Modeling of Pattern-Based Block Motion Estimation and Its Application
Jang-Jer Tsai, Member, IEEE, and Hsueh-Ming Hang, Fellow, IEEE
Abstract—Pattern-based block motion estimation (PBME) is one of the most widely adopted compression tools in the contemporary video coding systems. However, despite that many researches have studied PBME, few have yet attempted to construct an analytical model that can explain the underneath principle and mechanism of various PBME algorithms. In this paper, we propose a tical PBME model that consists of two components: 1) a statis-tical probability distribution for motion vectors and 2) the minimal number of search points (so-called weighting function) achieved by a search algorithm. We first verify the accuracy of the proposed model by checking the experimental data. Then, an application ex-ample using this model is shown. Starting from an ideal weighting function, we devise a novel genetic rhombus pattern search (GRPS) to match the design target. Simulations show that, comparing to the other popular search algorithms, GRPS reduces the average search points for more than 20% and, in the meanwhile, it main-tains a similar level of coded image quality.
Index Terms—Genetic search, modeling, motion estimation, pat-tern-based block motion estimation (BME), video coding.
I. INTRODUCTION
B
LOCK MOTION estimation (BME) is a critical com-ponent in an efficient inter-frame coding. However, it is a highly computation-intensive process. Many researches have proposed fast algorithms to reduce its computational requirement. However, few researchers, to our knowledge, have tried to construct an accurate model for the BME process. To be specific, it is a model that unveils the relationship among the video sequences, the search methods, the computational complexity and the output video quality. Our aim is to construct an explicit mathematical model for BME.According to [1], the fast BME algorithms can be classified mainly into two categories: 1) reducing of number of checking (search) points and 2) lowering computational complexity in cal-culating the block-matching criterion for each checking (search) point. This study focuses on the algorithms in the first category. The first fast BME category roughly consists of three sets of tools for reducing the search points: 1) an operative threshold for early decision mechanisms [2]–[4], 2) the selection of good initial search points [3], [5], and 3) an effective set of search patterns [4], [6]–[8]. Combing all these tools, the latest BME Manuscript received August 03, 2006; revised August 26, 2007. First pub-lished December 09, 2008; current version pubpub-lished January 21, 2009. This paper was recommended by Associte Editor T. Wiegand.
J.-J. Tsai is with Department of Electronics Engineering, National Chiao-Tung University, Hsinchu 30010, Taiwan (e-mail: [email protected]).
H.-M. Hang is with Department of Electronics Engineering, National Chiao-Tung University, Hsinchu 30010, Taiwain, and Department of Computer Sci-ence and Information Engineering, National Taipei University of Technology, Taipei 10061, Taiwan (e-mail: [email protected]).
Corresponding Author: H.-M. Hang, Department of Electronics Engi-neering, National Chiao-Tung University, Hsinchu 30010, Taiwan (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TCSVT.2008.2009248
algorithms achieve a dramatic speed-up in finding the near-op-timal candidate motion vectors while maintaining a desired level of quality. The first and second sets of tools rely heavily on the data dependency of neighboring image data. Consequently, the search pattern plays a key role in deciding the performance of a search algorithm especially when the data correlation is low. In this paper, we like to explore the following problems. Why does one search pattern outperform the others? What is the underlying mechanism behind it? Is there a search pattern that handles nearly all sequences well? Moreover, can we construct a mathematical model that describes the underlying mechanism? An attempt is made in this paper to answer these questions.
In this paper, we will construct a simple and yet effective sta-tistical model for the pattern-based BME (PBME). Also, based on this model, a novel genetic PBME algorithm is devised. The rest of this paper is organized as follows. Section II presents the probability distribution functions of the motion vectors ac-quired by full search (FS). In Section III, we analyze the search points of several representative PBME algorithms and formu-late the weighting functions (WF). Based on the proposed prob-ability distribution function for motion vectors and the WFs of different PBME algorithms, Section IV constructs a statistical model for PBME. To demonstrate the usefulness of this model, a new genetic rhombus pattern search is presented in Section V, which shows good performance for both low motion and rela-tive high motion sequences. Lastly, we conclude this paper by Section VI.
