國立高雄大學資訊管理學系(碩士班)
碩士論文
資訊中心機率型資訊安全投資之分析
Probability-based Information Security Investment Analysis
on Information Centers
研究生:陳軍達 撰
指導教授:王學亮 博士
致謝
碩士班兩年的學習生涯,隨著論文的付梓,即將演奏結束的樂章。兩年的學習過程, 豐富了我的人生,有著喜怒哀樂的心情起伏,滿滿的回憶與不捨,將常在我心,並在未 來的旅途中日漸晶瑩光耀。 這段時間以來,承蒙恩師王學亮老師之引領,從碩一入學至今,王老師總是給予協 助,使我學習到獨立思考與解決問題的能力,令我受益匪淺。王老師對於論文的內容, 不下無數次的悉心指導與耐心指正,使得論文得以順利完成。另外,十分感謝口試委員 鄭炳強教授與蕭漢威教授審閱論文,並於口試期間,給予寶貴的建議與指正論文的疏失, 使得論文更趨完備。 感謝楊新章老師與丁一賢老師兩年來的切磋討論與經驗傳承,使我獲益良多,撰寫 論文更為順利。感謝學長昱仁,他的專業知識與經驗分享,不僅充實我的學識,更是助 我成功的墊腳石。感謝患難與共的碩二同學,宗儒、思揚、智翔、恆慈、齊祥、東建、 佑寧、冀威,兩年來的共同生活、互相勉勵,讓我忘不了這段美好的時光。感謝碩一學 弟,坤裕、慶鴻、國隆、裕晟、偉鈞、瑋宬、永平、靖孙,你們的付出,讓我的碩士生 涯增添許多光彩,並留下了深刻的印象。由衷感謝所有幫助過我、關懷過我的朋友,在 此致上深深的謝意。 最後,要感謝敬愛的母親,媽媽身兼父職,打理家裡的一切,兩年來在高雄生活, 讓我心無旁鶩地完成學業,感謝妹妹,幫忙整理家務,照顧爺爺、奶奶,讓我不必掛念 家裡的瑣事,感謝你們,我愛你們。 陳軍達 謹誌於 國立高雄大學 資訊管理學系(碩士班) 中華民國九十八年六月II
資訊中心機率型資訊安全投資之分析
研究生:陳軍達
指導教授:王學亮 博士
國立高雄大學資訊管理研究所
摘要
由於資訊威脅逐年增加,造成各大企業與組織日趨嚴重資源損失及個人隱私之嚴重 侵犯,因此如何提高資訊之安全性是一個倍受關注的研究課題。本研究提出一個簡單、 有效的資訊安全投資模型,協助一般資訊中心計算其最佳之資訊安全投資策略,以提升 其整體之資訊安全性。 針對一個資訊中心,本研究首先提出一個簡單的模型來表達其結構。此模型基本上 使用兩個概念元件–資源(resource)及過濾器(filter)來表達整個資訊中心的所有實體,以 及使用 4 個基本式樣(pattern)來表達資訊中心各元件之間的各種可能之連接性。接著我 們提出一個機率式的計算模型來計算各個概念元件之被成功入侵(或稱不安全性)之累 進機率。最後基於最小投資最大效益回收的原則,我們提出一個演算法以計算各過濾器 (即防禦實體)之最佳投資以達到資訊安全之最佳提升。實驗結果顯示,對單層之資訊中心架構,我們的數值計算結果與 Gordon & Loeb[11] 之理論分析結果一致。同時,我們對無法用理論分析之一般常見的雙層資訊中心架構進 行分析比較並提出其差異性。若能給定適當之入侵機率函數,本研究所提之計算模型可
做為一個簡單有效率之資訊中心資訊安全最佳投資計算工具之一。
關鍵字:資訊安全、資訊中心、不安全性機率、資訊安全投資、資訊安全經濟、最佳化 投資
IV
Probability-based Information Security Investment
Analysis on Information Centers
Student: Chun-Ta Chen
Advisor: Dr. Shyue-Liang Wang
Institute of Information Management
National University of Kaohsiung
ABSTRACT
In recent years, the growing threat to information security has caused tremendous amount of loses to organization and serious breaches to personal privacy. How to improve the information security has become an important research topic lately. In this work, we propose a simple but effective information security investment model to assist information center to calculate the optimal information security investment for the proposition of enhancing their information security.
For a given information center, we first propose a simple model to represent the structure of the information center. Basically the model proposes using two conceptual components: resource and filter, to represent all the information center entities, and using four basic patterns to represent the possible connectivities among the conceptual components. Then we propose a probability-based calculation model to calculate cumulative probabilities of insecurity of insecurity of each resource when an attack occurs. Finally, we propose an
algorithm to calculate the optimal investments on the filters to enhance overall information security, based on max expected net benefit of the investment.
To examine the feasibility of the proposed model, we perform numerical experiment on one-tier and two-tier information center structures. Numerical simulations show that the calculated results coincide with analytical results[11] for simple one-tier structure. In addition, numerical simulations on two common two-tier information center structures, which can not be analyzed theoretically, we presented. When combined with property-assumed security breach function on filter, the proposed model can be a simple but efficient tool to calculate the optimal security investment for information centers.
Keywords: Information Security, Information Center, Probability of Insecurity, Investment of
VI
論文目錄
第一章 緒論 ... 1 1.1 研究背景與動機 ... 2 1.2 研究目的... 4 1.3 研究限制... 5 1.4 論文架構... 6 第二章 資訊安全相關之文獻探討 ... 7 2.1 資訊安全技術相關研究 ... 8 2.2 資訊安全管理與投資相關研究 ... 10 第三章 機率型資訊安全投資模型 ... 13 3.1 問題定義與研究步驟 ... 15 3.2 資訊中心之結構表達方式 ... 17 3.3 計算資源之累進不安全性機率 ... 20 3.4 最佳投資效益之計算 ... 23 3.5 演算法... 27 第四章 資訊安全投資模擬實驗與分析 ... 31 4.1 單層架構分析 ... 32 4.2 雙層架構分析 ... 39 4.2.1 雙層串聯架構(Multi-Home) ... 39 4.2.2 雙層非串聯架構(Non-Multi-Home) ... 43 第五章 結論與未來研究方向 ... 47 參考文獻... 49圖目錄
