When sending the signal to the neighboring station, the slot counter is reset to zero. That is, the quota of a node is renewed every time SAT-signal visits the node. The major drawback of this global fairness is that quotas can only be renewed when a node receives SAT-signal, and which may need several of ring times depending on the value of quota. Therefore, the maximum access delays are within the order of round trip times. When the ring network is overloaded, the access delays seen by each node will oscillate between zero and the maximum value depending on when a packet comes in relative to the recent SAT-signal visit.
The standard, IEEE 802.17, Resilient Packet Ring (RPR) deploys a rate-based fairness algorithm. Current RPR networks are single-channel systems (i.e., each fiber carries a single wavelength channel) and are expected to be primarily deployed in metro edge and metro core areas. It adopts destination stripping enables nodes in different ring segments to transmit simultaneously, resulting in spatial reuse and increased bandwidth utilization. RPR provides a three-level class-based traffic priority scheme. As a rate-based MAC, an RPR station implements several traffic shapers to smooth and control the rate of each traffic class. The three-level classes: class A (divided into A0, A1) for a low-latency low-jitter class, class B (BCIR, B-EIR) for a class with predictable latency and jitter, and class C be a best effort transport class. The two traffic classes C and B-EIR are called fairness eligible (FE), because such traffic is controlled by a fairness algorithm. The shapers for classes A0, A1, and B-CIR are preconfigured; the bandwidth for class A0 is called reserved. And, the downstream shaper, set to the unreserved rate (other than class A0), ensures that the total transmit traffic from a station does not exceed the unreserved rate. While the FE
shaper is dynamically adjusted by the fairness algorithm for control class B-EIR and class C. RPR also includes a local fairness algorithm to solve the unfairness among the contending stations.
In summary, ATMR allows the last active node to initialize a reset-signal rotating on the ring to inform all nodes to re-start a new cycle. MetaRing uses a token-based signal circulating around the ring. When a node receives the token, it either forwards the token and thus starts a new cycle immediately, or holds the token until the node has no data to send or the quota of previous cycle expires. These schemes were shown to achieve high network utilization and great fairness. However, they cause cycle lengths to prolong several ring times, resulting in a large maximum delay bound and delay jitter, and thus poor bursty-traffic adaptation. In the rate-based schemes, RPR (IEEE 802.17 Resilient Packet Ring) is based on a pre-determined leaky bucket rate to transmit data, in combination with a local-fairness algorithm to resolve the potential congestion problem. Comparing with the quota-based schemes, the rate-based scheme was shown to reduce the maximum delay bound [29]. However, the leaky rate is modified only after receiving the feedback from the downstream nodes when congestion occurs. As a result, due to using the pre-determined rate and the slow response to rate changes, the scheme yields poor statistical multiplexing gain and dissatisfying delay-throughput performance especially under the high-burstiness fluctuating traffic condition. The goal of this thesis is to present a quota-based MAC scheme that tackles the performance problem from a perspective of the determination of the quota rather than the cycle length.
1.1.3 A Survey on WDM Ring Networks
There have been numerous OPS WDM slotted-ring networks proposed in the literature [3]. In the following, we assess three well-known prototyping networks that
are most relevant to our work. First, Hybrid Optoelectronic Ring NETwork (HORNET) [9] is a bi-directional WDM slotted ring network in which each node is equipped with a tunable transmitter and a fixed-tuned receiver. It employs a MAC protocol, called Distributed Queue Bidirectional Ring (DQBR), which is a modified version of IEEE 802.16 Distributed Queue Dual Bus (DQDB) protocol [30]. DQBR requires each node to maintain a distributed queue via a pair of counters per each wavelength to ensure that packets are sent in the order they arrive at the network. With DQBR, HORNET achieves acceptable utilization and fairness at the expense of high control complexity for maintaining the same number of counter pairs as that of wavelengths. Moreover, due to the use of fixed-tuned receiver, HORNET statically assigns each node a wavelength as the home channel for receiving packets. Such static wavelength assignment results in poor statistical multiplexing gain and thus throughput deterioration.
The second prototyping network, called Ring Optical Network (RingO) [10], which is a unidirectional WDM slotted ring network with N nodes where N is equal to the number of wavelengths. Each node is equipped with an array of fixed-tuned transmitters and one fixed-tuned receiver operating on a given home wavelength that identifies the node. Such a design gives rise to a scalability problem. RingO employs a MAC protocol, called a synchronous round robin with reservations (SR3) [11], which is a combination of the synchronous round-robin (SRR), token-control quota based (Multi-MetaRing), and slot-reservation mechanisms. The scheme was shown to achieve high utilization and fairness. As for the fairness-scheme, Multi-MetaRing, it inherits all the pros and cons from the MetaRing. Specifically, there are W numbers of tokens rotating on W wavelengths. The scheme encounters an additional problem in which a node may hold several tokens at the same time due to the fact that only one data packet can be sent per slot time. The problem results in an increase in access
delay and throughput degradation.
The metro network of the European IST Data And Voice Integration over DWDM (DAVID) [12,13] attempted to address the overall efficiency of ring-to-ring traffic, and fairness and QoS control inside a metro ring. DAVID is structured to be comprised of several independent fiber rings interconnected via a buffer-less SOA-based packet switch, i.e., the hub node. The hub node is responsible for forwarding data packets among different rings of the network in the optical domain via an available wavelength. Due to having multiple rings, the hub requires each node to make slot reservation prior to the transmissions and has to resolve a feasible wavelength-to-wavelength permutation [15] at all times. Within each ring, the Multi- MetaRing scheme is employed to ensure the fairness control. Each active node is equipped with a tunable transmitters, a tunable receiver, and an SOA-based slot eraser, enabling high slot reuse but at the expense of prohibitive system cost.
