運用多模式表決提升預測效益之研究
8
0
0
全文
(2) 值。在某些公司中,利用顧客早期的消費行 為,就可以準確預測其未來使用率。. 許多具有價值的顧客,另外業者也只能憑著過 去 的 經 驗 來 決 定 顧 客 未 來 的 反 應 率 (David Shepard Associates, 1995)。[5]. 顧客關係管理的法則,可以歸納成:在適 當的時間,以適當的價格,對適當的顧客提供 適當的商品或服務。. Kalakota & Robinson(1999)指出顧客生 命週期分獲得(acquire)加強(enhance)保留 (retain)三階段。在獲得階段應採創新及便利 策略以吸引客戶。在加強階段應採降低成本及 利用交叉銷售策略以加強客戶。在保留階段應 採傾聽客戶需求及研發新產品策略以保留客 戶。[11]. 2.2 貝氏分類法 貝氏分類法(Bayesian classification) 是統計分類法,它可預測類別機率,如一已知 樣本屬於某一特定類別之機率。貝氏分類乃基 於貝氏理論,分類演算法之研究顯示簡單貝氏 分類法之功能似決策樹及類神經網路分類,在 應用於大型資料庫時亦有高正確性及快速。 [1,2]. Quinlan(1986,1987,1993)的 ID3 歸納 學習演算法是採用資訊理論中的不純度函數 為基礎,最終形成決策樹[12,13,14],此方法 已有效運用在許多領域。決策樹在建構過程 中,可以發掘出一般所了解的分類規則[3, 4]。決策樹的演算過程簡單,不必繁雜運算即 可完成決策樹的動作。在處理分類過程時能夠 掌握連續性以及屬於某一範疇的變數。在預測 及分類上,決策樹之分析結果能提供極重要資 訊。. 簡單貝氏分類法假設某一類別之一屬性 值與其他屬性值無關,稱為類別條件獨立,以 簡化相關計算。 貝氏理論乃令 X 為樣本,其輸出類別為未 知,令 H 為假設:X 屬於一特定類 C,P(H|X) 表示樣本 X 中假設 H 成立之機率。 P(H|X)為後驗機率,即 X 條件下之 H 機 率。例如:樣本含水果,以其顏色及形狀描述, 若 X 為紅色圓形,H 表示 X 為蘋果,則 P(H|X) 表示信心-當我們看見 X 為紅色圓形時,X 為 蘋果。反之,P(H)為 H 之先驗機率(Prior probability)。例如表樣本為蘋果之機率,後 驗機率 P(H|X)比先驗機率 P(H)需更多背 景知識。. 2.1 顧客市場區隔 Michael J.A. Berry & Gordon S. Linoff (2000) 以為顧客市場區隔是將顧客區分成互 斥(mutually exclusive)群集的程序。在同一 群集內,都是某些特性上極為相似的顧客。市 場區隔相當有用,因為這可以在資料探勘的過 程,加入特定領域的專業知識,針對不同的顧 客族群,推出不同的促銷活動,也建立各自獨 立的預測模型。這樣區隔使得資料探勘不需重 新發現已知的事實,因此會發展出較好的預測 模型。. P(X|H)為 X 在 H 條件下之後驗機率,即 已知 X 為蘋果,則 X 為紅色圓形之機率;P(X) 為 X 之先驗機率,表水果樣本中為紅色圓形的 機率。. 資料探勘演算法可用來協助客戶市場區 隔。這些資料探勘分類方法,不同於商業上熟 知的分類。原因是這些分類並非掌控企業的重 要因素。或者這些分類可能是掌控企業的因 素,但管理者不熟悉這些分類,無法善加利 用。. 如何估計機率?P(X) ,P(H) ,及 P(X|H) 可由已知資料估計,貝氏理論為. P(h | x) =. 顧客生命週期是指顧客和企業間關係的 不同階段。顧客生命週期很重要,因其直接影 響長期顧客的價值。首先,顧客生命週期是一 個架構,可以用來了解顧客消費行為。資料探 勘可以在顧客生命週期的不同階段中切入,因 此了解顧客生命週期可以讓資料探勘的過程 更有效率。除此之外,某些顧客生命週期所發 生的事件是很重要的。若能預測這些變化,將 會帶來很大的好處。. P ( x | h) p (h) p ( x). 與其他分類法比較,貝氏分類之誤差最 小,但實際上因我們假設條件獨立之不正確, 故與其他方法比較之實證研究顯示其稍遜競 爭力。 2.3 決策樹歸納法 決策樹為像流程圖之樹形狀結構,內部節 點表示一屬性之測試,分支表示測試之結果, 葉節點表示分類或類別分佈。最上層稱根節 點。(1). 整個顧客生命週期中,不同的階段都有其 重要事件。每個階段都有資料探勘及顧客關係 管理可以切入的點。. 為了分類,將樣本之屬性值加以測試,由 根 至葉 節點沿 著樣本 中含 分類值 之路 徑追 蹤,決策樹易於轉換為分類規則。. 已確定顧客的行為,通常都隱藏在記錄每 次交易的詳細資料中。要善用這些資料,必須 學會如何從中萃取有用的特徵。. 描述學習決策樹之基礎演算法。建立決策 樹後,分支反映訓練資料中之雜質或離群值, 修剪以除去這些分支,以達改進新資料正確分. 顧客早期的消費及使用率資訊非常有價 2.
