The 47th IEEE International Midwest Symposium on Circuits and Systems
LSI Design for MPEG-4 Coding System
Yung-Chi Chang, Wei-Min Chao and Liang-Gee Chen
DSP/IC Design Lab
Department of Electrical Engineering and Graduate Institute of Electronics Engineering National Taiwan University, Taipei, Taiwan, R.O.C.
A b s t m c t - This paper presents an LSI design for MPEG-4 video coding. We adopt platform-based architecture with an em- bedded RISC core and efficient memory organization. A fast mo- tion estimator architecture supporting predictive diamond search and spiral full search with halfway termination is implemented to make good compromise between compression performance and design cost. Several key modules are integrated into an efficient platform in hardwarehoftware co-design fashion. With high de- gree of optimization in both algorithm and architecture levels, a cost-efficient video encoder LSI is implemented. It consumes 256.8mW at 40MHz and achieves real-time encoding of 30 CIF
(352x288) frames per second.
I. INTRODUCTION
The emerging MPEG-4 standard becomes the main tech- nique of the mobile devices and streaming video applications such as smart phone and handheld PDA devices. The im- proved coding efficiency and many advanced functionalities of MPEG-4 come with much higher computational complexity compared with previous standards. According to the computa- tional complexity analysis reported in [ 11 and [2], the dominat- ing computation-intensive tasks in MPEG-4 core profile cod- ing are motion estimation(ME) and shape encoding, which to- gether contribute more than 90% of the overall complexity. For simple profile without shape coding tools, ME becomes the most significant one. It belongs to highly regular low-level task, and a huge amount of data access through frame buffer is also required. So, dedicated architectures and local buffers are heav- ily relied for efficient implementations and data access reduc- tion. For other coding tasks, including DCT/IDCT, Q/IQ, and MC, dedicated architectures can be adopted for these highly regular tasks. Programmable architectures are suitable for the other less-demanding but high-level task, such as system con- trol.
Several MPEG-4 video chips have been reported in the past. To satisfy rich functionality of future multimedia, some are im- plemented in software [3] based on the low-power DSP plat- form. They have highest flexibility but to achieve the real-time performance under the limited resources, the fast algorithms of ME and DCT are applied and the compression quality de- grades. Some [4] use the dedicated hardware methodology to achieve low power and low area cost. Lack of potential for fu- ture modification of advanced algorithms and higher design ef- fort are disadvantages. Hence, some [5] [6] adopted the hybrid softwarehardware co-design to compromise the performance and flexibility for complex coding flow.
In this paper, a RISC-based platform with hardware acceler- ators is presented to implement MPEG-4 video encoding al- gorithms. The optimization in both algorithm and architecture level is applied. Not only the key components but also the con- nection optimization are discussed in this paper. First, the cod-
PROGRAM
L
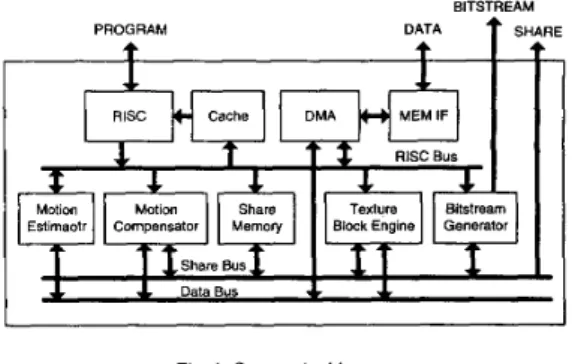
Fig. 1 . System Architecture
ing system is divided into three main subsystems, motion, tex- ture, and bitstream, which are optimized by observing the rela- tionship at the algorithm and architecture level. In motion sub- system, the hybrid motion estimator supporting both predictive diamond search and spiral full search with halfway termination for real-time or high compression quality applications are pro- posed to reduce the dominant cost in the typical coding system. In the texture subsystem, the efficient interleaving schedule and substructure sharing technique among quantization and DC/AC prediction are proposed [7] to reduce the cost further. In the bitstream subsystem, to handle the complex bitstream syntax and avoid inefficient bit-level storage, the hardwarekoftware co-operations scheme is applied for the bitstream generation. After the optimization described above, a compact MPEG-4 video encoder LSI is implemented.