II. PROBABILITYDISTRIBUTION FORMOTIONVECTORS In order to design a good search pattern set, many papers dis-cussed the nature of motion vectors (MVs). The authors of [9] empirically gather the statistics of the motion vectors around the initial search point. And [10] assumes that the motion vector dis-tribution can be approximated by either Gaussian or Laplacian probability distributions. So far, we have not found an attempt of finding a probability distribution function (PDF) that has a very precise match to the motion vectors.
We select a few representative training sequences to gen-erate motion vectors at various bit rates under the settings given in Table I. These sequences are coded by a MPEG-4 SP@L3 encoder using FS. All the sequences are in CIF (352 288) format. Only the first frame is coded as I frame, and all the re-maining frames are coded as P frames. The motion vector search range is set to 16, the initial quantizer step size is set to 15, and the block size is set to 16 16. When the quantization step varies to achieve the desired bit rate, the peak signal noise ratio (PSNR) quality of the coded video sequence ranges from 26dB (poor but acceptable) to 40dB (visually the same as original). A. Motion Vector Distributions
In our experiments, we test two kinds of initial motion vec-tors (served as the origins of the PBME search), namely, the zero 1051-8215/$25.00 © 2009 IEEE
TABLE I
TRAININGSEQUENCES ANDTHEIRCODINGPARAMETERS
motion vector (ZMV) and the predicted motion vector (PMV). Herein, ZMV is defined by (1), and PMV is defined by (2), which is specified by the MPEG-4 standard.
(1) (2) where is the adjacent upper block of the current block, is the adjacent left block, and is the neighboring up-right block.
Based on the motion vector data obtained by applying FS to video sequences, we find that the motion vector distribu-tions with respect to (w.r.t.) PMV generally have a more sym-metric shape as compared to the motion vector distributions w.r.t. ZMV. In addition, the PMV-based motion vectors have a much smaller standard deviation. They cluster better. Therefore, the motion vector distributions w.r.t. PMV are used in the rest of this paper. The statistics of the motion vectors w.r.t. PMV of all the selected training sequences show that both the horizontal mean values and vertical mean values are close to zero. Thus, these motion vector distributions are zero-biased w.r.t. PMV. Furthermore, the correlations between the horizontal compo-nents and the vertical compocompo-nents of motion vectors are nearly zero for all our training sequences.
B. Normalized Independent 2-D Distribution
Based on the above observations, three popular zero-mean normalized independent 2-D distributions are considered as can-didates for modeling the MV distribution: 1) Gaussian distribu-tion funcdistribu-tion (3), 2) Laplacian distribudistribu-tion funcdistribu-tion (4), and 3) Cauchy distribution function (5). Note that ,
and is the geographical area of
in our experiments. The parameters ( , , , , and ) are functions of the MV variances
(3)
(4)
(5)
Remark: Strictly speaking, the zero correlation between the horizontal components and vertical components of motion vec-tors does not imply that they are statistically independent. How-ever, we justify the correctness of these probabilistic models using the goodness-of-fit test [11] as follows.
To find out which of the three PDFs best approximates the PDF of motion vectors acquired by FS, a well-known good-ness-of-fit test, 2-D KS test [12], is adopted. The statistic de-fined in [12] is used as the measure of similarity between the hypothesized PDF (the modeled data) and the observed PDF (measured data). To be more specific, the statistic is the max-imum absolute difference between two cumulative probability distributions function, as defined in (6), wherein
and are the cumulative PDFs of the model and the measured data, respectively, and A is the geographical area
of in our experiments
(6) A smaller statistic implies that the hypothesized PDF matches better the observed PDF. The motion vector probability distri-butions acquired by FS, , are tested against the aforesaid hypothesized zero-mean, normalized, independent 2-D distri-butions with the same variances. These hypothesized distribu-tions with the same variance of MV acquired by FS are called , and , respectively. In our exper-iments, generally has the smallest statistic values. However, according to [12], the values of statistic in our ex-periments are too large to claim that any of these three 2-D dis-tributions has a good match to the target . C. A Fitted Probability Distribution
To construct a more accurate PDF model, we extend and propose a new form of PDF denoted by , which is defined by (7). For each of the selected training sequences, and are optimized such that the maximum discrepancy
be-tween and is minimized, and and
are adjusted such that the variances of are the same as those of the training sequences. The with the fitted
pa-rameters that match becomes .
