國
立
交
通
大
學
土木工程學系
碩
士
論
文
啟發式和弦搜尋演算法之改良及應用
Improvement and Application of Heuristic Harmony
Search Optimization Method
研 究 生:江長潤
指導教授:潘以文 博士
啟發式和弦搜尋演算法之改良及應用
Improvement and Application of Heuristic Harmony Search
Optimization Method
研 究 生:江長潤 Student:Chang- Jun Chiang 指導教授:潘以文 博士 Advisor:Dr. Yii-Wen Pan
國 立 交 通 大 學 土 木 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Department of Civil Engineering
College of Engineering
National Chiao Tung University
In Partial Fulfillment of the Requirements
for the Degree of
Master
in
Civil Engineering
July 2012
Hsinchu, Taiwan, Republic of China
I
啟發式和弦搜尋演算法之改良及應用
學生:江長潤 指導教授:潘以文 博士 國立交通大學土木工程學系碩士班 中文摘要 啟發式演算法發展至今,已成功應用於各種領域。本研究旨在改善既 有 之 啟 發 式 和 弦 搜 尋 最 佳 化 演 算 法 ( Harmony-Search Optimization
Method
)以提高其應用時之適用性與搜尋結果之收斂性。本研究以既有和 弦搜尋演算法為基礎,針對啟發式演算法之集中強化(Intensification)與多 樣化(Diversification)進行改善,以取得兩者間最佳之平衡。本研究先以 參數自由設定之和弦搜尋演算法(Parameter-Setting-Free Harmony Search, 簡 稱 PSF-HS)結合粒子群法(Particle Swarm Harmony Search, 簡稱 PS-HS)令和 弦演算法中控制多樣化之參數 HMCR 與及控制調音率之參數 PAR 隨著迭代 次數動態調整,使演算法於搜尋階段處於高多樣化的階段隨迭代次數增加 而逐漸降低,漸次提高集中強化之比重,藉此提高和弦搜尋演算法的搜尋 速度。再於驗證分析中,針對離散式例題分別加入移動平均、調音方向、 粒子群法等方法以改善其搜尋所需迭代次數;針對連續式例題則於收斂階 段時加入數值微分的方法以改善其收斂效果。隨後以經過修改與驗證後之 演算法應用於新山壩滲漏問題之反算分析,並比較前人採用原版和弦搜尋II 演算法之計算結果,證明採用本研究之改良方法可得到收斂更佳的解。復 以國道 3 號 3.1k 邊坡問定問題進行反算分析,比對災後調查報告與現地資 料結果,展示此方法於實際反算分析應用時之適用性與有效性。 關鍵字:啟發式最佳化演算法、和弦搜尋演算法、移動平均、粒子群法、 梯度法、反算分析
III
Improvement and Application of Heuristic Harmony Search
Optimization Method
Student:Chang- Jun Chiang Advisor:Dr. Yii-Wen Pan Department of Civil Engineering
National Chaio Tung University
英文摘要
ABSTRACT
Heuristic optimization methods (HOM) have been successfully applied in various disciplines. This thesis aims to improve the existing harmony search (HS) method, as one of the HOM, in order to improve its applicability and convergence rate. The thesis attempts to seek a balance between intensification and diversification of the HOM. The improved algorithm combines the strategy of “parameter-setting-free (PSF) harmony search” (PSF-HS) with “particle swarm (PS) harmony search” (PS-HS). This algorithm enables the HMCR (which is the parameter controls diversification) and the PAR (which is the parameter controls intensification) to adjust dynamically along with iterations. It is able to emphasize diversification in the early search stage, and gradually transform to intensification in the later iterative stage to improve the search efficiency of the HS method. Several improved strategy on the HS method were tested and examined; these strategies include the usage of moving average in the PSF method, the control of tuning direction, the adding concept of the PS
IV
method, and the shift to the gradient method in the final iterative stage. These improved algorithms were verified through two examples, including one discrete variable problem and one continuous problem. Finally, the improved methods were applied to the back analyses of two practical geotechnical problems to demonstrate their applicability and usefulness.
Key Words:Heuristic optimization method, Harmony search method, Moving average, Particle swarm method, Gradient method, Back analysis.
V
誌謝
光陰似箭,兩年的碩士生涯轉眼間已結束,完成碩士論文的這兩年內 有歡笑有淚水,十分感謝我的指導教授潘以文老師的細心的指導與鞭策。 讓我能夠順利畢業,另外也十分感謝 Meeting 時提供許多意見與方向的廖志 中老師,讓我每次 Meeting 後都能有所突破,這兩年內有兩位老師的指導與 督促,才能讓我再兩年內順利畢業,在此對兩位老師致上十萬分的敬意。 在此也要感謝四位口試委員黃燦輝老師、林炳森老師、田永銘老師與 吳博凱老師,有他們給與我論文寶貴的意見以及不辭辛勞仔細的檢查論文 內容與細節,才能讓我順利完成碩士論文,在此也對他們致上十萬分的敬 意。 在此也要感謝求學過程中有方永壽老師、林志平老師、單信瑜老師以 及黃安斌老師傾囊相授的教學,讓我在課堂上獲得不少寶貴的經驗與知 識。 接下來必須感謝我們潘廖研究團隊的明萬學長、國維學長與慧蓉學姊 感謝你們細心的指導,讓我從你們身上學會做研究的精神與身為一個大地 工程師在現地必須具備的技能與知識。 然後要感謝的當然就是阿康學姊囉,沒有妳的話我想我光是寫從演算 法摸索到開始寫程式就可能會花費幾年的時間,真的是能讓我完成這本論 文的大貴人,在此志上崇高的敬意。 還有要感謝一起出差共患難的好同學,潘廖車神 APU、做研究最認真 的小昱、最照顧我的齊學長、實驗室的志強與晚上一起努力的大布丁。有 你們在我這兩年多的時間過得多采多姿,也很感謝你們有福同享有難同當,VI 讓我關關難過關關過,十分感謝他們。 最後要感謝我的好朋友林門的志昇,我們互相鞭策對方,一有鬆懈就 要馬上提醒對方,沒有你的鞭策我想我現在可能還沒畢業吧,也感謝他在 我有困難時常常能伸出援手,在此對這位好同學致上無比的敬意。 當然還要感謝親愛的學弟妹們,婉容、芋頭、暉凱、阿村、包包與靖 哥的幫忙,特別是口試時細心的安排與接待口試委員等,讓我能無後顧之 憂的盡情演出,真的十分感謝你們。 此外要感謝防災中心的助理們與最重要的佳廷學姊,沒有你們我就不 用過活了,感謝你們的支持與照顧。 最後要感謝我的家人,體諒我時常因研究而不能花時間陪伴他們,並 且在後面默默的支持我,讓我能無後顧之憂的全力衝刺碩士論文,一百萬 分的感謝他們。 要感謝的人太多了,在這邊對沒感謝到的朋友與同學致上我的一萬分 敬意。
