Design and Implementation of High-Speed and
Energy-Efficient Variable-Latency Speculating Booth
Multiplier (VLSBM)
Shin-Kai Chen, Chih-Wei Liu, Member, IEEE, Tsung-Yi Wu, and An-Chi Tsai
Abstract—Data hazards cause severe pipeline performance
degradation for data-intensive computing processes. To improve the performance under a pessimistic assumption on the pipeline efficiency, a high-speed and energy-efficient VLSBM is proposed that successively performs a speculating and correcting phase. To reduce the critical path, the VLSBM partial products are partitioned into the -bit least significant part (LSP) and the self-reliant -bit most significant part (MSP), and an estimation function stochastically predicts the carry to the MSP, thereby allowing independent calculation of the partial-product accumulation of parts. When a carry prediction is accurate, the data dependence is hidden and the correcting phase is bypassed, thereby ensuring the potential speed-up of the pipelined datapath. If a prediction is inaccurate, the speculation is flushed and the correcting phase is executed to obtain the exact multiplication. The simulation results verify the effectiveness of the proposed VLSBM. When applied to a DSP algorithm with a data hazard (or dependence) probability , , the results show that the proposed VLSBM outperforms the original Booth multiplier and the fastest conventional well-pipelined modified Booth multiplier when . For the case of high with , the proposed VLSBM improves approximately 1.47 times speedup against the fastest conventional pipelined Booth multiplier (@UMC 90 nm CMOS) and, furthermore, approxi-mately 25.4% of energy per multiplication and 7% of area are saved. By examining multiplications during three multimedia application processes (i.e., JPEG compression, object detection, and H.264/AVC decoding), the proposed VLSBM improves the speed-up ratio by approximately 1.0 to 1.4 times, and reduces the cycle count ratio by approximately 1.3 to 1.8 times in comparison to the fastest conventional two-stage pipelined Booth multiplier.
Index Terms—Adaptive carry estimation, error compensation,
speculating multiplier.
I. INTRODUCTION
T
HE parallel multiplier is a fundamental element of various computing and signal processing applications [1]. The la-tency for multiplication is generally divided into three steps: 1) Manuscript received September 04, 2012; revised December 05, 2012; accepted January 17, 2013. Date of current version September 25, 2013. This work was supported in part by the Nation Science Council, Taiwan, under Grant NSC101-2220-E-009-029- and Information and Communications Research Labs (ICL), Industrial Technology Research Institute (ITRI), Taiwan, under Grant 101-EC-17-A-05-01-1111, and by a grant of chip fabrication in the National Chip Implementation Center (CIC), Taiwan. This paper was recommended by Associate Editor C. H. Chang.The authors are with the Department of Electronics Engineering, National Chiao Tung University, Hsinchu, Taiwan (e-mail: [email protected]. tw).
Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TCSI.2013.2248851
the generation of partial products; 2) a reduction-tree process that simplifies partial products into two rows; and 3) the final ad-dition of the result by a carry-propagation adder (CPA) [2]–[6]. Because all partial product bits within each column are summed in parallel, the Wallace tree compression is superior during the second step. For the parallel multiplier CPA, a carry-lookahead adder (CLA) has been frequently applied because of its reduced critical path.
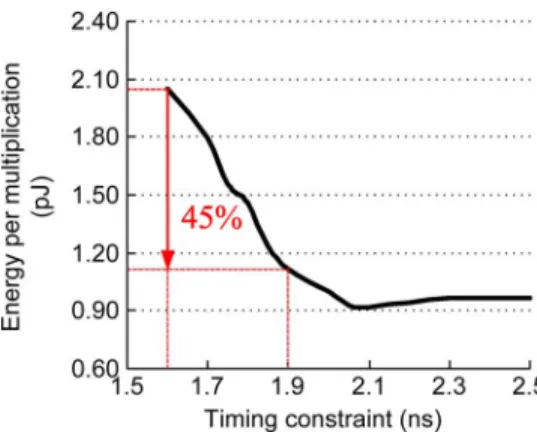
On synchronous VLSI designs, synthesis tools employ a significant volume of logic- and gate-level optimizations to minimize the critical path. For example, the circuit re-struc-turing method reduces the logic depth, thereby decreasing the circuit delay, whereas the gate-sizing approach replaces the critical path cells with those of high driving strength. Although these techniques effectively reduce the critical path, they require an additional overhead of silicon area that inherently increases the energy dissipation [1]. Fig. 1 shows an example of the energy-delay plot of an 8 8 carry-save-array (CSA) multiplier using a UMC 90 nm CMOS cell library. The x-and y-axes in Fig. 1 represent the synthesis timing constraint, and the energy per multiplication of the multiplier (evaluated by 10,000 random multiplications), respectively. As shown in Fig. 1, a period of 1.9 ns of the CSA multiplier consumes up to 1.1 pJ per multiplication. When operated for 1.6 ns using an identical architecture, the CSA multiplier speed-up increases by approximately 19%; however, more than approximately 82% of the energy dissipates.
Pipelining is an effective approach to alleviate the drawback from aggressive logic- and gate-level timing optimizations while maintaining sufficient throughput. Fig. 2 shows a multi-plier-enhanced five-stage pipelined (IF:ID:EXE:M:WB) RISC. Because no operation in the M-stage exists for any arithmetic instruction, a fast two-stage pipelined multiplier can be inte-grated to enhance multiplicative performance. However, true data dependence causes a pipeline stall cycle to be inserted, despite a forwarding path being employed (Fig. 2(b)). Con-sequently, under the assumption of poor pipeline efficiency, the throughput benefit of the pipelined datapath is eventually undermined by data hazards [1].
It is possible to hide data dependence by employing a spec-ulative functional unit (SFU), which is an arithmetic unit that employs a predictor for the carry signal [7]. Without waiting for the true carry propagation, the SFU predicts the carry of one or more cells in the design. Similar to a microprocessor branch predictor, a true carry prediction causes the data dependence to be hidden. Conversely, when inaccurate carry predictions occur, 1549-8328 © 2013 IEEE
Fig. 1. Energy-delay plot of 8 8 CSA multiplier (@ UMC 90 nm CMOS).
Fig. 2. Multiplier-enhanced 5-stage pipelined RISC: (a) datapath, (b) timing diagram of two dependent instructions.
error detection logic and the associated error recovery are nec-essary to generate (or reconfirm) the real result. However, the cumbrous overhead or complex control could have an adverse impact on the SFU performance [7].
