國 立 交 通 大 學
電機與控制工程學系
碩 士 論 文
具有使用者可調性主從式指令快取記憶
體控制器之多核嵌入式處理器
Design of Multi-Core Embedded
Processor Using Configurable
Master-Slave I-Cache Controller
研 究 生:周經翔
指導教授:林進燈 博士
具有使用者可調性主從式指令快取記憶體控制
器之多核嵌入式處理器
Design of Multi-Core Embedded Processor Using
Configurable Master-Slave I-Cache Controller
研 究 生:周經翔 Student:Ching-Hsiang Chou
指導教授:林進燈 博士
Advisor:Dr. Chin-Teng Lin
國立交通大學
電機與控制工程學系
碩士論文
A Thesis
Submitted to Department of Electrical and Control Engineering
College of Engineering and Computer Science
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering
June 2006
Hsinchu, Taiwan, Republic of China
具有使用者可調性主從式指令快取記憶體控制
器之多核嵌入式處理器
Design of Multi-Core Embedded Processor Using
Configurable Master-Slave I-Cache Controller
學生:周經翔
指導教授:林進燈 博士
國立交通大學電機與控制工程研究所
Chinese Abstract中文摘要
無論是在一般應用的嵌入式處理器(General Embedded Processor) 或是著重 於運算的數位訊號處理器(Digital Signal Processor, DSP),cache miss幾乎都是影響 效能的一個很大的因素。由於cache miss的penalty常常都是數千週期甚至上萬週 期,所以如果可以設計一個可以減少cache miss次數及總miss penalty的快取記憶 體控制器,便可以有效的提升處理器的執行效能。本論文設計了一個可實現於晶 片中的指令快取記憶體控制硬體演算法,此演算法使用在一般的應用程式均能有 效的減少指令快取記憶體(I-Cache)的總miss penalty,而在具有大量迴圈運算及函 式呼叫的多媒體應用程式中尤有顯著成效,為驗證該演算法的可靠性及正確性, 本論文也設計出一個VLIW架構的多核心嵌入式處理器,以做為該指令快取記憶 體控制器的作用平台,並整合成為一顆嵌入式處理器晶片。此晶片採用UMC 0.18 μm 製程,以Cell-based方式設計,晶片面積約 3.1x3.1 mm2,預估最大操作頻率 在 135MHz。
Design of Multi-Core Embedded Processor Using
Configurable Master-Slave I-Cache Controller
Student: Ching-Hsiang Chou
Advisor: Dr. Chin-Teng Lin
Department of Electrical and Control Engineering
National Chiao Tung University
English Abstract
Abstract
Cache miss is a very significant factor to affect its efficiency for the General Embedded Processor in general applications or the Digital Signal Processor(DSP) emphasizing on computing operations. The cache miss results in the penalty of wasting of thousands of cycles or more. For this reason, if we design a cache controller that can reduce the number of cache miss and save miss penalty, we will enhance the efficiency of the processor. In the paper, an I-Cache controller hardware algorithm that can be applied in Chip is introduced. When this algorithm is applied for general application program, it can efficiently reduce the total miss penalty of the I-Cache. Even more, we can see the significant effect when it is applied for the multi-media application that has many loop operations and function calls. In order to prove the dependability and the correctness of the algorithm, the thesis designs a multi-core embedded processor that has VLIW architecture. That can be used for the operation platform of the I-Cache controller, and be intergraded into a embedded processor chip. This Chip is fabricated in UMC 0.18μm process and designed in the way of Cell-based. The chip area is 3.1x3.1 mm2 , and the max operation frequency is operated at 135MHz.nese Acknowl
誌謝
本論文的完成,首先要感謝指導教授林進燈博士這兩年來的悉心指導,讓我 學習到許多寶貴的知識,在學業及研究方法上受益良多,也學習到許多做事的態 度及技巧。另外也要感謝口試委員們的的建議與指教,使得本論文更為完整。 其次,感謝資訊媒體實驗室的學長鍾仁峰博士、劉得正博士及資工系的范倫 達教授的指導協助,同學峻谷、家昇及宗哲的相互砥礪,及所有學長、學弟們在 研究過程中所給我的鼓勵與協助。尤其是鍾仁峰博士及范倫達教授,在計算機理 論及下線流程上給予我相當多的幫助與建議,讓我獲益良多。 感謝我的父母親對我的教育與栽培,並給予我精神及物質上的一切支援,使 我能安心地致力於學業。 謹以本論文獻給我的家人及所有關心我的師長與朋友們。目 錄
中文摘要 ...ii
Abstract...iii
誌謝 ... iv
目 錄 ... v
圖 目 錄 ...viii
表 目 錄 ... ix
第一章 緒論 ... 1
1.1 簡介 ...1
1.2 論文架構 ...4
第二章 主從式快取記憶體控制器 ... 5
2.1 主從式快取記憶體控制器原理...5
2.1.1 主從式快取記憶體控制器硬體演算法...5 2.1.2 使用者可調性設計...8 2.1.3 低功耗設計...102.2 主從式快取記憶體控制器架構...11
2.2.1 程式初始指令讀取控制... 11 2.2.2 位置比較器...12 2.2.3 發生cache miss時的處理 ...12 2.2.4 處理器中斷時的處理...132.3 主從式快取記憶體模擬器...15
2.3.1 主從式快取記憶體與L1 快取記憶體控制模擬器 ...15 2.3.2 測試程式碼產生器...16 2.3.3 效能指標...16 2.3.4 效能測試...17 2.3.5 功率管理...24 2.3.6 延伸比較...242.4 結語 ...25
第三章 多核嵌入式處理器 ... 26
3.1 VLIW處理器架構 ...26
3.1.1 VLIW處理器核心 ...26 3.1.2 VLIW處理器指令集 ...30 3.1.3 子核心特色...34 3.1.4 不同子核心間的資料讀取與寫入...343.2 軟體開發環境 ...34
3.2.1 組譯器...34 3.2.3 模擬器...373.3 智慧型DMA控制器 ...39
3.3.2 智慧型DMA控制器架構 ...41 3.3.3 智慧型DMA使用流程 ...423.4 整合 ...43
3.5 結語 ...46
第四章 晶片實現與結果驗證 ... 47
4.1 晶片製作 ...47
4.1.1 設計流程...47 4.1.2 合成結果...48 4.1.3 佈局與封裝...484.2 測試驗證 ...52
4.2.1 餘弦轉換(Discrete Cosine Transform) ...52
4.2.2 快速傅立葉轉換(FFT) ...53 4.2.3 量化線性預估係數(LPC)...54
4.3 效能比較 ...56
第五章 結論 ... 58
參考文獻 ... 59
附錄 ... 64
A. 測試程式 ...64
B. 佈局驗證結果說明 ...69
C. CIC下線報告書(A) ...70
D. CIC下線報告書(B) ...73
E. Module I/O...76
圖 目 錄