謹將這本論文獻給愛我的人與我愛的人
VII
目錄
中文摘要 ... I 英文摘要 ... III 誌謝 ... V 目錄 ... VII 圖目錄 ... X 表目錄 ... XIII 第一章 緒論 ... 1 1.1 研究動機與目的 ... 1 1.2 研究流程 ... 2 1.3 論文內容 ... 5 第二章 文獻回顧 ... 6 2.1 工程最佳化演算法 ... 6 2.1.1 工程最佳化演算法的基本架構 ... 6 2.1.2 常見問題型態的數學模式 ... 9 2.2 最佳化演算法 ... 10 2.2.1 最佳化的演算法的發展 ... 10 2.2.2 常見最佳化演算法 ... 12 2.2.3 最佳化演算法之優缺點 ... 15 2.3 啟發式演算法 ... 16 2.3.1 常見啟發式最佳化演算法 ... 17 2.3.2 啟發式演算法的發展方向 ... 33 2.4 小結 ... 35 第三章 研究方法與規劃 ... 36 3.1 電腦輔助程式與最佳化方法之選擇 ... 36VIII 3.1.1 MATLAB 計算軟體 ... 36 3.1.2 FLAC 分析軟體... 37 3.1.3 最佳化演算法之選擇 ... 37 3.2 最佳化演算法之擬定流程 ... 38 3.2.1 修改和弦搜尋演算法 ... 38 3.2.2 驗證分析之規劃 ... 42 3.3 研究案例模擬之策略與規劃 ... 48 3.3.1 新山壩滲漏問題 ... 48 3.3.2 國道 3 號 3.1k 崩坍事件 ... 60 第四章 最佳化方法之驗證 ... 65 4.1 不連續性問題 ... 65 4.1.1 OHS 與 PSF-HS 之比較 ... 65 4.1.2 PSF-HS 之改良 ... 67 4.1.3 可靠度分析 ... 73 4.2 連續性問題 ... 74 4.2.1 改變待定變數個數之結果 ... 74 4.2.2 數值微分 ... 77 4.2.3 可靠度分析 ... 79 4.3 小結 ... 80 第五章 案例反算分析 ... 81 5.1 新山壩滲漏問題 ... 81 5.2 國道 3 號 3.1k 崩坍事件 ... 84 5.2.1 初步參數測試 ... 84 5.2.2 反算分析結果 ... 86 5.2.3 反算分析結果之比對 ... 89
IX 5.3 小結 ... 90 第六章 結論與建議 ... 91 6.1 結論 ... 91 6.2 建議 ... 94 參考文獻 ... 95
X
圖目錄
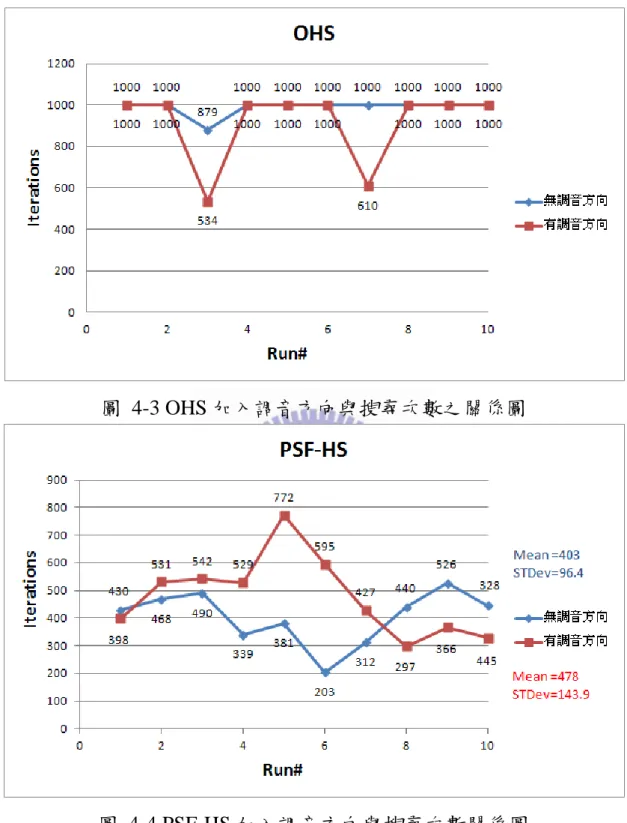
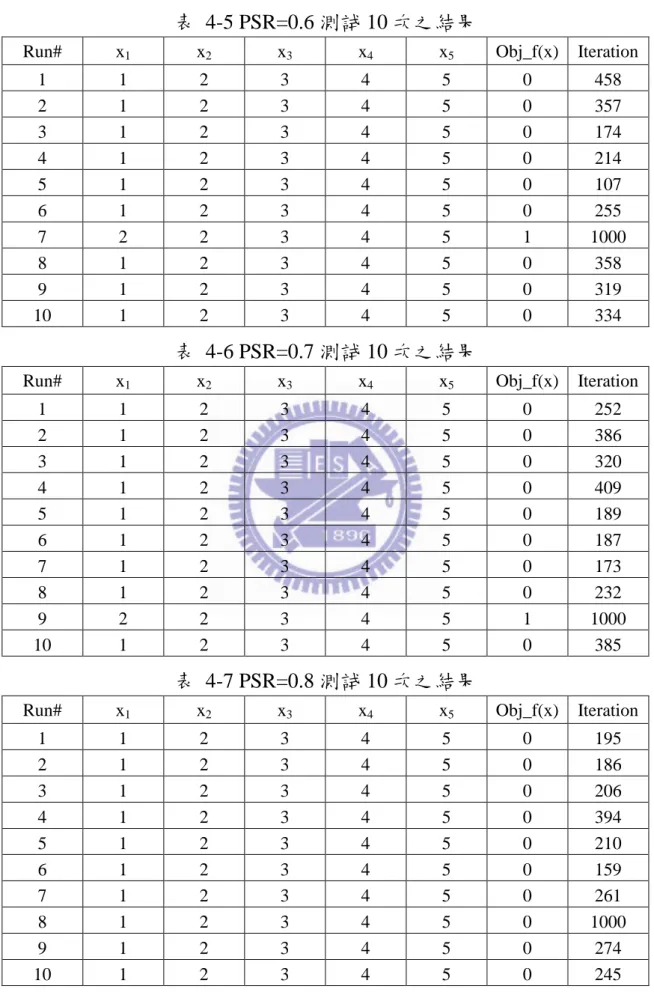
圖 1-1 土石壩滲流之最佳化問題反算流程圖 ... 3 圖 1-2 研究流程圖 ... 4 圖 2-1 工程最佳化演算法(改繪自 Reklaitis 等人,1983) ... 7 圖 2-2 單變數模式(改繪自 Reklaitis et al.,1995) ... 9 圖 2-3 螞蟻族群演算法示意圖 ... 21圖 2-4 HS 模擬與設計變數對照圖(Lee & Geem,2005) ... 25
圖 2-5 隨機產生初始和弦記憶 ... 27
圖 2-6 和弦搜尋最佳化演算法流程圖(Lee & Geem,2005) ... 28
圖 2-7 新和弦產生之概念(Lee & Geem,2005) ... 28
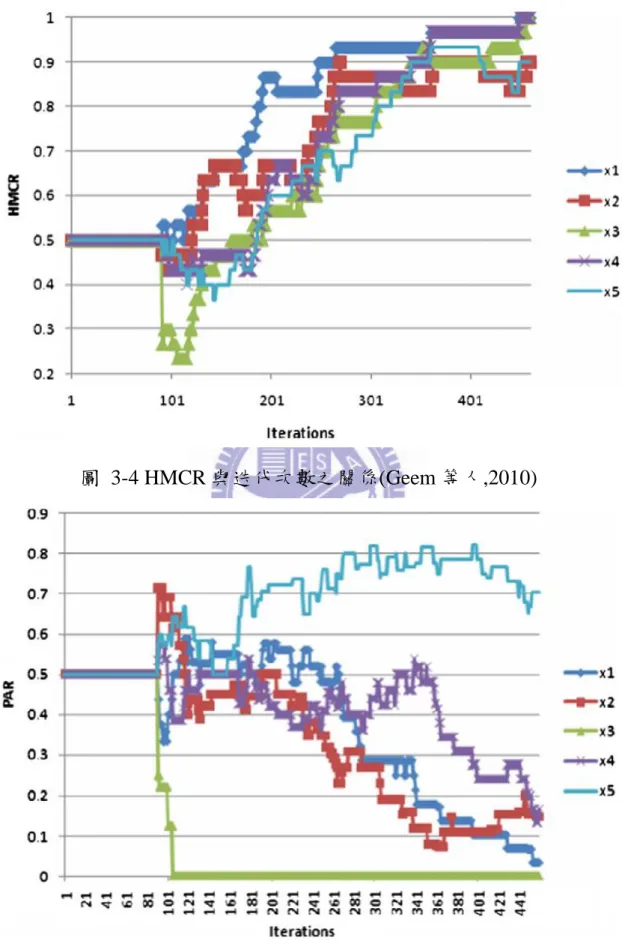
圖 2-8 Rehearsal 產生之記錄矩陣(Geem 等人,2009) ... 30 圖 3-1 原版和弦搜尋最佳化演算法流程圖 ... 40 圖 3-2 修改後和弦搜尋(HS)最佳化演算流程圖 ... 41 圖 3-3 PSF-HS 找到最佳解所需之迭代次數(Geem 等人,2010) ... 43 圖 3-4 HMCR 與迭代次數之關係(Geem 等人,2010) ... 44 圖 3-5 PAR 與迭代次數之關係(Geem 等人,2010) ... 44 圖 3-6 第一部分之研究流程 ... 45
圖 3-7 The egg crate function 在(0,0)有全域最小值 0... 46
圖 3-8 第二部分之研究流程 ... 47 圖 3-9 新山水庫俯視圖(Google 地球) ... 48 圖 3-10 新山大壩 Sta.0+195.29 橫斷面圖(改繪自 國立交通大學,2010) . 49 圖 3-11 新山壩俯視圖(改繪自 國立交通大學,2010) ... 50 圖 3-12 新山壩 Sta.0k+170m 斷面圖(改繪自 國立交通大學,2010) ... 50 圖 3-13D4 量水堰排除降雨影響之滲水量與庫水位關係圖 ... 51 圖 3-14 排除降雨影響之壩體總滲水量與庫水位關係圖 ... 51
XI 圖 3-15 新山水庫滲漏位置圖(陳冠亨,2006) ... 52 圖 3-16 新山壩斷面各材料透水係數分布圖(單位:cm/sec) ... 53 圖 3-17FLAC 模擬新山壩 Sta.0+170m 與材料參數圖 ... 54 圖 3-18FLAC 網格建立(1 網格尺寸為 2m×2m)與初步分析飽和度圖 ... 54 圖 3-19 水位觀測井對應於下游殼層位置圖 ... 54 圖 3-20 新山壩漸進式之 HM 最佳搜尋結果之飽和度圖 ... 56 圖 3-21 新山壩漸進式之 HM 最佳搜尋結果之壩材變數圖 ... 56 圖 3-22 水平濾層之透水係數漸進式示意圖 ... 57 圖 3-23 災害發生位置 (摘自國道 3 號 3.1 公里崩塌事件原因調查工作總結 報告) ... 60 圖 3-24 災害發生現場情形 (摘自國道 3 號 3.1 公里崩塌事件原因調查工作 總結報告) ... 61 圖 3-25 邊坡破壞範圍(99/4/26 航照)... 61 圖 3-26 滑動面之幾何形狀 ... 62 圖 3-27 假設之地下水壓力面分佈示意圖 ... 63 圖 4-1 HMCR 加入移動平均後之變化 ... 67 圖 4-2 PAR 加入移動平均後之變化 ... 68 圖 4-3 OHS 加入調音方向與搜尋次數之關係圖 ... 69 圖 4-4 PSF-HS 加入調音方向與搜尋次數關係圖 ... 69 圖 4-5 變數數量與迭代次數關係圖 ... 76 圖 4-6 主要修改方法之可靠度分析 ... 79 圖 5-1 新山壩漸進式之迭代次數與 HM 目標函數之關係圖 ... 82 圖 5-2 低地下水位 φ 與 F.S.之關係圖 ... 87 圖 5-3 低地下水位 α 與 F.S.之關係圖 ... 87 圖 5-4 高地下水位 φ 與 F.S.之關係圖 ... 88
XII
XIII
表目錄
表 2-1 傳統與啟發式最佳化演算法之比較 ... 15 表 2-2 Intensification 與 Diversification 之比較 ... 16 表 2-3 Intensification 與 Diversification 主控參數與 5 個演算法說明 ... 32 表 2-4 六個常見最佳化方法適用性比較 ... 33 表 3-1 調音方法修改前後之比較 ... 39 表 3-2 FLAC 初步模擬新山壩之相關資料 ... 55 表 4-1 OHS 與 PSF-HS 參數設定 ... 66 表 4-2 OHS 運算 10 次之結果 ... 66 表 4-3 PSF-HS 運算 10 次之結果 ... 66 表 4-4 PSR=0.5 測試 10 次之結果 ... 70 表 4-5 PSR=0.6 測試 10 次之結果 ... 71 表 4-6 PSR=0.7 測試 10 次之結果 ... 71 表 4-7 PSR=0.8 測試 10 次之結果 ... 71 表 4-8 PSR=0.9 測試 10 次之結果 ... 72 表 4-9 PSR=1.0 測試 10 次之結果 ... 72 表 4-10 PSR=0.5~1 之測試結果 ... 72 表 4-11 可靠度分析之結果 ... 73 表 4-12 演算法參數設定與收斂條件 ... 74 表 4-13 變數量=2 測試 10 次之結果 ... 74 表 4-14 變數量=3 測試 10 次之結果 ... 75 表 4-15 變數量=4 測試 10 次之結果 ... 75 表 4-16 變數量=5 測試 10 次之結果 ... 76 表 4-17 PSF-HS 修改 1 版加入微分方法之參數設定 ... 77 表 4-18 PSF-HS 修改 1 版加入微分方法於 bw 非定值之結果 ... 77XIV 表 4-19 PSF-HS 修改 1 版加入微分方法於 bw 定值之結果 ... 78 表 5-1 新山壩漸進式以 PSF-HS 修改 1 版搜尋之結果 ... 82 表 5-2 目標因子原本與修改 1 版之比較 ... 82 表 5-3 PSF-HS 修改 2 版 δbw 之設定 ... 83 表 5-4 演算法初始參數設定 ... 84 表 5-5 待定參數於 OHS 方法測試 100 次之結果 ... 85 表 5-6 待定參數於 PSF-HS 修改 1 版方法測試 100 次之結果 ... 85 表 5-7 待定參數於 PSF-HS 修改 2 版方法測試 100 次之結果 ... 85 表 5-8 待定參數之靈敏度測試 ... 86 表 5-9 反算分析 10 次之結果 ... 86
