國 立 交 通 大 學
高 階 主 管 管 理 碩 士 學 程
碩 士 論 文
以類神經網路建構上市櫃公司危機預警模
型之研究
The Study of Constructing an Early Warning Model for Financial
Crisis by Using Artificial Neural Network Method
研 究 生:蔡興華
指導教授:王克陸 博士
中文摘要
本研究的目的在於利用倒傳遞類神經網路建立上市櫃公司的危機預警模型, 用於預測企業是否會在未來的某個年度發生危機。其中危機定義的範圍,限制於 上市櫃公司的股票被證交所改列為全額交割股或被處以停止交易時。由於類神經 網路模型同時考慮了線性與非線性關係,且其具有高速計算能力、高容記憶能 力、學習能力、及容錯能力,相較於傳統的區別分析研究方法,應該會有較高的 預測正確率。因此除了建立倒傳遞類神經網路預警模型之外,亦使用相同的樣本 建立羅吉斯迴歸預警模型,以比較兩者的預測能力。利用目標年度前一年、前二 年、及前三年的財務比率數據,建立的個別模型,倒傳遞類神經網路預警模型的 預測正確率較羅吉斯迴歸模型有更佳的預測能力。其預測值與實際值的擬合程度 較好,誤差較小。此外,觀察兩種預警模型三種年度模型的預測結果,可以發現 愈是遠期的資訊,在預測的效果上愈差。 關鍵字:類神經網路、倒傳遞、羅吉斯迴歸、財務危機、預警模型英文摘要
The purpose of this research is to construct an early warning model for financial crisis of the listed companies by using artificial neural network (ANN) with back propagation (BP) algorithm. ANN has error tolerance ability, learning ability, high speed computational ability, and high-volume memorizing ability. It also considers both linear and nonlinear relationship at the same time. To compare with the traditional method, we also adopt logistic regression method to build early warning model. Results show that the accuracy rate in forecasting financial crises is superior for ANN model than that of logistic model.
Keyword:Artificial Neural Network, Back-Propagation, Logistic Regression, Financial Crisis, Early Warning Model
誌 謝
感謝王克陸老師指導我、協助我,讓我能順利完成我的的論文,在此深表謝 忱;感謝交大 EMBA 三屆陳朝煌學長的鼓勵,讓我能有機會到交大學習,獲得成 長的喜悅;期間內人曹之媛女士的支持及信杰的協助一併在此致謝。
目錄
中文摘要 ...i 英文摘要 ...ii 誌 謝 ... iii 目錄 ...iv 圖目錄 ...v 表目錄 ...vi 一、緒論 ...1 1.1 研究動機...1 1.2 研究目的...2 1.3 研究範圍及限制...2 1.4 論文架構及流程...3 二、文獻回顧及探討 ...5 2.1 危機的定義範圍...5 2.2 財務比率變數...6 2.3 相關危機預警模型文獻回顧...12 2.4 類神經網路危機預測模型文獻...19 三、研究方法 ...21 3.1 類神經網路-倒傳遞法...21 3.2 羅吉斯迴歸概述...35 四、研究設計及結果 ...37 4.1 研究設計...37 4.2 數據蒐集與整理...39 4.3 分析結果與比較...40 五、結論與建議 ...47 5.1 結論...47 5.2 建議...48 參考文獻 ...49 中文部分...49 英文部分...50 附錄 一 危機與正常公司樣本配對表 ...52圖目錄
圖 1 論文流程圖 ...4 圖 2 簡單神經元模式 ...22 圖 3 單層類神經網路架構 ...24 圖 4 兩層類神經網路架構 ...25 圖 5 雙彎曲函數圖形 ...27 圖 6 實驗網路架構 ...38表目錄
表 1 解釋變數彙整表 ...7 表 2 類神經網路-前一年模型預測結果 ...41 表 3 類神經網路-前二年模型預測結果 ...42 表 4 類神經網路-前三年模型預測結果 ...42 表 5 羅吉斯迴歸-前一年模型預測結果 ...43 表 6 羅吉斯迴歸-前二年模型預測結果 ...44 表 7 羅吉斯迴歸-前三年模型預測結果 ...45 表 8 兩種模型之預測正確率及誤差均方根合併列表 ...46一、緒論
1.1 研究動機
企業經營者與投資人皆不願意見到公司的股票被證交所打入全額交割 股或處以停止交易,對經營者而言,這代表的是企業管理不善,導致公司 淨值低於資本額的一半,公司存在著可能倒閉的隱憂,而經營者則可能遭 到撤換;對投資人而言,這代表的是所投資的股票,將在其他投資人的拋 售下,造成損失,價格極有可能低於面值的一半,而在流動性不足下,投 資人更可能會遇到無法迅速變現的困境,為求脫手而誘使股票必須再次跌 價。因此若能以較長期的資料事先監控上市櫃公司未來股票是否會被列入 全額交割股,將可說是分析股票的重要工作。若能建立一套準確度高的預 警模型,除了投資人外,基金管理者及任何內外部關係人將可以避免錯誤 的判斷發生。在國內外文獻中,都是利用公司的財務比率預測是否會發生 危機,顯示經營不善將可以由財務比率中看出端倪,因此在預測公司是否 被列入全額交割股時,將使用財務比率作為模型的參數。定義本研究的問 題後,則必須找到一個比較適合的研究方法來解決問題。一般的統計方法 是屬於線性模型,如複迴歸分析、羅吉斯迴歸分析、區別分析等,要符合 特定的母體分配假設。真實世界中,若只採用線性模型,將錯失非線性關 係的重要資訊,而在數據方面,也常不符合特定分配,如常態分配。因此, 一方面傳統的方法無法滿足我們的要求,一方面隨著電腦運算速率以及演 算法的進步,本研究將使用的類神經網路模型來進行危機預測。1.2 研究目的
本研究的目的,在於發展一個以財務比率為參數的類神經網路模型來 預測上市櫃公司是否將會被改列為全額交割股或暫停交易。首先將選取的 上市櫃公司分為兩類,一類是股票沒有被改列為全額交割股或暫停交易的 公司,另一類則是股票被改列為全額交割股或暫停交易的公司,再利用類 神經網路的學習能力,並以選定的數據來進行預警模型的訓練、修正、驗 證及設立。一旦預警模型被建立,最直接的獲益人將是投資人。 此外,由於類神經網路模型同時考慮了線性與非線性關係,具有高速 計算能力、高容記憶能力、學習能力、及容錯能力,相較於傳統的區別分 析,應當會有較佳的預測準確度。除了建立類神經的預警模型,也拿之與 一般在區別分析中常用的羅吉斯迴歸模型來進行比較。類似 Udo(1993)所 採用的方式,本研究驗證兩者在特定的樣本下,以何者成功預測的百分比 高,來作為準確度比較的依據。1.3 研究範圍及限制
在真實世界的客觀條件下,本研究不得不設定研究的範圍及限制。在 研究對象方面,選擇的是以上市櫃公司為研究母體,,而不是由任何只是 登記有案的公司來取樣,這完全是基於非上市公司資料在公正上的質疑以 及合法取得的困難。在產業分佈方面,幾乎遍及所有的產業,只排除了銀 行證券相關產業,主要原因是其會計財報的特殊性,不同於一般產業,其 無法提供本研究所設定眾多的自變數。在解釋變數的選取上,為避免任意 選擇無謂的變數,本研究選擇了國際期刊文獻所使用過的財務比率。就數 據的期別資料而言,使用的是年度的資料。而在可能出現遠期的延遲影響 的效果之下,我們不只使用危機事件前一年的各項財務比率,而是也加入 了事件發生前二及前三年的各項財務比率,建立三種年度模型,不同年度 但名稱相同的財務比率代表的是不同的解釋變數。1.4 論文架構及流程
