國立臺中教育大學教育測驗統計研究所理學碩士論文
指導教授: 楊 志 堅 教授
準概似估算法於潛藏變數間交互作用之
正確性研究
研究生: 黃 玉 玲 撰
中 華 民 國 九 十 六 年 一 月
摘要
潛藏變數間交互作用的估算之重要性在近年的研究中漸漸被重視,但對於交 互 作 用 實 際 估 算 的 效 率 至 今 仍 未 有 較 完 整 的 相 關 研 究 。 準 概 似 估 算 法 (Quasi-Likelihood Method)是這幾年間針對相關議題所研發的估算方法,本研 究以模擬研究,設計三個潛藏變數與一個潛藏變數間交互作用的結構方程模式, 藉以探討準概似估算法在不同樣本數與交互作用大小的組合下之估算正確性,並 將研究所得的結果條列如下: 1. 準概似估算法的估算正確性會隨樣本數變大而有增強的趨勢。 2. 準概似估算法的估算正確性在樣本數為 100 時,會明顯低於樣本數大於 200 以上時。 3. 準概似估算法的估算正確性會隨潛藏變數交互作用變小而有增強的趨 勢。 關鍵字:交互作用、準概似估算法、結構方程模式Abstract
The estimation of interaction between latent variables was emphasized recently, but there are no completely reports about the efficiency of the estimation. Quasi-Likelihood Method is the new method of the corresponding issue. The Monte Carlo method is used for simulation in this study and let the model include three factors and one interaction variables. Depending on sample size and interaction, we focus on the validity of the estimation of Quasi-Likelihood Method between different sample size and different interaction. According to this research, the major findings included:
1. The validity of the estimation of Quasi-Likelihood Method are increasing as the sample size are increasing.
2. The validity of the estimation of Quasi-Likelihood Method at the sample size 100 was lower than the sample size was bigger than 200 obviously.
3. The validity of the estimation of Quasi-Likelihood Method are increasing as the interaction are decreasing.
目錄
壹、緒論 ... 1 貳、潛藏變數交互作用 ... 2 參、潛藏變數交互作用估算方式比較 ... 5 肆、模擬研究 ... 12 伍、研究結果 ... 16 陸、結論與建議 ... 22 參考文獻 ... 24圖目錄
圖 1 具有潛藏變數交互作用之結構方程模式模型圖 ... 2 圖 2 Klein & Muthén ( 2002)模式架構圖 ... 6 圖 3 蒙帝卡羅模擬四種估算之正確性比較圖 ... 8 圖 4 模式架構圖 ... 12 圖 5 各因素負荷量設定值之架構圖 ... 14 圖 6 不同樣本數下各交互作用量所估算之 MSE 值 ... 19 圖 7 不同潛藏變數交互作用下各樣本數所估算之 MSE 值 ... 21表目錄
表 1 蒙帝卡羅模擬四種估算之正確性比較表 ... 7
表 2 四種處理方法相對優缺點之摘要表 ... 10
表 3 不同樣本數及交互作用下之 MSE 值 ... 17
壹、緒論
