ATTRIBUTE SELECTION FOR THE SCHEDULING OF
FLEXIBLE MANUFACTURING SYSTEMS BASED ON FUZZY
SET-THEORETIC APPROACH AND GENETIC ALGORITHM
Yi-Hung Liu
Department of Mechanical Engineering
Chun Yuan Christian University, Taiwan, R.O.C.
Han-Pang Huang
*Department of Mechanical Engineering
National Taiwan University, Taipei, 106, Taiwan, R.O.C.
Yu-Sheng Lin
Graduate Institute of Industrial Engineering
National Taiwan University, Taiwan, R.O.C.
ABSTRACT
Assigning proper dispatching rules dynamically has been shown to enhance various performance measures for a flexible manufacturing system (FMS). To achieve this, real-time salient information of the system is extracted and then a rule’s dispatching mechanism is built for the scheduling task. For a dynamic scheduled FMS, two critical issues dominate the performance; the first is the selection of system attributes and the second is the design of the dispatching mechanism. This paper aims to deal with the first issue.
A good attribute evaluation method should provide the information from which attribute are selected or removed. In this paper, a supervised attribute mining algorithm (SAMA), which is based on the fuzzy set-theoretic approach and genetic algorithm (GA), is proposed to execute this function. SAMA is able to rank attributes according to their relative importance. In the experiment, a FMS is conducted to demonstrate the validity of the proposed SAMA. The experimental results indicate that the attribute evaluation task and optimal attribute subset selection can be achieved by using the SAMA. Moreover, compared with using all system attributes without selection, performance of the FMS can be improved by using the optimal attributes as input of the scheduler.
Keywords: Flexible manufacturing system, dynamic scheduling, attribute selection, fuzzy
theory, genetic algorithm
1. INTRODUCTION
An FMS combines the merits of an automated production/transfer line and the flexibility of a job shop. An FMS is able to manufacture a number of different parts on a variety of groups of machines and other stations, such as load/unload and input/output buffers, by an automated material handling system [1-4]. With the above benefits, an FMS has several significant advantages including the improvement of machine utilization, enhancement of the throughput, reduction of the number of work-in-process (WIP), mean flow time, the number of tardy parts, and the use of smaller batches.
Scheduling plays an important role in the
production control in an FMS, which contains several real-time decisions, such as part type and machine selection [3]. Since Montazeri et al. [5] had concluded that dispatching rules have a great impact on various system performance criteria, researchers started to investigate the relationship between various system performance criteria and the assigned dispatching rules for FMSs. Several methods have been proposed over the last decade and can be divided into several categories, including simulation-based and scheduling with dispatching rules [6-7], artificial intelligence (AI) approaches [8-9], dynamic programming approaches [10-11], heuristic approaches [3, 12-13], pre-emptive method [14], and the hybrid approaches [15-16].
*
To achieve high performance for an FMS, a good scheduling system should make a right decision at a right time according to system statuses. Although a number of scheduling approaches have been proposed, the selection of system statuses, i.e., the system attributes, were accomplished by taking trail-and-error or heuristic rules. However, a set of better attributes would achieve higher classification accuracy for the rules dispatching because the attribute and dispatching rule refer to the feature and the class in the pattern recognition domain, respectively. Therefore, performing an attribute selection mechanism to obtain a set of salient attributes for the scheduling can reduce the time of designing and achieve higher classification accuracy so that high system performance of FMSs is attained. This paper aims to achieve this goal.
Various useful classical statistical techniques to achieve feature evaluation have been described [17]. Several methods based on fuzzy set theory [18-21] have also been proposed. Fuzzy set theoretic approaches to feature selection are based on entropy and fuzziness index measures [20-21], fuzzy c-means [18], and ISODATA algorithms [19]. Other approaches for feature selection are based mainly on artificial neural networks [22-25] and hybrid methods [26-28]. These methods are classified as supervised or unsupervised based on whether the class information is known or not. For example, the methods proposed in [20-23,26,28] fall into the supervised category, whereas those in [19,24-25,27] are unsupervised.
The proposed SAMA combines some attempts: using the fuzzy set-theoretic approach and GA optimization under the supervised training. The underlying principle includes the development of a multi-dimensional fuzzy- entropy-based attribute evaluation index (FAEI) and optimization using GA with population solutions. SAMA can automatically provide useful information so that we can select optimal attribute subset from the original attribute set according to their relative importance in the attribute space.
The rest of this paper is organized as follows. Details of the proposed supervised attribute mining algorithm (SAMA) will be illustrated in Section 2. Section 3 will formulate the FMS model for the experiment, including the physical layout and the product order. Experimental results and some discussions will be given in Section 4. Finally, we have some conclusions in Section 5.
2. SUPERVISED ATTRIBUTE
MINING ALGORITHM
This section will introduce the formulation of the proposed SAMA. It is noted that one dispatching rule forms one class. If there n system attribute candidates to be evaluated, a row data, called a pattern, is in n-dimensional attribute space.