(3) 淨度 purity)是決策樹法之核心,包括系統亂 度 值 (Entropy) 及 吉 尼 指 標 (Gini Index) 。吉尼指標是以一位義大利經濟學家 命名,計算吉尼指標時,可以設想取出母體裡 的某一成員,且在下一次取出之前先將它放 回。此多樣性指標是第二次取出的成員與第一 次取出的,分屬不同類別的機率。多樣性指標 值高表示集合裡幾種類別的分佈平均﹔指標 值低表示其中有一種類別較他類多出許多。最 好的分割條件是能夠讓記錄集合之多樣性指 標值降低最多的。[4]. 類之目標。決策樹可應用於商業、遊戲及醫 學,它為多種商業規則歸納之基礎。 樹中每一節點所選之測試屬性皆以資訊 增益加以衡量,這種衡量稱為屬性選擇量度或 量度一完善的分割。含最高資訊增益之屬性 ﹙或最大量之減少﹚被選為該節點的測試屬 性。這屬性能將樣本分類 所需資訊最小化, 且使分類所含雜質最小化。這種資訊理論方法 使分割物件所需測試最小化且保證可得一簡 化樹。 令 S 為含 s 資料樣本之集合,假設標記 m 個 不 同 屬 性 表 示 m 個 不 同 類 , Ci ﹙ 其 中 i=1,…,m﹚令 Si 為 S 在 Ci 類之樣本數目,欲 分類某樣本所需期望資訊為 m. I ( s1 , s2 ,..., sm ) = −∑ pi log 2 ( pi ),. 2.5 多模式表決 在資料探勘領域,由機械學習產生的模式 可靠性是依靠訓練資料之量及品質、與學習演 算法是否適合目前的問題而定,一種比較可靠 作決策的方法是合併幾種不同模式的輸出,合 併由機械學習產生的模式的比較有效方法是 收納法(bagging) 、加權收納法(boosting)。 它 們比 使用單 一模式 更能 提升預 測效 益。 [1,2]. (1). i =1. 其中 Pi 為任意一樣本屬於類 Ci 之機率且 其值為 Si/S,注意因資訊以 bits 編碼,故以 基底 2 之對數表示。 令 A 屬性含 {a1 , a 2 ,..., a v } 不同值,屬性 A 用來將 S 分成 V 個次集合 {S1 , S 2 ,..., S v }, 其 中 Sj 含 S 中具 A 中 aj 值之樣本,若 A 被選為 測試屬性﹙即為最佳分割屬性﹚,則其子集合 對應於 S 集合中含此節點之分支。令 s ij 為子 集合 Sj 中類 Ci 之樣本數,這系統亂度或由分 為子集合之期望資 訊為 v. E ( A) = ∑. s1 j + ... + s mj. s s1 j + ... + s mj. j =1. Bagging 及 boosting 皆使用集合多模式 法,作數值預測及分類。 合併不同模式之決策意即合併不同的輸 出成單一預測,在分類上此法最簡單者即投票 (或加權之投票) ,在數值預測時求其平均(或 加權之平均) 。Bagging 及 boosting 皆採用此 法 ,但 它們以 不同的 方法 導出個 別模 式, bagging 模式是同等加權,boosting 給較有影 響力之模式較大加權,正如一位經理依專家群 之不同經歷分別給所提建議不同的價值。. I ( s1 j ,..., smj ) (2). 其中 為第 j 項子集合之權 s 重,為 S 中全部樣本分出之子集合﹙含 A 中 aj 值﹚樣本數。系統亂度值愈小,則子集合 之純淨度愈高,對於一已知子集合 Sj, m. I ( s1 j , s2 j ,..., smj ) = −∑ Pij log 2 ( Pij ). 