自 1984 年 Kenny & Judd 利用可觀察之指標間的乘積(Kenny & Judd, 1984 ) 來定義潛藏變數(latent variable)間交互作用(interaction)開始,對於潛藏變數 間交互作用的估算之相關研究陸續受到重視。Jöreskog 在 2000 年時利用潛藏變數 分數(latent variable scores)來估算交互作用,Marsh, Wen & Hau 亦於 2004 年應 用具交互潛藏變數之非線性結構方程模式提出無限制估計策略。然而,僅管潛藏 變數間交互作用的估算之重要性已被廣泛接受,但對於交互作用實際估算的效率 至今仍未有較完整的相關研究。準概似估算法(Quasi-Likelihood Method;QML. Klein & Moosbrugger, 2000)則是這幾年間針對相關議題所研發的估算方法,相關 的初步研究(Klein & Moosbrugger, 2000; Muthén & Muthén, 1998-2002)顯示準概似 估算法在這個議題上具有相當的發展潛力。然而,卻沒有一篇研究明確指出各種 不同樣本數及因素負荷量下,其估算之正確性有何趨勢,是否在某一樣本數或某 一因素負荷量下,其估算之正確性會突然偏低,故本研究係以模擬研究針對準概 似法進行更深入的分析。 本研究的研究目的係在探討準概似估算法於不同樣本數與交互作用大小的 組合下之估算正確性,觀察其對於潛藏變數交互作用之估算效果,並試圖找出此 法是否有其不足之處,期望能提出適合此方法的適用準則,例如:準概似估算法 在小樣本時的估算偏誤與正確性等,以供實徵研究者在進行相關研究時有所參 考。將本研究的目的條列如下: 1、在不同的交互作用下,準概似估算法的估算正確性如何。 2、在不同的樣本數下,準概似估算法的估算正確性如何。
貳、潛藏變數交互作用
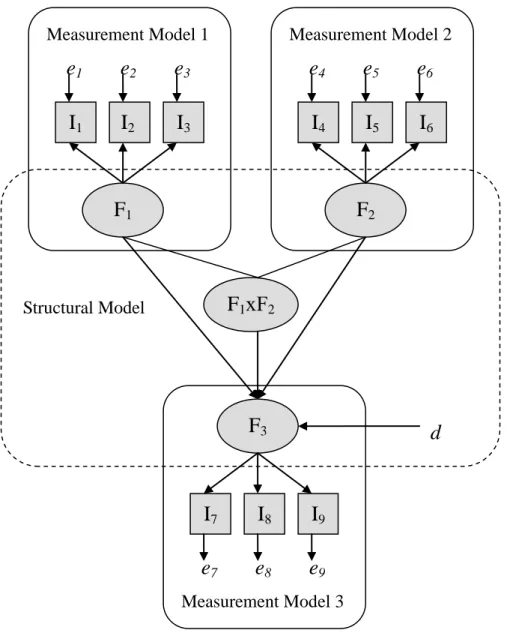
圖 1 具有潛藏變數交互作用之結構方程模式模型圖
圖 1 為具有潛藏變數交互作用之結構方程模式模型圖。如圖 1 所示,結構方 程模式包含了測量模型(measurement model)與結構模型(structural model)兩
d
Measurement Model 1 Measurement Model 2I
1I
2I
3I
4I
5I
6 Measurement Model 3F
3I
7I
8I
9F
1F
2F
1хF
2e
1e
2e
3e
4e
5e
6e
7e
8e
9 Structural Model個部分,前者指觀測變項(observed variable)與潛藏變項(latent variable)的相 互關係,即研究者可以直接觀察得到的變項。後者說明潛藏變項之間的關係,即 研究者無法直接觀察得到,但可以利用觀測變項來推估的變項(Bollen, 1989)。
舉例來說,如欲測得學生的數學能力(F3),可藉由學生多次的數學測驗成績(I7、
I8、I9)推估而得;如欲測得學生的創造力(F1),可藉由學生多次的創造力測驗
成績(I1、I2、I3)推估而得;如欲測得學生的智力(F2),可藉由學生多次的智
力測驗成績(I4、I5、I6)推估而得。其中數學測驗成績、創造力測驗成績與智力
測驗成績稱之為觀測變項,數學能力、創造力與智力則稱之為潛藏變項。
至於潛藏變數間交互作用方面,自從 Kenny & Judd (1984)利用可觀察之指標 間的乘積來定義潛藏變數(latent variable)間交互作用(interaction)開始,各種 針對潛藏變數間交互作用的定義相繼被提出。所謂潛藏變數間的交互作用,舉例 來說,在圖 1 中,假設潛藏變數 F1、F2、F3分別為學生的創造力、智力及數學 能力,而創造力與數學能力皆會對數學能力有所影響. 至於潛藏變數 F1 х F2則為 創造力與智力間的交互作用,亦會對數學能力造成影響,即創造力與智力皆高、 創造力高智力低、創造力低智力高及創造力及智力皆低的學生之數學能力是有所 不同的。 各種潛藏變數交互作用估算方法中,準概似估算法用在分析具有多重非線性 效果的複雜結構方程模式,已經明確地被發展成效率高、計算能力強的方法(Klein, & Muthén, 2002),在 Klein & Muthén (2002)的文章中將準概似估算法的估 算方式,做概略的敘述如下:
在一個非線性結構方程模式的參數模組中,利用近似的最大概概似指數函數 (maximization of an approximating quasi-loglikelihood function)進行估計,至於
準概似估算的概念(Carroll et al. 1995, pp. 269-272),是使用接近常態分配的條件
分配 f =(y | x = x , u = u ),藉由一級動差和二級動差分別定出平均數函數和變