1
第一章 緒論
1.1 研究動機與目的
最佳化問題無所不在,日常生活中的財務規劃、路徑規劃等問題皆是 最佳化問題。首先必須了解許多最佳化問題看似簡單,實際上並非如此, 最有名的例子就是送貨員問題,而尋求這些問題之最適解的方法就是最佳 化方法,最佳化方法發展到現在已廣泛應用於各種專業領域中,無論是數 學、物理學、化學、經濟學、統計學、醫學…等,只要是求解最佳解的問 題,經過適當簡化成數學模式後,都可藉由最佳化方法求得最適的結果。 最佳化方法當然也廣泛應用於工程領域中,如施工估價、工程設計、 結構材料輕量化、營建管理…等,於大地工程中可能運用於破壞案例之逆 推(反算)分析、參數標定、工程設計之最佳配置方案、風險決策分析等 問題。最佳化演算法大致可區分為傳統最佳化演算法與近年之啟發式演算 法,廣泛運用於各種工程科學與社會科學之問題。國外已有不少研究將近 年來最佳化方法中發展快速的啟發式演算法應用於大地工程問題(如 Cheng 等人,2007;Kahatadeniya 等人,2009)),這些研究內容大多著重在比較各 種啟發式方法應用於特定問題之求解效率的優劣,較少嘗試改進既有演算 法所存在之缺點。康詩凰(2011)曾運用啟發式最佳化演算法於實際大地工程 問題之逆推分析(土石壩滲流分析反算求解問題),展示其方法可行且有效, 但也建議其演算法仍有值得改善之空間。因此本研究之主要目的為改善啟 發式演算法,期能提高演算法的適用性,並可應用於各種不同的大地工程2 問題。本研究運用改善後之演算法分析實際邊坡破壞案例之反算,除展示 啟發式演算法之實際運用,並期望提供未來相關問題的參考。
1.2 研究流程
本研究希望藉由適用性高的工程最佳化方法應用於大地工程相關之問 題。首先進行文獻回顧,整理與介紹工程最佳化方法與其相關研究,並依 發展先後介紹傳統最佳化演算法與啟發式演算法。由於傳統最佳化方法於 實際應用時有許多限制且存在求解上的缺陷,並不易於直接應用於實際問 題,因此進一步回顧相較於傳統最佳化演算法應用限制較少的啟發式演算 法,並考慮本研究之目的為使用適用性高之最佳化方法應用於大地工程相 關問題,最後選擇和弦搜尋演算法做修改作為本研究之反算分析方法。 由於本研究之重點為演算法的改進,在實際案例之應用時,於邊坡穩 定反算之問題採極限平衡法分析,只需使用簡單之數學應用軟體(MATLAB) 即可使用最佳化方法進行分析,而於土石壩滲流最佳化反算問題採用有限 差分法之地工數值軟體 FLAC 做計算,並以 MATLAB 作為和弦搜尋最佳化 流程之主控伺服,藉由兩者互通之介面(文字)檔進行最佳化分析流程, 計算分析之流程圖表示如圖 1-1。 最佳化反算分析與應用之流程分為三個部份進行: 第一部分:最佳化演算法擬定 以和弦搜尋演算法為基礎,透過修改其演算法之參數變動法則與結合 其他演算法之優點加以改進,最後再於收斂階段導入數值微分的概念,將 此修改後的和弦搜尋演算法做為最佳化反算分析之方法。3 第二部分:驗證分析 分別以有解析解的連續與不連續之問題,將兩個問題之最小值設定為 目標函數,進行本研究之最佳化方法分析之驗證。 第三部分:實例應用 分別以國道 3 號 3.1k 七堵段崩坍事件與新山壩滲漏問題為本研究之最 佳化反算分析之展示範例。 最後綜合探討實例應用之反算分析結果,以瞭解本研究所擬定之最佳 化演算法於實際大地工程相關問題反算求解的功效。圖 1-2 為本研究之流 程圖。 主控伺服 (MATLAB) 計算引擎 (FLAC) 外掛 (資料傳遞) 外掛 (資料傳遞) 圖 1-1 土石壩滲流之最佳化問題反算流程圖
4 圖 1-2 研究流程圖 文獻回顧 最佳化方法之擬定與必要修改 驗證問題之選擇 搜尋解區間為 連續之問題 搜尋解區間為 不連續之問題 驗證分析 國道 3 號 3.1k 七堵段 新山壩 滲漏問題 結果與討論 實例應用
5
1.3 論文內容
本論文共分為六個章節,內容分別介紹如下: 第一章 緒論:說明本研究之動機與目的與其流程及內容。 第二章 文獻回顧:回顧本研究反算分析所用之方法,即工程最佳化方法, 整理並介紹最佳化演算法之沿革與相關研究,再說明為何選擇修改啟發式 演算法中的和弦搜尋演算法,作為本研究於邊坡穩定分析之最佳化問題求 解法。 第三章 研究方法與規劃:先擬定本研究所使用之最佳化演算法,繼而透過 兩個有解析解之連續與不連續問題驗證後,最後選定兩個實際案例新山壩 滲漏問題與國道 3 號 3.1k 七堵段邊坡作為本研究擬定之最佳化方法的研究 案例。 第四章 最佳化方法之改良與驗證:探討修改後之和弦搜尋演算法應用於解 析解問題之結果。 第五章 案例反算分析:本章內容為兩個實際案例最佳化反算分析結果與討 論,最後配合現地資料綜合探討兩個案例之邊坡穩定問題。 第六章 結論與建議6
第二章 文獻回顧
大地工程個案破壞後之原因探討,常會採用逆推(反算)分析(Inverse
analysis),採用試誤法(trial and error)固然可行,但效率與準確性往往有限,
更佳之策略則為善用最佳化分析方法。此外,進行大地工程設計時,配置 方案未必能選擇真正最佳組合,有時設計結果無法符合預期或是設計太過 保守造成工程成本的增加與材料的浪費。為有效解決此問題,應可善用最 佳化演算法(Optimization Algorithm)於工程分析與設計以獲得最可能之答案、 最佳之配置,並有助於決策判斷。 本研究主要是藉由修改後的和弦搜尋演算法(Harmony Search,HS)作為 求解大地工程上最佳化問題之方法。本章整理之文獻與討論分 4 個小節:2.1 節介紹工程最佳化與其組成的基本架構和數學模式;2.2 節先介紹最佳化演 算法的發展過程與常見的最佳化演算法,並說明為何選擇啟發式演算法 (Heuristic Optimization Algorithm)作為求解大地工程問題之方法。2.3 節進一
步對啟發式演算法之相關文獻做整理:2.4 節為小結,說明為何選擇修改和弦 搜尋演算法為本研究之最佳化演算法。
2.1 工程最佳化演算法
2.1.1 工程最佳化演算法的基本架構 工程最佳化演算法是用來求解工程上最佳化問題,如工程的設計、規 劃與決策等分析問題,無非是想節省成本與時間,因此藉由此方法來求得 最大效益的結果以解決工程最佳化問題。概略流程為將工程最佳化問題表7 示數學模式,透過最佳化理論求解,最後由求得的解來解闡釋整個最佳化 系統,此種不用真實操作求最佳解的方式稱為「工程最佳化演算法」,表示 如圖 2-1。 圖 2-1 工程最佳化演算法(改繪自 Reklaitis 等人,1983) 在將真實系統推導程數學模式時,Reklaitis 等人(1983)將構成工程最佳 化演算法的基本數學架構,分成四個要件: 1. 定義最佳化問題系統邊界 2. 效能規範 3. 變數 4. 系統模式化 最佳化演算法基本數學架構組成順序說明如下: 1.如何以適當的數學式來定義真實系統是相當重要的,這會影響整個最佳 化問題是否能有效求解,所求得的解是否有意義。應避免將問題過於簡化, 或是給太多不必要的考慮條件,甚至是關鍵因子完全被忽略了,因此要清 楚瞭解問題的需求,才能有效的定義最佳化問題系統邊界。 2. 接著決定問題之最佳化的目的是要滿足哪些要求,當考慮的目標不只一 個時,一般會選用一個為主要目標,其他則表示為限制條件,此類之要求 規定稱效能規範。
8 3. 再來選擇能夠充分反映問題特性的因子,即設計變數,變數的選擇取決 於問題考慮的仔細程度,若考慮太多不相關的變數或關鍵因子沒表達出來, 可能會得到非最佳解。 4. 最後一步系統模式化,也就是綜合上述三個步驟,使整個問題系統表示 為數學的模式。 典型問題是將最佳化問題轉換成函數形式求解最大值或最小值表示方 式,如式 2-1: min. (or max.) ( )f x (2-1) 限制條件 h xk( )0 g xj( )0 xiL xi xiU (or xiXi [ (1),..., ( )..., ( )])xi x Si x Si i 式中,函數 ( )f x 稱為目標函數(objective function); 變數 [ 1 2 3 ... ] T n x x x x x ,x向量有 n 個分量(維度); h xk( )0,等式限制條件之k 1,...,K; g xj( )0,不等式限制條件之 j1,...,J; xiL xi xiU (or xiXi [ (1),..., ( )..., ( )])xi x Si x Si i ,連續(或離散)變數 限制條件之i1,...,n,xiL、xiU為連續變數xi之下限與上限,S表 示集合