2.1 Fuzzy entropy based attribute evaluation
index
Suppose that there are l classes ( k l) to be classified, and each class has
p patterns. The attribute space for representing a pattern is an n dimensional attribute space , in which the attribute components denote various kinds of features. The distance between a pattern j k
C C C C1, 2,..., ,..., ) ,..., , (F1 F2 Fn F= C F ∈ and its corresponding mean in class is defined as the normalized Euclidean distance:
k C k n i ki ki ij j k F C m F F d ∈ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − =
∑
= , ) ( 2 1 1 2 α (1) where∑
= = p j ij ki F p m 1 1 (2) and k i ki ij j ki =N1⋅maxF −m , F ∈C α (3)In the above equations, ki denotes the mean of class
k along the ith attribute axis, ki is a normalization
factor, in which 1 is a positive number so that the value of would lie in the interval [0, 0.5], and p is the class size. We can use the multi-dimensional
m C α N ) ( j k F d π −
semi membership function to compute the intraclass ambiguity with the fuzzy entropy [32]
k j p j j k semi p k S d F F C p H =
∑
∈ = − , ))) ( ( ( 2 ln 1 1 π µ (4)where Sp(•) is the Shannon function and is expressed as )) ( 1 ln( )) ( 1 ( ) ( ln ) ( )) ( ( x x x x x Sp µ =−µ µ − −µ −µ ( 5 )
where the multi-dimensional semi−π membership function is defined as ⎩ ⎨ ⎧ < > ≤ ≤ − = − 0 5 . 0 , 0 5 . 0 0 , 2 1 ) ( 2 x and x if x if x x semi π µ (6)
The value of the index k increases monotonically as
the value of increases monotonically in the interval [0, 0.5]. Hence, if most of the patterns are concentrated around the center, the value of the index
k would then be low. In this case, the compactness of
patterns H ) ( j k F d H p j C Fj∈ k, =1,2,...., is high. Compactness
Let kki be the center of classes and
along the ith feature axis, ,
m ′ Ck Ck′ k k≠ ′ k,k′=1,2,...,l
∑ ∑
= ′ ≠ ′ = l k k k k k k F F H FAEI 1 ( ) ) ( γ (11) ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ + =∑
∑
= ′ = ′ p j k ij p j k ij i k k F F p m 1 1 ) ( ) ( 2 1 (7)The term Hk(F)/(
∑
k≠k′γkk′(F)) is close to the where patterns ij k,and ij k belong to class kand class k respectively. The normalized Euclidean
distance between the pattern and center of the two classes and is defined as
F )
( (F ) ′ C
C ′
k
C Ck′
minimum as tends to zero and ≠k′
k kk
tends toward the maximum. Conversely, this term has the
maximum when =1 and ≠k′
k kk
approaches zero. The FAEI index value decreases as the pattern F increases its membership value to its own one class, i.e., F increases its belongingness to only one class. In the meantime, F decreases its interclass ambiguity. The FAEI value increases as the pattern F decreases its belongingness to a specific class k. In the meantime, it
increases the ambiguities toward other some classes for some ) (F Hk
∑
γ ′(F ) ′(F ) γ ) (F Hk∑
C kk′≠ . Hence, the attribute evaluation becomes a task of minimizing the FAEI index, i.e., one can find the optimal attribute space subset by minimizing the FAEI index. However, there are no arguments in the index by which the FAEI can be minimized. Namely, there is no information about the relative importance of each feature
in the n-dimensional feature space.
i F k k j n i kki i k k ij j k k F C C m F F d ′ = ′ ′ ′ ∈ ∪ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − =
∑
, ) ( 2 1 1 2 α ( 8) and k k j i k k ij j i k k′ =N2⋅maxF −m ′ , F ∈C ∪C ′ α (9)where the factor k ′ki is the normalization factor so that
the value would lie in the interval [0, 0.5] and 2 is a positive real number. We can also obtain the membership value of the pattern k k to the
center of these two classes using the multi-dimensional α ) ( j k k F d ′ N C C F∈ ∪ ′ π −
semi membership function. Furthermore, the interclass ambiguity between the two classes can be obtained by computing the index of fuzziness (Kaufmann entropy) [33] for all patterns in the given two classes. Namely
In our previous study [28], the relationship between relative importance of a feature and its weighted factor has been derived. By incorporating the weighting factors into normalized Euclidean distances, the weighted distances are
k j n i ki ki ij i j k F C m F F d ∈ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − ⋅ =
∑
= , ) , ( 2 1 1 2 α ω ϖ(12) ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ + =
∑
∑
= ′ ′ − ∩ − = ′ − ∩ − ′ p j k j k k semi semi p j k j k k semi semi k k F d F d p 1 ) ( ) ( 1 ) ( ) ( )) ( ( )) ( ( 1 π π π π µ µ γ (10) k k j n i kki i k k ij i j k k F C C m F F d ′ = ′ ′ ′ ∈ ∪ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − ⋅ =∑
, ) , ( 2 1 1 2 α ω ϖ (13)where k and k . From the above
equation, the Kaufmann entropy k ′k has the minimum
( ) as the value equals zero, and k ′k
has the maximum ( ) as the value of . If most of the patterns k k are
clustered around the center of the two classes, the value of k ′k tends to zero. Hence, the k ′k value decreases
as the goodness of the features in discriminating between classes k and Ck′ decreases. The index of fuzziness
k
k ′ denotes the interclass ambiguity and is called the
separation index in this paper.
