國
立
交
通
大
學
資訊學院 資訊學程
碩
士
論
文
以有限狀態自動機達成XML簽章驗證的線性化
Linear XML Signature Verification Scheme Based on Finite Automata
研 究 生:李建賢
指導教授﹕謝續平 教授
葉義雄 教授
以有限狀態自動機達成XML簽章驗證的線性化
Linear XML Signature Verification Scheme Based on Finite Automata
研 究 生:李建賢
Student:Chien-Hsien Lee
指導教授:謝續平 博士 Advisor:Shiuh-Pyng Shieh
葉義雄 博士
Yi-Shiung Yeh
國 立 交 通 大 學
資訊學院 資訊學程
碩 士 論 文
A ThesisSubmitted to College of Computer Science National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master of Science
in
Computer Science July 2008
Hsinchu, Taiwan, Republic of China
以有限狀態自動機達成 XML 簽章驗證的線性化
研究生:李建賢
指導教授:謝續平
葉義雄
國立交通大學
資訊學院 資訊學程 碩士班
摘 要
XML 簽章的主要瓶頸在於 Canonical XML, Canonical XML 是 W3C 定義正規化 XML 文件的方法,此正規化流程稱為 Canonicalization (C14n),降低 C14n 的複雜度就能大幅 提升 XML 簽章的效能,此研究提供一個轉換模型來降低 C14n 的複雜度,在執行 XML 正規 化的過程中透過以有限狀態自動機為基礎的轉換模型將每一個 XML 節點轉換成非遞迴的 序列,在簽章驗證的過程中透過一個有限狀態轉換器就能在線性時間內將此序列還原回 Canonical XML,本研究提出得方法可以在 XML 簽章驗證時將正規化 XML 的複雜度降至 O(n),此方法同時具有 streaming 的特性,可以大幅降低記憶體使用率及提升運算速度, 適合使用於如防火牆及行動裝置這類低資源及低運算能力的裝置上。Linear XML Signature Verification Scheme Based on
Finite Automata
Student: Chien-Hsien Lee
Advisor:DR.Shiuh-Pyng Shieh
DR. Yi-Shiung Yeh
Degree Program of Computer Science
National Chiao Tung University
Abstract
XML Signature main bottleneck is Canonical XML. Canonical XML is a formalization
method for XML document defined in W3C Canonical XML [9]. This formalize process
called Canonicalization (C14n). Reducing the complexity of C14n can also significantly
improve the performance of XML Signature. This research provides a transformation model
to reduce the complexity of C14n. In the processing of C14n, the results of node operations
are converted to non-recursive binary sequence by the transformation model based on Finite
Automata. For signature verification, the binary sequence can be restored into Canonical
XML by Finite Automata in linear time. The proposed scheme can reduce the complexity of
Canonical XML to O(n) and streaming characteristics. The characteristics of streaming can
also substantially reduce memory usage and improve computing speed. This scheme is
suitable for applications such as firewall or mobile devices with limited -resource or low
誌 謝
本篇論文之所以能夠完成首先要感謝我的兩位指導教授葉義雄老師及謝續平老師, 感謝葉義雄老師開放式的教學方式循序引導我的研究方向,葉教授已於 2007 年 7 月辭世, 他為人處世的態度及對研究的熱忱將永存我心,感謝續平老師的大力幫忙在葉義雄老師 過世後協助我繼續完成論文,謝謝教授總是不厭其煩的指導我論文寫作的方法,並以你 豐富的經驗及卓越的學術素養提供我寶貴意見,循序引導我完成論文研究。其次要感謝 我的父母及家人,在工作及學業的壓力下能不斷支持及鼓勵我,讓我能繼續堅持下去。感 謝陳登吉老師及李鎮宇學長在葉教授過世後提供我諮詢及協助,再次感謝您及黃世昆老 師擔任我的口試委員。感謝陳耀良特助,有你的鼓勵及協助我才能再次踏上求學之路,感 謝呂宜薰副理、史素珍技術長及洪錦坤老大,有你們的幫助及體諒我才能兼顧工作及學 業,特別感謝陳振楠總經理的關心及幫忙,我才能以在職進修的方式來交大唸書,也再次 感謝您在百忙之中撥空擔任我的口試委員,謝謝品保組長楊博雄大哥常常提供諮詢,在 我為了論文頭痛的時候不厭其煩的聽我發牢騷。最後要感謝交大及所有指導過我的教授 給了我再一次求學的機會及美好的回憶。Table of Contents
1. Introduction ...1 2. Overview...3 2.1. XML-Signature Syntax ...3 2.2. Canonical XML ...7 2.3. XPath transformation ...8 2.4. XML Signature Processing ...9 3. Related Work ...103.1. Efficient Implementation of XML Security for Mobile Devices ...10
3.2. A Streaming Validation Model for SOAP Digital Signature...10
4. Proposed Scheme ...12
4.1. Methodology Analysis ...12
4.2. Conversion of Structure and Content in Canonical Processing ...14
4.3. Constructing Finite Automata of Canonical XML...18
4.4. Output Function for Generate Canonical Form...32
4.5. Example for CFA ...33
4.6. Support for XPath Transformation ...35
4.7. Complexity Analysis for CFA ...36
5. Performance Analysis ...38
6. Conclusion ...42
Appendix I The Algorithm of C14n Conversion...43
Appendix II The Sample of XML Document For Performance Testing...46
List of Figures
Figure 2-1 Example of XPath transformation ...8
Figure 2-2 XML Signature Process flow...9
Figure 4-1 Canonical XML Conversion...13
Figure 4-2 DOM tree traversing...15
Figure 4-3 Definition of CFA ...19
Figure 4-4 Diagram of CFA ...31
Figure 4-5 Example of CFA ...33
Figure 5-1(a) Comparison without XPath transformation...41
List of Tables
Table 4-1 Transition Table of CFA ...30 Table 5-1 testing environment ...38 Table 5-2 results of performance testing...40
1. Introduction
XML (Extensible Markup Language) [10] is a structure text standard derived from SGML [19]. It realized the platform independence for the digital information exchange for Web or everywhere. The e-commerce technologies such as Web Services [20] or ebXML [18] are all developed based on XML. In order to preserve the characteristics of xml, the W3C define the XML Signature [8] standard to guarantee that data integrity and non-repudiation for XML message exchange. The difference with XML Signature [8] and traditional Digital Signature [14] is that XML Signature is protecting application content, not binary Data. The traditional digital signature [14] if there is one bit different will have completely different results; XML Signature [8] is not the case. For example, the serialization result of one XML document may have two or more encoding, but they are equivalent. Because XML Parser convert the XML to Objects[11], the content encoding of each node is Unicode(UTF-16)[13].The other characteristics such as comment processing, character escape, external resource , reference resolve, attribute sorting[9] and so on are all increasing the complexity of XML Signature implementation.
In addition, XML Signature supports partial Sign Based on XPath [12] technology. The XPath can address the node in the DOM tree to determinate that which one must be added in signature computing. In Multi-Hop [18] transmission process, this technology supports Multi-Sign but does not affect the previous Signature.
Canonical XML (C14n) [9] is the core technology for XML Signature. C14n is designed to formalize XML document. Because the processing of XML is application-oriented, therefore application concern is the contents of the documents rather than presentation view. C14n ensure that the document is logically equivalent and not physically.C14n is a special-purpose compiler, but it generates formalize octet stream (UTF-8 encoding) [9] [15] instead of executable program.
C14n computing includes many complex processing such as attribute and namespace sorting, etc. The lower bound of complexity for sorting is nlogn[2], so total cost for all elements in document is about O(n(D+mlogm)) (D is the depth of node, m is the number of attribute or namespace[7]) . Other operations of Canonical XML such as XPath transformation [8] [12] all its complexity is about O(n2) or more complex. Therefore, the lower bound of XML Signature Complexity can be
defined in O(n2). Thus, the performance of XML Signature main bottleneck can be defined in
C14n. Reducing the complexity of C14n can also significantly improve the performance of XML Signature.
Recently, the performance research for XML Signature still depends on XML Parsing Model [11] [17] and XML Signature Syntax Processing [8] improvements. Thus, they cannot reduce the complexity anymore.
However, the C14n effort for Sign Processing is not avoided, because these operations such as parsing [11] [17], searching and sorting operations [9] cannot be eliminate. Since these efforts are unavoidable, why do not use these operations potential to improve the performance of verification. Therefore, the objective of this research is to reduce the complexity of C14n for XML Signature verification.
