國立交通大學
電機與控制工程學系
碩 士 論 文
相機陣列影像縫合之快速校正技術
Fast Calibration Techniques for Auto-Stitch of Camera Array
Image
研 究 生:莊詠麟
指導教授:董蘭榮 博士
相機陣列影像縫合之快速校正技術
Fast Calibration Techniques for Auto-Stitch of Camera Array
Image
研 究 生:莊詠麟 Student:Yung-Lin Ghuang
指導教授:董蘭榮 博士 Advisor:Lan-Rong Dung
國 立 交 通 大 學
電 機 與 控 制 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Department of Electrical and Control Engineering
September 2008
Hsinchu, Taiwan, Republic of China
相機陣列影像縫合之快速校正技術
研 究 生:莊詠麟 指導教授:董蘭榮 博士
國立交通大學電機與控制工程學系
摘要
這篇論文的目標是發展一個使用影像縫合技術於相機校正設計,加快相機校 正速度的演算法。近年來因為相機校正技術需要輔助校正物且機器的精確性誤差 的關係,因此影像縫合技術在相機校正領域佔有越來越重要的地位。而在影像縫 合的應用上,考慮縫合速度和影像品質的權衡是件非常重要的事。傳統的演算法 由於為了達到夠好的影像品質,因此消耗了相當大的運算量,也因為如此,傳統 的演算法不適用於硬體的實作。因此本篇論文提出一個快速的演算法,在擷取特 徵點的時候由內外往外擴散慢慢刪除,並且使用適應性的方法讓擷取特徵點的步 驟停止。接著我們在RANSAC的部份也使用特殊的技巧來擷取matching points做 RANSAC,使擷取到的matching points容易呈現兩極化的現象,如此就不需要做 大量的RANSAC,此兩個步驟都大大地節省CPU time,加快速度但卻可以得到一 樣的影像品質。最後我們也發現在多台Sensor的角度、位置、距離都已經固定的 前提下,其影像彼此之間的轉換關係是固定的,因此我們只要跑過一次完整的演 算法即可求出彼此之間的轉換關係,所以之後的校正只要透過其固定的轉換關係 即可校正,如此的發現非常有利於我們在硬體實現的突破,因此校正的速度將可 以大幅地改善。Fast Calibration Techniques for Auto-Stitch of Camera Array
Image
Student:Yung-Lin
Chuang
Advisor:Lan-Rong Dung
Institute of Electrical and Control Engineering National
Chiao-Tung University
Abstract
The objective of this thesis is to develop an algorithm of AutoStitch for Camera Calibration and to improve the speed of Camera Calibration. Because the technique of Camera Calibration needs some auxiliary patterns to do the calibration and the error correctness of the machines, Auto-Stitch has been played an important part in the field of Camera Calibration. In applications of Autostitch, it is imperative to consider the speed of stitch and performance trade-offs. Traditional methods spend a lot of execution times in order to get good performance. Because of this, it is not suitable to use traditional methods in hardware. This thesis develops an algorithm to improve the speed of Autostitch. In the step of Features Extraction, it deletes Feature Points from small search range to broad search range and uses a special adaptive method to stop this step. After this, we use adaptive method in RANSAC times and repeat proper times to accomplish the performance that we want. We don’t need to do a lot of RANSAC times. These two steps economizing the CPU time, higher speed but we can almost get the same performance. Finally, we also find that if the angle, position, and the distance of the multi-sensor are fixed, the rule of transformation can be fetched through our algorithm just one time. After this, we can use the fixed transformation to
do other calibration. This method is useful to realize in hardware and the speed of calibration can be improved substantially.
誌謝
本篇論文得以順利完成,首先要感謝的是我的指導教授──董蘭
榮教授,在碩士班的兩年間,董教授不厭其煩地指導我,當我陷入瓶
頸時,董教授亦適時地指點我正確的方向,讓我不至於常常失焦,並
且及時做出修正,並且提供非常豐富的資源,讓我能好好潛心於學習
研究,讓我在這兩年間獲益良多。
同時,也感謝實驗室的學長──穎毅、盟淳、宗錫、騰轟、學之、
文豪、俊衛、峻轍、志惟、仕捷、信承,在我的求學過程中給予指點
與幫助,以及陪伴兩年的同學們──XT、Lander、小康、Kong,在課
業與生活上的互相扶持、分擔紓解彼此的壓力,給了我一段美好的研
究所時光。當然也要感謝實驗室可愛又嘴砲的學弟妹們和兩位正妹助
理──邱哥、罩哥、智聖、小嘉鴻、貞如、乃禎、惟茵,因為有了你
們使得枯燥煩悶的實驗室常常很嗨。
最後要感謝我的家人的支持,有了你們的鼓勵,使我無後顧之
憂,才能夠安心地完成碩士班學業。
謹將此論文獻給所有關心我的人,在此致上最深的謝意。
章節目錄
中文摘要 i 英文摘要 ii 誌謝 iv 章節目錄 v 圖目錄 vii 表目錄 x 第一章 簡介...1 1-1 相機校正(Camera Calibration)與影像縫合(AutoStitch)的應用....1 1-2 相機校正(Camera Calibration)與影像縫合(AutoStitch)演的缺點2 1-3 影像縫合與校正在效能上的考量...5 1-4 章節規劃...6 第二章 背景...72-1 影像縫合流程(The Flow of AutoStitch)...7
2-2 特徵點擷取(Feature Extraction)...7
2-2.1 特徵點定義...7
2-2.2 ㄧ般Harris Corner取法...9
2-2.3 適應性非最大化壓縮法(Adaptive Non-Maximal Suppression) ...14
2-3 特徵點匹配(Feature Matching)...17
2-3.1 最小平方差SSD(Sum of Squared Differences)...17
2-3.2 次近鄰居法(Second-Closest Neighbor)...18
2-5 歪斜影像(Warp Image)...26
2-6 混合影像(Blending)...28
第三章 使用BUMS與PRSC影像縫合快速演算法設計...33
3-1 Bottom-Up Maxima Selection(BUMS)...33
3-1.1 傳統適應性非最大化壓縮法之深入討論...33
3-1.2 BUMS流程(The flow of Bottom-Up Maxima Selection)...39
3-1.3 特徵點均勻分佈特性驗證(Verification of the Uniform Distribution of the Feature Points)...45
3-2 極化型隨機取樣程序(Polarized Random Sample Consensus)...48
3-2.1 RANSAC執行次數之討論(Discussion of RANSAC Times)...48
3-2.2 極化型隨機取樣程序流程(The Flow of Polarized Random Sample Consensus)...51
第四章 模擬結果之探討與比較...57
4-1 BUMS運算效率模擬(Simulation of Computational Efficiency for Bottom-Up Maxima Selection)...57
4-2 PRSC運算效率模擬(Simulation of Computational Efficiency for Polarized Random Sample Consensus)...60
