Mining Association Rules with Ontological Information
Ming-Cheng Tseng
Institute of Information
Engineering, I-Shou University,
840,Taiwan
[email protected]
Wen-Yang Lin
Dept. of Comp. Sci. & Info.
Eng., National University of
Kaohsiung, 811, Taiwan
[email protected]
Rong Jeng
Dept. of Information
Management, I-Shou University,
840, Taiwan
[email protected]
Abstract
The problem of mining association rules incorporated with domain knowledge has been studied recently. Previous work was conducted individually on two types of knowledge, classification and composition. In this paper, we revisit this problem from a more unified
viewpoint. We consider the problem of mining
association rules with ontological information that presents not only classification but also composition relationship. Two effective algorithms are proposed with empirical evaluation displayed.
1. Introduction
It is well-known that the data mining process is knowledge intensive. It has been shown in many applications that with the aid of domain knowledge, one can discover more meaningful patterns and enrich the semantics of discovered rules. The most popular method in organizing the domain knowledge is employing ontology [3][8], which is an explicit specification of a conceptualization that can help us to define and share knowledge.
One of the most important patterns in data mining is to discover association rules from a database. An association rule is an expression of the form, X Y, where X and Y are sets of items. Such information is very useful in making decision for business management. In the past few years, there has been researches investigated the problem of mining association rules with classification or composition information [4][5][7], showing the benefit of incorporating domain knowledge and proposing effective algorithms.
In this paper, we revisit this problem from a more unified viewpoint. We consider the problem of mining association rules with ontological information that presents not only classification but also composition relationship. Two effective algorithms are proposed with empirical evaluation displayed.
The remaining of the paper is organized as follows. A review of related work is given in Section 2. The problem of mining association rules with ontology is formalized in Section 3. In Section 4, we describe the proposed methods for finding frequent itemsets. A simple example is provided for illustration. In Section 5, we present the experimental results. Finally, our conclusion is stated in the last section.
2. Related work
Mining association rules in presence of taxonomy (classification hierarchy) information was first addressed in [6]. The problem is named as mining generalized association rules, which aims to find associations among items at any level of the taxonomy. Another closely related work but with different purpose was conducted in [4], which emphasized “drill-down” discovery of association rules.
In [5], Jea et al. considered the problem of discover multiple-level association rules with composition (has-a) hierarchy and proposed a method. Their approach is similar to [7].
In [2], Domingues and Rezende proposed an algorithm, called GART, which uses taxonomies, in the step of knowledge post-processing, to generalize and to prune uninteresting rules that may help the user to analyze the generated association rules.
3. Problem statement
Let I{i1, i2,…,im} be a set of items, and DB{t1, t2,…,tn} be a set of transactions, where each transaction
titid, Ahas a unique identifier tid and a set of items A
(A I). To study the mining of association rules with ontological information from DB, we assume that the ontology of items, T, is available and is denoted as a directed acyclic graph on IE, where E {e1, e2, …, ep}
including generalized items J {j1, j2, …, jq} and
composite items K{k1, k2, …, kr}, i.e., EJ K. There
are two different types of edges in T, taxonomic edge (denoting is-a relationship) and meronymic edge (denoting has-a relationship). We call an item j a generalization of item i if there is a path composed of taxonomic edges from i to j, and conversely, we call i a specialization of j. On the other hand, we call item k a component of item i if there is a path composed of meronymic edges from i to k, and we call i an aggregation of k.
Definition 1 Given a transaction t tid, A, we say an itemset B is in t if every item in B is in A or is an extended item of some item in A. An itemset B has support s, denoted as ssup(B), in the transaction set DB if s% of transactions in DB contain B.
Definition 2 Given a set of transactions DB and an ontology T, an association rule is an implication of the following form, A B, where A, B I E, A B , and no item in B is an extended items of any item in A, and vice versa. The support of this rule, sup(A B), is equal to the support of AB. The confidence of the rule, conf(A B), is the ratio of sup(A B) versus sup(A). Definition 3 The problem of mining association rules is that, given a set of transactions DB and a ontology T, find all association rules that has support and confidence equal to or greater than a user-specified minimum support ms and minimum confidence mc, respectively.