By assuming that each output bit of the -bit adder is depen-dent only on the preceding bits (when is significantly less than ), Verma et al. proposed a fast -bit almost-correct adder (ACA) [8]. Compared with the -bit CLA provided by Design-Ware, the simulation results (@ UMC 0.18 CMOS) in [8] increased the speed-up of the -bit ACA throughput by approx-imately 1.5 times when . Unfortunately, an error occurs when the carry chains equal or exceed bits. To improve the addition reliability, previous research proposed a variable-la-tency speculating adder (VLSA) [8] by integrating error detec-tion logic into the ACA, which achieved a critical path almost identical to that of a conventional CLA, and an error recovery process (i.e., the original CLA) that reproduced the true addi-tion. Therefore, the proposed -bit VLSA [8] required approx-imately 50% more silicon area overhead to achieve a speed-up similar to that of the DesignWare CLA. Previous research pro-posed a modified VLSA that improved the accuracy to 99.46% when applied to a fixed or specific application [9]. However, this required 25% more silicon area [9] than the original VLSA [8]. Although the ACA is faster than the VLSA, it is less reli-able. However, they are both potentially unsuitable for the fast and reliable parallel multiplier CPA. Based on a probabilistic re-sult-speculation technique, this study proposes a design for an
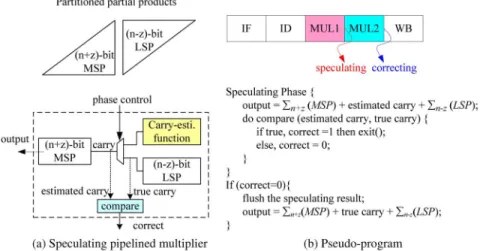
efficient variable-latency speculating multiplier (VLSM). The VLSM design concept and block diagram in Fig. 3 comprise the following two operating phases: 1) the speculating phase and 2) the correcting phase. To reduce the critical path, the multiplier partial products are partitioned into the -bit most sig-nificant parts (MSP) and the -bit least significant parts (LSP). During the speculating phase, the partial-product accu-mulations of the LSP and the MSP are performed in parallel and independently. Without waiting the true carry from the LSP, the carry to the -bit MSP is generated by the carry estima-tion funcestima-tion (Fig. 3(a)). Consequently, the speculating output of the VLSM is
(1) which can be forwarded to the successive instruction for further processing. Note that in (1) is the partial-product
summation of the -bit MSP and is the
sum-mation of the -bit LSP minus the carry. If is true, the corresponding correcting phase is bypassed and the data depen-dence is hidden; thus, the multiplier stall cycle is saved. If an inaccurate prediction occurs, the speculation is flushed and the exact multiplication is obtained by summing , the true carry, and during the correcting phase. Un-like the VLSA [8], the error recovery of the proposed VLSM is simple; thus, correcting the miss-carry-prediction does not di-minish the overall performance of the VLSM.
Suppose that the accuracy probability of the carry estimator
is , , and the VLSM critical stage delay
is . Different carry estimators with different values produce various and values for the VLSM. This study defines the effective cycle time of the VLSM as
(2) The design goal of the VLSM is to minimize . With a more accurate carry estimator (i.e., ), the throughput obtained by the VLSM is more efficient. However, ensuring high-accuracy probability may inevitably increase the critical path of the VLSM. Thus, the tradeoff between and the of the VLSM must be considered carefully.
To examine the cost function carefully, this study proposes a high-speed, area-/energy- efficient 16 16 variable-latency two-stage pipelined modified Booth multiplier (VLSBM). Applied a DSP algorithm with a data hazard (or dependence) probability , , the optimized VLSBM outper-forms not only the original Booth multiplier but the fastest, well-pipelined modified Booth multiplier if . Under a pessimistic assumption on the pipeline efficiency, i.e. for the case of high with , the proposed VLSBM improves approximately 1.47 times speedup against the fastest conven-tional pipelined Booth multiplier (@UMC 90 nm CMOS) and approximately 25.4% of energy per multiplication and 7% of silicon area are saved. Compared to the fastest conventional two-stage pipelined Booth multiplier, an examination of the multiplicative performance of the proposed VLSBM for three multimedia application processes (JPEG compression, object detection, and H.264/AVC decoding) shows that the proposed
Fig. 3. Proposed variable-length speculating multiplier (VLSM): (a) Block diagram and (b) pseudo-program.
VSLBM obtains a performance speed-up and cycle count reduction ratios of approximately 1.0 to 1.4 times, and 1.3 to 1.8 times, respectively.
The remainder of this paper is organized as follows. Based on conditional probability theory, Section II briefly intro-duces three carry estimation schemes (Type-I, Type-II, and Type-III) that were developed originally by Liao et al. [20] for the fixed-width Baugh-Wooley multiplier. With different truncation widths of the partial products, the three types of carry estimation functions are generalized and developed, not only for Baugh-Wooley multipliers but for modified Booth multipliers. Based on the generalized carry estimation schemes, Section III details the optimized VLSBM design and presents simulation and experimental results that verify the effective-ness of the proposed VLSBM. Finally, Section IV presents a conclusion.
II. GENERALIZEDCARRYESTIMATIONS FOR -PT FIXED-WIDTHMULTIPLIERS
By handling sign bits of the 2’s-complement integers effi-ciently, the Baugh-Wooley multiplication algorithm is applied frequently to design regular multipliers. Given integers and
,
(3) where , a parallelogram of the -row, -column partial products of Baugh-Wooley multiplier is shown in Fig. 4, where and is the binary inversion of . Clearly, the -bit MSP and the -bit LSP divide the partial products into two groups. and (Fig. 4) are defined by the summations of the most significant column and the re-maining -bit LSP columns, respectively. For simplicity, this
study defines and , then
. To reduce the critical path by diminishing the number of rows of partial products, the Booth’s multiplication algo-rithm is developed. Table I shows that the radix-4 (or modified)
Booth encoder transforms -bit into
-digit . With similar
rep-resentation of , Fig. 5 shows the reduced -row, -column partial products of the modified Booth multi-plier. Hence, the results of the direct-truncation (DT), post-trun-cation (PT), or full-precision (FP) multipliers are expressed as
(4) where is the carry-in to and operator rounds to the nearest integer. Without propagating the true from LSP to MSP, the DT multiplier is fast and economical, although it causes a significant loss in precision.
To design an efficient VLSM, this study defines the -bit fixed-width -PT multiplier, (Fig. 6). By defini-tion, the -PT multiplier summates the most signifi-cant columns of the partial products, and subsequently rounds or truncates to the -bit result. , , and (Fig. 6) are the sum-mations of the most significant columns, the -th most significant column, and the remaining columns of the -bit LSP, respectively. Note that Fig. 4 (or Fig. 5) is a special case of the -PT multiplier. With , , and , the -bit -PT multiplication can be expressed as
(5) where denotes the carry to for the -PT multi-plier.