在本文的架構中,如【圖 1】所示,最初的第一章的緒論說明了研究 的動機、目的以及研究範圍。第二章的文獻回顧將介紹本研究中危機的定 義範圍,採用的財務比率、概述相關的危機區別分析模型及其文獻、以及 應用類神經網路的危機預警模型之相關文獻。在第三章的研究方法中,將 介紹本研究所使用的類神經網路倒傳遞法(back-propagation)模型的發展 及實證應用,另外也將簡介羅吉斯迴歸模型。在第四章的研究設計及結果, 首先將進行實證研究的設計、及數據的蒐集與處理,再者將介紹所獲得的 類神經網路和羅吉斯迴歸兩種危機預警模型結果,而結果包含了兩種相關 指標-預測正確率及誤差均方根,進一步地也利用這兩個指標比較兩者的 預測正確率。第五章則是本研究的結論及後續的研究建議,說明本研究的 成果,提及未來研究範圍可擴展之處以及在研究限制上的釋放。圖 1 論文流程圖
研 究 動 機 與 目 的 文 獻 回 顧 研 究 方 法 介 紹 研 究 設 計 及 結 果 結 論 與 建 議二、文獻回顧及探討
2.1 危機的定義範圍
本研究將危機的認定範圍,限制在上市櫃公司股票第一次被證券交易 所改列為全額交割股的發生,或第一次被處股票暫停交易,且在這兩種情 況發生前並未出現過危機。在文獻上對於危機有不同的組合定義,係由全 額交割股、停止交易、下市、及經法院裁定重整等事件合併定義而成。但 是,由於股票在下市之前可能即有跡可循,常常先被處以變更交易方式, 或暫停交易等。在此時的股價常低於票面值,已造成投資人重大的股票跌 價損失,而不必等到下市發生。因此,本研究不將下市處份列為危機的定 義範圍。2.1.1 改列為全額交割股的條件
當上市櫃公司股票被改列為全額交割股時,皆根據台灣證交所的規 定。台灣證券交易所股份有限公司營業細則第四十九條指出,上市公司有 下列情事之一者,對其上市之有價證券得變更原有交易方法為全額交割: 1. 其依證券交易法第三十六條規定公告並申報之最近期財務報告或投資 控股公司之合併財務報告顯示淨值已低於實收資本額二分之一者。 2. 未於營業年度終結後六個月內召開股東常會完畢者,但有正當事由經報 請公司法主管機關核准,且於核准期限內召開完畢者,不在此限。 3. 其依證券交易法第三十六條規定公告並申報之年度或半年度財務報告 或投資控股公司之合併財務報告,因未依有關法令及一般公認會計原則 編製或揭露,或因委任人,受查者之限制,致會計師未能實施必要之查 核程序,經其簽證會計師出具未能將其保留之原因充分揭露或未能將可 能影響之科目及其應調整金額充分揭露之保留意見者。 4. 違反上市公司重大訊息查證暨公開相關章則規定,經通知補行辦理公開 程序,未依限期辦理且個案情節重大者。 5. 董事或監察人累積超過三分之二(含)以上受停止行使董事或監察人職 權之假處分裁定。6. 本公司基於其他原因認有必要者。
2.1.2 處停止交易的條件
上市公司股票的暫停交易,係按台灣證券交易營業細則第 50 條的規 定。其內容如下:上市公司有左列情事之一者,對其上市之有價證券應由 本公司依證券交易法第一百四十七條規定報經主管機關核准後停止其買 賣;或得由該上市公司依第五十條之一第二項規定申請終止上市: 1. 未依法令規定期限辦理財務報告或財務預測之公告申報或投資控股公 司檢送之財務報告未再編製合併財務報告者。 2. 有公司法第二百八十二條之情事,經法院依公司法第二百八十七條第一 項第五款規定對其股票為禁止轉讓之裁定者。 3. 檢送之書表或資料,發現涉有不實之記載,經本公司要求上市公司解釋 而逾期不為解釋者。 4. 在本公司所在地設置證券過戶機構後予以裁撤,或虛設過戶機構而不 辦過戶,並經本公司查明限期改善而未辦理者。 5. 其依證券交易法第三十六條規定公告並申報之財務報告或有投資控股 公司之合併財務報告,有未依有關法令及一般公認會計原則編製,且情節 重大,經通知更正或重編而逾期仍未更正或重編者;或其公告並申報之年 度或半年度財務報告或投資控股公司之合併財務報告,經其簽證會計師出 具無法表示意見或否定意見之查核報告者,但會計師因對繼續經營假設或 被訴事件等產生疑慮而出具無法表示意見之查核報告者,不在此限。 6. 違反上市公司重大訊息查證暨公開等相關章則規定,個案情節重大,有 停止有價證券買賣必要之情事者。 7. 其他有停止有價證券買賣必要之情事者。2.2 財務比率變數
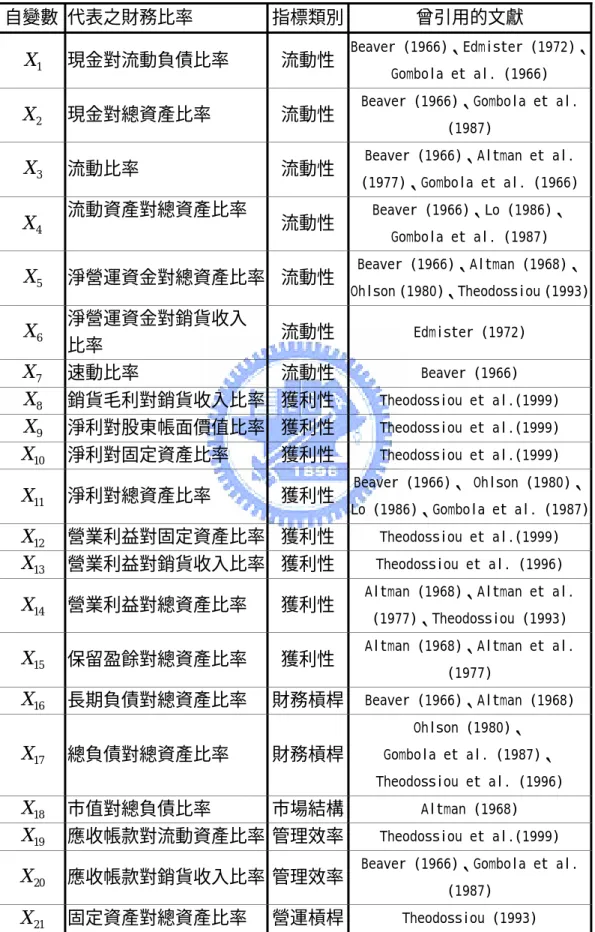
在解釋變數方面,本研究選取了過去相關的財務危機模型文獻中,屬於在檢定上顯著的二十三個 財務比率,整理於【表 1】。這些比率可歸類為流動性、獲利性、財務槓桿、市場結構、管理效 率性、以及活動性等指標。表 1 解釋變數彙整表
自變數 代表之財務比率 指標類別 曾引用的文獻 1 X 現金對流動負債比率 流動性 Beaver (1966)、Edmister (1972)、 Gombola et al. (1966) 2X 現金對總資產比率 流動性 Beaver (1966)、Gombola et al.
(1987)
3
X 流動比率 流動性 Beaver (1966)、Altman et al.
(1977)、Gombola et al. (1966) 4 X 流動資產對總資產比率 流動性 Beaver (1966)、Lo (1986)、 Gombola et al. (1987) 5 X 淨營運資金對總資產比率 流動性 Beaver (1966)、Altman (1968)、 Ohlson (1980)、Theodossiou (1993) 6 X 淨營運資金對銷貨收入 比率 流動性 Edmister (1972) 7 X 速動比率 流動性 Beaver (1966) 8 X 銷貨毛利對銷貨收入比率 獲利性 Theodossiou et al.(1999) 9 X 淨利對股東帳面價值比率 獲利性 Theodossiou et al.(1999) 10 X 淨利對固定資產比率 獲利性 Theodossiou et al.(1999) 11 X 淨利對總資產比率 獲利性 Beaver (1966)、 Ohlson (1980)、 Lo (1986)、Gombola et al. (1987) 12 X 營業利益對固定資產比率 獲利性 Theodossiou et al.(1999) 13 X 營業利益對銷貨收入比率 獲利性 Theodossiou et al. (1996) 14
X 營業利益對總資產比率 獲利性 Altman (1968)、Altman et al.
(1977)、Theodossiou (1993)
15
X 保留盈餘對總資產比率 獲利性 Altman (1968)、Altman et al.
(1977) 16 X 長期負債對總資產比率 財務槓桿 Beaver (1966)、Altman (1968) 17 X 總負債對總資產比率 財務槓桿 Ohlson (1980)、 Gombola et al. (1987)、 Theodossiou et al. (1996) 18 X 市值對總負債比率 市場結構 Altman (1968) 19 X 應收帳款對流動資產比率 管理效率 Theodossiou et al.(1999) 20
X 應收帳款對銷貨收入比率 管理效率 Beaver (1966)、Gombola et al.
(1987)
21
22 X 存貨對銷貨收入比率 管理效率 Beaver (1966)、Edmister (1972)、 Theodossiou (1993)、 Theodossiou et al. (1996) 23
X 銷貨收入對總資產比率 活動性 Altman (1968)、Gombola et al.