先介紹 bagging,假設由問題定義域隨機 選出幾個相同大小的訓練資料集。假想用一特 定 機器 學習技 巧以建 立各 資料集 之一 決策 樹,你可想像這些樹實際相同且作每一新測試 集之相同預測。但這些假設是錯的,特別當訓 練資料集很小。. (3). i =1. s ij. 其中 Pij = 且為 Sj 樣本屬於類 Ci 之 機率。 A 分支 S j. 若思考由機械學習產生的模式為個別決 策樹,我們可將每一測試案例投票以合併決策 樹,若某類獲較多投票,則取此正確者,通常 以投票預測時,獲較多票者會被列入考慮,若 作用於新訓練集,投票預測之決策不會變壞, 合成分類通常會比僅由一資料集所建立的決 策樹更正確。. 之編碼資訊為. Gain( A) = I ( s1 , s2 ,..., sm ) − E ( A). (4). 換言之, Gain( A) 為 A 屬性值而減少系 統亂度值。演. 可 由 偏 差 一 變 異 分 解 ( bias-variance decomposition)之理論說明合成多假說之效 果,假設我們有大量相同長度之獨立訓練集, 使用其產生不定數目之分類,一測試案例由所 有分類法作處理再由多數投票決定答案,在理 想的情況,由於學習設計不是完美故仍有誤 差,誤差率依所用機械學習方法是否符合題目 而定。. 演算法計算每一屬性之資訊增益,選含最 大資訊增益之屬性為 S 集合之測試屬性,建立 此節點並標記為該屬性,以每一屬性值建立分 支,並據以切割樣本。 綜合言之,決策樹推論演算法可用於許多 應用領域之分類,這些系統並未使用領域知 識,決策樹推論之學習及分類步驟非常快速。 整體說來,鎖定顧客的回應率較高─這是用 RFM 分析無法預測到的結果。. 一分類法之所有期望誤差乃是由偏差及 變異之加總而得,即偏差一變異分解。合併多 分類法可以減少變異降低期望誤差。包含愈多 的分類法,愈可減少變異。. 2.4 吉尼指標法 多樣性(diversity)的概念(反之則為純 3.
(4) 好,可以讓我們接觸更多對該產品有興趣的顧 客(從本來的 10%加到 17.03%)。. 通常僅有一組訓練集,不可能得到更多資 料。Bagging 試著將上述方法用在已知訓練 集,以消除學習方法之不穩定,每一次並不是 用新樣本,而是將原訓練資料刪除某些案例且 重複其餘者,隨機取樣,替代以建立一新資料 集,因 bootstrap 法估計學習法之概化誤差, bagging 代 表 bootstrap aggregating 。 Bagging 將學習設計用於每一人工推導之資 料集,由投票產生之分類法以供預測。. 3.2 促銷成本評估 累計獲益圖可以提供令人驚異的因素,卻 無法讓使用者得知該模型的量化評估。促銷活 動可能真的符合預算,而該模型也可能藉此找 到更多對產品有興趣的顧客,但此促銷活動會 為 公司 帶來收 益嗎? 這是 在預算 最佳 化之 後,下一步需要了解的。要進行量化評估,需 先發展淨利模型(net revenue model)。淨利 模型需要一些額外的資訊才能進行:. Bagging 及理想程序之差異在於導出訓練 集之方法,bagging 並非由定義域得到獨立資 料集,而是由原訓練資料中再取樣,再取樣之 各資料集皆不同,但由 bagging 程序導出之合 成模式一定比單一模式好很多。. 在這次的促銷活動中,對該商品有興趣的 顧客,要花費大約 2000 來訂購該商品。