圖 3.1 單層資訊中心架構(One-Tier Information Center) ... 13
圖 3.2 單層資訊中心架構-R1的搜尋樹... 18
圖 3.3 單層資訊中心架構-R1的搜尋樹之簡化圖... 19
圖 3.4 單一過濾器 (Single Filter,1F) ... 20
圖 3.5 串聯過濾器 (Multiple Serial Filter,mSF)... 20
圖 3.6 並聯過濾器 (Multiple Parallel Filter,mPF) ... 21
圖 3.7 平行過濾器 (Multiple Interface Filter,mIF) ... 21
圖 3.8 安全威脅機率函數... 24
圖 4.1 單一資訊系統... 32
圖 4.2 攻擊者不穿透資源之攻擊樹... 33
圖 4.3 攻擊者穿透資源之攻擊樹... 34
圖 4.4 F1=F2時 R1的累進不安全性機率 ... 35
圖 4.5 Type I 單層架構的投資金額 v.s. Gordon 和 Loeb ... 36
圖 4.6 Type II 單層架構的投資金額 v.s. Gordon 和 Loeb ... 36
圖 4.7 Type I 單層架構的總預期淨利潤 v.s. Gordon 和 Loeb ... 37
圖 4.8 Type II 單層架構的總預期淨利潤 v.s. Gordon 和 Loeb ... 37
圖 4.9 Type I 單層架構的最佳投資 v.s. Gordon 和 Loeb ... 38
圖 4.10 Type II 單層架構的最佳投資 v.s. Gordon 和 Loeb ... 38
圖 4.11 Multi-Home 雙層資訊中心架構 ... 39 圖 4.12 Multi-Home 雙層資訊中心架構交錯效應:不安全機率... 40 圖 4.13 Multi-Home 雙層資訊中心架構(移除 F2及 F4) ... 41 圖 4.14 簡化後之路徑... 41 圖 4.15 單排資訊中心架構... 41 圖 4.16 Multi-Home 雙層資訊中心架構交錯效應:投資前的預期損失... 42 圖 4.17 Type I Multi-Home 雙層資訊中心架構總預期淨利潤 ... 42 圖 4.18 Type II Multi-Home 雙層資訊中心架構總預期淨利潤 ... 43 圖 4.19 Non-Multi-Home 雙層資訊中心架構 ... 43 圖 4.20 Non-Multi-Home 雙層資訊中心架構交錯效應:不安全機率 ... 44 圖 4.21 Non-Multi-Home 雙層資訊中心架構交錯效應:投資前的預期損失 ... 45 圖 4.22 Type I Non-Multi-Home 雙層資訊中心架構總預期淨利潤 ... 45 圖 4.23 Type II Non-Multi-Home 雙層資訊中心架構總預期淨利潤 ... 46
1
第一章 緒論
近年來資訊科技發展快速,軟硬體技術及網路不斷的進步,使得人人都能使用高效 能的設備,例如個人電腦,人們可以使用個人電腦,透過網路散播病毒,或者安裝惡意 攻擊軟體,輕易的威脅其他電腦,尤其現今是資訊科技發達的年代,不僅僅是威脅,甚 至駭客入侵電腦的行為也層出不窮,因此資訊安全已成為相當重要的研究主題之一。由 於網際網路的發展迅速,資訊的流通更為方便,駭客更容易入侵資訊系統,若企業必頇 使用資訊系統,就必頇防堵駭客入侵,企業無時無刻都在面對資訊系統的脆弱性以及資 訊安全的威脅,本研究將深入探討此一問題。 本章首先介紹研究背景與動機,說明在資訊科技發達的背景下,會產生的資訊安全 的問題,接著介紹研究目的,說明本研究使用的研究方法與研究步驟,以及得到的結論, 再來介紹研究限制,說明本研究的限制條件,並在這些限制條件完成研究,而在最後一 部分說明本論文的架構。1.1 研究背景與動機 二十一世紀資訊科技的蓬勃發展,包括了電腦效能的提升以及網際網路發達,已讓 人類的生活有著重大的改變。資訊科提的蓬勃發展,除了帶來便利的生活之外,也能讓 駭客使用強大的資訊技術,而容易入侵資訊系統,帶給企業重大的傷害,因此,資訊科 技的發達,能讓人們享受便利的生活,同時令人擔憂的資訊安全問題也隨之而來,如今, 已使得資訊系統面臨嚴重的威脅。這些威脅包括了(1)未經管理者授權使用資訊系統, 如駭客入侵電腦,竊取機密資料或竄改資料等。(2)有限權的管理者也有可能竊取機密 資料或竄改資料。(3)使用者在傳輸資料時,被駭客偷取資料或竄改。(4)資訊系統感染 電腦病毒或木馬。資訊系統除了面臨嚴重的威脅之外,也必頇面對本身的脆弱性,資訊 系統的功能越多、開放的服務越多,本身的漏洞或產生的錯誤(bug)也越多。資訊系統 面對這些脆弱性與威脅,資訊安全的防護措施顯得相當重要,因此資訊安全也越來越受 重視,企業必頇加強資訊系統的安全,或者做出有效的投資,才能在享受便利資訊的同 時,又能面對資訊安全的威脅。 經過多年的發展以及研究,對於加強資訊系統的安全,這些研究已提出了相當多的 方法,而且也提出了許多的防禦技術。這些方法與技術主要分成兩大類,其中一類是, 建立一個滿足安全規範的系統,例如 Bell 和 LaPadula[5]所提的存取安全模式(access
security model),Sutherland[28]所提的基於資訊流模式(information flow model)和 Goguen 與 Messeguer[10]所提的非干涉模式(noninterference model),這些資訊安全的研究,都是 指滿足安全規範後,即有某程度上的安全,一旦違反安全規範,即造成系統之不安全性, 這些研究將於第二章有更詳細的介紹。
另一類則是資訊安全的處理方式,這個處理方式是建立資訊系統,使得此資訊系統 的不安全性或本身的脆弱性降至最低。例如 Moskowitz 與 Kang[21]所提的不安全流模式 (insecurity flow model)。Sheyner 等人[4],Ammann 等人[23],Phillips 等[26]則提出以攻
3
擊圖模式(attack graph models)來分析系統的脆弱性。這些研究都屬於分析系統的不安全 性,本研究將於第二章做更詳細的介紹。 加強資訊系統的安全之研究著重在技術層面,針對特定型態的攻擊,能提出良好的 防禦措施。雖然對症下藥的防禦措施有不錯的效果,但相對於不同型態的攻擊,特定的 防禦措施並無法完全防禦,防禦措施若無法抵禦攻擊,一旦被攻擊者成功攻擊,即代表 被入侵,入侵之後,即造成損失。在這樣的環境下,我們必頇採取不同種類的防禦措施, 建立的防禦措施種類越多,代表能抵禦不同型態的攻擊,而投資在每一種類防禦措施的 金額越多,代表保護能力越好,就越不易被外來的攻擊所入侵,亦會減少企業的損失。 因此,企業必頇投資在不同種類的防禦措施,以建立起完善的保護機制,適當的投 資是相當重要的,過多的投資,會造成企業無謂的損失,過少的投資,會無法發揮保護 的效果,仍舊會被外來的攻擊所入侵。每一個組織(或企業)平均每年損失二佰萬美元, 這表示資訊安全的需求沒有被適當的分配[11],才會導致嚴重的損失。為了減少損失, 勢必要投資一些金錢,投資的金額越多,保護機制就越完善,代表外來的攻擊者越不容 易入侵,同時可減少損失。本研究著重在進行有效的投資,以降低整個系統的不安全性。
1.2 研究目的 企業欲保護資訊系統,避免資訊系統的毀損,而造成損失。保護資訊系統需考量兩 種方式,一種是避免外力入侵,例如攻擊者想破壞資訊系統,得到對攻擊者有利益的資 源;另一種是降低本身資訊系統的脆弱性,若資訊系統的脆弱性足以威脅整個企業,則 同樣會造成損失。不論哪一種保護方式,只要是能避免損失的保護措施,本研究統稱為 “過濾器”。 若資源遭受威脅或攻擊,則會造成損失,企業為了減少損失,勢必要提高過濾器的 保護能力,提高保護能力之後,攻擊者成功攻擊的機率會降低,資訊系統本身的脆弱性 也會降低。企業投資金額在資訊系統,可提高過濾器的保護能力,當企業投資的金額越 多,資訊系統的防禦能力就越高,但投資過多時,會使得企業的投資成本過高。若是企 業投資的金額太低,造成資訊系統的防禦能力不足,資源易受到威脅,因此,適當的投 資是很重要的。除了投資的分配之外,還頇考量資源的重要性,若資源非常重要,一旦 被入侵,會造成企業莫大的損失,這種情況企業必頇投資大量的金額,以提高過濾器的 保護能力。 考量企業的投資成本、被入侵的機率及資源的重要性,本研究提出一套方法,協助 企業找出最適合的投資分佈。由於不同的企業,其內部資訊系統的架構未必相同,對於 不同的資訊系統而言,每一資源被入侵的機率也不相同,企業要投資在過濾器的金額也 會有變動。因此,此套方法用在不同資訊系統架構中,都要能找到最適合的投資分佈。 本研究不僅要找出最適合的投資分佈,同時也要找到最大的投資效益。本研究目的 在於提出適合的方法,並用此方法在不同的資訊系統架構中找出投資分佈,再根據投資 成本、被入侵的機率及資源的重要性,找到最大的投資效益,為企業獲得最大的利潤。