4-3 整體運算效率模擬(Simulation of Total Computational Efficiency for the Algorithm)...62
4-4 轉換矩陣H的重覆使用性質(Reusability of Homography H)...64
第五章 結論與未來發展...68
圖目錄
圖 1-1.1 相機陣列校正技術範例...1 圖 1-2.1 360 度環場影像 1 ...3 圖 1-2.2 360 度環場影像 2 ...3 圖 1-2.3 全自動絕對座標縫合影像...4 圖 2-2.1 特徵點示意圖...8 圖 2-2.2 只取一般 Corner 範例一...10 圖 2-2.3 只取一般 Corner 範例二...11 圖 2-2.4 ni 分別取(a)200 (b)350 (c)500 的結果...11 圖 2-2.5 Corner Detector 顯示圖,場景為國立交通大學運動場...13 圖 2-2.6 Corner Detector 顯示圖,場景為國立交通大學運動場和宿舍...13 圖 2-2.7 適應性非最大化壓縮法(ANMS)範例一...15 圖 2-2.8 ANMS 流程圖...16圖 2-2.9 The highest corner strength 法與 ANMS 比較圖範例一...16
圖 2-2.10 The highest corner strength 法與 ANMS 比較圖範例二...17
圖 2-3.1 SSD(Sum of Squared Differences)示意圖...18
圖 2-3.2 次近鄰居法(Second-Closest Neighbor)的流程圖...19 圖 2-3.3 次近鄰居法(Second-Closest Neighbor)的成功機率圖表...20 圖 2-3.4 特徵點擷取與特徵點匹配的範例一...20 圖 2-3.5 特徵點擷取與特徵點匹配的範例二...21 圖 2-4.1 RANSAC 範例一,圖為交通大學工程五館...24 圖 2-4.2 RANSAC 範例二,圖為台北 101 ...25
圖 2-4.3 RANSAC(RANdom SAmple Consensus) flow chart ...25
圖 2-5.2 歪斜影像範例二...26 圖 2-5.3 沒有使用 RANSAC 的歪斜影像...27 圖 2-5.4 .沒有使用 RANSAC 的縫合影像...27 圖 2-6.1 原始影像與歪斜影像的相對位置已經吻合...28 圖 2-6.2 沒有用特殊 Blending strategy 呈現的失真影像範例一...29 圖 2-6.3 沒有用特殊 Blending strategy 呈現的失真影像範例二...29 圖 2-6.4 Weight Function 示意圖...30 圖 2-6.5 歪斜影像對應的權重函數...30 圖 2-6.6 原始影像對應的權重函數...31 圖 2-6.7 兩張圖的相對位置與權重函數關係...31 圖 2-6.8 經過 Blending Strategy 所產生的縫合影像...32 圖 3-1.1 適應性非最大化壓縮法(ANMS)範例一...34 圖 3-1.2 ANMS 流程圖...35
圖 3-1.3 ANMS 與 Search Range r 之深入分析範例一...36
圖 3-1.4 ANMS 與 Search Range r 之深入分析範例二...38
圖 3-1.5 修正型 ANMS 演算法流程圖...40
圖 3-1.6 BUMS 與 Search Range r 之深入分析範例一...41
圖 3-1.7 BUMS 與 Search Range r 之深入分析範例二...43
圖 3-1.8 Bottom-Up Maxima Selection(BUMS)流程圖...45
圖 3-1.9 特徵點較為集中的情況範例...46 圖 3-1.10 特徵點較為分散的情況範例...47 圖 3-2.1 失敗 RANSAC 與失敗的縫合影像...49 圖 3-2.2 執行不同次數 RANSAC 的內部點結果與縫合影像...50 圖 3-2.3 極化型隨機取樣程序(PRSC)流程圖...53 圖 3-2.4 PRSC 臨界值取高標的結果...55 圖 4-1.1 測試模擬的 12 組 Pattern...58
圖 4-1.2 縫合三張影像...60 圖 4-2.1 傳統 RANSAC 與 PRSC 運算量比較圖...62 圖 4-3.1 傳統演算法與快速演算法比較圖...63 圖 4-4.1 Multi-Sensor 相對位置固定情形下,轉換矩陣重複性的實驗步驟....65 圖 4-4.2 轉換矩陣 H 重複性質的基底 Pattern...65 圖 4-4.3 使用相同的轉換矩陣 H 所校正的影像...66 圖 5-1.1 透視圖...68 圖 5-1.2 多 Sensor 平台範例...69 圖 5-1.3 多 Sensor 平台影像及縫合影像...70 圖 5-1.4 焦距過近的縫合影像...70
表目錄
表 3-1.1 SR 從無限大往內縮回時特徵點擷取數量與增加數量統計表範例一...37 表 3-1.2 SR 從無限大往內縮回時特徵點擷取數量與增加數量統計表範例二...39 表 3-1.3 SR 從 r=1 往外擴張時特徵點擷取數量與剔除數量統計表範例一...42 表 3-1.4 SR 從 r=1 往外擴張時特徵點擷取數量與剔除數量統計表範例二...44 表 3-2.1 匹配點經過 5000 次 PRSC 投票結果之關係表...52 表 3-2.2 執行 10 次 PRSC 低標和均標的成功機率比較...56 表 4-1.1 縫合兩張圖的傳統 ANMS 與 BUMS 的計算效率比較...59 表 4-1.2 縫合三張圖的傳統 ANMS 與 BUMS 的計算效率比較...59 表 4-2.1 縫合兩張圖的傳統 RANSAC 的 PRSC 的計算效率比較...61 表 4-2.2 縫合三張圖的傳統 RANSAC 的 PRSC 的計算效率比較...62 表 4-3.1 縫合兩張圖時傳統演算法與我們快速演算法的計算效率比較...63 表 4-3.2 縫合三張圖時傳統演算法與我們快速演算法的計算效率比較... 63第一章 簡介
1-1 相機校正(Camera Calibration)與影像縫合(AutoStitch)的應
用
隨著相機校正和影像處理的發展,影像縫合(AutoStitch)近幾年在影像處理 中已經佔有越來越重要的地位,其可應用的範圍也越來越廣,除了攝影愛好者原 本受限於相機角度有限而無法拍攝廣角影像,因為 AutoStitch 的發展而一償宿 願,其他還有如 Camera Motion[1]-[3] ,Scene Motion[4]-[6],Advanced Camera Modelling[7],Photometric Modelling[8]-[10],監視系統、軍事系統方面, 如圖 1-1.1,AutoStitch 的應用也是越來越趨於廣泛。在早期 AutoStitch 或 Camera Calibration 技術尚未成熟的時候,所有的影 像要縫合或是校正,都需要人工徒手靠著繪圖軟體來接合或手動修正,這種人工 方法相當麻煩,而且效果不盡理想。直到在相機校正領域[40]-[41]提出了用相 機相對位置來做校正,[11]-[14]提出了利用 direct method 來做影像縫合校正, 此技術才突破了人工徒手校正的瓶頸,之後[3],[15]-[16]更近一步提出了 feature-based method,影像縫合與校正技術才慢慢趨近於成熟,feature-based method 比起 direct method,運算量更加節省,並且拒絕 outlier 的能力更強, 其校正結果自然誤差更小更加可靠。
1-2 相機校正(Camera Calibration)與影像縫合(AutoStitch)演的缺
點
通常一個好的相機校正方法需要考慮幾種因素,第一、自動化,即不需使用 者給定一些參數的初始值或是校正的過程當中還需要使用者做適當地調整。第 二、精確性,相機之間彼此的相對位置精確性是否足夠,校正過後的結果是否夠 精確,當然直接影響校正的好壞。第三、計算效率,盡量避免去解高次的非線性 方程式,特別是一些需要重複執行相當多次的地方。第四、具備彈性,使相機校 正技術可適用於各種不同的環境當中。第五、適用性,能適用於各種不同的相機, 而不只是限定在特殊的高檔攝影機。 在相機校正(Camera Calibration)的演算法當中,常常使用的方法是測試兩 相機之間彼此的參數,並且適當地使用輔助校正物來做校正,但此種方法卻有幾 種缺點,第一,多相機相對位置之間彼此的誤差,有可能希望彼此之間夾角是 30 度,但事實上卻有誤差變成 31 度,以致於校正上也有誤差。第二,需要輔助 校正物來做校正,增加校正的複雜度,也增加成本,因此近年來在相機校正的領 域都是使用彼此之間的對應點來做校正,即影像縫合(AutoStitch)技術。如此即 使相機之間彼此有所誤差也會因為 AutoStitch 的技術而補償回來,並且此方法 也不需要任何輔助校正物來做校正,只需一個固定的場景即可,因此影像縫合校 正技術已成為近年來相機校正技術的核心,在本篇論文當中我們也將採取影像縫 合的方式來做相機的校正技術並加以改良。 在要做影像縫合(AutoStitch)之前,我們需要先知道影像縫合在演算法上會 遇到的瓶頸或缺點有哪些。第一,效能(performance)的判定:縫合影像結果的效 能好壞,在目前的文獻裡還沒有較精確的準則來衡量,只能憑著肉眼的判斷來衡 量縫合影像結果的好壞,且影像縫合的效能判定也會因需求的不同而有不同的判 定,例如:360 度環場影像(360° Panorama Image)[17]-[20]、全自動絕對座標 縫合影像(Automatically Absolute Coordinated Image Stitching)……等。360 度環場影像(360° Panorama Image)所希望達到的效果是可以看到前後左右所有360 度的影像[17]-[20],但是這樣的影像往往會造成扭曲的效果,與真實世界 (ground truth)不符合,如圖 1-2.1、圖 1-2.2。在強調 360 度環場影像(360° Panorama Image)的前提下,這兩張圖達到了我們的要求,即前後左右 360 度的 影像皆可看到,但是我們也不難發現,這兩張圖很明顯地失真了,圖 1-2.1 的竿 子應該是直的,卻被扭曲了,圖 1-2.2 的工作牆壁應該是平的,卻被扭曲了。為 了達到 360 度環場影像的效果,卻失去了原本真實世界的內容(content) 。全自 動絕對座標縫合影像(Automatically Absolute Coordinated Image Stithing) [21]-[22]所希望是達到與真實世界(ground truth)內容一樣的結果,所以相對
