Ontology-Incorporated Mining of Association Rules in Data
Warehouse
Wen-Yang Lin
Department of Computer Science
and information Engineering,
National University of Kaohsiung,
Kaohsiung, Taiwan 811, R.O.C.
[email protected]
1
Chin-Ang Wu, Ming-Cheng Tseng,
Chuan-Chun Wu
Department of Information Management,
I-Shou University
Kaohsiung County, Taiwan 840, R.O.C.
[email protected]
1Chin-Ang Wu is also a lecturer in Cheng Shiu University,
Nioa Song, Kaohsiung County, Taiwan
Abstract
With the rise of the Internet and the development of various electronic information resources, mining useful information from large databases has become one of the most important issues in information research for users. Data warehousing plays the key role in providing data for data mining tools to explore knowledge. However, there are still many problems that cause users to spend extra time to get genuine knowledge. In this paper, we explore the problems with contemporary association rule mining in data warehousing systems, explain the essence and propose a framework that incorporates ontologies to resolve the problems. Some interesting research issues and technical challenges on realizing such ontology-incorporated association rule mining in data warehousing systems are pointed out.
Keywords: Data Warehouse, Association Rule Mining, Ontology, Multidimensional Association Rules
1. Introduction
In the knowledge economics era, how to use data efficiently to promote business competition and opportunities is a non-reversible movement. Information technologies have provided many applicable solutions, but many decision analyses are still greatly dependent on professionals’manual judgments; therefore, we expect that a good system should provide efficient, convenient and thorough mining mechanisms, as well as meet the users’ professional demands. In other words, developing a system environment that provides users a way to repeatedly discover important rules or facts based on their professional judgment is absolutely an issue that research workers in the knowledge mining fields can not avoid. The main purpose of this paper is to explore the problems with contemporary data warehouse mining systems, explain the essence of
incorporating ontologies to resolve the problems. Some interesting research issues and technical challenges on realizing such ontology-incorporated mining of association rules in data warehouse systems are pointed out.
The rest of this paper is organized as follows. In section 2, we introduce some background terminology. In section 3, problems with contemporary data warehouse based association mining are discussed. The framework of ontology-based data warehouse mining system is proposed in section 4. In section 5, research issues and technical challenges are discussed. Section 6 studies the related work and finally this paper concluded in section 7.
2. Background Terminology
2.1 Ontology
The term ontology was originally a philosophy specifying the concept of reality. In recent years, ontologies have been adopted by the artificial intelligence realm as a knowledge expression, sharing and reuse tool. Assorted research defined the term “ontology” differently. According to W3C Web Ontology Working Group [17]: “An ontology formally defines a common set of terms that are used to describe and represent a domain knowledge.”T. Gruber [9] defines ontology as: “Aset of definitions of content-specific knowledge representation primitives: classes, relations, functions, and object constants.”Thus, the use of ontology can build up a domain of knowledge. Through the use of ontologies, the relationships among concepts in the domain can be further analyzed. Ontologies can be used in many domains such as intelligence network agent, electronic commerce, knowledge management, data mining and so forth.
Data warehouse is a new generation of decision support systems proposed by W. H. Inmon [13]. The large quantity of data accumulated constantly by the enterprises over a long–term operation has become an important asset for the managers to use as operational history and auditing base and for the decision makers to do decision analysis. Nevertheless, the data usually stored in different information systems and caused at least the following drawbacks [13]: (1) decision analysts would not know where to acquire related data; (2) when analysts use data from different sources, the analyzing result could then be drawn differently; (3) prior to analysis, due to the disbursement of data, analysts are required to perform time consuming data cleaning, such as data transformation and extraction; therefore the results are not often up-to-date.
To amend these drawbacks, data warehouse is used to store transformed and extracted data from different data sources based on the requirements of the analysts. Users can then reduce the query process time widely by querying directly in the data warehouse system without having to integrate related information from different databases sources. A complete data warehouse has three components: source databases, data marts and the front end tools for analysis, which usually are OLAP, query/report tools and data mining software. Fig 1 is a typical data warehouse framework.
