Mining Fuzzy Weighted Browsing Patterns from Time
Duration and with Linguistic Thresholds
Tzung-Pei Hong*
Department of Computer Science and Information Engineering National University of Kaohsiung
Kaohsiung, 811, Taiwan, R.O.C. [email protected]
Ming-Jer Chiang
Institute of Information Engineering I-Shou University
Kaohsiung, 840, Taiwan, R.O.C. [email protected]
Shyue-Liang Wang
Department of Computer Science New York Institute of Technology
New York, USA [email protected]
--- * Corresponding author
Abstract
World-wide-web applications have grown very rapidly and have made a significant
impact on computer systems. Among them, web browsing for useful information may be most
commonly seen. Due to its tremendous amounts of use, efficient and effective web retrieval
has become a very important research topic in this field. Techniques of web mining have thus
been requested and developed to achieve this purpose. In this paper, a new fuzzy weighted
web-mining algorithm is proposed, which can process web-server logs to discover useful
users’ browsing behaviors from the time durations of the paged browsed. Since the time
durations are numeric, fuzzy concepts are used here to process them and to form linguistic
terms. Besides, different web pages may have different importance. The importance of web
pages are evaluated by managers as linguistic terms, which are then transformed and averaged
as fuzzy sets of weights. Each linguistic term is then weighted by the importance for its page.
Only the linguistic term with the maximum cardinality for a page is chosen in later mining
processes, thus reducing the time complexity. The minimum support is set linguistic, which is
more natural and understandable for human beings. An example is given to clearly illustrate
the proposed approach.
1. Introduction
World-wide-web applications have recently grown very rapidly and have made a
significant impact on computer systems. Among them, web browsing for useful information
may be most commonly seen. Due to its tremendous amounts of use, efficient and effective
web retrieval has thus become a very important research topic in this field. Techniques of web
mining have thus been requested and developed to achieve this purpose. Cooley et. al. divided
web mining into two classes: web-content mining and web-usage mining [7]. Web-content
mining focuses on information discovery from sources across the world-wide-web. On the
other hand, web-usage mining emphasizes on the automatic discovery of user access patterns
from web servers [8].
In the past, all the web pages were usually assumed to have the same importance in web
mining. Different web pages in a web site may, however, have different importance to users in
real applications. For example, a web page with merchandise items on it may be more
important than that with general introduction. Also, a web page with expensive merchandise
items may be more important than that with cheap ones. Besides, the time durations for the
pages browsed are however an important feature in analyzing users’ browsing behavior. In
this paper, we thus attempt to mine fuzzy weighted browsing patterns from the browsing time
of customers on each web page. The minimum support is given as a linguistic value, which is
and the page importance and the minimum support are linguistic, fuzzy-set concepts are used
to process them.
The fuzzy-set theory has been used more and more frequently in intelligent systems
because of its simplicity and similarity to human reasoning [20, 21]. The theory has been
applied in fields such as manufacturing, engineering, diagnosis, and economics, among others
[11, 15, 17]. Several fuzzy learning algorithms for inducing rules from given sets of data have
been designed and used to good effect with specific domains [2, 4, 9-10, 18]. Some fuzzy
mining approaches were proposed in [5, 13, 16, 19].
The remaining parts of this paper are organized as follows. Several mining approaches
related to this paper are reviewed in Section 2. The notation used in this paper is defined in
Section 3. The proposed web-mining algorithm for fuzzy weighted browsing patterns from
time durations of pages are described in Section 4. An example to illustrate the proposed
fuzzy web-mining algorithm is given in Section 5. Conclusions are finally given in Section 6.
2. Review of related mining approaches
Agrawal and Srikant proposed a mining algorithm to discover sequential patterns from a
set of transactions [1]. Five phases are included in their approach. In the first phase, the
transactions are sorted first by customer ID as the major key and then by transaction time as
the second phase, the set of all large itemsets are found from the customer sequences by
comparing their counts with a predefined support parameter α. This phase is similar to the
process of mining association rules. Note that when an itemset occurs more than one time in a
customer sequence, it is counted once for this customer sequence. In the third phase, each
large itemset is mapped to a contiguous integer and the original customer sequences are
transformed into the mapped integer sequences. In the fourth phase, the set of transformed
integer sequences are used to find large sequences among them. In the fifth phase, the
maximally large sequences are then derived and output to users.
Besides, Hong et al. proposed a fuzzy mining algorithm to mine fuzzy rules from
quantitative data [14]. They transformed each quantitative item into a fuzzy set and used
fuzzy operations to find fuzzy rules. Cai et al. proposed weighted mining to reflect different
importance to different items [3]. Each item was attached a numerical weight given by users.
Weighted supports and weighted confidences were then defined to determine interesting
association rules. Yue et al. then extended their concepts to fuzzy item vectors [19].
3. Notation
The notation used in this paper is defined as follows.
n: the total number of log records;
m: the total number of web pages;
d: the total number of managers;
l: the total number of fuzzy regions;
Di: the browsing sequence of the i-th client, 1≤i≤c;
ni: the number of log data in Di, 1≤i≤c;
Did: the d-th log transaction in Di, 1≤d≤ni;
Ig : the g-th web page, 1≤g≤m;
Rgk: the k-th fuzzy region of Ig, 1≤k≤l;
g id
v : the browsing duration of page Ig in Did;
g id
f : the fuzzy set converted from vidg ;
gk id
f : the membership value of v in region idg gk R ;
gk i
f : the membership value of regionR in the i-th client sequence Dgk i ;
gk
count : the count of region R ; gk
max-count :g the maximum count value among all countgkvalues for page Ig;
max-R : g the fuzzy region of page Igwith max-countg;
Wgh: the transformed fuzzy weight for the importance of page Ig, evaluated by the h-th
manager, 1≤ h≤ d; ave
g
W : the fuzzy average weight for the importance of page Ig;
It: the t-th membership function of item importance, 1≤ t≤ u;
ave
I : the fuzzy average weight of all possible linguistic terms of item importance;
wsupg: the fuzzy weighted support of page Ig;
α
: the predefined linguistic minimum support value;minsup: the transformed fuzzy set from the linguistic minimum support value
α
;wminsup: the fuzzy weighted set of minimum supports;
Cr: the set of candidate weighted sequences with r linguistic terms;
r
L : the set of large weighted sequences with r linguistic terms.
