Fast and Accurate Recognition
of
Very-Large-Vocabulary
Continuous Mandarin Speech for Chinese Language with
Improved Segmental Probability Modeling
Jia-lin Shenl and Lin-shan Lee1l2
1. Dept. of Electrical Engineering, National Taiwan University 2. Information Science, Academia Sinica
Taipei, Taiwan, R.O.C. [email protected]
A
bs t
r
act
This paper presents a fast and accurate recogni- tion of continuous Mandarin speech with very large vocabulary using a n improved Segmental Probability Model(SPM) approach. In order to extensively uti- lize the acoustic and linguistic knowledges to further improve the recognition performance, a few special techniques are thus developed. Preliminary simula- tion results show that the final achievable rate for the base syllable recognition with the improved Segmental Probability Modeling is as high as 91.62%, which in- dicates a 18.48% error rate reduction and more than 3 times faster than the well-studied sub-syllable-based CHMM. Also, a tone recognizer and a word-based Chi- nese language model are included and the achieved recognition accuracy for the finally decoded Chinese characters is 92.10%.
1
Introduction
Chinese language is not alphabetic and input of Chinese characters into computers is still difficult. Although there exist almost uncountable number of words in Chinese language, a nice characteristic of the language is that each word is composed of one t o sever- al characters which are all monosyllabic, and the total number of phonologically allowed Mandarin syllables is only 1345. Also, Mandarin Chinese is a tonal lan- guage. There exist 4 lexical tones and 1 neutral tone. These 1345 Mandarin tonal syllables can be reduced to 408 base syllables disregarding the tones. Since the tones can be separately recognized using the primarily pitch contour information, fast and accurate recogni- tion of the 408 Mandarin base syllables becomes the key problem for Mandarin speech recognition with very large vocabulary. Hidden Markov modeling HMM) of
problem [I], but here a different approach called Seg- mental Probability Modeling (SPM) appropriately u-
tilizing the monosyllabic nature of Mandarin speech is investigated in detail and improved performance was obtained.
SPM was first proposed for the recognition of isolat- ed Mandarin base syllables[2]. This model is very sim- ilar t o continuous hidden Markov model (CHMM) ex- sub-syllabic units has been found very use
I
ul in thiscept that the state transition probabilities are deleted and the states equally segment the syllable. In order to extend the applications of SPM t o continuous speech recognition, the concatenated syllable matching(CSM) algorithm was previously developed[3], which has the following form :
where T[u] is the accumulated score at a point U,
Si(.,.) is the score when the SPM for the syllable i was matched with utterance section (u,v).
In the present research, a few special techniques are developed to further improve the SPM-based contin- uous Mandarin speech recognition with very large vo- cabulary. First, a modified SPM (MSPM) is proposed for better modeling the intra-syllabic and inter-syllabic acoustics and coarticulation. Secondly, the fundamen- tal quefrency (or the first cepstrum coefficient) dips are found very useful in the detection of the syllable boundaries in the CSM algorithm. Thirdly, a non- uniform alignment( NUA) and a. segmental weighting (SW) processes are developed t o further improve the recognition accuracy. Finally, a syllable filter based on linguistic knowledge is applied t o eliminate some impossible syllable candidates considering the linguis- tic admissible transition between syllables. Prelimi- nary experimental results show that these techniques can improve the recognition accuracy step by step and the final achievable recognition rate can be as high as 91.62%, which indicates a l8.48% error rate re- duction and more than 3 times faster than the well- studied sub-syllable-based CHM[M. Besides, integrat- ing the tone recognition and the linguistic processing, 92.10% recognition accuracy for the finally decoded Chinese characters is achieved.
This paper is organized as follows. In Section 2, the proposed MSPM is discussed. Then, the dips in the fundamental frequency contour for CSM algorithm is evaluated in Section 3. The NUA and SW process- es for improving the MSPM’s are discussed in Section 4. In Section 5, the syllable filter integrating linguis- tic knowledge is presented. The tone recognition and linguistic processing are described in Section 6. The experimental results are performed and analyzed in section 7. Section 8 finally makes the concluding re-
marks.