5 1.3 研究限制 本研究中所提到的資訊系統架構,包含多個過濾器和多個資源,在此假設過濾器與 過濾器之間是獨立的,互不影響。例如攻擊者成功攻擊一個過濾器之後,接著再攻擊下 一個過濾器,是不受之前過濾器的影響,即代表成功攻擊的機率是獨立的。攻擊者成功 攻擊資訊系統後,即可存取資源(代表被入侵),本研究假設資源一旦被入侵後,隨即遭 受此資源的全額損失,即攻擊者一旦成攻存取資源,是不會有部份損失的。 本研究假設一般會面臨的情況,並未針對特殊情況做假設,如攻擊者只入侵特定的 資訊系統,或只攻擊某特定的過濾器等,本研究未考慮此極端的現象,在此研究限制下, 將針對研究目的進行研究。
1.4 論文架構 在本論文中,第一章為緒論,包含背景、動機、目的以及研究限制,概述了整篇論 文。第二章為資訊安全相關之文獻探討,介紹本論文的相關研究,分別說明模型架構與 理論基礎,並同時討論這些研究的特色與本研究的相關性。第三章為機率型資訊安全投 資模型,說明本研究要探討的問題,並建立研究步驟,最後提出演算法,依照研究步驟 一步一步執行。本研究依照前人的理論基礎,並延伸[29][31]之研究,我們提出一個表 達資訊中心的結構與計算不安全性機率之方法,使用此表達方式以及計算方法可求得最 佳化之投資模式。第四章為資訊安全投資模擬實驗與分析,本章內容由前述之方法執行 而得,並與前人的研究做比較。本章之實驗首先檢測所提模型之正確性與表現能力,並 將檢測結果以圖表方式呈現,接著繼續分析資訊系統的架構,在分析的過程中,找出最 佳的投資組合,此投資組合並非只有一個結果,此結果以圖表的方式呈現,以表達最詳 細的資訊。第五章為結論與未來研究方向,探討我們的研究結果與未來可行之研究。
7
第二章 資訊安全相關之文獻探討
本章中探討與資訊安全相關文獻,這些研究大致可分為兩類,其中一類是屬於資訊 安全技術方面,另一類是資訊安全管理與投資的相關研究。 首先本研究探討資訊安全技術的相關研究,這部分收錄了關於技術方面的研究,針 對特定的攻擊方式,都有獨特的見解。接著是資訊安全管理與投資的相關研究,這部分 收錄了關於管理及投資方面的研究,從相關研究中,逐漸描繪出本研究的基本模型,由 此基本模型,衍生出各種不同的模型,並對不同的模型進行分析。分析基本模型的同時, 本研究將分析結果與其他模型的實驗結果做比較,之後才續繼分析這些衍生出的模型。2.1 資訊安全技術相關研究 現實生活中,總有駭客的存在,他們想要入侵資訊系統,使用一些手段竊取有利益 的資源,為了保護資訊系統遠離破壞,資訊安全顯得相當重要。資訊安全經過多年的發 展和研究,對於如何加強資訊系統的安全,已有方法來評估資訊系統的漏洞與安全性, 同時也提出了許多防禦技術,來修補漏洞、加強安全性以及防範外來的威脅。 加強資訊系統安全的方法有很多種,資訊安全技術相關的研究主要分成兩大類,其 中一類是建立一個滿足安全規範的系統。例如 Bell、LaPadula[5]提出一個存取安全模式, 這個模式包含了多個安全的核心,可分為三個主要的部分:描述性的能力(元素)、一般 性的結構(限制性的原理)、特殊的解決方法(原則),當系統執行指令時,必頇滿足一組 預先設定之條件,此為存取控制之條件,例如,多層次安全(multilevel security)。除此 之外,Ammann、Wijesekera、Kaushik[4]所提的是提出多種以圖為基礎的算法來產生攻 擊樹,他們觀察攻擊圖,並分析攻擊圖,藉此得到許多資訊,例如可找出攻擊的漏洞。 還有 Sutherland [28]所提的基於資訊流模式(information flow model)的非演譯性模式
(nondeducibility),非演譯性模式的模型是不可推斷的模型,這個模型提出了不可推斷性 的概念,從一個輸出的結果,無法推論出原始輸入的訊息。Goguen、Messeguer[10]則 是提出非干涉模式(noninterference model),非干涉模式是指在所有使用者中,有一個群 體,這個群體做了任何事,不影響另一個群體。舉例來說,無論第一個群體下了什麼指 令,第二個群體無法看到。這一類資訊安全技術相關的研究,都是指滿足安全規範後, 即有某種程度上的安全,一旦違反相關的安全規範,即有可能破壞系統的安全性。 另一類資訊安全技術相關的研究是資訊安全的處理方式,這個處理方式是建立資訊 系統,使得此資訊系統的不安全性或本身的脆弱性降至最低。例如 Moskowitz 與 Kang[21] 所提的不安全流模式(insecurity flow model),即試圖分析系統不安全性之機率。除此之 外,Sheyner、Wing[26]提出一種攻擊圖,可以描述敵人利用系統的脆弱性,來達到敵
9
人所追求的一個狀態,系統管理者使用此攻擊圖可以決定系統的脆弱程度,同時也能部 署安全政策來保護系統。Phillips 和 Swiler[31]提出了一個以圖形為基礎的方法來做網路 的脆弱性分析,這個方法是非常有彈性的,它可以分析外部網路和內部網路的攻擊,也 可以分析特殊資源的危險性或者檢測攻擊的範圍。Kanta Matsuura[8]則是延伸 Gordon 和 Loeb[11]的研究,提出"資訊安全生產力空間"(Productivity Space of Information
Security),一般使用想知道如何有效降低脆弱性與威脅,Kanta Matsuura 說明可透過資 訊安全生產力空間,提出了一套解決方法,有效的降低脆弱性與威脅。在不同程度的威 脅,有各自的解決方法,同樣的,在不同程度的脆弱性,也能透過資訊安全生產力空間, 找出最適合的解決方式。這一類資訊安全技術相關的研究是屬於分析系統的不安全性, 藉由分析資訊系統,來了解資訊系統的不安全性。
2.2 資訊安全管理與投資相關研究 由前一節的研究得知,資訊系統的安全性非常重要,導致了大量的相關研究,包括 了提出存取安全模式、找出攻擊的漏洞、非干涉模式等,都是有關資訊安全技術面的研 究。除此之外,還有以不安全流模式分析系統不安全性之機率、找出資訊系統的脆弱性、 提出生產力空間等,這類型的研究都是專注於減少資訊系統的威脅。 除了資訊安全技術性的研究之外,管理層面也應注意,管理人員必頇要具備一些的 相關知識,才能與技術人員溝通。若不注重管理層面,即使有了技術,卻無法發揮應有 的效果。資訊安全管理包括了Rolf Hulthén[18]所提出的研究,在資訊安全的領域中,專 業人員很難將專業的訊息傳達給管理者,原因在於並非每個管理者都有資訊安全等專業 知識的背景,通常管理者接收訊息後,只能了解一點點,或者完全不懂,以致無法做出 有效的決策,Rolf Hulthén的目標是希望專業人員能將正確的訊息傳達給管理者,這些 訊息包括了資訊系統的威脅、脆弱性、安全性以及入侵的損失,因此必頇建立一套安全 投資的決策系統,讓管理者容易理解,並提供給管理者做出有效的決策。Vineet Kumar、
Rahul Telang、Tridas Mukhopadhyay[19]說明資訊中心的規劃人員無法完全了解資訊安 全管理人所部署的資訊系統,他們提供了一個框架幫助企業設計優化的機制,避免規劃 人員不了解資訊系統的可用性和機密性,而造成損失。另外,Sebastian Sowa、Lampros Tsinas、Roland Gabriel[27]提出了一個方法論,使得企業和資訊安全連接在一起,讓資 訊安全的管理者,更容易面對不同的挑戰,這個方法經過許多年的驗證,證明是可靠的、 一致的而且準確的。Gordon、Loeb、Lucyshyn[12][13]分別在2002年及2003年說明,從 一個經濟學的角度,檢視有關資訊安全威脅的問題。做決策的管理者,必頇制定出良好 的政策 ,根 據不 同的 風險和 不同 的敵 人有 著不同 的政 策, Vicki M. Bier 和Vinod
Abhichandani[6]提出了一個方法,應用遊戲理論來制定最佳的決策,以避免攻擊者的威 脅,同時提出了一些有用的觀點。Kevin J. Soo Hoo[16]使用量化決策分析,提出一個候 選人塑模方法,明確整合不確定性與可塑性,允許不同程度的塑模細節,以解決許多以
11
前塑模失敗的情況,塑模成功之後,能提供有用的資訊給管理者。
雖有資訊安全管理層面的相關研究,但有關資訊安全投資的研究相對較少,資訊安 全投資的研究屬於經濟面的相關研究,這類的研究是根據資訊系統所遭遇的風險以及可 能獲得的利潤,以傳統的決策來做分析,並找出最佳化的投資。相關的研究包括了Jens