Fig 1. A typical data warehouse framework [3] To provide OLAP with efficient data storage and data analysis, star schema, proposed by Kimball [14], is a prevalent data model being used in most commercialized data warehousing systems currently. Fig 2 is an example of star schema.
2.3 Multidimensional Association Rules
An association rule is an expression of the form X Y, where X and Y are sets of items. Such a rule reveals that transactions in the database containing items in X tend to also contain items in Y. The probability, measured as the fraction of transactions
that contain X also contain Y, is called the confidence of the rule. The support of the rule is the percentage of the transactions that contain all items in both X and
Y.
A multidimensional association rule explores the association between data values from different dimensional attributes in data warehouses. Following the work in [25], we can divide multi-dimensional association rules into three different types: intra-dimensional association rule, inter-dimensional association rule, and hybrid association rule.
Definition 1. Consider a transaction table composed of k dimensions. Let xim and yjn be the
values of dimensions Xiand Yj, respectively. The form
of a multi-dimensional association rule is:
X1= “x1m”,X2= “x2m”,….,Xi= “xim” Y1= “y1n”, Y2= “y2n”,….,Yj= “yjn”
(1) Intra-dimensional association rule: This kind of association rule indicates association among items from only one dimension. For example, the following rule,
Product.Sub_category = “AcerPC” Product.Sub_category =“HP printer” involves only the attribute Product.Sub_category, which means that people who purchase “Acer PC” also likely to purchase “HP printer”.
(2) Inter-dimensional association rule: This kind of association rule involves more than one dimensions, but the value of each dimension appears only once in the rule. For example, the following inter-dimensional rule:
Customer.Education = “College”, Product.Sub_category = “HP printer”
Supplier.City = “Taipei”
contains three dimensions, Customer.Education, Product.Sub_category, and Supplier.City, and the value of each dimension occurs only once. This rule means that people whose education level is “College” and purchase “HP printer”tend to get it from the supplier located in “Taipei”.
(3) Hybrid association rule: This kind of association rule can be regarded as a combination of inter-dimensional and intra-dimensional associations. Values of a dimension can appear more than once in a rule. For example, the following hybrid-association rule:
Customer.Education = “College”, Product.Sub_category = “AcerPC” Product.Sub_category = “HP printer”,
shows that people whose education level is “College” and purchase “Acer PC”also likely to purchase “HP printer”.
Definition 2. Suppose a star schema S containing a fact table F and m dimension tables {D1, D2,…,Dm}.
Let T be a jointed table from S composed of a1, a2,…, akattributes, such thatai, ajAttr(Dk), 1i, j r,
1 k m. Here Attr(Dk) denotes the attribute set of
dimension table Dk. A meta-pattern of
multidimensional associations from T is defined as follows
MP:tG, tM, ms, mc,
where ms denotes the minimum support, mc the minimum confidence, tG the group of transaction
attributes, tMthe group of item attributes, for tG, tM
{a1, a2,….,ak} and tGtM=.
The above-mentioned meta-pattern for three different multidimensional association rules are as follows:
1. Intra-dimensional associations: tGand |tM| = 1.
2. Inter-dimensional associations: tG=and |tM|2.
3. Hybrid associations: tGand |tM|2.
3. Problems with Contemporary Data
Warehouse Based Association Mining
Systems
Recently, the integration of data warehouses and data mining techniques has become the dominated system platform for knowledge discovery applications. Although this scheme is commonly adopted by the knowledge discovery community, contemporary data warehouse mining systems have many problems. The most important of the problems include: A) lacking structural and/or semantic exploration of the stored data; B) lacking facilities in capturing user’s mining behavior; and C) lacking effective and active functions for maintaining discovered knowledge.