Fig. 4. Partial products of n-bit Baugh-Wolley multiplier.
Fig. 5. Partial products of n-bit modified Booth multiplier. TABLE I
MODIFIEDBOOTHENCODING. (NOTETHAT ISSET TO0.)
If , previous studies [10]–[31] have proposed applying the -values (to estimate ) to compensate for the truncation error and obtain fast and accurate fixed-width multipliers. Previous studies first presented constant error compensations [10]–[12]; adaptive accurate error compensations, which relied on input bits, were subsequently proposed by [13]–[31]. By exhaustive simulations, Van et al. [14] generalized results obtained by Jou et al. [13] to develop the heuristic carry esti-mation for the Baugh-Wooley multiplier. By applying linear regression analysis, Jou et al. [15] proposed the simple carry estimation for the modified Booth multiplier. With exhaustive simulations for the modified Booth multiplier, Cho et al. [16]
Fig. 6. The -bit fixed-width -PT multiplier.
successfully proposed a closed form of the estimated carry, which is generated by non-zero Booth encoded digits. Except for 2’s-complement multipliers, Juang and Hsiao [18] derived the statistical analysis for the binary-sign-digit (BSD) Booth multiplier. However, the conditional bits used in [18] were poorly selected. Based on conditional probability theory, Liao
et al. [20] derived three adaptive carry estimation schemes for
2’s-complement Baugh-Wooley multipliers (Type-I, Type-II, and Type-III). Subsequently, with a different approach from [20], Li et al. proposed the probabilistic carry estimation bias (PEB) for the modified Booth multiplier [28]. The PEB error performance was further improved in [31] by applying an adaptive conditional-probability estimator (ACPE). In brief, the conditional probability carry estimators do achieve the highest accuracy performance (not only for Baugh-Wooley multipliers [20] but also for modified Booth multipliers [31]); however, they are too complex for implementation [27].
To minimize hardware cost, the majority of the discussed error compensation approaches predicted by observing one column of partial products (i.e., ). By examining further columns of partial products, the generalized carry estimator further minimizes the truncation error [23], [29]–[31]. Song et
al. performed exhaustive simulations to adaptively compensate
for the truncation error by establishing two types of binary threshold. [23] investigated columns of the partial products to obtain accuracy carry estimations for the modified Booth multiplier. Wang et al. [29] performed time-consuming simulations that improved the results obtained by Cho [16], thereby resolving the truncation errors. Moreover, based on PEB, Chen et al. derived a generalized PEB, namely GPEB [30], for the design of a power-efficient modified Booth mul-tiplier. Furthermore, they also showed that when , the ACPE Booth multiplier [31] improved speed-up by up to 25.2% speed (@ TSMC 0.18 CMOS) with only a 0.39 dB SNR loss compared to the results obtained by using the conventional Booth PT multiplier.
Without loss of generality, this study assumes that the bits of and are independently and identically distributed (i.e., i.i.d.) random variables with probabilities
Observing that the partial product is generated by input bits and , Liao et al. proposed the Type-I carry estimation scheme by conditioning (or ) [20]. By further investigating dependencies among , , , and (Fig. 4), they considered
the row vector (i.e., ) and the
anti-diagonal vector (i.e., ),
respectively, where the entries are jointly dependent on and , respectively. It is evident that the -bit LSP can be deter-mined either by row vectors or by anti-diagonal vectors
, . Thus, the Type-II and the Type-III
carry estimation schemes were subsequently proposed [20]. The three types of carry estimation schemes provide a systematic ap-proach to discovering and examining the dependencies among , , and , and can be generalized to design various fixed-width -PT multipliers.
A. Type I—Carry Estimation Conditioning on
1) -PT Baugh-Wooley Multiplier: Previous research [20]
has shown that . Given by , the value
of can be estimated by its expectation (i.e., ).
There-fore, the conditional expectation of the -PT Baugh-Wooley multiplier is expressed as
(6) Hence, by (5) and (6), conditioning on , the generalized Type-I carry estimation function of the -PT Baugh-Wooley multipliers can be obtained using
(7) Note that by (6), the generalized Type-I carry estimation scheme is hindered by high computation complexity, which is linearly proportional to the bit-width .
2) -PT Modified Booth Multiplier: By assuming the bits
of are i.i.d. random variables, the probabilities of the Booth encoded digit , , can be determined readily (Table II). From Table II, it concludes that
. Hence, the following is obtained:
Consequently, the following conditional expectation of is
With similar derivations, the following are obtained:
Therefore,
(8) where stands for the non-zero Booth encoded digit, (i.e., ). Note that considering only when estimating is reasonable. Consequently, the generalized Type-I estimation of for the -PT modified Booth multiplier (i.e., ) is
TABLE II
PROBABILITY OFBOOTHENCODEDDIGITS
(9) Hence, using (5), (9), the Type-I carry estimation
of the -PT modified Booth multiplier can be calculated by
(10) Equation (10) not only coincides with the ACPE proposed in [31], but also is analogous to the results obtained by Wang et
al. [29] and Cho et al. [16] if . Furthermore, from (9), the computational complexity of the generalized Type-I carry estimation scheme for the -PT modified Booth multiplier is linearly proportional to bit-width .
B. Type II—Carry Estimation Conditioning on
1) -PT Baugh-Wooley Multiplier: The Type-II carry
esti-mation considers row vectors , , in which the elements within are jointly dependent on . Thus, given by
, [20] shows that
(11) It can be proven that the following equation is true when calcu-lating in Fig. 4:
(12) The right-hand side of (12) calculates based on the row-major order, whereas the left-hand side is ordered by the anti-di-agonal order. Hence, provided by , conditional estimation
of the -PT Baugh-Wooley multiplier is
(13)
Hence, by (5) and (13), the generalized Type-II carry estimation of the -PT Baugh-Wooley multiplier ((i.e., ), is
(14) Liao et al. [20] verified that if , (14) coincides with the results obtained by Jou [13] and Van [14], [17].
2) -PT Modified Booth Multiplier: For some ,
, and , the probability
can be derived readily from the information obtained from Table II as
Hence, the following equation is obtained:
Consequently, given that with and for certain
and when ,
such that and , the joint probability
can be derived by
With similar derivations, is
ob-tained. The following conditional probabilities are then obtained by
Thus,
These mathematical expressions imply that
(15) Therefore, the generalized Type-II conditional expectation
of the -PT modified Booth multiplier is
(16) Using (5) and (16), the Type-II carry estimation
of the -PT modified Booth multipliers can be calculated by
(17) Using (16) or (13), the computation complexity for the gener-alized Type-II carry estimation remains high, although it is less than that of the Type-I scheme.