(1987)
資料來源:整理自Theodossiou & Kahya(1999)的研究
茲將各變數分述如下:
1. 現金對流動負債比率(Cash to Current Liabilities):
此比率比速動或流動比率更能測驗出一企業之即期償債能力,屬於流 動性的測試指標。文獻中使用這個指標的學者有 Beaver (1966)、Edmister (1972) 及 Gombola et al. (1966)等。
2. 現金對總資產比率(Cash to Total Assets):
呈現現金在總資產中所佔的比重,比重愈高,資金調度的靈活性愈大, 屬於流動性的測試指標。文獻中使用這個指標的學者有 Beaver (1966)及 Gombola et al. (1987)等。
3. 流動資產對流動負債比率(Current Assets to Current Liabilities) : 即流動比率,屬於流動性的測試指標。經常被用來作為企業短期償債 能的指標,實務上以達到 150%以上為宜,比率愈大,流動負債獲得償還的 可能性愈大。文獻中使用這個指標的學者有 Beaver (1966)、 Altman et al. (1977)及 Gombola et al. (1966)等。
4. 流動資產對總資產比率(Current Assets to Total Assets):
屬於流動性的測試指標。流動資產所佔的比重愈大,企業資金運用可 以更靈活。文獻中使用這個指標的學者有 Beaver (1966)、Lo (1986)及 Gombola et al. (1987)等。
5. 淨營運資金對總資產比率(Net Working Capital to Total Assets): 屬於流動性的測試指標。淨營運資金等於流動資產減去流動負債,因 此淨營運資金更能為企業所靈活運用。文獻中使用這個指標的學者有
Beaver (1966)、Altman (1968)、Ohlson (1980)及 Theodossiou (1993) 等。
6. 淨營運資金對銷貨收入比率(Net Working Capital to Sales): 屬於流動性的測試指標。文獻中使用這個指標的學者有 Edmister (1972)。
7. 速動資產對流動負債比率(Quick Assets to Current Liabilities): 即速動比率,屬於流動性的測試指標,用以檢測企業在短期內可變現 償還流動負債的能力,速動比率越高,表示企業短期償債能力越佳。而其 中速動資產包括了現金、有價證券、應收票據、應收帳款等易變現之資產(流 動資產 -存貨 -預付款項 -其他流動資產)。文獻中使用這個指標的學者有 Beaver (1966)。
8. 銷貨毛利對銷貨收入比率(Gross Profit to Sales):
用以測度企業產銷效能,屬於獲利性的測試指標。就經營績效衡量觀 點而言,比率愈高者佳。因為愈高表示銷貨成本愈低,企業所獲得的利潤 也愈多。文獻中使用這個指標的學者有 Kahya et al.(1999)。
9. 淨利對股東帳面價值比率(Net Income to Book Value of Equity): 用以測度企業自有資本運用效能,屬於獲利性的測試指標。比率愈高, 表示企業當局運用股東權益之效率高。文獻中使用這個指標的學者有 Kahya et al.(1999)。
10. 淨利對固定資產比率(Net Income to Fixed Assets):
用以測度企業固定資產運用效能,屬於獲利性的測試指標。比率愈高, 表示企業當局運用固定資產之效率高。文獻中使用這個指標的學者有 Kahya et al.(1999)。
11. 淨利對總資產比率(Net Income to Total Assets):
用以測度企業總資產的運用效能,屬於獲利性的測試指標。比率愈高, 表示企業當局運用總資產之效率高。文獻中使用這個指標的學者有 Beaver
(1966)、 Ohlson (1980)、Lo (1986)及 Gombola et al. (1987)。
12. 營業利益對固定資產比率(Operating Income to Fixed Assets): 同樣是用以測度企業固定資產運用效能,屬於獲利性的測試指標。比 率愈高,表示企業當局運用固定資產之效率高。文獻中使用這個指標的學 者有 Kahya et al.(1999)。
13. 營業利益對銷貨收入比率(Operating Income to Sales):
屬於獲利性的測試指標,用以測度企業的經營效能,比例愈高者佳。 文獻中使用這個指標的學者有 Theodossiou et al. (1996)。
14. 營業利益對總資產比率(Operating Income to Total Assets): 屬於獲利性的測試指標,同樣是用來測度企業的經營效能,比例愈高 者佳。文獻中使用這個指標的學者有 Altman (1968)、Altman et al. (1977) 及 Theodossiou (1993)等。
15. 保留盈餘對總資產比率(Retained Earnings to Total Assets): 屬於長期獲利性的測試指標,用來測度企業的長期經營效能,比例愈 高者佳。。文獻中使用這個指標的學者有 Altman (1968)以及 Altman et al. (1977)。
16. 長期負債對總資產比率(Long-term Debt to Total Assets): 屬於財務槓桿指標,用以測度企業資產中由債權人提供資金比率的大 小,本比率並無最佳值,因為當此比率高時,可能是有些公司為把握出現 的投資機會所導致,因此比率高並不一定代表公司正處於危機之中,或將 來更可能發生危機。文獻中使用這個指標的學者有 Beaver (1966)以及 Altman (1968)。
17. 總負債對總資產比率(Total Liabilities to Total Assets): 即負債比率,屬於財務槓桿指標,用以測度企業資產中由債權人提供 資金比率的大小。就財務結構觀點而言,本比率愈低,對債權人的保障也 愈大。總負債包含了長短期的負債,當總負債過高時,將有無法支付的窘
境。文獻中使用這個指標的學者有 Ohlson (1980)、Gombola et al. (1987) 及 Theodossiou et al. (1996)。
18. 市值對總負債比率(MVE to Total Liabilities):
屬於市場結構指標,若企業的總負債愈多,且市值愈小,此比率將愈 小,這代表企業進行的舉債融資,在投資人的眼裡,並沒有使得公司市值 增加,反而代表的是經營績效不佳。文獻中使用這個指標的學者有 Altman (1968)。
19. 應收帳款對流動資產比率(Accounts Receivable to Current Assets): 屬於管理效率性指標。在正常經營狀況下,應收帳款愈少,代表著有 愈少的帳款會成為壞帳,帳目管理較有效率。文獻中使用這個指標的學者 有 Kahya et al.(1999)。
20. 應收帳款對銷貨收入比率(Accounts Receivable to Sales): 屬於管理效率性指標。應收帳款愈少,愈少壞帳發生,且現金相對較 多,流動性更好。文獻中使用這個指標的學者有 Beaver (1966)以及 Gombola et al. (1987)。
21. 固定資產對總資產比率(Fixed Assets to Total Assets): 屬於營運槓桿指標。用以測度企業總資產中固定資產所佔比率的大 小,但並無一定的標準,視行業特性而異。就資金的運用觀點而言,比率 愈小愈好。文獻中使用這個指標的學者有 Theodossiou (1993)。 22. 存貨對銷貨收入比率(Inventory to Sales): 屬於管理效率性指標。此比率愈低愈好,代表較少資金積壓在存貨上。 文獻中使用這個指標的學者有 Beaver (1966)、Edmister (1972)、
Theodossiou (1993)及 Theodossiou et al. (1996)等。
23. 銷貨收入對總資產比率(Sales to Total Assets):
屬於活動性指標。文獻中使用這個指標的學者有 Altman (1968)以及 Gombola et al. (1987)。
2.3 相關危機預警模型文獻回顧
2.3.1 單變量分析法
