行政院國家科學委員會專題研究計畫 成果報告
資訊萃取技術在生物醫學文獻上的應用與探討(2/2)
計畫類別: 個別型計畫 計畫編號: NSC94-2213-E-009-024- 執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日 執行單位: 國立交通大學資訊科學學系(所) 計畫主持人: 梁婷 計畫參與人員: 吳典松 朱俊榮 施並格 林裕祥 黃立泓 施曉茹 蘇傳堯 報告類型: 完整報告 報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢中 華 民 國 95 年 9 月 18 日
行政院國家科學委員會補助專題研究計畫
ˇ 成 果 報 告
□期中進度報告
(計畫名稱)
資 訊 萃 取 技 術 在 生 物 醫 學 文 獻 上 的 應 用 與 探 討
計畫類別:
ˇ
個別型計畫 □ 整合型計畫
計畫編號:NSC 94 - 2213 -E -009 -024 -
執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日
計畫主持人:梁婷
共同主持人:
計畫參與人員: 吳典松 朱俊榮 施並格 林裕祥 黃立泓
施曉茹 蘇傳堯
成果報告類型(依經費核定清單規定繳交):□精簡報告
ˇ
完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
ˇ
出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查
詢
執行單位:國立交通大學資訊工程系
I
資 訊 萃 取 技 術 在 生 物 醫 學 文 獻 上 的 應 用 與 探 討
中文摘要
在 本 計 畫 中 我 們 將 探 討 兩 個 議 題 分 別 是 萃 取 技 術 的 研 發 和 問 答 系 統 的 製 作 將 分 兩 年 來 進 行 。 在 第 一 年 我 們 開 發 有 效 實 用 的 自 然 語 言 處 理 技 術 和 文 件 探 勘 技 術 , 進 而 建 製 一 個 可 應 用 在 生 物 文 獻 的 自 動 資 訊 萃 取 系 統 。 主 要 的 工 作 將 包 括 生 物 實 體 名 稱 辨 識 、 名 稱 指 代 處理、關 係 的 辨 識 與 萃 取 。 我 們 結 合 法 則 式 和 統 計 式 的 方 法 來 強 化 實 體 名 稱 辨 識 的 效 能 。 此 外 我 們 利 用 文 件 探 勘 技 術 來 解 決 語 句 中 指 式 型 指 代 間 題 。 同 時 我 們 也 探 討 生 物 訊 息 和 非 生 物 訊 息 在 實 體 關 係 的 辨 識 和 強 度 計 算 上 的 影 響 力 , 並 利 用 探 勘 技 術 建 立 關 聯 法 則 以 處 理 存 在 於 語 句 中 的 實 体 關 係 的 語 言 問 題 。 在 笫 二 年 我 們 利 用 所 開 發 的 萃 取 技 術 進 行 以 生 物 資 訊 為 內 容 的 知 識 問 答 糸 統 的 製 作 , 主 要 的 工 作 將 包 括 生 物 資 料 庫 的 內 容 探 勘 分 類 、 查 詢 問 題 的 分 類 、 答 案 的 選 取 和 整 合 。 我 們 希 望 藉 由 此 計 劃 的 執 行,一 方 面 能 開 發 出 有 效 可 行 的 資 訊 萃 取 方 法 將 大 量 的 生 物 文 獻 資 料 轉 換 成 加 值 型 的 知 識 庫 ; 另 一 方 面 亦 提 供 使 用 者 一 個 有 效 的 知 識 萃 取 與 處 理 系 統 ,以 促 進 生 物 資 訊 的 探 勘 。 關 鍵 詞 : 自 然 語 言 處 理 、 資 訊 萃 取 、 文 件 探 勘 、 實 體 名 稱 、 指 代 處理、 關 係 辨 識 、 問 答 系 統Information Extraction In Biomedical Domain
Abstract
In this project, the issues associated with information extraction in biomedical domain are addressed in two years. In the first year, we develop an efficient information extraction system useful for biomedical literature by using natural language processing and textual mining techniques. This system will mainly address the tasks such as named entity identification, anaphora resolution, relation identification and extraction. We employ both statistical and linguistic models for named entities identification. We use textual mining to deal with those nominal anaphora problems. Meanwhile, the proposed relation recognition mechanism takes into account both the biomedical information encoded in the existing databases as well as the information directly mined from the literature. Besides, the problems associated with the linguistic varieties are tackled by using the proposed association rules.
In the second year we develop an on-line biomedical question answering system by applying information extraction techniques. The system addresses the issues such as question assembling and analysis, passage retrieval and answer extraction. In the proposed system answers can be extracted from corpus as well as semi-structured databases through different mining techniques. It is expected that the constructed system will be useful for the tasks such as knowledge acquisition and annotation.
We believe that the implementation of this project will be benefit for the tasks for knowledge acquisition and management, and, furthermore, potential scientific discovery.
Keywords: natural language processing, textual mining, information extraction, named entity identification, anaphora resolution, relation identification, question answering.
III
Table of Content
中文摘要...I Abstract ... II 1 Introduction ... 1 2 Related Works ... 22.1 Related works on biomedical NER ... 2
2.2 Related works on anaphora resolution in biomedical literature ... 2
2.3 Related works on relation recognition in biomedical literature ... 3
2.4 Related works on question answering in biomedical domain ... 3
3 The Proposed Methods and Results ... 4
3.1 The proposed named entities recognition ... 4
3.2 The proposed anaphora resolution for biomedical literature ... 4
3.3 The proposed relation recognition from biomedical literature... 4
3.4 The proposed specific-domain question answering... 5
3.4.1 Rule-based approach for identifying definitional question ... 5
3.4.2 Naïve-Bayes classifier for classifying other type questions... 6
3.4.3 Concept identification ... 6
3.4.4 Ontology-based Query Expansion ... 8
3.4.5 Retrieval procedure and ranking ... 8
3.4.6 Results and Analysis... 9
4 Concluding Remarks... 9
5 Reference... 10
Appendix ... 13
1 Introduction
In this project, the techniques useful for information extraction from biomedical literature are explored. The techniques involve the tasks like named entity recognition, anaphora recognition and biomedical relation recognition. Besides, a prototype of question answering system in biomedical domain is implemented with the application of these proposed techniques.
