Re-mining of Ontological Association Rules under Support
Threshold Refinement
Ming-Cheng Tseng
Wen-Yang Lin
Rong Jeng
Institute of Info. Eng.
Dept. of Comp. Sci. & Info. Eng.
Dept. of Info. Mangt.
I-Shou University
National Univ. of Kaohsiung
I-Shou University
[email protected]
[email protected]
[email protected]
Abstract
The problem of mining association rules incorporated with domain knowledge (ontology) has attracted lots of researchers’attention recently. In our previous work, we have investigated this problem and devised two efficient algorithms, called AROC and AROS, for mining association rules with ontological information that presents not only classification but also composition relationship. In real applications, however, the work of discovering interesting association rules is an iterative process; the analysts have to continuously adjust the constraint of minimum support to discover informative rules. As such, how to shorten the response time for each re-mining process is a crucial issue for realizing interactive mining environment. In this paper, we continue the study of ontological association mining towards is avenue. An incremental algorithm is proposed. Empirical evaluations showed that the proposed algorithm can significantly reduce the computation time spent on rediscovery of frequent itemsets and is more efficient than running AROC or AROS afresh.
Keywords: Data re-mining, ontological association rules, ontology, support refinement.
1. Introduction
The problem of mining association rules incorporated with domain knowledge (ontology) [11] has attracted lots of researchers’attention recently. In our previous work, we have investigated this problem and proposed two Apriori-based algorithms, AROC and AROS [28]. In real applications, however, the work of discovering interesting association rules is an iterative process; the analysts have to continuously adjust the constraint of minimum support and/or minimum confidence to discover real informative rules. As such, how to shorten the response time for each re-mining process is a crucial issue for realizing interactive mining environment.
In this paper, we continue the study of ontological association mining towards this avenue and propose an algorithm, called RARO (Remining of Association Rules with item Ontology), for accomplishing the work of rediscovering frequent ontological itemsets
with respect to user’s refined support threshold. Our algorithm is featured by utilizing the most recently discovered frequent itemsets and adopting the technique lending from incremental mining, which can significantly reduce the number of candidate itemsets as well as database rescanning. Empirical evaluations showed that our algorithm is much more efficient than that applying our previously proposed AROC and AROS algorithms afresh to accomplish the re-mining task.
The remainder of this paper is organized as follows. A description of the problem of concern is given in Section 2. In Section 3, we explain how to re-mine ontological association rules under multiple minimum support refinement and describe the proposed RARO algorithm. Evaluation of the RARO algorithm is described in Section 4. A description of related work is given in Section 5. Finally, our conclusion is stated in Section 6.
2. Problem Statement
Let I{i1, i2,…,im} be a set of items, and DB
{t1, t2, …, tn} be a set of transactions, where each
transaction titid, Ahas a unique identifier tid and
a set of items A (A I). To study the mining of association rules with ontological information from
DB, we assume that the ontology of items, T, is
available and is denoted as a graph on IE, where E {e1, e2, …, ep} represents the set of extended items
derived from I. There are two different types of edges in T, taxonomic edge (denoting is-a relationship) and
meronymic edge (denoting has-a relationship). We
call an item j a generalization of item i if there is a path composed of taxonomic edges from i to j, and conversely, we call i a specialization of j. On the other hand, we call item k a component of item i if there is a path composed of meronymic edges from i to k, and we call i an aggregation of k. Figure 1 illustrates an ontology constructed for I {HP DeskJet, Epson EPL, Sony VAIO, IBM TP}, and E {Printer, PC, Ink Cartridge, Photo Conductor, Toner Cartridge, S 60GB, RAM 256MB, IBM 60GB}.
Note that in nature the frequencies of items are wide-ranging, and intuitionally, an item representing a category or a component shall occur more frequently than its specializations or aggregations. A uniform
support threshold would refrain the discovery of informative rules consisting of rarely occurred items or primitive items. To avoid this problem, we have adopted the multiple minimum support specification proposed in [18]. Composition Classification Photo Conductor Toner Cartridge HP DeskJet Printer Epson EPL -Ink Cartridge - - -RAM 256MB IBM 60GB Sony VAIO PC IBM TP S 60GB
-Figure 1. Example of an item ontology. Definition 1. Let ms(a) denote the minimum support of an item a in I E. An itemset A = {a1,
a2,…,ak}, where aiI E for 1 i k, is frequent
if the support of A is larger than the lowest value of minimum support of items in A, i.e., sup(A)minaiA
ms(ai).