4. The proposed algorithm
Log data in a web site are used to analyze the browsing patterns on that site. Many fields
exist in a log schema. Among them, the fields date, time, client-ip and file name are used in
the mining process. Only the log data with .asp, .htm, .html, .jva and .cgi are considered web
pages and used to analyze the mining behavior. The other files such as .jpg and .gif are
thought of as inclusion in the pages and are omitted. The number of files to be analyzed is
thus reduced. The log data to be analyzed are sorted first in the order of client-ip and then in
the order of date and time. The duration of each web page browsed by a client can then be
calculated from the time interval between the page and its next page. Since the time durations
web page uses only the linguistic term with the maximum cardinality in later mining
processes, thus making the number of fuzzy regions to be processed the same as the number
of original web pages. The algorithm thus focuses on the most important linguistic terms,
which reduce its time complexity.
The importance of web pages is considered and represented as linguistic terms. The
proposed fuzzy weighted web-mining algorithm then uses the set of membership functions for
importance to transform managers’ linguistic evaluations of the importance of web pages into
fuzzy weights. The fuzzy weights of web pages from different mangers are then averaged.
The algorithm then calculates the weighted supports of the linguistic terms of web pages from
browsing sequences. Next, the given linguistic minimum support value is transformed into a
fuzzy set of numerical minimum support values. All fuzzy weighted large 1-sequences can
thus be found by comparing the fuzzy weighted support of the representative linguistic term
of each web page with the fuzzy minimum support. Fuzzy ranking techniques can be used to
achieve this purpose. After that, candidate 2-sequences are formed from fuzzy weighted large
1-sequences and the same procedure is used to find all fuzzy weighted large 2-sequences. This
procedure is repeated until all fuzzy weighted large sequences have been found. Details of the
The algorithm:
INPUT: A set of n web log records, a set of m web pages with their importance evaluated by d
managers, three sets of membership functions respectively for browsing duration,
web page importance and minimum support, and a pre-defined linguistic minimum
support value
α
.OUTPUT: A set of fuzzy weighted browsing patterns.
STEP 1: Select the records with file names including .asp, .htm, .html, .jva, .cgi and closing
connection from the log data; keep only the fields date, time, client-ip and file-name.
STEP 2: Transform the client-ips into contiguous integers (called encoded client ID) for
convenience, according to their first browsing time. Note that the same client-ips
with two closing connections are given two integers.
STEP 3: Sort the resulting log data first by encoded client ID and then by date and time.
STEP 4: Calculate the time durations of the web pages browsed by each encoded client ID
from the time interval between a web page and its next page.
STEP 5: Form a browsing sequence Di for each client ci by sequentially listing his/her ni
tuples (web page, duration), where ni is the number of web pages browsed by client
ci. Denote the d-th tuple in Di as Did.
STEP 6: Transform the duration value vidg of the web page Ig in Did into a fuzzy set g id f , represented as 2 .... , 2 1 1 + + + idglgl g g id g g id R f R f R f
the browsing duration of web pages, where Ig is the g-th web page, Rgkis the k-th fuzzy region of page Ig, fidgk is vidg ,sfuzzy membership value in region Rgk, and
l is the number of fuzzy regions.
STEP 7: Find the membership value gk i
f of each region Rgk in each browsing sequence Di
as gk id D d gk i f f MAXi 1 =
= , where |Di| is the number of tuples in Di.
STEP 8: Calculate the count of each fuzzy region Rgk in the browsing sequences as:
∑
= = c i gk i gk f count 1 ,where c is the number of browsing sequences.
STEP 9: Find max-
(
gk)
l k g count MAX count 1 =
= , where 1≤g≤m, m is the number of web pages in
the log data, and l is the number of linguistic regions for web page Ig. Let max-Rg be
the region with max-countg for web page Ig. The region max-Rg will be used to
represent the fuzzy characteristic of web page Ig in later mining processes.
STEP 10: Transform each linguistic term of the importance of the web page Ig, which is
evaluated by the h-th manager, into a fuzzy set Wgh of weights using the given
membership functions of item importance, 1≤g≤m, 1≤h≤d.
STEP 11: Calculate the fuzzy average weight Wgave of each web page Ig by fuzzy addition as:
ave g W =
∑
= ∗ d h gh W d 1 1 .STEP 12: Calculate the fuzzy weighted support wsupg of the representative region for each
wsupg = c ave g W R max− g × ,
where c is the number of the clients.
STEP 13: Transform the given linguistic minimum support value
α
into a fuzzy set (denotedminsup) of minimum supports, using the given membership functions for minimum
supports.
STEP 14: Calculate the fuzzy weighted set (wminsup) of the given minimum support value as:
wminsup = minsup × (the gravity of ave I ), where u I I u 1 t t ave
∑
= = ,with u being the total number of membership functions for item importance and It
being the t-th membership function. ave
I thus represents the fuzzy average weight
of all possible linguistic terms of importance.
STEP 15: Check whether the weighted support (wsupg) of the representative region for each
web page Ig is larger than or equal to the fuzzy weighted minimum support
(wminsup) by fuzzy ranking. Any fuzzy ranking approach can be applied here as
long as it can generate a crisp rank. If wsupg is equal to or greater than wminsup, put
Ig in the set of large 1-sequences L1.
STEP 16: Set r = 1, where r is used to represent the number of the linguistic items kept in the
STEP 17: Generate the candidate set Cr+1 from Lr in a way similar to that in the aprioriall
algorithm [1]. Restated, the algorithm first joins Lr and Lr , under the condition that
r-1 linguistic terms in the two sequences are the same and with the same orders.
Different permutations represent different candidates. The algorithm then keeps in
Cr+1 the sequences which have all their sub-sequences of length r existing in Lr.
STEP 18: Do the following substeps for each newly formed (r+1)-sequences s with linguistic
web browsing pattern
(
s
1→
s
2→
....
→
s
r+1)
in Cr+1:(a)Find the fuzzy weighted count (wfis) of s in each browsing sequence D as: i
) ( 1 1 j j is ave s r j is Min W f wf = + × = , where j is
f is the membership value of linguistic term sj in Di and
ave sj
W (derived in STEP 11) is the average fuzzy weight for sj. The region sj
must appear after region sj-1 in Di. If two or more same subsequences exist in
Di, then choose the maximum wf value among those of these subsequences is
by fuzzy ranking.
(b) Calculate the fuzzy weighted support (wsups) of sequences s as:
c wf wsup c i is s
∑
= = 1 ,where c is the number of the clients.