Grossklags、Nicolas Christin、John Chuang[14]提出五種資訊安全的經濟模型,並比較同 質性與異質性。在各種經濟模型中,結合遊戲理論,找出最適合的投資方式,包括了保 險、保護、不予理會等不同的方式。在此模型中,也說明政府可能採取的政策,以達到 最小的損失。另外,在一個網路環境裡, Moskowitz與Kang[21]定義了保護域(protection domain),保護域包含了一組或多組的相關資訊資產,且資訊資產是受到保護的。以企 業為例,這些資訊資產包括了伺服器、資料庫等有關的資源,而保護域是由實體或邏輯 的元件所組成,保護域也可以有階層的關係。這些受到保護的資訊資產本研究統稱為資 源。另外,Yue Chen, Barry Boehm, Luke Sheppard[9]提出T-MAP方法,藉用計算攻擊路 徑的權重,可以量化安全威脅,一般企業對於此方法較敏感,此方法也可用來分析投資 效應。Kjell Hausken[15]提出了四種不同的邊際投資效益,分別是持續減少、先增後減、 持續增加、無變化等四種,相對於Gordon和Loeb[11]所提出的簡單模型,最大的投資效 益是預期損失的37%,這四種不同的分類,不再是最大的投資效益是預期損失的37%, 而是四種不同的投資分類。Jan Willemson[31]提出兩個類似Gordon和Loeb[11]所提出的 威脅函數,他說明投資達到100%是存在的。還有,Julie J.C.H. Ryan, Daniel J. Ryan[24] 同樣提出一個量化的數學方法,說明如何計算脅威機率函數(breach probability function), 這是以Kaplan Meier和Nelson Aalen 所提出的無母數估計方法,來估計預期損失和投資 之後的安全性。Stuart Edward Schechter [25]提出一個計算平均值的方法,來測量安全性, 並預估系統面對的危險性,他也提供量化的方法來增加安全性和減少威脅。國內亦有資 訊安全投資的相關研究,洪肇蔚[2] 所做之研究企圖指出在各種程度的威脅下最適的資 訊安全投資策略。當威脅程過高的情況下,企業的管理者不適宜將資金集中在資訊安全 產品的再購買及投入,應當從員工使用資訊科技產品的安全教育訓練及資訊科技產品本
身的脆弱性方向進行探討,才能從根本處解決資訊安全問題並使資金投入有效率的發揮。 瞿鴻斌[3]提出企業可藉由資訊安全風險評估的方法論,找出組織營運流程中每項資訊 資產的風險,藉以有效控管與分配資源。定量風險評估是以量化數據評估資訊安全事件 發生的頻率與發生後的影響,因此定量化風險評估提供企業有效率的方法,適當地將資 源分配給需要控管的資產,提供最好的資訊安全投資報酬率。 Gordon 和 Loeb[11]提出一個簡單的模型,在一網路環境裡,這個模型裡包含了一 個攻擊者,一個保護機制,以及一個資源。網路環境有駭客入侵、電腦病毒、木馬程式、 間諜程式、…等,這些以非正常方式存取資源的動作都稱為攻擊者。企業為保護資源, 建立了保護機制,保護機制可以是防毒軟體、防火牆、入侵偵測軟體,或者是阻擋非法 入侵的設備。資源是一個被保護的資訊資產,任何攻擊都會試圖擊破保護機制,造成威 脅,一旦資源被成功攻擊,就會造成損失。每個系統都有脆弱性,企業想投資一些金錢 來降低被入侵的機率,但 Gordon 和 Loeb[11]說具有高脆弱性的系統不值得投資,高脆 弱性的系統必頇花費大量的金錢才能降低被入侵的機率,投資報酬率太低,最適合投資 的資訊系統是中程度的脆弱性,它的投資報酬率是最高的。 由於 Gordon 和 Loeb[11]所提出的架構中,僅有單一攻擊者、單一保護機制以及單 一資源。此研究的目的是在資訊安全中,得到最佳的投資模式。當脆弱性增加時,最佳 的投資金額可能是遞增的或是先遞增後減少,而最適合的投資點不是在高脆弱性或低脆 弱性,而是在中程度的脆弱性時,最適合投資,且最適合投資金額總是小於預期損失的
37% (1/e)。本研究將延伸 Gordon 和 Loeb[11]的研究,詳細探討 Gordon 和 Loeb 所提出 的架構。
13
第三章 機率型資訊安全投資模型
在 Gordon 和 Loeb[11]的研究中,僅有單一攻擊者、單一資訊系統以及單一資源。 本研究將 Gordon 和 Loeb[11]所提出的資訊系統做更詳細分析,並以多個過濾器和多個 資源來表示資訊系統,對於常見的資訊系統,將之繪出拓樸架構,做進一步的研究。 本研究將攻擊者、過濾器以及資源都分別視為一個節點,若節點和節點之間可以互 通,則會產生一條連線,例如攻擊者能攻擊到過濾器,則可產生一條連線,或是過濾器 可連接到資源,也可產生一條連線。將所有節點以及節點之間可能的連線全部繪出,則 可以產生拓樸架構,本研究稱之為資訊中心架構,如圖 3.1 所示。 F1 R1 F2 R2 Attack圖3.1 單層資訊中心架構(One-Tier Information Center)
圖 3.1 表示有一個攻擊者、兩個過濾器,和兩個資源,不僅可看出所有節點,同時 也可看出,所有節點之間可能的連線。以一個攻擊者而言,其攻擊的是存取資源,攻擊 者可以循著既有的連線進行攻擊,成功入侵資源之前,若過到過濾器,則攻擊者有一定 的機率能通過過濾器,通過的機率越低,代表攻擊者越不容易通過過濾器,也就越不容 易入侵資源。資源本身並無任何的防禦能力,一旦被入侵,則會造成損失。 目前針對資訊系統做分析的相關研究較少,針對資訊系統的相關研究,也僅針對整 體的架構進行研究,並無詳細分析資訊系統,本研究則是分析資訊系統,並探討之。 本研究對此架構定義問題,提出研究方法。在網路外部的環境,有不同的攻擊型態, 由於攻擊的型態不只一種,因此,在本章會定義出攻擊型態。除了攻擊型態之外,資訊
系統的架構也有不只一種,前面所述僅介紹簡單的模型,在本章除了會定義簡單的模型 之外,亦會定義複雜且實際的模型,以符合現實的狀況,為了能將複雜的模型以容易計 算的方式來分析,本研究以三個階段的步驟來計算,分別是資訊中心之結構表達方式、 計算資源之累進不安全性機率、最佳投資效益之計算,此一連串的步驟為研究方法,接 著是執行此研究方法,執行的方式是以執行演算法來完成。我們將三個階段的演算法寫 成三支程式,接著用個人腦電腦一步一步執從此三支程式,執行完成之後,本研究可以 得到各種結果,此結果將於第四章進行深入的剖析。
15 3.1 問題定義與研究步驟 根據 Gordon 和 Loeb[11]所提出的資訊安全投資模型,企業所要保護的對象是一個 資訊的集合,這個集合可以是公司、客戶、會計帳、策略計劃、公司網站等,若要增加 安全性,則必頇滿足機密性、完整性、可用性、鑑別性與不可否認性。一個攻擊者欲攻 擊企業所要保護的對象,必需先成功攻擊過濾器,在攻擊者成功攻擊通過濾器之後,才 可存取資源,本研究假設資訊系統中,共有 f 個過濾器,r 個資源,不同的架構,過濾 器和資源的數量也不同,f、r 會根據不同的架構有不同的值。一個攻擊者要入侵資源, 其攻擊並非只有一種,Gordon 和 Loeb[11]定義了兩種攻擊型態,分別為 Type I、Type II, 兩種攻擊型態各有特色,攻擊型態在本章第四節有更詳細的說明。 對於企業而言,想要降低被成功入侵的機率,降低被成功入侵機率方法就是提高過 濾器的防禦能力,因此必頇投資金額在過濾器。但不同的資訊中心架構有不同的安全性, 不同的安全性會造成不同的投資分佈,也就是說,投資金會隨著不同的資訊中心而改變, 如何表達資訊中心顯得相當重要。接著,不同的資訊中心,因架構不同,所以安全性也 不相同,如何表達安全性,本研究先以樹狀結構來表達攻擊者攻擊資訊中心資源之路徑, 接著再計算攻擊路徑之機率,以求出不安全性機率。資訊中心的系統內,包含多個元件, 如過濾器共有 f 個,資源有 r 個,如何計算這些元件的不安全性機率,本研究會運用先 前提及的兩種攻擊型態,再做分析。最後,也是最重要的,如何降低資訊中心的不安全 性,在本研究中會提出一套方法,計算資訊中心的投資分佈,投資分佈可供企業做參考, 並且改善資訊中心的不安全性。 在 Gordon 和 Loeb[11] 所提出的資訊安全投資模型中,僅有單一攻擊者、單一系統 以及單一資源,在此單一系統本研究視為一個過濾器,若攻擊者的目標是存取資源,攻 擊者必頇先成功攻擊系統,才能存取資源。本研究詳細探討單一系統,並將此一系統以 更詳細的架構來考分析,此一系統可再細分為多個過濾器,而資源的部分則考慮多個資
源,使得此一模型不再是簡單的架構。過濾器和過濾器之間有路徑可以連接,資源和資 源之間也有路徑可以連接,而過濾器和資源也有路徑可以連接,連接而成的架構,是一 個網狀的拓撲架構,在這樣的架構內,攻擊者的攻擊路徑不只一條,攻擊者有多條路徑 可入侵系統並存取資源。 若從攻擊者的位置開始分析,直至攻擊到資源為止,會產生攻擊路徑圖,此攻擊路 徑圖相當複雜且不易計算。本研究不使用攻擊路徑圖的方法來計算資訊系統的脆弱性, 如[22]是產生攻擊路徑圖來計算安全性。本研究是以資源的位置開始分析,並產生攻擊 路徑圖,此種方式較上述方法更容易計算,透過攻擊路徑圖,本研究解析之後,並分析 計算被入侵的機率。 本節分為三個部分,即本研究的三階段研究步驟,這三階段步驟是連續的,一個階 段完成之後,接續執行下一階段,直至三個階段都完成為止。 第一階段是資訊中心之結構表達方式,我們以建立拓樸架構方式表達資訊中心之結 構,並以資源做為根節點建立樹狀模型。因為本研究是以資源的位置開始分析,所以樹 狀模型的根節點是資源,葉節點則是攻擊者,當樹狀模型建立完成後,對於攻擊者的攻 擊路徑即一目了然。 接著第二階段是計算資源之累進不安全性機率,藉由樹狀結構,我們知道攻擊者所 有的攻擊路徑,本研究以遞迴的方式計算所有攻擊的路徑,並求出根節點的機率,也就 是資源之累進不安全性機率。 最後第三階段是最佳投資效益之計算,當每一資源的不安全性被計算之後,再乘上 預期損失金額,即是預期損失。不同的攻擊型態,會導致不同的安全性,企業的目的是 降低不安全性,以及獲得最佳的投資效益,如何投資才能有最佳的投資效益,這是研究 步驟的最後一個階段。