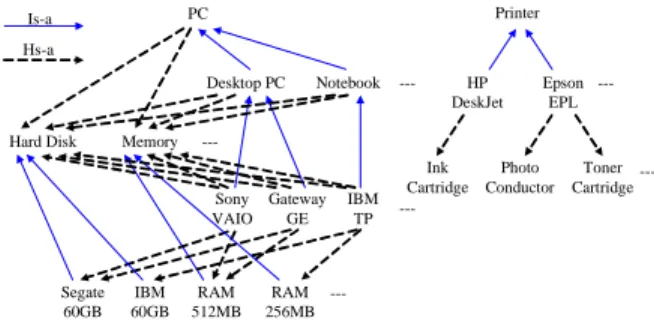
For example, consider the ontology in Figure 1. For primitive purchased item “Sony VAIO”, “PC” and “Desktop”are its generalizations, while “Segate 60GB” and “RAM 512MB”are its components. It is likely to discover the following association rules:
PC HP DeskJet, or
Product with IBM 60GB HP DeskJet.
The first rule asserts that people who purchase “PC” producttend to purchase“HP DeskJet”,while the second one implies that people who purchase a product containing “IBM 60GB”tend to purchase“HP DeskJet”. ---Memory Hard Disk Notebook Desktop PC PC ---RAM 256MB Segate 60GB IBM 60GB RAM 512MB Sony VAIO Gateway GE IBM TP Printer HP DeskJet Epson EPL ---Ink Cartridge Photo Conductor Toner Cartridge ---Hs-a Is-a
Figure 1. Example of ontology
4. The proposed methods
4.1 Algorithm description
As founded in [1], the task of association rule mining can be decomposed into two phases: frequent itemset generation and rule construction. Since the second phase is straightforward and less expensive, we concentrate only on the first phase of finding all frequent itemsets. We propose two algorithms, called AROC and AROS, which are derived from the Cumulate and Stratify algorithms, respectively, presented in [7], wherein ARO stands for Association Rules with Ontological information.
The main problem arisen from incorporating ontological information into association rule mining is how to effectively compute the occurrence of an itemset A in the transaction database DB. This involves checking for each item a A. Intuitively, we can simplify the task by first adding the generalized and composed items, i.e., extended items, of all items in a transaction t into t to form the extended transaction t*. We denote the resultant extended database as ED.
There is one thing worthy of special care. A purchased item also might be a component of other purchased items. After the addition of extended items into transactions, to differentiate whether an item is directly purchased by customers or is an indirectly purchased component we introduce the asterisk symbol ‘*’to an item that denotes indirectly purchased component.
The first algorithm we proposed, called AROC, is deployed following the Cumulate algorithm in [7] with some extensions derived from the following lemmas and enhancements:
Lemma 1 [7] The support of an itemset A that contains both an item a and its generalization ais the same as the support for itemset A{a}.
Lemma 2 The support of an itemset A that contains both an item a and its component ais the same as the support for itemset A{a}.
Observation 1 Itemset pruning: Any candidate itemset that contains both an item and its generalization or its component can be pruned.
Observation 2 Extension piltering: The extension (generalization or component) of an original item can be added into a transaction only if the item does appear in at least one candidate itemset being counted currently.
Figure 2 gives an overview of the proposed AROC algorithm.
Another algorithm we introduced, called AROS, is an extension derived from the Stratify algorithm in [7]. The most distinguished feature of AROS goes to the course of occurrence counting of candidate itemsets. Adopting the concept of stratification, we divide the set of candidate
k-itemsets Ck, according to the classification and
composition relationship, into two disjoint subsets, called maximal candidate set MCk and residual candidate set
RCk, as defined below:
Input: (1) DB: the original database; (2) T: the item ontology; (3) ms:
the ms setting.
Output: L: the set of frequent itemsets for DB with T w.r.t. ms. Steps:
1. repeat
2. if k1then Generate C1from item ontology T; 3. else Ckapriori-gen(Lk1);
4. Delete any candidate in Ckthat possesses classification or composition relationship between items; /* Observation 1 */ 5. for each transaction tDB do
6. for each item at do
7. Add all generalizations or components of a in T into t and remove any duplicates; /* Observation 2 */ 8. for each itemset ACkdo
9. if A in t then count(A)++;
10. Lk{A | ACkand sup(A)ms}; 11. until Lk
12. LUkLk;
Figure 2. Algorithm AROC
Definition 5 Consider a set Skof candidates in Ckinduced
by the schema (a1, a2,…,ak1,, where ''means“don't
care”.A candidatek-itemset Aa1, a2,…,ak1, ak) is a
maximal candidate if none of the candidates in Sk is a
generalization of A or a component of A. That is, MCk
{A | ACk,(A
~
ã1, ã2,…,ãk1, ãk)Ck, for aiãi, 1
i k1, and ãkbeing a generalization or a component of
ak)}. The residual candidate set RCkCkMCk.