(c) Check whether the weighted support (wsups) of sequences s is greater than or
wsups is greater than or equal to wminsup, put s in the set of large (r+1)-
sequences Lr+1.
STEP 19: IF Lr+1 is null, then do the next step; otherwise, set r = r + 1 and repeat Steps 17 to
19.
STEP 20: For each large r-sequence s (r > 1) with fuzzy weighted support wsups, find the
linguistic minimum support region Si with wminsupi ≤ wsups < wminsupi+1 by
fuzzy ranking, where:
wminsupi = minsupi × (the gravity of ave I ),
minsupi is the given membership function for Si. Output sequence s with linguistic
support value Si.
The linguistic weighted browsing patterns output after step 20 can then serve as meta
knowledge concerning the given log data.
5. An example
In this section, an example is given to illustrate the proposed fuzzy weighted web-mining
algorithm. This is a simple example to show how the proposed algorithm can be used to
generate fuzzy weighted browsing patterns for clients' browsing behavior according to the log
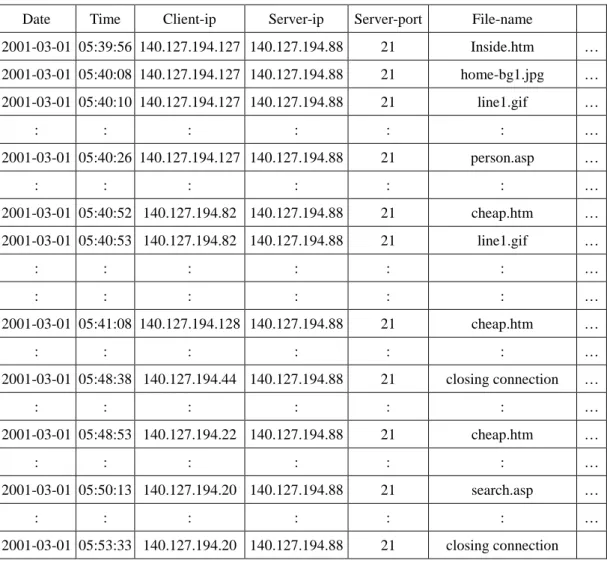
Table 1: A part of the log data used in the example
Date Time Client-ip Server-ip Server-port File-name
2001-03-01 05:39:56 140.127.194.127 140.127.194.88 21 Inside.htm … 2001-03-01 05:40:08 140.127.194.127 140.127.194.88 21 home-bg1.jpg … 2001-03-01 05:40:10 140.127.194.127 140.127.194.88 21 line1.gif … : : : : : : … 2001-03-01 05:40:26 140.127.194.127 140.127.194.88 21 person.asp … : : : : : : … 2001-03-01 05:40:52 140.127.194.82 140.127.194.88 21 cheap.htm … 2001-03-01 05:40:53 140.127.194.82 140.127.194.88 21 line1.gif … : : : : : : … : : : : : : … 2001-03-01 05:41:08 140.127.194.128 140.127.194.88 21 cheap.htm … : : : : : : … 2001-03-01 05:48:38 140.127.194.44 140.127.194.88 21 closing connection … : : : : : : … 2001-03-01 05:48:53 140.127.194.22 140.127.194.88 21 cheap.htm … : : : : : : … 2001-03-01 05:50:13 140.127.194.20 140.127.194.88 21 search.asp … : : : : : : … 2001-03-01 05:53:33 140.127.194.20 140.127.194.88 21 closing connection
Each record in the log data includes fields date, time, client-ip, server-ip, server-port and
file-name, among others. Only one file name is contained in each record. For example, the
user in client-ip 140.127.194.127 browsed the file inside.htm at 05:39:56 on March 1st, 2001.
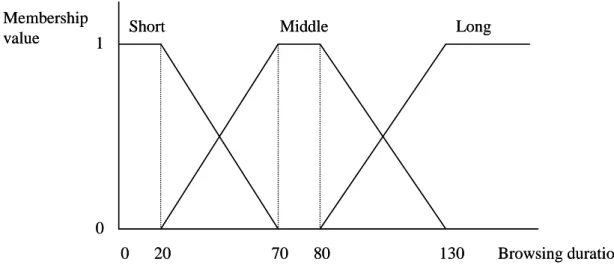
Assume the membership functions for a browsing duration of a web page are shown in
Figure 1: The membership functions for a browsing duration of a web page
In Figure 1, the browsing duration is divided into three fuzzy regions: Short, Middle and
Long. Thus, three fuzzy membership values are produced for each duration according to the
predefined membership functions. For the log data shown in Table 1, the proposed fuzzy
web-mining algorithm proceeds as follows.
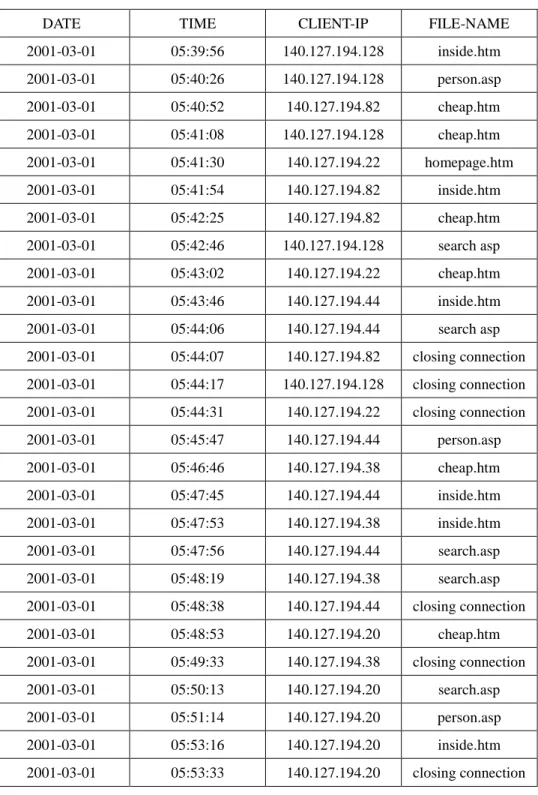
Step 1: The records with file names being .asp, .htm, .html, .jva, .cgi and closing
connection are selected for mining. Only the four fields date, time, client-ip and file-name are
kept. Assume the resulting log data from Table 1 are shown in Table 2. Membership value Browsing duration Middle Short Long 0 0 1 20 70 80 130 Membership value Browsing duration Middle Short Long 0 0 1 20 70 80 130
Table 2: The resulting log data for web mining.