Named entity recognition (NER) from biomedical literature is one fundamental task involved in the automation of biomedical databases. Similar to the recognition in general domains, the issues associated with biomedical entity recognition are open vocabulary, synonyms, boundaries and sense disambiguation. In this project, both empirical rule and statistical approaches to protein entity recognition are presented and investigated on a general corpus GENIA 3.02p and a new domain-specific corpus SRC. Experimental results show the rules derived from SRC are useful though they are simpler and more general than the one used by other rule based approaches. Meanwhile, a concise HMM-based model with rich set of features is presented and proved to be robust and competitive while comparing it to other successful hybrid models. Besides, the resolution of coordination variants common in entities recognition is addressed. By applying heuristic rules and clustering strategy, the presented resolver is proved to be feasible.
As to the anaphora resolution in biomedical literature, it is noticed that pronominal and nominal anaphora are the two common types of anaphora. In this project, a resolution approach is presented by using rich set of syntactic and semantic features. Unlike previous researches, the verification of semantic association between anaphors and their antecedents is facilitated by exploiting more outer resources, including UMLS, WordNet, GENIA Corpus 3.02p and PubMed. Moreover, the resolution is implemented with a genetic algorithm on its feature selection. Experimental results on different biomedical corpora showed that such approach could achieve promising results on resolving the two common types of anaphora.
For relation recognition from biomedical literature, the complex sentence analysis presented in past literature is not practical enough to deal with rapid growth of biomedical literature. Some researchers using patterns to extract relation have been presented, yet, for example, the relations between two proteins locating at different sentences are not considered. In order to enhance the recognition accuracy, more features are considered in this project. A two-stage method for extracting protein-protein interactions from biomedical literature is proposed. In the first stage, patterns are utilized to match sentences containing interaction relation. In the second stage, a Naïve Bayes classifier is constructed by considering more features, like surface features, co-occurrence, co-citations, and protein property features. We use two corpora as our testing data. One is collected from MEDLINE abstracts, containing 155 abstracts, and the other containing 100 abstracts is collected from the references for proving interactions in DIP. We use the interaction pairs from DIP to justify our extraction method. The result shows that our approach can yield 62% and 61% F-score in both corpora, respectively.
At last, we implemented a prototype of specific-domain question answering. As we know, automation of question answering task involves question processing, information retrieval and answer extraction. It is noticed that more than 60% of QA errors are attributed to question processing. Hence the presented QA approach is designed with the aim to enhance QA performance by concerning question type classification and query expansion. Generally, more explanation questions are raised by a user using a system like medical QA system. The questions are like “Who is at the greatest risk for heat-related illness?” rather than “Who invented the toothbrush?” Hence, the proposed system is constructed with the exploitation of outer ontologies like UMLS and a domain-specific search engine like PubMed. Unlike most
2
previous researches focusing on UMLS as the domain expansion, we use the concepts in UMLS to extract Concept-Verb-Concept patterns (“CVC patterns” for short) from training corpus so as to improve the rank of answer texts. We use Naïve bayes model for question analysis so as to classify questions into diagnosis, therapy, and etiology and use query expansion to increase the recall for document retrieval. A combined ranking is presented for ranking answer texts and it is proved to yield promising results on 203 questions in terms of 0.63 MRR.
2 Related Works
2.1 Related works on biomedical NER
Recent textual mining approaches useful to biomedical NER can be divided into rule-based, statistical and hybrid methods. Generally, rule-based approaches employ the information of terms and hand-craft rules to produce candidates which are then verified by using lexical analysis [1] [2] [5]. Yet rule-based methods are essentially lack of portability and scalability. On the other hand, statistical models have been widely employed for their portability and scalability, such as Hidden Markov Model (HMM), Support Vector Model (SVM), Maximum Entropy (ME), and etc. The recognition accuracy achieved by these models generally depends on a well-tagged training corpus and a well set of features [3] [6] [7] [8] [9]. Recently, hybrid approaches are proposed by combining coded rules, statistical model and dictionaries [4] [8]. As pointed in [9], it can be expected that systems on a specified evaluation corpus with help of dictionaries tend to perform better than the general ones without help of any dictionaries. For example, the recognition performance is significantly improved when both dictionary and rules are applied together with a ME-based recognition mechanism in [4].
2.2 Related works on anaphora resolution in biomedical literature
In past literature, different strategies for resolving anaphora have been presented by using syntactic, semantic and pragmatic clues. For example, grammatical roles of noun phrases were used in [14] [15]. In addition to the syntactic information, statistical information like co-occurring patterns obtained from a corpus is employed during antecedent finding in [11]. However, a large corpus is needed for acquiring sufficient co-occurring patterns and for dealing with data sparseness. On the other hand, outer resources, like WordNet, are applied in [12] [17] [18] and proved to be helpful to improve the performance of an anaphora resolution system like the one presented in [17] where animacy information is exploited by analyzing the hierarchical relation of nouns and verbs in the surrounding context learned from WordNet. Nevertheless, using WordNet alone for acquiring semantic information is not sufficient for solving unknown words. To tackle this problem, a richer resource, the Web, was exploited in [19] where anaphoric information is mined from Google search results at the expense of less precision.