k j C F ∈ Fjk′∈C ′ γ 0 = ′ k k γ dk ′k(F) γ 1 = ′ k k γ 5 . 0 ) ( = ′ F dkk F∈C ∪C′ γ γ C γ
where ϖ is the weighting set, , . FAEI is now a function of the set ) ,..., ,.. (ω1 ωi ωn ϖ = n i i 1, 1,2..., 0<ω < =
ϖ. Namely, the class structure in the attribute space can be dynamically changed by setting different combinations of weighting sets. The worse the discriminability of the classes along the ith attribute axis, the lower the weighting factor i, i.e., the lower the
relative importance of feature i. Conversely, the better
the discriminability of the classes along the ith attribute axis, the higher the value of the weighting factor i, i.e.,
the higher the relative importance of attribute i. Thus,
attribute mining becomes the task of minimizing the FAEI subject to the set
ω F
ω F ϖ.
Based on the compactness and separation indices mentioned above, SFM defines a fuzzy-entropy-based attribute evaluation index (FAEI):
2.2 Minimizing the FAEI via GA
The optimization task can be performed in several approaches such as nonlinear programming and simulated Annealing algorithm [29-30]. In this study, we use the genetic algorithm [31] to search the global optimal weighting set so that FAEI can be minimized, and the steps are as follows
Step 1: Prepare the training set. Determine the population size, encoding mechanism, selection reproduction procedure, crossover rate, and mutation rate
Step 2: Start with an initial population randomly (a set of strings or chromosomes).
Step 3: Evaluation of fitness (inverse of FAEI) of every string and selection of appropriate candidate strings to form the mating pool.
Step 4: Crossover and mutation.
Step 5: Repetition of steps 3 and 4 until the stopping criterion is reached. Namely, the cost of FAEI for all populations remains at a low value and no changes are observed.
3. FMS FORMULATION AND
SIMULATION SETUP
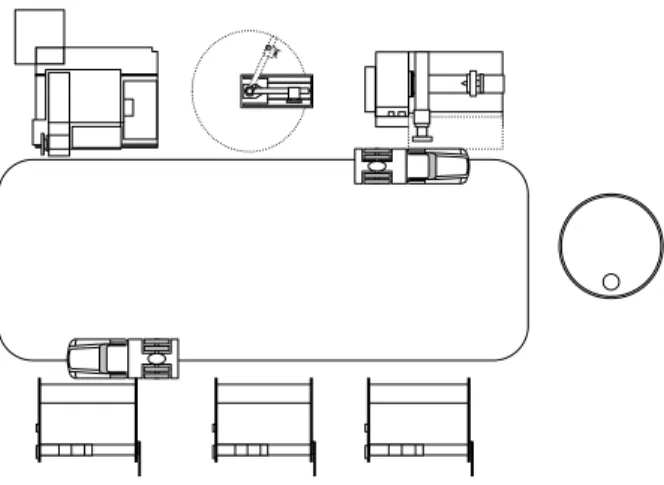
The FMS used in this paper is a modification of the model presented in [5], and is shown in Fig. 1. The FMS model consists of three machine families (M1, M2, and M3), three load/unload machines, and a WIP buffer with enough capacity to prevent deadlock. The M1 and M2 machine families have two machines respectively, while the third family M3 has one machine only.
Figure1. FMS layout
Table 1. Part routing and processing times
Part ID Part Routing Processing Times (min.) 1 L,M2,L,M1,L,M2,L 3 ,1 1 ,1 0 ,2 0,3,14,3 2 L,M2,L,M1,L,M2,L,M1 3 ,1 0 ,1 0 ,2 4,3,10,3 3 L,M2,L,M1,L,M2,L 3 , 1 5 , 3 , 3 0,10,21,3 4 L,M2,L,M1,L,M2,L 3 , 1 2 , 3 , 5 3,10,33,3 5 L,M2,L,M1,L,M1,L,M2,L 8 , 1 6 , 5 , 2 5,5,22,10,24,8 6 L,M2,L,M1,L,M1,L,M1,L,M2,L 5 ,2 5 ,1 5 ,2 4,5,22,10,38,3,57,10 7 L,M2,L,M1,L,M1,L,M1,L,M2,L 5 ,2 8 ,1 5 ,2 7,5,25,10,40,3,35,10 8 L,M2,L,M1,L,M1,L,M1,L,M2,L 5 ,3 6 ,1 5 ,3 0,5,32,10,49,3,25,10 9 L,M2,L,M1,L,M1,L,M1,L,M2,L 5 ,4 5 ,1 5 ,4 2,5,34,10,80,3,23,10 10 L,M2,L,M1,L,M1,L,M1,L,M2,L 5 ,5 2 ,1 0 ,6 1,5,61,30,112,3,38,50 11 L,M3,L,M3,L,M2,L,M2,L 12,95,12,45,3,36,50,51,21
Table 2. Dispatching rules used in the scheduled FMS Dispatching rule Description
FIFO SPT SIO SRPT CR DS EDD
Select the job according to the rule of first in first out Select the job with the shortest processing time Select the job with the shortest imminent operation time Select the job with the shortest remaining processing time
Select the job with the minimum ratio between time now until due-date and its remaining processing time
Select the job with minimum slack time Select the job with the earliest due-date
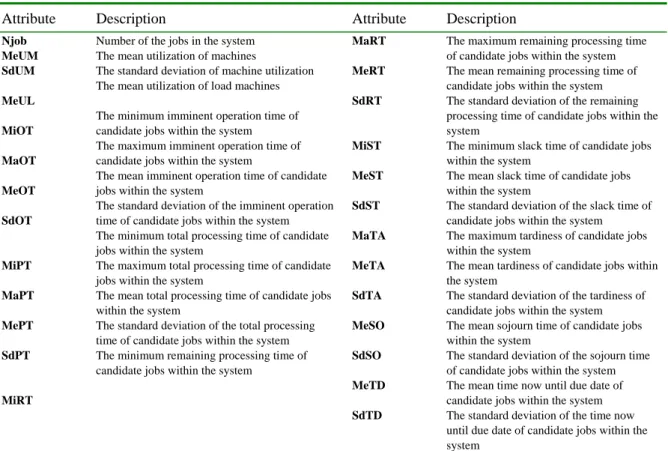
Table 3. Attribute candidates to be evaluated for the scheduling of the FMS
Attribute Description Attribute Description
Njob MeUM SdUM MeUL MiOT MaOT MeOT SdOT MiPT MaPT MePT SdPT MiRT
Number of the jobs in the system The mean utilization of machines
The standard deviation of machine utilization The mean utilization of load machines The minimum imminent operation time of candidate jobs within the system The maximum imminent operation time of candidate jobs within the system
The mean imminent operation time of candidate jobs within the system
The standard deviation of the imminent operation time of candidate jobs within the system The minimum total processing time of candidate jobs within the system