DATE TIME CLIENT-IP FILE-NAME
2001-03-01 05:39:56 140.127.194.128 inside.htm 2001-03-01 05:40:26 140.127.194.128 person.asp 2001-03-01 05:40:52 140.127.194.82 cheap.htm 2001-03-01 05:41:08 140.127.194.128 cheap.htm 2001-03-01 05:41:30 140.127.194.22 homepage.htm 2001-03-01 05:41:54 140.127.194.82 inside.htm 2001-03-01 05:42:25 140.127.194.82 cheap.htm 2001-03-01 05:42:46 140.127.194.128 search asp 2001-03-01 05:43:02 140.127.194.22 cheap.htm 2001-03-01 05:43:46 140.127.194.44 inside.htm 2001-03-01 05:44:06 140.127.194.44 search asp 2001-03-01 05:44:07 140.127.194.82 closing connection 2001-03-01 05:44:17 140.127.194.128 closing connection 2001-03-01 05:44:31 140.127.194.22 closing connection 2001-03-01 05:45:47 140.127.194.44 person.asp 2001-03-01 05:46:46 140.127.194.38 cheap.htm 2001-03-01 05:47:45 140.127.194.44 inside.htm 2001-03-01 05:47:53 140.127.194.38 inside.htm 2001-03-01 05:47:56 140.127.194.44 search.asp 2001-03-01 05:48:19 140.127.194.38 search.asp 2001-03-01 05:48:38 140.127.194.44 closing connection 2001-03-01 05:48:53 140.127.194.20 cheap.htm 2001-03-01 05:49:33 140.127.194.38 closing connection 2001-03-01 05:50:13 140.127.194.20 search.asp 2001-03-01 05:51:14 140.127.194.20 person.asp 2001-03-01 05:53:16 140.127.194.20 inside.htm 2001-03-01 05:53:33 140.127.194.20 closing connection
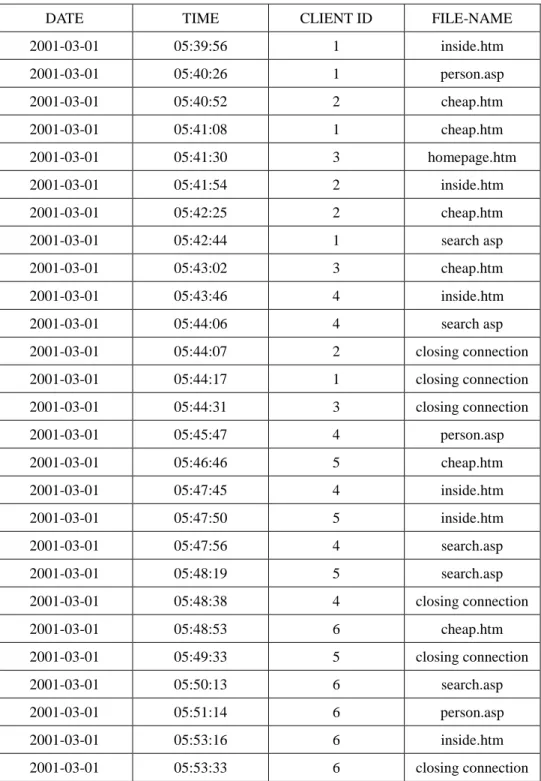
Step 2: The values of field client-ip are transformed into contiguous integers according to
each client’s first browsing time. The transformed results for Table 2 are shown in Table 3.
longin.htm, search.asp, cheap.htm and person.asp were browsed in this example.
Table 3: Transforming the values of field client-ip into contiguous integers.
DATE TIME CLIENT ID FILE-NAME
2001-03-01 05:39:56 1 inside.htm 2001-03-01 05:40:26 1 person.asp 2001-03-01 05:40:52 2 cheap.htm 2001-03-01 05:41:08 1 cheap.htm 2001-03-01 05:41:30 3 homepage.htm 2001-03-01 05:41:54 2 inside.htm 2001-03-01 05:42:25 2 cheap.htm 2001-03-01 05:42:44 1 search asp 2001-03-01 05:43:02 3 cheap.htm 2001-03-01 05:43:46 4 inside.htm 2001-03-01 05:44:06 4 search asp 2001-03-01 05:44:07 2 closing connection 2001-03-01 05:44:17 1 closing connection 2001-03-01 05:44:31 3 closing connection 2001-03-01 05:45:47 4 person.asp 2001-03-01 05:46:46 5 cheap.htm 2001-03-01 05:47:45 4 inside.htm 2001-03-01 05:47:50 5 inside.htm 2001-03-01 05:47:56 4 search.asp 2001-03-01 05:48:19 5 search.asp 2001-03-01 05:48:38 4 closing connection 2001-03-01 05:48:53 6 cheap.htm 2001-03-01 05:49:33 5 closing connection 2001-03-01 05:50:13 6 search.asp 2001-03-01 05:51:14 6 person.asp 2001-03-01 05:53:16 6 inside.htm 2001-03-01 05:53:33 6 closing connection
Step 3: The resulting log data in Table 3 are then sorted first by encoded client ID and
Table 4. The resulting log data sorted first by client ID and then by data and time
DATE TIME CLIENT ID FILE-NAME
2001-03-01 05:39:56 1 inside.htm 2001-03-01 05:40:26 1 person.asp 2001-03-01 05:41:08 1 cheap.htm 2001-03-01 05:42:46 1 search asp 2001-03-01 05:44:17 1 closing connection 2001-03-01 05:40:52 2 cheap.htm 2001-03-01 05:41:54 2 inside.htm 2001-03-01 05:42:25 2 cheap.htm 2001-03-01 05:44:07 2 closing connection 2001-03-01 05:41:30 3 homepage.htm 2001-03-01 05:43:02 3 cheap.htm 2001-03-01 05:44:31 3 closing connection 2001-03-01 05:43:46 4 inside.htm 2001-03-01 05:44:06 4 search asp 2001-03-01 05:45:47 4 person.asp 2001-03-01 05:47:45 4 inside.htm 2001-03-01 05:47:56 4 search.asp 2001-03-01 05:48:38 4 closing connection 2001-03-01 05:46:46 5 cheap.htm 2001-03-01 05:47:53 5 inside.htm 2001-03-01 05:48:19 5 search.asp 2001-03-01 05:49:33 5 closing connection 2001-03-01 05:48:50 6 cheap.htm 2001-03-01 05:50:13 6 search.asp 2001-03-01 05:51:14 6 person.asp 2001-03-01 05:53:16 6 inside.htm 2001-03-01 05:53:33 6 closing connection
Step 4: The time durations of the web pages browsed by each encoded client ID are
calculated. Take the first web page browsed by client 1 as an example. Client 1 retrieves the
March 1st, 2001. The duration of inside.htm for client 1 is then 30 seconds (2001/03/01,
05:39:56 - 2001/03/01, 05:40:26).