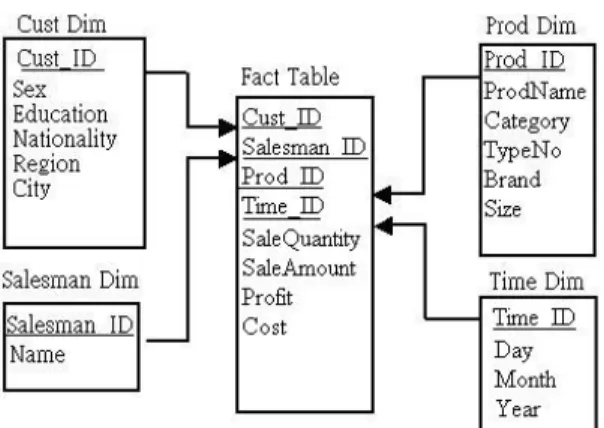
A. Lacking structural and/or semantic exploration of the stored data. Contemporary data warehousing systems are mostly based on relational databases, which cannot thoroughly describe organizational relation between data. For example, the star schema in Fig 2 shows simply the relationships between fact table and dimension tables and overlooks the concept hierarchies of dimensional attributes as shown in Fig 3, which bear essential information for performing typical OLAP operations, such as roll-up, drill-down, and slice-and-dice. If the data warehouse system can provide the relationships between organization structures and semantics of data, the user can prevent improper data selection, thus avoid mining of some meaningless and useless rules or patterns. Avoiding such errors would further reduce the repetitiveness in mining process and improve the effectiveness.
Fig 2. Sale_Star an example of star schema
Fig 3. Dimensional attribute hierarchy for Sale_Star.
B. Lacking facilities in capturing user’s mining behavior. Data mining is an individual independent and more or less subjective process. Perception of the mining results and their representation usually depend on personal preference such as subset selection, parameter settings, data constraints, etc. Current mining systems, however, provide astonishingly few mechanisms in capturing and analyzing users’mining behaviors to learn individual preference for later assistance in constructing more appropriate mining query. And the situation becomes worse when mining from huge volumes of warehousing data. If we could collect personal user profiles, such as data range, parameter settings and even some meaningful data patterns, then we would utilize them in the course of the mining process to get more meaningful and valuable rules or patterns to meet the user’s need.
C. Lacking effective and active functions for maintaining previous discovered knowledge or to respond to users’new interests. Traditional data mining process acts in a passive way; it is activated only by users’enquiries. In this way, users have to keep track of any change of the circumstances, launching new mining process to acquire the most updated information. Such changes include data update to the data warehouse, new problems, and new business requirement, etc. And requiring users to always be aware of these novelties is not realistic.
For example, when data in the data warehouse is changed, the user’s mining process can be triggered
automatically and can produce new fitting rules or patterns. This is the idea of active data mining. If the previous mining query can be recorded then the system can trigger the renewed mining process automatically based on the history query information.
4. Ontology-based
Data
Warehouse
Mining System
In this section we will describe the concept of data warehouse mining system combined with ontologies and elaborate how ontologies would help data mining. To make the description more conceivable, we will illustrate the idea in the context of multidimensional association rules mining.
4.1 System framework
It is well known that the data mining is a knowledge intensive process in that it requires domain-specific knowledge (ontology) [1][7][12]. In this paper we proposed a data warehouse mining system that combines ontologies in order to build the framework of semantic relations or structural relations of data which current relational star schema could not achieve. Additionally, ontologies of both domain knowledge and personal user preference could also be integrated into the system. The resulting system framework is shown in Fig 4, where the shadowy part is the major concern of this paper.
Fig 4. The proposed ontology-based data warehouse mining system framework. In the following we will describe the constituent of schema ontology, domain ontology and personal user preference ontology.
A schema ontology is used to describe metadata of the data warehouse, including schema structures, dimension hierarchies, dependency relationships among attributes, and the types of measures along
dimensions. The hierarchical relationships between attributes also imply the functional dependency between them. The less granulated descendent determines the value of its ancestor. The unique ID in each dimension also implies the functional dependency between the ID and other attributes in that dimension. There will not be any two records sharing the same key. Fig 5 is an example of schema ontology.
