國立臺中教育大學資訊工程學系碩士論文
工作流程排程問題中工作次序評定、群組及
配置方法之研究
Task Ranking, Clustering, and Allocation in
Workflow Scheduling
指導教授:黃國展 博士
研究生:劉曉青 撰
致謝
兩年的時間過的比想像中的快,整個求學過程要感謝的人太多了。從碩一 Meeting 的時候會緊張,到碩二 Meeting 的偶爾晚到,整個過程可以說是非常快樂(雖然有點沒 印象碩一做了哪些工作。) 從老師身上學到的做人處事的道理和人生觀念,我覺得比起專業技能,這些東西對 我來說更加的重要。另外,我也從同學身上學到很多程式設計的觀念。在論文口試的時 候,學弟們也幫了很多忙。我對你們的尊敬比珠穆朗瑪峰還高,對你們的感激之情比馬 德里亞海溝還深……。等等諸類聽起來有點噁心的話就算了吧,感激之情放在實驗室的 冰箱。接觸 workflow scheduling 算一算也差不多有四年了,之後的人生若少了 workflow 總覺得哪裡怪怪的。一開始接觸這個領域其實只是因為不知道要做什麼,不過研究越來 越深入之後突然覺得這真是一個有趣的領域,可以套用在各種稀奇古怪的地方。(從道 路交通道理論研究,workflow scheduling 真是無所不在) 雖然手排很累、看到 BUG 跳出來有想死的衝動、一打開前人的程式跑數據驗證就想 放棄拿遊戲機來玩。不過還是希望畢業之後還能繼續研究 workflow scheduling。 2015.07.21
摘要
隨著平行處理技術的進步以及格網與雲端計算等新興平台的出現,越來越多大型科 學和工程應用逐漸採用工作流程的模式來表達其計算架構及內部不同計算模組間的相 依性與資料傳遞關係。因此工作流程的排程議題日形重要,文獻中已有許多相關的排程 方法被提出與討論。分群導向的方式為其中最主要的一類工作流程排程方法。本論文的 主要貢獻有三,其中第一部分針對分群導向的排程方法,提出了新的工作優先順序決定 方式。在第二部份,我們對分群導向的排程方式提出新的資源分配方法。而在第三部分, 我們針對多個工作流程的分群導向排程議題,提出了新的資源配置方法,以同時考量計 算資源適合程度及工作群組完成時間的角度出發,來進一步提升工作流程的執行效率。 上述這些新提出的排程方法都經過一系列模擬實驗的詳細效能評估,並與目前常用的典 型工作流程排程方法進行比較。實驗結果指出,我們的方法比起目前常用的排程方法, 可以達到顯著的工作流程執行效能提升效果。 關鍵字:工作流程排程、分群導向的方式、工作優先順序評定、計算資源配置Abstract
The importance of workflow scheduling is ever increasing for parallel and distributed computing since more and more large-scale scientific and engineering applications are built based on the workflow model for describing the complex execution and communication dependency among constituent software modules and programs. Many approaches have been proposed to deal with the challenging workflow scheduling problem. Clustering-based approaches are one of the major types of workflow scheduling heuristics. In this thesis, we make three contributions to the two major steps in clustering-based workflow scheduling through developing and evaluating new task ranking and allocation methods. In the first part, we propose new task ranking methods for clustering-based scheduling approaches based on the new ideas of remaining workload and hybrid ranking, in contrast to the single path-oriented concept widely used in existing methods. In the second part, we develop a new adaptive subgroup allocation scheme to further improve workflow execution performance. In the third part, we propose an innovative adaptive dual-criteria task group allocation method which considers both task group’s finish time and potential resource utilization and adaptively partitions task groups into subgroups to effectively improve overall multi-workflow execution performance. The proposed approaches were evaluated extensively with a series of simulation experiments and compared to existing methods. The experimental results show that our approaches have potential to outperform existing methods significantly in many cases.
Table of Contents
致謝 ... II
摘要 ... III
Abstract ... IV
Table of Contents ... V
List of Figures ... VI
List of Tables ... VIII
Chapter 1. Introduction ... 1
Chapter 2. Related Work ... 5
Chapter 3. Task Ranking and Task Group Allocation ... 8
3.1 Task Ranking in Clustering-based Workflow Scheduling ... 8
3.2 Adaptive Task Allocation for Clustering-based Workflow Scheduling... 12
3.3 Task Group Allocation for Online Multi-workflow Scheduling ... 16
Chapter 4. Performance Evaluation ... 24
4.2 Adaptive Task Allocation for Clustering-based Workflow Scheduling... 27
4.3 Task Group Allocation for Online Multi-workflow Scheduling ... 31
Chapter 5. Conclusions ... 40
List of Figures
Figure.1.1: A workflow example of fork-join DAG structure ... 2
Fig. 3.1 Comparison of the PCH and our new ranking mechanism... 12
Fig. 3.2 A task clustering example ... 13
Fig. 3.3 Comparison of the pure Best Fit heuristic and our dual-criteria
mechanism ... 19
Figure.3.4 Individual task allocation in list-based workflow scheduling
approaches ... 21
Figure.3.5 Advantage of adaptive task group rearrangement ... 21
Figure.4.1: Ranking fork-join workflows on 30 resources (CCR = 0.1) ... 26
Figure.4.2.: Ranking fork-join workflows on 30 resources (CCR = 1) ... 26
Figure.4.3.: Ranking fork-join workflows on 30 resources (CCR = 10) ... 27
Figure.4.4: Experimental results for workflows of different CCR ... 28
Figure 4.5: Schedules of different allocation methods (a) Example workflow
(b) PCH allocation (c) adaptive subgroup allocation ... 30
Fig. 4.6 CCR = 0.1 and inter-arrival time range=30 seconds ... 32
Fig. 4.7 CCR=1 and inter-arrival time range=30 seconds ... 32
Fig. 4.9 CCR=0.1 and inter-arrival time range=500 seconds ... 33
Fig. 4.10 CCR=1 and inter-arrival time range=500 seconds ... 34
Fig. 4.11 CCR=10 and inter-arrival time range=500 seconds ... 34
Fig. 4.12 DAG structure of a real workflow application LIGO ... 35
Fig. 4.13 inter-arrival time range=30 seconds for LIGO ... 35
Fig. 4.14 inter-arrival time range=500 seconds for LIGO ... 36
List of Tables
Chapter 1. Introduction
Scheduling task graphs, also known as workflows, on parallel computing platforms has long been an important research topic and is well known to be a NP-complete problem [1, 2]. With the advancement of technology and emergence of grid and cloud computing, now many large-scale scientific and engineering applications are usually constructed as workflows, whose structure can be represented by traditional parallel task graphs, due to large amounts of interrelated computation and communication [4]. Many open source workflow management systems, such as ASKALON [22], DAGman [23], Gridbus [24], Pegasus [25], have been developed to support workflow applications in parallel and distributed systems.