C. Type III—Carry Estimation Conditioning on
1) -PT Baugh-Wooley Multiplier: The original Type-III
carry estimation in [20] employed a 2D condition of and , which is too complex for implementation. For simplicity, this study considers the anti-diagonal vector for de-veloping the generalized Type-III carry estimation scheme. Because and are symmetrical and i.i.d. random variables,
and are concluded.
2) -PT Modified Booth Multiplier: Any two distinct
ele-ments (e.g., and ) within the anti-diagonal vector , , are determined by two different encoded digits (e.g., and , ). Because the bits of are i.i.d. random variables, the encoded digits and can be considered to be uncorrelated (i.e., ). Hence, the following is obtained:
Similarly,
Consequently, the generalized Type-III carry estimation for the -PT modified Booth multiplier is similar to that for the Type-II scheme, except for the different expectation from (15). Hence, the generalized Type-III expectation of the -PT modified Booth multiplier can be obtained by rewriting (16) as
(18)
By (5) and (18), the generalized Type-III carry estimation of the -PT modified Booth multiplier is
(19) Based on (18) and the given and , the is just a constant. If , (19) coincides with the PEB [28]; it is anticipated that the generalized PEG [30] is analogous to (19) for the general case.
Before concluding this subsection, although some carry es-timation functions presented here are not new to the literature, the generalized three types of carry estimation schemes provide systematic and complete approaches to designing each type of fixed-width multipliers. The mathematical formulations unified by conditional probability theory are more readable than those presented in [28]–[30]. Moreover, the error performance of the Type-III carry estimation scheme improves gradually when is high. This indicates that the Type-III carry estimation scheme, given a constant bias by (18), employs a simpler circuit to achieve higher performance accuracy.
III. VARIABLE-LATENCYSPECULATINGBOOTHMULTIPLIER Based on generalized conditional-probability carry estima-tions for the -PT modified Booth multiplier, this study proposes an optimized 16 16 variable-latency speculating two-stage pipelined modified Booth multiplier (VLSBM).
A. The Proposed Architecture
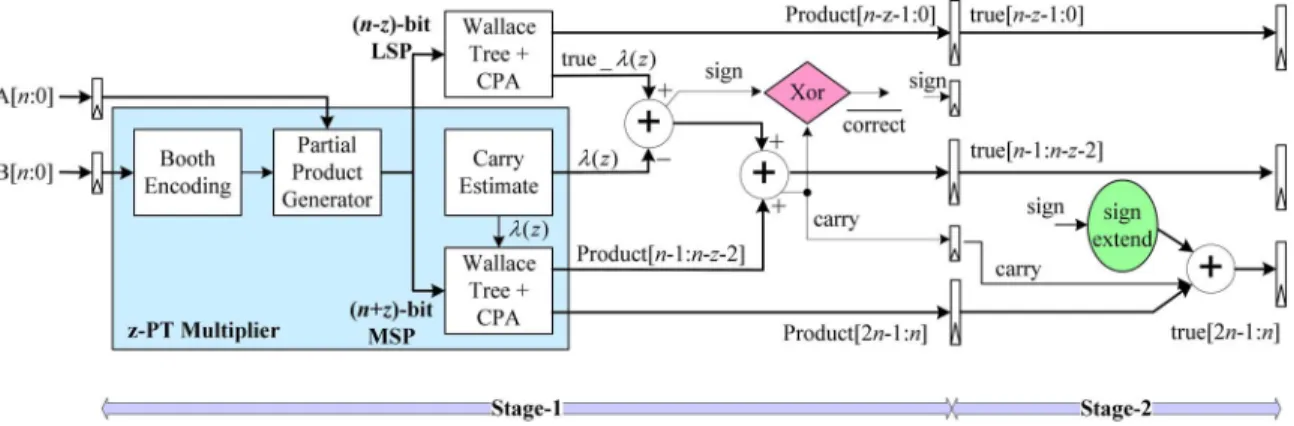
Fig. 7 shows the comprehensive microarchitecture of the proposed VLSBM, which comprises the following two oper-ating stages: 1) Stage-1 performs the speculoper-ating phase of the VLSBM and 2) Stage-2 is the error recovery. To reduce the critical path, the VLSBM partial products are partitioned inde-pendently into the -bit MSP and the -bit LSP. For the differentiation, the “ ” shown in Fig. 7 is employed to signify the speculation, and the “ ” represents the -bit exact multiplication of the VLSBM.
Without waiting the from the -bit LSP,
and can be calculated in parallel during the speculating phase with the predicted .
1) Error Detection and Error Recovery: The (possible) error
recovery of is separated by the
following two parts in the proposed VLSBM: 1) the primary
-bit compensation for and 2)
the successive -bit compensation for . As
shown in Fig. 7, the error correction of each part is performed in stages to reduce the critical path.
Because is always true, at the end of the Stage-1
we obtain . It is
readily proven that can be obtained by sub-tracting the predicted from , and then adding it to
the . Consequently, to verify the
pre-diction, an adder and subsequent subtractor are applied (Fig. 7). The sign of the difference is recorded by the
Fig. 7. The proposed speculating 2-stage pipelined modified Booth multiplier.
“sign” bit for further use. The following procedure is based on the true value of the sign bit.
(a) If :
This means that an under-estimated (or correct) has been predicted. If a prediction is inaccurate,
is the compensation that should be added to
specu-lative for error correction.
After the first -bit compensation for
in the speculating phase, the carry of the error-compensation adder is recoded (Fig. 7). The fol-lowing procedure is called based on the truth value of the recorded carry bit.
(i) If :
This means that no remainder is required for
fur-ther compensation of during
the correcting phase. Hence, the “correct” bit is set to 1 and
.
(ii) If :
This means that a non-zero carry must be added
to during the correcting
phase. Hence, the “correct” bit is set to 0.
(b) If :
This means that, for , an over-estimated prediction has been encountered, which leads to
. Hence, the sign-extend unit is neces-sary for error compensation. Similarly, the difference should be calculated, and then
sub-sequently added to during
the compensation stage error correction. At the end of Stage-1, the carry of the error-correction adder is recoded to supervise the following procedure.
(i) If :
This means that, except for sign-extended bits, no remainder requires compensation for during the correcting phase. Hence, the “correct” bit should be set to 0.