Note that both RingO and DAVID adopt Multi-MetaRing as their fairness control scheme. Recall that MetaRing is a quota-based scheme, thereby most relevant to our work. In MetaRing, a control message SAT-signal (which stands for SATisfied) rotates around the ring, and the quota of a node is renewed every time SAT-signal visits the node. In Multi-MetaRing, it is simply designed by independent multiple MataRing with one separate SAT-signal for each channel (i.e. W number of SAT-signals for W number of data channels). In other words, there are multiple token-like signals rotating on the multiple channels to ensure the fairness among nodes. The quota of a particular channel of a node is renewed only when the node receives the token on that channel. Therefore, Multi-MetaRing inherits all the disadvantages from the MetaRing. That is, the maximum access delays are within the order of round trip times. When the ring network is overloaded, the access delays seen by each node will oscillate between zero and number of round trip times. This
outcome is especially unsuitable for bursty metro traffic and real-time traffic. When applying to WDM networks, Multi-MetaRing encounters an additional problem in which a node may hold several tokens at the same time due to the fact that only one data packet can be sent per slot time (due to the fact that each node is equipped with only one transmitter). The problem results in an increase in access delay and throughput degradation.
1.1.4 Existing MAC Schemes with QoS assurance
in WDM Networks
For future optical Wavelength Division Multiplexing (WDM) networks, OPS WDM networks have been envisioned as a future framework for next-generation Internet (NGI), which is expected to support integrated multimedia services with various quality-of-service (QoS) requirements [31-42]. Expected supported services include constant bit rate (CBR), variable bit rate (VBR), and available bit rate (ABR). The real-time traffic, such as CBR and VBR traffic, referred to as high priority data, is subject to a centralized/distributed call admission control (CAC) [43-48] that accepts connections if all demands are guaranteed to be satisfied. While the ABR traffic which is referred to as low priority data takes advantages of all the remaining bandwidth. Pertaining to such OPS WDM networks, one of the most interesting and challenging issues is to design an efficient medium access control (MAC) that flexibly accommodates maximal real-time traffic with remarkable QoS performance while still sustaining exceptional aggregate system throughput.
Most existing MAC schemes with QoS provision primarily focus on two major challenges, the reservation mechanism and the accommodation of real-time traffic. In single-channel networks, such as IEEE 802.16 Distributed Queue Dual Bus (DQDB) protocol [30], Asynchronous Transfer Mode (ATM), and IEEE 802.17 Resilient Packet Ring (RPR) [28], support QoS by rate-basis reservation, which allocates the
required rates of bandwidth for real-time traffic. However, in WDM networks, they adopt slot-basis reservation schemes [31-34], where they clearly specify which data slots are reserved for real-time traffic. Since in most of the current WDM networks, each node is equipped with only one receiver, bringing in a receiver-contention problem (two packets destined for the same node are prohibited at the same slot time). If the real-time traffic is only rate-reserved, it may fail to transmit due to the receiver-contention problem. As to regard the accommodation of real-time traffic, most approaches focus on the bandwidth requirements estimation, such as guaranteed bandwidth (peak rate), effective bandwidth, and dynamic measurement bandwidth [43-48]. Both guaranteed bandwidth and effective bandwidth are often over-estimated, thereby resulting in poor system utilization. While the measurement-based bandwidth is too complex and difficult to be properly predicted, it is either over-estimated or under-estimated (poor QoS guarantee). In this thesis, we simply tackle the problem from the perspective of a given proportion of bandwidth left over for the bursty traffic rather than the actual bandwidth estimation.
In WDM ring networks, existing researches propose QoS provision by slot-basis reservation but either in inflexible or over aggressive reserved manner, thereby causing poor statistical multiplexing gain for real-time traffic or system utilization degradation. The methodologies in [31,32] make reservation at their corresponding preferential frame-based slots, which were pre-assigned either on a per-source-destination basis [31] or per-destination basis [32] to suit the hardware limitations imposed by their network architectures. Since each node is equipped with one fixed-tuned receiver tuned to its home channel, the reservation can only be done at some pre-assigned wavelength and at some pre-assigned slot times. While [32] solves the scalability problem, thus the number of the nodes is greater than the number of wavelengths. These schemes indeed satisfy the QoS requirement. However,
because they make reservations only at particular slots, they are rather inflexible and inefficient, leading to poor statistical multiplexing gain for real-time traffic. Another scheme [33] makes high-priority-marks at the control channel and shares with all nodes whenever a node fails to transmit any high priority data. Although the share among nodes confines the total number of reservations and lowers the mean delay, it could still make too many redundant reservations, especially when it deals with highly-bursty traffic (VBR traffic). In such networks, the scheme compensates by compressing the bandwidth for best-effort traffic, thereby degrading the overall system utilization. Despite of the disadvantages discussed above, all the schemes for WDM ring networks focus primarily on the slot-reservation methodology only, lacking an overall evaluation of real-time traffic performance and do not include a viable CAC function which adapts to the VBR traffic.
1.2 Motivation and Objectives
Our major goal has been the design and prototype a high-performance optical packet-switched metro WDM ring network (HOPSMAN). In this thesis, we present the architecture and the MAC scheme of HOPSMAN [7,8]. HOPSMAN has a scalable architecture in which the node number is unconstrained by the wavelength number. Nodes are equipped with high-speed photonic hardware components that are capable of performing nanosecond-order OPS operations. HOPSMAN also encompasses a small number of server nodes that are additionally equipped with optical slot erasers capable of erasing optical slots resulting in an increase in bandwidth efficiency. In essence, HOPSMAN is governed by a novel medium access control (MAC) scheme, called Probabilistic Quota plus Credit (PQOC), which is further enhanced with QoS assurance, called Probabilistic Quota plus Credit with QoS
Assurance (PQOC/QA). The proposed MAC scheme embodies a highly efficient and fair bandwidth allocation in accordance with a quota being exerted probabilistically. Unlike the existing quota-based schemes, our goal is to determine the quota rather than the cycle length. Taking the server-node number and destination-traffic distribution into account, we analytically derive the probabilistic quota. Besides, the MAC scheme introduces a time-controlled credit for regulating a fair use of remaining bandwidth particularly in the metro environment with traffic of high burstiness. Extensive simulation results show that HOPSMAN with our proposed MAC scheme achieves great fairness and exceptional delay-throughput performance under a wide range of traffic loads and burstiness.
