行政院國家科學委員會專題研究計畫成果報告
無線通訊環境下以語音擷取網路資訊相關技術之研究 ( I ) − 總計畫
計畫編號:NSC 89-2213-E-002-175
執行期限:89 年 8 月 1 日至 90 年 7 月 31 日
主持人:李琳山 國立台灣大學資訊工程學系
E-mail: [email protected]
ABSTRACT
The rapid development of the Internet and the World Wide Web has created a global network that will soon become a physical embodiment of the entire human knowledge and a complete integration of the global information activities. It is believed that one of the most user-friendly and natural approaches for accessing the network will be via human voice, and the integration of spoken language processing technologies with broadband wireless technologies will be a key to the evolution of a broadband wireless information community. This report offers an overview of the above concept, some technical considerations and some recent results.
Keywords: Wireless, Information Access, Internet, WWW, Broadband, Linguistic Knowledge, PAT tree, Lexicon, Document Classification.
1. INTRODUCTION
The commercialization of the Internet and the invention of the World Wide Web (WWW) has prompted the creation of a universe of virtually unlimited, network-accessible information that range from private, secure databases to free, publicly available services. Such typical examples as digital libraries, virtual museums, distant learning, network entertainment, network banking and electronic commerce have indicated that this global information network will soon become a physical embodiment of the whole human knowledge, and a complete integration of the global information activities. As the global information network evolves, efficient while user-friendly technologies for accessing the information infrastructure becomes increasingly important. Traditionally, the information infrastructure is accessed through a computer that is physically tied to the network.
The success of broadband wireless technologies will bring a new dimension into the way the above information is accessed or retrieved. Since full mobility support is possible, the user will no longer be constrained by the tether of the wire. The data rates of the future broadband wireless systems range from 384 kbps (IMT-2000) to 10s of Mbps (wireless LAN), which are capable of carrying multi-media traffic. However, as the size of the handset shrinks, traditional keyboard or keypad input and screen output becomes increasingly inconvenient.
Therefore, an efficient, flexible, and user-friendly approach specially suitable for broadband personal wireless communicators is an important enabling factor for “anytime, anywhere” access to the information infrastructure. Speech is one of the most user-friendly and natural mechanisms for information access, and Chinese spoken language processing technologies, after diligent research efforts for decades, have matured to a point where many useful and commercially beneficial applications become feasible recently. Therefore, a good integration of advanced Chinese spoken language processing and broadband wireless technologies will be a key factor for evolution of a speech-enabled information society for the Chinese community in a broadband wireless era.
2. THE BROADBAND WIRELESS
ENVIRONMENT
In essence, broadband wireless refers to the multimedia-capable high data rate (greater than 384 kbps) services provided to mobile wireless terminals. The ultimate goal of broadband wireless is to provide services to mobile users with the same high quality and broadband characteristics as fixed networks without the tether of the wire. Mobility should be fully and seamlessly supported, i.e., users should receive exactly the same services wherever and whenever they access the network. Physical limitations and channel impairments, including limited bandwidth, power and complexity constraints, multipath propagation, signal fading, interference, and noise, present significant technical hurdles that must be overcome in order to provide reliable high-data-rate wireless mobile communication services. The efforts to overcome these technical challenges have led to several emerging system approaches, including the evolution of second-generation cellular systems to higher data rates, the so-called third-generation cellular system, broadband wireless local access systems, and wireless local area networks (WLAN’s) [1-6]. Although these emerging systems sometimes compete with each other, it has become a common understanding that different broadband wireless technologies must peacefully coexist and somewhat interoperate with each other in order to achieve the goal of providing ubiquitous tetherless broadband access to the global information network. Thus, although the emerging technologies may differ in many aspects such as air interface, data rate, coverage area, supported mobile speed, interoperability and interworking, seamless information transfer among different systems is expected in the future. As shown in Figure 1, the emerging