9 2.1.2 常見問題型態的數學模式 最佳化演算法依問題複雜度、考慮條件或變數間之關連性等,可分成 各種不同的問題型態,而設計者可依不同問題型態選擇適當的求解方法。 不論哪種最佳化問題,為了求解上的需要,基本上都會簡化為數學模式來 求解,因此,下面對照式 2-1 說明一般最佳化模式之不同問題型態分類: 1. 限制性與非限制性:除了目標函數與目標變數外,不考慮任何條件時, 稱非限制性最佳化模式;反之,當變數值有上、下限或目標函數需要滿 足次要目標時,稱限制性最佳化模式。 2. 單變數與多變數:當變數x向量為一個分量時,稱為單變數最佳化模式; 變數x向量不只一個分量時,稱為多變數最佳化模式。 3. 連續、不連續與離散變數:當變數在某設計值範圍內稱為連續變數;在 不同區間考慮不同函數關係的變數稱為不連續變數;若以數量、規格、 尺寸或二選一等方式為設計因子,稱離散變數,如圖 2-2。 圖 2-2 單變數模式(改繪自 Reklaitis et al.,1995)
10 4. 單目標與多目標:單目標最佳化模式,如 2.1.1 節說明工程最佳化演算 法的數學架構的效能規範,也就是無論有多少個最佳化目標,目標函數 只考慮一時,稱之;相對的,當目標函數代表不只一個最佳化目標時, 稱多目標最佳化模式。 5. 線性與非線性規劃:當目標函數與限制條件兩者為線性模式且x為連續 變數,稱之為線性規劃(Linear Programming,LP)問題;若目標函數為 非線性則稱非線性規劃(Nonlinear Programming,NLP)。 除了上述常見五種分類外,還可以更細部地將最佳化法架構不同要件, 組合起來分類成更多型態。另外一種特殊分類為靜、動態問題,其主要不 同在於:當要求變數 * x 是否為最佳解時,稱靜態最佳化問題;而動態問題則 是要如何找出最佳解,關於動、靜態問題在 2.2.2 節有詳細的說明。
2.2 最佳化演算法
2.2.1 最佳化的演算法的發展 最佳化演算法的應用無所不在,涵蓋了各種學科與專業領域,甚至是 日常生活中的問題,如財務分配的規劃、送貨員問題等都是其應用。在大 地工程領域中,各種正向與反向的問題只要能適當的定義成數學模式後, 也都能應用最佳化演算法求取最佳解。11 傳統最佳化演算法清楚的定義,經過不斷的數值分析與疊代可得到最 適的結果。因此傳統最佳化演算法需要有數學的基礎,如向量與矩陣的運 算、微積分、線性代數等。 最佳化演算法的源起可追溯至 Newton、Lagrange 與 Cauchy 的年代, 而後由 Bernoulli、Euler、Lagrange 與 Weirstrass 奠定利用變分學 (Calculus of Variations)方法處理最佳化問題的基礎。由於最佳化計算 過程耗時,在二十世紀中期前發展緩慢,直到電腦問世之後,計算耗時的 問題才得以解決。之後發展出一系列與線性規劃(Linear Programming)相 關之方法。在 20 世紀末,最佳化演算法結合了人工智慧的啟發式演算法問 世,如基因演算法(Genetic Algorithms)、類神經網路法(Neural Network Method)等。最後近年來發展出一系列擬生的啟發式演算法,如螞蟻族群演 算法(Ant Colony Optimization,ACO)、粒子群法(Particle Swarm Optimization, PSO)等。
12 2.2.2 常見最佳化演算法 最佳化演算法發展至今,根據求解方式可分為傳統最佳化演算法與啟 發式最佳化演算法,這個小節主要介紹運用較多數學技巧的傳統最佳化演 算法。在介紹簡單的傳統最佳化演算法前,先以分析變數目的之靜、動態 問題為兩大主體分類,並參考 Reklaitis 等人(1983)之文獻,整理介紹如下: 1. 靜態問題:判斷在區域內給定之變數值 * x 是否為最佳解(一般都可表示 為最小值方式求解)。在此只簡略介紹數學判斷方法與求最佳解的基本 數學概念。假設函數 f 是二次可微分,若要滿足x*為區域內極小值,則 f 在x*處的一階與二階微分須滿足充分和必要條件。 必要條件: * ( ) 0 f x (2-2) 2 * * ( ) ( ) 0 f x H x (2-3) 充分條件: 若 * ( ) 0 f x 且 * ( ) 0 H x 其中 2 2 2 1 1 2 2 2 1 ( ) n n n f f x x x H x f f x x x ,Hessian 矩陣。
13 2. 動態問題:以最佳化方法和運用數學技巧等方式來找出或求得最佳解 * x 。 其概念就是給定初始值或初始條件,循序漸進的推導或在問題範圍內做 搜尋的迭代方式,直至求得最佳解或滿足最佳化條件為止。 而實際應用之問題多屬動態問題,動態問題中又可依變數量分為單變 數與多變數問題,發展出的方法種類繁多,在此不多做贅述,其中一種方 法:最陡坡降法(Steepest Descent Method),本研究中在修改版本的和弦搜尋 演算法會應用此方法的概念,此法的主要精神是利用函數的一階導數配合 一個與目標函數差值有關之係數來決定下一次迭代的移動方向與移動大 小。 無論是哪種最佳化演算之數學方法,依搜尋過程所需運算的目標函數 導數項次可簡單分為,零次法、一次法、二次法…、高次法,而工程最佳 化之問題大部份只需計算至二次導數就可解決。除零次法外,基本上都要 運算複雜的導函數值,且導數方法的限制為導數值要存在或連續等假設情 況下才能使用。儘管這些方法在數學上的理論求解架構相當有系統性,或 是所得到的最佳解符合理論最佳解或是極逼近最佳值,但於實際問題上的 應用上可能不是單純假設或簡化可以求解的,比如:大規模的NP-complete 問題(代表問題之一就是售貨員問題,此類問題隨著變數增加,計算量不只 隨冪函數遞增,甚至可能成呈指數遞增),需要大量計算時間同時需儲存大
14
量計算產生數值,因此必須考慮電腦或計算機的計算效率和記憶體大小。 因而近年來由最佳化演算數學方法中之零次法,逐漸發展出一系列所謂之
「啟發式最佳化演算法」(Heuristic optimization algorithms),可依問題特性
來設計,並能在有效計算時間內求出可被接受的近似最佳解。 啟發式演算法結合了隨機搜尋演算法的優點(如:能跳脫出,陷入局部 性搜尋的困境、比較不會有數值計算上的問題產生、搜尋原理簡單和能有 效搜尋到最佳解附近區域)與直接搜尋方法的優點(如:能使用當前或之前 的計算值資料,類似使用者能夠考慮以往的經驗來決定下一次迭代的設計 值一樣、加快收斂速度…等)。 傳統啟發式最佳化演算法的搜尋方法通常是,先利用貪心法則(Greedy Approach)在短時間內將問題範圍縮小至最佳解附近區域,並得近似起始 點,接著再以局部最佳化方法來改善此近似值。而一般常見的啟發式最佳 化演算法有:遺傳演算法(Genetic Algorithm,GA)、模擬退火法(Simulated Annealing,SA)、禁忌搜尋法(Tabu Search,TS)…等最佳化演算法,此部分 在接續的 2.3 節有介紹。因此,接下來就對傳統數學最佳化演算法與啟發式 最佳化演算法之優缺點做比較。
15 2.2.3 最佳化演算法之優缺點 由 2.2.2 節可知,傳統最佳化演算法求解過程一般順序是:先給定起始 值和初始條件,以數值方法或技巧決定下一個搜尋點的移動方向和步長大 小,漸漸地縮小搜尋範圍並趨近鄰近的最佳解的求解法;相對的啟發式最 佳化演算法的求解方式,則是在整個問題系統中做有系統性的隨機搜尋, 直到滿足設計者期盼的目標值或目標條件為止。以下對傳統最佳化演算法 與啟發式最佳化演算法,在設計或求解上之優、缺點比較如表 2.1。 表 2-1 傳統與啟發式最佳化演算法之比較 優點 缺點 傳 統 最 佳 化 演 算 法 演算法之參數設定簡單 主觀性給定起始值 適用簡化或假設性問題 需計算導數資料 以導函數搜尋之迭代次數少 需記憶體儲存導數資料 不需嘗試各種情況 屬區域性搜尋之局部最佳解 實際應用的限制相當多 適用範圍小 啟 發 式 最 佳 化 演 算 法 簡單搜尋概念求解 主觀性設定終止搜尋條件 不用給定起始值 演算法參數的設定需經過測試 才能得到適用的參數值 不需繁雜的數學式 全域性搜尋 隨機搜尋之迭代方式,其迭代 次數比能使用函數之導數搜尋 方法多。 能跳脫局部解情形 適用範圍廣
16
2.3 啟發式演算法
