品牌形象之直覺模糊多元屬性模型及比較分析
Measuring Brand Image by Intuitionistic Fuzzy
Multiattribute Models: A Comparative Analysis
陳亭羽
1Ting-Yu Chen
施麗琴
2Li-Chin Shih
長庚大學工商管理學系 國立中央大學企業管理學系
1
Department of Industrial and Business Management, Chang Gung University and
2Department of Business Administration, National Central University
(Received December 25, 2008; Final Version October 9, 2009)
摘要:消費者於購買產品時,經常藉由品牌形象作為決策的依據,但由於人類的思考模式隱含 著主觀的認知以及複雜的想法,影響著其本身的購買行為,且消費者之間的知覺型態有所差異, 對於問卷選項評價的表達亦是模糊的。過去研究在衡量品牌形象上,多半使用李克特尺度或語 意差別尺度的衡量工具,並利用單一數值加以表達的量化方法;此外,過去研究也將欲衡量之 品牌形象屬性視為連結性關係,但非連結性的屬性關係卻有可能存在於消費者心中。故本研究 利用直覺模糊尺度作為衡量工具,發展以直覺模糊集合為基礎之三種不同的多元屬性模型衡量 品牌形象,主要依據評估函數計算品牌的品牌形象分數,其中亦加入非連結性屬性關係的考量, 且以計分函數發展排序方法,將其排序結果與傳統方法做比較分析,結果發現本研究建構之衡 量模型優於傳統方法,能得知各品牌之形象屬性間的細微差距,且能找出更貼近消費者心中之 品牌形象排序,給予衡量品牌形象更多的詮釋。 關鍵字:品牌形象、直覺模糊集合、多元屬性模型、評估函數、計分函數
Abstract: The consumers often evaluate the products through brand image to influence purchase decisions. But human thinking includes subjective cognitions and complex thought which influence
本文之通訊作者為陳亭羽,e-mail:[email protected]。
purchase behaviors, and consumers’ perception types are diverse. Then, their evaluations of the items in the questionnaire are imprecise, so most of previous researches have used Likert Scales or Semantic Differential Scales to measure brand image and using a single value to capture it is not a suitable measurement. Besides, the past studies usually figure out the relation of the attributes are conjunctive, but sometimes there exist disjunction relations among attributes. In view of this, we develop Intuitionistic Fuzzy Scales and three multiattribute models based on Intuitionistic Fuzzy Sets to measure brand image. We use evaluation functions and Score functions to compute the scores of brand image and the ranking order of the brands. And also include disjunction relations among attributes Further more, we compare the calculation results of our models and traditional methods to find out a most appropriate model for assessing brand image. According to empirical results, it shows that using the Intuitionistic Fuzzy Scales can acquire approximate estimations of respondents’ actual judgments. Using these valid and suitable measurement models, the enterprises can measure brand image and find a little gap between two attributes through the Intuitionistic Fuzzy questionnaire and refer the models of this study to understand the consumers’ thoughts concerning brand image.
Keywords: Brand Image, Intuitionistic Fuzzy Sets, Multiattribute Models, Evaluation Functions, Score Functions
1. 緒論
品牌形象 (brand image) 已經被企業視為差異化競爭優勢的重要來源,Schiffman and Kanuk (2007; p167) 提到消費者會依據品牌形象作出產品選擇,且在高競爭市場中產品越來越複雜,因 此消費者越會依賴產品屬性的形象與信念去進行購買決策。此外,McDaniel et al. (2006; p.185) 提及品牌形象會形成消費者對於產品的態度。而且消費者對品牌形象的考量亦會主導其購買時 的選擇,產品的購買通常是因為其符號或象徵與選購者的地位或自我認知相符合,並非產品本 身功能性的差異 (Roth, 1995)。因此,長期累積品牌形象及建立品牌形象與消費者之間良好的溝 通,將是促使商品差異化的策略之ㄧ。 然而,徐村和等 (民 90) 指出近年來的研究常為了尺度建構上的方便,均以李克特尺度 (Likert scale, LS) 或語意差別尺度 (semantic differential scale, SDS) 的量化方式,衡量研究對象
的認知狀態。而且Dobni and Zinkham (1990) 整理多位學者衡量品牌形象之工具,如索斯洞尺度
(Thurstone scale)、語意差別尺度和史德培尺度 (Stapel scale) 等技巧,其皆以單一數值的方式衡 量品牌形象之屬性。不過,其實人類的思維是主觀的,具有不明確的喜好,對品牌形象衡量選
項評價的知覺表達也是模糊不清的,再加上品牌形象是一種心佔率程度的模糊性概念,如果單 純利用明確數值進行主觀評估時,並無法突顯品牌形象在消費者內心的認同程度 (徐村和、林凌 仲,民96)。可是傳統的量化方式,一方面將模糊認知直接以數值加以表示,往往難以合理表達 人類語意的差異性和模糊性,因而產生語意值轉換誤差。另一方面,假設區間尺度等距的問題, 容易忽略不同語意型態的受訪者所存在的語意膨脹與貶值的現象。根據Bradly et al. (1962) 的研 究,語意區間的距離是不相等的,且多位學者的研究實證顯示等距尺度量化方式易造成估計參 數的偏差 (Bollen and Brab, 1981; Olsson et al., 1982)。
此外,在模糊理論的研究中,經常使用模糊數來衡量語意性措辭,但由於函數之計算過程 困難以及個人不同的邏輯思維,所使用尺度型態不同,故若使用模糊數衡量語意性措辭將會產 生單一轉換值的嚴重問題。有鑑於此,本研究將改以直覺模糊多元屬性模型衡量品牌形象,利 用直覺模糊集合 (intuitionistic fuzzy sets) 的尺度代替傳統衡量尺度,使消費者能依據心中對於 該品牌的形象屬性填寫出所認知之分數範圍。此衡量方法較能符合實際狀況,有效改善傳統衡 量工具所產生的問題,透過游移不定程度表示語意上的模糊性,相較於模糊數之衡量方式更加 明確。另一重點在於過去研究於衡量品牌形象之屬性關係時,皆以連結性 (conjunction) 關係的 方式呈現,即同時考慮所有屬性進行決策,但是構成品牌形象的這些顯要屬性,亦可能以非連 結性 (disjunction) 表示之。舉例來說,有些消費者於購買汽車時,會要求該車必須同時具備多 個屬性 (如功能優越、符合其社會地位的象徵、安全性佳等),才會認為該品牌之形象較佳,但 是亦有一些消費者認定只要具備其中一個品牌形象的屬性 (如產品設計佳),即使該車功能不是 很優越、沒有完全符合其社會地位的象徵、安全性不是最好的,但其對於該品牌之品牌形象仍 有較高的正面評價。故由此可知,品牌形象屬性的關係已經不再只是單純的連結性關係,而需 加入非連結性關係作進一步的探討。 根據上述之研究動機,本研究之目的是以直覺模糊多元屬性模型為基礎發展品牌形象之衡 量方法,並與傳統衡量方法 (李克特尺度) 之量化結果作一比較分析,找出較符合消費者對於品 牌形象的主觀評價之衡量模型。