在屬於質因變數的財務分類預測之研究中,最早使用單變量統計方法 來進行實證的是 Beaver(1966)。單變量分析法係利用單一的財務指標(財 務比率)配合二分類檢定法(Dichotomous Classification Test)來作為衡 量的工具,其進行區分的過程為分別將企業失敗前各年所計算而得之財務 比率之大小順序排列,以便觀察失敗企業與未失敗企業的分佈情形,從而 尋求一最佳失敗與未失敗的分界點,使分類錯誤的百分比最低。找出最佳 分類點後,即可挑出錯判的企業,藉而求得歸類錯誤率。此種方法是利用 無母數統計方法之 Mann-Whitney-Wilcoxon 檢定法的創意。 其後 Beaver(1968)又以單變量分析法為模式,對財務危機公司進行預 測研究。其蒐集樣本公司的財務比率資料為自變數,分析失敗前一至三年 財務比率如負債比率、速動比率、資產報酬率,並以此作為預測之因子。 Beaver 認為,由於市場效率的不完全,最符合現實的模式最有效,也就是 簡單模型可能較好。依其實證所得到財務危機發生前一、二、三年的預測 準確率分別為 87%、79%、77%。
2.3.2 多變量區別分析法
由於企業的財務特性是表現在多方面的,而如單變量分析法只使用單 一的財務指標似乎太簡陋了,沒有任何一個財務指標可健全到概括所有的 財務特性。因此,即有學者主張應該利用多重指標來建立預測模型。 Altman(1968)是首先利用逐步多元區別分析(Stepwise Multiple Discriminant Analysis)建立失敗預測模型的學者,其將二十二個財務比 率逐步萃取,最後得出五種最具共同預測能力的財務比率,構成一條類似 迴歸方程式的區別函數,如下所示,可產生一綜合性指標,稱之為 Z Score, 5 4 3 2 1 0.014 0.033 0.0064 0.999 012 . 0 X X X X X Z = + + + + 其中,X1:營運資金/總資產2 X :保留盈餘/總資產 3 X :息前稅前盈餘/總資產 4 X :權益市值/總負債 5 X :銷貨淨額/總資產 。 在分類時以歸類錯誤總合最小一點作為預測失敗與成功的分界點,利用驗 證樣本所求得的Z Score視是否大於分界點而將企業歸類為成功或失敗。在 Altman研究中,Z score的臨界值為2.675,若大於該值則為正常公司,否 則判定為失敗企業。
Altman et al.(1977)將 Altman 的 Z Score 模型加以擴充修改,將自
變數擴充為另外七個,分為「資產報酬率」、「盈餘穩定性」、「利息保障倍 數」、「保留盈餘對總資本比」、「流動比率」、「普通股帳面價值對總資產帳 面價值比」以及「公司規模」,並用以建立「ZETA」模式。此模式在失敗前 一年有高達 96%的預測能力。 Deakin(1972)合併Beaver和Altman的研究。隨機抽取1964~1970 年間正常與危機公司各三十二家進行研究,且利用Beaver研究中具有顯著 區別能力的十四項財務比率,分別為每一年建立二次式區別函數模型 (Quadratic Function)。其研究顯示,其區別效果的正確率達80%,雖自第 四年起即明顯下降,但還是比單變量分析來的佳。 Blum(1974)首次對企業失敗建立了一套理論架構,認為企業為流 動性資產之儲水槽(Reservoir of Liquid Assets),當任一情況發生使得 水槽的水減少時,企業發生失敗的機率將增加。其研究1954~1968年間,一 百一十五家失敗公司按行業、員工數及銷貨淨額為標準配對一百一十五家 正常公司,建立多變量區別模型,而變數的選取和以往不同的地方是以現 金流量的概念,並考慮比率的趨勢、變異性指標(Variability Indicators)。研究顯示「現金流入量 負債總額」、「淨值 負債總額」 與「兩年速動資產 存貨」的趨勢三項變數最具區別能力。而模型在失敗 發生前一年與前二年的正確區別率分別為94%和80%。 何太山(民國66年)為國內第一位運用多變量區別分析建立銀行放款信 用評分制度。其研究1975~1976上半年度間,自兩銀行中選擇五十五家信用 優良戶,與五十二家信用不良戶,再從中抽取三十家為原始樣本,其餘為 保留樣本,並以七個變數建立區別模型,研究顯示,正確區別率原始樣本 與保留樣本分別為83%與91%。
2.3.3 Probit 模型
適用於二分類選擇的 Probit 模型,也可以是一種建立財務危機預測的 方法,其屬於質應變數迴歸模型(Qualitative Dependent Variable Regression Model)。和古典迴歸模型不同之處在於質應變數為間斷型數 值,而傳統迴歸模型之應變數為連續型。由於質應變數迴歸模型的應變數 具有二項分配性質,其誤差項亦會有二項分配性質,與古典之常態假設不 同。因此無法利用普通最小平方法來處理此種迴歸問題,而必須採用一般 化最小平方法(Generalized Least Square Method, GLS)。又 GLS 所求得 之估計值並無法保證落在 0 與 1,違反二分類假設。Probit 模型將此估計 值經由標準常態分配的轉換,而成機率形態,亦即將模型轉換成事件發生 之機率,同時為了使事件發生的機率為原模式之非遞減函數,故以機率分 配之累積函數來表示事件發生之機率,其值將介於 0 與 1 之間。在應用時 必須設定一機率臨界值 * Z ,當 Probit 模型求出的機率值大於Z ,即可視* 為事件發生;反之,則無事件發生1 。 陳明賢(民國 75 年)選擇了 11 家危機公司與 19 家正常公司作為樣本, 利用 Probit 模型進行區別分析,其危機發生前五年的預測能力分別在 80~93.3%之間。其研究並發現以流動比率,營運資金對總負債,以及固定 資產對淨值比率等之 Probit 模式,進行危機企業之預測。在預測能力及穩 定性方面均較國外研究 Altman(1968)佳。
2.3.4 羅吉斯模型
羅吉斯模型與 Probit 模型在學理上相當類似,不同之處在於後者機 率估計係經由標準常態分配的轉換而得,而前者則是使用羅吉斯分配 (Logistic Distribution)。同樣地,在應用上必須設定臨界值,以辨別事 件的發生與否。此模型的內容在本文第三章會有更詳細的介紹。 Ohlson(1980)認為在一般線性迴歸或判定分析中,需假設誤差項符合 多變量常態分配,而 Logistic 模型的優點在於不論自變數或母體為間斷、 連續或混合都可引用以為分析,且當自變數母體為未知或非常態時,使用 1羅吉斯模型處理判別分析較為可靠。其採取九個財務比率,包括公司規模、 負債比率、淨營運資金比率、流動比率倒數、破產與否虛擬變數值、資產 報酬率、最後兩年虧損與否虛擬變數值、純益變動率等。其研究結果顯示, 失敗前一年的預測準確率高達 96.12%。 張正忠(民國 88 年)首先採用瀑布羅吉斯模式( Cascaded logistic model )進行預警模式之建構,並採三大構面去剖析公司是否會發生危機之 指標,分別為財務比率構面、產業因素構面、及其他質性及量性因素構面, 並進一步採用動態分析之方式,深入瞭解公司發生危機前財務狀況之變化 時點。研究結果指出,整合得到的瀑布羅吉斯模型,其正確分類率及預測 能力皆較各類型變數單獨建立之模型來的好,也顯示出此模型具有不錯的 實用性。其前三年模型的預測正確率分別為 80%、76%、以及 75%。 白欽元(民國 91 年)利用羅吉斯迴歸搭配主成份分析,探討從量化的財 務資料中建構出適用於中小企業的財務危機預警模式。模型中選取各三十 家失敗與正常公司,及十八財務比率。在其不同子模式的研究結果顯示, 整體預測正確率達 85%以上,對危機企業預測正確率最低亦有 83.3%,且發 現以主成份分析後,資料構面經過縮減,對危機預警模型的解釋與預測能 力有提高的效果。
2.3.5 CUSUM 財務危機預警模型
多變量CUSUM(Cumulative Sum)是一種時間數列研究方法,源自於品質 管制方法上的生產品質監督系統,可以建立出一CUSUM管制圖,此方法最早 經由Theodosiou(1993)的引用,結合Vector ARMA模型而建立動態化財務危 機預警模式的主要架構。其主要的概念是在於研究者獲得一組符合某種分 配的樣本後,常常可發現這組樣本可再分成幾個子樣本,雖然這些子樣本 符合相同的分配,但是確有不同分配參數,此差異即可作為分類財務危機 與正常公司的參考。已知財務危機與正常公司具有相同分配但俱有不同的 參數,當接受偵測的企業之財務指標變數由符合原來正常公司參數的分 配,是否動態偏離到另一具有不合格參數的同類分配時,即可判斷危機的 發生與否。在應用時,不同參數的分配將有不同的CUSUM值,當企業之CUSUM 值超出某危機臨界值L時,即可預期此企業會發生財務危機。CUSUM模式與其他統計模式最大的不同處在於其不僅反映當期的財務狀況,也延續了前 期的財務狀況變化,可充份表達財務危機循序發生的概念。
