Maintenance of Fast Updated Frequent Trees for
Record Deletion Based on Prelarge Concepts
Chun-Wei Lin†, Tzung-Pei Hong‡* and Wen-Hsiang Lu† †Department of Computer Science and Information Engineering
National Cheng Kung University Tainan, 701, Taiwan, R.O.C. {p7895122; whlu}@mail.ncku.edu.tw ‡Department of Electrical Engineering
National University of Kaohsiung Kaohsiung, 811, Taiwan, R.O.C.
Abstract
The frequent pattern tree (FP-tree) is an efficient data structure for association-rule mining without generation of candidate itemsets. It was used to compress a database into a tree structure which stored only large items. It, however, needed to process all transactions in a batch way. In the past, we proposed the Fast Updated FP-tree (FUFP-tree) structure based on the concept of pre-large itemsets to efficiently handle the newly inserted transactions in incremental mining. In addition to record insertion, record deletion from the databases is also commonly seen in real-applications. In this paper, we attempt to modify the FUFP-tree maintenance based on the concept of pre-large itemsets for efficiently handling deletion of records. Pre-large itemsets are defined by a lower support threshold and an upper support threshold. It can help reduce the rescan of the original database. The proposed approach can thus achieve a good execution time for tree maintenance especially when each time a small number of records are deleted. Experimental results also show that the proposed Pre-FUFP deletion algorithm has a good performance for incrementally handling deleted records.
Keyword: data mining, FUFP-tree, Pre-FUFP algorithm, pre-large itemsets, record deletion, maintenance.
1.
Introduction
Years of effort in data mining have produced a variety of efficient techniques.
Depending on the types of databases processed, these mining approaches may be
classified as working on transaction databases, temporal databases, relational
databases and multimedia databases, among others. On the other hand, depending on
the classes of knowledge derived, the mining approaches may be classified as finding
association rules, classification rules, clustering rules and sequential patterns [4],
among others. Among them, finding association rules in transaction databases is most
commonly seen in data mining [1][3][5][10][11][17][18][21][22].
In the past, many algorithms for mining association rules from transactions were
proposed, most of which were based on the Apriori algorithm [1], which generated
and tested candidate itemsets level-by–level. This may cause iterative database scans
and high computational costs. Han et al. thus proposed the Frequent-Pattern-tree
(FP-tree) structure for efficiently mining association rules without generation of
candidate itemsets [12]. The FP-tree [12] was used to compress a database into a tree
structure which stored only large items. It was condensed and complete for finding all
FP-Growth was executed to derive frequent patterns from the FP-tree. They showed
the approach could have a better performance than the Apriori approach.
Hong et al. proposed an algorithm based on pre-large itemsets to handle the
inserted transactions in incremental mining, which can further reduce the number of
rescanning databases [13]. It used a lower support threshold and an upper threshold to
reduce the need for rescanning original databases and to save maintenance cost. The
upper support threshold was the same as that used in the conventional mining
algorithms. The support ratio of an itemset had to be larger than the upper support
threshold in order to be considered large. On the other hand, the lower support
threshold defined the lowest support ratio for an itemset to be treated as pre-large. An
itemset with its support ratio below the lower threshold was thought of as a small
itemset. The algorithm did not need to rescan the original database until a number of
new transactions have been inserted. Since rescanning the database spent much
computation time, the maintenance cost could thus be reduced in the algorithm.
Hong et al. also proposed the Fast Updated FP-tree (FUFP-tree) structure to
efficiently handle the newly inserted transactions in incremental mining [14]. The
parent nodes and their child nodes were bi-directional. Besides, the counts of the
sorted frequent items were also kept in the Header_Table of the FP-tree algorithm. In
addition to record insertion, record deletion from the databases is also commonly seen
in real-applications. In this paper, we thus attempt to modify the FUFP-tree
maintenance algorithm based on the concept of pre-large itemsets for efficiently
handling deletion of records. Based on two support thresholds, the proposed approach
can effectively handle cases in which itemsets are small in an original database and
also small in the deleted records. Experimental results show that the proposed
FUFP-tree deletion algorithm based on pre-large itemsets could achieve a good
performance for handling the deletion of records.
The remainder of this paper is organized as follows. Related works are reviewed
in Section 2. The proposed Pre-FUFP deletion algorithm for deleted records is
described in Section 3. An example to illustrate the proposed algorithm is given in
Section 4. Experimental results for showing the performance of the proposed
algorithm are provided in Section 5. Conclusions are finally given in Section 6.
In this section, some related researches are briefly reviewed. They are the
FUFP-tree structure (which is based on the FP-tree structure) and the concept of
pre-large itemsets.
2. 1
The FUFP-tree structure
The FUFP-tree structure is the same as the FP-tree structure [12] except that the
links between parent nodes and their child nodes are bi-directional and the items are
not necessarily placed in the order of frequencies. Bi-directional linking will help
fasten the process of item deletion in the maintenance process. Besides, the FUFP-tree
structure has only a very small derivation from the FP-tree structure.