Furthermore, we enhance the MAC scheme with QoS assurance. PQOC/QA not only inherits the original basic design of PQOC, but also integrate with QoS support (it supports CBR, VBR and ABR traffic). To support QoS and to resolve the receiver-contention problem inherent in WDM network, PQOC/QA adopts slot-basis reservation through a simple and flexible marking mechanism, thereby achieving high statistical multiplexing gain for real-time traffic and establishing real-time traffic connections only within a single ring time under normal loads. To adapt to VBR traffic, instead of focusing on estimation of the bandwidth requirements, PQOC/QA employs constant mean rate reservation on each cycle of the ring and well accommodates VBR traffic fluctuation by the remaining quota (excluding the quota used by the reservation). Along with a simple but effective CAC function, the minimum (guaranteed) remaining quota is controlled by a predefined quota ratio. Therefore, if the quota ratio is set reasonably, the probability that the fluctuation of VBR traffic fails to transfer due to expired quota is significantly small. Consequently, PQOC/QA can well accommodate VBR traffic fluctuation, thus achieving exceedingly low VBR delay and jitter. Moreover, through the simple CAC, the
network can simply provide guaranteed load of real-time traffic and also obtain guaranteed setup queueing time. Further, based on a non-aggressive reservation mechanism (mean rate reservation) and a flexible transmission strategy, the overall performance achieves not only QoS assurance, but also retains the maximal system utilization.
Another important goal of our work is to propose the analysis of the expected setup queueing time. The system is modeled as an M/G/m queue under the first-come-first-served (FCFS) service discipline, where the maximum admissible quota of real-time traffic is modeled as the number of servers. Our main contribution is a novel approximation derivation yet accurate results for a multi-server queueing system with the specific service time in our system, an exponential duration plus an extra constant value. Actually, almost no exact results are known for the first moment of the stationary waiting time distribution in a multiple-server queueing system (M/G/m). Exclusively, the accurate results have only been attained for a limited number of special service distributions, such as the exponential [50], deterministic [51], Erlang [52-54] and hyperexponential-2 [54-56] distributions. Most work provides approximation formulas [52-69] which estimated the mean queueing time for the M/G/m queue from the first two or three moments of the service distribution. They propose approximation results only maintained a less than 10% relative error for certain properties of service distributions. In this thesis, we develop a novel approximation for a particular general service distribution, and we show that the analytical results match well with the simulation results of the mean setup queueing time.
The remainder of this thesis is organized as follows. In Chapter 2, we present the network and node architectures of HOPSMAN. In Chapter 3, we describe the MAC scheme (PQOC) and delineate the analysis for the determination of the probabilistic quota and also show the simulation results. In Chapter 4, we elaborate on the details of the MAC scheme (PQOC/QA) which enhances PQOC with QoS assurance and present a novel analysis of queueing time by an M/G/m queueing system and also show the simulation results. Chapter 5 focuses on the hardware implementation of the testbed and the demonstration of a potential application for HOPSMAN. Finally, concluding remarks are given in Chapter 6.
Chapter 2. General Network and Node Architectures
2.1 Network Architecture
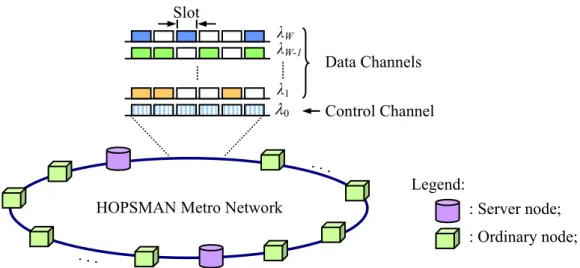
HOPSMAN is a unidirectional WDM slotted-ring network with multiple WDM data channels (λ1-λW, at 10 Gb/s) and one control channel (λ0, at 2.5 Gb/s), as shown
in Figure 1. Channels are further divided into synchronous time slots. Each data-channel slot contains a data packet in addition to some control fields to facilitate synchronization. Within each slot time, all data slots of W channels are fully aligned with the corresponding control slot. Each control slot is then subdivided into W mini-slots to carry the status of W data slots, respectively.
HOPSMAN contains two types of nodes: ordinary-node (O-node), and server-node (S-node). Each node of both types has a fixed transmitter and receiver pair for accessing the control channel. While an O-node is a regular node with only one tunable transmitter and receiver pair for accessing data channels, an S-node is equipped with multiple tunable transmitter and receiver pairs, and an additional
Slot
Figure 1. HOPSMAN: network architecture. Legend: HOPSMAN Metro Network
. . . : Server node; : Ordinary node; . . . Control Channel Data Channels λ0 λ1 λW λW-1
optical slot eraser. It is important to note that, HOPSMAN requires at least one S-node, and as will be shown later, bandwidth efficiency improves cost-effectively by using only a small number of S-nodes.
2.2 Node Architecture
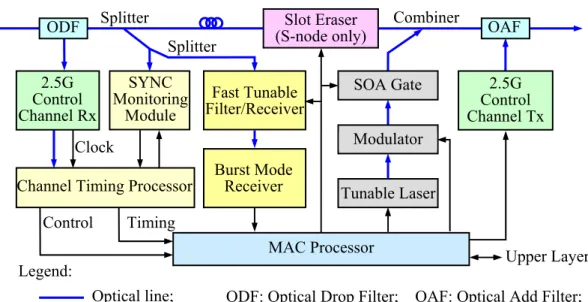
The node architecture is shown in Figure 2. It is best described as consisting of two building blocks for control-channel processing and data-channel accessing. For control-channel processing, a fixed optical drop filter (ODF) at the input port first extracts the optical signal from the control channel slot by slot. The control information is electrically received by a fixed-tuned receiver, and processed by the MAC Processor. While the control information is extracted and processed, data packets remain transported optically in a fixed-length fiber delay line. The channel timing processor, in coordination with the SYNC monitoring module, is responsible
Figure 2. HOPSMAN node architecture. Clock
Splitter
ODF (S-node only)Slot Eraser Combiner OAF
2.5G Control Channel Rx Modulator SOA Gate MAC Processor Tunable Laser 2.5G Control Channel Tx SYNC Monitoring Module
Channel Timing Processor Timing Fast Tunable Filter/Receiver Upper Layer Burst Mode Receiver Splitter Control Optical line; Electrical line; Legend:
ODF: Optical Drop Filter; OAF: Optical Add Filter; SOA: Semiconductor Optical Amplifier;
for extracting the slot boundary timing and for subsequently providing the activation timing for other modules. Having obtained the control information, namely the status of W data channels, the MAC processor then executes the PQOC scheme to determine the add/drop/erase operations for all W channels and the status updates of the corresponding mini-slots in the control channel. Finally, a fixed-tuned transmitter inserts the newly-updated control signal back in the fiber, which is, in turn, combined with data channels’ signal via the optical add filter (OAF).