Experi-ments show that and range from 1.13 to 2.2 for the training sequences. This indicates the variations among the training se-quences are considerably large
(7)
Despite the large individual differences among the training sequences, we find that and are generally around 1.67. We
TABLE II
STATISTICDOF2-D KS TEST ONSOMEREPRESENTATIVESEQUENCES
thus choose to simplify . The resultant distribution is called as defined by (8)
(8)
In Table II, the 2-D KS tests show that has a smaller statistic in comparison with , , and . Note that the parameters ( ) of
are obtained by numerical methods so that the variances of match the data statistics of motion vectors acquired by FS. In summary, we propose a new probability distribution that models the PDF of the motion vectors. It consti-tutes the first element of our complete PBME model.
III. SEARCHPOINTS INPATTERN-BASEDSEARCHALGORITHMS Search patterns are generally devised based on the assump-tion that the matching cost surface is uni-modal; in other words, the matching cost associated with a search point is smaller when it is closer to the global minimum. Under this assumption, the number of search points is defined to be the minimal number of search points in all possible paths leading to the best-matched point from the starting (initial) point. Because the (shortest) search path is determined by the search pattern in general, the search point number depends on the search pattern. Therefore, it (number of search points) is a discrete function of the loca-tion and is called weighting funcloca-tion (WF). By examining the search process of a PBME, we can construct its corresponding WF. Note that the global uni-modal cost surface assumption is too strong and it is not always valid for typical video sequences [6]. Often it is valid within a small neighborhood of the global minimum point. Consequently, the WF does not represent the actual number of search points. To be exact, it represents the lower bound of the number of search points. But the statistics also show that the number of actual search points is highly cor-related with our defined WF.
Four representative pattern-based search methods, four step search (FSS) [7], diamond search (DS) [8], enhanced hexag-onal search (EHS) [6], and easy rhombus pattern search (ERPS), are used to illustrate the construction of weighting functions. Herein, ERPS is ARPS [4] without searching various MV pre-dictors and it uses PMV as the starting point. These pattern-based search algorithms are chosen because of their well-rec-ognized performance.
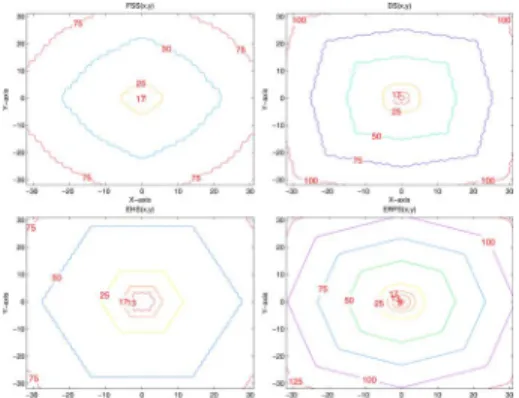
Fig. 1 shows the contour plots of the WFs of FSS, DS, EHS, and ERPS, respectively. The value on a contour represents the
Fig. 1. Contour plots of the WFs of FSS, DS, EHS, and ERPS, respectively.
least number of search points for a search algorithm to move from the origin to a point (location) on the contour. Because EHS moves faster than any other algorithms, EHS surpasses the other algorithms at distant locations. Its weighting function has smaller values at the outer contour. On the other extreme, because has the smallest values around the starting point, ERPS has advantages in slow motion situations. Therefore, by looking into the WF of a search algo-rithm, we understand why one search algorithm works better for a particular situation (fast motion or slow motion). WF is the second element of our complete PBME model.