在這 2000 元中,包含該商品的成本、運送及搬運 費 200 元。. 三、個案研究 M 公司是一家型錄郵購公司,打算花費 2,000,000 元來促銷,並希望儘可能有效地運 用這筆錢。促銷活動的預算必須控制在某個範 圍之內,因此必須儘量針對可能會購買的顧客 來加以促銷。如何得知誰可能會有興趣?有四 種常用的方法可用:. 以上是發展一套簡易淨利模型所需要的 資訊。資訊中的兩個關鍵項目是: 郵寄型錄的成本是 20 元。 b.賣出一件商 品的淨利是 2000-200=1800 元。 通常會將這兩個項目表示成本矩陣(cost matrix,見表 1) [4]。例如,預期會購買產 品,且真的有購買的顧客,會為公司帶來 1780 元的收入。為何是 1780 元?是由其淨利減去 郵寄目錄的成本而得來。預期會購買產品,但 沒有購買的顧客,使公司損失 20 元,也就是 郵寄型錄的成本。. a. 從名單中,隨機選擇顧客,或推測有 興趣的人會是誰。 b. 進行 RFM 分析,鎖定最近曾消費多 次、花費大額金錢的顧客。 c. 根據過去的經驗,建立資料探勘預測 模型,來預測誰可能會對此商品有興趣。. 表 1 M 公司成本矩陣. d. 運用資料勘查(data exploration)以 及非監督性資料探勘,找出可能對商品有興趣 的人。. 預測是否購買 實際有購買. 3.1 累計獲益圖. 實際沒有購買. 有. 1780. -20. 沒有. 0. 0. 在此必須注意的是,在淨利模型中,只有 用到成本矩陣中的預測有購買那一行。這麼做 是正確的。促銷活動所接觸到的顧客,是公司 預期對該產品有興趣的顧客。由於預測不會購 買的顧客,並非促銷活動鎖定的目標,因此在 該行中,就沒有成本或淨利。換句話說,在淨 利模型中,沒有用到預測不會購買該產品的顧 客。. 傳統促銷活動中,M 公司每寄出一件商 品,需要花 20 元。這 20 元包含了型錄製作、 印刷、郵寄的成本。且最少需寄出 20,000 封 信。 M 公司有 2,000,000 促銷預算,因此可以 寄給 100,000 名顧客。可以輕易地發現, 100,000 大於 20,000,因此符合此促銷活動的 最低需求。最簡單的方法,是將所有的顧客加 以評分,針對分數最高的前 100,000 名加以促 銷。. 要預測收益情況,還需要其他三項資訊。 第一是預估一般大眾中,會購買該產品的比 例。累計獲益圖可以告訴我們,執行一個特定 模型可以讓結果變好多少,但並沒有說到底有 多少人會購買該產品。. 圖 1 之累計獲益圖(cumulative gains chart)是觀察資料探勘結果常用的圖表。此圖 的目的,是提升促銷績效,如:依表 2RFM 法 得知只要針對所有顧客的 10%促銷,就可以接 觸到所有對該產品有興趣的顧客中的 17.03%。依表 4dti 加權 RFM 法得知只要針對 所有顧客的 10%促銷,就可以接觸到所有對該 產品有興趣的顧客中的 20.39%。. 第二項資訊是促銷活動的固定成本。有 時,經常性的成本也會用來當成促銷活動規模 的下限。之前曾經提到,M 公司促銷活動的下 限是 20,000 名顧客。這代表如果該活動最低 促銷人數 20,000 人都對該產品沒興趣的話, 該活動的經常性成本是 400,000 元。. 在此例中,可以利用資料探勘來將促銷活 動最佳化。建立模型來評估顧客對某產品的偏. 最後一項資訊是郵寄名單的潛在規模。此 項資訊必須轉換成一個數字,就好像 3%的購 4.