Theodossiou & Kahya(1999)以時間序列累積和的統計方法論為基礎, 建構美國證交所和紐約證交所之製造業與零售業的定態財務危機模型。使 用期望成本函數為最小之類神經網路型態搜尋方法來選變數,考慮變數由 54 個變數的集合選出的,包含二十七個原始變數及其一階差分。搜尋方法 所使用的另一準財是隨時間模型的定態性,因為過去財務危機模型的財務 變數大部分具有隨時間績效惡化的非定態情形。搜尋方法設計為每次允許 每一種類變數一個解釋變數進入模,因為包含兩個以上相同種類的變數不 被預期顯著增進模績效。最佳定態累積和模型藉由包含四個解釋變數的搜 尋程序產生「平減總資產取對數的變動」、「存貨銷貨收入比率的變動」、「固 定資產總資產比率的變動」、營運收入 銷貨收入比率的變動」,模型表現結 果和最要非定態模型一樣皆具有良好的平均績效。此模型具有區別公司財 務變數之變動是因為「序列相關」,或是因為「財務危機所導致平均數結構 永久轉變」的能力。檢定結果顯示模型隨時間是穩健的,而且優於以線性 判別分析與邏輯特統計方法為基礎的模型。 徐淑芳(民國 87 年)以多變量 CUSUM 時間序列分析建立預警模式,採用 多構面、較長期的財務資訊,以提高模式預警能力。採用因素分析萃取因 素後再以因素分析轉換的結果建立預警式,涵蓋較廣泛的相關資訊,提高 模式預警能力。實證顯示可達到 90.48%的預測正確率。 張隆鐘(民國 82 年)針對掌握長時間以來序列性發生的財務危機訊 息,以多變量 CUSUM 模式為基礎,發展一套動態化財務危機預擎模式,用 以進行財務危機之控制與預防。其以國內股票上市公司為樣本母體,進行 動態化預警模式的實證研究,研究結果顯示,(1)財務危機企業之存貨對銷 售額比率與固定資產對總資產比率,平均而言高於財務健全企業之比率。 (2)財務危機企業之每股盈餘對每股市價比率、營運資金對總資產比率、與 營業利益 對總資產比率,平均而言低於財務健全企業之比率。(3)經以兩 家財務危機企業之財務資料做模式驗證的結果,財務危機企業之累積 CUSUM 分數,在時間變化過程中呈現出急速退化的現象,其在變更股票交 易方式之前,累積 CUSUM 分數即已退化至危機臨界值以下。
2.3.6 EWMA 模型
EWMA類似CUSUM模式係源自於品質管制學門中,統計製程管制
(Statistical Process Control,簡稱SPC)是監控製程品質非常重要的一種 方法,其利用樣本資料來監視製程變動的情形,以期儘早發現製程之異常 現象再著手進行製程之改善,以減少不必要的品質損失。傳統的管制圖- 蕭華特管制圖(Shewhart Control Chart)是利用個別之樣本觀測值藉以判 斷製程是否在管制的狀態內,由於此一管制方法只考慮用個別觀測值來偵 測製程的變動,故適用於對製程較大變動之偵測;然而,對於微量變動, 便無法快速偵測出異常。為了改善此缺點,Robert(1959)提出指數加權移 動平均管制圖(Exponentially Weighted Moving Average Control Chart, 簡稱EWMA管制圖),此係將資料中的每一觀測值給予其權數,並透過加權平 均的觀念將過去資料之訊息考慮進來,以使得權數呈指數遞減之形式,因 而當時稱作幾何移動平均管制圖(Geometric Moving Average Control Chart)。EWMA為一特殊時間序列模型,除了在品質管制上有監控品質的功 能外,也可用於財務危機的預測,具有較CUSUM管制圖易於解讀的優點。EWMA 模式是採用加權的概念,首先利用VARMA中參數估計的結果帶入其計算式中 求得EWMA 值,而當EWMA值落到下界-L以下,則會被判定為危機公司。 金慧貞(民國 90 年)首先採用多變量 EWMA 模式,進行財務危機預警模 式之建立,再進一步驗證此模式之預測能力。實證結果顯示,總體來說 , EWMA 模式在測試樣本方面之預測正確率為 85.71%,顯示此模式具有不錯的 預測能力,且與其他相關研究常用之 CUSUM 模式有類似的表現。
2.3.7 比例危險模型
Cox 於 1972 年提出比例危險模式(Proportional Hazards Models, PHM),屬於隨機過程模型(Stochastic Process Model),但其假設時間函 數不會影響危險率(Hazard Rate),而危險率為計算存活機率的主要參數。 此模型主要是利用修正的存活函數(Survival Function)求出各樣本存活 機率或失敗機率(存活機率與失敗機率的和為一),並設定一臨界值,其值 可以是下市公司佔樣本之比例,當個別樣本的失敗機率大於臨界值時,即
歸類為失敗;反之為存活。此模型首先利用 Cox 迴歸分析(Cox’s Regression Model )求得上市公司有哪些公司指標或市場因素會影響日後其存活,在得 出哪些變數為顯著後,即用以修正存活函數,並求得各公司樣本的存活機 率,預測上市公司是否歸類為存活。 王宗興(民國 90 年)於台灣上市公司股票上市後存活分析中,利用 Cox(1972)提出的比例危險模型進行台灣上市公司股票上市後存活分析實 證研究。此乃國內首篇研究文獻以上市公司上市時點的「公司屬性」與「市 場特質」等可能影響存活反應的預後因子(Proganostic Factor)來分析預 測 上市後在交易所的存活期。係利用台灣 238 家上市公司股票樣本進行 分析,觀察樣本截至九十一年三月底,共計二十六家存活失敗終止上市, 二百一十二家仍舊存活於證券交易所掛牌買賣。實證顯示,上市時的發行 規模、內部人持股比例及初始股價報酬率與上市後存活期具有顯著相關, 可作為解釋上市存活能力的預後因子,且正確區別能力達 65.55%。
2.3.8 加速失敗時間模型
類似於比例危險模型,加速時間模型(Accelerated Failure Time Model)也發始於 Cox(1972),屬於隨機過程模型,但重視的是時間對相關 參數的影響,假設了危險率除了分別受時間及共變數之影響外,與此二者 的交互作用也有相關,且不同的機率分配設定,有其不同的危險率相對應, 常用的分配如 Gamma, Weibull, Lognormal, Exponential Distribution 等。在區別預測方面與比例危險模型相同,是以危機公司佔樣本之比例為 臨界值,比較由模型所求得之失敗機率。 蔡龍學(民國 80 年)於上市公司財務預警模式研究中,應用加速失敗時 間模型,以一百零九家上市公司為樣本,挑選二十項財務比率,以因素分 析萃取出主要變數。其結果顯示,失敗企業具有一些特質與正常企業不同, 如流動性偏低、舉債比率過高、企業經營能力低落與獲利能力不佳等特質。 在失敗前一年模式中的預測正確率為 80.73%,其前二年模式中的預測正確 率為 80.73%。在有關失敗時點的預測,實證結果顯示預測之存活期間往往 低於實際存活期間。 陳渭淳(民國 89 年)於上市公司失敗預測之實證研究中,考慮個別失敗
企業存活函數,利用 GGD 母系下四種分配(Gamma, Weibull, Lognormal, Exponential)及具非單調危險函數特質之 Loglogistic 分別進行配適度測 試、存活相依性檢定、影響存活期間因子判定與失敗危險函數估計及失敗 時點預測。利用加速失敗時間模型建立本土化的失敗預測,實證結果顯示 董事會結構特性、速動比率具有顯著相關性,其模型的預測正確率為 56.67%。
2.4 類神經網路危機預測模型文獻
Salchenberger et al. (1992)利用倒傳遞網路模型來發展儲貸機構 (Savings and Loan Associations) 的倒閉預警模型。模型結構為一個輸 入層,一個內含三個結點的隱藏層,以及一個輸出層。在自變數的選擇方 面,則與在研究中做為比較預測能力的羅吉斯模型一樣,引用了五個財務 比率。該研究蒐集了兩百家財務比率樣本做為模型訓練用,其中倒閉與非 倒閉機構各一百家。另外也蒐集了四百零四家樣本做為模型驗證用,其中 倒閉者七十五家,非倒閉者三百二十九家。研究結果顯示,在以 0.5 作為 區別值 (Cutoff)或稱判別值(Threshold Value)時,倒傳遞網路的準確度 是 96.8%,羅吉斯模型則是 94.3%。在區別值是 0.2 時,前者是 95.8%,後 者則是 92.3%。Tam & Kiang(1992) 利用類神經網路進行銀行危機的預測,並與傳統 的危機模型比較預測準確度。該研究使用的類神經網路倒傳遞模型,結構 為一個輸入層,一個內含十三個結點的隱藏層,以及一個輸出層。在自變 數及樣本的選取方面,使用了銀行危機預測文獻中曾舉用過共十九種財務 比率,並找了各五十九家的倒閉與非倒閉銀行,共一百一十八家銀行作為 模型的訓練樣本,且另找了各二十二家的倒閉與非倒閉銀行,共四十四家 銀行作為模型的準確度的測試樣本。研究結果顯示,針對測試樣本利用前 一年的財務比率進行銀行倒閉預測的失敗率只有 14.8%, 也較多變量區別 分析模型的 15.9%及羅吉斯模型的 18.2%為低。 Udo(1993) 在其預測公司倒閉的研究中,利用了倒傳遞網路做為其危 機預警模型,該模型引用了十六個其它較早文獻曾使用過的財務比率做為 釋解變數。網路結構亦為三層,其中隱藏層含有四個節點。在樣本的選取