Simple symbols are used here to represent web pages for convenience. Let A, B, C, D
and E respectively represent homepage.htm, inside.htm, search.asp, cheap.htm and person.asp.
The durations of all pages browsed by each client ID are shown in Table 5.
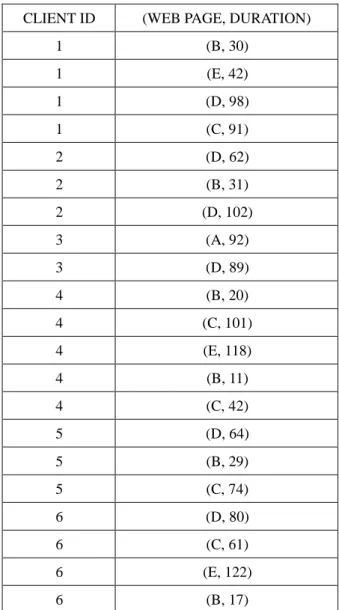
Table 5: The web pages browsed with their durations.
CLIENT ID (WEB PAGE, DURATION)
1 (B, 30) 1 (E, 42) 1 (D, 98) 1 (C, 91) 2 (D, 62) 2 (B, 31) 2 (D, 102) 3 (A, 92) 3 (D, 89) 4 (B, 20) 4 (C, 101) 4 (E, 118) 4 (B, 11) 4 (C, 42) 5 (D, 64) 5 (B, 29) 5 (C, 74) 6 (D, 80) 6 (C, 61) 6 (E, 122) 6 (B, 17)
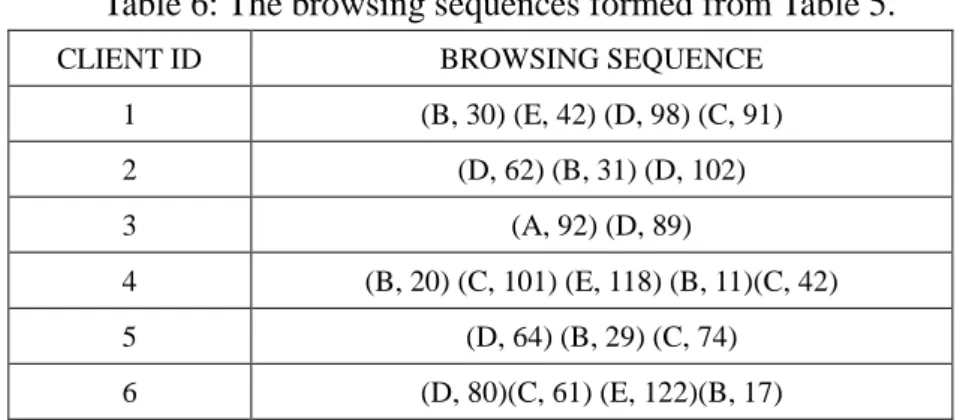
tuple is represented as (web page, duration). The resulting browsing sequences from Table 5
are shown in Table 6.
Table 6: The browsing sequences formed from Table 5.
CLIENT ID BROWSING SEQUENCE
1 (B, 30) (E, 42) (D, 98) (C, 91) 2 (D, 62) (B, 31) (D, 102) 3 (A, 92) (D, 89) 4 (B, 20) (C, 101) (E, 118) (B, 11)(C, 42) 5 (D, 64) (B, 29) (C, 74) 6 (D, 80)(C, 61) (E, 122)(B, 17)
Step 6: The time durations of the file names in each browsing sequence are represented as
fuzzy sets. Take the web page B in the first browsing sequence as an example. The time
duration “30” of the web page B is converted into the fuzzy set
) . 0 . 0 . 2 . 0 . 8 . 0 ( Long B Middle B Short B + +
by the given membership functions (Figure 1). This step is
repeated for the other web pages and browsing sequences. The results are shown in Table 7.
Table 7: The fuzzy sets transformed from the browsing sequences.
CLIENT ID FUZZY SETS
1 + + + + Long C Middle C Long D Middle D Middle E Short E Middle B Short B . 2 . 0 . 8 . 0 , . 4 . 0 . 6 . 0 , . 4 . 0 . 6 . 0 , . 2 . 0 . 8 . 0 2 + + + Long D Middle D Middle B Short B Middle D Short D . 4 . 0 . 6 . 0 , . 2 . 0 . 8 . 0 , . 8 . 0 . 2 . 0 3 + + Long D Middle D Long A Middle A . 4 . 0 . 6 . 0 , . 2 . 0 . 8 . 0 4 + + + Middle C Short C Short B Long E Middle E Long C Middle C Short B . 4 . 0 . 6 . 0 , . 0 . 1 , . 8 . 0 . 2 . 0 , . 4 . 0 . 6 . 0 , . 0 . 1 5 + Middle C Middle B Short B Middle D . 0 . 1 , . 2 . 0 . 8 . 0 , . 0 . 1 6 + + Short B Long E Middle E Middle C Short C Middle D . 0 . 1 , . 8 . 0 . 2 . 0 , . 8 . 0 . 2 . 0 , . 0 . 1
Step 7: The membership value of each region in each browsing sequence is found. Take
the region D.Middle for Client 2 as an example. Its membership value is max(0.8, 0.6)=0.8.
The membership values of the other regions can be similarly calculated.
Step 8: The cardinality of each fuzzy region in all the browsing sequences is calculated
as the count value. Take the fuzzy region D.Middle as an example. Its cardinality =
(0.6+0.8+0.8+0.0+1.0+1.0) = 4.2. This step is repeated for the other regions, and the results
are shown in Table 8.
