A text mining approach for automatic construction of hypertexts
Hsin-Chang Yang
a,*, Chung-Hong Lee
baDepartment of Information Management, Chang Jung University, Tainan 711, Taiwan, ROC
bDepartment of Electrical Engineering, National Kaohsiung University of Applied Sciences, Kaohsiung, Taiwan, ROC
Abstract
The research on automatic hypertext construction emerges rapidly in the last decade because there exists a urgent need to translate the gigantic amount of legacy documents into web pages. Unlike traditional ‘flat’ texts, a hypertext contains a number of navigational hyperlinks that point to some related hypertexts or locations of the same hypertext. Traditionally, these hyperlinks were constructed by the creators of the web pages with or without the help of some authoring tools. However, the gigantic amount of documents produced each day prevent from such manual construction. Thus an automatic hypertext construction method is necessary for content providers to efficiently produce adequate information that can be used by web surfers. Although most of the web pages contain a number of non-textual data such as images, sounds, and video clips, text data still contribute the major part of information about the pages. Therefore, it is not surprising that most of automatic hypertext construction methods inherit from traditional information retrieval research. In this work, we will propose a new automatic hypertext construction method based on a text mining approach. Our method applies the self-organizing map algorithm to cluster some at text documents in a training corpus and generate two maps. We then use these maps to identify the sources and destinations of some important hyperlinks within these training documents. The constructed hyperlinks are then inserted into the training documents to translate them into hypertext form. Such translated documents will form the new corpus. Incoming documents can also be translated into hypertext form and added to the corpus through the same approach. Our method had been tested on a set of at text documents collected from a newswire site. Although we only use Chinese text documents, our approach can be applied to any documents that can be transformed to a set of index terms.
q2005 Elsevier Ltd. All rights reserved.
Keywords: Automatic hypertext construction; Self-organizing maps; Text mining
1. Introduction
The use of hypertexts for information representation has been widely recognized and accepted because they provide a feasible mechanism to retrieve related documents. The emergence of the World Wide Web (WWW) pushes it further since the HTML format, which is the standard format for documents in the WWW (or the web pages), provides the capability of incorporating navigational hyperlinks and multi-media objects in simple syntax. As a result, the WWW attracts numerous contributions in such format from all over the world. It is estimated that there exist more then 3 billion web pages worldwide and more than 1 million new web pages being created each day.
Therefore, the majority of hypertext documents in the world exist in the WWW as web pages. Unfortunately, most of the web pages were created manually using some kind of authoring tools. Although such authoring tools are easy to use and provide sufficient functionality for individual users, manual construction of web pages is still, if not impossible, a very hard work for those content providers that produce a large amount of web pages constantly or periodically. Moreover, manual construction is always unstructured and unmethodological. To remedy such inefficiency, we need a method to automatically transform a ‘flat’ text, which is an piece of ordinary text without any hyperlinks, into a hypertext rather than creating a hypertext from the ground up. Thus research of automatic hypertext construction arises rapidly in recent years.
To transform a flat text to a hypertext we need to decide where to insert a hyperlink in the text. A hyperlink connects between two documents where at one end of the hyperlink is the source text which may be an individual word or a sentence and at the other end is the destination text which
www.elsevier.com/locate/eswa
0957-4174/$ - see front matter q 2005 Elsevier Ltd. All rights reserved. doi:10.1016/j.eswa.2005.05.003
* Corresponding author. Tel.: C886 6278 5123; fax: C886 6278 5657. E-mail addresses: [email protected] (H.-C. Yang), leechung@ mail.ee.kuas.edu.tw (C.-H. Lee).
may be another document or a different location of the same document. Different types of hyperlinks may be used depending to the kinds of functionality that need to be implemented by the hypertext. For example, according to
Agosti, Crestani, and Melucci (1997), there are three types of hyperlinks, namely structural links, referential links, and associative links. The first two types of hyperlinks are usually explicit and may be easily created manually or automatically. The associative hyperlinks, however, require a understanding of the semantics of the connecting documents. Such understanding also requires much human effort. Nowadays, automatic creating of associative hyperlinks, or semantic hyperlinks in other literature, plays a central role in the development of automatic hypertext construction methods because these hyperlinks may provide the most effective exploring paths to fulfill the users’ information need. The critical points in creating associative hyperlinks are two-fold: one is to find the source texts to be linked; the other is to find the documents which are semantically relevant to these sources. Both tasks require understanding of text semantics that could be revealed by a text mining process.