An FUFP tree must be built in advance from the original database before new
transactions come. The counts of the sorted frequent items are also kept in the
Header_Table. When new transactions are added, the FUFP-tree maintenance
algorithm will process them to maintain the FUFP tree. It first partitions items into
four parts according to whether they are large or small in the original database and in
the new transactions. Each part is then processed in its own way. The Header_Table
In the process for updating the FUFP tree, item deletion is done before item
insertion. When an originally large item becomes small, it is directly removed from
the FUFP tree and its parent and child nodes are then linked together. On the contrary,
when an originally small item becomes large, it is added to the end of the
Header_Table and then inserted into the leaf nodes of the FUFP tree. It is reasonable
to insert the item at the end of the Headrer_Table since when an originally small item
becomes large due to the new transactions, its updated support is usually only a little
larger than the minimum support. The FUFP tree can thus be least updated in this way,
and the performance of the FUFP-tree maintenance algorithm can be greatly
improved. The entire FUFP tree can then be re-constructed in a batch way when a
sufficiently large number of transactions have been inserted.
Several other algorithms based on the FP-tree structure have been proposed. For
example, Qiu et al. proposed the QFP-growth mining approach to mine association
rules [19]. Mohammad proposed the COFI-tree structure to replace the conditional
FP-tree [23]. Ezeife constructed a generalized FP-tree, which stored all the large and
non-large items, for incremental mining without rescanning databases [9]. Koh et al.
adjusting procedure and spending more computation time than the one proposed in
this paper. Some related researches are still in progress.
2. 2
The concept of pre-large itemsets
A pre-large itemset is not truly large, but may be large with a high probability in
the future. Two support thresholds, a lower support threshold and an upper support
threshold, are used to realize this concept. The upper support threshold is the same as
that used in the conventional mining algorithms. The support ratio of an itemset must
be larger than the upper support threshold in order to be considered large. On the
other hand, the lower support threshold defines the lowest support ratio for an itemset
to be treated as pre-large. An itemset with its support ratio below the lower threshold
is thought of as a small itemset. Pre-large itemsets act like buffers and are used to
reduce the movements of itemsets directly from large to small and vice-versa.
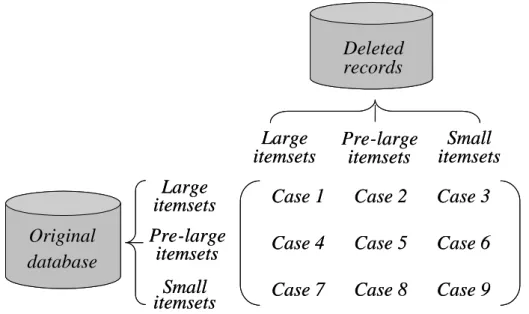
Considering an original database and some records to be deleted by the two
support thresholds, itemsets may fall into one of the following nine cases illustrated in
Large itemsets Large itemsets Pre-large itemsets Original database New transactions Small itemsets Small itemsets
Case 1 Case 2 Case 3 Case 4 Case 5 Case 6 Case 7 Case 8 Case 9
Pre-large itemsets Large itemsets Large itemsets Pre-large itemsets Original database Deleted records Small itemsets Small itemsets
Case 1 Case 2 Case 3 Case 4 Case 5 Case 6 Case 7 Case 8 Case 9
Pre-large itemsets
Figure 1: Nine cases arising from and the original database and the deleted records
Cases 2, 3, 4, 7 and 8 above will not affect the final association rules. Case 1
may remove some existing association rules, and cases 5, 6 and 9 may add some new
association rules. If we retain all large and pre-large itemsets with their counts after
each pass, then cases 1, 5 and 6 can be handled easily. Also, in the maintenance phase,
the ratio of deleted records to old transactions is usually very small. This is more
apparent when the database is growing larger. It has been formally shown that an
itemset in case 9 cannot possibly be large for the entire updated database as long as
the number of transactions is smaller than the number f shown below [13]:
u l u S d S S f ( ) ,
lower threshold, and d is the number of original transactions.
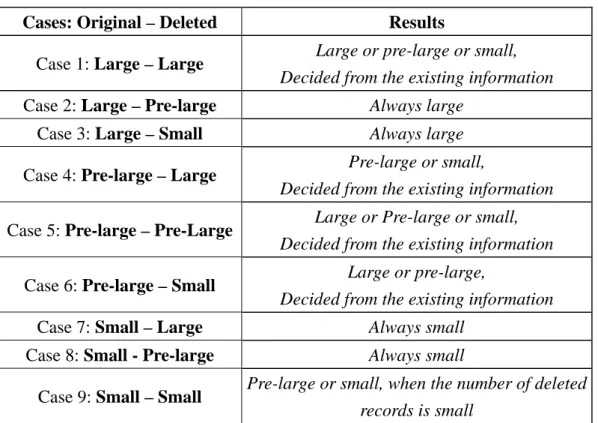
A summary of the nine cases and their results is given in Table 1 [13].