2. 文獻回顧
2.1 品牌形象之概念與定義
品牌形象被視為一種資訊的提示,亦是市場行銷中的重要一環。消費者藉著持有的品牌形 象推論產品的品質,繼而激發消費者的購買行為,而品牌形象儲存於消費者記憶模式中,成為 購買決策的重要考量因素。近年來,品牌形象的研究大致可歸納出兩種形式,一種是所謂的品 牌概念形象 (brand concept-image),另一種則是以顧客行為理論為基礎的品牌形象,因此,本研究彙整兩種形式之內容,將其分為四種觀點定義品牌形象。
第一,以「知覺」為觀點。Park et al. (1986) 認為品牌形象是被企業的溝通活動所影響的一 種知覺現象,也為消費者藉由品牌之相關活動進而產生對品牌的瞭解。然而,也可以是行銷人 員藉品牌管理所創造出的知覺,任何產品品牌於理論上皆可被分於為功能性、象徵性、或經驗 性形象三個類別。其後多位學者 (Dobni and Zinkham, 1990; Foxall et al., 1998; Jenni and Byron, 2003; Perry and Wisnom III, 2002) 亦以「知覺」為觀點定義品牌形象,認為品牌形象乃消費者對 於該品牌之知覺加總。第二,以「聯想」為觀點。兩位學者 (Aaker, 1991; Keller, 1993) 由另一 觀點「聯想」定義品牌形象,認為品牌形象反映在消費者記憶中所持有的品牌聯想上,而且當 消費者擁有不同的聯想時,將對品牌形象有不同的影響效果,所以可將品牌形象視為品牌聯想。 第三,以「需求」定義品牌形象。Keller (2001) 認為品牌形象是讓品牌能符合顧客心理或社會 層面的需求。第四,以「信念」為觀點定義品牌形象。Kotler and Gertner (2002) 認為顧客會根 據每個品牌之所有屬性所發展出來的品牌信念,即對某一特定品牌所持有的信念組合,稱為品 牌形象。 綜合上述,歸納出品牌形象大致可分為知覺、聯想、需求和信念四個觀點。定義本研究之 品牌形象為消費者對該品牌的屬性會發展出不同的信念組合,藉著對該品牌的全部知覺加總, 累積成記憶中所持有的品牌聯想,依此來判斷該品牌是否能符合消費者自己心理或社會層面的 需求。
2.2 品牌形象之來源
過去研究中,對於品牌形象來源主要可分成三個構面。其中,Biel (1992) 解釋品牌形象為 產品屬性的集合及顧客對於品牌名稱所產生的連結,包括了企業形象、產品形象與使用者形象。 這三種形象的組成又可細分為「功能性屬性」與「柔性屬性」兩種特性:功能性屬性為對有形 特質的特殊感覺,如速度、價格、企業於此產業經營時間長度等,而柔性屬性的資料,則傾向 較為情感面的屬性,如驚奇、信賴、歡樂、無趣、創新等。 此外,Keller (1993) 於探討品牌形象概念時,主要分作品牌聯想的種類、品牌聯想的喜好 度、品牌聯想的強度及品牌聯想的獨特性。其中,品牌聯想之種類是依據抽象程度將品牌聯想 做區別的一種方式 (Alba and Hutchinson, 1987; Chattopadhyay and Alba, 1988),其可分為屬性 (attributes)、利益 (benefits) 或態度 (attitudes) 三個層面。第一,屬性,為區分產品或服務的描 述性特質,可細分為產品相關屬性 (product-related attributes) 與非產品相關屬性 (non-product- related attributes)。第二,利益,為消費者對於產品及服務屬性所賦予的個人價值及意義,可細 分為(1)功能性利益 (functional benefits):為產品和服務性消費的內在優勢,且通常反映產品相關 屬性。這些利益通常和基本動機相連結,如生理上和安全性需求 (Maslow, 1970),且意味著渴望 問題的排除或避免 (Rossiter and Percy, 1987)。(2)象徵性利益 (symbolic benefits) 為產品和服務性消費的外部優勢,且通常反映非產品相關屬性,以及和社會贊同或個人的符號與外表的自我 評價之基本需求相關。因此,消費者會去評價一個品牌的名聲、獨有性或流行性是否與自我概 念相符 (Solomon, 1983),故可知象徵性利益應該特別和社會上引人注目以及具有「標誌 (badge)」 的產品相關。(3)經驗性 (experiential benefits)則關係到使用該產品或服務的感覺,且反映於產品 相關屬性。滿足經驗上的需要,如知覺的愉悅感、多樣性與認知的刺激。第三,態度,代表消 費者對該品牌的整體評估,為品牌聯想中層次最高且最抽象的。 經由文獻得知,品牌形象係根據連結網絡方式所形成的一種知覺現象 (Keller, 1993),其網 絡連結型態為對品牌不同資訊的連結,如分作功能性或柔性屬性 (Biel; 1992),或依其屬性作區 隔分為產品相關、非產品相關屬性 (陳振燧、洪順慶,民90),或其包含的層面皆可分類為功能 性、象徵性、與經驗性三類型 (Biel, 1992; Keller, 1993; Park et al., 1986)。然而,即使區分層面 具有差異,但多類似於功能性、象徵性與經驗性作分類。此外,因本研究著重於消費者使用產 品的知覺與對於產品屬性的個別評價,希望對於品牌形象做知覺總和的評估,並能探討連結與 非連結屬性之間的關係。因此,依據本研究之品牌形象定義,試圖從消費者的角度說明其對於 產品及服務屬性所賦予的個人價值及意義進行討論,依此來判斷該品牌是否能符合消費者自己 心理或社會層面的需求。故本研究將採用Keller (1993) 的品牌形象之利益聯想方式作為研究的 分類構面,再將其個別屬性進行連結與非連結關係的探究,衡量出品牌形象之整體分數,此做 法較貼近本研究對於品牌形象之定義。
2.3 品牌形象之衡量方法與技巧
過去研究指出衡量品牌形象有很多種方式,有一些學者衡量一個品牌的個別構面 (Pohlman and Mudd, 1973),亦有其他學者單一衡量品牌的整體形象 (Dolich, 1969)。此外,品牌形象的衡 量可以是與該品牌為競爭對手的另一品牌做絕對或相對的比較 (Boivin, 1986),有關於顧客的理 想點或廣告形象 (Keon, 1983),亦或者是個人真實的自我形象或理想的自我形象 (Sirgy, 1985) 等方式。因此,Dobni and Zinkham (1990) 整理出不同時期對品牌形象的衡量方法與技巧,針對 不同學者採取對整體品牌形象或多構面間的衡量,將其分為三個階段:第一階段,重要屬性確 認,如焦點團體 (focus groups)、深度訪談 (depth iInterviews) 等技巧;第二階段,衡量工具的創造,例如可以使用語意差別尺度、史德培尺度和Q-Sort 技巧等作為衡量品牌形象之工具;第 三階段,品牌分數之計算,以因素分析、多元尺度分析、區別分析、聯合分析等技巧計算各品 牌之品牌形象分數。 由過去的衡量方法可知,計算品牌形象的分數皆是將各構面或各屬性視為必要條件,也就 是數學集合裡的交集概念,如消費者購買保養品時,會評估產品的安全性、功能優越、瓶身圖 騰設計、舒服的感覺、是否有名人推薦等屬性,過去研究認定消費者皆將五個屬性視為皆符合 其要求 (安全性足夠、功能優越、瓶身圖騰設計好看、給予自己舒服的感受、因為有名人推薦而
購買),就會對於該品牌之形象有較高的正面評價,此為本研究所提及之連結關係。然而,若消 費者認為只要安全性很足夠,其他四個條件不完全具備 (功能沒有特別優越、瓶身圖騰設計普 通、沒有舒服的感受、沒有名人推薦) 也會認為該品牌形象佳,故安全性即為本研究所提及之非 連結的屬性,與其他形象屬性為非連結關係,也就是數學集合裡的聯集概念。綜合上述,本研 究定義「連結」為消費者將各構面或各屬性皆視為必要條件,若全部符合期望則對於該品牌會 有較高的品牌形象,「非連結」則為消費者僅將眾多構面或屬性的其中之ㄧ視為必要條件,即使 其他條件不佳,若此條件符合期望則對於該品牌亦會有較高的品牌形象。因此,本研究特別進 一步探究品牌形象之連結與非連結的關係,透過不同的評估準則關係建立本研究之衡量模型, 能使各品牌計算出來的形象分數更貼近消費者內心的思維,而非單向地解讀消費者的屬性決策。 其中,本研究在衡量工具上非採用過去傳統尺度,而改以直覺模糊尺度衡量每一個屬性之 分數,故在運算上亦不同以往。然而,過去研究指出模糊集合的總和運算中,可以將數個直覺 模糊集合加總並產生單一個直覺模糊集合,故本研究在計算整體品牌形象時,將採用多元屬性 模型處理改良後的衡量工具所收集之資料,希望以評估函數與一般化平均運算之方法獲得品牌 形象之分數,找出消費者依據品牌形象對於多種品牌可能之決策排序。而品牌形象衡量,即使 所分作的構面層次具有差異,但所做的衡量方式多採用形容詞語作一測量項目 (Graeff, 1996; Porter and Claycomb, 1997)。因此,本研究根據消費者心中品牌形象作一形容詞語的測量,採用 功能性、象徵性與經驗性形象之個別屬性來對品牌形象整體作一探討。除此之外,相較於構面 分析,形象屬性的分析得以探討出消費者心中更為準確的品牌形象。例如,消費者可能只重視 功能性裡的產品設計,將其視為非連結性屬性,但此時若分析構面可能導致不符合消費者內心 評估品牌形象的準則。也因此後續則以全部屬性衡量整體品牌形象的分數進行結果分析與模型 的建構。