啟發式最佳化演算法,是以理論概念將最佳化問題表示成一系列的設 計變數,配合模擬自然界現象等最佳化策略,啟發我們設計演算法架構, 並考慮先前搜尋結果來引導下一次迭代,以隨機方式而非以導函數資料來 改善最佳解的演算法,此演算法兼顧 Intensification 與 Diversification 之特性, 概念類似工程上探測(Exploration)與鑽探(Exploitation),能克服傳統最佳化 演算法計算上的缺陷。 在介紹常見的啟發式演算法前,必須先瞭解演算法的主要精神,從 Yang(2009) 可 知 啟 發 式 演 算 法 的 搜 尋 精 神 主 要 是 由 兩 個 元 素 構 成 : Intensification 與 Diversification。而此兩元素權重對於求解的優劣效率有相 當重要性,比較如表 2-2(改自康詩凰(2011))。 表 2-2 Intensification 與 Diversification 之比較 比較 翻譯 比喻 值域 解 效率 Intensification 加強版 開發 局部 收斂 快 Diversification 多樣化 探測 整體 發散 慢17 2.3.1 常見啟發式最佳化演算法 啟發式演算法與一般數值最佳化演算法最大不同在於求解方式為有系 統的多次隨機搜尋直到達目標條件為止,而非以計算導數值方式求解。相 較於隨機搜尋,啟發式演算法並非是盲目的隨機產生新的解,而是透過模 擬自然界生物的行為來引導搜尋解的方向。 這類方法最大優點是:求解效果佳,且相對於傳統求解最佳化法上, 較不受限於如何適當選取初始值的問題,並以隨機方式搜索得到的解較靈 活、較能跳脫局部解情形,因此也不用記錄求解過程大量函數導數資料, 應用範圍也較廣。以下簡單介紹一些常見的啟發式最佳化演算法:遺傳演 算法、模擬退火法、禁忌搜尋法、螞蟻族群演算法、粒子群法、和弦搜尋 演算法。
18 1. 遺傳演算法(Genetic Algorithms,GA) 又稱基因演算法,由 John Holland 在 1975 年以達爾文進化論的「物 競天擇,適者生存」所發展的一種搜尋演算法,這是最早出現的啟發式 演算法,當時克服了許多傳統最佳化演算法的缺陷。此法是模擬生物過 程對環境的適應能力,適應力高者,表示生存能力強,因此遺傳給下一 代的機率相對較大。 搜尋步驟: 1.先將變數進行編碼(Encoding),以二位元或實數方式表示成染色體和 基因的形式。 2.定義目標函數與基因選擇的準則。 3.隨機產生一組初始族群(Population),並評估初始族群中,由不同染色 體組成所代表的個體,即求函數值,並有各別被選取的機率大小。 4.接著運用遺傳演算法三個運算元,進行基因的選擇(Selection)與複製 (Reproduction)、交配(Crossover)和突變(Mutation),產生下一代新的一組 族群以改善當前的族群。 5.重復更新直到到達目標為止。 方法特性: 適用於各種型態之問題,如:連續或不連續、線性或非線性、靜態 或動態等問題,應用上比較不受限。此方法最大的缺點在於需將變數進 行編碼與定義基因的遺傳準則,儘管如此,基因演算法仍是一套被廣泛 使用的啟發式演算法。
19 2. 模擬退火法(Simulated Annealing,SA) 主要是 Kirkpatrick 等人在 1983 年提出,以 Metropolis 等人在 1953 年以蒙地卡羅的統計機率觀念,模擬分子在高溫狀態下,分子隨機散佈 在範圍空間中移動,逐漸冷卻的行為。 搜尋步驟: 1.定義初始溫度以及變數之初始值。 2.設定最後的收斂溫度與迭代次數。 3.定義冷卻準則(即接受機率,會隨溫度降低而變小)。 4.接著在初始值附近找出一個新設計點目標值,判斷新設計值是否小於 當前值,若是的話就取代當前值,否則就以隨機亂數判斷是否接受此設 計值 5.重複更新直到到達目標為止。 方法特性: 模擬退火法相較於傳統最佳化法能跳出局部解,是因為允許搜尋過 程也可接受目標值較高的設計點。缺點為當設計問題的溫度區間太大時, 所需計算的時間久。應用上,適用不連續的問題。
20 3. 禁忌搜尋法(Tabu Search,TS) Glover,1986 年以模仿記憶方式所發展的一種最佳化演算法。記憶 之前搜尋結果以避免陷入局部解,也稱輔助式啟發性演算法。 搜尋步驟: 求解步驟與 SA 類似,搜尋概念一樣為選定一起始點,接著在起始 點附近,隨機搜尋不在短期記憶之禁忌列表(Tabu List)中的下一個移動 點,如果目標值比原本的點還差,則將此點加入禁忌列表並繼續搜尋, 如目標值比原本的點好,則將原本的點加入禁忌列表並且往新的點移動 若有則取代之,重複此步驟直到滿足終止條件止。 方法特性: 與 SA 相同要決定一起始點;短期記憶量越大,越不會陷入局部解, 相對地,要儲存整個記憶列表的容量也會隨之變大;雖可利用長期記憶 提升搜尋的多樣化,但全域性搜尋能力尚不足;應用上,特別適用工程 管理方面問題。
21
4. 螞蟻族群演算法(Ant Colony Optimization,ACO)
Dorigo 等人於 1991 年由觀察螞蟻群覓食所發展的演算法,螞蟻搬 運食物回程時,會分泌一種荷爾蒙的費洛蒙(Pheromone),且荷爾蒙濃 度會隨時間消散蒸發,其他螞蟻可依不同濃度大小之路徑機率選擇覓 食路徑,依此方式重覆至最後,可發現幾乎所有螞蟻都走同一條接近 最短路徑,如圖 2-3。 圖 2-3 螞蟻族群演算法示意圖 搜尋步驟: 1.定義目標函數。 2.定義費洛蒙濃度消散率。
δ
(2-4)
是位於 i,j 路徑上的費洛蒙數量。 γ為費洛蒙的蒸發系數,γ 。 為螞蟻移動後釋放的費洛蒙數量。通常 ,如果路徑上 沒有螞蟻經過,則 。22 3.透過位置移動公式決定螞蟻下一次移動點的位置: α α
(2-5)
α與β為費洛蒙影響因子,通常皆設定為 2。 是路徑 i,j 上的費洛蒙初始值,通常 , 為路徑距離。 4. 重複更新直到到達目標為止。 方法特性: 適用問題規模,廣特別適用路線規劃方面問題,於簡單問題可在短 時間得相近之最佳解,而複雜問題則比其他演算法更能得較好的解;缺 點為實際應用時需將問題轉換成路徑方式表示。而影響最大的是路徑選 擇的機率與費洛蒙更新的參數設定,決定是否能搜尋成功的關鍵。23
5. 粒子群法(Particle Swarm Optimization,PSO)
由 Kennedy 和 Eberhart 在 1995 年提出,與 GA 與 ACO 一樣是以群體 為基礎所發展的一種最佳化演算法,模擬鳥群或魚群在空間中覓食的社 會行為,但是粒子群法相較之下概念簡單許多,不需要用到突變與交配 運算元,也不需要用到費洛蒙濃度,取而代之的是用空間中的距離與空 間中粒子群互相的溝通。 搜尋概念為將個體視為粒子,一開始隨機產生各粒子的初始位置和 初始速度;計算出表示各粒子適應力的函數值;接著每顆粒子會依本身 經驗與直覺,在範圍空間內移動至覺得較佳的位置,即產生修正的速度 與對應位置,比較函數值是否比當前好;當群體中有更佳的函數值時, 粒子之間會相互溝通,並引導各粒子漸漸地往當前所謂的全體最佳解移 動;依此方式不斷產生新的位置和速度直到滿足終止條件為止。 搜尋步驟: 1.定義目標函數。 2.隨機產生 n 個粒子與其初始位置和初始速度,計算每個粒子的目標函 數值。 3.每顆粒子產生新的速度並移動到新的位置(2-6 式),並比較函數值是 否比當前好,如比較好則取代粒子當前的目標值以及其位置。
24 α (2-6) 與 為介於 0~1 間的隨機值; 為當前全域性目標函數最佳值; 為第 i 個粒子的目標函數最佳值,i=1~n; α 與 為設計參數,通常皆設定為 2。 4.當每顆粒子更新完當前的目標值之後,再判斷每個粒子更新後的目標 值是否比原本群體的最佳目標值好,如比其好則取代之。 5. 重複更新直到到達目標為止。 方法特性: 考慮當前解群體的資訊;適用領域相當廣,大多情況下比 GA 收斂 快,特別是對於動態系統提供了一個高適應性的最佳化方法;各粒子擁 有各自的記憶與判斷力;屬於區域與全域共同評估的搜尋法。
25 6. 和弦搜尋演算法(Harmony Search,HS) 2001 年由 Geem 等人所提出發表,為一種進化版的啟發式演算法, 發展至今已有 10 年之久。此方法模擬音樂家們使用不同樂器一起即興 演奏下,每位音樂家各自記憶所彈奏的曲調,並藉由每次合奏後來調音, 因此,經過數次的即興演奏後所演奏的音樂會越來越和諧、越美妙,依 此種方式產生的最佳演奏概念來求解,稱和弦搜尋演算法,如圖 2.4。
圖 2-4 HS 模擬與設計變數對照圖(Lee & Geem,2005)
搜尋步驟:Geem (2010)說明最先進的 HS 演算法架主要分成 7 大步驟 步驟 1: 問題公式化(problem formulation)
步驟 2: 參數設定(algorithm parameter setting)
步驟 3: 隨機產生初始記憶(random tuning for memory initialization) 步驟 4: 改善和弦:隨機選取、考慮記憶與調音 (harmony improvisation : random selection, memory consideration, and pitch adjustment)
步驟 5: 記憶更新(memory update)
步驟 6: 滿足終止目標(performing termination) 步驟 7: 終曲(cadenza)