The rest of the paper is organized as follows. Section 2 describes the concept of XML Signature. The related work and limitation are introduced in Section 3. Section 4 describes the detail of proposed scheme, and the analysis of performance is given in Section 5. The conclusion is in Section 6.
2. Overview
XML Signature is a digital signature scheme designed for XML document signing. It depends on Document Object Model (DOM) for preserve XML document feature. DOM is a platform and language independent interface. XML Document can be converting to a DOM tree by XML parser. It allow program or script to access and update the content,structure and style dynamically by tree operation. Canonical XML is the core technology for XML Signature. It is a formalize method for XML by traversing DOM tree. In addition, XML Signature is also supporting partial sign by XPath transformation. It provides more flexibility to process XML document after document sign.
In this chapter, we will explain the concept of XML Signature. Section 2.1 introduces the syntax of XML Signature. The purpose of Canonical XML (C14n) and XPath transformation are illustrated in Section 2.2 and Section 2.3. Section 2.4 will describe the detail of XML Signature Processing.
2.1. XML-Signature Syntax
XML Signature format is also a XML document after signing. In this section, we will introduce the syntax and its element. The XML Signature syntax is showed as follows.
<Signature ID?> <SignedInfo> <CanonicalizationMethod/> <SignatureMethod/> (<Reference URI? > (<Transforms>)? <DigestMethod> <DigestValue> </Reference>)+ </SignedInfo> <SignatureValue>
(<KeyInfo>)? (<Object ID?>)* </Signature>
The document root is Signature element. It contains SignedInfo, SignatureValue,KeyInfo and Object four elements. These elements will be explained in the following.
Signature:
Signature element is the document root of XML Signature. It contains an attribute of id to identifier the Signature block. The example is showed as follows.
<ds:Signature Id="SIG20061208100303765" xmlns:ds="http://www.w3.org/2000/09/xmldsig#">
SignedInfo:
SignedInfo is the block to be signed for XML Signature. It contains CanonicalizationMethod, SignatureMethod and Reference 3 element. These elements will be explained respectively in the following.
z CanonicalizationMethod:
This element presents the algorithm of Canonicalization (C14n). C14n is the formalization method for XML. We will illustrate C14n in Section 2.2. The example is showed as follows.
<ds:CanonicalizationMethod
Algorithm="http://www.w3.org/TR/2001/REC-xml-c14n-20010315"></ds:Ca nonicalizationMethod>
z SignatureMethod:
This element presents the algorithm of Digital Signature. The example is showed as follows.
<ds:SignatureMethod
Algorithm="http://www.w3.org/2000/09/xmldsig#rsa-sha1"></ds:SignatureM ethod>
z Reference:
This element contains the content reference for document sign. The content reference can be contained in the same XML document or exist in external resource everywhere. It has the URI attribute to identifier the location of content. It also contains Transforms, DigestMethod and DigestValue 3 elements. We will explain these elements in the following.
Transforms:
This element is optional. It contains one or more Transform element. The Transform element presents the algorithm for content transformation. The transform algorithm convert the content of reference by URI attribute to another format. Such as C14n algorithm to convert a XML document to its canonical form.
DigestMethod:
It present the digest algorithm for calculate the reference content digest value after transformation.
DigestValue:
It presents the digest value for reference content after transformation. The example of Reference is showed as follows.
<ds:Reference URI="#xxx"> <ds:Transforms> <ds:Transform Algorithm="http://www.w3.org/TR/2001/REC-xml-c14n-20010315"></ds:Transform> </ds:Transforms> <ds:DigestMethod Algorithm="http://www.w3.org/2000/09/xmldsig#sha1"></ds:DigestMethod>
<ds:DigestValue>w+EVhhaShIexMB0P7acWmdjnuIw=</ds:DigestValue> </ds:Reference>
SignatureValue:
This element presents the signature value for XML Signature process. The source for sign is the SignedInfo block. The flow has two-step. First, Canonical the SignedInfo block to get an octet stream. Second, calculate the Signature for the octet stream by signature algorithm and key. The example is showed as follows.
<ds:SignatureValue>Okt8tnVm5HFoH0WvKiehm2eEZ0+rmFM2RsIVXOhPewvSsVus52/XeObN S+YRoSoa5b6hiOpDovGgzwUFl8vU1K+2llleaaJe+XeAcqo1sZGWQY15dcKCXH/EmvPk4mtp5/e j0KQ93JHmOyM1RBvluX03IWmO6HohRjQa8DFOw1k=</ds:SignatureValue>
KeyInfo:
This element is optional. It presents the sign key information and certificate for document sign. The example is showed as follows.
<ds:KeyInfo> <KeyValue> <RSAKeyValue> <Modulus>qXckWQKfZVBSeUxxGWpeMj/3ROF0atV9Q9RKnKmz+GcbNx99zyMJUeYcs y11TQbpaqBViI0Qw/naIEHnV6TThY+lyZOXzUSlD3Yd0GNBWqvK40fdm8V511GoKVaR Zze4iS6EdkAYKtVRQD/kTdESn8MeLPmJar11Xqs2RbbSGX0=</Modulus> <Exponent>AQAB</Exponent> </RSAKeyValue> </KeyValue> <ds:X509Data> <ds:X509IssuerSerial>
<ds:X509IssuerName>CN=Hello Test XML CA, OU=Evaluation Only, O=HELLO-CA.COM Inc., C=TW</ds:X509IssuerName>
<ds:X509SerialNumber>1163646748</ds:X509SerialNumber> </ds:X509IssuerSerial>
<ds:X509SubjectName>CN=12345678-01-001, OU=TST, OU=12345678-RA-001, OU=Hello Test XML CA, O=Finance, C=TW</ds:X509SubjectName>
<ds:X509Certificate>MIIEIjCCA4ugAw………..BupPdB</ds:X509Certificate> </ds:X509Data>
</ds:KeyInfo>
This element is optional. It contains the extra information or a XML document for XML Signature. The example is showed as follows.
<dsig:Object Id="Res0" xmlns="" xmlns:dsig="http://www.w3.org/2000/09/xmldsig#"><ele1> <ele2 id="xxx">xxx</ele2>
</ele1></dsig:Object>
2.2. Canonical XML
XML Canonicalization (C14N) is a formalization process for XML document. It defines a set of rules to convert each Node in the XML DOM tree to canonical form. Because XML document comparison is based on the principle of logically equivalent, the document must be formalized before comparison. In this section, we will describe the outline of C14n.
The rules of C14n contain the operations of syntax and structure. The rules of syntax formalize define the lexical formatting for content display with each node. The rules of structure formalize define the serialize order for node traversing. The node types for syntax formalize contain Document Root, Element, Attribute Node, Text Node, Processing Instruction (PI) Node and Comment Node. For example, the text node value, except all ampersands are replaced by & all open angle brackets (<) are replaced by <, all closing angle brackets (>) are replaced by >, and all #xD characters are replaced by 
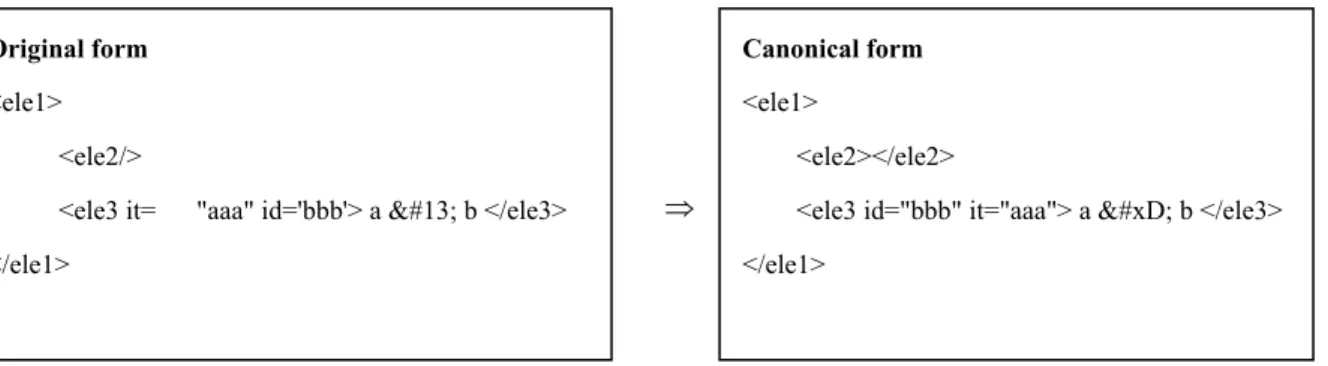
. The rules of structure formalize include the traversing order, namespace inheritance and attribute sorting. The document order is defined by the location of node and its relationship. The node traversing is following this order. In addition, the lexicographic order defines that which namespace or attribute is greater another by lexical. For example, the attribute “it” is greater “id”, because the first character code is equal, but the second character code “t” is greater “d”. Therefore, the attributes in element will be sorted by lexicographic order. Otherwise, the qualifier name (QName) for attribute is combining its local name and namespace prefix name. Thus, we must resolve the namespace value for prefix before sorting. The example of Canonical XML is showed as follows. The empty element ele2 converts
to start tag and end tag of ele2. The attributes it and id of ele3 are sorted by lexicographic order (ascending). The decimal code “13” in text node converts to hex code “D”.