3. 研究方法
3.1 傳統衡量工具限制與模糊問卷形式
在行為科學的研究中,經常使用李克特尺度或語意差別尺度,作為衡量受訪者態度或意見 的工具。其中,使用李克特尺度者 (例如五等尺度:非常同意、同意、普通、不同意、非常不同 意等語意性措辭),均將應答者所選擇的答案直接轉換成 5、4、3、2、1 分 (閔建蜀、游漢民, 民79)。但徐村和等 (民 90) 研究結果發現,傳統問卷方式係假設任何兩種尺度間的差距都相等, 此種任何人對語意的模糊知覺皆為相同的假設過於強烈,無法反映受訪者的真實認知。同時對 使用不同語意型態的受訪者,使用相同的語意措辭,若給予相同的轉換值,則忽略了語意膨脹 與貶值現象的盲點。而且因為所收集的資料是間斷性的,故在往後的統計分析工作上亦會受到許多限制。
傳統問卷設計之缺點如下:(1)人類的思考與行為本來就充滿著模糊過程,傳統問卷的數字 常被過度解釋 (Manski, 1990),(2)為了簡化或降低數字模式的複雜性,卻忽略實際狀況的相關與 動態特質,且單一邏輯也使多重感受的受訪者無所適從 (吳柏林,民 84),(3)尺度等距的假設會 產生衡量誤差 (Measurement Error),導致結果稀釋,並且低估 Pearson 相關係數,使分析結果趨 於保守 (Bohrnstedt, 1970)。此外,根據 Bradley et al. (1962)、Churchill (1995)、Zikmund (1991) 的研究,顯示李克特尺度和語意差別尺度之類別間距離往往不是相等的。Babakus et al. (1984) 及Bollen (1989) 利用驗證性因素分析 (confirmatory factor analysis, CFA),探討尺度等距假設對 模型估計的影響,結果顯示各種峰態分布下,尺度等距假設的模式,其參數估計會產生顯著偏 誤現象,且模式容易發生型Ⅰ的謬誤。 因此,應用區間值的模糊特性所做的分析調查,可使研究者處理不確定性的問題。將模糊 邏輯觀念運用在問卷調查分析上,提供嶄新的蒐集與分析資料的理念,且改以隸屬函數方式表 達人類的真實想法及意見,其效果較傳統方式更貼切 (林信惠等,民 86)。若要求受訪者以連續 區間的方式,表示態度與意見的模糊性,確實能較完整地蒐集到人們的真實感受 (吳柏林,民 84;林信惠等,民 86)。該模糊問卷形式應用面甚廣,如產品投資組合的定位問題 (徐村和、李 達章,民86)、信用卡 (Hsu and Lee, 1998)、購屋者行為 (徐村和等,民 87)、針對消費者需求的 差異,評估其對於產品的認知與滿意度 (Temponi et al., 1999)、建立零售業者降低消費者購物不 確定性的決策模型 (徐村和、林凌仲,民 94)、網路旅遊風險之評估 (Hsu and Lin, 2006) 等管理 領域之研究。
在模糊理論的研究,經常使用模糊數來衡量語意性措辭,Chen and Hwang (1992) 提出一個 應用模糊理論將語意性措辭模糊數 (fuzzy number) 轉換成明確數值 (crisp number) 之方法。但 由於函數間的計算過程困難,且個人不同的邏輯思維,對單一措辭亦會有著不同的模糊認知, 若使用模糊數衡量語意性措辭將會產生單一轉換值的嚴重問題。故本研究利用直覺模糊集合轉 換成數值之方式衡量品牌形象,此方法可有效解決並改進傳統衡量工具的缺失,且以直覺模糊 集合的隸屬函數,可推究真實語意結構,透過游移不定的程度加以表示清楚。
3.2 直覺模糊集合觀念
模糊集合的概念最早由Zadeh 在 1965 年所提出,而後 Atanassov 於 1983 年提出直覺模糊集 合的概念,並於1986 和 1999 年加入未知之資訊,即游移不定的程度 (Atanassov, 1986;1999), 定義直覺模糊集合: } )) ( ), ( , {(x x x x X A A A (1) 其中,A 表示某個品牌之直覺模糊集合,即每一個屬性在某個品牌的整體表現;X 表示所有屬性之集合;x 表示某個屬性; 表示隸屬程度,即某個品牌在某個屬性上表現優良的程度,A 則A 表示非隸屬程度,即某個品牌在某個屬性上表現不佳的程度;A:U
0,1,A:U
0,1,故 兩者相加必須界於0 到 1 之間。隨後,加入游移不定的程度,其定義如下: ) ( ) ( 1 ) (x A x A x A (2) A 為游移不定的程度,即對於某品牌具備某屬性的遲疑或不確定程度。3.3 以 IFS 為基礎之品牌形象衡量方法
過去許多學者利用直覺模糊集合在多屬性運算上的發展提出許多相關研究,本研究將根據 Chen and Tan (1994) 與 Klir and Yuan (1995) 所提出的多屬性決策方法與平均運算式發展品牌形 象的衡量模型。其中,對於屬性間的運算方式多以平均運算中的算數平均進行運算,而本研究 將進一步利用模糊運算裡的交集運算、聯集運算與平均運算建構三大品牌形象之衡量模型。相 較於傳統模型,本研究所建構之衡量模型其討論範圍將更為廣泛,且對於品牌形象的預測更為 精確,其為在模糊加總運算中交集運算、聯集運算與平均運算所涵蓋的整體結果範圍。 3.3.1 評估函數法本研究將利用Chen and Tan (1994) 所提出之評估函數 (evaluation function; E1) 為模型之
一,即E1模型,其相關定義如下。假設A為品牌的集合與X為品牌屬性的集合: } , , , {A1 A2 Am A , X {x1,x2,,xn} 接著,假設每一個方案的特徵表現為直覺模糊集合: )} , , ( , ), , , ( ), , , {( 1 i1 i1 2 i2 i2 j ij ij i x x x A i1 ,2, ,m, j1 ,2, ,n 其中,
A
i代表第i
個方案,即本研究之第i
個品牌;xj代表第j個品牌形象準則,即本研究之第 j個屬性; 表示第ij i個品牌滿足第j個形象屬性的程度, 則表示第iji
個品牌無法滿足第 j個 形象屬性的程度,故(xj,ij,ij)則代表第i個品牌的第 j個屬性之隸屬程度及非隸屬程度,即是 某品牌在某個形象屬性上的表現。 假設某品牌之產品具備非連結性的屬性條件,如同時擁有多個形象屬性,xh、xk、xp等, 亦或者是只擁有單一個形象屬性(xs),其定義表示如下: h x 且 xk 且 … 且 xp 或 xs (3) 然而,定義中的「且」與「或」所代表的意義即為「交集」與「聯集」的概念。假設在模 糊集合運算中有兩個品牌分別為A與B,並且其為論域X中的兩個模糊集合,則A
和B
之交集 可以記作AB。此時,亦為X中的一個模糊集合,其函數之定義如下:
( ), ( )
) )(
(AB x T A x B x (4)
其中,xX;T表示模糊交集 (Fuzzy Intersections, t-norms)。典型的t-norms函數之定義如下:
標準交集 (Standard Intersection):T1(a,b)min(a,b) (5)
代數積 (Algebraic Product):T2(a,b)ab (6)
界限差 (Bounded Difference):T3(a,b)max(0,ab1) (7)
反之,A與B的聯集可以記作AB,將T改以U 表示模糊聯集 (Fuzzy Union, t-conorms)。典
型的t-conorms函數之定義如下:
標準聯集 (Standard Union):U1(a,b)max(a,b) (8)
代數和 (Algebraic Sum):U2(a,b)abab (9)
界限和 (Bounded Sum):U3(a,b)min(1,ab) (10)
其中,a,b
0,1 ,a和b皆代表隸屬度值。 因此,評估函數 (E1) 為衡量某品牌 (Ai) 之品牌形象的正面與負面程度,即為本研究品牌 形象之分數,其定義如下: ) , ( )} ), , , , ( ( ), ), , , , ( ( { ) ( 1 Ai U T ih ik ip is T U ih ik ip is Ai Ai E (11) 其中, 表示隸屬程度,即第Aii
個品牌具備必要屬性程度,
Ai表示非隸屬程度,即第i
個品牌 不具備必要屬性程度。 3.3.2 修正評估函數法Liu and Wang (2007) 認為 Chen and Tan (1994) 之計算無法有效將游移不定的程度分給隸屬 程度與非隸屬程度,因此,提出修正評估函數 (E2),本研究將利用 Liu and Wang (2007) 之修正
評估函數衡量品牌形象,為本研究的模型之二,即E2模型。