Definition 2. Given a set of transactions DB and an ontology T, an association rule is an implication of the following form,
A B,
where A, BI E, A B , and no item in B is a generalized item or a component of any item in A, and vice versa. The support of this rule, sup(A B), is equal to the support of A B. The confidence of the rule, conf(A B), is the ratio of sup(A B) versus sup(A), i.e., the percentage of transactions in
DB containing A that also contain B.
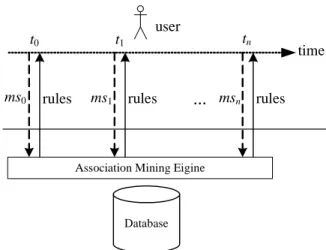
It is well-known that association mining is an iterative process [10]. Analysts usually have to iteratively set different minimum supports in the mining process to find real interesting associations among items. Thus, a complete session of mining task indeed is composed of a sequence of trials (re-mining phases). Figure 2 depicts such an iterative process, where ms0, ms1, …, msn denote the sequence of
support threshold trials before satisfied association rules are discovered.
Given a set of transactions DB, an item ontology T, and the set of discovered frequent itemsets with respect to the last specified support threshold msold
(corresponding to msi, for 0i n1), the problem
of ontological association rules re-mining is to discover the set of frequent itemsets with respect to the newest support threshold msnew(corresponding to
msi).
3. The Proposed Algorithm
3.1 Description
Previous work [3, 4, 5, 15, 22, 23, 27] on the problem of incremental maintenance of discovered
Database Association Mining Eigine
ms0 ms1
time
rules rules
...
msn rules usert0 t1 tn
Figure 2. Interactive association mining under support threshold refinement.
association rules under database update has demonstrated that by making use of the discovered frequent itemsets can avoid unnecessary computation and database scan in the course of ongoing update. This paradigm works as well for updating frequent itemsets under minimum support refinement. The intuition is that a frequent itemset A remains frequent if msnew(A) msold(A), and an infrequent itemset A
keeps infrequent if msnew(A)msold(A). For example,
if the minimum support is changed from 35% to 25%, then the previous frequent itemsets are still frequent, and we only need to mine the original infrequent itemsets from the original database. On the other hand, if the minimum support is changed from 35% to 55%, all we have to do is to compare the support of previous frequent itemsets with the new minimum support to decide whether those itemsets are frequent or not, saving the need of rescanning the original database.
In view of this, a better approach is to, within the set of discovered frequent itemsets LED, distinguish the frequent itemsets from the others and utilize them to avoid unnecessary computation as well as database scan.
Lemma 1. If an itemset A is frequent in a database with respect to msoldand msnew(A)msold(A), then A is
frequent in the database with respect to msnew.
Lemma 2. If an itemset A is infrequent in a database with respect to msold(A) and msnew(A)
msold(A), then A is infrequent in the database with
respect to msnew(A).
Lemma 3. If an itemset A is frequent in an original database with respect to msold(A) and is
frequent in an incremental database with respect to
msnew(A), and msnew(A) msold(A), then A is also
frequent in the updated database with respect to
msnew(A).
Lemma 4. If A is infrequent in an original database with respect to msold(A) and is infrequent in
an incremental database with respect to msnew(A), and
msnew(A)msold(A), then A is also infrequent in the
The above paradigm, summarized in Table 1, however, has to be modified to incorporate ontological information. Note that in the presence of ontology, an itemset can be composed of items, primitive or extended, in the ontology. The main problem thus is how to effectively compute the occurrence of an itemset A in the transaction database
DB. This involves checking for each item a A.
Intuitively, we can simplify the task by first adding the generalized and component items, i.e., extended items, of all items in a transaction t into t to form the extended transaction t*. We denote the resultant extended database as ED.