2.3. XPath transformation
XPath is a language for addressing parts of XML document. XPath filtering is a process to transform a XML node set to anthers with XPath expression. The XPath expression is a predicate for node testing. If the node has satisfied the predicate, will be added to result set. Finally, we can get a node set for XPath transformation. The XPath transformation is very complex operation. Its complexity is O(n2) or more complex(exponentiation).
<aaa xmlns="http://www.hello.com"/> <bbb attr1=”xxx”> <ccc > <ddd/> </ccc> </bbb><eee/> </aaa> XPath expression
(//. | //@* | //namespace::*)[ self::bbb or parent::ccc]
<bbb xmlns= " http://www.hello.com/" attr1=”xxx”><ddd></ddd></bbb> bbb ccc ddd eee aaa default namespace inheritance
Figure 2-1 Example of XPath transformation
Canonical form
<ele1>
<ele2></ele2>
<ele3 id="bbb" it="aaa"> a 
 b </ele3> </ele1>
Original form
<ele1>
<ele2/>
<ele3 it= "aaa" id='bbb'> a b </ele3> </ele1>
The example of XPath transformation is presented in Figure 2-1. The xml document is converted into a document tree of nodes. We test each node in document tree to determine which one satisfy the XPath predicate. The XPath expression is meaning that select all nodes which itself is “bbb” or its parent is “ccc”. We can find that node “bbb” and node “ddd” is satisfying the predicate. However, the node “bbb” also inherited the default namespace from node “aaa”. Because the result of XPath transformation is just a subset of original document, the definition of default namespace will be missing. To inherit the default namespace of ancestor node will fix this problem.
2.4. XML Signature Processing
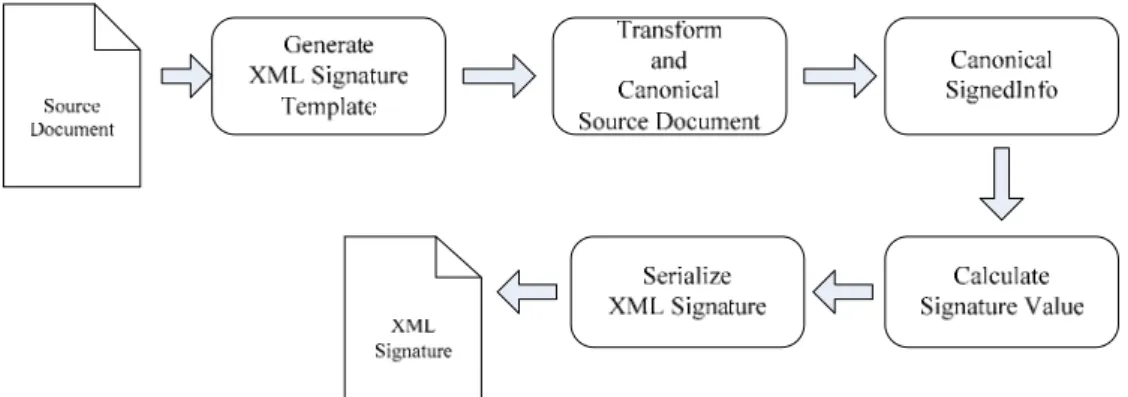
XML Signature has three computing process in its processing flow. First, the digest value in the reference element must be calculated. Secondly, the SignedInfo block must be formalize by canonical algorithm. Finally, we calculate the signature value for the canonical form of SignedInfo. Figure 2-2 presents the processing flow of XML Signature calculation. The first step is generating the template document of XML Signature. Next, we can execute the computing processes in previous illustrate and filled the empty value in this template. Finally, the XML Signature can be output by serialize the Signature document. The process of verification is similar to signing. First, verify the digital signature for SignedInfo. Secondly, verify the digest value for each reference element.
3. Related Work
Efficient Implementation of XML Security for Mobile Devices [4] and A Streaming Validation Model for SOAP Digital Signature [1] are two researches to improve the performance of XML Signature. These two scheme are focused on XML Parsing Model [11] [17] and XML Signature Processing flow improvements. The scheme analysis and limitation will be illustrated in the following.
3.1. Efficient Implementation of XML Security for Mobile Devices
Efficient Implementation of XML Security for Mobile Devices [4] implements XAS API to process XML Signature all operations in memory. This scheme improves processing flow to avoid duplicate node traversing. First, it generates XML Signature template in memory. Secondly, calculates the digest value for each reference node. Finally, calculate the signature with “Signedinfo” node. The actor emphasized that this processing flow is streaming, but the performance cannot get significantly improvement. This skill is commonly used in XML Signature Syntax Processing since the specification was released in 2001, but it still depends on the original methods of Canonical XML and XML Syntax Processing. With process flow improvement, the key point to improve performance is reducing the number of DOM [11] tree traverse in C14n. In 2002, we have a study to complete all operations in C14n such as namespace Inheritance and attribute sorting in one pass, and then get substantial performance improvement. Now the apache XML Security Project [21] also uses this skill. However, this is the limit of the original method for C14n; the low bound of its complexity still exists.
3.2. A Streaming Validation Model for SOAP Digital Signature
A Streaming Validation Model for SOAP Digital Signature [1] implements a SAX-Like [17] XML parser to eliminate the effort of DOM Tree construction. The scheme is a streaming parsing
model to optimize parser. Therefore, it can reduce the time of traversing XML. However, this paper eliminates some C14n feature such as XPath transformation [8] [12] support etc., these feature can only support in DOM Parser. SAX can only traverse forward, it cannot search node in XML. Only DOM model supports node search with ancestor/descendent or sibling nodes. Some operations such as PI/Comment [10] locate or namespace [7] inheritance and attribute sorting [9] become difficult or impossible. Therefore, the actor was limiting this paper to deal with general cases. The complexity of C14n still has not reduced.
Since the limit of C14n processing always exists, the only way to defeat the low bound of complexity in C14n is abandoning the original C14n methodology. The proposed scheme is a new methodology to defeat this limit.
4. Proposed Scheme
Finite Automata is commonly using to process lexical or syntax [6]. We design a scheme based on finite automata to convert the Canonical XML into a sequence of structure and content. By this scheme, we can reduce the complexity to linear. In this chapter, the organization is described as follows. We begin with a methodology analysis in Section 4.1. Section 4.2 introduces the conversion of Canonical XML. Section 4.3 describes the definition of finite automata to accept the language defined in Section 4.2. Section 4.4 defines the output function call defined in finite automata for proposed scheme. Section 4.5 provides an example for implementation. XPath transformation supporting will be illustrated in Section 4.6. Finally, the complexity analysis will be discussed in Section 4.7.
4.1. Methodology Analysis
To reduce the complexity of C14n must to find the key point of bottleneck in C14n. In the computation model of C14n, it contains parsing, document tree traversing and node operations three main process. We will analysis the issue of each process and its solution in the following.
Parsing﹕XML is a text document. XML Parser parsing the XML document to build an object
tree. The tree is named DOM. Each node in the DOM tree has its type and value. DOM tree presents the relationship of node in the document structure. The tasks of parser contain syntax validation, node generation and tree building. To eliminate the parsing process is to preserve the structure of object node and its relationship in the DOM tree.
Document Tree traversing﹕C14n is a process of DOM tree traverse. The operations of C14n
apply to each node to generate its canonical form. The DOM Tree is a recursive structure. To traverse DOM tree must have stack to record the parent node of current node. The amount of memory need is also huge. To preserve the relationship of node without stack is impossible for original model. The Finite Automata is seems a good model to satisfy theses requires. It can store
the relationship of node by state and execute in the environment with limited-resource.
Node operation﹕C14n defines some complex operations for each node type. These operations
formalize each node to generate its canonical form. To avoid these operations is to preserve the canonical form of node after formalize.