11. S Y S T E M A R C H I T E C T U R E
Fig.1 depicts the proposed platform-based system with hard- ware accelerators to achieve a MPEG-4 video coding func- tionalities. RISC takes responsibility for MB level hardware scheduling, coding mode decision, motion vector coding, and other high level procedures. Other hardware accelerators im- prove the system performance by parallel processing according to the parallelism of algorithms. Motion estimator (ME) car- ries out motion estimation with the search range -16.0 to +15.5 pixel unit. Motion compensator (MC) interpolates pixels in reference frames into compensated blocks by specified motion vectors. Texture block engine (TBE) carries out discrete cosine transform (DCT), inverse cosine transform (IDCT), quantiza- tion (Q), inverse quantization (IQ), and AC/DC prediction on texture pixels in block unit. Bitstream generator (BTS) pro- duces headers, motion information, and texture information in the format of variable length codes. In addition, share memory builds the direct channels from MC to TBE and BE to BTS to decrease the traffic of the data bus. DMA involved in dedicated commands efficiently generates the proper addresses issued by
0-7803-8346-X/04/$20.00 0 2 0 0 4 IEEE
Frame-based ma
Word-based map
I
?',;Icee
I
ReconstructedframeI
lnfz::&n
I
BitstreamI
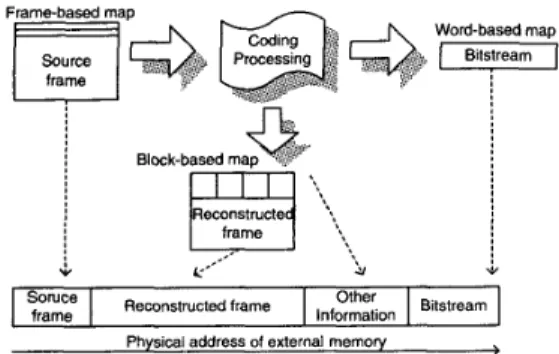
Physical address of external memoy >Fig. 2. Heterogeneous memory organizations for data with different features
RISC. Four global bus channels are used in this system. First, RISC bus broadcasts controlling information to each hardware modules. After applying operations issued by RISC, hardware modules respond processed side information for MB coding mode decision at RISC. At the same time source, reference, and reconstructed frames required by hardware modules are passed through DMA and then provided by DATA bus. Hardware modules efficiently access the data automatically according to pre-determined scheduling. These parts are integrated into a single chip with the firmware stored outside for prograrnmabil- ity through PROGRAM bus after taped out. SHARE bus can transfer DCT coefficients, quantized coefficients, or other im- mediate information in the testing mode. The developing time and effort can be reduced through this information.
111. MEMORY ORGANIZATION
We separate the memory organization into an off-chip mem- ory and several on-chip memory blocks. Off-chip memory con- tains source frames, reconstructed frames, and ACDC infor- mation. On-chip memory is used as local buffers to eliminate the bus bandwidth. Due to the penalty of irregular accessing to and from off-chip RAM, the memory addressing should be more regular and consecutively for efficient bandwidth utiliza- tion. So, we make access to and from off-chip RAM more suc- cessively by using random access on-chip RAM. For MPEG-4 video coding, block-based memory organization is efficient to burst reading a block of data for video processing. However, the common video inputloutput devices usually adopt the raster scan direction. It makes addressing more regular if frame data is arranged in frame-based scheme. Therefore, we use hetero- geneous memory organization for off-chip RAM as shown in Fig. 2 . The source frames are stored in the frame-based way, while the reconstructed frames are store in the block-based way for processing in the future. The bitstream data and A CD C in- formation is arranged as traditional 1-D addressing. After this arrangement, the data access to/from off-chip will more con- secutive.