Table 1: Nine cases and their results
Cases: Original – Deleted Results
Case 1: Large – Large Large or pre-large or small,
Decided from the existing information
Case 2: Large – Pre-large Always large
Case 3: Large – Small Always large
Case 4: Pre-large – Large Pre-large or small,
Decided from the existing information
Case 5: Pre-large – Pre-Large Large or Pre-large or small,
Decided from the existing information
Case 6: Pre-large – Small Large or pre-large,
Decided from the existing information
Case 7: Small – Large Always small
Case 8: Small - Pre-large Always small
Case 9: Small – Small Pre-large or small, when the number of deleted
records is small
3.
The Proposed Pre-FUFP D
eletion Algorithm for Record Deletion
The notation used in the proposed Pre-FUFP deletion approach for record
3. 1
Notation
D: the original database;. T: the set of deleted records;
U: the entire updated database, i.e., D-T; d: the number of transactions in D; t: the number of transactions in T;
Sl: the lower support threshold for pre-large itemsets;
Su: the upper support threshold for large itemsets, Su >Sl;
I: an item;
SD(I): the number of occurrences of I in D; ST(I): the number of occurrences of I in T; SU(I): the number of occurrences of I in U.
Pre_ItemsD: the set of pre-large items from D; Pre_ItemsT: the set of pre-large items from T; Lar_ItemsT: the set of large items from T;
Reduced_Items: the set of items for which the deleted records have to be reprocessed for updating the FUFP-trees;
Branch_Items: the set of items for which the updated database has to be reprocessed for updating the FUFP-trees;
Rescan_Items: the set of items for which the updated database has to be rescanned to determine whether the items are large;
3. 2
The Proposed
Deletion Algorithm
An FUFP tree must be built in advance from the initially original database before
the records are deleted from the original databases. Its initial construction is similar to
that of an FP tree. The database is first scanned to find the items with their supports
larger than a predefined minimum support, which called large items. Next, the large
construct an FUFP tree according to the sorted order of large items. The construction
process is executed tuple by tuple, from the first transaction to the last one. After all
transactions are processed, an FUFP tree is completely constructed. Besides, a
variable c is used to record the number of deleted records since the last re-scan of the
original database with d transactions. The details of the proposed algorithm are
described below.
The Pre-FUFP deletion algorithm:
INPUT: An old database consisting of (d-c) transactions, its corresponding
Header_Table storing the frequent items initially in descending order, its
corresponding FUFP tree, a lower support threshold Sl, an upper support
threshold Su, its corresponding pre-large table storing the set of pre-large
items from the original database, and a set of t deleted records.
OUTPUT: A new FUFP tree after record deletion by using the Pre-FUFP deletion
algorithm.
STEP 1: Calculate the safety number f of deleted records according to the following
formula [13]:
u l uS
d
S
S
f
(
)
.STEP 3: Divide the items in the deleted records into three parts according to whether
they are large, pre-large or small in the original database.
STEP 4: For each item I from STEP 3, which is large in the original database
(appearing in the Header_Table), do the following substeps (Cases 1, 2 and
3):
Substep 4-1: Set the new count SU(I) of I in the entire updated database as:
SU(I) = SD(I) - ST(I),
where SD(I) is the count of I in the Header_Table (original
database) and ST(I) is the count of I in the deleted records.
Substep 4-2: If SU(I)/(d-c-t) Su, update the count of I in the Header_Table
as SU(I), and put I in the set of Reduced_Items, which will be
further processed to update the FUFP tree in STEP 5;
Otherwise, if Su SU(I)/(d-c-t) Sl, remove I from the Header_Table, connect each parent node of I directly to its
corresponding child node in the FUFP tree, set SD(I) = SU(I),
and keep I with SD(I) in the pre-large table;
Otherwise, item I is small after the database is updated;
remove I from the Header_Table and connect each parent
FUFP tree.
STEP 5: For each deleted record with an item J existing in the Reduced_Items,
substract 1 from the count of J node at the corresponding branch of the
FUFP tree.
STEP 6: For each item I from STEP 3 which is pre-large in the original database, do
the following substeps (Cases 4, 5 and 6):
Substep 6-1: Set the new count SU(I) of I in the entire updated database as:
SU(I) = SD(I) - ST(I).
Substep 6-2: If SU(I)/(d-c-t) Su, item I will be large after the database is
updated; put I in the set of Branch_Items, which will be
further processed to update the FUFP tree in STEP 9;
Otherwise, if SuSU(I)/(d-c-t) Sl, set SD(I) = SU(I) and keep
I with the new SD(I) in the pre-large table;
Otherwise, remove item I from the pre-large table.
STEP 7: For each item I from STEP 3 which is neither large nor pre-large in the
original database but large or pre-large in the new transactions (Cases 7 and
8), put I in the set of Rescan_Items, which is used when rescanning the
database in STEP 8 is necessary.