(ii) If :
This means that, except for sign-extended bits, a non-zero carry must be added to
during the correcting phase. Adding the all-ones vector and the non-zero carry-bit obtains the all-zeros vector. Therefore, the “correct” bit
should be set to 1 because is
identical to .
Consequently, based on this discussion, the correct (or valid) bit is the reverse of the logical disjunction (or exclusive) of the two-condition bits: the sign bit and the carry bit, which indicates that the speculation is valid (i.e., ) if the two-condition bits have identical truth values.
B. Optimized VLSBM by Design Space Exploration
A crucial issue during the early stage of system design is the selection of the appropriate parameters among the possible design spaces or alternatives. The design alternatives typically involve multiple metrics of interest, such as speed, area, and power (or energy). To provide an example, the 16 16 VLSBM is discussed in this subsection.
As shown in Fig. 7, the delay in Stage-1 (i.e., ) dominates the VLSBM critical path, which ends at “ .” To achieve the highest throughput of the proposed VLSBM, this study explores the cost function by (2). Theoretically, the accu-racy probability of the 16 16 VLSBM can be evaluated using
(20) Table III shows the simulation results for , and the estimated cost of the proposed VLSBM with certain and dif-ferent carry estimation schemes. Note that in Table III is de-noted by the tightest timing constraint (or the minimum clock period) of the VLSBM, as simulated by Synopsis Design Com-piler (@ UMC 90 nm CMOS cell library).
Based on parallel prefix computation, previous studies have frequently applied the CLA to the final adder of the multiplier to obtain improve system speed. Although the CLA is the fastest, it requires a large area overhead. Because the multi-level Wal-lace tree compression causes the input signals to arrive sepa-rately, a full adder of partitioned carry select adders [2] and a full adder comprising a conditional sum adder (CSMA) and conditional carry adder (CCA) [3], [4] were proposed to reduce the surface area. Therefore, the area-efficient CPAs presented in [2]–[4] were implemented. However, their speeds are slightly lower than those obtained by the CLA (DesignWare). To pro-vide a unified and fair evaluation of for design space ex-ploration, this study forces Synopsis Design Compiler to apply
TABLE III
EXPLORATIONRESULTS OF THE16 16 VLSBM WITHDIFFERENT @ UMC 90 nm CMOS CELLLIBRARY
: is the tightest timing constraint
the fastest DesignWare binary adders, i.e., the Carry look-ahead
synthesis model (cla), for the VLSBM CPA, which is a similar
approach to that applied in [8].
As shown in Table III, for a given , the simulated of the VLSBM with the Type-I scheme is greater than that of the Type-III scheme; however, the accuracy performance of the Type-I scheme is superior to that of the Type-III scheme. By examining the associated cost shown in Table III, the proposed 16 16 VLSBM may achieve the optimized performance by applying the Type-III carry estimation scheme with or . Because of the smaller (i.e., 1.50 versus 1.53 ns), the case with is preferable.
C. Implementation Results
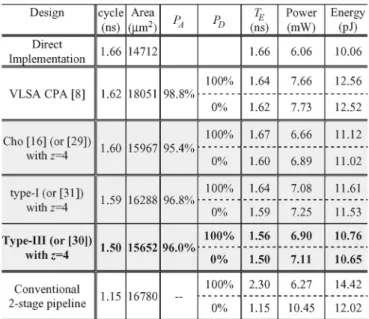
The silicon implementation results of numerous reliable 16 16 two-stage pipelined modified Booth multipliers are sum-marized and compared with the direct implementation of Booth PT multiplier, as shown in Table IV. To perform a fair compar-ison, the synthesis conditions considered in each multiplier in Table IV are identical.
By direct implementation, the simulated minimum period (i.e., tightest timing constraint) and the area of the 16 16 Booth PT multiplier are approximately 1.66 ns and 14,712 , respectively. Based on an evaluation of 100,000 random multiplications, the average energy per multiplication is ap-proximately 10.06 pJ.
Inserting pipeline registers to design the fastest, well-bal-anced two-stage pipelined modified Booth multiplier (shown in the last row of Table IV), the minimum period is reduced to 1.15 ns, which is approximately 1.44 times faster than that of the original one if no data-dependent hazard occurs, (i.e., if ). Nevertheless, an increase of up to 14.1% and 19.5% occurs for area overhead and of energy dissipation, respec-tively. Performance degradation occurs if . Because the latency of a multiplication is two cycles, the multiplier instructions within the DSP algorithm may cause a significant portion of stall cycles by data dependencies. Let denote the clock period of the fastest two-stage pipelined modified Booth
TABLE IV
VLSI IMPLEMENTATIONRESULTS OFDIFFERENT16 16 BOOTHMULTIPLIER
@ UMC 90 nm CMOS CELLLIBRARY
multiplier. For a given DSP application with multiplier-stall dependence probability , the effective cycle time of the fastest two-stage pipelined modified Booth multiplier is
(21) Compared to the original non-pipelined Booth multiplier, if , then ; that is, the throughput benefit of the two-stage pipelined multiplier is overcome definitely. Hence, to minimize to improve performance, data-intensive computing processors require a significant amount of time-con-suming and error-prone hand-optimized assembly language programming efforts. Moreover, as shown in Table IV, the additional energy dissipation is wasted (i.e., 14.42 pJ versus 12.02 pJ) because of the pipeline hazards for the case of high
.
In contrast, if the pipelined multiplier is capable of result-speculation, the data dependence might be hidden, thereby the stall cycles due to data dependence are saved. Suppose that the cycle time of the proposed VLSBM is , where differs from and is generally greater than . When data dependence occurs and the speculation result is true, the VLSBM requires only one cycle (i.e., ) to complete the multiplication. Con-versely, an incorrect speculation invokes the correcting phase to obtain the exact multiplication; hence, is necessary. Table V details the latencies required to complete a reliable multiplica-tion for the VLSBM. Given by and , the effective per-formance of the VLSBM then becomes
(22) If approaches 1, then the most effective performance of the VLSBM is clearly achieved (i.e., ), regardless of the application. Consequently, the potential speed-up benefit of the pipelined data path is ensured. This assists software porting on
TABLE V
LATENCY FORCOMPLETING THEMULTIPLICATION FORVLSBM
data-intensive computing processors because no assembly lan-guage programming is necessary during compiling.
Under identical synthesis conditions, four reliable 16 16 VLSBMs are tested (Table IV) to conduct a fair comparison. The first VLSBM directly applies the VLSA proposed in [8] to design the CPA of the modified Booth multiplier. With the ad-ditional circuits for error detection and error recovery, the sim-ulated minimum period of the VLSA-based VLSBM is 1.62 ns, which is slightly faster than that of the original modified Booth PT multiplier by direct implementation. Further investigation using the mentioned 100,000 random multiplications, the of the VLSA-based VLSBM is approximately 98.8%, which is the highest accuracy. However, the silicon area increases by ap-proximately 22.7%. Consequently, directly applying the VLSA to design the CPA of the modified Booth multiplier appears im-practical.