In most research works, workflows are represented by Directed Acyclic Graphs (DAG) for describing the inter-task precedence constraints [3]. In practice, most common workflow applications have more regular structures than the random synthetic DAGs usually studied in previous works. As discussed in [4], DAGs of fork-join control structures are a common type of underlying structures for many workflow applications. Therefore, in this thesis we focus on the scheduling issue of workflows containing fork-join DAG structure. Figure 1.1 is an example of such kind of workflow structure. Each node represents a task which can be realized by a specific software program and can be allocated to a processor for execution. The number next to each node indicates the required execution time of the task. The edges represent the dependence between tasks and the number next to an edge means the inter-task data transmission cost. Nodes like node B are called fork nodes and nodes like node F are called join nodes hereafter in this thesis. A workflow scheduler has to schedule and allocate each task according to the dependence specified in the workflow definition. There are
languages and middleware, such as BPEL [26] and Xavantes [27], developed for programming such kinds of workflow applications.
Figure.1.1: A workflow example of fork-join DAG structure
Many approaches have been proposed to deal with the challenging workflow scheduling problem in the literature [10, 28, 29, 30, 31, 32, 33, 34, 35]. Clustering-based methods are one of the major types of workflow scheduling approaches and have the advantage of minimizing inter-task communication costs, which makes them superior to other kinds of methods in many cases. Due to the complexity, most previous workflow scheduling research focused on scheduling a single workflow on parallel systems [10, 28, 29, 30, 31, 32]. However, as modern high-performance computing platforms, such as grid and cloud, become prevalent, many users would run their workflow applications simultaneously on the same platform. It becomes an inevitable issue to schedule multiple concurrent workflows efficiently. In addition, although most previous researches on clustering-based workflow scheduling focused on the task clustering issue, recent research [18] showed that task allocation utilizing idle time gaps between scheduled tasks is a promising direction for efficient multiple workflow scheduling.
In general, workflow scheduling consists of two major steps: task ranking and task allocation. In the task-ranking step, the scheduler assigns a rank value to each task according to a specific mechanism, e.g., the bottom level (rank) of each task [12]. In the task allocation step, the scheduler continuously allocates each task or each task group, according to its
priority, to appropriate resources for execution with a specific resource selection mechanism, e.g., Earliest Finish Time (EFT) principle [10, 12]. Different scheduling heuristics differ in these two steps and leads to different schedules. For clustering-based approaches, there is an additional step between the above two steps, called task clustering, aiming to cluster several inter-related tasks into a group before allocation for effectively minimizing the inter-task communication costs. In the first part of this thesis, we propose and evaluate new task-ranking methods for clustering-based workflow scheduling.
Path Clustering Heuristic (PCH) is a typical clustering-based workflow scheduling approach and was developed for dealing with fork-join based workflows specifically, which has been shown effective in [4, 5]. As a clustering-based method, PCH partitions a workflow into several task groups first, and then allocates these task groups onto processors for execution. The former part of clustering-based methods concerns task clustering and has received much research attention previously. On the other hand, little attention has been paid on the later part of clustering-based methods which deals with task group allocation. In the second part of this thesis, we present a new task group allocation method for further improving the performance of clustering-based workflow scheduling.
Most previous task allocation approaches adopted simple heuristics which focused on a single principle, e.g. best resource fitness or Earliest Finish Time (EFT). In the third part of this thesis, we study the issue of task group allocation for clustering-based multi-workflow scheduling and make contributions including proposing an efficient dual-criteria task group allocation method and analyzing the relative advantage of the best-fit and EFT principles across different workload conditions and workflow properties. Our method uses a mechanism which considers both resource fitness and tasks’ EFT when allocating task groups and can adjust the
weights of different principles for adapting to different situations. In addition, an adaptive task group rearrangement mechanism is adopted in our method. These two mechanisms together enable our method to improve the overall multi-workflow execution performance effectively.
The rest of this thesis is organized as follows. Chapter 2 discusses related works on workflow scheduling. In chapter 3, we present our ranking method, task group allocation method for a single workflow, and task group allocation method for multi-workflow scheduling. Chapter 4 presents the simulation experiments and discusses the results of performance evaluation. Chapter 5 concludes this thesis.
Chapter 2. Related Work
Since workflow scheduling is a challenging NP-complete problem, many heuristic methods have been proposed in the literature. Most workflow scheduling algorithms usually can be classified into three categories: (1) list-based, (2) clustering-based, and (3) duplication-based.
A list-based heuristic approach maintains a list of all tasks of a workflow application according to their priorities and then schedules the tasks based on the list. There are several list-based heuristics proposed in the literature [10, 28, 29, 30, 31, 32]. One of the most famous list-based approaches is Heterogeneous Earliest Finish Time (HEFT) developed by Topcuoglu, Hariri, and Wu in [10]. HEFT first computes the rank value of each task based on its computation and communication costs as well as the dependency with other tasks. After that, the tasks are put into a queue in the descending order of the rank value. Then, the scheduler allocates each task in the queue onto the processor which can lead to the earliest finish time for the task.
The main idea of clustering-based heuristic methods is to reduce communication delay by clustering the tasks of heavy communication into the same group. The Path Clustering Heuristic (PCH) in [4] is a typical example of clustering-based heuristics. It first uses the clustering technique to build groups of tasks based on the inter-task dependency. After that, each group of tasks is allocated onto a single processor for execution in order to minimize the inter-task communication costs. Clustering-based heuristics usually adopt an iterative procedure consisting of two steps: task clustering and task group allocation. Several task clustering approaches for workflow scheduling have been proposed in the literature [12],
including linear clustering [13], single edge clustering [14, 15], list scheduling as clustering [6, 9], and Path Clustering Heuristic (PCH) [4, 5]. However, little research attention has been paid on task group allocation in clustering-based workflow scheduling. In the second part of this thesis, we explore the issues of task group allocation and propose a new method for further performance improvement of single workflow execution.
A duplication-based heuristic method tries to reduce the communication cost for a task to transmit data to its succeeding task(s) by duplicating the task on the destination processors [11]. When scheduling a single workflow, the duplication-based heuristics were shown potential to achieve good performance. However, they might not be appropriate when scheduling multiple concurrent workflows since task duplication in one workflow would consume extra computation resources and thus might delay the finish time of other workflows.
In the task ranking step, most of the previous approaches rank all the ready tasks in a workflow based on a single concept, e.g., bottom rank [10]. Moreover, the concept is usually path-oriented and related to the critical paths within the workflow. On the other hand, our ranking methods adopt a dual mechanism for ranking tasks, where the tasks on the allocated critical paths and other tasks are ranked based on different criteria.
Compared to previous task allocation approaches, our adaptive dual-criteria task group allocation method proposed in this thesis adopts two innovative mechanisms for clustering-based multiple workflow scheduling. The first is an adjustable idle time gap selection mechanism and the second is an adaptive task group rearrangement mechanism. Based on these two mechanisms, the proposed task group allocation method is expected to
further improve the overall multi-workflow execution performance compared to previous approaches.
Chapter 3. Task Ranking and Task Group
Allocation
We investigate two important issues, task ranking and task allocation in workflow scheduling. This chapter presents several task ranking and allocation methods for clustering-based approaches.
3.1 Task Ranking in Clustering-based Workflow
Scheduling
HEFT [10] is one of the most famous list-based workflow scheduling approaches. Many later list-based and clustering-based approaches [1, 21] follow the task ranking and allocation mechanisms in HEFT. In HEFT [10], the priority of each task is calculated in a way similar to the bottom-level calculation for DAG in [12]. Several other possible task-ranking methods were also mentioned in [10], however, without further discussion and evaluation. In the following, we describe several alternative task-ranking methods and illustrate their potential to outperform the popular task-ranking mechanism in HEFT [10] under certain circumstances.