圖 2-1(a):主從式快取記憶體架構圖...5 圖 2-1(b):L1 快取記憶體 ...6 圖 2-1(c):主從式快取記憶體...6 圖 2-1(d):master和slave切換後的圖...7 圖 2-1(e):參數值的使用流程。...10 圖 2-2(a):主從式快取記憶體控制器三級管線架構圖。...11 圖 2-2(b):主從式快取記憶體預先存取流程圖。...13 圖 2-2(c):主從式快取記憶體操作流程圖。...14 圖 2-3(a):主從式快取記憶體的效能提升示意圖。...18 圖 2-3(b):PLC對主從式快取記憶體的效能提升示意圖。 ...20 圖 2-3(c):1k-entry時的比較結果。 ...21 圖 2-3(d):2k-entry時的比較結果。 ...21 圖 2-3(e):4k-entry時的比較結果。 ...22 圖 2-3(f):8k-entry時的比較結果。...22 圖 2-3(g):可利用主從式快取記憶體架構大幅改善的特殊例子...23 圖 3-1(a):VLIW架構多媒體訊號處理器的組成結構 ...27 圖 3-2(a):組譯器(Assembler)的用途...35 圖 3-2(b):圖形化介面組譯器(Assembler) ...36 圖 3-2(c):平行處理指令的使用...36 圖 3-2(d):利用倒寫管線以便用高階語言的寫法描述管線。...38 圖 3-3(a):智慧型DMA 的架構...42 圖 3-3(b):智慧型DMA的使用流程 ...43 圖 3-3(c):VLIW處理器與智慧型DMA的整合架構圖 ...44 圖 3-3(d):智慧型DMA與處理器及週邊的對應圖 ...45 圖 3-3(e):VLIW處理器存取智慧型DMA暫存器-記憶體對映...45 圖 4-1(a):晶片設計流程...47 圖 4-1(b):晶片佈局圖...49 圖 4-1(c):打線圖...50 圖 4-1(d):腳位圖...50圖 4-2(a):DCT-2 Post-layout Simulation的運算結果 ...53
圖 4-2(b):512 點FFT前 32 點的運算結果...54
表 目 錄
表 3-1(a):資料搬移指令列表...30 表 3-1(b):算數邏輯運算指令列表...31 表 3-1(c):跳躍指令列表...32 表 3-1(d):其他指令列表...32 表 3-1(e):智慧型DMA控制指令列表 ...33 表 3-3(a):智慧型DMA與DMA面積比較 ...41 表 4-1(a):合成的結果...48 表 4-1(b):晶片設計規格...51 表 4-3(a):與其他DSP的規格比較表 ...56 表 4-3(b):與DSP運算效能比較表 ...57第一章 緒論
1.1 簡介
現行大部分的處理器在加速的部分都是採取 Super-scale[1]的方式,配合 Tomasula's algorithm 做動態排程[9],以達到管線最佳使用效能。VLIW 架構受限 於程式的相容性,因此一度成為處理器設計領域的冷門架構。然而德州儀器後來 將 VLIW 的架構實現於要求效能的數位訊號處理器上,並成功地廣泛應用於多 媒體系統中。VLIW 架構之所以能在數位訊號微處理器市場中成功,除了它以簡 易的方式達到平行處理的目的[12][13],更重要的,在講求效能的數位訊號處理 上,使用處理器的韌體開發者大都會去把程式碼針對所使用的特定處理器進行最 佳化排程[2][5],以達到最好的執行效能。有些數位訊號處理器的程式開發人員 甚至會手動做調整以達到最大的指令平行度,這使得原先 VLIW 的缺點:相容性 及非動態排程都因為這個理由而消失了。而易於增加及減少處理核心的特點,在 現今講求 IP 化的 IC 設計領域變的十分具有優勢,這也是 VLIW 架構的處理器在 現今數位訊號處理器市場重新崛起的原因。 目前在現行大部份講求低功率、小面積的嵌入式處理器及數位訊號處理器中 [11],指令快取記憶體控制都還是採用 L1-Direct Map 的架構[30]。少部份高價位 的嵌入式處理器及數位訊號處理器則容許比較大面積的 L2 架構[19],不過這只 是為了讓快取記憶體在大容量上可作有效管理而產生的架構上的變化[22],在第 一層(L1)的快取記憶體的控制模式幾乎都還是採取 Direct Map 策略。然而傳統的 Direct Map 的控制方式在遠距離函式呼叫返回及在跨越快取記憶體容量邊際的 迴圈運算-也就是當只有部份指令在快取記憶體中的迴圈運算時,會發生大量的 cache miss,也直接的影響了 cache miss penalty。這對於常常使用函式呼叫及迴 圈運算的多媒體程式是十分不利的,如果沒有好的編譯器對指令作最佳化輔助
[4],那將會顯著的降低了原有處理器的效能。然而對於種類繁多的嵌入式處理 器市場裡,要開發出能針對不同使用者採用的不相同的處理器及該處理器配置的 不同大小的指令快取記憶體作最佳化的編譯器是相當不容易的,一般目前大部份 的嵌入式處理器的編譯器都還是只能針對特定的處理器進行指令的最佳化。
無論是在一般應用的嵌入式處理器(General Embedded Processor)[25]或是著 重於運算的數位訊號處理器(Digital Signal Processor, DSP)[24],cache miss 幾乎都 是影響效能的一個很大的因素。由於 cache miss 的 penalty 常常都是數千週期甚 至上萬週期,所以如果可以設計一個可以減少 cache miss 次數及總 miss penalty 的快取記憶體控制器,便可以有效的提升處理器的執行效能。
影響 cache miss 發生的原因通常是快取記憶體的 entry 數量,在一般 RISC 處理 器指令長度固定的情況下,快取記憶體的大小跟 cache miss 的次數會呈現反比例 的關係,這個現象在指令快取記憶體(I-Cache)中尤其明顯[27]。然而就單一處理 器於同一應用而言如果使用不同的快取記憶體控制器,由於在遇到 cache miss 時 的處理方法不相同,所以不能只由 cache miss 的次數判定效能而應由真正反映在 時間差異的 cache miss penalty 的週期數目來決定。對於比較不同的快取記憶體控 制器,cache miss 的次數多卻不一定會造成比較多的 penalty cycle 的這個現象是 要去注意考量的。 本論文設計了一個可實現於晶片中的快取記憶體控制硬體演算法並命名為 主從式快取記憶體控制器,並在這篇論文中以指令快取記憶體的控制作效能實 驗。此演算法使用在一般的應用程式均能有效的減少指令快取記憶體的總 miss penalty,而在具有大量迴圈運算及函式呼叫的多媒體應用程式中尤有顯著成效。 為驗證該演算法的可靠性及正確性,本論文也設計出一個 VLIW 架構的多核心 嵌入式處理器,以做為該指令快取記憶體控制器的作用平台。主從式快取記憶體 的設計具有以下的特點:
1. 具有保存跳躍前指令的機制:
相同於 L1 Direct Map 快取記憶體控制器所使用的快取記憶體的大小(這 裡指的是 entry 數目),主從式快取記憶體控制器將一樣大小的快取記憶體分 為數等分,大小相等的 sub-cache。每次當 cache miss 發生時,原先的指令保 存在當前提供處理器指令的 sub-cache 中,新的指令則取代掉最近最久未使用 (未使用即未提供處理器指令)的 sub-cache(LRU sub-cache),這樣的方法對於 跳躍後還會返回的程式 ex:Function Call,就不會造成二次的 cache miss。
2. 提供使用者對參數作最佳化設定的介面 主從式快取記憶體控制器針對與 L1 Direct Map 快取記憶體控制器使用 同等大小的快取記憶體作分割,每個 sub-cache 的大小只會是原本快取記憶體 大小的 1/n(假設切成 n 等分),如此會導致每次 miss 時補充的指令也會只有原 先的 1/n,在往後的執行反而容易因此造成 cache miss,這是這種設計的一個 trade-off[26],為了降低這個 trade-off 所帶來的影響,在此演算法中設定了一 個參數來讓使用者設定跳躍發生後經過多少個週期如果原先的跳躍還未返 回,就判定不會返回,而可以提前對存放原先跳躍前指令的 sub-cache 進行新 指令的取代,而這個參數可以利用處理器的模擬器先預先執行過觀察,或者 實際用處理器晶片進行測試利用 ICE 來進行觀察測量得到。另外,此指令預 先存取機制也可搭配處理器的 Branch-Prediction 機制一同作用[3]。 3. 方便用數位的方式對快取記憶體進行功率管理 常見快取記憶體降低功率的方法大都是在佈局圖上用 Full-Custom 的設 計方式來作規劃。而在主從式快取記憶體控制器裡,可以對每個 sub-cache 分別進行開關控制,也就是說除了正在使用的 sub-cache 需要將它的時脈打 開,其餘未使用的 sub-cache 可以將其時脈關掉,正在保存指令的 sub-cache
則可給予較低的時脈。用 gated clock 的方式來達成快取記憶體的功率控制, 如此就可以用數位的方式做到。相較於同等大小的 L1 快取記憶體,較常見 的方法還是在佈局圖上以 Full-Custom 的方式進行細步設計才能達到效果。
1.2 論文架構
本篇論文中,第二章介紹主從式快取記憶體控制器設計,從硬體架構到效能 測試有詳細的說明。第三章介紹主從式快取記憶體控制器與數位訊號處理器的整 合,從 VLIW 數位訊號處理器架構到開發工具製作,及週邊矽智產的整合。第 四章在介紹晶片實現的過程,包含模擬驗證方法及結果,晶片製作,及測試效能 的比較。最後,在第五章做總論。第二章 主從式快取記憶體控制器
本章介紹主從式快取記憶體控制器的設計,包含其原理、架構、效能測試、 特點及比較。2.1 主從式快取記憶體控制器原理
2.1.1 主從式快取記憶體控制器硬體演算法
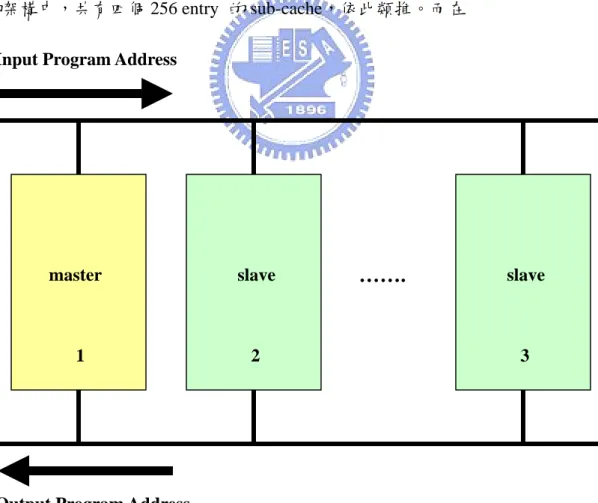
圖 2-1(a)為主從式快取記憶體的架構圖。主從式快取記憶體主要是把 L1 快 取記憶體的 entry 拆成若干等份。以一個擁有 1k entry 的 L1 快取記憶體(圖 2-1(b)) 為例,在分為兩個 sub-cache 的架構中,共有兩個 512 entry 的 cache,四個 sub-cache 的架構中,共有四個 256 entry 的 sub-cache,依此類推。而在Input Program Address
Output Program Address
master slave
…….