Text mining concerns of discovering knowledge from a textual database and attracts much attention from both researchers and practitioners. The problem is not easy to tackle due to the semi-structured or unstructured nature of the text documents being processed. Many approaches have been devised in recent years (for example, Feldman & Dagan, 1995). In this work, we apply the self-organizing map algorithm (Kohonen, 1997) to perform the text mining process. All documents of a corpus are first clustered into document clusters according to the co-occurrence patterns of the index terms which were extracted from the documents. The common terms that represent the general concepts of the documents in a document cluster are also revealed by a labeling process and are clustered into a word cluster. Since the self-organizing process could reveal the relationship among documents as well as index terms, such text mining process may also be used to find the associative hyperlinks. The terms in a word cluster are used to establish the sources of some hyperlinks. Destinations of these hyperlinks are obtained by examining the corre-sponding document cluster. As a result, we may create hyperlinks based on the relevance among documents discovered by the self-organizing process and system-atically construct a hypertext which contains effective exploring paths.
The structure of this paper is as follows. We will discuss some related works in Section 2. Later in Section 3 we will give an application example of the automatic hypertext construction system. Such scenario will be referenced when example is needed. We also give an overview of the proposed method. In Section 4 we introduce the text mining process that generates two feature maps. We then describe the automatic hypertext construction method in Section 5.
The experimental result for the proposed method is presented in Section 6. Finally, we give some conclusions and discussions in Section 7.
2. Related work
2.1. Hypertext construction methodologies and systems Research on automatic construction of hypertext arose mostly from the information retrieval field. A survey of the use of information retrieval techniques for the automatic hypertext construction can be found inAgosti et al. (1997). There was no neural network based methods had made significant contribution in this field according to their survey. Another survey of hyperlink generation is presented inWilkinson and Smeaton (1999). Salton et al. (Salton & Buckley, 1989; Salton, Buckley, & Allan, 1992; Salton, Allan, & Buckley, 1993, 1994) use the information provided by the computation of the similarity between fragments of documents in order to identify content links. Their works are based on vector space model and provide basis for many hypertext construction methods.Agosti and Crestani (1993)
design a methodology for automatic construction of hypertexts that will be used in information retrieval tasks. They establish a concept model that consists of three levels, namely concept level, index term level, and document level and devise a five-steps process to construct the links among concepts, index terms, and documents. They use popular information retrieval techniques in the above-mentioned process to avoid justification of new methods. The methodology is later implemented in TACHIR (Agosti, Crestani, & Melucci, 1996) and Hyper-TextBook project (Crestani & Melucci, 2003).Dalamagas and Dunlop (1997)
suggest a methodology for the automatic construction of hypertext which is tailored to the domain of newspaper archives and is based on Salton’s approach. Threads, which are substories within a story, are identified by applying clustering techniques to articles’ segments that correspond to subtopics within the main topic of an article and then linking the segments which belong to the same cluster. The method is later implemented in News Hypertext System (Dalamagas, 1998).Green (1997, 2000)proposes a method for automatic hypertext construction by analyzing lexical chains in a text based on the Wordnet. The lexical chains are discovered and their importance is evaluated. Such importance is later used in calculating paragraph similarity and building inter-paragraph links. Another type of links, namely the inter-article links, are built by determining the similarity of the two sets of chains contained in two articles.