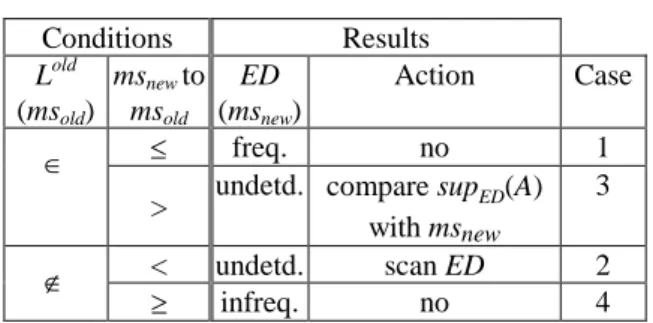
Table 1. Conditions for frequent itemsets inference with respect to support threshold
refinement. Conditions Results Lold (msold) msnewto msold ED (msnew) Action Case freq. no 1
> undetd. compare supED(A) with msnew
3
< undetd. scan ED 2
infreq. no 4
There is one thing worthy of special care in forming the extended transactions. A purchased item might be a component of other purchased items as well. Consider Figure 1 for example. Item like“Ink Cartridge”could beacomponentof“HP DeskJet”or be a primitive item purchased directly. To differentiate these two situations, when an item a serves as a component item, we append an asterisk to the item a (a*), and when a* appears in an association rule, it should be interpreted as “component of some item”. For example, the following rule
IBM TP Ink Cartridge*
denotes that people who purchase “IBM TP”are likely to purchase those products with component Ink Cartridge. But a similar rule shown below exhibits different meaning, “people who purchase IBM TP are likely to purchase Ink Cartridge.”
IBM TP Ink Cartridge
The main steps of the proposed RARO Algorithm are described as follows:
Inputs: (1) DB: the database; (2) the old multiple minimum support (msold) setting; (3) the new multiple
minimum support (msnew) setting; (4) T: the item
ontology; (5) old k k old L
L : the set of old frequent itemsets.
Output: new
k k new L
L : the set of new frequent itemsets with respect to msnew.
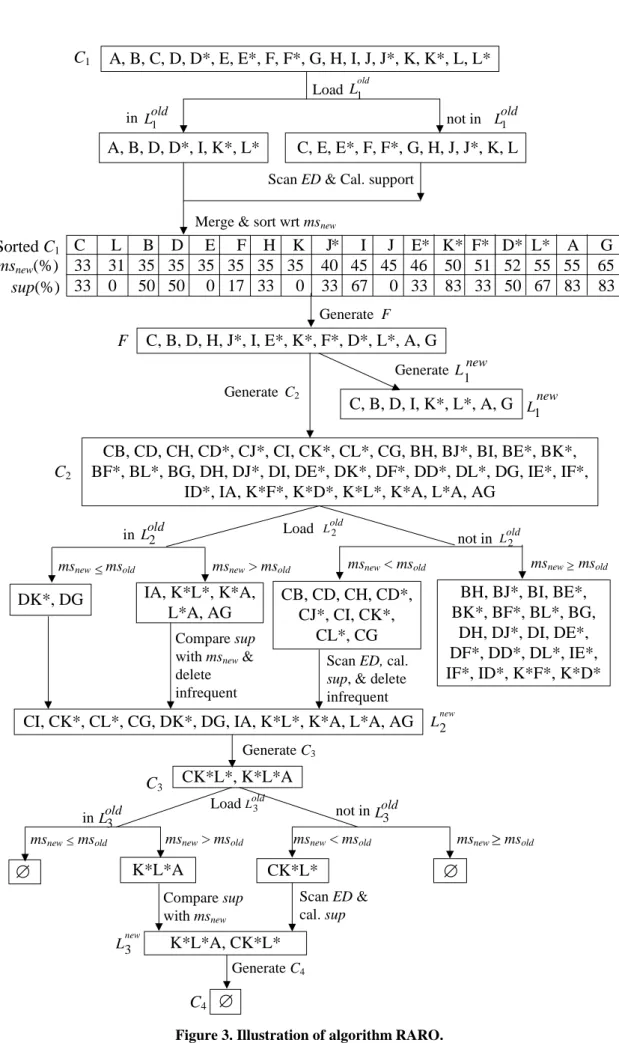
Steps:
1. Initialize C1as IE. 2. LoadLold1 .
3. Sort C1 in increasing order of their mss, and create frontier set F [18] and new
L1 .
4. Generate the set of candidate 2-itemsets C2from
F (calling C2-gen(F) [17]).
5. Add extended items in T into DB to form ED. 6. Delete any candidate in C2that consists of an
item and its extension. 7. Load old
L2 .