Data-channel accessing corresponds to add and drop operations of data packets based on the broadcast-and-select configuration. Specifically, packets of all wavelengths are first tapped off (“broadcast”) through wideband optical splitters. They are in turn received (“select”) via an optical tunable filter/receiver. The realization and use of such a tunable receiver makes HOPSMAN scalable, namely the number of nodes is no longer constrained by the number of wavelengths. To transmit a packet onto a particular wavelength, the node simply tunes the tunable transmitter to the wavelength. Finally, to discontinue unneeded data packets on any wavelengths, the Slot Eraser (in an S-node only) employs a pair of Mux/Demux and an array of W SOA on/off gates to re-insert new null signals on the wavelengths.
There are three main challenging issues about the hardware implementation of HOPSMAN [7]. They are the synchronization of the data and control channels, and the design and implementation of high-speed photonic tunable receivers, and optical slot erasers. We now briefly describe our solutions to meeting these challenges. First, the channel timing synchronization is ensured via two levels of alignment: coarse-grained and fine-grained synchronization. The first-level coarse-grained synchronization is achieved by inserting a fixed short-fiber delay line in the optical data-channel path to accommodate the basic control computation latency. The fine-grained synchronization is accomplished by matching a fixed-pattern preamble
field (i.e., the SYNC field) at the beginning of each control slot. Second, the fast optical tunable filter/receiver is implemented based on a polarization-insensitive four-wave-mixing (FWM) method, which uses a sampled-grating distributed-Bragg-reflector (SGDBR) fast tunable pumping laser and an SOA. Due to the fact that the receiver’s tuning delay solely depends on the tuning speed of the pumping laser, our FWM-based tunable filter/receiver achieves a tuning time of less than 25 ns. Finally, the optical slot eraser has been built with a Mux/Demux pair and an array of SOA gates, which can be turned on/off in 5 ns and achieve an on/off extinction ratio greater than 30 dB.
Chapter 3. MAC Scheme– Probabilistic Quota plus Credit
HOPSMAN is governed by a MAC scheme, called Probabilistic Quota plus Credit (PQOC) [8]. In this section, we first describe the basic concepts of probabilistic quota and credit. We then present the analytic derivation for the determination of the probabilistic quota, which is followed by the detailed algorithm of the scheme.
3.1 Design Principles and the Detailed Algorithm
Before presenting the MAC scheme, we first introduce a term that will be frequently used throughout the rest of the thesis. Since each ordinary node (O-node) has only one tunable receiver, receiver-contention [3] occurs when there is more than one packet destined for the same receiver in a single slot time. Thus, two packets that are destined for the same node are prohibited to simultaneously occupy a single slot time via two different wavelengths. Likewise, because an O-node has only one tunable transmitter, any O-node is restricted to access at most one wavelength in a single slot time. Such a limitation is referred to as the vertical-access constraint.
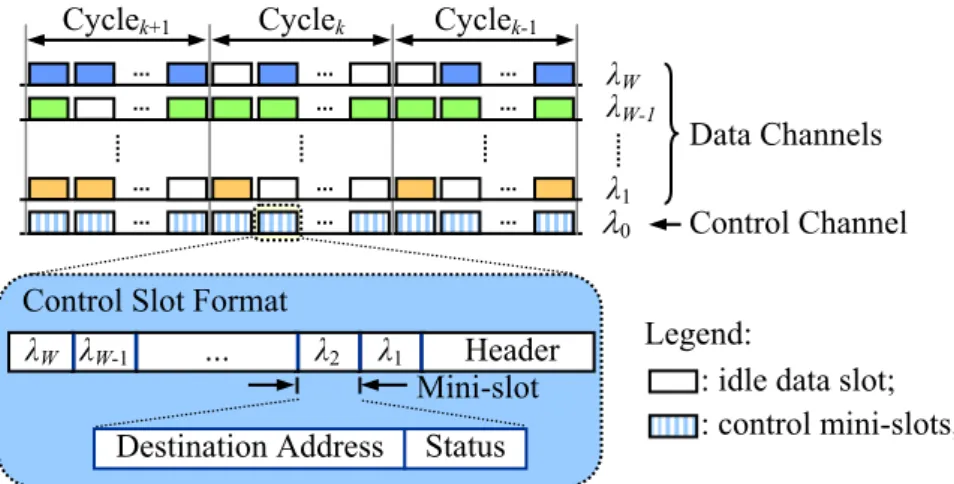
The entire WDM ring is divided into a number of cycles (see Figure 3), each of which is composed of a pre-determined, fixed number of slots. Basically, PQOC allows each node to transmit a maximum number of packets (slots), or quota, within a cycle. Significantly, even though the total bandwidth is equally allocated to every node by means of the quota, unfairness surprisingly appears when the network load is high. This is because upstream nodes can access empty slots first, resulting in an increasing tendency for downstream nodes to encounter empty slots that are located vertically around the back of the cycle. This issue, as well as the vertical-access constraint, gives rise to poorer throughput and delay performance for downstream
nodes. To resolve the unfairness problem, the quota is exerted in a probabilistic rather than a deterministic fashion, as “probabilistic quota” implies. In other words, rather than transmitting packets immediately if there remains quota (and idle slots of course), each node makes the transmission decision according to a probability. For example, the probability is set to be equal to the quota divided by the cycle length. The determination of the probabilistic quota will be detailed in the following subsection. Such an approach evenly distributes the idle slots within the entire cycle at all times and thus eliminates unfairness against downstream nodes. It is worth noting that, using the probabilistic quota a node may end up making fewer packet transmissions than its quota. This is caused by failing to find idle slots when the access is permitted according to the probability. The problem can be simply resolved by unconditionally granting a packet transmission in a subsequent slot time when there exists an idle slot.