Kurohashi, Nagao, Sato, and Murakami (1992) construct hypertext structure for a computer science dictionary by finding sentential patterns among the texts to establish the relations between words. Such approach is rather restrictive and can only be applied to specific corpora such as the one they used. A early work by Salminen, Tague-Sutcliffe,
and McClellan (1995) combines formal grammar and document indexing techniques to convert semi-structured text to hypertext. Their method can only apply to those documents that have hierarchical structure.Shin, Nam, and Kim (1997)also use a hybrid approach which combines two similarity measures, namely the statistical similarity and semantic similarity, to create good hypertext, where the statistical similarity is traditional tf$idf weighting scheme and the semantic similarity underlies a thesaurus. Lin, Ha¨ma¨la¨inen, and Whinston (1996)develop a system named Knowledge-Based HTML Document Generator that incor-porates the knowledge derived from regularly updated databases to facilitate the creation and maintenance of HTML documents. However, this system cannot be applied to arbitrary documents that fed randomly and relies on analysis as well as authoring expertise in the creation process.Tudhope and Taylor (1997)use semantic closeness measures on subject, spatial, and temporal dimensions to create hyperlinks for navigation purpose.
2.2. Hyperlinks analysis
Mehler (1999) outlines a theoretical framework for criteria of hypertext construction. He uses the concept of lexical cohesion as a linguistic criterion for text linkage in a sense that if two texts comprise semantically similar words so that they form a lexically cohesive whole, those texts represent valid candidates for text linkage. Moreover, the lexical cohesiveness is measured by the help of semantic space model where the distance of meaning points represent semantic similarity as a result of similar usage regularities of words.Allan (1996, 1997)discuss the way the hyperlinks could be automatically typed. He calculates the similarity between documents and between parts of documents. The documents, or parts of them, are then linked according to their similarity. Six types of hyperlinks, namely revision links, summary/expansion links, equivalence links, com-parison/contrast links, tangent links, and aggregate links, are identified by analyzing the links.
2.3. Text mining
Text mining has received lots of attention in recent few years. Many researchers and practitioners have involved in this field using various approaches (Tan, 1999). Among these approaches, the self-organizing map (SOM) (Kohonen, 1997) model plays an important role. Lots of works had used SOM to cluster large collection of text documents. Examples can be found in Kaski, Honkela, Lagus, and Kohonen (1998), Lee and Yang (1999), and Rauber and Merkl (1999). However, there is few work had applied text mining approaches, particularly the SOM approach, to automatic hypertext construction. One close work byRizzo, Allegra, and Fulantelli (1998)used the SOM to cluster hypertext documents. However, their work was
used for interactive browsing and document searching, rather than hypertext authoring.
3. Application scenario example and system overview We describe a scenario that the automatic hypertext construction process may apply. A newswire site named HCY News produces news articles from reporters all over a country. A reporter sends back his reports in plain texts for rapid publishing. Without any postprocessing, the HCY news translates these articles into HTML format and posts them on their web site. A reader surfs on the news site and reads an article about NBA games that mentions the player Michael Jordan. He wants to find more articles about Michael Jordan. The only way he can do here is to use the search facility provided in this site to search the theme he wants. However, he finds there are more than 1000 articles about M. Jordan and is overwhelmed. On the other hand, he may also search a theme and disappointedly finds no result. On either way he may decide to log off from this site because it is so inconvenient for him to find interesting news. After losing many eyeballs, HCY news decides to provide navigational links in their news articles. However, manual construction of these links seems inapplicable because it requires additional human resources and is slow, incorrect, and inconsistent. The introduce of an automatic hypertext construction system solves all these problems. Upon feeding the system some legacy news articles in plain text format, the system transforms these articles into hypertext form systematically in short time. Incoming news may also be transformed and incorporated into the hypertext data set. Now, when a user reads an article, he will see some important terms with hyperlinks on them. He can click on a link when he is interested on the theme. He may also go through other semantically related articles directly by the help of additional links generated by the hypertext construction system.
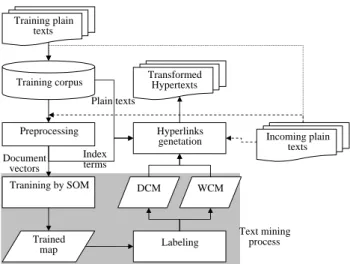
The functional components and data flows in our method are depicts inFig. 1. We briefly describe the major steps of the construction process in the following:
Step 1. Corpus construction. A set of plain texts are collected and will be used for training. This set of texts will be transformed to hypertexts later. Step 2. Preprocessing. Text preprocessing is performed
to transform these texts into index terms. Various kinds of index term selection methods are applied to reduce the number of index terms. A text is then transformed into a vector according to its index terms.