8. Divide C2 into four parts: those in Lold2 with
msnewmsold(Case 1); those in Lold2 with msnew>
msold (Case 3); those not in Lold2 with msnew<
msold(Case 2); and those not in Lold2 with msnew msold (Case 4). For simplicity, these four sets
are denoted as
C
,C
,C
, andC
, respectively.9. For itemsets in
C
, add them into newL2 . 10. For itemsets in
C
, compare their support w.r.t.msnewand delete those infrequent itemsets.
11. For itemsets in
C
, scan database ED to count their supports and delete the infrequent ones. 12. Create newL
2 = newL
2 C
C
.13. Generate candidates C3 from
L
new2 (calling Ck-gen(Lk-1) [17]).
14. Repeat Steps 6-11 for new candidates Ckuntil
no frequent k-itemsets
L
newk are created.3.2 An Example
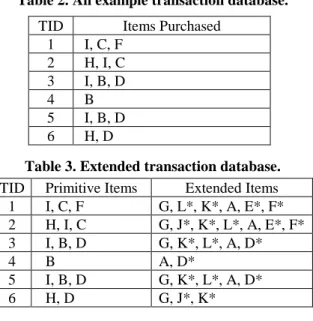
Suppose that the ontology is as Figure 1 and the transaction database is as Table 2. To simplify the illustration, we use item “A”to stand for“Printer”, “B”for“HP DeskJet”,“C”for“Epson EPL”,“D” for “Ink Cartridge”,“E”for“Photo Conductor”,“F”for “Toner Cartridge”, “G” for “PC”, “H” for “Sony VAIO”,“I”for“IBM TP”, “J”for “S 60GB”, “K” “for “RAM 256MB”,“L”for “IBM 60GB”, “M”for “MC”,“N”for“ACER N”, “O”for “B 5GB”and “P” for “IBM 80G”. The new and old multiple minimum supports (msnewand msold) associated with each item
in the ontology are set as follows:
item A B C D E F G H I msold(%) 37 34 35 35 35 35 85 38 42 msnew(%) 55 35 30 35 35 35 65 35 45 item J K L D* E* F* J* K* L* msold(%) 35 35 35 36 45 50 40 50 45 msnew(%) 45 35 31 52 46 51 40 50 55
Table 3 shows the extended database after inserting the extensions of primitive items. The discovered frequent itemsets with respect to msold.are
shown in Table 4. The flow for generating the new set of frequent itemsets as msold refined to msnew is
illustrated in Figure 3.
Table 2. An example transaction database.
Table 3. Extended transaction database. TID Primitive Items Extended Items 1 I, C, F G, L*, K*, A, E*, F* 2 H, I, C G, J*, K*, L*, A, E*, F* 3 I, B, D G, K*, L*, A, D* 4 B A, D* 5 I, B, D G, K*, L*, A, D* 6 H, D G, J*, K*
Table 4. Discovered frequent itemsets wrt old minimum support.
4. Empirical Evaluation
In this section, we evaluate the performance of the proposed algorithm, RARO, against our previously proposed algorithms AROC and AROS. All three algorithms were implemented with two different support counting strategies: horizontal counting and vertical intersection. For differentiation, the algorithms with horizontal counting are denoted as AROC(H), AROS(H) and RARO(H), while the algorithms with vertical intersection counting are denoted as AROC(V), AROS(V) and RARO(V). Synthetic datasets, generated by the IBM data generator [1] with artificially–built ontology, were used in the experiments. The parameters settings are shown in Table 5.
For the setting of multiple minimum support thresholds, we adopt the Confidence-Lift Support (CLS) specification [17], which utilizes the following formula to generate multiple minimum supports for each item ai: ms(ai) = n i -n i a sup a sup mc max a sup i i i if 1 1 if ), ( )}, ( , { ) ( 1
where mc stands for minimum confidence and n for the number of items, sup(ai) sup(ai+1), and when
ms(ai) is less than 0.75%, we set as ms(ai)0.75%.
All experiments were performed on an Intel Pentium-IV 2.80GHz with 2GB RAM, running on Windows 2000.
The evaluation was performed by inspecting two extreme cases of support refinements: (1) all items having less new minimum supports, i.e., msnewmsold,
and (2) all items having larger new minimum supports, i.e., msnewmsold. This is because the performances of
the algorithms with other specifications are bounded by these two cases. For differentiation, algorithm RARO under the former case is denoted as RARO1 while it is denoted as RARO2 for the latter case.