The maximum total processing time of candidate jobs within the system
The mean total processing time of candidate jobs within the system
The standard deviation of the total processing time of candidate jobs within the system The minimum remaining processing time of candidate jobs within the system
MaRT MeRT SdRT MiST MeST SdST MaTA MeTA SdTA MeSO SdSO MeTD SdTD
The maximum remaining processing time of candidate jobs within the system The mean remaining processing time of candidate jobs within the system The standard deviation of the remaining processing time of candidate jobs within the system
The minimum slack time of candidate jobs within the system
The mean slack time of candidate jobs within the system
The standard deviation of the slack time of candidate jobs within the system The maximum tardiness of candidate jobs within the system
The mean tardiness of candidate jobs within the system
The standard deviation of the tardiness of candidate jobs within the system The mean sojourn time of candidate jobs within the system
The standard deviation of the sojourn time of candidate jobs within the system The mean time now until due date of candidate jobs within the system The standard deviation of the time now until due date of candidate jobs within the system
Different part types have different processing routes. Each part has to be processed among the three families but with different sequences. Namely, each part type has its own processing route. The sequence of operations for each part is fixed, and the routes (process plans) of the eleven part types are listed in Table 1. In this table, the load and unload machines are denoted by L.
Several assumptions are as follows. Different jobsarrive randomly at the FMS with aconstant time interval of 31 minutes and every job has its due date.
The transportation time is considered to be negligible in this paper and each machine can only process a job at a time. Seven dispatching rules that have been used in the scheduling researches are selected in this paper and are listed in Table 2. Furthermore, three performance criteria are chosen and they are throughput (TP), mean flow time (MFT) and number of tardy parts (TD), respectively.
A scheduler seeks to identify important system attributes under various performance criteria. Therefore, all possible system attributes are exhaustively examined. Table 3 lists the 26 attribute candidates that will be examined in this paper. These attribute candidates are selected from the earlier researches [34-37]. This paper aims to apply the proposed SAMA to select salient attribute subset from a large number of attribute candidates.
4. RESULTS AND DISCUSSIONS
1) Training set preparation for the attribute selection
A training set is generated by executing a number of simulation runs under a specific performance criterion. Three training sets have to be prepared because three performance criteria are used. The simulation period for each run is 10,080 minutes composed of 7 multi-pass scheduling periods and the time interval of making a decision is 1440 minutes. A dispatching rule is assigned to the next scheduling period randomly at each decision point. It is noted that the first dispatching rule for the long run is set as the FIFO. Time between the arrivals of various jobs is set as 31 minutes. Three different part mix ratios are used (see Table 4) and each part ratio has 40 random seeds to generate 40 distinct job arrival sequences. Totally 120 job arrival sequences are generated.
By taking trail-and-error, a training instance is obtained which has the optimal performance through a large number of simulations under a specific part ratio and a specific job arrival sequence. A training instance supports seven training row data, each of which is a row vector of dimensionality 27. Dispatching rules are labeled from Class 1 to Class 7. Therefore, there are totally 840 training row data
Table 4. Defined part ratios in this study (%) Part Ratio 1 Ratio 2 Ratio 3
Lot 1 25 11 5 Lot 2 5 11 5 Lot 3 5 11 5 Lot 4 8 12 16 Lot 5 16 6 16 Lot 6 16 8 9 Lot 7 1 8 8 Lot 8 5 7 8 Lot 9 12 7 7 Lot 10 5 2.5 4 Lot 11 2 16.5 16
obtained under a specific performance criterion. Namely, a training set is a dimension of 840 by 27. The simulation of the FMS is realized by the tool of eM-Plant v4.6.