Table 8: The counts of the fuzzy regions
REGION COUNT REGION COUNT REGION COUNT
A.Short 0.0 C.Short 0.8 E.Short 0.6
A.Midlle 0.8 C.Midlle 3.2 E.Midlle 0.8
A.Long 0.2 C.Long 0.6 E.Long 1.6
B.Short 4.4 D.Short 0.2
B.Midlle 0.6 D.Midlle 4.2
B.Long 0.0 D.Long 1.0
Step 9: The fuzzy region with the largest count value among the three possible regions
for each file is selected. Take the web page A as an example. Its count is 0.0 for Short, 0.8 for
Middle, and 0.2 for Long. Since the count for Middle is the largest among the three counts, the
region Middle is thus used to represent the web page A in later mining processes. This step is
repeated for the other web pages. Thus, "Short" is chosen for B, “Middle” is chosen for A, C
and D, and "Long" is chosen for E.
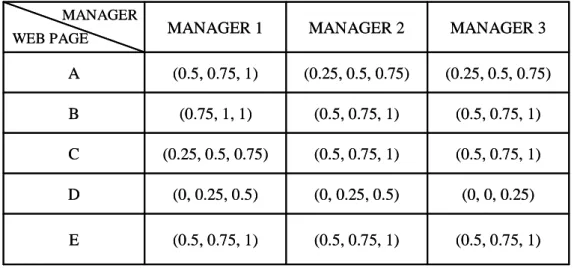
by three managers as shown in Table 9.
Table 9: The importance of the web pages evaluated by three managers
Assume the membership functions for importance of the web page are given in Figure 2.
Figure 2: The membership functions of importance of the web page used in this example
In Figure 2, the importance of the web page is divided into five fuzzy regions: Very
Unimportant, Unimportant, Ordinary, Important and Very Important. Each fuzzy region is
represented by a membership function. The membership functions in Figure 2 can be Weight Membership value 1 1 0.5 0.25 0.75 Very Unimportant Unimportant Important Very Important Ordinary 0 0 Weight Membership value 1 1 0.5 0.25 0.75 Very Unimportant Unimportant Important Very Important Ordinary 0 0 MANAGER Important Important Important E Very Unimportant Unimportant Unimportant D Important Important Ordinary C Important Important Very Important B Ordinary Ordinary Important A MANAGER 3 MANAGER 2 MANAGER 1 WEB PAGE MANAGER Important Important Important E Very Unimportant Unimportant Unimportant D Important Important Ordinary C Important Important Very Important B Ordinary Ordinary Important A MANAGER 3 MANAGER 2 MANAGER 1 WEB PAGE
represented as follows:
Very Unimportant (VU): (0, 0, 0.25),
Unimportant (U): (0, 0.25, 0.5),
Ordinary (O): (0.25, 0.5, 0.75),
Important (I): (05, 075, 1), and
Very Important (VI): (0.75, 1, 1).
The linguistic terms for the importance of the web pages given in Table 9 are
transformed into fuzzy sets by the membership functions given in Figure 2. For example,
Page A is evaluated to be important by Manager 1. It can then be transformed as a triangular
fuzzy set (0.5, 0.75, 1) of weights. The transformed results for Table 9 are shown in Table 10.
Table 10: The fuzzy weights transformed from the importance of the web pages in Table 9.
Step 11: The average weight of each web page is calculated by fuzzy addition. Take web
page A as an example. The three fuzzy weights for web page A are respectively (0.5, 0.75, 1),
MANAGER WEB PAGE (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) E (0, 0, 0.25) (0, 0.25, 0.5) (0, 0.25, 0.5) D (0.5, 0.75, 1) (0.5, 0.75, 1) (0.25, 0.5, 0.75) C (0.5, 0.75, 1) (0.5, 0.75, 1) (0.75, 1, 1) B (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.5, 0.75, 1) A MANAGER 3 MANAGER 2 MANAGER 1 MANAGER WEB PAGE (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) E (0, 0, 0.25) (0, 0.25, 0.5) (0, 0.25, 0.5) D (0.5, 0.75, 1) (0.5, 0.75, 1) (0.25, 0.5, 0.75) C (0.5, 0.75, 1) (0.5, 0.75, 1) (0.75, 1, 1) B (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.5, 0.75, 1) A MANAGER 3 MANAGER 2 MANAGER 1
(0.25, 0.5, 0.75) and (0.25, 0.5, 0.75). The average weight is then ((0.5+0.25+0.25)/3,
(0.75+0.5+0.5)/3, (1+0.75+0.75)/3), which is derived as (0.33, 0.58, 0.83). The average fuzzy
weights of all the web pages are calculated, with results shown in Table 11.
Table 11: The average fuzzy weights of all the web pages
WEB PAGE AVERAGE FUZZY WEIGHT
A (0.333, 0.583, 0.833)
B (0.583, 0.833, 1)
C (0.417, 0.667,0.917)
D (0, 0.167, 0.417)
E (0.5, 0.75, 1)
Step 12: The fuzzy weighted support of each web page is calculated. Take the web page
A as an example. The average fuzzy weight of A is (0.333, 0.583, 0.833) from Step 11. Since
the region Middle is used to represent the web page A and its count is 2.0, its weighted
support is then (0.333, 0.583, 0.833) * 0.8 / 6, which is (0.044, 0.078, 0.111). Results for all
the web pages are shown in Table 12.
Table 12: The fuzzy weighted supports of the representative regions for the web pages
ITEM FUZZY WEIGHTED SUPPORT
A.Middle (0.044, 0.078, 0.111)
B.Short (0.428, 0.611, 0.733)
C.Middle (0.222, 0.356, 0.489)
D.Middle (0, 0.117, 0.292)
E.Long (0.133, 0.2, 0.267)
minimum supports. Assume the membership functions for minimum supports are given in
Figure 3.
Figure 3: The membership functions of minimum supports
Also assume the given linguistic minimum support value is “Low”. It is then transformed
into a fuzzy set of minimum supports, (0, 0.25, 0.5), according to the given membership
functions in Figure 3.
Step 14: The fuzzy average weight of all possible linguistic terms of importance in
Figure 3 is calculated as:
Iave = [(0, 0, 0.25) + (0, 0.25, 0.5) + (0.25, 0.5, 0.75) + (0.5, 0.75, 1) +(0.75, 1, 1)] / 5
= (0.3, 0.5, 0.7).
The gravity of Iave is then (0.3 + 0.5 + 0.7) / 3, which is 0.5. The fuzzy weighted set of
minimum supports for “Low” is then (0, 0.25, 0.5) × 0.5, which is (0, 0.125, 0.25).