Otherwise, do the following substeps for each item I in the set of
Rescan_Items:
Substep 8-1: Rescan the original database to decide the original count SD(I)
of I.
Substep 8-2: Set the new count SU(I) of I in the entire updated database as:
SU(I) = SD(I) - ST(I).
Substep 8-3: If SU(I)/(d-c-t) Su, item I will become large after the database
is updated, put I in the set of Branch_Items;
Otherwise, if SuSU(I)/(d-c-t) Sl, set SD(I) = SU(I) and keep
I with SD(I) in the pre-large table;
Otherwise, neglect I.
STEP 9: Insert the items in the Branch_Items to the end of the Header_Table
according to the descending order of their updated counts.
STEP 10: For each transaction in the updated database with an item J existing in
Branch_Items, if J has existed at its corresponding branch of the FUFP tree
for the transaction, add 1 to the count of node J; otherwise, insert J at the
end of its corresponding branch and set its count as 1.
In STEP 5, a corresponding branch is the branch generated from the large items
in a transaction and corresponding to the order of items appearing in the
Header_Table. After STEP 11, the final updated FUFP tree by using the Pre-FUFP
deletion algorithm to process deleted records is constructed. The records can then be
deleted from the original database. Based on the FUFP tree, the desired association
rules can then be found by the FP-Growth mining approach as proposed in [12].
4.
An Example
In this session, an example is given to illustrate the proposed Pre-FUFP deletion
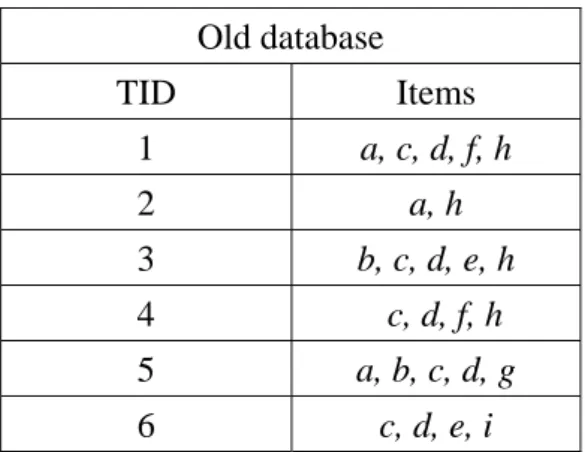
algorithm for maintaining an FUFP tree when records are deleted. Table 2 shows a
database to be used in the example. It contains 10 transactions and 9 items, denoted a
to i.
Table 2: The original database in the example
Old database TID Items 1 a, c, d, f, h 2 a, h 3 b, c, d, e, h 4 c, d, f, h 5 a, b, c, d, g 6 c, d, e, i
7 b, e, g, f, h
8 a, b, c, d, f, g
9 a, b, f
10 a, c, e, f, i
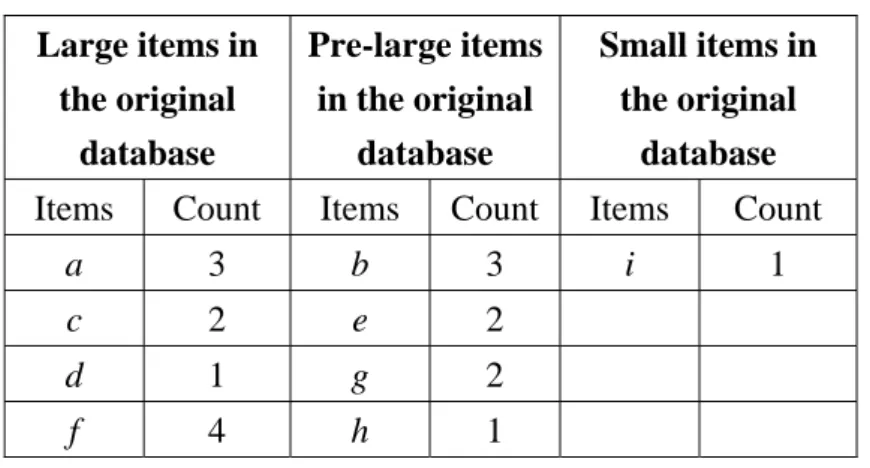
Assume the lower support threshold Sl is set at 30% and the upper one Su at 60%.
For the given database, the large 1-itemsets are a, c, d and f, from which the
Header_Table can be constructed. The FUFP tree are then formed from the database
and the Header_Table, with the results shown in Figure 2. Besides, the sets of
pre-large items for the given database are shown in Table 3.
Header Table
Item Frequency Head
c 7 a 6 d 6 f 6
{}
Null
c:7
a:4
d:3
f:2
a:2
f:1
d:3
f:1
f:1
f:1
Null
Null
Null
Null
Figure 2: The Header_Table and the FUFP tree constructed
Table 3: The pre-large itemset for the original database
Pre-large itemset in the original database Items Count
e 4
g 3
h 5
Assume the last four records (with TID 7 to 10) are deleted from the original
database. The proposed Pre-FUFP maintenance algorithm proceeds as follows. The
variable c is initially set at 0.