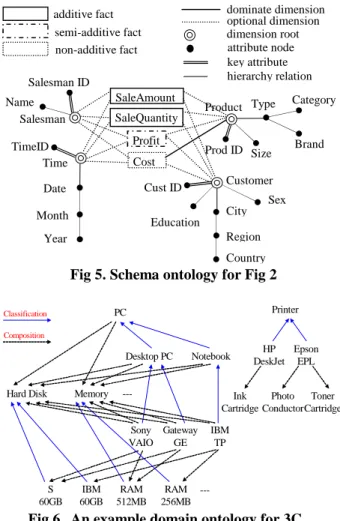
A domain ontology is used to construct the domain knowledge of the mining subject, (i.e.: for sales data, the structure of conceptual layer, and relationships among customer types and product types). The contents are specific and adaptable to certain domains. Fig 6 is an example of domain ontology for 3C products. It explores both classification and composition relationships which can contain the information such as what components a PC has, what product belongs to what brand, compatibilities of software to OS and also the compatibilities among hardware, etc.
Fig 5. Schema ontology for Fig 2
---Memory Hard Disk Notebook Desktop PC PC ---RAM 256MB S 60GB IBM 60GB RAM 512MB Sony VAIO Gateway GE IBM TP Printer HP DeskJet Epson EPL Ink Cartridge Photo Conductor Toner Cartridge Composition Classification
Fig 6. An example domain ontology for 3C products.
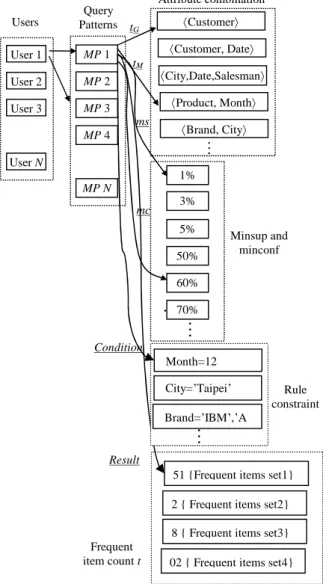
A personal user preference ontology is used to collect user history query patterns, such as grouping attribute and mining item combinations, parameter setting (i.e. minimum support and minimum confidence), conditional constraint and the result of
additive fact semi-additive fact non-additive fact dominate dimension optional dimension Product Type Size Brand Category SaleAmount SaleQuantity Profit Cost Customer Sex City Region Country Time Date Month Year Salesman Education Name Salesman ID Prod ID Cust ID TimeID key attribute dimension root hierarchy relation attribute node
mining (i.e.: the frequent item sets). Fig 7 is an example of user preference ontology.
4.2 Benefits
of
utilizing
ontology
for
multidimensional associations mining
In this subsection, we will elaborate on how the data mining process can benefit from the integration of warehouse schema ontology, domain knowledge ontology and user preference ontology into the data warehouse framework. For illustration, let us consider mining multidimensional association rules from the sales star in Fig 1 with dimension hierarchy in Fig 2 and see how ontology can help the process.
Fig 7. An example user preference ontology. A. It makes more rigorous the warehouse mining query. That is, it helps formulate/correct user queries and avoid inability to generate acceptable rules or patterns. For example, consider the following scenario query:
Question: Is there the phenomenon that customers
living in some particular city tend to buy some
particular products in some particular month?