The remaining reliable 16 16 VLSBMs shown in Table IV apply the proposed architecture shown in Fig. 7, although they employ the following carry estimation schemes: 1) the (Type-I-like) Cho’s result [16]; 2) the Type-I scheme (or APCE [31]); and 3) the Type-III scheme (or GPEB [30]). Cho et al. [16] con-ducted exhaustive simulations and proposed the accurate carry estimation function as follows:
(23)
which differs slightly from (10). Hence, and the cor-responding are different from those of the Type-I carry estimation scheme. The implementation results shown in Table IV verify the effectiveness of the proposed optimized 16 16 VLSBM by using the Type-III carry estimation scheme with , which employs the minimum area overhead to achieve the highest effective throughput, as well as dissipating the least energy per multiplication. Unlike the conventional pipelined Booth multiplier, the effective throughput of the optimized VLSBM always outperforms the non-pipelined Booth multiplier, regardless of the value. The speed-up ratio, area overhead, and energy consumption are increased by 6.4% to 10.6%, 6.4%, and 5.9% to 7.0%, respectively. Compared to the fastest pipelined Booth multiplier, the pro-posed VLSBM is area-/energy-efficient, and reduces the area overhead and energy dissipation by approximately 7% and 11.4% to 25.4%, respectively. Furthermore, if , the throughput of the optimized VLSBM always outperforms the conventional pipelined Booth multiplier. As anticipated, the optimized VLSBM alleviates the performance degradation for the pipelined data path caused by high values.
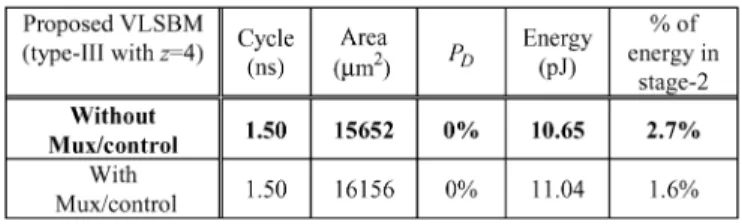
TABLE VI
IMPLEMENTATIONRESULTCOMPARISON OF THEWITH/WITHOUT ANEXTRA
MULTIPLEXER IN THESTAGE-2OF THEPROPOSEDVLSBM
Before concluding this subsection, by not equipping a mul-tiplexer to select the correct result from the multiplier, Stage-2 of the proposed VLSBM (Fig. 7) is performed continually, re-gardless of the speculation result, which might consume more (dynamic) power. However, an additional multiplexer and con-trol mechanism requires additional area overhead, which causes more power leakage. Table VI shows the implementation re-sults of the proposed VLSBM with and without an additional Stage-2 multiplexer when . If the multiplexer is used, the energy consumed by the simple addition for Stage-2 error recovery can be conserved (i.e., 1.6% versus 2.7%). However, the total energy and the area of the VLSBM increase when the multiplexer is equipped. Consequently, we assert that the design of the proposed VLSBM without an additional Stage-2 multi-plexer is preferable (Fig. 7). The silicon area of the proposed optimized VLSBM can be reduced further by applying a full adder combining both CSMA and CCA [3], [4]. The area of the modified VLSBM is decreased to 14 458 ; however, the es-timated minimum period is increased slightly to 1.51 ns.
D. Experimental Results for Real Workloads
In this subsection, three real multimedia applications (JPEG compression, the human face object detection, and H.264/AVC decoding) are examined to verify the multiplicative perfor-mance of the proposed VLSBM integrated by classic five-stage pipelined 32-bit MIPS processors.
The open-source C-language reference codes of the applica-tions tested in this study are available on the Internet (see Inde-pendent JPEG Group (IJG) [33], Open Source Computer Vision [34], and H.264/AVC JM Reference Software [35]). The open-source programs were compiled using a GNU-based C com-piler for MIPS processors with an optimization option of “-o1,” which attempts to reduces the code size without performing ad-ditional optimizations. To emphasize the effectiveness of the proposed VLSBM with the discussed applications, an ad-hoc framework is developed for the dynamic profiling of the soft-ware applications to trace the actual operand values driven to the processor multiplier, and to check the RAW (read-after-write) hazard of each multiplier instruction when produced during ex-ecution.
For the application of a 512 512 JPEG image compression [33], 2,064,384 multiplications were recorded with a of ap-proximately 0.76. Two standard test images (Lena and Baboon) were used to test the performance of the proposed VLSBM. The results show that the values are approximately 93.9% and 94.1%, respectively. Furthermore, the required cycle count values of the proposed VLSBM-enhanced MIPS for these images are 2,162,201 and 2,157,110, respectively. Compared
TABLE VII
MULTIPLICATIVEPERFORMANCEEVALUATIONS FORREALAPPLICATIONS
to the conventional 2-stage pipelined Booth multiplier, the ratio of the average cycle count reduction is approximately 1.7. Table VII (top) shows the experimental results for the 512 512 JPEG image compression application. Compared with the fastest pipelined Booth multiplier with , the multiplicative speed-up ratio of the proposed VLSBM for the 512 512 JPEG compression can be estimated by
(24) where and are the average cycle counts required for the conventional pipelined Booth multiplier and for the proposed VLSBM, respectively.
Fig. 8 shows that five typical 320 240 photos are applied for the facial object detection application examination (OpenCV v2.0.0) [34]. Depending on the selected photo image, although
Fig. 8. Five selected photos for object detection application.
the number of multiplications for facial object detection is not constant, the estimated for each image test is approximately 0.36, as shown in Table VII (center), and the simulated of the proposed VLSBM is approximately 89%–90%. Compared to the conventional 2-stage pipelined Booth multiplier, the average cycle count reduction ratio is approximately 1.3. Similar to (24), compared to the fastest conventional two-stage pipelined archi-tecture, the multiplicative speed-up ratio of the proposed opti-mized VLSBM for object detection is obtained by
Although the effective throughput is almost identical, approxi-mately 16.5% of the total energy is conserved by employing the proposed optimized VLSBM.