IV. STATISTICALMODEL FORPATTERN-BASEDBLOCK MOTIONESTIMATION
Based on the problem formulation in Sections II and III, the average search points (ASP) of a PBME algorithm for a se-quence can be described by (9). It depends on both search al-gorithm (SA) and the video sequence. Mathematically, it is the sum of the products of WF and the MV PDF at all locations within the search area, where denotes the number of search points acquired by a specific algorithm,
denotes the motion vector distribution acquired by a specific al-gorithm on a specific sequence, and is the search area. It is
clear that we can get and only after
we apply a specific search algorithm to a specific sequence. In this paper, we propose to use (10) for modeling ASP. In (10), ASP is a linear function of the sum of the products of and . Thus, it consists of two compo-nents: MV distribution (sequence dependent) and WF (SA de-pendent). By tuning the values of and , we can compen-sate for the modeling errors. Given a SA, we pre-analyze it and obtain . Given a specific sequence, we can pre-cal-culate MVs using FS and obtain . Then, one can use (10) to estimate the ASP values of an SA when it is applied to a specific sequence
(9) (10) We need to justify that the above model is valid for real data. There are two methods to decide and . In the first method, we apply a fixed SA to a set of training sequences to compute
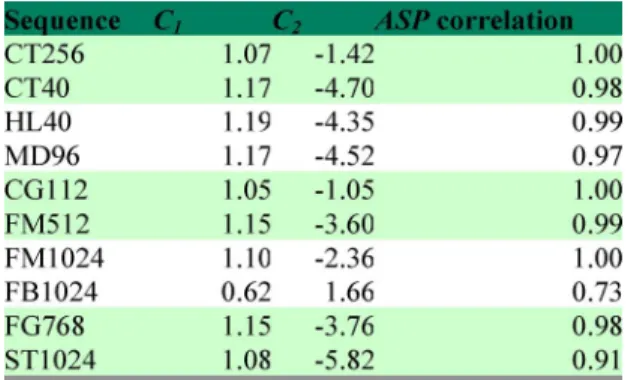
TABLE III
REGRESSIONPARAMETERS(C ANDC )AND THECORRELATION
COEFFICIENTSBETWEEN THEMODEL-PREDICTEDASPAND THE
TRUEASP. (1STMETHOD)
TABLE IV
REGRESSIONPARAMETERS(C ANDC )AND THECORRELATION
COEFFICIENTSBETWEENMODEL-PREDICTEDASPAND THE
TRUEASP. (2NDMETHOD)
and by the regression method. Our objective is that the model with trained and can predict the ASP of a new se-quence accurately. In the second method, we apply a few search algorithms (the training algorithms) to a specific sequence, and then calculate and based on the acquired data. In this case the goal is that the model with trained and can predict the ASP values of a new algorithm.
In the first method, and are obtained from a set of training sequences with one specific search algorithm. Table III displays the and values for each search algorithm. The last column is the correlation coefficient between the actual ASP and the predicted ASP. One may notice that the correlation coef-ficients are all very close to 1, which indicates that the predicted ASPs are nearly the same as the actual ASPs.
In the second method, and are obtained by applying a set of search algorithms (training algorithms) to a specific se-quence. We then predict the ASP value of a new algorithm by using the proposed model. Table IV displays the and values for the 10 sequences and the correlation coefficients be-tween the predicted ASP and the actual ASP. The correlation coefficients are very close to 1 except that for the FB1024 se-quence. This may be due to the high motion contents of FB1024. In spite of the small number of training algorithms, the coher-ence between the predicted ASP and the actual ASP is very high for all 10 sequences.
The first method and the second method are designed for dif-ferent scenarios. The first method is used to predict the ASP of a new sequence (for a given specific search algorithm), while the second method is used to predict the ASP of a new search algorithm (for a given specific sequence). Due to different sizes of training samples and different purposes, the accuracy com-parison between these two methods may not be meaningful.
Fig. 2. Search patterns for GRPS.
V. ANAPPLICATION: PATTERN-BASED SEARCH ALGORITHMDESIGN
How can we devise a new pattern-based search algorithm with the help of the previous analysis? We do this in three steps. We first construct a target WF based on the analysis in the past two sections. Then, we devise a search pattern that hopefully achieves the desired WF. At last, we evaluate its performance by simulation on real pictures.
The first step of designing a new search algorithm is to find a WF that has the smallest possible values at all locations, be-cause, in our proposed model, WF is the only algorithm-depen-dent parameter that determines ASP.
Most effective PBME algorithms consist of two stages: 1) coarse regular search stage and 2) fine ending search stage. The purpose of the regular search stage is to fast locate the potential optimal motion vectors, and the ending stage is to determine the best-matched point in a small neighborhood. Each stage may use one or several search patterns. In the regular search stage, because the shortest path between two points in a plane is a strait line, the fastest search path for a search algorithm is the strait line from the starting point directly to the best-matched motion vector. Based on the previous experiments, we suspect that a doable search method moves at most one unit distance horizontally or vertically per step. As shown in Fig. 2(a), the minimal number of search points for
reaching the motion vector is “ .”