STEP 1: The safety number f for deleted records is calculated as:
. 5 6 . 0 10 ) 3 . 0 6 . 0 ( ) ( u l u S d S S f
STEP 2: The four deleted records are first scanned to get the items and their
counts. The results are shown in Table 4.
Table 4: The counts of the items in the deleted records
Item Count a 3 b 3 c 2 d 1 e 2 f 4 g 1 h 1 i 1
STEP 3: All the items a to i in Table 5 are divided into three parts, {a}{c}{d}{f},
{b}{e}{g}{h} and {i} according to whether they are large (appearing in the
Header_Table), pre-large (appearing in the pre-large table) or small in the original
database. Results are shown in Table 5, where the counts are only from the deleted
records.
Table 5: Three partitions of the items from deleted records
Large items in the original database Pre-large items in the original database Small items in the original database
Items Count Items Count Items Count
a 3 b 3 i 1
c 2 e 2
d 1 g 2
f 4 h 1
STEP 4: The items in the deleted records which are large in the original database
are first processed. In this example, items a, c, d and f (the first partition) satisfy the
condition and are processed. The support ratios of items c and d are larger than 0.6.
Take item c as an example to illustrate the substeps. The count of item c in the
Header_Table is 7, and its count in the deleted records is 2. The updated count of item
c is thus 7-2 (= 5). The updated support ratio of item c is 5/(10-0-4) 0.6. Item c is
the Header_Table is thus changed as 5, and item c is then put into the set of
Reduced_Items. Items d is similarly processed.
The support ratios of items a and f are smaller than 0.6 but larger than 0.4. Items
a and f will thus become pre-large after the database is updated. They are then
removed from the Header_Table and their corresponding branches in the FUFP tree,
and put in the pre-large table with its updated count as 6-3 (= 3) and 6-4 (= 2),
respectively.
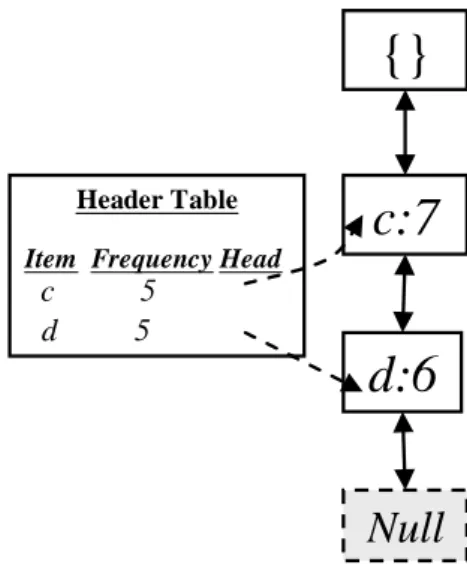
After STEP 4, the set of Redueced_Items = {c, d}, and the updated FUFP tree is
shown in Figure 3.
Header Table
Item Frequency Head
c 5 d 5
{}
c:7
d:6
Null
Figure 3: The Header_Table and the FUFP tree after STEP 4
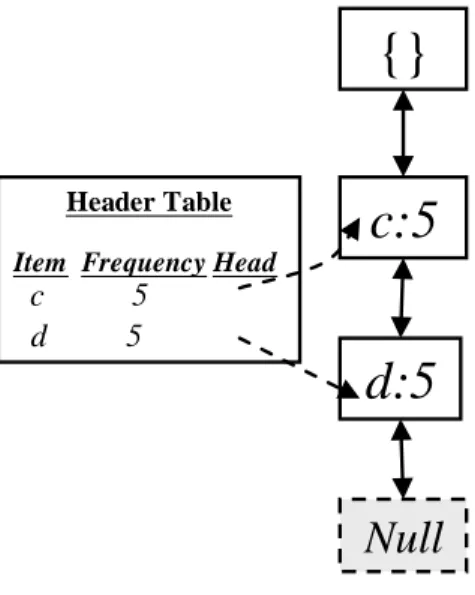
existing in the Reduced_Items. In this example, Reduced_Items = {c, d}. The
corresponding branches for the deleted records with any item in the set of
Reduced_Items are shown in Table 6.
Table 6: The corresponding branches for the deleted records with items c and d
Transaction No. Items Corresponding branches
8 a, b, c, d, f, g c, d
10 a, c, e, f, i c
The first branch shares the same prefix (c, d) as the current FUFP tree. The count for
items c and d are then subtracted by 1 since they have to be deleted from the previous
FUFP tree after the databases is updated. The same process is then executed for
another branch. The final results after STEP 5 are shown in Figure 4.