slave1 2 3
圖 2-1(b):L1 快取記憶體 本篇論文的架構裡sub-cache的個數一定是 2 的冪次方(2 ) (圖 2-1(c))。 1024/2n個 entry 圖 2-1(c):主從式快取記憶體 n 當一開始程式執行時,快取記憶體內還無任何指令。主從式快取記憶體從編 號第一顆的 sub-cache 開始填入指令,而編號第一顆的 sub-cache 也將成為最初提 供處理器提取指令的 sub-cache,在這個演算法裡,當下處理器提取指令的 sub-cache 稱為 master,其餘的 sub-cache 稱為 slave(圖 2-1(a)),這也是將此控制 器命名為主從式快取記憶體控制器的原因。舉例來說,1024 個指令將從程式記 憶體讀入,編號一的 sub-cache 將存入 512 個指令,編號二的 sub-cache 也將存入 下 512 個指令,依此類推。完成了整個快取記憶體的初始化後,快取記憶體發送 信號通知處理器表示可以開始接受處理器的讀取,讀取的方式有兩種,在省電模 式下是先比對目前被設為 master 的 sub-cache 的 Tag 部份是否有符合,如果符合 就將指令輸出,若沒有符合則恢復其餘被設為 slave 的 sub-cache 的工作頻率,並
平行比對目前所有被設為 slave 的 sub-cache 的 Tag 部份,如果有符合的便將該 sub-cache 設定為 master,原先的 master 設定為 slave,並將指令輸出至處理器。 而在高速模式下則是一開始就平行比對包含 master 及 slave 在內的所有 sub-cache 的 Tag 部份,符合的 sub-cache 設定為 master,原先的 master 設定為 slave,並將 指令輸出至處理器。舉例如編號一的 sub-cache 的 Tag 部分沒有符合,然而在編 g 有符合,則將編號二的 sub-cache 設為 master(圖 -1(d))。依上述演算法,在整個主從式快取記憶體的架構下,這種情況並不會造
真正的 cache miss,只是作為 master 的 sub-cache 改變了而已。 號二的 sub-cache 中的 Ta
2 成
Input Program Address
Output Program Address
slave master
…….
slave1 2 3
圖 2-1(d):master 和 slave 切換後的圖
當真正的 cache miss 發生時(意思是在主從式快取記憶體架構下的所有 sub-cache 都 miss),在 L1-Direct Map 機制裡,處理器被停下,等待 cache 將新指 令從指令記憶體讀取進來取代現在存放在快取記憶體的指令[18][20]。而在主從
式快取記憶體控制器的機制裡,處理器被停下,然後對最近最久未使用的 sub-cache(LRU sub-cache)作指令的取代。此外,觀察指令快取記憶體的存取特 性,由於指令都有地域性(locality)的現象,所以如果要在硬體中以比 RU 更簡 化的方式實現,又幾乎保持 LRU 的特性,可以選擇取代離 master 最遠的一顆 sub-cache。其理由為離 master 最遠的 sub-cache 應是對於現在執行的指令中地域 性最差的,自然有很高的機會成為 LRU。以演算法而言,也就是對 master 的 sub-cache 的編號後一顆的 sub-cache 作指令取代(若 master 已經是編號最後一顆 的 sub-cache,則取 L 代編號第一顆的 sub-cache,採用環狀排序)。舉例來說,若現 master 是編號第一顆,則對編號第二顆的 sub-cache 作取代,依此類推。而指 令取 所造成的 miss,未來如果又跳回原本的程式區間,在主從式快 取記憶體架構下就不會再次發生 cache miss,這種情況典型發生在函式呼叫和函 式返回及跨邊界的迴圈運算,然而在 L1-Direct Map 架構下,這種情況仍舊會發 c
2.1.2 使用者可調性設計
在代結束後,依據之前決定 master 的演算法,被 replacement 的那一顆 sub-cache 會成為 master。
由於是將原先 master 的後一顆 cache 作指令取代,所以原先的指令都還保留 在原本作為 master 的 sub-cache(即 miss 前作為 master 的 sub-cache)裡面。所以如 果是因為跳躍指令 生 ache miss。 主從式快取記憶體控制器有一個 trade-off 在於當主從式快取記憶體控制器 與 L1 Direct Map 快取記憶體控制器使用同等大小的快取記憶體作分割,每個 sub-cache 的大小只會是原本快取記憶體大小的 1/n(假設切成 n 等分)。這樣會導 致每次 miss 時補充的指令數量也會只有原先的 1/n,在往後的執行反而容易因此 造成 cache miss。為了解決這問題,做法是提供使用者設定一個參數(如果在實際 晶片應用,使用主從式快取記憶體控制器的晶片設計者必須留一組 I/O pin 以便
利於該晶片使用者將此參數由外部輸入至晶片或在應用程式中以軟體的方式進 行設定。),這參數的意義是跳躍發生後經過多少個週期如果還未返回,就判定 不會返回,而可以提前對存放原先跳躍前指令的 sub-cache 進行新指令的取代。 由於每個 sub-cache 都是獨立的,有自己的 I/O port,因此不同的 sub-cahce 間可 平行的作輸出入動作。例如在此情況下,作為 master 的 sub-cache 可以繼續對 處理 iss 但是其他的情況下 都可以有三百個週期作預先提取的動作,而可能因此避免大量因為快取記憶體空 不足所產生的 cache miss。上述提到取捨的情形,須以統計分析的方式去作權 2-1(e)。 以 器提供指令,而作為 slave 的 sub-cache 就可以與程式記憶體進行溝通,把新 的指令讀取進來。 判斷跳躍發生後經過多少個週期如果還未返回,就判定不會返回的這個參數 可以利用處理器的模擬器預先執行過觀察,或者實際用處理器晶片進行測試利用 ICE 來進行觀察測量得到。這裡提供一個基本的測量方式:先統計程式執行時發 生的所有的跳躍到返回之間的週期數,如果到下次發生 cache miss 前從未發生返 回,則該跳躍不列入統計。將有效的跳躍返回的週期數數據取最大值,則超過該 數值者必然不會發生返回,即為所須之參數值。然而這是最簡易直觀的測量方 法,但是量測出的參數卻未必是最有利的。考慮一種情況如:當幾乎所有的跳躍 返回週期數都集中在三百個週期以內,然而卻有一組是六百個週期,若為了那一 組將參數定為六百,則大部分的情況下都少了三百個週期可作指令的預先提取, 如果將參數定為三百,雖然有一組可能會因此發生 cache m 間 衡的,才能得到最有利的參數值。整個過程如圖
2.1.3 低功耗設計
方。相較於同等大小的 L1 快 憶體用數位的方式幾乎很難進行整塊快取記憶 的功率管理,比較可行的方 法還是要在佈局圖上以 Full-Custom 的方式細步調整才能達到效果,主從式快取先利用
simulator
執行過一
次,統計出
所有跳躍
後到返回
中間的週
期數。
再經由統
計分析,權
衡出最適
合的參數
數值。
最後晶片
使用者利
用程式化
的方式將
該參數值
設定至
Cache 控制
暫存器中。
圖 2-1(e):參數值的使用流程。 主從式快取記憶體控制器的另一項特點就是可以用數位邏輯的方式來作功 率的控制管理,以降低不必要的功率消耗,達到低功率的設計。由於主從式快取 記憶體裡每一個 sub-cache 都是獨立的,擁有自己的 I/O,因此可以對每一個 sub-cache 作個別的控制。一般快取記憶體降低功率的方法大都是類比策略,也 就是在佈局圖上用手動的方式來作規劃。而在主從式快取記憶體控制器裡,可以 利用開關邏輯的方式來達成快取記憶體的功率控制,也就是說除了正在使用的 sub-cache 需要將它的 enable 打開,其餘的 sub-cache 可以將其 enable 關掉,用開 關邏輯的方式來達成快取記憶體的功率控制。然而控制的方式也牽扯到作為快取 記憶體的元件特性,如果該元件有使用時脈,也可以用 gated clock 的概念對時脈 信號作控制,可以選擇降頻或關閉時脈信號(如:DRAM),然而有些元件這些操作 可能會導致儲存的資料流失,這是必須要注意的地 取記 體 記憶體控制器對於簡化低功率設計上具有優勢。2.2 主從式快取記憶體控制器架構
nous的SRAM Model,工作頻率配合處理器為135MHZ。此控制器為三 管線結構。第一級為控制級,負責sub-cache的主從地位仲裁,sub-cache預先讀 指令的決策,cache miss時與外部記憶體的溝通控制以及處理器發生中斷時的 變處理。第二級為Tag的搜尋比較 t時的資料讀取,將指令送往 理器。 圖 2-2(a):主從式快取記憶體控制器三級管線架構圖。2.2.1 程式初始指令讀取控制
程式剛開始執行時,快取記憶體內並沒有指令,所以需要從指令記憶體中 將指令讀取進來。讀取的方式是從編號第一顆的 sub-cache 開始,將所有的 sub-cache 都填滿指令,因此與 L1 的快取記憶體相比較,所容納的總指令數是相 的 本論文實作主從式快取記憶體控制器的RTL Model,記憶元件採用CIC提供 的Synchro 級 取 。第三級為當Hi 應 處Signal Control
Tag Compare
ge 2:Instruction Provide
Stage 1: Sta Stage 3: 下面將針對每一級中的重要元件的功能逐一介紹。 當 同 。初始化完成後,發送 Ready 信號給處理器,處理器的程式計數器才開始計 數。2.2.2 位置比較器
取記憶體entry數 1024=210,則 16-10=6,比較前 位。) 作比較,若相同則判定則Hit,由下一級將指令輸出至處理器。若不同 he的Tag作比較,若有相同,則將該sub-cache 設定為master,由下一級將指令輸出至處理器。若所有sub-cache的Tag都沒有吻 。2.2.3 發生 cache miss 時的處理