上,選擇了各 200 家的倒閉與非倒閉公司,共 400 家公司作為模型的訓練 樣本,且另找了各 50 家的倒閉與非倒閉公司,共 100 家公司作為模型的準 確度的測試樣本。研究結果顯示,利用訓練出來的倒傳遞模型來對測試樣 本進行預測,發現前一年的財務比率的準確度高達 94.7%,前二年的財務 比率則是 82%,而一般迴歸模型則分別為 80%及 72%。 Atiya(2001) 蒐集了四百四十四家倒閉公司及七百一十六家非倒閉公 司,共一千一百六十家公司。其中選取訓練樣本四百九十一家,驗證樣本 六百六十九家,且兩者中倒閉公司對非倒閉公司比率皆為 62%。類神經網 路模型依所選用的自變數而分為以「財務比率為基礎」以及「以價格比率 為基礎」兩類自變數集合模型,而在財務比率的選取時間上,則遍及了被 預測時點的前一個月至三十六個月廣泛的期間,並粗分為(1)六個月以內、 (2)六至十二個月、(3)十二至十八個月、(4)十八至二十四個月、(5)超過 二十四個月五種集合。因此其預測模型依不同變數集合、不同時間集合將 有 2×5=10 種。研究結果顯示,「財務比率為基礎」模型的預測準確率依時 間分別為(1)90.77%、(2)87.04%、(3)80.95%、(4)65.63%及(5)57.14%;「以 價格比率為基礎」模型的預測準確率依時間分別為(1)86.15%、(2)81.48%、 (3)74.60%、(4)78.13%及(5)66.67%。 楊浚泓(民國 90 年)於考慮財務操作與合併報表後之財務危機預警模 式中,除了採用傳統的財務比率外,亦增加了大股東質押比、子公司購回 母公司股票、及短期投資比例三項財務操作變數,並考慮合併報表與一般 報表的差異性。實證顯示,加入了財務操作指標後,在類神經網路預測模 式下整體公司的正確預測率由 90.625%提升到 93.75%。 唐筱菁(民國 90 年)於整合財務比率與智慧資本指標建構企業危機預 警系統- MARS 與類神經網路之應用中,透過無母數方法-多元適應性雲形 迴歸及人工智慧工具 倒傳遞類神經網路方法的使用,建立一整合財務比率 及智慧資本指標的企業危機診斷模型。實證結果顯示,加入智慧資本指標 有助於偵測企業危機的發生,提昇模型鑑別效果;而二階段整合模式無論 在個別或整體判別正確率均優於單一模式之結果。各種模式的預測率均在 75%以上。
三、研究方法
本研究主要是利用類神經網路來建立危機預警模型。類神經網路有兩 個主要的特徵:第一,神經網路具有可適應性(Adaptive)及可學習 (Trainable)的功能。第二,神經網路是一巨型平行處理系統,俱有高速運 算及容錯運算的特性。在本研究的實證過程中,採用的是多層型類神經網 路並搭配倒傳遞演算法進行模型的訓練,以求達到最佳的預測準確度。此 外,也將利用傳統上預測效果最佳的羅吉斯迴歸,配合逐步求解法後建立 另一危機預警模型,用以作為類神經網路在預測準確度上的比較。3.1 類神經網路-倒傳遞法
本節將介紹倒傳遞類神經網路的發展,首先是自然界的腦神經網路的 運作,再來則是類神經網路如何模倣腦神經網路的運作而建立的運作模 式,最後則是介紹倒傳遞類神經網路的演算法及其在財務上的應用。3.1.1 腦神經網路
神經網路(Neural Network)是用來指明連接各個神經元(Neuron)的網 路。神經元主要由神經細胞核(Soma)、神經軸(Axon)、神經樹(Dendrites)、 及神經節(Synapses)所構成。人腦中主管思考辨識的大腦皮層中,大約含 有 10 的 11 次方個神經細胞,細胞間利用神經樹相連,相接的點即為神經 節,每個細胞大約有一千個神經節,神經節可說是神經網路上的記憶體, 神經網路上的知識是貯存在這節點上的,而兩細胞間的信號係經由神經樹 所傳遞。神經網路俱有學習的功能,當外界刺激神經細胞而產生的信號電 流通過兩神經樹上的神經節時,會去改變節點上的權重(是一種化學能), 在人的認知及辨識學習過程中,外界變化的剌激所產生的電流反覆在網路 上流動時,節點上的權重會隨之改變,然而會慢慢的趨向穩定,此時學習 即告完成。往後當外界進入的信號電流值與貯存在神經網路上的權值相符 時,外界的事物便會為神經網所辨識出來。大腦因為有這樣複雜連結架構, 所以被公認為世界上最複雜的生物機械。3.1.2 類神經網路
類神經網路(Artificial Neural Networks, ANN)是從生物學上所得到 的靈感,主要是模仿腦神腦網路(Neural networks, NN)的架構,利用簡單 神經元式的處理器(Neural Processor),組成大量平行計算架構(Massive Parallel Architecture)。主要的想法是來自於人腦在圖型及語音辨識方 面遠比數位電腦來的優秀,科學家認為人腦中必定有某種計算原理,才能 完成這種高速的圖型及語音辨識。類神經網路即是要了解這種計算原理, 以設計出功能強大的計算系統。隨著神經解剖學及神經生理學、心理學的 進步,科學家可以利用有關腦神經組織的運作方式,建立數學模型及學習 法則,來模擬腦神經的功能。在 1943 年,McCulloch 和 Pitts 首次提出類 神經網路之系統研究。在 1947 年,他們以圖形辨職作為網路探討之範例。 他們所研究的系統架構,大都如下圖所示之簡單神經元模式2 。 臨界值 輸出 : :
圖 2 簡單神經元模式
類神經網路架構中存在了所謂的類神經元(Artificial Neuron),用以 模仿腦神經元簡單的特性,當信號傳入神經元,每個輸入的信號皆乘上其 所對應出的已訓練權衡值,所有經過權衡值的信號相加後,即可以進行辨 別工作。在 1949 年時,Hebb 提出了學習法則(Learning Algorithm),在 當時是最早且唯一用科學方法證明類神經網路具學習能力的學者,為類神 2有關類神經網路的發展史更詳細的介紹,請見盧炳勳等(民國 81 年)著之「類神經網路理論與應 用」以及靳蕃等(民國 81 年)著之「神經網路與神經計算機」。 1 X 2 X n X 1 W 2 W n W∑
經網路訓練法則的鼻祖,今天大部分更複雜更有效率的訓練法則都是從 Hebb 所提出的學習法則所演變而來。該法則介紹了權衡值會根據來源及目 的神經元的輸出而進行調整,其調整方式如下式所示:
(
n+)
=W( )
n +α Wij 1 ij OUTiOUTj 其中,( )
n Wij :調整之前第 i 個神經原至第 j 個神經原之間的權衡值,(
n+1)
Wij :調整之後第 i 個神經原至第 j 個神經原之間的權衡值, α :學習速率常數, OUTi:第 i 個神經原的輸出,同時它也是第 j 個神經原的輸入, OUTj:第 j 個神經原的輸出。類神經網路架構上可分為單層網路( Single Layer Artificial Neural Networks)及多層網路(Multilayer Artificial Neural Nerworks)。雖然 單一個類神經元具有簡單的圖樣辨識能力,然而真正具有神經計算功能則 必須將類神經元連接成類神經網路,最簡單的網路是由一群類神經元組成 單層網路,如【圖 3】所示,此為一層的類神經網路,由下至上看似乎是 兩層網路,但下邊的圓點其作用只是負責分配輸入信號,並無計算的能力, 所謂的一層是指一組權衡值與其後所連接的神經元而言因此在類神經網路 的定義中,輸入層不可算為一層,在此為方便說明,故標為輸入層。若輸 出向量 Y 沒有再經特定函數轉換,則將等於輸入向量 X 乘以加權值向量 W。 輸入向量融入權衡值後即提供為輸出層的輸入值,而由於輸出層已是最後 一層,故此輸入值將等於輸出層的輸出值,由圖中可見每個輸入向量皆會 參與輸出層上各節點的計算。
輸出向量 Y 輸出層 加權值向量 W 輸入層 輸入向量 X
圖 3 單層類神經網路架構
多層類神經網路係將類神經元排列,以模仿腦神經分層式的結構,這 些多層類神經網路的能力已經被證明比單層類神經網路具備有更強大的計 算能力。多層類神經網路可以由兩個以上的單層網路串接而成,將前一層 的輸出信號作為下一層的輸入信號,經處理後再次輸出信號。以兩層類神 經網路為例,可如【圖 4】所示,由輸入向量至隱藏層為一層,由隱藏層 至輸出層為第二層,同樣地,在圖中的輸入層只是為方便說明輸入向量的 位置,其並不代表為一層。輸入向量中的每一個成分皆參與隱藏層中各節 點上輸入值的計算,此輸入值又將作為隱藏層中各節點的輸出值,隱藏層 的各輸出值又繼續參與下一層,亦即輸出層各節點上輸入值的計算,此第 二個輸入值又將等於輸出層的最後輸出值。輸出向量 輸出層 隱藏層 輸入層 輸入向量