In the task-ranking approach of HEFT [10], called bottom rank hereafter in this thesis, the bottom rank of a node represents the length of the longest path starting with it and is
defined as follows. The bottom ranks of the tasks in a directed acyclic graph can be computed recursively by traversing the graph upward starting from the exit nodes of the graph.
( ) { ( )( ( ))
where is the computation cost of node represents each child of , ( ) is the set of children of and represents the communication cost between and .
Another possible task-ranking approach discussed in this section is called top rank, which is similar to the top-level calculation for DAG in [12]. The top rank of a node ni is
defined as follows, which represents the length of the longest path ending in it. The top ranks of the tasks in a DAG can be computed recursively by traversing the graph downward starting from the entry nodes of the graph.
( ) { ( )
( ( ))
where ( ) is the set of parents of .
In the following, we first describe another task-ranking method, called bottom amount, for workflows of fork-join structure [28]. As defined in the following, the bottom amount rank differs from the existing bottom rank in that it sums up the bottom ranks of a task’s all children instead of choosing the largest one as in the bottom rank approach. The bottom amount rank is more capable of representing the amount of remaining workload depending on a task than the bottom rank. This feature is even important for scheduling workflows of fork-join structure. The bottom amount rank of a node is defined as follows. The computation of bottom amount rank requires the calculation of bottom rank to be performed first.
( ) {
∑ ( ( ))
( )
In the following, we propose a new task-ranking approach for clustering-based workflow scheduling. In contrast to previous task-ranking approaches which rank the tasks based on a single criterion, e.g., bottom rank or bottom amount rank, this new approach is a dual mechanism which ranks the tasks on the allocated critical paths by their top rank+bottom rank and ranks other tasks by their bottom rank or bottom amount rank. Therefore, there are two variants for the new approach: allocated top+bottom and bottom rank (ATBBR) and
allocated top+bottom and bottom amount rank (ATBBAR). Since the top rank represents the
length of the longest path ending in a node and the bottom rank represents the length of the longest path starting from a node, the top+bottom rank of a node is the length of the longest path going through the node. As a critical path is the longest path within a DAG, the nodes of the largest top+bottom rank are those nodes on the critical path.
The proposed approach tries to make a balance between two philosophies. The first is giving higher priority to the tasks on the allocated critical paths which are the tasks with the highest top+bottom rank. The second philosophy is ranking a task according to the amount of remaining workload depending on it, e.g., bottom rank or bottom amount rank. The approach aims to give higher priority to the tasks on the allocated critical paths [12] which might be different from the critical paths determined simply based on the workflow structure properties. The allocated critical paths in our approach are determined based on the actually allocated partial schedule, which might change during the scheduling process. Therefore, the proposed approach adopts a dynamic mechanism which updates the top rank of each remaining task after a task is scheduled. This dynamic mechanism enables it to more accurately find the tasks
on the actual critical paths and give them higher ranks, aiming to reduce the makespan of overall workflow execution effectively.
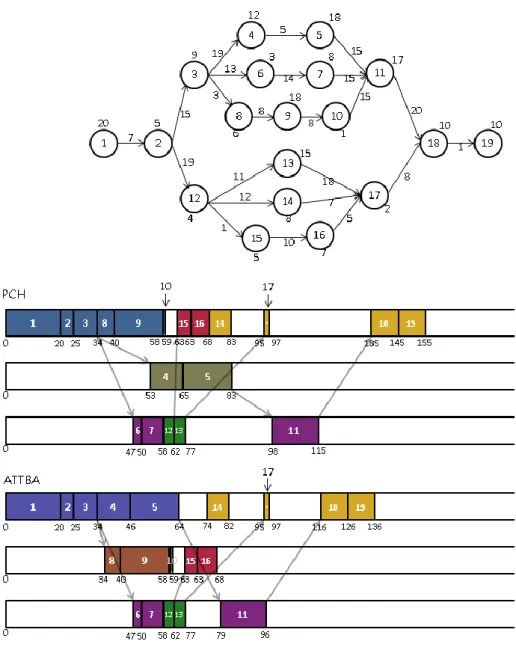
In a clustering-based workflow scheduling approach, there are in general two steps where task ranking information is needed, including choosing the start task of a new group and selecting the next task to join a group. In PCH [4], it adopts the bottom rank when choosing the start task of a new group and uses the top + bottom rank for selecting the next task in a group. In this section, we propose that by adopting different task ranking information at these two steps, the workflow execution performance can be further improved. Figure 3.1 is an illustrative example where the upper schedule is produced by PCH [4] and the lower schedule is generated by our approach which adopts the allocated top+bottom and bottom
amount rank (ATBBAR) when choosing the start task of a new group. The example in Figure
3.1 shows that our new task ranking method can significantly improve the overall workflow execution performance in terms of makespan.
Fig. 3.1 Comparison of the PCH and our new ranking mechanism
3.2 Adaptive Task Allocation for Clustering-based
Workflow Scheduling
Existing clustering-based approaches, e.g. PCH [4, 5], usually adopt an iterative two-step framework for workflow scheduling, as shown in Algorithm 1. The first step within the
iterative procedure, i.e. the while loop in Algorithm 1, adopts a task clustering scheme to find a group of unscheduled tasks, which varies in different clustering-based methods. The clustering technique in the first step focuses on reducing the communication costs between tasks. Figure 3.2 is an example of the typical task clustering technique used in PCH [4] [18]. In this example, the clustering process generates four task groups: {1, 2, 3, 4}, {5, 6, 7, 8, 9, 10}, {11 12}, and {13, 14, 15}, as shown with different colors in Figure 3.2. Then, in the second step a heuristic is applied to allocate the task group onto a processor based on some performance criterion, which is usually the Earliest Finish Time (EFT) of the task group in most methods. In this section, we adopt the same scheduling framework as PCH and develop a new adaptive subgroup allocation scheme to further improve workflow execution performance.
Fig. 3.2 A task clustering example
Algorithm 1: Clustering-Based Workflow Scheduling
1. Compute all tasks attributes
2. while there are unscheduled nodes do 3. group ⇐ get_next_group()
4. allocate(group)
Algorithm 2 shows the task group allocation mechanism, the function allocate( ), used in PCH. It simply tries to allocate a task group into the earliest free time period of a processor’s schedule which can accommodate the entire task group. For each processor, a such earliest free time period can be found. Among all processors, the one with the earliest free time period will be chosen to allocate the task group for execution, i.e. the function get_best_resource( ) in Algorithm 2. Such a task group allocation mechanism can minimize the communication costs along the path going through the tasks in a task group, such as the communication cost between tasks 1 and 2 in Figure 3.1. However, such a simple mechanism might not be effective for some tasks, e.g. the join node 11 in Figure 3.1, since they depend on more than one task. The allocation of join nodes should be more flexible in order to reduce as many communication costs as possible.
Algorithm 2: Task Group Allocation in PCH
1. allocate(group) 2. begin
3. resource ⇐ get_best_resource(group) 4. schedule the entire task group on resource
5. end
To further improve the performance of existing clustering-based workflow scheduling methods, we propose an adaptive subgroup allocation mechanism as shown in Algorithm 3. The proposed mechanism partitions a task group into several subgroups for individual allocation. The first task in the task group is the starting task of the first subgroup. After that, each join node in the task group will start a new subgroup. This arrangement gives flexibility to the allocation of join nodes while retaining most benefits of clustering-based methods, and is expected to achieve better workflow execution performance.