Liu and Wang (2007) 藉由直覺模糊點運算之定義計算 Chen and Tan (1994) 所提出之評估函
數,將評估函數之隸屬程度與非隸屬程度分開運算,利用一對參數 ( ,x ) 經由x 次重新分配 游移不定的程度 ( 1( ) i A E ) 給隸屬程度或非隸屬程度,將所獲得的部份與評估函數之隸屬度或非 隸屬度做加總,即可得到一個新的直覺模糊集合。相關定義如下: ) ( 1 ) ( ) ( 1 1 1 i (1 ) i (1 ) i i i x E A x x x E A x x x E A old A new A (12) ) ( 1 ) ( ) ( 1 1 1 i (1 ) i (1 ) i i i x E A x x x E A x x x E A old A new A (13) 若 ,則其定義如下: ) 0 ( , ) ( 1 1 E A x x x x x old A new Ai i i (14)
) 0 ( , ) ( 1 1 E A x x x x x old A new Ai i i (15) 其中, ,x x
0,1 及xx 1,且 old A x i , old A x i ; old A old A A E i i i 1( ) 1 ; old Ai 表示公 式(11)中的 ,Ai old Ai 表示公式(11)中的 i A ; new Ai 表示第i
個品牌具備必要屬性的程度, new Ai 表 示第i
個品牌不具備必要屬性的程度。此外,由於 Liu and Wang (2007) 將其定義用於選擇方案時的風險概念上,故可知當 愈大
時,表示將游移不定之程度分配至隸屬程度或非隸屬程度愈多,即表示風險愈高,故當 的 時候,即表示風險最大。由上述定義可知,每個品牌在不同分配次數下皆有不同之隸屬程度與 非隸屬程度,故修正評估函數 (E2) 之定義如下: ) , ( ) ( 2 new A new A i i i A E (16) ) , ( ) ( 1 1 2 new A new A i i i A E (17) 其中,E2(Ai)則表示衡量第
i
個品牌之品牌形象的正面與負面程度,即本研究品牌形象之分數。 本研究將設定 =1, 2, 3, 4, 5, 6 以及 的參數模型。 3.3.3 新評估函數在本研究中將使用區間模糊集合 (interval-valued fuzzy set) 的尺度衡量各問項,並將所得之 資料轉換成直覺模糊集合之數據,以便之後之計算。Deschrijver and Kerre (2003) 研究指出直覺 模糊集合理論 (intuitionistic fuzzy set theory) 與區間模糊集合理論 (interval-valued fuzzy set theory)具有同構性質,在數學上是等價的,只是兩者使用不同的語義方式 (semantics)呈現。透 過一對一函數之轉換,Liu and Wang (2007) 證明直覺模糊集合與區間模糊集合皆是相同的模糊 集合概念,且兩者之間的轉換亦是相等的,故直覺模糊集合之理論上的定義可被延伸至區間模 糊集合的概念上。
因此,本研究亦利用區間模糊集合可以轉換成直覺模糊集合之特性,將多個直覺模糊集合 進行平均運算,若函數 h 符合單調遞增 (monotonic increasing) 和等冪性函數 (idempotent function),則加總運算亦可稱為平均運算 (averaging operations)。其中,本研究將使用平均運算 計算出一般化平均值 (generalized means),其相關定義如下: 1 2 1 2 1, , , ) ( n a a a a a a h n n (18) 其中, R ( 0),且ai0;當參數 0時,函數h 即收歛為幾何平均數 (geometric mean); 當參數 1時,函數h 即為算術平均數 (arithmetic mean),亦為傳統線性加總之運算方法;當 參數 1時,函數h 即為調和平均數 (harmonic mean)。
過去學者利用傳統計量方法衡量品牌形象時,皆利用連結性法則運算所得的每一個屬性之 分數,即為平均運算法中的算術平均數,但本研究之屬性亦可能出現非連結性的狀況,屬性之 條件如下: 1 x 且 x 且…且2 xn1 或 x (19) n 因此,為了處理上述之交集與聯集的問題,其新評估函數之相關定義如下: ) , ( )) ( )), ( , ), ( ), ( ( ( ) ( 1 2 1 3 Ad d A n i n i i i i U h A x A x A x A x i i A E (20) 其中, U 為標準聯集,且需分別計算出交集部分的 之下界値 (lower bound, ) 與上界値 L (upper bound, ),再運用聯集之概念,計算出品牌形象分數。運算過程如下: R 1 1 2 1 ) 1 ( n n L 1 1 1 2 2 1 1 1 ) ( ) ( ) ( n n n R ))) ( 1 , 1 ( ), , ( ( ) , ( ) ( 3 L n R n n d A d A i U T A E i i 其中,E3(Ai)即表示衡量某一品牌之品牌形象的正面與負面程度,即為本研究品牌形象之分數。 本研究將設定 =1, -1, 5, -5 以及 0的參數模型。 3.3.4 品牌形象排序方法 利用上述所提出之三種評估函數法,皆可以得到消費者對於各品牌的品牌形象之分數,因 此,本研究為了能找出各品牌之排序,運用計分函數 (score function, S )衡量各品牌滿足消費者 之必須條件的適合度,其運算結果即可排序品牌之優劣。首先,Chen and Tan (1994) 所提出之 計分函數之相關定義如下: i i A A i w A E S( ( )) (21) 其中,w1,2,3,w1表示評估函數法;w2表示修正評估函數法;w3表示新評估函數法;
1,1 )) ( (Ew Ai S ,若其值在
S(Ew(Ai))i1,2,,m
之間為最大時,表示該品牌 (A ) 為最佳選i 擇。隨後,Hong and Choi (2000) 探討多評準模糊決策的問題,提出正確性函數(accuracy
function,H)估算評估函數的正確性程度,協助消費者選擇較適合之品牌。定義如下: i i A A i w A E H( ( )) (22) 其中,H(Ew(Ai))愈高表示評估函數的正確性愈高。
但是,Li et al. (2001) 分析 Chen and Tan (1994) 提出的計分函數,發現有些時候會有相等的 情況,而無法計算出方案的排序。因此,將計分函數重新定義為S 和1 S ,透過兩階段決策方法2 衡量方案滿足決策者必須條件的適合度,當S 計算出的方案分數皆相等時,可再利用1 S 計算出2 各方案之優劣排序。其定義如下: i A i w A E S1( ( )) , i A i w A E S2( ( )) 1 (23) i i A A i w A E S1( ( )) , i A i w A E S2( ( )) 1 (24) 其中,S 和1 S 的值愈大表示該品牌滿足消費者者必要條件的適合度愈佳,即表示消費者對於該2 品牌之品牌形象分數愈佳。本研究將公式(23)所計算出之排序以符號「Ⅰ」表示;公式(24)所計 算出之排序則以符號「Ⅱ」表示。此外,本研究再整合上述學者之定義,提出另外兩種兩階段 決策方法,其定義如下: i A i w A E S1( ( )) , i i A A i w A E H( ( )) (25) i i A A i w A E S1( ( )) , i i A A i w A E H( ( )) (26) 其中,公式(25)所計算出之排序以符號「Ⅲ」表示;公式(26)所計算出之排序則以符號「Ⅳ」表 示。
4. 實證研究
4.1 問卷設計
本研究期望能利用實證資料來檢驗所研提之品牌形象衡量模型的可行性與適用性,找出與 受訪者所做出之品牌形象排序較為相符的模型。其中,產品因功能性、經驗性和象徵性等不同 的屬性而有不同之產品類別,消費者亦會產生不相同的品牌形象。由於本研究在建構品牌形象 之衡量模型,故選定「手機」作為實證研究之產品。手機發展的初期只有少數人負擔得起,因 而成為個人炫耀與代表價值的象徵;到了成長期,競爭者的出現、價錢的調整與使用者的反應, 業者開始加入不同的附加價值以區別市場吸引新消費群。而在大量生產後,手機產品開始有品 牌效應、特殊功能的設計、品質或是使用族群的區別,而朝小眾市場的方向前進 (彭啟人,民94)。 又由於資訊科技的進步,台灣手機用戶的普及率快速上升,至2004年已達到一個手機用戶至少 有一個以上手機門號的現象,此外,手機可說是全球最普及的IT產品,其普及程度幾乎已成為 民生必需品,成為現代人一種不可或缺的配件之一,可見手機對於消費者的重要性已不在話下。 2007年雖爆發美國次級房貸的全球風暴,但卻不影響手機產業在2007年維持穩健成長,在歐美 銷售旺季、新興市場銷售暢旺、及中國與亞太地區新年長假效應,產業需求面持續增溫,2007 全年11.51億支的手機產量目標順利達成 (拓墣產業研究所,民97)。由此可知,多數消費者可以較容易獲知各手機品牌的特性,以及根據需求進行汰舊換新的動作,進而比較能夠有效評估與 品牌形象相關的屬性。 此外,創市際研究顧問 (民96) 的手機消費調查研究顯示,男性與女性人數之比例約為1:1, 且主要消費者之年齡層約為20-29歲,故本研究將依此性別比例以及年齡層選定研究對象。因此, 業者如何藉由品牌形象的力量傳達給不同的消費者,便是目前在眾多同質性產品選擇中脫穎而 出的重要關鍵。本研究根據林世懿 (民95) 的調查將手機品牌依據持有率分成三個群組,將挑選 持有率30%以上的兩個手機品牌 (Nokia、Motorola)、持有率15%~30%的一個手機品牌 (Sony Ericsson) 及持有率15%以下的兩個手機品牌 (OKWAP、Samsung),共五個品牌,作為衡量品牌 形象之產品。 4.1.1 品牌形象之操作型定義與衡量問項 過去許多研究將品牌形象依利益分作三個構面:功能性形象、象徵性形象和經驗性形象(郝 靜宜,民87;陳建翰,民 92;鄭仁偉等,民 89;Keller, 1993;Porter and Claycomb, 1997),因 此,本研究根據學者對於品牌形象構面區分,將品牌形象分為功能性形象、象徵性形象及經驗 性形象,並給予其操作型定義,(1)功能性形象:滿足消費者解決實際的產品需求問題之相關條 件;(2)象徵性形象:強調滿足消費者內在需求的條件,如社會認同、自我價值等;(3)經驗性形