圖 4 兩層類神經網路架構
類神經網路在訓練上可分為監督式訓練(Supervised Training)及非 監督式訓練(Unsupervised Training),監督式的訓練必須事先知道目標向 量(Target Vector),將輸入向量跟目標向量兩者稱為一個訓練對 (Training Pair)。一個類神經網路的訓練經常需要很多的訓練對,當一組 輸入向量放進去之後,就可以計算網路的輸出,並比較目標向量,而計算 兩者之間的誤差。此誤差會由後往前一層一層的傳遞,權衡矩陣就會依據 某種學習法則來調整,以便達到誤差最小。訓練對一組組餵進去,每次計 算其誤差並調整權衡矩陣,一直到全部的訓練對都餵進去之後,計算全體 的誤差總和,若低於某一容忍值則訓練完成,否則需重複此一程序一直到 收斂為止。雖然監督式的訓練已經有很多成功的運用例,但是它仍被批評 在生物學上很難實行,因為很難想像腦子裡面的訓練機構能夠比較正確的輸出跟真實的輸出,並將誤差往後傳遞回去。如果腦子裡面有這種機構, 那目標向量又從何而來呢?非監督式訓練比較接近生物神經系統的學習方 式,它是由 Kohonen 等科學家所研究出來,它不需要目輸出向量,因此不 用跟實際輸出向量比較,訓練資料純粹由輸入信號組成。訓練的法則是修 正網路的權衡矩陣以產一致的輸出向量,所謂一致的輸出向量就是不論是 輸入訓練向量或接近訓練向量都會得到相同的輸出向量。這種訓練的方式 是將訓練資料及與其統計性質相類似的向量歸為一類,將某一類的訓練資 料輸入,會得到一個輸出向量,但是訓練之前無法得知該訓練資料會產生 怎樣的輸出向量。因此,在完成網路的訓練之後,必須將網路轉換成較易 理解的型式,而這工作並不難,確認一個網路的輸入-輸出之間的關係非常 簡單。
3.1.3 倒傳遞學習法
在倒傳遞法(Back-propagation)出現以前,1970 年代至 1980 年代初 期類神經網路的研究領域曾陷入低潮,原因是當時研究的單層的類神經網 路不能求解許多用普通方法就可以解得的簡單問題。當時也曾考慮以多層 的類神經網路來求解,但在訓練上卻苦無合理的學習法則,因為必須有目 標向量才能進行訓練,但多層網路中的隱藏層卻無目標向量,以致無法以 那時的學習法則進行訓練,一直到倒傳遞學習法的發明才解決這個問題。 倒傳遞學習法的出現,對於類神經網路的復甦扮演極重要的角色,它對於 多層網路的訓練不愧是一種非常有系統的方法,唯一的限制是其數學式較 難理解。但不可否認的是該學習法的成就是非常顯著的,其延伸了類神經 網路的應用範圍,非常多的運用已被各種研究領域所開發出來。倒傳遞學 習法目的是調整權衡值,使得一群輸入加進去後能夠產生想要的輸出。其 利用縮小誤差為依據以調整權衡值,而縮小誤差的方法則是所謂的「最陡坡降法(The Gradient Steepest Descent Method)」。此外,為了能在模型
中應用最陡坡降法,倒傳遞法將輸出值以平滑可微分的轉換函數進行轉 換。以下將詳細介紹倒傳遞法3 。 3 倒傳遞法的介紹及數學推導參考自葉怡成(民國 82 年)所著「類神經網路模式應用與實作」。
1.網路架構 倒傳遞類神經網路的架構同樣地如【圖四】所示,包括了以下各層: 輸入層:用以表現網路的輸入變數,其處理單元數目依問題而定。使用線 性轉換函數,即 f
( )
x =x。在此為方便說明,把輸入層亦視為一 層。 隱藏層:用以表現輸入處理單元間的交互影響,其處理單元數目並無標準 方法可以決定,經常需以試驗方式決定其最佳數目。使用非線性 轉換函數。網路可以不只一層隱藏層,也可以沒有隱藏層。 輸出層:用以表現網路的輸出變數,其處理單元數目依問題而定。使用非 線性轉換函數。 倒傳遞網路最常用於轉換輸出值的非線性轉換函數為雙彎曲函數 (Sigmoid Function),( )
x e x f − + = 1 1 ,函數圖形如【圖 5】所示,此函數 當自變數趨於正負無限大時,函數值趨於常數,其函數值域在[0, 1]之間。圖 5 雙彎曲函數圖形
1
0
2.訓練步驟概述 在一個包含了一個輸入層、多個隱藏層、及一個輸出層的多層網路中, 訓練倒傳遞網路需要以下步驟: (1)從被訓練組中選擇一個訓練對(一對輸入向量和目標向量),送到網 路的輸入層。 (2)計算網路的輸出 (3)計算網路輸出與目標值的之間的誤差。 (4)依據某種方式來調整網路的權衡值,使得誤差最小。 (5)針對每一個訓練重複步驟 1 至 4,直到整組的誤差在一個容忍值以 下。 在上述步驟中,存在著順向傳遞(Forward Pass)及逆向傳遞(Reverse Pass)兩種傳遞方式。之中的步驟 1 及 2 為順向傳遞,傳遞方法是信號由輸 入層進入網路後,由第一層乘上權衡值後計算而得到輸出,此輸出被當成 後一層的輸入,到達後一層後乘上該層權衡值而再次得到輸出,如此一層 一層地傳遞下去,直至到達輸出層為止。步驟 3 及 4 則是逆向傳遞,是指 誤差信號往後傳遞,逆向的一層一層的傳遞,到達各層時即調整該層的權 衡值。利用誤差信號往後傳遞的方法,解決了隱藏層無目標向量即無法訓 練多層網路的問題。 3.網路演算法 以下將說明倒傳遞演算法如何應用一個訓練範例的一輸入值向量 X ,與一目標輸出向量T ,修正網路加權值W,而達到學習的目的。在倒 傳遞網路中,第n層的第 j 個單元的輸出值為第n−1層 i 個單元輸出值的非 線性函數:
( )
n j n j f net A = (1) 其中 n j net = 集成函數=∑
− − i j n i ijA W 1 θ (2) f = 轉換函數 i = 第n−1層的單元數j = 第n層的單數。 由於監督式學習旨在降低網路輸出單元目標輸出與推論輸出值之差距,所 以一般以下列的誤差函數表示學習的品質:
( )
∑
(
−)
= j j j A T E 1/2 2 (3) 其中T = 輸出層目標輸出值 j j A = 輸出層推論輸出值。 因此網路的學習過程變成上述能量函數最小化的過程,通常以最陡坡降法 來使能函數最小化,即每當輸入一個訓練範例,網路即小幅調整加權值的 大小,調整的幅度和誤差函數對該加權值的敏感程度成正比,即與誤差函 數對加權值的偏微分值小成正比: ij ij W E W ∆ ∆ ⋅ − = ∆ η (4) 其中W =介於第ij n−1層的第 i 個處理單元,與第n層的第 j 個處理單元間的 連結加權值。 η=學習速率(Learning Rate),控制每次以最陡坡降法最小化誤差函數的 步幅。 而∂E ∂Wij 可用微積分學的連鎖法則而得 ∂ ∂ ∂ ∂ = ∂ ∂ ij n j n j ij W net net E W E (5a) ∂ ∂ ∂ ∂ ∂ ∂ = ∂ ∂ ij n j n j n j n j ij W net net A A E W E (5b) 其中 1 1 − − = − ∂ ∂ = ∂ ∂∑
n i k j n k kj ij ij n j A A W W W net θ (6)( ) ( )
n j n j n j n j n j net f net f net net A ′ = ∂ ∂ = ∂ ∂ (7)而 n j A E ∂ ∂ 則可分為二種情況: (1)第n層即為最終層,即網路的輸出層: 將第(3)式代入第二項得
( )
(
)
(
n)
j j k n k k n j n j A T A T A A E =− − − ∂ ∂ = ∂ ∂∑
2 2 / 1 (8) (2)第n層不是最終層,是網路的隱藏層之一,可利用連鎖律得: ∂ ∂ ∂ ∂ = ∂ ∂ + +∑
n j n k k n k n j A net net E A E 1 1 (9) 將第(2)式代入第二項得 jk i k n i ik n j n j n k W A W A A net = − ∂ ∂ = ∂ ∂∑
+ θ 1 (10) 為了簡明定義 n k n k net E δ − = ∂ ∂ (11) 將第(10)、(11)式代入第(9)式得∑
⋅ − = ∂ ∂ + k jk n k n j W A E δ 1 (12) 總結 ij W E ∂ ∂ 可分成二種情況: (1)W 處於輸出層與隱藏層之間 ij 將第(6)、(7)、(8)式代入第(5b)式得(
−) ( )