The domain-specific ontologies like UMLS (Unified Medical Language System) has been employed in [10] in such a way that frequent semantic types associated to agent (subject) and patient (object) role of subject-action or action-object patterns can be extracted. The result showed such kind of patterns could gain increase in both precision (76% to 80%) and recall (67% to 71%). On the other hand, Kim and Park [16] built their BioAR to relate protein names to SWISS-Prot entries by using the centering theory presented by [13] and salience measures by [10].
2.3 Related works on relation recognition in biomedical literature
There are several approaches presented for extracting relations from biomedical literature. For example, system GENIS [24] was designed to deal with a wide variety of different relations between biological molecules by analyzing most frequently used sentence structures. On the other hand, Daraselia et al. [22] utilized an ontology as a filter to select correct sentence structures and they have high precision 91% but low recall 21%. In order to improve the efficiency and reduce the workload of processors, some researchers use shallow parsers [20] [21] [23]. They identified certain phrases and extract dependencies between subject and object relationship without considering the structure of an entire sentence.
Unlike NLP techniques, researchers, like SUISEKI [28], employed a set of patterns which were predefined manually by filtering large amounts of text. These patterns are used to identify a direct or indirect interaction between two proteins. Huang et al. [25] used a dynamic programming algorithm to discover interaction patterns in the way of aligning relevant sentences and key verbs for identifying protein interactions. They extracted the interactions between proteins by matching the discovered patterns and the recall and precision rate were 80% and 80.5%, respectively. Oyama et al. [27] extracted the features that characterize each protein appearing in the interactions from several databases, like SWISS-PROT and PIR, and mined the association rules from interaction-based transactions. Ramani et al. [26] took an advantage of co-occurrence analysis to extract protein pairs from Medline abstracts.
2.4 Related works on question answering in biomedical domain
Many researches [29] [33] [35] [36] related to specific domain QA have been reported during the last decade. The specific domain QA is usually considered into four steps: the utilization of domain ontology, question processing, document retrieval, and answer processing. Zhang
et al. [36] uses the concepts of ontology to tag the question and the documents in order to
measure the similarity between the question and the documents. Wang et al. [35] consider the ontology as the keyword expansion for the question in order to gain more information. Soo et
al. [33] integrate the biological literatures from the Web into the ontology automatically. The
method presented in [29] uses the medical FAQ from the Web as the data source for the medical QA. In the this project, we consider how to utilize the concepts of ontology and the medical resources, i.e. medical FAQ and literatures, to deal with the medical questions in question processing and document retrieval.
For question processing, most specific domain QA adopts question classification as the essential component to deal with the given questions. Researches classify the questions by identifying the format of answers, such as Yes/No format [29], description format [29] [36], and NE format [36]. In our study, the concept information and the syntactic relation from the given question are concerned in order to make document retrieval work efficiently. A knowledge-based approach proposed by Navigl et al. [32] is used to do word sense disambiguation. Furthermore, the frequency of co-occurrence in UMLS is used to identify the concept.
For document retrieval, the okapi function is used to score the question concepts and keywords for retrieving the documents [36]. On the other hand, query expansion will increase the performance for document retrieval [30]. So the relations in the UMLS Metathesaurus are used to expand the query in [29] which the hierarchical relations are concerned as the important clue to increase the performance in document retrieval.
For answering definitional questions, Xu et al. [31] consider the linguistic features as the important clues to extract the definitions from the documents. With the growth of Web, the surface patterns [34] are utilized to collect the definitions from Web. In the project, we use the
4
definition database from UMLS to answer the definitional question. If the definition is not found in it, the online dictionary is queried to answer the question and expand the definition database at the same time.
3 The Proposed Methods and Results
3.1 The proposed named entities recognition
In this project, the recognition for protein entities from PubMed corpus is addressed so as to facilitate the automation of protein interaction databases construction. In order to mine more features relevant to protein entities, we assembled a domain-specific protein corpus SRC (SwissProt_Ref Corpus) extracted from SwissProt reference articles and tagged it by using SRC entry collection. The kernel NER is approached with two empirical strategies. One is rule-based strategy which exploits the patterns information mined from SRC. Experimental results show that the derived patterns are useful for NER task even though the number of the patterns is relatively less than the rules used in two popular systems Kex or Yapex. On the other hand, a concise HMM-based strategy is presented with a back-off strategy to overcome data sparseness. Experimental results on both GENIA corpus and the domain-specific SRC showed that the presented approach could achieve promising results in terms of 77% F-score in the case of strict annotation, proving that our approach is portable and competitive.
Besides, the recognition of the entities in coordination variants is concerned in this project. To resolve such term variants, a method based on heuristic rules together with clustering strategies is presented. Experimental results on GENIA corpus 3.0 proved the feasibility of the proposed approach by achieving 88.51% recall and 57.04% precision.
For detail description about the proposed method, please refer the attached conference paper presented in NLDB 2005, Alicante, Spain.