The first step to evaluate the above question is correctly forming the mining query. This query can be represented in the multidimensional association rule pattern formulation [Cust.City = ?] [Prod.ProdName = ?] [Time.Month = ?] and its context is as follows:
mine multidimensional associations grouping_ID Time_Date
mining_set Cust.City, Time.Month, Prod.Name from Sales_Star
with minsup=1%, minconf=50%
The queries formed by users can possibly fall into some improper group-by and/or mining item attribute combinations. This would lead to redundant mining data space and/or mining results and waste the efforts of the mining process accordingly. To solve the problem, the relationships revealed in the schema ontology include schema structures, dimension hierarchies, dependency relationships and the measures would be help. There are some observations which can be induced from the schema ontology to provide knowledge for users and systems to refer.
Observation 1. From Definition 2, ai, aj
Attr(Dk), let {ai, aj}tG, if ajis functional dependent
on aithen this tGis a redundant form for tG–{aj}.
For example, an inexperienced user forms the following query:
mine multidimensional associations grouping_ID Cust_ID, Cust.Sex mining_set Prod.Brand, SaleQuantity from Sales_Star
with minsup=1%, minconf=50%
The meta-pattern has tG1= {Cust.ID, Cust.Sex} which
is actually a redundant form of tG2 = {Cust.ID}
because Cust.Sex is functional dependent on Cust.ID. The mining space for tG1and tG2is exactly the same.
Observation 2. From Definition 2, ai, aj
Attr(Dk), let {ai, aj} tM, if aj is functional
dependent on aithen this meta-pattern is redundant to
produce associations of the value pairs in each of them one value is dependent on the other.
For example, a meta-pattern of tM =
{Product.Name, Product.Size} with the following query:
mine multidimensional associations grouping_ID Cust_ID
mining_set Prod.Name, Product.Size from Sales_Star
with minsup=1%, minconf=50% User 1 User 2 User 3 User N ms mc tM tG
…
1% 3% 5% 50% 60% 70% MP 1 MP 2 MP 3 MP 4 MP N Customer Customer, Date Product, Month City,Date,Salesman Brand, City Users PatternsQueryMinsup and minconf Attribute combination
151 {Frequent items set1} 62 { Frequent items set2} 78 { Frequent items set3} 102 { Frequent items set4} Frequent item count t Result
Rule constraint Month=12 City=’Taipei’ Brand=’IBM’,’A
ConditionThe mining item Prod.Name determines the value of Prod.Size, the other mining item. This query will generate redundant result rules because the result rules will be the associations between product names and their sizes. The example of a redundant rule i.e. (Product.Name, “IBM TP”) -> (Product.Size, “17 inch * 15 inch * 1 inch”)) which is tedious as it is the known fact.
Note that a hierarchical relationship is a special case of functional dependency. The descendant’s value determines its ancestor’s value in the hierarchy. For example, tG= {Cust.ID, Cust.City} is actually a
redundant form of tG= {Cust.ID} because Cust.City
is the classification parent of Cust.ID.
Observations of the relationships in the schema ontology can help forming correct queries, hence obtaining correct results and save system resources and processing time.
B. It makes more innovative the warehouse mining results. That is, it can extend the concept from the existing data to generate nontrivial rules or patterns. For transaction data with hierarchical levels, some previous work mentioned extension of association rules [6][10][11][21] and sequential patterns [22] from primitive into generalized or leveled format.
The association rule mining can be extended to include items from the domain ontology by the systems. In the 3C domain ontology example of fig 6, “S60GB”and “RAM 512MB”are components of “Sony VAIO”. If “Sony VAIO”is a purchased item in the data warehouse association mining, the system can also include “S60GB”and “RAM 512MB”as the extended items. The count of these 3 tiems can be increment by one simultaneously. In addition to the associations among the purchased items, the extended rules of components of those purchased items can be excavated also. A rule such as, [Domain.Prod.Name = “IBM 60GB”] [Domain.Prod.Name = “RAM 512MB”] can be generated as a consequence.
On the other hand the classification relationships in the domain ontology can provide extra information to generalize the purchased items to a richer concept of groups. The class the purchased items belong to can be included as a mining item. The mining rules such as, [Domain.Prod.Name = “DesktopPC”] [Domain.Prod.Name = “Printer”], could be generated in spite of purchased items include only model names of the products, namely “Sony VAIO”, “Gateway GE”, “HP DeskJet”and not the classified titles such as “DesktopPC”, “Printer”.