保留了原先發生跳躍前的指令。這樣的方法 於跳躍後還會返回的程式 ex: Function Call,就不會造成二次的 cache miss。而當 cache miss 時主從式快取記憶體控制器將發送 NOP 指令給處理器,因此 不需要其他的信號線來對處理器發出中斷,維持管線的流暢性及設計上的簡化, 當處理器的程式計數器開始計數後,計數值(Program Counter: PC)將會被送 到快取記憶體控制器中,快取記憶體控制器依照PC後幾位的值 (位數由快取記憶 體大小所決定,如 1024 個entry則看後 10 位,為 2 的次方數。) 去讀取Tag值與 PC值的前幾位 (位數由快取記憶體的大小和程式記憶體的大小作決定,如程式記 憶體的entry數是 65536=216,快 六 則將程式計數器的值與其餘的sub-cac 合的,則為發生cache miss cache miss 一旦發生,主從式快取記憶體將把新的指令讀進最近最久未使用 的 sub-cache(LRU sub-cache),因此 對 在發生跳躍後,依據 2.1.2 的使用者可調性設計,跳躍後到達使用者設定的參數 值的週期數,則會執行預先存取指令的動作,將存放跳躍前指令的 sub-cache, 做為新指令的取代(如圖 2-2(b))。 一直到快取記憶體的指令更新完畢,才會重新由發生 Miss 的 PC 所對應的指令 開始送出至處理器,同時有信號通知處理器的程式計數器可以重新開始計數。
2.2.4 處理器中斷時的處理
處理器中斷時,主從式快取記憶體控制器將把現在的 PC 值記錄起來,而輸 指令會維持在 NOP 指令,一直等待處理器的中斷解除,才會由發生中斷的 PC 置開始重新執 存取。操作流程如 。 圖 2-2(b):主從式快取記憶體預先存取流程圖。 出 圖 2-2(c) 位 行快取記憶體的……
master
sub-cache
Program Memory Processorsu
Instruction Load Instructionb-cache
PC input
Cache miss and prepare to load new instructions Send instruction
to processor and set the sub-cache master Send instruction to processor Instruction provide N Y Instruction Memory Processor Core Slave sub-caches hit? Y N Master sub-cache hit? Tag Search Interrupt Processing Instruction Pre-Load Cache Initial Cache Control 圖 2-2(c):主從式快取記憶體操作流程圖。
2.3 主從式快取記憶體模擬器
為了驗證比較主從式快取記憶體控制器與 L1-Direct Map 控制器的效能差 異,除了 RTL Model 外,本論文中也以 C++語言製作了兩者的模擬器,並製作 了測試程式產生器(Testbench Generator),以方便自動的大量驗證比較效能。2.3.1 主從式快取記憶體與 L1 快取記憶體控制模擬器
為了比較兩者的效能,必須先整理出快取記憶體本身會影響效能的參數,首 先針對要比較的 L1 架構的 cache 定出下列參數。 L1_Cache_Size L1 cache 的大小。L1_Cache_Line_Size L1 cache line 的大小。
L1_Cache_Entry_Amount L1 cache 的 entry 數目。 N_Way N-Way associative 的 L1 cache。
其中 L1_Cache_Entry_Amount = L1_Cache_Size / L1_Cache_Line_Size, N_Way=1 時為 Direct Map 架構,由於 L1 的架構也有可能是 N-Way associative 的架構,因此在模擬器實驗中也一併比較。
接下來針對對應的主從式快取記憶體架構定出以下參數:
MS_Cache_Amount 主從式快取記憶體架構下的 sub-cache 個數。 MS_Cache_Line_Size 主從式快取記憶體架構下每個 cache line 的大小。 MS_Cache_Entry_Amount 主從式快取記憶體架構下每個 cache 的 entry 數
其中在一般情形下 MS_Cache_Line_Size = L1_Cache_Size,
而 L1_Cache_Entry_Amount = MS_Cache_Entry_Amount * MS_Cache_Amount。
以上是跟本身快取記憶體的大小結構等有關的參數,然後測試程式本身的特 性也會影響執行的效能結果,因此測試程式產生器必須能產生不同特性的測試程 式,才能作準確的分析,與測試程式相關的參數將在下一節中作介紹。
2.3.2 測試程式碼產生器
本論文也以 C++語言開發出了一個測試程式碼產生器,以便產生出具有不同 特性的測試程式。測試碼產生器將針對下列的參數作隨機種子,產生出具有各種 特性的測試程式: Code_Size 測試程式的長度。 General_Jump_Freq 平均多少個指令會發生一次跳躍。 General_Jump_Depth 平均每次跳躍的深度距離。 General_Jump_Freq_Off 為避免跳躍太頻繁的一個 offset,確保幾個指令以後 才會發生一次跳躍。 General_Jump_Freq_Upp 為避免跳躍太久未發生的一個參數,表示至少多少 個指令應該發生一次跳躍。 CR_Ratio 有返回動作的跳躍在程式跳躍指令中佔的比例。2.3.3 效能指標
模擬器每執行一個測試程式,就會記錄與效能有關的結果參數,如下 :MS_Cache_Miss_Times master-slave cache miss 的次數。
MS_Cache_Penalty_Cycle master-slave cache miss 所造成的 penalty cycle 數。
L1_Cache_Miss_Times L1 cache miss 的次數。
L1_Cache_Penalty_Cycle L1 cache miss 所造成的 penalty cycle 數。
如前 1.1 節所述,對於不同的快取記憶體控制器,不能只以 cache miss 的次 數作為效能的判斷依據,所以最終效能的判斷是用 cache miss penalty 的週期數來 決定。
2.3.4 效能測試
本論文利用測試程式產生器產生大量的測試程式來進行效能測量,測量時參 數跟本論文實際發展的晶片使用的參數完全相同,如下: L1 快取記憶體大小:2k x 64 (bit) 主從式快取記憶體大小:2k x 64 (bit) 主從式快取記憶體 sub cache 個數:2 sub cache 大小:1k x 64 (bit)測試程式個數:20000 筆
測試程式碼大小上限:32768 行
測試程式碼執行週期數上限:2000000 cycles
本論文的效能測量的觀察,如圖 2-3(a),為在不同 CR_Ratio (有返回動作的 跳躍在程式跳躍指令中佔的比例。)的測試程式中,使用主從式快取記憶體控制
器對於使用 L1-Direct Map 快取記憶體控制器的效能增進百分比,在此將主從式 快取記憶體架構整體的效能提升參數定義名稱為 Eff_Improve,其計算方式如下: Eff_Improve=(L1_Cache_Penalty_Cycle - MS_Cache_Penalty_Cycle) / L1_Cache_Penalty_Cycle (2.1) 圖 :主從式快取記憶體的效能提升示意圖。 觀察模擬結果,可發現 與 呈現正成長的關係,當 的值越大,也就是 式快取記憶體的架構的效能提升也就越大。此外,即使 CR_Ratio 的值很低,主 L1-Direct Map 快取記憶體架構,換句話說主 從式快取記憶體在任何的測試程式情形下,效能都還是優於或等於 2-3(a) CR_Ratio Eff_Improve
CR_Ratio function call/return 的現象越明顯的測試程式,主從
從式快取記憶體架構的效能仍不輸
L1-Direct Map 的快取記憶體架構。
深入對模擬曲線進行分析,發現 CR_Ratio 與 Eff_Improve 雖是正成長,但 是卻不是 1:1 成長,也就是 CR_Ratio 成長 10%,Eff_Improve 卻不會也跟著成 長 10%這麼多,這裡與模擬前預估的情況有差異。探究原因後發現,在跳躍發生 call/return 區間在 L1 cache 的 size 以內會使 CR_Ratio 高可是效能上卻看不出(即 確實有 call/return 發生,但是因
的
為 L1 本身不會 miss,所以效能上看不出。)。這 種跳躍在每個測試程式中的跳躍比例佔了越 20%~60%,自然的造成了 CR_Ratio
1 成長。
re-fetch Load Count),針對主從式快取記憶體控制器使用 PLC 及不使用 PLC 的
消弭 sub-cache 的個數增加導致每個 sub-cache 的大小縮減所帶 的 trade-off( 因 為 L1_Cache_Entry_Amount = MS_Cache_Entry_Amount *