2
Modified SPM (MSPM)
(b) Conventionally each Mandarin syllable is decom-
posed into a n INITIAL/FINAL format. Here INI- TIAL means the initial consonant of a syllable and FINAL means the vowel or diphthong) part but in- 22 context independent(C1) INITIAL’s and 41 context independent(C1) FINAL’s. The 22 CI INITIAL’s can be further expanded t o 113 context dependent CD) following FINAL’s. It has been found that these 113 CD INITIAL’s and 41 CI FINAL’s give very good re- sults for Mandarin speech recognition[l]. A segment sharing concept for SPM has also been proposed be- fore[4] and found very useful in the present problem, in which the first few segments of the SPM’s for the syllables having the same CD INITIAL’s share simi- lar characteristics thus can share the same segments of the models and so do the remaining segments of the models for the syllables having the same CI FINAL’s. Furthermore, in order t o include a ”transition seg- ment” modeling the transition from the FINAL of a
syllable t o the INITIAL of the next syllable, a total of 41* 22+1)=943 transition segments will be need- ed if a
\
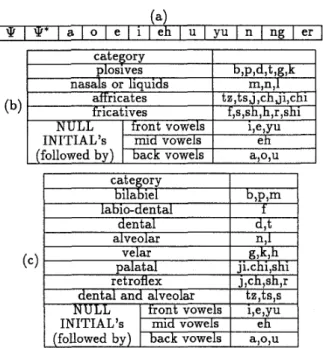
1 syllable transitions are considered. Instead, here all the possible ending phonemes of FINAL’s can be classified into 12 categories as shown in Ta-ble l.(a) , while the INITIAL’s can be classified into 7
or 11 classes as shown in Table l.(b) and (c). In this way, the number of transition segments is reduced t o 12x(7+1)=96 or 12x(11+1)=144 respectively. These segment-shared SPM’s plus the transition segments constitute the modified SPM (MSPM) proposed here in this paper, for better modeling the intra-syllabic and inter-syllabic acoustics and coarticulation, as shown in Fig.1. The first few segments are used t o model the 113 CD INITIAL’s, the following several segments for the 41 CI FINAL’s and the last segment is the transition segment.
cluding possible media an
6
nasal ending. There existINITIAL’s considering the beginning phoneme o
I
theaffricates t z , t s j ,chji,chi
’ fricatives f,s,sh,h,r,sh1
NULL I front vowels i.e.vu
I
I II
INITIAL’s (followed by)I
*
I I*
I I II
I I “ m d vowelsI
ehback vowels
I
a,o,u.
(4
I r E I v ! * I a I o I e I 1 I eh I U I vu I n I ne: I erI
category bilabiel labio-dental dental category Dloslves I b.D.d.t.e:.k b , P P d.t I nasals or liauids I m.n.1 I velar palatal retroflex (c) ji.chi,shi +k,h.
1.ch.sh.rt
alveolarI
n,l dental and alveolar t Z , tS , SI
(followed by)I
back vowelsI
a,o,uI
Table 1: (a)The 12 classes of the ending phonemes of FINAL’s, and (b), (c) the classification of the INI- TIAL’S into 7 and 11 classes.has the form,
where { a k } , k = l
...
P, are the linear prediction coeffi-cients while { Z k } ,
k=1
...
P, are the poles correspondingto the modes of the linear system of speech. As a con- sequence, the relationship between { a k } and { z k } can
be derived [5] :
IC = L..P (3)
a i , = 2 1 k
+
2 2 k+
. a .+
2;INITIAL FINAL transition segment
The fundamental quefrency c1 is the first term of the Figure
’:
the structure Of the modified ’PM (MSPM)* Ipc-derived cepstrum and can be ,thus, obtained,3
Fundamental Quefrency Dips
In the CSM algorithm, the dips in the energy con- tour are first used to predict the ossible syllable be- ginning frames in a n utterance[l][37. However, the syl- lable boundary detection in continuous speech using energy dips is usually unstable and coarse because of the co-articulation effect in continuous speech. In this paper, the dips in fundamental quefrency contour are found very useful in the detection of syllable bound- aries which can be used in place of the energy dips. This is because of the INITIAL/FINAL characteris- tics of Mandarin Chinese which will be discussed as belows.