Var(y1t | xt = x, ut = u)。 準概似估算法的原則是在假設另一個幾近於函數 f =(x, y)的函數式 f * =(x, y),使得 f(x, y) = f2(x, Ry)f3(y1 | xt = x, ut = Ry) ≈ f2(x, Ry)f3 *(y1 | xt = x, ut = Ry) = f *(x, y) 其中,f2(x, u)為一個常態的密度函數,而f3*(y1 | xt = x, ut = Ry)則為一個單一 性的常態密度函數,其期望值和變異數分別為E [ y1t | xt = x, ut = Ry ] 與 Var(y1t | xt = x, ut = Ry)。
關於本研究所使用之準概似估算方法係使用 Muthén & Muthén (1998-2002)中 所敘述之計算方式。
參、潛藏變數交互作用估算方式比較
就具有潛藏變數交互作用的結構方程模式而言,由於各種估算方法皆被陸續
提出,故在許多文獻中,各種估算方法之正確性及效率紛紛被併列比較,以下就 兩篇估算方法比較的文獻加以討論。
Klein & Muthén 於 2002 年時,利用蒙帝卡羅(Monte-Carlo)研究的方式比 較了準概似估算法、LMS 法(Klein, 2000;Klein & Moosbrugger, 2000 )、
LISREL-ML 法(Jöreskog & Yang, 1996, 1997; Yang-Jonsson, 1997)以及 2SMM 法
(Wall & Amemiya, 2000)在估算潛藏變數交互作用時的優劣。他們將具有潛藏 變數交互作用之結構方程式定義如下: . 其中 ξ1t、ξ2t 為潛藏變數,而 ξ1t ξ2t 則為潛藏變數 ξ1t 與 ξ2t 之交互作用。 ) ( 2 1 12 2 2 1 1 t t t t t t t t
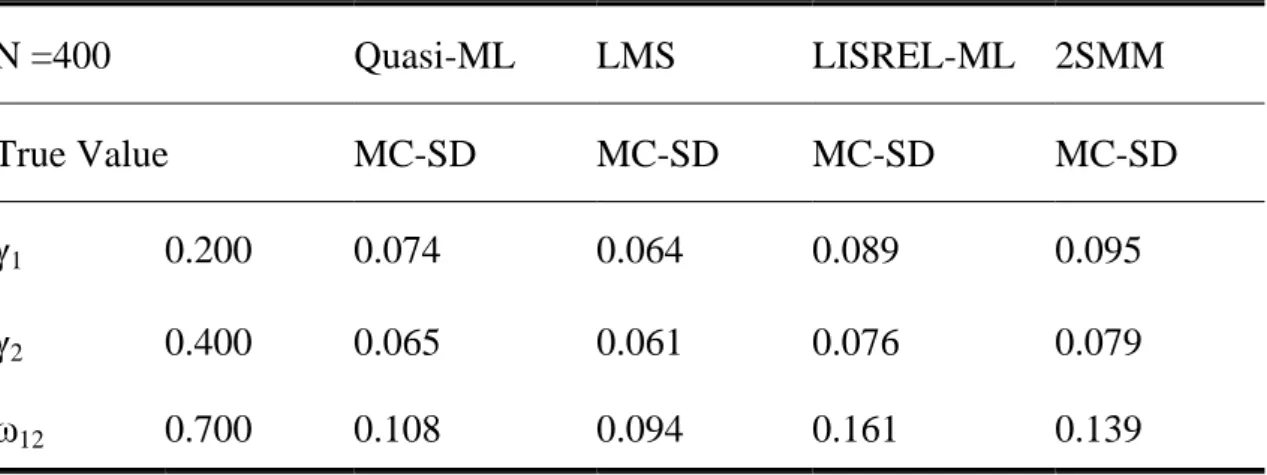
本研究根據Klein & Muthén 於2002年研究報告中的模式描述,將該模式之模 式結構圖繪製如圖2,而表1為模擬樣本N = 400,重複次數為500次的估計結果比 較表: 圖 2 Klein & Muthén ( 2002)模式架構圖 γ2 ω12 γ1 λ4 λ3 λ2 λ1
I
1I
2I
3I
4I
5 ξ1 ξ2 ξ1ξ2 ηt λ5表 1 蒙帝卡羅模擬四種估算之正確性比較表 (引自 Klein & Muthén, 2002, p11,Table 1)
N =400 Quasi-ML LMS LISREL-ML 2SMM True Value MC-SD MC-SD MC-SD MC-SD γ1 0.200 0.074 0.064 0.089 0.095 γ2 0.400 0.065 0.061 0.076 0.079 ω12 0.700 0.108 0.094 0.161 0.139 在表1中,γ1、γ2、ω12 的真實值分別為0.200、0.400、0.700,進而比較其MC-SD
(Calculation of The Mean and The Standard Deviation of The Esatimates.),MC-SD
值越低表示其估算正確性越高。研究結果發現,Quasi-ML與LMS不論在估算ξ1t
的因素負荷量 γ1、ξ2t 的因素負荷量 γ2 亦或潛藏變數交互作用 ξ1tξ2t 的因素負荷
量ω12時,其MC-SD值皆低於LISREL-ML及2SMM。本研究根據表2的結果將其整
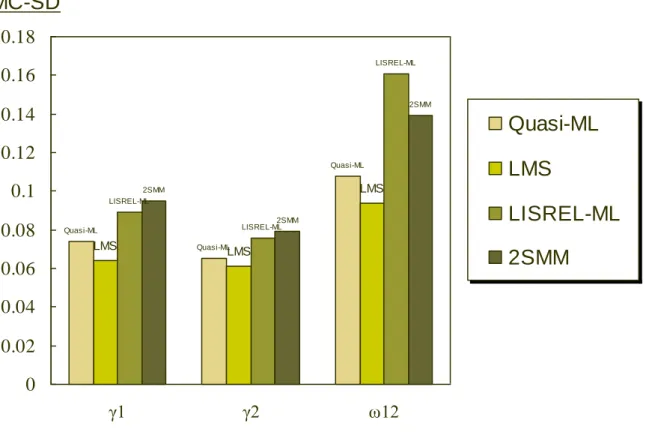
圖 3 蒙帝卡羅模擬四種估算之正確性比較圖
雖然 QML 法所計算出的 MC-SD 值在 γ1, γ2, ω12上皆高於 LMS,但其差異對
另外兩種方法而言是相對小的。此外,在比較複雜的模式時,LMS 與 LISREL-ML 是無法使用的(Klein & Muthén, 2002)。但在此篇研究,僅針對樣本數為 400, 以及潛藏變數交互作用為 0.7,並未針對準概似估算估算法在各種樣本數及各種 潛藏變數交互作用下作進一步的分析。 Quasi-ML Quasi-ML Quasi-ML LMS LMS LMS LISREL-ML LISREL-ML LISREL-ML 2SMM 2SMM 2SMM 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 γ1 γ2 ω12
MC-SD
Quasi-ML
LMS
LISREL-ML
2SMM