MS_ 改進及 sub-cache 的 大 小 的 關 係 。 因 此 使 用 PLC 的 改 善 比 例 參 數 定 義 名 稱 為 Eff_Improve_by_PLC,其中: Eff_Improve_by_PLC= (MS_Cache_Penalty_Cycle_No_PLC - MS_Cache_Penalty_Cycle) / MS_Cache_Penalty_Cycle_No_PLC (2.2) MS_Cache_Penalty_Cycle_No_PLC : 主從式快取記憶體未使用 PLC 時的 Miss Penalty Cycle。 圖 2-3(b) 與 Eff_Improve 無法 1: 本論文針對使用者輸入預先存取參數(詳見 2.1.2)定一名稱為 PLC (P 結果作一比較,以觀察 PLC 為主從式快取記憶體所帶來的增益。由於 PLC 當初 的設計目的是為了 來 Cache_Amount,詳見 2.3.1。),所以觀察重點放在 PLC 帶來的效能 是當使用不同的 sub-cache size 時所展現出式(2.2)的結果。
圖
況發 大小較小,每次能預先存取的指令數也較少。),整體的主從式 取 架構的 Miss Penalty 會開始高於 L1-Direct Map 快取記憶體架構的
Miss Penalty,因此晶片 b-cache 大小及個數
時便可以此現象為重要的參考指標。
本論文也針對一般嵌入式處理器常使用的快取記憶體大小,在 General Case 下針對不同個數的 sub-cache 的情形作比較。實驗中快取記憶體大小分別為 1k-entry(即 cache line 總數為 1k),2k-entry,4k-entry,8k-entry,在 20000 筆測試 程式中,分別對 sub-cache 的個數為 2,4,8 的情形作測試。每筆測試程式都會 跑過 sub-cache 的個數為 2,4,8 的情況,然後統計每種情形下擁有幾次最少的 cache miss Penalty 的測試程式筆數。圖 2-3(c)~圖 2-3(f)是模擬後的結果。
2-3(b):PLC 對主從式快取記憶體的效能提升示意圖。
結果如預期,當 sub-cache 本身的 size 越小,PLC 平衡此 trade-off 的功能越 顯著,然而此模擬也觀察出了一個現象,當 Eff_Improve_by_PLC 的值超過 50% 時,即使使用了 PLC,預先存取的速度還是略嫌不足(其原因為,由於此情 生於 sub-cache 的
快 記憶體
1k-entry: 圖 2-3(c):1k-entry 時的比較結果。 2k-entry: 圖 2-3(d):2k-entry 時的比較結果。 4k-entry:
圖 2-3(e):4k-entry 時的比較結果。 8k-entry:
圖 2-3(f):8k-entry 的比較結果。
比較以上結 ,可知在 1k 及 2k 的時候,以拆成兩顆
sub-cache 為在 general case cache miss alty 最少的。在 entry 數為 4k 的時候, 則是拆成 4 顆為最少的,8k 時候則為 8 顆。在本實驗裡可發現,在 general case 下每個 sub-cache 1k-entry 表現為最好。 時 快取記憶體 entry 數在 下 Pen 的 果 的大小以
接下來本論文將針對一個常見的特殊情形進行探討,以便明確的突顯主從式 快取記憶體的優勢,考慮下列的情形 :
For(i=0;i<100;i++)
{
圖 2-3(g):可利用主從式快取記憶體架構大幅改善的特殊例子 當函式 在記憶體位置較遠,且函式內容較大,而被呼叫時無法和主程 , ,所以會被反覆呼叫,而迴圈前 後又還需要處理主程式的運算,所以會造成反覆大量的 ,本論文也針 對此 做了測試,得到結果如下: L1_Cache_Penalty_Cycle : 997376 S_Cache_Miss_Times : 3 enalty_Cycle : 768 的工作,而使用主從式快取FFT(x,y,z)
}
…… ……
FFT 式同時被放進快取記憶體中 由於又在迴圈內部 cache miss caseCall Return Ratio : 0.995754 L1_Cache_Miss_Times : 974
M
MS_Cache_Miss_P Eff_Improve : 0.99923
由此結果發現,在主從式快取記憶體的架構下,cache miss 的次數及 Penalty Cycle 都大幅減少,以致於 Eff_Improve 大幅提升。此例在數位訊號處理的應用 中尤其常見。而在現行大部分的處理器遇到這樣的情形,大都是仰賴高性能的編 譯器對迴圈進行展開(loop unrolling)及重組指令間的相對位置來減少 cache miss 的發生,然而性能佳的的編譯器研發並不是一件容易
記憶體架構就可以自然的去處理掉這種會造成重複且大量 cache miss 的情況,提 解決方法。 個 sub-cache 的 Enable 及 CLK 進行控制, 達到功率的控管。然而由於在不同大小的快取記憶體,使用目前已研究出的各 未再 耗設 由於在嵌入式處理器中,L1 指令快取記憶體的架構幾乎都還是以 Direct-Map Direct-Map 的架構,然而若 的架構作比較 ,主從式快取記憶體仍舊具有以 下 N-W 1) N- 架構的搜尋時間長,以 4-way 而言,每次要循序搜尋四個
cache line(entry),而主從式快取記憶體架構可以平行搜尋每個 sub-cache,即 e 個數增加也不會因此延長處理的時間。 架構相較於主從式快取記憶體架構,比較困難用數位的方 式管理 架構 只有一組 為單一顆 供了另一種硬體上的
2.3.5 功率管理
如 2.1.2 節所述,主從式快取記憶體架構中由於每個 sub-cache 是獨立的,有 各自的 I/O,因此可用邏輯的方式對每 來 種數位的低功耗設計方法[13][16],可能都會有不同的效果表現,因此本論文並 深入對此進行探討,而是留作另一個研究主題,對各種已研發出的數位低功 計方法搭配主從式快取記憶體架構進行比較。2.3.6 延伸比較
的方式。因此本論文硬體實作上的對照組也是採取 延伸探討與 N-Way Associative [33] ay Associative 所沒有的優點: Way Associative 使 sub-cach 2) N-Way Associative power。記憶體架構每個 sub-cache 都是獨立的 pin,因此主從式快取記憶體架構可以 平 行 的 做 指 令 的 預 先 存 取 工 作 且 不 必 中 斷 正 在 做 指 令 輸 送 給 core 的 sub-cache[14]。
2.4 結語
本章節針對主從式快取記憶體架構以及 L1-Direct Map 快取記憶體架構比較 兩萬組 general case 的測試程式。觀察出在測試程式發生跳躍返回比例(CR atio)越高的情形下,主從式快取記憶體的表現越好,然而在跳躍返回比例(CR atio)很低的情形下,主從式快取記憶體的表現依舊優於或等於 L1-Direct Map取記憶體的表現。另外也對主從式快取記憶體在不同大小(1k entry~8k entry) 快取記憶體空間的情形下對兩萬組 general case 的測試程式做比較,得出在不 大小的快取記憶體空間的情形下,如何切割 sub-cache 的 size 為最佳方法。 了 R R 快 的 同
第三章 多核嵌入式處理器
主從式快取記憶體控制器硬體地位上為一 IP,不能單獨存在運作,需搭配 一個處理器。因此,本論文也製作出一個 64 位元超長指令集架構(VLIW)處 理器核心,以呈現完整的應用。以下章節將說明此超長指令集架構處理器的特 性、指令集、軟體開發環境及可搭配的其他 IP 作一介紹。3.1 VLIW 處理器架構
本 論 文 設 計 的 VLIW 訊 號 處 理 器 擁 有 七 級 管 線 架 構 的 設 計 , 為 一 個 Multi-co e 和 Multi-Ram 的處理器 IP,Multi-core 可以是 DSP 運算單元、或微控 (Program counter)抓取進入處理器內部後, 會先進入預先解碼(Pre-decoder),在這一級將一個 64bit 的 VLIW 長指令做拆解,成為 2 節)來規劃,組譯器及處理器直接支援智慧型 DMA 的設定及使 用,周邊裝置(或 IP)可利用標準的 APB 格掛上匯流排,將外部的取樣訊號透 過智慧型 DMA 輸出,架構如圖 3-1(a)。
3.1.1 V
VLIW 斷模組/指令抓取模組、快取記憶體模組、指令預解碼模組、指令解碼模組、暫 存器模組、 r 制單元。當一個指令透過程式計數器兩個 3 bit 的指令,並決定兩個 32bit 指令分別應該進入哪一個 core 中執行。 當指令進入某一個核心時,會先對該指令進行解碼,接著到暫存器提取所需要的 資料到 ALU 中執行,最後將結果存回暫存器或記憶體中。周邊裝置的存取透過 智慧型 DMA(3.3 規 ,將資料儲存在內部記憶體,或內部運算的結果送到周邊裝置上
LIW 處理器核心
架構訊號處理器擁有七級管線架構,七級管線包含程式計數/跳躍判 算數邏輯單元模組及隱含的寫回級,以下分別描述其主要的工作簡述如下:
架構多媒體訊號處理器的組成結構
1. : ,目
Instruction Fetch/ Program Counter / Branch Predict
Cache
Instruction Pre-decoder
Core A Core B
Instruction Decoder Instruction Decoder
Register File Register File
ALU ALU Smart DMA RAM_A RAM_B APB I2S 圖 3-1(a):VLIW