圖 1-2.1 360 度環場影像 1(本圖 Pattern 來源出自[42])
圖 1-2.3 全自動絕對座標縫合影像 位置也必須一樣,如圖 1-2.3。圖 1-2.3 縫合影像所顯示的影像內容與真實世界 的內容(ground truth)完全一樣,連相對位置也一樣,但是很明顯地我們也可以 發現為了達到相對位置一樣的效果,在縫合的過程必須也把影像做歪斜,以致於 縫合後的結果越來越歪。此處的歪斜與前面 360 度環場影像的扭曲不一樣,360 度環場影像是為了達到 360 度環場效果所以導致相對位置不同以致失真。全自動 絕對座標縫合影像[21]-[22]是為了達到絕對座標都與真實世界一樣所以造成影 像的歪斜,因為沒有顯示出來的部份本來就沒有拍攝到,因此根本不會被縫合出 來。因此,影像縫合的效能判定也會因需求的不同而有不同的判定,目前還沒有 較一個精確的準則來衡量效能(performance)的判定。 第二,運算量過大:在 1-1 節我們有大概提到,早期所有的影像要縫合或是 修正,都需要人工徒手靠著繪圖軟體來接合或手動修正,這種方法好處是完全不 用機器來運算,但是人工方法相當麻煩,而且效果不盡理想。直到[11]-[14]提 出了利用 direct method 來做影像縫合與校正,才突破了人工徒手校正的瓶頸, 但是 direct method 因為是用整張影像來比較,所以運算量非常大,之後 [3],[15]-[16]更近一步提出了 feature-based method,運算量比較節省,但就 整體影像縫合(AutoStitch)而言,運算量過大還是一個存在已久的問題,本篇論
文主要的目的之一就是希望可以節省傳統的演算法運算量,甚至在某些前提的假 設下,運算量可以壓低到適合用於硬體實作上。
1-3 影像縫合與校正在效能上的考量
正如 1-2 所提到的,在影像縫合(AutoStitch)的領域裡,還沒有一套精確的 準則來判斷縫合過後的影像品質好壞,但從整個影像縫合(AutoStitch)系統的角 度來看,仍然可以大約把影像縫合系統(AutoStitch System)的效能分成以下幾 方面來探討: (1) 縫合影像本身的品質好壞:縫合過後的影像清楚與否、是否有不合理的 內容(圖片搭不起來) ,首要決定了影像縫合系統效能的好壞。 (2) 縫合影像本身與真實世界內容(ground truth)的誤差:不同於第一點, 有些影像即使縫合出來效果清晰無誤,但是卻與真實世界內容(ground truth)有相當的誤差,正如 1-2 提到的,影像縫合的效能判定也會因需 求 的 不 同 而 有 不 同 的 判 定 , 360 度 環 場 影 像 (360 ° Panorama Image)[17]-[20]所縫合出來的影像,相當清楚無誤,但是卻和真實世 界內容(ground truth)有段相當的誤差,所以在第二點上仍然視我們的 需求而判定。 (3) 縫合演算法的強健度:越強健的演算法自然能夠相容越多組的影像內 容,即越強健的演算法可適用於各種不同的樣本影像(Pattern) ,若是 縫合演算法不夠強健,自然地某些較為 critical 的樣本影像(Pattern) 即無法適用,在影像縫合系統(AutoStitch System)的效能考量中最為 重要。 (4) 運算量多寡:正如 1-2 所提到的,影像縫合的發展歷史當中,從 direct method 再到 feature-based method,節省了許多的運算量,但是就整 個影像縫合系統(AutoStitch System)而言,運算量過大還是一個存在 已久的問題。綜合以上的分析以及討論,我們在(1)-(3)都與傳統演算法相同的情形下, 提出一套屬於我們自己的快速演算法,使得縫合運算量(4)大大地再降低,甚至 在某些前提的假設下,運算量可以壓低到適合用於硬體實作上。
1-4 章節規劃
本 章 節 中 , 介 紹 了 目 前 相 機 校 正 (Camera Calibration) 與 影 像 縫 合 (AutoStitch)的應用範圍以及在本論文裡所要探討的事情做個簡單的描述。接下 來第二章中,會說明影像縫合(AutoStitch)的基本背景理論和演算法來做相機的 校正。第三章我們就影像縫合(AutoStitch)在設計過程中所遭遇到的困難,和問 題的解決方法,做進一步的了解與探討。並針對各種不同的狀況做比較,模擬結 果列於第四章中。最後第五章再對這一連串的分析所發現與觀察到現象做個總 結。第二章 背景
2-1 影像縫合流程(The Flow of AutoStitch)
在影像縫合(AutoStitch)的過程中,大致上可分成幾個步驟,第一,特徵點擷 取(Feature Extraction) 。為的是要讓在影像縫合的剛開始,並不需使用影像中的 每個像素(pixel)來做運算,只需要找出幾個夠特殊的點(即特徵點)來做代表即 可。第二,特徵點匹配(Feature Matching) 。在初步擷取特徵點過後,我們也 需要做初步的特徵點匹配,以確認兩張圖當中的特徵點哪些是彼此對應到的。第 三,剔除掉錯誤的匹配點。承接第二步驟,因為在初步特徵點匹配的過程結束之 後,仍然有可能會存在錯誤的匹配點,因此需要建立一套機制使得錯誤的特徵點 可以被剔除掉。第四,歪斜影像(Warp Image) 。正如 1-3 所提到的,不同需求 的 影 像 縫 合 在 效 能 上 的 判 定 準 則 也 不 一 樣 , 本 篇 論 文 以 對 座 標 縫 合 影 像 (Automatically Absolute Coordinated Image Stithing)來做基準,即相對位 置也要與真實世界內容(Ground Truth)一樣。所以第四步驟我們需要把影像做歪 斜使其可以跟另一張影像正確地縫合。第五,混合影像(Blending) 。在把影像 歪斜過後,最後一步就是要做適當地混合,不同的混合方法所呈現出來的最後縫 合影像結果也不盡相同。接下來在第二章中我們將針對上列影像縫合的基本步驟 做一個完整地背景介紹。
2-2 特徵點擷取(Feature Extraction)
2-2.1 特徵點定義
正如 1-1 當中所提到的,在早期所有的影像要縫合或是修正,都需要人工徒 手靠著繪圖軟體來接合或手動修正,這種人工方法相當麻煩,而且效果不盡理 想。直到[11]-[14]提出了利用 direct method 來做影像縫合與校正,此技術才 突破了人工徒手校正的瓶頸,之後[3],[15]-[16]更近一步提出了 feature-based method,即不需用整張影像的像素(pixel)來做運算,只需要找出幾個夠特殊的點(即特徵點)來做代表即可,[23]-[32] 分別提出了許多不同的方法,其中[26] Harris Corner Detector 的作法,是把影像當中的角落(Corner)擷取出來。首先我 們需要先知道為什麼需要找角落來當特徵點,若我們使用影像中比較平坦(flat) 的點來當特徵點,則往上下左右稍微移動一點點,所看到的東西仍會很像,所以 這不是一個適合的特徵點。接著,若我們使用影像中邊界(edge)的點來當特徵 點,則此點往某兩個方向稍微移動一點點,所看到的東西仍會很像,仍然不是一 個適合的特徵點。最後,若我們使用影像中的角落(Corner)點來當特徵點,則此 點往上下左右稍微移動一點點,所看到的東西仍會很不一樣,因此我們可以得知 角落點(Corner)為我們所希望找到的特徵點,圖 2-2.1 即是一個最簡單的例子。 (a) (b) (c)角落點(Corner) (b)邊界(Edge) (a)平坦(Flat) 圖 2-2.1 特徵點示意圖 (c)
2-2.2 ㄧ般 Harris Corner 取法
接著我們要來討論如何找出影像的角落點以作為特徵點,[26]首先把每個 輸入影像的點拿來做計算, , , , 2 , 2 x y x y x y I I I × I I I 表示我們去計算每點在不同 方向的微分,以及他們彼此相乘和各自的平方,w 為高斯函數,對於每個影像中 的 Pixel,算出運算式 2-1 中矩陣的特徵值 2 2(
)
(
*
)
(
*
)
(
)
Ix
w
Ix
Iy
w
A
Ix
Iy
w
Iy
w
⎡
⊗
⊗
⎤
= ⎢
⊗
⊗
⎥
⎣
⎦
---(式)2-1 當 式 2-1 矩 陣 特 徵 值 計 算 出 來 後 , 我 們 去 觀 察 計 算 出 來 的 特 徵 值 (EigenValue): (1) 如果這兩個特徵值都很小,表示此點與附近的關係為平坦的(flat) , 不是我們想要的情況(我們想要的為角落) 。 (2) 如果兩個特徵值其中一個很大,另一個很小,表示此點與附近的關係為 邊界(Edge) ,也不是我們想要的情況(我們想要的為角落) 。 (3) 如果兩個特徵值都很大,表示此點與附近的關係為角落(Corner) 。 會有上述的特質是因為我們都知道矩陣的特徵值代表它梯度(Gradient)的 大小,所以當特徵值越大表示梯度越大,但是當只有一個特徵值很大,另一個很 小時,表示只有一個方向的梯度(Gradient)很大,另一個很小,很明顯地此種狀 況為邊界(Edge) 。相對地,當兩個特徵值都很大時,表示兩個方向的梯度 (Gradient)都很大,這就是我們所想要的角落點(Corner) 。在此因為求特徵值 需要花費較多的運算樣,[23]提供一個代替的方法,假設λ1,λ2為矩陣A的兩個 特徵值,則我們只要去計算式 2-2 的反應函數(Response Function)即可知道此 點是Corner的可能性有多大: 2 2R=