Marsh, Wen & Hau(2004)比較了四種潛在變數交互作用的估計方式,分別 為無限制的處理方式(unconstrained approach)、有限制的處理方式(constrained
approach)、廣義添加乘積指標的處理方式(The Generalized Appended Product
Indicator Approach, GAPI ) 以 及 準 概 似 估 計 法 ( Quasi-Maximum-Likelihood
Approach, QML),而在這篇研究中,將具有潛藏變數交互作用之結構方程式定義 如下: 其中 ξ1、ξ2 為潛藏變數,而 ξ1 ξ2 則為潛藏變數 ξ1 與 ξ2 之交互作用,並將 各種估算法之相對優缺點分析如表2。 ) ( 4 . 0 4 . 0 1 2 3 1 2
t ta :對大樣本而 言, 所 有處理方 式的精 確度 都類似, SE 皆小 QML GAPI 有限制的 無限制的 (Approach) 處理方式 表 2 四 種處理 方法 相對優缺 點之摘 要表 (引自 M arsh, W en & Hau, 2004, p297, T able 9) 需要特殊 軟體 能在大部分 SEM 套裝軟體 (允 許 非 線 性 限 定 )中使用 能在大部分 SEM 套裝軟體 (允 許 非 線 性 限 定 )中 使用 能在所有 SEM 套 裝 軟 體 中 使 用 易取性 (Accessibili ty) 用 適 當 的 軟 體 就容易實 現 需 要 指 定 複 雜 的非線性 限定 需 要 指 定 複 雜 的非線性 限定 容易實現 ; 並 不 需 要 非 線 性 限 定 易成性 (Ea se of implementa tion) 相對無偏 相對無偏 相對無偏 相對無偏 常態 偏誤 (Bias) 具潛在大的偏 差;端視其分 佈;當 樣本 增大 偏差不會 變小 偏差相對 小 ; 當 樣本增大偏差 會變小 佈 差;端視其分 具潛在大的偏 ; 當 樣本增 大 偏差不會 變小 偏差相對 小 ; 當 樣本增大偏差 會變小 非常態 相對小 的 SE 相對大的 SE 相對小的 SE 相對大的 SE (小樣本下 ) a 精確度 (Precision) 相對最大 相對小 相對大 相對小 型 I 誤差 檢定 相對最大 相對小 相對大 相對小 檢定力
Marsh, Wen & Hau(2004)所比較的結果發現:在易取性方面,無限制的處 理方式能在所有 SEM 套裝軟體中使用,而準概似估算法所需使用之特殊軟體, 已可由網站上輕易取得試用版本,但有限制及 GAPI 則無法在不允許非線性限定 的軟體中使用;在易成性方面,無限制的處理方式與準概似估算法皆容易實現, 而有限制的處理方式與 GAPI 則需要指定複雜的非線性限定;在精確定方面,樣 本大時,所有處理方式的標準誤(Standard Error, SE)皆小,但在小樣本下,準 概似估算法之 SE 則是相對最小的;至於檢定能力方面,準概似估算法則不及其 他處理方式來得強。但在此篇研究,僅針對樣本數為 100、200、500,以及潛藏 變數交互作用為 0.0、0.2、0.3 時作比較,並未針對準概似估算法在各種樣本數及 各種潛藏變數交互作用下作進一步的分析。 故根據以上的回顧,準概似估算法被證實在許多情況下皆優於其他有限制 式、無限制式等數種估算方法,但一般的實徵研究者若一昧的使用準概似估算 法,而不顧其是否在某些情形下是不適用的,也許會造成相當大的危險性,故本 研究將進一步確認準概似估算法在各種估算情形下的特性,進行其在估算具有潛 藏變數交互作用的估算正確性研究,以供實徵研究者作為參考之用。
肆、模擬研究
圖 4 模式架構圖 本研究利用模擬研究的方式進行估算,首先架構出本研究的模式結構圖,如 β32 β34 β31 λ9 λ8 λ7 λ6 λ5 λ4 λ3 λ2 λ1I
1I
2I
3I
4I
5I
6I
7I
8I
9F
1F
2F
1хF
2e
4e
6e
7e
8e
9d
F
3e
2e
1e
3e
5而 F1、F2與 F3各有三個觀測變項,分別為(I1、I2、I3)、(I4、I5、I6)和(I7、
I8、I9)。(λ1、λ2、λ3、λ4、λ5、λ6、λ7、λ8、λ9)為觀藏變項與潛藏變項的因素負
荷量,(β31、β34、β32)為潛藏變項與潛藏變項間的因素負荷量,(e1、e2、e3、e4、
e5、e6、e7、e8、e9)為觀測變項的殘差項,而 d 則為潛藏變數 F3的殘差項。