3.2 The proposed anaphora resolution for biomedical literature
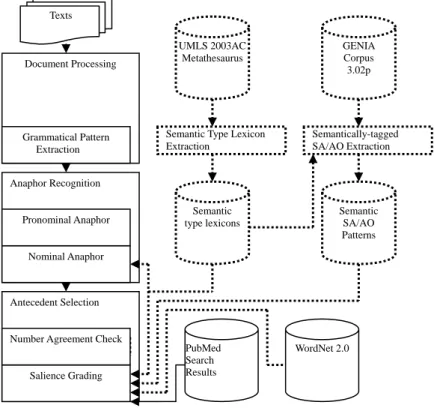
In this project, a resolution procedure as shown in Figure 3.1 is presented for tackling both nominal anaphora and pronominal anaphora in biomedical literature by using morphological, syntactic and semantic clues. For nominal anaphora resolution, semantic association between anaphora and its antecedents is predicted with the semantic lexicons mined from UMLS and WordNet. For unknown entities, the semantic association is discovered by mining the search results with the help of PubMed, the search engine for MEDLINE databases. On the other hand, semantic coercion type of pronominal anaphor is done by semantic-tagged SA/AO patterns, which were pre-collected from GENIA 3.02p corpus. Unlike manual decision of feature sets at salience grading on antecedent selection, the presented resolution is boosted with a genetic algorithm. Experimental results on the evaluation corpus MedStract, the presented resolution is promising for its 92% F-Score in pronominal anaphora and 78% F-Score in nominal anaphora.
For detail description about the proposed method, please refer the attached conference paper presented in IJCNLP 2005, Jesu Island, South Korea.
3.3 The proposed relation recognition from biomedical literature
In this project, the interactions between protein pairs are addressed. The SWISS-PROT database is used as our lexicon to identify protein entities in corpus by maximum matching procedure. Through corpus preprocessing, protein pairs are formed and processed by the proposed extraction method. As shown in Figure 3.2, the proposed relation extraction is
Grammar: [Question Word + Be + Noun Phrase] Question Word: What | Who
Be: is | are | was | were | be
Noun Phrase: ((Term1) (Term2) (Term3)…headword) | ((Term1 (Term2 (Term3 (…)))) headword)
divided into two stages. In the first stage, a set of predefined patterns mined from training corpus is employed to recognize relations from the testing sentences. In the second stage, the classifier based on Naive Bayes model is used for classifying each protein pair into two classes: “yes” or “no” by using a rich set of features which are verified with the Chi-Square test. The predefined features are described in detail in TABLE 1.
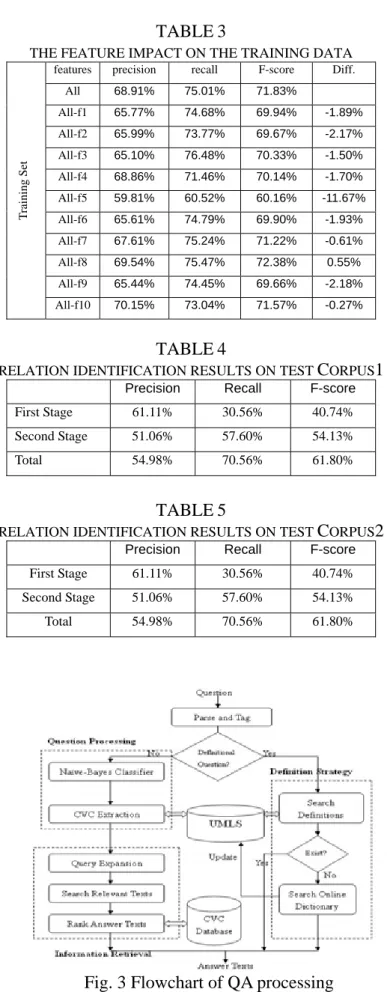
In order to select the best features, we incorporate the presented classifier with a genetic algorithm. TABLE 2 shows that we can have 74% F-score with the selected features and it is indeed better than the results yielded by using all features. TABLE 3 shows the impact of each feature in the training data. It reveals that the reference similarity feature plays a critical role for interaction extraction. Besides, the recognition performance is also justified with two corpora “Corpus1” and “Corpus2” with the best set of features selected by the genetic algorithm. (‘Corpus1 contains 155 Medline abstracts, and “Corpus2” contains 100 abstracts collected from the references listed in DIP.) The experiment results are displayed in TABLE 4 and TABLE 5, respectively. We can find that 61% F-score is achieved on both corpora, showing that the two-stage method is feasible for relation extraction.
For detail description about the proposed method, please refer the master thesis done by Hsiao-Ju Shih, Institute of Computer Science and Engineering, National Chiao Tung University 2006.
3.4 The proposed specific-domain question answering
The proposed QA processing is shown in Fig. 3.3 in which a given question is first identified to be is definitional or not. If the question is definitional type, the definitional strategy will be involved to process the question. If the question is the other types, a Naïve-Bayes classifier is employed to classify the questions into three target types. On the other hand, we use ontology-based expansion to expand the query term in order to increase the recall. Finally, we measure the returned texts by considering both TF-IDF and extracted concept patterns. Details of the implementation steps are described in the remaining subsections.
3.4.1 Rule-based approach for identifying definitional question
There are 108 definitional questions which have been classified manually in 910 pairs of the collected FAQs. We parse these questions and analyze the sentence structure. There are 88% definitional questions parsed as the following two structures.
The headword is the most important word for the noun phrase in the parsing tree. And then we can take the noun phrase to search the definitions in UMLS. The rules used to recognize definitional questions are listed as follows:
6
(i). The length of POS sequence is less and equal than four.
(ii). [“What or Who” + “be” + NP], the question structure is identified as structure 1 or structure 2.
(iii). The question contains only one NP. (iv). There are no prepositions in NP.
In the experiment, we take 40 definitional questions from TREC-9 to evaluate the definitional rules. The experimental results show that 36 questions are detected by these rules. The accuracy rate is 90% in the test data. Some errors are resulted from wrong parsing tree or tags.