λ λ
1 2-k( + ) = det (A)-k trace (A)
λ λ
1 2×
---(式)2-2 其中根據文獻參考的經驗法則,k 在 0.04~0.15 之間都可以有彈性的空間,不同於式 2-1 的運算方法,在計算式 2-2 當中,只須計算加減法以及乘法,因此運算 量將會比式 2-1 減少許多。圖 2-2.2、圖 2-2.3 即為一個 Corner Detector 的例 子,藍色圓圈即為 Corner。但是從式 2-1 中或從圖 2-2.2、圖 2-2.3 我們不難發 現 , , , 2, 2 x y x y x y I I I × I I I 都是由每個 Pixel 周圍 3*3 大小範圍的值求得,也就 是說此 Corner 找出來只相對於周圍的 3*3 而言是 Corner,但是對於一張影像而 言,3*3 的視窗大小其實是一個非常小的範圍,以我們的兩種 Pattern Size 分 別為 500*752 和 640*480 而言,若單就式 2-1 和式 2-2 所擷取出來的特徵點至少 會有 4000~6000 個以上的特徵點,數量非常龐大,如圖 2-2.2,只用單純式 2-1 和式 2-2 的擷取特徵點法,左邊影像有高達 5018 個特徵點,右邊影像也有 4972 個特徵點,數量非常龐大,圖 2-2.3 也有類似的結果,但這些點的確都是我們所 要的 Corner 特徵點,只是它所相對應的範圍只在周圍的 3*3 大小而已。 圖 2-2.2 只取一般 Corner 範例一,左邊影像有 5018 個特徵點,右邊影像有 4972 個特徵點
圖 2-2.3 只取一般 Corner 範例二
若是要用這些特徵點來接著執行接下來 AutoStitch 的步驟仍然是可行的, 最後仍然會縫合成功,但是可想而知的在 Matching 部分和 RANSAC 部分,其運算 量一定會非常地龐大進而拖垮了整個演算法的執行效率。因此通常會在 Response Function R 定下一個臨界值 T,比 T 大的值就令為最後的特徵點,比 T 小的值就 剔除掉,或是直接定下另一種臨界值 ni,取 Response Function R 裡面前 ni 強 的特徵點,ni 由使用者自行決定,不同的 ni 有不同的效果,圖 2-2.4 分別顯示 ni=200、350、500 的效果,我們可以發現 ni=200 的時候點數較少但是卻是比較 強健的 Corner 點,ni=500 的時候點數較多但是卻是比較沒這麼強健的 Corner 點,整體來說 ni 取幾點並沒有一定的好壞,取 200 點雖然比較強健而且點數少, 但是卻不能保證取 200 點到最後 match 和 RANSAC 之後點數還足夠可以縫合,取
(b) ni=350 (c) ni=500 圖 2-2.4 ni 分別取(a)200 (b)350 (c)500 的結果 500 點雖然點數較多且較為不強健,但卻經過 match 和 RANSAC 之後比 200 有保 障足夠的點數可以成功縫合,因此取 ni 幾點並沒有一定的好壞,但爲了保障最 後要有一定足夠的點數可以縫合,[27]使用 ni=500 來作臨界值,即取 Response Function R 裡面前 500 名的點進來,如圖 2-2.4(c)、圖 2-2.5、圖 2-2.6,我們 會發現這幾張影像不同於圖 2-2.2、圖 2-2.3 當中的特徵點是所有 3*3 大小的 Corner 都放進去,所以點數特別多,對於之後的演算法執行效率上非常不好, 但圖 2-2.4(c)、圖 2-2.5、圖 2-2.6 只取這些 Response Function R 裡面特徵點 當中前 ni=500 名的,對之後的演算法執行效率有非常大的幫助。
圖 2-2.5 Corner Detector 顯示圖,場景為國立交通大學運動場
2-2.3 適 應 性 非 最 大 化 壓 縮 法 (Adaptive Non-Maximal
Suppression)
在使用影像縫合(AutoStitch)於相機校正的演算法中,運算消耗量與特徵點 的多寡是呈現超線性(superlinear)的關係,因此有效地限制特徵點的數量是非 常重要的,在 2-2.2 當中提到使用固定常數 ni=500 來限制特徵點個數,但即便 如此,我們還是需要考量到這種方法只考慮到周圍 3*3 視窗大小的範圍(Search Range),我們希望達到每個特徵點(Feature Points)可以影響的範圍達到比 3*3 更大並且特徵點可以儘可能地平均分散在整張影像上,此特性非常重要,因為在 縫合兩張影像的過程當中,可能兩張影像的重疊部分(overlap)非常少,或是剛 好沒有特徵點存在於兩張影像重疊的部份,則縫合的結果會大大的受到影響,此 部分在 3-1.3 我們會提出一個例子作為驗證,因為這樣的需求,[27]提出了適應 性非最大化壓縮法(Adaptive Non-Maximal Suppression)簡稱 ANMS,ANMS 即是 希望提出一套強健的策略,使得特徵點可以被壓縮在一定的數量,並且所擷取出 來的特徵點也可以平均分散在整張影像當中。圖 2-2.7 即是一個例子,(a)(b) 兩個圖使用 the highest corner strength 法,分別取所有候選特徵點(candidate points)當中反應函數(Response Function)R 的前 250 強和 500 強的 corner 點 進來,(c)(d)使用 Adaptive Non-Maximal Suppression(ANMS)法,取點的數量 同樣是分別取 250 個點和 500 個點,我們會發現(c)(d)的特徵點(Feature Points) 比起(a)(b)的特徵點(Feature Points)在整張影像上的分佈均勻多了,這是一個 非常好的特性,如圖 2-2.7(a) ,我們可以清楚地觀察到大部分的特徵點(Feature Points)都集中在上半部份,下半部份特徵點非常少,因此若有另ㄧ張縫合影像 的重疊部分(overlap)是與圖 2-2.7(a)的下半部分重疊,則這兩張圖的匹配點 Matching Points 會非常的少,因為下半部份存在的特徵點本來就很少,因此能 夠被 Matching 到的點當然很少,如此的情況非常不利於我們的影像縫合。但是 同樣的圖若換成是圖 2-2.7(c) ,圖 2-2.7(c)或(d)當中,因為沒有此種情況,
(a) Strongest 250 (b) Strongest 500
(c) ANMS 250 (d) ANMS 500 圖 2-2.7 適應性非最大化壓縮法(ANMS)範例一 而且所有的特徵點較為均勻分佈,因此若有另ㄧ張縫合影像的重疊部分(overlap) 是與圖 2-2.7(c)的下半部分重疊也不會造成太大的影像,因為本身下半部份就 有 許多 的特 徵點 可以 提供 之後 作 Matching 和縫合 的動 作, 因此 能有 像 圖 2-2.7(c)(d)這樣均勻分佈而且特徵點數目又控制在所希望的大小是一個非常不 錯的特性。 接著我們要介紹 ANMS 在實作上的方法,我們知道若只用式 2-1 和式 2-2 求 出來的特徵點只考量旁邊周圍 3*3 視窗大小的範圍,若在 5*5 的範圍中此點也是 最大,則此特徵點的可靠度必然比 3*3 的視窗大小更可靠,以此類推,當視窗大 小為無限大時,找出來的特徵點必然最為強健,因此在實作上,[27]提出了針對 式 2-2 的 Response Function R 裡面的每一點,去比較此點周圍的視窗大小值, 並且 Search Range r 從無限大開始往內縮回,當某個點為此 Search Range 的最
Test Max. condition of every response points
Pick those points as the final matching point
SR = SR-1 Put all response points into a pool,
# of points=500
yes
no
圖 2-2.8 ANMS 流程圖
大值時,就令此點為 ANMS 的特徵點。當 Search Range 從無限大往內縮回時,特 徵點數目也會相對增加,當特徵點數目增加到我們想要的數目 ni 時([27]令 ni=500) ,ANMS 才停止擷取特徵點,這樣的推論是非常合理的,因為一旦在某
個 Search Range r 時出現了某個特徵點,那麼此點必定會繼續出現在 的情
形之下。圖 2-2.8 為 ANMS 的流程圖,圖 2-2.9 和圖 2-2.10 為 The highest corner strength 法與 ANMS 的兩個比較圖範例,由圖我們也可以發現 ANMS 比起 The highest corner strength 法,特徵點的分佈均勻多了。
'
r <r
圖 2-2.10 The highest corner strength 法與 ANMS 比較圖範例二
2-3 特徵點匹配(Feature Matching)
2-3.1 最小平方差 SSD(Sum of Squared Differences)
當擷取完特徵點(Feature points)之後,接下來需要把兩張圖的特徵點彼此 之間做匹配(Matching) ,看看 A 圖裡面的所有特徵點在 B 圖裡面是對應到哪些 點,最簡單的方法是直接去計算兩個特徵點周圍的一個小範圍的 SSD(Sum of Squared Differences) ,並定下一個臨界值(Threshold)為門檻,因為當兩個點 彼此是對應點,則其附近的 Pixel 值會非常接近,所以當 SSD 越小,自然表示兩 個 A 圖的(x1,y1)點很有可能是對應到 B 圖的(x2,y2)點,如圖 2-3.1 和式 2-3, 此方法又有人稱為 Nearest Neighbor 法或 Closest Neighbor 法,這種方法最為 簡單和直觀,但卻有許多缺點,在稍後我們會提到。 2 2 2 2 2