In the ending stage, to decide precisely the location of the best candidate motion vector generally requires to search at least the neighboring 4 points and the current point (center) itself, as shown in Fig. 2(b). The resulting contour plot of
is depicted in Fig. 3.
The second step is to choose proper search patterns that fulfill the desired WF. By simplifying the genetic search algorithms in [13] and [14] and combining the rhombus search patterns, we propose a genetic rhombus pattern search (GRPS) algorithm described below.
1) Initialization: Check the starting point, PMV, and set it as the parent point.
2) Mutation: Randomly select a next generation point (the mutation point) from the untested points of a rhombus pat-tern centered at the parent. (That is, check one of the four solid points in the coarse search pattern in Fig. 2(a).) 3) Competition: Select the survivor between the parent and its
mutation based on their matching costs.
a) If the mutation is better than the parent, the mutation is the survivor (the next parent). Go to step 2.
Fig. 3. WF of GRPS.
b) If the parent is better than its mutation, the parent is the survivor (the next parent) and check if there is any remaining untested mutation point in the four points of a rhombus pattern. If there is one, go to step 2; oth-erwise, (that is, all points in the ending search pattern, Fig. 2(b), are checked,) go to step 4.
4) End: Set the current survivor as the final motion vector. Comparing Fig. 3, the contour plot of , with the contour plots of the four popular algorithms in Fig. 1, we can find that GRPS has the same or smaller number of search points as ERPS near the starting point, and it has a smaller number of search points than EHS in locations away from the starting point. In other words, it achieves the smallest number of search points at nearly all locations, when compared to the four popular search algorithms.
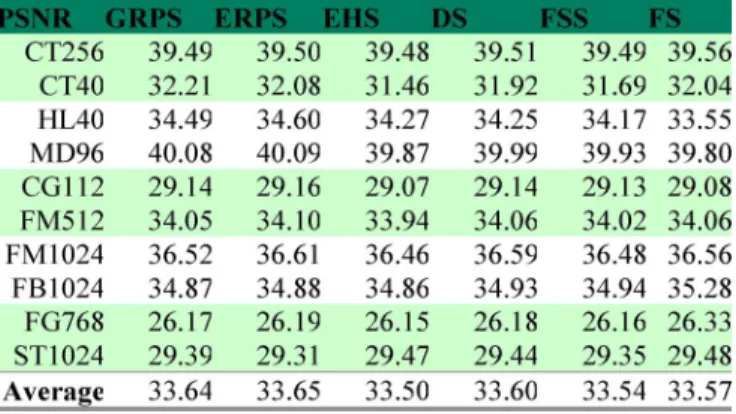
Lastly, we evaluate the performances of the proposed GRPS by conducting experiments on the selected training sequences. The results are shown in Table V (average number of search points), Table VI (PSNR), and Table VII (performance compar-ison). In Table VII, the computing gain (CG) is defined as the ratio of ASP minus one, and the quality gain (QG) is defined as the PSNR difference. In summary, the ASP of GRPS on av-erage is 22% faster than that of ERPS, 56% faster than EHS, 130% faster than DS, 172% faster than FSS, and 145 times faster than FS. On the other hand, the PSNR of GRPS is on average better than all other search algorithms, except for ERPS. Com-pared with ERPS, the quality loss of GRPS is very small, around 0.01dB. Therefore, GRPS outperforms all the other search algo-rithms in terms of ASP for all training sequences, and its coding quality is comparable with all the other algorithms.
The GRPS algorithm has fewer ASP because the proposed genetic pattern search calculates and compares the matching cost of the parent with that of one randomly selected point in the search pattern. On the average, the genetic algorithm saves about 50% search points when the matching error surface is nearly monotonic. In the worst cases, its behavior is the same as the non-genetic sibling. Considering the probability of being trapped into the local minimum, a genetic algorithm roughly has a similar behavior as its non-genetic sibling. The reason is that both of them terminate the search process when the matching error of the center point is smaller than those of all points in the
TABLE V
ASP (AVERAGENUMBER OFSEARCHPOINTS)
TABLE VI
PSNR (PEAKSIGNALNOISERATIO)
TABLE VII
CODINGPERFORMANCECOMPARISON
search pattern. But they may be trapped into different locations. We have examined the motion vectors produced by GRPS and by the other search algorithms. Using the MVs produced by FS as the ideal target, the average absolute differences in MVs are similar for the five fast SAs (including GRPS) discussed in this paper. Also, the average SAD differences of these five SAs are similar.