2) GA setting
After deriving SAMA, the dynamically scheduled FMS is used to validate the algorithm. Also, the proposed SAMA is used to find the salient attribute subset from 27 candidates for the scheduling. Before performing GA to minimize the index FAEI, some genetic operations in GA search must be set first.
All weighting factors are randomized in [0,1] initially, and then encoded into binary 10-bit strings (chromosomes). Therefore, the resolution of a weighted factor is 1024 in [0,1] such that the relative importance can be obtained more precisely. The population size is set to 200, the mutation rate is set to 0.01%, and the crossover rate is set to 1.0. The roulette wheel selection is used to be the evolution operation. The fitness function is defined as the inverse of the index FAEI, and the cost of each generation is defined as the summation of all populations in the generation.
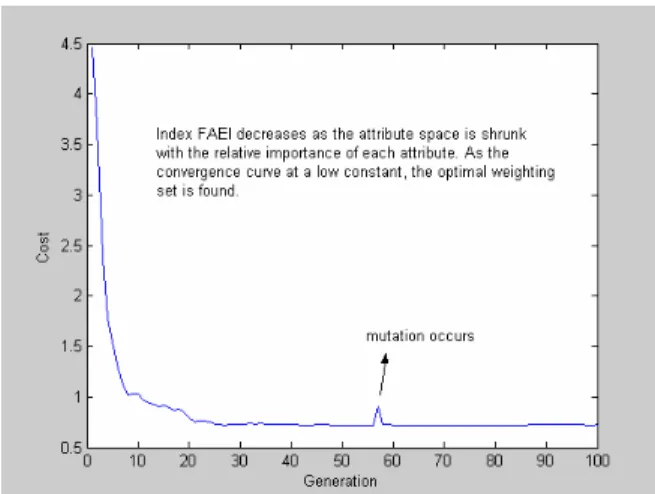
A genetic algorithm search with 50 generations is called a run. It is worth mentioning that the time of a run is less than two minute by using a personal computer with Pentium IV-2.66 GHz CPU. The off-line attribute evaluation process is coded with Matlab 5.3. This indicates that the attribute evaluation task can be accomplished in a very short time. Optimal weighting factors are determined when the convergence curve keeps at a constant during the evolution. A convergence curve of minimizing FAEI subject to weighting set via GA is shown in Fig. 2. In this case, the training set is obtained under the minimization of throughput performance that has been described in the training set preparation. The rank of an attribute is determined by its corresponding weighting factor,
ω
, i.e., the relativeFigure 2. Minimizing FAEI via GA
importance. The higher the rank is, the more important the attribute is.
3) Evaluation via SAMA
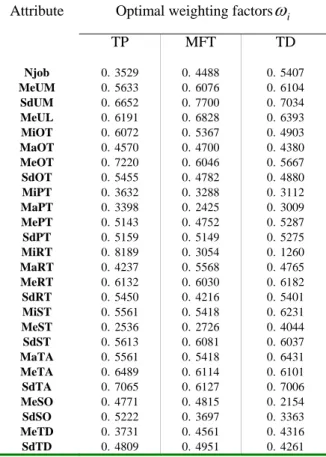
After setting parameters of GA, we perform SAMA three times to find the three optimal weighting sets of attributes since three performance criteria are used. The results are listed in Table 5. From Table 5, we can find some interesting results. As we had mentioned in the last section, the higher the weighting factor is, the more important of the attribute is. Therefore, we can rank these attributes according to their relative importance. For instance, five attributes, SdUM, MeUL, MeTA, MeRT and SdTA, are better attributes for all performance criteria because their corresponding weighting factors are high compared with other attributes. Another interesting result is that an attribute may be the best one for one performance criterion while it may be the poor attribute for the rest performance criteria. For instance, for performance TP, MiRT is the best attribute (ω=0.8189) while it shows
inadequacies for classifying dispatching rules for both performance MFT ( ω=0.3054 ) and TD (ω=0.1260). This indicates that salient attributes of each performance may not be the same.
It is necessary to determine a threshold such that those system attributes, whose weighting factors that are larger than the threshold, are chosen as salient attribute subset. In this study, we define the threshold as 0.6. The selected attributes for each performance criterion are listed in Table 6.