Algorithm 3: Adaptive Subgroup Allocation
1. allocate(group) 2. begin
3. while there are unallocated tasks in group do 4. n <= the first unallocated task in group 5. subgroup <= n
6. remove n from group
7. while group is not empty do
8. n <= the first unallocated task in group 9. if (n is not a join node)
10. subgroup <= subgroup ∪ n 11. remove n from group
12. else 13. break; 14. end if 15. end while
16. resource ⇐ get_best_resource(subgroup) 17. schedule the subgroup on resource 18. end while
3.3 Task Group Allocation for Online Multi-workflow
Scheduling
This section presents our task group allocation approach for clustering-based multi-workflow scheduling, featuring two mechanisms, adjustable idle time gap selection and
adaptive task group rearrangement, for improving overall multi-workflow execution
performance.
Most previous clustering-based workflow scheduling approaches focused on how to cluster the tasks in a workflow into different task groups [4]. Although these task groups have to be allocated onto computing resources for execution after the clustering phase, few studies discuss the task group allocation issue. When scheduling workflows onto computing resources, because of inter-task dependency and data communication costs, there are idle time gaps formed between scheduled tasks on each resource. In [16] Stavrinides and Karatza proposed an approach to efficient utilization of the idle time gaps through bin packing techniques. Although, in their approach, the list scheduling heuristic is applied to determine the allocation sequence, the idea can be applied to other kinds of workflow scheduling approaches, too [17]. In the experiments in [16], the Best Fit (BF) principle was shown to achieve the best overall performance.
Although Best-Fit allocation has the potential to improve resource utilization, it might delay tasks’ start time and in turn degrade the performance of entire workflow because it skips some earlier available time gaps to find the fittest one. Therefore, in our task group allocation method, we adopt an adjustable dual-criteria idle time gap selection mechanism to further improve multiple-workflow scheduling performance through making a balance
between the task group’s finish time and the fitness of an idle time gap. The dual-criteria mechanism defines a score function for evaluating each idle time gap which is large enough to accommodate the task group to be allocated. The score of each time gap is calculated by summing up the Earliest Finish Time (EFT) of the task group, if allocated on the time gap, and the difference between the lengths of the time gap and the task group. The time gap with the smallest score will be chosen to allocate the task group.
Since the effectiveness of a task group allocation method might be influenced by several different factors, e.g. workflow characteristics and workload conditions, to make the proposed dual-criteria mechanism more flexible for different conditions we give an adjustable parameter in the score function for adjusting the relative weights of the two different attributes. The score function is defined as follows, where σ is an adjustable parameter ranging between 0 and 1, f is the evaluation of time gap fitness calculated by subtracting the required computation time of the entire task group tx from the period of the candidate time gap,
and the function EFT( ) calculates the earliest finish time of tx if allocated on the candidate
time gap.
( ) ( ) ( ) (1)
Figure 3.3 is an example comparing the pure BF principle and our dual-criteria idle time gap selection mechanism. There are three workflows to be scheduled as shown in Figure 3.3(a). Figure 3.3(b) is the schedule produced by the pure BF principle and Figure 3.3(c) is the result generated by our dual-criteria idle time gap selection mechanism, where σ is set to 0.5. Figure 3.3 shows that our dual-criteria mechanism improves the overall workflow execution performance in that the finish times of two workflows get earlier, from 104 to 51 and from 117 to 116, respectively, while the performance of the other one remains the same.
Therefore, the average makespan of all the three workflows is reduced from 111.6 to 93.6 as shown in Figure 3.3(d).
(a)
(c)
(b) (c)
average makespan 111.6 93.6
(d)
Fig. 3.3 Comparison of the pure Best Fit heuristic and our dual-criteria mechanism
The dual-criteria idle time gap selection mechanism discussed tries to allocate an entire task group into a single gap on a specific resource. However, clustering-based workflow scheduling approaches sometimes might lead to task groups too large to fit into any single idle time gap. This, if happening, would result in both degraded resource utilization and delayed task completion time. In the following, we propose an adaptive task group rearrangement mechanism to cooperate with the adjustable dual-criteria idle time gap selection mechanism for further improving the overall multi-workflow execution performance. In traditional clustering-based workflow scheduling approaches, the task groups are formed simply based on the workflow properties before the task allocation stage. Our adaptive task group rearrangement mechanism allows a task group to be split into several subgroups for independent allocation at the task allocation stage, in order to efficiently utilize resources and, in turn, improve the overall workflow execution performance.
Someone might question why not just adopting the list-based workflow scheduling approach instead of allowing a task group in the clustering-based approach to be split into subgroups. Figures 3.4 and 3.5 illustrate the potential advantage of our adaptive task group rearrangement mechanism. In Figure 3.4, each task is allocated independently as in the list-based workflow scheduling approaches, resulting in some unnecessary inter-task communication overheads. On the other hand, in our adaptive task group rearrangement mechanism, each task group will be cut into subgroups only when necessary at the task allocation stage. At each decomposition activity, an original task group is cut into two new subgroups. The first subgroup contains the largest number of tasks which can be fitted into the gap under consideration, and the other subgroup consists of the remaining tasks. The first subgroup will be allocated first and the second subgroup will be put back to the ready queue, waiting for later allocation decision. Since each subgroup would contain as many tasks as possible, the inter-task communication costs can be minimized. Figure 3.5 shows the potential advantage of our adaptive task group rearrangement mechanism. The largest subgroup which can be allocated is shown near each idle time gap. In Figure 3.5, finally all the four tasks will be allocated in gap C since that leads to the least EFT of the entire task group, resulting in better overall performance compared to Figure 3.4. This example shows that our adaptive task group rearrangement mechanism can retain the advantage of clustering-based workflow scheduling to the largest degree while providing additional flexibility for task allocation.
Figure.3.4 Individual task allocation in list-based workflow scheduling approaches
Figure.3.5 Advantage of adaptive task group rearrangement
The score function (1) is not appropriate when adopting adaptive task group rearrangement since not every gap can accommodate the entire task group and thus the EFT of the entire task group is not available. To overcome this difficulty, a new score function is defined as follows, where and are two adjustable parameters for controlling the relative weights of the three effects and + ranges between 0 and 1. For idle time gaps which are large enough to accommodate the entire task group, the last term of the score function (2) is zero and the entire score function will become identical to the score function (1).
( ) ( ( )(
The following provides an algorithmic description of our adaptive dual-criteria task group allocation approach. The algorithm evaluates each idle time gap in the system in turn according to the above score function in the two nested for loops between lines 1 and 17. Lines 3 to 5 deal with the case that the gap can accommodate the entire task group. Lines 6 to 9 handle the case that current gap is not large enough for the entire task group by cutting the task group into two subgroups for allocating the first subgroup first. Lines 11 to 15 are common to both cases for choosing the most appropriate gap. After the two nested loops, the best gap is found and the task group is split into two subgroups if necessary according to the gap size. The first subgroup is allocated onto the gap and the second subgroup will be put back into the ready queue for later allocation.
Algorithm: Adaptive Dual-Criteria Task Group Allocation Input:
Tr: total number of resources
nt: the number of tasks in the task group to be allocated ni: total number of gaps on resource i.