The mining results, therefore, cover beyond the transaction data warehouse and can be expanded to the information the domain ontology provides. Extensive knowledge can be obtained from the incorporation of multidimensional data warehouse association mining with domain ontology hence.
C. It makes more efficient the warehouse mining process. This is in two aspects: In one place, the relationship exploited by the domain ontology would prune impossible item combinations to accelerate the discovering of meaningful rules or patterns. In another place, user preference ontology can be utilized to prevent repeated mining.
(1) Minimizing data mining searching boundaries
As mentioned in B, combining the multidimensional association mining with the domain ontology will richen the mining results. Furthermore, it can facilitate the minimization of data mining searching boundaries. For example in fig 6, “S 60GB”and “IBM 60GB”are classified as hard-disk and “RAM 512MB”, “RAM 256MB”are classified as RAM which are all compatible components of a “Desktop PC”. A domain ontology incorporated association rule mining can confine the mining item set to a specific class in the domain ontology. For example, a user might be interested in mining associations among the “DeskTop PC”related items only which include the components and sub-class of the “DeskTop PC”and the information is in the domain ontology. It is valuable for decision makers to learn what parts of a Desktop PC would be bought together often in order for them to suggest what combinations of a desktop PC set can possibly be popular. By excluding items which are not related to the Desktop PC, the searching space can be reduced fairly, thus saves the resources and the time of processing. Without utilizing the domain ontology, users would not know what composes a PC and can not achieve the efficient and effective association mining as described.
Some specific concepts from domain ontology can be included in a query as constraints instead of always making them inventively by users.
(2) Alleviate repeated mining
The user preference ontology keeps the association mining history of users. The contents include the query and the mining results which can be referred by users prior to providing a new query to the system. For a user without association mining experiences, the user preference ontology can be considered as a helpful tool which provides users with abundant query format samples to refer. Questions like how to select the grouping attributes and the interested mining-items, how to decide minimal support and minimal confidence and what results would a specific query generate can be referred in the user preference ontology. Duplicate efforts, if any, can also be avoided by utilizing the user preference ontology.
Data mining is a repeated sequence of searching process [7]. Analysts usually have to modify the query settings persistently throughout the association
rule mining process until they get the acceptable results. The purpose is to dig important and useful knowledge patterns that fit their requirements.
In addition to the duplicate query checking, users can edit the mining conditions based on the existing settings in the user preference ontology. This mechanism can provide users to dig further information starting from current existing results in the user preference ontology and acquire more information to the users need effectively and save the processing time compared to the condition while no user preference ontology is given.
Take the following multi-dimensional association mining query as an example.
mine multidimensional associations grouping_ID Cust_City, Time.Date mining_set Prod_Name
from SALES_STAR
with minsup=1%, minconf=50%
Assuming the searching scope remain fixed, the frequent itemsets would remain as useful frequent itemsets when only the minimum support dropped from 1% to 0.5%. Therefore all the frequent item sets in the user preference ontology are eligible and only frequent items of supports between 0.5% and 1% should be processed further. Mining association rules is time consuming, thus the previous mining results can be utilized toward the saving of time [5].
D. It makes more active the warehouse mining operation refreshing. When data in the data warehouse is changed due to the transaction data source change, the new mining process have to be launched again to gain the most up to date knowledge. User preference ontology provides the possibilities to trigger the necessary process automatically to produce new fitting rules or patterns. The new mining process launched by the system is based on the association mining history recorded in the user preference ontology which will not be feasible if user preference ontology is not available.
Some rules should be derived for the system to follow in order to trigger active mining processes properly. For example, a rule of appraising the freshness of frequent item sets should be derived in order for the system to trigger the mining process automatically to gain the more up to date rules because the history frequent items might be stale according to the rule. Since the system can trigger the process automatically, the execution can be arranged on a less occupied time.