4) Validity demonstration with classification accuracy
After the attribute selection, we have to demonstrate the validity of the results. The relative importance of the attributes, obtained from SAMA, can be validated in two ways. The first is the scatter plots, which displays the patterns in 2D or 3D
Table 5. Optimal weighting factors of attributes resulted from SAMA among different performance
criteria
Optimal weighting factors
ω
i Attribute TP MFT TD Njob MeUM SdUM MeUL MiOT MaOT MeOT SdOT MiPT MaPT MePT SdPT MiRT MaRT MeRT SdRT MiST MeST SdST MaTA MeTA SdTA MeSO SdSO MeTD SdTD 0.3529 0.5633 0.6652 0.6191 0.6072 0.4570 0.7220 0.5455 0.3632 0.3398 0.5143 0.5159 0.8189 0.4237 0.6132 0.5450 0.5561 0.2536 0.5613 0.5561 0.6489 0.7065 0.4771 0.5222 0.3731 0.4809 0.4488 0.6076 0.7700 0.6828 0.5367 0.4700 0.6046 0.4782 0.3288 0.2425 0.4752 0.5149 0.3054 0.5568 0.6030 0.4216 0.5418 0.2726 0.6081 0.5418 0.6114 0.6127 0.4815 0.3697 0.4561 0.4951 0.5407 0.6104 0.7034 0.6393 0.4903 0.4380 0.5667 0.4880 0.3112 0.3009 0.5287 0.5275 0.1260 0.4765 0.6182 0.5401 0.6231 0.4044 0.6037 0.6431 0.6101 0.7006 0.2154 0.3363 0.4316 0.4261Table 6. Selected system attributes with threshold 0.6 Performance Selected system attributes
TP SdUM, MeUL, MiOT, MeOT, MiRT, MeRT, MeTA, SdTA
MFT MeUM, SdUM, MeUL, MeOT, MeRT, SdST, MeTA, SdTA
TD MeUM, SdUM, MeUL, MeRT, MiST, SdST, MaTA, MeTA, SdTA
attribute space, providing the visualization of pattern distribution, i.e., the structural description.
In this case, the scatter plots are not easy to obtain because the number of system attributes is so large that the number of scatter plots becomes comparatively much larger. Since there are 26 attribute candidates to be evaluated,
325
)
!
24
!
2
(
!
26
=
2D scatter plots are needed at most. It is difficult to accomplish this task compared with displaying scatter plots of Iris data [28]. The second way is the usage of the classification result.In order to demonstrate the validity of the ranking from the SAMA, the k-nearest neighbor (K-NN) algorithm is used as the classifier to acquire the classification rates for three sets of attributes. The first set contains all the 26 attribute candidates. The second set is the attribute subset obtained from the
SAMA and the defined threshold (see Table 6). The third is the complement of the second set. Namely, the values of weighting factors of the attributes in the third set are smaller than those in the second set for every performance criterion. In order to avoid the existence of a tie, the k is set as an odd value, k=3. The classification results are listed in Table 7.
From the results, it is found for the second set that the K-NN classifier results in 74.34%, 76.32%, 75.98% for the seven classes defined in Table 2 under the three performance criteria TP, MFT, and TD, respectively. They are much higher than the results given by the first and the third sets. Obviously, the third set, in which the attributes have lower weighting factors, will encumber the classification rate when selecting all the attributes to classify the seven dispatching rules. According to classification results shown in Table 7, the selected attributes obtained from SAMA can indeed achieve higher classification accuracy. Also, the results obtained from the proposed SAMA demonstrate the validity of the ranking results.
It is worth mentioning that the classification rate can be enhanced by using many advanced classification techniques such as neural networks and fuzzy logic inference engine. However, the goal of this study is to provide an automatic solution to attribute selection for the scheduling of an FMS, which is able to select an optimal attribute subset from attribute candidates without taking trial-and-error. This can make the classifier design easier and can achieve higher classification rate. However, the K-NN classifier used here is just to acquire the classification rates that describe the pattern distribution in attribute space indirectly. The study of intelligent scheduler design will be the one of the critical issues for the scheduling of FMS in the future.
Table 7. Classification rates of using different attribute sets as inputs of K-NN classifier among
different performance criterion (%)
TP MFT TD The first set
(26 attributes, see Table 3)
The second set
(selected attributes, see Table 6)
The third set
(complement of the second set)
57.60 74.34 44.13 61.34 76.32 42.76 64.56 75.98 48.48
5. Conclusion
Selecting a set of proper system attributes as input of a scheduler is critical to the dispatching problem of the flexible manufacturing system (FMS).
This paper proposes a supervised attribute mining algorithm (SAMA), which is able to automatically select salient system attributes possessing the salient discriminative abilities for classifying dispatching rules. SAMA achieves this goal, according to simulation results under three different performance measures. Also, the selected attributes enhance the classification accuracy of rule dispatching for the FMS.
REFERENCES
1. Goyal, S. K., K. Mehta, R. Kodali, and S. G. Deshmukh, “Simulation for Analysis of Scheduling Rules for a Flexible Manufacturing System,” Integrated Manufacturing Systems, 6(5), 21-26 (1995).
2. Ip, W. H., K. L. Yung, H. Min, and D. Wang, “A CONWIP model for FMS control”, Journal of Intelligent Manufacturing, 13(2), 109-117(2002) 3. Rama Bhupal Reddy, K., Xie Na, and Velusamy
Subramaniam, “Dynamic Scheduling of Flexible Manufacturing Systems” in Innovation in Manufacturing Systems and Technology (IMST) (2004); URI: http://hdl.handle.net/1721.1/3903. 4. Chase, R. B., N. J. Aquilano, Production and
Operations Management—Manufacturing and Services, 7th ed., IRWIN,. 88-89(1995).