Step 15: The fuzzy weighted support of the representative region for each web page is
compared with the fuzzy weighted minimum support by fuzzy ranking. Any fuzzy ranking Minimum support Membership value 1 1 0.5 0.25 0.75
Very Low Low Middle High Very High
0 0 Minimum support Membership value 1 1 0.5 0.25 0.75
Very Low Low Middle High Very High
0 0
approach can be applied here as long as it can generate a crisp rank. Assume the gravity
ranking approach is adopted in this example. Take web page B as an example. The average
height of the fuzzy weighted support for B.Short is (0.428 + 0.611 + 0.733) / 3, which is 0.591.
The average height of the fuzzy weighted minimum support is (0 + 0.125 + 0.25) / 3, which is
0.125. Since 0.591 > 0.125, B.Short is thus a large fuzzy weighted 1-sequence. Similarly,
C.Middle, D.Middle and E.Long are large fuzzy weighted 1-sequences. These 1-sequences are
put in L1 (Table 13).
Table 13: The set of fuzzy weighted large 1-sequences for this example
1-SEQUENCE COUNT
B.Short 4.4
C.Middle 3.2
D.Middle 4.2
E.Long 1.6
Step 16: r is set at 1, where r is used to store the number of the linguistic items kept in
the current sequences.
Step 17: The candidate set C2 is first generated from L1 as follows: (B.Short, B.Short),
(B.Short, C.Middle), (B.Short, D.Middle), (B.Short, E.Long), (C.Middle, B.Short), (C.Middle,
C.Middle), (C.Middle, D.Middle), (C.Middle, E.Long), (D.Middle, B.Short), (D.Middle,
C.Middle), (D.Middle, D.Middle), (D.Middle, E.Long), (E.Long, B.Short), (E.Long, C.Middle),
Step 18: The following substeps are done for each newly formed candidate sequences in
C2.
(a) The fuzzy weighted count of each candidate 2-sequence in each browsing sequence is
first calculated. Here, the minimum operator is used for intersection. Take the linguistic
browsing sequence (B.Short, C.Middle) for Client 4 as an example. There are three possible
subsequences of (B.Short, C.Middle) in that browsing sequence. The average fuzzy weight of
web page B is (0.583, 0.833, 1) and the average fuzzy weight of web page C is (0.417,
0.667,0.917) from Step 11. The fuzzy weighted count for the first possible subsequence
(B.Short (1.0), C.Middle (0.6)) in the browsing sequence for Client 4 is calculated as:
min(1.0*(0.583, 0.833, 1), 0.6*(0.417, 0.667,0.917)) = min((0.583, 0.833,1), (0.25, 0.4, 0.55))
= (0.25, 0.4, 0.55). Since it has the largest fuzzy value among all the three possible sequences
by fuzzy ranking, (0.25, 0.4, 0.55) is then the fuzzy weighted count for (B.Short, C.Middle) in
this browsing sequence. The results all the clients for the sequence (B.Short, C.Middle) are
shown in Table 14.
Table 14: The fuzzy weighted count of the sequence (B.Short, C.Middle) in each client
CLIENT B.Short C.Middle (B.Short , C.Middle)
1 (0.467, 0.667, 0.8) (0.333, 0.533, 0.733) (0.333, 0.533, 0.733) 2 (0, 0, 0) (0, 0, 0) (0, 0, 0) 3 (0, 0, 0) (0, 0, 0) (0, 0, 0) 4 (0.583, 0.833,1) (0.25, 0.4, 0.55) (0.25, 0.4, 0.55) 5 (0.467, 0.667, 0.8) (0.417, 0.667, 0.917) (0.417, 0.667, 0.8) 6 (0, 0, 0) (0, 0, 0) (0, 0, 0)
(b) The fuzzy weighted count of each candidate 2-sequence in C2 is then calculated.
Results for this example are shown in Table 15.
Table 15: The fuzzy weighted counts of the candidate sequences in C2
SEQUENCES COUNT SEQUENCES COUNT
(B.Short, B.Short) (0.583, 0.833, 1) (D.Middle, B.Short) (0, 0.467, 1.167) (B.Short, C.Middle) (1, 1.6, 2.083) (D.Middle, C.Middle) (0, 0.433, 1.083) (B.Short, D.Middle) (0, 0.2, 0.5) (D.Middle, D.Middle) (0, 0.1, 0.25)
(B.Short, E.Long) (0.4, 0.6, 0.8) (D.Middle, E.Long) (0, 0.167, 0.417) (C.Middle, B.Short) (0.25, 0.4, 0.55) (E.Long, B.Short) (0.8, 1.2, 1.6) (C.Middle, C.Middle) (0.167, 0.267, 0.367) (E.Long, C.Middle) (0.167, 0.267, 0.367)
(C.Middle, D.Middle) (0, 0, 0) (E.Long , D.Middle) (0, 0, 0)
(C.Middle, E.Long) 0.25, 0.4, 0.55) (E.Long, E.Long) (0, 0, 0)
The fuzzy weighted support of each candidate 2-sequences is then calculated. Take
(B.Short, C.Middle) as an example. The fuzzy weighted count of (B.Short, C.Middle) is (1, 1.6,
2.083) and the total number of the client is 6. Its fuzzy weighted support is then (1, 1.6, 2.083)
/ 6, which is (0.167, 0.267, 0.347). All the fuzzy weighted supports of the candidate
2-sequences are shown in Table 16.
Table 16: The fuzzy weighted supports of the sequences in C2
SEQUENCES WEIGHT SUPPORT SEQUENCES WEIGHT SUPPORT
(B.Short, B.Short) (0.097, 0.139, 0.167) (D.Middle, B.Short) (0, 0.078, 0.194) (B.Short, C.Middle) (0.167, 0.267, 0.347) (D.Middle, C.Middle) (0, 0.072, 0.181) (B.Short, D.Middle) (0, 0.033, 0.083) (D.Middle, D.Middle) (0, 0.017, 0.042) (B.Short, E.Long) (0.067,0.1, 0.133) (D.Middle, E.Long) (0, 0.028, 0.069) (C.Middle, B.Short) (0.042, 0.067, 0.092) (E.Long, B.Short) (0.133, 0.2, 0.267) (C.Middle, C.Middle) (0.028, 0.044, 0.061) (E.Long, C.Middle) (0.028, 0.044, 0.061)
(C.Middle, D.Middle) (0, 0, 0) (E.Long , D.Middle) (0, 0, 0)
(c) The fuzzy weighted support of each candidate 2-sequence is compared with the fuzzy
weighted minimum support by fuzzy ranking. As mentioned above, assume the gravity
ranking approach is adopted in this example. (B.Short, B.Short), (B.Short, C.Middle) and
(E.Long, B.Short) are then found to be large 2-sequences. They are then put in L2.