VI. CONCLUSION
A systematic approach is taken in constructing a mathe-matical model for the PBME algorithms. With the assistance of goodness-of-fit tests, we propose a new PDF, an extended
Cauchy distribution, for the motion vector distribution. It matches well the real motion vector PDF produced by FS. We then suggest a so-called WF that describes the minimal search points of a search algorithm. The WF of a certain PBME algorithm is estimated by analyzing the search process of that PBME. The complete PBME model includes these two elements: the statistical PDF derived from a video sequence and the WF derived from a search algorithm. With the proposed model, we can predict the performance of a new search pattern without actually applying the search algorithm to a video sequence. Thus, it helps us in constructing new search patterns (algorithms). An application example is given. Starting from an ideal WF target, we propose a GRPS algorithm, which outperforms all other popular search algorithms in speed while maintaining a similar PSNR quality.
REFERENCES
[1] C. Zhu, W. S. Qi, and W. Ser, “Predictive fine granularity successive elimination for fast optimal block-matching motion estimation,” IEEE
Trans. Image Process., vol. 14, no. 2, pp. 213–221, Feb. 2005.
[2] P. I. Hosur and K.-K. Ma, “Motion vector field adaptive fast motion estimation,” presented at the 2nd Int. Conf. ICICS, Singapore, Dec. 1999.
[3] A. M. Tourapis, O. C. Au, and M. L. Liou, “Predictive motion vector field adaptive search technique (PMVFAST) – Enhancing block based motion estimation,” Proc. VCIP, pp. 883–892, Jan. 2001.
[4] Y. Nie and K.-K. Ma, “Adaptive rood pattern search for fast block-matching motion estimation,” IEEE Trans. Image Process., vol. 11, no. 12, pp. 1142–1449, Dec. 2002.
[5] A. M. Tourapis, O. C. Au, and M. L. Liou, “New results on zonal based motion estimation algorithms-advanced predictive diamond zonal search,” in Proc. IEEE ISCAS, May 2001, vol. 5, pp. 183–186. [6] C. Zhu, X. Lin, L. P. Chau, and L. M. Po, “Enhanced hexagonal search
for fast block motion estimation,” IEEE Trans. Circuits Syst. Video
Technol., vol. 14, no. 10, pp. 1210–1214, Oct. 2004.
[7] L. M. Po and W. C. Ma, “A novel four-step search algorithm for fast block motion estimation,” IEEE Trans. Circuits Syst. Video Technol., vol. 6, no. 3, pp. 313–317, Jun. 1996.
[8] S. Zhu and K.-K. Ma, “A new diamond search algorithm for fast block-matching motion estimation,” in Proc. ICICS, Sep. 9–12, 1997, vol. 1, pp. 292–296.
[9] C. H. Cheung and L.-M. Po, “Novel cross-diamond-hexagonal search algorithms for fast block motion estimation,” IEEE Trans. Multimedia, vol. 7, no. 1, pp. 16–22, Feb. 2005.
[10] Y. Liu and S. Oraintara, “Complexity comparison of fast block-matching motion estimation algorithms,” in Proc. IEEE ICASSP, May 2004, vol. 3, p. iii-341–4.
[11] S. D. Silvey, Statistical Inference. London, U.K.: Chapman Hall, 1975.
[12] J. Peacock, “Two-dimensional goodness-of-fit testing in astronomy,”
Monthly Notices of the Royal Astronomical Society, vol. 202, pp.
615–627, 1983.
[13] C.-H. Lin and J.-L. Wu, “A lightweight genetic block-matching algo-rithm for video coding,” IEEE Trans. Circuits Syst. Video Technol., vol. 8, no. 4, pp. 386–392, Aug. 1998.
[14] M. F. So and A. Wu, “Four-step genetic search for block motion esti-mation,” in Proc. IEEE ICASSP, May 1998, vol. 3, pp. 1393–1396.