Step 3. Clustering and labeling. We construct a neuron map and perform the self-organizing map cluster-ing algorithm on the document vectors. A labelcluster-ing process is conducted to label each document to some neuron. We also apply another labeling
process to label some important terms to the neurons. After the labeling processes, we obtain two feature maps.
Step 4. Hyperlink generation. A plain text is transformed to its hypertext form by adding hyperlinks that are generated by analyzing the two feature maps. We should note that online transformation of plain texts into hypertexts is possible in our method. When an incoming plain text enters, it will be preprocessed into index terms. The hypertext generation process then use these index terms together with the two discovered feature maps to add hyperlinks to the original text. The incoming texts can also be added to the training corpus to expand it for future use.
4. Text mining by self-organizing maps
We should first perform a text mining process on the corpus to enable the creation of hypertexts. In this section, we will describe the details of the text mining process. First in Section 4.1 the preprocessing steps are described. Later in Section 4.2 we will give an approach that adopts the popular self-organizing map (SOM) algorithm to cluster plain text documents. Finally, we describe how to generate two feature maps that reveal the relationships among documents and keywords, respect-ively, in Section 4.3.
4.1. Document encoding and preprocessing
Our approach begins with a standard practice in information retrieval, i.e. the vector space model (Salton & McGill, 1983), to encode documents with vectors, in which each component of a document vector corresponds to a different index term. It should be mentioned here that we will use ‘word’ and ‘index term’ interchangeably wherever
appropriate. In this work the corpus contains a set of flat texts most written in Chinese. For simplicity and generality, we will denote a piece of flat text as a document hereafter. First we apply an extractor to filter out HTML tags and extract index terms from the documents. Since we adopt a Chinese corpus, these index terms are composed by Chinese characters. Traditionally, there are two schemes for extracting terms from Chinese texts, namely the character-based scheme and the word-character-based scheme (Huang & Robertson, 1997). We adopt the second scheme because individual Chinese characters generally carry no context-specific meaning. After extracting words, they are used as index terms to encode the documents into binary vectors. In such vector, a component with value 1 indicates that its corresponding word appears in the document; otherwise, value 0 indicates the absence of the word.
A problem with this encoding method is that if the size of the vocabulary is very large the dimensionality of the vector is also high. In practice, the resulting dimensionality of the space is often tremendously huge, since the number of dimensions is determined by the number of distinct index terms in the corpus. In general, feature spaces on the order of 1000–100,000 are very common for even reasonably small collections of documents. As a result, techniques for controlling the dimensionality of the vector space are required. Such a problem could be solved, for example, by eliminating some of the most common and some of the rarest index terms in the preprocessing stage. Several other techniques may also be used to tackle the problem. Examples are multidimensional scaling (Cox & Cox, 1994), principal component analysis (Jolliffe, 1986), and latent semantic indexing (Deerwester, Dumais, Furnas, & Landauer, 1990).
In information retrieval several techniques are widely used to reduce the number of index terms. Unfortunately, these techniques are not fully applicable to Chinese documents. For example, stemming is generally not necessary for Chinese texts. On the other hand, we can use stop words and thesaurus to reduce the number of index terms. In this work, we use several approaches to reduce the size of the vocabulary. First, we keep only the nouns because we believe the nouns carry most of the semantics in texts. Second, we ignore the terms appear extremely few times. Finally, we manually constructed a stop list to filter out less important words in the texts.
We use binary vector scheme to encode the documents and ignore any kind of term weighting schemes. Such decision is made according to the following reasons. First, we cluster documents according to the co-occurrence of the words, which is irrelevant to the weights of the individual words. Second, our experiments showed no advantage in the clustering result by using term weighting schemes(classical tf and tf$idf schemes were used). As a result, we believe the binary scheme is adequate to our need. Training plain texts Training corpus Tranining by SOM DCM WCM Trained map Labeling Hyperlinks genetation Transformed Hypertexts Incoming plain texts Preprocessing Text mining process Index terms Plain texts Document vectors
and intra-cluster sources could be used in Eq. (9). Fig. 7
depicts the distribution of link densities of every document for s1Z10 and s2Z5. We can observe that about 1.3% of
documents (43 out of 3268) have link densities that are greater than 1. The reason is that our labeling method uses the trained weights directly. If the synaptic weight corresponding to a word exceeds a threshold, the word is labeled to the WCM and may be selected as a source. Therefore, the number of sources for a document may exceed the number of non-zero components in a document vector. Table 1 lists several statistics of the generated hyperlinks. The use of link densities to select appropriate values of s1and s2is still under investigation.