Header Table
Item Frequency Head c 5 d 5
{}
c:5
d:5
Null
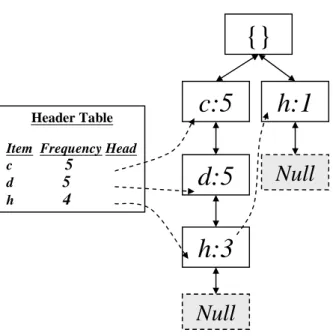
Figure 4: The Header_Table and the FUFP tree after STEP 5
STEP 6: The items in the deleted records which are pre-large in the original
database are processed. In this example, items b, e, g and h satisfy the condition and
are processed. Take item h first as an example to illustrate the supsteps. The count of
item h in the pre-large itemset is 5, and its count in the deleted records is 1. The
updated count of item h is thus 5-1 (= 4). The new support ratio of item h is
4/(10-0-4) 0.6. Item h will thus become a large item after the database is updated. h is then put into the set of Branch_Items.
Next, the new support ratios of items b and e are both 0.33, which is between the
lower and the upper thresholds. Items b and e are then put into the pre-large table and
their counts are updated as 2. At last, the new support ratio of item g is smaller than
0.3. It is thus removed from the pre-large table. After STEP 6, we can get Branch_
Items = {h}.
STEP 7: Since the item i is neither large nor pre-large in the original database
and is small in the deleted records, it is thus put into the set of Rescan_Items, which is
STEP 8: Since t+c = 4+0 < f (= 5), rescanning the original database is
unnecessary. Nothing is done in this step.
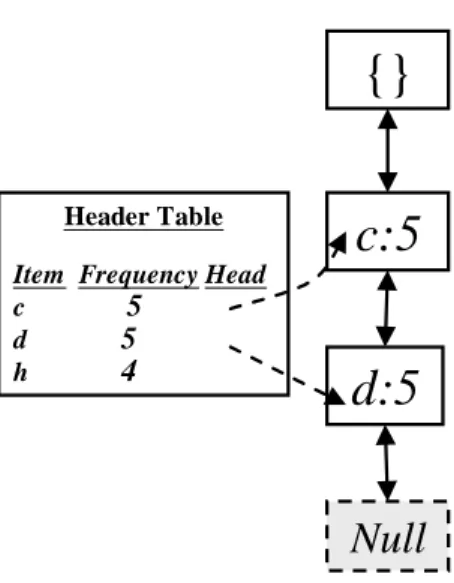
STEP 9: The items in the set of Branch_Items are sorted in descending order of
their updated counts and then inserted into the end of the Header_Table. In this
example, the set of Branch_Items contains only h and no sorting is needed. Item h is
thus inserted into the end of the Header_Table. The Header_Table after this step is
shown in Figure 5.
Header Table
Item Frequency Head c 5 d 5 h 4
{}
c:5
d:5
Null
Figure 5: The Header_Table and the FUFP tree after item h is added to the Header_Table
database for items existing in the Branch_Items. In this example, Branch_Items = {h}.
The corresponding branches forthe updated database with h are shown in Table 7.
Table 7: The corresponding branches for the updated database with item h Transaction No. Items Corresponding branches
1 a, c, d, f, h c, d, h
2 a, h h
3 b, c, d, e, h c, d, h
4 c, d, f, h c, d, h
The first branch is then processed. This branch shares the same prefix (c, a) as
the current FUFP-tree. A new node (h:1) is thus created and linked to (d:5) as its child.
The results after the first branch is processed are shown in Figure 6.
Header Table
Item Frequency Head c 5 d 5 h 4
{}
c:5
d:5
Null
h:1
Null
Figure 6: The Header_Table and the FUFP tree after the first branch is processed
Note that the counts for items c and d are not increased since they have already
been counted in the construction of the FUFP tree. The same process is then executed
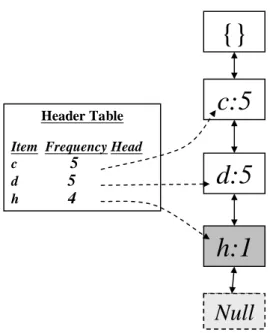
for the other three corresponding branches. The final results are shown in Figure 7.
Header Table
Item Frequency Head c 5 d 5 h 4
{}
c:5
d:5
Null
h:3
h:1
Null
Null
Figure 7: The Header_Table and the FUFP tree after STEP 10
STEP 11: Since t (= 4) + c (= 0) < f (= 5), set c = t+c = 4+0 =4.
Note that the final value of c is 4 in this example and f - c = 1. This means that
one more record can be deleted without rescanning the original database for Case 9.
Based on the FUFP tree shown in Figure 7, the desired large itemsets can then be
5.
Experimental Results
Experiments were made to compare the performance of the batch FP-tree
construction algorithm, the FUFP-tree deletion algorithm and the Pre-FUFP deletion
algorithm for record deletion. When records were deleted, the batch FP-tree
construction algorithm constructed a new FP-tree from the updated database. The
process was executed whenever records were deleted. The FUFP-tree deletion
algorithm and the Pre-FUFP deletion algorithm were executed for record deletion in
the way mentioned in Sections 2.1 and 3.