[ 1( 1
, 1
)
2( 2
, 2
)]
i jS
F x
i y
j
F
x
i y
j
=− =−=
∑ ∑
+
+
−
+
+
--(式)2-3F1(x1-2,y1-2) F1(x1-1, y1-2) F1(x1,y1-2) F1(x1+1,y1-2) F1(x1+2,y1-2)
F1(x1-2,y1-1) F1(x1-1, y1-1) F1(x1,y1-1) F1(x1+1,y1-1) F1(x1+2,y1-1)
F1(x1-2,y1) F1(x1-1,y1) F1(x1,y1) F1(x1+1,y1) F1(x1+2,y1)
F1(x1-2,y1+1) F1(x1-1,y1+1) F1(x1,y1+1) F1(x1+1,y1+1) F1(x1+2,y1+1)
F1(x1-2,y1+2) F1(x1-1,y1+2) F1(x1,y1+2) F1(x1+1,y1+2) F1(x1+2,y1+2)
F2(x2-2,y2-2) F2(x2-1, y2-2) F2(x2,y2-2) F2(x2+1,y2-2) F2(x2+2,y2-2)
F2(x2-2,y2-1) F2(x2-1, y2-1) F2(x2,y2-1) F2(x2+1,y2-1) F2(x2+2,y2-1)
F2(x2-2,y2) F2(x2-1,y2) F2(x2,y2) F2(x2+1,y2) F2(x2+2,y2)
F2(x2-2,y2+1) F2(x2-1,y2+1) F2(x2,y2+1) F2(x2+1,y2+1) F2(x2+2,y2+1)
F2(x2-2,y2+2) F2(x2-1,y2+2) F2(x2,y2+2) F2(x2+1,y2+2) F2(x2+2,y2+2)
圖 2-3.1 SSD(Sum of Squared Differences)示意圖
2-3.2 次近鄰居法(Second-Closest Neighbor)
在 2-3.1 的 SSD 方法(或稱 Closest Neighbor 法)是一種最直觀最簡便的方 法,但是在影像中的特徵點可能因為背景的模糊或是對應點根本不在所對應的影 像當中,所以理論上來說應當不會產生好的 Match 在所對應的影像上,因此 SSD 並不是很好的方法,[28]提出了次近鄰居法(Second-Closest Neighbor)來有效 地剔除掉這種不該有好 Match 的特徵點。 次 近 鄰 居 法 (Second-Closest Neighbor) 的 構 想 是 每 一 對 好 的 匹 配 點 (Matching Points) 相 對 於 其 他 對 匹 配 點 , 都 應 該 要 夠 獨 特 並 且 有 區 別 性 (discriminative) ,因此我們對於某個特徵點 Matching 時,除了計算最近的距 離(Closest Neighbor) d1,也去計算次近的距離(Second-Closest Neighbor) d2,若是這兩個的比例 D=d1/d2 大於 0.8,則表示此組的 Matching 太過類似(d1/d2 接近 1),則我們把這組 Match 剔除掉並稱他們為錯誤的 Matching Points。相反地 若 是 D=d1/d2 小 於 0.8 , 則 表 示 此 組 的 Matching 夠 獨 特 有 區 別 性 (discriminative) ,我們稱這兩個特徵點為一組好的 Matching Points。圖 2-3.2 為次近鄰居法(Second-Closest Neighbor)的流程圖。圖 2-3.3 為使用 40000 的 特徵點(Feature points)來作次近鄰居法,水平軸為 d1/d2 的比例,垂直軸為 false match 的機率,由圖我們可以發現當 d1/d2 比例很低時,表示此組的 Matching 夠獨特有區別性,圖形也顯示 false match 的比例也非常低,但是當 d1/d2 比例很高時(大於 0.8) ,表示此組的 Matching 太過類似,圖形也顯示 false match 的比例也非常高,應該要剔除掉,[28]聲稱此種作法可替除掉 90%的 false match,但只會剔除掉 5%的 correct match,比起 SSD 作法,算是相當值得。圖 2-3.4、圖 2-3.5 為次近鄰居法的範例,(a)-(b)為特徵點擷取,(c)-(d)為特徵 點匹配,我們會發現(c)(d)的許多點都成功對應到了。
Put all the Feature Points in Image B
into a pool
Compute the Closest Neighbor distance d1 &
the Second Closest Neighbor distance d2
d1/d2 > 0.8
yes
Discard this
Matching Points
Get Feature Point <a1> which is in Image A
Reserve this
Matching Points
no
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
Ratio of distances(closest/next closest)
PD
F
PDF for Ratio
PDF for correct matches PDF for incorrect matches
圖 2-3.3 次近鄰居法(Second-Closest Neighbor)的成功機率圖表
(a) (b)
(c) (d) 圖 2-3.4 特徵點擷取與特徵點匹配的範例一
(a) (b)
(c) (d) 圖 2-3.5 特徵點擷取與特徵點匹配的範例二
2-4 剔除掉錯誤的匹配點(Delete The False Match)
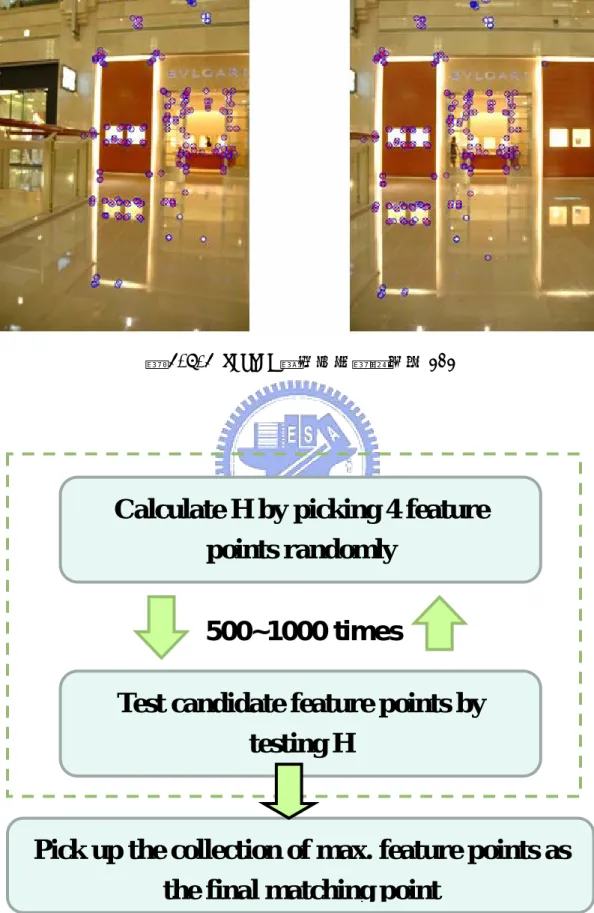
經過特徵點匹配(Feature Matching)後,我們會發現有許多的特徵點都彼此 對應到了,而且大部分皆為正確的匹配(correct Match) ,但是由圖 2-3.4 和圖 2-3.5 當中我們也不難發現仍然有少數的特徵點彼此的對應是錯誤的(即 False Match) ,所以在特徵點匹配之後的下一個動作,就是要把錯誤的匹配點剔除掉 (Delete The False Match) ,[33]-[34]提出了幾種方法來建立一個正確的模 型,再利用此模型來剔除掉錯誤的資料(data) ,這些方法不僅可以適用於影像 上,也可以適用於許多統計資料的處理。而在[36]-[37]都使用[33]的作法來建 立正確的模型以剔除掉錯誤的特徵點。[33]使用隨機取樣程序(RANdom SAmple Consensus)來建立模型剔除掉錯誤的資料,簡稱 RANSAC。RANSAC(RANdom SAmple Consensus)為一套使用隨機取樣來估計影像轉換參數的強健估計機制,在一般的 例子裡,RANSAC 會隨機取 n 個 data 來建立一個模型,並且用剩餘的(N-n)個 data 來測驗此模型是否正確,但是並非每次取的 n 個 data 都是好的 data,自然地經 過測試過後會顯示不是一個好的模型,所以通常 RANSAC 都要執行一定的次數才 能擷取出最後我們所要的正確 data。至於要重複多少次,則完全看使用者和問 題的不同而定,當然,RANSAC 是在大部分的資料都是正確只有少部分資料是錯 誤的情況下才能使用,但是在 2-3 我們已經經過初步的特徵點匹配(Feature Matching)來淘汰大部分錯誤的匹配點,因此剩下來的匹配點大部分都是正確的 (由圖圖 2-3.4、圖 2-3.5 我們也可以看到) ,因此 RANSAC 在這個地方是絕對適 用的,以下為 RANASC 步驟的流程: (1)隨機地取n個樣本資料進來。 (2)使用這n個樣本資料來建立一個模型Φ。 (3)把剩下的(N-n)個樣本資料代入Φ模型,測試此模型的建立是否 正確。 (4)重複執行K次。 (5)把最大聯集的內部點(inlier points)取出來做最後的結果。
由上面的 RANSAC 流程我們並不難發現 RANSAC 流程當中有許多參數都是由使 用者自己決定的,例如:如何定義樣本資料的數目 n、如何定義重複執行次數、 如何定義何為內部點(inlier points),這些都沒有一定的答案,而是根據我們 遇到的問題來決定。[36]-[37]當中使用樣本資料數目 n=4,重覆執行次數 k=500,定義內部點為 500 次當中最大對應成功次數的樣本資料,之所以會這樣 定義的原因,我們先看式 2-4 和式 2-5。式 2-4 為兩個 2D 座標互相轉換的關係 矩陣,式 2-5 為是 2-4 的矩陣型式。
P
'
= P
H
--- (式)2-4⎤
⎥
⎥
⎥⎦
1 )
2 )
0
0
'
'
1
1
w x
a
b
c
x
w y
d
e
f
y
w
g
h
⎡
⎤
⎡
⎤ ⎡
⎢
⎥
=
⎢
⎥ ⎢
⎢
⎥
⎢
⎥ ⎢
⎢
⎥
⎢
⎥ ⎢
⎣
⎦
⎣
⎦ ⎣
---(式)2-5 將式 2-5 做簡單的展開,如式 2-6。'
(
'
(
1
( 3 )
w x
a x
b y
c
w y
d x
e y
f
w
g x
h y
=
+
+
=
+
+
=
+
+
"
"
"
--- (式)2-6 將式 2-6 的(1)-(3)×x'和(2)-(3)×y'得到式 2-7'
'
'
'
'
'
a x
b y
c
g x x
h y x
x
d x
e y
f
g x y
h y y
y
+
+ −
−
−
=
+
+
−
−
−
=
---(式)2-7 再將式 2-7 展開成矩陣的型式得到式 2-8,1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2
0
0
1
0
0
0
'
'
'
0
0
0
0
1
'
'
'
0
1
0
0
0
'
'
'
0
0
0
0
1
'
'
'
0
.