Furthermore, if a node cannot use up its entire quota in a cycle, i.e., has fewer packets than its quota, the node yields the unused bandwidth (slots) to downstream nodes. In return, the node earns the same number of slots as credits. These credits allow the node to transmit more packets beyond its original quota in a limited number of upcoming cycles, called the window. That is, the credits are only valid when the number of elapsed cycles does not exceed the window. The rational behind this design is to regulate a fair use of unused remaining bandwidth particularly in the metro environment with traffic that is bursty in nature. Notice that there are system tradeoffs in PQOC involving cycle length and window size. For example, the smaller the cycle length, the better the bandwidth sharing; the larger the window size, the better the bursty-traffic adaptation, both at the cost of more frequent computation. The cycle length and window size can be dynamically adjusted in accordance with the monitored traffic load and burstiness via network management protocols. These issues go beyond the scope of this thesis.
The implementation of PQOC is fairly simple. As shown in Figure 3, each control slot contains a header (for synchronization purpose), and W mini-slots carrying the statuses of the corresponding W data slots. There are four distinct states for each data slot- BUSY, BUSY/READ (BREAD), IDLE, and IDLE/MRKD (IMRKD). A node wishing to transmit in a cycle and attaining access permission on the basis of probabilistic quota must first find an IDLE slot. If it succeeds, the node transmits the packet and alters the state from IDLE to BUSY. Otherwise, the node unconditionally transmits its packet on the next available slot without casting the probability again. A destination node that has successfully dropped a packet modifies the slot state from BUSY to BREAD. This allows the next S-node to erase the data slot by changing the status from BREAD back to IDLE, enabling slot reuse by downstream nodes. Furthermore, if a node has no packets to transmit but attains access permission on the basis of probabilistic quota, the node then earns the remaining number of slots as credits for future use, by altering the same number of data slots from IDLE to IMRKD. Finally, a node uses its credits to transmit more packets beyond the probabilistic quota on any IMRKD data slots within the window, and subsequently updates the state to BUSY.
Cyclek+1
Figure 3. Cycle and slot structures. Mini-slot
Control Slot Format
Destination Address Status
λW-1 λW … λ2 λ1 Header Cyclek Cyclek-1 Control Channel Data Channels λ0 λ1 λW
: idle data slot; : control mini-slots; Legend:
The detailed PQOC algorithm is given in Figure 4. An npqueue number of packets that have newly arrived or failed to transmit in the previous cycle are scheduled to transmit in the current cycle. The algorithm is executed on a per-slot basis. If the slot is marked as the beginning of a cycle, the algorithm determines three variables: PQ, the number of idle slots to be marked (nsimrkd), and the number of credits available up to this cycle (nc). Basically, PQ is computed according to Equation (6) which will be detailed in the next subsection; nsimrkd takes the greater value between 0 and (Q-npqueue), and nc is calculated on a sliding window basis. nc can also be given based on a fixed window rather than the sliding window strategy. Usually, a sliding window strategy is superior to a fixed window strategy with respect to bursty-traffic adaptation, albeit at the cost of requiring greater computing effort and storage needs. Finally, the primary work of the algorithm is to determine whether transmission of packets is allowed or not, as clearly depicted in the Transmission process (Step 5-6) in Figure 4.
Variables
Q : quota;
nc : number of credits to be used;
nsimrkd : number of idle slots to be marked;
npPQ : number of packets allowed to be transmitted based on prob. quota; npqueue : number of packets in the queue;
ws : credit window size;
q[i] : number of remaining quota in cycle i; c[i] : number of credits used in cycle i;
Slot type
Header : {CYCLE_BEGIN, NORMAL}; Status : {BUSY, BREAD, IDLE, IMRKD};
Main Process() /*execute at each slot time*/ 1. Read the control slot;
/* Computation at the cycle begin */
2. if (slot’s Header is CYCLE_BEGIN)
/*enter the mth cycle*/
Add the number of arrivals of pre-cycle to npqueue;
Determine PQ according to Equation (6);
nsimrkd = max(0, Q - npqueue); npPQ=0;
nc=max(0,min( , −1 ( [ ] [ ])) = − −
∑
m − queue i m ws np Q q i c i ); q[m]=Q; c[m]=0; endif /* Receive packets */3. Receive the packet destined to it, and update BUSY to BREAD;
/* Server node erases packets */
4. if (node is S-node) Erase BREAD packets; Update BREAD to IDLE; endif
/* Transmission process */
5. if (Randomize(PQ))
npPQ++; /*store transmission allowance */
endif
6. if (exist a vertical-access-constraint-free packet) switch
case ( nc>0 and exist(IMRKD) ): /*transmit by credit */ nc --; c[m] ++;
Transmit the packet; npqueue --;
Update IMRKD to BUSY;
break;
case ( npPQ >0 and exist(IDLE) ): /*transmit by quota using IDLE */
npPQ --; q[m] --;
Transmit the packet; npqueue --;
Update IDLE to BUSY;
break; case ( npPQ >0 and exist(IMRKD) ):
/*transmit by quota using IMRKD */
npPQ --; nsimrkd++; q[m] --;
Transmit the packet; npqueue --;
Update IMRKD to BUSY; break; otherwise No transmission; endswitch endif /* Mark slots */
7. if (nsimrkd > 0 and exist(IDLE))
nsimrkd --;
Update IDLE to IMRKD; endif
3.2 Bandwidth Allocation- Probabilistic Quota Determination
Assume that there are S server-nodes (S-node 1 to S-node S) in the network dividing itself into S sections (sections 1 to S). Each section contains more than one node including the server node of the section. To simplify the illustration, the S-node for a section is placed in the most downstream location in that section. Namely, section 1 is preceded by S-node S in section S; and section k is preceded by S-node
k-1 in section k-1, for k=2 to S. More specifically, for a network with N nodes, we
have , where N 1 S k k N N =
=
∑
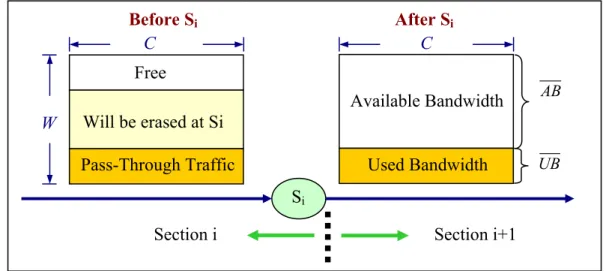
k is the total number of nodes in section k.Moreover, a slot passed by an S-node is considered as either Available
Bandwidth (AB) if the slot is empty or erased, or used bandwidth (UB) if the slot is
non-empty and cannot be erased (have not been read) (see Figure 5). Thus, the quota for a node can be computed as the mean value of the total amount of AB observed by a section divided by the total number of nodes in the section. For instance, in an observed section (referred to as section b), we attain Qb = AB Nb/ b, where Qb denotes
the quota to be allocated to any node in section b, AB the mean value of the total b
amount of AB passed down by S-node b-1, and Nb is the total number of nodes in section b. Notice that the value of AB is relevant to the traffic destination b
distribution; and S-nodes are possible to receive more traffic than O-nodes. Accordingly, we derive in the sequel a closed form for AB under two different b
Case 1
In this case, traffic is uniformly distributed to all nodes. Moreover, for simplicity we consider a prevailing case in which S-nodes are evenly located in the network, namely Nk =N/S, where k=1 to S. Accordingly, each node is given the same AB and quota Q, where Q= AB N S/( / ), for all nodes in the network.