17 3.2 資訊中心之結構表達方式 對於不同的企業,有不同的資訊中心網路架構,本研究首要解決的是如何表達一個 資訊中心架構。資訊中心架構包含許多元件,主要有攻擊者、過濾器、資源,攻擊者是 位於網路外部的環境,網路內部環境包含過濾器和資源,企業欲保護的對象是資源,過 濾器即是企業用來保護資源的方式,攻擊者欲入侵並存取資源,就必頇先攻擊過濾器, 成功攻擊過濾器之後,才能存取資源。 本研究以攻擊者、過濾器、資源來表達一個資訊中心架構,如圖 3.1 所示,此為單 層的資訊中心架構,此架構中有一個攻擊者(Attack)、兩個過濾器(F)、兩個資源(R),共 有 5 個節點,每兩個節點之間,若有通路,則可以連線。企業想保護的是資源,而攻擊 者想入侵的也是資源,攻擊者要入侵資源的路徑有很多條,例如攻擊者想入侵 R1,由
Attack 開始,到 R1結束,可能的攻擊路徑有< Attack, F1, R1>,< Attack, F2, R1>,< Attack,
F1, F2, R1>,< Attack, F2, F1, R1>,< Attack, F1, R2, F2, R1>,< Attack, F2, R2, F1, R1>,共
有 6 條路徑可入侵資源。以圖 3.1 的拓樸架構表示資訊中心,各元件之間的關係,以及 攻擊路徑都一目了然,本研究接著建立攻擊樹,以攻擊樹的方式表示 6 條可能的攻擊路 徑。 本研究採用建立搜尋樹之方法,將整顆的樹建立完成。本研究對於指定之資源,倒 推至攻擊的起始點,指定之資源為樹的根節點,攻擊的起始點為樹的葉節點,從資源開 始,以廣度優先的搜尋方式,將子節點一一找出,進而產生一顆攻擊樹。資訊中心架構 中的任一個資源,都可產生一顆搜尋樹,每一個葉節點至根節點的路徑,都是一條攻擊 路徑,且每條攻擊路徑所經過的節點均不重覆。 本研究建立搜尋樹時,考慮兩種情形。一種是攻擊者入侵資源後,即停止攻擊;一 種是攻擊者入侵資源後,仍然可以往下一個節點前進並入侵,因此,同樣的資訊中心架 構下,在不同的情形,會產生不同的搜尋樹。
本節以「攻擊者入侵資源後,仍然可以往下一個節點前進並入侵」為例。以圖 3.1 為例,以 R1為起始點,建立一顆樹,而連接到 R1的節點有 F1和 F2,因此,R1可以往 下連接 F1和 F2這兩個子節點。現在只看到 F1,連接到 F1的節點有 A,F2,R2,R1,而 R1已出現在父節點,因此 R1不再往下建立節點,而 A 是攻擊者,已是葉節點,因此也 不再往下建立節點。剩 F2和 R2必頇往下建立節點,現在只看 F2,連接到 F2的節點有 A, F1,R2,R1,同樣的,A 是葉節點,不再往下建立節點,F1和 R1已出現在父節點,因 此不再往下建立節點,如此只剩 R2必頇往下建立節點,連接到 R2的節點有 F1和 F2, 而 F1和 F2已出現在父節點,因此這兩個節均不再往下建立節點,至此,左子樹已建立 完成,其餘未完成的部分,依照同樣的方法,可將子樹建立完成,當完成之時,即產生 一顆 R1的搜尋樹,此搜尋樹如圖 3.2 所示。 R1 F1 F2 A F2 A F1 R1 R2 R2 R1 A F1 F2 R1 R2 R2 R1 A F1 F2 F1 F2 A F1 R1 R2 F1 F2 F2 F1 F2 R1 R2 A 圖3.2 單層資訊中心架構-R1的搜尋樹 圖 3.2 中,灰色節點表示不再往下建立子樹,白色節點表示可以繼續往下建立子樹, 直到不能建立為止,圖 3.2 表示的是一般狀況下,建立搜尋樹的結果。若我們將灰色部 分去除,並保留葉節點是攻擊者(A),則簡化後之結果如圖 3.3 所示,圖 3.3 更淺顯易懂, 之後本研究的計算都以簡化後的圖,做為計算的基準。
19 R1 F1 F2 A F2 A R2 A F1 R2 A F2 A F1 A 圖3.3 單層資訊中心架構-R1的搜尋樹之簡化圖 建立此搜尋樹後,在下一節裡,本研究說明資源之累進不安全性機率計算方法。
3.3 計算資源之累進不安全性機率 攻擊者想入侵任一資源時,必頇先通過過濾器,過濾器有防禦效果,會降低攻擊者 入侵的機率,因此並非每一條路徑成功的機率都是百分之百,本研究可求出此資源被成 功入侵的機率,而計算機率的方式,本研究使用四種不同的基本式樣計算此一資源的機 率,即是此一資源的不安全性。 在建立將樹狀模型後,本研究根據樹狀模型並採用底部向上(button-up)的方式,來 計算根節點資源的機率,在計算機率時,會遇到四種不同的基本式樣,這四種基本的式 樣包括了單一過濾器(Single Filter,1F)、串聯過濾器(Multiple Serial Filter,mSF)、並聯 過濾器(Multiple Parallel Filter,mPF)、及平行過濾器(Multiple Interface Filter,mIF)。
F
1R
1 Attack v1 v1 1 圖3.4 單一過濾器 (Single Filter,1F) F1 F2 FJ R1 v1 v1 v2 v1v2 v1v2 ..vJ Attack 1 ...21 F1 R1 F2 Attack FJ v1 v2 vJ 1- (1-vi)..(1-vJ) 1 1 1
圖3.6 並聯過濾器 (Multiple Parallel Filter,mPF)
F
R
1 Attack ... v1 v2 vm v 1- (1-vvi)..(1-vvm)圖3.7 平行過濾器 (Multiple Interface Filter,mIF)
圖 3.4 為單一過濾器,攻擊者通過過濾器的機率是 v1,通過後,即可以入侵資源, 所以資源的累進不安全機率為 v1。 圖 3.5 為串聯過濾器,有多個不同的單獨過濾器串聯在一起,攻擊者需通過每一個 過濾器,才能入侵資源。假設每一個過濾器的不安全機率分別為 v1、 v2、…、 vj,則 資源的累進不安全機率為 v1〃 v2〃〃〃 vj。 圖 3.6 為並聯過濾器,有多個不同的單獨過濾器並聯在一起,攻擊者只需通過一個 過濾器,即能入侵資源。假設每一個過濾器的不安全機率分別為 v1、 v2、…、 vj,依 照並聯的計算方法,我們可以得到資源的累進不安全機率為 1-(1-v1)(1- v2)…(1- vj)。 圖 3.7 為平行過濾器,攻擊者有多條路徑能到過濾器,而每條路徑都有一定的攻擊 機率。我們假設過濾器的不安全機率為 v,每一條攻擊路徑的機率為 v1〃 v2〃〃〃 vm, 算法與並聯過濾器類似,均為並聯的算法,因此我們得到 R1的不安全機率為 1-(1-vv1)(1-
vv2)…(1- vvm)。 了解基本的式樣後,我們即採取底部向上(button-up)的方式以及使用遞迴的方式來 計算機率。由葉節點開始,直到根節點為止,過程中的每一個節點,都能呼叫對應的基 本模組,計算出被入侵的機率,如此一直計算到根節點,即可求得指定之資源的累進不 安全機率。 求得指定之資源的機率後,本研究將加入一項變數–投資金額,下一節即介紹最佳 投資效益之計算。
23 3.4 最佳投資效益之計算 先前提到,一個攻擊者要入侵資源,其攻擊並非只有一種,Gordon 和 Loeb 定義了 兩種攻擊型態,兩種攻擊型態各有特色。第一種是 Type I 的攻擊型態,其安全威脅機率 函數為 , ,本研究將 α 與 β 的參數設為 1,即 α=β=1, Huang 等人[17]說明 α 與 β 在 Type I 安全威脅機率函數的意義,α 與 β 是投資的影響程 度,也就是說,α 與 β 值越大,每一分錢所投資的效益越大,可以降低更多的威脅,而 β 的影響程度遠比 α 大,因此 β 越大,能使每一分錢投資的效益更多,其威脅機率的影 響程度是呈指數遞減,α 越大,威脅機率的影響程度是呈倍數遞減。過濾器共有 f 個,j 代表第 j 個過濾器,v 是初始機率, 是第 j 個過濾器的投資金額,此函數表示,當我們 在第 j 個過濾器投資 金額時,被成功攻擊的機率。Type I 的特色是分散式攻擊(distribute), 例如電腦病毒(virus)或間諜程式(spyware),它們會潛伏在資訊系統裡,等待機會進行大 規模的攻擊,因此主機被成功攻擊的機率越高,所受到的損失就越多。當 Type I 初始 機率 v 越高時,過濾器被成功攻擊的機率也越高,因本研究設定 α=β=1,所以不投資 時,初始機率即代表被成功攻擊的機率,投資 金額,計算此函數值,即為過濾器被成 功攻擊的機率。 第二種是 Type II 的攻擊型態,其安全威脅機率函數為 , , 本研究將α 的參數設為 1,即 α=1,Huang 等人[17]說明 α 在 Type II 安全威脅機率函數, 與α 在 Type I 安全威脅機率函數具有不同的意義,α 是投資的影響程度,也就是說,α 值越大,每一分錢所投資的效益越大,可以降低更多的威脅,威脅機率的影響程度是呈 指數遞減,其餘參數的設定與 Type I 是一樣的。Type II 的特色是目標式攻擊(target), 例如駭客(hacker)攻擊,專門攻擊特定的主機或是銀行的資訊系統,以進行破壞、修改、 竊取有價值的資料等,若是主機被成功攻擊的機率很小,損失就很小,甚至沒有損失, 因為駭客無法入侵其他同類型的主機;若是主機被成功攻擊的機率很大,損失就會很大,