.
.
.
.
.
.
.
.
0
0
1
0
a
b
x
y
x x
y x
x
c
x
y
x y
y y
y
d
x
y
x x
y x
x
e
x
y
x y
y y
y
f
g
h
⎡ ⎤ ⎡ ⎤
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
−
−
−
⎡
⎤
⎢ ⎥ ⎢ ⎥
⎢
−
−
−
⎥
⎢ ⎥ ⎢ ⎥
⎢
⎥
⎢ ⎥ ⎢ ⎥
⎢
−
−
−
⎥
=
⎢ ⎥ ⎢ ⎥
⎢
−
−
−
⎥
⎢ ⎥ ⎢ ⎥
⎢
⎥
⎢ ⎥ ⎢ ⎥
⎢
⎥
⎣
⎦ ⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎣ ⎦ ⎣ ⎦
-(式)2-8 注意式 2-8 是可以往下無限延伸的,由式 2-8 我們可以發現有a~h總共八個參數, 每個樣本資料點可產生兩個方程式,所以至少需要 4 個樣本資料點以產生八個方 程式,以提供我們解出這 8 個未知參數,這也就是為什麼[36]-[37]使用的RANSAC 每次取 4 個樣本資料點來建立模型,因為資料點取越多越容易取到錯誤的點,以 致於建立錯誤的模型,但是又必須取一定的點數來解答八個未知參數,所以使用 n=4。並且[36]-[37]也用簡單的機率模型來粗略證明當重複執行次數k=500 時, 模型錯誤的機率已經小於 10-14 ,因此使用k=500,最後在內部點(inlier points) 的部分求出來之後,再把所有內部點代入式 2-8 並使用[35]direct linear transformation(DLT)以得到最後最精確的模型H。圖 2-4.1、圖 2-4.2 為RANSAC 的兩個範例,藍色圈為經過初步Matching的結果,紅色叉為經過RANSAC的結果, 我們會發現所有Match都正確對應到了。圖 2-4.3 為RANSAC的流程圖。 圖 2-4.1 RANSAC 範例一,圖為交通大學工程五館圖 2-4.2 RANSAC 範例二,圖為台北 101
Calculate H by picking 4 feature
points randomly
Test candidate feature points by
testing H
Pick up the collection of max. feature points as
the final matching point
500~1000 times
2-5 歪斜影像(Warp Image)
在 2-4 經過 RANSAC 剔除掉錯誤的匹配點,同時也建立了正確的模型 H 之後, 下一步就是要使影像做歪斜(Warp Image) ,在 1-2 曾經提到我們所使用的前提 是 全 自 動 絕 對 座 標 縫 合 影 像 (Automatically Absolute Coordinated Image Stithing) , 希望是達到與真實世界(ground truth)內容一樣的結果,所以相 對位置也必須一樣,假設我們在 Sensor 皆為水平移動的前提下(本篇論文皆如此 假設),要縫合兩張影像一定要把其中一張影像做歪斜,因為他們彼此的關係不 是 水 平 移 動 就 可 縫 合 的 , 必 定 有 某 種 投 影 的 關 係 , 我 們 稱 為 透 視 投 影 (Perspective Projection) ,其關係是即為式 2-5,因此我們只要把需要做歪 斜的影像座標經過式 2-5 即可得到新的歪斜影像,如圖 2-5.1、圖 2-5.1,左邊 的影像經過 H 做歪斜即為右邊的影像。 圖 2-5.1 歪斜影像範例一 圖 2-5.2 歪斜影像範例二
到這裡我們也可以從另一個角度來看如果沒有作 RANSAC 會有什麼樣的結 果,圖 2-5.3 和圖 2-5.4 顯示沒有作 RANSAC 步驟的歪斜影像(Warp Image)和縫 合影像 ,我們可以看到這兩張影像完全失真了,會有這樣的結果是因為沒有使 用 RANSAC 來剔除掉錯誤的匹配點,進而使用了錯誤的匹配點求得錯誤的模型 H, 自然地歪斜影像和縫合結果就不正確了。
圖 2-5.3 沒有使用 RANSAC 的歪斜影像
2-6 混合影像(Blending)
經過 2-5 歪斜影像的步驟後,兩張圖的相對位置已經吻合(見圖 2-6.1),最 後一步就是要把兩張影像作混合(Blending) ,理想情況若是在拍攝影像時,光 源皆沒有任何改變,並且每一張圖的受光度都一樣(表示每張圖的明暗程度都一 樣),理論上應該是可以直接將兩張圖放在一起而不用作任何的動作,但事實上 並非如此,在擷取影像的過程當中,即使是 multi-sensor 並且同步擷取影像, 圖 2-6.1 原始影像與歪斜影像的相對位置已經吻合 仍然會因為角度的不同而在明暗度上有些落差,如圖 2-6.1 我們就可大約觀察出 右圖比左圖稍微亮一點,若是沒有經過特別的混合策略就縫合,會造成影像的失 真或是我們不希望看到的邊界層次的情況產生,如圖 2-6.2、圖 2-6.2。我們可 以發現因為影像受光度的不同,若是沒有聽過特殊的混合策略來縫合,所會造成 的邊界層次失真情況產生,因此有一個好的混合策略也是非常重要的。 在此我們使用常見的線性混合(Linear Blending)來做縫合,[39]提出的線 性混合(Linear Blending)理論使用距離的遠近為權重函數(Weight function) 來解決邊界線不均勻的問題,使兩張影像在縫合時可以有平均的動作,圖 2-6.4、圖 2-6.2 沒有用特殊 Blending strategy 呈現的失真影像範例一
為其示意圖,Hl 為左邊影像的權重,Hr 為右邊影像的權重,越靠近本身影像的 中心則權重越高,越靠近另ㄧ張影像則權重越低,圖 2-6.4 中間重疊的部份都介 於 0~1 之間,是爲了方便之後作平均的動作,圖 2-6.5、圖 2-6.6 為兩張圖分別 對應的權重(Weighting) ,我們會發現兩張權重圖是不一樣的,歪斜影像的權重 圖也是歪斜的,原始影像的權重圖卻是長方形的,原因即是因為他們是分別由不 同的圖產生的權重函數,當 Pixel 的距離離影像中心點越近則權重越大,距離越 遠則權重越小,且所有權重皆介於 0~1 之間,因此產生了圖 2-6.5、圖 2-6.6, 我們也可發現兩張權重圖越往中心點越亮,此即表示他們的權重越大。 圖 2-6.4 Weight Function 示意圖 圖 2-6.5 歪斜影像對應的權重函數
圖 2-6.6 原始影像對應的權重函數 產生權重函數之後,最後只要利用簡單的平均關係即可將影像來作縫合, 根據式 2-9 即可得到每個重疊地方的 Pixel 值,進而消除圖 2-6.2、圖 2-6.3 因 為光線強度不同所造成不均勻失真的效果。 1 1 n i i l i n e a r i n i i I W I W = = × =
∑
∑
---(式)2-9 圖 2-6.7 兩張圖的相對位置與權重函數關係圖 2-6.8 經過 Blending Strategy 所產生的縫合影像 圖 2-6.7 為兩張圖的相對位置與權重函數關係,由圖我們可以看到不僅兩 張圖相對位置已經吻合,其權重函數(Weight Function)也已經確定,因此只要 經過式 2-9 即可得到每個重疊地方的 Pixel 值,圖 2-6.8 為經過 Blending Strategy 所產生的最後縫合影像,我們可以明顯地看到它改善了圖 2-6.2 所產 生的失真效應。
第三章 使用 BUMS 與 PRSC 影像縫合快速演算法設計
在第二章介紹了一些關於影像縫合的基本理論之後,接下來本篇論文所要談 的,是關於影像縫合演算法在設計或執行過程當中可能會遭遇到的問題,針對此 來做說明以及尋求解決的辦法。
3-1 Bottom-Up Maxima Selection(BUMS)
3-1.1 傳統適應性非最大化壓縮法之深入討論
在 2-2.3 當中我們介紹了適應性非最大化壓縮法(Adaptive Non-Maximal Suppression)的演算法,本節我們要繼續 ANMS 對於 AutoStitch 的優缺點來做深 入的探訪與分析。
讓我們先回顧一下在特徵點擷取(Feature Extraction)的步驟使用 ANMS 的 優點,之所以會從 the highest corner strength 進展到 ANMS,主要的原因有 兩個:第一、ANMS 所擷取的特徵點比起 the highest corner strength 可以平均 分散在整張影像當中,這是一個非常好的特性,因為在縫合兩張影像的過程當 中,可能兩張影像的重疊部分(overlap)非常少,或是剛好沒有特徵點存在於兩 張影像重疊的部份,則縫合的結果會大大的受到影響。圖 3-1.1(a)(b) 大部分 的特徵點都集中在上半部份,下半部份特徵點非常少,因此若有另ㄧ張縫合影像 的重疊部分(overlap)是與圖 3-1.1(a)的下半部分重疊,則這兩張圖的 Matching Points 會非常的少,因為下半部份存在的特徵點本來就很少,如此的情況非常 不利於我們的影像縫合。但是同樣的圖若換成是圖 3-1.1(c) ,因為所有的特徵 點較為均勻分佈,因此若有另ㄧ張縫合影像的重疊部分(overlap)是與圖 3-1.1(c) 的下半部分重疊也不會造成太大的影像,因為本身下半部份就有許多的特徵點可 以提供之後作 Matching 和縫合的動作,因此能有像圖 3-1.1(c)(d)這樣均勻分
(a) Strongest 250 (b) Strongest 500
(c) ANMS 250 (d) ANMS 500
圖 3-1.1 適應性非最大化壓縮法(ANMS)範例一
佈而且特徵點數目又控制在所希望的大小是一個非常不錯的特性。第二、特徵點 個數可以壓制在一定的數目以下。運算消耗量與特徵點的多寡是呈現超線性 (superlinear)的關係,因此 ANMS 同樣也把特徵點個數壓制在 ni=500,使得特 徵點數目不至於過多進而拖垮整個演算法的運算效率。因為同時具備這兩個優 點,ANMS 在擷取特徵點的使用相當普遍。