Lemma 3 Consider three k-itemsets (a1, a2,…,ak), (a1, a2,…,a) and (ak 1, a2,…,a), wherek ak
is a generalized item of akandak is a component item of ak. If (a1, a2,…,
k
a) or (a1, a2,…,a) is not frequent, then neither is (ak 1,
a2,…,ak).
Based on above concepts, rather than computing the occurrences of all candidates in Ckin the same pass as in
AROC, we first count candidates in MCkand then proceed
to RCk, hopefully waiving the necessity of counting some
candidates in RCk. The AROS algorithm is shown in
Figure 3.
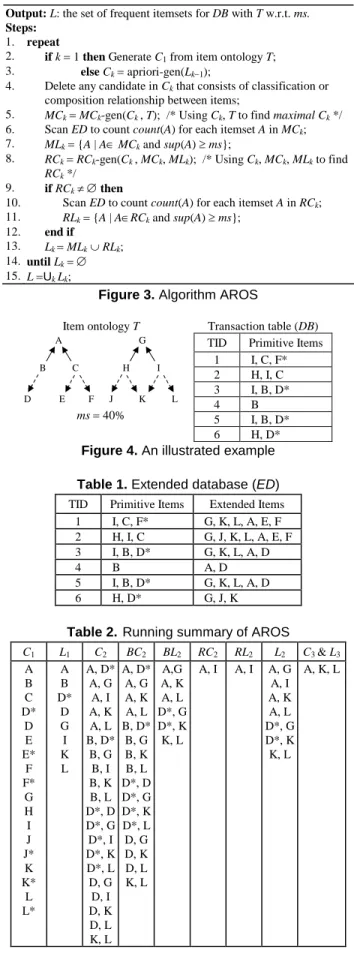
4.2. Example
We use Figure 4 to illustrate our algorithms. Table 1 shows the extended database. The running summary of AROS is shown in Table 2. The running summary of AROC is the same as Table 2, but without columns BC2, BL2, RC2and RL2.
Input: (1) DB: the original database; (2) T: the item ontology; (3) ms:
the ms setting.
Output: L: the set of frequent itemsets for DB with T w.r.t. ms. Steps:
1. repeat
2. if k1then Generate C1from item ontology T; 3. else Ckapriori-gen(Lk1);
4. Delete any candidate in Ckthat consists of classification or composition relationship between items;
5. MCkMCk-gen(Ck, T); /* Using Ck, T to find maximal Ck*/ 6. Scan ED to count count(A) for each itemset A in MCk; 7. MLk{A | AMCkand sup(A)ms};
8. RCkRCk-gen(Ck, MCk, MLk); /* Using Ck, MCk, MLkto find
RCk*/ 9. if RCkthen
10. Scan ED to count count(A) for each itemset A in RCk; 11. RLk{A | ARCkand sup(A)ms};
12. end if
13. LkMLkRLk; 14. until Lk 15. LUkLk;
Figure 3. Algorithm AROS
Item ontology T Transaction table (DB)
H G I J K L B A C D E F ms40%
TID Primitive Items 1 I, C, F* 2 H, I, C 3 I, B, D* 4 B 5 I, B, D* 6 H, D*
Figure 4. An illustrated example Table 1. Extended database (ED)
TID Primitive Items Extended Items 1 I, C, F* G, K, L, A, E, F 2 H, I, C G, J, K, L, A, E, F 3 I, B, D* G, K, L, A, D 4 B A, D 5 I, B, D* G, K, L, A, D 6 H, D* G, J, K
Table 2. Running summary of AROS C1 L1 C2 BC2 BL2 RC2 RL2 L2 C3& L3 A B C D* D E E* F F* G H I J J* K K* L L* A B D* D G I K L A, D* A, G A, I A, K A, L B, D* B, G B, I B, K B, L D*, D D*, G D*, I D*, K D*, L D, G D, I D, K D, L K, L A, D* A, G A, K A, L B, D* B, G B, K B, L D*, D D*, G D*, K D*, L D, G D, K D, L K, L A,G A, K A, L D*, G D*, K K, L A, I A, I A, G A, I A, K A, L D*, G D*, K K, L A, K, L
5. Experimental results
In this section, we evaluate the performance of the proposed algorithms, AROC and AROS. Synthetic datasets, generated by the IBM data generator [1], are used in the experiments after adding generalized and component items. The parameters are that number of items is 362 items, average size of transactions 20 items, groups 30, levels 4, and fanout 5. We also adopted two different support counting strategies into the implementation of each algorithm: one with the horizontal counting [1], and the algorithms are denoted as AROC(H) and AROS(H); the other with the vertical intersection counting [6], and the algorithms are denoted as AROC(V) and AROS(V).