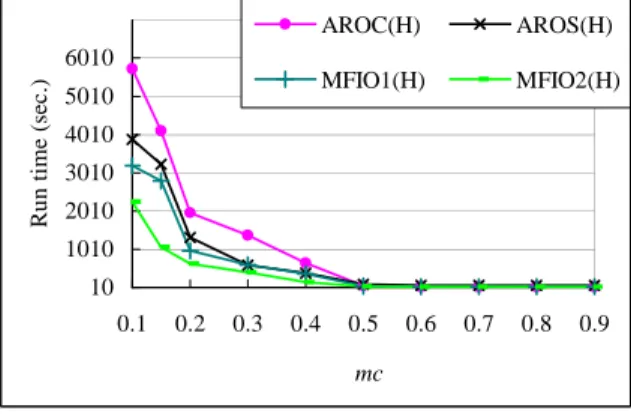
As the results shown in Figure 4, RARO2(V) leads the first. RARO1(V), however, performs only a little better than AROC(V) for mc lower than 0.4. In Figure 5, RARO2(H) performs 210% faster than AROC(H) at mc 0.2 while RARO1(H) performs approximately 104% better than AROC(H). RARO1 performs only a little better than AROC. This is because the number of undetermined candidates that require rescanning the original database increases significantly as msnewmsold.
5. Related Work
In the past decade, various strategies have been proposed to realize the interactive (or online) association mining, including pre-computation [1, 7, 13], caching [21], and incremental update [8, 14, 19, 20].
The general idea for pre-computation strategy is to pre-compute all frequent itemsets relative to a presetting support threshold, and once the specified support threshold is larger than the presetting value, the qualified association rules can be immediately generated without the burden of an expensive phase for itemset generation. With a similar philosophy, the caching strategy tries to eliminate the cost spent on frequent itemsets computation by temporarily storing previously discovered frequent itemsets (may be accompanied with some infrequent itemsets) that are beneficial to subsequent association queries. The effectiveness of this strategy relies primarily on a successful design of the cache replacement algorithm. The third strategy can be regarded as a compensation for the first two strategies. During the course of a sequence of re-mining trials with varied support thresholds, the incremental update strategy endeavors to utilize the discovered frequent itemsets in previous trial to reduce the cost for subsequent re-execution. TID Items Purchased
1 I, C, F 2 H, I, C 3 I, B, D 4 B 5 I, B, D 6 H, D old
L
1 sup(%)L
old2 sup(%)L
old3 sup(%)B D D* A I L* K* 50 50 50 83 67 67 83 D, K* D, G A, I A, L* A, K* A, G L*, K* 50 50 67 67 67 67 67 A, L*, K* 66.7
CB, CD, CH, CD*, CJ*, CI, CK*, CL*, CG, BH, BJ*, BI, BE*, BK*,
BF*, BL*, BG, DH, DJ*, DI, DE*, DK*, DF*, DD*, DL*, DG, IE*, IF*,
ID*, IA, K*F*, K*D*, K*L*, K*A, L*A, AG
Compare sup with msnew&
delete infrequent
K*L*A, CK*L*
C2
C4
Generate C3C1
C, B, D, H, J*, I, E*, K*, F*, D*, L*, A, G
F
C, B, D, I, K*, L*, A, G
Scan ED & Cal. supportGenerate F
Generate Generate C2
in Lold1 not in Lold1
Load Lold1
A, B, D, D*, I, K*, L*
C, E, E*, F, F*, G, H, J, J*, K, L
Merge & sort wrt msnew
A, B, C, D, D*, E, E*, F, F*, G, H, I, J, J*, K, K*, L, L*
1
Lnew
Scan ED, cal.
sup, & delete
infrequent
CI, CK*, CL*, CG, DK*, DG, IA, K*L*, K*A, L*A, AG
L2newCK*L*, K*L*A
DK*, DG
IA, K*L*, K*A,
L*A, AG
CB, CD, CH, CD*,
CJ*, CI, CK*,
CL*, CG
Load Lold2BH, BJ*, BI, BE*,
BK*, BF*, BL*, BG,
DH, DJ*, DI, DE*,
DF*, DD*, DL*, IE*,
IF*, ID*, K*F*, K*D*
msnew msold msnew> msold msnew< msold msnew msold
K*L*A
CK*L*
msnew msold msnew> msold msnew< msold msnew msold
3 new L Compare sup with msnew Scan ED & cal. sup
C3
Generate C4 not in Lold2Sorted C
1C
L
B
D
E
F
H
K
J*
I
J
E* K* F* D* L*
A
G
33
31 35 35 35 35 35 35
40 45 45 46
50 51 52 55 55
65
33
0
50 50
0 17 33
0
33 67
0 33
83 33 50 67 83
83
ms
new(%)
sup(%)
1 Lnew in Lold2 LoadLold3 not inLold3 inLold3
Table 5. Parameter settings for synthetic data generation.