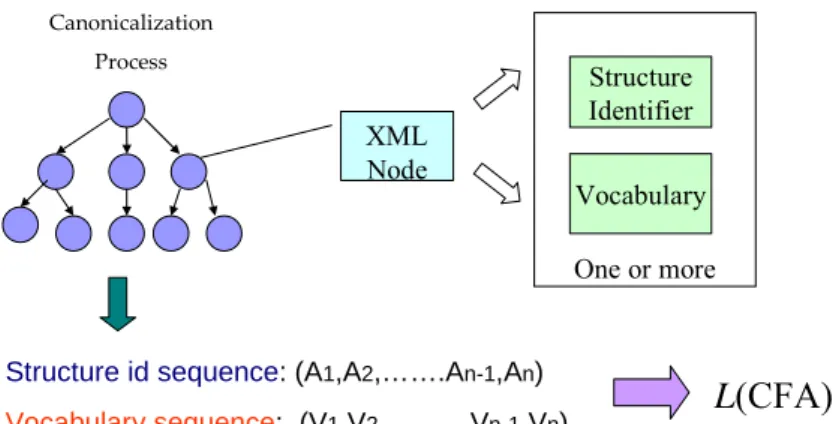
By previous analysis, we can begin to construction an efficient model for C14n based on Finite Automata. First, we convert canonical XML into a new language in canonicalization process. In Figure 4-1, each XML node is converted into a new form with structure and content. In the end of process, we can get two sequences structure identifier and vocabulary. Structure identifier defines the structure of each part in node. Vocabulary defines the canonical form of variable value in node. These two sequences form a new language L(CFA).
One or more Canonicalization Process XML Node Structure Identifier Vocabulary
Structure id sequence: (A1,A2,…….An-1,An)
Vocabulary sequence: (V1,V2,………Vn-1,Vn) L(CFA)
Figure 4-1 Canonical XML Conversion
Secondly, we need a machine to accept the new language L(CFA). CFA is the finite state transducer that accepts the language L(CFA) and generates Canonical XML.
L(CFA)
C14n(XML)
In Section 4.2, we will describe the algorithm of language conversion and define the structure identifier and its vocabulary for each node type. The finite state transducer CFA will be
constructing in Section 4.3.
4.2. Conversion of Structure and Content in Canonical Processing
We want to convert canonical form of each node to its structure and content in the processing of Canonical XML. Canonical XML is a process of XML traversing; it is a recursive process flow. The process is similar to the operation of DFS (Depth First Search) [2], so it needs stack to record ancestor node. Our model depends on Finite Automata and streaming processing model, so we cannot store previous state. If we want to generate a non-recursive sequence after transformation, we must decomposition of one node to a number of structures. We will explain the transformation rule for different types of nodes in the following.
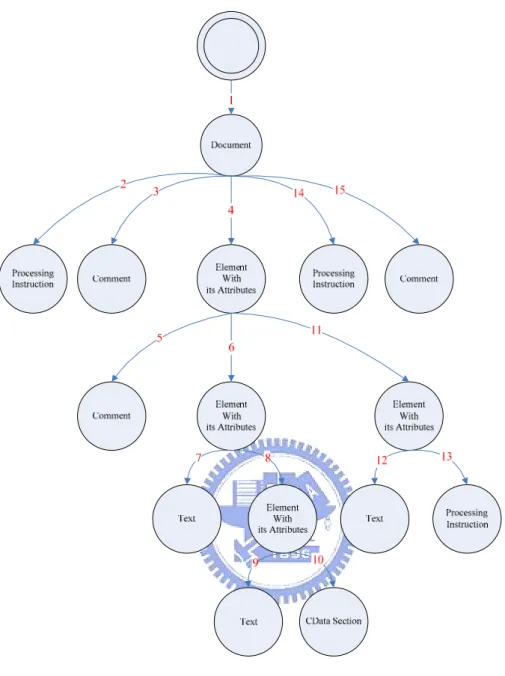
The engine of Canonical XML processing each node in DOM tree traversing. The processing flow of this traversing is showed as Figure 4-2. Each node is processing in document order defined in XPath. The document order define that the order of each node occurs in the XML representation after expansion. The traverse order is marked in each age of document tree.
For proposed scheme, the tree structure must to convert into a linear sequence. To reach this purpose can be regenerated the structure of nodes in the tree. Some nodes such as Document or Element in Figure 4-2 have descendents. The process of these nodes is traversing as deep as possible along the tree path. For go back to ancestor, the traversing need stack to record the path. To convert this recursive structure to a linear sequence is just to preserve the relationship of adjacent nodes. In addition, the Attribute node is contained in Element node. To convert the Element node to a simple structure must to extract Attribute from Element. For node converting, the set of node type is defined in the following.
Figure 4-2 DOM tree traversing
Then, we define the transformation rule of each node type. The rules include how to convert node to structure identifier and its content. Because each node has fixed symbols and variable contents, therefore the meaningful content of each structure is just the variable content. The variable content of node is named vocabulary. For this transformation, we can convert Canonical XML into two sequences of structure identifier and its vocabulary.
In following, the transformation rule will be explained for all node type. In addition, its structure identifier and vocabulary will be defined.
Document: The processing of document fragment and document is the same, so there is no
separate definition for document fragment. Document node is the root of the tree, the others types of node are all in its context. Document node is converted into two structures with start document and end document. The syntax of Element node is defined as follows.
<Document> Æ DS <Context> DE
<Context>={Element, Attribute, PI, CDATA Section, Text, Comment}
The identifier of document start is defined as DS. The identifier of document end is defined as DE. Both two structures do not contain any vocabulary.
Element: The element node consists of Stag and Etag in it syntax. The Stag consists of start tag,
attributes and end tag. The syntax of Element node is defined as follows.
element ::= STag content ETag
STag ::= '<' Name (S Attribute)* S? '>' => '<' Name ÆSTB and '>'ÆSTE ETag ::= '</' Name S? '>' => ETag Æ ET
STag is converted into two structures with beginning and ending of start tag. The identifier of the start tag beginning is defined as STB, and the identifier of the start tag ending is defined as STE. Then, Etag is converted into one structure. The identifier of Etag is defined as ET. The vocabulary of the structures of STB and ET is the element name. The structure of STE is no vocabulary, it just identify the ending of start tag.
Attribute: The attribute node is composed of name and value. The syntax of Attribute node is
defined as follows.
Attribute ::= Name Eq AttValue => Name ÆATTRN and AttValueÆATTRV
Attribute node is converted into two structures with attribute name and attribute value. The identifier of attribute name is defined as ATTRN and the identifier of attribute value is defined
ATTRV. Therefore, the vocabulary of ATTRN is attribute name, and the vocabulary of ATTRV is the canonical form of attribute value.
Processing Instruction (PI): PI is a simple and independent structure. The syntax of PI node is
defined as follows.
PI ::= '<?' PITarget (S (Char* - (Char* '?>' Char*)))? '?>' PITarget ::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l'))
=>PI ÆPIC| PIB| PIA
PI is converted into to one structure by its location in document. The location of PI determines its structure identifier. It has tree different structure for its location. The structure identifier of PI node appears before the root element is defined as PIB. The structure identifier of PI node appears in the context of root element is defined as PIC. The structure identifier of PI node appears after the root element is defined as PIA. The vocabulary of PI is the canonical form of its target with data.
CDATA Section: It is a simple and independent structure. The syntax of CDATA Section node is
defined as follows.
CDSect ::= CDStart CData CDEnd CDStart ::= '<![CDATA['
CData ::= (Char* - (Char* ']]>' Char*)) CDEnd ::= ']]>'
=>CDSect Æ CDS
The CDSec consists of three parts CDStart, CData and CDEnd. CDATA Section is converted into one structure. The identifier of CDATA Section is defined as CDS. The vocabulary of this structure is the canonical form of its CData value.
Text: Text is only a sequence of characters. The syntax of Text node is defined as follows. CharData ::= [^<&]* - ([^<&]* ']]>' [^<&]*)
Text Æ TN
Therefore, it converts to one structure. The identifier of Text node is defined as TN. The vocabulary of this state is the canonical form of CharData.
Comment: Comment is a simple and independent structure. The syntax of Comment Section
node is defined as follows.
Comment ::= '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->' Comment Æ CNC | CNB | CNA
Comment is converted into one structure by its location in document. The location of Comment also determines its structure. It has tree different structure for its location. The structure identifier of Comment node appears before the root element is defined as CNB. The structure identifier of Comment node appears in the context of root element is defined as CNC. The structure identifier of Comment node appears after the root element is defined as CNA. The vocabulary of this tree state is the canonical form of Comment’s data.
Now, we can add these transformation rules into the C14n process to convert Canonical XML into a new language CFA. The algorithm is described in Appendix I.