6. Related Work
If concept hierarchy or taxonomy is taken as a kind of ontology, then the research of incorporating ontology into data mining can be traced back to 1995
when Han & Fu [11] and Srikant & Agrawal [21] proposed to combine conceptual hierarchy knowledge to mine so-called multilevel association rules and generalized association rules, respectively. Their work was later extended by Chien et al. [4], incorporating not only classification hierarchy but also composition hierarchy information. These researches, however, concentrated on the design of algorithms without discussion of ontology structure design and its benefit to data mining. Until recently, this was exploited by several studies, including ontology-based induction of classification rules [16] [24], ontology-based explanation of association rules [6][23], and ontology-guided new attributes generation from databases [18], etc. Cespivova et al. [2] has conducted a systematic study by revealing the roles of medical domain ontology in each aspect of the KDD process. Similar study was also presented in [8].
Currently, the research on data mining and data warehousing are mostly concentrated on data mining from data cube or multi-dimensional database. J. Han’s research group pioneered this research subject. They combined OLAP and data mining to develop DBMiner, a system that provides mining association rules, classification, prediction and clustering from data cube [12]. In [20], Psaila and Lanzi studied layer association mining from a data warehouse and presented a layered association pattern as well as a conceptual method of mining.
To our knowledge, [19] is the only work up to date that exploits the issue of incorporating ontology into knowledge discovery from data warehouses. In particular, this paper aims at building an enterprise knowledge portal that integrates OLAP and information retrieval functionality via ontology; the issue of data mining yet is left unanswered.
7. Conclusions
In this paper, we have proposed an ontology incorporated data warehouse mining system in which schema ontology, domain ontology and user preference ontology are included to reinforce the functions for the plain data warehouse mining system. The benefits and the utilization of the ontologies to the system have been discussed. Rigorous mining query, innovative mining results and the efficient mining process are the advantages being brought about in the system. The contents of coupling the personal user preference ontology, domain ontology and schema ontology to the data warehouse mining system were presented to effectively generate the knowledge patterns that match user requirements.
User preferences can vary naturally when the external circumstances vary and both schema structures in data warehouse and domain knowledge change by time. Therefore schema ontology, domain
ontology and user preference ontology would be changing accordingly. Under such circumstances, how to process data mining efficiently to regain new knowledge patterns or maintain previous mined knowledge patterns is an important and challenging research issue to conquer. Ascertain all possible change of ontologies and learn the effect of each change to the previous mined rules or patterns would facilitate the design of satisfactory and efficient algorithms. The influences of different changes of ontology to multi-dimensional association rules will also be further explored.
Acknowledgements
This work was supported by the National Science Council of ROC under grant NSC 94-2213-E-390-006.
References
[1] J.M. Aronis, F.J. Provost, and B.G. Buchanan, “Exploiting background knowledge in automated discovery,”in Proc. 2nd Intl. Conf. Knowledge Discovery and Data Mining, 1996.
[2] H. Cespivova, J. Rauch, V. Svatek, M. Kejkula, and M. Tomeckova, “Roles of medical ontology in association mining Crisp-Dm cycle,”in Proc. ECML/PKDD Workshop on Knowledge Discovery and Ontologies,
2004.
[3] S.Chaudhuriand U.Dayal,“An overview of data warehouse and OLAP technology,”ACM SIGMOD Record, Vol. 26, 1997, pp. 65-74.
[4] B.C. Chien, M.H. Chung, and T.C. Wang, “Mining fuzzy association ruleson Has-A and Is-A hierarchical structures,” in Proc. 10th
Conf. on Artificial Intelligence and Applications, 2005.
[5] B. Czejdo et al., “Materialized views in data mining,”Proc.of 13th International Workshop
on Database and Expert Systems Applications,
2002, pp. 827-831.