(5) 設定的各個分數。. 買率轉換成金額,如 450,000 元一樣。對 M 公 司來說,我們假設會有一百萬人收到郵購型 錄。. e. 將每一位顧客的三個分數加總,依分 數排序以找出可能對商品有興趣的人。. 表 2 顯示根據以上假設,所計算出促銷活 動帶來的收益(每名購買商品顧客的淨利為 1780 元、沒有購買商品的顧客需花費成本 20 元、經常性成本為 400,000 元、整體人口中, 會購買此商品的比例為百分之一、共有一百萬 名顧客)。第一欄是百分之幾的顧客,下三欄 是此模型成效的測量。GAIN 代表在該百分比 中,有購買該商品顧客的比例,其範圍是從 0%到 17.03%。CUM 是累計收益(cumulative gain),為所有截至該百分比為止,所有收益 的綜合。前百分之十的顧客內,含有所有購買 該產品顧客的 17.03%。百分之十至百分之二 十之間的顧客,則含有所有購買該產品顧客的 11.98%以上。總和來說,前百分之二十的顧 客,含有全部購買該產品顧客中的 29.01%。 LIFT 這一欄,則顯示截至目前的百分比,使 用此模型的成果較隨機選取模型好多少。. 四、實證分析 M 郵購擁有大約 200 萬的顧客名單,這些 人會收到定期的型錄。其而與 32 家長期配合 銀行每年要寄送約 60 期,400 萬份的型錄─ 一年就超過 400 萬份的型錄。像 M 這樣的公 司,若每件郵寄成本下降一點點,或者顧客意 願度上升一點點,就會增加數百萬的營收。因 而資料探勘在此便可大展所長。 在一次行銷活動中,M 郵購擬由 44385 筆 有效客戶中篩選 rfm 值最高的某部份以寄出 型錄;先求 44385 筆有效名單之 rfm 三變數之 變異係數,再以本研究加權 rfm 三變數而得每 一客戶之 rfm 值,製作效益評估表。[2] 表 7 至 11 為加權 RFM 模型的效益評估。 由表 12 各 RFM 模型的 F 量度知 M 郵購應採多 模式表決法加權 RFM 模式由 44385 筆有效客戶 中篩選 rfm 值最高的 30%,即 13315 筆以達利 潤最大化,其他的效益包括透過剩餘產能再執 行 3 檔篩選;能在同樣銷售資源中執行更多檔 的銷售活動;找出顧客需求以減少不必要的銷 售接觸;增長銷售週期;提昇顧客再銷售率, 提昇顧客忠程度,提昇銷售效率。. GAIN、CUM、以及 LIFT 的數字皆可互相交 換。意思是說,給定其中一個欄,就可以算出 其他兩欄的值。很重要的兩個欄位是人數(有) 和人數(無),分別代表截至目前的百分比,預 測 出來 會購買 和不會 購買 該商品 的顧 客數 目。因此,在百分之十到二十之間,預測出來 會購買商品的人數是 2,901,不會購買的人數 是 197,099,總和是 200,000 人。利用這些數 字,再加上之前敘述過的收益矩陣(profit matrix),就可計算出公司的收益。. 五、結論. 必須注意的是,收益從-400,000 元開始 計算,在前百分之二十的時候,到達最大值。 之後便開始減少。此為這類曲線的正常狀態。 另一方面,也可由表中看出,將型錄目錄寄給 所有的顧客是不划算的。若只寄給前百分之二 十的顧客,則是划算的。了解收益曲線可以讓 公司得知促銷活動虧損的原因,並加以改善。 然而,相同的模型,如果採用的數字不同,產 生出來的收益曲線會有很大的不同。. 傳統 RFM 分析法是依 RFM 三項指標給分將 分數加總即可得到各別客戶的相對價值.但缺 乏 RFM 間權重之分析技術,使 RFM 喪失許多關 於客戶的資訊.本研究將多模式表決法應用於 RFM 間權重之分析,以改良傳統 RFM 分析法, 使直銷業者不會因衡量標準不同使結果遺漏 任何具有價值的顧客,另外業者也能憑著過去 的經驗來決定顧客未來的反應率。 多模式表決法比使用單一模式更能提升 預測效益,由表 12 各 RFM 模型的 F 量度知多 模式表決法的 F 量度決策值為 0.5042,比其 他 三 種 單 一 模 式 的 F 量 度 值 (0.4597 、 0.5002、0.5009)分別提升預測效益 9.68%、 0.78%、0.66%,故 M 郵購應採多模式表決法加 權 RFM。. 表 3 顯示 RFM 積分經貝氏法加權後所產生 的收益矩陣。表 4 顯示 RFM 積分經決策樹歸納 法加權後所產生的收益矩陣。表 5 顯示 RFM 積 分經吉尼指標法加權後所產生的收益矩陣。 表 6 顯示 RFM 積分經多模式表決法加權後 所產生的收益矩陣。產生的步驟為: a. 給每一位顧客設定三個分數(即三模 式各設定一個分數,共三個分數)。. 150.00. b. 依下式計算各模式在十一點平均反查 法中各點的成TP 功率。 + TN. 100.00. 購買百分比. 50.00. 加權百分比. 0.00. TP + FP + TN + FN. 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%. 購買百分比 17.03 29.01 39.78 49.40 58.53 66.08 75.19 82.85 91.43 100.0 加權百分比 20.39 36.18 47.77 57.48 66.14 73.56 80.49 87.3 94.17 100.0. c. 以各點的成功率分別加權各模式所設 定的一個分數。. 圖 1 累計獲益圖. d. 以各模式的 F 量度分別加權各模式所 5.