象:滿足消費者心理上的樂趣知覺以及多樣化需求。完整的構面與題項之定義置於附錄 A。於
此本研究參考Del Río, et al. (2001) 、郝靜宜 (民 87)、陳振燧、洪順慶 (民 87) 與陳建翰 (民 92) 對品牌形象構面所做的衡量問項。其中,陳建翰 (民 92) 之 研究設定手機作為實證研究之產品, 量表之構面信度皆大於0.8 以及因素負荷量皆大於 0.5,且具備良好的信度與效度,又本研究發 現過去研究雖將品牌形象依利益分作三個構面,但多數僅探討功能性形象與象徵性形象,而忽 略經驗性形象的重要性,亦或者將其視為另ㄧ體驗性之研究議題。因此,本研究之問卷設計涵 蓋了三個構面,符合Keller (1993) 所提之三形象構面理論進一步探究品牌形象,透過 18 個屬性 使本研究之衡量模型能夠較完整分析消費者對於品牌的多元屬性評估。不單只是瞭解各品牌於 功能上的差距與自我形象的符合程度,亦可從其身上的經驗得知內心更為深刻的感受,由此評 估各品牌的形象差異,能更精確地獲知產品的功能優勢、象徵特性以及賦予消費者的經驗價值。 故本研究主要依據且修正其量表以發展本研究對品牌形象的問項,如表1 所示。 此外,本研究中強調整體品牌形象分數之高低,探討屬性間的關係,而非構面間的關係。 又品牌形象是以「相對的好壞」而非「絕對的優劣」的比較方式。此外,多數消費者在挑選產 品時,會累加屬性的分數,即便其重視功能性的產品,亦會透過象徵性或經驗性的其他屬性產 生對一品牌形象的評價。故後續分析研究提出構成品牌形象的這些顯要屬性,不一定要以連結 性形式呈現,其亦可以非連結性的形式呈現。因此,依據上述彙整之屬性,透過深度訪談的方 式,讓 30 位受訪者依照個人想法選擇非連結性的屬性,且可以複選,結果發現「產品設計」
表1 品牌形象構面之問項 構面 學者(年代) 問項敘述 功能性形象 郝靜宜 (民87) 該品牌的產品是實用的 該品牌的產品給我安全性的印象 陳振燧、洪順慶 (民87) 整體來說,該品牌的產品設計很好 該品牌的產品是功能優越的 該品牌的產品是可信賴的 Del Río (2001) 該品牌的產品品質很高 該品牌注重持續改善產品的功能 象徵性形象 陳振燧、洪順慶 (民87) 使用該品牌的產品是流行的 郝靜宜 (民87) 使用該品牌的產品能反映您的個人風格 使用該品牌的產品能作為社會地位的象徵 我的朋友很多擁有該品牌的產品 Del Río (2001) 該品牌在產業中是領導品牌 該品牌擁有良好的名聲 我可能因為名人的推薦而採用該品牌的產品 經驗性形象 陳振燧、洪順慶 (民87) 該品牌給予我溫馨的感覺 該品牌給予我舒服的感覺 該品牌給予我有趣的感覺 該品牌給予我歡樂的感覺 (86.67%) 的比率最高,其次為「品質」(46.67%) 以及「實用」(40.00%),故本研究將「產品設 計」視為各模型中的非連結性屬性。 4.1.2 尺度設計與前測 本研究在此欲使用直覺模糊集合作為問卷測量的工具,擺脫傳統單一點數值之測量方式的 缺點,且結合直覺模糊集合來代表語意尺度的隸屬函數,不但減少傳統問卷衡量尺度中主觀設 定隸屬度函數與尺度等距而造成的偏差,亦可解決模糊問卷中,使用模糊數轉換所造成的缺點。 故本研究為設計一套較能使受訪者接受之問卷形式,期望能降低受訪者的填答障礙以及拒絕填 答的可能性。因此,研提以下三種表現方式:(1)問卷形式為受訪者在[0,10]的線段上劃出對於品 牌形象的感受範圍,(2)問卷形式為受訪者在[0,1]的線段上劃出對於品牌形象的感受範圍,(3)問 卷形式為受訪者在括號內依照自己內心對於品牌形象的認同程度,填入一個[0,100]的區間分 數,分數越高表示對於該品牌之形象越正面。 經由前測結果發現,第三種以填寫分數的比例最高(59%),其原因在於受訪者認為該方法的 理解程度較高,所需花費的填答時間少,需投入心力亦在可接受範圍內。整體而言,受訪者認 為填寫分數的方式複雜度較低,亦較容易填寫,可以表達自己較為精確的同意程度,且不會產 生抗拒的心理。因此,本研究的問卷形式將採用[0,100]的區間分數作為問項之填答方式。此外,
由於過去調查品牌形象的研究中,問卷內容大多數以李克特尺度進行調查,所以本研究除了採 用直覺模糊尺度衡量消費者對於品牌形象的真實感受外,亦與傳統李克特尺度進行對照比較。 進而瞭解何種衡量方式較能貼近消費者心中對於不同手機之品牌形象的看法。其中,傳統問卷 以李克特五點尺度衡量方式。
4.2 研究對象與抽樣方法
本研究採便利取樣,以大專院校學生族群作為研究對象,抽樣的對象為曾經購買過或使用 過五個手機品牌之消費者。由於本研究為基礎研究,且問卷所需填答內容多,需尋找高度配合 且有較多閒暇時間的消費者進行問卷之填寫,故以大專院校之學生作為樣本。其中,由於手機 屬於生命週期較短的科技產品,因此對於年輕人而言,汰換率與購買經驗相對較高且較多。然 而,本研究衡量的是品牌形象,所以受訪者亦可經由自己的直接使用經驗或間接從親朋好友、 網路等口碑獲得五種品牌的相關資訊以衡量各品牌的形象屬性。此外,選取學生較能夠避免外 生因素干擾及受訪者想法的差異導致模型收斂的問題,亦能提高內部一致性。4.3 問卷發放之作業流程
由於本研究需要受訪者對於五個品牌的手機進行分數填答以及給予排序,因此會先以口頭 詢問的方式瞭解受訪者是否具備購買經驗或使用經驗,若受訪者具備該條件才會開始發放問 卷。本研究問卷一共分為三階段,在第一階段中受訪者會隨機拿到直覺模糊問卷 (如附錄 B) 或 傳統問卷進行填寫,當受訪者填完第一階段之問卷後才會發放第二階段之問卷。於第二階段中, 受訪者填寫之問卷會異於其在第一階段中所填寫之問卷,最後則需要受訪者填寫基本資料與排 序之問卷。4.4 資料分析
4.4.1 樣本結構分析與信效度分析 本研究共發放76 份直覺模糊問卷與 76 份傳統問卷,總計 152 份問卷,剔除無效樣本 12 人, 有效樣本為64 人,共 128 份問卷,有效回收率為 84.21%。其中,男性樣本數為 31 人,女性樣 本數為33 人,男性與女性之比例為約為 1:1,而受訪者主要的年齡層為 21-25 歲,占總樣本的 75%;學院別的部分則是以商學院/管理學院所佔之比例較多,占總樣本的 90.63%,其餘則為工 學院。受訪者之可支配所得 (零用錢) 在 6001-9000 元占總樣本的 34.38%,其次有 29.69%之受 訪者的可支配所得為3001-6000 元。就目前使用手機數目而言,以受訪者使用 1 支手機之比例最 高,為54.69%,其次為 2 支手機,佔總樣本的 35.94%。手機更換頻率的部份,皆以半年以上為 基準,其中,平均一年至二年更換手機的受訪者占總樣本的54.69%,而二年以上則占有 35.94%。 本研究以有效樣本中的傳統問卷進行信度分析,採用Cronbach’s α 係數來檢驗信度的內部一致性,由於本研究主要調查各品牌手機之形象排序。因此,本研究以手機為單位來進行品牌形 象構面之信度分析,結果確認信度值皆高於0.7 以上,表示內部一致性的程度高,如表 2 所示。 此外,效度意指問卷題目的適切性與正確性。本研究亦進行因素分析,發現 KMO 取樣適切性 量數達 0.850,而 Barlett 達顯著水準,表示資料適合作因素分析,顯示品牌形象區分為三個因 素 (分別定義為功能性形象、象徵性形象與經驗性形象),所萃取的因素可以解釋全體變異數達 70.497%。另外,檢視每個因素的項目因素負荷量皆達 0.5 以上,除第 12 題之因素分數偏低,但 仍接近一般設定數值0.3。因此,本研究再進一步進行驗證性因素分析,利用 AMOS 7.0 軟體以 最大概似法進行參數估計來確認量表的因素效度,發現以平均變異數萃取量來表示潛在變項可 以解釋觀察變項的比値,Fornell and Larcker (1981) 建議該值應大於 0.5 以上。本研究的標準化