, : adjustable parameters and + ranges between 0 and 1 gapi(j): size of the jth gap on resource i.
gapi(j).end: the end time of the jth gap on resource i sizet: size (total computation cost) of the task group t
task_gapi(j).end: the expected finish time of the task group if allocated onto the jth gap on resource i without considering the gap size
Variables:
min: the lowest score found so far, initialized as ∞ tempmin: the temporary score of current gap
finali.end: the expected finish time of the task group if allocated onto the last task’s finish time on resource i
i : index of resource.
j : index of gap on resource i.
Output:
found_gap: the index of the gap for allocation
found_res: the index of the resource on which the gap is found k: index of the decomposition point of the task group to be allocated
1. for i= 1 to Tr do
2. for j = 1 to ni do
3. If (gapi(j) sizet and task_gapi(j).end gapi(j).end ) then
4. Tempmin = score according to formula (2) using and with the last term being zero and the first subgroup equal to the entire task group 5. k = nt
6. else
7. According to gapi(j), decompose the task group into two subgroups, 8. k = the index of the last task in the first subgroup after decomposition 9. tempmin=score calculated according to formula (2) using and
10. end if
11. if (min > tempmin ) then
12. min = tempmin 13. found_gap = j 14. found_res = i 15. end if 16. end for 17. end for
18. allocate the first subgroup into the jth gap on resource i, and put the second subgroup back to the ready queue
Chapter 4. Performance Evaluation
In this section, we evaluate the proposed approaches through a series of simulation experiments, which compare the proposed appraoches with previous methods in the literature in terms of average makespan of all workflows. Here, the makespan of a workflow is defined to be the time period between its arrival and its finishing execution.
4.1 Task Ranking in Clustering-based Workflow
Scheduling
This section evaluates the proposed task-ranking methods for clustering-based workflow scheduling. The performance metric used in the experiments is makespan, which represents the total execution time for a workflow application. It is used to measure the performance of a scheduling algorithm from the perspective of workflow applications. In each experiment, the average makespan of 100 different workflows is used to evaluate different scheduling methods.
We implemented a DAG generator to randomly generate synthetic workflows with fork-join DAG structure for the following simulation experiments. Fork-join DAGs are generated as follows:
1. The generator generates a DAG with one entry node and one exit node.
2. Each DAG contains 1–2 fork-join structures randomly.
3. Each fork operation produces 2–10 branches randomly.
4. Each branch contains 2–6 nodes randomly.
5. Each node has the computation cost ranging from 1 to 100 s.
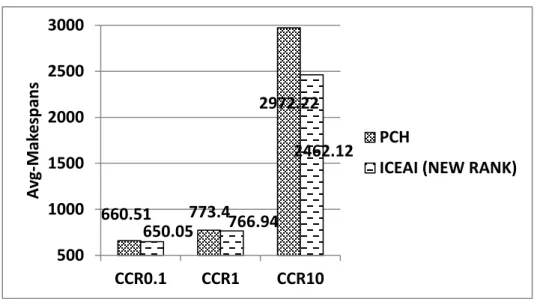
Figures 4.1 to 4.3 show the experimental results comparing PCH [4] and our new task ranking method for three different Communication-to-Computation Ratio (CCR) [12]. When CCR is one, PCH [4] and our method achieve quite similar performance. However, as CCR grows, our method delivers increasing performance improvement compared to PCH [4].
Figure.4.1: Ranking fork-join workflows on 30 resources (CCR = 0.1)
Figure.4.2.: Ranking fork-join workflows on 30 resources (CCR = 1)
660.51 660.31 660 660.2 660.4 660.6 660.8 661 CCR0.1 A vg -M ak e sp an s PCH ATBBA_T+B 838.61 827.63 800 805 810 815 820 825 830 835 840 845 850 CCR1 A vg -M ak e sp an s PCH ATBBA_T+B
Figure.4.3.: Ranking fork-join workflows on 30 resources (CCR = 10)
4.2 Adaptive Task Allocation for Clustering-based
Workflow Scheduling
This section presents a series of simulation experiments which evaluate the proposed adaptive subgroup allocation method in terms of makespan. The adaptive subgroup allocation method is compared to the typical allocation mechanism in PCH [4, 5]. The experimental results are shown in Figure 4.4 for workflows of different CCR properties. The performance shown in each experiment is the average makespan of 100 different workflows scheduled by the evaluated methods. Our adaptive subgroup allocation method outperforms PCH significantly in all the three experiments, and the performance improvement rises as CCR increases. 2972.22 2886.84 2840 2860 2880 2900 2920 2940 2960 2980 CCR10 A vg -M ak e sp an s PCH ATBBA_T+B
Figure.4.4: Experimental results for workflows of different CCR
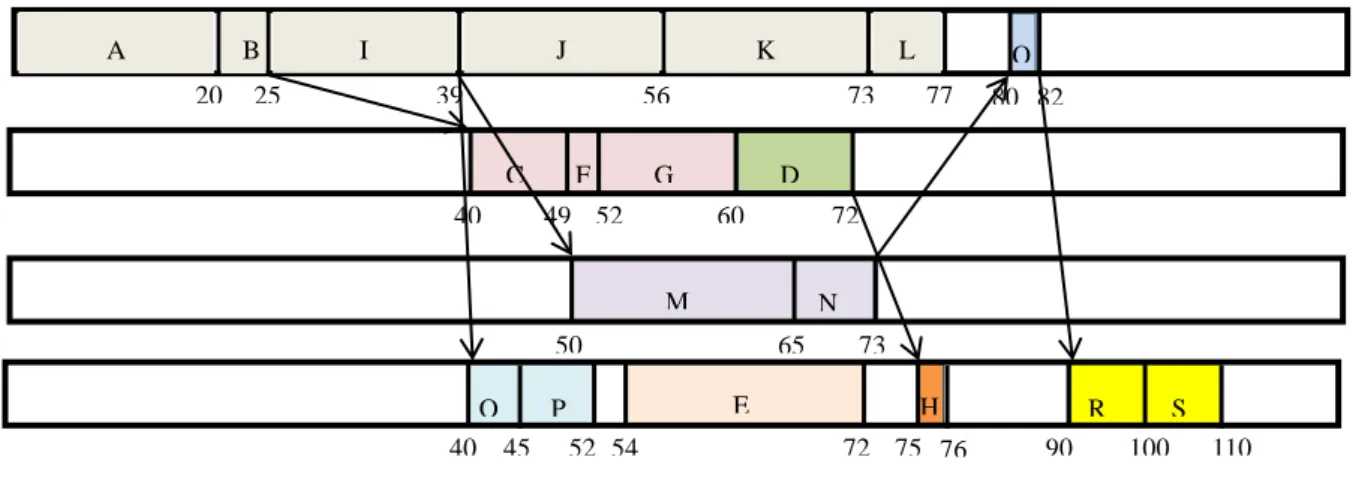
Figure 4.5 is an example illustrating how our adaptive subgroup allocation method can outperform PCH. Our method partitions a task group into several subgroups adaptively for individual allocation based on each join node. This arrangement gives flexibility to the allocation of join nodes while retaining most benefits of clustering-based methods, and thus achieve better workflow execution performance.