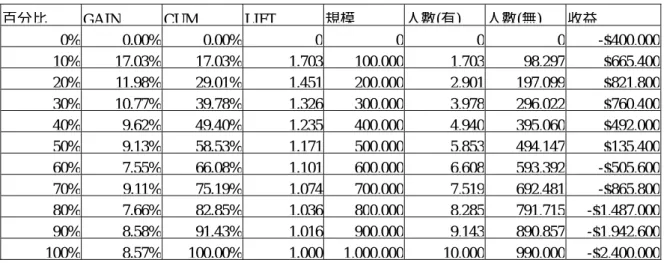
(6) [7] D.C Schmittlein, and R.A. Peterson, ”Customer Base Analysis: An Industrial Purchase Process Application”, Marketing Science, 13, pp. 41-67. 1994. [8] A. M. Hughes, Strategic Database Marketing, Probus Publishing. 1994. [9] Bob Stone, Successful Direct Marketing Methods, 5th ed., Lincolnwood, IL. NTC Business Books. 1994. [10] M. L. Roberts, “Expanding the Role of the Direct Marketing Database,” Journal of Direct Marketing, 6, pp.51-60. 1992. [11] Kalakota, Ravi and Marcia Robinson E-Business: Roadmap for Success, Mass.: Addison- Wesley. 1999. [12] J. R. Quinlan, “Induction of Decision Trees”, Machine Learning, vol. 1, no. 1, pp. 81 –106. 1986. [13] J. R. Quinlan, "Simplifying Decision Trees," International Journal of Man-Machine Studies, 27, 3, pp. 221-234. 1987.. 六、參考文獻 [1] Jiawei Han and Micheline Kamber , Data Mining: Concepts and Techniques. Morgan Kaufmann Publishers . USA. pp. 284-289. 2000 [2] L. H. Witten and Eibe. Frank , Data Mining: Practical Machine Tools and Techniques with Java Implementations, Morgan Kaufmann. 2000 [3] Dorian Pyle, “Data Preparation for Data Mining ”,Morgan aufmann. 1999. [4] Michael J.A .Berry and Gordon S. Linoff ” Mastering Data Mining”, John Wiley & Sons,Inc. pp. 114-117. 2000. [5] David Shepard Associates The New Direct Marketing: How to Implement a Profit-Driven Database Marketing Strategy, New York: Richard D. Irwin, Inc. 1995. [6] D.C. Schmittlein, L.G. Cooper and D.G. Morrison ,”Truth in Concentration in the Land of (80/20) Laws”, Marketing Science, (Spring), 12, pp. 167-183. 1993.. [14]J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann. 1993. 表 2 M 公司收益矩陣(RFM 模式) 百分比. GAIN. 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%. CUM. 0.00% 17.03% 11.98% 10.77% 9.62% 9.13% 7.55% 9.11% 7.66% 8.58% 8.57%. 規模. LIFT. 0.00% 17.03% 29.01% 39.78% 49.40% 58.53% 66.08% 75.19% 82.85% 91.43% 100.00%. 0 1.703 1.451 1.326 1.235 1.171 1.101 1.074 1.036 1.016 1.000. 人數(有). 0 100,000 200,000 300,000 400,000 500,000 600,000 700,000 800,000 900,000 1,000,000. 人數(無). 0 1,703 2,901 3,978 4,940 5,853 6,608 7,519 8,285 9,143 10,000. 收益. 0 98,297 197,099 296,022 395,060 494,147 593,392 692,481 791,715 890,857 990,000. -$400,000 $665,400 $821,800 $760,400 $492,000 $135,400 -$505,600 -$865,800 -$1,487,000 -$1,942,600 -$2,400,000. 表 3 M 公司收益矩陣二(貝氏法加權 RFM 模式) 百分比. GAIN 0% 10% 20% 30% 40%. 0.00% 19.03% 13.08% 11.79% 10.19%. CUM 0.00% 19.03% 32.11% 43.90% 54.09%. 規模. LIFT 0 1.903 1.606 1.463 1.352. 0 100,000 200,000 300,000 400,000. 6. 人數(有) 0 1,903 3,211 4,390 5,409. 人數(無) 0 98,097 196,789 295,610 394,591. 收益 -$400,000 $1,025,400 $1,379,800 $1,502,000 $1,336,200.