因素負荷量多介於0.5~0.89 之間,具有良好的收斂效度,而平均變異數萃取量介於 0.734 至 0.897 之間表示有良好的區別效度,且各構面之組合信度皆高於0.9,顯示內部一致性頗高,由該結果 發現第12 題並無嚴重影響信度與效度的結果。整體因素分析之結果如表 3 所示。 又因後續的品牌形象分析是以18 個屬性進行計算,重點在於測驗題目內部之間的一致性, 故項目分析針對題目進行適切性的評估。回頭檢視題目總分相關法,結果顯示第12 題的修正項 目總分相關係數為0.639 (0.3 以上即可)。且全部 18 個項目的 Cronbach’s α 係數原為 0.937,刪除 第12 題的係數為 0.934,進一步分析「象徵性形象」構面的 7 個項目之 Cronbach’s α 係數原為 0.848,刪除第 12 題的係數為 0.844,皆表示刪除該題項並無法提升內部一致性。此外,依據因 素負荷量判斷法,結果也顯示第12 題的因素負荷量為 0.652 大於 0.5,可以保留。綜合上述,本 研究仍舊將其視為衡量模型的形象屬性之一,當屬性條件越多,越可以精確地得知每一品牌形 象的個別屬性差異以及更完整地探討消費者內心對於單一品牌的屬性評估為何,提供後續衡量 模型建構的進一步探究與分析。 4.4.2 傳統問卷分析 本研究對於傳統問卷之品牌形象分數的計算方式為分別對五家手機進行分數之加總計算, 進一步依照總分依序給予一到五名之排序,最後再利用Spearman 等級相關分析分別計算有效樣 本所填寫之手機品牌形象排序與本研究所計算之排序的相關係數值,並就全部的 值作平均數 表2 品牌形象構面之 Cronbach’s α 係數 手機品牌 構面 Nokia
(諾基亞) (摩托羅拉) Motorola Sony Ericsson (新力易利信) (英華達) OKWAP Samsung (三星)
功能性形象 0.8690 0.8726 0.8428 0.8697 0.9134
象徵性形象 0.7489 0.8050 0.8644 0.8682 0.8807
表3 品牌形象之因素分析結果 因素一 因素二 因素三 組合 信度 平均變 異抽取 1. 該品牌的手機是實用的。 0.815 0.9837 0.8972 2. 該品牌的手機給我安全性的印象。 0.826 3. 整體來說,該品牌的手機設計很好。 0.879 4. 該品牌的手機是功能優越的。 0.806 5. 該品牌的手機是可信賴的。 0.873 6. 該品牌的手機品質很高。 0.859 7. 該品牌注重持續改善手機的功能。 0.516 8. 該品牌的手機能反映您的個人風格。 0.686 0.9523 0.7343 9. 使用該品牌的手機是流行的。 0.699 10.使用該品牌的手機能作為社會地位的象徵。 0.836 11.該品牌在手機產業中是領導品牌。 0.504 12.該品牌擁有良好的名聲。 0.285 13.我的朋友很多擁有該品牌的手機。 0.672 14.我可能因為名人的推薦而採用該品牌的手機。 0.805 15.該品牌的手機給予我溫馨的感覺。 0.869 0.9787 0.8959 16.該品牌的手機給予我舒服的感覺。 0.875 17.該品牌的手機給予我有趣的感覺。 0.861 18.該品牌的手機給予我歡樂的感覺。 0.892 解釋變異數% 52.485 10.309 7.703 累積解釋變異數% 52.485 62.794 70.497 與標準差之計算。其中, 值平均數為 0.7773, 值標準差為 0.1713,隨後將與此平均數與標 準差作比較。 而 值低於 0.6 的樣本有 13 人約占整體的 20.31%,其中,7 人為男性以及 6 人為女性,多 數收入低於6000 元 (69.23%),且僅擁有 1 支手機 (69.23%)。本研究繼續探討這些樣本是否於 填答直覺模糊問卷亦呈現相關係數較低的現象,但結果發現每一樣本於三大模型之品牌形象排 序的相關係數平均數表現幾乎皆大於0.7 以上,如表 4 所示。表示本研究之品牌形象衡量模型可 得與消費者心中較接近之排序,再分析傳統問卷的原始資料則得知此類受訪者於填寫傳統問卷 時,就排序前三名之手機的品牌形象分數極為接近,導致計算出之排序與其本身所填寫之排序 出現差異,故相關係數落在0.4~0.6,樣本 47 的相關係數甚至僅為 0.1。進一步探究發現五個品 牌分數的差距都只有 1~2 分,表示利用單一數值計算有可能無法表達其品牌之間的微小差異, 導致與其內心之品牌形象排序有所不同。 此外,本研究亦希望瞭解樣本於填寫品牌形象屬性時的分數範圍,求取全部樣本於直覺模 糊問卷所填寫之18 個屬性的隸屬度、游移不定程度、非隸屬度以及於傳統問卷所勾選同意程度
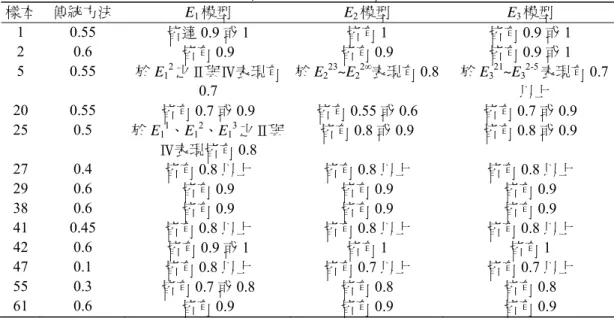
表4 部分樣本之等級相關係數比較 樣本 傳統方法 E1模型 E2模型 E3模型 1 0.55 皆達0.9 或 1 皆有1 皆有0.9 或 1 2 0.6 皆有0.9 皆有0.9 皆有0.9 或 1 5 0.55 於 E12之Ⅱ與Ⅳ表現有 0.7 於 E223~E22∞表現有0.8 於 E321~E32-5表現有0.7 以上 20 0.55 皆有0.7 或 0.9 皆有0.55 或 0.6 皆有0.7 或 0.9 25 0.5 於 E11、E12、E13之Ⅱ與 Ⅳ表現皆有0.8 皆有0.8 或 0.9 皆有0.8 或 0.9 27 0.4 皆有0.8 以上 皆有0.8 以上 皆有0.8 以上 29 0.6 皆有0.9 皆有0.9 皆有0.9 38 0.6 皆有0.9 皆有0.9 皆有0.9 41 0.45 皆有0.8 以上 皆有0.8 以上 皆有0.8 以上 42 0.6 皆有0.9 或 1 皆有1 皆有1 47 0.1 皆有0.8 以上 皆有0.7 以上 皆有0.7 以上 55 0.3 皆有0.7 或 0.8 皆有0.8 皆有0.8 61 0.6 皆有0.9 皆有0.9 皆有0.9 的數值轉換之隸屬度的平均數。分析結果發現樣本在填寫傳統問卷時的品牌形象屬性分數幾乎 都會落在直覺模糊問卷之游移不定程度的範圍中,且可看出五個品牌之品牌形象屬性的分數差 距以及整體品牌形象的排序,如圖1~圖5所示。 由分布圖可知總樣本認為OKWAP的品牌形象較差,其隸屬度皆落在0.6以下,Nokia與Sony Ericsson之整體分布圖較為接近,其排序也都為前兩名,而Motorola與Samsung之品牌形象排序則 位於中間。整體而言,樣本配合度高,有較多的時間能夠專心填寫兩份問卷,故整體樣本於填 寫傳統問卷與直覺模糊問卷時的一致性較高,表示若使用本研究之直覺模糊問卷收集資料,非 但不會有亂填的情況,更可得到比傳統問卷更進一步的訊息,瞭解受訪者內心對於每一個屬性 之游移不定的程度。 4.4.3 直覺模糊問卷之模型分析
本研究利用發展的E1模型、E2模型與E3模型計算手機之品牌形象分數與排序,進一步利用計
算出的排序與受訪者之品牌形象排序做Spearman等級相關分析,並彙整整體有效樣本之相關係 數的平均數與標準差及計算出每個模型求得之相關係數優於傳統方法的樣本個數比例,最後與 傳統問卷之結果進行平均數與標準差比較分析。
(1) 模型與樣本代號說明
為了將各程序知之結果標示清楚明確,故本研究於後續內容中,將品牌形象模型以及比較 程序訂定代號,分別以E1ab、E2acb與 E3acb代表三種運算模型,其中,a 表示三種交集與聯集的
品牌 - Nokia 0 0.2 0.4 0.6 0.8 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 題號 直 覺 模 糊 數 值 0 0.2 0.4 0.6 0.8 1 模糊 ν 模糊 π 模糊 μ 傳統 μ 圖1 樣本於品牌 Nokia 之個別形象屬性的平均數分布圖 品牌 - Motorola 0 0.2 0.4 0.6 0.8 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 題號 直 覺 模 糊 數 值 00.2 0.4 0.6 0.8 1 模糊 ν 模糊 π 模糊 μ 傳統 μ 圖2 樣本於品牌 Motorola 之個別形象屬性的平均數分布圖 品牌 - Sony Ericsson 0 0.2 0.4 0.6 0.8 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 題號 直 覺 模 糊 數 值 0 0.2 0.4 0.6 0.8 1 模糊 ν 模糊 π 模糊 μ 傳統 μ 圖3 樣本於品牌 Sony Ericsson 之個別形象屬性的平均數分布圖