By this transformation, the each node in Canonical XML is converting to two sequences of structure identifier and its vocabulary. It is forming a new language. In next section, we will construct a Finite Automata to accept this language and generate Canonical XML for our purpose.
4.3. Constructing Finite Automata of Canonical XML
In previous section, Canonical XML is converted into a new language. Now we can begin to construction the Finite Automata [3] to accept the language and generate Canonical XML. Finite
automata have three major models generator, acceptor and transducer [22]. Generator only outputs and without input. Acceptor only receives input and without output. Transducer accepts input and generates output. For proposed scheme, we need a transducer to accept the structure sequence and generate Canonical XML. The transducer can be implement interpreter or compiler etc. Therefore, we want to construct a finite state transducer. A finite state transducer is a 7-tuple (Q, Σ, δ, q0, F, Γ, λ) [5].The term Q is a finite set of states. The term Σ is the finite set of input symbols. The term δ is transition function for states. The term q0 is the initial state in Q. The term F is the set of final states in Q. The term Γ is the finite set of output symbols. The term λ is the output function. The finite state transducer for proposed scheme is named Canonicalization Finite Automata (CFA).The definition of the Finite State Transducer CFAis defined as follows.
CFA = ( Q , Σ, δ, q0, F, Γ, λ) Q is a finite set of states for CFA
Σ is the input alphabet, it denotes the set of structure identifiers in the Canonical XML plus the end symbol
q0 ⊆ Q is the initial state for finite automata CFA
F ⊆ Q is the set of final states for finite automata CFA
δ : Q× Σ→ Q is the state transition function for DOM tree structure
Γ is the output alphabet, it denotes the set of functions call for generate canonical form each structure
λ : Q×Σ →Γ is the output function
Figure 4-3 Definition of CFA
Now, the term in CFA will be explained in the following. First, the set of alphabets is defined by structure of identifier in Section 4.2. Because the automata accepts the language defined in Section 4.2. If the automata accepts the sequence of structures, the structure validation
of XML document is correct. We collect all identifiers defined in Section 4.2 and plus an identifier EOS for the set of alphabet. The EOS is indicating the end of sequence. The list of all alphabets is defined in the following.
Σ = {All structure identifiers defined in Section 4.2} U EOS
⇒{DS,DE,STB,STE,ET,ATTRN,ATTRV,CDS,TN,PIC,PIB,PIA,CNC,CNB,CNA,EOS} By the set of alphabet, we can define the set of states Q. The definition of state is that if a state Si
can accept alphabet A, the state is moving to SA. SA is label name of the state after transition .The
definition is rewrite as follows.
∀ A∈Σ ,∃ SA∈Q
In addition, we define a state for the initial state and named “Start”. Because any state can accepts the alphabet “EOS” must move to the final state, so the state SEOS is the final state. Now, we can
define all states in Q.
Q = Start U{ SA | for all A ∈Σ}
q0 = Start
F = { SEOS }
The set of output alphabet Γ is the function call for each structure. It depends on the alphabet Σ. If any state can accept alphabet A in Σ, the transition must output a function call G(A). Therefore, the definition of output function can be rewrite as follows.
λ : ∀ A∈Σ ,∃ G(A)∈ Γ
⇒Γ = { G(A) | for all A∈Σ}
The function call G(A) will be defined in Section 4.4. Finally, we will define the transition function δ for each state in Q. Because the state presents the structure of Canonical XML in DOM traversing, the transition can be find in XML DOM structure.
In following, we will induct the transitions of state from the DOM structure and traversing order in C14n. First, we represent the DOM structure to a Context-Free Grammar in the following.
○1 <S> Æ <Start><Document><End> | <Start><Document fragment><End>
○2 <Document>Æ<Start Document><PCB><Element><PCA><End Document>
○3 <PCB>Æ <PIB><PCB> | <COMMENTB><PCB> | ε
○4 <PCA>Æ <PIA><PCA> | <COMMENTA><PCA> | ε
○5 <Document fragment> Æ <Element> | <PI> | <PIB> | <PIA>| <Comment> | <COMMENTB> |
<COMMENTA> | <Text> | <CDATASection>
○6 <Element> Æ <Beginning of Start Element><Attrs><Ending of Start
Element><Content><End Element>
○7 <Content> Æ <Element><Content> | <PI><Content> | <Comment><Content> |
<Text><Content> | <CDATASection><Content> | ε ○8 <Attrs> Æ <Attr><Attrs> |
ε
○9 <Attr> Æ <Attribute name><Attribute value>
○10<Start Document> Æ DS
○11<End Document> Æ DE
○12<Beginning of Start Element> Æ STB
○13<Ending of Start Element> ÆSTE
○14<End Element> ÆET
○15<Attribute name> Æ ATTRN
○16<Attribute value> ÆATTRV
○17<Text> ÆTN ○18<CDATASection> ÆCDS ○19<PI> Æ PIC ○20<PIB> Æ PIB ○21<PIA> Æ PIA ○22<Comment> Æ CNC ○23<COMMENTB> ÆCNB ○24<COMMENTA> ÆCNA ○25<Start> Æ
ε
○26<End> Æ EOSThe transition of each state in Q is the set of alphabets it can be accepted. Because the state SA is the result of state Si accepted alphabet A, to find the next adjacent alphabet with alphabet A
in this language can get the transition of SA. We can find the next adjacent alphabet by derived
The transition of state “Start” is derived as follows:
Because the Start is the initial state, the alphabet A isε for this sate by previous description. The alphabet ε can be map to variable <Start>. By rule 1, the next adjacent variables of “<Start>” are <Document> and <Document fragment>. Each arrow in the following indicates the derive process. The rule defined in context-free grammar in this section is applied in each derive process. The rule number is appending in each arrow.
<Document>
↓○2
<Start Document><PCB><Element><PCA><End Document>
↓○10
DS
<Document fragment>
↓○5
<Element> | <PI> | <PIB> | <PIA>| <Comment> | <COMMENTB> | <COMMENTA> | <Text> |
<CDATASection> <Element>
↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element> ↓○12
STB
<PI> <PIB><PIA> <Comment> <COMMENTB> <COMMENTA> <Text> <CDATASection>
↓○19↓○20 ↓○21 ↓○22 ↓ ○23 ↓ ○24 ↓○17 ↓○18
PIC PIB PIA CNC CNB CNA TN CDS
The state of “Start” can accept alphabets DS, STB, PIC, PIB, PIA, CNC, CNB, CNA, TN and CDS.
The transition of state “SSTB” is derived as follows:
By rule 6, the alphabet STB is mapping to variable “<Beginning of Start Element>” for state SSTB.
<Attrs> ↓○8
<Attr><Attrs> |
ε
↓○9<Attribute name><Attribute value> ↓○15
ATTRN
If <Attrs> is
ε
, the next adjacent variable of “<Beginning of Start Element>” in rule 6 is <Ending of Start Element>.<Ending of Start Element> ↓○13
STE
The state of “SSTB” can accept alphabets ATTRN and STE. The transition of state “SSTE” is derived as follows:
By rule 13, the alphabet is mapping to variable “<Ending of Start Element>” for state SSTE.
By rule 6, the next adjacent variable of “<Ending of Start Element>” is <Content>.
<Content> ↓○7
<Element><Content> | <PI><Content> | <Comment><Content> | <Text><Content> | <CDATASection><Content> | ε
<Element> ↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element> ↓○12
STB
<PI> <Comment> <Text> <CDATASection> ↓○19 ↓○22 ↓○17 ↓○18
PIC CNC TN CDS
If < Content > is
ε
, the next adjacent variable of “<Ending of Start Element>” in rule 6 is <End Element>.<End Element>
↓○14
ET
The transition of state “SET” is derived as follows:
By rule 14, the alphabet ET is mapping to variable “<End Element>” for state SET.
By rule 6, the <End Element> is in the end of this rule. Therefore, we want to find the next adjacent with <Element>.
By rule 2, the next adjacent variable of “<Element>” is <PCA>.
<PCA>
↓○4
<PIA><PCA> | <COMMENTA><PCA> | ε
↓○21 ↓○24
PIA CNA
If <PCA> isε , the next adjacent variable in rule 2 is “<End Document>”.
<End Document> ↓○11
DE
By rule 5, we find the “<Element>” is the end of this rule; we want to find the next adjacent variable with “<Document fragment>”.
By rule 1, the next adjacent variable of “<Document fragment>” is “<End>”.
<End> ↓○26
EOS
By rule 7, the next adjacent variable of “<Element>” is <Content>.