將以上之結構模式圖分成測量模型與結構模型,以數學模式表式如下: 一、測量模型 I = Λ × F + E;其中F=〔f1 f2 f3 f1×f2〕 I1 = λ1 × f1 + e1 I2 = λ2 × f1 + e2 I3 = λ3 × f1 + e3 I4 = λ4 × f2 + e4 I5 = λ5 × f2 + e5 I6 = λ6 × f2 + e6 I7 = λ7 × f3 + e7 I8 = λ8 × f3 + e8 I9 = λ9 × f3 + e9 二、結構模型 F = B × F+D;其中F=〔f1 f2 f3 f1×f2〕 f1 = β11 × f1 f2 = β22 × f2 f3 = β31 × f1 + β32 × f2 + β33 × f3 + β34 × ( f1 × f2 ) + d f1 × f2 = β44 × ( f1 × f2 ) 至於模式中各個因素負荷量(λ1、λ2、λ3、λ4、λ5、λ6、λ7、λ8、λ9、β31、β32) 的值分別設定為(1、1、1、1、0.8、0.8、1、0.9、0.9、1、1),並且,為確保研
究結果的差異並非來自潛藏變數 f1 與 f2間的相關程度,故將潛藏變數 f1 與 f2間 的相關程度設定為 0,將各設定值表示如圖 5。 圖 5 各因素負荷量設定值之架構圖 模式中潛藏變數交互作用的因素負荷量 β34分別設定為 0.0、0.1、0.2、0.3、 0.4、0.5、0.6、0.7、0.8、0.9、1.0 共 11 種,依據此十一種模式,分別產生樣本 1 0.8 β34 1 0.9 0.9 1 0.8 1 1 1 1
I
1I
2I
3I
4I
5I
6I
7I
8I
9F
1F
2F
1хF
2e
4e
6e
7e
8e
9d
F
3e
2e
1e
3e
5 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0數為 100、200、300、400、500、600、700、800、900、1000 筆共 10 種不同的 樣本數情境,因此,基於不同的潛藏變數交互作用之因素負荷量以及不同的樣本 數之下,共有 110 種不同的情境產生,針對這 110 種不同的情境,分別模擬 500 筆資料集觀察其 MSE (Mean Square Error)來進行準概似估算法之估算正確性研 究,其中,MSE 為變異數分析中母體變異數的估計值,亦等同於估計值與目標值 距離平方後的平均值, 2 34 34 1 ) ( 1 i n i i f n MSE 其中,34i =第 i 個估計值,34 =目標值。本研究藉以探討準概似估算法之估算 正確性是否會因潛藏變數交互作用之因素負荷量值以及樣本數不同而有所差異。
伍、研究結果
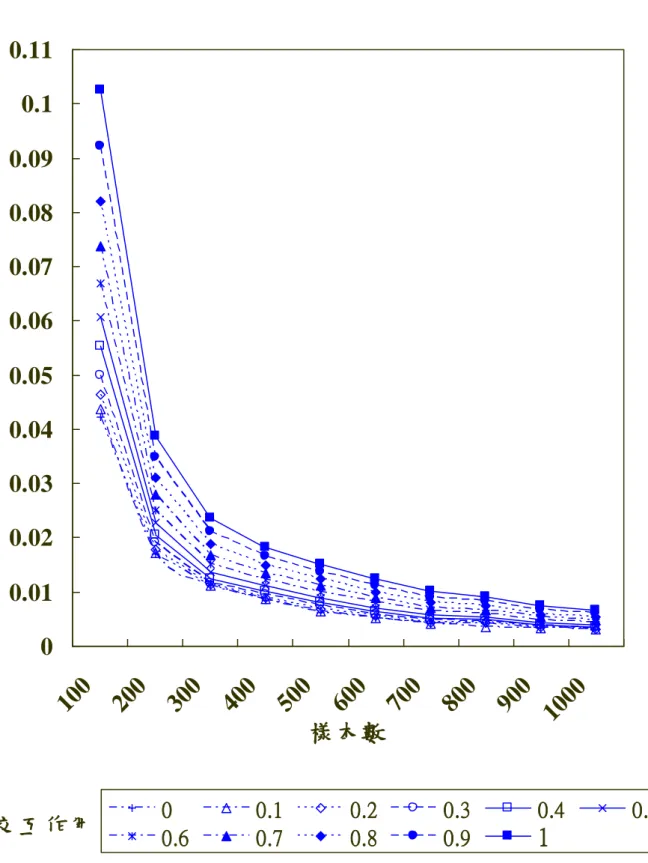
根據以上的模式架構進行模擬研究,並針對兩個不同的研究主題進行討論, 分別為不同的樣本數下,準概似估算法的估算正確性如何,以及在不同交互作用 下,準概似估算法的估算正確性如何。 根據圖 5 的模式架構進行模擬研究,得到藉以比較估算正確性的數據整理如 表 3,表 3 的內容即為在不同的樣本數及潛藏變數交互作用下所估算出的 MSE 值。橫列代表在固定樣本數下,不同的潛藏變數交互作用間,準概似估算法估算 具有潛藏變數交互作用模式時的 MSE 值。直列代表在固定交互作用下,不同的 樣本數間,準概似估算法估算具有潛藏變數交互作用時的 MSE 值。例如,若欲 比較不同樣本數之間的估算正確性,樣本數為 100,在潛藏變數交互作用依序為 0.0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0 下,所估算出的 MSE 值 分別為 0.0422、0.0438、0.0465、0.0465、0.0554、0.0608、0.0670、0.0738、0.0821、 0.0922、0.1026。若欲比較不同潛藏變數交互作用之間的估算正確性,潛藏變數 交互作用為 0.9 時,在樣本數依序為 100、200、300、400、500、600、700、800、 900、1000 下,所估算出的 MSE 值分別為 0.0922、0.0348、0.0211、0.0165、0.0137、 0.0112、0.0090、0.0082、0.0075、0.0067。 然而,我們可以發現,在表 3 中,最大的 MSE 值是在樣本數 100、潛藏變數 交互作用為 1.0 時具有最大值 0.1026,不論是在何種樣本數及潛藏變數交互作用 下,使用準概似估算法所估算出的 MSE 值皆不大於 0.1 左右。