The experiments were performed in C++ on an Intel x86 PC with a 3.0G Hz
processor and 512 MB main memory and running the Microsoft Windows XP
operating system. A real dataset called BMS-POS [25] were used in the experiments.
This dataset was also used in the KDDCUP 2000 competition. The BMS-POS dataset
contained several years of point-of-sale data from a large electronics retailer. Each
transaction in this dataset consisted of all the product categories purchased by a
customer at one time. There were 515,597 transactions with 1657 items in the
dataset. The maximal length of a transaction was 164 and the average length of the
The transactions in the BMS-POS database were first used to construct an initial
FP-tree. The minimum threshold was set at 1% to 5% for the three algorithms, with
1% increment each time. 2,000 transactions were then deleted from the database. For
the Pre-FUFP deletion algorithm, the upper minimum support threshold was set at
1% to 5% (1% increment each time) and the lower minimum support threshold was
set at 0.5% to 2.5% (0.5% increment each time). The execution times and the
numbers of nodes obtained from the three algorithms were compared. Figure 8
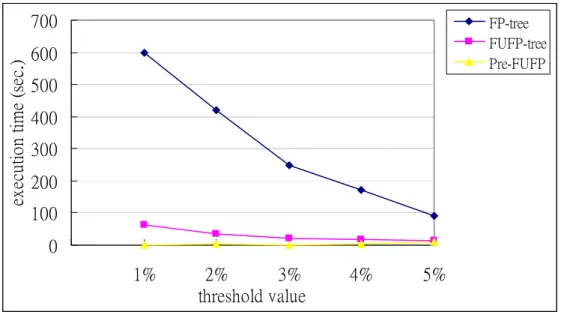
shows the execution times of the three algorithms for different threshold values.
0 100 200 300 400 500 600 700 1% 2% 3% 4% 5% threshold value ex ecut io n t im e (s ec. ) FP-tree FUFP-tree Pre-FUFP
Figure 8: The comparison of the execution times for different threshold values
ran faster than the other two. Note that the FUFP-tree deletion algorithm and the
Pre-FUFP deletion algorithm may generate a less concise tree than the FP-tree
construction algorithm since the latter completely follows the sorted frequent items to
build the tree. As mentioned above, when an originally small item becomes large due
to deleted records, its updated support is usually only a little larger than the minimum
support. It is thus reasonable to put a new large item at the end of the Headrer_Table.
The difference between the FP-tree and the FUFP-tree structures will thus not be
significant. For showing this effect, the comparison of the numbers of nodes for the
three algorithms is given in Figure 9. It can be seen that the three algorithms
generated nearly the same sizes of trees. The effectiveness of the Pre-FUFP deletion
algorithm is thus acceptable.
0 200000 400000 600000 800000 1000000 1% 2% 3% 4% 5% threshold value num b er o f node s FP-tree FUFP-tree Pre-FUFP
Figure 9: The comparison of the numbers of nodes for different threshold values
Experiments were then made to show the execution times and the numbers of
nodes of the three algorithms for different numbers of deleted records. The minimum
support threshold was set at 4% for the batch FP-tree algorithm; the upper and the
lower support thresholds were set at 4% and 2%, respectively, for the FUFP and the
Pre-FUFP deletion algorithms. The transactions from the BMS-POS database were
used to construct an initial FP-tree. 2,000 transactions were then sequentially deleted
each time for the experiments. Figure 10 shows the execution times required by the
three algorithms for processing each 2000 deleted records.
0 30 60 90 120 150 180 210 -2000 -4000 -6000 -8000 -10000 number of transactions ex ecu ti o n t ime (s ec.) FP-tree FUFP-tree Pre-FUFP
Figure 10: The comparison of the execution times for sequentially deleted records
205000 210000 215000 220000 225000 230000 235000 -2000 -4000 -6000 -8000 -10000 number of transactions num be r of node s FP-tree FUFP-tree Pre-FUFP
Figure 11: The comparison of the numbers of nodes for sequentially deleted records
Again, the Pre-FUFP deletion algorithm ran faster than the other two and had
nearly the same node numbers as they had.
6.
Conclusion
In this paper, we have proposed the Pre-FUFP deletion algorithm for record
deletion based on the concept of pre-large itemsets. The FUFP-tree structure is used to
efficiently and effectively handle deletion of records in data mining. Using two
user-specified upper and lower support thresholds, the pre-large itemsets act as a gap
deleted. The proposed Pre-FUFP deletion algorithm processes deleted records to
maintain the FUFP tree. It first partitions items of deleted records into three parts
according to whether they are large, pre-large or small in the original database. Each
part is then processed in its own way. The Header_Table and the FUFP-tree are
correspondingly updated whenever necessary.