Parameter Value
|DB| Number of original transactions 200,000 |t| Average size of transactions 20
N Number of items 362 R Number of groups 30 L Number of levels 4 F Fanout 5 10 210 410 610 810 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 mc R u n ti m e (s e c .) AROC(V) AROS(V) RARO1(V) RARO2(V)
Figure 4. Performance evaluation under varying multiple minimum support refinement using
vertical intersection counting.
10 1010 2010 3010 4010 5010 6010 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 mc R u n ti m e (s e c .) AROC(H) AROS(H) MFIO1(H) MFIO2(H)
Figure 5. Performance evaluation under varying multiple minimum support refinement using
horizontal counting.
If concept hierarchy or taxonomy is taken as a kind of ontology, then the research of incorporating ontology into data mining can be traced back to 1995 when Han & Fu [12] and Srikant & Agrawal [25] considered incorporating conceptual hierarchy knowledge to mine so-called multilevel association rules or generalized association rules, respectively. In [25], the problem was named as mining generalized association rules, which aimed to find associations among items at any level of the taxonomy, while the work conducted in [12] emphasized “drill-down” discovery of association rules.
In [16], Jea et al. considered the problem of discover multiple-level association rules with composition (has-a) hierarchy and proposed a
method. Their approach is similar to [12], and was later extended by Chien et al. [6], incorporating not only classification hierarchy but also composition hierarchy information. In [9], Domingues and Rezende proposed an algorithm, called GART, which uses taxonomies, in the step of knowledge post-processing, to generalize and to prune uninteresting rules that may help the user to analyze the generated association rules.
6. Conclusions
We have investigated in this paper the problem of remining ontological association rules under minimum support refinement and presented an efficient algorithm. Empirical evaluation showed that the algorithm is very efficient to complete the remining process under multiple minimum support refinement, and superior to adopting our previous proposed algorithms for mining ontological association rules, AROC and AROS, to accomplish the remining process. In the future, we will continue this study to find more efficient algorithms. We will also consider incorporating other types of semantic relationships pointed out by Storey [26], including possession, attachment, attribution, antonyms, synonyms and case.
Acknowledgements
This work is partially supported by National Science Council of Taiwan under grant No. NSC95-2221-E-390-024.
References
[1] C.C. Aggarwal and P.S. Yu, “Online generation of association rules,” Proc. of the 14th International Conference on Data Engineering,
pp. 402-411, 1998.
[2] R.Agrawaland R.Srikant,“Fastalgorithms for mining association rules,”Proc. of 20th Int.
Conf. on Very Large Data Bases, pp. 487-499,
1994.
[3] D.W. Cheung, J. Han, V.T. Ng, and C.Y. Wong, “Maintenance of discovered association rules in large databases: An incremental update technique,”Proc. of the 12th 1996 Int. Conf. on
Data Engineering, pp.106-114, 1996.
[4] D.W. Cheung, V.T. Ng, B.W. Tam, “Maintenance of discovered knowledge: a case in multi-level association rules,”Proc. of the
2nd Int. Conf. on Knowledge Discovery and Data Mining, pp. 307-310, 1996.
[5] D.W. Cheung, S.D. Lee, and B. Kao, “A general incremental technique for maintaining discovered association rules,”Proc. of the 5th
Int. Conf. on Database Systems for Advanced Applications (DASFAA'97), pp. 185-194, 1997.
[6] B.C. Chien, M.H. Chung, and T.C. Wang, “Mining fuzzy association rules on Has-A and Is-A hierarchical structures,”Proc. of the 10th Conf. on Artificial Intelligence and Applications,
2005.
[7] B. Czejdo, M. Morzy, M. Wojciechowski, and M. Zakrzewicz, “Materialized views in data mining,” Proc. of the 13th International Workshop on Database and Expert Systems Applications, pp. 827-834, 2002.