Step 19: Since L2 is not null, r = r + 1 = 2. Steps 17 to 19 are repeated to find L3. C3 is
then generated from L2. In this example, C3 is empty. L3 is thus empty.
Step 20: The linguistic support values are found for each large r-sequence s (r > 1). Take
the sequential pattern (B.Short → C.Middle) as an example. Its fuzzy weighted support is
(0.167, 0.267, 0.347). Since the membership function for linguistic minimum support region
“Middle” is (0.25, 0.5, 0.75) and for “High” is (0.5, 0.75, 1), the weighted fuzzy set for these
two regions are (0, 0.125, 0.25) and (0.125, 0.25,0.375). Since (0.125, 0.25,0.375) < (0.167,
0.267, 0.347) < (0.25, 0.375, 0.5) by fuzzy ranking, the linguistic support value for sequence
(B.Short → C.Middle) is then “Middle”. The linguistic supports of the other two large
2-sequences can be similarly derived. All the three large linguistic browsing patterns are then
output as:
1. (B.Short → B.Short) with a low support;
2. ( B.Short → C.Middle) with a middle support;
These three linguistic browsing patterns are thus output as the meta knowledge
concerning the given log data.
6. Conclusion and future work
In this paper, we have proposed a new fuzzy weighted web-mining algorithm, which can
process web-server logs to discover useful users’ browsing behaviors from the time durations
of the paged browsed. In the log data, each transaction contains only one web page. The
mining process can thus be simplified when compared to that for multiple-item transactions in
Agrawal and Srikant 's mining approach [1]. Since the time durations are numeric, fuzzy
concepts are used here to process them and to form linguistic terms. Besides, different web
pages may have different importance. The importance of web pages are evaluated by
managers as linguistic terms, which are then transformed and averaged as fuzzy sets of
weights. Each linguistic term is then weighted by the importance for its page. Only the
linguistic term with the maximum cardinality for a page is chosen in later mining processes,
thus making the number of fuzzy regions to be processed the same as the number of original
web pages. The algorithm therefore focuses on the most important linguistic terms, which
reduces its time complexity. The minimum support is also given linguistic. Fuzzy operations
including fuzzy ranking are then used to find fuzzy weighted browsing patterns. Compared to
more natural and understandable for human beings.
Although the proposed method works well in fuzzy weighted web mining and can
effectively manage linguistic minimum supports, it is just a beginning. There is still much
work to be done in this field. Our method assumes that the membership functions are known
in advance. In [6, 12], we proposed some fuzzy learning methods to automatically derive the
membership functions. In the future, we will attempt to dynamically adjust the membership
functions in the proposed web-mining algorithm to avoid the bottleneck of membership
function acquisition.
References
[1] R. Agrawal, R. Srikant: “Mining Sequential Patterns”, The Eleventh International
Conference on Data Engineering, 1995, pp. 3-14.
[2] A. F. Blishun, “Fuzzy learning models in expert systems,” Fuzzy Sets and Systems, Vol. 22,
1987, pp. 57-70.
[3] C. H. Cai, W. C. Fu, C. H. Cheng and W. W. Kwong, “Mining association rules with
weighted items,” The International Database Engineering and Applications Symposium,
1998, pp. 68-77.
[4] L. M. de Campos and S. Moral, “Learning rules for a fuzzy inference model,” Fuzzy Sets
[5] K. C. C. Chan and W. H. Au, “Mining fuzzy association rules,” The 6th ACM
International Conference on Information and Knowledge Management, 1997, pp.10-14.
[6] C. H. Chen, T. P. Hong and V. S. M. Tseng, "A cluster-based fuzzy-genetic mining
approach for association rules and membership functions", The 2006 IEEE International
Conference on Fuzzy Systems, pp.6971-6976, 2006.
[7] R. Cooley, B. Mobasher and J. Srivastava, “Grouping web page references into
transactions for mining world wide web browsing patterns,” Knowledge and Data
Engineering Exchange Workshop, 1997, pp. 2 –9.
[8] R. Cooley, B. Mobasher and J. Srivastava, “Web mining: information and pattern
discovery on the world wide web,” Ninth IEEE International Conference on Tools with
Artificial Intelligence, 1997, pp. 558 -567
[9] M. Delgado and A. Gonzalez, “An inductive learning procedure to identify fuzzy
systems,” Fuzzy Sets and Systems, Vol. 55, 1993, pp. 121-132.
[10] A.Gonzalez, “A learning methodology in uncertain and imprecise environments,”
International Journal of Intelligent Systems, Vol. 10, 1995, pp. 57-371.
[11] I. Graham and P. L. Jones, Expert Systems – Knowledge, Uncertainty and Decision,
Chapman and Computing, Boston, 1988, pp.117-158.
[12] T. P. Hong, C. H. Chen, Y. L. Wu and Y. C. Lee, "A GA-based fuzzy mining approach to
Soft Computing, Vol. 10, No. 11, pp. 1091-1101, 2006.
[13] T. P. Hong, M. J. Chiang and S. L. Wang, ”Mining from quantitative data with linguistic
minimum supports and confidences”, The 2002 IEEE International Conference on Fuzzy
Systems, Honolulu, Hawaii, 2002, pp.494-499.
[14] T. P. Hong, C. S. Kuo and S. C. Chi, "Mining association rules from quantitative data",
Intelligent Data Analysis, Vol. 3, No. 5, 1999, pp. 363-376.
[15] A. Kandel, Fuzzy Expert Systems, CRC Press, Boca Raton, 1992, pp. 8-19.
[16] C. M. Kuok, A. W. C. Fu and M. H. Wong, "Mining fuzzy association rules in
databases," The ACM SIGMOD Record, Vol. 27, No. 1, 1998, pp. 41-46.
[17] E. H. Mamdani, “Applications of fuzzy algorithms for control of simple dynamic plants,
“ IEEE Proceedings, 1974, pp. 1585-1588.
[18] J. Rives, “FID3: fuzzy induction decision tree,” The First International symposium on
Uncertainty, Modeling and Analysis, 1990, pp. 457-462.
[19] S. Yue, E. Tsang, D. Yeung and D. Shi, “Mining fuzzy association rules with weighted
items,” The IEEE International Conference on Systems, Man and Cybernetics, 2000, pp.
1906-1911.
[20] L. A. Zadeh, “Fuzzy logic,” IEEE Computer, 1988, pp. 83-93.