Suppose an all-pole filter H z) of order P is used t o represent the system transfer
I
unction of speech, whichc1 = a 1 = z1
+
z2+
...
+
z pBecause { a k } are all real, the poles { z k are either re-
reduced t o the sum of the projection on the real axis for all poles in Z-domain. It is noted that when the poles occur in the right half plane of Z-domain, high- er value of c1 can be obtained, while the poles in left half plane imply lower value of c1. Since the spectral peaks for FINAL’s usually locate in the low frequency part while those for INITIAL’s usually locate in high frequency part, some falling gaps in the fundamental quefrency contour will occur in the transition from FI- NAL t o INITIAL. In addition, since th e INITIAL’s are much shorter in the whole syllable such that the majority part of INITIAL’s is co-articulated with the following FINAL’s, the fundamental quefrency contour (4)
a1 or complex conjugate pairs. There
f )
ore, c1 can bewill immediately rise from INITIAL to FINAL. In oth- er words, there exist some fundamental quefrency dips in the inter-syllable transition boundaries. The dips in the fundamental quefrency contour are believed t o be more accurate and stable than that in the energy contour due t o the INITIAL/FINAL characteristics of Mandarin speech.
4
Non-uniform Alignment and
Segmental Weighting
In SPM's, the stochastic state transition behavior in HMM's is replaced by a deterministic process, i.e., u-
niform segmentation. However, the INITIAL part and the transition segment in a syllable are usually much shorter than the FINAL part, but very important for the recognition of Mandarin syllables. As a result, a non-uniform alignment( NUA) process instead of uni- form segmentation is developed to divide the syllable section into segments in an utterance using a non- linear function. This non-linear function is designed such that the INITIAL and transition parts occupy less length of the whole syllable, which has the form :
n = 1,
...,
N (5)where g(n is the ending point for segment n, N is the syllable section. Also, a ( n ) is a non-negative mono- decreasing function except that cr(N
-
1) = - a ( l ) . Ap- parently, a ( N ) equals to zero such that g(N) = L.Then, a nonlinear segmental weighting (SW) func- tion is used to emphasize the likelihood score of the most discriminative parts, i.e. the INITIAL and tran- sition parts. This segmental weighting function is com- posed of N elements, i.e. { w l , w2,
...,
W N } , where eachwj is a constant positive value. As a consequence, the
syllable section score Si U, U ) for syllable i in eq.(l) in-
tegrating the NUA and
L
W processes can be expressed as :total num
b
er of segments, and L is the length of thisN
si(.,.)=
K C w j d j ( u . + g ( j - l ) , u + g ( j ) ; & ) (6)j = l
factor, w , is the weighting factor for segment j and
d j ( a , b; X i j ) represents the segmental probability of segment j between the section (a,b) when matching with the model A ; , j .
5
Syllable Filter
In order to integrate some linguistic knowled e to further improve the recognition performance, a syaable filter is finally applied to eliminate some illegal sylla- ble candidates such that a more accurate s llable path can be obtained. In addition, the syllabz filter can increase the number of correct candidates to improve
the linguistic processin
.