[8] Z.H. Deng, X. Li, and S.W. Tang, “An efficient approach for interactive mining of frequent itemsets,” Proc. of the 6th International Conference on Web-Age Information Management, Lecture Notes in Computer Science 3739, pp. 138-149, 2005.
[9] M.A. Domingues and S.O. Rezende, “Using taxonomies to facilitate the analysis of the association rules,” Proc of the 2nd Int.
Workshop on Knowledge Discovery and Ontologies, pp. 59-66, 2005.
[10] U.Fayyad,P.S.Gregory,and S.Padhraic,“The KDD process for extracting useful knowledge from volumesofdata,”Communications of the ACM, Vol. 39, No. 11, pp. 27–34, 1996. [11] T.R. Gruber,“A translation approach to portable
ontology specifications,”Knowledge Acquisition, Vol. 5, pp. 199-220, 1993.
[12] J. Han and Y. Fu, “Discovery of multiple-level association rules from large databases,”Proc. of
the 21st Int. Conf. on Very Large Data Bases,
pp.420-431, 1995.
[13] J. Han, “Toward on-line analytical mining in large databases,”ACM SIGMOD Record, Vol. 27, No. 1, pp. 97-107, 1998.
[14] C. Hidber, “Online association rule mining,”
Proc. of 1999 SIGMOD Conf., pp. 145-156,
1999.
[15] T.P. Hong, C.Y. Wang, Y.H. Tao, Incremental data mining based on two support thresholds, in:
Proc. of the 4th Int. Conf. on Knowledge-Based Intelligent Engineering Systems and Allied Technologies, 2000, pp.436-439.
[16] K.F.Jea,T.P.Chiu and M.Y.Chang,“Mining multiple-level association rules in has-a hierarchy,”Proc. of the Joint Conf. on AI, Fuzzy System, and Grey System, 2003.
[17] W.Y. Lin and M.C. Tseng, “Automated support specification for efficient mining of interesting association rules,” Journal of Information Science, Vol. 32, No. 3, pp. 238-250, 2006.
[18] B. Liu, W. Hsu, and Y. Ma, “Mining association rules with multiple minimum supports,”Proc. of
1999 Int. Conf. Knowledge Discovery and Data Mining, pp. 337-341, 1999.
[19] J. Liu and J. Yin, “Towards efficient data re-mining (DRM),”Proc. of the 5th Pacific-Asia
Conference on Knowledge Discovery and Data Mining, Lecture Notes in Artificial Intelligence 2035, pp. 406-412, 2001.
[20] X. Ma, S. Tang, D. Yang, and X. Du, “Towards efficient re-mining of frequent patterns upon threshold changes,”Proc. of WAIM'02, Lecture
Notes in Computer Science 2419, pp. 80-91,
2002.
[21] B. Nag, P.M. Deshpande, and D.J. DeWitt, “Using a knowledge cache for interactive discovery of association rules,”Proceedings of
Knowledge Discovery and Data Mining, pp.
244-253, 1999.
[22] K.K. Ng and W. Lam, “Updating of association rules dynamically,” Proc. of 1999 Int. Symposium on Database Applications in Non-Traditional Environments, pp. 84-91, 2000.
[23] N.L. Sarda and N.V. Srinivas, “An adaptive algorithm for incremental mining of association rules,” Proc. of the 9th Int. Workshop on
Database and Expert Systems Applications (DEXA'98) , pp. 240-245, 1998.
[24] A. Savasere, E. Omiecinski, and S. Navathe, “An efficient algorithm for mining association rulesin largedatabases,”Proc. of the 21st Int. Conf. on Very Large Data Base, pp. 432-444,
1995.
[25] R.Srikantand R.Agrawal,“Mining generalized association rules,”Future Generation Computer
Systems, Vol. 13, Issues 2-3, pp. 161-180, 1997.
[26] V.C. Storey, “Understanding Semantic Relationships,”Very Large Databases Journal,
Vol. 2, No. 4, pp. 455-488, 1993.
[27] S. Thomas, S. Bodagala, K. Alsabti, and S. Ranka, “An efficient algorithm for the incremental updation of association rules in large databases,”Proc. of the 3rd Int. Conf. on
Knowledge Discovery and Data Mining, pp.
263-266, 1997.
[28] M.C. Tseng, W.Y. Lin, and R. Jeng, “Mining association rules with ontological information,”
Proc. of 2nd Int. Conf. on Innovative Computing, Information and Control, Japan, 2007.