因為駭客還有很高的機率能入侵其他同類型的主機。當 Type II 初始機率 v 越高時,過 濾器被成功攻擊的機率也越高,因本研究設定α=1,所以與 Type I 的情形是一樣的,不 投資時,初始機率即代表被成功攻擊的機率,投資 金額,計算此函數值,即為過濾器 被成功攻擊的機率。 我們會針對此兩種攻擊型態進行分析,並結合不同的拓樸架構,計算出最佳的資訊 安全投資策略。 圖 3.8 為兩種攻擊型態的安全威脅機率函數,在此假設未投資前,被成功攻擊的機 率是 0.7(即初始機率),圖中橫軸表示投資金額(單位:元),縱軸表示成功攻擊機率,不 論哪一種攻擊型態,只要有投資金額,成功攻擊機率就會降低,投資越多,成功攻擊的 機率就越低。一開始投資時,Type I 比 Type II 的成功機率要來得低,但投資金額較多 時,Type II 的成功機率卻比較低,這是因為 Type II 的攻擊行為像駭客,我們只要對特 定過濾器進行投資,提高過濾器的防禦能力,擋住駭客的攻擊,其成功攻擊的機率就會 大幅降低,但 Type I 的攻擊行為像病毒一樣的隨處攻擊,不可能只針對特定地點進行防 禦,因此,投資過多的金額,效率就會降低。 圖3.8 安全威脅機率函數 在先前提及的樹狀模型,本研究考慮兩種入侵情形,一種是入侵資源後即停止攻擊, 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 1 2 3 4 5 6 7 8 9 10 P rob ab il ity of In se cu rity s(z ) Investment z Type I Type II
25 一種則是繼續攻擊。計算此機率時,若是入侵資源後即停止攻擊,則會設定資源被入侵 之機率為 0,另一種則為 1。 由於每個資源被入侵時,都會造成損失,我們假設損失為 L,不同的資源有不同的 損失,因此,第 i 個資源的損失我們記為 Li。 不同的過濾器有不同的安全性,即攻擊者能成功通過過濾器的機率不同,我們假設 此機率為 v,第 j 個過濾器,其機率我們記為 vj, 。 本研究透過前一節所述,可計算出每個資源被入侵的機率,我們假設被入侵的機率 為 p,不同的資源有不同的被入侵機率,因此,第 i 個資源的被入侵機率我們記為 pi, 。 為加強過濾器的安全性,勢必會對過濾器加強投資,此投資金額我們假設為 z,對 於不同的過濾器有不同的投資金額,因此,第 j 個過濾器的投資金額我們記為 z,j 。 投資 zj金額後,資源被入侵的機率有所改變,因此,我們將其機率寫成 zj的函數 pi (z1, z2,…, zj)。此函數表示投資金額在每個過濾器後,第 i 個資源被入侵的機率,本研 究將投資金額以向量表示 z = (z1, z2,…, zf),因此,函數可改寫成 ,同時, 表 示在不投資的情況下,第 i 個資源被入侵的機率。 再來,我們可以計算損失的期望值,在不投資的情況下,第 i 個資源損失的期望值 為 ;投資 z 金額後,第 i 個資源損失的期望值為 ,因此,投資之後, 第 i 個資源所獲得的利潤為 ,我們將全部 r 個資源所獲得的利潤加 總,並化簡式子,總利潤為 。 過濾器共有 f 個,因此,全部的投資金額為 ,我們將總利潤減掉總投資金額 即可得到淨利潤,如下所示:
由以上式子,我們可以得知,在不同的投資金額下,可獲得的淨利潤。輸入所有可 能的投資金額後,可以得到所有的淨利潤,而最大值即為最大的淨利潤,此時的投資金 額也就是最佳的投資金額。我們可以從中發現,投資必頇有規劃,過多的投資,造成成 本過高,反而無法獲得任何利益,適當的投資是很重要的。在各種資訊中心架構,有各 自適合的投資方式。不同的攻擊型態,也有各自適合的投資組合,不同資訊中心架構配 合不同的攻擊型態,其計算會更複雜,投資金額會有變化,本節所提出的算式,可在不 同的架構及不同的攻擊型態中,找出最適合的投資分佈,並使投資效益最大化。
27 3.5 演算法 前面介紹的三階段研究步驟,在本節以實際的方法來完成。本節所介紹的演算法都 是對照研究每一步的研究步驟,一個演算法,對照一個步驟,因此,每一個演算法都 是相關的,而且有順序性。 第一階段是表達資訊中心之結構,我們以兩個概念元件–資源及過濾器來表達資訊 中心之結構,並以資源為根節點建立樹狀模型,只要將「資訊中心拓撲架構」輸入到程 式後,並執行此第一階段的程式,即可產生一個搜尋樹。 第二階段是計算資源之累進不安全性機率,將「每一個過濾器的不安全機率」及第 一階段所產生的「搜尋樹」輸入到程式後,並執行程式,此程式會自動計算出資源之累 進不安全性機率。 第三階段是最佳投資效益之計算,即找出改善不安全性之策略,此階段是最後一個 階段,只要將「資訊中心拓樸架構」、「過濾器的投資金額」和「每個資源的預期損失金 額」,即可求出此架構的最佳投資組合。由於每種架構中,都包含多個資源,因此,執 行第三階段的程式時,會多次呼叫第二階段的程式,直到所有資源都被計算為止,此程 式的執行時間較長。 第一階段的演算法是建樹,先前已解說建樹的方式,本節則提出實際建樹的演 算法,演算法如下: 攻擊樹演算法 輸入: (1)資訊中心拓樸架構 (2)要計算的資源 輸出:此資源的攻擊樹
Function BFS(G;R;A;T)
//Build attack tree T for attack node A to resource node R in Graph G 1. Initialize a queue BFQ with node R, T is CurrNode
;
2. While (BFQ is not empty){ 3. CurrNode = BFQ.dequeue();
4. NextNodeSet={nodes that can be reached from CurrNode and do not appear in
ancestor nodes};
5. If (NextNodeSet is empty) delete CurrNode form the tree; 6. For (each node NextNode in NextNodeSet){
7. Add an edge from CurrNode to NextNode;
8. If (NextNode is not node A) enqueue(BFQ, NextNode);} // end for 9. }; //end while 第二階段則是計算每一個資源的累進不安全機率,同樣的,前一節已解說計算的方 法,本節則提出演算法,計算累進不安全機率的演算法如下: 累進不安全機率演算法 輸入: (1)選定資源之攻擊樹 (2)每一個過濾器的不安全機率 輸出: 資源不安全的累加機率
29
Function AP(T;P)
// Recursive calculation of accumulative probability P from attack tree T 1. p = 0; //initialization
2. If T = node A, return p = 1; 3. If T has one child{
4. If 1F or mSF then //one or no child 5. p = v *AP(T.child);
6. else if mIF then { //more than one child
7. let c =T.child; 8. p = 1-(1-v*AP(c.child(1))...(1-v*AP(c.child(m)); 9. }; 10. }; 11. else 12. p = 1-(1-v*AP(c.child(1)))...(1-v*AP(c.child(m))); 13. Return p; 第三階段則是求出最大利潤,根據第二階段的演算法,再加上每一個過濾器的投資 金額,即可求出最大利潤,本研究截取程式碼的核心部份,其虛擬碼如下所示: 最佳投資分佈演算法 輸入: (1)資訊中心架構 (2)每個過濾器的投資金額 (3)每個資源的預期損失
輸出: 最佳的投資組合
Function TENB( ;Li)
// Calculate Total Expected Net Benefit for the information center and find the optimal investment that maximizes TENB( )
1. ; //f=2
2. Z= ; //Total investment 3. TENBmax=0;
4. ;
5. For ( 1=0 to =large){ // is investment
6. For { //large is a large number 7. If ( is over total investment) {