660.51 773.4 2972.22 650.05 766.94 2462.12 500 1000 1500 2000 2500 3000 CCR0.1 CCR1 CCR10 A vg -M ak e sp an s PCH
(a) (b) 20 25 39 56 73 77 40 49 52 60 72 77 84 95 97 107 117 50 65 73 54 72 75 76 A B I J K L C F G M N E H O P Q R S D 19 A B C L D F I E G H J M O N P Q R K 7 15 3 8 14 8 15 15 20 1 1 20 5 9 5 19 13 8 1 15 11 12 18 8 10 S 7 5 12 18 3 14 17 17 4 15 8 5 7 2 10 10
(c)
Figure 4.5: Schedules of different allocation methods (a) Example workflow (b) PCH allocation (c) adaptive subgroup allocation 20 25 A 39 56 B I J K 73 L 77 40 49 52 60 72 50 65 73 40 45 52 54 72 75 76 90 100 110 C F G D M N E H O P 80 82 Q R S
4.3 Task Group Allocation for Online Multi-workflow
Scheduling
This section evaluates the proposed adaptive dual-criteria task group allocation method for clustering-based multiple workflow scheduling. The proposed method is compared with previous approaches, including the best-fit heuristic in [16], the EFT heuristic in PCH [4] [18], and the EST + fitness approach [17].
Figures 4.6, 4.7, and 4.8 compare the adaptive dual-criteria task group allocation method with previous approaches in terms of average makespan under different CCR values. In the figures, adjustable allocation represents an approach that adopts only the adjustable idle time gap selection mechanism, while adaptive dual-criteria is an approach adopting both adjustable idle time gap selection and adaptive task group rearrangement. Next to the name of
adjustable allocation is a pair of parentheses indicating the best weight of fitness, i.e. in
score function (1), and the pair of parentheses next to adaptive dual-criteria contains the weights of fitness and EFT, i.e. and in score function (2), which lead to the best performance in that case. The inter-arrival time between two consecutive workflows is determined by a random number within a range. In the experiments of Figures 4.6, 4.7, and 4.8, the range of inter-arrival time is 30 seconds. The experimental results indicate that
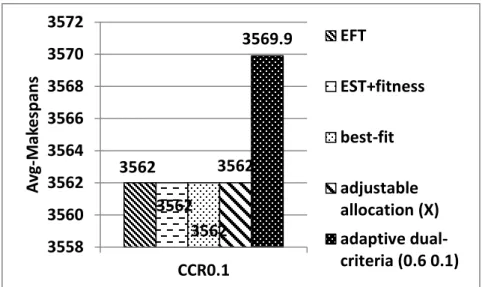
Fig. 4.6 CCR = 0.1 and inter-arrival time range=30 seconds
Fig. 4.7 CCR=1 and inter-arrival time range=30 seconds
3562 3562 3562 3562 3569.9 3558 3560 3562 3564 3566 3568 3570 3572 CCR0.1 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (X) adaptive dual-criteria (0.6 0.1) 3661.2 3661.3 3661.2 3661.2 3585.5 3540 3560 3580 3600 3620 3640 3660 3680 CCR1 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (X) adaptive dual-criteria (0.1 0.4)
Fig. 4.8 CCR=10 and inter-arrival time range=30 seconds
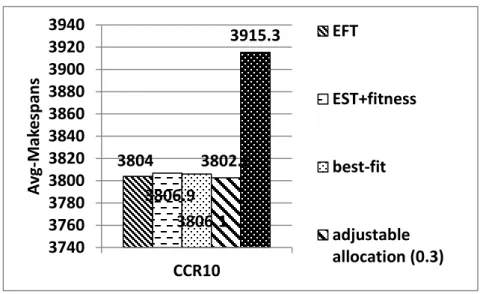
Figures 4.9, 4.10, and 4.11 presents the evaluation of the proposed adaptive dual-criteria method when the range of inter-arrival time between workflows is 500 seconds, much longer than in Figures 4.6, 4.7, and 4.8. In this scenario, our adaptive dual-criteria method outperforms the previous approaches under all the three CCR values. Again, the adaptive dual-criteria approach achieves larger performance improvement whenCCR is one. It achieves the least performance for large CCR value, i.e. CCR=10.
3804 3806.9 3806.1 3802.6 3915.3 3740 3760 3780 3800 3820 3840 3860 3880 3900 3920 3940 CCR10 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (0.3) 3451 3446.5 3550.2 3445.6 3343.9 3200 3250 3300 3350 3400 3450 3500 3550 3600 CCR0.1 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (0.2) adaptive dual-criteria (0.5 0.4)
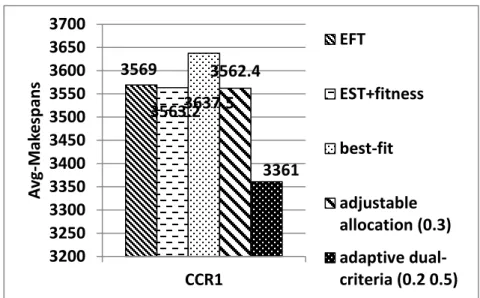
Fig. 4.10 CCR=1 and inter-arrival time range=500 seconds
Fig. 4.11 CCR=10 and inter-arrival time range=500 seconds
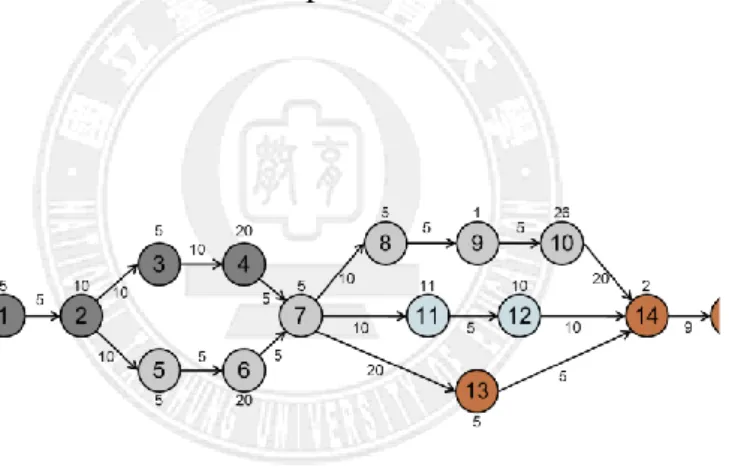
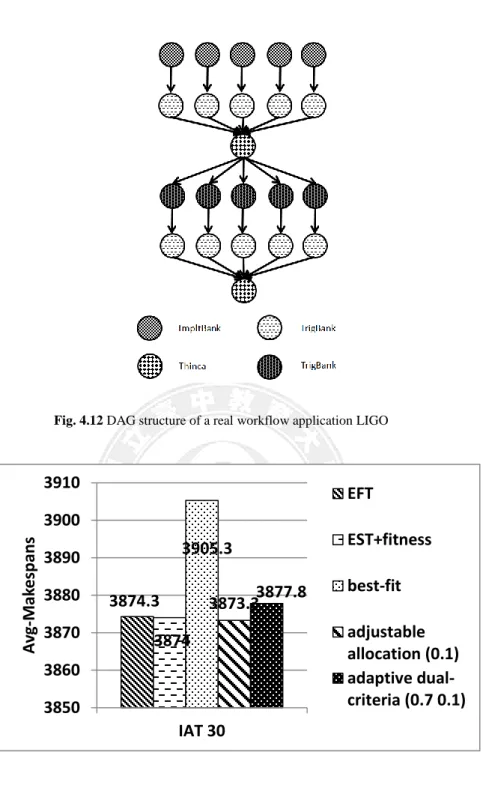
Figures 4.13 and 4.14 show the experimental results based on the structure and properties of a real workflow application, LIGO [19], as shown in Figure 4.12. The experimental results show that our adaptive dual-criteria approach can achieve better performance than previous methods in [16][18][20] for larger inter-arrival time.