<Content> ↓○7
<Element><Content> | <PI><Content> | <Comment><Content> | <Text><Content> | <CDATASection><Content> | ε
<Element> ↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element> ↓○12
STB
<PI> <Comment> <Text> <CDATASection> ↓○19 ↓○22 ↓○17 ↓○18
If < Content > is
ε
, the next adjacent variable of “<Ending of Start Element>” in rule 6 is <End Element>.<End Element>
↓○14
ET
The state of “SET” can accept alphabets PIA, CNA, DE, EOS, STB, PIC, CNC, TN, CDS and ET The transition of state “SATTRN” is derived as follows:
By rule 15, the alphabet ATTRN is mapping to variable “<Attribute name>” for state SATTRN.
By rule 9, the next adjacent variable of “<Attribute name>” is <Attribute value>.
<Attribute value> ↓○16
ATTRV
The state of “SATTRN” can accept alphabet ATTRV
The transition of state “SATTRV” is derived as follows:
By rule 16, the alphabet ATTRV is mapping to variable “<Attribute value>” for state SATTRV.
By rule 9, the <Attribute value> is the end of this rule. Therefore, we want to find the next adjacent variable with <Attr>.
By rule 8, the next adjacent variable of “Attr” is “Attrs”.
<Attrs> ↓○8
<Attr><Attrs> |
ε
↓○9
<Attribute name><Attribute value> ↓○15
ATTRN
If <Attrs> is
ε
, the next adjacent variable of “<Attrs> in rule 6 is <Ending of Start Element>. <Ending of Start Element>↓○13
STE
The state of “SATTRV” can accept alphabets ATTRN and STE. The transition of state “STN” is derived as follows:
By rule 5, the variable “<Text>” is the end of this rule. Therefore, we want to find the next adjacent variable with “<Document fragment>”.
By rule 1, the next adjacent variable of “<Document fragment>” is “<End>”.
<End> ↓○26
EOS
By rule 7, the next adjacent variable of “<Text>” is <Content>. <Content>
↓○7
<Element><Content> | <PI><Content> | <Comment><Content> | <Text><Content> | <CDATASection><Content> | ε
<Element> ↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element> ↓○12
STB
<PI> <Comment> <Text> <CDATASection> ↓○19 ↓○22 ↓○17 ↓○18
PIC CNC TN CDS
If < Content > is
ε
, the next adjacent variable of “<Ending of Start Element>” in rule 6 is <End Element>.<End Element>
↓○14
ET
The state of “STN” can accept alphabet EOS, STB, PIC, CNC, TN, CDS and ET. The transition of states “SCDS”, “SPIC”, “SCNC” is derived as follows:
By rule 18, the alphabet CDS is mapping to variable <CDATASection> for state SCDS.
By rule 19, SPIC is mapping to variable <PI>.
By rule 22, SCNC is mapping to variable <Comment>.
All three variables are in rule5 and rule7, the transition is same as “STN”
The states of “SCDS”,” SPIC” and “SCNC” can accept alphabets EOS, STB,PIC,CNC,TN,CDS and
The transition of state “SPIB” is derived as follows:
By rule 20, the alphabet PIB is mapping to variable <PIB> for state SPIB.
By rule 3, the next adjacent variable of <PIB> is <PCB>.
<PCB>
↓○3
<PIB><PCB> | <COMMENTB><PCB> | ε
↓○20 ↓○23
PIB CNB
If <PCB> isε , the next adjacent variable of “<PCB>” in rule 2 is <Element>.
<Element> ↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element> ↓○12
STB
By rule 5, we find the “<PIB>” is the end of this rule; we want to find the next adjacent variable
with <Document fragment>.
By rule 1, the next variable of “<Document fragment>” is <End>.
<End> ↓○26
EOS
The state of “SPIB” can accept alphabets PIB, CNB, STB and EOS. The transition of state “SPIA” is derived as follows:
By rule 21, the alphabet PIA is mapping to variable <PIA> for state SPIA.
By rule 4, the next adjacent variable of <PIA> is <PCA>.
<PCA>
↓○4
<PIA><PCA> | <COMMENTA><PCA> | ε
↓○21 ↓○24
PIA CNA
If <PCA> isε , the next adjacent variable of “<PCA>” in rule 2 is <End
Document>.
<End Document>
↓○11
By rule 5, the “<PIA>” is the end of this rule; we want to find the next adjacent variable with
<Document fragment>.
By rule 1, the next adjacent variable of “<Document fragment>” is <End>.
<End> ↓○26
EOS
The state of “SPIA” can accept alphabets PIA, CNA, DE and EOS.
The transition of state “SCNB” is derived as follows:
By rule 23, the alphabet CNB is mapping to variable <COMMENTB> for state SCNB.
By rule 3, the next adjacent variable of <COMMENTB> is <PCB>.
<PCB>
↓○3
<PIB><PCB> | <COMMENTB><PCB> | ε
↓○20 ↓○23
PIB CNB
If <PCB> isε , the next adjacent variable of “<PCB>” in rule 2 is <Element>.
<Element> ↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element>
↓○12
STB
By rule 5, the “<COMMENTB>” is the end of this rule; we want to find the next adjacent variable
with <Document fragment>.
By rule 1, the next adjacent variable of “<Document fragment>” is <End>.
<End> ↓○26
EOS
The state of “SCNB” can accept alphabets PIB, CNB, STB and EOS. The transition of state “SCNA” is derived as follows:
By rule 24, the alphabet CNA is mapping to variable <COMMENTA> for state SCNA.
<PCA>
↓○4
<PIA><PCA> | <COMMENTA><PCA> | ε
↓○21 ↓○24
PIA CNA
If <PCA> isε , the next adjacent variable of “<PCA>” in rule 2 is <End
Document>.
<End Document>
↓○11
DE
By rule 5, the “<COMMENTA>” is the end of this rule; we want to find the next adjacent variable
with <Document fragment>.
By rule 1, the next adjacent variable of “<Document fragment>” is <End>.
<End> ↓○26
EOS
The state of “SCNA” can accept alphabets PIA, CNA, DE and EOS. The transition of state “SDS” is derived as follows:
By rule 10, the alphabet DS is mapping to variable <Start Document> for state SDS.
By rule 2, the next adjacent variable of “<Start Document>” is <PCB>.
<PCB>
↓○3
<PIB><PCB> | <COMMENTB><PCB> | ε
↓○20 ↓○23
PIB CNB
If <PCB> isε , the next adjacent variable of “<PCB>” in rule 2 is <Element>.
<Element> ↓○6
<Beginning of Start Element><Attrs><Ending of Start Element><Content><End Element> ↓○12
STB
The transition of state “SDE” is derived as follows:
By rule 11, the alphabet DE is mapping to variable <End Document> for state SDE.
By rule 2, the “<End Document>” is the end of this rule; we want to find the next adjacent variable with <Document>.
By rule 1, the next adjacent variable of “<Document>” is <End>.
<End> ↓○26
EOS
The state of “SDE” can accept EOS.
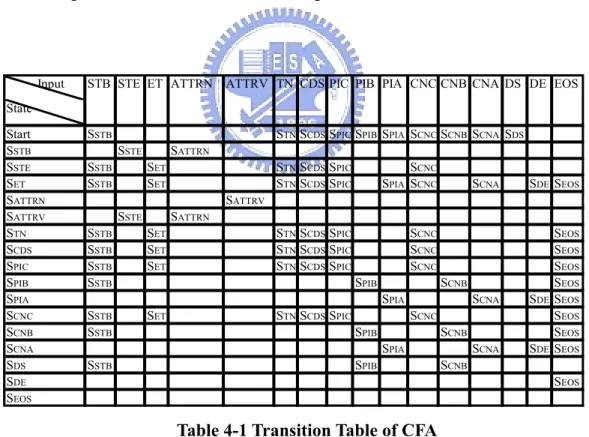
The SEOS is the final state. It cannot accept any alphabet. Finally, we get all the transitions in Table
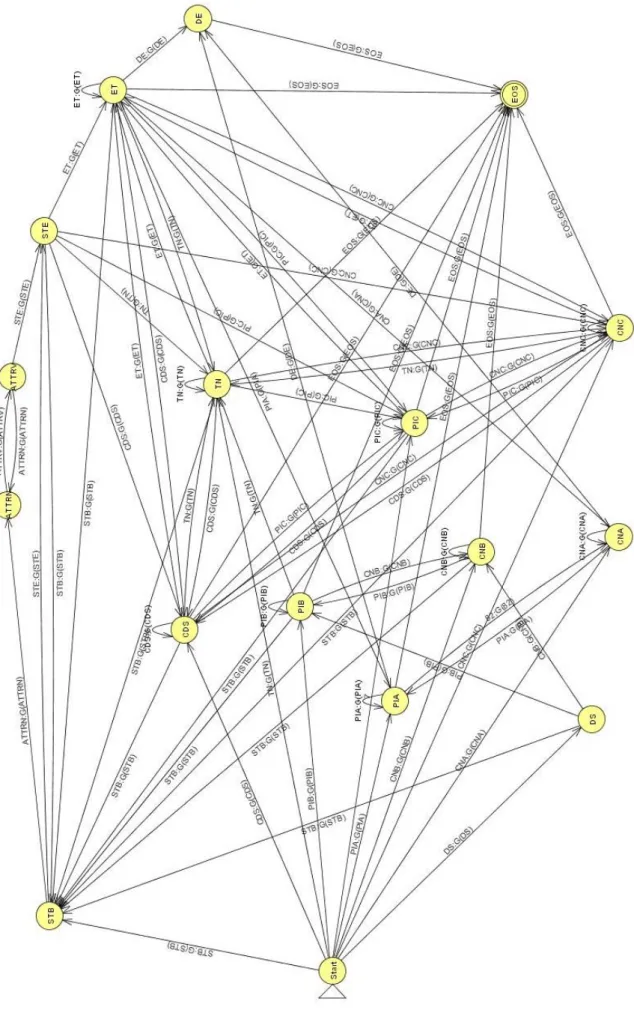
4-1 and the diagram of finite state transducer in Figure 4-4.