The value of AB can be computed as the mean total bandwidth (total number of slots in a cycle) minus UB. Thus, in the sequel we analyze the UB value passed through S-node b-1. The analysis is presented in two parts: one is to consider the transmissions from any section to itself, and the other is to consider the transmissions from a section to the other sections. For the first part, since the total amount of traffic (slots) generated from any section (take section k as an example) is Q·(N/S), thus the traffic amount from section k to section k itself is Q·(N/S)/S. Within this amount of traffic, the proportion Q·(N/S)/2S will be erased by the most downstream node (S-node) of the section. Notice that erasable traffic corresponds to the traffic sent from upstream to downstream nodes within this section. Therefore, the remaining traffic,
Q·(N/S)/2S, which is sent from downstream to upstream nodes within this section, will
Free Will be erased at Si Pass-Through Traffic Available Bandwidth Used Bandwidth AB UB Si
Section i Section i+1
W
C C
Before Si After Si
be passed through the entire ring and seen by the section as UB.
For the second part, take section b+2 as an example. The traffic that is sent from section b+2 and passed through the entire ring and seen by S-node b-1 and section b as UB is the sum of the traffic destined to sections b and b+1. Thus, the UB is equal to 2·Q·(N/S)/S. Finally, with all sections taken into account by summing all UB which passes through S-node b-1, and given that the total bandwidth in a cycle is C·W, where C is the total number of slots in a cycle and W the number of wavelength channels, we obtain AB as the following equation
1 1 1 2 S k N k AB C W Q S S S = − ⎧ ⎛ = ⋅ − ⎨ ⋅ ⎜ + ⎝ ⎠ ⎩ ⎭
∑
⎞⎟ . (1) ⎫⎬With the equation,Q=AB N S/( / ), we can attain the closed form solution for Q, as 2 2 C W S Q N S ⋅ ⎛ = ⎜ ⎞⎟ + ⎝ ⎠. (2)
Case 2
In this case, S-nodes are to receive additional traffic amount than O-nodes. We derive a closed form for AB under an assumption that a probability pb A of destination traffic is uniformly distributed among all nodes (including the S-nodes), while the remaining probability 1–pA (=pS) of traffic is additionally destined to all S-nodes. Clearly in the case of pS=0, destination traffic is uniformly distributed among all nodes in the network. Regarding the value of pA, it can be obtained through periodic traffic monitoring via network management protocols, which are beyond the scope of this thesis.
through S-node b-1. The value of AB can be computed as the mean total bandwidth b
(total number of slots in a cycle) minus the mean UB. Thus, in the following we analyze the mean UB passed through S-node b-1. The analysis is presented in two parts: one is to consider the transmissions from any section to itself, and the other is to consider the transmissions from a section to the other sections. For the first part, since the total amount of traffic (slots) generated from any section (take section k as an example) is Qk·Nk, thus the traffic amount from section k to section k itself is (Qk·Nk·pS/S)+(Qk·Nk·pA·Nk/N). Of this amount of traffic, the fraction (Qk·Nk·pS/S)+(Qk·Nk·pA·Nk/2N), will be erased by section k’s most downstream node, i.e., S-node k. Notice that the second term corresponds to the traffic sent from upstream to downstream nodes within section k. Therefore, the remaining traffic,
Qk·Nk·pA·Nk/2N, which is sent from downstream to upstream nodes within section k, will be passed through the entire ring and seen by section b as UB.