5. Montazeri, M., L. N. Van Wassenhove, “Analysis of scheduling rules for an FMS,” International Journal of Production Research, 28(4), 785-802 (1990). 6. Jeong, K. C., and Y. D. Kim, “A Real-Time
Scheduling Mechanism for a Flexible Manufacturing System: Using Simulation and Dispatching Rules,” International Journal of Production Research, 36(9), 2609-2626(1998).
7. Sabuncuoglu I., “A Study of Scheduling Rules of Flexible Manufacturing Systems: a Simulation Approach,” International Journal of Production Research, 36(2), 527-546(1998).
8. Jahangirian, M., and G. V. Conroy, “Intelligent Dynamic Scheduling System: the Application of Genetic Algorithms,” Integrated Manufacturing Systems, 11(4), 247-257(2000).
9. Min, H. S., “Development of a Real-time Multi-objective Scheduler for Semiconductor Manufacturing Plants,” PhD Thesis, Purdue University, July(2002).
10. Rau, K. R., O. V. K. Chetty, “Production Planning of FMS under Tool Magazine Constraints: a Dynamic Programming Approach, International Journal of Advanced Manufacturing Technology, 11,
366-371(1996).
11. Langevin, A., D. Lauzon, D. Riopel,” Dispatching, Routing, and Scheduling of Two Automated Guided Vehicles in a FMS, International Journal of Flexible Manufacturing Systems, 8, 247-262(1996).
12. Liu, J., and B. L. MacCarthy, “General Heuristic Procedures and Solution Strategies for FMS
Scheduling,” International Journal of Production Research, 37(14), 3305-3333(1999).
13. Jeng, M. D., C. Shilin, and Y. S. Huang, “Petri Net Dynamics-Based Scheduling of Flexible Manufacturing Systems with Assembly,” Journal of Intelligent Manufacturing, 10(6), 541-555(1999). 14. Chan, F. T. S., H. K. Chan, H. C. W. Lau, R. W. L.
Ip, “Analysis of Dynamic Dispatching Rules for a Flexible Manufacturing System,” Journal of Materials Processing Technology, 138,
325-331(2003).
15. Kim, C. O., H. S. Min, and Y. Yih, “Integration of Inductive Learning and Neural Networks for Multi-Objective FMS Scheduling,” International Journal of Production Research, 36(9),
2497-2509(1998).
16. Reyes, A., H. Yu, G. Kelleher, S. Lloyd, “Integrating Petri Nets and Hybrid Heuristic Search for the Scheduling of FMS,” Computers in Industry, 47, 123-138(2002).
17. Devijver, P. A. and J. Kittler, Pattern Recognition: A Statistical Approach. London: Prentice-Hall(1982). 18. Bezdek, J. C., Pattern Recognition with Fuzzy
Objective Function Algorithms. NewYork: Plenum Press(1981).
19. Bezdek, J. C. and P. F. Castelaz, “Prototype classification and feature selection with fuzzy sets,’ IEEE Transaction on Systems, man, and Cybernetics,
7, 87-92(1977).
20. Pal, S. K. and Basabi Chakraborty, “Intraclass and interclass ambiguities (fuzziness) in feature evaluation,” Pattern Recognition Latter, 2, 275-279, (1984).
21. Pal, S. K. and Basabi Chakraborty, “Fuzzy set theoretic measure for automatic feature evaluation,” IEEE Transactions on Systems, Man, and Cybernetics, 16, 754-760(1986).
22. Ruck, D. W., S. K. Rogers, and M. Kabrisky, “Feature selection using a multilayer perception, ‘ Neural Network Computing, 20, 40-48(1990). 23. Priddy, K. L., S. K. Rogers, D. W. Ruck, G. L. Tarr,
and M. Kabrisky, “Bayesian selection of important features for feedforward neural network,” Neurocomputing, 5, 91-103(1993).
24. Lampinen, J. and E. Oja, “Distortion tolerant pattern recognition based on self-organizing feature extraction,” IEEE Transactions on Neural Networks,
6, 539-547(1995).
25. Kraaijveld, M. A., J. Mao, and A. K. Jain, “A non-linear projection method based on Kohonen’s topology preserving maps,” IEEE Transactions on Neural Networks, 6, 548-559 (1995).
26. De, R. K., N. R. Pal, and S. K. Pal, “Feature analysis: Neural network and fuzzy set theoretic approaches,” Pattern Recognition, 30, 1579-1590, (1997). 27. Pal, S. K., R. K. De, and J. Basak, “Unsupervised
feature evaluation: A neuro-fuzzy approach”, IEEE Transactions on Neural Networks, 11(2), 366-376 (2000).