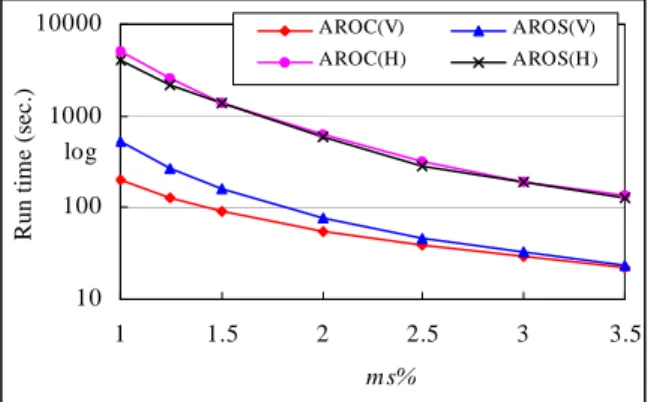
We first compare the execution times of AROC and AROS for different settings of ms with |DB| 200,000. The results are shown in Figure 5. At low ms, AROC(V) outperformed AROS(V), with the gap increasing as the ms decreased. The reason is that AROS(V) spent too much time on finding maximal candidate itemsets. However, at low ms, AROS(H) performs a little better than AROC(H) because scanning the database dominates over most of the time in horizontal support counting.
10 100 1000 10000 1 1.5 2 2.5 3 3.5 m s% R u n ti m e (s e c .) AROC(V) AROS(V) AROC(H) AROS(H) log
Figure 5. Execution times for various ms
We then evaluated the algorithms under varying transaction sizes at ms1.5%. The results are shown in Figure 6. AROC(V) performed 750% faster than AROS(V) at transactions 20,000, with the gap decreasing as the transaction increased since the advantage of pruning candidates by maximal candidate itemsets in AROS(V) is gradually overwhelmed by increasing transactions.
6. Conclusion
We have investigated the problem of mining association rules with ontological information. We
presented two algorithms, AROC and AROS, for discovering frequent itemsets. Experimental results showed that these two algorithms have good linear scale-up characteristic. In the future work, we will study the maintenance aspect of this problem.
10 100 1000 10000 2 4 6 8 10 12 14 16 18 20 Number of transctions (x 10,000) R u n ti m e (s e c .) AROC(V) AROS(V) AROC(H) AROS(H) log
Figure 6. Execution times for various transactions
Acknowledgement
This work is partially supported by National Science Council of Taiwan under grant No. NSC 95-2221-E-390-024.
References
[1] R.Agrawaland R.Srikant,“Fastalgorithms for mining association rules,”Proc. of 20th Int. Conf. on Very Large Data Bases, 1994, pp. 487-499.
[2] M.A. Domingues and S.O. Rezende,“Using taxonomies to facilitate the analysis of the association rules,”Proc of 2nd Int. Workshop on Knowledge Discovery and Ontologies, 2005, pp. 59-66.
[3] T.R. Gruber,“A translation approach to portable ontology specifications,”Knowledge Acquisition, Vol. 5, 1993, pp. 199-220.
[4] J. Han and Y. Fu, “Discovery of multiple-level association rules from large databases,”Proc. of 21st Int. Conf. on Very Large Data Bases, 1995, pp.420-431.
[5] K.F.Jea,T.P.Chiu and M.Y.Chang,“Mining multiple-level association rules in has-a hierarchy,” Proc. of the Joint Conf. on AI, Fuzzy System, and Grey System, 2003. [6] A.Savasere,E.Omiecinski,and S.Navathe,“An efficient
algorithm for mining association rulesin largedatabases,” Proc. of 21st Int. Conf. on Very Large Data Base, 1995, pp. 432-444.
[7] R. Srikant and R. Agrawal, “Mining generalized association rules,”Future Generation Computer Systems, Vol. 13, Issues 2-3, pp. 161-180.
[8] V.C. Storey, “Understanding Semantic Relationships,” Very Large Databases Journal, Vol. 2, No. 4, 1993, pp. 455-488.