Experimental results also show that the proposed Pre-FUFP deletion algorithm
runs faster than the batch FP-tree and the FUFP-tree construction algorithm for
handling deleted records and generates nearly the same tree structure as them. The
proposed approach can thus achieve a good trade-off between execution time and tree
complexity.
References
[1] R. Agrawal, T. Imielinksi and A. Swami, “Mining association rules between sets
of items in large database,” The ACM SIGMOD Conference, pp. 207-216, 1993.
[2] R. Agrawal, T. Imielinksi and A. Swami, “Database mining: a performance
perspective,” IEEE Transactions on Knowledge and Data Engineering, pp.
[3] R. Agrawal and R. Srikant, “Fast algorithm for mining association rules,” The
International Conference on Very Large Data Bases, pp. 487-499, 1994.
[4] R. Agrawal and R. Srikant, “Mining sequential patterns,” The Eleventh IEEE
International Conference on Data Engineering, pp. 3-14, 1995.
[5] R. Agrawal, R. Srikant and Q. Vu, “Mining association rules with item
constraints,” The Third International Conference on Knowledge Discovery in
Databases and Data Mining, pp. 67-73, 1997.
[6] M.S. Chen, J. Han and P.S. Yu, “Data mining: An overview from a database
perspective,” IEEE Transactions on Knowledge and Data Engineering, pp.
866-883, 1996.
[7] D.W. Cheung, J. Han, V.T. Ng and C.Y. Wong, “Maintenance of discovered
association rules in large databases: An incremental updating approach,” The
Twelfth IEEE International Conference on Data Engineering, pp. 106-114, 1996.
[8] D.W. Cheung, S.D. Lee and B. Kao, “A general incremental technique for
maintaining discovered association rules,” In Proceedings of Database Systems
for Advanced Applications, pp. 185-194, 1997.
[9] C. I. Ezeife, “Mining Incremental association rules with generalized FP-tree,”
Proceedings of the 15th Conference of the Canadian Society for Computational
[10] T. Fukuda, Y. Morimoto, S. Morishita and T. Tokuyama, “Mining optimized
association rules for numeric attributes,” The ACM SIGACT-SIGMOD-SIGART
Symposium on Principles of Database Systems, pp. 182-191, 1996.
[11] J. Han and Y. Fu, “Discovery of multiple-level association rules from large
database,” The Twenty-first International Conference on Very Large Data Bases,
pp. 420-431, 1995.
[12] J. Han, J. Pei and Y. Yin, “Mining frequent patterns without candidate
generation,” The 2000 ACM SIGMOD International Conference on Management
of Data, pp. 1-12, 2000.
[13] T. P. Hong and C. Y. Wang, "Maintenance of association rules using pre-large
itemsets," Intelligent Databases: Technologies and Applications, Z. Ma (Ed.),
Idea Group Inc., 2006, pp. 44-60.
[14] T. P. Hong, J. W. Lin and Y. L. Wu, “A fast updated frequent pattern tree", The
2006 IEEE International Conference on Systems, Man, and Cybernetics, pp.
2167-2172, 2006.
[15] J. L. Koh and S. F. Shieh, “An efficient approach for maintaining association
rules based on adjusting FP-tree structures,” The Ninth International Conference
on Database Systems for Advanced Applications, pp. 417-424, 2004.
databases,” The Tenth IEEE International Conference on Tools with Artificial
Intelligence, pp. 24-31, 1998.
[17] H. Mannila, H. Toivonen and A. I. Verkamo, “Efficient algorithm for
discovering association rules,” The AAAI Workshop on Knowledge Discovery in
Databases, pp. 181-192, 1994.
[18] J. S. Park, M. S. Chen and P. S. Yu, “Using a hash-based method with
transaction trimming for mining association rules,” IEEE Transactions on
Knowledge and Data Engineering, pp. 812-825, 1997.
[19] Y. Qiu, Y. J. Lan and Q. S. Xie, “An improved algorithm of mining from FP-
tree,” Proceedings of the Third International Conference on Machine Learning
and Cybernetics, pp. 26-29, 2004.
[20] N. L. Sarda and N. V. Srinivas, “An adaptive algorithm for incremental mining
of association rules,” The Ninth International Workshop on Database and Expert
Systems, pp. 240-245, 1998.
[21] R. Srikant and R. Agrawal, “Mining generalized association rules,” The
Twenty-first International Conference on Very Large Data Bases, pp. 407-419,
1995.
[22] R. Srikant and R. Agrawal, “Mining quantitative association rules in large
Management of Data, pp. 1-12, 1996.
[23] O. R. Zaiane and E. H. Mohammed, “COFI-tree mining: A new approach to
pattern growth with reduced candidacy generation,” IEEE International
Conference on Data Mining, 2003.
[24] S. Zhang, “Aggregation and maintenance for database mining,” Intelligent Data
Analysis, pp. 475-490, 1999.
[25] Z. Zheng, R. Kohavi and L. Mason, “Real world performance of association rule
algorithms,” The International Conference on Knowledge Discovery and Data