3.4.2 Naïve-Bayes classifier for classifying other type questions
A Naïve-Bayes classifier is used to classify the non-definitional questions into the pre-defined types, namely: diagnosis, therapy and etiology. We collect 8,729 medical documents classified by PubMed as the training data. Then we filter out stop words or medical proper nouns in UMLS. The remaining monograms (single word) and bigrams (adjacent two words) are clustered into 18 groups by a typical K-means algorithm. Meanwhile, we extract POS sequence from the classified questions and use POS sequence as one feature for our classifier. We follow the Bayesian Theorem (defined by Equation (1)) to train the question classifier by the features of grams and POS sequence. Each question is assigned with one unique question type. In the testing phase, we take 453 questions randomly from the rest FAQs. There are 85% precision and 86% recall for diagnosis, 84% precision and 94% recall for therapy and 82% precision and 88% recall for etiology.
3.4.3 Concept identification
Concept identification is presented with the help of UMLS for each medical phrase in the question so as to transform the NP-Verb-NP pattern into CVC pattern. Since UMLS is the multi-node structure, it is necessary for us to do concept disambiguation. We use the co-occurrence information in UMLS and the concept probabilistic function is designed as equation (3). Then we use the association function defined as (2) to measure which concepts are the most possible one to be associated in the sentence. Details of concept identification steps are summarized as following.
Algorithm for Concept Identification IF the question contains only one noun phrase
THEN we get all concepts for the noun phrase from UMLS OTHERWISE
(i). Identify all concepts for noun phrases
(ii). Calculate the probability for all concepts of the noun phrases according to the co-occurrence in UMLS
(iii). Calculate the association value to choose the most possible concept by equation (2) and assign it to the noun phrase
( r, )h ( r h)* (h r) (2)
Association X Y =Prob X →Y Prob Y →X
( , ) ( ) (3) ( ,*) r h r h r freq X Y Prob X Y freq X → = Xr∈{X1, X2…, Xi}, Yh ∈{Y1, Y2…,Yj}
freq(Xr, *): any concepts in UMLS co-occur with concept Xr
freq(Xr, Yh): concept Xr co-occur with concept Yh
3 1 arg max ( ) ( | ) (1) c c i k Prob P C P F C = =
∏
C = {diagnosis, therapy, etiology} Fi = {unigram, bigram, POS sequence}
8 ( , , ) ( ) (4) ( , ) ( , ) ( , , ) A B t A B A B freq C Verb C Degree CVC
freq C Verb freq Verb C freq C Verb C
=
+ −
freq(Verb,CB) = the co-occurrence for (Verb,CB)
freq(CA,Verb) = the co-occurrence for (CA,Verb)
freq(CA,Verb,CB) = the co-occurrence for (CA,Verb,CB)
The extracted CVC patterns are used to score the answer texts in information retrieval. In the training phase, we use 400 medical terms as the keywords in UMLS to query the PubMed and collect 8,729 medical abstracts for training materials. The strategy is that all noun phrase preceding and succeeding the key verbs are extracted in the medical abstracts. If the noun phrase is a pronoun, the noun phrase which is preceded or succeeded the pronoun is extracted instead of the pronoun. Then noun phrases are combined with their preceding and succeeding verb as NP-Verb-NP patterns which are then transformed into CVC patterns.
For the verb in CVC patterns, we use the synsets of verb in WordNet to cluster CVC patterns into 4,496 groups and then we weigh each CVC pattern by equation (4).
At run time, we use CVC pattern extracted from the given question to retrieve the stored CVC patterns from the training result and use the relevant CVC patterns to score the answer texts returned by search engine.
3.4.4 Ontology-based Query Expansion
The query expansion is done with the the synonyms and hierarchical relations in UMLS Metathesaurus. The expanded strategy is described as follows:
3.4.5 Retrieval procedure and ranking
In the proposed QA, we use PubMed as the major information retrieval platform and Google as the minor platform. PubMed is triggered to retrieve the relevant medical texts if there exists. If not, Google will be triggered to retrieve the snippets according to the keywords from the given question.
The answer texts are measured by equation (5) based on TF-IDF. For each medical term in query
(i). Add the synonym variants in UMLS to the query (ii). Add its parent terms in UMLS to the query (iii). Add its child terms in UMLS to the query
(iv). Add other relations defined in UMLS to the query
, , , 0.5 (0.5 ) * log (5) max i j i j i j i freq N W freq n = +
∑
∑
freqi,j: the frequency of term i in the answer text j
N: the number of answer texts
Beside the TF-IDF rank, we also compute the rank for each CVC of the answer texts by scoring the degree of the CVC patterns checked in common between the question and the answer texts.
3.4.6 Results and Analysis
Two indicators are used to measure the performance for our method. One is the Mean Reciprocal Rank (MRR). Another is the Human Effort (HE). The HE is defined as the user finds the answer in the least rank of passages returned.