接著我們要從另一個角度來看適應性非最大化壓縮法(ANMS)的缺點,在 2-2.3 當中我們有提到 ANMS 為了達到整張影像平均分布的效果,因此把反應函 數 Response Function R 的搜尋範圍 r 從無限大往內縮回,當某個點為此 Search Range 的最大值時,就令此點為 ANMS 的特徵點。當 Search Range 從無限大往內 縮回時,特徵點數目也會相對增加,當特徵點數目增加到我們想要的數目 ni 時 ([27]令 ni=500) ,ANMS 才停止擷取特徵點。如圖 3-1.2。
Test Max. condition of every response points
Pick those points as the final matching point
SR = SR-1 Put all response points into a pool,
# of points=500 yes no 圖 3-1.2 ANMS 流程圖 但是在這裡因為 Search Range r 剛開始就從無限大搜尋,但是特徵點卻很 少,之後慢慢往內縮,特徵點數目才慢慢增加。也就是說剛開始 Search Range r 很大時,運算量消耗非常多,但是能擷取出來的特徵點卻非常少(因為 r 很大表 示限制嚴格,能擷取進來的特徵點較少) ,這不是一個好的現象,正常來說當演 算法某部份消耗很大運算量時,則希望這部份能發揮較大的效果,但是 ANMS 這 裡卻剛好相反,運算量消耗非常多,但是能擷取出來的特徵點卻非常少。並且根 據統計,整個 AutoStitch 流程當中,特徵點擷取佔最大的運算量,也就是 ANMS 為了達到平均分佈的效果,使得 r 從無限大往內縮,但是在這裡卻因此佔了縫合 影像流程當中最 Critical 的部份,拖垮了整個影像縫合演算法的效率。如圖 3-1.3,圖 3-1.3(a)顯示 ANMS 的結果,圖 3-1.3(b)顯示 Search Range r 從無限 大縮回時,特徵點數量與 Search Range r 的對應關係圖,我們會發現剛開始 r 很大時,特徵點累積數量很少,到後面 r 慢慢縮小到 20 以下,特徵點數量才開 始慢慢變多,但是在剛開始因為 r 很大,所以要花上相當大的運算量,在運算效 率上相當不划算。(在此我們定 r=影像長寬的最小值除以 10 代替 r=無限大,因
50 40 30 20 10 0 100 200 300 400 500 600 700 Search Range N u m be r of F e at ur e P o int s
Number of Feature Points V.S Search Range
(a) (b) 50 40 30 20 10 0 20 40 60 80 100 120 Search Range Num b e r o f ad de d P o in ts in th is S e ar c h Ra ng e
Number of added Points V.S Search Range
(c)
圖 3-1.3 ANMS 與 Search Range r 之深入分析範例一 (a)ANMS 的結果
(b)Search Range 從無限大往內縮回時的特徵點擷取數量累積圖 (c)Search Range 從無限大往內縮回時的特徵點增加數量圖
表 3-1.1 SR 從無限大往內縮回時特徵點擷取數量與增加數量統計表範例一 SR >50 50 49 48 47 46 45 44 43 42 41 Points 0 31 31 33 33 34 35 36 40 44 45 add 31 0 2 0 1 1 1 4 4 1 1 40 39 38 37 36 35 34 33 32 31 30 46 48 50 56 60 63 65 69 70 74 78 2 2 6 4 3 2 4 1 4 4 6 29 28 27 26 25 24 23 22 21 20 19 84 91 96 100 105 110 119 129 149 156 168 7 5 4 5 5 9 10 20 7 12 24 20 19 18 17 16 15 14 13 12 10 156 168 192 215 243 280 317 365 413 608 12 24 23 28 37 37 48 48 84 0 為使用 r=無限大時,真實運算量將會非常驚人,我們將此作為簡化並模擬,另 ㄧ方面也方便做 Worse Case 的考量) 。圖 3-1.3(c)顯示 Search Range r 從無 限大縮回時,特徵點增加數量與 Search Range r 的對應關係圖。我們也可以更 清楚地觀察到當 r 很大時,特徵點增加的數量非常少,一直到 r 慢慢縮小到 20 以下,特徵點增加的數量才慢慢增加,如此的狀況實在相當不符合運算效率。表 3-1.1 更進一步說明了 ANMS 的統計情況,因我們假設 r 從影像長寬的最小值除 以 10 開始往內縮,此 Pattern 大小為 752*500,所以 r 設定為從 50 開始往內縮, 大於 50 先假設為 0,我們會發現當 r 從無限大往內縮回時,特徵點增加的數量 都非常少,在 r 縮小到 19 之前,特徵點增加的數量沒有超過 20 的,這是一個非 常不好的現象,以 r=49 為例,表示我們去搜尋影像中每個 pixel 附近的 99*99 範圍的視窗大小,卻只讓我們增加兩個特徵點,實在是相當不划算。圖 3-1.4 與 表 3-1.2 使用了另外一個 Pattern 也有一樣的現象,在我們的研究當中總共測試
了 12 組的 Pattern 都有一樣的現象,這現象是相當合理的,因為當 r 很大,表 示限制較嚴格,因此能擷取到的特徵點自然較少,當 r 慢慢變小,能擷取到的特 徵點自然慢慢變多。 50 40 30 20 10 0 100 200 300 400 500 600 Search Range Num ber of F eat ur e P oint s
Number of Feature Points V.S Search Range
(a) (b)
100
(c)
圖 3-1.4 ANMS 與 Search Range r 之深入分析範例二 (a)ANMS 的結果 (b)Search Range 從無限大往內縮回時的特徵點擷取數量累積圖 (c)Search Range 從無限大往內縮回時的特徵點增加數量圖 50 40 30 20 10 0 10 20 30 40 50 60 70 80 90 Search Range N u m b e r o f a d d e d P o in ts i n th is S e a rc h R a n g
Number of added Points V.S Search Range
表 3-1.2 SR 從無限大往內縮回時特徵點擷取數量與增加數量統計表範例二 SR >48 48 47 46 45 44 43 42 41 40 39 Points 0 30 31 33 34 35 37 38 41 43 45 add 30 1 2 1 1 2 1 3 2 2 1 38 37 36 35 34 33 32 31 30 29 28 46 50 54 56 58 60 61 64 64 68 70 4 4 2 2 2 1 3 0 4 2 4 27 26 25 24 23 22 21 20 19 18 17 74 81 88 98 108 120 131 154 187 215 249 7 7 10 10 12 11 23 33 28 34 27 16 15 14 13 12 11 10 9 276 307 333 368 404 442 488 582 31 26 35 36 38 46 94 0
3-1.2 BUMS 流程(The flow of Bottom-Up Maxima Selection)
經過 3-1.1 傳統 ANMS 的深入分析之後,我們不難發現傳統 ANMS 演算法雖 然有平均分佈於整張影像的優點,但卻大大地犧牲了運算量,因此我們提出一套 快速的演算法,稱為 Bottom-Up Maxima Selection ,簡稱 BUMS。BUMS 比起傳 統 ANMS 演算法,可以達到一樣的目的,但運算量卻大大地降低。
傳統 ANMS 演算法因為剛開始 Search Range r 為無限大,但是能擷取到的 特徵點數目又很少,不符合運算效益,因此我們很直接地想到應該把 Search Range r 從內往外擴張,即 r=1 開始往外擴張,當 r 越大時,表示擷取出來的特 徵點越可靠,當然也越少,當特徵點數目剔除掉剩下 500 個點時,演算法即停止, 注意,到這裡只是初步構想,最後的 BUMS 尚未成型。目前暫時稱為修正型 ANMS,
Test Max. condition of every response points
Pick those points as the final matching point
SR = SR+1 Put all response points into a pool, SR=1
# of points=500
yes
no
圖 3-1.5 修正型 ANMS 演算法流程圖
圖 3-1.5 為修正型 ANMS 的演算法流程圖,我們可以看出傳統 ANMS 從 Search Range r 為無限大開始往內縮回,相當消耗運算量,但修正型 ANMS 演算法從 r=1 往外 擴張,比起傳統 ANMS 當然節省相當多運算量。
接著修正型 ANMS 之後,我們想到因為修正型 ANMS 從 r=1 往外擴張,但在 擴張的過程當中,會有一些重複的點是不用繼續測試它的最大值情況,只需測試 上一個 r 當中所擷取出來的候選特徵點(candidate points)即可,因為若在 r=A 的情況都無法成為可能的特徵點,那麼在 r=A'> A 的情況就更不可能成為特徵 點了,傳統 ANMS 之所以需要重複判斷是因為 r 由外往內縮回,所以當 r=B 不是 特徵點時並不一定代表 r=B'< B 一定不是特徵點,所以需要重複判斷。另外我 們也考慮到是否一定要取 ni=500 做為臨界值,若是 ni<500 可以節省後面的運算 量,或是 ni>500 一定足夠做縫合嗎?因此我們試著仿照 3-1.1 的做法去觀察當 Search Range r 從 r=1 往外擴增時候的特徵點擷取數量和特徵點剔除數量與 r 的對應關係圖,如圖 3-1.6。圖 3-1.6(b)表示 r=1 往外擴張時的特徵點擷取數量 與 r 的對應關係圖,我們會發現剛開始當 r=1 時,擷取到的特徵點非常多,之後 當 r 往外擴張,特徵點數量便急速下降,再往外擴大到約超過 25 之後,特徵點