For the second part, let’s take section b+2 as an example. The traffic that is sent from section b+2, passed through the entire ring, and seen by S-node b-1 and section
b as UB, is the total amount of traffic destined to sections b and b+1. Thus, the mean UB becomes Qb+2·Nb+2·((ps/S)+(pA·Nb/N)) + Qb+2·Nb+2·((ps/S)+(pA·Nb+1/N)). Finally, with all sections taken into account by summing all UB which pass through S-node
b-1, and given that the total bandwidth in a cycle is C·W (where C is the total number
of slots in a cycle and W the number of data channels), we obtain A Bb as the
following equation 1 , where 2 S A k b k k k k p N AB C W Q N U N = ⎧ ⎛ ⎞⎫ = ⋅ − ⎨ ⎜ + ⎟⎬ ⎝ ⎠ ⎩ ⎭
∑
1 1 ( ) ,if ( ) ( ),if 1 k S A m m b k S k S A m S A n p p N b k S S N U p p N p p N k b S N S N − = − ⎧ + ≤ ⎪⎪ = ⎨ ⎪ + + + ≤ ⎪⎩
∑
∑
∑
1 m b= n= ≤ < . (3)Notice that Equation (3) cannot be solved because there is more than one unknown variable (AB and Qb k’s) in the equation. In the following, we solve the equation under a prevailing case in which S-nodes are evenly located in the network, namely N1=N2=N3=…=NS=N/S. In this case, due to the same behavior of S-nodes, we obtain the same quota Q, where Q AB N S= /( / ), for all nodes in the network. With this additional equation and the simplified version of Equation (3) as
1 1 2 S A k p N k AB C W Q S S S = ⎧ ⎛ − = ⋅ − ⎨ ⋅ ⋅⎜ + ⎝ ⎠ ⎩ ⎭
∑
⎞⎟ . (4) ⎫⎬we can attain the closed form solution for Q, as 2 2 S C W S Q N S p ⎛ ⎞ ⋅ = ⎜ ⎟ − + ⎝ ⎠. (5)
With the quota determined, we are now ready to obtain the probabilistic quota, denoted as PQ. Given the total number of packets currently in the queue as npqueue, PQ can simply be expressed as
min ( , queue) Q np Q P C C = . (6)
3.3 Simulation Results
In this section, we present simulation results to demonstrate the performance of HOPSMAN with respect to throughput, access delay, and fairness. The settings of parameters for simulation are given in the following. The network has a total of 20 nodes (N=20), in which node 1 is always designated as an S-node. There are 20 cycles on the ring. Each cycle consists of 100 slots per wavelength. Without specific indication, traffic destinations are assumed to be uniformly distributed among all nodes (pS=0). The credit window size is 10. Traffic is generated following either a Poisson distribution or a two-state (H and L) Markov Modulated Poisson Process (MMPP) [70] for modeling smooth and bursty traffic, respectively. Specifically, the MMPP is characterized by four parameters (α, β, λH, and λL), where α (β) is the probability of changing from state H (L) to L (H) in a slot, and λH (λL) represents the probability of arrivals at state H (L). Accordingly, given λL=0, the mean arrival rate can be expressed as β×λH/(α+β), and traffic burstiness (B) can be given by B=(α+β)/β. Finally, simulation is terminated after reaching a 95% confidence interval. Due to having multiple S-nodes, the traffic intensity (TI) to be generated per slot per wavelength is unequal to the normalized load (L) per slot per wavelength. They can be related, however, according to Equation (5), as
2 / S 2 Q TI L L C W N S p ⎛ ⎞ = ⋅ = ⋅⎜ ⋅ ⎝ − ⎠ S ⎟ + . (7)
From Equation (7), given S S-nodes in the network, the maximum value of TI (defined as the maximum throughput ( )) occurs at the normalized load L being equal to one. That is,
S max T 2 2 S max S S T S p = − + . (8)
From Equation (8), we observe that S increases when p max
T S is increased. This is
because more traffic destined to S-nodes will enable more data slots being erased, i.e., more usable bandwidth after S-nodes. Consequently, if the network inspects that an extra percentage of traffic is additionally and constantly being sent to S-nodes (pS), it can re-compute and extend the value of quota for each user achieving greater throughput. As previously described, the determination of the pS value is a network management issue and out of the scope of the thesis.
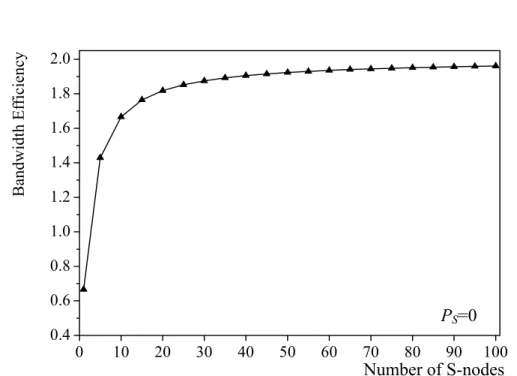
We further compare the bandwidth efficiency (η) among the three different bandwidth reuse strategies: source stripping, destination stripping and server stripping. The server stripping indicates that the data can only be removed from the S-nodes and the bandwidth can be reused by the downstream nodes. Assume that the bandwidth efficiency of source stripping is 1 (η =1). As to destination stripping, the network capacity is almost twice as large as that of unidirectional rings with source stripping under uniform traffic (η≅2). Regarding the server stripping, based on Equation (8) and with pS=0, we obtain 2
2
S S
η=
+ . Consequently, we draw the results of HOPSMAN bandwidth efficiency as shown in Figure 6. The figure shows that the bandwidth efficiency rises most dramatically when the network is equipped with only a few number of server nodes. However, as the number of server nodes increases, the increase of the network capacity is quite limited. Note that the destination stripping is equivalent to that the system is with each node as a server node. The result shows that the server stripping is more cost-effective than the destination stripping; therefore, the server stripping is considered as an excellent bandwidth reuse scheme.
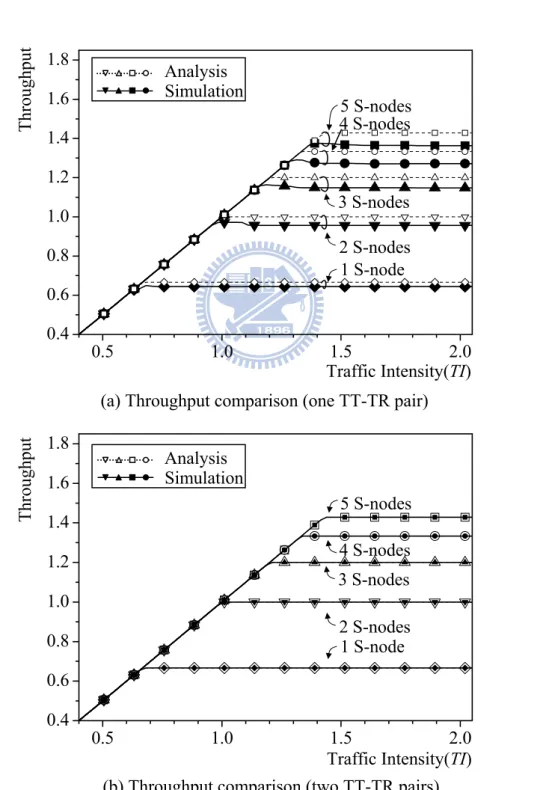
In Figure 7, we first draw comparisons of the analytic and simulation results on system throughput under different S-node numbers and two different tunable-transceiver-pair settings. Analytic results are obtained based on Equation (7)
and (8). In the simulation, we assume there are 60 nodes in the network. The results plotted in Figure 7(a) and (b) are obtained from the system with one and two pairs of optical tunable transceivers at each node, respectively. First, we observe from Figure 7(a) that due to the vertical-access constraint when each node is equipped with only one pair of tunable transceivers, the resulted throughput performance is lower than the theoretical maximal throughput that is derived by the above analysis. To justify this fact and to demonstrate the validity of the analysis, we use the second setting in which each node is equipped with two pairs of tunable transceivers, with the result that the vertical-access constraint is lifted. Results are shown in Figure 7(b). From the figure, analytic results are shown to be in profound agreement with the simulation results. Moreover, it is clear that increasing the S-node number results in an improvement in throughput, but at a declining rate as the number of S-nodes grows. For example, the throughput improves most dramatically when the network changes from having one S-node to two S-nodes. The result explains the economy and efficiency of
0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0
Figure 6. Bandwidth efficiency of HOPSMAN.