Input State
Start SSTB STNSCDSSPICSPIBSPIA SCNCSCNBSCNA SDS
SSTB SSTE SATTRN
SSTE SSTB SET STNSCDSSPIC SCNC
SET SSTB SET STNSCDSSPIC SPIA SCNC SCNA SDESEOS
SATTRN SATTRV
SATTRV SSTE SATTRN
STN SSTB SET STNSCDSSPIC SCNC SEOS
SCDS SSTB SET STNSCDSSPIC SCNC SEOS
SPIC SSTB SET STNSCDSSPIC SCNC SEOS
SPIB SSTB SPIB SCNB SEOS
SPIA SPIA SCNA SDESEOS
SCNC SSTB SET STNSCDSSPIC SCNC SEOS
SCNB SSTB SPIB SCNB SEOS
SCNA SPIA SCNA SDESEOS
SDS SSTB SPIB SCNB SDE SEOS SEOS CNA DS DE EOS PIB PIA CNC CNB ATTRV TN CDS PIC STB STE ET ATTRN
4.4. Output Function for Generate Canonical Form
In this Section, we will describe the output function call defined in Section 4.3. Γ = { G(A) | for all A∈Σ}
In Section 4.2, the Canonical XML is converted into two sequences of structure identifier and its vocabulary. The vocabulary sequence is the input of function G. The function G may read a vocabulary from vocabulary sequence to generate its canonical form for each structure. All function call in Γ will be defined as follows.
Each function may be call the function ReadV() to generate Canonical XML. The function ReadV() is define to read one vocabulary from vocabulary sequence.
G(DS){ do nothing } G(STB) { print '<' ; print ReadV(); } G(STE){ print '>'; } G(ET){ print ReadV(); print "</"; print '>'; } G(ATTRN){
print 0x20; //a space print ReadV(); print '='; } G(ATTRV){ print '"' ; Print ReadV(); Print '"'; } G(TN){ print ReadV(); } G(CDS) { print ReadV ; } G(PIC){ print "<?""; print ReadV() ; print "?>"; } G(PIB){ print "<?""; print ReadV() ; print "?>"; print '0xA'; }
G(PIA){ print '0xA';
print "<?""; print ReadV() ; print "?>"; } G(CNC) { print "<!- -"; print ReadV(); print "- - >"; } G(CNB){ print "<!- -"; print ReadV(); print "- - >"; print '0xA' ; }
G(CNA){ print '0xA' ;
print "<!- -"; print ReadV(); print "- - >"; } G(DE){ do nothing }
4.5. Example for CFA
In Figure 4-5, a simple xml document is converted into two sequences of structure identifier and vocabulary. For implementation, we also convert vocabulary sequence into vocabulary table and its index sequence. Then we can combine structure sequence with vocabulary sequence. The vocabulary index follows structure alphabet. The process to generate canonical xml from this sequence by CFA will be illustrated in the following.
Figure 4-5 Example of CFA
Step1: We start with the Start state and read input DS. The state moves to SDS from Start.
This step does not generate any output.
Step2: To read input PIB, the state moves to SPIB from SDS. The engine of CFA reads
vocabulary index 1 and converts index 1 to real vocabulary “pi-without-data”. This step generates output <?pi-without-data?> before a newline.
Step3: To read input CNB, the state moves to SCNB from SPIB, The engine of CFA reads
vocabulary index 2 and converts index 2 to real vocabulary “Comment 1”. This step generates output “<!--Comment 1-->” before a newline.
1 pi-without-data 2 Comment 1 3 doc 4 xmlns:ns1 5 nctu:csie 6 ele1 7 ns1:id 8 ec202 9 hello 10 everyone <?pi-without-data ?> <!--Comment 1-->
<doc xmlns:ns1="nctu:csie"><ele1 ns1:id="ec202">hello<![CDATA[everyone]]></ele1></doc>
○1○2<?pi-without-data?>
○3<!--Comment 1-->
○4<doc○5 xmlns:ns1=○6"nctu:csie"○7>○8<ele1○9 ns1:id=○10"ec202"○11>○12hello○13everyone○14</ele1>○15</doc>○16○17
Structure with vocabulary Sequence
DS PIB 1 CNB 2 STB 3 ATTRN 4 ATTRV 5 STE STB 6 ATTRN 7 ATTRV 8 STE TN 9 CDS 10 ET 6 ET 3 DE EOS
Step4: To read input STB, the state moves to SCNB from SSTB. The engine of CFA reads
vocabulary index 3 and converts index 3 to real vocabulary “doc”. This step generates output “<doc”.
Step5: To read input ATTRN, the state moves to SATTRN from SSTB. The engine of CFA reads
vocabulary index 4 and converts index 4 to real vocabulary “xmlns:ns1”. This step generates output “xmlns:ns1=” after a space.
Step6: To read input ATTRV, the state moves to SATTRV from SATTRN. The engine of CFA
reads vocabulary index 5 and converts index 5 to real vocabulary “nctu:csie”. This step generates output “nctu:csie”.
Step7: To read input STE, the state moves to SSTE from SATTRV. This step generates output
“>".
Step8: To read input STB, the step moves to SSTB from SSTE. The engine of CFA reads
vocabulary index 6 and converts index 6 to real vocabulary “ele1”. This step generates output “<ele1”.
Step9: To read input ATTRN, the state moves to SATTRN from SSTB. The engine of CFA reads
vocabulary index 7 and converts index 7 to real vocabulary “ns1:id”. This step generates output “ns1:id=” after a space.
Step10: To read input ATTRV, the state moves to SATTRV from SATTRN. The engine of CFA
reads vocabulary index 8 and converts index 8 to real vocabulary “ec202”. This step generates output " ec202".
Step11: To read input STE, the state moves to SSTE from SATTRV. This step generates output
“>”.
Step12: To read input TN, the state move to STN from SATTRV. The engine of CFA reads
vocabulary index 9 and converts index 9 to real vocabulary “hello”. This step generates output “hello”.
vocabulary index 10 and converts index 10 to real vocabulary “everyone”. This step generates output “everyone”.
Step14: To read input ET, the state moves to SET from SCDS. The engine of CFA reads
vocabulary index 6 and converts index 6 to real vocabulary “ele1”. This step generates output “</ele1>”.
Step15: To read input ET, the state moves to SET from SET. The engine of CFA reads
vocabulary index 3 and converts index 3 to real vocabulary “doc”. This step generates output “</doc>”.
Step16: To read input DE, the state moves state to SDE from SET. This step does not generate
any output.
Step17: To read input EOS, the state moves to SEOS from SDE. The engine of CFA reach final
state and the process is finishing.
We get a Canonical XML octet stream [9] in the end of the process with the sequence. In addition, we also get a streaming model for generate Canonical XML.
4.6. Support for XPath Transformation
For XPath transformation [8] [12], we must test each node in DOM to decide which node satisfy the XPath [12] expression. Finally, we can get a node set for this transformation. The node set is a partial of full document or document fragment. The serialization of the node set is not a valid xml, so we cannot parse it again. If we want to keep canonical form of original xml and hold down the XPath transformation result in this transformation model, the engine of CFA must decides which node is including in the node set after XPath transformation. For this purpose, the operations of canonicalization and XPath node testing will be combined in a process. XPath node testing is executed to check which node satisfies XPath expression before node formalize. To mark the structure identifier is an efficient method to identify which node is in the set after XPath
transformation. For implementation, the structure identifiers are all defined less than 128. Thus, the last bit of a byte can be used to mark the node for XPath transformation.