28. Huang, H. P. and Y. H. Liu, “A GA-based fuzzy feature evaluation algorithm for pattern recognition,” Proceedings of the 10th IEEE International Conference on Fuzzy Systems, 2, 833-836(2001). 29. Himmelblau, D. M., Applied Nonlinear
Programming, New York: McGrawHill(1976). 30. Laarhoven, P. J. M. van and E. H. L. Aarts,
Simulated Annealing: Theory and Applications, Published by D. Reidel Publishing Company(1987). 31. Gen, Mitsuo and Runwei Cheng, Genetic Algorithms
& Engineering Design, John Wiley & Sons, Inc(1997).
32. Luca, A. D. and S Termini, “A definition of non probabilistic entropy in the setting of fuzzy set theory,” Information and Control, 20, 301-312 (1972).
33. Kaufmann, A. and M. Gupta, Introduction to fuzzy arithmetic: theory and applications, New York: Van Nostrand Reinhold Co.(1985).
34. Cho, H. and R. A. Wysk, “A robust adaptive scheduler for an intelligent workstation controller,” International Journal of Production Research,” 31, 771-789(1993).
35. Chen, C. C. and Y. Yih, “Identifying attributes for knowledge-based development in dynamic scheduling environments,” International Journal of Production Research, 34, 1739-1755(1996).
36. Park, S. C., N. Raman and M. J. Shaw, “Adaptive scheduling in dynamic flexible manufacturing systems: a dynamic rule selection approach,” IEEE Transactions on Robotics and Automation, 13, 486-502(1997).
37. Arzi, Y. and L. Iaroslavitz, ”Operating an FMC by a decision-tree-based adaptive production control system,” International Journal of Production Research, 38, 675-697(2000).
ABOUT THE AUTHORS
Yi-Hung Liu is currently an assistant professor in the Department of Mechanical Engineering at Chun Yuan Christian University, Taiwan, R.O.C. He received the M.S. degree from the Department of Engineering Science and Ocean Engineering, National Taiwan University in 1996, and the Ph.D. degree in Mechanical Engineering from the National Taiwan University in 2003. His research topics are in the areas of applications of pattern recognition, data mining, image processing, machine vision, and machine learning.
Han-Pang Huang graduated from National Taipei Institute of Technology in 1977, and received the M.S. and Ph.D. degrees in electrical engineering from The University of Michigan, Ann Arbor, in 1982 and 1986, respectively.
Since 1986 he has been with the National Taiwan University, where he is currently a Professor in the Department of Mechanical Engineering and Graduate Institute of Industrial Engineering. He was
the Vice Chairperson of the Mechanical Engineering Department from August 1992 to July 1993, Director of Semiconductor Industry Teaching Resource Center from January 2001 to December 2001, Director of CIM Education Center, Taiwan IBM and Tjing Ling Industrial Research Institute from August 1989 to July 1996, the Director of Manufacturing Automation Technology Research Center from August 1996 to July 1999. He has served as the Associate Dean of College of Engineering, National Taiwan University since August 2000. His research interests include machine intelligence, network-based manufacturing systems, intelligent robotic systems, prosthetic hands, nano manipulation and nonlinear systems. Dr. Huang holds several patents on dexterous hands, real-time communication control and semiconductor manufacturing.
Dr. Huang is a member of Tau Beta Pi, IEEE, SME, CFSA, CIAE. He was the Chapter Chair of IEEE Robotics and Automation Society Taipei Chapter (1996-1998), the Editor-in-Chief of Journal of Chinese Fuzzy System Association, the Program Chair of the 1998 International Conference on Mechatronic Technology (ICMT’98), the General Vice Chair of the Eighth International Fuzzy Systems Association World Congress (IFSA’99), 1999, and the Organizing Committee Chair of the 2002 Asia-Pacific Conference on Industrial Engineering and Management System. He is also the Publication Chair of 2003 IEEE Intl. Conf. on Robotics and Automation, Program Chair of 2003 Intl. Conf. on Automation Technology, and Program Co-Chair of 2004 IEEE Intl. Conf. on Networks, Communication, and Control. He has published more than 170 referred papers and conference papers. He is the co-author of the books “Fuzzy Neural Intelligent Systems: Mathematical Foundation and the
Applications in Engineering,” published by CRC Press in January, 2001, and “Introduction to Nano Engineering,” published by Princeton International Publishing Co., 2003. He was the Guest Editor of IEEE/ASME Trans. on Mechatronics in 2001. He was the Editor-in-Chief of the Journal of Chinese Fuzzy System Association from September 1997 to September 1999.He was the Editor-in-Chief of the International Journal of Fuzzy System from September 1999 to December 2002. Currently, he is the FIRA Associate Editor, the Editorial Board of International Journal of Advanced Robotics, the Senior Editor of the International Journal of Electronic Business Management, and the Associate Editor of IEEE Trans. on Automation Science and Engineering. He received the Ford University Research Award (1996-1998). He has received three-time Distinguished Research Awards (1996—2002), and Research Fellow Award (2002-2005) from National Science Council, Taiwan R.O.C. He is named in Who’s Who in the World 2001, 2002, and Who’s Who in the R.O.C. 2002.
Yu-Sheng Lin received the B.S. degree from the Department of Industrial Management Science at National Cheng Kung University in 2001, and the M.S. degree in Industrial Engineering from the
National Taiwan University in 2004. His research area includes the system simulation and the fab. scheduling.