For the high-definition H.264/AVC decoder application [35], the CIF Foreman sequence was examined. The H.264/AVC de-coder displays CIF I- and P-frames, using all inter- and intra-prediction modes. The motion compensation employs a single reference that applies all block sizes, with a search range of 16
pixels . In the study of 106,716,335
multiplications, a value was obtained of approximately 0.85. The experimental results show that the of the Foreman se-quence is approximately 95%. Compared to the conventional 2-stage pipelined Booth multiplier, the average cycle count re-duction ratio is approximately 1.8. Similar to (25), compared with the fastest conventional two-stage pipelined architecture, the multiplicative speed-up ratio of the optimized VLSBM for the high definition H.264/AVC decoder application is approxi-mately
Thus, the experimental results verify the effectiveness of the proposed VLSBM.
IV. CONCLUSION
Data hazards cause severe performance degradation in the pipelined datapath of data-intensive computing processes. Under a pessimistic assumption on the pipeline efficiency, this study implemented an optimized VLSBM. Without waiting for the true carry propagation, the VLSBM applies a condi-tional-probability carry estimator for the carry signal. Similar
to the branch predictor used in microprocessors, if a true carry prediction occurs, the multiplier-stall cycles caused by data de-pendence can be hidden. Examined by the instruction streams in the real workload: JPEG compression, object detection, and H.264/AVC decoder, experimental results reveal that the proposed VLSBM obtains a speculation accuracy between ap-proximately 89% to 95%, thereby achieving a cycle count ratio reduction of approximately 1.3 to 1.8 . Thus, the potential speed-up benefit of the pipelined data path is ensured. The pro-posed VLSBM is useful for software porting on data-intensive computing processors because no time-consuming efforts for assembly language programming are necessary when com-piling. If , the speed of the proposed VLSBM is greater than that of the fastest conventional well-pipelined modified Booth multiplier (@ UMC 90 nm CMOS). More-over, area overhead and energy dissipation are reduced by approximately 7% and 11.4% to 25.4%, respectively. The contributions of this study are detailed as follows: 1) the first high-speed and area-/energy-efficient architecture is proposed for the variable-latency speculating modified Booth multiplier, which hides approximately 90% of the multiplier-stall cycles, thereby ensuring the pipelined data path of data-intensive com-puting processors; 2) based on conditional probability theory, a complete and systematic framework of three carry estimation schemes for -PT fixed-width multipliers (for the modified Booth multiplier and the Baugh-Wooley multiplier) have been developed; and (3) thorough design-space considerations are provided for constructing the optimized VLSI architecture of the proposed 16 16 VLSBM. Numerous simulations were performed and experimental results obtained that verify the overall effectiveness of the proposed VLSBM.
The future direction of this research will consider additional pipeline stages. Devising an efficient control and error recovery mechanism for compensating for inaccurate predictions without adversely impacting the overall performance are the most crit-ical challenges [7].
REFERENCES
[1] K. K. Parhi, VLSI Digital Signal Processing Systems. New York, NY, USA: Wiley, 1999.
[2] J. Fadavi-Ardekani, “ Booth encoded multiplier generator using optimized Wallace trees,” IEEE Trans. Very Large Scale Integr.
(VLSI) Syst., vol. 1, no. 2, pp. 120–125, Jun. 1993.
[3] W.-C. Yeh and C.-W. Jen, “High-speed Booth encoded parallel multi-plier design,” IEEE Trans. Computers, vol. 49, no. 7, pp. 692–701, Jul. 2000.
[4] Q. Li, G. Liang, and A. Bermak, “A high-speed 32-bit signed/unsigned pipelined multiplier,” in IEEE Int. Symp. Electronic Design, Test &
Applications, DELTA, 2010, pp. 207–211.
[5] R. K. Yu and G. B. Zyner, “167 MHz radix-4 floating point multiplier,” in Proc. 12th Symp. Computer Arithmetic, 1995, pp. 149–154. [6] G. Even and P.-M. Seidel, “A comparison of three rounding algorithms
for IEEE floating-point multiplication,” IEEE Trans. Computers, vol. 49, no. 7, pp. 638–650, Jul. 2000.
[7] A. A. Del Barrio, S. O. Memik, M. C. Molina, J. M. Mendias, and R. Hermida, “A distributed controller for managing speculative functional units in high level synthesis,” IEEE Trans. Comput.-Aided Des. Integr.
Circuits Syst., vol. 30, no. 3, pp. 350–363, March 2011.
[8] A. K. Verma, P. Brisk, and P. Ienne, “Variable latency speculative ad-dition: A new paradigm for arithmetic circuit design,” in Proc. Des.,
Automat. Test Eur., 2008, pp. 1250–1255.
[9] A. Cilardo, “A new speculative addition architecture suitable for two’s complement operation,” in Proc. Des., Automat. Test Eur., 2009, pp. 664–669.
[10] Y. C. Lim, “Single-precision multiplier with reduced circuit com-plexity for signal processing applications,” IEEE Trans. Computers, vol. 41, no. 10, pp. 1333–1336, Oct. 1992.
[11] M. J. Shulte and E. E. Swartzlander, Jr., “Truncated multiplication with correction constant,” VLSI Signal Processing, vol. VI, pp. 388–396, 1993.
[12] S. S. Kidambi, F. El-Guibaly, and A. Antonious, “Area-efficient mul-tipliers for digital signal processing applications,” IEEE Trans.
Cir-cuits Syst. II: Analog and Digital Signal Processing, vol. 43, no. 2, pp.
90–95, Feb. 1996.
[13] J.-M. Jou, S.-R. Kuang, and R.-D. Chen, “Design of low-error fixed-width multipliers for DSP applications,” IEEE Trans. Circuits Syst. II:
Analog and Digital Signal Processing, vol. 46, no. 6, pp. 836–842, Jun.
1999.
[14] L.-D. Van, S.-S. Wang, and W.-S. Feng, “Design of the lower error fixed-width multiplier and its application,” IEEE Trans. Circuits
Syst. II: Analog and Digital Signal Processing, vol. 47, no. 10, pp.
1112–1118, Oct. 2000.
[15] S.-J. Jou, M.-H. Tsai, and Y.-L. Tsao, “Low-error reduced-width Booth multipliers for DSP applications,” IEEE Trans. Circuits Syst. I, vol. 50, no. 11, pp. 1470–1474, Nov. 2003.
[16] K. J. Cho, K. C. Lee, J. G. Chung, and K. K. Parhi, “Design of low-error fixed-width modified Booth multiplier,” IEEE Trans. Very Large Scale
Integr. (VLSI) Syst., vol. 12, no. 5, pp. 522–531, May 2004.
[17] L.-D. Van and C.-C. Yang, “Generalized low-error area-efficient fixed-width multiplies,” IEEE Trans. Circuits Systems I: Regular Papers, vol. 52, no. 8, pp. 1608–1619, Aug. 2005.