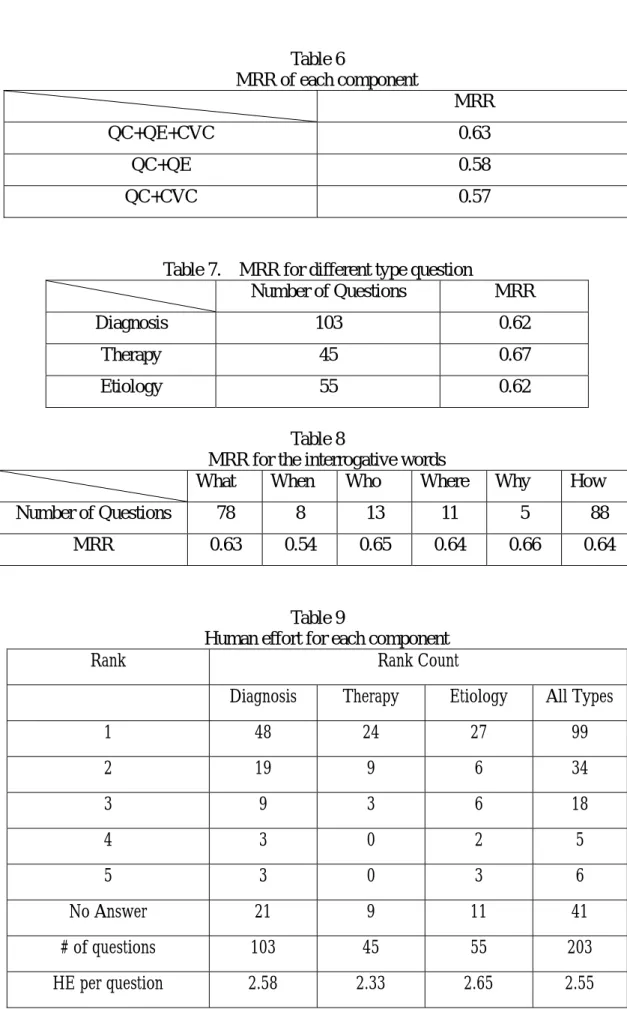
Table 6 shows the experimental results on 55 questions from testing corpus and it is noticed that the proposed question classification (QC), query expansion (QE) and CVC patterns ranking indeed improve the QA performance. Table 7 shows the experimental results on 203 set-aside FAQ questions of different types. Table 8 shows the experimental results on the questions from view point of interrogative words. Table 9 shows the results in terms of Human Effort (HE) and it shows that the answer passage is at the top 2 (or top 3) in the returned texts from the proposed QA.
There are some errors attributed to the following reasons: (1) Incorrect POS tagging.
(2) Assign the wrong category for the given question. (3) Assign the not appropriate concept to noun phrase.
For detail description about the proposed method, please refer the master thesis done by Li-Hong Huang, Institute of Computer Science and Engineering, National Chiao Tung University 2006.
4 Concluding Remarks
In this project, we presented different textual mining strategies and natural language techniques for resolving biomedical knowledge extraction from on-line biomedical literature. We address four basic issues, namely, entity recognition, anaphora resolution, relation recognition and question answering.
The proposed entity recognition is focused on protein entities in this project. Both empirical rule and statistical approaches to protein entity recognition are presented and investigated on a general corpus GENIA 3.02p and a new domain-specific corpus SRC. Experimental results show the rules derived from SRC are useful though they are simpler and more general than the one used by other rule based approaches. Meanwhile, a concise HMM-based model with rich set of features is presented and proved to be robust and competitive while comparing it to other successful hybrid models. Besides, recognition for the entities in coordination variants is also concerned. To our best knowledge, our approach is the first one to cope with the term variants in the named entity extraction from biomedical texts. Partial results of this research have been presented in NLDB2005, Alicante, Spain. (“Empirical Textual Mining to Protein Entities Recognition from PubMed Corpus”, NLDB 2005, Lecture Notes in Computer Science 3513, pp. 56-66, 2005. (SCI extended)).
The second issue is the resolution for pronominal and nominal anaphora in biomedical literature. The resolution is constructed with a salience grading on various kinds of syntactic and semantic features. Unlike previous researches, we exploit more resources including both domain-specific and general thesaurus and corpus while dealing with semantic and syntactic agreement between anaphors and their antecedents. Experimental results on different corpora
10
prove that the semantic features provided with the help of the outer resources indeed can enhance anaphora resolution. Compared to other approaches, the presented best-first strategy with the genetic-algorithm based feature selection can achieve the best resolution on the same evaluation corpus. Partial results of this research have been presented in IJCNLP 2005, Jesu Island, Korea. (Anaphora Resolution for Biomedical Literature by Exploiting Multiple
Resources, IJCNLP 2005, Lecture Notes in Artificial Intelligence 3651, pp. 742-753, 2005.
(SCI extended)).
The third issue is automation of relation recognition among entities. In this project, we focus the protein interaction recognition from biomedical literature by employing both database and textual mining techniques. Unlike previous researches which are generally based on linguistic methods, a two-stage recognition approach is proposed in this project with the aim to improve the recognition recall. The first stage involves utilizing linguistic patterns which imply interaction relation from sentence structures. The second stage is based on a Naïve Bayes classifier which employs a rich set of features, including surface features, co-occurrence, co-citations, and protein features. We use two corpora as our testing data. One is a corpus of 155 MEDLINE abstracts, and the other contains 100 abstracts which are collected from the references for proving interactions in DIP (Database of Interaction Proteins). The result shows that our approach can yield 62% and 61% F-score on both corpora and it indeed enhance the low recall yielded by a general linguistic recognition approach.
The fourth issue we addressed in this two-year project is the implementation of a specific-domain QA prototype which is able to efficiently resolve the questions frequently raised by end-users. We apply UMLS, a domain–specific ontology to query expansion. Beside, we present a new answer passage ranking by weighing the transformed concept patterns mined at the training phase. The patterns provide a more general outlook for medical QA with respect to different kinds of question types. The presented QA is verified with different kinds of questions by various measurements. The results show that the proposed QA is able to retrieve the answer passage in the top 2 (or top 3) returned texts. Partial results of this research have been presented in IJCNLP 2005, Jesu Island, Korea. (“Web-based Unsupervised
Learning for Query Formulation in Question Answering”, IJCNLP 2005, Lecture Notes in
Artificial Intelligence 3651, pp. 519-529, 2005. (SCI extended)). .
5 Reference
[1] Fukuda, K., Tsunoda, T., Tamura, A., and Takagi, T.: Towards Information Extraction: identifying Protein Names from Biological Papers. The 3rd Pacific Symposium on Biocomputing. (1998) 707-718.