(7) 50% 60% 70% 80% 90% 100%. 9.56% 7.73% 7.04% 7.09% 7.09% 7.40%. 63.65% 71.38% 78.42% 85.51% 92.60% 100.00%. 1.273 1.190 1.120 1.069 1.029 1.000. 500,000 600,000 700,000 800,000 900,000 1,000,000. 6,365 7,138 7,842 8,551 9,260 10,000. 493,635 592,862 692,158 791,449 890,740 990,000. $1,057,000 $448,400 -$284,400 -$1,008,200 -$1,732,000 -$2,400,000. 表 4 M 公司收益矩陣三(決策樹歸納法加權 RFM 模式) 百分比 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%. GAIN 0.00% 20.39% 15.79% 11.59% 9.71% 8.66% 7.42% 6.93% 6.81% 6.87% 5.83%. CUM. 規模. LIFT. 0.00% 20.39% 36.18% 47.77% 57.48% 66.14% 73.56% 80.49% 87.30% 94.17% 100.00%. 0 2.039 1.809 1.592 1.437 1.323 1.226 1.150 1.091 1.046 1.000. 0 100,000 200,000 300,000 400,000 500,000 600,000 700,000 800,000 900,000 1,000,000. 人數(有). 人數(無). 0 2,039 3,618 4,777 5,748 6,614 7,356 8,049 8,730 9,417 10,000. 0 97,961 196,382 295,223 394,252 493,386 592,644 691,951 791,270 890,583 990,000. 收益 -$400,000 $1,270,200 $2,112,400 $2,198,600 $1,946,400 $1,505,200 $840,800 $88,200 -$686,000 -$1,449,400 -$2,400,000. 表 5 M 公司收益矩陣四(Gini 指標法加權 RFM 模式) 百分比 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 百分比 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%. GAIN 0.00% 20.39% 15.79% 11.65% 9.65% 8.66% 7.42% 6.93% 6.81% 6.87% 5.83% GAIN 0.00% 20.87% 15.71% 11.57% 9.68% 8.68% 7.38% 6.82% 6.78% 6.78% 5.73%. 規模 人數(有) 人數(無) 收益 LIFT 0.00% 0 0 0 0 -$400,000 20.39% 2.039 100,000 2,039 97,961 $1,270,200 36.18% 1.809 200,000 3,618 196,382 $2,112,400 47.83% 1.594 300,000 4,783 295,217 $2,209,400 57.48% 1.437 400,000 5,748 394,252 $1,946,400 66.14% 1.323 500,000 6,614 493,386 $1,505,200 73.56% 1.226 600,000 7,356 592,644 $840,800 80.49% 1.150 700,000 8,049 691,951 $88,200 87.30% 1.091 800,000 8,730 791,270 -$686,000 94.17% 1.046 900,000 9,417 890,583 -$1,449,400 100.00% 1.000 1,000,000 10,000 990,000 -$2,400,000 表 6 M 公司收益矩陣四(多模式表決法). CUM. CUM 0.00% 20.87% 36.58% 48.15% 57.83% 66.51% 73.89% 80.71% 87.49% 94.27% 100.00%. 規模. LIFT 0 2.087 1.829 1.605 1.446 1.330 1.232 1.153 1.094 1.047 1.000. 0 100,000 200,000 300,000 400,000 500,000 600,000 700,000 800,000 900,000 1,000,000 7. 人數(有) 0 2,087 3,658 4,815 5,783 6,651 7,389 8,071 8,749 9,427 10,000. 人數(無) 0 97,913 196,342 295,185 394,217 493,349 592,611 691,929 791,251 890,573 990,000. 收益 -$400,000 $1,356,600 $2,184,400 $2,267,000 $2,009,400 $1,571,800 $900,200 $127,800 -$651,800 -$1,431,400 -$2,400,000.