[18] T. B. Juang and S. F. Hsiao, “Low-error carry-free fixed-width multi-pliers with low-cost compensation circuits,” IEEE Trans. Circuits Syst.
II, vol. 52, no. 6, pp. 299–303, Jun. 2005.
[19] A. G. M. Strollo, N. Petra, and D. De Caro, “Dual-tree error compen-sation for high performance fixed-width multipliers,” IEEE Trans.
Cir-cuits Syst. II, vol. 52, no. 8, pp. 501–507, Aug. 2005.
[20] Y.-C. Liao, H.-C. Chang, and C.-W. Liu, “Carry estimation for two’s complement fixed-width multipliers,” in Workshop on Signal
Processing Systems (SiPS), Banff, Canada, Oct. 2006, pp. 345–350.
[21] S.-R. Kuang and J.-P. Wang, “Low-error configurable truncated mul-tipliers for multiply-accumulate applications,” Electron. Lett., vol. 42, no. 16, pp. 904–905, Aug. 3, 2006.
[22] H.-A. Huang, Y.-C. Liao, and H.-C. Chang, “A self-compensation fixedwidth Booth multiplier and its 128-point FFT applications,” in
Proc. IEEE Int. Symp. Circuits Syst., 2006, pp. 3538–3541.
[23] M. A. Song, L. D. Van, and S. Y. Kuo, “Adaptive low-error fixed-width Booth multipliers,” IEICE Trans. Fundam., vol. E90-A, no. 6, pp. 1180–1187, Jun. 2007.
[24] J.-H. Tu and L.-D. Van, “Power-efficient pipelined reconfigurable fixed-width Baugh-Wooley multipliers,” IEEE Trans. Comput., vol. 58, no. 10, pp. 1346–1355, Oct. 2009.
[25] N. Petra, D. De Caro, V. Garofalo, E. Napoli, and A. G. M. Strollo, “Truncated binary multipliers with variable correction and minimum mean square error,” IEEE Trans. Circuits Syst. I, vol. 57, no. 6, pp. 1312–1325, Jun. 2010.
[26] C.-H. Chang and R. K. Satzoda, “A low error and high performance multiplexer-based truncated multiplier,” IEEE Trans. Very Large Scale
Integr. (VLSI) Syst., vol. 18, no. 12, pp. 1767–1771, Dec. 2010.
[27] N. Petra, D. D. Caro, V. Garofalo, E. Napoli, and A. G. M. Strollo, “Design of fixed-width multipliers with linear compensation function,”
IEEE Trans. Circuits Syst. I, vol. 58, no. 5, pp. 947–960, May 2011.
[28] C.-Y. Li, Y.-H. Chen, T.-Y. Chang, and J.-N. Chen, “A probabilistic estimation bias circuit for fixed-width Booth multiplier and its DCT applications,” IEEE Trans. Circuits Syst. II, Exp. Briefs, vol. 58, no. 4, pp. 215–219, Apr. 2011.
[29] J.-P. Wang, S.-R. Kuang, and S.-C. Liang, “High-accuracy fixed-width modified Booth multipliers for lossy applications,” IEEE Trans.
Very Large Scale Integr. (VLSI) Syst., vol. 19, no. 1, pp. 52–60,
Jan. 2011.
[30] Y.-H. Chen, T.-Y. Chang, and C.-Y. Li, “Area-effective and power-efficient fixed-width Booth multipliers using generalized probabilistic estimation bias,” IEEE J. Emerging Sel. Topics Circuits Syst., vol. 1, no. 3, pp. 277–288, Sep. 2011.
[31] Y.-H. Chen and T.-Y. Chang, “A high-accuracy adaptive conditional-probability estimator for fixed-width Booth multipliers,” IEEE Trans.
Circuits Syst. I, vol. 59, no. 3, pp. 594–603, March 2012.
[32] S.-R. Kuang, J.-P. Wang, and C.-Y. Guo, “Modified Booth multipliers with a regular partial product array,” IEEE Trans. Circuits Syst. II, Exp.
Briefs, vol. 56, no. 5, pp. 404–408, May 2009.
[34] Open Source Computer Vision v 2.0.0 [Online]. Available: http://sourceforge.net/projects/opencvlibrary/files/opencv-win/2.0/ OpenCV-2.0.0a-win32.exe/download
[35] H.264/AVC JM Reference Software [Online]. Available: http:// iphome.hhi.de/suehring/tml/
Shin-Kai Chen was born in Taiwan. He received the B.S. degree in electronics engineering from National Chiao Tung University, Taiwan, in 2004, where he is working toward the Ph.D. degree.
His research includes processors for embedded computing system, digital signal processing, and system software designs.
Chih-Wei Liu (M’03) was born in Taiwan. He re-ceived the B.S. and Ph.D. degrees, both in electrical engineering, from National Tsing Hua University, Hsinchu, Taiwan, in 1991 and 1999, respectively.
From 1999 to 2000, he was an integrated circuits design engineer at the Electronics Research and Ser-vice Organization (ERSO) of Industrial Technology Research Institute (ITRI), Hsinchu, Taiwan. Then, near the end of 2000, he joined SoC Technology Center (STC) of ITRI as a project leader and even-tually left ITRI at the end of Sepember 2003. He is
currently with the Department of Electronics Engineering and the Institute of Electronics, National Chiao Tung University, Hsinchu, Taiwan, as an Associate Professor. His current research interests are SoC and VLSI system design, processors for embedded computing system, digital signal processing, digital communications, and coding theory.
Tsung-Yi Wu was born in Taiwan. He received the B.S. degree in electrical engineering from Chang Gung University, Taoyuan, Taiwan, in 2010. He is currently pursuing the M.S. degree in the Department of Electronics Engineering, National Chiao Tung University, Hsinchu, Taiwan.
His research interests include low-power design, digital signal processing, and computer architecture.
An-Chi Tsai was born in Taiwan. She received the B.S. degree in electrical engineering from National Dong Hwa University, Hualien, Taiwan, in 2007, and the M.S. degree in electronics engineering from Na-tional Chiao Tung University, Taiwan, in 2012.
She is currently a senior engineer at the ITE Tech. Inc., Hsinchu, Taiwan. Her research interests include SoC and VLSI system design, IC design, and digital signal processing.


![Fig. 8 shows that five typical 320 240 photos are applied for the facial object detection application examination (OpenCV v2.0.0) [34]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7570857.125183/11.888.61.432.130.831/typical-photos-applied-facial-detection-application-examination-opencv.webp)