systems promise the creation of a future“broadband wireless environment ” in which the mobile users have ubiquitous tetherless broadband access to the global information network. On the other hand, wireless channels are relatively unreliable due to multipath fading propagation. Furthermore, mobile wireless terminals are often used in noisy environments such as in a car or in a crowded shopping mall. The computational power of a mobile wireless terminal is often limited due to concerns in portability and battery life. As a result, voice access technologies applied to broadband wireless must overcome many technical hurdles. For example, the complexity and power drain of the speech processors built on the mobile wireless terminals must be low enough for the terminals to handle. Speech recognition technologies, if implemented on the mobile terminal, must deal with such impairments as variable and generally poor microphone reception and background noise. In cases where the speech signals or speech feature parameters are transmitted wirelessly to a speech recognition server that is located somewhere in the network, the speech signals or feature parameters must be tailored to fit in the limited bandwidth even when broadband wireless is used. Speech recognition in these cases must also deal with such impairments as lost frames due to transmission errors or network congestion, low-bit-rate speech coding, as well as poor microphone reception and background noise, all of which result in significant speech quality degradation. Furthermore, in general speech recognition is required to be very robust and reliable because back-up methods such as keypad or touch-tone input may become too cumbersome or even no longer available. Speaker verification technologies for user authentication also face similar challenges. On the other hand, text-to-speech synthesis and dialogue systems must deal with the variable and generally longer delay encountered in broadband packet-switched networks, lost frames, as well as degraded speech quality due to the limited bandwidth of wireless communications. Furthermore, multi-lingual capabilities may be needed. For example, although the input speech is in Chinese, the information to be accessed may be in many different languages. Language identification and machine translation technologies will be needed in such cases.
3. LINGUISTIC KNOWLEDGE
PROCESSING IN FUTURE NETWORK
ERA
In the future network era, huge volume of information on all subject domains will be readily available via the network. Also, all the network information are dynamic, ever-changing and exploding. Furthermore, many of the spoken language processing applications will have to do with the content of the network information, which is dynamic. In order to cope with such a new network environment, automatic approaches for the collection, classification, indexing, organization and utilization of the linguistic data obtainable from the networks will be very important. On the one hand, high performance spoken language processing technology can hopefully be developed based on such huge volume of linguistic data on the network. On the other hand , it is also necessary that such spoken language processing technology can be intelligently adapted to the content of the dynamic and ever-changing network information. Considering all the above, some basic concepts have been developed and briefly summarized here.
Fig.2 depicts the linguistic knowledge (lexicon, language model, plus others) used in the future network environment. In order to handle the “live” language in the network era, as shown in Fig 2, unlimited dynamic corpora are collected from the network resources every second and various ever-changing linguistic knowledge are continuously extracted from such network information automatically, such as the multiple dynamic lexicons and multiple dynamic language models for different subject domains. The dynamic collections of linguistic knowledge on all possible subject domains provide a much more powerful base to handle the “live” language in the network era for future spoken language processing technology. Although there may always exist some linguistic knowledge which can’t be easily generated completely automatically and human efforts are still needed, automatic generation of linguistic knowledge will always be an attractive goal to pursue in the future.
Web Server Corporate Intranet Intelligent Agent WLAN
AP
Core Network Broadband Wireless Access 3G Cellular Systems EDGE/ DWC-136 ATM or IP Backbone The Internet PSTNInternet Corpora Spoken Language Processing Document Processor Other Linguistic Knowledge automatically obtained from the Internet Linguistic Knowledge
(most parts automatically obtained from the Internet) Multiple Dynamic Language Models Multiple Dynamic Lexicons
Fig.2. The Linguistic Knowledge Used in Future Spoken Language Processing Technology Environments
With the above concept, many relevant linguistic knowledge processing technologies based on the concept of PAT-tree have been developed [7]. An initial framework is shown in the block diagram in Fig 3. A document classifier is used to divide the documents collected from the Internet into different categories of classified corpora. A PAT tree generator is then used to construct the PAT trees for the classified corpora including all documents classified to each corpus. These PAT trees for the classified corpora can then be used as pattern indexing files for information retrieval, N-gram language models in speech recognition, for live lexicon construction and new documents classification, etc.[7].