0 5 10 15 20 25 30 35 0 1000 2000 3000 4000 5000 6000 Search Range N um ber of F eat ur e P oi nt s
Number of Feature Points V.S Search Range
(a) (b) 0 5 10 15 20 25 30 35 0 100 200 300 400 500 600 700 800 Search Range N u tur int
Number of deleted Points V.S Search Range
s e P o ed F ea del et m ber of (c)
圖 3-1.6 BUMS 與 Search Range r 之深入分析範例一 (a)BUMS 的結果
(b)Search Range 從 r=1 往外擴張時的特徵點擷取數量圖 (c)Search Range 從 r=1 往外擴張時的特徵點剔除數量圖
表 3-1.3 SR 從 r=1 往外擴張時特徵點擷取數量與剔除數量統計表範例一 SR 1 2 3 4 5 6 7 8 9 10 Points 5018 4819 4068 3296 2616 2071 1673 1336 1093 902 delete 199 751 772 680 545 398 337 243 191 139 11 12 13 14 15 16 17 18 19 20 763 653 566 494 438 383 354 305 279 262 110 87 72 56 55 29 49 26 17 20 21 22 23 24 25 26 27 28 29 30 242 229 208 184 174 161 147 138 132 126 13 21 24 10 13 14 9 6 6 10 31 32 33 34 116 108 98 93 8 10 5 下降的數量才慢慢趨近於緩和。圖 3-1.6(c)顯示當 r=1 往外擴張時,特徵點剔 除掉的數量與 Search Range r 的對應關係,我們可以清楚看到剛開始 r=1 往外 擴張到約 r=15 時,剔除掉的特徵點數量都非常多,之後 r 超過 15 之後,剔除掉 的特徵點數量才趨近於緩和。到了這裡我們已經可以非常清楚了解到為什麼 BUMS 可以比傳統 ANMS 節省相當多的運算量,因為 BUMS 剛開始 r 很小時就擷取出相當 多的特徵點,運算效率相當高,但是傳統 ANMS 剛開始 r 很大時擷取到的特徵點 數量卻相當的少,需要繼續做相當多的運算,因此 BUMS 自然可以比傳統 ANMS 節 省相當多的運算量。圖 3-1.7 和表 3-1.4 使用另一個 Pattern 也顯示出相同的結 果。在我們的研究當中總共測試了 12 組的 Pattern 都有一樣的現象,原因是因 為剛開始 r 很小往外擴張時,因為特徵點很多,所以容易碰到其他的特徵點並做 比較,經過比較之後此點不是此 r*r 範圍視窗裡面最大的值就會被剔除掉,因此 剛開始往外擴張時容易剔除掉很多的特徵點,但是隨著特徵點越來越少,能夠碰
0 5 10 15 20 25 30 35 40 45 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 Search Range N u m ber of F eatur e P o in ts
Number of Feature Points V.S Search Range
(a) (b) 0 5 10 15 20 25 30 35 40 45 0 100 200 300 400 500 600 700 800 Search Range N um b er o f de let ed F e at ur e P o int s
Number of deleted Points V.S Search Range
圖 3- Range r 之深入分析範例二 (c) 1.7 BUMS 與 Search (a) BUMS 的結果 (b)Search Range 從 r=1 往外擴張時的特徵點擷取數量圖 (c)Search Range 從 r=1 往外擴張時的特徵點剔除數量圖
表 3-1.4 SR 從r=1往外擴張時特徵點擷取數量與剔除數量統計表範例二 SR 1 2 3 4 5 6 7 8 9 10 Points 4672 4450 3710 3035 2420 1795 1371 1098 873 716 delete 222 740 675 615 625 424 273 225 157 92 11 12 13 14 15 16 17 18 19 20 624 558 486 445 411 382 357 323 284 238 66 72 41 34 29 25 34 39 46 38 21 22 23 24 25 26 27 28 29 30 200 174 156 140 126 1 14 109 105 98 92 26 18 16 14 12 5 4 7 6 3 31 32 33 34 35 36 37 38 39 40 89 86 83 82 74 70 65 63 61 57 3 3 1 8 4 5 2 2 4 4 41 42 53 50 50 3 0 到其他特徵點並做比較的機率就越低,因此能夠刪除特徵點的機會就會低,所以 到最後越往外面擴張,特徵點擷取數目與特徵點剔除數目就越趨近於飽和。
綜合以上,在 Bottom-Up Maxima Selection (BUMS)當中,我們的做法是把 Search Range r 從 1 開始往外擴張,並且在擴張的過程當中只針對候選特徵點 (Candidate Points)來做擴張,不是候選特徵點的就不重複做,另外我們也不使 用 ni=500 做最後的特徵點,而是當某個 Search Range r 剔除掉的點小於 50, BUMS 即停止,會這樣做的原因是因為當特徵點剔除數量<50 時,整個特徵點已經 趨近於收斂,如表 3-1.3、表 3-1.4 都可以清楚地觀察到此特性。例如當表 3-1.4
的 r=13 時,特徵點剔除的數量只剩下 41 個,之後都越來越趨近飽和,因此若 r 繼續往外擴張,特徵點剔除的數量會越來越少,Search Range 變大但是能剔除 的特徵點數量卻越來越少,不符合運算效率,因此我們定當特徵點剔除數量小於 50 時,BUMS 即停止,且如此的做法可以適應性地選擇特徵點的數量,若是特徵
圖 3-1.8 Bottom-Up Maxima Selection(BUMS)流程圖
fication of the Uniform
Dis
總共有 14 個,並且我們去計算兩張影像特徵點的 X 軸與 Y 軸標準差,圖 3-1.9 點數量小於 500 點,對之後的 Matching 也有很大的幫助,如圖 3-1.8。
Put all response points into a pool, SR=1
3-1.3 特徵點均勻分佈特性驗證(Veri
tribution of the Feature Points)
在前面幾節當中,我們曾經不只一次談到特徵點的均勻分佈將會對影像的縫 合有很大的益處,因此本節將簡單地提出一個例子來並用標準差的方式來做驗 證,圖 3-1.9 顯示特徵點擷取較為集中的情況,影像中的內部點(Inlier Points)
Test Max. condition of every candidate points
Pick those remainder points as the final matching point
SR = SR+1 # of deleted points<50
yes
(a) 匹配點(Matching Points)與內部點(Inlier Points)
(b)歪斜影像 (c)縫合影像 圖 3-1.9 特徵點較為集中的情況範例
(a) 藍色圈為匹配點(Matching Points),紅色叉為內部點(Inlier Points) (b) 歪斜影像
(a) 匹配點(Matching Points)與內部點(Inlier Points)
(b)歪斜影像 (c)縫合影像 圖 3-1.10 特徵點較為分散的情況範例
(a) 藍色圈為匹配點(Matching Points),紅色叉為內部點(Inlier Points) (b) 歪斜影像
![圖 1-1.1 相機陣列校正技術範例(本圖來源出自[44])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8620455.191469/13.892.133.756.853.1101/圖111相機陣列校正技術範例本圖來源出自44.webp)
![圖 1-2.1 360 度環場影像 1(本圖 Pattern 來源出自[42])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8620455.191469/15.892.135.747.445.735/圖12136度環場影像1本圖Pattern來源出自42.webp)
![圖 1-2.3 全自動絕對座標縫合影像 位置也必須一樣,如圖 1-2.3。圖 1-2.3 縫合影像所顯示的影像內容與真實世界 的內容(ground truth)完全一樣,連相對位置也一樣,但是很明顯地我們也可以 發現為了達到相對位置一樣的效果,在縫合的過程必須也把影像做歪斜,以致於 縫合後的結果越來越歪。此處的歪斜與前面 360 度環場影像的扭曲不一樣,360 度環場影像是為了達到 360 度環場效果所以導致相對位置不同以致失真。全自動 絕對座標縫合影像[21]-[22]是為了達到絕對座標都與真實世界一](https://thumb-ap.123doks.com/thumbv2/9libinfo/8620455.191469/16.892.136.761.107.424/全自動絕須一樣如圖實世界在縫合致於縫合後的結果不一樣全自動.webp)