7. Conclusions and discussions
In this work we devised a novel method for automatic hypertext construction. To construct hypertexts from flat texts we first develop a text mining approach which adopts the self-organizing map algorithm to cluster these flat texts and generate two feature maps, namely the document cluster map and the word cluster map. These maps model the co-occurrence patterns among the trained texts. The construc-tion of hypertexts is achieved by analyzing these maps. Two types of hyperlinks, namely the intra-cluster hyperlinks and the inter-cluster hyperlinks, are created. The intra-cluster hyperlinks create connections between a document and its relevant documents while the inter-cluster hyperlinks connect a document to some irrelevant documents which reveal some keywords occurred in the source document. An aggregate link may also be created for each document to include all intra-cluster links. Experiments show that not only the text mining approach successfully reveals the co-occurrence patterns of the underlying texts, but also the devised hypertext construction process effectively con-structs semantic hyperlinks among these texts.
The hyperlinks constructed here are all inter-document hyperlinks which the sources and destinations should be different documents. We do not construct the intra-document hyperlinks, which sources and destinations fall in the same documents, due to the relatively short lengths of the training documents. However, in situations that long articles are incorporated in the corpus and the need for intra-documents hyperlinks arises, we could just segment the long articles into a set of short articles and use these short ones in training. When a destination belongs to some segmented article, we will create an intra-document hyperlink by reassigning the destination to the appropriate part of the unsegmented original document.
We use the SOM algorithm to cluster documents. The clustering process is generally long. Although we can adopt faster clustering algorithm such as k-NN or C2ICM (Can, 1993), we rely on the nature of SOM to perform the text mining process.
References
Agosti, M., & Crestani, F. (1993). A methodology for the automatic construction of a hypertext for information retrieval. In: Proceedings of the 1993 ACM/SIGAPP symposium on Applied computing (pp. 745–753). Indianapolis, Indiana, USA.
Agosti, M., Crestani, F., & Melucci, M. (1996). Design and implementation of a tool for the automatic construction of hypertexts for information retrieval. Information Processing and Management, 32, 459–476. Agosti, M., Crestani, F., & Melucci, M. (1997). On the use of information
retrieval techniques for the automatic construction of hypertext. Information Processing and Management, 33, 133–144.
Allan, J. (1996). Automatic hypertext link typing. In: Proceedings for the Hypertext’96 Conference (pp. 42–52). Washington, DC, USA. Allan, J. (1997). Building hypertext using information retrieval.
Infor-mation Processing and Management, 33, 145–159.
Can, F. (1993). Incremental clustering for dynamic information processing. ACM Transactions on Information Systems, 11, 143–164.
Cox, T. F., & Cox, M. A. A. (1994). Multidimensional scaling. London: Chapman & Hall.
Crestani, F., & Melucci, M. (2003). Automatic construction of hypertexts for selfreferencing: The hyper-textbook project. Information Systems, 28, 769–790.
Dalamagas, T. (1998). Nhs: A tool for the automatic construction of news hypertext. In: Proceedings of the 20th BCS-IRSG Colloquium on Information Retrieval. Autrans, France.
Dalamagas, T., & Dunlop, M. D. (1997). Automatic construction of news hypertext. In: Proceedings of the Hypertext—Information Retrieval— Multimedia Conference(HIM ’97) (pp. 265–278). Dortmund, Germany. Table 1
Some statistics of the generated hyperlinks
Average number of inter-cluster hyperlinks per document 9.22 Average number of intra-cluster hyperlinks per document 2.37 Average number of aggregate hyperlinks per document 13.93
Average link density 0.798
Standard deviation of link densities 0.173
Deerwester, S., Dumais, S., Furnas, G., & Landauer, K. (1990). Indexing by latent semantic analysis. Journal of the American Society for Information Science, 40(6), 391–407.