[2] Hou, W. J. and Chen, H. H.: Enhancing Performance of Protein Name Recognizers using Collocation. ACL 2003 Workshop on Natural Language Processing in Biomedicine, (2003) 25-32.
[3] Lee, K.J., Hwang, Y.S., and Rim, H.C.: Two-Phase Biomedical NE Recognition based on SVMs. ACL 2003 Workshop on Natural Language Processing in Biomedicine, (2003) 33-40.
[4] Lin, Y., Tsai, T., Chiou, W. Wu, K., Sung, T.-Y., and Hsu, W-L.: A Maximum Entropy Approach to Biomedical Named Entity Recognition. 4th Workshop on Data Mining in Bioinformatics (2004).
[5] Olsson, F., Eriksson, G., Franzen, K., Asker, L., and Liden, P.: Notions of Correctness when Evaluating Protein Name Taggers. 19th International Conference on Computational Linguistics. (2002) 765-771.
[6] Settles, B.: Biomedical Named Entity Recognition Using Conditional Random Fields and Rich Feature Sets. Int’l Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA), Geneva, Switzerland (2004).
[7] Takeuchi, K. and Collier, N.: Bio-Medical Entity Extraction using Support Vector Machines. ACL 2003 Workshop on Natural Language Processing in Biomedicine, (2003) 57-64.
[8] Zhou, G.D. and Su, J.: Named Entity Recognition using an HMM-based Chunk Tagger. 40th Annual Meeting of the Association for Computational Linguistics (2002).
[9] Zhou, G., Zhang, J., Su, J., Shen, D. and Tan, C. L.: Recognizing Names in Biomedical Texts: A Machine Learning Approach. Bioinformatics, Vol. 20, (2004)1178-1190.
[10] Castaño, J., Zhang J., Pustejovsky, H.: Anaphora Resolution in Biomedical Literature. In International Symposium on Reference Resolution (2002)
[11] Dagan, I., Itai, A.: Automatic processing of large corpora for the resolution of anaphora references. In Proceedings of the 13th International Conference on Computational Linguistics (COLING'90) Vol. III (1990) 1-3
[12] Denber, M.: Automatic resolution of anaphora in English. Technical report, Eastman Kodak Co. (1998)
[13] Grosz, B.J., Joshi, A.K., Weinstein, S.: Centering: A framework for modelling the local coherence of discourse. Computational Linguistics 203.225 (1995)
[14] Hobbs, J.: Pronoun resolution, Research Report 76-1. Department of Computer Science, City College, City University of New York, August (1976)
[15] Kennedy, C., Boguraev, B.: Anaphora for everyone: Pronominal anaphora resolution without a parser. In Proceedings of the 16th International Conference on Computational Linguistics (1996) 113-118
[16] Kim, J., Jong, C.P.: BioAR: Anaphora Resolution for Relating Protein Names to Proteome Database Entries. ACL Workshop on Reference Resolution and its Applications Barcelona Spain (2004) 79-86
[17] Liang, T., Wu, D.S.: Automatic Pronominal Anaphora Resolution in English Texts. In Computational Linguistics and Chinese Language Processing Vol.9, No.1 (2004) 21-40 [18] Mitkov, R., Evans, R., Orasan, C.: A new fully automatic version of Mitkov's
knowledge-poor pronoun resolution method. In Proceedings of CICLing- 2000 Mexico City Mexico (2002)
[19] Modjeska, Natalia, Markert, K., Nissim, M.: Using the Web in Machine Learning for Other-Anaphora Resolution. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP2003) Sapporo Japan
[20] G. Leroy and H. Chen, “Filling preposition-based templates to capture information from medical abstracts,” in Proc. 7th Pacific Symposium on Biocomputing, pp.350-361, 2002. [21] J. Pustejovsky, J. Castano, and J. Zhang, “Robust relational parsing over biomedical
literature: extracting inhibit relations,” in Proc. 7th Pacific Symposium on Biocomputing, pp.362-373, 2002.
[22] S. Novichkova, S. Egorov, and N. Daraselia, “MedScan, a natural language processing engine for MEDLINE abstracts,” Bioinformatics, vol. 19, no. 13, pp. 1699-1706, 2003. [23] G. Leroy, H. Chen, and J. D. Martinez, “A shallow parser based on closed-class words to
capture relations in biomedical text,” Journal of Biomedical Informatics, vol. 36, pp. 145-158, 2003.
[24] C. Friedman, P. Kra, H. Yu, M. Krauthammer, and A. Rzhetsky, “Genies: a natural-language processing system for the extraction of molecular pathways from journal articles,” Bioinformatics, vol. 17, pp. 74-82, 2001.
[25] M. L. Huang, X. Y. Zhu, Y. Hao, D. G. Payan, K. B. Ou, and M. Li, “Discovering patterns to extract protein-protein interactions from full texts,” Bioinformatics, vol. 20, no. 18, 2004.
[26] A. Ramani, E. Marcotte, R. Bunescu, and R. Mooney, “Using biomedical literature mining to consolidate the set of known human protein-protein interactions,” in Proc.
12
ACL-ISMB Workshop on Linking Biological Literature, Ontologies and Databases: Mining Biological Semantics, pp. 46-53, 2005.
[27] T. Oyama, K. Kitano, K. Satou, and T. Ito, “Extraction of knowledge on protein-protein interaction by association rule discovery,” Bioinformatics, vol. 18, no. 5, pp. 705-714, 2002.
[28] C. Blaschke and A. Valencia, “The frame-based module of the SUISEKI information extraction system,” IEEE Intelligent Systems, pp. 14-20, 2002.
[29] C. H. Wu, J. F. Yeh, and M. J. Chen, “Domain-Specific FAQ Retrieval Using Independent Aspects,” ACM Transactions on Asian Language Information Processing, Vol. 4, No. 1, pp. 1-17, March, 2005.