0 10 20 30 40 50 60 70 80 90 100
PS=0
Bandwidth Ef
ficiency
HOPSMAN behind the scarce use of S-nodes.
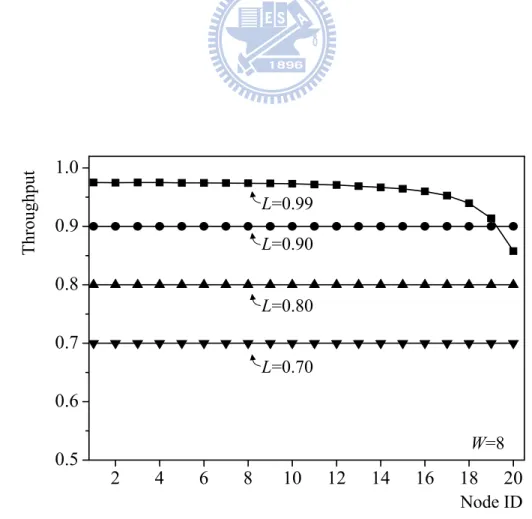
Focusing on the network with one S-node (Node 1), we next examine the throughput and delay performance of HOPSMAN under various loads and burstiness. Simulation results are displayed in Figure 8 and 9. As depicted in Figure 8, despite the
Figure 7. Analytic and simulation results on system throughput under different S-node numbers.
0.5 1.0 1.5 2.0 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 Traffic Intensity(TI) Throughput Analysis Simulation 5 S-nodes 1 S-node 2 S-nodes 4 S-nodes 3 S-nodes
(a) Throughput comparison (one TT-TR pair)
0.5 1.0 1.5 2.0 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 Analysis Simulation 5 S-nodes 1 S-node 2 S-nodes 4 S-nodes 3 S-nodes Traffic Intensity(TI) (b) Throughput comparison (two TT-TR pairs)
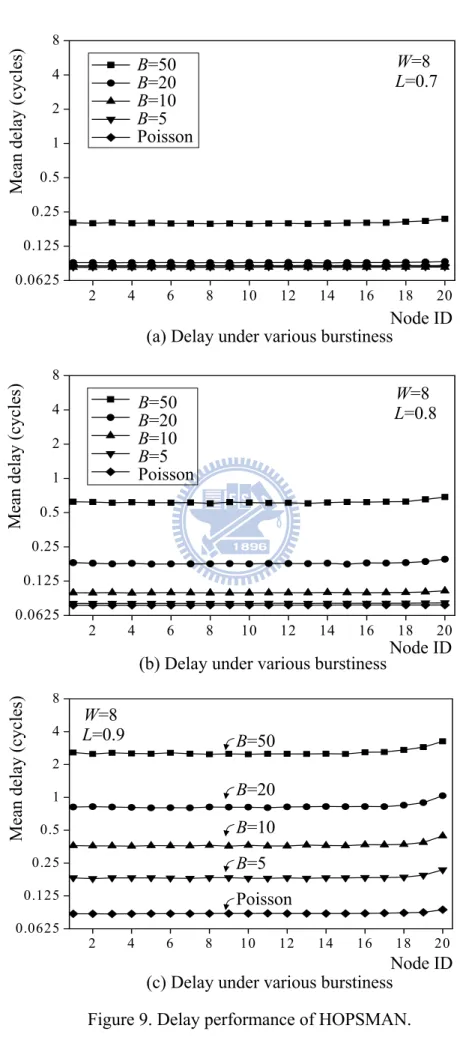
vertical-access constraint, the probabilistic-quota design helps HOPSMAN achieve 100% throughput and fairness under all loads that are less than or equal to 0.9. However, as the network becomes highly saturated when the load reaches 0.99, we observe inevitable throughput deterioration for downstream nodes as a result of the vertical-access constraint. An intensive comparison of delay with and without the probabilistic-quota design will be given shortly. We show in Figure 9(a)-(c) that HOPSMAN guarantees delay fairness under all non-saturated loads. As expected, delay increases with the traffic burstiness. Most importantly, as shown in Figure 9(a), HOPSMAN achieves remarkably low delay under L=0.7. Taking this result, along with other results in Figure 8 taken into consideration, it is clear that HOPSMAN achieves superior bandwidth allocation under heavier loads while being able to provide random access under lighter loads.
Figure 8. Throughput performance of HOPSMAN.
2 4 6 8 10 12 14 16 18 20 0.5 0.6 0.7 0.8 0.9 1.0 Throughput L=0.99 L=0.90 L=0.80 L=0.70 W=8 Node ID
0.0625 0.125 0.25 0.5 1 2 4 8
(a) Delay under various burstinessNode ID
2 4 6 8 10 12 14 16 18 20
Mean delay (cycles)
B=50 B=20 B=10 B=5 Poisson W=8 L=0.7
(b) Delay under various burstiness
2 4 6 8 10 12 14 16 18 20 0.0625 0.125 0.25 0.5 1 2 4 8 Node ID
Mean delay (cycles)
B=50 B=20 B=10 B=5 Poisson W=8 L=0.8
(c) Delay under various burstiness
2 4 6 8 10 12 14 16 18 20 0.0625 0.125 0.25 0.5 1 2 4 8 B=50 B=20 B=10 B=5 Poisson Node ID
Mean delay (cycles)
W=8
L=0.9