26 一開始將問題以數學模式表示,即公式化;接著給定參數值或相關 參數設定後;以完全隨機模式產生一組解(和弦)作為初始和弦記憶向量 (HM),以上(步驟 1~3)歸類為問題的初始化,如圖 2-5;接下來(步驟 4~6)為問題的搜尋方式,設定演算法參數之機率(HMCR、PAR、bw)後 隨機產生一個解(和弦);此新產生的和弦若是比 HM 中任一個好,則剔 除最差者並取代之;接著一直重複步驟 4、5 直至達終止目標為止。步 驟 7 類似樂曲接近結尾的一段裝飾奏,將最佳解(和弦)再做一次演奏或 修飾後來收尾。演算法完整流程表示如圖 2-6。 假 設 搜 尋 解 區 間 為 一 群 離 散 的 值 ( 即 bw 為 定 值 ) , 形 式 如 ,在改善和弦階段中分三種方式產生 新和弦,分別是隨機選取(式 2-7)、考慮記憶(式 2-8)與調音(式 2-9),而 決 定 以 哪 種 方 式 產 生 新 和 弦 是 以 和 弦 記 憶 比 率 (Harmony Memory Considering Rate,HMCR)與調整比率(Pitch Adjusting Rate,PAR)控制, 並以兩者參數關係來改善最佳化搜尋,其中第三種產生和弦的調音方法, 其調整量的大小為 bw(Bandwidth),三種產生新和弦之概念如圖 2-7。
27 方法特性: 離散、連續或不連續變數均能使用;不用給定初始值;較不受區 域性限制;原理簡單,使用容易;搜尋解的量不會因變數量增加而大 幅度上升。 (2-7) (2-8) (2-9) 圖 2-5 隨機產生初始和弦記憶
28
圖 2-6 和弦搜尋最佳化演算法流程圖(Lee & Geem,2005)
29
Geem 等人(2009)將和弦搜尋演算法加入了粒子群法的概念(藉由群體 中當前的最佳粒子來引導群體的往最佳解移動),與原版本之差別為選取 HM 產生新的和弦時加入一 PSR(Particle Swarm Rate)機率參數判斷考慮是 否要選取當前 HM 中目標值最佳的和弦。 此外 Geem 等人(2010)又針對和弦搜尋演算法提出了一套參數自由設定 的方法(Parameter-setting-free technique) ,主要的目的是將原本為定值的 HMCR 與 PAR 調整為可隨迭代次數改變,此方法包含三個步驟: (1) Random tuning:與原版和弦搜尋演算法相同,隨機產生與和弦記憶大小 (HMS)一樣多的初始和弦記憶,如圖 2-5。 (2) Rehearsal:利用初始的HMCR與PAR產生m倍HMS的新和弦(一般設定初 始HMCR與PAR為0.5,HMS為30,m為3),並額外設置一個與HMS大小 相同的記錄矩陣,記錄每次產生新和弦時的操作為隨機產生、選取和弦 記憶或是調音產生,如圖 2-8。 (3) Performance:在每次迭代前利用式 2-10 與式 2-11 計算出 HMCR 與 PAR 以產生新和弦,如果新和弦有更新 HMS,則同步更新記錄矩陣。
(2-10)
(2.11)
30 圖 2-8 Rehearsal 產生之記錄矩陣(Geem 等人,2009) 此方法與原版和弦搜尋的差異在隨機產生和弦記憶後,透過 Rehearsal 的步驟來調整 HMCR 與 PAR 以產生新的和弦記憶,在面對各種實際問題時, 若無明確待定參數的 HMCR 與 PAR 的設定指標時,此方法可有效解決此問 題。 啟發式最佳化演算法除了上述的方法外,近年來也發展出許多模擬生 物行為的啟發式演算法,如:Bee Algorithms(BA)、Bat Algorithms (BA)、 Firefly Algorithms(FA)…等,此類方法搜尋的概念類似,因此接下來介紹目 前實際應用成功較多的 Firefly Algorithms。
31 7. 螢火蟲演算法(Firefly Algorithms,FA) 此演算法為 Yang 在 2007 年所提出,透過模擬螢火蟲利用閃爍的螢光 吸引異性的行為所發展的演算法。 搜尋策略:螢火蟲在吸引異性時,會閃爍螢光,而螢光的強度除了與 自身的發光強弱有關外,與其他螢火蟲間的距離也有關係,因此當一隻螢 火蟲要尋找,另外一隻異性螢火蟲時,起初可能相距太遠因此採隨機飛行 的方式尋找,當兩隻螢火蟲靠近時可以透過閃爍的螢光吸引而尋找到目 標。 方法特性:由於此方法是在問題的解集合空間中平均散佈 N 隻螢火蟲, 再開始做搜尋,不會有陷入局部解之問題,收斂速度快。適用問題範圍廣, 離散與連續的函數皆可使用。其主要控制因子為螢光的強度(式 2-12): (2-12) I0為螢光源之強度,I 為螢光傳遞距離 r 後的強度, 為光吸收率。 可看出只要當離目標直越近時,I 的值就會越大,收斂速度快,如果當散佈 於解集合空間的螢火蟲不夠多時,容易錯過全域性的最佳解,因此如何在 此兩參數間做平衡是搜尋是否成功的關鍵。
32 在介紹完上述幾種常見的最佳化演算法後,從先前介紹的啟發式演算 法可知 Intensification 與 Diversification 對於求解的優劣效率有相當重要性, Yang (2009)整理幾個常見的最佳化演算方法(SA、ACO、PSO、FA、HS) 比 較 Intensification 與 Diversification 之主控參數與說明如表 2-3。 表 2-3 Intensification 與 Diversification 主控參數與 5 個演算法說明 控制參數 Intensification Diversification SA 溫度 趨近設定低溫 高溫高能狀態 ACO 費洛蒙濃度、蒸 發率 螞蟻分泌費洛蒙,依 濃度選擇路徑機率 隨機行走 PSO 位置、速度 粒子本身經驗與群 體判斷 隨機排列 FA 距離 螢火蟲發光相互吸 引 隨機飛行 HS 記憶率、調音率 音樂家記憶(寫譜) 隨機的機率取樣
33 2.3.2 啟發式演算法的發展方向 啟發式最佳化演算法於工程上的應用範圍相當廣泛,在實際應用時, 不論是在何種領域,最終都是透過轉換成數學式後以最佳化方法求解。由 於不同的演算法適用於不同的問題型態,而要為某些問題而發展出一套演 算法相較修改既有演算法困難許多,因此後續研究中,許多學者嘗試改善 與修正原有的演算法,以增加其研究之演算法的適用性與搜尋效率,相關 文獻如下: 1. Mahdavi 等人 (2006)針對 HS 搜尋過程之調音參數(PAR、bw)做動態修 改,並以例子比較和驗證其有效性。 2. Cheng 等人(2007b) 選出 6 個常見的最佳化方法對應用於邊坡穩定分析 問題深淺適用性做比較—SA、GA、PSO、HM(SHM、MHM) 、TS 與 ACO,如表 2-4。 表 2-4 六個常見最佳化方法適用性比較 問題複雜性 適用方法 一 般 ~ 簡 單 ( 變 數 <20) 每種方法都適用,以 HS 和 GA 最有 效。TS 和 ACO 視問題而定。 一 般 ~ 簡 單 ( 變 數 >20) MHM 和 PSO,求解時間不因問題複 雜程度不同而太大變化。 更複雜或大量變數 PSO。 有 軟 弱 薄 層 PSO。 特殊作用情況 收斂較易失敗,SA 和 PSO。
34 3. Gao 等人(2009)提出兩個修正 HS 方法,可用來處理多模式型態和限制 性之最佳化問題。第一種是以魚群演算法為靈感來使用 HM 處理多重模 式型態之問題;第二種則是直接處理限制條件,最後以相關例子來模擬 並驗證此兩種修正方法。 4. Jiang 等人(2010),結合 HS 之特色用以改善 SA 退火速度,主要方式是 將 HS 所產生的新解,當作 SA 之初始條件狀態去搜尋,並以一些常見 的最佳化數學式測試,結果顯示改善後的 SA 收斂速度比原始 SA 和其 他演算法快。 5. Mukhopadhyay 等 人 (2008) 以 統 計 分 析 方 式 推 導 並 證 明 母 體 變 異 數 (Population-variance)與 HS 搜尋解之性能,並做一些參數探討。 6. Wang 和 Huang(2010),說明 HS 應用範圍相當廣泛,但有些困難之處在 於如何選擇適當的參數值,因此用一些數學技巧使參數值也能有經驗性 的隨迭代過程變化,並與原始 HS 和一些改良的 HS 方法比較,其結果 是更好的。
35
2.4 小結
本研究之目的為應用最佳化演算法於大地工程相關問題,而從 2.3.2 節 可知,可透過修改既有的演算法提高演算法的適用性與搜尋效率,因此從 2.3.1 節介紹啟發式演算法中挑選適用性高的做修改,首先排除 GA、ACO 兩種方法,因為 GA 需先將問題變數編碼,而 ACO 需將問題轉換成路徑方 式表示,接著 SA 與 TA 則受限於問題的搜尋區間大小,因此也排除在外, 最後考慮 PSO、FA 與 HS 三種方法,PSO 是以當前最佳解來引導其他解移 動的方向,相較於 HS 整體的隨機搜尋性較差,FA 則是先將所有可能解均 勻散布於解的空間,再快速收斂至最佳解的區域,但是相較於 HS 收斂的參 數設定較複雜,且 Geem(2010)提出的參數自由設定的和弦搜尋演算法 (PSF-HS) 相 較 於 PSO 與 FA 更 能 有 效 控 制 搜 尋 的 Intensification 與 Diversification,因此本研究選用和弦搜尋演算法來做修改,最後為了提高 收斂速度,在和弦搜尋演算法趨近收斂階段時,會改以傳統最佳化演算法 中的最陡坡降法做計算以提高收斂速度。 除了和弦搜尋演算法的修改,也會對演算法的參數設定跟搜尋效率與 搜尋次數的關係做研究,期望能改善和弦搜尋演算法於實際應用時的缺點, 進而應用於複雜的大地工程問題。36