的是把程式計數器加一,並處理跳躍,最後決定程式計數器的值。再把 程式計數器的值,轉成程式記憶體的位址,送進下一級的快取記憶體去 抓取指令。其中,由於有些指令在 ALU 級時會需要處理中指令的程式 表示現在的管線是否在 Stall 狀態,決定要不要執行該級動作。 指令為 64-bit,然而若快取記憶體模組本身有切級, 則實際管線總級數必須將快取記憶體模組的級數也一併作計算,以本論 此 VLIW 訊號處理器,則總級數為九級。 下面的兩個處理器核心做運算。 則,所以當增加新的 IP 處理核心,尤其 判斷,指令碼的提前抓取也很方便 的動作。 碼去做解 碼,指令中有兩個來源暫存器的位置,一個目的暫存器的位置。這些位 置可以對下一級的暫存器組取得來源運算元並提供未來 ALU 級寫回的 料的直接交換。由於此處理器整 合智慧型 DMA 模組的設計,因此新增一些智慧型 DMA 控制指令。還 慧型 DMA 一組存取控制暫存器的位址訊號線,以決定智慧型 計數器值,所以必須把程式計數器值一級一級地傳下去,因此,程式計 數器值會傳進下一級的暫存器。在處理跳躍指令時,為了避免浪費跳躍 指令發生後一個指令被抓取,設定兩個訊號做為防止跳躍發生時的指 標,用以 2. Cache:將 PC 位址傳到快取記憶體去抓指令,其中 PC 的位址線為 16-bit,傳回 VLIW 文所使用的主從式快取記憶體架構為例,由於快取記憶體控制器架構為 三級,因此若搭配
3. Instruction Pre-decoder : 這一級的目的是把一個 64-bit 的 VLIW 長指
令,切割成兩個 32-bit 的指令分別交給 由於整個設計都是朝 IP 化的原 是新增不同類的處理器核心時,本級電路會判斷不同的指令運算適合什 麼樣的核心去處理。指令碼也在此級被抓取,判斷怎樣的指令要交給哪 一個處理核心執行需要指令碼去進行 在下一級的指令解碼器中做作解碼 4. Instruction Decoder:這一級的目的是把指令依照對應的指令 目的位置。內建兩組處理核心,所以也提供了指令去從兩個處理核心中 互相提取對方暫存器組的資料,方便資 需提供智
DMA 的控制參數要寫到哪一個智慧型 DMA 控制暫存器內。 F 處理核 用暫存器。 核心(core A) 暫存器 中斷、內部優 、與其他 P 狀態設定所使用的 regi 2 讀 1 寫的格式,負責提供 碼器所解 來源運 級算出的目的運算元寫 。在此模 有很多 組的輸出信 的是把這些 U 級要 號經由 級中,利用這些信號來完成 ata forwa 動作。 ALU:本級功能是計算出邏輯或運算值,為了 Data 作, Data memo ite back U 級內 forwarding 的
利用 一級傳 成,目 RAW
ack U 或 M g File 的動 LU 寫入
M
除了以上基本的管線模組設計外 包含以下五種說明:
1. Bit Reverse:針對 FFT 運算所增加的 memory 定址模式[34],例如位址
: 數位訊號處理運算中有很多固定次數迴圈的 運算,利用一個良好的跳躍預測(Branch prediction),使處理器不會有 Control hazard 造成的不必要 Stall。
4. Data Forwarding 機制。 測採用 Prediction-untaken 方法設計。 5. Register ile : 每個 心有 32 個通 主處理 有額外的 16 個中斷 來處理外部 先權中斷 I ster。暫存器組為 解 碼出的 算元值,並將 ALU 回 組中, 連接 ALU 級模 號,目 AL 用到的信 管線級送往 ALU D rding 的 6. forwarding 的實 ry 及 Wr 這兩級隱含在 AL 。Data 機制是 前面一級 回的信號實作而 的是為了減少 hazard。 7. Write-B :由 AL emory 寫回 Re 作,或由 A DMA 或 emory。 ,還有一些特殊硬體設計需求被強調出來, (01101)可被轉成(10110)的位置儲存。 2. 一個指令週期完成乘加運算。
3. Regular Loop Prediction
良好的
3.1.2 VLIW 處理器指令集
處理器指令集共分五大類:資料搬 算、跳躍指令、其 、智慧型 DM ,列表如下: 指令 : VLIW 移、算數邏輯運 他類指令 A 控制類 資料搬移Instruction Opcode Example Mode
MOVRC 000001 MOV rd,data Direct
MOVRR 000010 MOV rd,rs Reg-Reg
MOVRM 000011 MOV rd,address Direct MOVMR 000100 MOV address,rs Direct MOVMRR 000101 MOV @rs2,rs Indirect
MOVRRM 000110 MOV rd,@rs Indirect
MOVARR 100010 MOV rd(a),rs(b) Reg-Reg MOVB 101111 MOVB rd,base(rs) Displacement
MOVI 110000 MOVI rd,rs1(rs2) Index
MOVREVRM 101010 MOV rd,address Bit Reverse MOVREVMR 101011 MOV address,rs Bit Reverse MOVREVMRR 101100 MOV @rs2,rs Bit Reverse MOVREVRRM 101101 MOV rd,@rs Bit Reverse
(a):資料搬移
IW 處理器共提 t、Reg to Reg、 t (base add)、
表 3-1 指令列表
Index、 Bit reverse 六大類的定址模式,其中 取不同處理 的通用暫存器的
算數與邏輯運算指令 :
MOVARR 可以互相提
器核心 內容。
Instruction Opcode Example
ADDRR 001000 ADD rd,rs1,rs2
SUBRR 001010 SUB rd,rs1,rs2
MULRR 001100 MUL rd,rs1,rs2
ADDRC 000111 ADD rd,data
SUBRC 001001 SUB rd,data
MULRC 001011 MUL rd,data
MACR 100111 MAC rd,rs1,rs2
MACC 110001 MAC rd,rs1,data
ANDRR 001110 AND rd,rs1,rs2 ORRR 001111 OR rd,rs1,rs2 XORRR 010000 XOR rd,rs1,rs2 INVR 010001 INV rd,rs 表 3-1(b):算數邏輯運算指令列表 跳躍指令 :
Instruction Opcode Example
JMP 010010 JMP address
JBE 010100 JBE rs1,address
JNE 010101 JNE rs1,address
JMB 010110 JMB rs1,address
JLB 010111 JLB rs1,address
JBER 011000 JBER rs1,rs2,address
JNER 011001 JNBR rs1,rs2,address
JMBR 011010 JMBR rs1,rs2,address
JLBR 011011 JLBR rs1,rs2,address
CALL 100011 CALL address
RET 011110 RET
表 3-1(c):跳躍指令列表
Address 的部分也可以是 Label,組譯器會自動轉換成對應的位址。 其他指令:
Instruction Opcode Example
SET 011100 SET A,rs
INTOK 011101 INTOK
SHR 100000 SHR rs
SHL 100001 SHL rs
Instruction Opcode Example
LOOP 110010 LOOP 100
END_LOOP 110011 END_LOOP
ENDC 011111 ENDC 表 3-1(d):其他指令列表
SET 指令是當 VLIW 處理器沒有連接匯流排時,利用這指令可以設定兩個 16-bit 的 I/O port ,與外界溝通;INTOK 是處理軟體中斷的指令,利用這指令可 發出軟體中斷;SHR 將 rs 向右移一位元;SHL 將 rs 向左移一位元。LOOP 與 END_LOOP 則是迴圈控制指令,LOOP 後面的數值為迴圈重複的次數。
智慧型 DMA 控制相關指令 :
Instruction Opcode Example
SDMAD 100100 SDMAD data
SDMAR 100101 SDMAR rs
GDMA 100110 GDMA rd
DMAOK 101001 DMAOK
GDMAR 101110 GDMAR rd,address
處理器暫存器內的數值來設定智慧型 DMA 的控制暫存器。 GDMA 指令則是以一個處理器暫存器的值來存放一個智慧型 DMA 是否已經做 完的旗標。DMAOK 指令是智慧型 DMA 的所有控制暫存器都設定完以後,產生 通知智慧型 DMA 可開始運作的信號。GDMAR 指令則是將智慧型 DMA 的結果 暫存器的值放入處理器暫存器中。
表 3-1(e):智慧型 DMA 控制指令列表
SDMAD 指令是以 10 進位數值的方式直接設定智慧型 DMA 的控制暫存器。 SDMAR 指令則是以
3.1.3 子核心特色
主核心除了資料的搬移及運算外,同時可處理分支跳躍、外部中斷、內部優 先權中斷、與其他 IP 的狀態設定。而副核心只拿來處理運算及資料搬移指令, 可以需求自由的增加副核心數量,為 flexible n-core parallel processor[32]架構,每 個 core 的 Reg 可互相存取。
3.1.4 不同子核心間的資料讀取與寫入
當運算完成後,必須將運算結果寫回 的來源有兩
個:本身的 core,其他的 core。在本論文裡,要將自己的 core 的運算結果寫入 至其他的 core 中,必須使用指令 MOVARR,而優先權上,若發生本身的 core 及
其他 core 同時發生寫入的現象,則以本身的 的寫入為優先,同時並發送中 斷信號給其他的 core。 邏輯上出現此一情況,而開發工具發現程式設計者寫出這樣的程式也應會發出警 示訊息。
3.2
3.2.1 組譯器
硬體設計外,處理器的軟體支援是相當重要,為此發展了圖形化介面的組譯 器(Assemb ),提供機械碼(Machine code)的轉譯、程式記憶體(Program rom) 的產生、及錯誤資訊(Debug information),讓使用者能夠利用以上資訊來除錯產生Testbench。