Here a syllable bigram isderived t o describe the f!nguistic admissible transition from one syllable to another. The syllable bigram used
here is trained from a large Chinese text corpus which consists of a total of 4.2M chamcters (2.7M words) collected from daily newspapers. Therefore the sylla- ble airs with higher probability in the s llable bi ram impPy stronger linguistically connection ietween tiem. Therefore, eq.(l) can be replaced by the following for- m:
T~[Y
-
11 =;,z$JZ(a-
1)+
S ~ ( Z , Y - 1)+
d'h=-1(i),i](7)where maxk means the k-th highest score in the 408xm accumulated probabilities, h z - l ( l ) is the top 1 syllable candidate in the frame point x-1 (and P h = - l ( 2 ) , i is the transition probability from syllable hz-l(l t o i. Al-
so, r ] is a weighting factor t o emphasize t
h
e syllable filter probabilities. In other words, for each possible ending point, the top m candidakes must be calcu- lated. It is clear that the recognition process inte- grating these syllable transition information is time- consuming. Instead, the syllable filter can be added in the post processing in which comparable improvement in the recognition accuracy can be achieved with much higher recognition speed.- -
6
Tone Recognition and Lin-
guistic Processing
From e q ( l) , for each syllable section in an utter- ance, not only the base syllable recognition is eval- uated but the tones can be recognized in the same phase[l]. Therefore, the final output in the acoustic processing is the tonal s llable recognition result. Here the CHMM is used as t
K
e tone recognizer with a total of 5 models each for one tone. Combining the base syllable and tone recognition results, a tonal syllable lattice with 10 candidates is first constructed for the linguistic processing. Then the tonal syllable lattice is transformed into a word lattice via a lexical access pro- cess. Finally the word-based Chinese language model trained from the Chinese text corpus mentioned previ- ously is used to find out the most possible characters, words and sentences.7
Experiments and Discussion
The speech database used here for speaker depen- dent task was produced by two male and two female speakers. Each speaker produced 3 sets of all the 1345 isolated Mandarin tonal syllables and 2 continuous ut- terances each for 352 phonetically balanced sentences (with a total of 2701 syllables covering all the 1345
Mandarin syllables). Also, 3 paragraphs randomly ?e-
lected from daily newspapers covering the economlcs, politics and societ y news separately were produced in continuous mode which is composed of totally 106 sen- tences or 1215 syllables. For base syllable recognition, Cepstral coefficients of order 14 arid the corresponding 14 delta cepstral coefficients are derived from the LPC coefficients and used as feature parameters. Instead, the pitch and energy together with their first and sec- ond order delta coefficients are used to form a feature vector with dimension 6 in the tone recognition.
In the following experiments, the 3 sets of 1345 iso- lated syllables are used in training initial models, the
2 x 352 phonetically balanced continuous sentences are used in re-estimating the continuous model parameter-
s, and the rest of 3 articles are used in testing. The recognition rates are evaluated as the percentages of correctly recognized syllables minus insertion rates and deletion rates. Moreover, the results here are average of the four speakers.
As shown in Table 2, the experimental result using syllable-based S P M a nd CSM algorithm provides a n accuracy of 61.27% only, but it can be significantly increased t o 73.91% with the segment sharing concep-
t. Also, the recognition speed is improved by exactly 4 times as compared t o t h e s llable-based SPM. Fur- thermore, the modified SPM [MSPM) with the transi- tion segment representing t h e inter-syllable transition-
s is performed in experiments 3 and 4. The experi- ments with 7 and 11 classes of INITIAL’S are tested respectively where the error rates are further reduced by 10.43% and 7.82% in comparison with the segment shared SPM with slightly increased recognition time. T he above experimental results are obtained using the energy dips in the CSM algorithm. However, when the full search mode is applied, i.e., every frame is the pos- sible beginning syllable point, the reco nition rates can be immediately increased from 7 6 . 63 gto 83.70% with more than 12 times of recognition time as also listed in Table 2. Now when t h e energy dips are replaced by the fundamental quefrency dips, the recognition com- plexity is almost unchanged but the accuracy can be significantly improved to 83.59%. Then, the proposed non-uniform alignment(NUA), the segmental weight-
ing (SW) function and syllable filter are added in the
segment shared SPM using CSM algorithm. I t can be found that the recognition rates can be improved step by step and finally t o as high as 89.53% and the time needed t o recognize a syllable is 0.38 sec in the last row of Table 2.