品牌 - OKWAP 0 0.2 0.4 0.6 0.8 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 題號 直 覺 模 糊 數 值 0 0.2 0.4 0.6 0.8 1 模糊 ν 模糊 π 模糊 μ 傳統 μ 圖4 樣本於品牌 OKWAP 之個別形象屬性的平均數分布圖 品牌 - Samsung 0 0.2 0.4 0.6 0.8 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 題號 直 覺 模 糊 數 值 00.2 0.4 0.6 0.8 1 模糊 ν 模糊 π 模糊 μ 傳統 μ 圖5 樣本於品牌 Samsung 之個別形象屬性的平均數分布圖 牌形象的排序方法,即公式(3.35)至(3.38),b = Ⅰ, Ⅱ, Ⅲ, Ⅳ;c 則表示模型之參數,即E2模型中 的參數 = 1, 2, 3, 4, 5, 6 及 →∞與E3模型中的參數 = 1, -1, 5, -5 及 →0。 (2) 模型之分析結果與討論 本研究將計算模型所計算出的排序與受訪者填寫的排序之Spearman等級相關係數,其中, 整體樣本的平均數、標準差以及每個樣本利用模型所計算出之品牌形象的相關係數大於每個樣 本利用傳統問卷之相關係數的個數比例,即其個數占整體64個樣本的比例,各模型之參數與排 序方法的分析結果如下: 1) E1模型
由表 5 可知,以平均數而言,數値較高的衡量模型皆落在T 與2 U 的方法中,其中,以排序2 方法Ⅳ表現最佳,其平均數高達0.9047 以及標準差低於 0.1000,其次為排序方法Ⅰ、Ⅱ與Ⅲ; 若分析個數比例則發現結果與平均數趨於一致,其中,排序方法Ⅰ、Ⅲ與Ⅳ皆達89.06%,且排 序方法Ⅱ亦達85.94%。因此,該模型之整體表現以T 與2 U 的方法為最適衡量模型。 2 2) E2模型 由表6可知,以平均數而言,數値較高的衡量模型皆落在T 與2 U 的方法中,其中,以參數2 =3, 4, 5, 6 之表現最佳,其平均數高達0.8875及標準差為0.1120,其次則以參數=1, 2, ∞ 之平均 數0.8859為次佳;若分析個數比例則發現結果與平均數趨於一致,T 與2 U 方法之參數=1, 2, 3, 4, 2 5, 6, ∞ 的比例皆達84.38%。因此,整體表現以T 與2 U 的方法為最適衡量模型。 2 3) E3模型 由表7可知,以平均數而言,數値較高的三個衡量模型皆落在T 與2 U 之方法中,其中,以2 參數→0 之排序方法Ⅱ與Ⅳ的表現最佳,其平均數高達0.9219及標準差為0.0881,其次為參數= 1 之排序方法Ⅰ,其平均數亦高達0.9219及標準差為0.1061;若分析個數比例則發現結果與平均數 趨於一致,參數=1, -1、參數→0 之排序方法Ⅱ與Ⅳ、參數= 5 之排序方法Ⅰ與Ⅲ以及參數= -5 之 排序方法Ⅱ與Ⅳ的比例皆達98.44%。反之,發現利用界限差與界限和之方法分析品牌形象的結 果較差,其平均數甚至出現負值且皆低於0.3,優於傳統方法之個數比例亦低於30%,因此,該 模型之整體表現為T 與2 U 的方法為最適衡量模型,而2 T 與3 U 的方法則為較不理想的衡量模型。 3 4) 綜合比較 由上述結果發現,三大模型中的156種參數方法下,其相關係數的平均數大於傳統方法之相 關係數的平均數共有136種,即表示約有87.18%衡量手機品牌形象之模型較傳統方法更貼近受訪 者心中的排序狀況。其中,優於傳統方法之各參數的平均數皆大於0.85,且共有32種衡量模型 之平均數大於0.9。此外,本研究亦利用相關係數之個數比例作為另一比較分析傳統問卷與直覺 模糊問卷的指標,當比例越高即表示在此模型與參數所適合的樣本數越多,其通用性也越高。 其中,共有14種衡量模型之個數比例高達98.44%,表示64個有效樣本中僅1個樣本的相關係數低 於傳統方法,可知其通用性較高,主要分布於E2模型之T 與2 U 的各參數中。 2 除了比較單一種模型中的單一參數之外,本研究在不考慮模型內參數之變化,僅針對 E1 模型、E 2模型與 E3模型進行不同交集與聯集之運算下,透過將各模型之三種交集與聯集的所有 表5 E1模型之分析結果 E11Ⅰ E11Ⅱ E11Ⅲ E11Ⅳ E12Ⅰ E12Ⅱ E12Ⅲ E12Ⅳ E13Ⅰ E13Ⅱ E13Ⅲ E13Ⅳ 平均數 0.8766 0.8898 0.8625 0.8883 0.8969 0.8938 0.8938 0.9047 0.8773 0.8867 0.8544 0.8852 標準差 0.1391 0.1155 0.1716 0.1161 0.1234 0.1052 0.1256 0.0999 0.1400 0.1193 0.1963 0.1184 個數比例 84.38% 84.38% 79.69% 84.38% 89.06% 85.94% 89.06% 89.06% 84.38% 82.81% 79.69% 82.81% 註:粗體字表示於該模型中表現較佳者
表6 E2模型之分析結果 E211Ⅰ E211Ⅱ E211Ⅲ E211Ⅳ E212Ⅰ E212Ⅱ E212Ⅲ E212Ⅳ E213Ⅰ E213Ⅱ E213Ⅲ E213Ⅳ 平均數 0.8727 0.8711 0.8727 0.8711 0.8695 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 標準差 0.1303 0.1393 0.1303 0.1393 0.1284 0.1393 0.1393 0.1393 0.1293 0.1393 0.1393 0.1393 個數比例 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% E214Ⅰ E214Ⅱ E214Ⅲ E214Ⅳ E215Ⅰ E215Ⅱ E215Ⅲ E215Ⅳ E216Ⅰ E216Ⅱ E216Ⅲ E216Ⅳ 平均數 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 0.8711 標準差 0.1293 0.1393 0.1393 0.1393 0.1293 0.1393 0.1393 0.1393 0.1293 0.1393 0.1393 0.1393 個數比例 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% E21∞Ⅰ E21∞Ⅱ E21∞Ⅲ E21∞Ⅳ E221Ⅰ E221Ⅱ E221Ⅲ E221Ⅳ E222Ⅰ E222Ⅱ E222Ⅲ E222Ⅳ 平均數 0.8695 0.8695 0.8695 0.8695 0.8859 0.8859 0.8859 0.8859 0.8859 0.8859 0.8859 0.8859 標準差 0.1305 0.1305 0.1305 0.1305 0.1193 0.1180 0.1119 0.1180 0.1180 0.1180 0.1180 0.1180 個數比例 79.69% 79.69% 79.69% 79.69% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% E223Ⅰ E223Ⅱ E223Ⅲ E223Ⅳ E224Ⅰ E224Ⅱ E224Ⅲ E224Ⅳ E225Ⅰ E225Ⅱ E225Ⅲ E225Ⅳ 平均數 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 0.8875 標準差 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 0.1120 個數比例 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% E226Ⅰ E226Ⅱ E226Ⅲ E226Ⅳ E22∞Ⅰ E22∞Ⅱ E22∞Ⅲ E22∞Ⅳ E231Ⅰ E231Ⅱ E231Ⅲ E231Ⅳ 平均數 0.8875 0.8875 0.8875 0.8875 0.8859 0.8859 0.8859 0.8859 0.8727 0.8727 0.8727 0.8727 標準差 0.1120 0.1120 0.1120 0.1120 0.1134 0.1134 0.1136 0.1136 0.1300 0.1288 0.1300 0.1288 個數比例 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 84.38% 79.69% 79.69% 79.69% 79.69% E232Ⅰ E232Ⅱ E232Ⅲ E232Ⅳ E233Ⅰ E233Ⅱ E233Ⅲ E233Ⅳ E234Ⅰ E234Ⅱ E234Ⅲ E234Ⅳ 平均數 0.8711 0.8727 0.8727 0.8727 0.8727 0.8742 0.8727 0.8742 0.8727 0.8766 0.8727 0.8767 標準差 0.1278 0.1288 0.1278 0.1288 0.1288 0.1294 0.1288 0.1294 0.1288 0.1288 0.1288 0.1288 個數比例 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 79.69% 81.25% 79.69% 81.25% E235Ⅰ E235Ⅱ E235Ⅲ E235Ⅳ E236Ⅰ E236Ⅱ E236Ⅲ E236Ⅳ E23∞Ⅰ E23∞Ⅱ E23∞Ⅲ E23∞Ⅳ 平均數 0.8727 0.8766 0.8727 0.8766 0.8727 0.8773 0.8727 0.8773 0.8719 0.8719 0.8719 0.8719 標準差 0.1288 0.1282 0.1288 0.1282 0.1288 0.1294 