Reg File,而寫回 Reg File
core (然而理論上不應該會有此情形發生,程式設計者應避免 )
軟體開發環境
ler 及Assembler Data Rom Machine Code Debug Information Testbench Assembler Assembler Data Rom Data Rom Machine Debug Code Information Testbench Testbench 圖 3-2(a):組譯器(Assembler)的用途 圖型化介面組譯器如下圖,使用 Visual C++完成演算法部分,使用 VB 做組 譯器的圖形介面,並用 dll 作連結,並提供編輯檔案的能力。當完成編輯檔案後, 須先經過 compile 的動作,確保無錯誤產生。最後經由 Build 的動作,產生所需 :產生十六進位的程式碼,提供晶片測試的資料。 :產生程式記憶體的資料,提供模擬及後續測試必備的資料。 的檔案: pop.txt bin.txt
Compile
Build
Directory
File list
Message w
Edit area
indow
圖 3-2(b):圖形化介面組譯器(Assembler) VLIW 處理器使用超長指令集的設計核心,在編寫程式及組譯時須注意: 平行處理:平時以處理核心 B,則需在兩 指令間加上分隔符號『||』,若不需有處理核心 A,則須指令 B 前加上 『NOP』指令,如下圖: 圖 3-2(c):平行處理指令的使用 A 為主,若需使用處理核心Instruction A
||
Instruct
ion B
||
Instruction B
NOP
3.2.2 計次性迴圈的處理
在數位訊號處理的應用中,for迴圈是非常常見的,for迴圈的特性是只要是 在迴圈次數內,則每次都會跳躍至迴圈開始處,因此不同於一般的conditional 每次要去判斷是否要跳躍,像for迴圈這種regular loop,可以不經判斷而在 ,而減少管線在跳躍處理上造成的Penalty Cycle。 本論文開發出的組譯器遇到 指令時,會去計算LOOP到END_LOOP間 的指令數,然後將此數值與迴圈要重複運行的數值都編入機械碼中,處理器內部 有兩個counter分別存入這兩個數值。存放LOOP到END_LOOP間的指令數的 ounter此時會控制程式計數器,以避免抓取到END_LOOP以後的指令而影響效 存放迴圈重 counter則提供處理器跳離迴圈的依據。本論文就是以 軟體聯合硬體的方式來解決計次性迴圈[10],這樣的方法與常見的Hardware Loop 解3.2.
本論文也針對該處理器以高階語言(C++) simulator,以便能快速 驗證各種測試程式。而寫這樣的模擬器困難的地方就是在於要拿一個本身沒有平 行處理概念的語言 C/C++,去模擬一個有平行處理概念的管線。本論文製作的模 擬器採用的設計方式是類似 software pipeline 的觀念將程式每個 iteration 倒著選 一個指令然後送到硬體去循序。由於 code 是循序的。所以如果把要用來處理管 線的迴圈倒著寫的話,就可以達到該效果,以一個五級的 RISC 管線架構為例, branch 每次的迴圈尾就直接返回迴圈頭 LOOP 會 c 能,而 複次數的 的 決方式也是不相同的,然而都可以達成目的。3 模擬器
設計了一個如下圖所示:
//級五 Write Back
以便用高階語言的寫法描述管線。
這種實作方法類似在資訊科學領域演算法中 tail-recursion 的概念,遞迴的時 候會發現把處理動作倒著寫會較好處理,因為遞迴本身是用到先進後出的堆疊, 邏輯上和 software pipeline 作 iteration 的取樣很相似。
利用此模擬器可以得到每個測試程式在每一個cycle時暫存器及記憶體的內 容,並計算hazard Penalty Cycle個數,方便對程式開發者進行效能
For(cycle++) { //級四 ALU . … //級一 Fetch } …. … //級三 Reg_File . //級二 Decoder …. …. 執行方向 圖 3-2(d):利用倒寫管線 個數及總共的 上的分析,也方便除錯的工作。
3.3 智慧型 DMA 控制器
3.3.1 智慧型DMA控制器功能
DMA 僅有連續資料傳輸及透過 LLI(Linked List Item)不連續資料傳 ,並且支援四種傳輸模式,記憶體到記憶體、記憶體到周邊、周邊到記憶體、 周邊到周邊。針對目前 控制器的研 著重在傳輸效率的提升和通 訊應用層面。為了使得記憶體內資料的提取及運算更有效率[29],因此,本處理 器搭配了實驗室開發的智慧型 DMA 控制 2005 年由蘇育緯製作並發表碩士 論文:智慧型直接記憶體存取器設計[38 用 DMA 有控管大量資料的特性及 結合 DMA 資料傳輸與數位訊號處理能力的 IP[15],有效率地輔助一般訊號處理 器做解決大量資料 試後發現,本處 器和智慧型 DMA 的結合,可達成具有 DSP 的工作能力。智慧型 DMA 的主要 (a)應 仍必須將所有資料搬入記 憶體中來處理,既沒有效率又佔用匯流排的頻寬。本論文提出的智慧型 DMA 改 善原始 DMA 傳輸設計,並提供四種定址方式有效處理資料搬移問題: 本處理器搭配有本實驗室研發的智慧型 DMA 控制器,下面將針對該控制器 的功能,架構,使用流程,作一簡介,詳細內容請參考本實驗室畢業之蘇育緯學 長於 2005 年發表的碩士論文:智慧型直接記憶體存取器設計。 傳統 輸 DMA 究[17],僅 器(於 ]。)利 排序與大量乘加(MAC)運算功能[37],經測 理 設計特點如下: 用上支援廣泛的 I/O 系統,並有效率地處理資料流: 多媒體訊號處理需要有大量的資料流做為輸入輸出,因此必須設計一個 DMA 模組,支援匯流排結構,並對 I/O 進行大量資料移動、緩衝及控管的工作。 一般的 DMA 僅支援連續資料傳輸,因此在處理數位訊號資料時顯得沒有效率, 若只需要移動資料的一半(如: down sampling 動作),
增/遞減定址法(Increasing/Decreasing Addressing) 環狀定址法(Circular Addressing) 鏡射定址法(Mirror Addressing) 索引 (b)輔助 DSP 運算的 Co-processor: 智 慧 型 DMA 控 制 器 內 建 了 一 組 乘 加 運 算 器 ( multiply-and-accumulate, MAC),搭配上述四種定址法,使得只能處理資料傳輸的 DMA 提升到運算的層 次,如:DCT、FIR、DWT…等運算[7]。
DCT:Mirror + Index-based + Increasing Addressing DWT:Increasing + Decreasing Addressing
FIR:Increasing + Decreasing Addressing
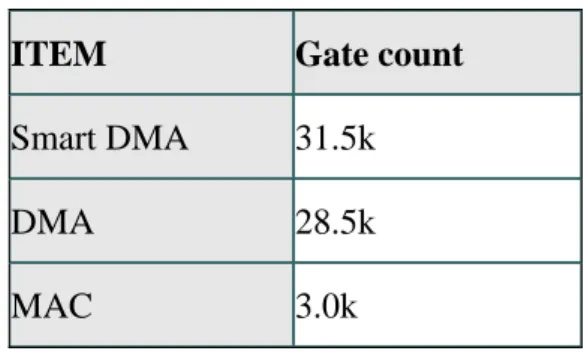
(c)增加少量硬體成本達到 DSP 效能: 智慧型 DMA 支援雙通道資料記憶體快速向量運算[21],擁有直接存取兩個 記憶體的能力,且在 I/O 匯流排上支援 APB 匯流排的標準[8][31],使用者能夠 在周邊匯流排上加掛相容 APB 介面的周邊裝置,擁有記憶體到記憶體、記憶體 到周邊、周邊到記憶體、周邊到周邊四種傳輸模式。如表 3-3(a),加上 MAC 運 算單元後,僅增加 10%的 Gate Count,成本相當低。 遞 定址法(Index-based Addressing) 透過以上四種定址法的組合,達到選取有效資料,排除無效的資料,降低頻寬的 使用,並提高資料傳輸的效率及降低處理器的負擔。
ITEM Gate count
Smart DMA 31.5k
DMA 28.5k MAC 3.0k
表 3-3(a):智慧型 DMA 與 DMA 面積比較
3.3.2 智慧型 DMA 控制器架構
一般的 DMA 與智慧型 DMA 架構的差別在於後者在通道控制器對定址法的 支援、內建 MAC 運算器、因應不同功能的暫存器組、不同匯流排的支援和直接 支援雙記憶體 ,包含通道 控制器、優先權仲裁器、暫存器組、乘加運算器、中斷控制器及記憶體介面[23], 其設 的介面等[36]。智慧型 DMA 整體架構設計如圖 3-3(a) 計方法參閱智慧型直接記憶體存取器設計[39]。Grant1 Grant0 Source Register bank 圖 :智慧型 的架構 智慧型 的設定方式如圖 ,將來源暫存器、目的暫存器及控制暫 存器設定後,配置暫存器必須最後一步設定,用以將通道致能。此時可去處理其 工作,待中斷發生後,智慧型 DMA 處理的工作跟著結束。在設定暫存器後, 值多會被保留下來,因此,若每次設定僅需選擇有改變的暫存器設定即可。 3-3(a) DMA
3.3.3 智慧型 DMA 使用流程
DMA 3-3(b) 他 其 Destination Control Configuration ch1 ch0 DSP Interrupt request ALU Memory interface Source Destination Control Configuration FIFO0 controller Channel FIFO1 l controller Channe Prioritizing Arbiter APB Bus Status APB Decoder ACC Grant1 t Source Register bank Destination Control Configuration ch1 ch0 Gran 0 DSP Interrupt request ALU Memory interface Source Destination Control Configuration FIFO0 controller Channel FIFO0 controller Channel FIFO1 l controller Channe FIFO1 l controller Channe Prioritizing Arbiter APB Bus Status APB Decoder ACCStart Setting Register Source Register Destination Register Control Register Channel Enable Configuration Register Interr pt Occurred? u End YES NO Do other thing Interrupt Occurred