[30] D. Moldovan, M. Pasca, S. Harabagiu, and M. Surdeanu, “Performance Issues and Error Analysis in an Open-domain Question Answering System,” In Proceedings of
ACM Transactions on Information Systems, vol. 21, pp. 133-154, 2003.
[31] J. Xu, R. Weischedel, and A. Licuanan, “Evaluation of an Extraction-Based Approach to Answering Definitional Questions,” In Proceedings of the 27th annual
international ACM SIGIR conference on Research and development in information retrieval(SIGIR-2004), pp. 418 – 424, 2004.
[32] R. Navigli and P. Velardi, “Structural Semantic Interconnections: A Knowledge-Based Approach to Word Sense Disambiguation,” IEEE Transactions on Pattern Analysis
and Machine Intelligence, Vol. 27, Issue 7, pp. 1075 - 1086, July, 2005.
[33] V. W. Soo, H. Y. Yeh, S. N. Lin, and W. C. Chen, “Ontology-based Knowledge Extraction from Semantic Annotated Biological Literatures,” The Ninth Conference on
Artificial Intelligence and Applications, 2004.
[34] W. Hildebrandt, B. Katz, and J. Lin, “Answering Definition Questions Using Multiple Knowledge Sources,” In Proceedings of the 2004 Human Language Technology
Conference and the North American Chapter of the Association for Computational Linguistics Annual Meeting (HLT/NAACL 2004), Boston, Massachusetts, pp.49-56,
2004
[35] Y. C. Wang, J. C. Wu, T. Liang, and J. S. Chang, “Using the Web as Corpus for Un-supervised Learning in Question Answering,” In Proceedings of ROCLING, pp.191-198, 2004.
[36] Z. Zhang, L. D. Sylva, C. Davidson, G. Lizarralde, and J. Y. Nie, “Domain-Specific QA for the Construction Sector,” In Workshop of ACM SIGIR Conference, July 29, 2004.
Appendix
Fig. 1. System architecture overview.
Fig. 2. Extraction flowchart.
Antecedent Selection Anaphor Recognition
Texts
Document Processing
Nominal Anaphor
Semantic Type Lexicon Extraction Semantic type lexicons PubMed Search Results Salience Grading WordNet 2.0 Semantically-tagged SA/AO Extraction UMLS 2003AC Metathesaurus GENIA Corpus 3.02p Semantic SA/AO Patterns
Number Agreement Check Pronominal Anaphor Grammatical Pattern
14
TABLE2
FEATURE SELECTION EXPERIMENTAL RESULTS WITH TRAINING CORPUS
Feature Precision Recall F-score Total features 68.91% 75.01% 71.83% Genetic features all-{f8,f10} 72.55% 75.58% 74.49% TABLE1
THE FEATURES DESCRIPTION
Feature No Description
1 The dice value of the frequencies of the protein
pair in the same sentences Distance
2 The average of minimum distances of the protein
pair in an abstract
Word 3 The cosine value of the protein pair which are
presented as m-word vectors
4
The dice value of the frequencies of the protein pair in the same abstracts searched by the PUBMED.
Co-citation
5 The maximum of reference similarities for
protein pair.
6 The similarity of the topic “function” in the
SwissProt database.
7 The similarity of the topic “similarity” in the
SwissProt database.
8 The similarity of the topic “subcellular location” in the SwissProt database.
9 The similarity of the topic “subunit” in the
SwissProt database. Topic
10 The similarity of the topic “catalytic activity” in the SwissProt database.
Fig. 3 Flowchart of QA processing TABLE3
THE FEATURE IMPACT ON THE TRAINING DATA
features precision recall F-score Diff.
All 68.91% 75.01% 71.83% All-f1 65.77% 74.68% 69.94% -1.89% All-f2 65.99% 73.77% 69.67% -2.17% All-f3 65.10% 76.48% 70.33% -1.50% All-f4 68.86% 71.46% 70.14% -1.70% All-f5 59.81% 60.52% 60.16% -11.67% All-f6 65.61% 74.79% 69.90% -1.93% All-f7 67.61% 75.24% 71.22% -0.61% All-f8 69.54% 75.47% 72.38% 0.55% All-f9 65.44% 74.45% 69.66% -2.18% T raining Set All-f10 70.15% 73.04% 71.57% -0.27% TABLE5
RELATION IDENTIFICATION RESULTS ON TEST CORPUS2
Precision Recall F-score First Stage 61.11% 30.56% 40.74% Second Stage 51.06% 57.60% 54.13%
Total 54.98% 70.56% 61.80%
TABLE4
RELATION IDENTIFICATION RESULTS ON TEST CORPUS1
Precision Recall F-score First Stage 61.11% 30.56% 40.74% Second Stage 51.06% 57.60% 54.13% Total 54.98% 70.56% 61.80%
16 Table 6 MRR of each component MRR QC+QE+CVC 0.63 QC+QE 0.58 QC+CVC 0.57
Table 7. MRR for different type question
Number of Questions MRR
Diagnosis 103 0.62 Therapy 45 0.67 Etiology 55 0.62
Table 8
MRR for the interrogative words
What When Who Where Why How
Number of Questions 78 8 13 11 5 88
MRR 0.63 0.54 0.65 0.64 0.66 0.64
Table 9
Human effort for each component
Rank Rank Count
Diagnosis Therapy Etiology All Types
1 48 24 27 99 2 19 9 6 34 3 9 3 6 18 4 3 0 2 5 5 3 0 3 6 No Answer 21 9 11 41 # of questions 103 45 55 203 HE per question 2.58 2.33 2.65 2.55