8. end for}; //budget constrain
9. ; 10. If TENB > TENBmax then
11. TENBmax=TENB;
12. ; // ; 13. };
14. };
31
第四章 資訊安全投資模擬實驗與分析
本研究分析不同的資訊中心架構,在研究的過程中,發現不安全性機率的分佈有特 殊的現象,因此在各節中,本研究同時探討不安全性機率的研究結果,而後再探討最佳 的投資組合。 在 3.5 節中,演算法的執行結果可得出一份不安全性機率以及最佳的投資組合,藉 由此演算法做做數值分析,並檢測演算法的正確性與表現能力。本研究詳細分析資訊中 心架構,在各種架構中,求出不安全性機率,以及找出最佳的投資組合。 對於一般的資訊中心網路拓架構,本研究考慮兩種架構,一種是單層資訊中心架構, 另 一 種 則 是 雙 層 資 訊 中 心 架 構 , 其 中 雙 層資 訊 中 心 架 構 又 可 分為 雙 層 串 聯 架 構 (Multi-Home)和雙層非串聯架構(Non-Multi-Home)。 雙層資訊中心架構又可分為兩種,這兩種架構的基本算法與單層資訊中心架構是一 樣的,若要求出某一資源累進不安全的機率,可使用四種不同的基本式樣計算此資源的 機率,求出此一資源的不安全性。 本研究使用的電腦為 2660.046MHz 單核心處理器和 256MB RAM,所使用的作業 系統為 Linux Debian 2.6.22-6。 本研究從基礎的架構開始分析,第一節介紹單層架構,並與 Gordon 和 Leob[11] 的模型做比較。本研究計算單層架構的最佳的投資,以及計算 Gordon 和 Leob[11]的模 型之最佳投資,兩相比較較之下,發現兩者模型幾乎相同,證明本研究的方法是可行的, 接著用此方法分析雙層架構。第二節介紹雙層架構,雙層架構又分為兩種,此為更複雜 且實際的架構。在分析雙層架構時,本研究計算了預期損失、投資金額、投資分佈,同 時發現不安全性機率分佈的特殊現象,會連帶影響投資分佈, 因此一併探討這些研究 結果。4.1 單層架構分析
本研究與 Gordon and Leob[11]的單一資訊系統模型做比較,如圖 4.1 所示,並驗證 準確性。 F1 Attack R1 圖4.1 單一資訊系統 單層資訊中心架構(如圖 3.1 所示),本研究假設 ,表示在未投資前, F1的被成功攻擊的機率與 F2相同。 本研究運用第三章所提之方法,建立單層資訊中心架構的攻擊樹,建立攻擊樹時, 考慮兩種情況,一種是攻擊者攻擊到資源時,即停止攻擊,另一種情況是攻擊者攻擊到 資源時,繼續往下攻擊。本研究首先以前者為例,並以圖 3.1 之架構建立一個攻擊樹, 然後以 R1做為根節點,當攻擊樹建立完成後,其結果如圖 4.2 所示。圖 4.2 顯示,當攻 擊者攻擊到資源時,即停止攻擊,因此,若是葉節點為資源,即不再往下建立子樹。 圖 4.2 的每一個節點均有節點名稱,其名稱與資訊中心架構一樣,節點名稱的下方 標示被成功攻擊的機率,因為只有過濾器有防禦效果,因此,除了過濾器之外,其被成 功攻擊的機率都標示為 1,即一定會被入侵。每一條路徑旁都有標示機率,此機率代表 的是「到目前為止,被成功入侵的機率」,例如根節點上方的機率標示 0.206119,代表 攻擊者能成功攻擊 R1的機率為 0.206119。
33 圖4.2 攻擊者不穿透資源之攻擊樹 本研究同樣運用第三章所提之方法,以「攻擊者攻擊到資源時,繼續往下攻擊」為 例,並以圖 3.1 之架構建立一個攻擊樹,然後以 R1做為根節點,當攻擊樹建立完成後, 其結果如圖 4.3 所示。圖 4.3 顯示,當攻擊者攻擊到資源時,還會續繼攻擊,因此,若 是葉節點為資源,仍然會再往下建立子樹。不論我們以 R1或 R2做為根節點,其攻擊樹 和所有計算出來的機率階相等,因此,在呈現執行結果時,都以 R1為準,不再特別呈 現 R2的執行結果。
圖4.3 攻擊者穿透資源之攻擊樹 至目為止,本研究僅計算過濾器被成功攻擊的機率為 0.1,再來本研究針對機率的 變化,畫出曲線圖,觀察機率在變化時,資源被入侵變化為何。圖 4.4 顯示對單層資訊 中心架構(圖 3.1)中,在過濾器不安全機率的變化下,資源 R1的累進不安全機率的結果。 此圖很明顯的印證 R1的累進不安全機率與過濾器不安全機率成正比,當過濾器不安全 機率越高時,R1被入侵的機率就越高,這與本研究的預期相符,計算 R2被入侵的機率, 其結果與計算 R1相同。
35 圖4.4 F1=F2時R1的累進不安全性機率 先前的研究,是直接設定過濾器的被成功攻擊的機率,觀察建立攻擊樹的結果,接 下來本研究導入安全威脅機率函數,過濾器的被成功攻擊的機率不再直接設定,而是透 過此函數,求得被成功攻擊的機率。 先前已介紹,安全威脅機率函數有兩種,第一種是 Type I 的攻擊型態,安全威脅機 率函數為 ,第二種是 Type II 的攻擊型態,安全威脅機率函數為 ,其中 v 是初始機率,若要表示 F1過濾器的初始機率,本研究以 v(F1) 來表示,其餘變數在 3.1 已有介紹,此節不再贅述。
接著本研究將 Gordon and Leob[11]所提出的單一資訊系統模型做比較,由於單一資 訊系統僅有一個過濾器和一個資源,與我們所提出的單層資訊中心架構不同,因此我們 將比較兩種架構是否有差異,以驗證單層資訊中心架構與單一資訊系統架構是否有相同 的準確性,若是有相同的準確性,我們將做進一步的研究。 無論哪種攻擊型態,只要有投資,成功攻擊的機率就會降低,本研究將單層資訊中 心架構與 Gordon 和 Loeb 所提出的架構做比較,設定初始機率為 v=0.7,α=β=1,數值 分析結果顯示,成功攻擊機率的曲線,完全吻合 Gordon 和 Loeb 所提出的架構,無論 是 Type I 的攻擊(圖 4.5),或是 Type II 的攻擊(圖 4.6),成功攻擊的機率皆相同。 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Ac cu m u lative P rob ab il ity of In se cu rity F1 = F2 R1
圖4.5 Type I單層架構的投資金額 v.s. Gordon和Loeb
圖4.6 Type II單層架構的投資金額 v.s. Gordon和Loeb
接著,本研究繼續計算總預期淨利潤(TENB,Total Expected Net Benefit),在計算 之前,本研究假設初始機率為 v=0.7,α=β=1,且資源被入侵時,所受到的損失為 L=1000 元。數值分析結果顯示,在初期投資金額越多,總預期淨利潤越高,但投資過多之後, 總預期淨利潤開始下降,總投資淨利潤的曲線,完全吻合 Gordon 和 Loeb 所提出的架 構,無論是 Type I 的攻擊(圖 4.7),或是 Type II 的攻擊(圖 4.8),總預期淨利潤皆相同, 同時,我們發現,Type I 的初始機率為 0.7 時,最佳投資金額為 25 元;Type II 的初始 機率為 0.7 時,最佳投資金額為 15 元。 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 1 2 3 4 5 6 7 8 9 10 P rob ab il ity of In se cu rity Investment z Gordon&Loeb Type II One-Tier Information Center Type II 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 1 2 3 4 5 6 7 8 9 10 P rob ab il ity of In se cu rity Investment z Gordon&Loeb Type I One-Tier Information Center Type I
37
圖4.7 Type I單層架構的總預期淨利潤 v.s. Gordon和Loeb
圖4.8 Type II單層架構的總預期淨利潤 v.s. Gordon和Loeb
每一個初始機率的值,都有一個最佳投資金額,我們計算所有初始機率,找出最佳 投資金額分佈的曲線,在 Type I 攻擊下,其結果如圖 4.9 所示,從圖中可以觀察得知, 初始機率越高,最佳投資金額也越高,且與 Gordon 和 Loeb 的模型非常符合;在 Type II 攻擊下,其結果如圖 4.10 所示,同樣可以觀察得知,初始機率越高,最佳投資金額也 越高,且與 Gordon 和 Loeb 的模型非常符合。這表示本研究所提出的演算法與 Gordon
0 100 200 300 400 500 600 700 0 7 14 21 28 35 42 49 56 63 70 77 84 91 98 T E NB Investment z Gordon&Loeb TypeI One-tier Information Center Type I 0 100 200 300 400 500 600 700 800 0 6 12 18 24 30 36 42 48 54 60 66 72 78 84 90 96 T E NB Investment z Gordon& Loeb Type II One-tier Informatio n Center Type II