Finish the Job Start Setting Register Source Register Destination Register Control Register Channel Enable Configuration Register Interr pt Occurred? u End YES NO Do other thing Interrupt Occurred
Finish the Job
圖 3-3(b):智慧型 DMA 的使用流程
3.4 整合
本論文將智慧型 DMA 和 VLIW 處理器做一個整合,以作為驗證主從式快取 記憶體正確性及效能的平台。如圖 3-3(c),VLIW 處理器整合智慧型 DMA 成為 一個系統,擁有多個共用匯流排。程式記憶體為外接方式,內部兩個記憶體與智 慧型 DMA 共用兩個資料匯流排。智慧型 DMA 並支援周邊匯流排,增加整體的 擴充性。MS Cache
Program Rom
Core A
Core B
IRSmart DMA
Controller
data bus data bus
Ram
B
Ram
A
Peripheral bus I2 S Txd I2S RxdVLIW processor
圖 3-3(c):VLIW 處理器與智慧型 DMA 的整合架構圖 四條分開的匯流排,智慧型 DMA 與處理器共用二條資料匯流 排, 整個系統共有 透過資料匯流排讓處理器與智慧型 DMA 共用兩個資料記憶體。資料匯流排 的管制與衝突,由 VLIW 處理器解決,當沒有使用到記憶體相關的指令,記憶 體的主控權會釋放給智慧型 DMA,以解決衝突的情況。DSP RA AM RAMB Smart DMA APB BUS I2S receiver I2S transmitter DSP RA AM RAMB Smart DMA APB BUS I2S receiver I2S transmitter :智慧型 DMA 與處理器及週邊的對應圖 除了共用匯流排外,為了設定智慧型 DMA 的動作,處理器必須存取智慧型 DMA 的暫存器。整合兩個 IP 的方式有兩種,第一,是從硬體電路上直接支援, 有對應的指令解碼,存取智慧型 DMA 暫存器。第二,可以採用記憶體對映的方 式,更動電路較小,也不需增加額外的指令集,如下圖: 處理器存取智慧型 DMA 暫存器-記憶體對映 圖 3-3(d) 圖 3-3(e):VLIW 16x16 32-bit 16-bit 000 200 20f 1ff 512x32 Address Processor Core ster Bank Memor Regi 16 512
3.5 結語
本章節介紹了主從式快取記憶體控制器的驗證平台:一個 VLIW 的多核嵌 式處理器的架構及一個可增進訊號處理運算能力及輔助記憶體及 I/O 溝通效能 IP:智慧型直接記憶體存取控制器。VLIW 多核數位訊號處理器搭配上智慧型 直接記憶體存取控制器可達到數位訊號處理器(DSP)的效能,而主從式快取記憶 體將與 VLIW 多核數位訊號處理器核心及智慧型直接記憶體存取控制器在下一 章節裡整合成為一個 SOC 晶片。 入 的第四章 晶片實現與結果驗證
4.1 晶片製作
4.1.1 設計流程
依照標準的CIC Cell-Based Design Flow設計硬體[35],設計流程如下:
Specification Assembler Design Instructions Design HDL Code Design ModelSim Design Compiler HDL Simulation HDL & Scan-Chain
UMC18 Design Kit
Synthesis
Gate level Simulation
Auto Place & Route
SRAM BIST SOCEncounter ModelSim Syntest DFT Compiler Post-layout Simulation ModelSim DRC Calibre TEXT Editor C++ VB Specification Assembler Design Instructions Design HDL Code Design HDL Code Design ModelSim Design Compiler HDL Simulation HDL Simulation HDL & Scan-Chain
UMC18 Design Kit
Synthesis Gate level Simulation Gate level Simulation Auto Place & Route
Auto Place & Route
SRAM BIST SRAM BIST SOCEncounter ModelSim Syntest DFT Compiler Post-layout Simulation Post-layout Simulation ModelSim & LVS DRC & LVS DRC Calibre TEXT Editor C++ VB 圖 4-1(a):晶片設計流程 & LVS
4.1.2
初期功能的設計,以 Verilog 硬體描述語言實作,搭配 Mentor 公司出的 ModelSim 進行功能驗證。待功能驗證正確後,以 nopsys 公司出的 Design
Compi 路合成,Library 使用 製程。經由合成軟體 Design
Compi ,其結果如下:
合成結果
Sy
ler 進行電 UMC 0.18um
ler 合成後
ITEM Area(㎜2) Timing Fault coverage Multi-Core with 11 MS-Cache and SDMA 73973 7.15 ns 98.65 % 表 4-1(a):合成的結果
4.1.3 佈局與封裝
出的 SOC Encounter 佈局軟體,將合成後的電路放在晶片 上,並依據速度的要求,自動最佳化並繞線,結果如下: CHIP name :SD297_V2Technology :UMC 0.18um1P6M CMOS 128 CQFP Chip Size :3.126× 3.126 mm2 Gate Count :~400mW :135MHz (7.40 ns) 採用 Cadence 公司 Package : :118K gate count Power Dissipation Max. Frequency
使用Prime Power量測功率,跑驗證功能的測試程式,得到平均消耗功率約 4-1(b)為佈局圖,圖4-1(c)為打線圖,圖4-1(d)為對應的腳位圖,以 128-CQFP的方式包裝。
400mW。圖
圖 4-1(c):打線圖
而在後續的佈局驗證部分,使用Calibre的DRC(Design Rule Check)及LVS (Layout
晶片設計規格如表 4-1(b)。
VS Schematic)也驗證無誤。
Technology Description
Process UMC 0.18µm 1P6M Mixed Signal Architecture VLIW 9-stage pipeline
Synthesis Synopsys Design Compiler Gate Count 118K
Embedded Memory RAM(512x32)x2 RAM(1024x64)x2 RAM(1024x6)x2 Die size 3.1 × 3.1 mm2 Supply 1.8V/3.3V ± 10%
Input Delay Time Max 0.714ns/ Min 0.543ns Power consumption 400mW
Operating Frequency 125MHz Post-Sim Speed 135MHz
4.2 測試驗證
4.2.1 餘弦轉換(Discrete Cosine Transform)
採用定點數平移 13-bit 做 36 點 DCT-2 運算,比較使用主從式快取記憶體控 制器及未使用的結果是否一致以驗證該快取記憶體控制器的可靠性。結果如圖 4-2(a),共有 36 筆資料輸出。其數學式如下: 1-D 36-point DCT-2 輸入 X: 1 1 ... 1 0 ... 2 1 ] [ − ≤ ≤ = = N k k k β 1 0 , ) 2 ) 1 2 ( cos( ] [ ] [ 2 ] [ 1 0 − ≤ ≤ + =
∑
− = N k N n k n x k N k X N n π β圖 4-2(a): ayout 運算結果
4.2.2
轉換(FFT)
512 列出 為定點化 模擬與 Post-sim 結果,如圖 4-2(b),驗證無誤。 DCT-2 Post-l Simulation 的快速傅立葉
底下驗證了 點 FFT 結果, 前 32 點,分別 C 程式圖 4-2(b):512 點 FFT 前 32 點的運算結果
4.2.3 量化線性預估係數(LPC)
係數採用 Multi-stage Vector Quantization 化簡編碼 的大小,並使用 M-L 搜尋法加強 MSVQ 的精確度。圖 4-2(c) 為定點化 C 程式
驗證量化 Linear prediction 簿
圖 4-2(c):多級向量量化 C 程式執行結果 M_Paths Table
最佳的量化路徑結果