The input video source, reconstructed frames, and trans- formed coefficients for AC/DC prediction are stored in the ex- ternal memory. Direct Memory Access (DMA) plays a role to control memory interface (MIF) to read data from or write data to the external memory in a specified sequence after being ini- tialized by RISC. For this kind of data-intensive applications, DMA always have a heavy load to handle the traffic through the data bus. Therefore, three special functions are involved
lnsrrucrion Fetch Instruction Decode Register Read Data-path Execuration Write back
Fig. 3. Architecture o f RISC
in DMA to reduce addressing overhead and to provide pixel data more efficiently. It not only can improve the data access but also decrease the complexity of address generation in other hardware modules. First, the addressing generation combines the conversion process of 2-D to 1-D address. Second, the ad- vanced prediction mode allows motion vectors to point out of the VOP and the data is padded from the boundary pixels in this situation. DMA handles this problem of boundary data for ME and MC units that can focus on the current processing MB. Third, special addressing for half-pixel precision compensation is supported. Due to the half-pixel precision for motion com- pensation, the compensated block is read out in 9 by 9 pixels and may occupy the four blocks in the block-based memory organization. This kind of fixed addressing is designed in the control unit of the DMA to improve the performance.
IV. RISC ARCHITECTURE
In MPEG-4 video encoding flow, many decisions should be made to choose the optimal combination of coding modes to make efficient compression. The computation of these decision-making procedures is not high but complex. We adopt a RISC core in our coding system for these procedures. The special 2-operand MAX and MIN instruction is included for the median operations for MV predictor decision. Besides, a hard- wired datapath for multiplication and division is also provided. The most important task of the RISC core in the platform is to consult all other hardware units to make co-operation between software and hardware well. Basically, to achieve this goal, the information should be exchanged easily between these two parts without much overhead. The memory-map addressing and accessing is typically used for its simplicity and to trans- fer data to peripherals is just like the behavior of accessing the memory without dedicated ports or special mechanism. In tra- ditional RISC instruction set, it takes two instructions to send a specified data to memory. One instruction moves the data into a register and then the other one saves the data of the regis- ter to the memory. Therefore, we propose an immediate store instruction (SWI). If the constant number is decided to issue some units in the design time, this instruction can replace the two instructions of traditional RISC-like processor. It results in significant reduction in the code size.
The overall RISC architecture is presented in Fig. 3. Four stages pipeline is adopted, and program and data memory are separated. To avoid branch and data hazard, techniques of for- warding and hazard detection are employed in the flow decision unit. The instruction set is 21 bits and the word width of the reg-
I I Pattern Pattern
=
I
I
Pattern Generation .._.__...._ ~ ._._.._____
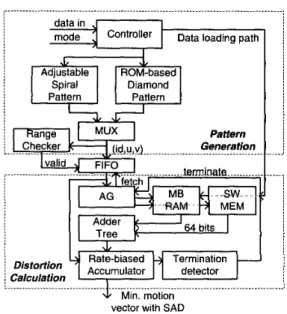
.... 64 bits Adder Tree vector with S A D Fig. 4. Architecture of motion estimatorister file that comprises 16 registers is 16 bits. To achieve cycle- accurately controlling, an inner-timer and polling technique are introduced. A special instruction, WAIT, is used to support this functionality. While the RISC encounters the WAIT instruc- tions, it goes into the idle state and waits until the next trigger events. The source of events may come from the inner timer or the external signal handler (ESH). The inner timer generates a wake-up signal after the specified count of cycles while the ESH receives the signals from peripherals to interrupt the idle state. In this way, RISC knows there are the events happens and read the information from RISC Bus.
v.