⋅ ′ ⋅ −1 − = ∂ ∂ n i n j n j i ij A net f A T W E (13) 若將第(6)式、(11)式代入第(5a)式得 1 − ⋅ − = ∂ ∂ n i n j ij A W E δ (14) 比較第(13)式與第(14)式得(
i i)
( )
nj n j = T −Y ⋅ f′net δ (15) (2)W 處於隱藏層與隱藏層之間 ij將第(6)、(7)、(12)式代入第(5b)式得
( )
1 1 − + ⋅ ′ ⋅ ⋅ − = ∂ ∂∑
n i n j k jk n k ij A net f W W E δ (16) 另可將第(6)、(11)式代入第(5a)式得 1 − ⋅ − = ∂ ∂ n i n j ij A W E δ (17) 比較第(16)式與第(17)式得( )
n j k jk n k n j W ⋅ f′net ⋅ =∑
δ +1 δ (18) 因此不論W 處於輸出層與隱藏層之間,或ij W 處於隱藏層與隱藏層之ij 間, ij W E ∂ ∂ 均可寫成通式 1 − ⋅ − = ∂ ∂ n i n j ij A W E δ (19) 其中 1 − n i A =W 所連接之較低層的處理單元之輸出值 ij n j δ =W 所連接之較上層的處理單元之差距量 ij =若連接的是輸出層與隱藏層,則(
)
( )
n j i i n j = T −Y ⋅ f′net δ ;若連接的 是隱藏層與隱藏層,則為( )
n j k jk n k n j W ⋅ f′net ⋅ =∑
δ +1 δ 。 將第(19)式代入第(4)式得 1 − ⋅ ⋅ = ∆ n i n j ij A W η δ (20) 此式即倒傳遞演算法之關鍵公式。 如果非線性轉換函數使用雙彎曲函數(Sigmoid Function)( )
j net e x f − + = 1 1 (21) 則 f′( ) ( )
netj = f netj ⋅[
1− f( )
netj]
(22)將第(22)式代入第(20)式得 n j δ =若連接的是輸出層與隱藏層,則
(
j j) (
j j)
n j = T −Y ⋅Y 1−Y δ ;若連接的是隱藏層與隱藏層,則 j
(
j)
k jk n k n j W ⋅H ⋅ −H ⋅ =∑
+ 1 1 δ δ 。 其中Y =輸出層處理單元的輸出值。 H =隱藏層處理單元的輸出值。 同理可證 n j δ η θ =− ⋅ ∆ (23) 此學習過程通常以一次一個訓練範例的方式進行,直到學習完所有的 訓練範例,稱為一個學習循環,一個網路可以將訓練範例反復學習數個學 習循環,直至達到收斂。 4.倒傳遞法學習步驟的數學模式 數學表達的倒傳遞學習步驟如下: (1)設定網路參數。 (2)以均佈隨機亂數設定權衡值矩陣 W _xh 及 W_hy ,與偏權值向 量θ _h 及 θ _y 初始值。 (3)輸入一個訓練範例的輸入向量 X ,與目標向量 T 。 (4)計算推論輸出向量 Y 。 (a)計算隱層輸出向量 H∑
⋅ − = i h i ih h W xh X h net _ θ_(
)
h net h h f net H − + = = exp 1 1 (b)計算推論輸出向量 Y∑
⋅ − = h j h hj j W hy H y net _ θ_( )
j net j j f net Y − + = = exp 1 1 (5)計算差距量 δ (a)計算輸出層差距量 δ(
j)(
j j)
j j =Y 1−Y T −Y δ (b)計算隱藏層差距量 δ∑
− = j j hj h h h H H W hy δ δ (1 ) _ (6)計算加權值矩陣修正量 ∆W ,及偏權值向量修正量 ∆θ (a)計算輸出層加權值矩陣修正量 ∆W _hy ,及偏權值向量修正量 y _ θ ∆ , h j hj H hy W =ηδ ∆ _ j j y ηδ θ =− ∆ _ (b)計算隱藏層加權值矩陣修正量 ∆W _xh ,及偏權值向量修正量 h _ θ ∆ , i h ih X xh W =ηδ ∆ _ h h h ηδ θ =− ∆ _ (7)更新加權值矩陣 W ,及偏權值向量 θ (a)更新輸出層加權值矩陣 W _hy ,及偏權值向量 θ _y hj hj hj W hy W hy hy W _ = _ +∆ _ j j j y y y _ _ _ θ θ θ = +∆ (b)更新隱藏層加權值矩陣 W _xh ,及偏權值向量 θ_h ih ih ih W xh W xh xh W _ = _ +∆ _ h h h h h h _ _ _ θ θ θ = +∆ (8)重覆步驟(3)至(7),直到收斂(誤差不再有明顯變化)或執行一定數 目 的學習循環。4.在財務領域的應用 雖然最是使用在科學領域,但倒傳遞類神經網路在財務預測領域上的 應用已是非常廣泛,可由葉怡成(民 86)所整理其在財務管理相關之預測用 途上得知。這些用途簡述如下: (1)國庫券利率預測 係利用消費者物價指數、國民生產毛額、M2 貨幣供給率等指標 作為輸入變數,即輸入層的結點數,並採用國庫券利率的多季移動平 均值作為輸出變數,即輸出層的結點數,搭配適當的隱藏層後,以現 有的實際數據經訓練,建立國庫券利率預測模型,可用以預測未來的 利率走勢。 (2)收盤指數預測 利用前一日、前二日、或前三日以上的開盤指數、最高指數、最 低指數、收盤指數、及成交值等作為輸入變數,並以目標日之收盤指 數變化率作為輸出變數,如此建立了收盤指數預測系統,可供投資人 進行投資決策。 (3)個人信用評估 利用孩子數目、職業別、房屋數、月收入、月支出、銀行帳戶數、 銀行信用卡數、付款情形等作為輸入變數,以付款分類作為輸出變 數,如{1,0,0}代表拖延很久才付款,{0,1,0}代表拖延數日才付款, {0,0,1}代表準時付款,可看出此時的輸出層為三個節點數。如此建 立的模型可用以預測一個信用卡申請人的付款信用。 (4)債券評等 可以利用一家企業的財務比率,如負債/(現金+資產)、銷貨/淨 值、流動資動資本、過去的收益成長、負債率、利潤/固定成本等, 作為輸入變數,而信用等級分類則作為輸出變數,如此所建立的模 型,企業將可用以預測新發行債券的評等,並進而訂立其發行利率, 避免因高估利率而增加成本,或低估而導致發行成果不佳。
3.2 羅吉斯迴歸概述
羅吉斯迴歸模型(Logistic Regression Model),在統計分析應用已 有很多年,羅吉斯迴歸早期由J.Berkson 於1944年所創,但是從1967年以 後,羅吉斯迴歸才漸漸普遍,現在對於二元的離散資料,尤其在醫學、生 物統計方面使用較為廣泛,後續學者加以推廣應用於行銷及財務中,羅吉 斯迴歸分析與區別分析同樣都可以解決分類變數的問題,但就分析方法及 使用限制而言,使用區別分析時所有的解釋變數皆需符合常態分配,而羅 吉斯迴歸分析方法則不必受到常態分配的限制,使用彈性較大。迴歸分析 是描述一個應變數與一個或多個預測變數之間的關係式,它是資料分析最 重要的工具,當我們探討結果的應變數是離散型,其分類只有兩類或少數 幾類時,以羅吉斯迴歸做分析,在很多領域已變成標準的分析方法。 Logistic 迴歸分析的目的有二,一在求取具顯著解釋能力的自變數,二是 透過所構建的模式,利用自變數來預測應變數發生的機率。 在本研究中,將應變數Y 定義為“是否發生財務危機”,它是一個離 散變數,企業發生財務危機時,其值為1;企業財務正常時則為0。兩種變 數的關係可以由下列多項式表示:
( )
X X X kXk f Y = =β0+β1 1+β2 2 +L+β , 今令 P 表示為成功(Y =1)的機率,它受自變數X 所影響。假設i P 與X 的i 關係滿足下式,即 ( ) ( )X f X f e e P + = 1 , 則其失敗的機率為 ( )X f e P + = − 1 1 1 , 將成功的機率與失敗的機率兩者相除可得: ( )X f e P P = − 1 此即所謂的優勢比(Odd Ratio)。 取對數後可得( )
X X X kXk f P P = =β +β +β + +β − 0 1 1 2 2 L 1 ln , 此種轉換方式稱為羅吉轉換(Logit Transformation)。當求得係數βi後,即可由下式求得 P 值: k k k k X X X X X X e e P β β β β β β β β + + + + + + + + + = LL 2 2 1 1 0 2 2 1 1 0 1 , 在應用時必須設定一判定值(Threshold Value),其值常被設為為0.5。當 羅吉斯迴歸模型所獲得的 P 值大於0.5時,則將此次試驗分類為成功 (Y =1);相反地,若輸出值小於0.5時,則分類為失敗(Y =0)。至於βi的求 法,則必須使用概似函數L