1000 900 800 700 600 500 400 300 200 100 樣本數 表 3 不 同樣本 數及 交互作用 下之 M SE 值 0.0032 0.0034 0.0041 0.0042 0.0051 0.0062 0.0085 0.0112 0.0170 0.0422 0.0 潛藏變數 交 互作 用 0.0032 0.0035 0.0036 0.0042 0.0052 0.0064 0.0087 0.0111 0.0172 0.0438 0.1 0.0033 0.0037 0.0043 0.0044 0.0055 0.0068 0.0090 0.0113 0.0179 0.0465 0.2 0.0036 0.0039 0.0046 0.0047 0.0059 0.0074 0.0095 0.0117 0.0190 0.0465 0.3 0.0039 0.0043 0.0050 0.0052 0.0064 0.0081 0.0102 0.0125 0.0205 0.0554 0.4 0.0043 0.0048 0.0054 0.0057 0.0071 0.0090 0.0112 0.0136 0.0227 0.0608 0.5 0.00 48 0.0053 0.0060 0.0064 0.0080 0.0100 0.0123 0.0151 0.0250 0.0670 0.6 0.0054 0.0059 0.0066 0.0071 0.0089 0.0111 0.0135 0.0168 0.0279 0.0738 0.7 0.0060 0.0067 0.0074 0.0080 0.0100 0.0124 0.0149 0.0188 0.0311 0.0821 0.8 0.0067 0.0075 0.0082 0.0090 0.0112 0.0137 0.0165 0.0211 0.0348 0.0922 0.9 0.0075 0.0084 0.0092 0.0101 0.0124 0.0152 0.0183 0.0236 0.0387 0.1026 1.0
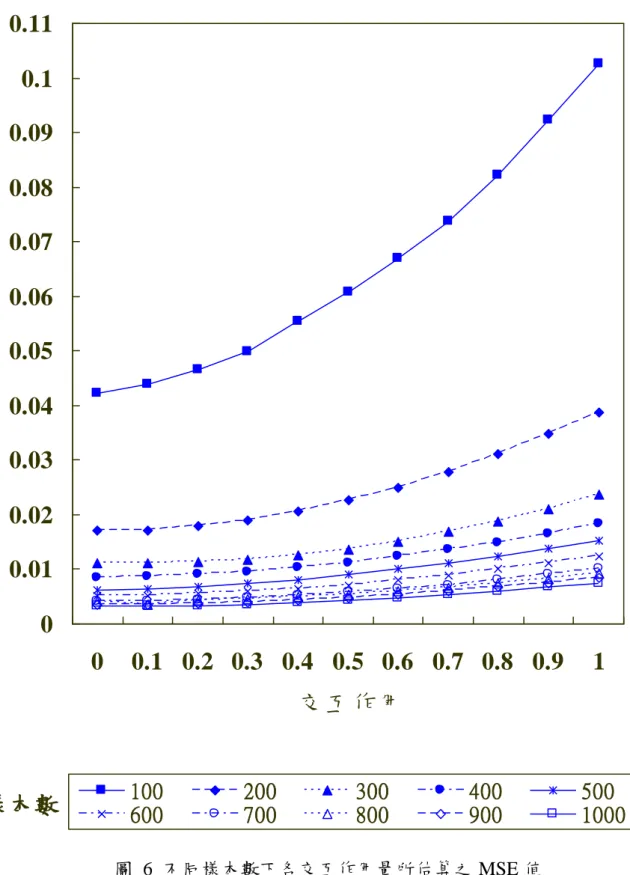
根據表 3 的數值,按照樣本數的不同,將其繪製 MSE 折線圖如圖 6。圖中 X 軸代表潛藏變數間的交互作用值,Y 軸代表準概似估算法在估算具有潛藏變數交 互作用模式時的 MSE 值,每一條曲線代表一種樣本數,分別為 100、200、300、 400、500、600、700、800、900、1000 共 10 條折線。由圖中可以發現,在不同 的樣本數下,準概似估算法在估算不同的潛藏變數交互作用時,其估算正確性, 即 MSE 值會隨著潛藏變數交互作用值增加而有遞增的趨勢。例如,當樣本數為 100 時,所估算出的 MSE 值分別為 0.0422、0.0438、0.0465、0.0465、0.0554、0.0608、 0.0670、0.0738、0.0821、0.0922、0.1026,呈現遞增的現象,並且在潛藏變數交 互作用為 0.0 時有最小值 0.422,為 1.0 時有最大值 0.1026,並且,此一遞增趨勢 會隨樣本數減少而變大,將此一遞增增勢整理如表 4。其中,本研究將 D 值定義 為各樣本數下,準概似估算法估算潛藏變數交互作用為 0.0 及 1.0 時所估算出 MSE 值的差距。 表 4 不同樣本數下之 D 值遞增趨勢表 樣本數 1000 900 800 700 600 500 400 300 200 100 D 值* 0.0043 0.005 0.0051 0.0059 0.0073 0.009 0.0098 0.0124 0.0217 0.0604 *D 值 = QML 法估算同一樣本數下潛藏變數交互作用為 0.0 及 1.0 時所估算出 MSE 值的差距。 藉由表 4 我們可以發現,當樣本數為 100 時,準概似估算法估算潛藏變數交 互作用為 0.0 及 1.0 時所估算出 MSE 值的差距為 0.0604,比起樣本數為 1000 時 的 0.0043 高出了 0.0561,差距是相當大的。
圖 6 不同樣本數下各交互作用量所估算之 MSE 值
樣本數
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0.11
0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1
交互作用
MSE
100
200
300
400
500
600
700
800
900
1000