MOTION ESTIMATOR ARCHITECTURE DESIGN To meet the requirement of various applications under the ac- ceptable cost, we adopt two kinds of algorithms for the mo- tion estimation of 16x 16 block size at integer-pixel precision. One is the spiral full search with halfway termination (called fast full search, FFS) which can achieve the same compression efficiency as the full search algorithm. The other is the dia- mond search starting from the predictor derived from neighbor- ing MBs (called predictive diamond search, PDS) and it meets the real-time specification under the visual quality degradation. Afterwards, the hierarchy scheme is applied for the motion es- timation for four 8x8 pixels blocks in a MB around +2 to -2 positions of the previous best motion vector. The half-pixel re- finement is also applied for all found integer-pixel motion vec- tors. The whole stages of motion estimation is described as fol- lows. The predictor is determined from neighboring MBs. ThePDS mode or FFS mode is employed to find the integer pixel motion vectors. The half-pixel refinement is applied around the motion vector found in the phase 2. For four 8x8 pixel blocks in a MB, the spiral search around -2 to +2 is applied to obtain four optimal motion vectors. Four times of half-pixel refinement is applied around the motion vectors found in the previous phases. Fig.4 depicts the hardware architecture of the motion estima- tor supporting PDS and FFS. This architecture mainly includes three processing stages and two buffers to store current MB and
Computer I I . U .b MEMIF
I
- -
Fig. 5. Configurable platform
the search window. Before performing motion estimation, the video coding system transfers data from external memory into these buffers to eliminate the bus bandwidth for calculating of sum of absolute difference in the following. Meanwhile, the adder tree accumulates the sum of the pixels in the current MB to save it into a register for the mode decision in the future. To speed up the data loading and reduce the bus traffic, the search window buffer can be loaded using column-by-column data-reuse scheme. After motion estimation starts, the pattern generation (PG) stage generates the valid candidate positions. Then these positions are passed through the FIFO stage and fetched by the distortion calculation (DC) stage. The DC stage is responsible for calculating SAD of candidate positions and finds the minimum one. The accumulation comparison elim- ination (ACE) unit performs the PDE algorithm to reduce the computational complexity.
VI. IMPLEMENTATION
A configurable platform shown in Fig. 5 is used to verify the functionality of our architecture design. This prototyping board is connected through the PCI interface to the host com- puter. Four separated memory with DMA modules are used to handle PROGRAM, DATA, SHARE, and BITSTREAM bus from our design. An arbiter is responsible for the memory ac- cess through PCI and memory. The MPEG-4 video encoder design is synthesized and placed on the FPGA chip. The RISC program is compiled to machine codes by the host computer and then sent to the program memory. Raw image data is trans- ferred from the host computer to the frame memory on the pro- totyping board. Video encoding is processed concurrently. Af- terwards, bitstream data are stored in the bitstream memory and then read from the host computer. Besides, the share memory can record the immediate information for debugging in the test- ing mode.
Fig.6 shows a micrograph of the encoder LSI and Table I de- picts its characteristics. The LSI contains 828K transistors and is fabricated on a 5.02 x 5.13 mm2 with 0.35 /I m and single- poly quadruple-metal CMOS process. The chip is tested and works successfully. The supply voltage is 3.3V and consumes 256.8mW at 40MHz working frequency. Table I1 shows the number of transistors, the area, and the size ratio to the LSI of each unit.
Table 111 gives a comparison of some MPEG-4 video codec
TABLE Ill
Architectures Comparison
Complexity Frequency (MHz)
Designer
I
[4] [SI [61 ProposedEncoding
I
CIF, QCIF, CIF, CIF, 15fps 15fps 15fps 3Ofps13.5 60 27 40
Fig. 6. Micrograph of this encoder
TABLE I
Charactemtics of the encoder chip
Technology Die Size
TSMC 0.35 p n 1P4M CMOS 5.02 x 5.13 mm2 Transistor count 828,692 trans.
On-chip memory 39,080 bits
Off-chip memory 2,027,527 bits
Clock frequency 40 MHz
Power consumption 256.8mW
Package 208 CQFP
Voltage 3.3v
ME algorithm Predictive diamond search & Search range -16.0 to +15.5 &
Advanced prediction mode 352 x 288 at 30 fos Encoding comolexitv TABLE I 1 CO$[ dimhution ME MC DCT/IDCT in TBE QhQ in TBE ACDCP in TBE RISC DMA VLC Share MEM Others (PAD etc.)