4. SOME RECENT RESULTS
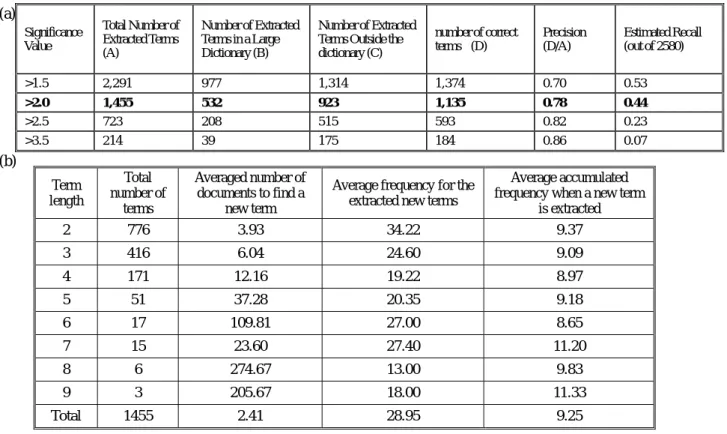
Some recent test results for the live lexicon are listed in Table 1. The news abstracts published by the Chinese News Agency of Taiwan from June 1 to 20 1999 were entered as the raw test corpora for extracting keywords and key terms, out of which a total of 2580 terms were selected manually as a reference for comparison. Different thresholds can be selected for the significance values of the terms to be taken as key terms. For example, in the second row of Table 1(a), when the threshold of significance value is taken to be 2.0, a total of 1,455 terms were extracted, out of which 532 are in a general domain dictionary but 923 are not. 1,135 terms out of the 1,435 extracted are in fact correct, i.e., within the 2580 manually selected. This gives a precision rate of 0.78(1,135/1,455) and a recall rate of 0.44(1,135/2,580). The results for the on-line extraction are in Table 1(b), in which the terms are extracted continuously when the news abstracts are entered one by one. The term length in Table 1(b)is the number of characters in a term. It can be found from Table 1(b) that roughly half of the key terms have only 2 characters, and there are much less key terms with more characters. Also, in average a new key term was extracted when 2.41 news abstracts were entered, and each key term appears 28.95 times in average in the entire news abstract database. Furthermore, when a new key term is extracted, it has appeared 9.25 times in average.
Some recent results for automatic document classification are listed in Table 2. These results are for news abstracts published
by the Chinese News Agency of Taiwan in January to June 1997, in which the news for January to May are taken as training documents, and those for June as testing documents. The news abstracts have been manually classified by the Chinese News Agency into 8 domains, such as politics, business, sports, weather, etc. So 8 PAT-trees for the 8 domains were constructed, and the test results can be easily compared with the manual classification results. In Table 2 the sizes of the training/testing documents and the PAT-trees are listed for all the 8 domains, together with the precision and recall rates.
For example, the precision rate for the sports news is 85.20%, i.e., out of those classified as sports news 85.2% are correct, and the recall rate is 78.60%, i.e., 78.60% of sports news are correctly classified into the sports domain. It can be found that the average precision rate is 72.00%, while the average recall rate is 65.50%. Also, the weather reports give the highest precision/recall rates, 100% for both cases, apparently due to the limited vocabulary and sentence structures.
5. CONCLUSION
It is believed that a good integration of Chinese spoken language processing and broadband wireless technologies will provide an extremely attractive solution for Chinese community to achieve the goal of “anytime, anywhere” access to the global information infrastructure. Although many difficult technical hurdles and substantial amount of work lies ahead, we believe that the practical demands from the users, the technical interests of the technology developers, and the business motivation of the service providers will soon merge to realize the vision.