同樣地,根據表 3 的數值,按照潛藏變數因素負荷量的不同,將其繪製 MSE 折線圖如圖 7。圖中 X 軸代表估算時所使用的樣本數大小,Y 軸代表準概似估算 法在估算具有潛藏變數交互作用模式時的 MSE 值,每一條曲線代表一種潛藏變 數因素負荷量,分別為 0.0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0 共 11 條折線。由圖中可以發現,在不同的潛藏變數因素負荷量下,準概似估算法在 估算不同的樣本數大小時,其估算正確性,即 MSE 值會隨著樣本數增加而有遞 減的趨勢。例如,當潛藏變數交互作用為 0.1 時,所估算出的 MSE 值分別為 0.0422、0.0170、0.0112、0.0085、0.0062、0.0051、0.0042、0.0041、0.0034、0.0032, 呈現遞減的現象,並且在樣本數為 100 時有最大值 0.0422,為 1000 時有最小值 0.0032。 根據表 3 的數值,準概似估算法在估算具有潛藏變數交互作用的模式時,若 樣本數大於等於 300,其 MSE 值之最大值為 0.0236,而當樣本數為 200 時,其估 算的 MSE 值明顯變得較高,交互作用為 1.0 時,高達 0.0387。從表 3 以及圖 6 中,我們可以發現,當樣本數為 100 時,不論在任何潛藏變數交互作用下,估算 所得的 MSE 值明顯高於其他樣本數下所計算出的 MSE 值,當潛藏變數交互作用 為 0.0 時所估算的 MSE 值具有最小值 0.0422 仍高於樣本數為 200 時的最大值 0.0387、當潛藏變數交互作用為 1.0 時所估算的 MSE 值具有最大值 0.1026。
圖 7 不同潛藏變數交互作用下各樣本數所估算之 MSE 值
交互作用
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0.11
100
200
300
400
500
600
700
800
900 1000
樣本數
MSE
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
陸、結論與建議
Klein & Muthén 於 2002 年的研究中,在樣本數為 500 的情況下作模擬研究, 藉由本研究的研究結果發現,當樣本數為 500 時,準概似估算法在估算具有潛藏 變數交互作用的模式中,估算正確性是值得信賴的。然而,在 Marsh, Wen & Hau (2004)的研究中,為了比較四種潛藏變數交互作用的估計方式之估算效果,使 用了三種樣本數 100、200、500 及兩種因素負荷量 0.0、0.2 下的模擬研究,我們 亦可藉由其研究數據發現,在同一種樣本數下,準概似估算法在估算潛藏變數交 互作用為 0.0 的估算正確性會優於估算潛藏變數交互作用為 0.2 的估算正確性, 而在同一個潛藏變數交互作用下,準概似估算法在樣本數較大的模式時,其估算 正確性會優於其估算樣本數較小的模式,此結果,亦能與本研究中準概似估算法 在估算具有潛藏變數交互作用的模式時,其估算正確性會隨樣本數變大而增、隨 潛藏變數交互作用變大而遞減的結果相呼應。 然而,本研究的研究目的在於探討準概似估算法在不同樣本數與交互作用大 小的組合下之估算正確性,觀察其對於潛藏變數交互作用之估算效果,並試圖找 出此法是否有其不足之處,期望能提出適合此方法的適用準則,以供實徵研究者 在進行相關研究時有所參考。因此,綜合上述的研究結果,本研究提出以下幾點 結論,以供實徵研究者作為參考: 1、 於本研究的研究設計內,準概似估算法的估算正確性會隨樣本數變大而 有增強的趨勢,故建議研究時樣本數越高,估算的正確性就會越高。 2、 於本研究的研究設計內,準概似估算法的估算正確性在樣本數為 100 時,會明顯低於樣本數大於 200 以上時,故建議研究者在研究時,需要 200 以上的樣本數,以提高估算法的估算正確性。
3、 於本研究的研究設計內,準概似估算法的估算正確性會隨潛藏變數交互 作用的改變而有所不同,本研究的研究設計潛藏變數交互作用間距為 0.1,正確性的變化會隨此距離作固定趨勢下降,例如樣本數為 500 時, MSE 最大值為 0.0152,最小值為 0.0062。故建議研究者在做此類研究 時,應注意到如潛藏變數交互作用值較大時,若使用準概似估算法,則 估其估算正確性便需要作進一步的考驗。 以上之研究,主要係針對本研究中的模型設計作深入探討,為一具有三個潛 藏變數及一個潛藏變數交互作用的模式,故本研究所得結論是依據在設定下所得 之結論,對於其他的模型設定下,其推論力仍需進一步作驗證。至於本研究對於 後續之相關研究,有以下幾點建議: 1、 本研究所設定的模型為具有潛藏變數交互作用的模型中較基本且具代 表性的模型,故後續的研究中,可針對較複雜的模型作深入研究。例如, 模式中具有兩組以上的潛藏變數交互作用等。 2、 本研究所設的觀測變項為常態分配的連續變數,未來可將觀測變項設定 為二元或類別資料進行深入研究。