3569 3563.2 3637.5 3562.4 3361 3200 3250 3300 3350 3400 3450 3500 3550 3600 3650 3700 CCR1 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (0.3) adaptive dual-criteria (0.2 0.5) 3722.4 3723.4 3774.2 3721.9 3691.9 3640 3660 3680 3700 3720 3740 3760 3780 3800 CCR10 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (0.4) adaptive dual-criteria (0 0.8)
Fig. 4.12 DAG structure of a real workflow application LIGO
Fig. 4.13 inter-arrival time range=30 seconds for LIGO
3874.3 3874 3905.3 3873.3 3877.8 3850 3860 3870 3880 3890 3900 3910 IAT 30 A vg -M ak espans EFT EST+fitness best-fit adjustable allocation (0.1) adaptive dual-criteria (0.7 0.1)
Fig. 4.14 inter-arrival time range=500 seconds for LIGO
The time complexity of choosing a good gap for task group allocation depends on serval factors, including the number of resources, the number of gaps on each resource in the partial schedule, and the score evaluation function. In our implementation of the methods evaluated in the experiments, each gap would be checked and given a score before determining the best gap for allocation. Therefore, the time complexity of different methods differs mainly in the score function. Among the task group allocation methods evaluated in the experiments, EFT has the lowest time complexity since it doesn’t have to calculate the fitness value of each gap. All the other methods, EST+fitness, best-fit, and our adaptive dual-criteria method, have to calculate the fitness value and even perform further computation in the score function, resulting in higher time complexity. Our adaptive dual-criteria method has the most complex score evaluation function, as shown in equation (2), and thus has the highest time complexity. Figure 4.15 compares the scheduling overheads of different methods measured in the experiments. EFT has the smallest overhead. The overheads of EST+fitness, best-fit, and adjustable allocation are very close to each other. Our adaptive dual-criteria task group
3762.6 3724.5 3841.3 3722.3 3693.4 3600 3650 3700 3750 3800 3850 3900 IAT 500 A vg -M ak e sp an s EFT EST+fitness best-fit adjustable allocation (0.5) adaptive dual-criteria (0.5 0.1)
allocation approach requires the longest computation time. However, compared to the long execution time of scientific workflow applications, usually in hours or even more, the scheduling overhead, in milliseconds, is negligible.
Fig. 4.15 Scheduling overheads in milliseconds
Table 4.1 shows resultant average makespan of applying our adaptive dual-criteria task group allocation approach to the set of workflows in Figure 4.11 with different , values. The results indicate that careful selection of appropriate , values is important to achieve good performance. The difference between the best, (=0, =0.8), and the worst, (=0.9, =0.1), performance is enormous. The performance achieved by (=0.9, =0.1) is even worse than previous methods according to the data in Figure 4.11. Choosing the best , values is no easy. Exhaustive experiments, such as Table 4.2, based on historical workload data can help to find good , values for a specific system. The experimental results presented in this section also shed some light on how to choose appropriate , values based on information such as CCR values and average inter-arrival time.
Table 4.1. An exhaustive experiment on , values
α β 1-α-β makespans 484 515 515 515 671 0 100 200 300 400 500 600 700 800 EFT EST+fitness best-fit adjustable allocation(0.2) adaptive dual-criteria(0.1, 0.5)
0.0 0.1 0.9 3829.6 0.0 0.2 0.8 3810.0 0.0 0.3 0.7 3793.1 0.0 0.4 0.6 3754.6 0.0 0.5 0.5 3718.8 0.0 0.6 0.4 3700.4 0.0 0.7 0.3 3698.6 0.0 0.8 0.2 3691.6 0.0 0.9 0.1 3695.7 0.0 1.0 0.0 3712.2 0.1 0.1 0.8 3864.7 0.1 0.2 0.7 3827.6 0.1 0.3 0.6 3796.3 0.1 0.4 0.5 3749.8 0.1 0.5 0.4 3721.9 0.1 0.6 0.3 3707.6 0.1 0.7 0.2 3698.2 0.1 0.8 0.1 3704.4 0.1 0.9 0.0 3715.8 0.2 0.1 0.7 3953.6 0.2 0.2 0.6 3849.2 0.2 0.3 0.5 3806.8 0.2 0.4 0.4 3753.5 0.2 0.5 0.3 3723.5 0.2 0.6 0.2 3718.4 0.2 0.7 0.1 3709.1 0.2 0.8 0.0 3714.9 0.3 0.1 0.6 4060.6 0.3 0.2 0.5 3897.3 0.3 0.3 0.4 3813.6 0.3 0.4 0.3 3758.9 0.3 0.5 0.2 3740.0 0.3 0.6 0.1 3736.6 0.3 0.7 0.0 3734.7 0.4 0.1 0.5 4161.3 0.4 0.2 0.4 3951.4 0.4 0.3 0.3 3830.2 0.4 0.4 0.2 3789.3 0.4 0.5 0.1 3774.3 0.4 0.6 0.0 3774.7 0.5 0.1 0.4 4232.2 0.5 0.2 0.3 4000.1 0.5 0.3 0.2 3872.6 0.5 0.4 0.1 3841.5 0.5 0.5 0.0 1827.4 0.6 0.1 0.3 4312.7 0.6 0.2 0.2 4049.5
0.6 0.4 0.0 3910.4 0.7 0.1 0.2 4364.9 0.7 0.2 0.1 4108.3 0.7 0.3 0.0 4023.3 0.8 0.1 0.1 4430.2 0.8 0.2 0.0 4201.8 0.9 0.1 0.0 4521.3
Chapter 5. Conclusions
In this thesis, we investigate two important issues, task ranking and task allocation, in workflow scheduling and make three contributions. First, we also deal with online multi-workflow scheduling issue, which is becoming even more important in modern shared parallel computing platforms, e.g. cluster, grid, and cloud. Second, in contrast to previous task ranking methods which are based on a single path-oriented concept, our task ranking mechanism was developed with innovative ideas. The bottom amount rank is a dependent workload-oriented approach, being more capable of representing the amount of remaining workload depending on a task than the widely used bottom rank, calculated based on the concept of path. This feature is found to be especially useful for scheduling workflows of fork-join structure in the experiments. The proposed allocated top+bottom rank is a dual mechanism, which ranks critical tasks and non-critical tasks in two different ways, in contrast to previous approaches which rank all tasks based on a single criterion. The approach tries to make a balance between two philosophies: giving higher priority to tasks on critical paths and ranking a task according to the amount of remaining workload depending on it. Third, for task group allocation in clustering-based workflow scheduling, we propose an adaptive subgroup allocation mechanism which partitions a task group into several subgroups for individual allocation adaptively based on each join node. This arrangement gives flexibility to the allocation of join nodes while retaining most benefits of clustering-based methods, and is shown to achieve better workflow execution performance. We conducted a series of simulation experiments for extensive performance evaluation of the proposed approaches and compared them to previous methods in the literature. The experimental results show that our
References
[1] L. F. Bittencourt, R. Sakellariou, E. R. M. Madeira, “DAG Scheduling Using a Lookahead Variant of the Heterogeneous Earliest Finish Time Algorithm”, Proceedings
of the 18th Euromicro Conference on Parallel, Distributed and Network-based Processing, 2010.