INTERNET
Spoken Language Processing Applications Network Information Processing and
Organization Information Spider Document Classifier PAT tree Generator Classified Corpora Key Terms Extractor Linguistic Information Databases Document Processors Pattern Indexing Files PAT trees N-gram Language Models Classified Lexicons Process Data
REFERENCES
[1] A. Furuskar et al., “EDGE, Enhanced Data Rates for GSM and TDMA/136 Evolution,” IEEE Personal
Communications, June 1999, pp.56-67.
[2] R. van Nobelen et al., “An Adaptive Radio Link Protocol with Enhanced Data Rates for GSM Evolution,” IEEE
Personal Communications, February 1999, pp.54-64.
[3] N. Sollenberger et al.,“The Evolution of IS-136 TDMA for Third-Generation Wireless Services,”IEEE Personal
Communications, June 1999, pp.8-19.
[4] M. Austin et al., “Service and System Enhancements for TDMA Digital Cellular Systems,” IEEE Personal
Communications, June 1999, pp.20-33.
[5] J. Uddenfeldt, “Digital Cellular − Its Roots and Its Future,” IEEE Proceedings, Vol. 86, No. 7, July 1998, pp.1319-1324.
[6] E. Dahlman et al, “UMTS/IMT-2000 Based on Wideband CDMA,” IEEE Communication Magazine, Vol. 36, No., 9, September 1998, pp. 70-80.
[7] Lin-shan Lee, “Structural Features of Chinese Language − Why Chinese Spoken Language is Special and Where We Are”, International Symposium on Chinese Spoken
Language Processing, Singapore, December 1998.
Term length Total number of terms Averaged number of documents to find a new term
Average frequency for the extracted new terms
Average accumulated frequency when a new term
is extracted 2 776 3.93 34.22 9.37 3 416 6.04 24.60 9.09 4 171 12.16 19.22 8.97 5 51 37.28 20.35 9.18 6 17 109.81 27.00 8.65 7 15 23.60 27.40 11.20 8 6 274.67 13.00 9.83 9 3 205.67 18.00 11.33 Total 1455 2.41 28.95 9.25
Table 1 Recent Results for Live Lexicon Construction from New Abstracts (a)precision and recall
Table 2 Recent Results for On-line Document Classification
Domain PAT Tree Size Training Size Testing Size Speed on PⅡ266PC Precision Recall (K bytes) Doc # K bytes Doc # K bytes (#Doc/sec)
Politics 27,310 12,587 4,490 1,262 382.0 10.51 51.20% 92.50% Congress 15,852 10,114 2,490 1,173 227.0 15.45 69.40% 61.00% Business 7,071 7,337 1,800 1,082 219.0 15.03 91.40% 45.20% Education 4,894 2,942 775 424 87.4 11.13 62.30% 53.30% Sports 2,571 1,626 413 248 49.3 13.47 85.20% 78.60% Local 11,117 6,580 1,690 968 201.0 14.57 73.80% 43.40% Weather 867 2,896 3,130 435 474.0 8.97 100.00% 100.00% Events 5,844 989 1,690 132 193.0 3.8 39.10% 81.80% Total/Avg 75,526 45,071 16,478 5,724 1832.7 12.07 72.00% 65.50% Significance Value Total Number of Extracted Terms (A) Number of Extracted Terms in a Large Dictionary (B) Number of Extracted Terms Outside the dictionary (C) number of correct terms (D) Precision (D/A) Estimated Recall (out of 2580) >1.5 2,291 977 1,314 1,374 0.70 0.53 >2.0 1,455 532 923 1,135 0.78 0.44 >2.5 723 208 515 593 0.82 0.23 >3.5 214 39 175 184 0.86 0.07
(a)
Table 1 Recent Results for Live Lexicon Construction from News Abstracts (a) precision and recall rates (b)on-line results