As a comparison, three types of CHMM’s are also tested in Table 3. First, the sub-syllable-based CHM- M, with exactly the same 113 CD INITIAL’S and 41 CI FINAL’S as basic units are tested in experiment 10
[I]. The syllable duration limitation is then considered
and the syllable filter is finally added in experiments 11
and 12. It is noteworthy that comparing experiment 9 with 12, 18.48% error rate reduction can be obtained at more than 3 times of recognition speed using the proposed improved SPM techniques.
Finally, we combine a CHMM-based tone recognie- er and a word-based Chinese language model with the base syllable recognition t o find out the output char- acters. As shown in Table 4, it can be found that the
results for tones are 86.67% and the achieved top 1 and top 10 recognition rates for tonal syllables are 81.10% and 98.97% respectively. T he final results for charac- ter accuracy with 10 syllable candidates included in the tonal syllable lattice are as high as 92.10%.
8
Conclusion
In this paper, we applied a n improved Segmen- tal Probability Model (SPM) t o continuous Mandarin speech recognition with very large vocabulary and achieve very good performance both in accuracy and speed. A few special techniques are developed to fur- ther improve the recognition performance step by step by making use of the acoustic and linguistic knowl-
”
quefrency (7 classes)
’1. PIUS NlJA 85.69 0.0 0.16 0.35
8. DlUS
sw
86.27 0.0 0.16 0.35 ~edges. The final achievable rate is as high as 91.62%, which indicates a 18.48% error rate reduction and more than 3 times faster t h a n the well-studied sub-syllable- based CHMM. Adding a CHMM-based tone recog- nizer and a word-based Chinese language model, the achieved recognition accuracy for the finally decoded Chinese characters is 92.10%.
References
[l] Hsin-min Wang, Jia-lin Shen and Lin-shan Lee, ”Com- plete Recognition of Continuous Mandarin Speech for
Chinese Language with Very Large Vocabulary but Limited Training Data”, ICASSP, pp.61-64, 1995.
[2] Lin-shan Lee, et.aZ. ”Golden Mandarin(I1)
-
An Im-proved Single-Chip Real-time Mandarin Dictation
11. plus duration
Machine fo; Chinese Language with very Large Vo- cabulary” , ICA SSP, UP. 5 03-5 06. 19 9 3.
84.2’( 1 0.08 I 0.82 1 1.15
,
- _
[3] Jia-lin Shen, Hsin-min Wang and Lin-shan Lee, ” A n
Initial Study on A Segmental ProbabiKty Model Ap- proach t o Large-Vocabulary Continuous Mandarin Speech Recognition”, ICASSP, pp.133-136, 1994.
[4] Jia-lin Shen, Hsin-min Wang, Renyuan Lyu, Lin-shan
Lee. ”Incremental Speaker Adaptation Using Phoneti- cally Balanced Training Sentences for Mandarin Sylla- ble Recognition Based on Segmental Probability Mod- els”, ICSLP, pp. 443-446, 1994.
[5] M. Schroeder, ”Direct nonrecursive) Relationship Be- tween Cepstrum and
I,
inear Predictor Coefficients”,IEEE ASSP, pp. 297-311, Apr. 1994.
experiments
1
rateI
ins.1
dels.I
time1. svllable based SPM I 61.27 I 0.78 I 0.16 I 1.12 tone 2.segment shared Sphl
1
‘13.911
0.0I
0.16I
0.28 3. MSPM f7 classes)I
76.63I
0.0I
0.16 I 0.34 I I I I tonal svllable character.
MSPM (11 classes)I
75.95I
0.0I
0.16I
0.36.
using full searchI
83.’10I
0.16I
0.16I
4.23 (7 classes)6. using fundamental I 83.59 I 0.0 I 0.16 I 0.35
19. plus syllable filter
I
91.62I
0.0I
0.16I
0.38I
Table 2: The recognition results for experiments 1-8 using various types of SPM’s. The recognition rate is
x loo%, while
t o t a l s y l l a b l e s
the time (sec/syllable) needed is on Sun SPARCZO. exoeriments I rate I ins. I dels. I time
1
I
evaluated as c o r r e c t l y r e c o g n i z e d - i n s . - d e l s .
I
(top l jI
(top 10)I
accuracy