第三章 研究方法與規劃
本研究之主要內容為修改一已存在之演算法作為本研究之最佳化方法, 並以有解析解之數學問題做驗證,再將此最佳化方法應用於實際案例,最 後針對實際應用時演算法參數與問題待定參數之關係做探討。3.1 電腦輔助程式與最佳化方法之選擇
本節介紹求解最佳化問題所用之最佳化方法與求解最佳化演算計算過 程常用之電腦語言或程式平台(如:Fortran、C++、MATLAB…等),由於本 研究之主要目的為最佳化演算法的改善,於實際應用時,於邊坡穩定分析 選擇模式較單純的問題測試,因此只需選用 MATLAB 來當作其運算之工具, 於新山壩滲漏問題選用地工分析軟體 FLAC,並以 MATLAB 作為主控程式 進行和弦搜尋最佳化演算法之計算。 3.1.1 MATLAB 計算軟體MATLAB 是 MATrix LABoratory 的簡稱,為一功能強大的數學運算軟 體,也是一套專為工程和計算所設計的高效率電腦計算軟體。在科學計算 程式設計上的優勢有:操作容易、平台獨立性、預設函式與特別功能的工 具箱、和裝置無關的繪圖、使用者圖形介面、MATLAB 編譯器等優點。其 中選用 MATLAB 為執行程式主要原因之一為:其具有獨立的 MATLAB 編譯 器,此編譯方式可將原始 MATLAB 程式轉成獨立的執行檔。
37 3.1.2 FLAC 分析軟體
FLAC 代 表 Fast Lagrangian Analysis of Continua , 為 美 國 Itasca Consulting Group,Inc.為大地工程及開挖工程所發展的一套數值分析軟體, 採用顯式有限差分法求解,可應用在大地工程中基礎、邊坡穩定、隧道、 水利工程、地質鑽孔、堤壩滲流或地震分析等相關問題。FLAC 應用於滲流 方面問題上,能模擬流體在可滲透性介質中流動,除了可單獨模擬流動外 也可與力學模式進行模擬,以表達流體-固體相互作用等情形。此外,此軟 體可依使用者需要,選擇在指令視窗的驅動模式下或圖形介面驅動模式下 執行,因此,本研究選擇 FLAC 為本研究執行滲流分析計算引擎。 3.1.3 最佳化演算法之選擇 本研究採用和弦搜尋演算法(HS)做修改,原因如下: 1. 原理簡單,使用容易; 2. 對於變數為連續、不連續或離散型均適用; 3. 搜尋次數不會因變數量增加而成指數增加; 4. 演算法之收斂與發散參數(HMCR)與解的改善(PAR)皆由一隨機機率控 制,相較於其他演算法於實際問題應用時限制較少。
38
3.2 最佳化演算法之擬定流程
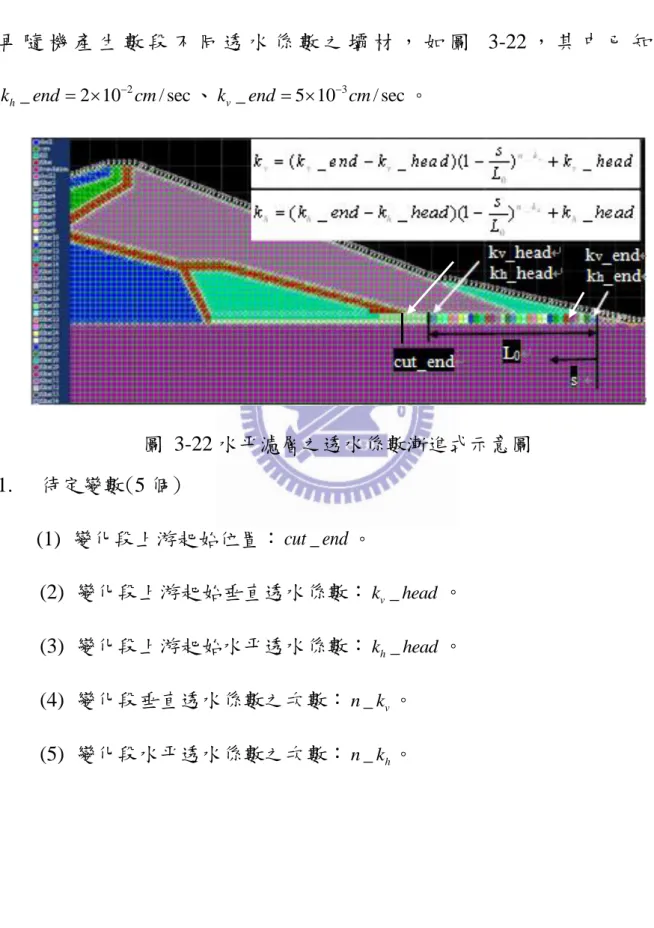
本研究最佳化演算法擬定流程分兩個部分詳述:3.2.1 節說明整個和弦 搜尋演算法的修改過程;3.2.2 節介紹修改後的演算法於驗證分析時的問題 選擇與如何定義收斂跟終止條件。詳細修改演算法參數設定則的流程會在 第四章做完整的說明。 3.2.1 修改和弦搜尋演算法 從 Geem 等人於 2001 年發表和弦演算法至今已成功應用於各種不同領 域的實際問題中,而 Geem 等人分別於 2009 年與 2010 年針對和弦搜尋演算 法 提 出 了 Particle-swarm harmony search(PS-HS) 與 Parameter-setting-free harmony search algorithm (PSF-HS),本研究採用 PSF-HS 之方法於第一階段 分兩個部分做修改,首先第一部分為結合粒子群法的概念,在選取和弦記 憶時選取當前目標函數值最好的和弦,接著第二部分為加入調音方向,透 過每次更新和弦記憶時記錄是以調音產生的新和弦,根據紀錄結果於下次 調音時決定新和弦的調音方向。最後再以 Geem 等人(2010)中 PSF-HS 的一 個測試問題做驗證。 第一階段的測試問題屬於一離散(調音值固定)且不連續的問題,然而許 多實際案例中之問題多屬連續性問題,故第二階段採連續性問題做測試,39 以第一階段修改後之演算法做修改,又由於原版和弦搜尋演算法於連續問 題之調音方法(調音時隨機產生一介於-bw~bw 之間的值)在收斂階段的改 善有限,因此本研究嘗試在收斂階段加入數值微分的觀念,流程為一開始 給定一固定的起始 bw 做演算,等到和弦記憶的值接近收斂時(收斂之定義 於下一小節 3.2.2 有詳細說明),再利用數值微分計算出下一次迭代用之調音 值,讓整個演算法於最後收斂階段能快速收斂至目標函數值附近,相較於 原版和弦收尋演算法的隨機產生的調音值,期望此法能夠在更短的時間內 得到更精確的結果。調音方法修改前後之比較如表 3-1,原版之和弦搜尋演 算法流程如圖 3-1,本研究擬定之最佳化方法之流程如圖 3-2。 表 3-1 調音方法修改前後之比較 原版 修改版 不連續問題 連續問題 不連續問題 連續問題 調音值
bw
-bw~bw
bw
bw
數值微分 無 無 無 有40 圖 3-1 原版和弦搜尋最佳化演算法流程圖 否 否 是 是 Step 1 問題模式化 Step 2 定義初始參數 Step 3 產生初始 和弦記憶(HM) Step 4 產生新和弦 (NewH) Step 5 比較 NewH 是否比 HM 中的好 Step 6 判斷是否滿 足終止條件 NewH 取代 HM 中最差者 停止
41 圖 3-2 修改後和弦搜尋(HS)最佳化演算流程圖 排練(performance) 3*HMS 次 否 否 是 是 Step 1 問題模式化 Step 2 定義初始參數 Step 3 產生初始 和弦記憶(HM) Step 4 產生新和弦 (NewH) Step 5 比較 NewH 是否 比 HM 中的好 Step 6 判斷是否滿 足終止條件 Step 7 數值微分 NewH 取代 HM 中最差者 更新記錄矩陣 (更新方法與 調音方向) 停止 初始的 HMCR、PAR 記錄矩陣計算 之 HMCR、PAR 粒子群法 結合
42 3.2.2 驗證分析之規劃 就本研究驗證分析之規劃,本節中分兩大部分說明之。,第一部分為 修改後方法與原版方法的收斂效率(在相同收斂準則下之結果)之比較,藉此 比較修改後之方法與原版的優劣,此部分借用 Geem 等人(2010)論文中曾採 用過之例題,以一不連續且搜尋解之區間為離散形態(即 bw 為一定值) 之問 題做為驗證問題。由於許多問題是屬於連續性之問題,因此第二部分藉由 一多目標連續函數,經可靠度分析比較各個版本的方法於收斂時與目標函 數誤差之範圍,期能藉此驗證本研究擬定之最佳化方法比原版本方法的搜 尋效率更好,搜尋解更接近真實解以及目標函數差值更小。 最佳化演算法必須清楚的定義終止條件(根據收斂準則或滿足最大迭代 次數做判斷),在傳統數學最佳化中是以收斂準則做判斷,是依據每次迭代 後最佳解的改變量(殘差值)做判斷,必須知道以殘差值做判斷並不能保證搜 尋的解是正確的,這是傳統數學最佳化會陷入局部解的原因之一,因此在 啟發式演算法中嘗試加入數值微分的概念,在當前的解都往正確的方向移 動時,加速演算法的收斂效果,如此可避免傳統數學方法會陷入局部解的 情形。 由於目前本研究著重於方法的改進,因此於方法之驗證時選用有解析 解的方程式做驗證,在經過多次的測試後,終止條件設定最大迭代次數為 1000 次,收斂準則為與目標函數真值之差值為判斷。
43 3.2.2.1 搜尋解為離散之不連續單目標問題 式 3-1 為 Geem 等人(2010)中 PSF-HS 的測試方程式。 Minimize (3-1) 此問題之最佳解為(1,2,3,4,5),Geem 等人(2010)的 PSF-HS 之測試結果 如圖 3-3,圖 3-4,圖 3-5。由於此問題之解區間為離散形態,且 bw 為定 值 1,因此終止準則為: (1) 最大迭代次數 N_maxsearch =1000。 (2). 圖 3-3 PSF-HS 找到最佳解所需之迭代次數(Geem 等人,2010)
44
圖 3-4 HMCR 與迭代次數之關係(Geem 等人,2010)
45 此部分之詳細規劃流程如圖 3-6。 圖 3-6 第一部分之研究流程 PSF-HS 方法 選定測試方程式 (式 3-1) PSF-HS 加入 調音方向之方法 PS-HS 方法 結果探討 (迭代次數、HMCR、PAR) 可靠度分析 (測試次數 1000) 擬定後續研究用之最 佳化演算法
46 3.2.2.2 搜尋解為連續之連續多目標問題
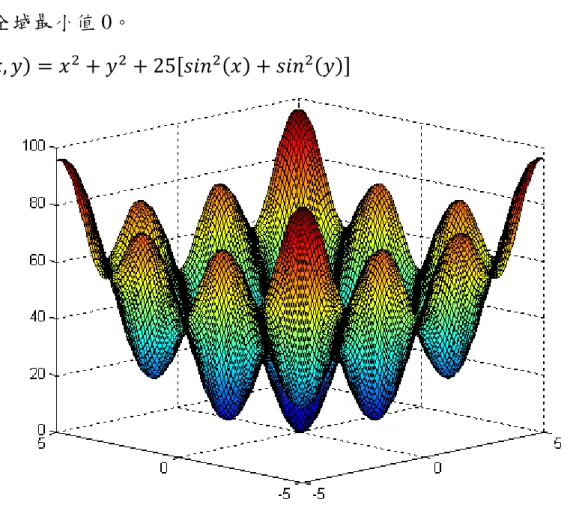