0.1288 0.1294 0.1306 0.1306 0.1306 0.1306 個數比例 79.69% 81.25% 79.69% 81.25% 79.69% 81.25% 79.69% 81.25% 79.69% 79.69% 79.69% 79.69% 註:粗體字表示於該模型中表現較佳者E3模型 表7 E3模型之分析結果 E311Ⅰ E311Ⅱ E311Ⅲ E311Ⅳ E31-1Ⅰ E31-1Ⅱ E31-1Ⅲ E31-1Ⅳ E310Ⅰ E310Ⅱ E310Ⅲ E310Ⅳ 平均數 0.9039 0.9039 0.9031 0.9070 0.9023 0.9023 0.9023 0.9055 0.9039 0.9039 0.9008 0.9070 標準差 0.1173 0.1145 0.1419 0.1116 0.1180 0.1139 0.1440 0.1110 0.1159 0.1186 0.1413 0.1158 個數比例 90.63% 89.06% 92.19% 90.63% 89.06% 87.50% 90.63% 89.06% 90.63% 89.06% 92.19% 90.63% E315Ⅰ E315Ⅱ E315Ⅲ E315Ⅳ E31-5Ⅰ E31-5Ⅱ E31-5Ⅲ E31-5Ⅳ E321Ⅰ E321Ⅱ E321Ⅲ E321Ⅳ 平均數 0.8938 0.8953 0.8844 0.8984 0.8922 0.9000 0.8906 0.9031 0.9219 0.9203 0.9203 0.9203 標準差 0.1454 0.1399 0.1642 0.1377 0.1212 0.1141 0.1566 0.1112 0.1061 0.0894 0.1072 0.0894 個數比例 90.63% 90.63% 89.06% 92.19% 90.63% 90.63% 90.63% 92.19% 98.44% 98.44% 98.44% 98.44% E32-1Ⅰ E32-1Ⅱ E32-1Ⅲ E32-1Ⅳ E320Ⅰ E320Ⅱ E320Ⅲ E320Ⅳ E325Ⅰ E325Ⅱ E325Ⅲ E325Ⅳ 平均數 0.9203 0.9203 0.9203 0.9203 0.8695 0.9219 0.8680 0.9219 0.9188 0.9125 0.9172 0.9109 標準差 0.1072 0.0858 0.1072 0.0858 0.1912 0.0881 0.1905 0.0881 0.1125 0.1 0.1135 0.0994 個數比例 98.44% 98.44% 98.44% 98.44% 85.94% 98.44% 85.94% 98.44% 98.44% 96.88% 98.44% 96.88% E32-5Ⅰ E32-5Ⅱ E32-5Ⅲ E32-5Ⅳ E331Ⅰ E331Ⅱ E331Ⅲ E331Ⅳ E33-1Ⅰ E33-1Ⅱ E33-1Ⅲ E33-1Ⅳ 平均數 0.9125 0.9203 0.9125 0.9203 0.0438 0.0438 0.0438 0.0438 0.1867 0.1898 0.1867 0.1898 標準差 0.1134 0.0839 0.1134 0.0839 0.5057 0.5057 0.5057 0.5057 0.5647 0.5686 0.5647 0.5686 個數比例 96.88% 98.44% 96.88% 98.44% 10.94% 10.94% 10.94% 10.94% 21.88% 23.44% 21.88% 23.44% E330Ⅰ E330Ⅱ E330Ⅲ E330Ⅳ E335Ⅰ E335Ⅱ E335Ⅲ E335Ⅳ E33-5Ⅰ E33-5Ⅱ E33-5Ⅲ E33-5Ⅳ 平均數 0.0875 0.0875 0.0875 0.0875 -0.0172 -0.0172 -0.0172 -0.0172 0.2414 0.2445 0.2414 0.2445 標準差 0.5336 0.5336 0.5336 0.5336 0.4877 0.4877 0.4877 0.4877 0.5834 0.5867 0.5834 0.5867 個數比例 14.06% 14.06% 14.06% 14.06% 7.81% 7.81% 7.81% 7.81% 25% 26.56% 25% 26.56% 註:粗體字表示於該模型中表現較佳者
平均數相加,再取其平均。可得知E1模型、E2模型與E3模型之相關係數的平均數皆明顯大於傳統 方法,且其相關係數的標準差亦小於傳統方法,但其中僅以E3模型之T 與3 U 所計算出的結果較3 差。此外,各模型之T 與2 U 方法的平均數皆為最高,又以E2 3模型之T 與2 U 方法為最接近消費2 者心中對於手機之品牌形象排序的最適模型。三大模型之整體分析結果如表8所示。 4.4.4 直覺模糊問卷之變數分析 本研究依據基本資料中的敘述性統計進一步進行分析,希望透過各變數之樣本相關係數平 均數瞭解樣本之間適用模型是否具顯著差異。整理各變數內容,進行兩個群組的劃分,其中, 受訪者之年齡集中於 20-30 歲 (98.44%) 以及學院別集中於商學院/管理學院 (90.63%),故在此 不做探討。依照三大模型和三種交集與聯集分別進行分析,將兩組樣本在 9 種衡量模型下的相 關係數平均數相加,再取其平均,進而比較群組之間在相同衡量模型下的平均數高低,瞭解其 所適用之模型與結果是否具差異。相關之分析結果如表9 所示。 由變數之相關係數平均數分析的結果可知,以性別而言,男性與女性於各模型下並無明顯 的差異,但仍可發現若要探討男性對於不同手機之品牌形象排序時,可利用E2模型衡量之,反 之,探討女性時則可利用E1模型;就個人可支配所得的部分,本研究發現個人可支配所得於6000 元以上的消費者在三大模型下之平均數幾乎皆高於所得6000元以下的人,故其內心之品牌形象 排序與塡答各品牌之問項時的排序結果較為相符,以E3模型之T2與U2方法為最適衡量模型。 此外,針對目前使用之手機數目的部分,使用2支手機以上的消費者在三大模型下之平均數 幾乎皆高於目前僅使用1支手機的人,以及手機更換頻率的部分,頻率為2年以下的消費者在三 大模型下之平均數皆高於2年以上的人。本研究認為此類消費者因為手機更換頻率較快,其較會 注意各品牌手機之資訊,容易經由購買或使用經驗比較出手機的品牌形象差異,故其內心之品 牌形象排序與塡答各品牌之問項時的排序結果較相符。整體而言,能貼近不同變數之消費者心 中的品牌形象排序衡量模型仍屬三大模型之代數積與代數和的方法。 表8 三大模型之等級相關係數的平均數與標準差 模型 Ti與 Ui E1模型 E2模型 E3模型 T1與 U1 (0.1371**) 0.8793* (0.1286**) 0.8709* (0.1279**) 0.9002* T2與 U2 (0.1146**) 0.8973* (0.1132**) 0.8868* (0.1120**) 0.9135* T3與 U3 (0.1467**) 0.8759* (0.1281**) 0.8734* (0.5413) 0.1091 註:* 表示平均數>0.7773 (傳統方法之平均數) 註:** 表示標準差<0.1713 (傳統方法之標準差)
表9 各變數群組於模型表現之分析 模型 Ti與 Ui E1模型 E2模型 E3模型 性別 男性 T1與 U1 0.8633 0.8779* 0.8868 T2與 U2 0.8844 0.8917* 0.9114 T3與 U3 0.8672 0.8801* 0.1753* 女性 T1與 U1 0.8970* 0.8666 0.9147* T2與 U2 0.9129* 0.8855 0.9179* T3與 U3 0.8866* 0.8677 0.0264 個人可支配所得 6000 元以下 T1與 U1 0.8300 0.8277 0.8642 T2與 U2 0.8480 0.8454 0.8852 T3與 U3 0.8273 0.8339 0.1328* 6000 元以上 T1與 U1 0.9109* 0.8986* 0.9233* T2與 U2 0.9288* 0.9134* 0.9317* T3與 U3 0.9071* 0.8988* 0.0938 目前使用手機數目 1 支 T1與 U1 0.8607 0.8595 0.8864 T2與 U2 0.8743 0.8747 0.9053 T3與 U3 0.8616 0.8637 0.1409* 2 支以上 T1與 U1 0.9017* 0.8847* 0.9169* T2與 U2 0.9250* 0.9015* 0.9234* T3與 U3 0.8931* 0.8852* 0.0707 手機更換頻率 2 年以下 T1與 U1 0.8860* 0.8787* 0.9019* T2與 U2 0.9055* 0.8922* 0.9249* T3與 U3 0.8780* 0.8813* 0.1600* 2 年以上 T1與 U1 0.8674 0.8571 0.8972 T2與 U2 0.8826 0.8773 0.8933 T3與 U3 0.8721 0.8595 0.0183 註:*表示同一種模型下優於對方