Total Trans. (k) 288 53 126 64 22 112 19 95 68 49 829
Area Size ratio
5.8 22.6 0.3 1.2 1.6 6.2 0.7 2.9 0.8 3.0 1.8 7 .O 0.3 1.2 0.7 2.7 2.8 10.9 10.9 42.3 25.8 100.0 (nam2) (%) 240 500 256.8
I
29 Power (mW) . . 20’500 1,700 829 Transistor (K)1
31150 (DRAM)I
0.18 0.25 0.35 0.35 Process (trm) \ r ~ - - ~ , I 28.048 117.506 110.25 25.801 Chip area (m,m2)LSI proposed before. In [4], it is a full dedicated hardware video codec design. It uses MVFAST for ME with search range -16-+15.5. In [5], it is a platform-based videokpeech codec design. It uses 3-step hierarchical search for ME with search range -32-+31.5. In [6], it is a platform-based video codec de- sign with ARMIAMBA. It uses a coarse ME with search range -8-+7.5. All chip designs adopts fast algorithms for motion es- timation. In the viewpoint of video encoder parts, our work has highest encoding complexity and the lowest cost meanwhile.
VII. CONCLUSION
In this paper, an efficient platform architecture design with hardware accelerators for MPEG-4 Simple Profile@Level 3 video encoder LSI is proposed. With the proposed hybrid mo- tion estimation and RISC modules, the system are implemented into 5.03x5.13 mm2 die size with 0.35 pm CMOS technol- ogy process. It works at 40MHz and consumes 256.8mW to meet the real-time encoding specification. The proposed de- sign achieves high performance with low design cost, which proves that a cost-effective MPEG-4 coding system LSI imple- mentation is realized.
REFERENCES
P. M. Kuhn and W. Stechele, “Complexity analysis of the emerging MPEG-4 standard as a basis for VLSl implementation,” in International Conference on Visual Communications and Image Processing, 1998. H .C. Chang, L. G. Chen, M. Y. Hsu, and Y. C. Chang, “Performance analysis and architecture evaluation of MPEG-4 video codec system,’’ in
IEEE International Svmposium on Circuits and Svstems (ISCAS), 2000, vol. 2 , pp. 4 4 9 4 5 2 .
A. Hatabu, T. Miyazaki, and 1. Kuroda, “QVGAKIF resolution MPEG-4 video codec based on a low-power and general-purpose DSP,” in IEEE Workshop on Signal Processing Svstems (SiPS), 2002, pp. 15-20, H. Nakayama, T. Yoshitake. H. Komazaki, Y. Watanabe, H. Araki, K. Morioka, J. Li, L. Peilin, S. Lee, H. Kubosawa, and Y. Otobe, “An MPEG-4 Video LSI with an Error-Resilient Codec Core Based on a Fast Motion Estimation Algorithm,” in IEEE International Solid-Sfare Circuits Conference (ISSCC), 2002, vol. I , pp. 3 6 8 4 7 4 .
M. Takahashi, T. Nishikawa, M. Hamada, T. Takayanagi, H. Arakida, N. Machida, H. Yamamoto, T. Fujiyoshi, Y. Ohashi, 0. Yamagishi,
T. Samata, A. Asano, T. Terazawa, K. Ohmori, Y. Watanabe, H. Naka- mura, S. Minami. T. Kuroda, and T. Furuyama, “A 60-MHz 240-mW
MPEG-4 Videophone LSI with 16-Mb Embedded DRAM.” IEEE Jour- nal of Solid-Stare Circuit, vol. 35, no. 1 I , pp. 171 3-1721, Nov 2000. J . H. Park, I. K. Kim, S. M. Kim, S . M. Park, B. T. Koo, K. S. Shin, K. B. Seo, and J. J. Cha, “MPEG-4 Video Codec on an ARM core and AMBA.” in Workshop and Exhibition on MPEG-4, 2001, pp. 95-98.
C. W. Hsu, W. M. Chao. Y. C. Chang, and L. G. Chen. “Cost-Effective Scheduling Of Texture Coding For MPEG-4 Video,” IEEE Inrertiationol Conference on Multimedia and E.spo(lCME‘O2). Aug 2002.