式 3-2 為蛋盒函數(The egg crate function),方程式之全域性最佳解為 (0,0),方程式的形狀如圖 3-7 所示為一多極值之方程式。此函數在(0,0)具 有全域最小值 0。
(3-2)
圖 3-7 The egg crate function 在(0,0)有全域最小值 0
為了解演算法於不同待定變數個數下迭代次數與收斂精度的關係,驗 證時採用,探討待定變數個數由 2 到 5 等情況下之結果。 (3-3) 終止準則為: (1) 最大迭代次數 N_maxsearch =1000。 (2). 此部分之詳細流程如圖 3-8
47 圖 3-8 第二部分之研究流程 選定測試方程式 (式 3-1) 以第一部分決定 之方法做改良 收斂時加入 數值微分 各種修改方式 綜合比較 各種修改方式 可靠度分析 (測試次數 1000) 擬定本研究於 實際案例模擬之 最佳化方法
48
3.3 研究案例模擬之策略與規劃
本節介紹本研究選用之兩個研究案例的背景資料與模擬規劃,而模擬 之結果與討論在第五章有完整的說明。 3.3.1 新山壩滲漏問題 康詩凰(2011)曾以新山壩之滲漏水問題為範例,示範和弦搜尋法結合地 工分析軟體於大地工程反算分析之運用。本論文亦借用同一問題,來展示 經本研究改善後的和弦搜尋法之功效。以下摘錄康詩凰(2011)對該案例背景 之整理與簡介。 3.3.1.1 背景 新山壩於民國 69 年完工,建於基隆市安樂區,為單一供應基隆與汐止 地區用水,於民國 87 年完成壩體加高工程,集水面積為 1.6 平方公里,壩 高 51m 加高至 66m,壩軸最長為 262m,壩頂標高由 EL.75m 升至 EL.90m, 主要期望蓄水量可由 400 萬噸增加為 1000 萬噸。圖 3-9 為新山水庫俯視圖。 圖 3.7 為新山壩 Sta.0+195.29 橫斷面圖,紅框為築高段。 圖 3-9 新山水庫俯視圖(Google 地球)49 圖 3-10 新山大壩 Sta.0+195.29 橫斷面圖(改繪自 國立交通大學,2010) 由圖 3-10 可看出,加高部分直接築於原有的壩體上,致使心層為傾斜 設計,濾層也隨之變成特別的ㄑ型,因此,新山壩為一典型不對稱型土石 壩。陳冠亨(2006)蒐集國內、外關於土石壩破壞案例或文獻做整理,主要有 壩頂溢流造成壩體侵蝕、管湧或滲漏造成之壩體侵蝕或集中滲流、邊坡滑 動、地震、沉陷…等破壞模式,由此可知壩體滲漏問題對土石壩穩定有其 重要性。此外,由國立交通大學(2010)報告指出,整理新山水庫過去滲漏文 獻,並施作非破壞性檢測資料與數值模擬的結果做整合推估,壩面異常滲 漏可能因壩體內存在特定滲流路徑或受限於濾層排水效能等情形而生,以 致新山壩目前最高庫水位仍停留在 EL.83m 左右。因此,本研究選用新山壩 為滲流分析研究對象。 考慮 FLAC 為二維數值分析軟體,需要選擇新山壩其中之一斷面為研 究滲流分析與建模參考圖使用。先參考圖 3-11 為新山壩俯視圖,其中紅色 數字為水位觀測井長期監測之水位資料;黃色區塊表示有長期蒐集到滲漏 水之位置;藍色箭頭方向表示壩體水流方向,且幾乎與壩軸成垂直關係。 另由紅色箭頭所指的 Sta.0k+170.68 表示此斷面附近之壩體,如圖 3-12 示, 對照出此斷面平台出水高程為 EL.46m,明顯高於由水位觀測井(L1、L2、 L3)繪製之浸潤面高程。
50 圖 3-11 新山壩俯視圖(改繪自 國立交通大學,2010) 圖 3-12 新山壩 Sta.0k+170m 斷面圖(改繪自 國立交通大學,2010) 然而,再考慮圖 3-11 上所標誌之紅色圓圈,因平台左右高差關係,D4 量水堰所蒐集到之平台滲出水為壩體左側,即 Sta.0k+170m 附近之出滲水, 其排除降雨影響之長期監測資料如圖 3-13,庫水位 EL.82m 時之滲水量約 0.5CMD。圖 3-14(D1 為加高前;D2 為加高後;括弧內之人工,表示監測 數據以人工方式量測)總壩體滲水量與庫水位關係圖,一樣為排除降雨影響 之長期監測資料,其中庫水位接近 82m 有幾筆數據接近 0 或超過 350 CMD, 應屬人為擷取數據之誤差。
51 圖 3-13D4 量水堰排除降雨影響之滲水量與庫水位關係圖 (國立交通大學,2010) 圖 3-14 排除降雨影響之壩體總滲水量與庫水位關係圖 (國立交通大學,2010) 0 1 2 3 4 5 6 7 8 9 10 75 77 79 81 83 85 庫水水位(m) C M D D4 0 50 100 150 200 250 300 350 400 77 78 79 80 81 82 83 84 庫水水位(m) C M D D1(人工) D2(人工)
52 圖 3-15 新山水庫滲漏位置圖(陳冠亨,2006) 選用新山壩 Sta.0+170m 作為研究模擬對象原因說明如下: 1. 有詳細設計圖可供 FLAC 建模使用; 2. 平台處有異常滲出水現象,與長期監測數據; 3. 在此斷面附近 5m 內有 3 孔水位觀測井之水位資料可供參考; 4. 此斷面雖然不是新山壩最大斷面,不過仍屬於次大之斷面,可足以用來 表示此壩體內部幾何關係。
53 圖 3-16為新山壩斷面各材料透水係數分布圖,由國立交通大學(2010)參考 自Peng 等人(2008)之底圖與中興工程顧問股份有限公司(2008)之壩材透 水係數來源(經透水試驗獲得),其中括弧參考自捷儀工程顧問(股)公司 (2004)之工程地質鑽探報告書之試驗結果。 圖 3-16 新山壩斷面各材料透水係數分布圖(單位:cm/sec) (國立交通大學,2010) 因此,FLAC 網格建模參考新山壩 Sta.0+170m 去設計;材料參數使用 參考國立交通大學(2010)數值模擬之參數,並以總壩體滲流量逆推各材料滲 透係數;此外,考慮壩體內部可能存有高透水通道,其透水係數參考國立 交通大學(2010)示蹤劑施放結果 (1.6×10-2 ~ 5.4×10-2 cm/sec);並考慮示蹤劑 施放當時之庫水位監測數據為 EL.82m,因此以庫水位 EL.82m 作為上游殼 層之邊界,而下游壩趾出水處也施加 4 m 高之水位,以造成水壓差;本研 究不考慮庫水位急速升降情形,因此以水壓變化與時間無關之穩態模式進 行滲流分析。FLAC 初步建模與各材料透水係數如圖 3-17;飽和度與網格 Fa Fb Fc
54 表示如圖 3-18;局部放大壩材與水位觀測井分佈如圖 3-19(黃色為井口; 藍色為水位所在網格;黑色為水位(壓)計埋設所在網格);其中 L1 水位與 水位計在同一網格,因此以黑色外框取代之,初步分析結果等資料如表 3-2。 圖 3-17FLAC 模擬新山壩 Sta.0+170m 與材料參數圖 圖 3-18FLAC 網格建立(1 網格尺寸為 2m×2m)與初步分析飽和度圖 圖 3-19 水位觀測井對應於下游殼層位置圖 foundation k=1.00×10-5 core kh=4.16×10 -6 kv=1.04×10 -6 shell kh=7.60×10 -5 kv=1.90×10 -6 filter k=3.60×10-4 fracture k=3.50×10-2 fill kh=6.00×10 -5 kv=1.50×10 -5 filter2 kh=1.44×10 -2 kv=7.20×10 -3 shell2 kh=4.00×10 -5 kv=1.00×10 -5
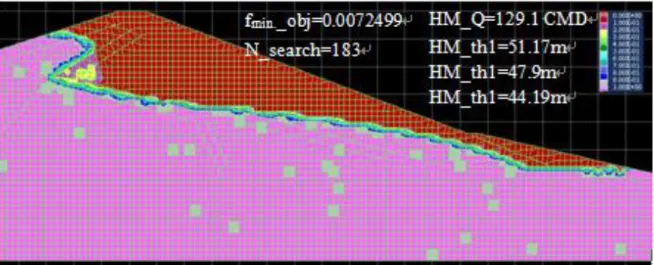
55 表 3-2 FLAC 初步模擬新山壩之相關資料 斷面 蓄水位高程 (m) 單位長度滲流量 (cms/m) 總滲流量(CMD) Sta.0+170m EL.82m 6.629×10-6 114.55 ※總滲流量(m3/day)=單位長度滲流量(m3/sec/m)×土壩平均總長度 (200m)×86400 ※單位壩長滲流量(m3/day/m)=單位長度滲流量(m3/sec/m)×86400 3.3.1.2 研究方法 本研究引用康詩凰(2011)之研究方法,滲流分析採用 FLAC 軟體進行計 算,並以 MATLAB 為主控伺服器進行和弦搜尋演算法之計算。 3.3.1.3 研究規劃 本研究以康詩凰(2011)論文中所考慮的一種境況,設定下游水平濾層透 水性(依二次函數)漸進變化,以本研究經改良驗證後之和弦搜尋演算法 進行演算,與康詩凰(2011)採用原版和弦搜尋演算法所得結果比較,藉此驗 證修改後之和弦搜尋演算法可進一步改善原版和弦搜尋法搜尋所需迭代次 數過多之缺點。 經迭代 200 次後,康詩凰(2011)發現其中最佳目標函數值計算結果出現 在第 183 次(N_search=183),該次目標函數值(fmin._obj)為 0.0072499。目標 因子總壩體滲流量(HM_Q)為 129.1 CMD,總水頭之目標因子 th1 最佳值為 51.17 m,水頭之目標因子 th2 最佳值為 47.9m 水頭之目標因子 th3 最佳值為 44.19m,與目標值 43m 差 2m 內,結果標示於圖 3-20 之飽和度圖上。此外, 將搜尋之最佳待定變數值標示於圖 3-21 壩材分布圖中。
56
圖 3-20 新山壩漸進式之 HM 最佳搜尋結果之飽和度圖