參考文獻
Bollen, K. A. (1989). Structural equations with latent variables: Wiley New York. Jöreskog, K. G. (2000). Latent variable scores and their uses. Lincolnwood, IL:
Scientific Software International,Inc. (Acrobat PDF file:
http://www.ssicentral.com/)
Jöreskog, K.G. & Yang, F. (1996). Non-linear structural equation models: The Kenny-Judd model with interaction effects. In G.A. Marcoulides & R.E. Schumacker (Eds.), Advanced structural equation modeling (pp. 57-87). Mahwah, NJ: Erlbaum.
Jöreskog, K.G. & Yang, F. (1997). Estimation of interaction models using the augmented moment matrix: Comparison of asymptotic standard errors. In W. Bandilla & F. Faulbaum (Eds.), SoftStat '97 (Advances in Statistical Software 6, pp. 467-478). Stuttgart: Lucius & Lucius.
Kenny, D. A., & Judd, C. M. (1984). Estimating the non-linear and interactive effects of latent variables. Psychological Bulletin, 96, 201–210.
Klein, A. (2000). Moderatormodelle. Verfahren zur Analyse von Moderatoreffekten in Strukturgleichungsmodellen (Moderator Models. Methods for the analysis of moderator effects in structural equation models). Hamburg: Dr. Kovac.
Klein, A. & Muthén, B. (2002).Quasi Maximum Likelihood Estimation of Structural Equation Models With Multiple Interaction and Quadratic Effects. Unpublished manuscript, Graduate School of Education, University of California, Los Angeles.
interaction effects with the LMS method. Psychometrika, 65, 457-474.
Marsh, H.W., Wen, W., & Hau, K.T. (2004).Structural equation models of latent interactions: Evaluation of alternative estimation strategies and indictor construction. Psychological Methods, 9(3),275-300.
Muthén, L. & Muthén, B. (1998-2002).Mplus User´s Guide. Los Angeles, CA: Muthén & Muthén.
Yang-Jonsson, F. (1997). Non-linear structural equation models: Simulation studies of the Kenny-Judd model. Uppsala, Sweden: University of Uppsala.