[6] M.A. Domingues and S.O. Rezende, “Using taxonomies to facilitate the analysis of the association rules,”in Proc. 2nd Intl. Workshop on Knowledge Discovery and Ontologies,
2005.
[7] U.Fayyad,P.S.Gregory,and S.Padhraic,“The KDD process for extracting useful knowledge from volumesofdata,”Communications of the ACM, Vol. 39, No. 11, 1996, pp. 27–34. [8] P. Gottgtroy, N. Kasabov, and S. MacDonell,
“An ontology driven approach forknowledge discovery in biomedicine,”in Proc. 8th Pacific Rim Int’lConf.on ArtificialIntelligence, 2004. [9] T.R. Gruber, “A translation approach to
portable ontology specifications,”Knowledge
Acquisition, Vol. 5, 1993, pp. 199-220.
[10] J.Han,“Mining knowledgeatmultipleconcept levels,” in Proc. of ACM International
Conference on Information and Knowledge Management, 1995, pp. 19-24.
[11] J. Han and Y.Fu,“Discovery ofmultiple-level association rules from large databases,” in
Proc. of the 21st Very Large Databases Conference, 1995, pp. 420-431.
[12] J. Han and M. Kamber, Data Mining: Concepts
and Techniques, Morgan Kaufmann, 2001.
[13] W.H. Inmon, Building the Data Warehouse, John Wiley & Sons, Inc., New York, NY, 1995.
[14] R. Kimball, The Data Warehouse Toolkit
Practical For Building Dimensional Data Warehouses, John Wiley & Sons, INC. 1996.
[15] F.A. Lisi and D. Malerba, “Inducing multi -levelassociation rulesfrom multiplerelations,”
Machine Learning 55(2), 2004.
[16] M.Nunez,“Theuseofbackground knowledge in decision treeinduction,”Machine Learning,
Vol. 6, No. 3, 1991, pp. 231-250.
[17] OWL Web Ontology Language Use Cases and
Requirements, http://www.w3.org/TR/webont-req/, 2004.
[18] J. Phillips and B.G. Buchanan, “Ontol ogy-guided knowledgediscovery in databases,”in
Proc. Intl. Conf. on Knowledge Capture, 2001.
[19] T. Priebe, and G. Pernul, “Ontology-based integration of OLAP and information retrieval,” Proc. of the 14th International
Workshop on Database and Expert Systems Applications, 2003, pp. 610-614.
[20] G. Psaila and P.L. Lanzi, “Hierarchy-based mining of association rules in data warehouses,” Proc. of ACM Symposium on
Applied Computing, 2000, pp. 307-312.
[21] R. Srikant and R. Agrawal, “Mining generalized association rules,”Proc. 21st Int.
Conf. Very Large Data Bases, 1995, pp.
407-419
[22] R. Srikant and R. Agrawal,“Mining sequential patterns: Generalizations and performance improvements,”Proc. of the 5th International
Conference on Extending Database Technology, 1996, pp. 3-17.
[23] V.Svatek,J.Rauch,and M.Flek,“Ontol ogy-based explanation of discovered associations in thedomain ofsocialreality,”in Proc. 2nd Intl. Workshop on Knowledge Discovery and Ontologies, 2005.
[24] M.Taylor,K.Stoffel,J.Hendler,“ Ontology-based induction of high level classification rules,”in Proc. of the SIGMOD Data Mining and Knowledge Discovery Workshop, 1997.
[25] Hua Zhu, “On-Line Analytical Mining of Association Rules,”Master’s Thesis, Simon Fraser University, U.S.A, Dec 1998.
![Fig 1. A typical data warehouse framework [3] To provide OLAP with efficient data storage and data analysis, star schema, proposed by Kimball [14], is a prevalent data model being used in most commercialized data warehousing systems currently](https://thumb-ap.123doks.com/thumbv2/9libinfo/7415950.104579/2.892.106.426.654.854/warehouse-framework-efficient-analysis-prevalent-commercialized-warehousing-currently.webp)