The engine of CFA only needs to check the mark with each structure identifier in sequence for XPath transformation. The complexity of each operation in state is not increasing. The process of CFA with XPath filtering is showed as follows.
SeqA: the sequence of structure identifier
Mark: the result of XPath node testing (true or false)
SeqA : (A1,A2,………An-1,An) ↑ ↑ Add ↑ ↑ ↑ Mark : (M1,M2,………Mn-1,Mn)
L(CFA) ⎯⎯→
⎯⎯→C14n(XML) with XPath Transformation
4.7. Complexity Analysis for CFA
In this section, we will analysis the complexity of CFA. The automata accept the sequence of structure identifier is always in linear time. Therefore, the complexity of output function call G(A) defined in Section 4.4 is the only factor for total complexity. The function calls G(A) define in Section 4.4 is just printing something. The complexity of each function call G(A) is O(1). For the sequence of CFA, there are at most n function calls G(A). The complexity of CFA is O(n). If the XPath transformation is added to CFA, the complexity is not change. Because it only escape some structure identifier in sequence for function call by mark describe in Section 4.6. The sequence of function call is less then without XPath transformation. The complexity is still O(n). In any cases, the CFA guaranteed that the complexity is O(n). This analysis is showed as follows.
CFA + Mark Check
Sn : (X1,X2,X3….Xn-1,Xn) is the sequence of structure identifier.
(X1,X2,X3….Xn-1,Xn) ( G(X1),G(X2),G(X3)….G(Xn-1),G(Xn) )
There are n G(A).
Each G(A) function call is just print something. The complexity of G(A) is O(1).
n × O(1) ⇒ O(n) ⎯
⎯→ ⎯CFA
5. Performance Analysis
The proposed scheme CFA guarantees that the complexity is always O(n) for any cases with Canonical XML and XPath transformation. To prove this improvement, the performance will be compared with original C14n scheme.
For performance testing, we make two test cases to show the difference of whether XPath transformation is enabled. Because XPath transformation is very complex, the huge performance gap is expected after XPath transformation enables. Therefore, the case1 is not including XPath transformation, and case2 is XPath transformation enabled. The testing document a small xml with all node type in C14n, and then clone the child nodes of the root element to expand size for samples. Therefore, the node number of test document is proportional to its size. The sample of xml document for performance testing is showed in Appendix II.
The C14n engine of Apache XML Security 1.4.1[21] is the implementation of original C14n scheme. The engine of CFA is also developing with the same language and platform from Apache XML Security 1.4.1. We also use the same I/O package in Apache XML Security 1.4.1 to serialize data. Thus, the performance issue only depends on algorithm.
The configuration of testing is showed in Table 5-1.
Experimental Host
CPU AMD Athlon XP 1700+
RAM 1 GB OS Windows XP JVM JDK1.4.2 Control Group (Original C14n scheme) Apache XML Security 1.4.1
For XPath transformation testing, we design three XPath predicate as follows to filter nodes. The complexity of each XPath predicate is different, but the result set of nodes is equivalent.
the node is text ※
C14N-1 : self::text() the node
※ is text or the parent of this node is context node and it has xxx children C14N-2 : self::text() | parent::node()/child::xxx
the node is text or the node has bbb ancestor and its ancestor bbb also has xxx children ※
C14N-3 : self::text() | ancestor::bbb/descendant-or-self::node()/child::vvv
These predicates are sorted by complexity as follows.
C14N-1 < C14N-2 << C14N-3
The detail of testing result is showed in Table 5-2. The node number of each sample is also presented in Table 5-2. We can find the node number of test document is proportional to its size. In Table 5-2(a), it presents the processing time of original C14n scheme and CFA without XPath transformation. In Table5-2(b), it presents the processing time apply the XPath transformation in C14n and CFA with different XPath predicate. This table also presents the Input/output sequence length of CFA. The result set of nodes is same for all three XPath predicates. Therefore, the output sequence length is not change for these predicates. Because the time of CFA only depends on output sequence length after XPath transformation, the process time is also not change for different predicates. Figure5-1(a) is showed the performance comparison without XPath transformation. Figure5-1(b) is showed the performance comparison with XPath transformation. In Figure5-1(a), the CFA always 60 times faster than Apache XML Security. In Figure5-1(b), the time of Apache XML Security is increasing very huge following document size and XPath predicate complexity. However, the time of CFA is not increasing any more, on the contrary the
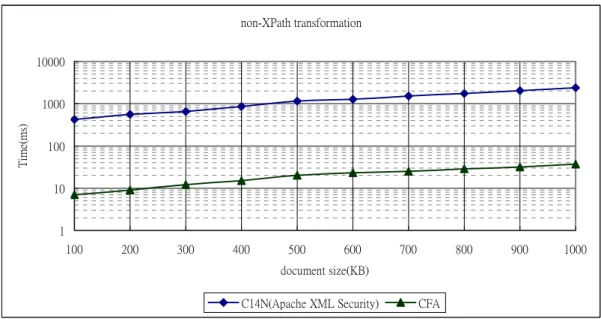
time is decreasing. Because the complexity of CFA is not change for XPath transformation [8] [12], but the sequence length of output is decreasing after XPath filtering. For 1MB document sample in Figure5-1(b), the CFA 6000 times faster than case C14N-1. Cases C14N-2 and C14N-3 is more complex than C14N-1, therefore the performance gap is bigger than C14N-1. CFA won the performance testing for all cases.
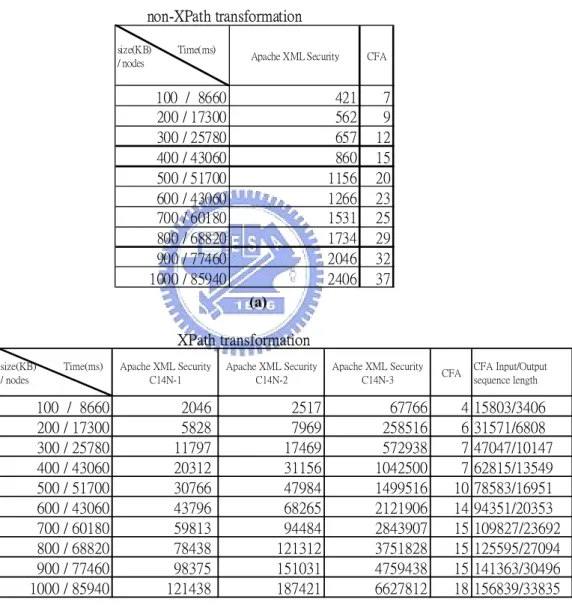
(a) XPath transformation size(KB) Time(ms) / nodes Apache XML Security C14N-1 Apache XML Security C14N-2 Apache XML Security C14N-3 CFA CFA Input/Output sequence length 100 / 8660 2046 2517 67766 4 15803/3406 200 / 17300 5828 7969 258516 6 31571/6808 300 / 25780 11797 17469 572938 7 47047/10147 400 / 43060 20312 31156 1042500 7 62815/13549 500 / 51700 30766 47984 1499516 10 78583/16951 600 / 43060 43796 68265 2121906 14 94351/20353 700 / 60180 59813 94484 2843907 15 109827/23692 800 / 68820 78438 121312 3751828 15 125595/27094 900 / 77460 98375 151031 4759438 15 141363/30496 1000 / 85940 121438 187421 6627812 18 156839/33835 (b)
Table 5-2 results of performance testing
non-XPath transformation
size(KB) Time(ms)
/ nodes Apache XML Security CFA
100 / 8660 421 7 200 / 17300 562 9 300 / 25780 657 12 400 / 43060 860 15 500 / 51700 1156 20 600 / 43060 1266 23 700 / 60180 1531 25 800 / 68820 1734 29 900 / 77460 2046 32 1000 / 85940 2406 37
non-XPath transformation 1 10 100 1000 10000 100 200 300 400 500 600 700 800 900 1000 document size(KB) Ti m e( m s)
C14N(Apache XML Security) CFA
Figure 5-1 (a) Comparison without XPath transformation
XPath transformation 1 10 100 1000 10000 100000 1000000 10000000 100 200 300 400 500 600 700 800 900 1000 document size(KB) Ti m e( m s) C14N-1 C14N-2 C14N-3 CFA