和 Loeb 有著相同的現象。
而此一數值分析預設的參數為 , ,α=β=1,過濾器只有
2 個,因此 。橫軸座標表示未投資前被成功攻擊的機率 v,縱軸座標表示最佳
的投資金額,即最大利潤。
圖4.9 Type I單層架構的最佳投資 v.s. Gordon和Loeb
圖4.10 Type II單層架構的最佳投資 v.s. Gordon和Loeb
0 5 10 15 20 25 30 35 0 0.07 0.14 0.2 1 0.28 0.35 0.42 0.49 0.56 0.63 0.7 0.77 0.84 0.91 0.98 O ptim a l Inv estm ent Initial Probability v(F1)=v(F2) Gordon&Loe b Type I One-tier Information Center Type I 0 50 100 150 200 250 0 0.07 0.14 0.21 0.28 0.35 0.42 0.49 0.56 0.63 0.7 0.77 0.84 0.91 0.98 O ptim a l Inv estm ent Initial Probability v(F1)=v(F2) Gordon&Loeb Type II One-tier Information Center Type II
39
4.2 雙層架構分析
在 4.1 節中已證明本研究所提出的演算法與 Gordon and Loeb 有著相同的準確性, 因此我們用相同的分析方法,做進一步的研究,我們 繼續分析雙層架構(Two-Tier Information Center)。雙層架構分析又分為兩種,一種是雙層串聯架構(Multi-Home),另 一種則是雙層非串聯架構(Non-Multi-Home),這兩種不同的架構,會導致不同的不安全 性機率,投資方式也不相同,分別詳述如下。 4.2.1 雙層串聯架構(Multi-Home) Multi-Home 雙層資訊中心架構如圖 4.11 所示,與單層資訊中心架構相比,在右邊 多了一層架構。 圖4.11 Multi-Home雙層資訊中心架構 本研究假設 ,且 ,透過第三章所提之方法,可求 得任一資源被成功攻擊的機率。如圖 4.12 所示,橫軸表示 F1及 F2機率的變化,且 F3 及 F4是固定值 0.4,縱軸表示 R1及 R3累進不安全性的機率。由於 R1及 R2是對稱位置, 因此兩者的機率是相同的,同理,R3及 R4的機率也是相同的,之後本論文不再贅述。 我們可以從圖中看出,不安全性機率有交錯的情形,經過仔細驗證,其交錯的位置是 。
圖4.12 Multi-Home雙層資訊中心架構交錯效應:不安全機率 當 F1及 F2的不安全機率小於 0.34 時,R1比 R3安全,這是由於攻擊者能攻擊 R3 的路徑較多條,而當 F1 的不安全機率很大時,R1 反而比 R3 不安全。這種情況在 Non-Multi-Home 雙層資訊中心架構也會有此現象,下一節我們會再討論。接下來,本 研究分析此種交錯現象。 經過分析,這種交錯現象是因為此種結構的問題。一般而言,攻擊會先入侵第一層, 而後才入侵第二層,因此,第一層通常是不安全的,第二層是安全的。 在第一層不安全性的機率很高時,符合我們一般的假設,但第一層不安全性的機率很低 時,卻發現第一層比第二層安全。這是由於 R1的路徑有 38 條,R3的路徑卻有 88 條, R3攻擊路徑數遠比 R1多。 我們簡化圖 4.11Multi-Home 雙層資訊中心架構,移除 F2及 F4兩個結點,如圖 4.13 所示,攻擊者要攻擊 R1,可能路徑為<A, F1, R1>,假設 F1的不安全性機率為 0.1(即假 設 F1的不安全機率很低時),則依照簡化的路徑來看,R1的不安全性機率即為 0.1;若 攻擊者的目標是 R3,可能路徑為<A, F1, R1, F3, R3>和<A, F1, R2, F3, R3>,由於 R1和 R2 不具防禦效果,被入侵的機率是 100%,因此我們移除 R1和 R2,簡化後的路徑為<A, F1, F3, R3>和<A, F1, F3, R3>,如圖 4.14 所示。接著,我們假設 F3的機率為 0.6,經由先前 提及的 4 個基本式樣來計算,我們得到 R3的不安全性機率為 0.1164,由此得知,R1比 R3安全,違背我們一般的假設。 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 MH -P ro ba bil it y o f Ins ec urit y v(F1)=v (F2), v(F3)=v(F4)=0.4 R1 R3
41 而當 F1和 F3的不安全機率為 0.9 和 0.6 時(即假設 F1的不安全機率很高時),R1和 R3的不安全機率為 0.9 和 0.7884,R3比 R1安全,符合我們一般的假設。 F1 Attack R1 R2 F3 R3 R4 圖4.13 Multi-Home雙層資訊中心架構(移除F2及F4) F3 F1 Attack R3 圖4.14 簡化後之路徑 在我們一般的假設中,只有一排的情形,如圖 4.15 所示,符合我們一般的假設, 但在雙層資訊中心的架構中,多了第二排,攻擊者入侵 R3的路徑大量增加,因此使 R1 和 R3的不安全機率(圖 4.12)產生了交錯的現象,然而,在第一層不安全機率大時,雙層 資訊中的架構會趨近於圖 4.14 的架構,所以符合鄉們一般的假設。 F1 Attack R1 F3 R3 圖4.15 單排資訊中心架構 接著,我們往下一步研究。我們分析了投資的預期損失,圖 4.16 顯示預期損失的 交錯效應,“MH”表示“Multi-Home”,也就是雙層串聯資訊中心架構,本研究假設 , ,α=β=1,若資源被成功攻擊,則損失 1000 元, 透過第三章所提之方法,我們可以求得預期損失,損失的交錯效應與機率的交錯效應之 原因是相同的。
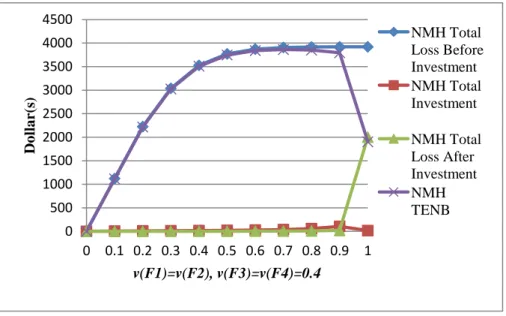
圖4.16 Multi-Home雙層資訊中心架構交錯效應:投資前的預期損失 圖 4.17 顯示投資前總預期損失、總投資、投資後總預期損失、總預期淨利潤,我 們假設 , ,α=β=1,若資源被成功攻擊,則損失 1000 元,這些數據結果都是根據 Type I 攻擊而求得的。我們可以從圖中得知,只要有小額的 投資,可讓損失大幅下降,而且總預期淨利潤有大量的增加。 圖4.17 Type I Multi-Home雙層資訊中心架構總預期淨利潤 圖 4.18 的數據是根據 Type II 攻擊而求得的,同樣的,我們假設 , ,α=β=1,若資源被成功攻擊,則損失 1000 元,與 Type I 有著相 0 500 1000 1500 2000 2500 3000 3500 4000 4500 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Do lla r( s) v(F1)=v(F2), v(F3)=v(F4)=0.4 MH Total Loss Before Investment MH Total Investment MH Total Loss After Investment MH TENB 0 500 1000 1500 2000 2500 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 E x pect ed L o ss v(F1)=v(F2), v(F3)=v(F4)=0.4 MH-R1-Expected Loss Before Investment MH-R3-Expected Loss Before Investment
43 似的結果。不同的地方在於不安全機率接近 1 時,TENB 突然下降,而預期總損失大幅 上升,這表示機率接近 1 時,不必有任何的投資。 圖4.18 Type II Multi-Home雙層資訊中心架構總預期淨利潤 4.2.2 雙層非串聯架構(Non-Multi-Home) Non-Multi-Home 雙層資訊中心架構如圖 4.19 所示,是從單層資訊中心架構中的 F1 及 F2 再延申一層。 F1 Attack F2 R1 R2 F3 F4 R3 R4 圖4.19 Non-Multi-Home雙層資訊中心架構 0 500 1000 1500 2000 2500 3000 3500 4000 4500 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Do lla r( s) v(F1)=v(F2), v(F3)=v(F4)=0.4 MH Total Loss Before Investment MH Total Investment MH Total Loss After Investment MH TENB