[2] M.R. Gary and D.S. Johnson, Computers and Intractability: A Guide to the Theory of NP-Completeness, W. H. Freeman and Company, 1979.
[3] M. Wieczorek, R. Prodan, A. Hoheisel, M. Wieczorek, R. Prodan, A. Hoheisel, “Taxonomies of the Multi-Criteria Grid Workflow Scheduling Problem”, Grid
middleware and services, pp. 237-264, 2008.
[4] L.F. Bittencourt, E.R.M. Madeira, “A Performance-Oriented Adaptive Scheduler for Dependent Tasks on Grids”, Concurrency and Computation: Practice and Experience vol. 20, pp. 1029–1049, 2008.
[5] L.F. Bittencourt, E.R.M. Madeira, F.R.L Cicerre, L.E. Buzato, “A path clustering heuristic for scheduling task graphs onto a grid”, Proceedings of the 3rd ACM
International Workshop on Middleware for Grid Computing, Grenoble, France, 2005.
[6] T. Yang and A. Gerasoulis, “DSC: Scheduling Parallel Tasks on an Unbounded Number of Processors”, IEEE Transactions on Parallel and Distributed Systems, vol. 5, no. 9, pp. 951-967, Sept. 1994.
[7] J. Liou and M.A. Palis, “An Efficient Clustering Heuristic for Scheduling DAGs on Multiprocessors”, Proceedings of the 8th
Processing, 1996.
[8] S. J. Kim and J.C. Browne, “A General Approach to Mapping of Parallel Computation upon Multiprocessor Architectures”, Proceedings of Int’l Conf. Parallel Processing, vol. 2, pp. 1-8, 1988.
[9] M. Wu and D. Gajski. “Hypertool: A Programming Aid for Message Passing Systems”,
Proc.IEEE Transactions on Parallel and Distributed Systems, vo.l, no.1, pp. 330-343,
July 1990.
[10] H. Topcuoglu, S. Hariri, M. Y. Wu, “Performance-effective and low-complexity task scheduling for heterogeneous computing”, IEEE Transactions on Parallel and
Distributed Systems, vol.13 no.3, pp260-274, 2002.
[11] G. Park, B. Shirazi, and J. Marquis, “DFRN: A New Approach for Duplication Based Scheduling for Distributed Memory Multi-processor Systems”, Proceedings of
International Conference of Parallel Processing, pp. 157-166, 1997.
[12] O. Sinnen, Task Scheduling for Parallel Systems, John Wiley, 2007.
[13] A. Gerasoulis, T. Yang, “On the Granularity and Clustering of Directed Acyclic Task Graphs”, Proceedings of IEEE Transactions on Parallel and Distributed Systems, 4(6):686-701, Jun, 1993.
[14] V. Sarkar (1989), “Partitioning and Scheduling Parallel Programs for Execution on Multiprocessors”, Journal of MIT Press, 1989.
[15] A. Gerasoulis, T. Yang, “A Comparison of Clustering Heuristics for Scheduling DAGs on Multiprocessors”, Journal of Parallel and Distributed Computing, 16(4):276-291, Dec, 1992.
[16] G. L. Stavrinides, H. D. Karatza, “Scheduling Multiple Task Graphs in Heterogeneous Distributed Real-TimeSystems by Exploiting Schedule Holes with Bin Packing Techniques”, Simulation Modelling Practice and Theory, vol. 19, issue. 1, pp. 540-552, January 2011.
[17] Y. L. Tsai, K. C. Huang, H. Y. Chang, J. Ko, E. T. Wang, C. H. Hsu, “Scheduling Multiple Scientific and Engineering Workflows through Task Clustering and Best-Fit Allocation”, Proceedings of 2012 IEEE Eighth World Congress on Services, June 24- 29, 2012.
[18] L. F. Bittencourt and E. R. M. Madeira, “Fulfilling Task Dependence Gaps for Workflow Scheduling on Grids”, Proceedings of the 3rd IEEE International Conference on
Signal-Image Technology and Internet Based Systems (SITIS), Dec, 2007.
[19] S. Bharathi, A. Chervenak, E. Deelman, G. Mehta, M.H. Su, K. Vahi, “Characterization of scientific workflows”, Proceedings of 3rd workshop on workflows in support of
large-scale science, Nov, 2008.
[20] L. F. Bittencourt and E. R. M. Madeira, “Towards the scheduling of multiple workflows on computational grids”, Journal of Grid Compute 8(3): 419-441, 2010.
[21] C. H. Hsu, C.W. Hsieh, C. T. Yang, “A generalized critical task anticipation technique for DAG scheduling”, Proceedings of ICA3PP 2007, pp. 493–505, 2007.
[23] DAGman (2015) http://www.cs.wisc.edu/condor/manual/
[24] Gridbus (2015) http://www.cloudbus.org/workflow/
[25] Pegasus (2015) http://pegasus.isi.edu/
[26] Business Process Execution Language (BPEL) (2015)
http://en.wikipedia.org/wiki/Business_Process_Execution_Language
[27] F. R. L. Cicerre, E. R. M. Madeira, L. E. Buzato, “A hierarchical process execution support for grid computing”, Concur. Comput. Pract. Exper, vol. 18, no. 6, pp. 581–594, May, 2006.
[28] K. C. Huang, Y. L. Tsai, H. C. Liu, “Task ranking and allocation in list-based workflow scheduling on parallel computing platform”, The Journal of Supercomputing vol. 71, issue. 1, pp. 217-240, January, 2015
[29] H. Zhao, R. Sakellarious, “Scheduling multiple DAGs onto heterogeneous systems”,
Proceedings of the 20th international conference on parallel and distributed processing,
2006
[30] C. C. Hsu, K. C. Huang, F. J. Wang, “Online scheduling of workflow applications in grid environments”, Future Generation Computer System, vol. 27, issue. 6, pp. 860–870, May, 2011
[31] A. Hirales-Carbajal, A. Tchernykh, R. Yahyapour, J. L. González-García, T. Röblitz, J. M. Ramírez-Alcaraz, “Multiple workflow scheduling strategies with user run time estimates on a grid”, Journal of Grid Computing, vol. 10, issue. 2, pp. 325-346, June, 2012
[32] P. C. Mu, J. F. Nezan, M. Raulet, “A list scheduling heuristic with new node priorities and critical child technique for task scheduling with communication contention”, Algorithm-Architecture Matching for Signal and Image Processing, Lecture Notes in
Electrical Engineering, vol. 73, pp. 217-236, 2011
[33] R. Garg, A. K. Singh, “Multi-objective workflow grid scheduling using ε-fuzzy dominance sort based discrete particle swarm optimization”, The Journal of
Supercomputing archive, vol. 68, issue. 2, pp. 709-732, May, 2014
[34] E. Deelman, G. Singh, C. Kesselman, “Optimizing grid-based workflow execution”,
Journal of Grid Computing, vol. 3, issue. 3-4, pp. 201-219, Sep, 2005
[35] S. Adabi, A. Movaghar, A. M. Rahmani, “Bi-level fuzzy based advanced reservation of Cloud workflow applications on distributed Grid resources”, The Journal of