Feldman, R., & Dagan, I. (1995). Knowledge discovery in textual databases (kdt). In: Proceedings of the first international conference on knowledge discovery and data mining (KDD-95) (pp. 112–117). Montreal, Canada.
Green, S. J. (1997). Building hypertext links in newspaper articles using semantic similarity. In: Proceedings of third workshop on applications of natural language to information systems (NLDB ’97). Vancouver, Canada.
Green, S. J. (2000). Lexical semantics and automatic hypertext construction. ACM Computing Surveys, 31(4), 22.
Huang, X., & Robertson, S. E. (1997). Experiments on large test collections with probabilistic approaches to chinese text retrieval. In: Proceedings of the second international workshop on information retrieval with Asian languages (pp. 129–140). Tsukuba, Japan.
Jolliffe, I. T. (1986). Principal component analysis. Berlin: Springer. Kaski, S., Honkela, T., Lagus, K., & Kohonen, T. (1998).
Websom-self-organizing maps of document collections. Neurocomputing, 21, 101–117.
Kohonen, T. (1997). Self-organizing maps. Berlin: Springer.
Kurohashi, S., Nagao, M., Sato, S., & Murakami, M. (1992). A method of automatic hypertext construction from an encyclopedic dictionary of a specific field. In: Proceedings of the third conference on applied natural language processing (pp. 239–240). Trento, Italy.
Lee, C. H., & Yang, H. C. (1999). A web text mining approach based on selforganizing map. In: Proceedings of the ACM CIKM’99 second workshop on web information and data management (pp. 59–62). Kansas City, MI.
Lin, Z., Ha¨ma¨la¨inen, M., & Whinston, A. B. (1996). Knowledge-based html document generation for automating web publishing. Expert Systems with Applications, 10, 381–391.
Mehler, A. (1999). Aspects of text semantics in hypertext. In: Proceedings of the 10th ACM conference on hypertext and hypermedia (pp. 25–26). Darmstadt, Germany.
Rauber, A., & Merkl, D. (1999). Using self-organizing maps to organize document archives and to characterize subject matter: How to make a map tell the news of the world. In: Proceedings of the 10th international conference on database and expert systems applications (pp. 302–311). Rizzo, R., Allegra, M., & Fulantelli, G. (1998). Developing hypertext through a self-organizing map. In: Proceedings of the WebNet 98 (pp. 768–772). Orlando, USA.
Salminen, A., Tague-Sutcliffe, J., & McClellan, C. (1995). From text to hypertext by indexing. ACM Transactions on Information Systems, 13, 69–99.
Salton, G., Allan, J., & Buckley, C. (1993). Approaches to passage retrieval in full text information systems. In: Proceedings of the 16th ACM-SIGIR conference (pp. 49–58). Pittsburgh, USA.
Salton, G., Allan, J., & Buckley, C. (1994). Automatic structuring and retrieval of large text files. Communications of the ACM, 37, 97–100. Salton, G., & Buckley, C. (1989). Automatic generation of content links for
hypertext. Technical Report on TR89-993, Department of Computer Science, Cornell University, Ithaca, NY.
Salton, G., Buckley, C., & Allan, J. (1992). Automatic structuring of text files. Electronic Publishing, 5, 1–17.
Salton, G., & McGill, M. J. (1983). Introduction to modern information retrieval. New York: McGraw-Hill.
Shin, D., Nam, S., & Kim, M. (1997). Hypertext construction using statistical and semantic similarity. In: Proceedings of the second ACM international conference on digital libraries (pp. 57–63). Philadelphia, PA, USA.
Tan, A. H. (1999). Text mining: The state of the art and the challenges. In: Proceedings of PAKDD’99 workshop on knowledge discovery from advanced databases (KDAD’99) (pp. 65–70). Beijing, China. Tudhope, D., & Taylor, C. (1997). Navigation via similarity: Automatic
linking based on semantic closeness. Information Processing and Management, 33, 233–242.
Wilkinson, R., & Smeaton, A. F. (1999). Automatic link generation. ACM Computing Surveys, 31, 27.