(8) 表 7 RFM 模型的效益評估 反查. 0.1703. 0.2901. 0.3978. 0.4940. 0.5853. 0.6608. 0.7519. 0.8285. 0.9143. 1.0000. 反應率. 0.5608. 0.4775. 0.4366. 0.4067. 0.3854. 0.3626. 0.3537. 0.3410. 0.3345. 0.3293. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. 0.2613. 0.3609. 0.4163. 0.4461. 0.4648. 0.4683. 0.4810. 0.4831. 0.4898. 0.4954. 名單縮減 F 量度. 表 8 貝氏法加權 RFM 模型的效益評估 反查. 0.1903. 0.3211. 0.4390. 0.5409. 0.6365. 0.7138. 0.7842. 0.8551. 0.9260. 1.0000. 反應率. 0.6275. 0.5293. 0.4824. 0.4458. 0.4196. 0.3922. 0.3693. 0.3524. 0.3392. 0.3297. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. 0.2921. 0.3998. 0.4597. 0.4887. 0.5058. 0.5062. 0.5021. 0.4991. 0.4965. 0.4959. 名單縮減 F 量度. 表 9 決策樹歸納法加權 RFM 模型的效益評估 反查. 0.2039. 0.3618. 0.4777. 0.5748. 0.6614. 0.7356. 0.8049. 0.8730. 0.9417. 1.0000. 反應率. 0.6723. 0.5964. 0.5249. 0.4738. 0.4360. 0.4042. 0.3791. 0.3597. 0.3449. 0.3297. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. 0.3129. 0.4504. 0.5002. 0.5194. 0.5256. 0.5217. 0.5154. 0.5095. 0.5049. 0.4959. 名單縮減 F 量度. 表 10 Gini 法加權 RFM 模型的效益評估 反查. 0.2039. 0.3618. 0.4783. 0.5748. 0.6614. 0.7356. 0.8049. 0.8730. 0.9417. 1.0000. 反應率. 0.6723. 0.5964. 0.5256. 0.4738. 0.4360. 0.4042. 0.3791. 0.3597. 0.3449. 0.3297. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. 0.3129. 0.4504. 0.5009. 0.5194. 0.5256. 0.5217. 0.5154. 0.5095. 0.5049. 0.4959. 名單縮減 F 量度. 表 11 多模式表決法的效益評估 反查. 0.2087. 0.3658. 0.4815. 0.5783. 0.6651. 0.7389. 0.8071. 0.8749. 0.9427. 1.0000. 反應率. 0.6881. 0.6030. 0.5292. 0.4766. 0.4385. 0.4060. 0.3801. 0.3605. 0.3453. 0.3297. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. 0.3203. 0.4554. 0.5042. 0.5226. 0.5286. 0.5241. 0.5168. 0.5107. 0.5054. 0.4959. 名單縮減 F 量度. 表 12 多模式表決的 F 量度比較 名單縮減. 10%. 20%. 30%. 40%. 50%. 60%. 70%. 80%. 90%. 100%. RFM 法. 0.2613. 0.3609. 0.4163. 0.4461. 0.4648. 0.4683. 0.481. 0.4831. 0.4898. 0.4954. 貝氏法加權. 0.2921. 0.3998. 0.4597. 0.4887. 0.5058. 0.5062. 0.5021. 0.4991. 0.4965. 0.4959. dti 法加權. 0.3129. 0.4504. 0.5002. 0.5194. 0.5256. 0.5217. 0.5154. 0.5095. 0.5049. 0.4959. Gini 法加權. 0.3129. 0.4504. 0.5009. 0.5194. 0.5256. 0.5217. 0.5154. 0.5095. 0.5049. 0.4959. 多模式表決. 0.3203. 0.4554. 0.5042. 0.5226. 0.5286. 0.5241. 0.5168. 0.5107. 0.5054. 0.4959. 8.
(9)
數據

相關文件
important to not just have intuition (building), but know definition (building block).. More on
Additional Key Words and Phrases: Topic Hierarchy Generation, Text Segment, Hierarchical Clustering, Partitioning, Search-Result Snippet, Text Data
Discovering the City by Mining Diverse and Multimodal Data Streams – IBM Grand Challenge: New York City 360. § Exploring and Integrating Multiple Contents and Sources for
In our AI term project, all chosen machine learning tools will be use to diagnose cancer Wisconsin dataset.. To be consistent with the literature [1, 2] we removed the 16
2 machine learning, data mining and statistics all need data. 3 data mining is just another name for
In developing LIBSVM, we found that many users have zero machine learning knowledge.. It is unbelievable that many asked what the difference between training and
This bioinformatic machine is a PC cluster structure using special hardware to accelerate dynamic programming, genetic algorithm and data mining algorithm.. In this machine,
Furthermore, in order to achieve the best utilization of the budget of individual department/institute, this study also performs data mining on the book borrowing data
